►
From YouTube: IETF101-NWCRG-20180322-1330
Description
NWCRG meeting session at IETF101
2018/03/22 1330
https://datatracker.ietf.org/meeting/101/proceedings/
D
A
So
this
is
the
coding
for
efficient
network
communications
research
group
again,
like
I,
said
we
have
a
very
full
agenda
inside
actually
so
for
people
who
are
new
here,
our
goal
is
essentially
to
foster
research
and
I.
Would
you
know
and
emphasize
the
word
research
here
in
network
and
application
layer
coding
to
improve
performance?
What
does
that
research
mean?
It
means
research
in
codes
and
coding,
libraries
and
you're
going
to
hear
about
some
of
that
in
the
early
presentations
here.
A
We
also
want
to
focus
on
protocols
that
will
facilitate
the
use
of
coding
in
existing
systems
a
lot
of
times.
The
reason
that
coding
is
not
used
is
because
there's
not
an
easy
way
to
access
this
code
from
inside
another
protocol,
and
we
want
to
look
into
real-world
use
cases
and
also
work
work
in
progress
in
other
working
groups
and
in
other
research
groups
and
outside
or
group
also,
okay,.
B
So
now
the
usual
not
well
slide,
in
fact,
not
exactly
usual,
because
it
has.
It
has
changed
recent,
but
the
underlying
documents
remain
the
same,
so
I
don't
want
to
go
through
this
slide
just
to
highlight
one
points.
That
is
very
important
in
our
case.
If
you
are
reasonably
aware
of
IPR
related
to
your
work
or
work
from
somebody
else,
then
please
you
need
to
do
nykeya
disclosure
rapidly.
B
You
can
have
more
details
in
BCP
79
again
of
this
list.
Bcp
29
best
current
practice
is
also
a
short
name
for
another
name
for
IFC
81
79.
So
have
a
look
at
that,
then,
concerning
some
administrative
stuff,
if
ever
you
are
looking
for
any
information,
any
piece
of
information
concerning
our
research
group,
then
you
need
to
go
to
the
data
tracker.
I
got
ITF
dot,
all
websites,
everything
is
there
the
documents,
the
milestones
the
agent,
the
the
Charter
everything
is
there?
B
Okay,
we
also
have
wiki,
but
we
are
not
using
it
so
much
for
the
moments
main
list.
The
slides
are
all
uploaded,
except
maybe
one
of
them,
but
I
hope
that
we'll
get
it.
This
is
the
Yun
presentation,
but
you
will
sign
it
to
us
all.
The
slides
also
wise
are
available
online
and,
of
course,
from
a
pest
station
is
fully
usual
mythical
system.
B
The
agenda,
as
I
said,
is
pretty
full.
We
have
zero
time
balance.
So
if
you
intend
to
present
something
then
make
sure
that
you
presentation
is
stay
within
the
allocated
time,
so
we
have,
except
one
exception,
of
a
quarter
of
our
for
each
your
first
ten
minutes,
presentation
and
five
minute
questions.
If
you
spend
more
time,
presentation
means
less
time
on
prostate
on
discussion
after
you.
A
So
a
little
bit
of
a
a
quick
status
about
what
is
going
on,
we
have
a
document
that
is
at
is
G
review,
which
means
that
it
will
be
LRC
very
soon
and
it's
the
network
coding
taxonomy,
which
describes
the
words
that
we
are
using
and
describes
the
functions
of
network
coding.
There
are
currently
individual
ideas
did
this?
Has
one
there's
RL
and
C?
There's
a
presentation
that's
going
to
be
here
presented
today
that
has
both
information
about
ONC
and
also
about
symbols.
B
D
E
E
E
So
the
objective
of
our
work
is
to
propose
jarick
transport
protocol
framework
plus
some
building
blocks,
and
particularly
the
elastic
encoding
window
next
slide,
and
today
everything
is
inside
the
same
document,
so
we
defined
the
protocol,
so
we
defined
some
packet
formats
and
we
also
defined
a
set
of
building
blocks.
So
everything
in
each
side
is
document,
and
this
is
why
I
want
to
discuss.
E
So
you
will
see
at
the
end
next
slide,
so
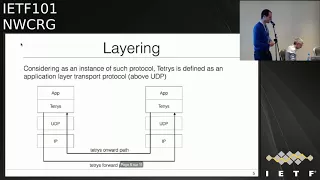
tetris
is
defined
as
an
application
layer,
Transfer
Protocol,
so
it's
n
to
n
and
above
UDP
next
slide.
So
the
use
case
are
unicast
and
multicast
communications
with
or
without
feedbacks.
So
in
the
protocol
part
we
like
it
simple.
So
we
have
three
packet
formats.
So
the
first
is
the
sauce
packet.
So
it's
just
to
pay
a
lot
with
an
ID.
The
second
is
a
credit
packet.
So
it's
a
runner
combination
of
some
sauce
packets
and
including
an
ID
plus
an
encoding
vector.
E
So
the
information
about
the
liner
combination
plus
decoded
packet
payload,
the
last
one,
is
the
acknowledge
pockets.
So
you
provide
some
feedback
like
packet
loss,
read
the
missing
pockets
or-
and
you
want
to
want
to
go
back
from
the
decoder
to
the
encoder
sonic
slide.
Ok,
so
we
proposed
this
encoding
vector,
so
this
is,
it
could
be
actually
the
first
building
block.
So
this
is
the
most
important
because
it
defines
how
we
code
the
data.
Ok,
so
each
coded
packet
contains
an
encoding
vector,
so
we
wanted
to
create
a
generic
encoding
vectors.
E
E
So,
for
example,
if
you
just
want
to
use
a
sliding
window
so
suppose
you
want
to
generate
an
encoding
vector
by
using
the
fighting
with
of
size
64
by
using
the
finite
field
with
2
to
power
8
elements.
So
you
want
to
code
simple
source
0
to
63,
so
you
actually
need
egg
bytes
to
store
all
the
information
about
the
liner
combination.
E
Yes,
so
another
building
block
could
be
the
generation
of
the
coefficients,
so
interest
will
propose
one
approach,
which
is
a
deterministic
way.
So,
basically,
you
are
inside
a
codec
coded
symbol,
I,
and
you
want
to
generate
the
coefficient
to
integrate
this
example
G.
So
you
have
defined
in
the
draft
a
method
to
just
to
generate
that
directly
so
coefficient
based
on
these
two
ideas,
so
you
don't
have
to
generate
all
the
coefficients
for
your
full
line
of
combination.
You
just
if
you
want
just
generate
1.
5
change
is
possible.
E
So
this
is
an
approach
we
propose.
Okay
does
not
cover
all
the
use
case,
internet
recording,
but
this
is
what
we
propose
all
right.
Okay,
so
now,
as
I
said,
everything
is
inside
the
same
document.
So
now
what
do
we
do?
Do
we
have
to
split
the
document
bit
between
the
protocol
and
a
set
of
building
blocks,
or
do
we
have
to
continue
with
this
Jerek
framework?
Or
do
we
have
to
create
something
addressed
by
defining
more
precisely.
C
F
Different
network
systems,
research
incident,
just
a
clarifying
question:
could
could
you
explain
to
some
of
us
that
don't
follow
all
the
details,
what
the
inner
overlap
if
any
and
field
of
applicability
between
this
and
the
TSV
are
encoding
drift
for
sliding
window,
RL
and
C.
That's
that's
happening
in
with
the
feck
frame.
Yes,
so.
E
F
A
So
I
and
I
think
there's
a
lot
of
overlap,
things
between
the
applicability
of
each
of
these
things,
but
we
would
like
also
to
allow
them
to
be
used
both
independently
or
to
address
the
same
problem.
But
then
you
could
choose
whatever
you
want.
Does
that
answer
your
question,
because
it
was
not
a
question
that
much
for
him
but
I
think
for
it
for
the
generic
group
I.
F
Think
it
answers
a
question.
I'm,
not
sure
I,
like
the
answer
very
much
in
the
sense
that
we
don't
have
a
neither
document
seems
to
provide
a
guy,
any
guidance
as
to
which
one
might
be
more
appropriate
for
any
given
thing-
and
you
know
you
mentioned
api's.
This
has
nothing
to
do
with
api's.
This
is
protocol
encoding
right
and
you
could
provide
a
generic
API
that
could
do
either
of
those
these
things.
F
But
then
who
decides
when
you
call
that
API,
which
one
gets
used
right
so
I
just
think
there
might
be
some
metal
work
to
be
done
to
give
the
community
some
guidance
and
I
don't
have
an
opinion
as
to
whether
technically
one's
better
than
the
other
for
this
or
the
other.
But
one
of
the
things
we
can
do
in
a
research
group
since
we're
doing
research
is
maybe
some
experimentation
that
later
can
provide
some
guidance
to
people
as
to
what
the
right
field
of
applicability
for
the
for
the
different
encoding
might
be.
Yes,.
B
As
I
saw
without
my
charts,
but
also
as
well
main
author
of
the
fact
frame
stuff,
that's
a
very
good
point
and
you
will
see
there
is
some
overlap
between
this
presentation.
The
presentation
that
will
appear
just
after
on,
like
it's
either
formats
and
also
some
overlap
with
what
I've
done
with
colleagues
in
the
context
of
fake
frame
for
freak
frame,
is
a
bit
special
because
it
was
focused
on
an
already
existing
protocol
with
some
specificities.
B
But,
yes,
there
is
some
commonality
and
we
need
to
have
common
understanding
and
guidance
regarding
how
to
format
others
in
an
appropriate
way
to
fulfill
the
requirements
of
that
on
this
and
that
protocol.
So,
yes,
this
is
work
that
we
need
to
be
done
and
I
wanted
to.
We
want,
in
with
Nigel
a
to
put
that
on
the
table
after
the
second
presentation,
yeah.
F
A
E
H
H
Yes
and
thank
you
for
the
other
author
summer,
who
is
with
us
remotely
and
surely
from
Chora
and
myself
and
hear
me
no,
can
hear
me
now:
yes,
okay,
so
and
Vince
from
from
inside.
So
can
you
okay?
So
the
agenda
is
essentially
a
general
motivation
and
the
objective
of
this
work
and
the
design
goals,
and
we
just
that
we
support
and
then
an
example
of
the
simple
representation
that
we
have
proposed
and
some
types
and
the
relationship
with
the
outer
protocol
and
some
limitations
of
this
work.
H
So
it's
a
related
to
the
first
presentation,
not
so
the
sort
of
the
out
the
starting
point
of
this
work
was
that
we
wanted
a
general
purpose,
very
low
overhead
presentation
of
coded
symbols.
So
it's
not
a
protocol,
it's
just
the
symbols
with
some
stuff
on
top
so
that
you
can
interpret
them
at
the
receiver.
H
You,
okay,
so
maybe
I
just
no!
No,
we
need
to
use
it.
Okay,
sorry,
sorry,
okay,
so
maybe
I,
just
okay!
So
try
this
one,
okay,
so
yeah.
So
the
motivation
is
a
representation
of
a
coda
symbol
that
because
we
need
that
in
in
multiple
different
protocols
and
if
we
can
reuse
that,
so
we
can
build
our
protocols
faster.
We
don't
need
to
redefine
this
every
time
like
the
last
and
and
also
the
chest.
H
No
and
then
we
can
give
up
some
interval
Otzi
between
implementations
of
the
underlying
code
of
the
coding,
libraries
and
stuff
like
that,
and
then
this
last
one
should
maybe
be
in
the
next
slide,
but
at
least
was
important
for
this
work.
That
was
that
we
wanted
to
accommodate
a
varying
frame
size
over
the
course
of
the
transposition
over
the
over
the
life,
the
transportation,
because
we're
working
on
a
network
where
that
happens,
to
be
the
case
that
the
underlying
frame
size
changes
during
the
because
of
some
changing
link
conditions.
H
So
so
we
have
the
goals
here.
They
know
we
want
to
know
era,
overhead.
You
know
we
want
to
support,
recording
because
it's
we
think
it's
an
important
feature
of
network
coding
that
we
need
and
and
we
want
to
be
able
to
generate
symbols
from
blocks
that
are
incomplete
in
case
of
a
block
code,
and
we
want
to
support
both
the
block
and
a
sliding
window
type
of
code.
H
So
the
features
that
we
have
included
as
a
consequence
of
this
is
a
variable
number
of
symbols
that
are
can
be
represented
within
each
of
these
representations,
because
we
have
a
usually
we
have
fixed,
simple
size,
and
that
means
that
the
only
thing
that
we
can
vary
is
the
number
of
symbols
we
put
into
each
representation,
unlike
unless
we
want
a
sort
of
a
purpose,
every
representation
for
each
simple.
And
if
we
have
that,
then
we
have
an
overhead
for
each
of
the
symbols
we
put
in.
H
So
that's
seriously
limits
the
sort
of
the
flexibility
we
have.
We
have
three
simple
types,
so
we
have
an
uncoded
and
I
code
it
and
a
recorded
one
so
similar
to
the
first
work
that
was
presented
so
in
order,
so
we
need
different
things
for
these
three
different
cases.
So,
in
order
to
be
efficient,
we
should
define
some
different
ones,
and
then
we
have
a
small,
small
and
a
large
encoding
window
which
essentially
limits
how
big
we
can
do,
how
much
data
we
can
put
in
our
blocks
and
in
our
windows.
H
So
here's
a
sort
of
a
generic
example
which
is
just
that
type
field.
We
have
these
different
types
and
then
we
have
a
field
for
some.
How
many
symbols
we
include
and
then
we
have
the
rank
of
at
the
encoder,
which
is
necessary.
If
you
want
to
encode
symbols
before
you
have
a
full
block,
for
example,
and
then
we
have
something
like
a
seed
or
a
coding
vector
that
we
include
and
the
data
that
is
encoded
next
I,
please
and
then
we
have
the
three
different
types.
H
H
Fixed
overhead
overhead,
the
regardless
of
how
many
symbols
we
will
put
into
the
representation
and
then,
in
the
case
of
a
recorded
symbol
we
put
in
the
coding
coefficients
or
if
we
have
some
system
where
we
don't
have
access
to
the
random
generator
or
something
else,
you
can
essentially
support
anything.
You
can
generate
an
arbitrary
coding
weight
so
any
way
you
want
and
put
that
into
this
representation,
but
it
also
cost
as
a
higher
weight.
H
So
it's
not
what
you
would
usually
do
and
the
reason
why
we
think
that
we
need
all
of
these
three
is
we
need
to
mix
and
that's
the
system
right.
That
could
be
that
most
of
the
traffic
is
uncoded
and
then
there's
a
little
bit
that
has
coded
or
recode
or
something
else.
So
if
we,
if
we
don't
permit
that,
we
can
change
that
they
are
interoperable,
then
we
will
not
be
most
efficient
so
in
relationship
to
with
the
outer
protocol.
Maybe
that's
a.
There
is
some
things
that
we
support
and
we
support
that.
H
You
can
essentially
put
any
number
of
representation
into
a
single
payload
and
then
in
each
of
these
representations
you
can
put
in
up
to
15
symbols,
and
then
we
have
two
different.
The
window
or
block
size
is
that
we
supported
a
small
one
up
to
a
thousand
approximately,
which
is
typically
enough,
a
block
code
and
then
there's
a
really
pick
one
up
to
two
hundred
and
sixty
something
if
you
want
maybe
a
really
big
sliding
window
so
and
then
there's
a
bunch
of
things
that
the
outer
protocol
needs
to
define
for
this
to
work.
H
So
it's
things
like
the
field,
the
symbol
size.
It's
the
type
of
representation
that
we
use
here
either
small,
a
large
and
typically
you
would
use,
would
choose
one
for
your
application
and
then
use
that's
route.
And
then
you
need
to
also
provide
the
block
ID
or
the
window
offset
in
the
outer
protocol,
and
that's
a
some
things
that
you
could
define
if
you
need
them
or
if
they
are
useful,
and
that
would
be
things
like,
for
example,
the
block
size
or
the
density
of
the
code.
H
B
Advanced
questions
I
have
okay,
so
thank
you
for
for
this
initiative,
because
it
is
something
that
was
missing
to
this
group
having
some
document
that
describes,
even
if
you
don't
go
into
the
details
for
the
moment,
but
that
describes
Ireland
C
is
something
that
was
considered
as
important.
We
put
that
in
the
milestones.
So
that's
great.
It's
also
important
to
start
discussions
on
protocol
headers
and
from
this
point
of
view,
we
need
to
work
together.
Well,
I
have
several
technical
commands
on
your
proposal.
B
B
You
is
a
janitor
and
ways
of
the
people
who
also
add
their
own
IDs
in
order
to
find
something
that
maybe
could
be
usable,
reusable
in
some
way,
maybe
not
for
all
the
use
cases
because,
for
instance,
I
was
mentioning
earlier
that,
with
fake
frame
we
have
some
already
existing
mechanism,
so
we
need
to
be
compliant
with
that,
so
that
require
not
specific
to
that,
but
also
otherwise
we
can
extract
some
ideas.
That's
are
more
or
less
aligned
with
what
you
present
it
with
what
Jonathan
presented
so
working
together.
B
B
B
B
End,
you
want
only
one
format:
no
I,
don't
necessarily
want
one
format,
it
depends.
I,
don't
have
the
answer
today.
It
depends
on
protocol
requirements.
In
that
case,
we
maybe
have
to
use
that
format,
because
it
makes
sense.
You
know
the
case,
we'll
have
another
format
but
at
least
having
a
single
document
and
see
what
alpha
we
can
go
into
this
direction.
Having
something
common
as
much
as
possible.
I,
don't
know
if
it
is
I,
don't
have
young.
So
today
we
need
to
think
about
it
together,
but
let's
try
to
work
together.
B
G
G
G
F
I
think
the
goal
is
a
good
one,
but
at
the
end
of
the
day
we
need
at
least
one
form
of
global
optimization,
which
is
that
we
have
n
formats
and
M
codepal
embeddings.
We
have
an
in
order
n
times
n
problem
in
terms
of
actually
putting
a
system
together.
So
the
caution
I
would
give
by
splitting
this
out
is
that
we
don't
run
two
parallel
efforts,
each
of
which
is
operating
in
its
own
degree
of
freedom
right,
so
so
that
we
wind
up
with
a
cross
product.
That's
you
know
unimaginably
large
right,
so
we.
F
To
constrain
the
number
of
protocol
embeddings,
we
have
or
constrain
the
number
of
format
we
have
or
both,
but
if
we
don't
constrain
either
one
we're
gonna,
you
know
I
mean
we've
seen
this
in
the
ITF
in
other
places
before
you
wind
up
with
a
gigantic
mess.
So
some
global
discipline
is
needed
here.
Yeah.
F
B
F
C
H
F
B
F
H
G
Yes,
I
completely
agree
with
Dave.
You
know
that
was
a
motivating
example,
particularly
for
instance,
for
recoding,
but
nothing
here
is
specific
to
Ireland,
see
in
terms
of
the
format
and,
conversely,
I
just
wanted
to
point
out
that
they
are.
They
have
been
proposals
and
they
did.
My
group
has
had
papers
on
doing
RL
and
C
without
conveying
without
conveying
the.
G
Presentation,
so
it's
a
motivating
example,
but
it's
it's
for
a
particular
it's.
It
enables
certain
things
that
are
effectively
coding,
which
are
particularly
nice
with
our
NSC,
but
but
it
is
really
just
a
generic
format.
What
happens
to
enable
certain
of
your
LMC
cases
that
that
we
have
found
to
be
very
effective
so
that
that
will
place
it?
It's
not
really
a
subset
or
or
super
set
it.
G
E
So
the
only
difference
between
a
recording
and
not
recording
is
you
just
need
the
coefficients
to
be
inserted
in
so
inside.
The
the
packets
right
I
think
this
is
the
only
friends
so
I'm
pretty
sure
we
could
imagine
a
format
generic
format
with
an
optional
field.
You
said:
okay,
I
want
the
coefficients
inside.
So
all
other
other
I
don't
want
the
coefficients,
so
it
should
be
pretty
simple
to
convert.
G
Yes,
so
the
recording
doesn't
always
require
the
yeah
that
does
not
always
require
the
the
conveyance
of
the
new
coefficients
upon
which
there
the
recoating
is,
is
affected,
so
you
know,
on
the
other
hand,
of
course,
there's
some
really
great
spaces
for
it.
But
again
it's
not
a
cynic,
one
on
condition.
I
just
wanted
to
make
that
clear,
and
indeed
some
of
the
papers
that,
for
my
group,
signed
fairly
on
on
on
sensor
networks,
which
people
generally
call
more
iot
right
now,
indeed,
did
not.
G
B
You,
okay,
so
I
think
we
are
almost
done
just
one
comment
because
we
already
mentioned:
we
already
had
some
discussion
offline
on
this
topic,
but
if
you
believe
there
is
an
idea,
disclosure
that
should
be
done
on
this
document,
please
do
that
rapidly
as
rapidly
as
possible.
There
is
a
an
exact
wording
in
the
BCP
79
that
says
as
rapidly
as
possible
after
document
submission
after
contribution.
So
please
keep
keep
that
in
mind.
One
more
comment
regarding
IPR
disclosure:
if
the
patent
is
not
yet
granted,
it's
not
a
problem,
there
is
a
checkbox.
B
J
Georgia
market
ask
occurred
on
we're
working
on
the
IPR
disclosure.
We
understand
that
you
know
it
should
be
disclosed
as
reasonably
as
possible,
not
as
rapidly
as
possible.
You
should
appreciate
that
you
know
the
IP
is
owned
by
predominantly
Hamilton
Caltech,
but
there
are
also
other
eight
universities
involved.
So
we
are
discussing
and
agreeing
the
best
licensing
strategy
and
approach,
but
you
know
we're
working
on
it
and
you
know,
as.
J
B
B
Yes,
next
and
we
well
I
updated
this
document
only
very
recently
yesterday.
In
fact,
sorry
for
that
we
try
to
do
better
next
time.
I
was
waiting
for
a
third
contribution.
So
now
this
document,
the
one
you
will
find
on
the
data
tracker-
includes
a
free
example
api's
for
sliding
window
codes,
nine,
the
one
from
jonathan
and
the
one
from
Morton,
so
those
free
api's
correspond
to
running
codes.
B
There
is
something
behind
them.
There
have
been
independently
developed
by
the
free
first
press.
Colleagues,
of
course
we
are
not
working
all
alone,
but
they've
been
indefinitely
developed.
So
that's
something
very
precious
and
there
is
also
a
link
to
a
fourth
implantation
of
sliding
window
codes,
the
one
from
Cedric
which
you
can
find
it.
You
are
yeah.
This
one
does
not
include
codec
API,
it's
developed
in
a
different
way.
There
is
no
standalone
codec,
so
I
mentioned
it.
We
can
use
it
to
get
inspiration.
We
can
also
discuss.
B
We
said
like
with
well
aware
of
foul.
We
can
do
that,
but
was
designed
in
different
ways,
so
there
is
no
fourth,
doesn't
the
only
free
examples
not
for
anyway,
so
we
have
analyzed
all
of
them,
and
we
came
with
a
few
preliminary
conclusions
on
several
questions
that
I
would
like
now
to
introduce
you.
They
are
not
in
the
document,
so
the
first
of
all
I
would
like
to
do
a
reminder
before
going
into
the
details.
B
We
need
to
understand
that
what,
while
looking
here
is
an
API
for
a
low-level
correction,
low-level
quake
will
include
a
certain
number
of
mechanisms,
but
certainly
not
all
of
them.
A
lot
of
stuff
will
remain
in
the
color
in
the
application
or
in
the
protocol.
That
will
use
this
low-level
correct.
So
we
are
the
correct
API
in
between,
but
a
lot
of
stuff
will
be
out
of
scope
for
this
API,
so
you
will
see
in
the
future
slides
some
of
them.
Some
of
the
questions
that
we
try
to
answer
are
really
dedicated
to.
B
B
So
the
first
question
is:
what
type
of
codec
should
we
focus
on
so,
of
course
we
need
to
have
something
which
is
as
generic
as
possible.
That's
the
title.
That's
goal,
but
we
add
we
need
to
take
an
important
decision.
Should
we
consider
poof
block
cuts
and
sliding
window
cuts
or
not.
We
discussed
that
together.
B
If
we
look
at
what
has
been
done
in
those
four
implementations,
you
will
see
that
three
of
them
concern
only
it
sliding
focus
only
on
sliding
window
cuts.
There
is
only
one
of
them
that
encompasses
both
block
cuts
and
sliding
window
cuts,
and
we
discussed,
and
for
the
moment
we
came
to
the
conclusion
that
we
should
focus
on
sliding
window
cuts
only
so
this
API,
which
should
be
an
API
for
sliding,
will
occurs.
B
F
B
Yeah
we
add
that
in
mind
some
parts
of
time.
Of
course,
a
block
code
is
a
sliding
window.
That
does
not
slide
so
there's
some
equivalence
from
this
point
of
view.
But
when
you
go
into
details
of
the
API
for
the
moments,
we
didn't
find
any
satisfying
manner
to
manage
both
in
this
in
a
unified
way
that
differences
technical
differences
and
when
you
try
to
to
address
them,
you
you
will
quickly
enter
into
problems
and
for
the
moment
we
have
no
solution.
Maybe
there
is
one,
but
we
I
didn't
find
them.
G
G
The
other
aspect
is
that
sometimes
you
get
implementations
which
start
out
as
a
block
code,
but
then,
because
of
the
way,
acknowledgments
are
managed
really
start.
Looking
very
much
like
a
sliding
window.
So
I
think
it's
important
to
realize
that
there's
really
quite
a
continuum
with
again
I
think
a
considerable
literature
behind
it
that
wouldn't
want
us
to
dismiss.
B
Yes,
there
is
a
continuum
but,
as
I
said,
when
you
go
into
details
and
want
to
design
an
API,
it's
not
that
easy
to
find
a
solution
that
encompasses
both
block
and
sliding-window
codes.
That
is
attractive
and
simple.
That
remains
simple,
even
for
a
particular
case
of
block
codes.
So
it's
a
very
practical
question
and
we
need
to
go
into
practical
considerations
yeah,
but,
yes
for
sure,
there's
a
continuum.
G
B
B
Second
question
is
now
one
of
those
questions.
Where
should
you
do
that
feature?
Will
it
be
inside
the
code
actually
be
on
top
of
the
collection?
So
should
the
API
consider
this
or
not
so
that's.
The
first
example
should
be
ad
you.
So
the
a
view
is
the
application
that
I
need
the
message
from
the
application.
Let's
say:
should
this
ad
you
to
source
symbols,
mapping
be
done
inside
the
codec
or
on
top
of
the
codec.
B
Should
the
API
consider
only
source
symbols,
Reaper
symbols,
which
is
the
conclusion
if
we
do
that
only
on
top
of
the
codec,
if
you
do
this
mapping
on
top
of
the
collec,
since,
in
that
case
the
API
will
only
see
and
consider
symbols,
or
should
this
be
inside
the
codec,
the
opposite
solution?
We
had
some
discussion,
there
are
impacts
in
terms
of
implementation
complexity.
B
This
mapping
is
not
trivial.
There
is
some
complexity
associated
to
this
mapping,
so
it's
once
again
an
important
question,
so
we
came
for
the
conclusion
for
now
after
discussing
that
should
be
done
by
the
color
outside
of
the
clique
to
keep
this
Killick
as
simple
as
possible.
The
a
consequence
is,
of
course,
comments.
No.
B
So
this
is
the
drawing,
so
on
top
of
the
correct
means
outside
of
the
API
so
yeah
in
this
example.
If
we
do
this
mapping
inside
the
protocol
inside
the
the
application,
let's
say
that
uses
the
codec.
The
codec
will
only
consider
symbols
because
this
mapping
will
be
done
before
entering
so
coming
back
to
the
format
discussion.
Just
for
a
second.
F
F
A
B
B
There
are
consequences.
This
is
once
again
a
very
important
question,
because
when
you
design
effect
scheme,
this
is
not
only
the
correct
part.
The
encoding
and
decoding
part
is
also
the
signaling
part
that
is
required
to
you
this
correct.
So
this
answer
in
this
question
will
also
answer
the
question:
does
the
codec
input
does
the
API
implements
a
fact
scheme
or
just
a
codec?
B
So
we
had
some
discussion
and
for
the
moment
our
position
is
that
once
again
we
keep
the
codec
as
simple
as
possible,
focusing
only
an
encoding,
encoding
and
decoding
sorry
and
leave
this
packet
error,
manipulation,
creation,
processing,
passing
inside
the
application
on
top
of
the
API.
So
that's
our
position
for
the
moment.
B
Fourth,
question
asked:
you
have
five
minutes:
should
the
codec
once
again
same
cat
same
type
of
question?
Should
the
codec
take
into
consideration
timing
aspects?
So
if
you
are
manipulating
real-time
flow,
there
is
a
limited
validity
duration
for
each
of
the
piece
of
information
that
you
will
send
to
the
receiver.
So
should
the
correct
should
be
yes
to
the
correct
and
the
API.
B
Where
are
those
tiny
aspects
or
not?
Once
again,
it's
as
implications
on
the
API
point
of
view,
because
that,
typically
with
slamming
window
codes,
whereas
this
distinction
between
decoding
window,
which
is
which
needs
to
consider
timing
aspects
and
linear
system
size
which
does
not
consider
tiny
aspect,
so
there
are
consequences
once
again.
I
don't
want
to
go
too
much
into
the
details,
but
the
implications.
So
we
add
once
again
our
discussion
and
for
the
moment
our
position
is
that
this
should
be
done
inside
inside
the
application
on
top
of
the
API.
B
Five
fifth
question:
this
is
especially
a
question
for
you
Dave,
and
you
you
mentioned
at
previous
ITF-
that
it
should
be
nice
to
take
into
consideration
other
constraints.
That's
a
very
good
point.
We,
but
unfortunately
none
of
us
has
any
sufficient
experience
in
the
domain
to
see
what
it
means.
What
are
the
implications
and
therefore
to
design
this
in
an
appropriate
way
or
avoid
some
mistakes
that
might
be
done
if
we
don't
keep
that
in
mind.
So
if
anybody
has
an
opinion
on
these
examples
ins,
then
we
would
appreciate
that.
B
F
F
Out
so,
if
you're
doing
the
coding
on
an
FPGA
yet
and
the
application
is
running
on
the
CPU
yeah,
if
the
API
is
passing
individual
symbols
back
and
forth,
uncoded
symbols
decoded
symbols
over
that
API
between
the
hardware
and
the
software
right.
It
won't
work
well,
so
you
have
to
consider
an
API
in
which
there's
inherent
ability
to
do
batching,
I
guess
so
that
so
that
the
interaction
this
is
the
control
interaction
with
the
hardware
can
operate
over
a
reasonably
large
number
of
input,
symbols
and
output,
symbols.
Okay,.
B
Okay,
that's
the
key
points
to
keep
in
mind.
Yeah,
okay,
I
will
probably
get
in
touch
with
you
to
try
fine
more
precisely
this.
But
yes,
yes,
thank
you.
Thank
you
very
much.
So
quick
final
slide.
To
summarize,
we
need
to
make
choices.
Those
choices
as
have
implications.
It's
not
obvious
to
see
what
are
all
the
implications
of
each
of
those
choices.
B
A
L
B
K
K
B
But
you
should
do
that
in
the
application
in
the
protocol,
not
in
the
collection
correct
when
whether
you
see
when
a
new
saw
symbol
has
been
decoded,
then
the
codec
will
give
it
back
to
the
application.
And
so
the
timing
will
be
that
the
wrong
timing.
When
this
happens.
But
if
you
have
a
maybe
you
are
running.
K
G
More
send
it
to
the
list.
Okay,
great
I
just
wanted
to
point
out
that
the
the
this
actually
announcer
I
think
to
the
question
that
was
being
asked
about
whether
there
are
implementations
there
are
FPGA
implementations
of
that
my
lab
did
with
the
lab
of
Anantha
Chandra
Carson,
our
current
Dean
of
engineering
on
FPGA.
We
also
have
done
this
in
with
a
you
know,
sponsored
by
the
semiconductor
Research
Council.
We
there
is
a
chip
implementation
of
network,
a
lot
of
and
by
the
way,
I
asked
answering
him,
and
you
has
a
question.
A
B
I
Basically,
the
problem
is
that
the
thing
is
interactions
between
net
recording
and
congestion
control
could
be
done
in
many
working
groups
at
the
IETF.
So
why
could
we
start
it
here?
First
T
is
that
we
have
already
Network
coding
and
congestion
control
interaction,
solutions
existing
and
also
the
discussion
needs
to
start
somewhere
anyway,
then
see
where
you
go
forward
through
the
objective
of
these
five-minute
discussions
that
may
be
worth
having
on
the
list
afterwards
is
to
see
whether
we
make
a
group
document
here
or
we
just
peek
I,
know,
I.
I
Control
scheme
at
the
consequence,
and
also
depending
on
I,
will
present
after
this
catch
a
use
case,
draft
on
network
ligand
satellites
and
the
problem
that
we
see
that,
depending
on
the
use
case,
because
network
coding
is
a
building
block
that
you
can
deploy
and
depending
on
the
use
case
and
the
traffic
you're,
considering
you
have
lots
of
different
possibilities
and
the
same
happens
here.
Sometimes
there's
no
point
in
actually
having
interactions
between
these
two
catch
country,
control
and
intercutting.
I
So
next
slide,
please
it's
just
example
on
what
is
it
that's
at
the
moment,
for
example,
we
have
things
that
are
at
the
user
space
and
we
already
have
quick
with
some
sort
of
network
coding.
We
can
do
some
middleware
network
coding
as
well
and
in
the
kernel.
These
are
examples
of
the
what
you
can
basically
be
below
a
transport
layer
and
have
no
interactions
at
all
with
TCP
you
can
have
as
well.
I
B
N
Now
that
might
not
actually
see
the
coding,
but
it
might
still
interact
with
the
congestion
controller,
that's
running
and
end
because
you
know,
for
example,
if
you
run
in
cubic
like
you,
don't
see
any
loss,
you're
like
oh
everything's,
going
great
and
you'd
like
get
some
huge
window
and
suddenly
it
explodes
and
goes
very
poorly.
So
it
may
almost
be
an
interaction
with
like
a
QM
as
a
secondary
layer,
I
guess
trying
to
figure
out
what
the
scope
is.
N
B
Always
discussions
but
well
Korean
vessels,
congestion
control
and
if
this
document
called
where
I
explained,
among
other
things,
that
K
we
can
do
things
in
an
intelligent
way.
Where
coding
will
not
negatively
impact
congestion,
control,
break
everything,
then
that
could
be
also
one
of
the
goals.
So.
F
So
if
you
have
a
static,
if
you
have
a
static
coding,
you'll
do
different
things
that
the
congestion
control
is
above
the
coding
then
below
the
coding.
But
if
you
have
a
dynamic
adjustment
of
the
coding
level
based
on
a
perception
of
loss,
things
get
really
complicated
and
I
don't
know
the
answer,
but
there's
not
enough
expertise
either
in
a
classic
congestion
control,
transport
group
or
in
a
coding
group
like
your
to
deal
with
that.
So
I
think
it's
a
really
good
research
problem
and
we
need
expertise
from
both
sides
to
deal
with
it.
F
O
Mr.
Dawkins
says
responsible
area
director
for
the
quick
working
group,
the
those
guys
are
encoding
everything
and
then
well
anyway.
Some
of
them
are
sitting
in
this
room,
so
there
I
know
there
is
communication
back
and
forth,
but
you
perhaps
perhaps
dropping
a
note
to
the
quick
chairs
would
be.
It
would
be
a
useful
thing
to
do
just
to
make
sure
so
that
they
can
make
sure
that
the
right
people
are
involved
from
that
side.
Thank
you.
Thank.
I
I
O
A
G
A
A
N
D
B
D
B
G
B
P
N
B
A
A
N
At
least
yes,
thank
you.
Okay,
sorry,
there's
another
kind
of
conversation.
Now
we're
coding
and
quick.
We've
talked
a
little
bit
back
and
forth
of
both
like
how
this
could
be
done
in
a
v2,
I
v1
was
done
and
I
Google
quick
a
long
time
ago
that
didn't
really
work
out
for
various
reasons
which
I
talked
about
in
previous
sessions.
N
So
I
I
want
to
say
that,
for
the
record
you
know,
I
know
a
fair
amount,
quick
as
a
transport
I'm,
not
a
coding
expert.
So
as
much
as
anything,
this
is
an
effort
to
kind
of
design,
an
architecture
that
would
fit
best
with
the
quick
transport
next
slide.
So
the
top
level
requirements
number
one.
We
don't
want
to
actually
change
quick
p1.
The
current
proposal
is
to
use
the
extension
mechanism
where
rude,
negotiate,
one
or
more.
You
know
forward
error
correction
frames
for
use
inside
quick
as
additional
frames.
N
N
Ideally,
they
would
all
have
the
same
base
frame,
but
the
actual
order,
correction
algorithm
being
used
would
be
different
depending
on
the
extension
tag,
and
you
know
you
potentially,
you
could
even
negotiate
like
two
or
three
if
that
was
suitable,
so
this
design
mostly
focuses
on
coding
taking
place
within
the
stream
or
across
multiple
streams,
so
kind
of
focusing
on
the
data
actually
being
delivered
as
a
few
slides
later
about
kind
of.
Why
we're
we're
shifting
in
that
direction?
N
But
the
key
thing
is
not
all
streams
actually
need
to
be
coded,
so
you
know
doing
it
on
a
packet
layer
is
less
natural
control
frames
usually
are
and
is
latency
sensitive,
and
it
also
may
just
fit
with
the
quick
extension
mechanism
a
little
more
seamlessly
and
it's
going
to
be
and
end
is
the
design.
So
quick
has
ended
and
pretty
much
everything
else.
Quick
is
encrypted
and
end
and
so
doing
coding
engined
is
the
most
natural
thing.
N
One
could
certainly
implement
a
middle
box
that
you
know
shared
the
ephemeral
keys
and
like
did
coding
within
the
network.
That
seems
extraordinarily
challenging
and
I
can
imagine
it
actually
be
worth
the
effort.
But
you
know
this
just
fits
into
visit
on
principle,
so
quick,
much
more
naturally
and
yeah
coding
happens
before
encryption,
because
it's
but
then
the
encrypted.
He
live
next
slide
yeah.
So
some
streams
may
need
to
be
coded.
N
Some
may
not
so
we're
gonna
negotiate
what
kind
of
algorithms
are
available
and
the
quick
handshake
the
PRI
mentioned
is
one
way
to
do
it
and
then
the
application
it's
a
it's
awful
desired
like
this
is
very
high
priority
or
maybe
I
have
extra
bandwidth
or
something
and
try
to
provide
some
signal.
Even
in
quit.
Today
we
actually
have
what's
called
like
a
bandwidth.
N
F
N
It
is
to
define
a
new
quick
base
frame
that
all
of
these
various
coded
approaches
you
could
use.
The
simple
version
would
have
a
type
assumed
ID
and
offset
into
the
stream
of
what
you're
trying
to
protect
and
recover
from,
and
then
add
a
the
length
of
the
number
of
bytes
of
code
and
within
it
you
know.
N
N
However,
we
can't
change
the
packet
numbers
or
we
don't
want
to
in
such
a
scheme,
but
we
do
want
to
allow
things
like
non-consecutive
packet
protection,
because
you
know
maybe
some
packets
are
important
and
others
are
not.
For
previous
reasons,
we
can,
you
know,
have
issues
with
things
like
path:
migration
which
caused
you
like
huge
jumps
and
packet
number
space,
and
so
in
general,
like
the
interaction
between
the
packet
numbering
and
the
code
and
kind
of
could
become
a
little
messy
in
some
edge
cases
that
we
thought
we
didn't
really
want
to
do.
N
One
of
the
worst
issues
is
actually
that
all
of
these
schemes
have
overhead.
You
know
it's
not
necessarily
huge,
but
it
is
so
amount
of
over
in
and
in
order
to
have
kind
of
one
coded
packet
that
protects.
You
know
some
number
of
other
packets.
The
natural
thing
is,
to
just
add
the
extra
overhead
to
the
one
that
has
the
coding
frame.
N
However,
that
would
blow
over
your
MTU
if
you're,
not
careful
so
then
you'd
have
to
under
fill
a
huge
number
of
other
packets,
which
also
in
turn
reveals
like
the
using
coding
to
the
path
and
is
generally
just
kind
of
a
little
bit
messy
multipath
makes
this
sort
of
worse,
not
better,
so
we're
kind
of
getting
away
from
that,
even
though
it
seemed
to
originally
like
the
the
most
obvious
way
to
do
things,
because
that's
how
quick
loss
recovery
works.
Also,
quick
loss
recovery
is
moving
away
from
being
packet
based
and
more
oriented
around.
N
Like
the
data.
That's
within
it,
then
TCP
style
loss
recovery
is
anyway,
so
the
new
idea
is
to
use
an
extension
frame
that
references,
one
or
more
streams,
as
I
said,
only
protects
latency
sensitive
data.
The
nice
part
about
an
approach
like
this
is
the
quick
RT
has
send
and
receive
buffers
that
you
can
base
this
on
and
so
to
a
large
extent,
it's
fairly
easy
to
access
the
existing
buffered
memory
kind
of
as
part
of
your
input
to
do
the
recovery,
so
it
flows
pretty
natural
from
like
an
architectural
perspective.
Worship,
that's
the
idea.
N
The
newer
idea,
which
is
suggested
by
christian
Hakuba,
also
an
active
participant
in
the
quick
working
group,
was
to
you
know,
at
least
for
a
prototype
purposes,
just
to
find
an
extension
frame
that
replaces
a
stream
with
you
know
some
combination
of
actual
data
and
coded
data,
and
you
know,
define
a
to
find
a
way
on
a
algorithm
basis
to
make
that
happen
and
just
kind
of
do
whatever
you
want
nice
part
about
this.
Is
it
really
allows
you
to
use
any
type
of
code?
N
You
could
possibly
imagine
it
avoids
interacting
with
quick
loss
recovery,
because
it's
not
a
stream,
so
clicks
not
going
to
actually
retransmit
it
for
you,
it's
just
going
to
declare
it
lost
and
you
can
do
whatever
you
want
and
yeah.
It
allows
maximum
experimentation
because
it
sort
of
offers,
but
it
also
you
know,
means
you
have
to
kind
of
roll
your
own
to
the
maximalist,
and
so
maximum
flexibility
and
maximum
work.
I
think
on
the
part
of
the
experimenter
next
slide.
N
So
first
step
is:
we
need
to
kind
of
figure
out
how
the
extension
mechanism
a
we
have
tool
and
the
extension
mechanism
quick
B.
We
have
to
figure
out
how
we're
actually
going
to
use
it
to
negotiate
multiple
different
coding
schemes.
We
need
to
choose
one
or
more
sample
codes.
You
know,
raptor
is
now.
The
original
version
of
raptor
is
not
encumbered.
Anymore
is
my
understanding,
so
that
certainly
could
be
an
option.
Reeth
Solomon
has
open
source
implementations
which
are
fairly
good.
N
You
know,
obviously,
those
are
two
very
different
types
of
codes,
but
so
it
would
be
sufficient
for
the
purposes
of
a
demo
or
something
and
then
implement
in
Pico,
quick
or
one
of
the
various
other
quick
stats.
Pico
quick
is
Christian
portion
stack
and
he
you
seemed
interested
in
actually
writing
code,
which
would
be
an
extremely
helpful
part
of
this
process,
because
my
extra
time
to
writing
code
is
great.
N
Code
is
sort
of
limited
these
days
next,
we'd
like
to
agree
on
an
API
that
we're
gonna
use,
so
we
can
allow
multiple
different
types
of
for
error.
Correction
algorithms
to
be
used
within
quick
I
would
ideally
you
know
we
defined
kind
of
a
basic
infrastructure
of
this
is
approximately
how
you
should
do
this,
and
then
we,
you
know
just
different
algorithms.
Would
negotiate
I,
don't
know
if
you
know
Vincent's
proposed
API
is
the
right
one.
N
It
certainly
does
restrict
some
types
of
codes,
so
it's
not
as
expensive
as
it
could
be,
but
it
also
may
be
fairly
applicable
if
we're
focusing
on
protecting
stream
data.
So
I
think
that's
something
we
kind
of
need
to
work
out
through
some
combination
of
experimentation,
and
you
know
feedback
from
this
group
and
the
quick
working
group
of
others
and
next
steps
is
this.
N
A
research
group
item
is
this:
something
we
eventually
want
to
migrate
to
quick
or
last
option
is:
maybe
we
should
just
run
some
more
experiments
and
come
back
in
you
know
for
eight
months
and
tell
you
what
we've
done.
Oh
yeah,
and
thank
you
for
your
help,
bring
the
document
on
the
cutting
aspects.
I
yeah.
A
N
I'd,
like
some
feedback,
also
on
the
transition
from
a
packet
based
to
a
stream
based
kind
of
direction,
and
whether
there
are
any
reasons
people
believe
that's
a
bad
direction
as
well
as
suggestions
on
the
API
question.
I.
Think
if
we're
gonna
have
a
very
flexible
API
for
plugging
this
and
these
algorithms
into
quick,
do
you
think
something
weapons?
Its
document
is
the
right
direction.
If
not,
should
we
be
considering
something
else
or
two
different
documents
or
two
different
frames
like
some
some
feedback,
there
would
be
great.
F
I,
don't
have
opinion
on
the
packet
versus
stream.
I
mean
quick
as
a
screen
protocol
most
aspect,
so
you
know,
and
we
better
it
had
better
work
well
in
at
modeling,
the
the
I/o
is
streams.
The
the
comment
I
wanted
to
make
is
we
things
may
work
out
a
lot
better.
If
we
try
to
do
this
at
the
same
time
and
in
coordination
with
the
way
we
do
multipath
if
those
two
things
start
happening
in
parallel,
without
sort
of
tight
cooperation,
you
know
there's
all
kinds
of
interesting
questions.
F
N
F
N
Q
We're
trying
to
ship
quick
version,
one
which
is
single
path
HTTP
only
and
and
we
are
trying
to
push
everything
away.
Dave
makes
a
good
point
right,
so
there's
synergies
here.
So
if
there's
a
lot
of
activity
on
quick
that
will
sort
of
begin
to
happen
once
v1
is
sort
of
stabilized
that
doesn't
mean
you
know,
I've
sees
out
it
made,
probably
is
going
to
happen
before
my
personal,
so
I
don't
really
know
if
we're
gonna
make
the
November
deadline,
but
my
guess
is
sort
of
within
the
three
months
window
around
at
that
time.
Q
When
we're
gonna
ship
it
finally
to
D
is
GU.
People
will
already
start
to
think
about
multipath
I'm,
probably
already
started.
Think
now,
all
right,
they're
still
Ivanka
is
for
example,
but
the
working
group
has
no
mind
chair
for
any
of
this
at
the
moment
there
doesn't
that
shouldn't.
Stop
you
guys
from
thinking
about
this
right,
but
but
don't
even
think
of
sending
his
email
time
before
you
have
all
jobs.
Don't
take
mine
chair.
L
And
I
good
money
so
Cedric
to
know
from
experience
so
I'm
working
for
I'm
coming
from
a
different
world
from
free
GBP
world
and
we're
using
righto
code
and
we're
using
righto
code
for
RTP,
and
we
are
doing
a
different
stream
so
differently.
The
approach
where
you
got
one
IP,
one
stream,
which
is
just
for
the
coded
data,
makes
sense,
especially
if
you
want
to
keep
kind
of
compatibility
with
a
RTP.
So
this
is
something
that
we
experiment
in
3gpp.
A
I
Hello
again,
this
is
just
tattoos
on
what
we
have
been
doing:
internet,
recording
and
satellite
draft.
Since
the
last
IETF
we
have
six
minutes
left,
so
I
will
be
quick
and
next
slide.
Please.
Basically,
what
I
wanted
to
show
in
this
slide
is
that
we
had
initial
objectives
with
this
document
and
we
have
been
doing
something
different.
I
So
next
slide,
please,
we
have
had
one
good
review
from
Tommaso
and
also
we
have
these
different
use
cases
and
that
we
go
through
these
use
cases
now
and
we
have
been
there
wasn't
much
invidious
cases
before
and
now
we
have
lots
of
lots
more
context,
and
there
are
some
missing
points
here.
So
next
slide.
Please
we
don't
have
much
time
and
I.
Think
I
will
just
show
you
here
what
we
have
in
the
document,
but
mostly
focus
for
the
end
of
the
presentation
where
we
may
have
some
discussions.
I
But
basically
this
is
the
use
case
when
you
have
two
satellite
terminals
which
are
under
the
same
beam
and
that
King
to
each
other,
and
basically
that
I
terminal
earthen
faith
and
a
beef
and
B,
and
then
the
satellite
combines
o2
and
send
the
combinations
of
the
two
signals
on
each
of
them.
Basically,
that
can
results
in
huge
bandwidth
savings
and
that
has
been
demonstrated
in
a
SMS,
2010
2010.
I
You
have
large
beans
that
you
can
cover
lots
of
terminals,
but
the
problem
is
that
when
you
want
to
have
a
reliable
transmission,
this
is
the
type
of
mechanism
that
you
can
use
and
basically
we
have
two
terminals
that
are
on
listening
to
the
same
multicast
server
and
both
terminal
can
send
what
packets
haven't
been
receiving
and
then
on
the
musical
server.
You
have
some
network
coding
mechanisms
that
resends
what
have
not
been
acknowledged
by
everyone
if
you've
already
implemented
in
norm,
but
actually
it's
not
the
same
coding
technique
that
can
be
used
in
norm.
I
Another
one
refers
to
what
has
been
presented
in
TCP
M
couple
of
days
ago,
where,
basically,
you
have
this
sort
of
concentrator
that
lets.
You
have
a
real
axis
of
multiple
technologies,
so
there
have
been
lots
of
research
activities
on
how
you
can
actually
use
network
coding
for
that
when
you
have
packets
that
are
lost
on
one
path
or
the
other,
you
can
actually
recover
them
by
using
you
don't
have
to
wait
for
the
packets
to
be
actually
which
it
starts
to
be
actually
acknowledged
on
the
path.
Actually
we
found
it.
I
This
is
something
that
is
missing
in
the
current
version
of
the
draft,
but
we
have
been
discussed
discussing
wizards
cut
earlier
this
week
radically.
This
is
the
use
case
of
delete
or
events.
Networking
for
those
who
don't
know
these
network
architecture
is,
might
be
somehow
different
to
what
you
may
know.
Basically
to
make
it
quickly.
We
have
the
bundle
protocol
and
underneath
we
have
these
conventions
layer
and
we
have
different
possibilities
of
including
networking
in
this
type
of
architecture.
I
I
I
Then
you
have
burst
losses
that
can
be
recovered
by
using
network
coding
schemes
at
higher
layer
than
the
physical
layer,
and
also
there
was
interesting
presentation
in
the
plenary
on
satellite
communication
and
basically,
we
are
actually
targeting
for
very
high
bandwidth,
optical
links
in
satellite
systems
and
that's
what
the
future
is
envisioned
at
the
moment
and
in
these
bandwidth
we
have
huge
valuations
so
introducing
network
coding
as
a
physical
layer
may
not
be
enough
in
the
near
future.
So
that
is
actually
interesting
for
even
fixed.
Tell
you
that
comm
telecommunications
tomorrow.
I
That's
also
another
use
case,
I
think
the
best
one
that
we
have.
Basically,
you
have
when
you
typically
have
an
an
internet
satellite
access
over
the
Europe.
You
actually
have
thousands
of
Gateway,
and
sometimes
where
you
have
channel
conditions,
are
bad.
You
want
to
switch
from
one
way
to
another
and
if
your
gateways
are
not
actually
properly
synchronized
that
may
results
in
packet
losses
and
network
coding
could
be
applied
at
different
layers
here
as
well
to
actually
improve
and
cop
from
the
losses
that
may
happen
when
the
Gateway
they
are
not
synchronized.
I
This
is
an
illustration
of
what
we
have
been
doing
with
the
manual
Lucia
ink
Ness.
We
have
an
open
platform
for
Austin,
whatever
that
con
experiments.
If
you
want
it
reads
a
variable,
we
have
lots
of
different
access
and
this
is
a
SATCOM
internet,
fixed
access
and
we
have
been
comparing
the
suit
put
of
TCP
communication
with
and
without
network
coding,
and
basically
what
we
can
see
on
the
right.
I
If
the
TCP
good
put
over
the
time
and
with
the
TCP
with
tetris,
you
have
actually
a
better
usage
of
the
channel
capacity
we
had
it
was.
We
were
lucky
because
when
we
were
doing
the
experiments,
it
was
a
rainy
day.
That's
when
we
actually
have
firing
cap
at
the
hang
capacity,
and
so
we
had
losses
and
was
not
actually
perfectly
working,
and
so
we
show
that
with
network
coding,
you
have
a
better
good
put.
I
That
being
said,
we
don't
speak
about
the
fairness
of
the
collision
control
because
it's
clear
that
when
you
send
more
data,
you
have
a
better
good
boot,
but
you
know
we
didn't,
has
impact
on
the
whole
other
users
that
only
enable
collision,
control
and
I
think
that's
more
interesting
for
the
congestion
control
potential,
soon-to-be
document
and
I
think
that
that's
it.
We
have
had
a
discussion
also
in
the
document
on
the
deployability
of
network
coding
schemes,
format,
sacrum
systems.
I
The
network
coding
scheme
that
you
would
deploy
is
not
the
same.
The
and
radically
what
I
wanted
to
say
mostly
is
about
the
virtualization
infrastructure
we
have
been.
What
we
are
doing
in
SATCOM
at
the
moment
is
the
same
as
what
is
acting
in
the
I
forgot,
the
name
of
the
draft
that
is
pointed
out
here
radically.
We
have
virtualized
infrastructure
where
you
can
actually
deploy
network
calling
functions
easily,
so
that
is
where
I
think
there
are
interactions
between
what
is
happening
in
other
working
groups
working
with
virtualization.
I
That's
it
the
what
we
we
have
not
actually
fulfilled
the
initial
objectives
that
we
had
on
the
document.
What
we
actually
doing
is
show
lots
of
use
cases
where
networking
is
important
and
interesting
for
satellite
communications.
We
also
have
some
discussions
on
how
we
could
easily
deploy
these
schemes
and
we
think
that
we
don't.
We
are
actually
not
sure
at
the
moment
how
to
progress
further
on
this
document.
Should
we
detail
the
use
cases
and
go
much
more
into
the
details
on
what
network
coding
schemes
is
relevant
or
not,
I
think
it's
not
the
case.
I
Maybe
what
we
could
do
is
look
at
the
network
coding
proposals
in
the
group
and
see
which
one
are
relevant
and
could
be
used
for
the
use
cases
we
proposed
and
we
have
been
trying
to
find
some
industry
or
interest
because
we
are
not
industry
and
we
are.
We
are
interacting
with
some
equipment
providers
or
psycho
operators
to
see
they
are
interesting
in
collaborating
this
draft.
I
G
No
thank
you.
That
is
a
very,
very
good
presentation
that
I
really
like
taxonomy
of
the
different
problems.
I
just
wanted
to
say
I-
might
go
ahead
and
share
a
white
paper
that
we
have
written
regarding
one
of
the
points
that
you
brought
up
around
dealing
with
failures
that
are
not
manageable
by
the
physical
layer
growth
I'll
be
putting
that
away
also
might
want
to
share
with
the
chairs
permission.
We
we
have
a
paper
with
decent
cloud,
was
now
adobe
labs
and
also
with
Doug
leaf
of
Trinity
College
Dublin
on
network
coding
for
SATCOM.
G
Lessons
learned
and
I
think
that
that
paper,
which
sent
a
couple
years
ago,
just
go
into
a
lot
of
these
things
and
I
also
wanted
to
point
out
some
of
the
some
of
the
testing
that
we've
been
doing
with
ocean
wolf
and
also
with
ISPs
in
the
Pacific
to
provide
to
provide
for
bandwidth,
starved
cities,
towns
and
islands
in
the
Pacific.
A
network
coding
based
satellite
internet
connectivity.
So
you
know
I,
don't
want
to
deluge
the
group,
but
I'd
be
happy
to
share
those.
G
B
M
M
So,
at
the
previous
meeting
at
the
networking
research
group
and
Sen
research
group,
we
introduced
our
initial
draft
regarding
the
its
background
and
content.
So
then
we
got
some
comments
regarding
a
relationship
between
the
kanji
information
ahead
and
the
security
and
over
and
comment
about
the
design
choice
regarding
food
determines
a
encoding
vector
to
generate
the
Kalinda
packet
and
its
impact
on
latency
and
the
comments
about
the
clarification
of
the
objective
and
the
scope
of
this
document.
C
M
So
this
objective-
the
objective
of
this
draft
aids
to
consider
research
challenges
other
whether
we
want
to
gather
under
the
research
results
to
establish
the
common
understanding
about
network
coding
for
CCM,
and
we
want
to
clarify
the
requirements
for
networking
for
Chien
and
for
hope,
free.
We
want
to
provide
a
useful
insights
to
network
orders
in
order
to
make
it
easier
to
apply
and
implement
network
honing
in
to
shishya
and
EMM,
so
now
actual
protocol
proposal
to
satisfy
the
requirement
is
out
of
the
scope
of
this
document.
But
we
will.
M
We
will
propose
a
actual
protocol
based
based
on
our
propelled
in
as
a
draft,
so
here
the
table
table
of
content,
current
content,
so
in
Section
two
we
introduced
incision
and
knee
and
background
and
its
basis
and
thus
accessory.
We
which
show
the
existing
prominent
researcher
desert
and
clarify
the
benefits
of
using
initiation
using
network
calling
in
shisha,
and
we
we
modify
the
section
for
content.
Naming
and
publish
up
additional
code
uses
a
feedback
from
previous
meeting
and
we
also
added
a
new
description
regarding
the
adopting
commercial
column
as
a
research
challenges.
M
So
there
was
no
discussion
about
network
coding,
Prospero
the
encryption
in
the
previous
documents,
so
we
added
the
case
of
we.
We
added
the
kitten
we're
coding.
Information
is
specified
at
the
meta
field,
not
to
engine
name
and
the
the
information
is
anchor
puted
together
with
they
wrote
and
the
way
discovery
it
feature
the
trees.
M
This
may
make
it
more
difficult
to
lay
anchored
at
mean
intermediate
or
not
in
terms
of
the
competent
computational
overhead
for
description,
the
coefficient
okay-
and
we
clarify
the
scenario
where
producer
statically
decides
a
ankeny
vector
to
generate
a
collet
packet,
and
we
describe
its
feature
in
this
case.
Latency
can
be
reduced
compared
to
the
case
where
a
consumer
determines
included,
encoding
vector
to
be
used
and
better.
In
this
case,
canta
to
register
need
to
obtain
the
name.
M
Get
clear
to
the
request:
it's
a
drawbacks
and
we
are
we
added.
We
modify
the
challenge
for
adopting
commercial
coding.
We
added
an
example
and
the
benefit
of
adopting
confusional
coding
approach
in
the
end
basis,
and
we
we
consider
research
challenges
such
as
how
to
fry
eight
into
she
in
terms
of
the
signaling
aspect
and
how
to
exploit
a
she
and
she
Sheehan
and
the
end
of
feature
to
enhance
performance
gain,
and
we
need
to
discuss
the
feasibility
and
the
practicality.
M
So
now
we
are
going
to,
we
are
going
to
design
the
commercial
Corning
and
to
apply
to
apply
into
a
shisha.
So
next
step
we
we
need
to
enhance
the
content
of
the
security
and
the
privacy
under
looting,
security,
monetary
and
Mary.
We
need
to
identify
identify
the
potential
research
challenge
if
we
use
for
and
then
we
we
were
starting
introducing
actual
protocol
proposal
and
we,
we
hope
free,
shows,
a
experimental
result
and
the
next
an
extra
meeting.
Thank
you.
A
B
G
G
B
B
B
C
Yeah,
so
this
is
it's
a
bit
different
perspective
of
network
coding
and
this
first
attempt
to
share
this
work
between
the
this
research
group
and
the
network
function.
Virtualization
research
group,
so
the
others
are
Romano.
Who
is
a
protocol
expert,
Luis,
Contreras
from
network
operator,
and
then
me
I'm
in
the
system
and
encoding.
So
it's
a
bit
interdisciplinary,
so
okay,
I
will
go
quickly.
C
So
what
we
have
our
basis
is
that
the
network
coding
can
be
seen
as
function
and
CF.
So
the
point
is
that,
under
the
network
software
each
station
point
of
view,
we
have
network
functions
which
are
basically
pieces
of
software.
We
should
be
efficiently
designed,
deploying
and
executed.
So
so
far
network
functions
were
just
as
small
set
of
functions
and
black
box
oriented
way
where
it
was
not
clear
how
they
were
they
could
be
implemented.
C
But
now
they
are
being
great,
has
a
great
development
by
different
vendors
for
many
types
of
applications
and
well
beyond
traditional
networking
functionalities.
So
then
this
is
our
point.
Network
coding
can
also
be
designed
as
a
network
cutting
function,
so
there
I
will
explain
now
and
how
it
will
be
the
rest
of
slides.
So
why
so?
There
can
be
many
explanations.
Our
preferred
foundation
is
that
there
are
two
distinguishing
features
in
network
coding
that
explain
why
seeing
them
as
a
function
makes
sense.
C
Hence,
with
this
transversal
application,
if
we
see
that
were
calling
as
a
network
in
function,
this
would
allow
us
implementing
network
coding
in
a
lot
of
cases,
just
thinking
of
them
as
software
pieces,
that
murabba
could
be
reused.
So
then
we
could
have
a
versatile
network
coding,
okay
way
of
applying,
which
can
be
also
modular,
understand,
provide
scalability
and
second,
also
a
distinguishing
feature
of
neural
coding
is
that
we
can
think
of
it
as
doing
a
mathematical
flow
engineering.
What
do
we
mean?
C
We
mean
that,
with
network
coding,
we
can
sit
like
a
packet
flows
interpreted
as
mathematical
objects.
As
we
know
here,
you
look
at
it
in
the
symbol,
perspective
micro,
symbol
perspective.
We
can
also
see
it
as
in
the
flow
sense.
So
then
you
can
see
this
that
the
network
coding
will
transfer
mathematically
the
flow
and
induces
properties
in
this
flow.
C
So
if
we
have
this
person
take
this
perspective
and
if
we
design
networking
functions
with
allowed
to
interpret
to
interpret
the
network
according
function
as
a
flow
engineering
service
which
then
can
be
given
by
network
operators
and
possibly
on
demand.
So
this
is
why,
then,
in
our
case,
we
do
have
use
cases
so
this
and
as
use
cases,
we
we
have
two
very
different
use
cases.
That
also
proves
our
case.
No,
our
arguments.
For
example,
we
have
this
european
space
agency
funded
project,
which
is
called
submit
code.
C
In
this
case,
we
do
a
very
typical
application
of
network
coding
for
improving
the
reliability
of
multicast.
We
use
rate
encoding
and
we
assume
overlay
hybrid
networks.
So
then
you
can
see
that
on
the
left,
you
can
you
we
have
just
the
satellite
as
a
as
a
physical
bent
pipe,
so
it's
almost
as
if
it
doesn't
exist
from
networking
point
of
view,
and
it
may
happen
that
for
this
case
we
have
very,
very
few
logical
nodes
that
need
to
re-encode.
C
Then
on
the
right.
You
have
that
the
the
network,
the
satellite,
is
also
a
encoder,
but
what
is
in
in
interest
here
is
that
you
see
that
we
need
to
control
the
operation
of
network
coding
all
along
that
the
topology
and
the
topology
itself
needs
to
be
demise.
So
all
these
controlling
thing
is
what
we
can
address
with
softer
ization
visualization.
C
Next,
then,
you
can
see
we
have
yet
another
completely
different
use
case,
which
is
the
use
of
networking
for
efficient
caching,
in
this
case,
while
in
the
other
case
it
was
another
relay
network,
we
have
here
a
broadcast,
also
hybrid
network,
where
the
satellite
is-
and
in
this
case
the
use
of
network
coding
is
for
the
efficient
multicast.
So
you
can
locate
that
they
they
populate
that
the
caching
efficiently.
So
it's
very
two
very
different
use
cases
where
our
ideas
can
apply
can
be
applied.
C
C
Blackbox
network
functions,
meaning
that
we
can
have
a
well-defined
functional
software
architecture
that
this
software
architecture
Maps
directly
to
solarized
network
architectures,
and
this
implies
centralized
controller,
which
is
a
little
bit
opposite
to
very
distribute
packet
networking
now,
even
if
we
propose
this
visible
internal
logic,
an
agreed
functional
software
architecture.
This
approach
also
enables
internal
interoperability
between
different
networking
functions,
because
you
can
still
have
blocks
that
are
proprietary,
so,
but
if
we
do
so,
we
can
prevent
the
stagnation
of
networking
ecosystems
doing
in
this
authorized.
Networking
due
to
that
everything
becomes
proprietary.
C
So
what
we
do
is
is
like
we
have
a
I'm,
a
protector
that
we
all
agree,
and
then
there
might
be
common
blocks
and
proprietary
blocks,
that
for
the
software
I
session
for
the
virtualization,
we
we
focus
on
on
integrating.
They
do
do
this
all
the
software
architectures
of
that
you
can
easily
integrate
in
a
virtual
network
functions
architectures
that
by
doing
these,
of
course,
you
can
take
advantage
of
a
unified
computation
approach
to
computational
network
sources.
C
We
proposed
to
have
to
present
here
and
the
other
network,
a
research
group,
so
then
what
we
have
proposed
is
that,
as
you
can
see,
this
presentation
is
different
to
the
previous
one.
Why?
Because
here
we
we
also
need
two
pi
system,
thinking
not
only
protocol.
Thinking,
for
this
reason
is
important
to
distinguish
in
which
domain
we
are
because
we
also
need
to
to
see
when
we
are
in
the
coding
domain,
meaning
design
of
code
books
and
coding
the
coding
schemes
in
too
difficult
or
which
performance
has
the
codes.
C
Then
we
have
the
functional
domain,
which
is
the
the
one
we're
talking
about
here
for
the
architecture
and
finally,
finally,
also
the
protocol
domain,
because
at
some
point
we
we
have
all
this
architecture,
but
we
need
protocols
to
be
operative,
so
so
what
it
in
this
draft
in
particular,
what
we
look
at
is
at
the
functional
domain.
What
are
the
functions
that
the
network
code
needs
so
in
this
domain?
C
So
for
this
software
architecture,
we,
what
we
have
done
is
to
distinguish
again
different
functional,
like
main
functional
components
of
the
software
Association
of
network
coding.
So
with
at
the
moment,
what
we
have
distinguished
at
this
three,
which
are
first
of
all
the
core
functionalities,
of
course,
which
is
coding,
recording
the
coding
functionalities
and
in
the
soft
look,
we
look
at
them
at
functionalities.
C
C
So
this,
for
this
means
that
we
will
be
using
these
types
of
network
code
is,
we
will
choose
depending
on
which
engineering
functionality
we
want
it
could
be,
it
could
be
a
congestion
control.
So
that's
why
I
wanted
to
make
the
point,
because
then
I
need
you
in
your
discussions
before
you
know.
We
are
like
a
logical
level
above
you
where
all
what
you
do
is
useful
for
us.
We
will
be
using
this,
so
this
might
also
mean
that
we
could
give
you
requirements,
for
example,
right
look.
We
need.
C
C
So
this
is
just
another,
since
we
are
system
thing
is
when
it
blocks
with
its
figures.
This
is
just
a
very
simple
way
to
to
see
that
we
have
in
the
software
architecture.
We
have
the
functions
that
will
map
directly
to
this
is
of
a
defined
network
architectures
and
today,
and
then
the
physical
structure,
functionalities.
C
Okay,
so
then
I
will
not
go
into
detail.
We
we,
we
do
have
four
readies
and
proposals
that
map
our
a
software
architecture
to
next
to
to
them
software-defined
network.
We
are
working
with
network
operator
on
this
to
have
the
key.
The
key
point
here
is
that
even
you
should
distinguish
the
the
nodes
which
will
Rhian
code
and
the
knows
that
only
transport,
the
the
coded
flow,
so
there
these
are
logical
differences
that
need
to.
We
don't
have
solutions
for
that.
So
this
is
what
we
are
looking
looking
into
here
so
this.
C
Finally,
what
are
I
just
now
described
ideas
so
identified
links
for
sure
with
the
visualization
research
group
and
the
moment
we
we
also
intend
to
have
the
same
presentation
here
and
there,
at
least
at
rest
are
with
and
then
also
with
drafts.
One
option
would
be
this
that
we
requirements
what
we
would
meet
from
this
higher
logic
point
of
view,
but
we
I
would
like
here
what
are
what
feedback
I
may
get.
What
this
useful
or
not
thank.
C
F
The
trade-offs
between
open
loop
and
close
loop
control,
because
most
of
these
naive
network
function,
chaining
sorts
of
things
only
consider
open
loop
control
and
for
a
lot
of
things
that
are
classically
done
with
NF.
You
don't
need
closed
loop
control
it
it
may
you
it
may
be
really
important
to
get
closed.
Loop
control
for
a
coding
application
where
that's.