►
From YouTube: 2020-03-13 Background jobs improvements demo
Description
Part of https://gitlab.com/groups/gitlab-com/gl-infra/-/epics/96
B
B
There
and
that's
because
of
the
Nikkei
two,
so
the
problem
with
this
is
that
we
don't
really
have
any
idea
what
best
effort
is
doing
and
which
kind
of
jobs
are
running
there
and
how
we
can
make
sure
to
run
efficiently
and
are
not
getting
in
each
other's
way.
Stuff
like
that,
and
if
new
jobs,
new
workers
and
therefore
new
queues
get
at
it.
B
We
also
don't
really
know
what
kind
of
work
they
will
be
doing,
so
they
just
get
lumped
into
the
best
effort
jump
into
with
the
rest
of
the
best
effort,
jobs
and
yeah.
We
have
no
idea,
so
that's
going
to
change
and
we've
added
the
annotation
attributes
like
worker
attributes,
to
the
workers.
They
need
to
indicate
that
they're
latency-sensitive,
if
they
are
CPU
memory
or
CPU
or
memory
bound
and
if
they
have
external
dependencies,
am
I
missing,
something
I
think
showing
them
or
bad.
That's
yeah,
Wow.
B
B
Cool
so
where
we
want
to
go
is
to
use
those
attributes
to
send
jobs
to
nodes
that
are
configured
for
the
workload
for
it.
For
example,
the
one
we
did
first
was
no
urgency
cpu-bound
jobs,
which
means
that
we
want
to
have
a
kind
of
a
limited
concurrency
on
them,
and
this
is
the
first
thing
that
that
that
we've
deployed
we
use
that
using
this
selector.
B
So
all
the
jobs,
all
the
workers
that
they
get
black
code
base
that
have
their
resource
pound
reset
to
CPU
and
don't
have
any
specific
urgency,
said
to
them
and
will
be
picked
up
by
this
kind
of
of
workers
and,
as
we
can
see,
that's
being
deployed
yeah
tonight
and
those
things
are
like
that.
Vm
is
now
picking
up
job.
B
A
C
C
B
B
What
we
could
do
is
like
as
soon
as
that
worker
gets
at
it.
We
don't
have
the
resource
boundary,
except
what
I
mean
really?
No
it's
memory,
but
we
don't
have
a
resource
boundary
and
then
create
an
issue
check
back
in
then
into
it
in
two
months
or
whatever.
When
it's
been
running,
and
we
can
make
that
calculation,
the.
C
B
A
Okay,
can
someone
just
like
I'm
looking
at
this
sheet
now
that
the
crack
created
and
new
shard
low
urgency
CPU
bound
has
a
couple
of
these
cues
there
I'm,
not
really
I,
don't
understand.
Why
is
this
CPU
bound
like?
Let's
use
an
example
of
update
old
mirrors?
Oh
sorry,
now
sorry
stuck
stuck
import
jobs.
Why
would
that
be
a
CPU
bound.
D
C
Other
thing
I'd
saved
Marin
is
it's
kind
of
difficult
to,
like
guess
all
the
reasons
why
things
would
be
CPU
on.
So
that's
why
we
just
use
data.
We
just
use
the
data
that
we
have
to
do
that
division.
So
if
it's
spinning,
like
33
percent
of
its
time
on
CPU,
then
we
consider
its
CPU
bound.
Otherwise,
we
don't
and
it's
its
basis.
B
C
A
C
They're
allowed,
and
that's
patently
not
true,
like
some
cues-
are
much
more
sensitive
to
to
failure
than
others.
So,
obviously,
I'd
like
like
I,
think
that
the
least
critical
should
be
like
a
ten
percent
error,
error
rate
but
I'm
using
10
percent
at
the
moment
for
everything,
because
the
the
you
know,
that's
that's
kind
of
what
I
can
get,
because
I
have
to
kind
of
use
the
lowest
common
denominator,
otherwise,
we'll
end
up
with
lots
of
the
Nerds.
B
There's
also
when
we
do
that,
we're
also
going
to
have
work
on
determining
which,
which
of
those
workers
that
currently
should
be
markers,
have
had
external
dependencies,
but
then
like,
for
example,
we
use
errors
incorrectly
for
retrying
the
option
so
on
sometimes
so.
For
example,
the
update
or
mirrors
worker
know
not
that
they
told
there's
work
at
the
repository
update
worker,
the
one
that
actually
does
the
pull
that
yeah
sometimes
fail
deliberately
to
be
retried
later,
which
affects
or
like
or
indicators,
but
it
shouldn't.
C
Yeah-
and
we
want
to
give
people
like
an
easy
way
of
doing
a
repeat,
but
maybe
we
should
have
at
that.
There's,
like
an
error
code
or
an
error,
condition
that
that,
like
it
leaves
sidekick-
and
it's
like
this-
is
a
transient
failure
and
it's
all
okay
and
we
kind
of
rely
on
side,
try
it
again
and
don't
count
it
as
an
arrow
or
something
like
that.
C
But
I
think
like
there's
a
lot
of
stuff
at
the
moment
where
you
know,
there's
there's
a
job
around
expiring
web
book
events
and
it
runs
four
times
a
day.
I
think
and
I.
Don't
think
it's
passed
in
months
and
the
reason
it's
failing
is
because
the
sequels
timing
out.
So
it's
it's
really
hurting
Postgres,
because
it's
running
and
and
just
timing,
arts-
and
you
know
we
don't
have
any
of
the
alerting
on
it.
So
we
need
to
put
a
loading
on
these
things.
A
B
C
B
C
Total
sequel
time
yeah.
So
do
you
want
to
just
press
B
on
there
to
make
it
big
that
people
can
see
a
screen
a
bit
better
yeah,
so,
like
I,
find
when
you're
looking
at
these
things
and
you're
trying
to
figure
out
if
there's
a
problem
like
summing
or
the
amount
of
time
spent
in
in
something
like
this
is
much
more
useful
like
a
straight
p95
latency,
because
obviously
you
can
have
lots
of
small
jobs
or
one
big
job
and
and
and
it's
a
way
of
being
able
to
aggregate
that
out,
covered.
C
F
So
yeah,
so
it's
a
summary:
we've
been
working
on
like
releasing
the
bow
profiling
for
actually
for
all
services
that
we
had
go
service
that
we
had
and
now
we
first
started
with
the
workhorse
web
fleet
and
that
that's
actually
staging,
and
we
can
see
some
interesting
things
already.
Craig
is
working
with
me
to
release
for
for
other
fleets
as
well
like
we
are
going
to
have
like
a
workhorse,
WebKit
and
API
separated
here.
So
it's
interesting
to
have
a
better
understanding
of
what's
happening
on
each
fleet,
which
is
interesting
so.
F
F
Yeah
we
have
like
CPU
time
we
keep
out
of
the
box,
which
is
interesting,
so
I
also
really
interesting
to
see
that
we
can
filter
by
the
top
50
percent.
So
it's
spending
like
true
one
minute
and
one
millisecond
to
two
seconds.
So
sorry,
one
second
to
two
seconds,
so
you
can
see
here
like
handle
file
uploads.
You
can
see
my
screen.
Well,
yeah!
Yes,
so,
yes,
it
points
your
file
in
the
internal
of
the
black
workhorse,
and
we
can
see
this
stack
trace
in
here.
F
It's
not
that
good
DUI
to
have
the
look
on
this
that
racing.
But
let
me
see
the
frame
here
yeah.
It
goes
to
another
screen
too
and
filters
that
there's
some
kind
of
fancy
filter
here.
So
it
just
filters
by
these
two
file
uploading,
it's
interesting
to
have
a
better,
better
look.
One
thing
that
we
need
to
do
yet
is
improving
the
version,
because
one
thing
that
the
go
profiler
do
is
like
separating
in
different
virtual.
F
So
let's
say
we
just
bump
a
version
on
workhorse
and
we
want
to
compare
to
an
old
version
the
differences
in
the
profilers.
We
don't
have
that
yet
we
need
you
to
provide
this
version
because
initially
we
were
expecting
to
have
like
a
name
for
with
the
version
of
the
service,
but
it's
not
reality
because
we
are
not
using
Google,
App,
Engine,
I,
think
yeah.
We
are
using
GCP
that
doesn't
have
this.
This
M
bar-
and
we
were
discussing
me
and
jar
these
days
about
that.
So
we
will
need
to
pass
this
to
the
profiler.
F
Which
means
that,
for
instance,
if
we
release
another
version
of
workhorse,
it
will
guide
like
get
a
little
bit
mix
it
so
need
to
see
that
okay,
this
this
version
was
related
on
this
time.
So
we
need
to
filter
it
on
the
time
spin
in
time
and
see
ok.
So
these
are
the
profilers
for
the
new
version
that
was
released
after
this
time.
It's
a
little
bit
trickier
it's
doable,
but
we.
F
Yeah
we
can
just
filter
after
this
deploy.
We
are
going
to
see
this
this
time
spent,
for
instance,
so
we
make
sure
that
just
for
this
this
space
of
time,
we
had
different
filers
for
these
release,
for
instance,
but
yeah
diversion
would
like
make
this
a
lot
lot
easier.
So
much
is
just
like
a
single
fine
change.
Should
choose
flight
lab
get
cancer?
We
already
passed
the
diversion
to
have
get
when
initializing
the
profile
at
the
the
monitoring
package,
so
it
just
need
to
use
that
version.
Basically,.
F
C
It's
the
it's
the
canonical
thing
and
we
use
it
in
Prometheus,
for
you
know,
so,
even
if
it's
wrong,
it's
gonna
be
the
same
as
Prometheus.
We
should
rather
use.
You
know
the
same
same
observability
values
if
you
just
go
back
to
the
front
page,
so
just
take
off
those
extra
filters
that
you've
got
there
just
go
back
to
the
CPU
time.
C
That
whole
stack
over
there
that
actually
I'm
I'm
pretty
certain
that
that
could
just
be
removed
because
almost
all
round
trippers
are
like
Singleton's
and
so
the
fact
that
we're
creating
all
of
these
all
the
way
down
to
like
a
big,
wasteful
siskel
there.
And
if
you
go
back
to
the
go
back
up
like
step
out
of
the
out
of
the
you
know.
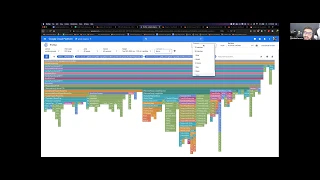
Obviously
the
vertical
length
is
sorry.
The
horizontal
length
is
the
percentage
of
time
that
we're
spending
in
that.
So
that's.
D
C
And
yeah
ten
percent,
and
so
that
I
bet
this
like
a
really
easy
one
in
in
just
making
a
single
one
of
those
is
there's
almost
never
any
reason
to
be
creating
a
round-trip
earn
every
request
and
I
bet.
You
that's
what's
happening
there.
So
that's
that's
dude!
If,
if
there's
all
of
this
goes
and
makes,
work
was
ten
percent
more
efficient
than
that.
F
C
C
F
C
C
A
But
the
problem
here
is:
if
we
have
develop
staging.
That
means
we
are
also
have
give
the
production,
which
is
going
to
be
far
more
useful
than
github
staging,
and
even
if
we
have
those
groups
that
you
are
mentioning
Andrew,
that
means
that
everyone
will
have
to
go
through
access
requests
and
no
no.
D
D
Have
to
be
an
entitlement
and
it's
gonna
have
to
be
part
of
on-boarding
and
off-boarding.
I
think
I
have
people
to
this
group.
That's
the
only
way
we're
going
to
do
it,
but
I
think
it
might
also
be
useful
for
law
excess
because
I
have
a
feeling
restricting
access
to
production
logs
is
going
to
be
coming
soon
and
we're
gonna
need
to
use
a
Google
group
for
that
as
well.
A
D
F
A
There
is
one
other
thing
about
this
topic.
Sorry,
although
can
we
make
sure
that
we
have
things
working
for
workers
first
before
we
continue
expanding
further,
so
make
sure
that
versions
are
working,
make
sure
that
people
have
access
on
staging
and
on
production
before
we
invest
any
additional
work
into
expanding
this
to
other
libraries.
A
Well,
it
will
be
useful,
I
question
whether
it's
going
to
be
useful
if
we
cannot
figure
out
access
if
we
have
to
continuously
go
back
and
forth
between
people
wanting
access
and
us
telling
us
well,
you
need
to
go
to
access
requests
without
any
proper
form.
I
would
like
to
have
that
handled
before
we
invest
working
together.
F
F
We
are
moving
this
our
idea,
moving
at
the
sidekick
closer
to
court
and
that's
a
big
topic.
We
are
planning
to
use
cyclic
cluster
as
a
single
source
of
truth,
using
this
omnibus
source
installations
everywhere
possible.
We're
already
using
on
get
like
on
so
would
be
interesting
to
spread
usage
even
on
DDK.
So
that's
the
step
I'm
right
now
on
this,
and
so
just
quickly
show
how
it
is
working
right
now.
F
Everyone
can
see
me
spring
sort
of
that
that
uses
the
work
that
Chandi
choocha,
Pass
and
white
card
to
cyclic
cluster
and
then
run
all
queues.
So
we
are
using
the
same
script
that
we
use
super
dedicate
right
right
here,
like
behind
the
scenes
and
if
you
run
passing
psychic
workers
you
to
try
to
run
these
background
jobs,
SK
processor,
up
still
figuring
out
that
the
best
name
for
this-
and
we
are
like
trying
to
simplify
the
interface
like
making
the
same
interface
for
the
old,
the
old
script
that
run
sidekick
and
the
new
script.
F
F
The
d-beam
background
jobs
is
being
used
like
stop
start
and
restart
supervisor
is
being
used
there.
So
we
need
to
kind
of
still
use
this
and
maintain,
but
the
good
thing
is
that,
like,
for
instance,
we
are
passing
out
these
and
if
you
pass
psychic
workers
like
say
one
or
two
behind
the
scenes,
it's
going
to
to
use
tactic
cluster
so
yeah
starting
to
processes,
so
start
that
that's
the
recommend
that
we
are
going
to
use
for
dedicating.
F
F
Know
that
I
was
just
going
to
say
that
the
other
commands
just
work
like
the
same.
Basically
when
passing
psychic
workers,
these
Falls
show
the
new
sidekick,
Plus
or
supervisor,
let's
say,
and
if
you
are
not
passing,
we
are
not
passing
this.
This
basically
runs
the
old
script
that
to
provide
sidekick,
go
on.
E
Yes,
what
I
was
gonna
say
was
like
we
didn't,
have
something
that
Mattias
had
an
issue
with
that
shouldn't,
be
an
issue
for
anybody
actually
using
this,
but
just
worth
calling
out
if
you're
starting
psychic
custom
manually.
A
lot
of
the
new
cue
syntax,
including
the
thing
that
means
run
all
to
use
which
is
star,
is
already
a
special
character
in
the
shell.
E
So
you
have
to
quote
the
arguments
like
if
you
run
psychic
cluster,
star
and
you're
running,
say
bash,
that's
gonna,
glob
it
cluster
and
then
every
file
in
the
local
direct
in
the
current
directory,
which
is
not
what
you
want.
You
need
to
quote
quote
it.
So
these
this
script
and
omnibus
already
quote
those
correctly
I'm,
just
calling
it
out
in
case
anybody's
trying
to
sell
with
that,
because
if
it
happened
to
Mattias
when
he
was
trying
this
out
and
it's
not
an
obvious
failure,
mode.
F
F
The
for
instance,
if
we
just
remove
that
and
start
foreground,
it's
going
to
use
psychic
the
dynamos
psyche,
correct,
stop
it
cool
yeah,
it's
using
two
different
spirits.
That's
basically
the
same
strategy
that
we
use
for
rolling
out
Homer.
We
have
the
same
same
idea.
We
have
web
web
unicorn,
winweb
Puma
and
a
web
single
web
script
to
fall
back
to
those
two
different
things
to
to
manage.
E
So
the
stuff
I
got
to
demo
is
not
only
in
progress
but
in
some
cases
broken
because
I've
had
a
week
of
struggling
with
various
things,
so
it's
actually
jobs
just
helped
fix
one
of
them
during
this
call.
So
that's
good
that
reduces
my
to-do
list
during
the
rest
of
the
day,
and
so
first
thing
we
already
had
a
histogram
for
CPU
time
in
prometheus.
E
We
just
didn't
actually
display
it
anywhere.
So
now
we
do
I
added
ones
for
database
and
get
early
time,
but
this
is
for
the
post
received
queue,
and
you
can
probably
notice
that
this
isn't
right,
because
the
post
received
Q
is
doing
gifts
operations,
so
the
p90,
the
P
95,
the
P
99
and
the
p50
should
not
be
all
the
same
all
the
time.
So
I
need
to
look
into
how
that's
recording
wrongly,
but
it's
not
a
bug
in
the
dashboard.
C
C
D
C
C
E
C
E
E
Much
gets
rid
of
everything
when
you
have
in
the
influx.
One
accept
method,
call
timings
and
do
we
even
have
the
employees
one
anymore
yeah,
so
the
method
timings
actually
can
be
really
useful
on
the
influx
one,
and
the
only
thing
about
them
is
I'm,
quite
curious.
What
happens
if
we
turn
off
the
method,
call
instrumentation
goodbye
twice
as
fast
well
yeah.
E
This
is
this
is
the
thing
right
like
it's
very
useful
to
know
that
expire
BranchCache
took
nineteen
point,
seven
nine
seconds
in
the
slowest
case,
because
obviously
that's
slow,
but
there
is
an
overhead
with
instrumenting
this
and
if
we're
not
really
supposed
to
be
using
these,
it
will
be
interesting
to
switch
them
off,
but
I'm
not
I'm,
not
touching
that
right
now,
I'm,
just
mentioning
that
as
a
side.
Note
and
yeah
I
don't
know,
I
know,
I
use
this
I,
don't
know
if
anybody
else
uses
this
okay.
I
might
add
a
warning
to
that.
C
E
C
E
Yeah
I
would
be
happy
turning
this
off
and
seeing
how
it
goes.
Yeah
I,
don't
want
to
do
that
right
now,
but
I
will
bored
anyway
yeah.
So
the
other
thing
I
did
relating
to
this
stuff
was
I
made
a
change
to
sort
of
sort
of
latency-sensitive.
We
used
we
now
instead
of
relation
sensitive
agent
label
yeah.
Now
we
have
urgency
high
because
we
had
latency
sensitive.
Yes,
no,
but
we
realized
we
needed
more
more
than
two
options,
so
I
changed
this
and
the
problem
was
so
when
I
changed
it.
E
We
knew
that
we'd
need
to
tell
the
on-call
sre
when
it
happened,
because
we
knew
that
it
would
trigger
some
alerts,
but
I,
don't
think
we
really
thought
through
that
it
would
affect
the
overall
SLA
days
as
well,
because
it
sort
of
feeds
up
into
those.
So
here's
an
example
of
what
happens,
so
this
is
using
latency
sensitive
and
it's
the
apdex
for
the
high
the
latency
sensitive
job
completion
and
then
this
second
query
is
the
same
for
urgency.
E
So
what
we
had
in
production
was
one
of
these
two
queries
at
a
time
and
you
can
see
that
the
problem
is
we
have
this
one,
but
then
we
lose
data
and
we
have
this
one,
but
we
don't
have
data
for
the
past.
So
at
this
point
it
was
recording
for
the
last
hour.
I
think
Andrews
changed
that
in
the
meantime,
but
the
problem
is
I.
Haven't.
C
C
E
So
what
we
actually
want-
and
we
already
have
this
for
other
metrics
just
more
abbe
Dex-
is
a
combination.
So
this
is
quite
a
long
query,
but
it's
not
that
complicated.
So
the
combination
is
just
this.
Oops
click
the
wrong
line.
It's
just
this
line
here,
which
okay
that
looks
spiky,
but
that's
because
the
scales
change,
but
basically
you
can
see
that
it's
pretty
pretty
flat
compared
to
the
other
two
and,
more
importantly,
it
touches
both
ends
of
the
chart,
which
is
neither
refers
to
two,
which
is
the
big
issue
there.
E
So
having
got
some
help
from
Java
to
actually
build
a
new
version
of
the
images
so
that
I
can
use
the
current
version
of
JSON
it
to
build
this.
It's
not
that
complicated
now
to
add,
combines
apdex
query,
so
that's
actually
adding
the
possibility
to
it.
So
this
is
what
we
could.
Slash
should
have
done
at
the
time
which
is
instead
of
having
changing
this
from
using
latency-sensitive.
Yes,
we
call
combined
and
we
have
urgency,
high
and
latency
sensitive
yes
in
there
and
then
once
that's
been
in
production
for
a
sufficient
amount
of
time.
E
We
uncombined
it
and
just
put
it
back
to
this,
but
there's
no
particular
urgency
on
combining
it,
because
you
know
the
combination
of
a
thing
that
exists,
or
the
thing
that
doesn't
exist
should
be
the
same
as
just
the
thing
that
exists
anyway.
So
it's
mostly
just
for
clarity
that
we'd
combine
it,
but
it
does
reduce
the
dependency
on
having
a
person
there
like
telling
the
SRA
on
call
this,
and
it
also
means
that
it
won't
great.
It
won't
affect
any
slis
or
SLA
x',
because
of
it
the
other
option.
E
C
E
This
repo
is
easier
to
get
stuff
merged
in,
like
this
repo
deploys
immediately,
as
opposed
to,
like
you
know,
having
to
get
held
up
for
a
security
release
or
whatever
it
doesn't
affect
customers.
You
know
like
they're
from
atheists,
we'll
also
be
getting
the
extra
labels
if
we
omit
it
both
on
the
application
side.
So
this
is.
This
is
definitely
the
better
way
forward.
So
yeah,
that's
part
of
the
fix
for
that.
The
second
part
of
the
fix
is
I'm,
going
with
adding
danger
to
this
repository
to.
E
Warn
if
you
change
something
that
is
so
often
when
you
change
these
you're
intending
to
change
them
and
even
in
the
mi,
where
I
change
this
I
was
intending
to
change
it.
But
if
we
just
have
like
a
warning
or
a
heads
up
like
that,
might
help,
we
still
need
to
figure
out
exactly
what
format
that
takes,
but
yeah
just
just
danger.
There
will
also
help
us
out
like
really
if
we
want
to
and
other
things.
So
yes,
please.
C
E
C
E
A
This
is
now
honestly.
This
is
so
important.
This
is
not
sidetracking
like
it's
really
important
for
our
our
sanity
and
health.
So,
if
you're
adding
review
you
reviewer
Rowlett,
that's
awesome
add
danger
if
you
add
that
to
also
some
other
projects
that
we
have
like
chef,
repo
and
so
on.
That
would
be
like
bonus
for
everyone
in
the
department,
so
we're
optimizing
here
for
the
department
not
only
for
for
us
yeah.
E
A
A
B
Wondering
a
little
bit
but
I,
don't
know
if
that's
really
something
worth
discussing,
but
then
regarding
the
whole
dropping
duplicate
jobs
like
we
now
can
see
duplicate
jobs
in
the
logs.
Sorry
about
the
snake
case.
Naming
of
that
show,
but
like
soon
we
will
be
able
to
drop
duplicate
jobs
and
I've
already
marked
the
authorized
projects
worker
as
an
idempotent.
But
we
there's
some
works
to
me
to
be
done
to
make
sure
that
we
have
enough
visibility
into
that
yeah.
E
Concern
with
that
is
that
it
is
very
useful
for
the
authorized
projects
worker,
but
they
also
want
to
be
very
cautious
around
changing
that
because,
like
you
know,
we
had
a
bunch
of
issues
in
the
past
where
that
wasn't
permissions
weren't
recomputed
correctly,
and
we
currently
don't
have
a
good
way
to
like
recompute
Commission's
for
everybody
stands
created
an
issue
for
that
and
it's
in
the
gate
lab
dr.
and
epic
that
he
created.
B
D
B
E
Sorry
some
authorized
projects,
jobs
have
two
arguments.
The
second
argument
is
a
unique
key
for
a
web
request.
That's
waiting
on
it.
So
if
the
second
argument
is
different,
we
can't
deduplicate
it,
but
we
are
not
going
to
add
that
key.
When
you
have
say
10,000
jobs
to
schedule
like
we
have
sometimes
because
the
web
requests
will
never.
The
web
requests
will
wait.
E
F
D
D
B
F
A
We
did
just
want
to
share
actually
no,
let's
end
on
a
high
note
hope
everyone
has
a
good
weekend,
thanks
for
hope,
hope.
You
have
a
good
weekend
thanks
for
another
great
week,
a
lot
of
great
work
here
and
it's
have
to
say
very
rewarding,
seeing
some
of
these
things
finally
reach
production.
So
thanks
to
crack
as
well
for
for
starting
to
roll
this
out.