►
From YouTube: Engineering Productivity Showcase 2021-10-12
Description
Albert discusses Selective Test Execution initiative
A
A
A
couple
of
files
will
be
a
handful
maximum
and
given
those
we
should
be
able
to
identify
tests
that
are
directly
related
to
those
changes
and
only
runs
those
specifically
so
with
that
we
hope
to
be
able
to
get
a
faster
pipeline
so
that
we
get.
We
get
faster
feedback
from
that
from
the
less
number
of
tests
being
run
as
well
as
saving
the
cost,
because
then
we
have
much
less
runner
time
being
used.
A
A
So
so
far,
what
we
have
I
mean
previously.
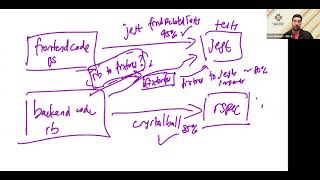
What
we've
done
was
that
every
back-end
code
will
run
almost
all
the
rspec
tests
and
then
every
front-end
changes
will
run
almost
every
all
right.
Oh
no,
it
will
run
all
the
jazz
tests
that
we
have.
So
we
want
to
be
more
selective
in
running,
only
related
jazz
tests
or
front
end
code
as
well
as
related
aspect
code
for
backend.
So
then
the
question
is:
how
do
we?
How
do
we
link
the
two
together
for
the
backend?
We
have?
A
A
A
Just
just
related
tests
for
all
front-end
changes,
so
so
the
challenge
is
now
between
the
back-end
code
and
just
so,
we
have
this
sort
of
dependency
right
now
we
run.
We
still
run
all
the
gest
tests
that
we
have
for
every
backhand
code
back
end
changes
because
there's
the
fixtures
in
the
middle,
so
fixtures,
the.
A
A
A
So
the
missing
pieces
missing
piece
will
be.
Then
right
now
is
this,
which
is
how
do
we
track
ruby
to
fixtures?
I
think
we
have
ways
we
probably
can
find
ways
to
do
it
because
of
how
the
the
test
is
written.
It's
an
aspect
test
which
just
generates
json
or
html
and
save
it
into
a
file
and
given
a
specific
file
name.
So
we
can
probably
trace
that
and
then
sort
of
use
similar
like
crystal
ball
or
something
just
to
keep
track
of.
A
A
A
A
Okay,
yeah
yeah,
I'm
not
gonna.
I
decided
not
to
go
through
that
here,
because
I
think
most
of
us
are
aware
about
that,
and
I
think
that
was
the
part
that
is
not
very
clear
is
how
all
the
pieces
are
fitting
together,
and
I
think
I
thought
it's
best
to
give
that
overview
sounds
good
yeah,
so
yeah
I'll
probably
draw
this
up
and
then
put
it
up
in
one
of
the
issue.