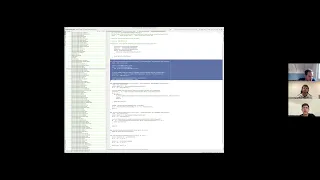
►
A
A
B
C
B
C
C
B
Yeah,
so
the
project
right
now,
as
you
know,
is
hosted
on
GitHub
and
it's
basically
one
repository
I
want
to
get
repository.
It's
a
very
I
would
say
basic
go
project,
it's
scaffolded,
actually
from
a
template
which
is
provided
by
hashicorp,
so
it's
called
I
think
terraform
provider
scaffold
where
you
can
look
at
and
you
have
like
a
very
minimal
terraform
provider.
B
So
a
lot
of
things
are
coming
from
there,
for
example,
make
files
the
basic
test,
setup,
I,
think
and
yeah
I
mean
I.
Think
best
would
be
to
look
at
some
very
basic
resource
and
some
very
basic
data
source
and
see
how
this
is
how
this
is
working.
And
then
we
can
also
see
how
the
provider
itself
is
configured
like
how
this
is
working
with
the
gitlab
client.
B
And
if
you
have
any
like
comment
or
question,
please
interrupt
me
anytime
yeah.
So
maybe
for
the
sake
of
familiarity,
we
can
look
at
the
gitlab
cluster,
H
and
resource
which
you
know
obviously
talks
to
the
API
for
their
cluster
agents
and
the
I
mean
I
I
assume,
and
you
need
to
correct
me
if
I'm
wrong,
but
I
assume.
You
know
how
how
research
looks
like,
inter
in
in
HCL,
so
it
will
be
something
like
this
right.
Let
me
try
again
the
the
increase
font
size.
B
Okay,
so
you
would
have
in
your
character
from
codes
to
use
that
you
would
have
a
research
declaration.
You
have
your
gitlab
cluster
agent,
give
it
a
name,
and
then
you
have
some
attributes
they're
called
in
in
terraform,
and
these
attributes
they
can
be
required
or
they
cannot
be
required
if
they're
required.
It's
called
an
argument
which,
for
example,
here
we
have
two
of
those.
We
have
a
project
and
we
have
a
name,
because
the
cluster
agent
always
must
have
a
project
and.
C
B
And
this
is
test
code.
We
can
go
into
this
later,
but
I
just
want
to
show
how
this
looks
like
so
that
we
can
make
the
connection,
and
the
first
thing
you
do
in
a
provider
is
register
all
your
data
sources
and
resources
to
the
provider
which
is
created
by
by
terraform
and
how
you
do
this
is
you
have
this
schema
resource
here,
which
is
just
a
type
and
it
can
have
a
few
like
functions
registered.
These
are
crop
functions.
Usually
so
you
have
a
create
function.
B
C
B
Of
the
of
the
resource,
so
it
defines
what
attributes
are
there
which
are
required,
what
type
they
are
and
so
on.
We
can
quickly
check
here
what
that
looks
like,
so
it's
basically
a
map
which
Maps
strings
to
schemas.
So
here
we
already
see
the
what
I
showed
before
we
have
a
project
required
attribute,
which
is
called
an
argument.
It
has
a
description.
It
has
a
type
here.
B
Also
it
has
a
forced
new
flag
and
this
Force
new
flag
is,
if,
if
you
do
an
update
to
this
particular
attribute,
terraform
will
delete
the
resource
and
recreate
it
instead
of
doing
an
update-
and
in
this
particular
case,
I
told
you
that
it
doesn't
have
an
update
function.
So
all
the
attributes
which
you
can
set
as
a
user
actually
need
to
be
set
as
Force
new,
because
it
cannot
update
right.
B
B
B
Yeah,
and
actually
here
the
force
knew
it
applies
for
the
entire
resource
right.
It's
not
that
this
applies
only
for
like
the
project
that
or
anything
like
this.
This
is
always
meant
to
replace
the
entire
resource
if
this
attribute
changes,
which
can
which
doesn't
make
a
lot
of
sense
here,
if
you
think
about
this,
that
it
would
only
replace
the
project
attribute,
but
it
makes
sense
if
you
have
like
a
sub
resource
inside
a
resource.
We
can
look
at
such
an
example
later,
but
yeah.
B
Let's
continue
with
this,
so
we
see
the
functions
here.
So
here
is
the
create
function.
We
have
the
read
function,
the
delete
function
and
here's
some
some
helpers
and
the
create
functions
here.
The
code
always
looks
very,
very
similar
from
resource
to
Resource,
and
here
the
first
thing
we
do
is
from
some
argument.
B
Here
we
get
a
gitlab
client,
which
is
an
instance
of
this
go
gitlab,
client
library,
and
it
also
it
already
has
authentication
everything
set
up
so
that
we
could
just
called
API
endpoints,
and
what
we
do
next
is
I
mean
what
you're
getting
here
actually
is
this.
This
D
is
usually
called
D,
the
variable
and
it's
a
type
resource
data,
and
this
contains
it's
it's
complex
or
complicated
to
to
to
explain
because
it
it
sometimes
it's
what
is
in
the
terraform
plan.
B
Sometimes
it's
what's
in
the
state,
and
sometimes
it's
what's
in
the
config,
depending
on
the
situation
where
this
resource
data
is
being
used
in
the
create
case,
there
is
no
state
yet
right
because
we're
creating
the
resource,
so
it
comes
from.
It
comes
from
the
conflict
right
which
the
user
wrote
like
the
one
we
saw
in
the
in
the
test
case
here.
B
So
the
resource
data
type
has
these
attributes
in
there
and
we
can.
We
can
fetch
those
by
using
this
get
method
here
provide
the
key
for
the
attribute
which
is
project
in
this
case,
and
we
we
cast
it
to
the
proper
type
we
need,
and
then
we
basically
set
up
the
the
options
for
the
for
the
gate,
lab
Library,
the
client
Library.
So
this
is
quite
specific
to
that
and
then
here
we
make
the
actual
call
to
gitlab
to
register
the
agent.
B
Given
our
options,
which
we
populated
here
for
the
project
and
once
this
happened,
we
built
an
ID
for
the
resource.
This
is
important
to
well.
Every
resource
needs
an
ID.
You
can
set
this
to
pretty
much
everything
but
buy
you
know
best
practice
and
because
that's
the
only
way
it
works
consistently
is
that
it
has
to
be
unique
for
that
resource.
B
Agent
ID
because
that's
that's
unique
and
and
then
we
we
own-
and
this
here
you
see
the
the
thing
I
told
you
before-
that
this
D
represents
the
plan,
basically
right
what
the
user
set
into
their
config,
but
then
on
the
same
object.
You
basically
set
data
and
this
is
going
to
be
in
the
state
afterwards
and
there
is
a
new
provider
framework.
It's
called
the
framework
you're,
not
the
SDK
and
there
this
is
separate.
B
So
we
want
to
have
every
attribute
in
the
state.
So
we
actually
want
to
have
all
of
these
inside
the
state,
and
we
could
actually
just
do
this
here.
We
could
do
set
name
equal
to
well,
I'm
just
sketching
it
here
to
this
option
name
and
then
it
will
go
into
the
into
the
state.
But
for
many
reasons
I'll
get
to
those.
We
actually
call
the
read
function
here
and
the
read
function
will
read
the
ID
here.
You
see
it
will
read
the
ID,
it
get
a.
B
It
gets
a
project
and
an
agent
ID.
So
basically
what
we
provided
it
here
and
we're
gonna
get
the
agent
from
gitlab
again
and
only
then
we're
going
to
populate
the
state
with
the
data
returned
from
gitlab,
and
this
is
what's
happening
in
this
these
two
lines
and
we
can
quickly
go
into
this.
But
it's
not
very
interesting
here.
We
have
just
have
a
map
which
is
then
represented
in
the
state,
so
you
set
the
project.
B
Name
is
pretty
much
everything
which
is
up
here
and
we
do
this
because
we
we
want
to
use
only
one
place
where
we
set
the
state,
which
is
this
read,
function
and
I
told
you
before
about
this
pass
through
importer
and
how
an
import
works
is
that
you
basically
say
this.
This
would
be
like
your
shell
command
here.
You
would
do
something
like
this
terraform
import,
gitlab
cluster
age,
and
this
and
then
here
you
provide
your
project.
B
C
A
B
Then
just
call
the
read
function,
so
this
means
that
we
use
the
same
logic
for
an
import
and
for
the
create
which
gives
us
kind
of
the
consistency
you
want
to
have
inside
a
resource
right.
We
don't
want
to
have
multiple
ways.
So
that's
why
we
we
use
this
password
important.
That's
why
we
call
the
read
here,
for
example,
in
the
create
so.
B
Okay
and
then
the
delete
pretty
much
the
same
thing.
We
read
the
idea
again
from
the
state
and
we
just
call
the
delete
endpoint
on
Gila
and
that's
it.
We
don't
have
to
clear
the
state,
that's
all
handled
by
terraform
itself,
yeah,
so
that's
a
very
simple
resource.
They
can
get
much
more
complex
and
much
bigger.
We
have
a
thousand
lines
of
resource
code,
horrible,
but
that's
how
it
is
right
now,
regarding
testing.
B
B
In
the
pipeline
on
GitHub
actions
at
the
moment,
it's
spawning
a
Docker
compose
it's
running
gitlab
in
there
and
we
test
against
it
and
what
it
does.
Is
it's
actually
like
we're
here.
This
is
a
basic
test.
We
create
a
project
in
kind
of
a
setup
manner
and
then
the
the
SDK
provides
us
a
like
a
testing
framework,
and
here
we
can
have
test
steps
and
we
can
provide
some
HCL
code
here
and
like
a
config
attribute.
B
So
this
is
basically
setup
code
for
a
test
step
inside
an
entire
test,
and
then
we
can
add
check
functions
which
check
the
state
afterwards
or
do
any
kind
of
assertions
for
this
config,
and
it
will
also
handle
a
few
things
for
us,
this
SDK
testing
stuff,
so
it
tests,
for
example.
If
this
is
applied,
it
will
apply
it
again
where
it
checks
the
plan
after
the
apply
and
checks.
B
A
B
B
B
It's
it's
like.
Actually,
the
tests
take
a
long
time
because
we're
actually
querying
git
lab
instances
right.
So
we
wanted
to
bring
that
time
down
a
little
bit
of
this
parallel
tests,
and
this
has
been
successful
so
far,
but
there
is
tests
which
are
changing
a
global
instance-wide
configuration,
so
we
cannot
run
everything
in
parallel
and
also
with
data
sources.
We
can
actually
look
at
the
data
source
now
explained
it
something
regarding
testing
there.
So
are
you
ready
to
move
on
to
data
source
to
see
how
that
looks
like
okay?
B
We
can
look
at
the
same
API
endpoint,
and
here
this
is
kind
of
a
newer
resource.
So
we
have
not
so
much
code
duplication,
but
usually
you
have
a
lot
of
duplication
between
resources
and
data
sources,
because
the
SDK
doesn't
provide
anything
to
us
and
just
historically,
in
this
code
base.
Everything
has
just
been
duplicated
yeah,
but
I
wanted
to
reduce
this
a
little
bit
in
the
past.
B
B
Name-
and
we
can
query
One
agent
in
this
case,
given
a
project
and
an
agent
ID,
and
we
also
I
mean
for
we
are
it's
the
same
from
the
SDK
perspective.
If
you
notice
the
types
here,
it's
the
same
thing:
a
data
source
and
a
resource,
it's
just
the
data
source
case.
It
just
has
a
read
function:
there's
no
create
there's
no
delete,
because
it's
just
reading
right,
it's
a
data
source,
so
it's
just
consuming
data
and
it
also
has
a
schema.
B
So
you
can
have
a
forced
new
attribute
inside
the
schema
of
a
data
source
which
absolutely
doesn't
make
any
sense,
but
you
can
have
it
for
some
reason,
and
this
is
sometimes
it
can
be
confusing.
At
least
it
has
led
to
bucks
in
the
past,
so
yeah
I
I,
hope
it's
better
in
the
new
framework.
But
it's
just
something
that
you
have
to
be
aware
of.
So
from
the
coding
perspective,
a
resource
and
the
data
source
are
essentially
the
same
thing,
but
the
data
source
is
like
a
downstriped
kind
of
resource
foreign.
A
B
A
B
C
B
Exactly
I
mean
there
is
users
using
this
provider
who
don't
have
everything
as
infrastructures
code
or
in
terraform.
They
do
some
setup
manually
and
then
they
want
to
use
that
inside
of
terraform
without
having
terraform
own
it
right,
because
once
you
create
something
with
terraform,
it's
meant
to
only
be
changed
from
within
terraform.
If
you
change
it
outside
of
terraform,
you
have
a
drift
that
you
have
a
kind
of
a
misalignment.
The
terraform
will
complain.
B
C
B
Yeah
to
create
this
mandatory,
they
release
mandatory
and
the
delete
is
mandatory.
The
update
is
the
only
one
which
is
not
mandatory
and
just
because
you
can
solve
an
update
by
replacing
so
deleting
and
recreating,
but
sometimes
actually-
and
this
is
like
a
shortcoming-
indicate
lab
API
as
well.
For
example,
protected
branches,
I,
don't
know
how
it
is
these
days,
but
protected
branches
settings
they
couldn't
be
updated
with
the
API
only
deleted
and
recreated,
and,
as
you
can
imagine,
if
I
replace
this,
there
is
a
short
amount
of
time
where
the
branch
is
unprotected.
B
B
B
B
B
Okay,
I
mean
we
we're
using
here
in
the
provider
you're
using
this
go
gitlab
Library,
which
is
using
the
rest
API,
and
this
has
been
a
problem
at
certain
points,
because
gitlab
claims
to
be
graphql
first,
so
for
some
endpoints,
the
rest
API
is
just
lacking
behind
and
we
had
made
an
attempt
to
use
graphql
inside
the
provider
and
we
have
actually
one
resource
just
looking
at
where
it
is
I.
Think
it's
the
current
user
yeah
here
where
we
actually
use
graphql.
You
can
see
the
query
here.
B
We
have
to
Define
some
types
and
everything
because
we
are
not
using
a
library
which
is
using
like
plain
graphql
but
I
I'm,
not
yet
convinced
that
that's
the
right
way,
because
graphql
is
nice.
If
you
have
like
Dynamic
queries
and
you
want
to
change
them
and
you
don't
really
know
a
prompt,
but
for
the
provider,
we
know
up
front
very
well
and
it's
everything
we
want
to
read
everything
and
we
want
to
mod
or
be
able
to
modify
everything.
B
A
C
B
If
this
graphql
I
mean
graph
graphql,
first
I
think
is
still
the
plan,
but
I
think
the
aim
is
to
have
parity
in
the
rest
API,
but
in
practice
I've
seen
this
not
happening,
I
mean
stuff
is
just
implementing
graphql,
for
whatever
reason
right-
and
this
may
be-
okay-
it's
just
in
the
provider-
it
has
been
a
pain
in
the
past.
So
if
we
came
a
lab
like
refine,
how
we
do
this
with
graphql
here,
maybe
type
it
a
little
bit
better.
B
So
yeah
these
are
resources,
data
sources,
the
provider
itself.
It
looks
quite
similar
to
a
resource,
actually
there's
this
new
function
and
which
is
called
by
I.
Think
that
yeah,
the
terraform
we
call
it
I
think
somewhere
when
we
very
instantiate
the
plugin.
We
call
this
new
thing:
it
returns
a
provider
and
here
again
you
see
this
schema,
which
is
the
same
thing
for
for
resources,
data
sources
and
the
provider,
and
here
is
basically
what
you
would
the.
B
B
This
configure
hook
and
it
configures
the
client
here-
creates
a
client.
It
sets
some
user
agent
and
everything
and
yeah
it's
it's
pretty
simple
here,
maybe
good
to
know
is
also
the
provider
runs
as
a
single
process
next
to
terraform
itself.
So
it's
not
loaded
inside
of
of
the
terraform
process
or
something
like
that,
but
it's
a
executable
spawned
by
terraform
being
communicated
through
grpc
and
but.
B
B
Yes,
so
there
is
a
make
file
here,
we've
just
run
go
build
and
that's
that's
building
the
binary.
So
let
me
see,
yeah
I
mean
you,
we
don't
use
like
bazel
or
any
any
other
additional
tool
chain.
We
just
use
yeah
plain,
go
tooling,
but
we're
we're
using
go
releaser
to
release
for
all
the
platforms
and
everything,
because
it's
released
for
all
all
possible
platforms
right,
so
you
have
FreeBSD
Windows,
Linux
and
Mac
in
all
those
architectures
Even
build
it
for
32-bit,
but
yeah.
B
These
binaries
are
also
signed,
and
then
I
briefly
talked
to
you
Michael
this
morning
about
how
this
is
deployed.
But
maybe
to
recap
the
pipeline
or
going
Easter
actually
creates
a
GitHub
release
similar
to
the
gitlab
release
and
attaches
these
binaries
there,
and
there
is
a
web
hook
inside
a
GitHub
configured
which
calls
the
terraform
registry
that
there
is
a
new
release
and
we
will
come
back
to
GitHub
look
at
the
release.
B
B
C
B
B
A
A
B
Of
Truth
the
source
code
here
and
the
documentation,
there's
also
examples
and
how
this
works
is
for
every
resource.
You
have
a
folder,
for
example,
here
for
the
the
cluster
agent,
and
there
is
always
a
import
sh
file
and
the
resource
TF
file,
and
it's
terraform
file.
You
you
just
do
examples,
whatever
you
want
and
in
the
import.
You
make
an
example
how
to
import.
B
This
is
the
command
that
I
scratched
before
for
the
import
and
those
are
being
taken
and
generated
inside
the
docs
and
there's
also
a
resource
folder,
and
in
here
we
have
a
markdown
file
for
all
the
resources.
So
here
you
already
see
it's
generated
by
this
Terror
TF
plugin,
docs
thingy
and
the
example
here.
So
that's
actually
copy
pasted
from
the
resource
TF
file.
I
showed
in
the
example
before-
and
this
part
here
is.
A
B
From
the
import
sh
file
from
the
examples,
so
the
examples
directory
and
the
go
descriptions
and
everything
there
is
being
combined
into
this
markdown
file.
We
see
right
here,
and
this
then
is
being
taken
by
the
harshi
coil
terraform
infrastructure,
whatever
they
have
in
place
to
populate
their
website
with
documentation.
A
B
B
There's
also
things
like,
for
example,
here
we
create
a
admin
token,
which
we
use
during
testing.
That's
a
shortcoming
at
the
moment
that
all
the
tests
use
this
admin
token
for
authentication.
So
we
don't
really
do
testing
like
Can
a
maintainer
use
this
particular
resource
right.
We
kind
of
missed
that
completely,
which
has
led
to
a
few
issues
in
the
past
as
well.
B
C
B
Actions
take
off
and
go
release
your
runs.
It
creates
a
lab
release,
entry,
a
change.
Actually,
the
change
log
has
to
be
handcrafted
at
the
moment.
It's
this
file
here
and
for
like
there
is
a
format
provide
or
specified
by
hashicorp
how
to
how
to
name
these
things.
What
to
put
this?
What
to
put
here.
B
B
That's
what
we
support
officially,
but
you
can
use
probably
much
older
gitlab
releases
for
certain
resources,
but
we
officially
test
against
the
last
three
and
we
test
we
test,
always
against
a
CE
instance
and
an
ee
instance
and
the
E
has
an
ultimate
license
and
we
somehow
need
to
have
this
license
available
for
testing
and
it's
actually
a
security
risk
at
the
moment
that
someone
can
actually
obtain
this
license.
If
they're
clever
enough,
it's
a
license
which.
A
B
B
C
B
B
Behavior
of
the
API
is
not
documented
at
all
or
in
99
of
the
cases,
and
this
is
actually
a
huge
issue
for
us,
because
when
you
create
a
resource
and
the
API
Returns,
what
does
that
mean?
Does
that
mean
that
the
resource
has
been
created?
Does
it
mean
that
the
resource
is
usable
because
it
mean
that
the
resource-
maybe
it's
not
even
created?
Maybe
it's
spawned
off
an
async
process
inside
gitlab
and
it
just
returned
with
an
ID.
B
So
we
have
a
lot
of
code
in
the
provider
where
we,
where
we
account
for
these
things,
like
waiting
for
a
group
to
actually
be
ready
and
usable
after
it's
been
created,
because
we
found
weird
behavior
that,
for
example,
if
you,
when
you
create
a
group,
it
returns
an
ID
and
results.
And
then
you
do
an
immediate
get
afterwards
and
the
group
is
not
found
which
we
don't.
B
It
may
have
to
do
with
like
replications
in
that
database,
whatever
it's
it's
a
very
weird
Behavior,
but
it
happens
so
all
of
these
kind
of
issues
you
run
into
regularly
and
it's
so
hard
to
debug
these
because
there's
no
documentation,
so
what
I've
been
doing
is
browsing
around
tlab
source
code
figuring
out
where
dispatches
async,
stuff
and
yeah.
If
you
develop
on
this,
you
will
run
into
these
kind
of
issues
all
the
time
and
yeah
it's.
It.
There's
also
configuration
for
this,
like,
for
example,
group.
B
When
you
delete
the
group,
you
can
have
a
deletion
delay.
I,
don't
know
if
you
know,
if
you
know
that,
but
like
what's
the
right
Behavior
there
for
the
elite
function,
should
we
wait
for
it
to
delete?
Should
we
not
wait?
Maybe
it's
set
to
seven
days.
Is
it
okay?
If
it
just
triggers
a
delay
deletion,
or
do
you
really
want
to
wait
for
a
deletion,
because
it's
set
to
two
minutes
right
or
what
is
the
you
don't
really
know?
Do
you
provide?
B
Do
you
provide
attributes
for
this
and
actually
the
terraform
provider
best
practices
mentioned
that
you
should
limit
yourself
to
API
features.
So
in
the
best
case
you
just
replicate,
we
did.
The
provider
is
just
a
pass
through
to
the
API
without
any
additional
logic,
so
we
are
kind
of
hesitant
to
implement
workarounds
to
make
stuff
work.
Implement
fictional
attributes,
to
let's
say
you
wait
for
the
region
of
a
group
and
these
kind
of
things.
B
B
B
B
I
have
to
say,
but
yeah
for,
for
example,
here
that's
that
particular
code.
Just
to
make
an
example
that
particular
code
is
here
to
wait
for
the
default
Branch
to
be
protected
when
you
create
a
project.
So
when
you
create
a
project
with
the
API
and
initialize
it
with
a
readme,
it
will
create
a
branch.
B
So
do
you
want
to
wait
for
this
turns
out.
People
want
to
wait
for
this,
because
also
you
may
want
to
change
the
settings
for
the
default,
prompt
protection,
and
now
we
actually
have
a
very.
This
is
a
very
interesting
scenario
which
is
currently
unsolved
and
unsupported
by
the
SDK.
So
if
you
have
a
resource,
it's
being
owned
by
terraform,
we
have
a
resource,
gitlab
project
and
we
have
a
resource.
Skid
lab
Branch
protection,
where
you
use
the
branch
protection
API
to
set
up
a
protection
for
a
branch.
B
This
will
be
owned
by
gitlab
and
by
the
terraform
provider.
Now,
if
you
create
a
project,
it
may
create
a
branch
protection,
but
you
cannot
change
this
using
terraform
out
of
the
box,
because
you
would
have
to
import
it
first
because
it's
not
owned
by
terraform.
So
what
do
you
do
right?
It's
it's,
and
all
these
this
is
so
difficult
to
first
to
understand
what
is
actually
happening
here.
B
If
you
have
a
bug
like
this,
which
we
had
right
so
yeah,
we,
what
we
did
is
we
we
added
a
flag
in
the
branch
protection
which
allows
to
basically
overwrite
the
default
Branch
protection,
even
if
it
already
exists
because
it
may
have
it
may
have.
It
may
have
been
created
out
of
pounds
of
the
telephone
provider
right.
So
it
may
have
been
a
side
effect
of
some
other
resource
which
has
been
created,
and
this
is
like
if
it
gets
difficult.
These
are
the
things
which
are
difficult
right.
B
A
B
Number
one
thing:
I'm
not
sure
if
it's
one
number
one,
but
it
certainly
is
one-
is
that
I
mentioned
the
code,
duplication
and
it
doesn't
look
like
a
lot.
It's
still
cumbersome.
If
you
write
a
resource,
why
do
I
have
to
do
this
again
for
a
data
source
if
I
I
have
I,
basically
almost
have
it
in
the
resource?
Why
can't
I
just
reuse
it
to
make
a
data
source
out
of
it?
So
it
would
be
very
nice
to
have
some
automatic
way
to
create
a
risk.
B
B
Yeah,
so
maybe
you
can
figure
something
out
there
as
well.
Also
organizationally,
which
I
would
love
to
see,
is
what
I
mentioned
before
having
people
in
GitHub
documenting
the
behavior
of
things
for
API
points,
for
example,
because
it's
so
valuable
for
users
not
only
for
the
provider
but
for
users
to
to
know
okay.
This
API
endpoint
actually
triggers
an
async
operation,
and
it
actually
comes
only
back
to
you
immediately
with
some
ID,
but.
B
A
B
Because
so
maybe
that's
also
on
the
list.
What
I
would
love
to
see
is
a
solution
for
the
go,
get
lab,
Library
maintenance,
because
it's
under
doing
this
and
he's
alone
doing
this.
I
I've
contributed
a
lot
there
and
for
gitlab
I
understand
that
gitlab
cannot
maintain
libraries
for
every
language
out
there,
but
we're
using
go
like
having
this
provider.
We
also
use
we
make
use
of
the
rest
API
and
the
agent
right
or
in
the
not
in
costs
using
the
rest
API.
So
maybe
you
can
also
use
it.
There
I
don't
know,
but.
A
Maybe
not
make
sense
right,
maybe,
but
so
I
looked
at
the
Gold
gitlab
plan
that
is
used
here
and
several
years
ago,
and
it
was
very
specific
for
this
project
and
it
kind
of
didn't
make
sense
to
make
it
more
generic.
So
it
is
very
simple
here,
and
that
is
the
specificity
for
this
project.
It
is
and
if
it's
not
worth
to
like
force,
everybody
to
use
the
same.
The
same
thing
I
think
in
this
particular
case.
B
Yeah
so
yeah,
but
I
think
it
makes
sense
to
at
least
there's
an
open
issue.
There
has
been
discussion
around
it,
but
I,
don't
I
haven't
seen
any
resolution.
Even
if
the
resolution
is
from
a
gitlab
organization
perspective.
We
don't
want
to
maintain
this,
but
let's
see
if
sander
grants
maintainer
permissions
to
one
of
us
at
least
so
that
we
can
fulfill
our
own
needs
in
time
or
timely
manner.
I,
don't
know,
let's,
let's
see,
maybe
something
nice
can
come
out
of
this.
A
C
One
thing
that
occurred
me
this
resembles
a
lot,
the
situation
that
we
have
with
the
we
have
the
import
group
in
git
LED,
it's
another
team
and
their
job
is
to
basically
implement
the
feature
to
export.
Gitlabs
repositories
features
all
that
and
import
it
somewhere
else
or
imported
from
GitHub
to
gitlab.
So.
B
C
These
features
that
are
related
to
get
importing
gitlab
instance
in
exporting,
and
they
are
always
like
running
behind
and
trying
to
catch
up
with
new
things
that
have
been
implemented
and
yeah.
They
have
their
own
standards
of
coding
and,
and
they
also
struggle
with
things
that
they
think
if
people
would
just
like
do
this
always
when
they
Implement
a
feature,
then
it
would
facilitate
our
work.
So
much
and
I
think
there
is
even
parts
of
the
documentation
on
our
handbook
for
developing.
That
asks
us
to
have
this
into
consideration
and
gives
us
some
hints.
B
B
I
I
think
a
lot
of,
or
at
least
a
few
teams,
I
know
of
in
gitlab
actually
use
the
provider
to
test
their
stuff.
I,
don't
know
who
this
is
I
may
follow
up.
I
think
these
guys
this
guy's
name
is
Anthony
or
something,
but
he
posted
a
few
issues
on
on
GitHub
onto
the
provider
and
I
was
like
yeah.
We
use
this
to
test
issue
Awards
these
kind
of
things.