►
From YouTube: MLOps Demo - November 5th 2021
Description
All demos: https://gitlab.com/gitlab-org/incubation-engineering/mlops/meta/-/issues/16
A
Hello,
everyone
and
welcome
to
another
mlaps
demo,
this
time
for
the
november
for
the
week
of
november
15th
2021
this
week,
we
have
very
exciting
updates
regarding
jupiter
experience
and
also
some
updates
on
exploration
for
pipeline
runners,
pipeline
runners
for
machine
learning.
So
first
of
all,
it
has
been
the
the
divs
have
been
integrated
into
the
code
base,
so
it
is
already
in
production,
it's
still
behind
a
feature
flag
and
it's
only
available
for
some
specific
projects
on
the
git
lab
organization,
but
it
can
already
be
seen
in
the
wild.
A
So,
for
example,
now
we
have
this.
This
is
a
radio
on
production.
This
is
public.
Anyone
can
take
a
look
at
this.
This
is
how
a
notebook
is
being
rendered
differ
is
being
rendered
for
new
commits.
You
can
see
that
we
also
added
code
highlighting
for
markdown,
so
it's
a
little.
It's
a
lot
easier
to
parse.
Even
there
are
things
we
can
still
improve
a
lot
of
them,
but
we
already
have
this
so
for
comparison.
A
A
That
is
quite
problematic
that
if
you
try,
since
we
are
rendering,
is
not
this
diff.
If
you
try
to
add
a
suggestion
over
here
and
you
just
change
anything
to-
I
don't
know
blah
over
here
and
you
add
the
comment.
This
will
completely
break
the
notebook.
If
you
apply
the
suggestion,
it
will
become
an
invalid
notebook
and
it
it's
not
really
a
good
experience
for
the
user.
So
what
we
will
do
we'll
disable
suggestions
for
now
for
for
python
notebooks.
A
A
So
what's
next
for
this,
of
course,
after
fixing
up
this
this
bug,
we
also
will
do
a
up
of
the
code
base.
We,
I
had
to
add
a
lot
of
logins
to
figure
out
some
additional
bugs,
but
also
we
want
to
start
working
on
a
richer
bits.
So
right
now
we
have
cleaner
dips,
but
we
want
to
do
a
rich
experience
for
notebooks.
A
For
example,
we
had
like
this
is
not
a
really
good
a
good
image,
but
if
this
was
a
valid
image,
we
wanted
to
display
this
along
with
the
diff,
perhaps
linkedin
not
linking
but
highlighting.
So
this
is
a
com.
This
is
not
really
useful.
This
can
be
a
little
bit
less
visible
or
grayish,
for
example.
So
add
a
little
bit
more,
a
better
rich
experience
for
dr
notebooks
within
gitlab
now
that
it's
already
cleaner-
and
this
is
for
drop
notebook,
so
very
exciting.
It
is
live.
A
A
So,
for
example,
if
I
reuse
a
random
forest
classifier,
I
have
number
of
estimators
that
I
can
configure
the
criteria
max
depth
mean
samples
and
a
lot
more,
and
these
affect
the
outcome
of
the
model
right.
What
we
want
to
do
is,
and-
and
you
can
optimize
is
that
the
same
way
that
you
can
optimize
machine
learning
mode,
you
can
optimize
the
algorithm
in
itself,
but
this
process
is
very
slow
because
you
have
to
iterate
over
many
times.
A
You
find
that
it's
a
search
problem,
so
you
can
either
go
random
search
and
just
like
research,
try
out
all
possibilities.
You
can
do
a
lot
a
little
bit
smarter
search
with
bayesian
approaches,
for
example.
But
the
point
is
that
it's
a
search
problem.
It
takes
a
long
time,
and
it's
very
repetitive,
so
it's
very
useful
to
have
this
is
a
pipeline.
A
A
For
now,
I
found
out
that
it's
impossible
to
run
a
loop
on
git
lab
pipelines,
so
you
cannot
do
the
iterations,
as
you
would
do.
Normally,
you
could
do
random
the
not
a
random
but
the
grid
search
which
is
try
out
everything.
So
you
can
use
child
parent
child
pipelines
to
try
out
every
single
possibility
and
get
the
results
in
the
end,
and
this
is
what
we're
gonna
try.
First,
so
first
we're
gonna
the
thing
that
I
did
so
far.
A
I
created
a
sample
data
set
that
has
seven
features
and
it
has
a
equation
that
depends
on
the
seven
features
and
what
I
do.
I
just
pick
my
data
set.
My
future
data
set
that
I
have
for
this
machine
learning
model
has
only
four
of
these
features,
which
means
that
it
doesn't
capture
the
whole
equation
in
it
right.
So
I
can
try
to
build
a
machine
learning
model
that
tries
to
predict
the
final
value,
and
I
did
this:
it's
a
random
forest
model,
classifier
and
okay.
A
It
achieves
this
accuracy
on
the
on
the
default
parameters,
so
that
one
score
for
this
is
0.73.
F1
score
is
a
measure
of
that
balances.
How
often
it
makes
right
predictions
and
how
often
it
makes
it
forgets
to
make
a
right
prediction.
Basically,
so
here
we
start
the
parameter
tuning,
so
we
create
a
grid
search
which
grid
search
means.
We're
gonna,
try
out
everything
all
the
possibilities.
So
I
have,
I
would
have
here
three
times
two
times
two
combinations
which
is
12
candidates
for
each
of
the
12
candidates.
A
A
So
we
do
the
the
parameter
training
over
here
and
we
have
the
results
which
are
very
known,
so
not
so
much
readable
over
here,
but
we
have
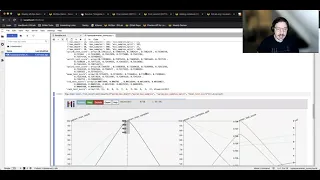
some
plots
here,
for
example,
plot
over
here.
The
the
test
score
versus
the
one
of
the
parameters
which
is
max
depth
max
depth
of
the
tree
is
how
many
nodes,
how
many
decisions
each
of
the
trees
can
make,
but
you
can
see
that
the
higher
results,
although
you
have
some
outliers,
but
the
higher
results-
happen
with
a
larger
max
depth.
A
So
you
usually
choose
an
a
larger
max
that
similar
with
max
samples.
You
see
that
the
scores
are
here
are
on
average
larger
than
the
squares
over
here,
but
with
the
new
sample
split,
it
doesn't
seem
to
change
a
lot.
It
kind
of
looks
okayish,
but-
and
you
have
this,
this
is
a
high
plot,
which
is
a
interactive
tool
that
it
makes
it
a
little
bit
easier
to
explore
the
parameter
space.
A
So
here
you
have,
each
line
is
an
experiment
with
different
parameters,
and
you
see
so
you
see
that
for
this
over
here.
Let
me
try
to
select
this
one.
The
best
parameter
that
you
thought
that
you
found
at
that
point.
Seven
three
eight
is
the
mean
splits
is
10.
The
param
is
500
like
samples
on
the
and
the
max
depth
extend,
so
you
can
see
where
each
of
the
parameters
fall
into
the
space
and
the
combinations
of
within
the
parameters
itself.
So
it's
a
pretty
cool
visualization
to
have.
A
Okay,
yeah
now
I
have
everything
so
yeah,
so
here
I
have
all
of
the
different.
I
have
even
the
time
the
scores
and
everything
for
this,
so
this
is
a
very
a
toy
project
that
we
can
use
now
for
implementing
the
pipeline.
So
the
next
steps
that
we
have
over
here
now
we
have
the
somewhat
decode
very
simple,
very
stupid.
It's
not
a
real
problem.
This
is
a
toy
one
that
we're,
but
is
already
enough
to
test
out
what
we
want
to
do.
A
A
You
can
think
that
even
the
choice
of
algorithm
itself
that
you
use
for
the
machine
learning
model
is
a
hyper
parameter,
so
this
hyper
parameter
tool.
You
could
step
at
one
step
before
or
one
step
into
the
search
that
would
be
the
one
to
identify.
What
is
the
best
algorithm
for
the
data
to
have
so
this
is
one
making
hyper
parameter
is
about
it's
a
good
step
towards
finding
out
if
you
can
do
ultiml
within
gitlab
or
not
with
gitlab
pipeline,
so
that
is
that
is
very
exciting
yeah.