►
From YouTube: Product Intelligence Think Big Session - April 2022
Description
Problem to solve: Metrics are timing out
Issue: https://gitlab.com/gitlab-org/gitlab/...
Think Big Epic: https://gitlab.com/groups/gitlab-org/...
A
Hello,
everybody
welcome
to
our
very
first
product
intelligence.
Think
big
session,
very
excited
for
this.
I
will
be
transparent
and
say
that
I'm
a
little
nervous,
because
I
want
this
to
be
useful
for
everybody,
and
so
you
know,
I
think
we're
just
gonna
go
with
it.
So
the
first
question
is:
why
are
we
doing
this?
What
is
the
point
of
this
thing
that
we're
trying
this
process
that
we're
trying
to
create
monthly?
A
The
product
kind
of
suffers
as
a
result,
and
so
teresa
torres
is
somebody
that
I've
been
reading
a
lot
about
she's
great
in
product,
and
she
says
that
when
your
product
trio
works
together
from
the
very
beginning
to
develop
and
understand
a
shared
understanding
of
the
customer
and
their
needs
and
their
pain
points
we're
in
a
position
collectively
to
make
a
much
better
product,
a
product
that
customers
love.
And
what
do
we
mean
by
product
trio?
A
So,
typically
teresa
talks
about
the
product
trio,
being
development,
product
and
design,
but
in
product
intelligence
we're
a
little
bit
different
right.
We
don't
have
a
lot
of
kind
of
customer
facing
ui
features,
and
so
I
like
to
think
about
this,
as
rather
than
the
design
team,
the
quality
team
steps
into
that
trio
space,
because
the
three
of
us
working
together
can
create
something
much
more
effective.
A
So
the
point
of
the
monthly
sessions
is
to
start
earlier
in
the
validation
cycle.
As
a
team
talking
about
the
problem
talking
with
our
customers
and
I'm
going
to
introduce,
we
have
some
guests
on
our
call
today
some
customers
and
really
understand
the
problem
that
we're
we're
faced
with
and
from
their
perspective
it.
A
You
know
how,
how
and
why
it
affects
them
and
then,
as
a
team,
try
to
identify
all
of
the
different
ways
we
can
solve
it
really
zoom
out
and
if
there
were
no
limitations,
you
know
what
are
all
the
different
ways.
We
can
attack
this
problem
and
then
zoom
back
in
using
you
know
the
the
constraints
that
are
available
to
us
to
determine,
which
is
the
best
method.
A
So
we
will
take
the
problem,
we'll
we'll
zoom
out,
then
we'll
zoom
back
in
and
then
the
results
that
we
come
up
with
collectively.
As
a
team
will
become
a
technical
spike
and
assigned
to
an
engineer
in
an
upcoming
milestone
to
take
the
ideas
that
we
refined
and
research
them
even
more
further
so
before
I
actually
dive
into
the
problem
itself,
are
there
any
questions
about
just
kind
of
what
is
the
think
big,
and
why
are
we
here.
A
A
I'd
like
to
talk
about
a
customer
use
case
that
runs
up
against
this
problem,
frequently
and-
and
that
is
from
the
the
composition,
analysis
group
from
the
secure
stage-
and
they
have
a
lot
of
database
based
metrics
and
an
example
is
counts,
license
management,
jobs
that
continue
continually
fail.
They
time
out
and
I've
invited
nicole
and
igor
from
the
team
to
talk
to
us
a
little
bit
about
the
problems
they
face
and
to
help
us
brainstorm
on
ways
that
we
can
solve
this.
B
Yeah,
sorry,
I
think
nicole,
could
probably
speak
better
about
this
than
I,
but
I
think
the
the
issue
sort
of
at
the
in
our
team
level
is
we
just
have
you
know
we
implement
the
the
metrics
as
documented
and
sort
of
expect
them
to
to
work
and
and
and
when
they
don't.
We
kind
of
don't
know
what
to
do
next,
and
I
think
that's
where
that's
where
we
nicole
would
come
in
and
kind
of
give
us
a
better
perspective
on
it.
I
mean
this.
B
This
is
why
I
think
she
wanted
us
to
be
on
the
calls
to
give
that
perspective
of
can't
really
dive
deep,
and
so
I
guess
the
expectation
of
it
working
is
something
that
that
maybe
we
need
to
address
more
like
from
our
like.
Maybe
we
need
to
troubleshoot
more
and
what
are
the
tools
and
what
are
the
documents
that
allow
us
to
do
that?
I
think
that
would
be
the
the
question
from
the
side
where
we
just
do
the
implementation.
A
Yeah
and
if
you
had
a
chance
to
watch
the
pre-video,
the
pre-recorded
video
to
this
session
nicole
talked
about
this
license
management
job
specifically,
so
the
tldr
of
of
what's
actually
happening
happening
from
the
get
lab
and
the
end
user
perspective.
Is
users
interact
with
this
license
management
feature
they
basically
have
to.
I
think
they're
like
making
a
call
to
to
verify
if
the
license
they
want
to
use
is
valid
or
something
of
this
nature.
A
I'm
not
an
expert
of
this
feature,
but
they
have
to
interact
with
the
future
and
the
actual
metric
that
they're
that
the
team
is
trying
to
instrument
or
count
is
whenever
a
user
interacts
with
that
feature.
For
the
first
time,
then
the
counter
should
be
incremented,
and
so
it's
a
database
based
metric
and
the
way
that
it's
been
structured.
It
just
continually
times
out,
and
so
hopefully
that
gives
a
little
bit
of
understanding
about
kind
of
how
they
use
the
counters
that
have
been
experiencing
this
problem.
A
A
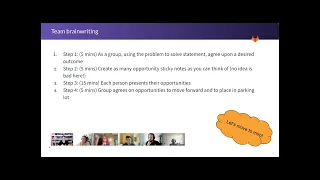
Yeah,
okay,
so
the
first
step
is,
as
a
group
we're
gonna
spend
about
five
minutes
or
so
now
these
times
that
I've
listed
is
just
to
keep
me
on
track.
So
I
don't
go
over
your
time,
but
please
you
we
can
go
longer
or
shorter
on
each
of
these
steps.
They're
not
hard
rule,
but
we're
gonna
spend
about
five
minutes
as
a
group
using
the
problem
statement
and
agree
upon
a
desired
outcome.
And
what
does
that
mean?
That
means
we
have
a
problem
to
solve
statement,
but
in
the
end,
what
do
we
want?
A
Our
solution
to
look
like
right,
so
we're
kind
of
just
looking
at
the
opposite,
rather
than
looking
as
a
problem.
We
want
to
create
a
target
goal
of
the
thing
that
we're
going
to
build
okay,
so
we're
going
to
spend
about
five
minutes.
Thinking
about
that,
I
will
document
that
piece
on
our
mural
board.
A
Then
the
next
step
is
the
team
is
just
going
to
collectively
jump
into
the
mirror
board
and
pick
a
color
and
start
putting
as
many
ideas
as
you
can
on
the
color
that
you
choose
if
we
run
out
of
colors.
Just
let
me
know
I
can
add
more
and
then
once
we
once
that
time
is
up,
we
will
each
person
will
kind
of
speak
high
level
to
what
they
were
thinking
in
terms
of
what
they
wrote
down.
This
is
a
no
pressure
situation.
A
If
you
really
are
not
sure
it's
okay
to
just
say,
I'm
not
sure
where
I
was
going
with
this,
but
I
I
somewhere
in
this
direction,
that's
totally
fine!
Then
we
will
refine
and
we'll
take
the
ideas
that
we
think
are
something
that
we
might
be
able
to
work
with
and
we'll
move
them
to
the
move
forward
box
and
the
ones
that
maybe
need
more
thoughts
and
and
not
quite
ready
or
don't
meet
our
desired
outcome.
We'll
put
them
in
the
parking
lot.
We
won't
throw
them
away,
they
might
be
good
for
other
purposes.
A
Then
the
next
step
is
to
take
the
things
that
we're
moving
forward
and
determine
technical
opportunities.
So
if,
for
example,
I
don't
if,
if
we
say
we
can
build
xyz,
then
this
becomes
the
xyz
and
these
are
steps
to
get
there.
And
then,
if
we
say
we
can
find
a
solution
using
abc,
then
this
is
the
abc
solution
and
technical
steps
to
get
there.
Then
these
two
opportunities
become
the
technical
spike
for
the
engineer
in
an
upcoming
milestone
to
break
down
and
determine
you
know
which
proposal
is
the
better
proposal?
A
C
I
have
a
question
if
we
can
return
a
bit
on
the
problem
that
we
want
to
solve,
to
make
sure
that
I
understand
how
we
define
the
problem,
because
I
I'm
trying
to
think
a
bit
more
about
this
and
I
might
see
two
problems
and
I'm
not
sure
if
I,
if
it's
the
same
for
everyone
or
maybe
I'm
missing
something.
So
there
is
the
case
where
the
metrics
are
timing
out,
which
is
a
valid
case,
and
we
have
this,
for
we
have
this
for
multiple
metrics,
especially
for
more
complex
metrics
in
large
tables.
C
C
C
C
A
C
A
And
I'm
embarrassed
that
I
did
not
figure
that
out,
so
this
is
not
a
problem
statement.
This
is
not
a
problem
statement.
This
is
a
solution
statement.
These
are
the
problem
statements
right,
so
we
shouldn't
jump
to
this
conclusion.
We
shouldn't
jump
to
this
conclusion
that
this
is
the
answer.
So,
let's
reframe
the
problem.
A
A
What
is
the
problem
here?
We
maybe
perform
us.
Maybe
yeah,
yeah
performance
is
negatively
affected
when
we
calculate
metrics
at
the
time
of
collection
right.
Does
that
sound
better?
But
these
are
the
three
problems
which
we
don't
necessarily
have
to
focus
on
all
three.
We
can
pick
one
okay,
so
this
is
a
super
great
point,
elena.
Thank
you
so
much
for
for
pointing
that
out.
So
the
real
problem
is
metrics
are
timing
out.
A
C
C
A
D
Toggled
onto
one
under
one
umbrella
here
so
probably
narrowing
is
down
to
only
one
of
those
would
help,
because
I
would
say
that
we
have
two
aspects.
The
coupling
metric
collection
from
computation
has
a
different
different
challenge
that
solves
different
problems
than
what
was
showcased
by
use
case
product
use
case,
because
this
is
a
different
thing
and
probably
the
coupling
would
not
solve
it.
It
may
help
it,
but
it
is
very
unlikely.
D
D
So
this
is
a
diagram
I
crafted
this
morning,
just
briefly
from
high,
very
high
level
sketch
out
how
the
process
of
service
being
reporting
looks
like
so
it's
time-based
triggered
for
each
instance.
Then
we
launched
the
process.
First,
we
collect
the
metrics.
Each
of
matrix
is
collected
from
the
database,
sometimes
from
the
redis,
but
general
general
is
collected
from
some
data
source.
D
D
Okay,
I
hope
I
make
it
so
clear
that
the
idea
is
to
break
it
into
the
two
processes
independent
from
each
other,
but
these
two
processes
doesn't
really
touch
the
problem
of
collection
of
the
each
matrix
and
the
timing
out
of
the
matrix
happens
here.
So
we
can
either
focus
on
splitting
this
one
process
into
two
independent
ones
which
solves
different
problems,
or
we
can
narrow
our
focus
down
to
this
area,
which
is
how
we
handle
matrix
collection
in
order
to
unblock
the
heavy
metrics,
which
was
stated
in
the
use
case.
A
That's
really
helpful.
Thank
you,
mikly,
I'm
going
to
give
you
edit
rights
to
or
you
should.
No,
I
haven't
got
given
it
out
yet,
but
to
the
deck.
Can
you
drop
that
into
the
deck
for
purposes
of
everybody
being
able
to
see
that
also,
you
know,
I,
I
think,
let's
not
limit
ourselves
to
a
specific
solution
in
that
you
had
just
suggested
potentially
reworking
metrics
collection
alina
also
mentioned.
Maybe
we
actually
instrument
that
type
of
metric
differently
that
doesn't
solve
the
metrics.
A
Our
timing
out
problem,
though
right
that
just
redirects
to
use
a
different
tool,
but
that
that
might
be
valid.
You
know,
I
think,
that's
perfectly
valid
to
say,
hey
for
heavy
metrics
that
are
continually
timing
out,
try
this
type
of
an
implementation.
So,
let's
my
point
being
is
I
don't
know
the
right
answer,
but
I
don't
want
to
limit
us
and
narrow
us
into
a
single
focus
in
this
next
step
of
the
of
the
process.
Is
that
fair,
okay,
awesome.
B
Sorry
could,
I
just
add,
a
alina
linked
in
the
in
the
original
issue.
For
this
event,
she
linked
issue
fixed
service,
paying
failing
metrics
for
the
entire
secure
stage,
so
we
are
just
one
instance.
It
seems
of
this
job,
failing
I'll,
just
link
this
related
issues,
so
it
seems
like
in
the
stage
that
we
have
we
have
I
just
put
in
the
documents.
We
have
a
whole.
All
every
other
team
in
our
stage
has
a
similar
issue,
so
I'm
curious
whether
other
stages
do
counts.
B
Maybe
they
don't
and
if
they
do
counts
and
they
don't
have
issues.
Why
are
theirs
different
than
ours
right,
so
so
we're
basically
just
doing
like
you
can
see
in
the
issue
that
I
linked
static
analysis.
Jobs
are
failing,
dynamic
analysis,
jobs
are
failing
secret
detection
and
dependency
scanning.
Those
are
all
under
the
stage.
So
I'm
curious
why
our
like
this
stage
is
different
than
others.
Maybe
they
just
don't
do
counts
at
all.
In
other
stages,.
D
So
this
is
thank
you
very
much
for
the
question
igor.
I
didn't
do
a
throw
analysis.
I
just
briefly
looked
into
your
metric,
the
one
which
is
in
the
use
case
and
what
it
appears
to
be
that
it
uses
ci
jobs
table
and
from
the
metrics
names.
It's
just.
I'm
recalled
I'm
recalling
this.
So
maybe
maybe
I'm
mistaken
here.
D
It
needs
to
be
confirmed,
but
all
of
this
matrix
seems
to
work
on
the
cia
jobs
table,
which
is
the
heaviest
table
that
exists
in
the
gitlab
database
and
it's
bigger
than
the
all
other
tables
by
the
orders
of
magnitude,
and
because
of
that,
all
the
metrics
that
try
to
count
on
this
particular
table
encounters
heavy
performance
requirements
which
are
not
the
case
for
the
most
of
the
other
tables.
That's
why,
for
this
particular
group
of
metrics,
they
fail,
even
though
they
are
correctly
instrumented
with
the
tools
that
are
provided.
D
It's
just
the
sure
challenge
of
the
volume
of
the
data
that
has
to
be
processed
rather
than
like,
for
example,
if
we
count
nodes
nodes,
let's
say
have
100
like
100
000
rows
and
ci
jobs
has
100
billions
of
rows.
That's
the
the
difference
and
that's
the
that's
the
challenge
and
probably
the
reason
why
you
see
the
failures
mostly
affecting
your
stage
and
not
the
other
stages.
The
other
stages
also
use
the
counts,
distinct
counts,
all
the
toolings
that
we
have,
but
they
operate
on
the
way
smaller
relations.
A
Okay,
what
do
you
think
about
moving
on?
Shall
we
move
to
miro,
okay
and
we're
going
to
take
our
revised
problem
statement
from
slide
four?
So
let
me
just
share
one
more
time:
okay,
and
what
we're
gonna
do
is
we're
gonna.
Take
sorry
slide.
Five.
Was
it
five?
No
here
it
is
slide
three,
so
the
problem
is
metrics
are
timing
out
now,
let's
take
this,
this
problem
statement
and
let's
create
a
desired
outcome.
Okay,
so
metrics
are
timing
out.
What
is
the
desired
outcome
of
whatever
solution
we
end
up
implementing?
B
I
I
just
update
what
I
said:
don't
I
kind
of
mentioned
it
just
from
the
perspective
of
the
engineering
on
my
team,
not
necessarily
from
product,
so
I
think
that
the
problem
is
still
the
timing
out
and
not
getting
the
metrics.
I
I
just.
I
was
kind
of
giving
my
perspective
about
not
knowing
how
to
fix
it.
So
I
I
it
is
a
problem
I
would
just
say
it's
secondary.
I
think
primary
I
would
say
to
solve
the
issue.
B
A
Yeah,
don't
worry,
eber
we're
all
safe
space
here,
we're
all
working
on
the
problem
together
collectively,
so
don't
worry
about
offending
us
nikolai.
So
maybe
I
like
how
you
you
addressed
the
problem
as
kind
of
a
high
level
statement.
You
know
customers
should
be
able
to
do
their
job
essentially
right,
let's
bring
it
in
just
a
little
bit
because
we
don't
want
to
get
into
solutioning
with
the
outcome
statement
right
should
we
currently
I
have
customers
should
be
able
to
instrument
database
metrics
which
do
not
fail.
C
A
A
A
What
are
all
of
the
opportunities
we
might
have
that
help
us
get
to
that
direction?
It
doesn't
have
to
be
a
single
solution
that
solves
that
gets
us
to
service
p.
Metrics
are
able
to
handle
any
scale
data
all
of
the
opportunities
you
can
think
of
right
that
get
us
walking
into
that
path.
Go
ahead
and
start
typing
here.
This
is
going
to
be
a
silent
process,
but
you
can
feel
free
to
talk
so
we're
going
to
spend
wha.
What
do
we
say
for
this
step?
I
think
it's
five
minutes.
A
A
C
Okay,
I
can
start
and
first
of
all
sorry
I
didn't
know
what
would
be
the
rule
of
the
sticker,
so
I
think
I
was
messing
around
with
different
stickers.
So
sorry
for
that,
until
I
realized
that
I
should
have
my
own
column,
I
thought
it's
about
color.
So
sorry
again,
I
was
I
might.
I
can
share
some
of
the
ideas
that
I
have
there
so
right
now
we
I
mean
we're.
We
do
have
already
multiple
databases.
C
This
was
implemented
recently,
but
database
is
optimized
for
github.com,
especially
for
the
operations
that
are
from
ui,
so
not
for
reading.
So
that's
something
that
it
was
discussed
before.
So
if
we
decide
at
some
moment
to
to
have
a
separate
database
which
can
be
used
and
optimized
only
for
the
purpose
of
reading
the
information
there,
that
could
be
something-
maybe
you
pre-aggregate
the
data
from
the
large
tables
so
prepare
the
data
before
and
have
smaller
sets
of
data
where
we
can
count
and
have
maybe
better
performance.
C
A
Who
wants
to
go
next?
I
should
mention
real,
quick
opportunities
that
we
move
forward.
Don't
have
to
completely
solve
the
problem
if
it
reduces
the
problem
or
solves
part
of
the
problem,
something
like
that.
That's
also
totally
valid,
so
don't
worry
too
much
if
it
doesn't
solve
the
problem.
That's
really
great
alina!
Thank
you.
E
A
E
D
The
use
case
was
directly
about
the
database
storage,
but
we
widened
out
to
say:
let's
assume,
that
we
have
any
kind
of
data
storage
that
we
want
to
read
the
information
from
and
how
to
make
it
possible
to
read.
Regardless
of
what
kind
of
scale
of
the
operation
is.
We
are
running
and
collecting
this
in
this
data
stretch.
E
Okay,
well,
then,
then,
my
first
keynotes
will
not
apply
as
the
second,
I
wrote
explore
db
level
tools
for
handling
big
scale
of
data.
Basically,
I
would
consider
making
like
a
google
research
on
postgres,
since
postgres
offers
lots
of
different
tools.
Maybe
there
are
some
kinds
of
like
operations
that
we
didn't
use
that
are
available
yeah.
That
was
the
idea.
D
D
D
F
Yeah,
I
can
go
next,
so
my
ideas
were
similar
to
what
would
already
mention
that
is
to
have
separate
aggregate
tables
which
is
similar
to
pre-aggregating
the
data.
So,
instead
of
querying
large
data
sets,
the
data
should
be
exported
into
a
smaller
data
set,
which
is
which
would
be
easier
to
query
over.
Another
thing
is
that
we
can
capture
the
inserts
as
events
as
other
people
have
mentioned.
F
So
you
know,
instead
of
querying
over
a
large
range
it'll,
just
increment
a
counter
or
something
in
a
database
or
in
some
sort
of
cache,
and
can
directly
fetch
the
aggregate
from
that
storage
solution.
The
last
thing
would
be:
if
we
do
not
want
to
have
a
separate
storage,
we
can
just
parallelize
our
calls.
Instead
of
having
a
very
large
range,
we
can
put
it
in
smaller
ranges
and
make
parallel
calls
to
each
of
the
range
and
then
aggregate
them
so.
B
My
idea
was
just,
I
think,
everyone,
multiple
people
mentioned
it,
but
I
was
just
reading
about
the
event
store.
There
was
a
recent
edition
that
we
have
in
the
gitlab
functionality
and
it's
just
basically
a
pub
sub
model
where,
rather
than
writing
to
the
database,
you
write
to
your
publisher.
You
write
out
to
a
stream
right
now
it's
redis,
but
it
can
actually
probably
be
backed
by
anything.
B
So
we
don't
have
to
think
about
the
technology,
the
issue
with
redistrict
scale
and
then
and
then
have
a
subscriber
receive
it,
and
you
could
probably
scale
out
how
many
subscribers
and
then
you
can
have
those
subscribers
publish.
So
you
can
have
like
a
topology
that
descends
into
an
ultimate
aggregator
and
it's
just
something
worth
trying.
I
saw
it.
I
just
remember
seeing
it
in
the
engineering
weekly
it's
it's
probably
a
good
easy
test
to
do
without
lots
of
infrastructure
to
stand
up.
G
Sure
I
can
go
next,
so
mine.
I
was
trying
to
think
outside
of
this
really
hard
problem
of
using
a
database
as
a
way
to
collect
product
analytics
events.
So
this
is
maybe
partly
like
a
comp.
Will
this
work
for
products
like
the
product
managers
that
care
about
these
events?
Will
this
actually
give
them
what
they
need?
But
the
idea
is
to
actually
not
use
the
database
at
all
and
to
collect
events
in
real
time
in
some
capacity,
either
from
the
back
end.
B
A
Okay,
cool
all
right,
so,
quick
time
check,
we
have
15
minutes,
so
we're
gonna,
we're
gonna
move
fast
here.
If
you
have
proposed
an
idea
that
you
already
know
is
not
valid.
For
this
specific
use
case
drop
it
in
the
parking
lot
feel
free.
If
you
know
that
somebody
else's
is
not
valid,
for
this
use
case
drop
it
in
the
parking
lot
short
joe's
here,
everybody's
friends.
A
A
A
And
as
a
reminder,
parking
lot
doesn't
mean
that
we'll
never
explore
this
idea.
Everything
that's
on
this
board,
move
forward
and
parking
lot.
I
will
create
an
issue
for
it's
a
matter
of
if
we're
going
to
relate
the
issue
to
this
problem,
we're
trying
to
solve
or
make
it
its
own
thing
that
we're
going
to
look
into.
A
A
All
right,
so
the
next
step
is
to
get
to
the
technical
opportunities.
Now
these
could
be
similar
to
what
our
sticky
notes
already
say
right
or
they
could
be
a
bit
more
high
level
opportunities.
So,
unfortunately,
I
can't
speak
to
these
things
because
they're
so
technical,
who
can
who
can
maybe
help
me,
walk
through
how
to
make
one
of
these
a
technical
opportunity.
D
I
think
if
we
are
looking
at
the
ambitious
high
level
goal,
then
probably
we
can
take
just
in
suggestions
as
the
desired
state
that
we
wish
to
go
and
then
see
how
we
get
there,
because
if,
by
looking
at
the
refine
or
move
forward
step,
it
seems
that
some
kind
of
pattern
emerged.
This
from
the
ideas
so
and
I
think
the
justice
is
the
most
high
level
and
ambitious
one.
So,
let's,
let's
aim
for
the
stars
and
then
see
how,
together.
A
Okay,
that's
really
that's
a
great!
I!
I
didn't
see
that
that
there
was
a
pattern.
So
that's,
I
think,
really
interesting.
We
might
reflect
on
later
in
our
retro
did
the
pattern
that
emerged.
Was
it
unexpected
yeah?
So
maybe
just
think
about
that
all
right.
So
if
we
use
one
opportunity
as
moving
away,
is
there
another
opportunity
that
you'd
like
to
explore?
Is
there
a
competing
opportunity.
D
You
want
to
have
the
the
second
one
I
would
say
that
kind
of
can
merge
the
town's
idea
of
capturing
large
table
inserts
as
events
with
using
some
dedicated
stretch.
I
would
myself
see
this
as
the
step
towards
the
moving
to
the
real
time.
Click
stream,
but
it
can
be
also
treated
probably
as
the
alternative,
depending
on
on
the
decision
and.
A
Okay,
so
the
dedicated
storage
could
be-
and
I
just
realized
by
the
way-
for
people
watching
this
video-
I
should
have
been
sharing
this
screen,
so
they
can
see
what
we
saw.
I
apologize
to
people
watching
the
video
okay,
so
this
could
be
a
competing
idea
from
this.
Is
that
what
you're
saying
me
play
potentially
okay
and
this
capture
large
table
inserts
as
events
does
that
align
with
this
one
or
this
one.
A
A
Ideas:
okay,
should
we
fill
these
in?
These
are
different
ways
to
get
to
this
right.
Should
we
fill
these
in
from
a
high
level
technical
plan
things
to
consider
when
investigating
these
ideas.
So
what
we
end
up
here
with
here,
this
is
going
to
be
the
research
or
the
spike,
the
technical
spike
that
will
be
assigned
to
an
engineer
in
an
upcoming
milestone.
So
do
we
want
to
give
that
engineer
more
context.
D
I
would
say
this
is
the
inputs,
so
this
is
the
way
how
we
get
the
data
in,
but
then
the
last
bracket
or
the
last
research
opportunity
should
go
into
how
we
get
this
data
out
of
the
instance,
so
how
we
get
the
real
time
stream
out
of
the
instance
how
we
get
the
data
out
of
the
get
storage
tool.
But
please
I'm
curious.
What's
the
the
rest
here,
I'm
gonna
call
things.
G
A
G
If
you're
talking,
so,
let's
assume
a
world
where
we
abandon
the
aggregate
metric
collection
via
service,
paying
as
it
traditionally
works
today
and
you're
collecting
in
real
time,
events
from
clients
of
you
know,
instance,
users
within-
and
you
know
a
vpc
of
that
instance
and
then
back-end
events
from
that
instance
itself.
You're
going
to
need
to.
G
A
G
You
know
not
the
same
application
but
another
application
running
in
the
same
vpc,
and
then
it's
collecting
data
from
the
instance
and
then
packaging
that
and
then
sending
a
big
payload.
You
know,
so
you
don't
get
the
click
stream
events
in
real
time
and
get
for
gitlab,
but
you
are,
you
still
send
the
full
payload
of
that
raw
json
data
anyway,
so
I
don't
know
yes,
this
is
a
really
good
question
and
that's
the
hard
part
with
this
one,
because
it's
a
very
different
model
of
collecting
data
than.
A
Quickly
from
logistics,
I
thought
I'd
schedule
this
for
an
hour,
but
I
see
I
scheduled
it
as
a
short
meeting,
so
I'm
sorry
that
we're
a
little
bit
over
here,
it's
okay!
If
we
don't
take
this
a
step
further
now,
would
anybody
like
to
continue
the
discussion
or
shall
we
end
it
here
and
the
next
steps
would
be?
A
To
that
point,
justin
we
have
a
number
of
team
members
that
are
not
here
and
we
want
their
feedback.
So
we
are
going
to
keep
this
open
until
the
end
of
april
to
receive
more
async
feedback
from
the
rest
of
the
team
and
take
this
exploration
further.
So
for
folks
who
participated
in
the
synchronous
event,
if
you
could
also
watch
the
conversation
asynchronously
and
participate
with
the
folks
who
are
going
to
be
participating
async
initially,
that
would
be
super
helpful
all
right.
A
So
next
steps
I'm
going
to
open
some
issues,
I'm
going
to
document
what
we
talked
about
here
today
in
the
main
issue,
and
I'm
going
to
open
a
retro
as
well,
so
that
I
can
get
feedback
on
how
we
can
improve
next
month's
big
session.
Thank
you,
everybody
for
your
participation
and
for
humoring
me
and
again
sorry
folks,
who
are
watching
this,
that
I
wasn't
sharing
my
screen
for
the
mirror.
Miro
maneuvers
and
I
should
have
been
have
a
great
rest
of
your
day.
Everybody
bye.