►
From YouTube: Advanced CI/CD GitLab Webinar
Description
Expand your CI/CD knowledge while we cover advanced topics that will accelerate your efficiency using GitLab, such as pipelines, variables, rules, artifacts, and more. This session is intended for those who have used CI/CD in the past.
A
A
All
right,
let's
kick
it
off!
Thank
you.
Everyone
for
joining
us
today,
we're
excited
to
to
be
going
through
our
content
of
advanced
CI
and
CD
with
you
today
before
I.
Kick
it
over
to
Conley
our
presenter
I
just
wanted
to
go
through
a
couple
of
housekeeping
items.
First
off
this
webinar
is
being
recorded,
so
you
can
plan
to
receive
that
here
in
the
next
couple
of
days
in
your
inboxes,
so
you
can
look
forward
to
that.
A
In
addition,
if
you
have
any
questions
that
come
out,
excuse
me
come
up
throughout
the
session.
Please
put
those
in
the
Q
a
portion
of
your
Zoom
window.
We'll
have
time
to
answer
those
throughout
and
Colony
will
have
some
time
at
the
end
to
answer
some
of
them
live
as
well,
and
with
that
I
will
kick
it
over
to
Conley.
B
B
All
right,
we
got
you
so
yeah.
Thanks
appreciate
that
Taylor
thanks
so
much
everyone
for
joining
us
today.
I
wanted
to
say,
first
and
foremost
that
I
want
to
start
with
the
most
important
thing
here,
which
is
you
all
this
presentation
and
the
work
that
Taylor's
team
does
is
all
in
hopes
of
providing
you
more
value
for
your
get
Live
subscription.
So
that
means,
if
you've
got
a
question,
definitely
don't
hesitate
to
put
that
in
the
chat.
B
I'm
gonna
save
some
time
about
10
minutes
or
so
at
the
end
for
Q
a
so
we'll
address
some
of
these
questions
live,
and
then
we
also
have
a
couple
folks
from
gitlab
that
are
going
to
be
answering
them
throughout.
So
don't
be
shy,
so
my
name
is
Conley
Rogers
I'm,
a
senior
technical
account
manager
for
our
strategic
Enterprise
accounts.
I'm
coming
to
you
to
you
from
Atlanta
Georgia.
B
Before
joining
gitlab
I
was
an
engineering
manager
at
Verizon.
Where
I
led
a
team
in
charge
of
sdlc
modernization,
we
would
publish
and
educate
teams
on
best
practices
how
to
utilize
insights
like
the
door,
4
and
cicd
type
analytics
to
have
more
productive
conversations
with
their
business
counterparts
or
product
management
teams.
B
A
couple
things
that
are
sort
of
like
out
of
scope
is
that
you
know
detailed
setup
and
configuration
for
CI,
CD
and
Runners.
We've
got
a
course
just
on
that,
so
you
can
look
that
up
in
our
Professional
Services
catalog,
as
well
as
in-depth
usage,
best
practices
for
project
management.
We've
got
a
course
just
on
that
and
then,
if
you
are
a
systems
administrator-
and
you
are
just
trying
to
understand
how
to
spin
up
gitlab
troubleshoot,
it
upgrade
it
Etc.
We've
got
our
own
sysadmin
training
for
that
as
well.
B
So
those
are
a
couple
things
that
are
sort
of
out
of
scope
today,
just
wanted
to
get
that
disclaimer
before
we,
we
Dive
Right
In,
all
right,
let's
get
into
it.
So
let's
start
with
what
we
call
the
gitlab
flow.
It's
Probably
sounds
like
a
branching
strategy.
You
know,
GitHub
flow
get
lab
flow,
get
flow,
are
all
branching
strategies,
but
this
is
more
of
a
process
and
I
know.
B
This
is
a
a
webinar
about
cicd,
but
I
wanted
to
start
with
the
bigger
picture
of
mine
because,
beyond
the
technology
of
the
pipelines
itself,
it's
a
process
to
ensure
that
you
get
the
most
from
your
investment
in
gitlab,
as
well
as
to
improve
collaboration
across
your
your
engineering
team
and
other
personas
like
security
and
change
management,
as
you
actually
are
writing
and
deploying
code.
So
that's
why
we
wanted
to
show
this
first.
B
So
this
is
the
gitlab
flow
process
that
we
recommend
for
devops
teams
to
follow,
while
using
gitlab
capabilities
within
a
concurrent
development
life
cycle.
So
you
start
with
sort
of
defining
and
managing
the
requirements.
The
desired
issue
that
you're
working
on,
whether
it's
technical
debt
issues,
whether
it's
features
and
bugs
or
whether
it's
a
security
risk
compliance
type
issue.
B
B
Instead
of
creating
your
branch
and
then
just
kind
of
going
off
and
making
commits
on
that
branch
and
pushing
that
back
to
server,
we
actually
encourage
and
even
have
prompts
in
the
UI
to
immediately
create
a
merge
request
after
you
create
that
branch.
So
this
works
for
more
than
just
the
git
lab
flow
branching
strategy.
It
works
for
for
many
branching
strategies,
it's
kind
of
agnostic
of
that.
B
So
the
reason
that
we
do
that
is
so
that
it
becomes
evident
to
the
rest
of
the
team
that
yes,
I
picked
this
issue
up
and
yes,
I
also
have
a
work
in
progress,
merge
request,
so
you
can
immediately
start
to
bring
in
the
right
stakeholders,
so
they
can
see
when
you
push
code
which
will
automatically
trigger
RCI
CDE
pipelines
by
default,
unless
you
configure
it
otherwise,
so
that
every
change
is
running
basic
lensing
and
static
analysis
and
you're
getting
really
fast
feedback
loops.
That's
just
from
the
developer
perspective.
B
They
can
also
see
if
that
pipeline
has
green
checks
across
which
tells
them
it's
it's
past
the
required
quality
Gates
then
it'll
spin
up
a
live
ephemeral
instance
in
like
a
non-production
environment,
you
know,
if
that's
the
type
of
application
that
you're
developing
and
that
it
can
do
such
so
that
we
can
perform
Dynamic
security
testing
on
a
running
instance
and
test.
For
you
know,
cross-site
scripting
and
dynamic
attacks
like
that,
once
it's
looking
good,
it's
passing
all
those
checks.
B
The
appropriate
approvals
and
separation
of
Duties
would
actually
come
in
at
this
point.
So
if
there's
any
kind
of
findings
in
those
scans,
it
may
require
an
additional
person
from
a
security
group
to
come
in
and
either
approve
it
or
review
it,
and
then
you
land
in
your
default.
So
that
would
be
once
that
merge
request
is
accepted.
It
runs
the
CD
workflow
for
deploying
into
a
release
and
packaging
that
up
into
a
release
and
then
deploying
into
your
environment
of
choice,
whether
that's
staging
then
to
production.
B
You
can
also
look
at
a
live
preview,
so
that's
getting
into
that
review
app.
You
know
live
preview
of
your
development
Branch
before
you.
Even
you
know,
send
it
to
your
default
branch
and
before
merging
it
into
a
stable
version
of
your
application,
then
you
can
deploy
to
multiple
environments
like
staging
and
production.
We
support
Advanced
features
such
as
Canary
deployments
for
this
for
incremental
rollouts.
B
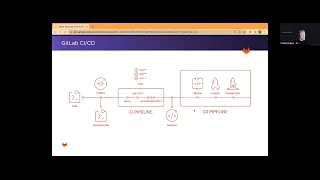
So,
let's
look
at
the
terminology
that
gitlab
uses
for
describing
and
defining
CI
CD.
You
know
the
the
largest
component
of
that
is
the
pipeline
itself,
so
this
is
a
set
of
one
or
more
jobs
and
it's
going
to
be
organized
into
stages
and
a
stage
is
that
next
piece
down
so
a
stage
is
a
local
grouping
of
jobs
that
pertain
to
a
phase
of
the
pipeline,
so
they
can
be
run
in
parallel,
which
improves
the
performance
of
your
your
flow
in
that
pipeline.
B
B
So
that's
really
what
what
makes
up
and
that's
what
you're
defining
in
infrastructures
code
using
yaml
files
to
do
so.
The
environments
is
where
you're
going
to
be
actually
deploying.
So
it
points
to
a
deployment
destination
is
all
in
one
file
version
and
stored
in
the
project
that
it
pertains
to
at
its
most
basic
function.
B
The
last
piece
is
the
git
live
Runner.
That's
the
infrastructure
piece
that
executes
everything
you
see
on
the
left
side.
You
can
have
as
many
Runners
as
you
like
as
many
as
you
need
to
handle
the
volume
and
load
from
your
engineering
department.
You
can
even
use
your
PC
if
you're
trying
to
test
certain
things
out
or
you
have
very
Niche
use
cases.
Just
you
know,
keep
in
mind.
That
means
that
members
of
the
project
will
be
using
your
laptop
as
as
a
runner.
B
So
the
pipeline
architectures
that
we're
going
to
cover
today,
you
know
as
we're
doing
this
ask
yourself:
how
can
I
use
these
Concepts
to
improve
my
pipeline
performance
and
functionality?
We've
got
five
different
flavors
that
we're
going
to
dive
into
starting
with
just
a
basic
vanilla
pipeline,
we're
going
to
get
into
directed
acyclic
graphs,
parent
child
pipelines
within
the
same
project,
Dynamic
child
pipelines
and
then
the
fifth
one
we're
going
to
hit
is
multi-project
Pipelines,
starting
with
the
simplest.
A
basic
pipeline
is
just
a
series
of
jobs
that
run
independently.
B
This
is
what
that
would
look
like
so
basic
build
tests
deploy
pipeline
here
with
the
jobs
to
find
yeah.
So
you
can
see
like
if
the
build
itself
is
successful.
You
then
start
to
run
a
series
of
tests.
You
know
probably
some
unit
testing
and
integration
testing
here,
there's
some
Logic
the
allow
failure
to
be
true
so
that
the
pipeline
can
proceed,
even
though
it
failed
those
tests
that
is
optional,
and
you
can
configure
that
and
then
for
deployment.
B
B
So
this
is
how
you
would
handle
a
scenario
like
that,
so
that,
when
you
are
deploying
into
a
production
or
even
uat
or
staging
environment,
that
it
waits
for
somebody
with
the
right
permission
to
click
that
manual
intervention
to
deploy
it
foreign
options
when
delayed
when
on
failure-
and
when
always
it's
just
more
ways
to
control
the
flow
of
a
pipeline.
If
you've
got
hard
requirements
to
always
run
something
to
to
run
it
on
failure
or
to
delay
running
a
a
job.
B
B
So
this
is
how
you
start
to
define
the
flow,
so
the
pipeline
flow
so
that
you
can
run
parallel
jobs
and
you
can
even
move
on
to
the
next
stage
if
certain
jobs
haven't
finished,
so
the
more
that
you
can
run
concurrently,
the
the
faster
that
job
or
that
pipeline
can
finish
as
a
whole.
So
this
is
great
for
moving
on
to
you,
know,
non-dependent
jobs,
so
that
you
can
keep
the
flow
moving
and
you
don't
get
hung
up
waiting
for
every
job
in
a
stage
to
continue
before
moving
forward.
B
So
that's
what
the
needs
keyword
allows
you
to
do,
so
it
defines
those
dependent
jobs,
and
this
is
kind
of
what
that
looks.
Like
just
an
example
of
using
the
needs
keyword,
you
can
Define
the
job
relationships.
So
if
gitlab
knows
the
relationship
between
jobs,
it
can
run
everything
as
fast
as
possible
and
even
skip
into
subsequent
stages
when
possible.
B
So
in
this,
in
this
example,
you
have
an
application
to
point
to
both
Android
and
iOS,
so
these
are
not
dependent
on
each
other
running.
So
if
you
wanted
to
create
a
needs
keyword
here,
you
can
speed
up
the
total
pipeline.
If,
if
say
the
Android
build
completes
faster
than
iOS,
then
it
can
move
on
to
running
all
of
the
tests
on
that
built
binary.
Instead
of
waiting
for
both
to
complete
okay.
B
This
is
a
visualization.
This
is
pretty
complicated,
not
gonna
lie,
but
you
can
start
to
see
the
flow
logic
by
using
our
UI
to
look
at
the
relationship
between
jobs.
So,
as
you
Mouse
over
it,
it's
going
to
highlight
the
dependency
paths
involved
and
then
you
can
also
click
on
multiple
pass
and
it's
and
it's
interactive.
So
if
you're
trying
to
figure
out,
you
inherited
a
project,
it's
very
complicated
and
you're,
trying
to
just
figure
out
what's
triggering
what
this
is
a
visualize,
a
visual
way
of
doing
so.
B
B
That's
when
this
would
would
start
to
become
very
useful,
so
it
combines,
if
you
combine
this
with
the
directed
acyclic
graph
pipelines,
you
get
the
benefits
of
both.
So
it
is
best
to
kind
of
use
every
tool
at
your
disposal
to
improve
the
efficiency
of
these
Pipelines
and
it's
useful
to
Branch
out
long-running
tasks
into
those
separate
pipelines.
So
that's
why
the
parent-child
architecture
is
very
useful,
so
along
the
lines
of
Simplicity.
B
This
feature
allows
you
to
call
other
yaml
files
from
within
the
same
project,
so
that
can
solve
for
issues
that
you
may
be
facing,
like
the
staged
structure
of
a
pipeline,
where
all
steps
in
a
stage
must
be
completed
before
the
first
job
and
the
next
stage
against
that
causes
arbitrary
weights
and
slows
things
down.
It
also
solves
for
configuration
for
the
single
Global
pipeline
that
could
become
very
long
right
if
you've
got
one
really
long.
B
So
you
may
be
deploying
multiple
micro
services
and
you
need
a
different
language
and
a
different
pipeline
to
handle
each
microservice.
That's
when
the
parent
shop
pipeline
becomes
very
useful,
so
those
Downstream
pipelines
that
are
triggered
could
be
running
separate
all
from
within
the
same
project.
B
Foreign,
so
this
is
sort
of
the
behind
the
scenes:
how
to
write
the
file
for
this
parent
child
pipeline
for
say,
a
mono
repo.
That's
deploying
those
micro
services
like
I
was
just
showing
in
that
example,
so
it'll
run
the
job
if
there
are
changes
in
those
files,
so
you
can
Define.
You
know
for
this
stage
in
particular
to
only
run
it.
B
If
there's
changes
in
this
project
dash
one
any
file
within
that
project,
and
then
you
can
include
files
from
elsewhere
within
the
project
so
that
it's
going
to
include
the
appropriate
Downstream
yaml
code
to
run
that
project
correctly
and
then.
Finally,
the
strategy
to
to
depend
means
that
it
holds
this
pipeline
until
the
other
pipelines
have
finished.
B
Number
four
of
five
is
the
dynamic
pipeline,
so
this
is
going
to
be
generating
pipeline
configuration
at
build
time.
It's
uses
the
generated
configuration
at
a
later
stage
to
run
as
a
child
Pipeline,
and
it's
useful
to
have
a
single
pipeline
configuration
with
different
settings
to
support
a
matrix
of
Targets
in
architectures.
B
This
technique
could
be
very
powerful
in
generating
pipelines
targeting
content
that
changed
or
to
build
a
matrix
of
Targets
in
architectures
dynamically
right.
So
you
can
see
this
test
lab
CI
gamble
file
is
being
generated
dynamically
in
places
generated
yaml
file
in
the
job
artifacts
store,
then
references
it
later
to
actually
run
the
pipeline
that
it
has
generated
dynamically.
There.
B
B
So
there's
there's
like
three
main
use
cases
for
for
using
this
we're
going
to
talk
about,
but
you
can
specify
you
know
specific
branches.
You
can
pass
variables
to
Downstream
pipelines
if
the
downstream
pipeline
fails,
it
will
not
fail
the
Upstream
pipeline.
So
that's
a
benefit
and
useful
when,
when
building
deploying
large
applications,
they're
made
up
of
different
components
that
have
their
own
projects
and
build
pipeline.
B
As
the
title
infers,
you
can
set
up,
git
live
CI
CD
across
multiple
projects,
so
that
a
pipeline
and
one
project
can
trigger
a
pipeline
in
another
project.
You
could
visualize
the
entire
pipeline
in
one
place,
including
all
cross
project
interdependencies
when
you
set
this
up
within
the
gitlab
UI
itself.
B
So
we
we
have
a
job
called
a
bridge
underneath
the
test
stage.
Okay
and
what
it
does
is
triggers
a
pipeline
in
the
project
path
from
Branch,
Main
and
simple
as
that.
But
but
there
are
some
other
great
use.
Cases
for
this
sort
of
the
simple
A
to
B
is
the
first
of
the
three,
where
a
project
that
just
triggers
the
pipeline
in
another
project
to
run
such
as
a
code
project
triggering
a
rebuild
of
its
documentation.
So
that's
like
a
simple
A
to
B
configuration
for
the
multi-project.
B
The
other
one
is
a
like
an
orchestrator
project
that
manages
the
build
and
deploy
of
multiple
other
apps
and
is
sort
of
that
parents
project
that
that
houses,
the
control
logic.
So
that's
orchestrating,
you
know
a
large
deploy
across
many
subsequent
repositories
and
then
the
third
one
is
is
called
versioning.
But
it's
really,
you
know
any
variable
that
you
need
to
pass
to
Downstream
projects.
This
is
a
great
reason
to
use
the
multi-project
pipeline.
So
you
know
say
you
need
to
pass
the
version
number
to
the
downstream
project.
B
A
B
Wow
a
lot
of
good
stuff
here,
so
you
can
actually
see
the
UI
for
for
when
it
shows
you
that
Downstream
graphic
within
the
gitlab
UI.
So
it's
helpful
to
visualize
everything
that
that
parent
job
is
kicking
off,
and
so
with
that
we
have
covered
the
five
different
architectures
of
get
live.
Ci.
If
you
want
to
learn
more
about
that,
you
can
go
to
our
documentation.
B
It's
just
gitlab
architectures!
So
you
can.
You
can
kind
of
read
it
more
examples,
more
yaml
code
that
you
can
copy
paste
and
start
to
play
around
with,
but
now
I
want
to
get
into
the
anatomy
and
components,
starting
with
the
variables
so
cicd
variables
are
a
type
of
environment
variable
you
can
use
them
to
control
the
behavior
of
jobs
and
Pipelines
store
the
values
that
you
want
to
reuse
and
avoid
hard
coding
values
in
your
kitlab
CI
yaml
file.
You
can
use
predefined
cicd
variables.
B
In
terms
of
using
these
and
injecting
them
into
your
pipeline,
you
could
do
it
a
number
of
ways
through
the
UI
at
the
project
level,
group
level
and
instance,
level.
You
can
set
variables
and
we'll
talk
in
a
sec
about
sort
of
the
hierarchy
of
which
ones
you
know
take
precedence
if
it's
defined
more
than
once
all
right,
so
you
can
see
within
the
project.
You
can
add
variables.
B
B
B
B
B
You
can
trigger
these
manually
through
the
UI.
If
you
need
to
like
run
a
report
or
a
freestyle
type
job,
you
can
trigger
through
the
UI
an
API
or
through
a
schedule.
So,
if
you're
needing
to
run
something
regularly
on
a
24-hour
48-hour
schedule,
you
can
also
do
that
and
then
the
variable
for
for
this
setting
is
CI
pipeline
Source
and
we'll
show
some
examples
where
you
can
change
that
that
pipeline
Source
or
you
can
disable
it
running
on
a
merge
requests.
B
The
basics
of
a
a
rule
and
sort
of
the
building
blocks
here
is
that
you
would
have
the
job
itself
being
defined,
and
you
know
say
that
only
on
web
run
would
you
want
this
job
to
to
be
kicked
off.
Then
you
need
to
create
the
rules
block
with
the
rules
keyword
and
then
you
can
Define
your
if
statements
to
reference
variables,
including
predefined
ones,
as
in
this
case
like
the
CI
pipeline
source,
is
web.
B
So,
if
you're
using
the
web
IDE,
then
you
can
trigger
this
job
to
be
run,
otherwise
it
won't
be
and
then,
as
it
claims,
this
job
will
only
run
when
the
pipeline
is
kicked
off
from
the
web
form.
Simple
example
is
just
going
to
Echo
a
string
that
says
that
this
is
this.
Job
will
only
run
when
the
pipeline
is
triggered
from
the
web
form
so
very
simple,
but
you
can
start
to
see
the
construct
of
a
job,
a
rules
block
an
if
statement
and
then
a
subsequent
script
or
action.
B
Sorry
I
think
my
headphones
Cut
Off
Taylor.
Can
you
hear
me
yep?
We
still
got
you
okay,
thank
you!
So
much
sometimes
it
just
does
that.
So
this
is
a
great
slide
to
screenshot.
If
you
want
to
just
kind
of
screenshot,
this
save
it
away
for
reference,
so
the
Clauses
that
you
can
choose
from
you
saw
the
the.
If
statement
you
can
also
do
you
know
if
you
know
changes
are
made
to
certain
files.
B
Only
then
do
you
run
the
subsequence
scripts,
so
that's
very
useful
for
for
improving
performance
of
your
Pipelines
and
then
the
operator
to
say.
If
you
know
this
is
pretty
standard
for
for
writing
any
kind
of
scripts.
The
results
for
when
that
operation
is
true
and
then
what
happens
as
a
result.
So
the
win
options
you
can.
You
can
have
as
always,
never
on
success
Etc.
So
this
is
kind
of
the
building
blocks
of
writing
the
rules
so
that
you
can
ensure
that
things
only
run
when
they
need
to
that
saves
time.
B
It
saves
resources
and
improves
efficiency,
so
I
threw
in
such
some
tips
and
tricks
for
speeding
up,
complex
pipelines.
Earlier
you
know,
the
directed
acyclic
graph
is
a
great
way
of
doing
that,
but
let's
take
a
look
at
some
other
ways
now
that
I've
covered
rules
and
variables,
so
the
first
one
is,
is
setting
run
rules.
B
This
is
one
of
my
favorites
right
now,
because
it
allows
you
to
say
these
files
didn't
change
so
I
don't
want
to
run
this
job
or
I
only
want
to
run
on
certain
branches
right.
So
it
allows
you
to
say
what
jobs
run
when
so
that
you
can
save
time,
especially
as
a
git
live
ciml
file
can
be
over
a
thousand
lines.
B
So
if
you
have
a
lot
of
say,
container
preparation
build
up
in
a
before
script,
it
might
be
a
sign
that
you
need
to
convert
that
section
into
like
a
Docker
file
and
a
new
repo
and
have
your
own
build
container.
But
if
there's
other
types
of
scripts-
and
it's
just
checking
for
certain
settings,
this
can
can
dramatically
accelerate
builds
where
there
are
a
lot
of
build
dependencies
to
wear
on
before
running
your
code.
B
So
one
last
thing
I
would
say
is
trying
it
both
ways
and
compare
contrast
to
see
which
ways
run
fastest
for
you
I
think.
That's
just
a
great
rule
of
thumb
so
that
you
can
get
used
to
using
more
complex
Concepts,
but
then
you're
very
pragmatic.
You
aren't
just
trying
to
use
it
because
it's
new
and
cool,
but
rather
it's
actually
improving
that
performance.
And
you
can.
You
can
measure
that
and
see
it
between
different
pipeline
builds
foreign.
B
Let's
go
through
a
couple
examples
of
rules
in
action,
so,
if
you're
trying
to
control
when
merge
request
pipelines
run
right.
So
if
you
don't
want
to
run
your
CI
pipeline
every
time,
a
merge
request,
event
happens:
you
can
set
that
rule.
If
you
do
want
it
to
run,
then
you
can
use
the
CI
pipeline
Source
on
merge,
request,
event
or
CI
pipeline
source
as
a
push
to
that
Branch.
So
those
would
then
trigger
it
unless
you
kind
of
say
otherwise
that
you,
you
don't
want
to
use
that.
B
B
So
this
can
just
again
save
time
or
even
control
the
types
of
tests
and
jobs
that
won't
run.
If
it's
a
schedule,
you
know
if
it's
a
scheduled
job
or
if
it's
say
you
wanted
to
kick
it
off
from
the
the
UI.
You
know
and
you
don't
need
it
to
run
a
whole
slate
or
a
whole
like
block
of
code
to
save
time
so
you're
only
trying
to
scan
like
a
binary
that
you're
pulling
in
as
a
dependency,
and
you
just
need
to
run
like
a
dependency
scan.
B
You
don't
need
to
do
the
full
SAS
and
you
don't
need
to
do
Secrets
detection
Etc.
You
can
cut
out
some
of
that
and
dictate
don't
run
this
block
if
it's
triggered
manually
through
the
UI.
Something
like
that.
So
I
wanted
to
share
that
as
a
second
example
and
then
as
the
third
example,
if
you're
trying
to
to
control
when
scans
are
run
based
off
of
the
contents
of
that
commit
or
of
that
merge
request.
This
is
how
you
can
go
about
doing
it
right.
A
B
B
The
fourth
example
is
a
sort
of
delayed
job,
so
this
job
is
going
to
run
three
hours
after
triggered
and
will
be
allowed
to
fail.
So
if
you've
got
say
like
a
long
running
either
script,
that's
custom
long
running
integration
tests,
something
that
you
know
is
going
to
take
a
while,
but
that
feedback
isn't
necessary
immediately.
B
The
workflow
rules
control
when
the
entire
pipeline
will
run
and
they're
outside
of
the
job
definitions.
We've
mainly
been
talking
about
up
to
this
point,
so
here
we
see.
If
the
commit
message
contains
whip
Dash
whip,
then
it
won't
run
the
pipeline
and
if
a
tag
was
applied
then
then
it
also
won't
run.
Otherwise
it
will
so
you
can
control.
You
know
if
I'm
just
saying
hey
this:
this
is
whip.
B
B
B
Those
generate
files,
binaries
packages
that
you'll
use
for
deploying
your
application.
It
also
generates
artifacts
for
reviewing
test
results.
So
we're
going
to
talk
about
managing
those
artifacts
for
a
minute.
Gitlive
allows
for
saving
artifacts
in
local
or
object
storage.
You
can
then
use
them
in
subsequent
jobs,
and
then
you
can
use
the
rules.
Logic
of
exclude
depends
and
when
to
control
what
is
added
and
when
to
determine
if
an
artifact
is
stored
or
not,
you
may
not
need
to
store.
B
It
may
be
something
that
you
just
need
in
the
job
to
run
your
tests
on
and
and
that's
good
enough.
So
that's
you
know
some
of
the
key
words
around
like
using
exclude
to
limit
what
is
added
using
to
pins,
to
limit
what
gets
downloaded
on
subsequent
jobs
using
win
to
determine
if
artifacts
will
be
stored
or
not,
and
then
the
expire
in
to
determine
when
artifacts
would
be
destroyed
very
good
to
to
have
especially
for
stuff
like
test
results.
I
think
those
are
only
stored
for
48
to
72
hours
by
default.
B
You
have
to
change
stat
expire
and
if
you
want
it
to
live
past
that
and
that's
just
to
to
save
space
and
costs
for
storage,
but
you
can
set
these
as
you
as
you
need
to
where
to
find
and
download
artifacts
in
the
gitlab
UI
So
within
the
pi
points
page,
you
can
see
that
you
can
download
the
artifacts
whether
that
is
the
compiled
code.
Whether
that
is
the
test
results,
you
could
do
it
on
the
jobs
page
within
a
specific
job
and
then
the
artifact
browser.
B
If
you're
using
our
our
package
registry,
you
can
you
can
download
it
from
there
if
you're
using
something
external,
then
you
would
just
be
sending
it
off
to
something
like
artifactory,
and
so
it
wouldn't
be
in
our
artifact
browser.
But
otherwise,
though
you
can
see
within
the
pipelines
and
the
jobs
themselves,
and
you
can
download
those
and
review
the
test
results
if
you
need
to.
B
As
far
as
the
administration
goes
and
a
self-managed
get
lab
instance,
job
artifacts
can
be
stored
in
local
or
object.
Artifact
expiration
times
can
be
configured
at
the
instance
level
and
then
artifact
downloads
fall
under
our
gitlab
access
control
and
it's
probably
pretty
small
but
I'll.
Just
tell
you
right
now
download
and
browse
job
artifacts
guests
all
the
way
through
reporter
developer,
maintainer
owner
they
can
do
that
they
can
browse
and
and
download
job
artifacts
so
good
to
know
so
that
you
understand
who
has
access?
B
B
Here
is
some
of
the
container
and
language
specific
package.
Registries
they
get
live,
supports
container
course,
dependency
proxy
and
then
some
language,
specific
package,
Registries
all
the
common
ones.
Npm
new
get
go
proxy,
so
you
can
see
that
and
we've
got
a
docs
page.
So
if
you
go
to
our
sites,
you
can
look
under
packages
and
find
the
full
list
and
details
here
if
you
want
to
kind
of
dig
around
a
little
bit
more
and
lastly,
a
quick
example.
B
You
can
see
here
in
this
example
that
we've
got
a
build
OSX
and
build
Linux
stages,
so
in
order
to
run
the
test
scripts
that
we
need
to
we've
got
to
make
sure
that
we're
using
the
right
artifact
right.
So
that's
where
the
dependencies
of
build
OS
X
come
into
play
so
for
the
test
stage.
That's
what
you
would
write
for
that
as
a
dependency
and
then
likewise
for
your
Linux
testing
to
take
place
you're
dependent
on
the
build
Linux
artifact
there.
B
Foreign
the
last
but
super
crucial
topic
is
on
includes
and
extent
super
powerful.
If
you
take
away
anything
from
this,
I
would
say
this
is
a
big
one,
just
in
terms
of
scaling
gitlab
cicd.
This
is
a
must-have.
So
that's
why
we're
hitting
it
here
towards
the
end
and
it's
building
upon
the
concepts
that
we've
covered.
An
include
statement
is
how
you
bring
in
external
yaml
files
to
your
git.
Live
CI
configuration
it's
helpful
because
it
allows
you
to
abstract
common
components
and
improve
readability.
B
It
can
save
you
a
ton
of
time
if
you
utilize,
other
templates
gitlab
comes
with
many
templates
as
part
of
your
install,
so
all
of
our
out
of
the
box
tests
like
SAS
Secrets
detection.
If
you
use
an
include
statement,
that's
all
you
have
to
do
it's
going
to
pick
up
the
appropriate
language.
A
code
was
written
in
and
it
scans
for
all
of
the
SAS
rules.
In
that
example,
Secrets
detection
same
thing:
it's
not
meaningless,
it's
dependent,
but
you
just
add
the
include
statement
for
Secrets
detection
and
boom.
B
It's
going
to
take
care
of
the
rest.
It's
like
two
lines
of
code.
So
that's
why
it's
so
powerful
and
it
saves
a
lot
of
time.
There's
different
methods
for
doing
this.
I
talked
about
the
the
templates
right,
which
are
provided
by
gitlab
at
the
very
bottom
here,
but
you
can
also,
you
know,
include
a
file
from
your
local
project
repository
that's
sort
of
the
parent
child
example.
I
gave
in
the
in
the
Architects
five
different
architectures
of
writing
a
pipeline.
B
So
that's
the
local
include,
if
you're,
just
trying
to
find
it
within
your
your
own
project
file.
If
you
want
to
include
a
file
from
a
different
project
repository
and
then
remote,
if
you
want
to
include
a
file
from
a
remote
URL,
so
if
there's
something
just
publicly
out
there
on
like
public
gitlab.com
that
you
want
to
pipe
in,
it
needs
to
be
public
visibility.
But
you
can
do
that
and
here's
the
examples
on
the
Syntax.
For
writing.
Those
includes.
B
Extints
is
another
way
to
improve
efficiency
and
you
know
eliminate
needs
for
rewriting
or
writing
lengthy
code
in
your
yaml
file
so
extends
a
similar
to
gamble
anchors,
but
it's
a
little
bit
more
flexible
and
readable,
so
I
did
want
to
touch
on
this
it'll.
Allow
you
to
enhance
and
reuse
configuration
sections.
B
We
say
you
know
no
more
than
three
just
for
performance
reasons
and
then
what
it
does
is
it
merges
the
configurations
and
from
the
you
know,
prospective
job
into
your
current
one
and
that's
going
to
save
some
time.
So
that's
kind
of
the
example
you
see
here
with
the
dot
tests
in
our
spec
becoming
one
single
job.
B
A
Great
thanks,
Colleen
yeah
I
just
opened
up
that
poll
just
a
couple
of
quick
questions.
We
we
love
to
get
your
feedback
on
on
today's
session
and
with
that
there
have
been
a
couple
of
questions
come
through
only
that
all
I'll
pose
to
you
to
to
answer
the
first
one
here.
What's
the
difference
between
Jenkins
and
gitlab
CI.
B
Yeah
this
is,
you
know,
kind
of
the
incumbents
one
of
the
original
best
ways
to
run.
Automation
for
for
your
projects
was
with
Jenkins,
and
so
fundamentally,
we
approach
it
different
than
Jenkins,
which
is
a
plug-in
based
model
where
you're
trying
to
maintain
install
upgrade
all
the
appropriate
plugins
to
kind
of
extend
the
features
of
Jenkins,
and
so
that's
got
inherent
risks
and
overhead
that
you
know
you
have
to
keep
upgrading
you
have
to
maintain,
which
could
be
very
intense,
especially
at
scale.
B
You
need
basically
a
couple
sres
to
do
this
properly
versus
the
gitlab
way
of
going
about
CI,
which
is
we're
going
to
give
you
those
templates
out
of
the
box.
It's
not
plug-in
based,
it's
infrastructure
is
code,
so
you
can
check
that
into
your.
Your
project.
Repositories
run
all
the
same
lensing
and
testing
on
that
that
you
would
your
actual
code,
so
it
just
facilitates
you
know
more
reusability
and
collaboration
across
you
know
the
Enterprise
and
so
very
fundamentally
different
ways.
B
A
B
Yeah
this
is
like
what
we
we
handle.
You
know
day
in
and
day
out,
our
customers
are
trying
to
ensure
that
they're
covered
across
the
Full
Slate
of
applications.
In
case
they
log
for
J
or
an
audit
comes
up.
How
can
you
ensure
that
you're
getting
the
same
rigor
across
hundreds
or
thousands
of
projects?
So
we
didn't
go
into
it
too
much
in
this
talk,
but
there
is
a
whole
section
of
gitlab
just
focus
on
compliance
and
making
sure
that
a
set
number
of
jobs
scans-
you
name,
it
runs
across
your
full
site
application.
B
So
I'd
encourage
you
to
look
into
the
compliance
framework
in
the
compliance
pipelines.
Those
are
two
ways
that
you
can
apply
a
label
to
your
project
systematically
and
then
that
will
pipe
in
a
gitlab
ciml
that
runs
ahead
of
the
local
project,
so
you
can
put
in
there
any
thing
you
want
and
the
developers
can't
change
that
unless
you
want
them
to,
but
you
probably
don't
and
so
there's
ways
to
make
sure
that
they
they
can't
change
that.
B
A
B
If
this
is
your,
you
know
day-to-day
job
and
your
like
a
devops
engineer,
you
know
say
trying
to
write
those
templates
keep
them
up
to
date,
sort
of
that
golden
CI
image.
If
you
will
like
there's,
there's
definitely
training
resources
that
get
lab
provides.
We've
got
our
own
certification
path
that
you
can
take
for
becoming
get
last
CI
intermediate
and
professional
as
well.
As
you
know,
just
getting
the
the
gist
of
best
practices
in
devops,
I,
highly
recommend
the
AWS
devops
engineer
professional
course
different
tooling.
B
It
may
even
make
you
appreciate
kitlab
more.
It
certainly
did
for
me,
but
it's
very
valuable
knowledge
to
have
here
trying
to
take
this
as
a
profession
and
go
deeper
and
deeper.
Then
you
know
I'd
recommend
those
those
different
options,
starting
with
Git
Live's
own
training.
So
you
get
all
the
nuances,
but
you
know
broader
speaking,
there's
there's
great
content
in
other
tools
and
platforms
too.
A
Awesome,
thank
you
well,
I
think
we're
we're
getting
close
to
just
about
here
at
time,
so
appreciate
everyone's
time
today.
Thank
you,
Conley
for
the
great
presentation
and
thanks
everyone
for
the
great
questions
that
came
through
I
think
this.
This
was
a
really
engaging
session,
so
with
that
we
will
wrap
up
and
and,
like
we
said,
we'll,
be
sending
out
the
slides
and
the
and
the
recording
here
in
the
next
day
or
so
have
a
good
rest.
Your
day,
everybody.