►
From YouTube: 2020-01-17 Background processing demo
Description
Part of https://gitlab.com/groups/gitlab-com/gl-infra/-/epics/96
A
Start
recording
yes,
so
the
first
thing
I
had
for
the
background
improvements
demo
today
wasn't
exactly
related,
but
it
wasn't
something.
I
was
working
on
and
it
took
a
while.
So
I
thought
I'd
share
it.
I'm
just
gonna
get
a
screen,
and
hopefully
I'll
get
this
right
so
should
be
able
to
see
my
browser
now.
So
we
had
an
issue
where
the
ASAP
queues
were
just
not
processing
any
jobs,
but
they
weren't
failing
on
anything.
A
They
were
just
completely
saturated
and
we
sort
of
had
a
look
and
it's
quite
hard
to
debug
this
after
the
fact
like.
If
we,
if
we
would
have
been
able
to
catch
it
during
the
incident,
maybe
it
would
have
been
easier
using
Perl
or
something
to
catch
this,
but
you
can
see
here
that
we're
we're
sort
of
guessing
about
the
rate
that
we're
adding
to
the
queue,
but
we
can
see
that
basically
the
processing
rate
went
down
instead,
so
we
don't
think
that
we're
pushing
a
bunch
of
jobs.
A
We
just
think
that
some
jobs
are
being
slowed
and
that
those
jobs
are,
you
know,
consuming
all
the
work
of
capacity
and
we're
room.
We're
stuck.
We've
got
some
in
flux,
DB
dashboards,
still
hanging
around,
which
are
actually
really
useful
for
this.
So
that's
because
they
instruments
certain
Ruby
methods
that
instrumentation
may
also
actually
slow
down,
get
lab
to
a
certain
extent.
A
That's
not
a
huge
issue,
because
either
Ruby's
slow,
you're
doing
slower
stuff
like
by
going
to
the
database
or
by
going
to
get
early
or
by
doing
something
like
that,
but
if
you're
actually
being
slow
in
Ruby
you're
blocking
any
other
threads
from
processing
as
well
I,
don't
really
know
how
to
correlate
these
ones.
To
be
honest,
they're,
just
weird
I
think
it
might
be
that
something
was
happening
inside
a
transaction
for
the
SQL
timings.
A
I've
got
no
idea
about
the
cash
timings
since
this
we've
added
database
timings
to
the
psychic
box,
which
actually
probably
would
have
been
a
bad
demo
subjective,
but
never
mind
so
what's
happening
here.
Is
that
we're
pushing
to
a
branch-
and
this
is
probably
going
to
be
easiest
actually,
if
I,
if
I,
show
the.
A
A
Sorry
I've
got
a
different
key
binding
when
I'm
in
my
editor.
Normally
so
we
update
some
Emma's,
we,
you
know,
do
some
general
stuff.
The
interesting
part
is
executing
related
hooks,
which
is
about
web
hooks,
essentially,
but
also
I,
think
there
are
a
couple
of
other
types
of
hooks,
but
basically
we're
talking
about
like
pushing
a
change
out
to
somewhere
based
on
the
change.
That's
just
been
pushed
to
the
repository
for
that
there
was
some
correlation
up
here
in
branch
create
hooks
here.
B
A
B
A
Cpu
time
and
the
guest
leader
ation,
which
are
both
high,
so
those
are
correlated
to
each
other,
and
we
can
see
an
influx
again.
We've
got
this
time
in
tight
push
service
and
also
in
commits
between
which
is
weird,
and
one
of
these
products
is
a
mirror.
So
I've
got
a
production
console
open
with
the
mirror,
but
nothing
that
share
any
confidential
information
and
because
this
is
a
mirror
of
the
get
lab
website.
So
it's
actually
quite
convenient
for
the
purposes
here
that
this
is
going
to
work.
A
A
So
right,
we've
got
two
projects
in
our
console:
we've
got
the
mirror
and
we've
got
the
upstream
now
they
pushed
this
commit
and
we're
trying
to
figure
out
how
many
commits
are
between
the
default
branch
and
this
commit.
So
when
you
push
a
new
branch,
we
say
like
how
much
does
this
diverge
from
the
default
branch
PI?
A
Master
Wars,
so
this
is
a
mirror.
It's
pushing
to
a
bunch
of
branches
at
once,
I'm,
not
quite
sure
why
maybe
they
restarted
mirroring
or
something
maybe
I,
don't
even
remember
if
it's
actually
a
get
loud
mirror
or
some
kind
of
manual
mirror
so
master
at
the
point
we
were
testing.
This
was
at
this
commit
master
at
the
point.
This
push
actually
happened
was
at
this
commit.
So
if
we
do.
A
I'll
put
the
counts,
I
mean
if
this
kind
of
speaks
for
itself,
like
it's
taking
a
lot
longer
so
what's
happening.
Is
we've
essentially
got
a
very
diverged
branch
such
at
10
seconds
to
get
54,000
commits.
We've
got
a
very
diverged
branch
in
this
case.
It's
because
the
mirror
has
mirrored
other
branches
before
the
default
branch
so
like.
A
But
even
if
we
did
facts,
we
would
still
have
this
issue.
If
you
just
push
two
branches
that
diverged
significantly
right,
like
you
know,
there's
nothing
in
gets
that
says
you
can't
have
two
branches
that
diverged
by
54,000
commits
from
each
other,
so
yeah
and
on
the
mirror.
It's
basically
the
same.
It's
fifty
four
thousand
four
hundred
a
four
commits,
obviously
compared
and
commit
shows
that
still
takes
ten
seconds.
The
other
thing
is
which
I've
actually
done
here,
because
I
did.
A
A
A
Yes,
oh
we
do.
Basically,
we
call
repository
commits
between
which
this
is
the
raw
bitterly
call
essentially,
and
then
this
commit
decorate
just
wraps
them
in
a
Ruby
wrapper
class
that
has
some
extra
handy
methods
for
the
applications
used
and-
and
this
itself
is
quite
slow,
CPU
wise
when
you
have
this
many
commits
so
I
think
in
this
issue.
A
Here
it's
like
a
second
on
a
console
box
which
you
know
isn't
actually
going
to
cause
this
incident,
but
like
the
console
box
has
basically
no
load,
and
you
know
when
you
have
multiple
sidekick
jobs
doing
this,
it
gets
trickier.
So
the
actual
really
frustrates
it
on
frustrating
thing
about
this,
but
the
I
guess
the
good
part
is
that
we
don't
actually
need
all
these
commits.
So
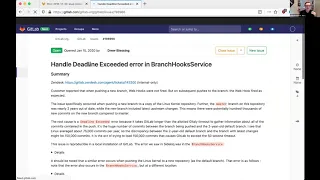
if
we
go
to
the
branch
hooks
service,
sorry
Facebook
service,
the
Square
Bay
of
inheritance.
Here,
no,
maybe
branch
hooks
service,
yeah.
Okay!
A
Here
we
go
so
if
we're
creating
the
default
branch,
we
get
the
commits,
but
we
limit
it
to
this
process
commit
limit
from
get
early.
Otherwise,
if
we're
creating
a
branch,
we
get
all
the
commits,
but
in
the
base
service
we
then
have
this
limited,
commit
method
that
takes
that
array
of
54,000
commits
and
gives
us
the
last
100,
so
we're
asking
Disney
for
54,000
commits
and
they're
drawing
away
all
but
the
last
100.
But
when
we
push
the
default
branch,
we
just
ask
Italy
for
the
last
100
commits
now.
A
Yeah,
so
we
call
this
special
RPC
to
commit
count
the
commits
in
that
ref
and
we
get
all
of
them
and
that
can
actually
also
exceed
its
deadline.
So
we
still
need
to
limit
that
one.
We
probably
need
to
limit
that
to
a
higher
limit
than
just
100,
but
in
this
case
they
were
pushing.
This
was
on
a
self-managed
instance,
so
it's
not
directly
affecting
scalability
in
the
sense
that
it's
mongolab
calm.
A
D
A
And
actually
that's
another
thing
here:
I,
don't
know
where
9999
comes
from,
but
good
projects
in
the
first
instance
where
there
was
so.
This
is
a
fairly
large
project,
but
not
necessarily
the
biggest
projects
that
showed
up
in
the
CPUs
is
list
had
a
commit
count
of
nine
nine,
nine,
nine
nine,
which
is
a
little
bit
suspicious.
So
maybe
that's
some
limit
that
we
hit
somewhere
else
where
that
I
don't
know
about
the
other
place
this
is
used
is
for
creating
events
on
your
like
user
feed,
but
I.
A
A
B
B
This
actually
kind
of
kind
of
ties
in
to
something
I
said
at
the
skeleton,
the
isolation
working
group.
One
of
the
things
that
would
be
amazing
is
if,
in
our
integration
tests
for
these
kind
of
events,
we
added
a
something
that
pushed
like
50,000
commits
in
the
single
code
and
actually
had
that
as
a
as
an
integration
test
to
come.
A
And
in
this
case
it's
really
wait.
It's
kind
of
a
balance
rate,
because
there's
always
going
to
be
a
case
where
you
can
push
the
limits.
I,
like
one
person
pushing
100,000
commits,
is
actually
fine
that
will
block
one
psychic
node
but
not
psychic
nodes.
The
problem
is
when
you
have
a
few
pushes
like
this.
At
the
same
time
like
we
did
in
the
mirror
in
case
that
blocks
all
of
them,
and
then
we
could
have
more
nodes,
but
we'd
still
have
the
same
problem.
B
B
I
was
messing
around
with
with
mermaid
and
Befana,
because
I've
seen
a
bunch
of
bullet
Prometheus
pumpkins
through
using
it
to
good
effect,
and
it
inspired
me
and
in
Marin
said
like,
but
can
we
order
generate
this
and
I
was
like?
No?
We
are
going
to
maintain
this
manually
and
obviously
that's
rubbish,
because
it'll
never
stay
up
to.
C
B
I
started
thinking
about
like
what
the
next
thing
we
could
do
with
it
is,
and
then
I
thought.
Well,
it's
actually
quite
easy
for
us
to
auto
generate
this,
and
so
we've
got
this
thing
that
I've
been
kind
of
working
on
on
the
side
called
the
metrics
catalog,
which
is
a
way
of
describing
like
all
metrics
in
the
system,
in
a
simple
way
and
then
generating
all
of
the
key
metrics
reporting
rules
from
the
simple
instructions
into
like
the
more
complex
ones,
so
that
we
don't
have
to
maintain
those
complex
instructor.
B
Accordingly,
it's
a
sauce
anymore,
and
so
we've
got
this
metrics
catalog
and
I'm
kind
of
slowly
going
through
all
services
and
I'm,
adding
all
the
services
in
here.
So
instead
of
having
like
reporting
rules
across
four
or
five
different
files,
we've
just
got
one
thing
say:
CI
runners,
we've
got
two
components
once
for
the
foiling
components,
and
for
that
we
look
at
the
get
lab.
B
So
what
we
kind
of
thing
it
is
that
what
I
figured
is
that
you
can
take
that,
and
you
can
add
to
that
like
the
dependencies-
and
you
can
say
this
service,
the
CI
runner
service
has
been
antsy
on
the
API,
and
the
web
service
has
got
a
dependency
on
Gidley,
greatest
sidekick,
greatest
cash,
Redis
and
eg
bansemer,
and
so
that's.
This
is
this
new
stanza
that
I've
added
to
the
description
of
each
service,
she's,
basically
saying
the
downstream
services
of
these
things
and
actually.
E
B
E
B
B
B
The
other
thing
is
that
at
the
moment
this
has
only
got
the
things
that
are
in
the
matrix
catalog.
So
as
more
things
coming
to
the
metrics
catalog,
we
get
more
things
here.
The
other
thing
that
you
can
do
with
it
is
in
say
the
giving
page
we
can
just
have
one
that's
giddily
and
it's
downstream
dependencies
rights
and
etc.
B
The
other
thing
that
you
can
do
in
future
is
we
could
say
we
could
kind
of
count
the
lanes
right,
and
so
you
start
getting
a
bunch
of
alerts
from
say
the
API
and
read
as
cache.
It's
pretty
easy
to
say.
Well,
the
API
is
dependent
on
the
Ritter's
cache
so
like.
Let's
prioritize
the
reddest
cash
is
being
through
the
back
and
we'll
will
kind
of
escalate
that
the
priority
of
those
alerts
that
are
coming
through
because
you.
B
The
ridaz
caches
is
performing
badly,
there's
no
way
that
the
API
can
perform
well
so
like,
let's
focus
on
the
downstream
issues
first
and
it's
not
about
hiding
that
two
runs
it's
just
about
prioritizing
them
by
the
date.
If
you
get
what
I
mean-
and
so
that's
pretty
easy
to
do,
but
yeah
it's
just
a
little
little
demo
of
of
generating
that
formality.
B
D
B
D
Can
be
very,
very
useful
during
debugging
like
I
like
right
now,
the
only
thing
I
keep
thinking
of
is
like
what
is
happening
with
the
runners
right
now
like
how
can
I
like
focus
on
that
and
figure
out,
what's
happening
right
like
it's
just
a
more
visual
person.
So
when
you
see
something
like
this
he's
just
kind
of
draws,
you
yeah.
B
B
You
know
this
was
if
given
we
had
a
very
high
rates-
and
you
know,
then
it
would
kind
of
be
pretty
obvious
if
you
were
getting
lots
of
alerts
in
the
system-
and
this
was
like
the
greatest
thing-
most
red-
not
rarest
thing,
then
you
know
it
might
be
really
obvious.
So
it's
kind
of
an
interesting
thing.
This.
A
B
Then
I'm
looking
into
it,
there
are
other
tools
that,
like
mermaid,
doesn't
seem
to
have
linking
like
that.
But
there
certainly
are
other
tools.
You
know
maybe
darts
or
something
like
that.
The
other
thing
I
was
thinking
is
like
this
could
be
incorporated
pretty
easily
into
the
people
at
common
engineering
blog.
So
you
just
generate
like
a
bunch
of
diagrams
for
there
automatically,
but
yeah
the
linking
would
be
super.
Useful
I
create
these
great
right.
I
haven't
focused
on
very
much
it,
but
I
said
you
picked
them
all
that.
D
Just
another
FYI
folks
demo
is
whatever
we
make
it
to
be,
so
no
apologies
needed
that
something
is
not
snazzy
and
great-looking.
The
point
is
discussions
like
we
want
to
expose
things
and
like
get
ideas
flowing
so
great
or
not
great
I'm,
and
already
like
finding
this
all
useful
sorry
John
I
needed
to
interrupt
you
there.
It's.
A
A
So
one
thing
we
want
to
do
is
at
the
moment
we
schedule
psychic
jobs
by
saying
that
you
know
these
cues
are
ASAP
and
these
cues
are
real
time,
and
these
cues
are
I,
can't
remember
the
names
but,
like
you
know,
we
have
a
bunch
of
names
for
like
priorities
and
it's
kind
of
hard
to,
like
you
know,
map
them
and
like
realize
in
your
head,
like
what
the
different
priorities
are.
So
Andrews
added
all
these
resource
boundaries.
So,
like
you
know
you
can
say
a
worker
is
CPU
bound
or
it's
memory
bound.
A
A
worker
has
external
dependencies.
So,
like
you
know,
it
needs
to
talk
to
external
services
to
do
stuff,
which
is
great
so
like
we
have
a
list
and
we
have
specs
that
allow
the
date
that
all
workers,
except
these
if
they
need
to
well,
not
simply
as
if
they
need
to
sorry
that
they
are
set
if
they're
a
required
attribute.
So
things
like
feature
category
are
required.
A
So
we
know
that,
like
you
know,
if
this
belongs
to
issues,
then
we
can
eventually
map
that
to
a
particular
stage
group,
because
feature
categories
are
more
stable
in
stage
groups.
This
is
all
repeating
what
Andrew
said
before.
So
the
idea
here
is
to
get
that
information
into
our
psychic
yeah
Mel
files.
So
we
have
this
all
qml
file,
which
has
a
list
of
all
the
cues
we
have
so
anything
before
a
coelom
is
a
namespace.
A
A
We
would
just
say
you
know,
run
the
crime
drop
queues
on
this
note,
but
maybe
we
want
to
actually
say
like
run
cpu-bound
workers
on
this
node,
because
this
node
has
more
CPU
or
stuff
like
that.
So
I
haven't
actually
done
that
part.
Yet
what
I've
done
instead
is
made
it
so
that
this
file
is
automatically
generated.
Sorry,
let
me
just
check
okay,
fine,
so
yeah
this
file
is
automatically
generated.
So
if
I
just
stash
that
and.
A
Switch
back
to
master
you'll
see
that
right
now,
it's
manual,
we
do
actually
have
a
spec
that
ensures
that
every
queue
is
in
this
file,
but
we
don't
automatically
generate
it,
which
is
fine
when
it's
just
names,
but
what
I
want
to
do
and
what
I'm
doing
next
is
going
to
change
this
from
a
so.
This,
at
the
moment,
is
an
array
of
strings.
A
That's
what
this
is
saying
in
Y
amel,
what
I'm
going
to
change
it
to
is
an
array
of
hashes,
so
we'll
have
not
only
the
cue
name
and
namespace,
but
also
the
other
attributes
that
we've
added,
so
we
could
stay
like
you
know,
run
all
workers
that
relate
to
the
feature.
Category
merge
requests
on
a
particular
node.
We
probably
wouldn't
do
that,
but
we
could.
A
Because
they
don't
necessarily
have
anything
in
common
other
than
they're
related
well,
maybe
merge
request
is
about
example,
but
like
just
because
things
belong
to
a
feature.
Category
doesn't
necessarily
hurt
mean
they
have
like
characteristics
in
common
about
what
they
need.
Like
some
merge
request,
jobs
might
need
to
talk
a
lot
to
external
services.
Some
might
not
some.
My
only
contact
the
database.
Some
might
you
know,
do
a
lot
of
get
early
work.
Some
might
do
a
lot
in
CPU.
Some
might
not.
So
as
a.
B
Bit
of
an
aside
at
the
moment,
the
pipeline's
priority
is
pretty
much
that
the
only
thing
that
kind
of
gathers
everything
that's
in
the
sidekick
pipeline's
queue
is
the
fact
that
there,
in
the
future
category
site
am
of
verify,
which
is
pretty
weird.
And
it's
exactly.
As
you
say,
it's
like
a
very
strange
way
of
defining
a
grouping.
Yeah.
A
I
mean
it's
not
I,
don't
think
it's
wrong.
I
just
think.
There's
better
ways
you
can
group
them
like
you
know,
and
one
nice
thing
about
grouping
them.
That
way
would
be
that
they
would
be
super
easy
to
like
attribute
things
to
a
particular
group,
but
it
wouldn't
necessarily
be
the
most
efficient
way
to
distribute
them.
That
way.
B
A
A
A
B
A
B
A
So
yeah
all
I'm
doing
now
is
also
generating
this
file
as
well.
Once
those
are
both
auto-generated,
then
I
can
actually
change
the
format
of
them
more
confidently,
like
I,
don't
want
to
change
the
format
for
them,
also
generating
them,
because
obviously,
then,
like
that's
kind
of
painful
and
before
I
change,
the
format
I
also
need
to
change
psychic
cluster
to
handle
both
config
file
formats.
So
it's
a
Multi
multi
step
in
our
process
that
as
well,
though,
it's
got
the
first
one
off
now,
the
second
one's
done
soon
and
then
we're
good
so
yeah.
A
B
Buta,
on
the
left
hand,
side
you
can
see
the
feature.
Category
latency
sensitivity
is
basically
saying
give
me
workers
that
have
these
attributes
and
then
you
will
run
those
together.
So
the
idea
is
that
you
want
to
put
all
latency
sensitive,
cpu-bound
ones
together,
but
then
also,
you
might
want
to
say,
do
every.
Let's
say
we
find
that
there's
a
queue.
That's
going
a
little
bit
out
of
control,
we
could
say:
do
one
of
these,
except
for
this
queue
and
the
the
the
language
is
very
simple,
because
it's
not
there.
B
C
C
B
Expression,
it's
like
it's
like
feature
category
in
X,
comma,
Y,
comma,
Z
and
feature
category
in
and
latency
sensitivity
in
CPU,
comma
memory.
So
it's
it's
more
like
it's
something
you
can
kind
of
pass
with
like
splits
and
because
you
just
basically
split
up
the
the
string
and
then
yeah.
It's
it's
not
even
like
a
puzzle.
It's
just
a
really
basic
language.
We
could.
B
It
doesn't
have
that
basically
it's
ands
and
ORS,
and
then
the
ins,
ins,
ins
and
paws,
but
if
we
wanted
to
make
it
more
expressive,
we
could
do
that,
but
obviously
the
cost
is
that
it's
more
complex
as
well.
So
you
just
got
any.
This
is
a
very
easy
thing
to
pass
into
it
to
understand.
I
ran
it
by
because
I
wasn't
the
kind
of
people
that
we
want
to
run
this
other
essary
teams.
B
D
D
D
We
have
right
now
the
cyclic
cluster
queuing
system
that
we
have
now
and
we
might
want
to
consider
how
like
whether
we
can
group
things
in
another
way
as
well,
in
an
additional
way
that
will
age
the
transition
to
kubernetes
so
right
now,
for
example,
project
expert
is
chosen
for
a
couple
of
reasons,
but
one
of
them
being
like
it's
going
to
easy
to
isolate
stuff.
So
we
might
want
to
be
able
to
include
like
more
cues
like
that
and
have
them
automatically
ported
to
communities
by
Becky's
work
already
in
the
application.
B
Like
what
like,
what
I
would
say
is
if
we
chose
non
latency,
sensitive
IO,
bound
jobs
like
those
are
probably
like
effectively
what's
running
on
best
effort
at
the
moment.
Those
would
maybe
be
like
it
good
and
and
maybe
we
actually
even
choose
a
future
category
and
as
opposed
to
what
I
was
saying
earlier
about
it's
a
silly
thing
to
select
on.
But
if
we
choose
like
low
priority
future
categories
and
kind
of
just
bring
them
on
as
they
arrive,
yeah.
A
B
No
they
what
we
did
was
we
did
like
a
whole
bunch
of
cost
rating
and
we
went
through
all
of
the
jobs
and
and
then
about
a
week
ago.
Actually,
the
last
time
I
was
in
this
demo,
we
just
which
was
last
Tuesday.
We
discovered
that
there'd
been
a
whole
bunch
of
changes
in
the
three
months
since
we
set
up
the
original
lot
and
I
just
went
and
changed
them
like
I
think,
like
portfolio
management
could
rename
to
epochs
or
something,
and
so
we
changed
them
and
it
has
to
match
up
with.
B
What's
in
the
stages,
ya
know
file
in
handbook,
so
you
know
John.
You
know
the
thing
that
generates
the
categories
page
in
the
handbook.
Is
this
massive
page
with
categories
and
it's
like
all
the
dris
yeah,
then
you
go
and
pasted
it
in
the
the
file
that
generates.
That
is
the
file
that
we
use
to
list
the
future
going
to
be
so
they're,
not
arbitrary.
They
come
from
that
that
sameness
and
also.
D
B
B
The
ideas
scopic
is
that,
like
we
like
something's,
going
a
cube
that
we've
never
heard
of
like
the
widgets
processor,
queue
is
going,
you
know
using
what
CPU
and
all
the
memory
and
like
well
the
widget
processor,
and
nobody
knows
what
to
do
with
it.
Going
you
look
on
there.
You
map
that
to
the
team,
widget
processor
is
the
widgets
team.
We
can
go
into
their
slack
channel,
we
can
say
guys
and
girls.
F
F
B
B
A
F
B
E
B
The
first
thing
go
do
that
I
went
to
was
Hugo
because
it's
good
and
it's
a
static
site,
generator
and
and
I
looked
at
it,
and
there
was
not
going
to
be
a
ton
of
work
to
get
it
to
make
a
documentation
sites,
and
so
I
wasn't
really
happy
with
that.
And
it's
a
few
other
static
site
generators
and
then
I
looked
at
view
press
which
is
obviously
based
on
new
J's,
which
is
what
all
of
our
front-end
teams
use
and
I
discovered
that
it's
got.
B
We
could
potentially
have
like
give
that
con
Engineering,
something
that
could
and
at
the
moment
to
subscribe,
some
silly
videos
and
stuff-
and
that
was
just
me
tasting
if
we
could
include
like
YouTube
videos
and
other
content
in
there.
But
obviously
it's
not
gonna
have
certain
videos
when
it's
finished
better.
Take.
B
D
D
The
issue
with
the
handbook
is
too
much
information.
It
is
extremely
difficult
to
find
things
these
days,
so
what
you
should
like,
in
my
opinion,
what
we
should
at
least
do
is
have
the
handbook
as
the
source
of
true.
Where
do
you
find
that
information?
So
you
go
there
and
you
type
Prometheus
economy
right
and
then
that
gives
you
the
link
and
where
you
have
like
these
big
pages,
where
you
can
actually
easily
navigate,
consume
that
information
and
so
on
same
thing
for
github.com
settings,
for
example,
application
defaults
plus
settings
that
we
set.
D
It
would
be
great
if
we
can
have
that
in
a
place
where
we
can
actually
show
that
in
one
go
automatically
generated.
Handbook
is
gitlab
the
company
place
of
information,
and
you
should
go
there
typing
github.com
defaults,
and
then
that
should
give
you
only
the
link
to
where
the
doozy
tails
are.
Instead
of
you
going
and
I,
don't
know,
yeah,
rapping
or
googling
for
this
application.
Setting
that
was
set
to
three,
for
example,
on
get
level
calm.
D
D
D
B
D
E
C
E
E
E
Bit
complicated
for
developers
now
to
provide
context
to
psychic
workers
if
that
the
first
two,
whatever
it
was
schedule,
the
request
and
so
on,
and
we
don't
want
to
introduce
extra
queries
when
we
do
that
and
so
on.
So
I
came
up
with
an
ID,
but
it
like
it
works,
but
it
looks
a
bit
complicated.
So
we'll
need
a
lot
of
documentation
and
helpers
and
stuff
like
that
and
I
wanted
to
run
that
by
other
people.
But
I
can
wait
till
next
week.
Let's.