►
From YouTube: 2020 12 07 Memory Team Weekly
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
All
right,
happy
monday,
welcome
to
this
version
of
the
memory
team
meeting.
There
are
a
few
topics
updates,
not
verbalize
there
and
jump
right
into
it.
So
there
was
an
issue
that
was
raised
and
I
think
it's
split
evenly
across
database
of
memory
team.
There
were
some
questions
about
puma
workers
and
questions
about
database
connections.
I
haven't
read
too
much
more
into
that,
so
maybe
coming
off,
you
can
take
a
look
and
I
will
have
someone
from
the
memory
team.
Take
a
look
as
well.
C
A
A
D
D
If
we
can't
align
on
that,
then
maybe
we
need
to
revisit
our
scoring
a
little
bit
and
talk
about
it,
but
in
an
ideal
world
you
know
we
can
just
look
at
this
now
and
say
like
do.
We
think
these
are
the
right
things
to
work
on.
That
was
the
one
of
the
outcomes
of
this.
This
exercise
right,
and
that
is
what
I
would
like
to
do,
because
ultimately,
those
are
the
things
that
should
go
into
an
epic.
D
E
E
D
D
Okay,
but
so
if
we
like,
let's
say
it
in
my
mind:
the
baseline
performance
measurement,
but
an
nd
c.
You
know
the
minimum
thing
that
we
can
do
in
order
to
establish
our
baseline.
We
should
definitely
do
next
right.
That
is
to
me,
otherwise
it's
very
hard
to
know
what
impact
we're
actually
having
in
my
mind,.
F
D
D
F
D
G
G
E
B
G
A
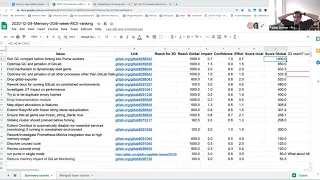
So
we're
bouncing
around
quite
a
bit:
do
we
want
to
record
some
local
scores
for
these
so
that
we
capture
them
all
and
have
something
to
compare
on
the
spreadsheet,
so
we
have
a
column
for
reach
further
to
gig,
which
I
think
is
the
intention
here,
and
then
we
can
calculate
here.
Is
that
what
you
were
looking
for,
if
ibm.
D
D
But
we
accept
that
because
our
our
goal
is
different
here
right
and
in
some
cases
both
are
true,
but
it's
like
it
benefits
everyone
and
small
instances,
but
in
other
instances
it
is
true
that
this
is
highly
relevant
for
very
small
instances
and
it
doesn't
actually
affect
large
instances
at
all
and
we
don't
care
either
right.
So
I
think
I
think
it's
a
question
on
like
what
what
we
are
trying
to
achieve
in
the
end
right
personally
right.
D
I
think
if
we
can
do
something
that
also
benefits
hundreds
of
thousands
of
users
right,
that's
a
global
optimization,
that's
maybe
more
beneficial.
You
know
than
something
that
only
goes
to
the
very
low
end,
but
we
can
strike
a
balance
right
and
do
some
things
that
are
global
and
some
things
that
are
local.
Only.
E
D
That
is,
that
is
my
understanding
right,
and
so
we
should.
We
should
try
primarily
we
should.
Ideally,
you
know
like
we.
We
do
these
things
first,
that
have
high
global
reach
and
high
impact
on
small
things
right,
but
if
we
have
things
that
are
very
impactful
for
small
instances,
those
are
also
important,
and
I
think
this
is
maybe
why
marking
those
as
in
this
reach
for
2
2g
right
is,
is
also
important,
as
in
you
know,
like
pick
the
ones
that
have
the
maximum
impact
on
on
our
2g
initiative.
A
Yeah
agreed-
and
I
I
don't
think
the
summary
or
the
goal
was
written
explicitly
anywhere
outside
of
the
two
gig
week,
epic,
on
what
we're
trying
to
reach
here.
But
the
goal
is
to
figure
out
how
small
of
a
footprint
can
we
get
for
the
single
installation,
and
I
think
I
just
linked
it
in
the
dock.
But
this
kind
of
gives
some
background
as
to
why
we're
doing
that
work
as
well.
So.
A
E
So
it's
definitely
not
zero,
and
not
one
thousand,
because
like
puma
single
is
like
replace,
replaces
this
logic
completely,
so
it
will
go
with
spawn
single.
It's
no
longer
relevant,
but
I
would
say
like
as
a
intermediary
option,
we
could
say
like
500,
because
we
could
use
this
step
until
we
implementing
puma
single,
because
puma
single
is
very
complex
in
terms
of
implementation.
C
C
E
A
D
So
I
think
we
are
primarily
like
we're
using
this,
though
it
feels
a
little
bit
more
as
an
impact.
You
know
how
many
of
those
people
like
how
big
is
the
impact,
rather
than
how
big
is
the
reach
right?
Yes-
and
I
think
that
is-
I
think
this
is
maybe
more
significant
in
this,
but
it
doesn't
really
matter
that
much
right,
because
we
can
we
can
rescale
these
to
one
or
we
scale
them.
Two
thousand.
I
think
that's
it's
more
about
the
ranking.
E
A
E
A
E
D
D
F
F
I
think
that
we
should
more
focus
on
disabling
the
actual
features
that
we
are
not
gonna
use,
and
then
we
can
like
work
on
this
as
some
kind
of
a
global
solution
and
architectural
change
that
will
affect
everything
else
by
allowing
us
to
disable.
It's
not
the
same
thing,
but
I
think
that's
what
will
have
much
more
impact
than.
F
E
G
G
B
G
G
B
G
I
B
It
seems
like
a
low
hanging
fruit
really
without
a
lot
of
effort,
so
I
I'm
not
sure
like
how
impactful
is
that,
but
like
impacts
at
0.3,
I
mean
like
this.
I
mean
impact
plus
reach
that
we
use
it's
kind
of
confusing,
because
it
makes
me
think
that,
like
we
should
multiplicate
1000
with
0.3,
which
would
be
like
the
impact,
so
I
would
say
something
like
1000
or
500
for
this
one.
G
G
I
think
this
is
way
too
high.
I
I
think
we
made
a
mistake
by
mix
by
by
changing
the
definition
of
impact.
To
be
honest,
because
this
to
me
is
reach
not
impact,
we
don't
even
know
how
much
remember
this
is.
Actually
we
do
know,
we
did
some
memory
dumps
and
this
just
the
code
that
we
load
to
do
instrumentation
is
is
like
not
even
close
to,
for
instance,
dropping
gitlab
exporter,
which
was
100
meg,
so
so
this
can't
be
larger
than
dropkit
live
explorer,
for
instance,.
D
G
F
F
B
G
F
G
G
B
B
E
B
G
A
G
E
B
B
B
G
E
D
D
E
B
I
I
mean,
from
my
perspective,
like
looking
at,
let's
say
these
six
items
like
it
has
a
mix
of
like
ensuring
that
we
catch
the
current
stuff,
how
they
behave,
but
we
also
have
like
big
items
that
gonna
reduce
memory
usage
in
these
constrained
amps
in
various
cases
and
some
of
them.
We
also
benefit
the
big
installs
as
well.
A
D
I
E
G
Now
I
also
wonder
if
it
makes
sense
to
bucket
up
some
of
them,
because
three,
seven
and
eight
to
me
they're
all
like
the
same
problem,
but
at
different
levels
of
granularity
like
in
this
order.
Actually
so
reducing
like
not
running
gitlab
monitoring
is
just
an
instance
of
running
a
non-essential
service
on
a
small
node
in
my
books
and
then
gitlab
exporters.
D
D
H
G
G
C
G
It's
one
of
the
biggest
ones,
and
it's
also
one
that
has
a
huge
amount
of
legacy
and
technical
debt
concentrated
in
it,
which
is
why
I
think,
there's
more
than
one
reason,
even
even
beyond
the
two
gigabyte
week.
I
think
we
should
get
rid
of
it
and
infrastructure
has
been
trying
to
get
rid
of
it
for
almost
a
year
now
yeah.
So
this.
D
G
G
Like
the
feature
teams
first
and
the
stakeholders
and
see
hey,
and
we
need
to
understand
a
bit
better,
first
like
what
what
yeah,
how
that
impacts
user
experience
and
or
are
you
I,
like
you,
excuse
me-
I
use
this
of
certain
that
run
get
up
on
a
certain
size
of
node.
Do
they
even
use
these
kind
of
features
stuff
like
that?
Okay,.
E
E
D
B
I
think
so
it's
more
about
testing
different
parameters
and
trying
out
which
one
may
be
the
good
one.
Also
like
we
can
tune
these
parameters
today,
like
with
the
generic
amiibo
settings,
if
you
would
have
to
so.
There
is
a
few
aspects
that
we
may.
This
could
be
like
initially
part
of
the
documentation
like
how
to
configure
your
gitlab
and
later
it
could
be
part
of
the
defaults
really
that
we,
let's
say
maybe
as
part
of
the
number
three
on
that
list.
B
B
Like
trying
some
different
values,
speaking
shipping
them
checking
how
they
behave
and
like
reassessing
or
like
constantly
like
how
these
values
behave
if
they
kind
of
like
impact
negatively
or
positively.
So
it's
not
like
that.
I
would
say
that
this
is
gonna,
be
a
set
of
stone.
It's
more
like
we
might.
We
might
choose
like
the
values
that
are,
let's
say,
like
more
conservative,
initially
but
later
more
aggressive,
and
we
may
figure
out
exactly
different
values
that
are
going
to
behave
differently.
B
D
E
G
Just
a
quick
clarification,
so
drop
gitlab
explorer
eight.
It
is
actionable.
I'm
working
on
this
already.
It's
just
like
there's
quite
a
lot
of
stuff
to
unpack,
and
it
just
requires
also
sticking
with
other
teams
on
some
things,
but
it's
definitely
actionable
because
we
can
still
leave
github
monitoring
enabled
by
default,
but
just
get
rid
of
this
thing,
and
that
would
also
have
a
100
megabyte
impact.
You
know
in
terms
of
memory
not
used.
F
F
Lots
like
require
the
code,
so
the
the
files
are
not
loaded
for
the
specific
features
and
when
we
confirm
that
the
like
way
or
mechanism
that
we
find
it's
working,
I
only
want
to
like
say
that,
like
finding
the
mechanism
will
not
have
direct
impact,
because
then
we
will
need
to
promote
that
and
change
the
the
actually
the
project
architecture
which
will
need
to
be
communicated
with
other
teams.
And
I'm
not
sure,
like
the
final
goal
here
is
just
to
like,
provide
away
and
confirm
that
it
can
work.
E
F
Again,
I'm
now
fully
focused
on
just
like
providing
a
way
to
dynamically
load
graphql
and
it's
tricky,
and
it
will
be
more
even
tricky
for
the
features
that
are
not
clear
like
for
the
graphql.
We
know
it's
not
used
in
sidekick.
We
don't
need
it
like.
We
don't
need
the
controllers.
We
don't
need
the
anything
out
of
graphql
in
the
sidekick,
but
for
some
other
features
that
are,
it
would
be
difficult
to
determine
like.
Should
we
lazy
law
then,
and
when-
and
I
guess
that
then
the
12.
H
D
Yeah,
okay,
but
sorry
I
think
we're
almost
out
of
time,
but
if
I,
if
I
summarize
this,
so
if
we
take
the
top
10
items
here
right
and
we
ignore
the
documentation,
because
you
know
that's
the
last
thing-
we
can
kick
off
the
discussion
on
non-essential
services.
You
know
that
is
something
we
can.
We
can
do
right
now.
D
We
could
start
the
work
on
the
gc
and
j
analog
parameters.
This
year
is
already
being
worked
on.
The
single
mode,
puma
could
be
started
relatively
soon.
Drop
like
the
gitlab
exporter
is
also
already
started.
Mathias
is
on
that
and
there
may
be
follow-up
work.
We
may
need
to
announce
deprecation
already
in
you
know
this
release,
for
example
right.
So
there
are
things
that
that
are
actionable
here
and
nikola.
D
D
No,
that
would
not
that
would
actually
be
great
okay,
and
then
we
can,
we
can
say,
like
these
are
all
things
that
we
may
want
to
do
in
the
future
right.
But
we
are
saying
you
know
we
are
we're,
starting
with
with
those
items
here,
because
these
some
of
them
to
me,
feel
more
like
epics
right
or
like
larger,
larger
efforts,
where
we
need
to
maybe
break
them
down
a
little
bit
further
to
really
make
sure
we
ship
something
small
right.
So
I
feel
just
those
things
here
in
flight.
D
Okay,
I
mean
that's,
that's
a
good
estimate,
because
I
would.
I
would
like
to
maybe
start
this
as
well
as
saying
like
look.
This
is
our
baseline
right
and
if
we
finish
these
seven
seven
or
eight
things
right,
we
estimate
that
the
combined
memory
impact
is
this,
and
then
we
can
also
when
we're
done
or
on
the
way
we
can
validate
this
further
and
actually
say.
This
is
what
we
are
observing,
whether
it's
it's
good
or
not,
because
that
that
is
what
we're
actually
trying
to
do.
Is
there?
C
E
G
A
D
Cool
and
also
before
I
drop,
I
really
appreciate
all
of
you
sort
of
going
with
this
right.
I
think
it's
a
little
bit
confusing
and
we
have
a
lot
of
numbers
and
it's
a
big
thing
right
and
often
it's
easier
when
you
do
it
the
next
time
right,
because
you
have
an
agreement
on
things,
but
I
still
think
it
flushed
out
some
of
the
things
that
we
were
not
so
sure
about
as
well
as
like
when
we
talk
about
reach.
D
What
were
you
trying
to
do,
and
why
are
we
doing
this
and
not
that?
I
think
that
is
also
valuable
in
its
in
its
own
right,
and
I
hope
that
maybe
for
another
epic
right
in
a
month
or
two
when
we're
doing
something
different.
We
can
do
something
like
this
again
right.
We
just
look
at
this
and
say
like
okay,
what
what
should
we
do
and
then
it
becomes
a
lot
easier,
and
you
know
you
get
better
at
it
and
it's
a
nice
tool
to
have
under
your
your
belt.
A
I
agree:
I've
found
it
personally
valuable
and
thanks
for
asking
for
the
overall
impact.
That
was
something
I
was
going
to
ask
for
too,
especially
in
this
milestone.
So
I
will
we'll
get
something
written
up
today
and
we
can
cover
it
asynchronously.
Sorry,
I
cut
off
alexia.
I
think
you're
going
to
say
something.