►
From YouTube: Manage:Import Onboarding - GitLab Migration
Description
An introduction to the GitLab Migration tool by George Koltsov.
A
A
Fill
out
the
source,
url
and
the
access
token
click
connect,
and
this
will
be
the
page
that
you're
going
to
be
presented
with
which
lists
top
level
groups.
On
your
instance,
once
you
select
the
group,
you
want
to
import
and
select
the
destination,
so,
for
example,
this
is
the
source
group
that
I
have
it's
opened
for
me
right
here.
A
A
You
can
export
a
project
or
a
group
and
download
the
tarball
file
and
then
on
the
destination
you
have
to
manually
select
that
file
and
upload
it.
So
if
you
have
a
lot
of
groups,
if,
let's
say
you
have
a
large
organization
and
you
have
to
migrate
over
a
com-
complex
group
structure,
you
know
with
a
number
of
subgroups
that
span
deeply
into
into
the
tree.
Let's
say
you
have,
I
don't
know
10
subgroups,
10
levels,
10
nested
levels
for
for
the
group
and
then
in
each
of
the
levels.
A
A
The
other
reason
is
import.
Export
is
a
single
process
that
can
take
quite
a
long
time,
especially
if
you
have
groups
or
projects
that
are
of
significant
size.
You
know
it
can
take
hours,
sometimes
tens
of
hours
to
import
or
export
a
certain
project.
So
the
new
approach
is
a
bit
more
distributed
across
multiple
setting
jobs,
which
should
help
with
performance
and
not
occupy
a
single
process
of
for
for
too
long.
A
A
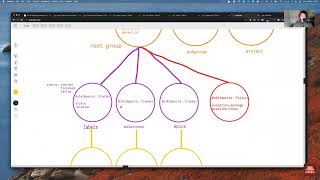
So
we
have
the
bulk
import
main
model
that
stores
the
overall
state
of
import
process,
and
I
did
a
little
drawing
and
I
apologize
in
advance
for
for
how
it
looks.
But
here
it
is,
and
I'm
going
to
move
around
to
show
you
a
bit
more
but
right
now
you
know
you
can
think
of
bulk
import
as
an
entity
that
has
that
keeps
track
of
state
for
the
overall
import.
A
A
You
know
the
url
and
the
access
token,
the
the
page
that
I
showed
you
before,
where
you
import
your
group
when
you
enter
this
information.
This
is
where
it
gets
stored.
In
order
for
the
background
processing
to
retrieve
the
data
you
know
and
to
use
that
information
to
to
connect
to
the
source
instance
and
yeah.
If
we
take
a
look
at
the
table,
structure
yeah
it
has
the
source
type,
don't
have
to
worry
about
it
too
much
at
the
moment.
A
It's
always
set
to
gitlab
at
the
moment,
but
ideally
the
the
grand
vision
for
this
code
base
is
to
be
able
to
migrate
all
of
the
importers
into
one
way
of
importing,
for
instance,
github
or
bitbucket,
etc,
but
yeah.
The
most
important
thing
is
status
now
and
the
second
thing
that
bulk
import
has
is
entities.
A
A
A
A
Again,
yeah,
I
apologize
for
this,
I'm
upgrades,
but
I
hope
it
does
get
the
point
across
that
for
every
bulk
import,
the
overarching
import.
We
have
a
number
of
entities
that
we
create
in
the
database
and
each
of
the
entities
represent
either
a
group
or
a
project,
and
they
all
have
also
status
of
that.
We
need
to
keep
track
of.
So
it's
like
a
tree
right,
so
we
have
the
import
that
has
its
own
status.
Then
individual
entities
has
their
own
status
as
well.
A
A
Yeah,
that's
the
representation.
But
if
you
take
a
look
at
the
contents,
you
can
map
out
the
you
can
recreate
the
same
structure
on
destination.
So,
for
instance,
we
have
this
record
here
and
the
source
full
path.
We
need
to
store
the
source
full
pass,
the
destination
name
destination,
namespace
and
then,
if
it's,
if
it's
a
group
entity,
then
it's
going
to
have
an
associated
namespace
id.
If
it's
a
project
entity,
it's
going
to
have
an
associated
project
id
and
obviously
the
source
tab
will
change.
A
A
A
That's
something
that
is
what
we're
going
to
cover
next,
so
just
one
more
time,
so
the
bulk
import
so
far
stores
the
state
for
the
overall
import
process,
the
configuration
stores
credentials,
the
entity
stores,
the
information
about,
or
project
to
import
and
the
import
state
as
well
to
keep
track
of.
What's
finished,
what's
still
in
progress
now,
the
next
thing
that
we
create
for
after
entity
is
pipeline
trackers.
A
So
if
we
have
a
look
at
the
imports
entity,
bulk
imports
entity,
it
has
many
trackers
and
it
has
many
failures
and
it
has
a
state.
You
know
the
the
model
itself
is
quite
small,
but
if
we
open
the
tracker
in
the
tracker,
we
store
the
relation
name
so,
for
example,
labels
milestones,
epics
whatever
and
the
pipeline
name.
A
If
we
have
a
look
at
the
trackers
table,
it
has
a
lot
of
information.
But
let's
say
we
focus
on
on
this
first
one.
For
now
you
know
it's
a
badges
pipeline
which
indicates
that
we
are
importing
badges
for
this
particular
pipeline
right.
The
job
id
the
stage
I'll
cover
stage
in
a
bit
and
the
status
2,
which
is
finished.
A
A
A
A
Where
you
have
something
like
this,
you
have
separate
parts
separate
pieces
of
responsibility
that
are
responsible
for
smaller,
smaller
things
right,
so
we
have
a
separate
extractor
that
goes
ahead
and
fetches
the
data.
Then
we
have
the
transform
layer
where
we
transform
the
data
to
fit
our
needs.
You
know
normalize
it
or
clean
it
or
whatever,
and
then
we
load
it
in
our
case,
all
of
the
all
of
the
use
cases
for
the
load
is
just
persisting
the
database,
but
you
can
think
of
the
load.
A
Pipeline
we
have
a
custom
dsl
built
for
bulk
import
pipelines
and
you
can
see
it
in
in
this
module
here.
Bulk
imports
pipeline.
You
know
it
allows
you
to
define,
extract
transformer,
extractor,
transformers
and
loaders.
You
don't
have
to
use
the
dsl.
If
you
don't
want
to,
you
can
just
use.
You
know.
A
A
If
you
haven't
seen
it,
it
might
be
useful
to
check
it
out,
but
the
major
thing
is
that
import
export
is
a
very
generic
to
the
point
where
it's
very
hard
to
understand.
What's
going
on,
and
in
order
to
understand
anything,
you
need
to
understand
everything
and
with
this
approach
we
wanted
to
steer
away
from
that
a
little
bit
and
provide
more
modularity
to
our
changes.
A
So,
for
instance,
if
you
take
a
look
at
relation
factory,
if
you
have
a
look
and
what's
going
on
here,
it's
quite
hard
to
understand
and
it's
it
is
a
factory
though
so
it
does
try
to
accommodate
for
all
types
of
data
coming
in.
But
we
wanted
to
have
a
modularity
with
our
with
the
new
approach
and
being
able
to
swap
in
and
out
modifications
on
demand
with
a
bit
greater
visibility.
A
A
So
we
have
a
an
example
pipeline
here
and
the
extractor
is
defined
for
the
graphql
extractor
and
there
are
currently
three
types
of
extractors
that
we
have
in
bulk
imports:
namespace
the
graphql
extractor,
it
just
fetches
the
data
from
graphqlm
api
and
we
use
that
data.
We
transform
it
and
then
we
create
we.
You
know
we
persisted
so
a
good
example,
actually,
maybe
to
show
not
the
members
pipeline,
although
that
is
a
good
one,
but
also
the
group
pipeline.
So
we
have
the
the
very
first
thing
that
we
do
during
group
import.
A
A
Abortion
failure
essentially
means
if
something
fails
and
we
couldn't
create
a
group
abort
the
whole.
The
whole
entity
market
has
failed
right,
which
kind
of
makes
sense,
because
you
don't
want
to
import
labels
or
import
anything
really,
if
you
don't
have,
if
the
group
creation
failed
right,
so
so
yeah,
some
of
the
pipelines
have
this
attribute,
which
help
prevent
some
sort
of
failing
imports.
A
A
You
can
see
that
there
is
a
tracker
for
it,
meaning
that
this
pipeline
is
going
to
be
to
be
executed
and
what
it
does
is
essentially,
okay,
it's
checking
if
the
group
that
we
just
processed,
if
it
has
any
subgroups,
if
it
does,
you
know
we,
we
actually
try
to
extract
this
data
from
source.
We
check.
Does
this
group
have
any
subgroups?
A
A
A
Okay,
that's
how
we
gradually
kind
of
fill
it
out
with
information
top
down
starting
with
root
perform
all
the
import
there
check
are.
Are
there
any
new
other
any
subgroups?
Yes
create
entities
for
that?
Are
there
any
projects,
yes
create
project
entities
for
that,
and
then
you
know
gradually
we
work
through
everything
you
know
the
subgroup
gets
processed
would
perform.
The
same
thing:
are
there
any
subgroups
in
this
group?
Yes,
okay,
create
more
entities.
A
A
Is
it
downloads
a
file
it
decompresses
it,
and
then
we
read
it
and
then
we
you
know,
yield
it,
that's
what
it
does
and
I
will
touch
on
into
json
pipelines
later
on,
but
yeah.
Currently
we
have
three
types
of
extractors,
I
mean
technically
two.
The
third
one
is
being
more
custom
for
the
rest.
Api
was
a
bit
more
logic,
you
know
like
downloading
the
file
decompressing
it
and
then
you
know
yielding
the
result.
A
A
A
Let
me
see
what
can
I
like,
for
example
here
you
can
just
define
the
load
methodness
directly
in
the
pipeline
and
yeah.
I
guess
the
the
good
thing
to
do
is
to
check
this
pipeline
module,
which
includes
the
runner
module
and
that's
where
the
run
method
is
defined.
You
know
that's
where
we
call
the
extractor,
then
we
perform
on
the
extracted
data,
we
run
all
of
the
transformers
and
then
we
call
the
load
method
as
well.
A
A
A
A
Let
me
open
the
oops,
let
me
open
the
project
one,
you
know
it's
quite
extensive.
What
we
import
and
export
is
quite
a
lot
right,
so
this
is
what
we
cover
in
project,
import,
export
and
one
of
the
tasks
for
this
solution
was
parity
with
import
export
tool
and
if
we
want
to
use
graphql
api
first
of
all,
we
don't
have
everything
in
graphql
api
to
cover
all
of
this.
A
But
what
became
apparent
is
that
nested,
subrelation
complexity
is
what
would
give
us
the
most
trouble
and
what
I
mean
by
by
that
is
this.
For
instance,
if
we
want
to,
let
me
show
you
if
we
want
to
fetch
a
list
of
merge
requests
that
includes
nodes
and
every
node
includes
events
and
every
event
includes
push
event
payload.
A
You
can
see
how
how
many
layers
of
nesting
there
are
one
two,
three
four,
but
there
can
be
virtually
unlimited
number
of
necessary
relations
right
and
that
became
problematic
with
graphql,
because
there
are
clearly
complexity
limits
on
gitlab.com
and
just
in
general,
on
on
graphql
api
that
we
ship
with
gitlab.
It
has
clearly
query
complexity
limits
that
we
cannot
exceed.
You
know
the
graphql
api
will
just
simply
not
return
as
a
result.
A
And
the
other
problem
is
graphql.
Api
has
nested
pagination.
That
would
be
extremely
difficult
to
manage
and
I
have
an
example
for
you
here.
For
example,
if
we
have
a
project
and
we
want
to
face
a
list
of
issues
and
by
default
the
page
number,
the
the
page
size
for
gitlab
is
100
and
you
cannot
exceed
that
you
or
maybe
you
could,
I'm
not
entirely
sure.
Maybe
it's
500
regardless.
There
is
a
limit
right
and
every
issue.
A
We
want
to
also
fetch
notes
and
for
every
note
we
want
an
author
and
a
word
emoji
and
for
every
collection
that
is
returned.
There
is
a
cursor
that
we
have.
We
have
to
to
manage
right.
It's
page
info,
okay,
the
syntax
is
not
valid,
but
people
who
worked
with
graphql
before
know
what
I
mean
like
there's
a
before
cursor
after
cursor
on
this
level.
A
So
there's
something
like
that
here.
There's
something
like
that
here,
oops
here
and
there's
something
like
that
here.
Can
I
purify
this?
No,
anyway,
you
get
an
idea
that
you
have
three
different
paginators
pagination
cursors
to
to
manage,
which
is
first
of
all
quite
difficult
to
do,
but
it
would
be
slow.
It
would
return
results
that
you
don't
need.
A
A
It's
slow
and
maintenance
hell
essentially,
and
on
top
of
that
we
would
be
producing
and
pass
one
queries
and
what
I
mean
by
that.
If
we
do
not,
if
we
do
not
use
this
approach
with
nested
pagination,
then
we
have
to
fetch
epics
or
fetch
any
subrelation
one
by
one
and
an
example
being
if,
let's
say
we
have
a
group
or
actually
no,
let's
say
we
have
we
import
500
issues,
no
problem
and
then
for
every
issue.
We
want
to
fetch
nodes,
so
that
is
going
to
essentially
be
issue.
A
A
So
we
decided
to
have
like
a
more
of
a
hybrid
approach
where
some
pipelines
we
use
graphql
some
pipelines.
We
use
rest
api
and
some
pipelines
we
use
into
json
and
simply
because
it's
much
faster
and
like
here,
10
000
apex
with
events
and
labels
is
a
file
that
is,
you
know
this
is
complete,
guess
but
let's
say
one
megabyte
comparing
to
doing
to
20
000
network
requests.
A
Obviously,
that's
going
to
be
way
way
faster,
both
processing,
wise
and
just
the
amount
of
time
it
takes
to
to
perform
all
these
requests,
and
also
the
import
of
nested
data
is
already
handled
by
import
export.
Quite
well,
although
it
does
bring
me
us
back
to
the
original
point
right,
the
big
disadvantage
like.
Why
did
we
want
to
we
have
this?
I
mean
one
of
the
solutions
is
so
that
the
user
doesn't
deal
with
files.
The
other
one
is
that
we
wanted
modularity.
A
A
But
members
pipeline
is
not,
and
the
rule
of
thumb
that
we
kind
of
landed
on
is
for
simple
flat
relay
for
flat
relations.
Like
members
labels
milestones,
you
can
probably
use
graphql
for
more
complex
stuff.
You
should
be
using
anti-json
pipeline,
just
nd
json
approach
right
just
because
it
handles
subrelations
so
much
better.
A
And
how
do
you
know
like
which
approach
to
use
mostly
you
just
take
a
look
at
the
import
experts
file.
If,
if
this,
if
the
subrelation
is
quite
flat,
you
know,
then
you
don't
even
you
might
not
need
it
to
use
the
indie
json
pipeline.
But
if,
let's
say
it's
something
like
this
right,
then
you
definitely
need
to
send
the
json
pipeline.
A
A
That
essentially
says
you
know
to
to
another
instance
of
gitlab:
hey,
please
export
the
relations
and
we
have
export
relations
api,
which
can
be
viewed.
It's
currently
available
for
group
export
not
for
project,
but
project
1
is
ongoing,
so
here
here
it
is
and
what
it
does
it's
very
similar
to
regular
export
where
you
have
a
tarball,
but
instead
of
a
tar
tarball,
you
get
a
small
gzipped
files.
A
A
And
boards
epics,
whatever
that
we
request
the
export
of
so
on
the
import,
starts,
we
go
to
source
and
we
ask
it:
can
you
export
all
of
your
data
and
then,
by
the
time
we
by
the
time
the
pipeline
starts,
the
nd
json
pipeline
starts?
We
fetch
that
information
from
from
source,
if
it's
available,
if
it's
not
available,
then
we
reschedule
the
job
in
the
future,
and
that
can
be
seen
here.
I
believe
right
here.
So
this
is
the
pipeline
worker,
and
here
we
check.
If
the.
A
A
A
A
A
A
A
A
A
A
Then
we
wait
for
the
entities
to
all
be
reported
back
and
then
we
finally
update
the
import
state
as
well
to
either
you
know,
finished
or
failed
and
yeah.
That's
that's
how
that's
how
it's
performed,
but
we
also
have
stage
file
for
projects,
but
currently
it's
under
development.
So
it's
it
doesn't
have
much
all
of
the
projects
that
I
show
I've
shown
you
here
are
empty.
They
don't
even
have
repository
yet
sorry,
that's
a
wrong
group.
A
A
Lastly,
the
current
comparison,
like
I
said
well,
I
mentioned
before
so
the
group
migration
is
covered
and
should
have
feature
priority
with
group
import
expert
project.
Migration
is
under
development
and
mostly
not
covered
it's
behind
the
feature.
Flag,
bulk
import
projects
and
overall
overall
feature
flags
for
feature
flag,
for
this
feature
is
bulk,
import.
A
Yeah,
I
guess
that's
the
that's
an
overview,
obviously
there's
a
lot
to
take
in
there's
a
lot
of
stuff
going
on.
I
haven't
even
shown
the
contents
of
the
anti-json
pipeline
module
and
I
probably
should
have-
and
I
will
right
now-
but
the
nd
json
pipeline
module
defines
the
transform
method
and
it
uses,
like
I
said
before
it
uses
import
export
functionality
was
the
relation
factory
where
we
transform.