►
Description
Watch the playback for a hands-on GitLab CI workshop and to learn how it can fit in your organization!
We will kick things off by going over the differences between CI/CD in Jenkins and GitLab, syntax requirements, advantages to using GitLab, and how you can achieve the same outcomes in GitLab. Getting started with CI/CD in GitLab will take a lot less time than tends to be required for Jenkins, and your users can stay in a single platform.
We will then dive into how to build simple GitLab pipelines and work up to more advanced pipeline structures and workflows, including security scanning and compliance enforcement.
A
A
A
So
if
you
would
mind
doing
that
through
the
session,
okay
folks,
we
still
have
people
joining
in,
but
we'll
get
started
as
we
have
a
lot
to
cover
today.
So
hello
and
welcome,
and
today's
session
we're
going
to
be
covering
gitlab
CI
for
Jenkins
users.
Today,
you're
going
to
be
provisioned
with
a
gitlab
ultimate
account
on
gitlab.com,
so
you
will
need
a
gitlab.com
username
to
be
registered
for
the
session.
A
A
You'll
also
have
access
to
the
training
environment
that
we
provisioned
today
for
the
next
four
days,
I
believe
and
finally,
I
do
have
my
colleagues
available
in
the
Q
a
section
of
Zoom
which
I
just
mentioned.
It's
not
the
chat
box.
It's
alongside
of
please
pop
your
questions.
In
there
we'd
ask
you
all
to
remain
on
mute
during
the
session,
just
so
that
we
can
keep
the
flow
going.
We've
a
lot
to
cover.
A
A
So
my
name
is
Justin
Conrad
I'm,
a
customer
success
engineer
here
at
gitlab
and
I
work
on
the
scale
team,
which
means
I,
mostly
Handler,
emea,
Enterprise
accounts,
it's
a
great
job,
I
love
working
here,
I
love
working
with
all
of
you
guys
and
your
your
efforts
with
devsecops
and
leveraging
gitlab
after
today's
session.
Please
feel
free
to
connect
with
me
whether
it's
on
LinkedIn
or
taking
a
look
at
some
of
my
contributions
on
gitlab
itself.
A
So
Jenkins
and
gitlab
so
I
guess
to
kick
us
off
today.
What
we're
going
to
do
is
take
a
quick
look
at
the
differences
between
Jenkins
and
gitlab
for
cicd,
and
this
is
mostly
to
give
you
a
sense
of
how
you
can
start
translating
your
pipelines
over
to
gitlab
when
we're
done
with
that
we'll
get
into
our
Hands-On
Workshop
the
material
there.
A
A
So
we're
going
to
start
talking
about
some
of
the
gitlab
platform
advantages
and
one
of
the
main
ones
is
reduced
tool.
Switching
so
people
are
having
to
make
their
commits
in
gitlab
and
then
go
over
to
Jenkins.
Cedar
manually
run
their
pipeline,
or
perhaps
you
have
a
trigger
setup
to
do
that,
for
you
with
gitlab
pipelines
operate
within
the
project,
where
developers
actually
create
their
commits
and
merge
requests,
you
can
access
all
pipelines
on
a
Project's
pipelines,
page
meaning
that
developers
don't
have
to
switch
tools
to
review
pipelines.
A
A
These
security
policies
are
actually
covered
in
some
of
the
optional
steps
of
today's
Workshop,
so
feel
free
to
go
through
them.
After
our
session
today,
as
I
said,
your
training
environment
will
be
provisioned
and
it'll
stay
alive
for
four
days.
I
believe
so
having
an
ultimate
subscription
will
also
allow
for
the
creation
and
enforcement
of
compliance
framework
pipelines
that
can
also
be
used
with
security
audits.
So
there's
a
difference
there
in
what
you
get
with
the
ultimate
subscription.
This
deck
will
be
shared
afterwards
and
you're
going
to
see
a
lot
of
stuff
underlying
throughout.
A
A
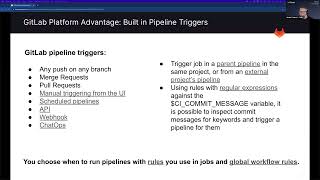
So
if
we
look
at
the
list
of
what
will
the
pipeline
get
triggered
by
you've
got
any
push
in
any
branch,
merge
requests
you've
got
scheduled
pipelines
which
run
GitHub
c,
o
CD
pipelines
at
regular
intervals.
You
can
trigger
them
via
an
API,
so
trigger
a
pipeline
for
a
specific
Branch
or
tag
with
an
API.
You
also
have
manual
triggering
from
the
UI,
which
we
will
actually
cover
today
as
well.
You'll
get
to
see
it
in
the
UI.
You've
got
web
hooks,
chat,
Ops
and,
of
course,
pull
requests.
A
The
main
instance
is
going
to
pull
everything
in
and
as
well
that's
an
option
if
you
need
to
take
that
route,
it's
also
possible
using
rules
with
regular
expression
against
the
CI,
commit
message
variable
and
it's
actually
possible
to
inspect
the
commit
message
and
look
for
you
know
certain
keywords
and
Trigger
pipeline
for
them.
So
that's
a
really
nice
option
there.
You
can
see
that
there's
so
many
ways
that
you
can
trigger
and
pipelines
and
it's
important
to
explore
in
a
while
to
see
what
best
fits
your
development
life
cycle.
A
One
of
the
use
cases
here
might
be
you
know,
maybe
you
don't
want
to
run
pipelines
for
every
single
portion
of
feature
Branch,
but
maybe
a
developer
once
in
a
while
wants
to
run
a
linter.
So
you
could
look
for
a
keyword
in
there
and
then
trigger
the
pipeline
with
them
entering
it.
And
if,
if
you
wanted
to
go
around
that
around
it,
that
way.
A
A
Now
the
really
neat
thing
about
this
is
that
users
who
are
triggering
the
pipelines
have
the
ability
to
pull
these
pipelines
the
pipeline
files
into
their
project
and
there's
a
couple
of
different
ways
that
that
can
happen,
and
but
all
that
they
have
to
have
is
read
access
to
that
Upstream
repository
that
has
the
pipeline
definitions
in
it.
So
essentially,
your
devops
seams
can
maintain
these
projects
that
have
the
template
repositories
in
them,
and
they
don't
have
to
worry
about
everybody
being
able
to
commit
to
it
so
with
the
pipeline
template
repositories.
A
One
thing
to
note
is
that
when
you
pull
these
files
in
and
run
them
as
pipelines
in
a
downstream
project,
they're
going
to
use
that
Downstream
projects
variable
context,
so
that
you
have
the
ability
and
we'll
be
talking
about
this
more
as
we
go
through
the
workshop
today.
But
you
do
have
the
availability
availability
to
set
variables
in
a
whole
host
of
different
ways
and
again
in
order
for
someone
to
be
able
to
run
that
pipeline.
A
They've
got
to
have
read
access
to
that
centralized
repository,
but
that's
all
that
they
have
to
have
this
centralized
repository
down
and
talk
about
can
have
a
ton
of
different
pipelines
in
it
if
it
needs
to,
and
it
can
contain
multiple
pipeline
definitions
for
different
conditions
that
exist
in
the
downstream
pipelines
or
for
different
types
of
projects.
Even
maybe
you've
got
a
python
and
node.js
projects
and
you
can
create
independent
pipelines
for
each
of
them.
A
So
projects
can
include
pipeline
files
from
external
repos
in
their
pipeline
files
so
that
they
can
create
their
own
gitlab
CI
yaml
file,
and
then
they
can
use
an
include
statement
to
include
the
Upstream
projects
if
they
want
to,
but
for
projects
that
don't
want
to
maintain.
And
we
all
know
that
these
exist.
A
Okay,
so
this
is,
this
is
an
important
one:
jobs
run
in
isolated
environments,
so
the
jobs
you
can
think
of
them
as
stages
and
Jenkins
so
stages
and
Jenkins
tend
to
have
the
steps
delineated
below
them
that
are
going
to
run
and
so
pipeline
jobs
run
independently
of
each
other,
and
they
have
a
fresh
environment
for
every
single
one.
If
this
is
unlike
a
Jenkins
agent,
where
the
sages
actually
run
sequentially
on
that
same
agent,
the
possibility
is
in
fact
it's
a
very
real
probability.
A
So
let's
say
your
job
produces
a
variable
and
you
need
to
be
able
to
evaluate
that
variable.
In
the
context
of
a
downstream
job,
you
can
do
that
with
these
dot
EnV
files
and
which
are
an
artifact
that
the
Upstream
job
would
leave
behind,
and
the
downtrend
job
would
then
require
using
either
the
needs
or
the
dependencies
keywords,
and
then
it
can
evaluate
it
in
the
context
of
its
own
runtime
and
I
mean
by
the
way
like
get.
A
That
runs
a
cleanup
after
every
single
job
to
ensure
a
clean
working
environment
for
its
next
job,
and
the
idea
is
that
these
Runners
are,
you
know
highly
disposable
and
highly
portable
and
Runners
can
run
for
any
project.
So
these
are
unlike
agents
where
you
configure
them
fairly
specifically,
and
they
could
just
run
for
any
project
that
you've
got.
A
A
Maybe
you
would
want
to
add
some
approvals
under
that,
so
that
somebody
can
approve
of
being
released
to
production
when
you
just
configure
a
manual
job
in
the
context
of
a
commit
they're
going
to
have
a
play
button
on
them
and
we'll
actually
be
able
to
show
you
that
later
in
the
UI
as
well
and
all
manual
jobs
are
going
to
have
that
play
button
on
them
and
any
developer
can
then
run
these
manual
jobs.
So
if
they
have
the
developer
role,
it'll
appear
for
them.
A
So
the
way
that
you
get
around,
that
is,
that
you
can
use
things
like
protected
branches,
for
example.
So,
in
pipelines
for
protective
branches,
only
users
who
are
allowed
to
actually
push
or
or
merge
to
that
protective
Branch
can
run
the
manual
jobs
and
if
the
job
is
run
in
a
protected
environment
which,
by
the
way,
is
a
setting
in
your
your
projects,
you
can
actually
make,
for
example,
a
production,
the
production
environment,
a
protected
environment.
A
You
can
also
add
deployment
approvals,
and
these
are
independent
of
who
can
click
on
that
that
run
button.
That
appears
in
the
UI.
You
can
add
two
or
three
approvals,
if
you
think
that's
appropriate,
maybe
one
and
if
that's
more
appropriate
and
you
can
actually
delineate
who
those
users
are
that
have
to
be
able
to
approve
it.
A
But
you
can
also
pick
the
people
who
are
allowed
to
run
the
jobs
in
the
protected
environments
too,
and
again,
you've
got
plenty
of
links
on
this
page
and
the
previous
one
that
that
will
link
out
to
what
we're
discussing
here.
I
know
it's
it's
a
lot
of
detail.
We're
trying
to
give
you
the
the
surface
level
to
set
the
scene
for
the
rest
of
the
CIA
Workshop
But,
be
sure
to
to
dive
into
these
links
that
are
shared
in
the
deck
afterwards.
I
think
you'll
you'll
get
some
great
Insight
from
them.
A
Okay,
so
obviously
you
know,
Jenkins
has
its
own
terminology.
Github
has
its
own
terminology.
So
it's
it's
good
to
kind
of
do
what
we
call
a
terminology
crosswalk
here,
where
we
can
reference
both
and
try
to
figure
out
what
we're
talking
about.
So
essentially,
it's
the
differences
in
syntax
that
we're
talking
about
here
and
and
we'll
cover
this
for
a
few
minutes,
so
I
mean
Jenkins
agents,
which
I've
already
touched
on
they're.
What
we
call
runners
in
gitlab,
there
are
very
different
kind
of
concept.
A
Agents
tend
to
be
highly
customized
for
projects,
as
we
said,
whereas
Runners
tend
to
be
highly
disposable,
so
they
can
be
just
reused
over
and
over
and
over
again,
you
do
have
the
ability
in
Jenkins
to
create
a
host
set
of
steps.
If
you
need
it
or
a
post
job,
you
can
support
that
with
actually
additional
stages
in
gitlab.
If
you
need
to
do
it,
and
but
remember
that
you
know
our
gitlab
runners
run
cleanup
jobs
already.
So
if
you're
only
using
that
to
do
a
cleanup,
it's
not
actually
needed.
A
The
runners
will
will
do
that
themselves
and
then
first,
look
at
stages
in
Jenkins,
which
I
tend
to
see
is
something
that
we
would
call
jobs
and
gitlab
and
because
they
tend
to
have
to
you
know
steps
enumerated
underneath
them.
We
actually
have
the
keyword.
Sorry,
we
have
a
keyword,
we
call
stages
but
stages
to
us
is
a
container
for
jobs,
and
so,
when
you
see
a
gitlab
pipeline,
you'll
see
kind
of
vertical
columns
and
JavaScript
listed
in
each
one
of
the
columns
and
those
are
stages
to
us.
So
later
on.
A
As
we're
going
to
the
workshop
I'll
be
able
to
show
you
what
I
mean
by
that
we'll
have
you
know
build
tests
and
Dev
stages.
I
think
are
in
it.
So
you'll
get
to
see
that
in
a
couple
of
minutes,
but
it's
just
good
to
be
aware
of
the
difference
and
when
you
delineate
the
steps
in
a
Jenkins
stage,
that
would
be
a
script
in
a
job
in
gitlabs
pipelines.
A
Now,
when
we
talk
about
the
next
one,
their
environment,
to
us
in
gitlab,
this
is
just
variables
and
variables
can
be
declared
in
a
job.
If
you
want
to
declare
specific
to
a
job
or
they
could
declare
it
globally
for
the
entire
pipeline.
That's
an
option.
If
you
want
to
take
that
road,
or
else
I
mean
either
one
is
sufficient
to
to
get
the
job
done.
It's
just.
However,
you
want
to
do
it.
What
fits
your
best
and
the
last
one
then
options
what
you
call
options
in
Jenkins.
A
I,
don't
see
anything
in
the
the
Q,
a
so
I'm
hoping
you're
all
following
along
nicely
and
please
Leverage
The
Q
a
and
not
to
chat.
If
you
do
have
any
questions
and
they'll
be
queued
up
for
my.
My
team
members
help
you
with
cool
so
now
with
respect
to
parameters,
and
this
is
not
actually
required
in
gitlab
when
you
go
to
run
a
manual
pipeline
you're
able
to
set
any
variable
that
you
want
to.
A
So,
if
you
go
to
the
pipelines
page
and
you
hit
run
pipeline
you're
going
to
have
the
opportunity
to
create
as
many
variables
as
you
want,
you
define
the
keys.
You
decide
to
define
the
the
values
for
it,
but
it's
also
possible
for
you
to
Define
these
variables
in
your
gitlab
CI
yaml
file
and
give
them
a
default
value
so
that
when
people
go
to
run
a
manual
pipeline,
it's
already
pre-populated
with
that
default
value.
A
You
know
it's
pretty
much
supported
in
the
in
the
same
way
that
it
is
in
Jenkins
now,
with
respect
to
triggers
and
cron.
Gitlab
is
tightly
integrated
with
Git
sem
pulling
options
for
triggers
are
not
needed
and
we
support
a
Syntax
for
scheduling
pipelines
and
again
that
link
there
on
that
deck
will
bring
you
out
there.
We
don't
need
to
go
through
it
today
and
but
I
would
recommend
going
off
and
taking
a
look
at
that
not
fall.
A
A
So
this
is
the
last
of
the
kind
of
terminology
crosswalk
slides
to
cover
today
with
respect
to
tools-
and
you
know-
we've
looked
into
tools
and
Jenkins
is
only
a
few
of
them
right
now,
they're,
primarily
supporting
Java.
We
don't
have
any
kind
of
tools
Direct
in
gitlab
and
best
practices
in
git
labor.
Actually,
too,
you
know
create
containers
of
your
own
that
already
have
these
libraries
pre-loaded
in
them,
and
then
you
can
store
those
and
get
them
and
consume
them
in
your
pipelines.
A
If
you
want
to
so,
it
makes
it
very
easy
and
convenient
way
for
you
to
kind
of
sub
out.
These
containers
create
your
own
Docker
files,
or
you
know
whatever
you
need
to
do
with
respect
to
input
it's
similar
to
the
parameters
keyword
again,
it's
not
needed
because
a
manual
job
can
always
be
provided
and
the
runtime
variable
entry
so
you're
covered
there
now
gitlab
does
support
a
when
keyword,
which
is
used
to
indicate
when
a
job
should
run
in
the
case
of
or
even
despite
failure.
A
We're
going
to
move
on
now
to
the
next
portion
of
today's
workshop
and
which
will
look
and
focus
mostly
on
CI
gitlab
we're
going
to
get
Hands-On
we're
going
to
get
to
to
get
a
feel
of
these
features
and
authoring,
some
pipelines
and
I
hope
you
get
great
benefit
from
it.
So
we
can
drive
on
this.
Is
our
agenda
for
the
workshop
portion
of
today.
First
we're
going
to
go
through
lab
setup
and
provisioning
your
training
environment
on
gitlab.com,
then
we're
going
to
go
through
the
setup
of
a
very
simple
pipeline.
A
We'll
then
move
on
to
look
at
execution
order
and
directed
acyclical
graphs
and
some
rules
and
failures
like
I,
discussed
and
also
SAS
and
artifacts.
Finally,
the
last
step
will
be
optional.
It
will
cover
transferring
out
the
project
and
we
won't
actually
go
through
that
step
by
step.
But
I'll
show
you
where
to
go
and
the
instructions
to
follow.
If
you
want
to
take
the
work
that
you
did
in
today's
training
environment
and
put
it
back
out
into
your
own
namespace,.
A
Okay,
so
let's
get
started
so
for
today's
session
we
have
a
fictional
new
startup
that
you're
all
a
member
of
it's,
creating
a
public
leaderboard
for
the
hit
new
racing
game,
Tanuki
racing.
So
let's
pretend
that
your
company
has
recently
swapped
over
to
using
gitlab
for
cicd
and
you've
been
tasked
with
learning
about
all
of
the
different
pipeline
capabilities.
A
A
A
So
you're
going
to
go
to
getlouddemo.com
you're
going
to
see
this
screen
and
you
want
to
click
on
this
blue
button.
That
says
redeem
invitation
code
now,
once
you
click
on
this
you're
going
to
be
brought
to
this
screen,
and
it's
this
invitation
code
here,
the
one
that
I
pasted
into
chat
that
you're
going
to
want
to
paste
in
there
you're
going
to
want
to
put
today's
invitation
code
into
the
box
and
just
click
on
the
blue
provision,
training
environment
button.
A
A
If
you
go
to
gitlab.com
or
if
you
know
it
already
great,
but
if
you
need
to
retrieve
it
on
gitlab.com,
if
you're
using
the
old
UI
and
your
profile
picture
will
be
in
the
top
right
hand
corner
if
you're
using
a
new
UI
it'll
be
in
the
top
left,
wherever
it
is,
click
on
your
profile
picture,
you'll,
get
a
drop
down,
you'll,
see
your
name
and
then
below
it.
You'll
see
your
username.
Now
it's
very
important
exclude
the
ad
symbol.
A
So
in
my
example
here
all
I
want
is
the
J
Conrad
2..
You
do
not
want
to
include
the
atom,
but
if
you
do,
it
won't
work.
So
if
you
can
grab
your
gitlab.com
username
you're
going
to
pop
it
in
box,
alongside
where
it
says,
getlive.com
username
paste
it
in
there
and
click
on
provision,
training,
environment.
A
A
Essentially,
this
is
going
to
be
your
link
to
the
provision,
training
environment.
You
can
get
there
by
clicking
the
URL
or
my
group,
so
I'm
going
to
go
ahead
and
do
it
now
follow
along,
if
you
don't
already
have
it
done
so
again,
this
is
gitlabdemo.com
I'm,
going
to
click
on
redeem
invitation
code,
I'm,
going
to
copy
today's
invitation
code,
paste
it
in
Vision,
training,
environment
and
my
username
great
now,
at
this
point,
I
can
click
here
or
here
it
will
bring
into
the
same
place
yeah.
This
is
what
you
should
end
up
with.
A
This
is
where
you
should
be.
This
is
your
training
environment
for
today,
and
if
you
get
to
this
stage,
which
you
all
should
by
now,
what
I'd
like
you
to
do
is
take
note
of
this
string.
So
you'll
see
it
after
my
test
group.
This
string
here
will
be
very
handy
for
a
future
step
where
we're
forking
a
source
project
for
today's
Workshop.
A
Alrighty
the
hero
I
can
see
you
in
the
chat
there.
If
you
don't
have
gitlab.com
account
you're
going
to
want
to
go
to
gitlab.com
or
users
forward,
slash
sign,
underscore
up
I
believe
it
is
and
set
up
a
sorry,
I
typed
in
gitlam
gitlab.
Obviously,
but
that's
the
link
it's
forward,
slash
users
or
as
a
sign
up
and
Morgan.
Maybe
you
can
paste
in
the
correct
link
there
for
the
hero
and
but
we
all
do
need
that
gitlab.com
username.
You
can
sign
up
for
a
free
one.
There.
A
Boom
Okay,
so
I
don't
see
any
major
chat
about
anyone
having
issues
with
anything
up
to
that
stage,
which
is
awesome,
I
trust
you're.
All
here
we've
copied
this
string,
put
it
somewhere
safe.
If
at
any
stage
you
got
this
or
anything
that
looks
like
that,
any
other
errors
you've
gone
wrong
somewhere,
there's
obviously
been
a
Miss
click
or
something
has
happened.
Reach
out
to
q,
a
either
myself
or
Morgan
will
help
you,
since
we
get
a
chance
and
we'll
send
you
in
the
right
direction.
A
A
So,
first,
what
I
want
you
all
to
do
is
click
on
the
link
that
I'm
going
to
paste
into
the
chat
gone
in
now.
So,
alas,
that
you
all
click
on
that
link,
I'm
going
to
do
it
now
myself
here
and
you
can
just
follow
along
with
me
on
the
screen
for
this
portion.
Essentially,
this
is
the
link
I
just
gave
you
and,
on
the
left
hand
side
you
can
see
that
this
is
the
training
environment.
A
What
I'm
saying
here
is
basically
telling
gitlab
I
want
you
to
Fork
this
source
project
into
my
training
environment,
I'm,
keeping
everything
else
standard
and
in
here
I
just
paste
it
in
that
string
and
I
select
the
only
option
that
appeared
for
me
now:
I'm
going
to
click
on
Fork
project
and
take
maybe
20
30
seconds.
Sometimes.
A
Great
when
it's
done
and
it's
completed
successfully
you're
going
to
see
this
little
notification
of
the
top
saying
the
project
was
successfully
forked
and
actually
over
here,
on
the
left
hand
side,
if
I
refresh
now,
we
should
see
that
it's
in
there
and
it
is
brilliant.
So
you
can
click
into
your
project
and
you
can
pretty
much
close
the
screen
over
here,
because
I'm
going
to
give
you
something
else
in
a
couple
of
minutes,
I'll
give
you
the
instruction
set.
A
Thank
you,
alrighty
I,
don't
see
any
major
questions
or
chatter
related
to
it.
So
hoping
you
all
followed
along
with
those
steps
and
your
Workshop
is
now
forked
just
again
to
cover
it.
Click
on
the
link
I
gave
you
in
chat
click
on
Fork
up
the
top
right
paste
in
your
workspace
or
your
training,
environment,
string
and
click
on
four
project,
and
this
is
the
next
step
that
we
want
to
do,
which
is
actually
removing
that
fork
relationship.
A
So
to
do
that,
you're
going
to
want
to
go
to
settings
in
general,
so
settings
in
the
left-hand
bar
and
then
General
and
you're
going
to
want
to
expand
out
Advanced.
If
you
scroll
right
down
to
the
bottom,
it
should
be
maybe
second
or
third
from
the
bottom.
You
want
to
click
on,
remove
Fork
relationship.
So
let's
go
do
that
now.
A
So
again,
I'm
in
my
project
on
the
left
hand,
side
I'm,
going
settings,
General,
I'm
scrolling
down
to
Advanced,
expand
you're,
going
to
remove
Fork
relationship.
It
asks
you
to
copy
and
paste
the
name
or
that
actually
asks
you
to
type,
but
you
can
copy
and
paste
the
name
of
the
workshop
click
and
confirm
again.
This
will
take
a
couple
of
seconds
and
off
the
top.
The
fork
relationship
has
been
removed
once
you
get
to
that
stage.
Just
click
on
this
bring
you
back
to
the
project
overview.
A
I've
just
fired
it
into
the
webinar
chat
and
I'm
going
to
open
it
up
alongside
here,
and
this
is
pretty
much
all
you
should
be
working
with
for
today.
So
on
the
right
hand,
side
or
the
left
hand
side
whatever
way
you
want
to
organize
it,
but
on
one
side
have
your
instructions
and,
on
the
left
hand,
side
have
your
training
environment.
A
You
can
see
here
one
through
four
the
steps
I'm
going
to
cover
with
you
today.
Five
is
totally
optional.
That's
if
you
want
to
transfer
the
project
out
afterwards
into
your
own
environment
and
then
six
and
seven
are
completely
optional
and
they
should
be
done
after
today,
at
some
stage,
as
I
said,
you're
going
to
main
access
or
keep
access
to
the
training
environment
for
a
couple
of
days.
So
it's
good
to
get
in
and
you
know
try
out
these
extra
features.
A
So,
let's
start
with
a
very
quick
reminder
on
how
gitlab
pipelines
work,
so
pipelines
are
defined
per
project
in
the
gitlab
CI
yaml
file
and
that's
always
stored
in
the
Project's
root
folder.
So,
firstly,
what
you're
seeing
here
up
on
this
screen
in
the
columns
or
the
stages
and
in
particular
we're
seeing
the
build
test
and
deploy
stage.
A
You
can
see
them
here
so
build
test
and
deploy
and
beneath
them
you
can
see
that
they
all
have
jobs
associated
with
each
so
to
build
and
deploy
stages
both
have
one
job
each
and
the
test
job
or
sorry.
The
test
stage
has
two
test
jobs
test
a
and
test
B.
So
you
can
see,
we've
got
three
stages.
These
two
only
have
one
job
and
test
then
has
two
jobs.
A
One
thing
to
know
about
gitlab
pipelines
is
that
by
default,
all
jobs
in
the
stage
must
complete
successfully
before
proceeding
to
the
next
stage.
So
in
our
example,
here
the
build
job
in
the
build
stage
would
have
to
complete
successfully
before
the
jobs
in
the
test.
Stage
can
never
begin,
and
the
other
thing
to
know
is
that
jobs
run
independently
and
sometimes
even
on
different
runners,
meaning
simply
that
you
can
execute
as
many
jobs
at
any
one
time
as
you
have
Runners.
A
Okay,
so
we're
going
to
take
a
quick
look
at
Job
statements,
so
in
this
job
in
particular
this
one
here
that
we're
looking
at
and
named
production
that
runs
in
the
deploy
function
stage.
You
can
see
that
the
before
script
and
script
statements
are
used.
So
there's
your
before
script
and
there's
your
script
statement
and
whenever
you're
writing
a
job,
you'll
always
have
the
script.
Keyword
defined
a
script
is
actually
the
only
required
keyword
that
a
job
needs
and
without
it
the
job
just
wouldn't
have
anything
to
do.
A
In
addition
to
script,
you
can
also
have
before
script
and
after
script,
and
so
before
script
runs
before
the
script
statement,
but
it
actually
runs
in
the
same
shell.
Its
main
purpose
is
to
run
steps
that
are
necessary
in
order
for
this
script
statements
to
actually
execute
properly.
A
good
example
will
be
a
before
script.
Installing
AWS
CLI
with
script
then
executing
some
AWS
CLI
commands
like
the
before
script.
A
There
is
an
after
script
and
that's
optional
after
script
runs
after
the
actual
script
keyword,
and
it's
worth
noting
that
after
script,
statements
are
executed
in
a
separate
shell
again,
a
good
example
of
uses
for
after
script
would
be
cleanup.
So
you
can
also
I
mean
it's
worth
noting
that
you
can
actually
evaluate
the
exit
code
of
script
in
after
script
and,
have
you
know
some
sort
of
additional
job
behaviors,
depending
on
the
result.
A
Cool,
so
let's
look
at
gitlab
Runners,
a
gitlab
runner
is
an
application
that
works
with
gitlab
cicd
to
run
jobs
in
a
pipeline.
When
you
register
a
runner,
you
can
actually
add
tags
to
it
and
when
a
cicd
job
runs,
it
knows
which
Runner
to
use
by
looking
at
these
assigned
tags
tags
are
actually
the
only
way
to
filter
the
list
of
available
Runners
for
a
job.
A
Okay,
so
in
terms
of
importing
the
application,
we
don't
need
to
do
that.
That's
just
the
forking,
the
source
project
we've
already
covered
that
you
want
to
scroll
down
to
step
two
immediately
and
look
at
creating
a
simple
pipeline.
So
first
click
the
project
overview
on
the
top
left
of
the
screen,
which
for
us
here
is
just
click
on
cicd
adoption.
Workshop
bring
you
to
this
page.
That's
your
project
overview
page
and
now
that
we
have
our
project
here.
We
want
to
go
ahead
and
take
a
look
at
the
gitlab
CR
yaml
file.
A
Now,
to
do
that,
we're
not
just
going
to
click
in
here
I'm
actually
going
to
bring
you
somewhere
else.
So
if
you
click
on
build
and
left
hand
side
and
go
to
pipeline
editor
so
again,
on
the
left
hand,
side
build
and
then
pipeline
editor.
This
opens
up
your
gitlab
CI
yaml
file
in
a
place
where
we
can
make
changes
live,
which
is
fantastic
and
it
does
things
like
you
know:
you'll
be
allowed
to
visualize
the
changes
you're
making
validate
the
syntax
that
you're
using
and
stuff
like
that.
A
So
I
like
to
recommend
using
the
pipeline
editor
for
this
stuff
and
cool,
so
you're
going
to
go
to
build
pipeline
editor
and
you'll.
Have
this
open
in
front
of
you
notice
that
we
have
a
simple
pipeline
already
defined?
We
have
two
stages,
build
and
test
which
you
can
see
up
here.
We've
defined
two
stages,
as
well
as
a
build
app
job,
which
is
this
guy
here
and
also
a
unit
test
job,
which
is
this
guy.
A
So
in
the
unit
test,
job,
which
is
this
one
down
the
bottom
here-
we
want
to
use
the
after
script
keyword
to
Echo
out
that
the
build
is
completed
so
first
to
edit
the
pipeline.
We
need
to
go
to
the
pipeline
editor
we're
there
already.
That's
fine,
and
essentially
what
we
want
to
do
is
add
in
this
after
script
keyword
and
it's
going
to
Echo
build
that
job
as
run.
You
have
two
ways
you
can
do
this.
A
You
can
pick
this
guy
off
by
copying
him
directly
here
and
pasting
below
the
the
script
section
make
sure
your
indentation
is
correct,
or
else
it
won't
work.
That's
one
way
of
doing
it.
The
other
way
of
doing
it
is
you
can
just
copy
this
whole
block,
because
it's
saying
your
new
unit
test
job
should
look
like
this.
You
can
see
the
after
script.
A
Keyword
is
included
and
you
can
just
replace
the
existing
block
with
that
block
either
or
will
do
the
job
once
you've
added
the
code,
you
can
go
ahead
and
click
on
Commit
changes
which
I'm
going
to
do
right
now,
and
it
should
immediately
trigger
the
pipeline
to
build
if
no
issues
were
detected
in
yaml
file,
which
they
shouldn't
be
and
for
troubleshooting.
You
can
use
a
validate
tab
to
see
when
your
pipeline
is
broken.
It's
it's
very
handy.
It's
this
guy
here
and
doing,
and
you
can
see
exactly
what's
happening.
A
You
can
see
that
the
simulation
for
our
example
completed
successfully
without
no
issues,
definitely
something
we're
playing
with
later
on
cool.
So
what
we
want
to
do
is
actually
go.
Look
at
that
change,
that
pipeline
running
for
a
change
so
we're
going
to
go
to
build
and
Pipelines
you
see.
Mine
is
still
running.
That's
okay,
I'm
going
to
click
onto
it!.
A
Alrighty
so
we've
gotten
our
simple
pipeline
set
up
and
we've
added
in
that
after
script
for
a
unit
test
job
we're
going
to
go
back
and
look
at
that
a
little
bit
later,
but
right
now
we're
going
to
talk
about
a
slightly
more
advanced
scenario,
with
job
execution
order
and
dags.
When
I
say
dags
I
mean
directed
acyclic
graphs,
as
you
can
imagine,
dags
is
a
lot
easier
to
say.
A
So
let's
talk
a
little
bit
about
execution
order
and
what
happens
by
default.
So
by
default
in
our
simple
pipeline
that
we
created
and
all
of
the
jobs
in
every
stage,
most
complete
successfully
before
the
next
stage
begins
no
jobs
execute.
Unless
all
the
preceding
jobs
are
successful
and
once
a
job
fails,
the
pipeline
execution
stops
completely
and
subsequent
jobs
will
not
be
executed.
So
in
our
example,
let's
imagine
buildup
fails
build
that
job
in
the
build
stage.
A
A
What
about
if
we
want
to
adjust
and
the
execution
order
of
a
pipeline
to
increase
efficiency,
so
the
pipeline
graph
shows
us
pipeline
stages
and
jobs.
That's
this
guy
over
here,
we've
just
seen
it
in
DUI
and
in
terms
of
execution
order.
In
this
scenario,
let's
imagine
that
the
QA
team
added
this
code
quality
job
to
the
test
stage.
A
It
makes
perfect
sense
that
this
job
should
be
added
to
the
pipeline,
but
one
drawback
is
that
it
means
that
by
default
it
can't
start
until
the
build-up
job
in
the
build
stage
completes
in
an
ideal
setup.
What
we'd
actually
like
to
achieve
is
that
these
jobs
run
in
parallel.
You
don't
want
the
core
quality
jobs
sitting
around
waiting
for
build
app
to
complete
before
it
can
start
because
they're
separate
separate
jobs,
separate
purposes,
and
if
we
can
do
that.
Obviously
it'll
boost
the
speed
at
which
the
pipeline
can
complete
and
increase
efficiency.
A
So
how
do
we
do
that
and
kind
of
an
adjustment
on
the
job
execution
order
and
we're
going
to
look
at
how
you
can
do
it
by
using
the
needs?
Keyword,
the
first?
Actually,
while
we
were
talking
about
code
quality,
it's
worth
mentioned
in
gitlab,
those
actually
have
a
call
Quality
template
and
they
can
also
be
used
and
will
cover
towards
the
end
of
today's
session,
how
those
templates
work
and
how
you
can
use
them.
It's
good
to
know
that
we
actually
offer
one
there
that
you
can
all
use
in
your
Pipelines.
A
So
now
you
can
see
at
the
end
of
this
code,
quality
job
snippet
that
we
have
here
you'll
see
the
needs.
Keyword
has
been
added
to
the
end
line,
and
this
keyword
allows
us
to
specify
which
other
jobs
need
to
be
run
before
this
job
can
start.
I
believe
in
this
needs
keyword,
value
empty,
we're
actually
asserting
that
this
code
quality
job
can
be
run
as
soon
as
the
pipeline
begins.
It
doesn't
need
anything
else
to
complete
it,
fires
up
straight
away,
and
it
can.
A
So
that's
the
needs
keyword
in
a
very
basic
setup.
You
can
actually
get
really
complicated
with
the
needs
keyword
if
you
want
to
or
Advanced
I
should
say
any
pipeline
that
has
more
than
tree
needs
in.
It
will
also
generate
what
we
call
a
directed
acyclic
graph.
A
dag
a
die
can
be
used
in
the
context
of
a
CI
CD
pipeline
to
build
relationships
between
jobs
such
that
execution
is
performed
in
the
quickest
possible
manner,
regardless
of
how
many
stages
may
be
set
up.
A
So
in
the
example
that
you
can
see
here
using
dike,
you
can
actually
relate
the
a
jobs
separately
from
the
B
jobs.
So
even
if
servers
a
has
taken
a
very
long
time
to
build
service,
B
doesn't
wafer
and
finishes
as
quickly
as
it
can.
A
good
example
of
this.
A
good
way
to
to
to
describe
it.
I
guess,
would
be
the
development
of
an
application
that
would
be
destined
for
Bose,
Android
and
iOS
platforms.
So
you
know
the
test.
A
It
is
worth
noting
another
use
case
that
actually
creates
a
stateless
pipeline.
That's
called,
and
essentially
you
can
build
a
stages
pipeline
where
you
declare
needs
on
every
single
job
in
general.
We
don't
recommend
it
as
it's
much
clearer
and
easier
to
follow.
If
you
just
do
the
jobs
by
category
settle,
but
it
is
worth
noting
that
it's
there
as
an
option
and
and
if
you're,
in
a
position
where
you
could
express
your
pipeline
100
by
only
using
the
needs
keyword,
it
can
increase
efficiency.
A
But,
as
I
said,
it's
not
really
our
go-to
okay
cool
time
first
stay
step,
two
in
our
Hands-On,
so
execution
order
and
dice
I'm
going
to
jump
back
over
here.
Hopefully
our
pipeline
is
finished,
running
quick,
refresh
yeah.
It
has
cool.
So
you
might
remember
in
our
last
step
we
edited
this
unit
test
job
to
include
an
after
script.
A
A
A
You
should
still
be
on
the
pipelines
page
we've
navigated
away
from
this.
So
that's
all
fine.
Basically,
what
we
want
to
do
here
is
go
back
to
our
pipeline
editor.
So,
on
the
left
hand
side,
if
you
can
click
on
build
and
go
back
to
pipeline
editor.
We're
going
to
go
back
in
here
now
make
a
couple
more
changes.
A
A
Now,
what
we've
done
here
is
we've
said
that
the
unit
test
job
needs
no
other
job
to
complete
to
start
running
and
cold
quality
job
needs,
no
other
job
start
running,
so
to
start
our
pipeline
when
it
kicks
off.
These
should
kick
off
straight
away
and
and
we'll
see
that
now
in
a
moment
again
I
added
lines
in
line
by
line.
If
you
want
to
just
copy
the
block,
you
can
do
it
here.
You
can
say
it.
Look.
The
new
unit
test
job
should
look
like
this.
A
Now
we're
going
to
use
the
left
hand
menu
again
to
go
to
build
and
Pipelines
and
mine
is
pending,
it's
probably
just
pending
for
an
available
Runner,
so
our
Runners
are
kind
of
scaled
for
these
training
environments
that
might
take
a
moment
to
have
something
available
to
actually
run
it.
For
me.
Okay,
it
started
now.
You
can
see
the
jobs
in
my
test
stage,
aren't
waiting
for
my
jobs,
my
bill
stage
to
run
anymore
or
to
complete
anymore,
because
we
had
added
those
empty
needs.
A
A
A
You
can
see
that
the
first
change
we're
making
here
is
we're
adding
in
the
new
stage,
so
we're
actually
adding
a
deploy
stage.
I'm
just
going
to
type
it
in.
You
can
copy
and
paste
this
block.
If
you
want
now
all
of
these
jobs,
we
want
to
add
in
underneath
our
code
quality
job,
and
these
are
all
going
to
generate
the
dike
that
we're
talking
about.
You
can
see
they're
all
super
simple
jobs,
but
what
you
do
see
as
well
is
that
their
needs
keywords
are
defined.
A
A
Okay,
now,
if
you
click
on
the
visualize
tab,
you
can
see
just
how
complex
the
many
stages
are.
So
you
remember
earlier
I
said
that
we
have
this
visualize
and
validate
type
they're,
so
helpful.
If
you
go
into
the
visualize
one
you're
going
to
see
this
relationship
all
show
off
now,
you'll
see
exactly
the
okay.
Deployee
actually
needs
test
e,
which
needs
building
and
so
on
and
so
forth.
So
that's
a
really
nice
way
of
looking
at
it.
Now
you
can
go
back
to
edit
and
click
on
Commit
changes.
A
Foreign
once
you've
committed
those
changes,
you
want
to
go
to
build
Pipelines,
and
you
can
see
here.
My
latest
one
is
running
I'm
just
going
to
click
into
it.
This
way
now
there's
a
couple
of
ways.
I
can
show
you
this.
You
can
see
here
on
this
default
view.
It's
grouped
jobs
by
stage,
so
you've
got
build
test
and
deploy.
A
You
can
also
group
it
by
dependencies,
which
shows,
especially
if
you
click
on
show
dependencies,
we'll
show
you
that
build
B
needs
test,
b
or
sorry
deploy,
B
needs,
test,
B
needs,
build,
B
and
so
on
and
so
forth.
The
other
way
of
looking
at
it
I'm
just
going
to
revert
that
back
to
the
way
it
was
is
by
actually
clicking
on
this
needs.
A
A
Okay,
folks,
we've
an
hour
done
and
I
think
it's
a
good
time
for
us
to
take
a
quick
break
by
my
time.
It's
two
minutes
to
the
hour.
So
let's
meet
back
at
five
past,
so
five
minutes
pass.
We
will
kick
it
off
jump
into
rules
and
failures
and
start
with
the
the
other
Hands-On
sections.
So
we'll
see
you
back
here
at
five
minutes
pass.
A
A
Sometimes
we
want
to
actually
allow
a
job
to
fail
and
for
it
to
be
flagged
as
failing,
but
not
stop
the
execution
of
the
rest
of
the
pipeline.
Now,
to
achieve
this,
we
can
use
the
allow
failure
keyword
on
the
job.
You
can
actually
see
it
down
here
on
this
job
here.
This
unit
test
job
setting,
disallow
failure,
keyword
with
a
value
of
true
means
that
subsequent
jobs
will
continue
to
execute,
even
if
this
job
fails.
So
you
might
remember,
at
the
start,
I
spoke
with
default
execution
and
stuff
like
that.
A
A
In
the
example
here,
you
can
actually
see
we've
added
dll
failure,
obviously
to
this
test
B
job,
and
this
is
actually
a
manual
job.
That's
where
you
see
the
play,
but
that's
like
one
we
referred
to
earlier,
but
if
this
was
a
non-manual,
if
it
was
just
a
standard
job,
it
would
have
started
executing
because
thesp
is
actually
allowed
to
fail.
You'll
always
see
that
Amber
exclamation
mark
If
a
job
has
failed
cool.
A
So
when
is
the
job
created
in
pipeline
when
a
new
pipeline
starts
gitlab
checks,
the
pipeline
configuration
to
determine
which
jobs
should
run
in
that
pipeline,
so
you
can
configure
jobs
to
run
depending
on
many
factors
like
the
status
of
variables
or
even
the
pipeline
type,
to
configure
a
job
to
be
included
or
excluded
from
certain
pipelines.
We
use
rules
and
it's
important
to
know
that
rules
are
evaluated
in
order
until
the
first
match.
A
Then,
when
a
match
is
found,
the
job
is
either
included
or
excluded
from
the
pipeline,
depending
on
the
configuration
default
behaviors
that
the
job
is
always
created
in
the
pipeline,
because
the
keyword
when
defaults
to
on
success,
we
also
know
that
the
default
behavior
of
a
job
is
to
stop
a
pipeline
if
it
fails,
because
the
keyword
allow
failure
defaults,
false
so
to
be
clear,
a
job
is
included
in
a
pipeline.
If
a
rule
evaluates
to
true
and
has
a
clause
of
when
on
success
went
later
when
always
or
no
rule
is
defined.
A
In
terms
of
evaluating
when
a
job
runs,
and
it's
worth
noting
that
rules
always
evaluate
prior
to
the
script
block,
if
statements
in
the
rules
block
can
reference
variables
as
well.
So
if
we
talk
about
what
exactly
can
this
rules
keyword?
Do
they
can
evaluate
lists
of
conditions?
They
can
evaluate
conditions
based
on
selected
attributes
of
a
job
and
they
can
determine
if
the
job
is
created
or
not
in
the
pipeline.
A
In
this
example,
here
we
have
a
rule
that
is
evaluating
the
CI
pipeline
source,
which
you
can
see
here
and
it's
equal
to
web.
So
if
it
matches
web
the
pipeline
or
sorry,
the
job
will
go
ahead
and
be
created
in
the
pipeline
and
just
your
information
is
this
thing
here
where
you
see
if
this
CI
pipeline
sources
web?
That's
actually,
if
someone
hit
the
manual
play
button
on
the
job
in
the
UI.
A
But
talk
a
little
bit
about
rules
in
Texas,
there's
a
real
nice
breakdown
of
us
and
first
you
have
Clauses.
If
which
can
be
a
variable,
changes
can
be
if
a
file
is
changed
or
not
exists,
whether
a
file
exists
or
not,
and
then
we
have
our
operators
so
you've
got
your
standard
equals
not
equals.
The
two
with
the
tildas
are
regular
Expressions,
so
not
equals
and
equals
to
whatever
regex
pattern.
You've
defined
and
then
the
double
Ampersand
is
to
join
two
operators
and
the
pipe
symbols
are
just
oars.
A
A
It's
good
to
know
how
to
make
a
job
in
your
pipeline
a
manual
step.
This
is
somewhere
when
manual
zero
here
when
manual,
and
it
presents
you
with
this
play
button
like
we've
seen
earlier
in
this
example.
The
only
time
this
actual
deployed
job
will
execute
is
when
someone
comes
to
the
UI
and
manually
clicks
the
play
button,
the
play
button
will
actually
only
show
to
those
who
have
permissions
to
run
it.
Unless
you
haven't
defined,
who
can
run
it,
then
any
developer
can
run
it.
A
So,
instead
of
when
on
success,
you
can
say
that
you
can
see
that
it's
defined
here
as
when
delayed
this
job
will
be
created
when
the
pipeline
is
for
merge
or
Master.
As
you
can
see
up
here,
sorry
merge
to
master
and
it'll
begin
in
three
hours,
so
you
can
see
it's
delayed
start
in
three
hours
and
you
might
ask
well
three
hours
from
what
and
the
answer
is
that
from
the
official
documentation
is
that
the
time
of
a
delayed
job
starts
immediately
after
the
previous
stage
has
actually
completed.
So
it's
three
hours
from
then.
A
Next
up
is
the
case
where
we
have
multiple
rules
and
the
when
keyword
in
play.
So
if
we
look
at
this
Pipeline
and
when
it
will
execute
well
it'll
be
created
in
any
pipeline
when
the
pipeline
source
is
not
merger,
press
event
or
schedule,
then
the
when
on
success
keyword
tells
the
job
to
execute
assuming
the
previous
job
success.
A
So
if
the
evaluation
got
this
far,
we
know
that
none
of
the
previous
criterios
matched
it's
good.
To
remember
that,
as
I
said,
rules
are
evaluated
in
order.
So
in
this
example
just
to
be
clear,
if
the
source
doesn't
match
merge,
request
event
and
the
source
then
doesn't
match
schedule,
it
will
be
created
on
success
of
the
previous
stage.
A
Here
are
some
more
keywords
that
rules
can
be
evaluated
again,
so
in
this
case
we've
if
changes
and
exists
which
we've
seen
on
the
syntax
deck
page
changes
only
creates
the
file.
Sorry
only
creates
a
job
if
a
file
and
want
to
specify
Pat
has
changed
in
your
current.
Commit
exists
only
creates
the
job
based
on
the
existence
of
a
particular
file,
and
this
is
also
an
example
of
rules,
evaluation
and
a
custom
variable
versus
the
predefined
variables
that
we've
already
seen.
So.
The
variable
here
is
actually
a
custom
variable.
A
And
this
is
kind
of
something
you
can
revisit
later
on-
it's
not
really
for
going
through
now,
but
perhaps
you
actually
want
to
understand
the
variable
processing
order,
and
this
is
a
good
slide
for
future
reference.
First,
it
shows
the
order
of
Precedence
of
a
variable
processing
from
highest
to
lowest.
A
A
Go
back
here
to
my
issues,
I'm
going
to
go
into
three
I'll
copy
and
paste
it
into
this
chat
again,
for
you
all
makes
it
easier
again
over
here,
come
back
up
to
your
project
overview
Page
by
clicking
on
it
over
here
alrighty.
So
the
first
thing
that
we're
going
to
want
to
do
as
part
of
these
steps
is
remove
the
huge
amount
of
jobs
that
we
added
to
demo
or
dag
in
the
last
step.
So
again,
we're
going
to
go
to
build
pipeline
editor.
A
Again,
to
ensure
that
we're
all
back
at
the
same
point,
here's
what
your
gitlab
CI
yaml
should
look
like.
So
if
you
want
to
be
super
confident
that
it's
done
correctly,
you
can
just
copy
this
select
all
within
the
pipeline
editor
and
paste
it
back
in
that's
exactly
what
your
coml
file
should
look
like
now,.
A
Let's
say
that
we
only
care
about
this
job
running
if
we
have
changes
being
pushed
into
Main.
So
to
do
this,
we're
going
to
add
the
rule
definition
defined
below
to
the
end
of
the
unit
test
job,
so
you're
going
to
grab
this
here's
my
unit
test
job.
You
see
the
needs
keyword
that
we
added
in
already
and
I'm
going
to
paste
it
in
there.
A
A
It's
going
to
add
a
new
line,
but
exit
one,
so
I'm
actually
forcing
this
job
to
fail.
I
want
it
to
fail.
I
want
to
see
what
happens
so
we're
adding
in
this
exit
one
aligned
to
your
code
quality
job
and
what?
If
we
also
wanted
to
allow
failure
on
a
rule
that
we'd
set
Let's
test
that
out
on
this
code,
quality,
job
and
change
the
rules
to
be
the
below
code.
So
I'm
going
to
copy
this
and
I'm
going
to
add
rules
below.
A
Perfect,
so
your
yaml
for
code,
quality
and
unit
test
should
now
look
like
this.
You
can
see
we
added
the
rules
to
the
unit
test
job
and
we've
added
the
the
rules
and
the
allow
failure
keyword
to
the
unit
test
job
again.
If
you
want
to
be
super
confident,
you
can
copy
this
and
just
replace
the
two
blocks.
A
A
So
remember
what
we've
done
here
right,
we've
told
code
quality
job
to
actually
failed.
We
added
in
this
exit
one
code,
so
it
should
fail.
It
should
be
allowed
to
fail.
In
other
words,
it
shouldn't
stop
the
processing
of
unit
test,
which
is
exactly
what
you
can
see
live
here.
We've
got
our
our
Amber
exclamation
mark.
It's
saying:
yeah
I
failed.
If
we
hover
over
it,
it
says
yeah.
This
has
failed,
but
you
can
also
see
it
saying
well,
actually,
I'm
allowed
to
fail.
We
click
into
it
as
well.
We
should
see
it.
A
And
because
it
was
committed
to
Maine,
our
other
job
is
running
just
fine
and
again
our
needs
keywords
and
we're
still
in
there.
So
they
all
just
started
straight
away
so
you're,
seeing
all
of
these
kind
of
things
come
together
now
from
from
the
different
keywords
that
we've
seen
through
the
workshop.
A
Hopefully,
you
all
got
that
far
and
got
to
see
it.
Your
pipelines
might
actually
run
a
little
slower
than
mine,
but
you
you
should
see
it
eventually
as
well.
You
know
you
can
revisit
this
after
today's
Workshop
go
in
and
and
dig
around
a
bit
more
and
have
a
look
like
you
can
see
your
failed
jobs
here,
yeah
and
dig
around
a
bit
more
and
picture
the
different
pipelines
that
we've
created
today
and
see
exactly
why
they've
behaved
and
the
way
that
they've
behaved
based
on
the
changes
that
we've
made.
A
Okay,
so
we're
now
going
to
look
at
sast
and
artifacts
and
basically
enabling
aerostatic
application
security
testing
and
how
to
direct
artifacts
to
subsequent
jobs.
If
that's
something
you
need
to
do
we're
nearly
at
the
end,
so
we'll
have
one
more
Hands-On
portion
after
this
bit
of
theory
and
then
the
rest
of
it
is
all
optional,
and
so
we
should
definitely
be
finishing
on
time
today,
which
is
good.
A
A
So
how
do
we
get
SAS
into
your
pipelines
and
every
time
I
say:
stats,
I'm,
referring
to
static
application,
security
testing,
and
it's
a
pretty
common
pattern
to
hear
from
automation,
Engineers
who
are
trying
to
find
ways
to
add
scans
to
development
pipelines.
This
is
really
common
requests
that
we
get
it's
normal
for
us
to
find
an
organization
may
already
own
really
good
Enterprise
grade
scanners
and
that
these
scanners,
you
know
they've
generally-
remained
unused
by
development.
A
A
This
problem
is
actually
why
it's
read
enough.
That
gitlab
now
has
an
entire
team
that
focuses
on
creating
scanning
jobs
that
can
be
added
to
your
pipelines,
making
the
barrier
to
add
scans
running
in
pipelines,
basically
zero,
it's
great
news,
but
how
do
you
go
about
putting
gitlab
SAS
into
your
pipelines?
Well,
that's
what
we're
going
to
look
at
if
you're,
looking
in
our
documentation.
It
literally
says
this
add
this
line.
A
Add
this
to
your
gitlab
ciamo,
it's
as
simple
as
include
template,
and
you
can
see
labciono
and
while
that's
super
simple
and
really
easy
to
achieve,
it's
good
to
actually
understand
what's
happening
here,
and
you
might
remember
back
at
the
start,
I
mentioned
templates
and
including
templates.
That's
what
we
can
look
at
now.
So
a
template
is
how
gitlab
engineering
is
able
to
share
pipelines
with
you.
It's
also
the
way
that
we
can
share
kind
of
cicd
best
practices
with
other
teams
throughout
your
organization
and
templates
are
not
magical
or
mysterious.
A
They
don't
do
anything
crazy
and
once
you
look
inside
one
which
we
will
in
a
minute,
you'll
see
that
they're
all
just
gitlab,
cicd
files
and
all
of
the
syntax
is
the
same
for
CI
stages,
jobs.
Everything
still
applies
so
you're
going
to
be
able
to
really
clearly
understand
the
jobs
that
you're
actually
adding
to
your
pipeline
by
including
these
templates.
A
A
This
is
the
template,
so
you
can
see
everything
in
here
super
easy
to
read:
there's
nothing
crazy
happening,
and
you
know
a
moment
ago
we
were
talking
about
SAS.
The
SAS
template
is
very
similar,
might
actually
be
here,
yeah,
it
is
gitlab,
there's
a
SAS
template.
So
when
you're
saying
you
know
turn
on
zast
or
say
it's
gone
in
my
pipelines,
you
include
a
template.
This
is
exactly
what
it's
doing.
A
You
can
go
in
here
and
see
the
exact
Behavior,
how
it's
coded,
what
it's
meant
to
do
and
all
of
the
the
details
and
variables
around
it.
It's
just
good
to
know
that
these
are
public.
Glenn,
have
a
root
around
be
very
comfortable.
What
you're,
including
your
pipelines,
most
importantly,
getting
an
understanding
of
how
they
actually
work.
A
Alrighty,
so
it's
important
to
know
that
you
know
there's
different
types
of
templates
as
well.
Actually,
what
I
should
say
is
there's
different
types
of
include
statements,
so
include
template,
which
is
the
one
you
just
seen
for
code
quality
and
for
SAS.
That's
used
if
you
want
to
include
something
that
you
get
from
gitlab
and
by
that
I
mean
gitlab
engineering,
something
we've
built
for
you.
A
There
are
a
variety
of
ways
that
we
can
actually
customize
the
behavior
of
jobs
in
our
pipeline.
We
can
override
the
default
behavior
of
a
template
job
by
specifying
keywords
in
a
local
job,
so
this
will
keep
most
of
the
job
the
same
but
use
any
value
set
specifically
in
the
job
in
the
local
CI
file.
A
So
you
might
remember
the
kind
of
predefined
variables
that
we
discussed
earlier
and
we
can
see
in
the
SAS
template
exactly
how
they're
defined
so
to
the
right
hand,
side
you'll,
see
the
SAS,
simply
you'll,
see
the
variables
section
and
you
can
get
into
seeing
exactly
how
they're
defined
again.
All
of
this
is
in
our
documentation
online.
A
So
by
default,
SAS
will
use
pattern
matching
to
decide
what
language
scanner
to
execute
and
if
we
did
want
the
variable
to
be
set
for
all
jobs
in
the
pipeline,
we
could
set
it
at
the
top
of
the
pipeline
file
instead
of
within
specific
jobs.
So
in
this
case
it's
a
simple
case
of
extending
a
template
job
and
setting
the
value
of
the
variable
SAS
excluded
scanners,
which
would
override
the
value
of
this
variable
in
the
template.
In
other
words,
you
can
override
it.
If
you
have
to.
A
A
There's
one
other
thing
to
be
aware
of
here
when
we're
talking
about
artifacts
and
is
that
you
must
have
the
the
appropriate
permissions
to
view
and
download
artifacts
for
public
projects.
Any
user
with
guest
permissions
are
greater,
can
view
and
download
them
and
for
private
projects.
You
need
to
be
reporter
permissions
or
grader.
A
And
just
look
in
here,
someone
Anonymous
said:
Can,
someone
Pace
to
complete
yaml
you'll,
get
it
in
one
of
the
previous
issues,
I'm
pretty
sure
it
was
in
number
three
yeah
so
step.
Three
and
number
three
will
give
you
a
good
start,
but
make
sure
you
go
down
and
add
the
next
couple,
but
that's
what
a
yaml
should
look
like.
They
could
labcio
yaml
at
this
stage
and
just
add
in
the
next
few
bits
and
you
should
be
able
to
to
catch
up,
Okay
cool,
so
SAS
and
artifacts.
A
Let's
do
our
Hands-On
portion
for
this,
and
so
first
we
need
to
get
back
to
editing
the
pipeline,
we're
going
to
go
to
build
again
and
pipeline
editor
and
under
where
we
Define
the
image
for
a
pipeline.
We
will
add
the
below
code
to
include
the
SAS
template
you
can
see.
Our
image
here
is
defined
as
node
17
and
I'm,
adding
it
right.
A
There
include
template,
which
tells
me
two
things:
I'm,
including
a
template,
but
second
of
all,
because
I've
used
the
include
template
setup,
it's
coming
from
gitlab
engineering,
then
you
can
see
it's
our
SAS
template
that
we're,
including
so
to
take
a
look
at
the
template
that
we
just
added
and
look
near
the
top,
the
edit
page
next,
where
you
select
the
branch.
So
that's
up
here
that
it's
referring
to
I'm
going
to
uncheck
it
you
see
here
is
your
branch
and
you've
got
this
little
icon
to
the
left
of
it.
A
If
you
click
on
that,
it
expands
this
open.
Now,
if
you
have
a
template
defined
as
being
included
here,
it
should
appear
here
and
you
should
be
allowed
to
click
on
it,
which
brings
you
right
to
it
and
you'll
be
able
to
take
a
good
look
at
it.
That
way,
as
well,
really
handy
if
you've
got
a
good
couple
of
them
listed
or
included,
and
you
want
to
take
a
look
through
them
now.
You
might
also
say
to
me
well
that
you
know
SAS.
A
A
Okay,
so
that
is
everything.
What
we
want
to
do
now
is
go
ahead
and
click
on
Commit
changes
and
we're
going
to
go
back
to
look
at
the
pipeline,
that's
being
built.
We
should
see
the
stage
now,
that's
bringing
in
this
SAS
job,
that's
created
by
the
templates
oops.
Sorry,
so
my
apologies
we're
going
to
build
and
Pipelines
last
one.
That's
running
sorry:
I
keep
hitting
the
wrong.
A
Right:
apologies
for
that
so
you'll
see
here.
There's
your
SAS
jobs
have
been
added
in
they've,
simply
been
created
and
added
to
the
pipeline.
Only
by
using
that
include
template
statement
just
super
helpful,
so
you
can
see
how
quick
and
easy
it
is
to
really
include
SAS
right
into
your
templates
are
sorry
right
into
your
Pipelines
okay,
so
we
can
move
on
now
to
look
at
it
using
inheritance,
enhancer
pipelines.
So
now
that
our
pipeline
has
run
ours
hasn't
finished.
A
Yet,
let's
build
off
of
the
SAS
template
using
inheritance,
so
we're
going
to
go
back
to
build
and
pipeline
editor
and
we
want
to
make
a
new
stage
called
security
and
that's
going
to
house
all
our
SAS
jobs,
so
we're
going
to
go
in
here,
call
it
security,
or
else
you
can
just
copy
and
paste
this
and
override
that
block.
If
you're
more
comfortable
with
it,
and
now
we
will
create
a
new
SAS
job
that
will
overwrite
some
of
the
functionality
from
the
template
we
included.
A
A
Now
this
can
take
a
little
bit
of
time
right.
So
the
idea
is,
we
want
to
leave
this
pipeline,
complete
with
the
hope
that
we
can
go
in
and
then
see
the
artifacts
that
have
been
created
now
the
chances
of
this
completing
on
time
I'm,
not
sure,
let's
see
if
it
does
grade.
If
not,
you
can
come
back
here
later
right,
so
go
to
build
and
Pipelines
and
up
here
you
see
this
download.
A
It's
already
actually
has
some,
so
you
can
see
there's
the
artifacts
from
the
SAS
jobs
and
we
went
back
in
defining
the
build
app
job
that
it
should
also
create
an
artifact.
So
once
our
build
app
job
finishes
in
this
pipeline,
if
I
go
there
again,
I
should
see
the
artifact
first
now
remember:
there's
a
good
number
of
places.
You
can
see
artifacts
I've
clicked
into
one
of
the
SAS
jobs,
and
you
can
see
the
artifacts
will
be
listed
here
as
well.
A
There's
a
few
places
you
can
go,
see
them
and
I
linked
them
actually
into
the
deck.
So
if
you
want
to
go
back
and
see
all
the
individual
places,
you
can
see
them
there,
and
but
this
is
a
very
common
place
to
grab
them
is
when
you
go
to
build
pipelines
and
over
here.
The
download
button
will
be
in
here.
A
Might
take
too
long
for
build
out
to
complete
for
me
to
go
in
and
show
it
to
you,
but
it'll
be
there
anyway,
you
can
do
it
afterwards.
That's
the
final
portion
of
our
Hands-On
pieces.
Now,
as
I
said,
you
know
if
we
go
back
here
to
the
issue
list.
You've
got
some
optional
stuff
to
go
through
so
transferring
the
project.
If
you
want
to
transfer
to
project
at
the
end
you're
more
than
welcome
to
do
that.
A
If
you
do
have
your
own
gitlab
ultimate
account
great,
if
not
be
aware
that
some
features
of
functionality
might
break
if
you're
bringing
it
out
to
a
lower
tier
subscription
and
but,
as
I
said,
you
actually
have
access
to
this
training
environment
anyway
for
a
couple
of
days.
So
in
that
training
environment
you
have
the
option
to
complete
these
two
optional
different
steps.
A
A
A
Okay,
folks,
we're
finishing
well
on
time:
I
hope
you
all
really
enjoyed
that
I
hope
you
got
something
from
it.
You
know
it's
good
to
kind
of
start
with
the
Jenkins
versus
get
that
piece
to
give.
You
brief
comparison,
even
if
it's
just
to
kind
of
highlight
you
know,
what's
it
called
the
git
lab
in
comparison
to
Jenkins
and
give
you
a
brief
overview
of
it.
It's
usually
a
session
that
generates
a
lot
of
questions.
A
You
can
pop
your
questions
in
the
Q,
a
it'll
be
off
camera,
we'll
be
off
audio,
but
I'll
hang
around
for
another
five
or
ten
minutes,
or
so
until
the
end
of
the
session
to
to
help
out
anyone
that
I
can
anyone
that
I
can't.
If
I
reply
to
you
at
my
email
address,
it's
probably
because
there's
something
we
can't
answer
quickly,
but
we
would
like
to
answer
for
you.
A
So
if
I
reply
with
my
email
address,
please
send
me
your
question
over
email,
I'm,
more
than
happy
to
assist
I
work
under
customer
success
team
here
in
Europe,
we've
got
a
couple
of
colleagues,
and
so
we
can
divvy
it
out.
If
there's
a,
if
there's
a
good
few
questions
coming
in,
we'll
make
sure
we
get
some
good
quality
answers
over
to
you,
if
it
results
in
a
call,
we
can
have
a
session
as
well
if
it's
required
so
yeah
I
hope
you
gained
value
from
today's
Workshop.