►
From YouTube: Overview on the GitLab release process
Description
Amy Phillips (Engineering Manager, Delivery) and Daniel Fosco (Senior Product Designer, Release) go over the release process for the GitLab application, and how the Delivery group is working towards full CD on GitLab.
Agenda & Notes (internal): https://docs.google.com/document/d/12plxvquQvhXie038FqjGmJ2CdDjPFlGrAvYn-U7hZng/edit
A
All
right,
so
I'm
here
with
amy
phillips
engineering
manager
on
the
delivery
group,
so
we're
having
a
chat
about
how
we
at
ditlab
deliver
the
gitlab
application
itself
and,
to
which
extent
we
use
our
own.
Our
own
release
features
on
that
life
cycle.
Amy,
I'm
sorry!
I
I
miss
your
your
request
to
look
at
the
agenda,
but
I
hope
you
were
able
to
take
a
look.
B
B
Now
we
coordinate
all
of
these
things
at
the
moment.
We're
running
a
hybrid
environment,
so
we're
using
vms
as
well
as
kubernetes
and
we're
coordinating
all
of
our
deployments
using
the
bridge
jobs
feature
that
just
came
out
a
couple
of
milestones
ago,
so
I
can
would
you
would
it
be
helpful
for
me
to
show
you
that
bridge
shop?
I
think
so
so.
B
So
we
run
all
of
our
things
via
chat
ups,
pretty
much
so
their
announcements
channel
is
our
main
main
source
of
keeping
track
of
what's
happening.
Let
me
just
take
back
to
the
beginning
of
the
day,
so
for
me,
my
sort
of
the
the
as
relief
manager
in
emir
time
zones
early
in
the
morning
the
first
package
starts
getting
created.
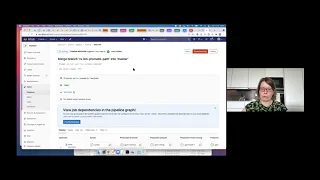
B
We
can
ignore
this
one,
but
what
happens
here
is
we
go
into
staging?
We
had
staging
failure
here
and
we
pass
through
to
canary,
so
we
can
see
the
package
numbers
so
every
time
we
pass
through
an
environment,
it
just
posts
out
here
with
our
with
our
package,
and
so
we
can
see
those.
But
what
we're
actually
doing
the
coordination
with
is
the
with
coordinated
pipelines.
So
I'll
show
you
this
one.
B
We
do
it
here,
so
we
let
this
we
come
in
here
and
hit
the
play
button
here,
all
right
and
what's
happening
alongside
one
of
the
reasons.
Some
of
our
things
are
different
is
all
of
our
every
milestone.
Every
release
we
track.
We
generate
auto-generate
a
release
issue,
and
this
is
what
the
release
managers
use
throughout
the
whole
month.
So
we
have
one
here.
B
We
have
steps
for
like
normal
things
around
creating
the
monthly
release,
but
we
also
have
in
if
there
are
any
special
steps
that
need
to
happen
that
month.
So,
for
example,
we
will
add
in
additional
steps
that
we
need
to
run
around
family
and
friends
day.
For
example,
like
we
go
into
a
soft
production
change
lock
on
family
and
friends
day,
so
we'll
pause
the
deployments
for
those
times.
B
We
post
a
comment
here
and
we
record
who
did
the
promotion
and
which
package
they
promoted,
and
we
have
a
couple
of
extra
things
that
we
do
that
we
check
before
we
do
a
promotion,
we're
checking.
There
are
no
active
incidents
running
on
production,
we're
checking.
There
are
no
active
change,
requests
of
severity,
one
and
two,
and
we
check
the
health
status
as
well.
So
these
things
will
also,
if
any
of
these
fail,
the
promotion
to
production
will
fail
and
it
will
be
logged
on
here.
We
probably
have
some
actually.
B
So
if
we
want,
if
there's
a
change
that
needs
to
happen,
for
I
think
we
have
one
open
actually,
if,
if
we
want
to
make
a
change
to
production
or
or
any
environment-
and
it's
not
automated,
so
we
have
a
handbook.
We
open
a
change
request
so,
and
this
allows
us
to
this
allows
us
to
record
through
the
process
that
we're
following.
So
this
is
the
process
right
and.
B
I'll
pop
it
under
the
validation,
because
it's
sort
of
related,
so
this
allows
us
to
sort
of
detail
out
the
process,
we'll
follow
and
any
approvals
that
are
needed.
So
it's
just
another
issue
and
it
gets
marked
up
with
a
a
change
severity.
Basically
so
that
I'm
sorry
criticality,
so
they
have
different
approval
levels
around
these
things,
so
we're
checking
anything.
That's
a
criticality
one
or
two.
Our
deployment
process
assumes
is
risky
enough
that
we
wouldn't
want
to
automatically
deploy
to
production.
B
B
Here
we
go
so
last
week
when
I
triggered
the
deployment
the
production
checks
failed.
So
this
is
I'll,
show
you.
This
is
one
of
the
first
steps
of
the
production
promotion
pipeline
and
it
failed
because
so
this
change
request
was
in
progress
and
this
was
updating
a
index
on
the
database
so
because
of
that
failure.
B
B
We
add,
on
a
reason,
for
why
we're
overriding
all
the
details
are
here
and
then
the
sre
who's
on
call
also
adds
a
comment
here
to
approve
this,
so
release
manager
can't
just
override
a
production
check
and
then
go
ahead
and
do
a
deployment.
So
this
is
kind
of
the
additional
compliance
piece
that
we
track
around.
What
is
being
deployed
to
production
and
who's?
Doing
those
deploys.
B
B
B
It
also
applies
over
the
weekend,
so
we
have
a
change
lock
that
runs
between
friday
evening
and
monday
morning,
so
that
we
can't
automatically
push
over
the
weekends
as
well.
Just
we
don't
have
many
sres
available
if
needed,
we
have
a
prepared
job
and
the
prepared
job
is
generally
checking
for
those
production
checks.
So
is
the
production
environment
healthy,
other
change,
requests
in
action,
other
other
deploys
that
are
still
going
on,
so
we
don't
want
to
deploy
over
each
other
or
any.
B
It
also
will
fail
if
the
last
deployment
didn't
pass
successfully
for
whatever
reason,
so
this
will
have
an
auto
fail
and
then
we
add
in
tracking.
So
this
is
where
we
report
on
the
the
issue,
and
then
we
can
see
here
the
pipeline
steps
excellent
failure,
so
we
do
assets
and
the
first
round
of
migrations,
and
then
we
do
gitly
prefect
the
production
fleet,
and
then
we
run
post
deployment
migrations
before
we
run
all
of
our
finished
jobs
right.
B
B
B
So
we
have
quite
a
lot
of
additional
tooling
and
steps
and
things
and
things
reporting
out
into
the
slap
channels
to
make
it
as
automated
as
possible.
Try
ideally
trying
to
get
to
continuous
deployment
and
just
have
the
whole
flow
go
through
and
just
have
it
so
that
if
something
goes
wrong
or
if
something's
unexpected,
the
process
can
halt,
ideally
would
roll
back
and
just
alert
the
release
managers.
So
that's
kind
of
what
we're
working
towards
at
the
moment.
A
B
Yeah
yeah
and
then
the
bit
that's
a
bit
more
complicated
is
if
we
have
an
incident.
So
if,
if
the
pipeline
fails
for
like
say
if
the
tests
fail
or
if
as
we're
deploying,
we
see
some
issue,
then
it
gets
a
bit
more
hands-on,
because
what
we'll
need
to
do
because
of
the
way
it's
because
it's
packaged
software.
What
we
need
to
do,
then,
is
like
pause.
Get
the
environment
back
into
a
good
state,
identify
the
failure,
get
a
fixed,
mr
and
then
manage
that
through
back
to
the
environment.
B
So
it's
a
little
bit
more
hands-on
at
that
point,
which
is
where
we're
kind
of
trying
to
move.
We
have
rollbacks,
we
have
a
rollback
pipeline,
it's
not
fully
automated!
Yet
there's
a
few
uncertainties
around
it
that
we
want
to
kind
of
iron
out
before
we
just
make
it
an
auto
roll
back,
but
yeah
handling
a
failure
means
there's
a
lot
more
coordination
involved.
A
Right
and
then
so,
looking
at
at
the
the
release
project,
I
could
see
that
if
you
go
to
the
environments
page,
it
says
the
environments
are
created
via
api
right
and-
and
I
understand
that's
because
you're
not
working
from
within
the
actual
gitlab
repository
urine
external
repository
and
that
more
or
less
mimics
how
lots
of
our
customers
need
to
work.
Can
you
talk
a
little
bit
to
the
limitations
of
having
to
work
on
a
separate
repository?
A
B
Yeah,
so
it's
very
much
set
up
like
this
in
this
way
for
permissions,
like
you
say,
this
gives
a
good
way
of
controlling
like
who
has
you
know,
access
to
be
able
to
deploy
all
the
things?
It
also
gives
us
a
bit
of
a
secondary
buffer,
which
is
we
operate,
gitlab
using
gitlab,
and
so,
if
gitlab.com
goes
down,
we
want
to
make
sure
that
we
actually
are
still
able
to
deploy
a
fix
and
use
our
tooling
so
having
it.
B
As
a
separate
ops
instance
gives
us
that
separation
so
be
incredibly
unlikely.
They
would
both
be
down.
They
are
different
instances,
so
we're
using
like
ce
as
well
as
ee,
so
we
get
to
sort
of
see
the
different
ones
they
update
on
different
cadences,
we're
using
the
like
nightly
build,
so
it
gives
us
a
little
bit
more
protection
to
guarantee
we'll
still
have
our
tooling,
but
in
terms
of
how
they
well
one
of
the
limitations,
we
see
the
biggest
one.
B
I
think
we
have
really
is
developers,
don't
have
visibility
of
things.
So
we
hear
quite
a
common
one.
We
hear
is
post
deployment,
migrations,
failing
and,
unfortunately,
developers
don't
have
the
logs
that
go
with
those
jobs
because
they
sit
inside
the
ops
instance.
So
we
have
a
few
problems
like
that,
where
just
general
visibility
is,
it's
definitely
not
ideal,
because
we're
operating
from
within
a
separate
instance.
A
B
That's
probably
reasonably
unusual:
we
have
a
few
things
that
are
a
little
bit
unusual
for
us.
We
rely
very
heavily
on
mirroring,
so
what
we'll
tend
to
do
is
mirror,
because
again
one
thing
that's
unique,
I
think
to
gitlab
is
the
fact
that
we
also
have
our
security
repositories
and
we
mirror
all
our
code
over
to
security.
So
we
can
do
security
fixes,
so
that's
very
uniquely
git
lab.
So
I
think
this
one's
fairly
unique
to
us,
I
think
permissions
and
having
a
good
way
of
actually
it's
almost
less.
B
A
B
Yeah,
so
what
we
try
and
do
is
there
are
times
where
there
are
features
that
already
exist
so
often
we'll
like
try
and
switch
things
over
like
piece
by
piece
like
if
something
comes
up
in
the
api.
For
example,
we
rely
very
heavily
on
the
api
and
that's
really
just
because
our
processes
are
reasonably
complicated,
so
we
tend
to
string
together
actions,
but
also
as
we're
trying
to
move
towards
continuous
deployment
in
an
ideal
world.
We'll
actually
just
have
an
automated
script
that
just
runs
through
all
of
these
steps.
B
So
we
try
and
have
everything
as
kind
of
an
automated
step,
but
so
yeah.
What
we'll
typically
do
is,
if
we
see
a
way
of
switching
over
to
say
we
just
recently
moved
over
to
bridge
jobs
and
what
we
used
to
do
before
was
have
kind
of
weights
in
our
pipeline.
So
we'd
wait
40
minutes
for
this
downstream
pipeline
to
hopefully
pass
if
it
didn't.
You
know,
we'd
take
action,
whereas
we
just
recently
refactored
the
pipeline,
so
we
could
have
bridge
jobs.
B
So
we
often
do
refactoring
of
our
tooling
to
try
and
take
advantage
of
get
our
features
or
in
more
rare
cases,
if
there's
something
bigger
where
we
are
finding
we're
kind
of
having
to
maintain
release
like
code
that
we
don't
like,
doesn't
really
make
sense,
we'll
try
and
get
it
into
the
product.
So
changelogs
are
there
good
example
of
that
one
we're
building
that
into
into
the
api
meant
we
could
delete
a
load
of
our
custom
coding,
but
also
it
puts
a
feature
back
into
it.
It's
a
little
bit
unusual.
A
B
So
it
works
quite
well
for
us,
so
the
reason
we
tend
to
come
in
this
way.
So
actually
we
have
one
here.
That's
happened
so
when
baking
time
completes
the
baking
time
is
just
an
arbitrary
time
for
us
it's
an
hour
at
the
moment
we
have
canary
running
and
then
what
happens
at
the
end
of
the
hour
is
release
tools,
alerts
the
release
manager.
B
So
this
was
quite
a
big
enhancement
for
us
recently
because
it
reduces
waiting
so
release
managers
don't
have
to
be
keeping
an
eye
on
the
clock,
they
just
get
a
ping
and
then
what
happens
here
is
we
get.
A
kind
of
report
of
is,
are
things
healthy
are
things
in
action
and
if
they
are
passing,
we
provide
a
link
straight
into
the
pipeline
and
we
can
promote
from
there.
So
for
us
it
works
well,
just
because
of
the
fact
that
the
information
is
coming
to
us
at
the
time.
B
We
need
to
take
an
action
and
we
get
this
kind
of,
like
short,
summary
of,
like
here's,
all
the
stuff.
Here's
what
you
need
to
do
so
that
we
find
that
quite
an
efficient
way
of
working.
It
could
be
something
in
in
the
product.
One
thing
that
we
don't
have
great
visibility
on
is
what's
inside
that
package,
so
we've
talked
a
little
bit
before
about.
Should
we
be
doing
something
else
where
actually
like?
B
B
Yeah,
like
all
the
commits
and
changes,
so
one
of
the
reasons
why
we
don't
use
it
too
much
at
the
point
of
deployment,
because
we
sort
of
treat
it
like
it's
a
package
and
ready
to
go.
But
if
this,
if,
as
we're
deploying
this,
we
see
issues
it's
a
little
bit
of
work
for
us
to
actually
go
back
and
pull
out
like
okay,
what
exactly
is
inside
this
package?
Did
we
change
something
on
this
database
table,
for
example,
that
might
be
contributing
to
this
problem?
B
So,
unfortunately,
with
a
change
log,
so
the
changelogs
come
with
the
releases,
but
they
don't
get
generated
until
the
point
where
we
create
the
release
so
they're
kind
of
like
a
a
lagging
piece
of
information.
So
yes,
they
would
have
it,
but
for
the
gitlab.com
stuff
they
they
don't
have
it.
At
this
point.
B
B
Or
after
it's
after
so
what
the
way
we
so
every
all
changes
go
to
getup.com
first,
so
we
try
and
deploy
as
frequently
as
we
can
in
throughout
like
every
day
but
throughout
the
month.
And
then
what
will
happen
before
the
22nd
is
release?
Managers
will
select
a
stable
package,
so
it's
usually
something
that's
been
on
gitlab.com,
for
you
know
some
hours
at
least
four
or
five
hours,
we'll
say:
okay,
it's
fully
deployed.
There
have
been
no
problems
reported
so
far,
things
are
performing
well,
we
will
package
that
point.
B
A
B
A
B
There's
two
cases
where
we
override
environment
locks,
one
is,
there
is
fine
and
it's
a
little
bit
more
casual
like
if
we
don't
want
everything
to
auto,
deploy
to
canary
or
whatever,
for
whatever
reason,
we
have
a
chat,
ups
command
to
lock
and
unlock
the
command,
the
environment,
and
that's
totally
fine,
but
the
more
difficult
ones
is
if
we
actually
need
to
override
the
actual
production
change
locks
which
we
do
sometimes.
So
if
we
have
an
incident,
we'll
need
to
override
them.
B
That
would
be
super
helpful
to
have
a
way
of
unlocking
an
environment,
but
also
having
that
it's
the
approval
piece.
So
if
we
have
a
hard
production
change
lock
in
place,
we
actually
need
like
someone
at
like
vp
level,
to
approve
us
on
that
and
at
the
moment
we
don't
really
have
a
good
way
of
capturing
that
and
having
that
kind
of
baked
into
the
who
does
the
overwrite.
A
B
A
B
Exactly
so
what
we
and
actually
is
pretty
much
the
same
when
we
override
a
regular
deployment.
So
what
we
we
have
a
pretty
clunky
process
where
we
ask
in
slack,
you
know
check
like
hey:
is
it
going
to
be
okay
to
overwrite
this
people
say
sure
yeah
we
do
the
override
and
then
they
have
to
go
and
add
a
comment
on
the
issue.
A
That's
super
interesting
because
I
remember
when
I
think
you
a
while
back
on
that
deployment
approval
issue
that
we're
going
to
pick
up
soon
in
the
future,
and
one
thing
I
had
in
the
back
of
my
mind
is
that
that
kind
of
approval,
ui
doesn't
necessarily
have
to
be
limited
to
approving
or
rejecting
a
deploy,
because
there
are
many
different
actions
that
need
to
be
approved
in
this
context.
Right
this
one.
B
A
B
Yeah,
that
would
be
super
helpful,
yeah
and
I
think
for
us,
I'm
not
sure
about
other
users,
but
certainly
for
us.
I
think
it's
much
more
around
recording
the
like
who
was
involved
and
what
approval
was
given
versus
the
like.
You
absolutely
can't
press
this
button
type
of
thing,
so
it's
just
having
that
audit
trail
is
more
of
our
our
requirement.