►
From YouTube: IETF100-NETMOD-20171115-1520
Description
NETMOD meeting session at IETF100
2017/11/15 1520
https://datatracker.ietf.org/meeting/100/proceedings/
A
B
C
D
B
B
D
C
E
Back
right,
okay,
so
I'm
going
to
give
an
update
on
the
nmda
datastore
architecture.
Architecture
draft
that's
been
through
last
call.
We
fed
to
resolve
most
of
the
comments.
There's
a
couple
of
outstanding
issues:
I
am
going
to
go
over
the
the
major
changes
we've
made
and
just
people
know
what
they
are.
Hopefully
these
all
been
discussed
on
the
list
and
tracked
anyway.
E
So
yes,
working
working,
call
working
with
law,
school
summary
summary
of
the
changes
and
then
I
would
spend
most
the
time
these
things
at
the
end,
if
possible
and
get
some
time
back
if
necessary.
So
we
had
18
issues
raised,
they
will
been
tracked
on
github
and
that's
the
URL
to
where
they
are
16
of
those
issues
that
effectively
regarded
has
been
closed.
So
we've
sent
the
final
text
or
a
post
text
back
to
the
ælis
and
in
some
cases
people
have
agreed
to
it.
E
In
other
cases,
just
silence
I
think
that's
fairly
normal,
but
we'll
ask
people
to
check
the
latest
version.
The
draft
the
sort
of
two
issues
still
being
tracked
as
I
open
one
under
them,
is
moving
TRC
to
one
one:
nine
language
and
that's
open
just
so
the
people
who
are
requesting
that
once
they've
read
the
latest
of
the
draft
and
check
that
they're
happy
with
that
and
then
the
other
issue
is
is
regarding
actions
and
our
pcs.
E
Again,
that's
been
discussed
on
the
alias
there's
a
proposed
solution
here,
which
is
the
same
one
that's
been
around,
but
I
will
cover
that
as
well.
So,
in
terms
of
the
summary
of
the
changes
looking
back
and
the
differences,
the
six
major
changes
that
I
can
track.
A
new
objective
section
has
been
added.
This
is
really
like
an
introduction
text,
so
feel
free
to
read
that
and
have
a
look
I'm,
not
gonna
cover
anymore.
We
updated
the
document
to
use
our
c2
on
1/9
language
to
our
best
efforts.
E
E
Now
it
only
applies
to
the
config,
true
subset
of
operational.
The
reason
we
did.
That
was
three
reasons.
One
is
it's
slightly
hard
to
define
where
the
source
of
the
origin
comes
from
for
the
config
force
data.
Often
this
is
system
or
looks
like
systems.
I
didn't
make
much
sense.
We
thought
it'd
be
quite
hard
to
implement
or
difficult
for
for
implementations
to
actually
track
this
and
provide
this.
E
They
wouldn't
want
it,
and
the
last
one
that
probably
was
the
winner
for
us
was
that
we
have
quite
a
simple
encoding
that
we
want
to
use
for
the
origin
metadata,
which
is
sort
of
hierarchical,
that,
if
you
don't
specify
the
origin
for
a
given
node,
it
inherits
from
its
parent.
So
it
picks
up
the
same
value.
So
in
the
mainline
case
that
if
your
or
your
configuration
has
come
from
your
intended
config,
you
could
mark
the
top
node
in
the
tree
is
intended
and
that
recurse
down
and
hits.
E
Similarly,
if
you
have,
if
you
can't
support
origin
metadata
again,
you
can
mark
the
top-level
node
as
being
origin
and
it's
unknown
or
not
so
I
common.
What
it
is,
it
might
be
unknown
and
affected
that
recur,
Sall
the
way
down
the
tree.
So
again,
that's
quite
simple
to
do
configuration
transformations.
So
this
is
the
new
text.
That's
wrapped!
On
this
slide,
some
reason
and
effectively
is
defined
as
the
addition
modification
or
removal
of
configuration
between
the
running
and
intended
data
stores.
E
Examples
of
this
are
in
active
configuration
and
templates
expansion,
so
the
aim
here
was
to
twofold:
one
is
to
take
out
things
like
templating
and
inactive
from
the
nominative
normative
text
from
the
document
we
didn't
want
to
actually
be
defining
either
of
those
we
just
wanted
to
use
them,
as
example.
So,
by
making
this
change,
they
now
effectively
just
become
examples
of
what
config
transformations
might
be
intended
is
now
defined.
E
We've
tweaked
that
to
be
defined
as
being
asked
these
conflict
transformations,
it
always
was
before
that's
now
become
more
explicit
and
we've
said
also
that
running
allows
you
to
have
configuration
there.
That
has
doesn't
yet
have
these
transformations
lie
to
it,
so
you
might
still
have
to
process
those.
E
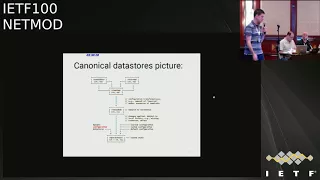
Right,
I'm
just
going
to
pull
out
the
data
source
picture
to
remind
people
of
what
it
looks
like
as
I
talk
about
what
the
meaning
these
data
stores
are
she
about
running
intended
and
operational?
There's
one
change
to
this
diagram.
Is
that
know
when
we
discussed
this
with
the
ITRs
folks,
the
last
ITF
he
turned
out
the
dynamic
data
stores
only
needed
to
be
configuration.
So
again,
those
are
now
classified
as
dynamic
configuration
data
stores
at
the
moment.
I,
don't
think
this
architecture
necessarily
constrains
that,
but
that's
the
use
case
that
we
have
today.
E
So
datastore,
schemas
and
performance,
some
of
the
discussion
points
that
came
up
was
to
get
more
clarity
on
the
exact
definitions
of
these
data
stores.
We
try
to
do
that,
and
so
we've
pulled
in
a
definition
of
what
a
datastore
schema
is
so
this
this
has
come
about
that
we're
using
the
term
schema,
it's
not
actually
defined
in
RFC
791
schema
is
so
our
way
around
in
this
document
was
to
define
datastore
schema
as
the
combined
set
of
schema
nodes
for
all
the
modules
supported
by
a
particular
datastore.
E
E
Think
on
schema
mount
is
that
some
of
these
terms
aren't
really
defined
in
a
brilliant
way,
and
it
would
be
quite
nice
potentially
to
define
these
terms
like
schema
by
datastore
schemes
defined
here,
and
this
document
might
be
a
possible
place
to
put
that
in
for
those
definitions
in
as
long
as
we
could
actually
achieve
that
quite
quickly
and
not
delay
this
document.
So
that's
a
question
I
think
to
the
working
group
is
whether
we
should
try
and
try
and
resolve
that.
E
Should
we
try
and
add
those
and
those
definitions
in
define
what
a
schema
is
define.
What
data
source
schema
is
a
continent.
What
are
the
ones
who
are
data
tree
might
have
been
another
one
there's
a
few
of
these
terms
that
we
also
to
understand
I
think
what
they
are,
but
we
don't
actually
define
them
anywhere.
Anyone
has
any
opinions
on
this
Oh
baby.
B
F
F
E
So
the
there's
no
ambiguity
in
this
document.
At
the
moment,
it's
more
actually
the
schema
mount
one.
That
has
the
ambiguity.
So
the
idea
is
we
put
those
references
in
here
because
we
can't
put
them
into
7950,
as
this
has
been
the
next
best
place
rather
than
defining
and
the
schema
map
document
I
would.
E
So,
in
terms
of
this
conformance,
it's
worth
pointing
out
that
we
there's
two
rules
to
the
NMD
nmda
conformance
again.
This
came
out
from
discussions.
One
is
that
all
conventional
data'
stores
must
have
the
same
data
store
schema.
So
that
says
that
start
up
running
candida
intended
all
have
the
same
schema.
You
can't
change
them.
You
can't
have
different
features
in
them.
You
can't
have
different
deviations
in
them
and
that
allows
configuration
to
move
between
those
data
sorted
in
an
easy
way.
E
It
does
also
limit
the
scope
of
what
those
configuration
transformations
can
do
and
what
they
may
be,
because
you
know
that,
whatever
their
whatever
modifications,
they
are
making,
it's
still
retained
within
the
same
schema
when
it
gets
to
intended,
and
then
we
allow
operational
to
be
the
superset
of
all
the
sort
of
configuration
data
stores.
So
all
the
schema
other
configuration
data
stores,
but
we
allowed
node
to
be
removed
by
deviation
so
and
modules
to
be
removed
from
that
list.
E
So
the
aim
here
is
to
effectively
try
and
try
to
be
realistic
as
to
what
what
informations,
what
implementations
might
be
able
to
do
and
be
realistic.
That
there's
going
to
be
some
time
in
terms
of
migration
that
there
be
times
that
you
can't
the
not
all
implementations
will
be
able
to
implement
all
this
operation
of
State
statement
straight
away.
So
we're
expecting
deviations
to
for
an
interim
period
on
this
operational
state,
datastore.
E
Updated
datastore
definitions
are
running,
so
we
said
that
that
may
include
configuration
that
requires
further
transformations
before
it
can
be
applied,
but
it's
always
defined
as
being
valid,
so
we're
not
changing
our
c7
950.
We're
saying
that
running
is
always
valid,
but
if
you
consider
that
in
the
case
of
these
configuration
transformations,
you'd
probably
effectively
say
that
you
had
to
take,
you
had
to
expand
them
as
part
of
that
validation.
So
there's
a
slight
sort
of
cheat
here
and
we're
saying
that
whenever
running
is
updated,
you
automatically
updates
intended
at
the
same
time.
E
A
E
But
it
may
change
independently
of
running,
so
we,
you
had
a
configuration
transformation
that
was
part
of
the
system,
for
example,
and
you
upgraded
the
software.
You
could
find
that
running
stayed
the
same,
but
intended
changes
because
one
of
those
configuration
transformations
change.
So
we
don't
have
many
cases
for
this.
We
wanted
to
keep
that
as
open
and
possibility,
and
then
the
final
one
that
we
did
in
terms
of
these
of
the
sort
of
review
comments
was
to
try
and
more
closely
relate
or
tie.
E
Finally,
the
definition
of
operational,
so
we
now
set,
as
I
said
before
the
schema
is
a
superset.
All
the
configuration
data
store
schemas
except
the
deviations,
allow
you
to
delete
nodes
and
you
may
choose
not
to
implement
modules
in
operational
we've
defined
the
term
in
use
and
in
particular
this
is
to
try
and
say
that
you
don't
have
to
return
data,
that's
not
in
use
and-
and
hence
this
is
to
avoid
the
case
that
you
have
to
return
lots
of
states
not
relevant.
E
E
We
say
that
semantic
constraints
may
be
violated
and
that's
the
same
as
what
it
was
before,
except
that
we've
now
included
lists
keys.
We
came
up
with
an
example
of
where
lists
keys
may
become
violated
and
hence
we
say
that's
required
and
but
we're
still
keeping
that
they're
constrained.
This
is
that
syntactic
constraints
must
not
be
violated.
You
have
to
be
able
to
encode
the
data
you're
returning
so
on
to
the
issue.
E
There's
outstanding
is
on
actions
and
our
pcs
there's
been
quite
a
lot
of
discussion
on
this
between
the
author's
and
on
the
alias,
and
so
this
is
coming
up
from
Martin's
email
that
summarized
this
issue.
The
problem
is,
is
which
data
store
is
used
to
evaluate
three
choices?
One
one
is
action,
ancestor
nodes,
the
second
one
is
action,
input
output
parameter
leaf,
ref
instance,
ref
must
and
win
statements,
and
the
third
one
is
assembly
for
our
pcs.
The
question
is
effectively
when
you
get
these
actions
or
our
PCs.
E
Where
do
you
evaluate
the
parameters
to
those
operations?
And
this
is
not
related
to
what
effect
those
actions
are?
Our
pcs
are
doing.
They
can
have
whatever
effect
they
like.
So
even
if
you
say
that
these
actions
and
our
PCs
are
limited
to
operational,
you
could
still
have
an
action.
Our
piece,
our
PC
that
says
I
want
to
reboot
the
server
or
I
want
to
modify
different
data
store.
So
this
isn't
about
what
effects
they
have.
It's
only
about
where
you
evaluate
the
parameters
for
them.
E
So
on
the
email
that
were
for
solutions
that
were
proposed,
I,
think
in
terms
of
the
discussion
that
has
happened
on
that,
the
the
preferred
solution
was
number
one
on
that
email
thread
which
is
effectively
for
the
moment,
always
used
this
draft
and
MDA
to
define
that
you
always
use
operational
for
this
is
one
and
two
should
be
one
two
and
three.
So
all
three
of
these
are
always
evaluated
in
the
context
of
operational.
E
So
that's
what
we
wanted
to
find
now,
but
in
future
we
could
extend
the
protocols
and
possibly
the
angle,
anguish
as
well
to
allow
these
to
be
evaluated.
Another
target
data
source
if
that
was
required.
So
in
the
case
of
actions
and
RPC,
it
might
be
the
case
that
you
would
add
a
datastore
parameter
to
those
RPC
operations
to
like
to
specify
different
datastore.
D
Isn't
that
it
sorry,
isn't
there
also
an
option
just
to
make
that
part
of
the
RPC
definition
the
rich
bit
which
datastore
it
operates
on?
So
if
you,
but
if
the
current
definition
is
always
operational,
perhaps
you
let's
say
want
to
operate
on
a
different
datastore
you
can
have.
You
could
end
up
having
one
that
says,
fig
Seaways
operate
on
config
and
and
so.
E
You
can
still
do
that
now,
that's
allowed
because
it's
that's
not
so
she
allowed
to
do
that
now,
because
this
isn't
about
where
that
C
operates
is
only
about
where
you
evaluate
the
arguments
and
so
the
new
edit
data
RPC
acts
on
whichever
datastore
you
specify
acts
on,
but
it
has
no
parameters
that
you
actually
have
to
evaluate.
So
it
doesn't
matter
where
you
value
8
it,
and
it's
saying
you
evaluate
against
operational.
That's
fine
and.
E
The
moment
yes
cuz
I,
don't
think
there's
as
many
examples
of
our
pcs
or
action
statements
that
this
actually
matters
for.
Okay,
there's
one
case
that
we
thought
that
might
might
be
useful,
but
I
don't
think
it
was
worth
delaying
this
document
now
to
do
that.
I
think
that
work
is
not
important
enough
to
delay
this
I
think
you
can
do
that
as
a
subset
update.
E
D
E
H
E
So
the
issue
is
not
about
where
the
RPC
is
acting
the
issues
about
any
parameters,
that's
right.
So
if
you've
got
parameters
that
have
to
be
evaluated
against
a
different
datastore,
then
that
would
require
future
work
that
require
new
work.
But
if
the
parameter
was-
and
so
an
example
be,
if
you
had
a
leaf
ref
to
a
given
node,
if
you
had
an
action
RPC
that
says
I
want
to
check
the
existence
of
this
node
in
the
dynamic
data
store,
then
you
can't
do
that.
H
E
You
can
add,
you
can
add
the
data
where,
if
you
like,
that's
not
a
problem,
that's
its
side
effects.
The
side
effects
could
be
anywhere.
It's
only
the
input
parameters-
okay,
just
looking
at
those
if
they
had
a
leaf
ref.
So
if
you
had
an
action
statement
that
said
I
operate
on
this
node,
then
that
node
would
had
to
exist
in
the
operational
state
datastore.
So.
I
E
E
E
D
E
E
E
J
So
if
you,
if
you
have
an
action
or
an
RPC
right,
that
has
an
an
argument
that
you
would
want
to
target
a
a
module,
a
plug-in
that
doesn't
exist.
It's
not
going
to
be
in
the
operational
piece,
but
you
expected
it
to
be
in
in
the
intended
or
take
advantage
of
the
intended
or
one
of
the
config
data
stores.
Are
you
saying
that
that's
not
possible
it
if.
J
L
E
E
M
Hello,
close
Christian
ops
et
earlier,
there
was
a
little
confusion,
I
think
when
Lou
said
something
about
the
RPC
on
acting
on
something
so
I
went
back
and
checked
my
math
and
everything
I'm,
not
sure.
If
we're
really
precise
and
it's
in
the
draft
right
now,
but
we
could
use
function,
terminology
right,
in
which
case
an
RPC
on,
would
be
the
input
right.
Okay,.
M
So
so
I
mean
it,
but
it
is
confusing
because
when
you
hear
the
RPC
on
acting
on
yes,
you
know,
then
you
were
thinking
he
meant
yeah,
you
know
was
it
acting
on
configure
this
or
that
and
they
could
be
acting
on
anything.
But
no,
in
fact,
it's
acting
on
the
operational
yeah
right,
because
that's
the
input
to
the
RPC
yeah
I,
don't
know
all.
D
H
So
I
just
checked
the
draft,
we're
actually
not
looking
at
the
interface
we've
done,
something
intelligent,
maybe
for
once
and
it's
just
an
ID,
so
I
think
we're
all
we
we
took
away
the
interface
reference,
so
I
think
we're
just
in
the
datastore
that
we're
a
part
of
so
that'll
be
good,
so
tell
Martin
to
look
in
the
RPC
section.
There's
the
next
top
ID!
That's
what
he
wants
to
look
at.
D
D
I'd
like
to
I'll,
do
a
read
through
a
shepherd,
but
expecting
I,
don't
think
I'll
find
anything.
Would
then
do
another
last
call
okay,
because
we've
had
a
bunch
of
changes
that
were
result
of
the
last
call
I
think
this
week
we've
hit
the
the
threshold
for
doing
another
one
and
then
we'll
publish
it
or
submit.
Excuse
me
we'll
submit
to
the
is
she
they.
D
Hi
I'm,
presenting
a
draft
that
Martin
and
I
have
been
working
on.
Martin
is
remote,
so
I'm
sure
he'll
chime
in
if
I
say
anything
he
doesn't
quite
agree
with
which
hopefully
won't
occur.
So
we're
talking
about
the
tree
diagrams
document
and
as
we've
talked
about
in
the
last
couple
of
meetings
we
have
tree.
D
D
What
we've
done
since
the
last
meeting
is
we've
tried
very
hard
to
close
off
all
the
issues,
so
that
we
might
reach
last
call
be
ready
for
last
call,
and
we
thought
we
had
done
so
until
we
had
a
little
discussion
on
the
list.
We'll
talk
about
that
in
a
moment.
The
other
things
that
we've
done
is
is
we've
completed
all
the
open
sections.
D
Most
of
the
changes
that
were
potentially
controversial
have
been
discussed
on
the
list,
so
the
current
representation
is
what
you
see
on
the
right
hand,
side
and,
if
you're
tracking
it
carefully
you
lis
with
the
discussion.
If
you're,
not
the
the
representation
should
look
pretty
familiar,
the
biggest
change
is
related
to
how
we're
dealing
with
mounted
modules
and
parent
reference
modules.
D
D
We
have
a
document
that
is
describing
a
format
that
was
this
primary
purpose,
but
then
we
ended
up
going
on
to
giving
guidelines
but
keep
in
mind
we're
talking
about
guidelines
to
authors
for
documents
not
for
modules.
It's
very
important
to
remember
that
we're
talking
about
this
is
a
purely
a
documentation,
focused
effort,
not
anything
that
ends
up
in
code
or
around
the
wire.
So
so
we
now
have
some
guidelines
in
this
draft.
D
We
also
have
60
87
bits,
which
is
guidelines
to
authors,
and
it
does
a
couple
of
things
which
sort
of
interesting
one
of
them
is:
has
a
section
251
that
points
to
this
document.
Then
it
has
another
section,
3
4,
with
very
minimal
guidelines
on
what
to
do
about
trees,
and
so
we
have
our
document
that
I'm
discussing
that
has
a
format,
definition
and
some
guidelines.
Then
we
have
60
87
bits
that
has
a
whole
bunch
of
guidelines.
D
The
authors
plus
a
little
bit
on
trees,
but
still
depends
on
this
one,
and
it
seems
like
this
isn't
the
optimal
arrangement
and
that's
really,
but
in
the
discussion
on
the
list,
so
one
option
that
we
have
is
we
remove
any
guidelines
from
this
document?
Put
it
into
60
87
bits.
Well,
that
may
be
nice.
It
means
that
we
have
to
reopen
60,
87
bits,
which
we
really
would
like
to
close
and
and
push
out.
D
It
also
goes
through
the
approach
of
whether
or
not
we
want
to
bundle
everything
into
big
documents
or
distribute
them
into
focus
documents
that
are
that
cover
a
topic
completely.
So
one
option
strip
out
guidelines,
move
it
into
60
87
bits.
Another
guideline,
I
think
this
has
been
another
proposal
that
I
think
was
circulated
on
list,
or
maybe
it
was
just
privately
is:
let's
just
get
rid
of
this
old
guidelines
thing.
D
It's
an
interesting
idea,
but
one
of
the
issues
with
that
is
other
people
who
don't
aren't
here
or
aren't
sort
of
in
the
know,
the
way
they
know
about
our.
What
we
do
here
is
rfcs
we
publish.
So
how
will
someone
who's
not
in
the
middle
of
the
IETF,
use
our
work
and
know
that
they're
supposed
to
follow
a
guideline?
They
won't.
D
So
the
last
option
is:
let's
put
all
the
guidelines
into
the
into
one
document
in
the
same
document
that
we
are
defining
the
trees
change.
Do
you
make
a
change?
Eighty-Seven
bits,
but
one
that's
very
minor
that
says
just
four
trees
go
read
our
draft,
so
those
are
sort
of
the
three
options:
I'll
state,
a
personal
preference
I'm
not
going
to
speak
for
Martin.
My
personal
preference
is
I
think
we
should
be
doing
three.
E
E
Hear
you
I'm
sorry
if
this
okay
is
that
better?
Just
if
there's
any
guidelines
that
need
to
go
in
a
document,
I
put
them
in
sixty
eighty
seven
bits,
but
actually
personally,
I
think
a
wiki
is
a
better
place
for
this
sort
of
stuff,
because
it's
constantly
churning
it's
constantly
changing
and
I
think
the
guidelines
will
continue
to
be
revised
and
then,
in
terms
of
your
question
as
to
how
tight
how
did
nan
ITF
has
learned
about
it,
you
have
an
informational
RFC
that
points
you
to
the
current
guidelines
on
a
wiki.
E
Six
to
eighty
seven
base
microphone:
oh
I'll
put
the
sixty
eight
seven
bits
draft
into
github
and
point
to
that
or
something
and
then
that
can
just
be
updated.
It
wouldn't
be
an
RFC
and
then
every
now
and
again
you
you,
you
stamp
it
Robert
Stein
through
the
process
and
say:
okay.
Now
it's
for
current
RFC.
J
Jim
Carey
Nokia,
so
you
know
in
other
places
we're
doing
the
same
thing
right.
You
know,
and
so
we
use
the
wiki's,
for
you
know,
guidelines
type
of
things,
because
you
can.
You
can
rub
the
stuff
a
little
bit
faster,
and
so
you
know,
I
would
recommend
with
same
thing
that
what
Rob
is
saying
you
know,
move
all
your
guidelines
over
into
a
better
place
that
you
can
more
quickly
maintain
and
be
more
responsive
to
to
to
the
work
right.
J
I
Maha
Shaitan
and
Danny,
my
buzzing
preference
actually
I,
would
agree
with
him
blow
and
I'll
personally
think
that
we
should
go
with
number
three,
but
what
only
we
choose
I
think
we
need
to
decide
soon,
because
we
have
authors
that
we
have
told
that
need
to
reference
this
document,
whatever
form
it
takes
as
a
reference,
rather
than
trying
to
cut
and
paste,
which
is
the
original
problem
we
began
with.
So
whatever
we
decide,
we
better
have
a
clear
guideline
because
we
have
people
waiting
on
their
documents
wanting
to
publish.
I
D
I'm
gonna
state,
my
personal
opinion,
I
think
this
is
an
informative.
Why?
Because
it
doesn't
go
on
the
wire
and
it's
not
a
best
common
practice
for
a
protocol.
So
my
personal
opinion
is:
is
it's
an
informational
document?
I
would,
of
course,
the
FIR
to
my
co-chair
and
the
ad
and
the
isg
if
they
want
to
change
that
and
at
leat
whatever
they
come
up
with,
is
fine
with
me,
but
I
think
it's
informational.
It's
not
a
protocol
bit
on
the
wire
loo.
D
P
So
Benoit
so
on
the
informational,
yes,
informational,
because
60
87
is
informational
right,
so
same
category
in
terms
of
options,
I
have
a
preference
for
one.
As
a
contributor
you
know,
I
keep
telling
is
its
industry-wide
problem.
We
need
people,
we
need
to
have
a
single
point
where
we
provide
guidelines.
We
are
heard
at
multiple
times
and
on
the
guidelines.
How
do
I
create
yang
models
etc?
A
single
place?
And
yes,
it
evolves.
The
guidelines
in
two
years
from
now
will
be
different.
They
will
have
some
ver
right,
so
reference
for
one.
E
Row
built
in
again
so
one
comment
about
like
I
Triple
E.
My
understand
is
that
when
they
were
looking
at
guidelines,
they're
looking
at
RC,
60
87
and
not
sixty
eighty
seven
base,
because
that
one
hasn't
actually
been
published
yet
so
they're
looking
at
the
older
state,
potentially
rather
than
the
one
that
the
current
draft
that
hasn't
yet
been
published
because
that's
what
they
want
to
reference
and
what
to
look
at
so
again.
The
same
issue
about
taking
a
long
time
to
update
the
guidelines
is
causing
a
problem.
I.
G
Don't
actually
I
support
number
two
and
I
agree
with
Rob
that
it
should
be
sufficient
and
to
wash
comment
I
think
it's
not
really
rules
about
life
and
death,
so
it's
not
necessary
to
check
these
rules
every
day.
I
think
that
just
if
I
end
at,
for
example,
indicate
that
some
rules
are
not
followed
and
it
might
be
possible
to
change
it,
but
I
think
a
vacay
would
be
a
good
solution
in
this
case.
G
D
D
Really
don't
like
the
notion
of
big
massive
documents
that
try
to
do
everything
at
once.
I
mean
I
think
that
that's
just
a
very
slow
way
of
working.
That's
a
personal
statement
as
off.
Yes,
co-author.
Excuse
me
as
well
as
someone
who
has
something
to
do
with
process
in
here.
I
just
want
an
answer,
and
so
that
we
can
push
this
thing
out
so
I
hope
we
can
reach
consensus
on
that.
Well
and
I.
M
Going
to
for
a
couple
comments
from
it,
let
me
just
throw
out
there.
I
know
mentioned
this
option
yet
the
option
is
we
published
a
document
with
a
pointer
to
a
wiki
that
has
ongoing
work
and
in
revision
right.
So
so
you
sort
of
can
bridge
the
gap
where
you
have
a
constant
standard
document.
You
can
point
people
at
like
I
Triple
E,
and
yet
you
can
also
track
new
work
quickly
because
it
develops
you.
M
B
This
is
Kent
channeling
Jabbar
Martin
says
that
he
favors
option
number
three.
He
says:
wiki's
have
a
tendency
to
not
be
alive
after
some
time.
Just
look
at
the
various
yang
wiki's
we
have
and
Jeff
Haas
says.
Wiki's
also
are
problematic
for
anything
that
is
intended
to
be
canonical
access.
Control
to
them
would
to
such
an
item
would
be
very
important.
B
B
L
L
They
other
something
else.
Let
me
state
first,
my
opinion
and,
and
the
option
I
think
should
be
interesting.
I
mean
I
support,
option
two,
but
because
I
think
having
everything
in
one
document
is
practically
very
difficult
to
achieve,
because
we
cannot
update
one
document
again
and
again
where
another
document
like
this
one
here
would
be
interesting
to
publish
as
soon
as
possible
and
the
wiki
would
be
actually
listing
references
to
RFC's
which
have
been
defined
as
guideline.
L
B
Okay,
there's
a
few
more
comments
from
jabber
Juergen
says
who
maintains
the
wiki
I'm,
not
sure
if
we
have
to
insert
that
right
now,
but
something
to
consider
I
mean
okay,
Jeff
Haase
says
additional
option.
There's
some
sort
of
Ayana
maintenance
moves
faster
than
a
full
RFC
and
Martin
says.
Links
to
the
RFC's
also
have
problems,
try
to
follow
the
link
to
security
considerations
and
60
87
hint.
It's
a
404.
Q
I'm
hoping
to
I
try
to
so
is
there
a
need
to
actually
progress
a
document
to
RFC?
So
if
you
have
a
document-
and
you
want
to
change
it,
just
don't
make
RFC
and
you
have
changed
control.
The
authors
have
changed,
control
over
is,
and
process
applies,
so
you
just
keep
it
a
draft
and
then
you
can
can
alter
it.
So.
D
B
P
D
Some
of
us
don't
have
great
ears,
and
if
we
hum
it's,
it
means
that
I
might
hear
a
few
people
in
the
front.
I'm
not
gonna,
hear
people
in
the
back,
so
I
we're
not
required
to
hum,
and
it
doesn't
work
for
my
ears
full
stop.
It
me
neither
I
can't
I
can't
handle
hums.
I
I
will
not
be
able
to
judge
the
results
as
a
chair.
If
we
hum
I'm
sorry
I
ears,
don't
work
that
way.
D
B
D
So
well,
I
guess:
I'll
look
to
the
chair
to
figure
out
how
we
move
forward
between
options.
Two
and
three.
Thank
you
very
much
for
the
input.
Oh,
they
we
had
one
last
open
issue.
I
believe
the
plan
is
just
to
go
with
what
Martin
had
suggested
on
email
and
I.
Believe
that's.
The
last
thing
is
his
use.
I'll
allow
for
the
the
uses
to
be
shown
and,
if
I
have
that
wrong,
we'll
correct
it
on
the
list.
D
R
Okay,
so
last
time
we
met
this
was
in
Prague
and
we
presented
our
proposal
for
the
yang
catalogue.
Essentially
the
thing
that
backs
up
yang
catalogue
org.
You
may
recall
that
we
are
not
necessarily
looking
for
standardization,
a
ratification
of
this
module.
What
we
are
doing
is
sharing
with
you
the
work
that
has
gone
on
to
create
a
metadata
repository
for
yang
modules,
some
of
the
things
I'm
going
to
talk
about
today,
Benoit
raised
in
terms
of
semantic
version.
These
things
have
been
driven
by
use
cases
that
we've
received
by
talking
specifically
with
operators.
R
So
one
of
the
things
we
wanted
to
do
is
expand
the
use
cases
for
the
catalog.
As
Benoit
has
said,
it's
about
the
tool,
it's
about
the
yang
modules,
it's
about
the
tooling
and
it's
about
the
metadata
and
that's
the
metadata
is
what
this
this
module
defines,
and
it's
directly
in
support
of
the
tooling,
which
is
directly
in
support
of
the
use
cases
that
the
operators
have
come
by.
R
For
those
of
you
who
can't
wait
for
the
movie
here
is
the
yang
tree
structure
for
both
the
module
and
the
vendor
sub
trees,
just-just
guidelines,
the
new
use
cases
that
we've
come
up
with
and
we
think
the
first
one
is
is
critical.
Every
operator
we've
talked
to
as
benoit
says
they
are
composing
service
modules.
R
They
need
to
understand
that,
given
a
module
or
given
a
release
of
code
for
a
specific
vendor,
tell
me
very
easily
very
quickly
what
modules
are
backwards,
incompatible,
meaning
which
ones
have
backward
incompatible
changes,
and
then
we've
added
additional,
tooling
and
I'll
show
you
that
in
a
minute
to
show
you
what
those
specific
changes
are
both
from
a
tree
type
as
well
as
the
textual.
So
those
are
the
first
two
use
cases.
R
Then
we
want
to
say
we
wanted
to
provide
a
comprehensive
metadata
store
to
drive
all
the
tooling
so
as
part
of
the
latest
version
of
the
yank
catalog.
All
of
the
tools
on
there
directly
use
this
module,
which
the
which
creates
or
or
stores
all
of
this
metadata,
and
then
one
of
the
things
that
Benoit
has
been
doing
and
is
is
is
trek
around
different
stos
is
to
be
able
to
say
here
are
your
modules
and
here's
how
they
relate
to
an
MDA
compatibility
or
compliance.
R
You've
seen
this
slide,
I
won't
spend
much
time
on
it.
We
are
algorithmically
or
heuristic
lis
determining
this
derived
semantic
version
that
will
help,
at
least
from
a
syntactic
standpoint,
show
users
or
consumers
of
yang
modules,
where
those
modules
are
different.
So
at
a
quick
glance
you
can
see
that
revision,
n
+
1
of
a
given
module
is
either
backward
compatible
or
not
to
revision
in.
So,
let's
take
an
example,
this
is
the
ietf
interfaces
from
this.
We
provide
a
link
in
our
API
in
our
yang
ma
in
the
yang
catalog
API.
R
That
will
allow
one
to
look
at
the
tree
side-by-side
tree
diffs,
as
well
as
the
side-by-side
textual
diffs.
If
there
is
a
semantic
version,
major
major
semantic
version
difference
in
this
case
revision,
10.0
of
the
yang
interfaces
module
as
re
ietf
interfaces
module
differs
in
this
way
from
version
2.0,
so
you
immediately
know
there's
backward
incompatible
change
by
the
major
revision
of
major
version
numbers
and
you
can
visualize
what
those
differences
are.
R
The
other
thing
that
we're
doing
is
again
being
able
to
track
the
full
store.
The
full
metadata
store
in
in
the
yang
catalog,
directly
feeding
this
into
tools,
and
we
have
an
API
to
access
it.
So
the
colorful
skittles
rainbow
you
see
up
there
of
the
impact
analysis,
is
directly
fed
from
the
metadata
we're
collecting
that
metadata
is
available
via
api's.
So
you
it's
linked
to
offer
the
catalog
page.
R
R
And
finally,
we
are
integrating
newer
tools
into
the
yang
catalog
that
will
allow
users
and
modules,
as
well
as
the
authors
of
modules,
better
make
use
of
that
learn
from
the
the
best
practices
in
terms
of
the
the
data
that
the
constructs
that
are
going
into
modules
and
be
able
to
say,
given
a
module,
how
can
I
consume
it?
How
can
I
create
a
script
and
test
it
against
my
devices
or
how
can
I
write
or
take
a
script
and
test
it
against
some
automated
test
suite?
So
as
part
of
the
hackathon?
R
This
time
around,
we
had
one
of
one
of
the
contributors
building
an
automated
test,
harness
based
on
coffee
based
on
neck
comedy
that
we
could
feed
scripts
from
our
yang
development
Kent
integration
into
to
be
able
to
test,
for
example,
the
examples
in
yang
modules
that
they
are
consistent
with
the
yang
module
definitions.
Our
next
steps
are
primarily,
first
and
foremost.
We
want
to
make
sure
that
all
then
and
all
stos
are
contributing
their
modules
in
a
publicly
consumable
fashion,
such
as
github,
and
that
they
publish
their
metadata
to
us.
R
R
G
We
can
be
quick
just
because
we're
I
think
it
would
be
useful
to
be
able
to
specify
this
meta
metadata
in
in
the
yang
module
itself.
So
perhaps
it
it
would
be
nice
to
have
an
extension
so
that
authors
of
new
modules
can
put
the
metadata
directly
there
so
that
it
can
be
used
with
other
tools,
and
it
will
be
clear.
So
maybe
sometimes
your
automatic
tools
cannot
determine
everything
perfectly,
so
this
would
be
I,
think
useful
and
a
nice
application
for
an
extension.
G
R
B
M
So
we've
had
two
revisions
since
it
was
last
presented
in
IDF
98,
and
the
changes
during
those
two
revisions
were
to
remove
a
per
module
tag
list.
So
originally
we
had
designed
it
so
that
the
tags
we
sort
of
had
the
tags
in
multiple
places.
We
had
them
in
an
augmenting
library.
We
had
them
in
a
global
list
and
we
also
had
them
per
module
list.
The
probably
the
per
module
list
is.
It
would
only
go
in
there
if
the.
M
It
does
operate
on
config.
That's
reset
so
here's
what
it
looks
like
now.
Well,
one
of
the
modules
we
have
a
module
tags
list
where
each
entry
is
a
module
identified
as
it
is
in
the
yang
library,
with
name
and
revision
and
then
a
list
of
tags,
the
RPC
reset
tags.
The
reason
that's
there
is
because
we
allow
the
user
to
delete
tags.
M
If
you
recall,
the
tags
can
be
added
in
three
places
by
the
module
author
by
the
vendor,
the
implementer
and
then
finally,
by
the
user,
and
then
the
user
is
a
in
case,
the
ultimate
arbiter
of
the
truth,
so
the
user
can,
for
example,
say
I.
You
might
have
tagged
that
as
supporting
this
feature,
but
I
found
out
your
buggy
and
so
I'm
gonna
remove
that
tag,
because
I
don't
think
that
you
support
that
feature.
M
M
This
was
raised
by
Rob
Weldon.
He
raises
to
me
just
this
IETF
about.
Should
we
separate
the
tag
config
from
the
tag
list
right
now
they
sort
of
are
the
same
right,
so
you
would
imagine
the
config
being
there.
If
there
was
predefined
tags,
they
would
already
be
there
in
the
list
and
that
you
could
then
go
in
and
write
a
new
list
that
removed
them.
That's
how
you
would
delete
tags
and
he
pointed
out
that
they
they're
trying
to
move
away
from
that
with
nmda
to
have
it
empty
right.
M
This
would
get
rid
of
the
need
for
the
reset
RPC
I
kind
of
like
when
they're
mapped
together,
because
it's
just
clean
looking
in
my
head,
but
I
do
see
this.
So
this
is
something
I
think
we
should
talk
about
in
the
list
and
also
the
I
think
glue
might
have
mentioned
that.
Maybe
we
should
just
remove
the
yang
library
augment
I
mean
why
have
two
lists?
We
have
the
the
case.
There
is
again
I
think
there's
a
case
may
be
for
XPath.
M
We
you
know,
because
you
can
do
nicer,
XPath
things
for
selecting
modules
when
they're
right.
The
the
data
is
right
next
to
each
other,
as
opposed
to
going
down
to
the
root
and
back
up
to
into
a
list.
So
and
then
we
have,
we
do
have
a
list
of
initial
standard
tags,
so
I
think
we
should,
you
know,
get
some,
maybe
more
a
little
bit
more
action
on
people
looking
at
that
just
see
if
you're
looking
it
over
and
seeing
if,
if
we've
got
what
people
think
is
a
good
base
set.
E
D
D
B
So,
as
promised,
we
wanted
to
pull
the
room
for
interest
in
this
draft,
so
first
interest
and
then
we'll
ask
for
adoption.
Okay.
So
if
you
are
interested
in
this
work,
we
think
it's
a
problem
that
needs
to
be
solved.
Please
raise
your
hand
I'm
gonna,
say
a
few
okay,
all
right,
and
likewise,
if
youth.
B
B
Okay,
the
problem
is
yang
extension
statement
yang
data
in
the
module
ITF
restaurant,
which
is
in
RFC
80/40,
can
be
used
to
define
a
data
structure
that
is
not
intended
to
be
part
of
a
data
store.
The
original
use
case
was
for
restaurant
resources
and
errors,
but
since
then
it's
been
used
to
define
file
formats
and
also
protocol
messages.
However,
this
solution
has
well
actually
three
limitations,
not
just
a
couple.
The
structure
cannot
be
augmented,
which
you'll
see
the
reason
for
wanting
to
do
so,
an
upcoming
slide.
B
The
structure
must
define
exactly
one
container,
which
is
an
issue
that
the
zero
touch
draft
is
having
concerned
with
and
also
creates
a
dependency
to
RSC
80/40
of
the
rest
count
draft,
which
is
kind
of
strange.
You
know,
for
instance,
the
zero
touch
draft
needing
to
have
a
normative
reference
to
this
restaurant
traffic
just
unnecessary
for
this
purpose.
B
The
solution
is
to
have
a
separate
document
that
defines
two
new
extension
statements,
the
first
being
yang
data,
which
is
yes,
it's
the
same
string,
but
it
would
be
a
different
prefix,
a
different
namespace,
so
it's
not
actually
we're
not
actually
removing
it
from
the
restaurant
drafter
and
which
would
be
intended
to
replace
IETF
restaurant
yang
data,
so
I
mean
there'd,
be
no
need
to
update
80/40
immediately.
It's
that
definition
could
stay
there.
You
know
indefinitely,
but
if
ever
there
were
an
update
to
80/40
it
could
at
that
time,
potentially
move.
B
We
moved
over
to
use
this
other
statement.
The
semantics
would
be
the
same,
but
it
remove
the
limitations
that
the
top-level
node
must
be
a
single
container
and
the
other
top-level
extension
statement
would
be
augment
yang
data,
which
could
be
used
to
augment
a
data
structure
defined
with
yang
data,
so
the
samokhin
issues
first,
should
we
also
define
a
new
statement
like
uses
yang
data
that
can
be
used
just
like
normal
uses
in
all
places
users
can
be
used.
The
drawback
is
that
we
get
two
ways
of
defining
reusable
structures,
grouping
and
yang
data.
B
This
came
from
the
animal
working
group
with
the
voucher
draft
and
then
separately,
there's
a
brewski
draft
and
the
brewski
draft
us.
The
voucher
draft
defines
a
uses
gang
data
to
define
a
data
structure
for
the
voucher.
The
brewski
draft
basically
wants
to.
It
is
a
voucher,
but
it
adds
in
some
additional
fields,
and
so
what
they
wanted
to
do
was
to
use
the
voucher
data
structure
and
then
and
then
you
know
augment
it
and
refine
it
to
the
needs
that
they
had.
B
G
General
I
would
say
it
would
be
really
useful
to
to
have
young
so
that
it
you
can
do
things
like
this
this
out
of
the
book,
so
that
yet
can
be.
We
discussed
it
already
several
times
before,
so
just
to
be
able
to
use
yank
for
defining
some
structures
that
need
not
necessarily
be
in
some
network
management
protocol.
They
just
are
and
things
like
that,
but
that's
of
course,
a
long
shot.
G
B
The
second
open
issue
currently
there's
no
way
to
define
special
error
info
content
for
RPC
or
actions.
A
gang
data
could
be
used
to
define
the
structure,
but
should
we
also
define
a
new
extension
statement
that
can
be
used
to
use
in
RPC
and
actions
to
refer
to
such
a
structure
and
the
example
on
the
screen
there?
You
can
see
where
we
have
the
map
error
info,
which
is
then
referring
to
a
yang
data
structure
and
I
think
this
would
be
necessary
for
the
SUBSCRIBE
notifications
or
notification
messages.
Draft
right.
S
B
So
that
is
the
last
slide
again,
there's
actually
two
dependencies
on
this
graph
from
the
net
comp
working
group,
both
the
zero
touch
draft
and
also
the
notification
messages
drafts
are
looking
for
this.
Those
are
chartered
working
group
items
within
the
neck
health
working
group,
and
now
this
is
essentially
a
dependency
for
them.
If
so,
we
would
like
to
see
this
draft
adopted
by
the
working
group,
and
maybe
the
chair
can
ask
about
that.
D
Supplement
so
given
that
this
is
extension
work,
this
is
the
logical
place
for
the
work,
so
I'm
not
going
to
ask
the
normal
question
of
how
many
people
think
we
should
be
solving
this
problem,
because
we
already
just
established
that
there's
another
working
group
that
really
requires
it
and
the
other
option
would
be
to
kick
this
back
to
the
other
working
group
and
that's
not
really
the
right
place
for
the
further
work.
So
I'm
going
to
jump
right
into
how
many
people
have
read
this
draft.
D
I'm,
sorry
again,
how
many
people?
Okay,
that's
a
very
few-
can
we
can
jump
to
adoption
but
well?
Why
not?
How
many
think
we
should
be
adopting
this?
This
work
into
the
working
group,
the
it's
also
very
few,
the
interesting
thing.
It
was
more
than
read
the
document,
but
not
by
much,
but
you
know
that's
sort
of
an
interesting
data
point.
D
Obviously
we'll
take
that
information
back
and
we'll
talk
about
it
and
go
from
there
it
while
we
don't
it's
Madonna,
have
AVI
support
for
immediately
going
to
last
sorry
adoption,
given
that
we
have
another
working
group
that
depends
on
it.
My
inclination
would
be
to
really
try
to
bring
this
into
the
working
group
because
it
seems
like
it's.
It's
pretty
important,
so
Rob.
E
D
D
M
D
D
Okay,
so,
unfortunately,
because
I
was
doing,
the
poll
I
missed
a
couple
of
comments
on
the
last
one
we
have
from
from
lotto
who's
in
the
room.
I'm,
not
gonna,
read
it.
We
have
from
your
again
the
scope
of
their
work
remains
unclear
to
me
and
there's
a
little
bit
of
a
side
discussion
that
goes
on
there,
but
I
think
it
doesn't
substantively
change
anything.
So
we
have.
T
So
in
this
draft
we
we
talked
about
finite
state
machine
young
model
for
finished
state
machine.
We
considered
three
use
cases
the
first
one
on
two
plain:
strat
data
playing
device
devices
in
optical
networks,
in
particular
transponders
in
case
of
optical
physical
layer
degradation,
so
they
can
reconfigure
their
itself
in
case
of
these
degradation.
The
second
use
case
is
related
to
custom
data,
probing
for
telemetry
application
and
the
third
use
cases
use
case
is
related
to
monitoring
of
packet
loss
and
Danai
and
delay
through
a
network
lasting
approach.
T
So
let's
go
to
the
first
use
case
at
the
state
of
the
art,
so
the
left
part
we
can
consider
an
optical
connection,
assume
a
degradation,
so
a
degradation
can
be
revealed
with
a
bit
error
rate
increase
above
a
threshold.
An
alarm
is
sent
to
the
on
or
on
demand
layer.
There
is
some
transmission
parameter
computation,
so
consider
the
change
of
modulation
format
or
forward
error
correction.
T
While
we
can
do
something
different
with
a
younger,
considering
a
young
model
for
finite
state
machine,
while
the
connection
is
still
active,
yes,
the
end
controller.
Instructs
the
transponder
on
how
to
reconfigure
itself
the
transponder
in
case
of
a
degradation
by
installing
a
finished
state
machine.
So
if
the
degradation
happens,
the
transponder
all
already
knows
what
to
do
and
the
recovery
can
be
faster.
T
The
second
use
case
is
related
to
tell
em
to
telemetry,
so
we
consider
dynamically
customized
the
network
data
collection
instead
of
raw
data
extraction,
in
order
with
the
name
of
reducing
the
telemetry
data
bandwidth,
taking
advantage
of
the
in
in
network
data
processing.
So
in
this
scenario
we
can,
we
can
consider
that
several
network
probes
can
be
described,
can
be
described
as
a
finished
state
machine.
An
example
is
the
congestion
control.
So
let
us
let
assume
to
two
thresholds
on
the
buffer
death.
A
T
The
third
use
case
is
related
to
the
monitoring
of
performance
measurements
in
multi-point
to
multi-point
large
networks.
So
we
considered
the
multi-point
to
multi-point
as
a
generator
case
bust,
but
this
can
be
applicated
also
to
point
to
move
to
point
to
point
here:
the
SDN
controller
can
orchestrate
the
performance,
the
performance,
measurements
and
the,
and
it
can
calibrate
how
going
too
deep
into
into
the
monitoring
data
we
can.
We
can
assume
the
metered
of
alternate
marking
for
for
the
performance
measurement
and
in
with
this
clustering
approach,
assume
to
divide
the
network
in
in
clusters.
T
So
if
we
have
no
particular
problems
of
the
delay,
we
can
consider
large
clusters,
but
we
can
go
when
we
have
problems.
We
can
go
in
more
in
deeper,
so
with
smaller
clusters
up
to
going
to
to
the
flows
and
again,
here
we
can
model.
We
can
assume
a
finished
state
machine
where
each
state
represents
a
composition
of
clusters.
T
T
One
transition
can
be
triggered
by
the
bit
error
rate
increase
of
the
optical
connection.
A
leaf
of
this
list
transition
list
is,
is
the
filter
to
further
express
the
the
transition.
So
in
this
case
we
can
put
a
threshold
on
the
bit
error
rate
so
that
when
the
bit
error
rate
is
above
this
threshold,
the
transition
is
triggered
to
the
transition
is
associated
an
action,
a
list
of
actions,
for
example
the
change
of
the
modulation
format,
to
provide
more
robustness
to
the
transmission
or
the
change
of
the
forward
error
correction.
T
And
then
we
have
the
the
attribute
execute
which
actually
calls
an
RPC
that
performs
the
task
of
modulation
format
change.
So,
in
summary,
we
presented
the
young
model
for
finite
state
machine.
Please
consider
that
this
draft
was
presented
in
Prague
in
another
working
group.
It
was
obvious
WG.
It
receives
comments
to
to
get
it
more
generic
model
and
including
more
more
use
cases.
So
we
included
two
more
use
cases
and
we
submitted
here
in
that
mod.
We
have
an
implementation
and
we
also
demonstrated
in
an
integrated
test
bit
of
optical
data
plane
and
control
plane.
U
U
T
T
M
A
M
T
D
Flew
just
to
follow
up
on
that,
but
it
seems
that
the
way
it's
defined
right
now
you
have
to
have
the
client
has
to
have
an
understanding
of
what
the
server
implements
and
so
like,
for
instance,
a
name
has
to
be
something
that's
well
known
by
both
right,
because
you're
triggering
specific
functions
that
you're
trying
to
have
the
client
trigger
specific
functions
in
the
server
right.
Yes,.
D
Yeah
I
think
so
I
just
I'm
a
little
lost
as
to
what
the
client
is
doing,
that.
What
flexibility
is
it
really
triggering?
You
know
it
seems
that
it
would
have
to
have
a
representation
of
this.
The
finite
state
machine,
that's
up!
That's
on
the
on
the
server
and
all
the
degrees
that
are
supported
and
it's
I
don't
know,
I'm
having
a
hard
time
understanding
what
what
this
is
getting
at,
but
let's
get
to
the
line
and
we
have
to
wrap
up
in
like
three
minutes
so
I'm.
Sorry,
one
minute
so
well.
T
E
Rob
Wilson
Cisco,
so
I've
no
idea
whether
is
enough
support
in
the
room
to
adopt
this
or
not
it'd,
be
interesting
to
see,
but
I
think
it's
generally
useful
to
try
and
standardize
these
models
so
that
if
you
got
similar
functionality
that
multi,
we
want
to
use
it's
nice
to
have
one
model
and
one
way
of
doing
it.
So
my
question
is:
if
there's
not
enough
support
in
this
room
to
adopt
this,
what
happens
then
I
mean?
D
Just
because
I'll
shortcut
occurs
that
at
the
time
I
don't
think
we
have
enough
understanding
in
this
room
to
do
an
adoption
call,
and
you
know
that
most
we
can
say
how
many
people
are
interested
in
in
talking
about
this
more
and
learning
more
I,
don't
think
we
we
can
do
more
than
that
right
now,
I
know,
I,
don't
personally
understand
this
enough
to
figure
out
whether
it's
a
useful
thing
or
completely.
You
know
something
else,
so
my
question
is:
if
there's
not
enough
support,
what's
the
next
action
not.
N
S
Just
to
put
an
offer
out
there,
I
know
that
they
Igor
brisk
and
he
was
looking
at
something
called
I've
been
conditioned
action
as
a
probable
statement
and
the
net
kampf
added
to
the
subscription
and
the
telemetry
work.
There
I'm
sure
he'd
like
to
chat
with
you
about
a
problem
statement.
If
you're
looking
to
help
define
what's
needed
for
this
group,
a
joint
problem
statement
would
be
pretty
good.
Yeah.
K
D
D
D
V
D
V
V
B
V
W
Little
slides,
yeah,
okay,
post
instead
a
problem
so
for
the
every
protocol
and
several
vendors
have
of
their
own.
Provide
young
modules
to
implement
to
the
ARP
functions,
suggest
cisco,
juniper
I
know.
Are
we
such
provider
model?
Can
we
applied
unto
their
own
devices?
However,
due
to
the
different
functional
device?
Providing
your
module
is
hard
to
use
a
cost
thirty
bodies
and
you
cannot
miss
the
demand
old
common
requirements
of
user.
W
So
in
this
case
imagine
a
scenario
that
a
service
provider
manicure
the
thousands
of
devices
and
these
devices
are
from
many
vendors
is-
must
be
a
disaster
gives
the
earth
there
is
no
way
to
control
this
device
in
the
stand
way.
So
so
a
solution
can
be
effects:
uncommon
for
properties
within
or
devices
the
implementing
the
app
she.
W
This
master
has
two
meanings:
customized
provide
a
unique
or
I
define
for
IP
configuration
function,
for
example
they
age
you
so
the
edging
in
some
problem,
your
model
because
they
time
out
or
they
expire
time
and
away
summarize
a
common
name,
the
aging
and
then
the
similar
is
the
interval.
It
is
sometimes
called
a
detector
in
the
wall
of
the
code.
W
Is
a
half
interval,
so
a
we,
we
can
give
a
única
name,
so
the
user
can
cannot
be
confused
by
this
similar
similar
names,
and
the
second
is
the
way:
providers,
the
common
core
properties,
for
example,
the
static
8fg
entry,
the
dynamic,
a
few
interest
and
the
prog
proxy
option.
Ok,
this
functions
is
where
to
find
the
in
every
protocol.
The
next
surface.
W
Hello
yeah,
so
here
in
this
graph,
the
wisdom
summarize
the
perfecter
of
epic
configuring
functions:
the
statical
epic
entry,
the
dynamic
yearning
of
every
entry,
the
prompt
they
actually
under
the
credit
us
eruption.
So
we
we
can
see
the
tree
WETA,
graham
the
docking.
He
know
a
prosthetic
table,
mister
static
applicant,
the
configuration
so
the
leaf
expat
time
describes
the
edging
time
of
the
dynamic
IP
entry.
The
lift
a
phenom
describes
the
weather
that
dynamic
immunity
is
disabled,
so
it
is
enabled
by
default.
Another
applicant,
prague,
proxy
describes.
W
The
weather
of
the
probe
got
Jeremy
is
deserve
order,
so
it
is
also
enabled,
by
default
and
at
the
EPI
profit
grouping
that
describes
a
common
configuration
of
our
happy
pop.
So
the
leaf
a
problem
interval
means
the
intervals
of
the
texting.
The
dynamic,
a
RP
entries
under
the
leaf
probably
x,
is
a
number
of
ng,
an
improper
attempts
for
a
dynamic,
dynamic,
happy
entry.
W
The
unit
custom
means
where
the
use
of
a
unique
custom
mode
to
send
a
happy
aging
proper
messenger
for
dynamic,
happy
entry,
so
it
is
also
enabled
by
default
and
finally,
the
happy
graduates.
A
grouping
describes
a
configurating
graduate
to
create
action,
so
the
container
happy,
if
Nimitz
it
is
described
the
maximum
number
of
time,
ik
happy
entry
as
Dutch
interface,
Kenda
go
next
surface,
so
the
next
steps
foster
the
language
other
models.
Here
we
are
measuring
the
comments
of
Alex
from
the
demo,
my
owner
list,
so
Alex
s
the
publish
the
model
IDF.
W
Actually,
it
is
also
called
as
a
fc7
2007.
It
is
Oh
overlaps,
the
data
being
provided
in
this
model,
and
then
it
gives
some
suggestion
to
avoid
the
duplication
of
data
where
perform
so
we
are.
We
are
saying
the
annex
for
this
one
of
our
questions
and
we
are
reversed.
They
we
have.
We
applied
the
corresponding
the
answer
in
the
posterity
on
the
list
so
and
the
way
we
already
revised
that
chapter
in
the
next
version-
and
here
we
also
want
to
the
more
storage
comments.
D
Okay,
thank
you
very
much.
Our
understanding
is
you've
also
presented
this
work
or
going
to
present
this
work
in
the
routing
working
group.
Do
you
have
a
feeling
as
to
which
place
you
think
is
more
appropriate
and
I
understand
that
that's
as
much
a
discussion
for
chairs
and
80s,
but
I'd
like
to
to
hear
your
opinion.