►
From YouTube: IETF100-NMRG-20171114-0930
Description
NMRG meeting session at IETF100
2017/11/14 0930
https://datatracker.ietf.org/meeting/100/proceedings/
A
Hello
good
morning,
everyone
welcome
to
this
Anna
Margie
meeting.
This
is
the
second
session
that
we
have
this
week.
Yesterday
we
have
the
first
session.
Yesterday
we
were
talking
about
mainly
on
intent-based
networking
in
the
some
kind
of
a
report
about
an
MRG
and
the
future
of
the
group
itself.
Today
we
are
going
to
concentrate
the
presentations
on
the
use
out
of
artificial
intelligence
for
network
management.
A
This
session
has
been
organized
after
call
for
participation
that
we
send
along,
of
course,
the
NMR
gmail
is,
but
also
together
with
out
our
other
medalists
in
other
communities
as
well.
The
approach
behind
this
session
is
that
we
wanted
to
revisit,
let's
say,
artificial
intelligence
techniques
and
solutions
to
observe
whether
they
can
be
used
for
network
management.
A
This
is
not
something
new,
because
network
management
has
been
already
observed
from
the
artificial
intelligence
perspective,
but
the
area
itself
major
along
the
years
and
then
it's
a
good
type
to
check
whether
artificial
intelligence
techniques
and
solutions
could
be
used
for
network
management.
In
this
as
a
new
context.
A
A
So
as
I
mentioned
before,
this
is
the
special
session
on
the
user
intelligence
for
network
management,
and
then
we
have
organized
the
presentation
in
let's
say
to
internal
sessions.
First
we're
going
to
see
a
set
of
presentations.
Then
we
have
some
questions
and
answers,
so
this
is
to
be
and
then
to
see
with
additional
presentations
and
then
in
2d.
We're
gonna
have
some
discussions,
conclusions
and
plans
for
the
future.
A
B
So,
thank
you.
So
I
will
start
by
motivating
a
little
bit
this
work
I.
Don't
think
they
need
to
explain
why
machine
learning
is
relevant
for
networking.
I
think
that
more
or
less
everybody
can
agree
on
that.
But
the
thing
is
that
it
is
working.
Ok,
now
it's
better,
but
I
would
like
to
in
this.
In
this
talk,
I
would
like
to
talk
about.
B
So
the
idea
is
to
use
these
deeper
informal
learning
techniques,
so
deeper
informal
learning
is,
let's
say
somehow
our
very
recent
breakthrough
that
we
can
claim
that
it
was
invented
by
Google
through
this
paper
in
2015,
where
they
managed
to
train
an
agent
to
play
a
video
game.
So
the
idea
in
this
case
was
that
you
have
a
nation
which
is
we
are
trying
to
teach
it
how
to
play
a
video
game.
The
agent
will
see
the
video
game
as
the
state,
ok,
and
it
will
act
upon
this
state
through
several
actions.
B
In
this
case,
it
has
three
different
actions:
right,
go
left
right
and
straight,
and
the
idea
is
that
the
agent
will
at
the
beginning
try
the
actions,
let's
say
randomly
like
a
human.
That
does
not
understand
anything
and
it
will
understand
how
the
actions
impact
environment.
Ok.
So
if
I
move
right,
what
happens
if
I
move
less
what
happens
and
so
on
and
after
a
while,
it
will
understand,
which
is
the
relation
between
the
actions
and
the
state,
and
the
idea
is
that
the
asian
has
a
goal
which
is
optimize
the
reward.
Ok.
B
So
what
Google
showed
in
this
paper
is
that
you
can
actually
train
an
agent
to
understand,
which
is
the
right
set
of
actions
so
that
in
the
long
term,
it
maximizes
the
reward,
which
means
that
learns
how
to
play
this
video
game.
So
we're
trying
to
do
exactly
the
same
to
networking,
which
is
it's
a
little
bit
straightforward.
In
our
case,
the
network
is
the
environment,
ok
and
then
the
act
Shen's
is
change,
something
upon
the
network.
B
We
need
to
change
like
the
routing
configuration
or
you
need
to
change
the
serving
fraction
path
or
you
need
to
change
something
outdoor
network.
Then
out
of
this
system,
when
you
change
something,
you
will
receive
two
signals.
The
first
one
is
the
state.
This
means
that
when
you
change
something
on
the
network,
something
will
change
right.
So
you
can,
you
can
understand
the
status,
and
this
is
a
very
broad
statement.
B
Many
many
different
answers
are
valid,
but
let's
say
that
you
can
think,
as
the
state
of
the
network
ask
the
traffic,
which
is
the
current
traffic
load
and
which
is
the
performance
that
my
network
is
providing
me
out
of
this
network
network
configuration
and
state,
and
then
you
have
the
reward.
The
reward
is
the
target
performance
of
the
network
right.
So
the
reward
is
how
well
more
than
the
target
performance.
B
B
Let
me
explain,
then,
what
kind
which
which
was
our
experiment,
which
I
have
to
say
that
it
is
a
work
in
progress.
We
have
a
paper
and
it
will
be
updated
with
new
results.
So
the
idea
is
that
you
have
one
of
these
deeper
informal
learning
agents
and
we
can
change
the
routing
configuration
and
for
this-
and
in
this
scenario,
we
have
assumed
that
the
routing
configuration
is
as
simple
as
the
weights
of
the
links
pretty
much
like
in
OSPF,
not
a
strictly
speaking
OSPF
as
the
IDF
protocol.
B
But
as
a
routing
protocol
that
you
set
the
weights
and
routing
happens,
then,
which
is
the
state
okay,
when
you,
the
state,
is
the
traffic
matrix?
Okay,
so
in
each
step
we
have
a
different
traffic
matrix.
The
traffic
matrix
can
be
actually
the
same
as
the
on
in
Russia.
Step
by
the
idea
is
that
in
each
step
the
agent
will
see
one
traffic
matrix
and
which
is
the
reward,
the
delay
okay,
depending
for
a
particular
traffic
matrix
and
for
a
set
of
weights.
B
What
you
will
get
is
a
certain
reward
delay
out
of
the
network,
then,
which
is
the
river
the
river
function.
So
we
train.
We
want
to
train
the
Asian
to
minimize
delay,
so
the
goal
of
the
Asian
is
find
the
right
set
of
weights
for
routing
such
that,
for
that
particular
traffic
matrix.
The
the
average
delay
is
minimum,
so
we
want
to
teach
the
agent
how
to
route
autonomously.
B
There
is
a
quite
interesting
discussion,
at
least
I
hope
that
you
find
it
interesting,
which
is
that
the
River
function
is
actually
the
network
policy
is
exactly
the
same.
So
what
we
understand
as
the
network
policy
and
yesterday
we
have
a
very
interesting
session
about
intent.
So
the
river
function
is
the
mathematical
representation
of
the
intent
that
you
need
to
install
on
the
Asian
so
that
the
agent
will
operate
the
network
following
that
policy,
I'm
going
to
jump
a
little
bit
over
the
methodology,
it's
also
in
the
paper,
but
pretty
much.
B
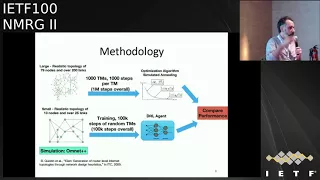
What
we
did
was
we
compared
the
performance
of
this
agent
with
a
very
quite
sophisticated,
optimization
technique,
a
traditional
atomization
technique,
which
is
called
simulated
annealing,
and
the
idea
was
that
so
in
in
RL.
What
we
do
is
we
train
the
system
with
100
thousand
steps,
random
steps
after
training
we
for
each
traffic
matrix.
B
We
asked
the
agent
okay
give
me,
which
is
the
optimal
weight
for
this
particular
traffic
matrix,
and
then
we
compare
that
with
a
similar
tunneling
with
it,
which
is
a
traditional
imaging
technique,
I,
which
is
a
search
base
and
for
in
this
case
for
annealing,
we
allow
it
to
run
for
1,000
steps.
So
we
asked
similar
tunneling
okay
for
this
particular
metric,
which
is
the
optimal
weights,
and
you
have
one
you
can
iterate
1,000
times,
so
you
can
find
you
can
test
1,000
different
weights.
B
So
it's
not
a
very
it's
a
fair
comparison
with
TRL,
but
well
it's
it's
enough
as
a
benchmark,
and
in
this
slide
you
can
see
how
the
Asian
learns.
This
is
the
traffic
intensity,
which
goes
well
beyond
100,
because
we
wanted
to
test
also
what
happens
when
you
have
a
network
which
is
very
separated
that,
if
he's
losing
a
lot
of
packets-
and
here
you
have
that
the
average
delay
and
each
box
plot
represents
how
many
training
steps
we
allowed
the
agent
to
have.
B
So
when
you
have
two
2000,
you
get
worse
performance
and
when
you
have
1000,
so
it
shows
that
the
Asian
is
learning,
and
you
can
see
this
very
common
exponential
decay
that
is
very
common
in
machine
learning.
So
the
more
training
you
get,
the
better
results
you
have
until
you
hit
a
flat
a
flat
curve-
and
this
is
the
performant
result
with
respect
to
simulated
annealing.
So
it's
the
same,
but
here
we
see
for
each
traffic
matrix,
which
is
the
delay
that
each
technique
achieves
and,
as
you
can
see,
both
results
are
quite
comparable.
B
B
So
from
that
point
onwards
on
the
presentation,
what
I
would
like
to
discuss
is
at
least
what
I
have
learned
and
which
are
my
conclusions
regarding
the
use
of
deep
brain,
formal
learning
techniques
in
networking,
so
I
have
tried
to
make
this
as
light
as
general
as
possible,
and
not
strictly
related
to
my
to
my
work
DRL.
They
have
amazing
advantage
in
in
our
area.
That's
at
least
my
opinion.
It's
a
quite
quite
an
amazing
technology.
So
on
the
one
hand
it
does
not
require
any
kind
of
prior
knowledge
of
the
network.
B
You
don't
have
to
explain
it.
I
have
this
amount
of
routers
the
capacity
of
the
links.
Is
this
one?
Nothing
because
it
understands
the
system
as
a
black
box
where
you
have
actions
and
you
get
a
reward?
That's
it!
So
that's
quite
quite
amazing.
It
works
online
and
in
real
time,
so
you
can
actually
run
it
and
expect
real-time
optimization
of
the
system,
something
which
is
extremely
hard
to
do
with
other
kind
of
techniques,
and
it
is
autonomously
not
just
for
optimizing,
but
also
for
learning.
It's
not
like
super
vise
learning.
B
Where
you
have
to
generate
a
dataset,
the
agent
will
generate
its
own
data
set.
You
don't
have
to
do
anything.
It
will
play
around
with
your
infrastructure
for
a
while
until
it
understands
how
it
works,
and
then
it
will
optimize
it.
So,
with
respect
to
traditional
optimization
techniques,
which
is
what
we
have
today
deployed,
it
provides
a
constant
optimization
time,
which
means
that
any
kind
of
optimization
technique
typically
has
to
iterate
I'm
trying
to
find
which
is
the
best
one
in
in
DRL
after
training.
It's
just
one
step.
B
That's
why
you
can
achieve
a
constant
time
optimization,
so
it's
model
free,
typically
for
optimism.
Our
typical
I
know
always
in
an
optimization
technique.
You
need
to
run
it
on
top
of
an
analytical
model
of
a
simulator
right,
and
then
the
analytical
technique
will
search
over
many
configurations
using
these
analytical
model
or
simulator.
To
try
to
find
which
is
the
optimal
one:
that's
not
the
case
for
DRL
you
can
make
it
learn
directly
on
your
infrastructure,
which
means
that
you
don't
need
to
simplify
anything.
B
It
doesn't
matter
how
complex
your
net
worries
and
with
enough
layers.
Although
this
has
to
be
confirmed
with
enough
with
a
deep
network,
you
should
be
able
to
learn
it
and
it's
a
black
box
optimization.
So
any
kind
of
optimization
is
tailored
to
the
problem
that
it
is
trying
to
optimize.
So
that's
not
the
case
for
general,
you
only.
So
if
you
want
to
change
your
optimization
function,
you
just
need
to
change
the
reward
function,
but
not
the
algorithm.
You
have
the
same
algorithm
for
different
reward
functions
and
in
a
duration,
optimization
technique
any
typically.
B
What
you
do
is
that
you
tailor
your
algorithm
to
your
optimization
goals.
Then,
of
course,
it
has
many
challenges
which
I
will
also
like
to
discuss.
The
first
one
is
training,
okay,
so
yeah,
it's
it's
very
cool,
so,
but
it's
very
hard
to
think
that
I
will
allow
an
agent
to
run
my
network
during
the
exploration
phase,
where
it
has
to
learn,
because
it
will
hit
actions
randomly
to
learn
what
is
happening
with
infrastructure
like
a
kid
right,
so
it
has
to
understand
how
things
work.
B
So
at
the
beginning,
it
will
be
a
little
bit
harsh
on
your
infrastructure
and
probably
you
are
not
going
to
allow
training
to
happen
online
and
that's
not
a
come.
That's
a
common
issue
not
for
us,
but
for
anyone
willing
to
apply
these
kind
of
techniques.
So
what
other
people
are
doing
is
well.
You
can
train
it
on
a
simulator,
that's
something
that
you
can
do,
and
people
are
doing
that
in
other
areas.
Then
you
lose
some
advantages
and
then,
once
you
have
the
system
trained,
you
put
it
online
to
work
in
the
real
network.
B
B
Then
there
is
a
second
challenge
and
that's
I
will
say
a
little
bit
more
conceptual,
but
I
will
say
it's
it's
bigger,
which
is
the
lack
of
explained
ability,
so
yeah,
deep,
neural
networks
are
very
cool.
My
students
are
very
happy
working
with
it,
but
at
the
end,
what
you
get
is
a
black
box.
It's
something
that
you
don't
know
how
it
works.
B
B
I
understand
that
from
the
industry
perspective,
that's
a
big
issue,
because
you
cannot,
it
won't
be
able
to
offer
you
anywhere
auntie's
and
it
won't
be
able
to
offer
you
any
kind
of
turret
shooting
if
it
breaks
you
don't
know
why
why
it
is
not
working
and
you
don't
know
how
to
fix
it
beyond
trained
it.
More
and
that's
I
understand,
for
the
industry
perspective
a
big
big
issue
also
in
terms
of
liabilities
and
so
on
and
again
that's
not
an
issue
just
for
us.
It's
an
issue
for
anyone
using
these
kind
of
techniques.
B
B
So
let's
say
that
you
have
an
intent
language,
you
compile
it
and
you
render
it
into
a
reward
function,
which
is
the
mathematical
representation
of
your
intent
language.
Once
you
have
done
that,
you
install
it
on
your
agent
and
then
the
agent
should
be
able
to
operate
following
that
policy.
So
I
believe
that
what?
Hopefully
you
find
it
relevant
for
for
this
working
group
for
this
research
group.
B
But
this
makes
me
ask
myself
some
questions
for
which
I
don't
have
an
answer
that
why
we
call
it
research
working
group,
I,
guess
the
first
one
is:
can
we
actually
represent
any
Network
policy
with
these
functions?
I
don't
know
because
those
functions
have
some
constraints.
For
instance,
they
are
continuous
and
so
on.
I,
don't
have
an
answer
for
that,
but
this
is
an
important
question.
B
If,
if
we
are
willing
to
go
that
path,
we
need
to
understand
if
this
reward
function
can
represent
any
kind
of
network
policy
and
then
okay,
how
we
can
compile
this
intent
language
into
these
River
functions.
So
as
a
summary
and
I'm
very
quick,
so
I
really
believe
that
this
is
an
amazing
technology.
B
It
is
to
me,
at
least,
it
really
represents
the
full
realization
of
an
autonomous,
intelligent
network,
which
is
something
that
we
have
been
discussing
out
in
the
past
and
to
me
this
is
what
and
how
I
understand
this
kind
of
autonomous,
intelligent
system,
but
it-
and
it
has
many
many
advantages.
Real-Time
operation,
plug-and-play,
no
configuration
just
pick
your
reward
function,
but
it
comes
with
important
challenges,
so
the
first
one
is
training
that
online
training
it's
challenging
and
the
second
one
is
that
it
doesn't
offer
any
warranties.
B
D
E
B
B
That
we
were
functioning
is
a
continuous
function
which
you
can
understand
it,
that
the
output
is
a
scalar
value,
so
the
higher
is
the
reward,
so
the
agent
is
trying
to
find
or
is
trying
to
act,
to
find
to
increase
all
always
this
value.
Okay,
so
the
higher
is,
is
the
better.
So
the
reward
function
should
be,
which
is
the
distance
between
in
a
mathematical
terms,
which
I
don't
know
how
to
do
that.
B
F
Presentation
or
I
want
to
ask:
do
you
consider
it
on
virtual
agent?
Because
if
we
simulate
the
top,
there
are
multiple
or
entity
in
multiple
our
motif
or
server.
So
I
guess
they
you
think
about
a
single
agent.
So
it
is
more
proper
to
SVN
cases.
But
if
we
reflect
or
your
network
infrastructure
is
involve
error
to
consider
multiple
age
on
vertical
Asian.
B
B
Will
12
vertical
or
will
12
wait
for
vertical
yeah?
So
we
only
did
one
Asian
on
top
of
an
SDN
controller,
finding
the
optical
optimal
configuration
for
a
single
network,
no
and
no
vertical
asian
anything
else
with
just
one
and
I:
don't
I!
Don't
for
this
scenario,
I,
don't
see
why
we
need
more
than
one.
G
B
Okay,
that's
a
let
me
elaborate,
so
another
limitation
of
these
kind
of
agents
is
that
the
action
is
space
cannot
be
very
large,
so
the
act,
the
output
of
the
agent
cannot
be.
Okay.
Give
me
the
CLL
configuration
formal
all
my
notes.
It
has
to
represent
like
levers
like
in
a
video
game
right,
so
a
few
levers
that
represent
how
you
steal
your
network.
So
in
this
case
the
Asian
was
choosing
the
weights
of
the
links
similar
to
our
or
SPF
I.
Guess.
G
B
A
H
H
Cvs
one
of
the
civil
one
of
the
popular
generative
models,
and
they
have
achieved
a
great
success
in
a
an
area
the
the
character
is,
it
can
extract
a
hidin
figure
from
the
training
site
data
and
then
reconstruct
the
distribution
model
of
the
focused
object,
because
this
this
24
faces
this
face
is
are
not
real.
They
are
generated
by
the
Civic
models.
H
If
we
input
the
label
such
as
we
want
a
female
or
male,
we
want
adult
or
children,
and
then
the
CV
can
generate
the
virtual
phases
for
us
and
why
we-
and
here
we
want
to
introduce
this-
can
conditional
aberration
or
auto
encoder
into
network
management
to
provide
inference
ability
for
the
qsr
performance.
This
is
our
basic
sort.
We
think
that
the
network
is
a
complex
system
and
the
curious
parameters
have
some
Haydn's,
that
is,
statistics
feeder,
which
is
hard
to
express
by
the
simple
distribution
formulas
or
the
combination
of
the
distribution
formulas.
H
Therefore,
we
can
use
the
CVA
II
to
model
the
network
us
and
then
we
can
use
the
Train
model
to
generate
the
new
samples
and
finally,
we
construct
reconstruct
the
curious
distribution
according
to
their
generated
samples.
That
is
always
truth,
be
a
pointer.
That
is,
we
input
a
condition
like
we
want
a
female.
H
If
you
want
a
busy
busy
tank
us
description
to
the
CVA
II
models,
and
then
it
can
generate
a
distribution
of
the
QoS
parameters,
and
then
we
can
do
some
actions
such
as
and
such
as
we
can
implement
the
proactive
operations
to
reserve
the
bandwidth
or
the
priority
sightings
or
migrate.
The
flow
of
we
focused
or
other
other
application
is.
We
can
evaluate
the
actions
that,
if
we
migrate
a
flow
or
VPN
sighting
to
a
new
path,
we
perform
well
enough
for
our
for
our
SLA
okay
and
this.
H
This
is
our
plan,
but
I
prefer
to
close
the
the
the
black
box.
As
this
looks
more
more
simple
here,
we
focus
on
the
icarus
variation
that
caused
by
the
traffic
such
as
we
pay
more
attention
on
the
queuing
delay
than
the
transmission
delay.
We
so
here
we
use
the
traffic
metrics
as
the
label
or
or
say
it,
the
condition
of
the
CVAG
model,
and
then
we
use
the
Q
s
as
the
other
value
like
this.
H
The
end
to
end
delay
may
be
ten
point
two
and
we
we
set
the
label
as
one
and
then
we
can
got
the
training
training
process
and
then
we
go.
We
obtain
the
CV
model
and
after
we
we
got
model,
we
can
infer.
We
can
infer
the
Q
s
distribution
by
into
the
traffic
metrics
as
a
label
or
as
the
condition,
and
then
it
will
generate
the
qsr
metric
samples
for
us,
and
then
we
can
use
these
samples
to
create
the
Q
s
distribution
in
any
conditions.
H
Here
we
have
a
simple,
simple
cases.
Is
a
demo
experiment
that
we
regenerate?
We
set
up
a
tent,
an
eye,
a
traffic
label
from
one
to
nine,
and
we
set
a
Hyden
rules
that
the
Q
s
label
is
the
the
Q
s.
Label
is
a
normal
distribution,
obey
the
normal
normal
distribution,
by
the
mean
the
mean
value
of
label,
multiple
10
and
the
very
earth,
and
the
variance
is
three
like
this.
We
have
this
distribution
of
the
proper
probability,
distribution
of
the
Q
s
parameters.
H
It
is
virtual
regenerated
and
then
we
use
1,000
sample
to
Train
the
CVAG
models
and
we
took
it
will
take
about
200
seconds
for
per
training
time
after
we
got
the
CV
model
and
we
will
test
whether
the
model
can
reboot
the
the
probability,
a
distribution
for
our
training
set.
So
we
input
the
training
label
from
1
to
9
such
as
you
will
input
the
label
to
whether
we
expect
the
CBA
model
can
output
Q
as
distribution
with
the
min
value
of
20
and
then
the
VAR,
the
variance
of
3.
H
That's
a
result
for
the
non
label.
We
can
obtain
the
accurate
distribution.
The
gray
is
not
very
clear.
The
gray
bar
the
great
curve
and
the
gray
bar
here
is
the
cases
or
the
samples
that
we
generated
and
the
red
one
is
the
the
cases
the
samples
the
CV
model
generated
for
us.
We
can
do.
You
can
see
that
this
it
looks
similar,
they,
the
arrow
of
mean
standard
and
the
19
point
like
this.
So
that
is
not
a
very
important
one,
because
many
many
AI
models
can
do
that.
H
The
answer
is
yes
for
the
non
label.
We
can
also
obtain
accurate
distribution.
So
here
this
label
11
to
14,
that's
very
important.
Somebody
may
say:
hyeon's
in
your
distribution
is
too
simple
and
you
have
only
two
parameters
and
one
of
the
1
now
is
a
fixed,
but
for
the
it
is
based
on
the
the
knowledge
of
human,
bring
that,
because
at
the
Machine
can
not
know
what
is
what
is
the
concept
of
the
normal
distribution?
H
Okay,
this
model
required
required
new,
maybe
new
merriment
technologies
to
feed
to
feed
such
as
we
need
more
high
frequency
and
accurate
accuracy
data
and
then
to
see
the
feed
out
this
model,
and
also
we
will
face
to
the
data
expression
and
the
transmission
problems.
Now
we
have
two
moles
for
the
CAE
training.
The
first
one
is
as
part
mode,
which
means
that
we
trained
the
model
severe
model
for
each
pass
as
a
unit
such
like
this
one.
H
H
If
we
can
do
that,
we
can
combine
each
of
the
note
as
a
past
as
the
path
q,
s
distribution,
but
now
we
we
cannot
simply
add
two
or
multiple
note
q
s
distribution
into
one,
because
it's
not
reasonable
in
mass,
so
why
we
use
severe
mode
when
why
not
use
other
mode?
We
have
some
advantages.
The
first
one
is
it
performed
quite
well
for
known
distribution
and
better
than
the
competitor
competitors.
One
of
the
competitors
in
the
area
is
against.
H
H
So
here's
a
conclusion
that
CV
can
can
use
to
model
the
network
Q
s
and
the
facility
has
been
approved
and
sir
and
second
one
is
severe-
has
many
advantage,
especially
it
can
infer
the
unknown
cases
and
third,
one
is
pass
mode
is
easier.
We
have
implements
that
we
will
try
to
explore
the
solution
for
the
node
mode.
It
is
still
a
challenge
and
said,
and
and
finally
we
can-
we
need
new
measurement
technologies
to
support
our
data.
Capturing
and
here
are
some
information
for
you
and
welcome
software.
I.
Do
not
think
it.
H
B
H
D
I
J
J
J
You
may
want
to
use
for
doing
some
Q
s
as
well
and
particularly
as
there
is
one
topic
which
is
traffic
classification,
when
you
aim
to
label
your
traffic
or
traffic
flows
with
some,
of
course,
letters
and
profiles,
which
can
be
different
depending
on
the
context
should
target
it
can
be,
for
example,
can
be
the
type
of
application
which
is
used
may
be.
The
user
may
be
the
type
of
the
attack
if
you
are
in
security
context
and
so
on.
J
If
you
want
to
try
some
service-
and
you
can
use-
maybe
DNS
name
and
so
on,
so
this
kind
of
standout
technique
in
order
to
to
know
what
type
of
traffic
or
what
equal
its
to.
And,
of
course,
if
you
can,
you
can
maybe
do
some
deep
packet
inspection
or
looking
at
the
content
of
the
packet.
In
order
to
add
a
bit
of
your
father
is
inside.
J
Of
course
it
has
a
wallet
change
and
no
a
mini
application
rely
on
same
framework,
so
it's
very
hard
to
distinguish
them.
Many
of
them
are
web-based
meaning
that
the
almost
all
use
the
same
protocol
I
mean
with
some
HTTP
HTTPS
and
so
on.
Of
course,
we
are
all
using
now
cloud,
CDN
and
so
on.
So
IP
addresses
are
not
so
very
valid
and
Iquitos
of,
for
example,
original
traffic,
and
of
course
there
is.
The
problem
is
the
encryption
technique?
J
Okay
with
privacy
and
concern
that
weighs
more
and
more
traffic
is
encrypted,
so
meaning
that
mainly
today,
it
would
be.
Maybe
a
big
carry
tacular.
A
lot
of
traffic
is
web-based
and
encrypted.
So
basically,
HTTPS
is
that
we
have
applied
a
lot
on
HTTPS
all
right.
So
yes,
of
course,
that's
good
to
have
encryption,
I
mean
for
user,
protecting
in
particular
you
your
privacy,
but
on
some
who
it's
also
legitimate.
J
If
you
do
some
network
operation
to
know
what
type
of
try
think
is
going
on
in
order
to
do
some
operation,
so
there
is
this
kind
of
need,
in
particular
for
security.
If
you
want
to
apply
some
security
policy,
you
need
a
bit
to
know
what
happens
and
then
somehow
you
mean
don't
need
to
break
and
you
should
not
break
the
user
privacy.
A
lot
of
solution
today
just
rely
on
an
HTTP
proxy
in
the
middle.
J
In
many
I
mean
many
companies
ensign,
which
I
think
is
not
good,
and
so
the
question
is:
can
we
do
some
directly
in
first
work?
I've
done.
Can
we
do
some
monitoring
and
fht
PPS
without
of
cross
decrypting,
whether
it
inside
so
this
is
a
first
example
and
very
rapidly.
I
will
show
you
because
I
present
you
this
example
in
a
previous
and
MLG
session.
So
that
is
that
ok,
so
different
kind
of
things
you
can
do
you
can
try
to.
J
If
you
look
at
where
we
can
try
to
look
at
what
is
a
web
page,
which
web
page
is
loaded
which
is
called
basically
a
website,
fingerprinting,
a
lot
of
record,
don't
try
to
categorize
traffic.
Is
it
fine
Apple
web?
Is
it
superior?
Is
it
a
voice
over
IP
and
so
on?
And
you
are
being
citizen
either
way?
We
try
basically
to
know
what
is
a
service
which
is
used.
So
basically
we
need
to
know
the
service
provider.
We
have
lay
your
classifier.
We
first
wait
to
know
what
is
a
service
provider
like
Google?
J
Is
it
Dropbox
is
a
book
and
Sun
and
then
the
different
services
that
the
heart
behind
so
we
will
want
a
z4
for
each
service
provider.
We
use
simple,
it's
a
simple
or
Revere.
It's
a
regular
decision,
tree
algorithm
to
do
that
and
one
one
main
I
mean
when
main
contribution
was
looking
so
digital
right
here.
Most
of
the
features
that
we
use
our
pretty
much
the
same
and
we
extended
a
bit
rather
than
look.
He
can,
for
example,
packets
I.
J
We
just
extract
the
encrypted
payload
and
we
apply
some
statistic
on
the
encrypted
pill,
and
actually
this
gives
better
results
here,
yeah
very
rapidly,
some
some
result
and,
as
you
can
show
here,
we
look
for
each
service
provider
in
which
a
range
of
co-education
we
are,
and
mainly
for
50
168
service
Friday.
We
have
a
classification,
so
we
are
really
able
to
know
what
is
the
service
I
use
for
this
provider
without
the
encryption?
What
is
the
traffic
with
an
accuracy
around
95
percent?
Okay
I
mean
not
in
too
much
into
the
detail.
J
J
We
know
that
there
is
probably
thios
there
is
a
scanning
and
so
on,
and
let
me
to
want
we
want
to
achieve
is
to
have
the
right
side
figure
right.
We
basically
have
the
different
kind
of
slices,
which
represent
the
scanning,
a
TCP
scan
we
have
on
the
docket
and
to
do
that.
We
try,
with
some
I'd,
say
no
sure
to
like
share
ricotta,
and
we
were
not
really
satisfied
with
the
result.
You
have
to
still
mainly
our
components
and
we
use
another
technique.
So
it's
traffic
is
not
on
fifty
by
the
primes.
J
We
should
not,
of
course,
in
analyze
individual
packet,
but
we
should
correct
them
in
order
to
find
the
right
pattern.
So,
even
if
it's
not
so
simple,
so
we
use
G
da,
which
is
topological
the
tanneries,
we
only
use
one
part
of
the
TDI
here
we
are
no
bit
further.
What
was
the
mapper,
which
is
R,
is
a
first
step,
which
is
basically
you
can
see
that
as
a
partition,
basically
stirring.
J
So
we
have
a
big
space
of
data
multi-dimensional
data
and
then
we
compose
few-
let's
say
a
per
cube
in
that,
and
we
are
this
intermediate
representation
that
we
built
in
the
middle,
which
is
based
on
kind
of
clustering,
and
then
we
measure
all
the
result
together.
Maybe
you
can
discuss
more
if
you
want
more
detail
about
this
technique,
but
with
this
technique
we
have
been
able,
of
course,
to
be
able
to
to
level
a
bit
more
they'd
help
you
have
in
the
document.
J
J
You
want
to
be
able
to
detect,
for
instance,
if
you,
if
you
think
about
security,
and
this
is
more
compliant.
If
you
are
a
bit
against
mass
surveillance,
because
you
don't
want
to
try,
for
example,
in
individual
user,
but
maybe
you
want
are
any
service
usage,
but
only
ones
have
issues
that
you
want
to
attract.
J
Of
course
you
have
to
think.
If
it's
you
can
do
your
honor
isn't
a
single.
Let's
say
that
instant,
so
multiple
that
instance
like
if
you
look
at
a
single
flow,
if
you
want
to
correlate
different
flow
together,
I
think
the
signal
technique
is
usually
a
more
efficient
but
is
more
difficult
to
apply.
I
will
so
then
we
have
the
methodology,
which
is
very
not
really
going
to
this.
It's
very
classical,
so
we
straining
and
so
on.
J
One
thing
that
I
want
to
point
out
is
already
point
to
it
and
in
the
mailing
list
as
well,
is
that
a
future
engineering
I
think
isn't
the
core
half
as
a
problem.
Choosing
the
right
feature:
I
mean
you:
can
you
can
use
a
different
algorithm?
We
need
people
just
just
try
a
lot
of
figures
on
without
thinking
first
about
maybe
the
second
slide.
Maybe
thinking
about
what
also
algorithm
really
works.
I
think
it's
really
important
to
know.
J
Use
of
course,
algorithm
like
black
box,
but
also
features
so
one
one
thing
which
I
think
is
very
a
representative
is
a
when
you
do
some
a
distance
metric.
Many
people
just
choose
algorithm
on
the
shelf.
They
use
distance
metric
on
the
Shelf,
for
example,
you
can
use
a
given
distance,
but
most
of
the
time
there
is
nonsense,
I'm
just
looking,
for
example,
at
port
number.
If
you
look
what
number
as
numerical
values,
of
course,
you
can
do
it,
you
can
apply.
J
Distance
can
compute
the
distance,
but
there
is
no
R
meaning
to
compute
a
numerical
or
akkadian
distance
between
port
numbers.
For
instance.
We
need
something
more
advanced
just
to
show
you
some
some
work,
we've
done
so
far.
Here
is
we
look
again
the
darknet
and,
of
course
there
is
some
semantics
in
sport
and
the
idea
was
not
to
automatically.
We
have
also
done
that
the
semantics
of
ports
from
knowledge,
but
to
build
our
knowledge
based
on
SciTech,
her
behavior.
J
J
Just
a
one
slide
in
the
rest
on
so
and
just
to
conclude,
I
really
think
that,
regarding
the
encrypted
use
case,
based
on
our
experience
on
what
you
can
win,
literature
I
think
if
you
target
well
precise
problem,
you
can
easily
find
a
solution,
can
find
algorithm
features
that
could
give
you
some
reasonable
and
good
results.
I,
don't
think
this
opera.
Of
course
it
suppose
that
you
are
adult
Amin
in
very
precise
database
for
different
environment.
So
there
is,
of
course,
some
things
that
you
have
to
fit,
and
it's
not
so
evident
like
that.
J
What
are
remaining
issues
that
most
of
the
case,
we
don't
consider
as
adverse
behaviors,
and
what
I
want
to
do
to
mention
is
that
the
fingers,
of
course,
is
always
evolving.
We
have
new
protocols,
have
kind
of
optimized
protocol.
If
you
look
at
HTTP
and
even
if
you
have
a
GPS,
of
course
on
top,
but
you
have
HTTP
to
so
know,
things
are
multiplexed
are
compressed
and
so
on.
So
it's
very
difficult
today
that
we
can
easily
apply
so
technique
because
you
before,
basically
we
have
one
flow
and
we
try
to
label.
J
Let's
go
if
I
can
do
an
analogy.
Today
we
have
the
big
Chanel,
where
we
put
everything
in
a
generic.
It's
all
the
same
application
all
encrypted,
it's
mixing
stationary
use
and
so
on.
It's
very
more
far
more
difficult
that
you
can
read
in
most
of
paper.
Actually,
if
you
look
with
the
new
context
and
I'm
that.
J
Okay,
so
it
depends
on
because
I
represent
a
different
use
cases
in
first-year
HTTP
use
case.
It's
quite
well
balanced
because
we
control-
or
we
collected
that
I
said,
of
course,
was
G
as
if
example,
for
the
darknet.
It's
not
so
well
balanced
because
I,
of
course
it's
real
data
that
we
gather.
So
we
cannot
really
control
the
different
proportion.
J
H
From
Paulie
I
have
a
question
that
you
said
that
you
need
to
collect
a
data
post
from
from
then
from
the
network
and
out
of
the
network,
and
my
question
is
how
you,
how
you
align
this
to
two
types:
two
types
of
data,
because
we
need
to
build
up
the
relationship
between
the
in
internal
internal
and
thank
you.
You.
J
Sure
I
mentioned
that
I
didn't
really
focus
on
that.
But
that's
true
that
in
cases
we
went
to
analyze
traffic,
we
need
also
some
knowledge
which
are
which
is
out
of
the
network
and
then
III
deepen
the
case.
Maybe
to
cite
an
example,
for
instance,
we
have
this
dark
net
space
and
also
we
have
also
only
pots.
So
there
are
two
different
I
mean
both
on
it
well,
but
two
difference:
Network
space,
for
example.
J
We
are
collecting
what
possible
which
I
use
by
the
attackers
when
they
try
to
connect
to
ssh
to
on
me,
but
and
we
can
fight
stance
if
you,
if
you
look
in
our
database,
we
can
see
that
that
some
hoes
are
some
changes
is
a
password
which
I
use
because
I
try
together.
If
I
get
some
other
devices
vio
two
devices
at
that
time,
and
so
you
can
see
also
the
same
change
in
the
port
which
are
targeted
or
in
the
in
the
document.
And
of
course
we
it's
really
depends
on
the
context.
J
L
L
L
F
J
If
I
understand
value,
what
question
was
regarding
the
features,
so
we
have,
we
have
difference
at
a
feature.
I
was
very
rapid
and
future,
so
classical
feature
has
features
that
you
extract
from
state-of-the-art.
That
has
been
used
for
I
should
GPS
traffic,
and
then
we
have
selected
set
of
features
that
then
you
have
full
features
which
is
state
of
just
features,
plus
our
new
features
on
encrypted
data,
and
then
we
have
features
which
is
a
selection
among
them.
If
I
go
back
to
once.
J
Okay,
here
you
can
see
what
other
the
selected
feature,
which
is
the
one
are
pouring
in
Pola,
the
ones
that
we
had.
It
is
user
as
one
from
state-of-the-art,
which
are
the
selected
feature
which
are
basically
based
on
an
information
gain
that
we
selection
and
then
so.
What
means
the
tables
at
for
each
line?
J
We
look
at
the
number,
so,
for
example,
the
first
line
is
the
number
of
service
provider
for
which
we
were
able
to
classify
between
95
and
Android
percent
of
the
service
which
have
been
used
and
so
on,
and
then
we
have
the
different
bins
and
so
for
so.
The
first
thing
is
the
one
most
from
penalty
for
the
best
classification,
because
it
means
that,
for
if
you
use
silicate
feature
51
of
service
provider,
I've
been
steep.
Services
of
59
of
service
provider
have
been.
M
J
J
The
idea,
because
I
think,
if
you
look
at
this
particular
gene
algorithm,
it's
I
would
call
near
we
had
time,
because
our
initial
goal
was
to
build
HTTP
firewall.
So
it's
I
think
in
terms
of
classification,
it's
very
fast
so,
but
the
problem
is
that
we
need
to
have
the
full
HTTP
session.
So
it
means
that
if
you
do
a
firewall,
you
cannot
block
the
connection.
You
need
to
observe
entirely
and
then
block.
M
J
N
N
J
N
O
Curatu
compeller
I
have
a
comment
for
you,
which
is
as
you're
doing
this
stuff
and
saying
how
well
you
can
classify
based
on
not
just
classical
features,
but
all
these
other
features
you're
suggesting
to
people
how
they
can
hide
their
traffic
better,
so
I
can
pad
my
packet
so
that
they
all
look
roughly
the
same
size.
I
can
adjust
the
inter
packet
gap
so
that
that
information
goes
away.
Just
a
comment.
Okay,.
P
So
the
motivation
is
the
following:
so
in
the
future
hyper-connected
society,
we
believe
that
we
will
have
a
major
challenge
in
controlling
and
managing
large
networks,
and
you
can
have
in
mind
the
AI
enabled
cloud
hosted,
applications
connected
through
5g
and
interconnecting
other
thousands
of
IOT
devices
until
end-users.
So
in
such
a
large
network,
traditional
approaches
to
management
will
be
challenged
because
they
require
and
the
link
of
a
model
in
advance
and
then
acting
and
the
reasoning
contact
model
a
while
in
such
a
large
and
complex
systems.
P
It
would
be
hard
to
learn
in
advance
the
model
that
maintain
it
update
it
because
it's
dynamics
of
this
large
system-
and
we
are,
after
a
noble
approach-
the
concept
of
learning
in
interaction
introduced
and
derived
from
reinforcement
learning.
So
the
idea
in
years
has
been
already
presented
by
the
first
presenter.
So
let
me
go
work
quickly
through
the
high-level
concept
here.
P
So
instead
of
building
an
advanced
model,
the
management
agent
will
learn,
generate
actions
on
the
environment
on
all
the
system
and
will
collect
the
feedback,
and
this
feedback
will
be
separated
into
two
for
two
flows.
The
first
one
is
the
interpretation
of
a
state,
so
it
will
we
define
notion
for
state
of
the
environment
and
it
should
also
identify
what
is
called
a
reward,
so
the
goodness
of
the
state,
how
good
is
the
state
from
the
Givens
the
objective
of
the
management?
P
So
let
me
go
to
the
next
chart
and
to
show
how
we
Nastasia
is
this
general
schema
and
we
apply
it
to
an
elastic
cloud
bed
application.
So
the
the
a
level
objective
is
protein
automatically
loan,
optimal
resource
management
policies
with
limited
priority
formation
and
adaptive
this
due
to
the
changing
environment.
So
we
are
experimenting
with
the
cloud-based
application
which
receives
a
very
low
and
it
can
scale
up
and
down.
Basically,
it
can
add
or
remove
virtual
machines
to
adapt
to
to
the
current
load,
so
the
reinforcement,
learning
module
will
generate
action.
So
what
we?
P
P
And
will
we
identify
here
the
state
as
being
a
combination
of
the
current
workload
and
the
current
capacity,
and
the
reward
is
provided
as
the
desirability
desirability
of
this
current
state
and
it
in
fact,
it
reflects
compromise
between
the
the
capacity
more
you
are
using
capacity.
This
is
your
reward
and
in
case
you
are
violating
necessarily
in
terms
of
the
response
time
you're
paying
a
penalty.
P
So
you
are,
you
are
in
good
shape
if
you
are
using
low
capacity
and
you
are
not
violating
the
wrestling
and
to
to
to
reason
and
to
build
the
the
optimal
policies.
The
algorithm
will
duel
the
so
called
Q
values
and
update
these
two
values
which
which
you
find
on
loan
pairs
of
state
inductions,
and
basically,
these
two
values
will
be
used
afterwards
to
to
who
identify,
see,
see
the
highest
Q
value
for
a
given
state
so
which
will
identify
the
best
action
to
be
executive
in
the
given
state.
P
So
some
some
results
we
will
present
here
are
basically
reflecting
the
the
the
ways
you
we
can
derive
automatically
the
control
decisions
by
maximizing
the
system,
efficiency
and
yeah.
We
need
to
mention
here
that
the
system
efficiency
is
defined
as
the
sum
of
discounted
rewards
over
the
entire
time
origin
of
your
system,
and
here
we
are
using
minimal
system
information,
no
no
system
model.
The
only
thing
we
know
about
the
system
is
its
state
and
reward
as
defined
previously,
so
we
we
are
observing
the
capacity
current
capacity.
P
We
observe
the
car's
response
time
under
the
workload
and
since
the
iterations
of
this
closed
loop,
iterations
of
the
learning
agent
shows
that
we
have
converges
of
convergence
of
the
average
system
efficiency
and
why
this
is
achieved
by
identifying.
This
is
the
best
trade-off
between
minimizing.
They
are
located
capacity
and
maximizing
the
customer
responsiveness
as
as
a
reward,
functional
indicating
and
on
the
next
chart,
then
we
will
show
how
the
system
it
can
adapt
to
the
changing
environment
and
to
do
that.
P
Elaborated
some
principles
for
state
and
the
reward
definition
in
some
prior
works.
The
state
definitions
I've
been
done
in
ways
that
do
not
respect
the
separation
of
causes
from
effects.
So
if
you
look
the
way
we
define
Z
state
it,
it
includes
all
the
only
kind
of
independent
attributes,
workload
and
capacity
which
lead
to
the
response.
Time,
which
causes
the
status
is
the
value
of
the
response
time.
P
So
the
first
time
some
other
words
were
including
the
response.
Time
is
the
notion
of
the
state,
so
it's
important
to
define
a
state
in
a
way
that
it
captures
some
independent
dimensions
of
the
system
and
then
the
design
of
a
minimal
reward
is
very
important.
So
it
makes
sense
to
the
engineer
and
makes
sense
to
the
user
of
the
system,
and
here
we
we
build
the
reward
fraction
which
has
a
meaning.
It
is
a
revenue
minus
the
cost
and
in
which
case,
the
return
which
was
the
discounted.
P
P
I
will
end
this
short
presentation
with
by
enumerating
a
few
open
challenges
with
where
we
reach
this
area.
So
the
first
one
is
the
unknown
reward
latency,
because
when
you
execute
an
action
of
the
system,
you
cannot
be
sure
that
this
the
effect
of
this
action
is
seen
immediately
in
the
next
iteration
of
jaraguá.
So
you
do
not
know
how
long
time,
how
is
the
inertia
of
the
system
is,
is
operating
so,
how
long
time
it
will
take
until
the
effect
of
your
action
it
will
be
upset.
P
This
can
be
annoying
that
issue,
because
you're
lowering
kanji
is
immediate
reward.
Another
problem
we
have
been
faced
is,
if
faint
actions,
these
feeling
actions
you
execute
on
your
system
can
be
really
executed.
So
your
algorithm
should
be
adapted
in
a
way
to
differentiate
between
successful
actions
from
which
you
observe
your
reward,
and
the
argon
should
learn
whether
these
actions
were
improving
or
not
the
reward
and
the
the
actions
which
didn't
succeed.
Just
from
system
perspective,
they
just
didn't
manage
to
execute
it
within
the
system,
so
they
will
introduce
the
noise
in
that.
P
In
that
case,
of
course,
the
general
problem
will
known
is
a
slow
convergence.
The
pole
start,
so
some
of
the
similar
approaches
should
should
be
put
in
place
to
to
accelerated
by
probably
introducing
some
domain
knowledge,
and
the
last
point
I
would
like
to
precise
here
is
the
abnormal
environmental
changes,
so
I
patient
here
that
when
the
environment
changes
your
postman,
learning
algorithm
can
can
do
miss
that
and
can
adapt.
But
what,
if
these
changes
are
situations
which
are
happening
very
rare?
P
So
you
don't
really
want
to
learn
anything
because
they
will
not
have
a
sufficient
time
horizontal
to
lead
your
auger
into
convergence.
So
you
would
like
basically
to
ignore
us
these
situations,
which
are
failure
situations
so
that
your
your
policies
are
not
kind
of
too
much
conservative
they
can
differentiate.
Is
the
normal
operational
changes
from
from
anomalies
and
failures?
P
P
This
is
the
point
in
fact,
abnormal
changes
like.
If
you
are
running
OpenStack
cloud,
you
can
have
OpenStack
problems
right
here,
your
your
cloud
environment.
You
can
be
in
abnormal
situation.
You
don't
want
to
learn
which
policies
to
apply
from
from
scaling
perspective
when
you
are
in
this
abnormal
situation.
You
want
to
tackle
this
abnormal
situation
by
some
specific
actions,
you
you
know
and
not,
learn
it.
What
you
do
you
want?
What
you
want
to
learn
is
when
the
system
is
operating
normally
it
is.
E
P
P
Yeah,
so
the
vault
Road
we've
considered
is
a
kind
of
arrival
workload.
If
indeed
you
can
challenge
the
system
by
providing
really
work
up,
which
changes
the
patterns
of
the
time.
So,
if
you
assume,
you
should
assume
that
you
will
converge
to
a
stationarity
should
converge
to
two
to
some
optimal
policies
and
there's
some
stationarity
assumptions.
If
your
input
load
is
is
not
stationary,
doesn't
have
any
repeated
pattern,
it
will.
P
No,
no,
you
don't
have
any
current
e2
to
converge
to
anything
may
be
another
answer,
or
so
is
that
the
underlying
assumption
is
that
your
system
is
behaving
like
a
Markovian
model.
So
your
workload
variations,
your
state
definition
should
be
done
in
a
way
that
your
workload
variations
are
still
preserving
this
Markovian
property.
P
If
they
do
not,
they
may
you,
you
cannot
claim
any
convergence.
So
in
this
particular
case,
we
we
we
had
a
pattern
of
daily
patterns.
In
fact,
what
you
see
on
the
left
is
daily
patterns
of
arrival
workload
and
it
so
you
have
I
think
one
week
of
data
or
a
bit
more
and
the
convergence
took
about
one
or
two
day
we
to
converge
to
the
right
policy.
K
Q
So
this
is
I
mean
it's
a
summary
of
a
project
that
is
about
to
finish.
That
is
a
cognate.
Only
these
the
idea
was
to
build
a
network
management
environments
that
should
be
based
on
in
general
model,
machine
learning,
weights,
use
machine
learning,
but
ideas
to
use
any
kind
of
data
and
intensive
techniques
to
apply
machine
learning,
basically,
it's
as
being
since
it
has
been
funded
by
the
European
Commission
and
the
5g
PPP
program
is
very
much
oriented
to
fire
use
cases.
Q
Apart
from
that,
there
has
been
another
applications
related
to
automated
car,
some
an
IOT
well
for
sure
they
are
it's
based
on
open
source
and
is
about
that
to
contribute
to
several
communities.
This
should
be
a
little
bit
more
colorful,
but
well.
This
was
I
can
tell
you
this
was
light
blue
and
the
dark
blue
and
is
difficult
to
see.
Q
But
basically,
what
we
have
here
is
the
usual
closed-loop
environment
for
controlling
which
what
you
have
is
a
set
of
policies
and
a
data
stream
that
is
generated
by
monitoring,
danger
phase
and
the
functions
that
are
running
well,
cognize
that
they
would
come
as
a
cognate.
Das
is
precisely
try
to
add
a
second
closed
loop
in
which
what
you
have
is
a
data
stream
and
a
set
of
the
score
relate
related
precisely
to
the
policy
engine.
Q
Q
You
a
better
PDF,
so
so
the
DSA
adding
this
it
is
that
that
you
have,
we
have
in
the
position
of
making
some
selection
of
the
different
trained
results
so
in
more
detail.
Basically,
this
is
the
same
diagram
at
the
beginning,
but
with
a
little
bit
more
of
detail
and
abs
that
precisely
that
song
over
there
is
where
several
different
mechanisms
for
machine
learning
several
different
mechanisms
for
training
the
the
policy
and
Jing
are
applied
with
datasets
that
are
generated
by
collecting
real-time
data
there.
Q
Q
We
are
assuming
that
the
in
underlying
infrastructure
is
based
on
any
V+
as
being
a
and
a
particularly
texture
in
which
what
you
have
is
a
double
double
is
the
end
controller
one
acting
as
the
vnf
level,
the
other
one,
acting
at
the
at
the
infrastructure
level.
So
we,
you
can
understand,
apply
Sdn
rules
for
the
to
control
the
behavior
of
the
different
functions.
Q
This
grows
in
more
detail
again,
so
you
can
see
here
over
there,
where
we
are
assuming
that
there
are
the
two,
the
two
Sdn
controllers.
Well,
it
will
be
here,
the
other
one
will
be
here.
This
would
be
controlling
how
the
different
ENS
are
interconnected.
The
other
one
is
controlling
the
they
behavior
of
the
vnf
themself.
Q
Databases
to
forward
the
different
streams
is
uses.
Several
tools
for
applying
the
machine
learning
processes
is
using
a
policing.
Jing
is
using
open
daylight
for
a
stallion
controller,
open
source,
mono
foreign,
if
your
castration
and
and
well,
we
are
using
up
in
AV
Brahmaputra.
That
is
a
little
bit
back
because
we
started
two
years
ago
and
we
decided
not
to
make
any
many
changes
to
the
infrastructure
itself
itself.
I
am
well
just
as
a
note.
Q
We
are
using
super
for
policy
definitions
for
the
obvious
changes
apart
from
this,
and
this
is
something
that
is
running
and
we
will
in
a
couple
of
weeks
we
are
going
to
go
to
Paris
to
to
set
up
the
final
demo
precisely
I
mean
not
to
part
two
part,
two,
the
real
Paris,
not
the
orange
Gardens.
We
are
going
to
have
the
meeting,
and
apart
from
that,
as
a
side
byproduct,
we
found
that
training,
training
and
models
and
using
those
data
sets
during
initial
data
sets
for
training.
Q
The
models
were
extremely
complex
because
they
were
a
horrible
lack
of
datasets
and
and
and
getting
data
set
is
extremely
complex
because
first
data
is
considered
asset
and
is
considered
more
and
more
an
asset
and
getting
significant
data
is
almost
impossible
even
internally.
In
the
same
organization
can
tell
you,
in
an
operator
like
telefónica
getting
real
operational
data.
Is
it's
a
real
nightmare
because
nobody
wants
to
this
closer.
Second,
there
are
important
privacy
concerns.
There
is
a
lot
of
concerns
about
that.
Q
You
will
be
exposing
and
well
with
the
new
C
GDP
are
here
in
Europe.
They
are
in
Europe,
so
it
will
be
completely
almost
completely
impossible
because
any
single
data
can
be
considered
as
person
and
third,
even
when
you
have
the
data
when
you
manage
to
get
the
data
and
you
get
to
manage
to
anonymize
it
etc.
In
many
cases
is
unusual
for
certain
real
scenarios,
because
you
don't
have
any
clue
about
what
what's
going
on.
Q
It's
true
that
with
a
tippler,
the
deeper
learning
processes-
and
you
don't
know
alike-
you
don't
need
to
rely
on
them,
but
then
making
validation
and
bring
in
the
testing
of
the
of
the
Train
datasets.
Unless
you
are
bold
enough
to
put
them
on
the
real
network
is
very
complicated
and
again,
if
you're
running
in
an
operator
environment
telling
the
guys
were
running
the
operations
they
you
know,
I'm
gonna
put
managing
a
piece
of
things
that
have
learned
from
some
data.
Whatever
controlling
the
network.
Q
Try
it
try
it
and
wait
a
couple
of
hundred
years
till
you
get
the
the
permission.
So
we
started
to
work
in
the
production
of
sound
synthetic
datasets.
We
started
something
that
we
call
the
mouse
world.
The
idea,
basically,
is
that
it's
a
laboratory
for
generating
synthetic
data,
they've
used
to
generate
traffic
samples
in
a
controlled
way
and
we're
not
allowing
that
we
can
mix
real
and
synthesize
data.
Take,
for
example,
is
injecting
real
data
mix
with
a
with
a
security
attack,
real
data
mix
with
a
a
viral
event
on
the
internet.
Q
Things
like
that,
so
we
are
in
the
position
of
generating
realistic
scenarios
and
use
them
to
train
and
validate
the
training.
This
is
something
that
I
told
you.
It
is
a
byproduct
of
the
connect
project
right
now,
but
we
are
really
willing
to
in
the
future,
with
the
VL
of
producing
something
that
is.
A
thing
is
very
important
for
all
these
to
happen,
that
these
are
open,
open,
datasets
and
even
open
synthesizing
tools,
so
experiments
and
results
can
be
replicated
and
just
to
finish,
please.
This
is
something
that
well
is
a
conclusion
about
that.
Q
We
have
to
apply,
for
example,
a
sensible
way
of
managing
data
sets
and
well
still,
there
are
challenges
before
we
see
this
happening
in
the
real
in
the
real
in
a
real
environment,
operational
environments,
we
have
first
of
all
that
the
networks
are
different
in
the
behavior,
that
from
the
fields
that
AI
has
been
applied
so
far,
it's
not
so
static
as
I,
don't
know
dynamic,
image,
recognition
or
or
she
stays.
This
is
the
Diagnostics
on
this,
like
that.
Q
We
desperately
need
data
data
sets
with
a
whether
meaningful
and
alberto
saying
before
we
in
these
environments
do
need
to
have
always
someone
to
blame.
You
have
to
understand
what
we
know
is
is
say
in
a
real
environment,
is
completely
and
applicable
to
have
something
that
you
have
just
dropped,
and
you
don't
know
what's
going
to
happen
and
why
any
any
problem
happen.
Well,
that's
all.
D
Q
Q
A
R
R
Q
About
shorty
yeah
troubleshooting,
you
no
no
definitely-
and
this
is
one
of
the
cases
that
has
been
demonstrated
precisely
by
the
people
from
the
Nokia
team
in
Israel,
something
that
they
called
oh
yeah,
try
not
to
identify
noisy
neighbours
and
during
the
during
the
execution
on
all
natural
functions.
Okay,.
A
K
Thanks
ji-sun
row,
so
this
talk
is
quite
different
from
what
we
have
seen
before:
it's
not
use
cases
or
techniques,
it's
more
I
would
say
a
new
initiative
in
I
Triple,
E
Comstock,
which
are
not
called
emerging
technology
initiative
before
that
it
was
called
subcommittee
or
committee.
So
this
one
is
called
Network
intelligence.
K
So,
as
I
say,
it's
kind
of
trying
to
build
a
new
community
initiative
inside
Comstock,
which
is
focused
on
network
intelligence,
it's
still
not
officially
approved.
This
is
in
the
process,
but
we
are
pending
approval
by
the
Comstock
et
Cie.
It's
not
completely
new
for
those
that
are
used
to
that
or
aware
that
it's
inherits
from
the
Chi
Kok
Technical
Committee
on
atomic
communication,
which
was
established.
We
said
several
years
ago
that
was
investigating
atomic
communication,
so
there
are
kind
of
legacy
around
that
kind
of
technologies
in
the
network
intelligence.
K
Currently,
the
the
mission
that
is
defined
for
this
ETI
is
essentially
to
support
and
endorse
the
research
in
the
domain
of
artificial
intelligence
for
software
networks
and
towards
future
networks.
So
this
is
really
not
the
goal
of
the
each
I
is
not
to
do
the
research
itself,
but
it's
to
provide
a
framework
to
support
the
researchers
in
the
publication
of
the
research
emergence
of
community
providing
avenues
for
for
discussions.
So
the
also
the
evolution
of
networks
towards
more
software.
K
Okay,
this
is
some
of
the
topics
that
are
listed
as
topic
of
interest
for
the
network.
Intelligence.
Eti
I
will
not
go
through
that.
It's
available
should
not
be
available
on
the
web
page
of
the
ETI,
but
probably
we
are
targeting
a
different
kind
of
artificial
intelligence
techniques,
machine
learning
techniques,
but
also
the
realm
of
autonomic
networking
and
data
analytics.
K
So
currently,
the
the
officials
of
this
ETI
are
listed
here.
The
chair
is
a
mind
reader
Yaya
from
Orange
Labs
in
France,
then
Raisa
Mohammed
patents
on
E,
which
is
from
Maria
Lin
in
Kannada
technical
program
generally
mom,
which
is
also
from
Canada
Sonali,
is
on
I'm
just
on
a
liaison
officer.
So
that's
why
I'm
doing
this
presentation
here
in
IETF
RDF?
K
We
are
trying
also
to
create
lesson
with
other
groups
in
other
standardization
bodies
and
secretary
revert
on
quad
area,
so
participation
to
this
ETI
for
those
that
are
not
aware,
you
don't
need
to
be
actually
member
to
join
the
sea,
tides
I,
would
say
community
of
researchers,
so
anyone
which
is
willing
to
participate
to
this
community
can
join.
You
just
ask
your
chairs.
K
You
will
subscribe
to
the
mailing
list
and
then
you
can
even
proposed
activities
or
events
in
the
CGI,
and
you
will
be
aware
of
what's
happening
there
already
some
activity
that
are
it
being
planned,
or
that
will
happen
soon
organized
by
the
people
involved
in
this
in
this
in
this
committee.
So
there
will
be
a
first
international
workshop
on
network
intelligence
co-located
with
the
I
CIN
conference
in
February
in
Paris.
You
have
to
link
to
the
Twitter
workshop.
The
deadline
is
already
over,
so
there
will
be
a
third
international
workshop
on
management
of
5g
networks.
K
The
Aeon
alienates
conference
next
year,
which
is
organized
by
our
side,
which
would
be
co-located
with
the
MPLS
Sdn
energy
conference
in
April
in
Paris,
and
we
have
some
people
attending
IETF
meetings
that
will
go
to
that
conference.
So
you
will
see
some
of
those
of
those
guys.
There
is
also
a
special
track
on
autonomic
network
management
organized
regularly
with
the
IMS
conferences.
So
this
is
also
a
topic
where
you
can
find
researches
on
this
aspect,
some
standards
area
where
members
we
try
to
get,
involve
and
active.
K
So
this
very
meeting,
ihe
F,
an
ITF,
but
also
you
will
see
later
presentation
on
the
HC
and
I
should
police
a
lot
committees
and
what
we
also
have
in
the
plan
is
to
organize
in
the
future,
especially
issues
for
various
Comstock
journals
and
magazines.
So
please
stay
aware
of
that
in
the
for
the
future,
and
that
concludes
my
presentation.
So
this
is
what
just
really
to
give
you
information
about
this
new
committee
that
is
setting
up.
K
S
Hello,
everyone,
this
is,
will
do
from
Huawei,
so
today,
I
will
actually
I
guess
in
last
year
or
before
last
year,
I
presented
some
I
mean
topics
about
this
work
at
that
moment
that
we
just
started
to
this
work.
Research
on
the
network,
inheritance
and
I
mean
in
last
I
mean
from
last
year
to
this
year
we
have
made
some
progress.
One
of
the
biggest
one
is
that
we
create
a
new,
is
G
in
SC
called
Eni
experiential
network
to
intelligence.
This
is
this
is
G
or
this
is.
S
This
group
is
focusing
on
the
network,
inherent
improvement
and
the
migration.
So
actually
today's
transition
is
a
joint
presentation.
Drones
Dresner
should
be
here
to
present
some
part
of
this
transition,
but
due
to
his
house
a
issue
it
cannot
be
here,
so
I
will
present
that
part
on
behalf
of
him
and
next.
S
C
S
It's
about
the
policy
working
M
yeah,
we
will
discuss
at
the
progress
and
the
third
one
is
from
one
of
my
colleague
as
we
are
doing
some
technical
work
on
how
to
development
and
how
to
implement
it
such
technologies
to
the
real
network.
So
we
have
a
new
use
case
and
the
proposed
that
has
a
draft
in
IETF,
and
this
one
yeah
is
something
we
are
doing
our
optical
network
and
helped
the
optical
network
to
collect
data
and
to
predict
the
healthy
status
of
optical
network.
So
this
will
be
presented
by
my
colleague
online.
S
So
this
is
the
basic
progress
of
our
I
mean
of
the
a
is
G,
so
this
was
established
in
the
February
of
this
year
and
they
are
more
than
15
companies
as
joined
as
members
already,
and
so
the
core
idea
of
this
work
is
I
listed
on
the
top
here.
So
when
we
were
proposing
this
work
to
SC,
we
meet
a
lot
of
challenges,
because
the
network
intelligence
is
a
very
big
idea.
So
it's
hard
to
I
mean
limited
the
scope
and
the
to
explain
was
the
detailed
idea
of
this
concept.
S
S
So
there
are
this.
Is
this
more
words
are
what
we
are
doing.
Actually,
it's
a
detailed
explanation
of
the
what
I
said
just
now,
and
so
in
the
first
phase,
we
will
specify
a
set
of
use
cases
and
the
architecture
in
the
second
phase
and
about
how
to
make
this
I
mean
the
three
key
elements
in
the
future,
and
so
the
the
figure
here
shows
the
progress.
S
So,
basically,
in
this
year
we
have
four
meetings
planned.
We
already
have
three
of
them,
so
the
first
two
are
held
in
the
headquarter
of
se
and
the
third
one
was
held
in
Beijing
I.
Guess
some
of
attendees
gear
have
drawn
that
one
that
was
a
house
I
mean
hosted
by
China
Telecom
and
a
third
and
the
fourth
one
will
be
held
by
son,
some
in
UK
close
to
London
so
next
year.
The
the
the
meetings
for
next
year
are
also
planned.
S
I
will
show
you
in
the
neck
next
page,
and
this
figure
and
the
other
figure
here
shows
they
the
rows
from
different
companies.
So
we
have
chairman
by
vice-chairman
from
far
away
from
China,
Telecom
and
Verizon,
and
we
also
have
some
main
players,
such
as
Samsung.
But
there
are
tech,
comes
SKT,
Intel
and
Chunghwa
Telecom
bla
bla.
So
basically,
because
this
is
G
was
founded
this
year,
so
they
are
also
still
many
operators
and
vendors
are
on
in
their
progress
to
join
us.
So
we
also.
We
also
hope
that
you
will
be
interesting.
S
This
work
and
join
us,
so
this
listed
the
ongoing
work
in
this
is
G.
So
basically
we
started.
We
already
started
for
work.
They
are
our
use,
cases,
requirement
gap,
analysis
and
the
terminology,
and
there
is
a
upcoming
work
about
the
architecture
which
were
proposed
by
Verizon
and
will
be
started
soon.
S
And
this
this
actually,
this
is
the
pager
I,
just
added
it
because
it
joins
not
here.
So
I
want
to
talk
a
little
bit
more
about
the
first
part,
so
the
use
case
is
already
received
more
than
fourteen
use
cases
for
both
the
wireline
network,
as
well
as
the
mobile
I,
mean
the
wireless
network.
So
basically
they
can
I'm
not
going
to
go
deep
into
this,
so
basically
they
can
be
summarized
into
three
categories,
so
one
is
the
resource,
management
and
optimization.
S
The
second
is
the
service
experience,
optimization
and
assurance,
and
the
third
one
is
a
for
the
detection
and
prediction.
So
basically
people
are
we
see
that
the
operators
they
want
this
working
group
to
help
them
to
resort
to
absorb
these
issues
that
it's
not
I
mean
deal
with
very
well
in
the
existing
network,
for
example,
they
still
need
a
many
menu
configuration
and
many
menu
decisions
on
this
work.
So
really
they
really
I
mean
wanted
this.
Such
a
solutions
come
out
from
the
industry.
S
So
this
this
listed,
the
the
you
know,
ecosystem,
because,
as
we
discussed
that
there
are,
many
organizations
are
working
on
these
directions.
Actually
we
are
just
one
of
them
and
in
se,
actually
we
are
we
set
up.
This
is
G
and
we
discussed
with
the
Board
of
SC
we
wanted
to
make.
This
is
G
as
the
core
as
the
core
group
to
make
people
I
mean
aligned
and
make
people
get
the
consensus
on
the.
What
is
the
concept
to
offer
the
networking
hydrants
and
what
we
are
doing
and
what
is
the
scope?
S
So,
basically,
we
you
know,
I
will
generate
the
concept,
the
mainstream
use
cases
and
the
requirement,
as
well
as
the
high
level
framework
and
the
requirement
for
the
interface
and
the
protocol,
and
the
data
models
will
be
filled
with
other
abdullah
by
other
organizations
such
as
ITF
3gpp.
So
we
also
have
some
colleagues
working
there
to
create
a
some
related
work
in
1:1
and
run
for
and
in
the
ITF.
We
have
the
data
models
here
working
and
for
the
itu-t.
S
Actually,
this
is
located
in
in
China,
its
meaning,
the
main
bodies
in
China,
but
it's
also
regarded
as
a
sure
organization
on
the
Sdn
and
NFV
aliens,
so
they
just
founded
a
new
group
called
AI
applied
again
applied
for
network.
Basically,
this
can
be
regarded
as
an
industry
group
for
how
operators
can
better
use
of
these
technologies,
so
they
so.
S
We
wanted
to
cooperate
with
the
mainstream
players
as
well
as
organizations,
and
we
already
send
out
many
lies
and
including
IDF,
MAF
and
many
are
seized
in
SE,
so
that
that's
poorly
the
existent-
and
this
is
what
we
see
for
the
evolution
of
the
near
future
about
these
networking
hydrants.
So
basically,
the
the
content
here
was
a
draw
on.
The
PI
was
drawn
from
the
keynote
speech
from
mr.
won't
how
in
you
PBF
in
this
year,
so
mr.
Montoya.
S
The
first
one
is
Adam
automatic,
meaning
that
you
have
the
automation
or
for
the
service
distribution
and
for
the
with
the
joint
of
the
integration
for
the
control
plane,
and
the
second
step
is
adaptive,
meaning
that
you
can
collect
the
data
and
you
can
meaning
that
you
can
analyze
the
data
and
you
can
improve
the
management
based
on
that
and
analyze
reads
out.
Actually,
this
concept
is
similar
to
what
Thiago
just
presented,
so
they
shared
a
similar
idea
and
for
the
third
steps.
S
Actually,
we
think
it's
more
like
a
future
work,
so
we
make
it
like
a
Chinese
Angie,
so
so
that
we
can
I
mean
well
use
the
the
AI
technology
to
to
largely
reduce
the
menu
and
configuration
and
the
many
decisions
in
a
network,
meaning
as
a
network
can
be
run
by
itself,
just
like
the
self-driving
cars,
meaning
that
you
have
your
intent.
Input
and
in
system
in
network
can
generate
the
policy
and
as
well
as
the
configurations,
its
and
make
batter
dismay,
can
even
better
decision
than
the
human
beings.
S
So
this
is
our
next
steps
and
as
well
as
the
agenda
for
the
meetings
on
upcoming
meetings
so
all
day,
as
I
said,
we
welcome
all
they
are
companies
join
us,
and
so
actually
we
have
online
meetings
almost
every
week.
So
we
already
have
20-plus
meetings
in
this
year
online
and
offline
so
offline.
Actually,
we
have
four
per
year
and
online.
We
have
ones
from
a
week,
so
this
listed
there
is
a
link
here.
S
You
can
click
and
find
all
the
meetings
information,
so
I
just
listed
the
the
the
rest
meetings
I
mean
for
the
for
the
rest
of
these
years.
So
from
this
month
we
have
this
online
meetings
on
each
work
items
and
the
in
December.
We
have
the
fourth
meetings
and
also
we
have
a
workshop
joined
by
other
organizations
and
in
your
next
year
we
already
planned
two
meetings
in
the
headquarter
of
SC.
S
Okay,
so
this
is
the
first
part
if
there
is
no
more
question
I
would
go
to.
The
second
part,
second
part
is
about
the
progress
of
EMF
the,
because
the
joint
is
not
here.
I
will
briefly
present
this
part
on
behalf
of
him.
So
as
you
might
know,
that
amia
started
policy
work
since
last
year,
so
they
have
so.
This
is
a
basically
a
summary
of
what
they
are
doing.
S
Actually
they
are
doing
a
extension
of
I
have
super
framework
and
they
defined
the
declarative
because,
as
supe
was
founded
in
I,
have
the
declarative
or
I
mean
enchant
party
is
not
in
the
scope,
so
actually
they
extended
this
and
they
do
the
declarative
and
intended
policies.
You
know
Asian
to
these
imperative
policies
in
yeah,
and
they
already
have.
The
information
on
the
I
mean
model
used
as
a
grammar
about
how
to
define
these
api's
and
yeah
else
DSL
and
physically.
They
define
that
these
three
DSL
for
and
with
mappings
to
each
other
are.
S
Policy,
the
clarity
policy
as
well
as
intent,
policy,
okay,
okay,
first,
so
I
will
speak
this
once
and
let's
go
to
the
third
part.
So
third
part
will
be
present.
If
you
have
any
questions
on
this
and
the
second
part
please
contact
to
draw
a
stress
on
it
directly.
So
the
third
part
is
about
the
use
case
on
the.
C
L
A
C
L
Dm
is
semester
of
combining
multiple
signals
are
not
the
beams
are
at
variously
Imperator.
Web
Lance
is
for
transmission,
a
lot
of
fiber-optic
media
and
a
WDM
system
use
multiplexer
as
a
transmitter
to
join
the
several
signals
together.
Andrea
did
Tim
multiplexer
address
to
server,
choose
split
them
apart
another
during
the
web
last
division
service
running
the
network.
Data
is
consistently
generated
from
the
webblock
division
device
and
it
can
reflect
the
first
process
of
the
service
learning
and
is
the
motivation
of
this
chapter
has
two
meanings.
L
The
first
one
is
the
inner
case
of
traditional
web
last
division.
Service
custom
is
a
custom
that
you
can
know
the
network
affair
after
the
service
interruption,
such
a
service,
very
as
the
inhibitions
and
easily
DS
to
the
large
service
interruption
Anna.
Secondly,
is
a
the
net
will
be
data
can
help
I'm
ready
to
change
the
tan
point
as
which
service
a
llama
llama.
L
Also,
this
is
risky
or
here
see
under
the
girl,
has
the
distri
point,
but
why
is
the
illustrator
of
Connor's
of
the
little
data
use
that
you
evaluated
the
performance
of
weblog
TV
service
and,
secondly,
is
demonstrated
defined
the
application
scenarios
of
narubu
data
in
web
last
Davinia's
service
and
the
last
is
the
present
the
exists,
existing
problem
of
many
network
data?
Next
nice
place?
Okay,
we
summarized
the
network
data.
This
has
three
attributes.
L
Okay,
we
are
cablecast,
there's
no
be
curious
case
and
the
fact
is
the
Alana
medicate
detection.
An
army
today
is
the
identification
of
items.
Events
all
of
these
observations,
which
do
not
conform
to
a
expected
pattern
or
other
items
in
data.
Typically,
the
learning
must
attend.
We
are
just
translate
to
some
kind
of
problem,
such
as
the
optical,
a
problem.
Okay,.
L
And
for
a
web
last
video
services
scenario,
Network
API
data
include
the
a
VC
B
D
F.
This
means
forward
error,
correction
coding
before
the
election
and
the
input
optical
power.
The
last
step
bias
current
and
the
other
key
factors.
This
test
statistic
data
can
be
further
used
to
do
today.
Last
division
service,
a
lamb
burning-
all
you
know
the
aku-aku
accuracy
rich
of
for
the
web
last
division,
KPI,
Alana,
meaty,
texture
and
the
second
is
the
risk
assessment.
L
So
this
is
a
component
aiming
aiming
at
provide
providing
a
estimation
of
the
overall
Network
investor
condition.
So
this
is
way
similar
to
the
pre
previous
use
case,
but
risk
assessment
modules
go
is
do
and
anticipate
the
network
EBIT
forecast
as
a
shortened
change
and
the
risk
in
the
network.
It
is
a
it
is
based
on
the
trend
of
little
bit.
Data
under
there
were
two
ways
to
access.
The
network
is
risk.
L
The
single
KPI
recording
another
module,
Modi
KPI
scoring
the
single
KPI
is
calling
is
the
usage
score
of
a
single
KPI
to
access
the
network
risk?
Also,
if
the
device
or
the
service
is
the
molecule
by
a
broker?
Several
key
KPI
the
risk
should
be
analysis
the
by
the
integration
of
this
KPI
scores.
Next,
this
okay.
L
On
a
signal,
the
trend,
a
KPI
data,
is
connected
according
to
the
equivalent
time
another
trainer
component
can
be
obtained
by
decomposing
the
stock
data
when
the
state
of
the
network
animal
is
in
the
process
of
the
gate,
violation
as
news
quiz
process
of
a
change
resulting
in
rising
or
falling
trend.
The
stretcho
that,
when
we
know
the
network,
an
amended
attribute
itself
defines
a
capias.
We
showed
that
it
can
maximums
spotted
so
once
the
comparing
value
is
the
smaller
than
the
statute.
The
closer
of
the
this
value,
the
newer,
the
reliability
of
the
clang.
L
So
we
can
see
the
the
the
time
the
the
town
left,
the
town,
bigger.
Okay,
this
is
user,
a
vetting
process
to
to
wet
the
sweetie
machine,
choose
the
single
one.
Then
we
can
see
the
right
right.
The
right
part
is
done,
motor
your
KPI,
we
use,
we
use
the
two
dimensions
of
a
KPI,
our
nanny
system,
so
the
course
is
corresponding.
Let's
go,
Kara
didn't
next
place.
L
So
how
to
make
matches
the
data
from
defender
time
time
period,
we
know
in
the
in
the
process
of
data
connection,
the
connection
period
of
the
same
KPI
may
be
different
from
each
atom,
for
example
from
multi-team
don't
domain
deployment
service.
There
may
be
many
different
connection.
Carry
the
phone
network
that
effective
artists
such
as
set
here,
seeking
all
the
five
per
minute
from
15
minutes
and
to
our
sometimes
they
come.
L
Comparing
is
co-founder
a
modest
among
this
dependent
to
miss
some,
so
we
need
to
modulus
terror
cell
from
the
banner
period
into
creditor-debtor,
said
using
the
metric
in
their
period,
such
as
the
mean
value,
antique
value
or
media
value.
So
we
we
are
very
well
well
welcome
you,
everyone
to
join
this
research
topic.
Thank
you.
H
Shinya
just
for
for
comment
will
you
please
tend
to
pay
the
priest
one
yeah,
maybe
maybe
I,
have
a
have
the
answer
about
your
open
issues
that
that
is
the
question.
I
just
asked
the
Germans:
how
to
align
the
data
from
different
scope.
I
think
that
it
is
depends
on
your
frequency
of
operations.
For
example,
if
you
do
operation
once
per
per
second,
that
the
the
higher
frequency
data
will
be
helpful
will
be
unhelpful,
it
will
be
a
noise
it
useless.
So
is.
H
The
answer
should
be
your
depends
on
your
frequency
of
your
operation
that
one
you
need
a
lower
operation
frequency
you
do
not
need
a
more
higher
frequency
data
to
feed
your
system.
That's
my
my
private
opinions.
So
thank
you
and
another,
and
none
of
comments.
I
stand
for
SC,
n,
GP,
a
walk
item,
six
idea
and
said
at
and
a
little
bit
surprised
that
there's
somebody
talk
about
SC
works
and
we
are.
H
T
Yes,
machine,
Howie
I
would
try
to
be
a
little
bit
short.
We
have
enough
time
for
discussing
you
summary
for
what
we
already
have.
The
efforts
in
idea
and
I
are
here
actually
people
that
we
did
have
the
mark:
M
Arg,
the
machinery,
the
sort
group,
as
purpose
research
group
for
almost
1/2
years,
we
did
have
some
Co
discus
lirikrekt
in
yo
Stata
use
cases,
but
given
the
there
are
so
many
useless
cases
in
various
error
of
network
with,
we
have
real
full
converging
to
certain
use
cases
and
reach
the
equipment.
T
What
maybe
you
know
standardized
so
here
we're
forming
another
a
fault,
as
most
of
you
may
already
join
the
menaced
s'
ID
net
meanest
way.
Actually
hands-on
training
is
to
start
from
this
April
under
IDF
and
up
now
we
already
have
more
than
300
350
and
we
actually
have
more
manliness
that
discussing
there
the
Mao
RG
before
there
are
45
active
participants.
B
T
We
actually
saw
a
lot
of
people
from
universities
so
far.
We
also
have
the
wonders
and
SPS
so
far.
We
have
very
few
participants
from
SPS,
but
actually
we
are
packing
to
post
the
ASP
Network
and
the
ice
P
networks,
and
we
saw
a
lot
of
participant
from
European
and
is
also
most
American
who's
in
dealing
in
AI
error.
T
This
gives
a
little
bit
reason.
Everybody
knows
how
important
to
apply
AI
into
the
network.
It
can
makes
the
network
be
less
human
and
dependent,
but
actually
there's
already
traditional
way
to
make
the
network
autonomic
by
using
the
affairs
way.
But
in
that
way
that
means
actually
the
network
devices
itself
may
become
more
complicated
because
whatever
they
autonomic
function,
you
want
put
in
you
need
to
carry
that
machine
learning
actually
actually
give
all
us
another
opportunity
which
may
able
to
you
know,
have
both
Hottentot
normals
and
to
reduce
the
complicity
of
the
network
devices.
T
This
is
the
adding
an
architecture
we
already
have
abstract.
In
this
we
have
three
layers:
infrastructure,
layer,
control,
layer
and
intelligence
layer.
We
put
all
the
machinery
and
AI
efforts
to
become
a
platform
which
can
trainee
from
the
worst
data
we
got
from
post
user
devices
and
through
the
measurement
function
from
the
network
devices,
they
provides.
T
T
Actually,
from
this
actual
architecture,
we
can
clearly
say
there
are
two
aspects
of
it.
Why
is
the
data
aspect
from
that's
how
the
we
could
get
the
data
from
different
scenarios
according
to
different
targets
and
pre
handling
process
them
before,
as
the
input
for
the
AI
platform
and
at
the
control
part,
also
requests
the
policy
to
be
formalized
and
to
be
able
to
understand
by
the
controlling
function
and
by
the
network
devices.
T
Okay,
I
already
acted.
Yes
is
actually
my
last
slides
in
this
I'm
not
going
to
go
into
the
details,
part
in
this,
and
you
can
see
there
are
a
lot
of
use
cases
and
each
use
cases
have
different
data
requests
and
for
the
control
aspects.
The
output
to
for
the
specific
scenarios
tasks
is
actually
also
different,
so
that
actually.
I
T
To
the
discussion
point
I
would
like
to
you
know:
Co
attention
is,
you
know
we
actually
still
struggling.
You
know
what
could
be
standardized
in
this
areas.
There
are
two
approaches
for
you
know
how
we
do
the
AI
or
machinery
in
the
net
network
errors.
First
of
all,
the
machine
learning
algorithm
itself
is
algorithm,
which
happening
in
whatever
in
one
was
in
one
network
devices.
So
that's
not
be
able
to.
You
know
us
become
standardized.
A
standardized
is,
is
what
happened?
Underwear
for
you
know,
deterrent
devices
of
all
at
least
patrolling
functions.
T
T
The
data
may
not
be
short
before
for
machine
learning
at
all,
particularly
for
those
real-time
machine
learning
tasks.
Then
there's
another
approach,
you
know
we,
maybe
we
examine
the
whole
data
set
from
the
aspect
of
machine
learning,
algorithm
what
the
tasks
we
would
like
to
complete
and
what
the
task
lead
for
data
as
input.
Then
we
can
work
back.
What's
the
what's
the
new
data,
we
did.
T
Yeah
there's
one
last
one
points
I
would
like
to
mention
years.
You
know
we're
always
thinking
you
know.
Where
is
the
possibility
possible
violence
between
the
very
specific
use
case?
And
you
know
some
something
could
be
abstracted
into
calm
along
multiple
use
cases,
because
a
standardization
we
would
like
to
get.
You
know
as
much
as
possible
a
value
from
the
standard
format
to
be
able
to
serve
multiple
tasks
rather
than
you
know,
go
too
deep
for
the
very
specific,
very
narrow
use
cases,
but,
as
you
can
see
from
this
figure
is
different
scenarios.
T
Different
tasks,
a
curry,
requests
very
different
data,
so
we're
in
the
middle
to
found
the
the
best
point
for
standardization.
That's
that's
also
another
point
where
we
need
to
discuss
and
the
result
of
discussing.
We
have
become
very
variable
input
for
ITF
standardization
and
we
we
have
to
be
ready
with
some
level
without
to
be
able
to
start
another
efforts
for
ITF
working
group.
U
U
So
so,
in
addition
to
the
natural
network
management,
there
are
also
studies
on
the
TCP
and
multimedia
and
the
even
the
the
new
English
placement,
some
and
some
other
areas.
So
we
needed
the
data
right
for
the
machine
learning
and
we
also
needed
some
kind
of
or
control
message
to
communicate,
that
between
each
other
to
sighted
the
parameters
and
also
the
result
to
the
network-
and
it
is
so
I
think
at
least
how
it
is
quite
important
de
thank.
A
So
these
were
the
presentations
that
we
have
today.
The
idea
of
this
session
is
to
bring
together
people
that
were
working
with
AI
for
network
management,
as
I
mentioned
in
the
beginning.
We
wanted
to
revisit
it
because
the
use
of
artificial
intelligence
for
network
management
is
not
new
Percy,
probably
more
than
10
years.
People
have
been
working
on
that,
but
the
AI
re
has
matured
along
and
then
we
as
her
research
group,
we
are
looking
for
directions
for
future
work
to
be
done
in
the
context
of
the
of
the
research
group
itself.
A
K
Anyone
willing
to
share
these
are
her
thoughts
about
what
we
have
run
today.
I
mean
general
comments
about
the
use
cases.
What
could
be
the
requirement?
We
need
to
tackle
what
will
be
research
items
who
would
like
to
investigate
in
the
research
group?
Just
share
your
fault,
it's
no!
It's
a
general
discussion.
We
want
to
try
to
build
a
kind
of
roadmap
for
the
research
group
or
maybe
beyond
the
research
group
of
what
we
can
achieve.
What
we
need
to
work
on.
Q
So
dependent
on
on
what
is
the
data
you
fit
to
them
and
I
think
that
having
having
a
set
of
open
data
sets
that
are
well-known
that
are
properly
I
mean
I'm
proper
metadata?
So
so,
whenever
you
report
a
result
on
a
particular
algorithm
or
a
particular
technique,
you
can
refer
to
the
edge
of
the
data
set.
You
have
been
used
and
these
results
can
be
reproduced
and
analyzed
it's
essential
if
what
we
want
is
something
apart
from
a
I.
Have
this
magic
here
that
has
these
nice
results
and
then
try
to
repeat
it.
Q
K
K
Can
we
imagine
a
similar
approach
of
similar
databases
for
network
of
a
specific
function
or
problems
in
networks?
This
is.
Is
it
the
right
way
to
think
or
is
it
completely
different
and
we
should
not
seek
to
have
reference
databases
but
to
have
maybe
focus
on
on
use
cases
and
what
are
the
properties
of
the
data
we
expect
to
solve
specific
programs
of
networks
I.
Q
Think
I
think
that
we
have
to
I
mean
the
goal
will
should
be
similar.
Maybe
you
similar
to
what
you
have
right
now
for
Biosciences,
for
example,
G
normal
things
like
that
probably
different
because
doesn't
make
any
sense.
The
data
sets
I'm
aware
of
have
more
than
20
years,
the
publicly
available
and
the
traffic,
while
the
traffic
that
is
reflected
there
is
I
mean
IP
traffic.
On
the
other
hand,
they
are
not
following
the
current
patterns.
They
don't
have,
for
example,
video
flows,
just
an
aside
in
our
example.
Q
So
probably
they'd
be
able
to
be
that
we
should
have
to
keep
those
data
data
banks
or
whatever
we
call
them,
because
it
should
be
a
set
of
data
sets
and
keep
them
updated
according
to
to
the
evolution
of
the
of
the
natural
search
buttons.
I
know,
I,
know
that
challenging
I
mean
it's
a
and
again.
Data
is
an
asset
and
is
complicated.
V
T
T
I
think
the
group
should
go
ahead
for
to
do
the
analysis.
Research
for
those
use
cases
try
to
found
out.
You
know
how
the
ce
o--'s
cases
could
be
come
together
and
just
to
do
some
kind
of
neck
gap
analysis.
You
know
what
the
use
cases
lead
it
and
the
current
network
cannot
provide
and
what
is
missing
to
be
better
AI
ready
network
or
network
management
saying
based
on
without
we
can.
You
know
somehow
fake,
where
maybe
the
direction
for
future
potential
standardization
work.
G
G
Different
vendors
have
different
implementation
and
use
a
different
classification,
and
that
lead
to
a
different
insight.
But
very
often
we
don't
have.
The
standards
came
to
a
classified
traffic
like
a
type
of
traffic
and
also
a
protocol
and
sub
protocol.
What
what
kind
of
level
we
need
to
obtain
the
insight?
I,
don't
need
for
the
London
mint,
which
is
very
important
basis,
which
I
say
is
kind
of
missing.
I
saw
some
proposal
to
have
a
standard
scheme,
but
when,
if
I,
do
it
be
a
would
be
a
very
good
thing?
A
Given
a
set
of
data
sets
that
were
shared
and
collected
from
important
backbones
around
the
world
that
same
data
set
shown
that
SNP
v3
was
not
used
that
much,
although
everybody
was
expecting
that
so
we
have
on
the
working
group
itself,
some
experience
on
that,
but
we
never
use
it.
Data
sets
for
these
artificial
intelligence
supports,
so
maybe
we
could
try
to
do
that
again
and
and
the
problem
with
data
sets
is
actually
having
people
willing
to
provide
the
data
so
that
we
can
collect
them
and
share
them
somewhere.
A
So
the
first
is
infrastructure
for
sharing.
Second,
is
having
the
willingness
to
share
data
set.
Another
aspect
that
Jefferson
was
that
we
have
used
study
areas
in
the
past
so
that
we
could
evolve
in
the
group
and
then
the
fact
that
we
need
not
only
to
check
the
case.
Studies,
but
also
we
need
to
analyze
them,
so
we
should
go
one
step
further
and
analyze
them
and
then
all
of
it
we
should
consider
assuming
more
specific
methodologies
instead
of
having
everybody
doing
the
wrong
way.
Maybe
come
up
with
some
methodology
that
could
be
reproducible.
C
I
think
we're
all
focusing
on
the
right
point
on
the
data
but
I
I
don't
see.
There
is
particular
AI
data,
so
we
got
out
the
data
you
mentioned
SNMP
and
today
s
episode.
We
still
have
to
use
it
and
you
knew
is
all
implemented.
There's
a
young
model
and
there's
open
config.
We
actually
prototype
early
model,
it
demo
late.
It
can
get
our
real-time
streaming.
C
That's
what
you
need,
if
you
don't
have
real
time
data
forget
about
it
right
whatever
when
you
use
is
15
minutes
ago
some
time
ago,
so
I
believe
how
these
are
foundation
work.
It
doesn't
directly
to
do
AI,
but
it's
tightly
coupled
without
them.
You
cannot
do
it.
So
on
top
of
that,
you
can
do
your
AI
in
centralized
approach
in
distributed
approach.
C
C
There's
a
'memory
processing
thing
and
all
things
you
need
to
skill
it
and
to
be
able
to
process
in
time
for
some,
maybe
for
long
term
study
training,
some,
maybe
just
for
immediate
troubleshooting,
so
I
think
we
made
my
mind
I,
don't
think,
there's
a
particular
AI
data,
but
a
I
depend
on
all
these
data.
If
we
have
enough
power
like
a
machine,
we
can
do
that
ourselves.
We
don't
so
we
need
the
AI.
C
We
need
all
the
algorithms
and
things
and
each
the
complexity
in
networking
or
say
the
full
stack,
all
the
applications,
e-commerce
and
so
on.
It's
really
different
than
like
natural
language,
like
image,
processing,
speech
recognition.
All
these
are
fixed
set.
These
are
distributed
all
over
the
place,
so
it
under
it's
unsupervised,
learning
a
lot
of
time
because
we
don't
have
label
the
data
Michael.
Thank
you.
Thank.
I
V
This
is
Jefferson
Aubrey.
Just
to
add
it
to
my
suggestion,
suggestion
before
I
think
it's
something
that
we
should
agree
before
is
to
have
some
kind
of
a
minimum
set
of
agreement
on
the
use
cases
or
the
data
sets
in
order
to
have
some
minimum
requirements
for
the
for
the
drafts
and
for
the
public
data
sets
and
I
think
this
we
could
do
in
the
mailing
list,
no
just
changing
an
opinion
using,
for
example,
the
use
cases
that
change
mentioned
before
that
are
sent
to
the
intelligent,
define
a
network
in
Middle
East.
B
So
this
is
Albert
I
I
would
like
to
share
my
opinion
on
the
data
sets
I
agree
that
the
desert
important
thing
when
were
training,
machine
learning
algorithm
but
I
also
agree
with
Diego.
They
are
an
asset.
So,
although
that
in
any
idea,
world
people
will
share
them,
maybe
this
is
not
going
to
happen
because
I
will
be
my
algorithms
will
be
as
good
as
my
data.
B
So
why
share
it
and
have
my
competitors
take
advantage
of
that
and
I'm
from
the
Academy,
so
I
don't
know,
but
I'm
I
don't
have
too
much
hopes
on
that.
But
in
any
case,
if
you
take
a
look
to
other
areas
like
computer
vision,
public
datasets
typically
are
not
used
for
training.
That's
not
true.
They
are
used
for
benchmark
sorry
for
testing
for
benchmark,
so
I
train
my
computer
vision,
algorithm
with
my
own
private
data,
and
then
there
are
some
public
datasets
where
everybody
goes
and
benchmarks
they
are
going.
So
it's
like
a
public
benchmark.
B
I
am
as
good
as
I.
Don't
know
I
have
a
92%
accuracy
with
that
public
benchmark,
but
this
is
just
to
for
comparison
from
competition
which
isn't
a
bad
thing.
Maybe
we
can
do
that
and
it's
a
way
for
people
to
understand
how
good
is
algorithm
that
by
vendor
is
selling
me,
but
public
datasets
for
training
I,
don't
see
it
happening.
I.
Q
That
does,
for
sure,
I
mean
that's
something
that
sharing
sharing
sharing
day
timing
data
that
has
a
real
commercial
values
and
value
is
something
that
we
won't
see
happening,
but
I
was
claiming
is
precisely
for
the
way
of
validating
the
results
and
reproducing
them,
which
is
benchmarking
if
you,
if
you
like,
and
we
one
might
make
a
reflection
about
on
separate
base
unsupervised
methods,
I'm
a
little
bit
concerned
that
again
deploying
unsupervised
methods
in
a
running
Network
is
something
that
I
I
don't
see.
I
mean
frankly,
I
cannot
imagine
telling
my
operations
guys.
Q
O
C
I
think
when
I
talk
about
and
supervise
the
other
thing,
it
just
small
for
a
particular
problem
in
our
domain.
That
a
is
very
you
know
this
distributed
right.
So
you
don't
have
one
methodology
solving
our
problem.
You
take
one
problem
that
may
be
fraud
detection.
You
develop
certain
methodology,
it
works
well,
it
goes
into
production.
We
do
have
them
in
production.
C
C
D
Jabbar
Stan
you're
asking
Santa
Fernandez
its
beauty,
its
value
of
your
data
stats
targeting
to
machine
learning
techniques.
It's
the
most
viable
thing
to
the
community
he
said
is
impossible
to
train
models
without
good
data
and
another
suggest
will
be
organized
competition
similar
to
cattle
like
the
schedule,
competition
online
yeah,
another
one
on
a
research
topic
Eric
from
moly.
D
A
Ok,
we
need
to
close
the
session
because
we
have
some
already
use
additional
minutes,
but
I
want
to
emphasize
one
thing.
We
have
nice
discussions
here.
We
would
like
to
have
these
discussions
in
the
mailing
list
as
well,
because
the
mailing
list
is
quite
quiet.
Of
course
we
try
to
provoke
these
discussions
on
the
mailing
list,
but
your
opinions
are
quite
important
over
there,
not
only
because
the
discussion
itself,
but
it
help
us
to
define
the
the
roadmaps.