►
From YouTube: GitLab 13.3 Kickoff - Create:Gitaly
Description
Planning issue: https://gitlab.com/gitlab-org/create-stage/-/issues/12672
Direction: https://about.gitlab.com/direction/create/gitaly/
A
Hi
I'm
James
Ramsay
group
product
manager,
here
at
gate,
lab
for
the
correct
stage
of
DevOps
lifecycle,
and
this
is
the
giddily
13.3
kickoff
call.
The
kiddley
group
works
on
git
storage,
related
features
at
gate
lab
and
one
of
the
features
we've
been
working
on
recently
is
get
early.
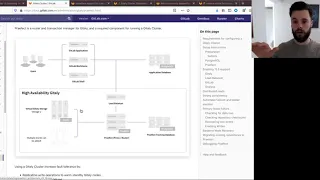
Cluster
get
early.
A
A
Today
it's
replicated
asynchronously,
so
my
right
will
only
go
to
one
of
the
giddily
nodes
and
then,
after
my
right,
succeeds,
it'll
then
be
replicated,
and
that
means
there's
a
delay
between
when
I
can
do
read,
proxying
and
there's
a
delay
where
an
outage.
If
that
occurred,
there
would
be
data
loss.
So
that's
a
bit
of
introduction
on
what
guilty
cluster
is
and
how
it
works.
A
The
other
area
is
continuing
to
improve,
read
distribution.
Our
first
implementation
does
have
some
performance
limitations,
which
is
why
it
still
marked
as
a
beta
and
we're
continuing
to
improve
it
and
monitor
and
test
it
in
get
lab
comm
on
a
subset
of
repositories.
And
so
we're
particularly
focused
on
improving
the
structure
of
the
SQL
database
and
tables
that
we're
using
and
preventing
those
routing
tables
from
growing
too
quickly
and
changing
too
often
so
that
we
can
make
it
fast
and
reliable
at
very
high
scale.
A
If
you
need
to
take
it
back
up
of
your
git
repositories
on
github
instance,
we
have
a
git
lab
backup
command
that
you
can
run
when
you've
ssh
into
the
server.
However,
for
large
github
instances
with
a
couple
hundred
gigabytes
of
repositories,
just
is
very
slow,
doesn't
really
work
and
there's
a
bunch
of
workarounds
that
we
have
in
our
documentation,
including
our
sink
and
some
other
techniques
to
take
backups,
but
we'd,
really
like
the
backup
tasks
to
work.
Well,
so
we're
working
towards
incremental
backups
and
the
first
stage
is
actually
to
implement
basic
concurrency
support.
A
So
that's
the
second
priority
that
we're
looking
at
and
finally,
we've
been
looking
at
partial
clone
and
support
for
large
files
in
git
for
quite
a
while,
and
one
of
the
key
areas
that
we're
looking
at
in
supporting
partial
clone
for
large
file
workflows
without
using
git
LFS
is
storing
those
large
binary
files
efficiently
and
we'd
like
to
be
able
to
store
them
on
cheaper,
more
cost-effective
storage
and
so
with
many
of
our
customers.
Object.
A
That's
better
suited
to
large
binary
files
that
are
resumable
in
their
upload
and
download
and
can
be
split
into
multi
parts
downloads.
So
we've
been
working
on
a
new
HTTP
driver
and
this
is
a
long-running
project
where
we're
investigating
its
significant
improvement
to
get
itself
to
support
this
and
we're
continuing
to
investigate
and
improve
this
something.