►
From YouTube: GitLab 13.12 - Enablement:Global Search
A
A
So
the
first
item
that
we're
actually
planning
to
work
on
in
1312
is
something
that
can
be
confusing
to
our
users
from
time
to
time.
The
scope
tabs
that
are
in
search
will
occasionally
move
change
or
even
disappear,
and
we
want
to
correct
that.
We
want
to
actually
have
this
so
that
it
is
consistent
and
we're
also
going
to
lock
the
order
of
those
tabs
in.
A
So
this
consistent
ordering
of
the
tabs
means
that,
if
you're
used
to
going
to
a
search
and
issues
being
in
one
place,
it
should
be
there
each
time
you
do
a
search
versus
moving
it
to
behind
merge,
requests
or
milestones.
It
should
all
be
organized
and
static
in
the
same
places
when
you
do
these
searches
in
the
future,
so
that
should
make
it
a
little
bit
easier
to
kind
of
navigate.
Remember
how
you're
actually
using
global
search.
A
That's
kind
of
that.
That's
one
of
our
key
deliveries,
we're
going
to
have
in
1312,
not
too
complicated
the
next
one
we
start
getting
into
something
that
is
a
lot
more
fun.
We
start
to
explore.
Some
of
the
additional
feature
sets
that
I
think,
are
really
going
to
help
people
navigate
through
search
and
create
a
lot
of
new
functionality,
we're
going
to
turn
the
projects
drop
down
into
a
multiple
select
option.
A
So
that's
going
to
look
something
like
this.
You
have
your
normal
search
that
comes
up.
You
have
your
group
and
project
drop
downs
and
now
you'll
be
able
to
use
check
boxes
to
actually
select
searching
against
multiple
groups,
and
that
will-
and-
and
this
is
essentially
better
than
what
you
have
today-
where
your
options
are
select
a
group
or
I'm
sorry,
you
select
a
project
or
select
all
of
them
and
there's
a
lot
of
times
when
you
don't
need
to
see
everything
you
just
want
to
see
a
handful
of
specific
projects.
A
Maybe
recent
projects
that
you've
been
working
on
or
have
been
contributing
to
and
so
you'll
be
able
to
do
that
now
by
by
actually
doing
multi-select,
which
I'm
pretty
excited
about
this.
This
is
actually
going
to
lead
to
a
a
lot
of
new
options
and
changes
for
us,
as
we
start
to
look
at
building
additional
feature
sets
out
for
global
search.
A
B
Hi,
I'm
terry,
I'm
one
of
the
senior
backend
engineers
on
the
global
search
team.
We've
been
kind
of
marching
along
on
moving
all
of
the
elastic
search
scopes
out
into
their
own
index.
That's
a
multi-milestone
work
that
we've
been
doing,
probably
over
the
last
few
months.
If
I
remember
correctly
so,
we've
completed
issues
and
notes
and
we're
now
moving
on
to
merge,
requests,
we're
going
to
be
going
through
the
same
process
and
I
feel
like
it
will
be
very
similar
to
the
work
that
we've
done
for
issues.
B
This
will
involve
denormalizing,
some
of
the
permission,
data
related
to
the
project,
visibility
level
settings
as
well
as
creating
some
new
advanced
search
migrations
to
update
all
of
the
existing
data
with
those
backfilled
fields
and
then
changing
the
searches
to
use
those
new
denormalized
fields,
rather
than
using
the
join
to
the
the
project
and
last
we'll
have
some
additional
migrations
to
pause.
Indexing
fully
move
all
the
data
over
and
then
do
some
cleanup
work
and
it's
it's
going
to
be
pretty
exciting.
B
A
You
know,
let's,
let's
talk
for
just
a
little
bit
more
about
splitting
these
scopes
up
right
because
we've,
you
know,
terry
we've
actually
put
a
lot
of
effort
into
taking
what
we
had
as
this
like
huge
massive
index,
and
I
I
can
of
course,
speak
more
clearly
to
what
exists
on
gitlab.com.
You
know
we
have
a
an
eight
terabyte
index,
that's
all
of
the
the
sas
information
from
all
the
ripas
and
everything
and
we've
been
breaking
that
out
into
these
other
indexes,
and
it's
it's
definitely
taken
some
resources.
A
B
A
No,
I
think
that's
a
great
call
out
right
like
if
I
yeah,
I
did
some
analysis
to
see
how
users
are
actually
using
the
different
scopes
a
few
weeks
ago
and
there's
it's
definitely
interesting
right.
When
you
look
at
how
many
users,
for
example,
use
issues
and
as
we
broke
issues
out
from
the
eight
terabyte
index
that
we
had
for
gitlab.com,
it
was
eight
gigs,
it
was
only
eight
gigs,
and
so
that
means
that
that
eight
gigs
of
data
is
actually
serving
out.
A
A
So
there's
there's
different
ways
to
kind
of
organize
the
information
that's
being
called
or
returned
and
queried
against.
So
those
results
have
have
gotten
a
lot
faster
when
you
go
and
do
an
issue
search
now,
they're,
almost
just
instantaneous,
I
mean
sub
second
response
times
in
most
cases,
and
so
I
I
think
you
definitely
see
like
a
big
performance
improvement
as
you
look
at
the
items
that
were
split
out
into
your
own
index
and
it
kind
of
makes
sense.
A
That's
why
right
they're
actually
searching
against
this
much
smaller
index
now
to
try
to
return
that
information
it.
It
also
probably
helps
with
indexing
when
we
actually
have
the
process
to
go
in
and
do
refresh
of
indexing.
It's
now
refreshing
those
things
against.
You
know
a
small
group
of
eight
gigs
versus
a
terabyte
so
that
that's
going
to
speed
things
up
quite
a
bit.
B
Yeah,
I
think
definitely
we'll
see
some
performance
improvements.
I
think
some
of
the
other
things
that
will
be
really
beneficial
is
it
allows
us
to
like
more
fine-tune
settings
for
index
that
could
potentially
also
improve
performance
right
now.
We
have
everything
in
one
giant
index.
We
have
settings
that
are
just
like
overall
for
everything,
but
you
know
if
issues
is
only
eight
gigs,
but
maybe
blobs
is
like
two
terabytes
that
will
allow
us
to
like
tune
those
even
better
to
allow
better
performance
for
searches.
A
So
it's
it's
going
to
map
data
for
like
an
issue
we're
looking
at
an
issue
here,
so
you
know
some
of
the
data
we
may
be
looking
at
has
to
do
with,
like
the
that's,
an
epic
sorry,
but
it
has
to
do
with
like
labels.
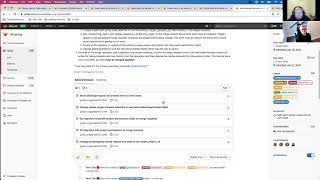
Let
me
pull
up
an
issue
here
for
reference
there
we
go
so
you
know
have
like
assignees
issues,
milestones,
iterations
lots
of
different
types
of
data
that
can
be
mapped
into
an
issue.
A
None
of
these
really
would
exist
at
a
file
or
in
the
the
code,
and
so
then
you
know
they.
They
don't
really
have
a
value
there,
but
if
they're
in
the
same
index
they
would
have
to,
they
would
have
to
exist
as
a
reference
somehow,
so
you
don't
have
to
manage
across
all
of
these
different
types
of
content.
A
You
can
manage
the
mapping
for
just
what's
in
that
particular
index,
which
seems
really,
you
know,
streamlined
and
helpful
for
being
able
to
build
out
feature
sets,
which
is
great
because
one
of
the
next
things
we
want
to
do
in
search.
Not
this
not
in
this
iteration
is
milestone
and
this
this
next
release,
but
future
we
want
to
be
able
to
build
out
the
the
features
that
are
coming
from
this.
B
Yeah,
that
definitely
will
it
leaves
us
with
a
lot
more
flexibility
in
so
many
areas,
most
of
which
are
well
not
most,
but
a
lot
of
them
that
the
users
will
see
will
be
performance,
but
in
terms
of
like
maintenance
of
the
data
and
the
ability
to
expand
new
features.
It's
going
to
give
us
a
lot
more
finer
tuned
control.
A
B
Oh,
I
think
well,
so
we
haven't
really
planned
for
anything
around
this,
but
I
just
think
it
may
give
us
more
control
to
possibly
only
pause
indexing
for
one
of
the
indexes.
If
we
only
want
to
do
something
with
merge
requests,
why
do
we
have
to
affect
everything
else
if
everything
else
is
split
off,
so
that
may
be
a
cool
new
future
direction
that
we
can
go
into
to
allow
for
like
more
zero
downtime
migration
capabilities
with
like
less
impact.
A
All
right
well
great!
Well,
thank
you
for
watching-
and
this
is
just
a
you
know-
real
quick
understanding
of
of
what
we're
actually
working
through
over
the
last
few
milestones
regarding
the
the
updates
we've
been
doing
for
splitting
out
these
scopes
and
we're
really
looking
forward
to
the
flexibility
it's
going
to
give
us
and
the
additional
features
that
we're
going
to
be
putting
on
the
table
over
the
next
few
releases.
So
thank
you.