►
From YouTube: IETF101-IRTFOPEN-20180321-0930
Description
IRTFOPEN meeting session at IETF101
2018/03/21 0930
https://datatracker.ietf.org/meeting/101/proceedings/
A
A
A
You
know,
because
you've
been
coming
to
research
groups,
that
we
have
research
groups
last
time,
if
you
were
here,
I
talked
about
how
they're
different
I'm
not
going
to
talk
about
that
this
time
and
that
we
have
an
IR
s
G
and
their
names,
and
all
that
information
is
on
the
IRT
F
dot.
Org
page
and
I've
noticed
that
some
people
don't
seem
to
know
this.
A
So
we've
got
a
couple
of
proposed
groups
in
process
now
the
the
den
group,
the
decentralized
internet
infrastructure,
which
really
should
be
called
deep.
It
subbed
in
and
path
aware
networking,
and
then
we
have
twelve
groups
all
together.
Counting
those
two
paths
aware
networking
had
their
third
meeting
yesterday
and
we
had
a
hum.
We
do
actually
Humphrey
can
because
who
doesn't
want
to
hum,
but
the
and
the
agreement
by
the
group
by
the
room
was
that
should
go
to
our
G
and
I
believe
it
will.
A
So
that's
something
another
bit
of
news
is
that
when
our
recent
group
gaya,
which
is
the
Internet
access
to
the
internet
for
all
globally,
is
having
they've
organized
helped
to
organize
with
the
IAB
the
technical
plenary
tonight.
So
there
are
three
gaya
themed
talks
and
they're
moderated
by
Jan
coffin
who's,
one
of
the
co-chairs
of
Gaia,
and
then
this
week,
everybody's
meeting
except
the
network
management
group.
A
We
we
do
feel
that
groups
should
meet
with
research
conferences
as
well
sometimes
and
they
they
regularly
meet
with
the
noms
conference
and
that's
what
they're
doing
and
then
today
you're
getting
the
first
look
at
a
potential
new
group,
which
is
the
quantum
internet
research
group
and
the
goal
here
is
to
have.
You
eventually
have
to
start
calling
yourself,
the
classical
internet
people,
if
you're
not
working
on
quantum,
so
we'll
see,
if
you're
convinced
of
that,
but
we'll
have
a
remote
speaker
on
that
shortly.
A
A
A
A
If
you
look
up
in
our
W
2018
or
look
at
the
I
RTF
page,
you
can
find
it
and
the
the
good
thing
is
that
you
can
either
submit
a
short
paper
like
a
couple
pages
of
something
that
says
hot
and
new,
or
you
can
submit
a
previously
published
paper
from
the
past
year.
So
you
don't
have
to
write
a
brand
new,
deep
12-page
research
paper.
A
A
If
you
want
to
get
more
involved,
you
probably
already
know
I
RTF,
discussed
and
announced,
and
we
have
wiki
links
for
all
the
research
groups
that
you
can
find
that
irth
orgs
a
mail
we
tweet
and
the
agenda
for
today
is
I'm
almost
done
and
then
rod.
Ben
meters
going
to
speak.
Stephanie
has
a
family
issue,
so
she
will
not
be
joining
us,
but
we
are
hoping.
A
These
are
the
two
proponents
for
that
research
group
and
they'll
rod
will
tell
you
about
how
to
get
more
involved
in
that,
and
then
we
have
our
applied
network
research
prize
talks
and
I'm
very
excited
about
those
now
introduce
those
when
we
get
there
so
I
think
we're
going
to
try
to
bring
rod
noise.
No,
let
me
tell
you
about
the
NRP
I'll
use
this
slide
when
when
we
come
back,
I
think
no.
Let's
do
it
now.
Sorry,
so
we
have
our
two
speakers
coming.
A
We
are
sponsored
the
the
AARP
provides
a
monetary
award
and
travel
funding
and
the
sponsors
that
make
that
possible
are
Comcast,
NBC,
Universal
and
the
Internet
Society.
So
thank
you
and
if
you
think,
you'd
like
to
sponsor,
please
let
me
know
get
in
touch
with
I
saw
for
myself
match
for
myself,
because
if
we
get
more
sponsorships,
we'll
bring
more
people
back
for
additional
meetings
to
allow
increased
engagement
and
I
wanted
to
say
also
that
we
have
a
wonderful
program.
Through
the
year
we
have
to
each
ITF.
A
We
had
the
largest
set
of
submissions
that
we've
ever
had
and
we
could
definitely
have
have
made
many
more
Awards
because
we
had
so
many
good
submissions,
so
I
think
you're
gonna
have
a
good
time
with
our
presentation
so
and
that's
it,
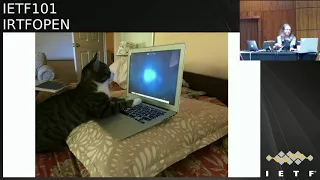
and
that
picture
is
to
tell
you
don't
be
like
that
cat.
Don't
read
your
mail
engage
during
our
meeting
and
it's
particularly
actually
for
the
art
research
group
chairs
who
who
should
look
around
and
if
you
see
people
being
like
that
cat,
you
probably
need
to
get
more
discussion
going.
B
B
Great,
so
thank
you
all
for
having
me
and
I'm
sorry
I'm,
not
actually
there
in
person.
I
would
love
to
be
in
London
with
you
all,
but
in
solidarity
with
the
the
whether
you're
having
there
we're
actually
having
snow
here
in
Japan.
Actually
in
Tokyo
for
the
first
day
of
spring,
we
planned
this
presentation.
Alison
asked
us
to
give
the
presentation,
based
on
the
email
that
she
and
Stephanie
I
had
exchanged
over
the
course
of
the
last
Oh.
B
This
was
actually
originally
her
idea
and
she
used
to
work
for
one
of
the
the
I
believe
for
an
ISP
and
the
Netherlands
before
actually
getting
involved
in
quantum
work.
So
she
and
I
both
have
a
long
history
with
actual
networking,
as
well
as
a
quantum
stuff.
So
that's
where
we
are
Allison.
Can
you
go
to
the
next
slide?
Please
I.
B
C
B
Okay,
so
was
mine.
He
is
actually
also
a
participant
in
IETF,
so
he's
one
of
the
other
people
who
actually
sits
right
at
this
border
of
quantum
and
classical
stuff.
So
after
I
go
offline
here
in
an
hour,
so
you
want.
You
can
track
down
shota
there
at
the
meeting
in
London
and
talk
to
him
about
it.
So
first
off
I
should
say
what
is
a
quantum
network
and
I
know
a
lot
of
people
in
the
room
are
already
familiar
with
quantum
key
distribution.
B
Quantum
key
distribution
is
a
way
to
use
quantum
effects,
to
create
a
shared
sequence
of
random
bits
that
the
physics
of
the
system
is
supposed
to
guarantee.
You
are
known
only
to
the
two
parties
at
the
endpoints,
and
then
you
can
use
that
set
of
random
bits
for
a
key,
a
key
for
IPSec
or
kls,
or
what
that's
the
easiest
way
to
implement.
B
If
it
works,
it
adds
to
the
longevity
of
the
secrecy
of
your
encrypted
information,
but
it
works
only
over
a
limited
distance,
100
kilometers
or
200
kilometers
through
fiber,
but
in
theory,
also
works
over
satellite.
In
fact,
there
have
been
demonstrations
of
that
over
the
course
of
the
last
couple
of
years.
B
It's
sort
of
weak
and
multi-hop
settings,
but
better
for
point-to-point.
It's
a
lot
easier
than
in
time
building
entangled
networks
at
the
physical
implementation
level,
but
it's
still
not
very
easy.
So
a
lot
of
you
are
probably
already
familiar
with
the
basic
idea
of
qkd
you've
heard
us
or
somebody
else
talking
about
it
at
some
point.
B
Entangled
networks
are
good
for
a
set
of
applications,
I'm
going
to
show
you
those
a
little
bit
more
in
the
next
slide
and
in
theory
using
quantum
repeaters,
which
are
not
like
classical
repeaters.
A
quantum
repeater
is
more
like
what
what
in
the
internet
world,
we
would
call
a
router
using
quantum
repeaters.
We
can
in
theory,
coupled
together
systems
that
are
as
an
arbitrary
distance
apart
within
sort
of
the
normal
limitations
of
networking,
as
opposed
to
the
distance
over
which
you
lose
a
single
photon,
which
is
the
limitation
in
unentangled
networks.
B
Also,
next
slide,
please,
okay,
so
on
this
slide,
I've
actually
got
who
of
how
I
think
about
the
applications
for
entangled
quantum
networks.
There
are
three
large
bubbles
there.
The
purple
one
is
reputed
cryptographic
functions,
the
blue
one
is
sensor
networks
and
that
yellow
one
is
distributed
computation
you
can
see
sort
of
on
there
on
the
Venn
diagram
that
there
are
a
set
of
potential
applications.
Qkd
is
in
the
middle
on
the
right.
B
B
So
that's
one
potential
use
another
one
or
two
in
the
distributed
cryptographic
functions
up
there
you
can
see
at
the
top
in
the
center
are
Byzantine
agreement
and
leader
election
and
if
you
look
at
Byzantine
agreement
and
secure
leader,
election
and
quantum
key
distribution
or
the
point
of
all
three
of
those
reduce
our
dependency
on
public
key
one-way
functions
and
computational
complexity
as
the
basis
for
for
security
proofs.
So
that's
one
potential
area
for
the
uses
of
quantum
networks
in
the
lower-right
sensor
networks.
B
Besides
qkd
itself,
there
are
two
or
three
other
good
uses
for
sensor
networks,
and
many
more
being
proposed
clocks
is
one
of
the
important
clock
synchronization.
There
have
been
several
algorithms
proposed
for
doing
this,
using
quantum
effects
that
would,
in
theory,
gain
us
synchronization
of
clocks
over
a
remote
distance
that
add
a
much
higher
level
of
precision
than
what
we
can
achieve
today,
using
GPS
or
NTP
or
really
classical
mekin,
so
that
clock
actually
is
a
form
of
reference
frame.
It
gives
you
it
tells
you
what
the
time
is
in
a
couple
of
different
places.
B
It
allows
them
to
essentially
synchronize
the
the
axis
of
time,
but
distributed.
Quantum
states
can
also,
in
theory,
be
used
as
a
reference
frame
in
the
physical
sense
as
well,
and
so
people
are
investigating
different
kinds
of
sensors
for
that,
and
also
for
what's
called
for
interferometry,
which
is
how
large-scale
astronomical
installations
collect,
light
from
multiple
telescopes
or
multiple
radio
antennas
and
combine
them
into
a
single
signal.
So
at
that
level
it's
very
much
a
physical
level
operation
that's
going
on
there
and
then
in
the
lower-left,
the
third
circle,
the
yellow
one
is
distributed.
B
Now,
why
is
that
different
from
just
being
able
to
do
what
you
can
do
today,
which
is
log
on
to
IBM's
website
and
use
a
quantum
computer,
that's
sitting
in
Yorktown
high
remotely
via
the
web?
Well,
if
you
begin
with
quantum
entanglement
between
your
site
and
the
mainframe,
then
it's
possible
to
do
what's
called
blind
computation
and
the
blind
computation
is
a
mechanism
for.
B
Execute
asking
a
server
to
execute
a
function
for
you
without
giving
the
server
any
information
about
the
input
data,
the
algorithm,
that's
being
executed
or
the
output
data.
So
it's
like
gendry's
homomorphic
encryption
in
in
terms
of
its
role
in
the
ecosystem.
Although
the
underlying
technology
is
very
different,
if
you're
familiar
with
homomorphic
encryption,
you
can
think
of
it
in
kind
of
same
use.
So
those
are
the
three
broad
areas
in
which
I
can
see
uses
for
a
quantum
network,
distributed
cryptographic,
functions,
sensor,
networks
and
distributed
computation.
Okay,
Alison
next
slide.
Please
ok,.
B
So
I
mentioned
repeat
a
minute
ago:
quantum
repeaters
quantum
repeaters
are
the
equivalent
of
routers
in
the
internet,
and
they
have
four
basic
tasks
which
are
listed
up
there
on
the
screen.
First
is
to
make
the
basic
entanglement
the
basic
quantum
state
over
a
single
hop
over
a
fiber
over
a
free
space
link.
B
B
The
third
task
is
to
extend
entanglement
across
multiple
hops,
so
you
know
the
behavior
of
a
network
and
then
the
fourth
task
is
to
actually
be
part
of
that
network,
including
dealing
with
routing
and
managing
resources
and
security
and
those
sorts
of
things,
and
it's
in
particular.
Those
last
couple
of
bullet
points
that
I
that
I
think
that
are
there
in
the
room
likely
to
be
able
to
make
a
positive
contribution.
George's
next
slide,
please,
okay,.
B
B
That
gave
you
just
three
minutes
on
the
the
why?
What
is
it
that
we
want
to
accomplish
by
doing
doing
this?
The
next
thing
I
want
to
do
is
to
sort
of
give
you
an
idea,
give
you
a
sense
of
what's
going
on
in
the
world
and
the
fact
that
this
is
in
fact
happening
on
the
right
hand,
side
of
the
slide
there.
You
could
read:
oh
just
logos
from
five
startup
companies
that
have
been
around
most
of
them
for
a
while.
B
Now,
but
overall,
in
the
quantum
information
industry,
there
are
now
more
than
50
startups,
many
of
them
that
have
been
created
within
the
last
year.
Some
of
them
are
hardware
companies
trying
to
build
quantum
computers.
Some
of
them
are
software
companies
trying
to
figure
out
how
to
use
the
existing
quantum
computers
and
the
some
of
them
are
networking.
B
Companies
that
are
here
on
the
slide
are
all
huge,
IT
companies
as
far
as
I'm,
aware
of
none
of
these
companies,
are
actually
working
on
quantum
computers
yet,
but
that
may
very
well
be
internal
efforts
that
they're
not
actually
talking
about
in
public,
so
it's
happening
in
the
startup
industry.
It's
also
happening
in
the
big
labs
IBM
Google
Intel,
the
Microsoft
are
getting
a
lot
of
attention
for
their
work
and
there's
also
event
venture
funding.
B
That's
out
there
there's
also,
of
course,
a
lot
of
support
from
governments
and
so
there's
an
entire
complete
ecosystem
of
people
who
are
working
to
create
a
quantum
information
technology,
industry
and
I.
Think
you
can
argue
that
that
the
fact
that
industry
already
exists
today,
so
the
technology,
the
knowledge
and
the
ecosystem
are
all
reaching
this
point
where
we
are
sitting
right
at
the
edge
where
it
where
this
whole
thing
is
going
to
blossom
over
the
next
several
years,
when
you
see
actually
Zeus
for
now
the
Quadro
repeaters.
B
B
The
leaders
of
this
particular
project
at
the
Technical
University
of
Delft
just
to
come
a
few
hundred,
kilometers
or
weary.
Well
right
now,
a
couple
of
years
ago,
this
was
published
in
October
24
pushing
on
three
years
ago,
since
the
experiments
we're
done
the
folks
at
Delft,
tiny
pieces
of
diamond
that
were
set
about
a
kilometer
apart
and
coerced
them
to
hold
qubits
quantum
bits
worth
of
data
in
there
inside
that
tiny
chip
of
diamond
and
also
to
emit
photons,
and
then
they
take
those
photons
and
they
route
them
together.
B
E
B
Just
want
them
entanglement
over
this
distance
of
1.3
kilometers
in
the
across
the
the
Delft
campus,
so
this
can
be
done
today,
an
optical
fiber
over
over
modest
distances,
it's
experimentally
up
and
running,
and
the
lat
the
group
end.
Delft
is
arguably
the
world's
best,
but
there
are
a
lot
of
people
who
are
working
on
similar
sorts
of
things
next
slide.
Please.
B
Now
this
was
actually
in
the
news
quite
a
bit
last
summer,
where
or
last
fall
when
they
talked
about
it
and
used
the
the
key
that
was
so
generated
to
encrypt
a
conversation
between
China
and
Vienna.
So
it
got
a
lot
of
press.
We
can
talk
about
the
actual
security
implications
for
all
of
that,
and
whether
or
not
you
have
to
trust
the
satellite
platform
and
things
like
that
for
qkd,
but
when
you're
actually
using
it.
Excuse
me
for
creating
entanglement
over
this
kind
of
distance.
B
There
have
also
been
experiments
from
Canada
and
Singapore,
and
the
other
picture
there
on
the
on
the
right
and
the
upper
part
is
actually
a
satellite
that,
when
it's
in
orbit
right
now,
that
was
put
up
there
by
Japan
last
year
as
well
so
satellite
work
and
also
ground-based
work
is
going
on
in
this
next
slide.
Please,
okay,.
B
And
ultimately,
there's
work
going
on
all
around
the
world,
but
Europe
right
now
is
one
of
the
places
where
that,
where
there's
a
tremendous
amount
of
not
individual
effort
but
very
focused
effort,
so
the
in
the
EU
has
a
quantum
internet
effort,
that's
known
as
the
quantum
internet
alliance.
There's
a
logo
for
it
there
on
the
left
and
a
URL
quantum
internet
dot
team,
and
you
can
see
going
back
by
going
to
that
website.
You
can
see
the
the
list
of
researchers
were
involved
in
this
Stephanie
again
is
one
of
the
prominent
researchers
that's
involved.
G
B
So
what
does
it
take
to
actually
build
one
of
these
networks?
This
slide
comes
from
a
paper
that
I
wrote
fully
a
decade
ago
on
protocols
for
quantum
repeaters
and
you'll,
see
that
there's
there's
sort
of
a
stack.
Many
of
you
in
the
room
probably
know
Joe
touch,
Joe
touch
and
I,
or
argued
about
this
quite
a
bit
over
various
meals
and
and
visits
to
each
other.
B
The
upper
layers,
everything
except
the
bottom-
is
actually
a
classical
control
protocol,
so
at
the
bottom,
in
the
purple
box
you
see
it
says
physical,
entanglement
and
red
letters
they're,
the
only
quantum,
that's
the
only
part
of
the
entire
system,
that's
actually
physically
quantum,
though
everything
else
that's
above
it
is
classical
protocols
for
controlling
the
behavior
of
this
quantum
system.
In
order
to
go
from
having
entanglement
that
exists
over
a
single
link
to
entanglement
that
actually
spans
end-to-end
from
your
your
communication
endpoints.
Now
the
protocol
stack
that's
above.
B
It
involves
a
series
of
functions
which
are
going
to
depend
on
certain
key
design
decisions
from
your
your
general
architecture,
from
your
your
quantum
repeaters.
But
this
is
a
reasonable
example.
Some
of
it
happens
over
a
single
hop.
Some
of
it
happens
over
two
hops
or
four
hops
along
the
path
chosen
through
the
network
and
that
some
of
it's
done
to
end-to-end,
and
that's
where
the
argument
with
Joe
touch
comes
in
is
all
right.
Well,
maybe
it's
not
really
a
layered
protocol
in
the
sense
that
the
ITF
is
a
customer
things.
B
It's
actually
much
more
of
a
distributed
computation,
because
all
of
the
individual
nodes
that
are
in
the
path
actually
participate
very
actively
in
the
entire
process,
as
you
are
conducting
your
communications
over
an
extended
period
of
time.
So
it's
it's
a
very
different
approach
and
the
Internet's
fire
and
forward
and
forget
approach
to
building
a
protocol.
But
this
is
an
area
where
classical
protocol
design
people
can
make
a
very
strong
positive
contribution
because
of
the
expertise
in
doing
these
kinds
of
things,
and
that's
it.
B
Yes,
so
Allison
perfect
timing
to
switch
to
the
next
slide
there.
So
we
are
getting
to
the
the
stage
of
wanting
to
take
all
of
this
and
discuss
these
kind
of
important
problems
again.
Any
network
how
you
deal
with
routing
and
how
you
deal
with
connections
set
up
and
how
you
deal
with
resource
management
and
how
you
deal
with
Internet
work,
interoperability
and
security,
and
all
these
kinds
of
issues
which
are
near
and
dear
to
the
hearts
of
the
people
that
are
there
in
the
room
at
IRT.
B
F
and
the
experimental
physicists
who
are
doing
the
work
so
far
have
no
idea
how
any
of
this
stuff
is
done.
They
don't
know
how
to
go
about
setting
up
a
connection
between
between
two
nodes
across
the
network.
They
don't
know
anything
about
how
you
do
resource
management
and
in
a
wide
area
network.
You
know,
know
what
multiplexing
means
in
a
single
channel,
but
not
so
much
across
an
entire
network,
for
example.
B
So
we
need
the
expertise
of
the
people
in
the
room
and
we
need
a
way
to
connect
classical
networking
people
to
the
experimental
community.
That's
beginning
to
do
build
these
quantum
repeated
networks,
so
Stephanie
proposed
two
or
three
months
ago
that
we
should
create
a
research
group
inside
a
by
RDF,
though
I
contacted
Allison
and
we've
been
exchanging,
some
email
about
it
and
so
far
the
proposed
is
Qi
RG.
The
mailing
list
is
open.
You
are
welcome
to
join
the
mailing
list.
B
I
B
Right
the
will
do
will
do
this.
I
did
want
to
mention
briefly
as
well
as
we're
finishing
up
that
there
are
also
queue,
can
be
oriented,
standardization
efforts
both
inside
of
Etsy
and
I,
Triple,
E
and,
of
course,
inside
of
the
IETF
we
have
been
talking
off
and
on
for
eight
or
ten
years
about
methods
for
incorporating
UK,
degenerated
keys
into
IPSec
and
dealing
with
other
outbound
out
of
be
and
key
management
mechanisms
for
key
generation
mechanisms.
So
there's
work,
that's
going
on
on
that
as
well.
Next
slide,
please.
B
A
B
B
J
Here
at
econo
Cosima,
thanks
for
a
talk,
I
have
a
one
qualifying
question
in
one
question
about
I
carrasco
network
and
a
contaminate,
oh,
so
the
first
name
first
question
is
so:
according
to
your
site,
page
number,
nine.
It's
like
there
is
no
IP
or
TCP
SciQuest
called
network
stack,
but
but
yours
your
figures
say
it's
like
a
that:
only
a
bottom
layer,
it's
that
quantum
network,
so
I
think
we
can
there
we
can.
J
It
seems
like
there
is
a
new
different
network
and
we
are
trying
to
create
the
quantum
network
instead
of
that
cross
car
network.
So
is
that
my
understanding
is
after
we
will
create
a
new
network.
Is
that
correct?
That
is
a
qualify
question
and
also
the
second
question
is
so
if
the
quantum
computer
cannot,
we
cannot
use
IP
or
those
kursk
or
network
stack.
So
in
this
case,
like
it's,
it's
a
little
bit
hard
to
connect.
The
connector
communicate
between
the
classical
network
and
quantum
network
so
do
use,
is
current
scope.
J
B
B
It
yeah
we
are
going
to
have
to
have
a
new
physical
layer,
so
there's
there's
no
getting
around
that
that's
going
to
mean
deploying
new
new
devices
with
new
transceivers
or
the
equivalent
thereof.
There
is
work
going
on
to
allow
that
to
multiplex
with
standard
tcp/ip
traffic
inside
the
same
fiber.
That's
been
demonstrated.
Experimentally,
so
you'll
need
new
load
new
nodes,
but
you
don't
necessarily
need
to
pull
come
the
completely
new
fiber
in
parallel.
B
All
of
those
other
functions
that
are
on
top
of
that
are
all
new
protocols,
but
of
course,
they
also
need
a
means
to
exchange
their
their
classical
messages
reliably.
So
so,
when
I
picture
the
the
the
protocols
PC
and
ES
I
picture,
those
communications
actually
happening
over
top
of
TCP
and
then
the
application
layer.
On
top
of
that,
is
the
it's
it's
a
what's:
what's
the
equivalent
of
an
HTTP
put
and
get
or
I
for
quantum
network?
What
is
a
request
from
an
application
to
the
network
itself?
B
What
what
is
it
that
it
that
that
you're,
a
classical
application,
that's
running
on
a
node
that
wants
to
take
advantage
of
these
services
provided
by
the
quantum
Internet?
How
does
it
make
that
request?
What
does
that
contain?
How
do
you
exchange
that,
and
how
do
you
agree
on
the
semantics
of
all
of
that,
so
those
colored
boxes
that
are
on
there
I
think
largely
will
ride
on
top
of
TCP
in
terms
of
the
actual
communication
that
gets
done,
but
it's
building
a
large
distributed
application
on
top
of
it.
K
West
vertical
USCIS
I,
you
know
originally
I
was
thinking
that
that
this
was
a
little
bit
early
in
the
in
thinking,
but
then
I
decided
that
I'm
wrong
there,
and-
and
we
want
to
get
this
sort
of
right
from
the
get-go
in
terms
of
Marie's
output
of
something
like
this
could
actually
affect.
You
know
the
development
of
the
hardware
and
the
technique,
so
I
think
that's
actually
that
the
timing
is
about
perfect,
so
I'm
excited
to
see
this
go
forward.
K
I
do
think
that
there's
a
few
other
topics
you
can
consider
adding
to
your
list
of
things
to
explore,
such
as
the
security
requirements
for
what's
going
to
be
layered
on
top
of
it,
in
particular,
with
respect
to
privacy
concerns
as
an
example.
Your
satellite
is
sort
of
a
classic
case
of
a
store
and
forward
mechanism
where
you
have
to
store
data
at
rest.
Well,
it
you
know,
while
it
travels
or
interplanetary
networks,
have
the
same
kind
of
thing
excuse.
K
My
ignorance
of
quantum
stuff
I'm,
actually
fairly
ignorant
and
it
may
show,
but
you
know
so-
the
quantum
routers
have
a
similar
property
where,
since
you're,
essentially
breaking
communication
between
in
the
middle
between
endpoints,
then
you're
disturbing
the
privacy
that
I
believe
is
offered
by
quantum
generally.
So
you
know,
what's
the
security
implications
of
that,
so
I
think
there's
a
number
of
things
that
need
to
be
considered
with
respect
to
what
sort
of
technologies
you
need
above
that
and
the
requirements
above
that,
do
you
still
need
to
do?
B
L
Actually
yeah
certain
I
mean
speaking
actually
is
not
a
question
just
comments
so
right
now
the
researchers
are
canta.
Networking
requires
organization
over
time,
neuroses,
I
yeah,
because
some
papers
started
to
propose
some
different
terminologies
for
washing
same
concept,
so
I
needed
a
I
need
a
place
for
open
discussion
for
such
things
as
otherwise.
So
you
know,
various
papers
which
use
these
different
terminology
will
lead
to
a
kind
of
help.
So
to
avoid
that.
M
L
Need
yeah,
we
need
an
open
discussion,
so
our
idea
is
a
best
price,
I
believe
so,
and
and
now
we
can
refactor
network
timing
of
this
property
here,
and
so
another
thing
is
so
one
thing
we
needed
to
discuss
enjoy
our
tea
is
the
obstruction
of
the
entanglement,
and
you
know
the
entanglement
is
a
very
quantum
property
and
no
Kruskal
need
talking.
It
doesn't
the
hub
the
counterpart
for
that.
So
we
should
carefully
discuss
the
obstruction
of
entanglement
and
at
last
yeah.
So
one
thing
so
is
a
one
benefit
to
talk
about
continuity
mean
iltf.
L
B
Thanks
actually
I
agree
with
with
all
of
those
comments.
In
particular,
you
know
that
I've
had
quite
a
bit
of
heartburn
where
the
the
physicists
reuse
a
term.
They
have
picked
up
from
classical
engineering
and
the
way
they're
using
it's
not
necessarily
wrong.
It's
just
so
different
from
the
way
we're
used
to
using
it
that
it's
causing
a
problem.
B
B
Theoretical
factors
of
implementations
are
very
different
from
from
the
real-world
implications,
and
so
doing
all
of
this
and
discussing
all
of
this
with
the
people
who
understand
real
networks
is
the
key
to
a
long-lived,
healthy,
robust,
extensible,
quantum
internet
architecture
and
I.
Think
the
IRT
F
has
a
lot
of
expertise.
That's
really
required.
N
N
So
so,
if
you
will
walk
on
this
corner
computing
discussion
in
this
ayat,
if
area,
how
do
how
do
you
get
IP
network
engineers
involved
in
this
discussion
and
also
on
how
do
you
link
on
the
corner
computer
guys
from
outside
this
community,
come
into
this
idea
community?
How
how
how
about
your
plan
for
that.
B
You
know
that
I'm
I
was
pleased
to
hear
the
earlier
comment
that
you,
the
I,
didn't
catch
the
name
of
the
guy
from
ISI
that
I
don't
know.
It
was
a
who
said
that
you
now
he
sees
that.
Maybe
now
is
the
right
time
if
we
and
and
it's
a
good
opportunity
for
people
to
be
involved
to
prevent
the
physicists
from
going
down
the
wrong
path,
now
convincing
the
physicists
that
they
need
to
be
involved.
That's
the
other
half
of
the
equation
and
we're
working
on
that
one
too.
B
But
there
are
already
hundreds
of
researchers
around
the
world
who
are
actually
working
on
this,
and
you
know
we
have
those
two
quantum
conferences
that
I
mentioned
the
workshop
for
quantum
repeaters
and
networks.
We
restrict
attendance
to
that
to
to
a
hundred
people
so
that
we
can
have
a
small
conversation,
but
we
could
have
twice
that
many
people
and
the
queue
crypt
conference
is
three
to
five
hundred
people
depending
on
the
location
there.
N
O
A
P
B
A
Q
A
O
O
O
F
Introduce
yourself
hi
everyone,
Muskaan
I'm,
gonna,
present
to
you
our
work
on
performance,
characterization
of
a
commercial
major
streaming
service.
My
current
affiliation
is
with
Akamai,
but
I
did
this
work
when
I
was
HDC
that
at
Princeton
and
interning
at
Yahoo
research,
so
we
all
have
had
that
experience
that.
F
F
O
M
A
F
Right
we're
back
in
business,
so
here's
the
list
of
performance
problems
that
we
found,
but
don't
worry
about
it.
I'm
gonna
walk
you
through
this
list
through
talk,
but
before
that,
let's
look
at
the
system
to
be
instrument
it.
So
you
can
get
an
idea.
What
could
go
wrong
before
we
show
you
what
did
go
wrong,
so
the
system
is
Yahoo's,
video,
streaming
system
and
the
way
that
streaming
works
very
high-level
overview.
F
It
starts
by
the
client,
which
is
your
player
requesting
and
receiving
the
manifest,
and
it
manifests
it's
the
list
of
available
bit
rates
and
then
there's
usually
an
adaptive
better
algorithm
on
the
player
that
chooses
which
bitrate
to
request
for
and
then
once
it
decides
the
mid
rate.
It
sends
an
HTTP
request
to
the
CDN
to
get
that
and
in
this
system
these
HTTP
requests
are
sharing
the
same
TCP
connection
and
it
chunk
in
this
system
is
six
seconds
once
these
requests
arrive
at
the
city
and
the
city
and
inspects
its
local
cache.
F
F
So
our
goal
in
this
study
is
to
identify
performance
problems
that
impact
video
QE
and
in
particular
make
the
users
are
happy,
so
you
know,
reduce
your
revenue
and
if
you
have
only
data
from
the
players
side,
for
example,
if
you
have
here
a
data,
for
example,
the
caveat
is
that
you
may
be
able
to
detect
some
of
these
problems.
You
may
be
able
to
say
there
was
a
rebuffering,
but
because
of
the
buffer
itself,
you
are
some
of
the
problems
get
masked
because
of
the
buffer.
F
So
you
may
not
see
an
immediate
impact
on
the
QE
and
also,
if
you
only
have
players
like
information,
you
cannot
detect
problems
that
happen
in
network
or
the
CDN
and
looking
at
it
from
the
other
side.
From
the
perspective
of,
if
you
have
only
data
from
the
CDN,
for
example,
server
logs,
you
may
be
able
to
detect
some
of
the
problems,
but
you
will
not
be
able
to
isolate
problems
that
are
within
the
clients
machine.
So,
fortunately,
for
us,
we
are
looking
at
this
from
a
contra
providers.
F
Point
of
view,
for
example,
Yahoo
or
Google,
could
do
this
and
what's
unique
about
them,
is
that
they
control
both
sides.
So
this
is
an
in-house
CDN
and
their
own
player,
and
once
you
have
mu
into
the
entire
path
of
the
video
delivery,
then
you
can
find
problems
everywhere
and
see
exactly
what
happened
for
each
chunk
that
you
had
buffering.
So
our
approach
relies
on
three
principles:
one
is
n
an
instrumentation.
F
F
Not
high,
so
what
do
we
mean
by
this
end-to-end
parent
measurement?
So
the
boat
lines
here
are
where
we
are
measuring
things
directly
and
the
dashed
lines
are
aware.
We
cannot
instrument
things
directly,
so
observations
based
on
interference
and
the
life
of
the
charm
starts
with
player.
Sending
an
HTTP
GET
request
writes
at
the
CDN.
The
CDN
has
some
processing
time
and
we
showed
that
with
d
CDN,
if
this
was
a
cache,
miss
and
back-end
needs
to
be
involved
to
get
the
first
byte,
then
there's
a
back
in
legacy.
F
Everything
that
is
not
measured
directly
is
shown
with
read
and
everything
that
is
measured
directly
in
this
instrumentation
shown
with
blue
and
then
finally,
the
first
byte
arrives
at
the
player.
The
time
difference
between
when
de
should
we
get
request
was
sent
and
when
the
first
fight
arrived
is
shown
with
TFB
first
by
the
way-
and
there
is
also
the
download
second
I
can
see
shown
with
red
DDS.
And
similarly,
when
you
have
the
last
part
of
the
chunk
of
writing,
that's
the
time
difference
between
the
first
and
the
last
is
shown
with
DL
you'll.
F
F
This
is
a
very
rich
area
of
research
and
they
have
shown
that
most
important
QE
factors
that
impact
the
users
experience
our
video
startup
time,
the
buffering
rate
with
your
qualities
such
as
betrayed
and
framerate,
and
we
look
at
these
factors
individually,
instead
of
coming
up
with
the
QE
score
because
of
two
reasons,
one
is
depending
on
the
type
of
content
that
you
have.
Some
of
these
factors
may
matter
more
than
the
others,
for
example,
for
a
breaking
news.
F
Video
start-up
time
matters
more
because
the
user
just
wants
to
see
the
news,
whereas
when
you're
sitting
to
watch
a
long
movie
the
start
time,
we
do
not
matter
that
much
or
give
you
a
quality
matters.
More
and
second,
is
the
length
of
the
video
shorter
videos.
Users
are
usually
less
patient.
You
want
to
have
the
results
you
want
to
have.
So
you
want
to
start
playing
right
away,
whereas
with
the
longer
video
the
user
is
already
patient,
they
have
it
in
their
mind
that
they're
gonna
sit
and
watch
to
our
video.
C
F
This
is
the
outline
of
the
talk
we've
already
gone
through
the
introduction.
I'm
gonna
show
you
the
measurement
data
so
that
we
have
and
then
what
are
the
problems
that
we
found
in
server-side,
network
or
client-side,
and
then
we're
going
to
conclude
the
talk
with
takeaways
on
what
can
be
done
about
these
problems.
F
F
This
is
a
video
on
demand.
Data
of
85
CDN
servers
across
the
u.s.
were
instrumented
selected.
Randomly
we
studied
65
million
video
sessions
and
more
than
half
a
billion
video
chunks.
The
users
are
predominantly
in
North
America
over
93%
and
mostly
non
mobile
users
that
are
not
using
proxy
we're
going
to
more
details
in
the
paper
and
how
we
remove
users
that
we
think
are
behind
a
proxy
and
the
main
reason
for
that
is.
F
We
want
the
TCP
measurements
to
reflect
the
path
between
the
server
and
the
client
and
usually
the
proxies
terminate
the
TCP
connections.
So
it
would
make
our
results
not
accurate
in
terms
of
the
video
streams
distribution.
This
is
a
popular
heavy
workload
with
66%
of
the
requester
I
mean
for
the
top
10%
of
the
titles,
and
most
of
these
videos
are
shorter
than
100
seconds.
F
So,
let's
dive
into
the
first
category
problems
the
server
side
problems,
so
our
measurement
in
the
server
side
comes
from
direct
measurement.
So
at
the
player
we
have
such
an
ideal
chunk,
ID
start
up
time
to
buffering
in
video
and
at
the
city,
and
we
have
such
a
tiny
chunk
ID.
Similarly,
we
are
measuring
server,
latency
back
in
latency
and
cache
Pyramus.
So
because
we
have
this
data
readily
available,
we
can
show,
for
example,
the
immediate
impact
of
several
latency
on
startup
time.
F
There
is
no
interference
there,
it's
just
ground
truth,
so,
for
example,
this
is
one
graph
that
we
can
do,
because
we
have
data
from
both
sides
and
you
can
show
the
impact
of
several
agency
instead
of
time.
The
x-axis
on
this
graph
is
the
several
ACC
milliseconds.
The
y-axis
is
the
start
time
of
the
video
in
seconds
and
you
can
see
how
it
significantly
increases
with
higher
server
latency.
So
next
we
are
interested
in
knowing.
Why
do
I
have
these
servers
with
these
high
latency?
F
The
first
issue
that
we
found
is
the
Apache
traffic
server,
Vishal,
timer
and
cache
misses.
So
what
happens
when
an
HTTP
request
arrives
at
the
CDN
is
that
it
first
inspects
the
memory
and
if
it's
not
there,
you
go
to
the
disk,
and
if
it's
not
there,
you
go
to
back-end.
However,
you
don't
want
to
overwhelm
the
back
end.
F
So
when
multiple
requests
come
for
the
same
content,
there's
usually
a
timer
there
that
stops
you
from
going
to
the
next
yearfor
for
a
while
to
not
overwhelm
the
backend
and
be
fine,
and
we
found
this
miss
configuration.
That
was
that
was
still
in
true
between
the
memory
and
the
disk,
and
it
was
impacting
about
65
percent
of
the
chunks
in
our
study,
but
even
more
important
than
that
is
cache
misses
we
found.
Cache
misses
in
this
system
increases
their
relation
significantly.
F
The
median
increases
by
40
times
an
average
by
10
times
when
your
server
side
has
a
cache
miss,
and
we
also
found
these
extreme
cases
where
several
agency
was
worse
than
Network
and
for
those
sessions
they
were
often
caused
by
cache,
misses
the
average
cache.
Miss
ratio
in
this
data
set
is
2%
for
the
sessions
that
had
more
server
latency
than
network
was
40
percent,
so
it
is
often
caused
by
this
significant
impact
of
cache
misses
on
the
server
latency.
F
Another
interesting
thing
that
we
found
is
that
server
side
problems
are
persistent.
It
means
that
once
the
session
starts
having
server-side
problems,
its
persistent,
it
stays
and,
for
example,
like
I,
said
the
average
cache
miss
ratio
is
2%.
If
you
look
at
the
conditional
probability
of
the
sessions
that
had
a
1
cache
miss
the
cache,
miss
ratio
for
those
sessions
goes
up
60%.
That
means
that
cache
misses
are
coming
in
groups
and
that's
usually
because
of
unpopularity
of
the
title.
F
So
once
a
title
is
unpopular,
its
chunks
are
more
likely
to
reside
in
disk
or,
worse
gate,
work
it
in
the
backend
and
you
start
having
cache
misses,
but
every
single
one
of
these
chunks
are
going
to
go
through
that
and
in
fact
we
found
interesting
paradox
in
the
system
that
it
seems
like
more
heavily
loaded.
Servers
seem
to
have
lower
latency,
but
this
is
a
result
of
the
Cashbook
is
mapping
cache
focus.
F
Mapping
is
you're
trying
to
have
hot
caches,
so
survey
is
sending
the
request
to
where
it
was
recently
served
from
which
causes
your
popular
content
to
go
to
the
same
servers
and
your
popular
contents
have
better
performance
because
of
the
reasons
Asian
nation,
but
you
also
have
more
requests
for
your
popular
content.
So
there's
this
there
are
these
servers
that
are
less,
have
less
demands
because
they're
serving
unpopular
content,
but
have
more
performance.
So
the
Connie
popularity
is
even
dominating
a
server
load
in
this
case.
F
So
our
network
measurements
come
from
us
instrumenting
or
host
care,
and
also
basically,
the
orange
box
here
is
showing
what
the
operating
system
is
doing,
which
is
there's
this
TCP,
infrastruc
and
os
is
collecting.
We
have
this
information
about
all
the
TCP
connections,
including
a
weighted
average
of
RT
T's
called
smooth,
Artie,
T
or
SRT
T
congestion
window
and
packet
retransmissions,
and
what
we
do
is
the
blue
box.
F
That
is,
we
pull
this
every
500
milliseconds
per
trunk
and
store
it
and
then
later
we
use
it
across
chunks
and
across
sessions
to
see
what
happened
in
a
network.
Of
course,
there
are
some
challenges
in
collecting
in
this
way
we're
looking
at
smooth
averages
of
Artie
T
or
s
RT
T's
instead
of
individual
RT
C's,
and
that's
not
sometimes
a
good
idea,
especially
if
you
are
dealing
with
these
long
connections
for
video
streaming,
because
the
SRC
C
is
not
reflecting
your
RT
t
during
this
chunk
exactly.
F
But
what
happened
in
all
the
previous
chunks,
this
network
snapshot
frequency
is
also
infrequent.
500
milliseconds
in
many
cases,
is
more
than
the
RT
t
of
the
connection,
but
it
comes
from
operational
limitations
and
how
often
we
have
you
were
allowed
to
pull
this
and
how
much
data
we
were
producing
in
terms
of
storage,
overhead
and
finally,
because
this
is
it,
this
is
it
operational
at
scale.
F
We
can't
collect
packet,
traces
and,
in
the
paper,
be
going
to
more
details
and
how
we
grapple
with
these
challenges,
but
I'm
just
going
to
show
you
they're
interesting
findings.
So
here's
another
similar
graph
that
you
can
do
because
we
know
that
a
network
latency
and,
for
example,
the
SRT
T
of
the
first
chunk-
and
we
also
know
the
set-up
time.
So,
if
you
look
at
the
SRT
T
of
the
first
chunk,
that's
the
x-axis
here
and
the
impacts
on
the
start
time
of
the
video.
The
impact
is
visibly
clear
and
how
it
impacted.
F
F
It's
just
the
variation
and
in
both
cases
we
find
that
majority
of
these
prefixes
are
in
enterprise
networks,
not
residential
networks,
and
what
we
speculate
is
happening
here
is
that
these
enterprise
networks
are
running
their
middleboxes,
which
are
causing
high
latency
and
high
latency
variation,
despite
the
fact
that
they're
so
close
to
the
city
ends.
Now,
of
course,
we
do
not,
and
we
do
not
have
in
network
data
to
confirm
it's
just
a
speculation
of
why
we
see
this
high
latency
in
only
in
enterprise
networks
and
not
residential
ones.
F
The
second
finding
is
the
impact
of
packet
losses.
This
is
this
graph
is
generally
what
we
expect
to
see
in
terms
of
how
your
transmission
rates
or
losses
impact.
We
do
QE
in
terms
of
your
buffering
rate.
Generally,
we
see
that
higher
loss
rate
indicates
higher
rebuffering
rate,
but
that's
not
all,
and
in
fact
we
saw
I'm.
F
So
what's
the
percentage
of
the
chunks
that
hadley
buffering
and
it
is
higher
for
first
chunk-
and
you
may
think,
because
of
the
loss
so
to
take
that
into
consideration,
we
calculated
the
green
wore
the
green
plots.
So
those
are
the
conditional
probability
of
percentage
of
chunks
that
Hadley
buffering
given
there
was
a
loss
at
this
chunk
and
you
can
see
that
if
there
is
loss,
the
percentage
of
the
repo
Franco
is
higher
for
everyone,
but
it
goes
significantly
higher
for
the
first
channel.
F
So
this
is
because
of
the
existence
of
a
buffer
in
a
video
streaming
fashion.
So
when
you
have
a
buffer
in
a
video
streaming
session
it
initially
it's
not
full.
So
it
cannot
hide
these
impacts
from
the
user.
But
later
on
in
the
video
sharing
session,
when
you're
on
a
haier
chunk
ids,
then
there
is
enough
buffer
to
hide
some
of
these
impacts
from
the
users.
F
So
here's
an
example
case
he's
a
very
extreme
case,
so
here
we're
looking
at
two
sessions:
red
had
rebuffering
and
green
did
not
have
any
buffering
and
you're
also
looking
at
the
distribution
of
the
last
race.
This
is
rich
transmission
rate
in
chunks,
and
you
can
see
that
the
red
session
that
happy
buffering
has
actually
generally
lower
lower
row.
F
Three
and
the
green
had
significantly
higher
rate
transmission
rates,
but
because
they
happened
after
the
first
four
chunks,
which
is
already
a
buffering
twenty
four
seconds
of
video,
because
each
chunk
is
six
seconds,
the
user
actually
never
finds
out
about
it.
Whereas
the
red
session
is
very
unlucky,
it
has
losses
in
the
first
truck
and
right
there.
It
has
a
deep
offering
so
here's
an
example
of
how
the
location
of
the
losses
seem
to
be
even
better
more
than
the
loss
rate.
F
M
F
F
Finally,
we
found
throughput
to
be
a
bigger
problem,
then
latency
for
media
streaming.
So
here
we
have
defined
a
performance
score,
which
is
a
direct
charge
generation.
In
our
case,
it's
six
seconds
divided
by
a
first
black
plus
last
byte,
and
the
first
byte
is
a
measure
of
latency.
If
you
remember
from
this
graph,
first
plague
was
the
time
difference
between
when
we
get
request
was
santander
in
the
first
boy
drive.
F
That
means
more
than
one
second
of
video
is
delivered
per
second
to
this
player
and
from
very
simple
queuing
algorithms,
if
you
have
more
than
one
second
video
delivered
to
your
player,
but
the
user
is
watching.
One
second
of
video
per
second
you're
gonna
build
up
buffer
and
when
the
score
is
less
than
1,
that
means
less
than
one
second
of
video
is
delivered
to
your
buffer.
Your
users
still
watching
one
second
of
video
per
second,
and
that
means
you're
depleting
the
buffer
expected
to
have
a
rebuffering
at
some
point.
F
Third,
categorical
problems
are
within
the
client.
So
what
is
the
client
download
stack
when
the
chunks
are
arrived
from
the
network
and
before
they
are
delivered
to
our
player?
They
go
through
the
download
stack
at
the
client,
which
is
the
neck,
the
OS
and
the
browser
before
they're
finally
handed
over
to
the
player
and,
unfortunately,
for
us
at
scale,
we
cannot
observe
the
download
stack
like
you
can
see
directly.
F
Because
we
can't
go
and
instrument
these
clients
and
see
what's
happening
at
their
browser
or
network
card,
so
here
we're
relying
on
detecting
outliers.
So
here
we're
doing
some
statistical
work
to
see
if
there
is
a
chunk
that
seemed
to
have
been
buffered
at
the
download
stack.
So
if
a
chunk
has
been
buffered
at
downloads,
that
I
expect
it
to
be
delivered
late
to
the
player,
and
that
means
that
I'm
expecting
the
first
byte
to
be
significantly
higher
than
others.
F
So
let's
say
it's
two
Sigma
away
from
my
mean,
but
also
because
it
was
buffered
at
the
download
stack
and
delivered
so
late
to
the
player.
I
expect
it
to
be
arriving
at
the
machines
throughput,
not
at
the
connections
throughput.
So
it's
gonna
have
very
high
stint
in
es
throughput
from
the
perspective
of
the
player.
So
let's
say
it's
2
Sigma
away
from
the
mean
again,
but
it
should
not
have
been
caused
by
network
and
server,
so
it
should
have
similar
network
and
server
performance.
F
So
here's
one
example
that
we
found
in
our
data
set
the
graph
on
the
top,
shows
you
the
latency
matrix
and
look
at
chung-kai
d7,
and
you
can
see
that
it
has
similar
RTT
and
several
metrics
server
latency,
but
it
has
a
significantly
higher
first
byte
delay
than
the
rest
of
the
chunks.
So
what
we
expect
this
happening
here
is
that
this
chunk
was
buffered
at
the
client
down
the
stack
and
deliberate
late
to
the
player,
and
then
the
throughput
measurements
are
at
the
bottom.
F
So
it's
important
to
be
aware
of
these
problems
that
we
can
only
find
with
once.
We
have
data
from
both
sides,
because,
if
you
don't
have
this,
each
side
is
going
to
blame
the
network
or
the
other
for
these
problems,
and
this
can
be
very
dangerous
in
the
video
streaming
world,
because
if
your
player
makes
incorrect
assumptions
about,
for
example,
agency
from
their
first
graph
and
if
the
adaptive
bitrate
algorithm
is
latency
sensitive,
it
can
cause
undershooting
because
it
may
freak
out
and
think
the
latency
had
a
spike
where
reality
it
didn't.
F
So
we
found
these
the
adonis-like
problems,
they're
transient
problems
that
are
that
I
just
described
to
you.
You
found
them
to
be
more
common
in
their
first
chunk
and
in
debate
where
we
going
to
more
details
of
how
this
could
be
a
possible
side
effect
of
Flash,
and
we
also
have
persistent
down
low
psych
problems.
The
persistent
download
psych
problems
are
not
very
common,
but
what's
important
about
them
is
once
they
happen.
F
They
they
often
are
the
most
important
factor
and
they
are
higher
than
network
and
server
latency
and
there's
more
in-depth
conversation
about
them
in
the
paper.
If
you're
interested
in
that
and
finally,
the
last
category
of
problems
are
the
rendering
stack
performance
problems.
So
what
is
rendering
stack
so
the
chunks
have
finally
arrived
at
the
player,
but
they're
not
ready
to
be
shown
on
the
screen.
Yet,
and
here
we
have
a
rendering
stack.
F
F
Now,
if
the
CPU
is
busy
and
you're
using
software,
rendering
the
quality
may
drop,
which
causes
high
frame
drops,
but
also
if
your
video
tab
is
not
visible,
your
browser's
do
optimizations
to
reduce
your
CPU
consumption,
so
they
intentionally
drop
frames
so
to
detect
these
problems
but
to
separate
them
from
browser
optimizations.
We
have
introduced
boolean
variable,
which
is
this
player
visible
or
not,
and
also
we're
measuring
the
drop
frames
and
then
for
each
session.
We
are
also
collecting
what
OS
and
browser
it
has,
and
there
are
some
interesting
findings
here.
F
First
one
is
that
good
rendering
is
actually
time
consuming.
We
found
that
the
multiplexing
decoding
and
rendering
takes
time,
and
you
have
to
provision
for
that
if
you
want
to
have
a
good
frame
rate
and
so
in
this
graph,
we're
showing
you
the
download
rate
of
the
chunk,
the
average
download
rate
of
the
chunk
and
x-axis
and
what's
the
percentage
of
the
drop
frames,
and
you
can
see
the
drop
up
to
about
one
and
a
half
second
per
sec.
And
that's
what
we
recommend
to
use
as
a
rule
of
thumb.
F
Next,
we
found
kind
of
a
paradox
again
higher
bit
rates
showing
better
rendering
so
higher
bit
rates,
put
more
load
on
CPU
and,
as
I
explained
to
you,
a
software
can
be
expensive,
so
we're
expecting
them
to
have
worse
frame
rate,
but
we
actually
see
them
having
better
rendering
framerate.
And
if
we
need
further
investigation,
you
can
see
the
numbers
in
the
paper,
but
in
summary,
we
found
these
high
higher
bit
rates
coming
from
connections
that
had
lower
RTT
variation
and
lower
assurance
machinery.
F
F
Second
per
second,
and
we
know
the
player
is
visible
because
we're
filtering
on
the
only
these
chunks
that
have
visibility,
so
the
user
is
actually
watching
and
we
divided
the
chunks
into
two
major
platforms,
Windows
and
Mac,
and
this
blue
guards
are
just
showing
you
the
percentage
of
the
chunks
in
each
platform
for
each
browser
and
they're
sorted
from
more
popular
to
this
popular
and
here
you're.
Looking
at
the
percentage
of
the
drop
frames
in
each
of
these
browsers
combinations,
you
can
see
the
trend
is
the
opposite
and
we
found
so
in
the
paper.
F
One
of
the
interesting
examples
are
Safari
is
actually
really
good
at
Mac,
but
it's
among
one
of
the
worst
on
Windows
and
on
Windows
other
section,
there's,
there's
some
less
popular
browsers
like
Yandex
and
see
monkey
that
we
found
that
had
huge
problems
in
terms
of
rendering
so
I
walk
you
through
all
these
problems.
But
let's
see
what
are
the
takeaways
I
mean?
What
can
we
do
about
all
of
these
problems
that
each
one
of
these
places?
So,
let's
start
with
the
CDN
I
discussed
three
problems
with
you
about
the
CDN
one.
F
Is
the
impact
of
cache
misses
so
in
this
workload,
we're
looking
at
popular
heavy
workloads
and
I
told
you
we
are
using
the
LRU
cache
eviction
policy
because
of
the
impact
of
cache
misses
that
are
so
high
and
the
workload
is
popular.
Have
you
proposed
using
other
policies
that
are
more
tuned
for
these
kind
of
workloads
like
GD,
size
or
perfect?
All
of
you
in
terms
of
the
cache
miss
persistence,
we
propose
prefetching
subsequent
chunks.
This
is
the
problem
that
I
discussed
with
you
that
once
the
session
starts,
having
cache
misses
it.
F
Every
one
of
its
chunks
is
gonna,
have
the
cache
misses
because
it
was
most
likely
an
unpopular
title?
Now,
it's
not
very
it's
not
that
simple
to
just
prefetch
the
subsequent
chunks,
because
in
many
cases
the
CDN
does
not
know
what
bit
rate
is
going
to
be
requested
in
the
next
chunk,
but
that's
a
whole
other
area
of
research,
but
it
talked
more
about
it.
If
you're
interested
for
the
low
latency
paradox
that
I
explained
to
you,
we
propose
better
load
balancing
we're
partitioning
the
popular
content.
F
F
F
It's
important
to
know
this
even
as
a
CDN,
because
sometimes
you
want
to
do
you
want
to
know
what
you
can
do,
but
sometimes
you
should
be
aware
of
what
you
shouldn't
do
so
in
this
case,
you
should
avoid
over
provisioning
servers
for
these
near
about
clients,
because
the
problem
is
not
that
they're
far
from
you
or
of
presence
and
in
case
of
prefixes
that
have
persistent
high
latency
or
variation
as
a
content
provider.
The
options
are
limited.
What
they
can
do
about
this
problem,
but
the
least
that
you
can
do
is
adjust
adaptive
algorithm.
F
Accordingly,
for
example,
you
can
start
with
the
more
conservative
bit
rate
or
increase
the
buffer
size
to
handle
these
legs.
You
see
variations
better
in
terms
of
the
earlier
packet
losses
that
are
more
harmful
and,
unfortunately,
more
comment,
I
discussed
using
server-side,
pacing
and
finally,
the
throughput
is
a
major
bottleneck.
We
think
that's
actually
good
news
for
ISPs,
because
it's
easier
to
fix
by
establishing
better
peering
points
their
latency,
the
takeaway,
is
on
the
client.
F
I
discussed
the
download
secretary
teensy
problem
with
you,
and
we
think
that's
an
important
problem
that
we
could
only
find
it
because
we
had
data
from
both
sides
and
we
could
confirm
that
this
problem
is
not
being
caused
by
the
server
or
the
network
and
I
talked
about
how
that
can
be
dangerous.
For
that
appetite
algorithm
we
can
cause
overshooting
or
undershooting,
and
what
we
propose
here
is
incorporating
some
server-side
TCP
metrics
or
some
awareness
of
the
network
path
to
the
player
and
I.
F
F
This
is
particularly
important
if
you
are
streaming
videos
that
people
care
about
frame
rate,
for
example,
sports-
that
there's
usually
that
one
frame
that
has
whether
or
not
it
was
a
thought
and
finally,
rendering
quality
differs
based
on
OSF
browser
and
I,
showed
you
some
example
browsers
that
even
in
good
conditions
and
similar
network
and
server
conditions,
they
seem
to
have
worse
rendering
quality.
It's
important
for
a
content
provider
to
know
this,
to
avoid
premature
optimizations,
for
example,
rerouting
this
client.
F
While
the
problem
was
that
the
clients
own
down
the
stack
is
not
helpful,
so
it
helps
Citians
a
nice
piece
to
know
where,
when
the
problem
is
the
client
to
avoid
premature
optimizations
there.
So
in
conclusion
this
in
this
work,
we
instrumented
both
sides
for
the
first
time,
the
client
and
the
city
and
server,
and
it
allowed
us
to
uncover
a
wide
range
of
problems.
G
As
you
said,
most
of
the
traffic
on
the
Internet
today
streaming
video,
so
clearly
something
people
care
about
and
I
think
we're
all
frustrated
by
seeing
that
little
spinny
wheel
waiting
for
it
buffering
I
had
one
comment:
you
talked
about
client
download,
stack,
late
nurses
and
working
for
Apple.
That's
the
area
of
this
that
I'm
more
involved
with
I.
Think
I
may
know.
What's
going
on
here,
so
I.
F
G
No,
you
were
talking
about
in
the
pipeline
the
various
delays
in
the
CD
and
the
network,
and
you
when
you're
talking
about
the
client
site,
download
stack
right
as
far
as
I
know,
there
is
no
networking
API
on
Windows
or
Linux
or
Mac.
That
will
just
sit
on
data
for
no
reason
and
not
deliver
it.
I
think
this
is
a
consequence
of
the
api's
in
order
delivery
of
data.
Yes,.
M
G
You
miss
in
a
common
Network
setup.
Now,
unfortunately,
we
have
lots
of
buffer
bloat,
so
you
could
easily
have
a
two
second
queue
on
your
cable
modem
link
and
you
lose
one
packet
and
far
we
transmit
fills
in
that
one
packet
really
fast,
but
it's
at
the
back
of
a
two-second
queue.
So
you've
got
all
this
data
arriving
piling
up
in
the
kernel.
The
sockets
API
can't
deliver
it.
Yes,.
F
M
F
We
can't
it's
probably
the
way
that
they're
handling
like
and
there's
a
buffer
there
and
how
they're
handling
the
data
delivery
that
causes
these
problems,
but
because
it's
a
black
box-
and
it's
like
a
footnote
in
the
paper
that
we
can
only
guess
this
is
what's
happening
and
we
confirm
it
is
not
at
the
OS
for
the
browser.
It
seems
to
be
there,
but
we
can't
really
measure.
What's
what
they're
doing
in
that
API
I.
G
G
K
Our
West
heard
occur,
USC
is
I,
am
excellent
presentation
and
work
very
thorough
and
I
really
enjoyed
it.
Having
said
that,
you
killed
my
dream
and
I've
had
this
dream
that
that,
with
the
advent
of
you
know,
users
can
go
out
and
find
the
things
that
they
want
and,
and
it
would,
they
had
helped
us
discover
new
things.
Unfortunately,
sort
of
your
caching
results
kind
of
indicate
that
video
streaming
services
are
it's
in
their
desire
to
bin
everybody
into
popular
titles.
K
Where
you
know
they,
they
won't
give
you
as
many
suggestions,
sideways
of
other
things
that
you're
interested
in
they're.
More
likely
to
give
you
suggestions
that
everybody
else
is
gonna
watch
too,
because
it's
cheaper
for
them
give
some
better
performance,
and
thus
you
know
better
ratings,
and
that
that's
sad,
but
thank.
S
F
R
A
A
A
E
Hello,
hello,
everyone,
good
cool,
okay,
so
good
morning,
everyone,
my
name,
is
Vasco
I'm,
a
third
year
PhD
student
at
the
University
of
Michigan
Ann
Arbor.
This
work
is
originally
appeared.
It
is
the
sitcom
2017
last
August,
so
today,
I
will
be
presenting
room,
a
new
solution
to
optimize
web
performance.
This
work
is
a
collaboration
with
Ravi
Mohammed
and
my
advisor
Harsha.
So
let's
get
started
so,
as
you
have
experience
using
a
mobile
phone
connected
to
a
cellar
network,
it's
very
very
common.
Nowadays
right
we
have
our
used
phones
to
surf
the
web.
E
E
But
despite
all
of
this
increase
in
mobile
web
usage,
as
you
may
have
speery
ensure
self-loading.
Many
of
these
pages
are
actually
pretty
slow.
No
systems
founded.
It
takes
almost
ten
seconds
to
load
the
median
mobile
retail
site
and,
on
the
other
hand,
double
clicked
founded.
It
takes
14
seconds
on
average
to
load
a
page
over
a
4G
connection,
so
we
also
confirmed
this
ourselves
using
a
nexus
6
phone,
a
reasonable
high
performance
phone
at
the
time
connected
to
a
good
LTE
network
in
the
Ann
Arbor
area
to
load
the
mobile
optimized
popular
pages.
E
So
one
thing
to
note
about
the
results
that
we
found
here
is
that
these
are
heavily
optimized
popular
pages.
So
the
numbers
that
we
get
here
is
on
the
better
side
of
things.
So
this
is
a
bar
chart
representing
the
page
load
times,
measured
in
seconds
of
the
Alexa
top
hundred
sites
overall
and
Alexis,
how
50
news
and
50
sports
sites,
the
top
of
the
bar
chart
is
the
median
page
load
time
and
the
whiskers
are
75
and
a
25%
house
at
the
median
page
load
time
for
the
Alexa
a
top
hundred
sites.
E
This
is
actually
pretty
slow,
considering
the
fact
that
some
studies
have
shown
that
a
five
second
page
load
times
has
25%
bounce
rate,
which
means
that
these
pages
are
actually
losing
some
money
right
and
on
the
other
hand,
if
we
take
a
look
at
the
Alexa
top
50,
News
and
50
sports
sites,
things
are
far
worse.
The
median
page
load
time
in
this
case
is
actually
10
seconds,
and
the
reason
why
things
are
much
worse
in
this
case
is
because
news
and
sports
sites
tend
to
be
more
complex
than
the
Alexa
top
100
sites.
E
Overall,
so
in
this
talk,
I
will
be
first
digging
into
why
web
pages
are
slow
to
gain
some
intuition
as
to
why
that's
the
case,
and
then
we
will
use
those
intuition
to
improve
web
performance.
Then
I'll
use
the
intuition
with
that.
We
get
from
the
first
place
to
explore
room
our
solution
to
make
web
page
slow,
faster
and
the
last
part
would
be
the
implication
of
workroom.
E
Now
let
me
take
you
to
into
why
webpage
is
slow.
Now,
let's
take
a
very
simple
example:
let's
say
we
load
one
to
load
a
page
from
a
calm,
and
this
a
calm
contains
only
one
image.
So
what
would
happen
when
this
page
gets
loaded
is
the
client
will
send
a
get
request
to
a
dot-com
era?
Comes
in
smack
their
response,
find
parts
that
discover
the
image
and
then
a
facial
image.
E
If
you
take
a
look
at
the
network
utilization
and
also
the
CPU
utilization
at
the
client,
as
you
can
see
here,
the
bars
with
the
solid
colors
are
times
when
these
resources
are
being
actively
used.
As
you
can
see
here,
there
are
no
periods
that
the
CPU
and
the
network
is
being
fully
utilized,
and
the
crux
of
the
problem
here
is
that
the
client
has
to
parse
or
execute
a
resource
to
discover
additional
resource
to
fetch.
E
The
page
load
times
when
the
CPU
is
the
main
bottleneck
is
actually
much
higher
than
the
page
load
time
with
Network
is
the
main
bottleneck.
So,
in
this
case,
the
medium
page
load
time
is
5
seconds
in
the
case
where
the
CPU
is
the
main
bottleneck,
so
that
experiment
implies
that
CPU
is
the
main
bottleneck
in
most
of
the
cases,
but
is
this
actually
the
case
everywhere?
E
E
E
So
just
to
recap
what
we
found
in
this
first
section
of
the
talk.
So
the
reason
why
web
pages
are
slow
right
now
is
browsers
needs
to
discover
resources
from
parsing
and
execution,
and
we
know
that
browsers
are
largely
serial
in
discovering
these
resources
and
performing
the
page
load
and
with
the
CPU
becoming
the
main
bottleneck
in
the
future.
This
process
of
discovering
resources
from
parsing
and
execution
will
not
become
any
faster,
so
we
have
to
somehow
think
rethink
the
way
page
load
should
work.
E
So
our
main
idea
in
our
project
is
to
somehow
have
the
server
to
become
more
proactive
during
the
page
load.
We
want
servers
to
eight
clients
in
discovering
resources
during
the
page
load
and
that's
the
main
theme
of
room
so
now
that
we
know
why
paper
web
pages
are
slow
and
gain
some
intuition
I'll
ask
you
how
we
can
make
web
pages
faster.
Let
me
walk
you
through
room,
our
solution
that
uses
that
intuition
to
make
web
facial
faster.
E
E
None
of
these
are
modified
everything
the
same
as
the
status
quo
right
now,
but
instead
of
only
sending
back
HTTP
response,
broom
also
used
SGP
to
push
to
push
resources
down
to
the
client.
So
that
client
can
receive
many
resources
before
it
needs
to
actually
fetch
it
I
discovered
them
from
parsing
our
execution,
but
push
itself.
E
It's
not
really
enough,
because
HTTP
push
only
allows
you
to
push
down
resources
that
the
origin
owns
right
so,
but
we
know
that
a
lot
of
these
pages
contain
third-party
resources,
so
we
are
missing
out
on
a
lot
of
resources
to
make
web
page
load
faster.
So
what
we
also
include,
in
addition
to
HTTP
to
push,
is
also
used.
Some
kind
of
dependency
hints
resource
hints
one
way
to
do
this.
Resources
is
to
use
link,
rel,
preload,
HTTP,
primitive.
E
Now,
in
order
for
the
server's
to
push
or
send
these
hints
back
to
the
client,
the
server
has
to
have
some
kind
of
module
to
discover
these
resources
right.
So
we
have
these
dependency
resolution
module
running
at
the
web
servers.
So
these
dependency
resolution
modules
are
just
simply
trying
to
find
resources
that
the
client
will
need
during
the
page
load
and
at
the
client.
We
have
some
kind
of
scheduling
mechanism
so
that
the
client
can
use
all
these
resources
as
effectively
as
possible.
E
Now
that
we
know
an
end
to
end
work
for
all
of
room
in
order
to
make
room
our
reality.
We
have
to
answer
these
two
main
questions
so
first
how
web
servers
can
discover
dependencies
in
the
first
place
and,
on
the
other
hand,
how
clients
can
schedule
these
fetches
of
resources
or
use
these
hints
from
the
server
effectively
so
that
it
maximize
the
benefit
that
it
should
receive.
So,
let's
first
turn
our
attention
to
the
web
server.
E
Let's
consider
this
strawman
approach
in
discovering
resources
for
the
client,
so
the
client
can
send
a
get
request
to
the
origin.
Write
this
web
server.
Foo.Com
can
start
a
page
load,
a
foo.com
itself
at
a
route
at
the
web
server.
Now
because
food
comes
web
server
is
a
server.
It
has
a
much
more
powerful,
CPU
and
also
a
highly
connected
network.
So
it
can
perform
this
page
load
much
much
faster
than
the
client.
E
E
Unfortunately,
it
doesn't
so.
There
are
two
drawbacks
with
this
approach.
First,
as
we
all
know,
web
pages
by
nature
is
very
dynamic.
There
are
a
lot
of
resources
that
is
dynamically
generated,
with
some
randomized
token,
in
the
URL
and
so
on,
so
by
using
everything
from
a
one
particular
load
and
hint
them
to
the
client
or
push
them
to
the
client.
E
Now,
on
the
other
hand,
as
we
all
know,
many
of
these
pages
contain
many
personalized
resources.
So
in
order
for
food
calm
in
this
case
to
account
correctly
account
for
personalization,
it
needs
to
get
a
hold
of
the
clients.
Cookies,
they're
party
cookies,
but
we
don't
food
calm,
doesn't
have
that
so
food
calm
will
never
be
able
to
correctly
account
for
third
party
personalization.
E
So
what
we
did
was
we
use
an
intersection
of
offline
loads
to
overcome
the
flux
in
URLs,
so
at
the
web
server
we
load
a
page
periodically
and
then
take
the
intersection
of
these
loads.
So
it
means
that
anything
that
is
randomly
generated
per
load
will
be
filter
out
by
the
in
because
of
the
intersection.
E
But
this
is
not
enough.
What
we
found
was
that
by
only
doing
this
intersection
of
offline
loads,
we
are
only
able
to
discover
70%
of
resources
that
can
be
discovered.
So
what
we
did
was
we
augment
online
parsing
of
the
HTML
on
top
of
intersection
of
offline
loads,
and
what
we
found
was
that
using
these
two
combined
online
offline
resource
discovery,
we
were
able
to
discover
most
of
the
resources.
E
So
let
me
walk
you
through
the
very
high-level
architecture
of
room
again,
so
room
sends
a
get
requests
to
the
web
server
web
server
uses
sends
back
a
response
with
the
HP
to
push
and
also
dependency
hints
uses
the
dependency
resolution
module
to
push
and
to
get
resources
to
push
and
also
hints.
So
one
approach
for
this
scheduling
would
be
have
to
server
just
push
everything
that
it
could
from
the
dependency
resolution
module
and
then
for
hints,
just
use
all
link
preload
lingual
well
plate
preload
hint
all
of
them.
E
This
sounds
great
as
well,
because
we
are
discovering
resources
much
earlier
in
the
page
load
and
things
should
work
well.
Unfortunately,
it
doesn't
work
well
either,
and
this
is
a
pretty
serious
problem
because
by
pushing
and
fetching
everything
in
the
first
place
at
the
beginning
of
the
page
load,
this
leads
to
contention
in
bandwidth
and
when
there's
a
contention
in
bandwidth.
Sometimes
the
important
resources
are
actually
being
delayed.
E
For
example,
a
blocking
script
or
some
CSS
will
get
delayed
and
by
and
because
of
those
resources
getting
delayed,
it
has
a
cascading
effect
throughout
the
page
load
and
it
can
end
up
hurting
the
page
load
process.
So
what
we
found
in
our
experiment
was
that
by
using
this
approach,
we
don't
see
any
page
load
time
improvements
and
even
worse,
sometimes
we
see
degradation
in
page
load
times.
E
So
what
we
did
instead
is
reprioritize
pushes
and
fetches
of
resources
that
can
potentially
have
children,
for
example,
HTML,
CSS
or
JavaScript,
and
one
very
important
detail
here
is
that
we
have
to
prop
scheduled
them
or
hint
them
based
on
the
schedule
that
they
will
be
processed.
We
don't
want
to
fetch
any
resources
out
of
order,
so
that,
because,
if
we
fetch
things
out
of
order,
some
resource
that
gets
processed
earlier
might
stop
waiting
after
some
resources
that
gets
processed
later.
E
So
now,
let's
take
a
look
at
how
room
scheduler
works
in
action,
so
at
the
beginning
of
the
page,
scheduler
fetches,
all
HTML,
Javascript
CSS.
This
can
both
be
in
the
form
of
HTTP
to
push
or
link
reload.
After
all
of
this,
fetches
is
done.
It
will
start
fetching
other
dependencies,
such
as
images
fonts
on,
in
other
words,
resources
that
will
not
have
any
children
and
that
doesn't
require
any
processing.
E
While
these
two
fetches
are
going
on.
We
also
allow
the
browser
to
parse
the
HTML
CSS
and
also
execute
a
JavaScript.
If
you
discover
any
resources
during
by
processing
these
resources,
we
also
allowed
them
to
go
out
now.
This
red
line
in
the
timeline
is
a
very
important
time
in
the
page
load
process.
This
red
line
is
the
time
when
all
the
bytes
that
needs
to
be
processed
at
the
client
is
actually
local
at
the
client
already.
E
So
now
that
we
have
the
two
components
of
room,
let
me
sum
up
room
and
then
we
can
see
how
well
room
works
compared
to
the
current
state
of
the
page
load.
So
room
start
by
Senate
get
request
to
the
origin.
Origin
sends
back
there.
She
P
response,
pushes
important
resources
and
also
didn't
provide
hints
of
other
resources.
E
E
So
what
we
found
was
that
brooms
dependency
resolution
is
actually
very
accurate
and
because
of
this
room
was
able
to
speed
up
page
load
in
many
of
the
cases
we
have
a
hub
of
results
in
our
paper,
but
today,
I'll
only
be
talking
about
how
well
room
works
over
the
stay,
as
quote,
if
you're
interested
in
other
results,
please
refer
to
the
paper
before
jumping
into
any
numbers.
Let
me
first
tell
you
how
we
evaluate
room,
so
we
used
an
ex
SX
phone
connected
to
a
4G
LTE
network
to
a
web
record
and
replay
environment.
E
So
the
reason
why
we
need
a
web
recording
replay
environment
is
because
room
requires
server-side
changes.
So,
ideally
we
want
to
use
a
live
experiment,
but
unfortunately,
getting
adoption
of
all
tests
would
be
very,
very
challenging
now
that
we
know
how
we
evaluate
room.
Let's
take
a
look
at
the
numbers,
so
using
that
evaluation
setup
we
evaluate
room
on
the
Alexa
250
news
and
50
sports
sites,
and
this
is
the
bar
chart
representing
the
page
load
times
measured
in
seconds
as
well.
E
The
top
of
the
bars
are
the
medians
and
also
the
whiskers,
our
75th
and
25th
percentile
page
load
times.
The
status
quo
load
is
for
this
set
of
pages
is
10
seconds
like
we
saw
earlier
so
when
we
enable
step2
on
all
domains.
We
saw
that
by
only
doing
that,
we
are
able
to
take
the
median
page
load
time
down
to
7.5
seconds,
but
if
we
enable
room
at
all
domains,
we
are
actually
getting
doubled
of
that
improvement
in
page
load
times
and
right
now.
E
So
if
we
evaluate
room
on
the
above
the
fold
time,
which
is
the
time
where
all
the
objects
appear
on
the
screen-
and
this
is
the
bar
chart
representing
the
above
the
fold
time
measured
in
seconds,
so
the
status
quo
load
takes
12
seconds
to
load
at
the
median
site
and
when
we
use
broom
broom
was
able
to
improve
the
page
that
above
the
fold
time
from
12
seconds
to
8
seconds.
So
that's
a
4
second
improvement
in
above
the
fold
time.
E
So
now.
One
assumption
that
we
made
in
all
of
our
evaluations
so
far
is
that
we
assume
that
everyone
adopts
room
but,
as
we
all
know,
adoption
is
challenging.
So
what
we
did
as
well
is
we
evaluate
room
when
room
is
incrementally
deployed.
So
in
this
example
here
broom
is
an
enable
at
all
the
domains
right.
So
what
we
did
was
we
consider
first
party
domains.
So
when
I
say
first
party
domains,
let's
say
we're
a
SP
n
com,
yes,
PN
comm
also
owns
ESP
and
cbn.com
right.
E
So
we
also
consider
ESPN
cbn.com,
also
part
of
the
first
party
domains,
because
we
assume
that,
if
they
are
going
to,
if
say,
ESPN
are
going
to
deploy
room,
they
might
as
well
deploy
room
everywhere
on
their
domains.
So
what
we
found
in
this
setting
is
that
most
of
of
benefits
that
we
saw
in
the
in
the
case
where
we
enabled
room
everywhere
is
actually
still
achievable
from
only
enabling
room
at
the
first
party
domains,
and
that
means
that
we
actually
don't
need
full
adoption
to
make
web
page
look
faster.
E
E
This
actually
consumes
a
lot
of
CPU
cycles
and
network
at
the
server's.
Imagine
if
you
have
thousands
of
pages
running
serving
at
your
web
server
by
doing
periodic
loads
of
these
pages
will
be
a
huge
pain.
So
what
we
think
that
we
could
do
is
maybe
the
client
can
help
the
server
discovering
these
offline
dependency
resolution.
So
maybe
we
can
crowdsource
all
these
URLs
during
the
page
load
that
the
client
sees
and
then
send
it
back
to
the
browser
you
may
thinking.
E
E
In
a
very
naive
implementation,
you
can
send
all
these
resources
as
a
list
back
to
a.com,
but
this
is
obviously
not
good
because,
let's
take
a
look
at
z.com,
slash
a
dot
HTML,
so
that
is
an
ad,
so
anything
below
that
can
be
personalized
or
targeted
to
the
user.
So
sending
all
this
to
a.com
means
that
we
are
giving
up
privacy
to
of
the
user.
E
So
what
we
could
do
instead
is
sending
everything
in
this
screen
encapsulation,
and
this
is
in
fact
enough
for
a.com
to
discover
offline
dependency
resolution
because
a.com,
if
you
recall
from
the
offline
from
the
strawman
dependency
resolution,
a.com,
cannot
discover
personalized
resources
correctly
anyway.
So,
by
sending
anything
everything
in
this
screen
in
caps,
encapsulation
is
actually
enough
and
then
anything
below
c-calm
can
actually
be
sent
to
just
see.
Comm,
and
this
is
not
also
not
violating
privacy,
because
see
Tehama
is
the
one
serving
the
ad.
So
sending
you
back
to
see.
Comm
would
be
fine.
E
Another
very
important
lesson
that
we
found
in
Froome
is
that
when
doing
these
pushes
and
fetches
of
dependencies
using
link,
rel
preload,
we
shouldn't
be
fetching
out
these
resources.
At
the
same
time
as
we
saw
that,
if
we
do
this,
we
don't
see
improvement
in
patient
or
times
and
worse.
We
are
seeing
degradation
right.
E
So
maybe
one
thing,
one
branch
that
we
could
do
regarding
these
person
prioritization
of
preloads-
is
that
include
some
kind
of
priority
to
the
link
rel
preload,
so
that
the
browser
knows
that
oh,
this
preload
is
actually
higher
priority
than
some
other
reload,
so
that
the
browser
can
schedule
the
load
of
these
resources
better.
In
fact,
this
is
an
on
a
draft
already
in
the
w3c.
E
C
T
May
offer
thanks
for
interesting
presentations,
really
really
nice
to
see
that
someone
actually
tries
that
out
in
practice
other
than
just
an
association
of
it.
I
have
a
question:
do
we
employ
any
mechanism
that
you
avoid
pushing
the
same
resource
twice
to
the
same
client
I'm,
not
talking
about
link
reload
preload,
because
the
client
would
decide
whether
it
has
that
resource
already?
But
if
you
like
push
the
CSS
on
each
and
every
page
that
sounds
wasteful
or
are
there
any
technologies
employed?
You.
T
E
D
D
So
I
know
the
figures
for
regular
web
pages
and
it's
tremendous
numbers
of
URLs
I.
Just
don't
know
if
people
who
are
optimizing
for
mobile
are
actually
giving
up
some
of
this
overhead,
which
was
always
understood
to
be.
You
know,
people
basically
we're
designing
web
pages,
thinking
that
CPU
and
network
is
unlimited,
and
that's
not
the
case
for
a
robot
all
right.
So.
D
E
D
Right,
which
means
that
actually,
if
the
people
serving
these
sites
really
thought
of
their
user
and
what
the
experience
would
be,
they
could
cut
down
on
this.
And
maybe
you
wouldn't
need
your
solution
as
much
I'm,
not
saying
your
solutions,
not
a
great
idea,
but
if
people
instead
with
trying
to
force
down
our
throats
lots
of
advertising
and
spyware,
actually
thought
of
the
customer
and
his
quality
of
experience,
they
could
solve
this
problem
without
needing
more
technology.
Right.
U
E
U
E
Think
that's
a
separate
issue
right
now.
Browsers
are
absolutely
designed
right
now.
Is
that
there's
one
c1
main
process
that
is
doing
all
these
tasks.
Sure
you
can
have
another
process
that
can
do
like
preload
scanning,
but
that's
separate,
but
the
main
thing
that
is
happening
is
one
in
one
process.
So
by
having
that
only
one
process,
you
are
able
to
only
execute
or
deuce
doing
something
waiting
on
the
network
on
only
one
process.
So
sometimes
they
see.
E
U
V
Hi
you're,
Vice,
I'm,
participating
or
leading
like
participating
in
the
priority
hints
work
that
you
mentioned.
I
think
it
would
be
extremely
interesting
to
integrate
the
concept
of
the
JavaScript
scheduler
into
the
browser's
resource
scheduling
process
and
in
that
context,
the
red
line
you
showed
where
you
know,
which
separated
the
critical
resources
from
the
non-critical
ones.
V
V
I'm
sure
we'll
still
need
processing,
but
just
the
the
part
that
I'm
interested
in
is
in
determining
in
real
time
determining
the
redline
determining
the
fact
that
everything,
critical
or
most
critical
things
finished
loading
and
we
can
start
loading.
The
nonverbals
like
defining
that
red
line
would
be
extremely
interesting.
Yeah.
D
V
E
E
W
Matt
Mathis
I
sort
of
had
a
continuation
of
that
thought.
It
feels
like
this
is
very
good
work
very
cool
stuff,
but
it
feels
like
you're
optimizing
it
the
wrong
layer
in
the
sense
that
the
content
providers
should
be
optimizing
better
ahead
of
time
and
they're,
not
for
some
reason
and
I
was
wondering
if
you
had
any
speculation
about
some
of
the
incentives
for
it.
Things
like
domain
sharding,
for
instance,
fills
me
to
me
is
an
example
of
a
technology
that
works
the
same
way
that
excessive
choice
in
the
grocery
store
works.
W
It
has
the
effect
of
crowding
out
competitors
because
you
can
provide
14
different
flavors
of
chips
to
use
for
ten
times
as
much
shelf
space,
and
what
this
means
is.
Is
it
underlying
somehow
underlying
some
of
the
people
have
inappropriate
ascent
incentives
and
you're
optimizing
away
some
of
their
incentives,
but
the
real
problem
is
they're.
Optimizing
against
you.
Did
you
look
at
any
of
the
sort
of
the
causes
of
why
this
stuff
was
done
in
ways
that
it
was?
E
W
V
A
I
left
the
slot
in
case
anyone
had
any
questions
or
wanting
to
make
any
observations,
but
we
could
also
wrap
up
early,
we're
gonna,
give
certificates
up
to
motion
and
and
basketball
now
and
honoring
their
their
prizes
and
there's
no
reason
why
everyone
has
to
watch
that,
but
but
I'm
very
grateful
to
you
two
for
giving
these
talk.
I
think
they
were
really
great
and
really
thorough
and
inspiring.
A
I
Hi
Alison
I
wondered
if
we
might
spend
a
few
minutes
talking
about
or
catching
the
I
heard
you
have
community
up
on.
What's
going
on
or
how
er
NW
was
formed,
the
the
research
workshop
first
I
want
to
say
thank
you
and
to
the
iStock
people
and
they
see
and
people
to
put
putting
that
together.
The
last
time
I
looked
at
it.
We
know
we
didn't
have
a
committee,
there
was
no
call
and
all
that
stuff.
I
So
a
bunch
of
people
did
a
bunch
of
great
stuff
to
get
that
in
order
and
in
I
guess
in
the
spirit
of
sort
of
transparency,
I
was
wondering
if
you
could
tell
us,
or
one
of
them
could
tell
us
how
the
committee
was
selected.
What
was
the
reach
and
diversity
goal
and
did
you
meet
it?
I
see,
there's
an
invited
talk,
that's
one
of
the
people.
That's
on
it's
on
the
program
committee
that
that's
an
unusual
thing.
A
So
the
invited
talk,
question
I
think
is
an
interesting
one,
because
there's
quite
a
bit
of
variation
between
committees
and
workshops
as
to
whether
that's
a
reasonable
thing
to
do,
or
not
it's
of
the
conflict
of
interest,
whether
it's
okay
for
people
who
are
on
the
committee
to
also
be
speakers,
I,
think
the
reason
they
see
that
the
invited
talk
so
early
was
to
try
to
give
a
strong,
a
strong
representation
of
some
of
the
topics
in
range.
With
respect
to
the
program
committee
I
think
it's
possible
that
that
committee
could
could
grow
some
more.
I
Of
running
it
during
IETF,
because
we're
already
multitrack
yeah
ITF,
so
that's
gonna,
be
a
huge
improvement
and
the
competing
idea
that
was
floated
last
year
was
having
an
hour
W
being
a
continuing
workshop,
where
people
could
keep
like
solving
the
other
problem
at
academia
that
you
keep
it's
hurry
up
and
then
wait
like
you
hurry
up
to
submit
your
thing.
You
wait
half
a
year,
so
I
love
us
having
it
different
than
you
like
this.
I
But
a
couple
of
the
things
just
looking
to
improve
is
we're
still
inviting
now
in
a
or
W
we're
inviting
already
published
stuff
there.
We
already
do
that
for
an
RP,
so
sure
he
had
a
venue
to
do
that
and
and
I
think
that
we
should
like
raise
the
bar
for
ourselves
to
say
how
did
we
select
the
committee
and-
and
things
like
you
know
that
got
that
kind
of
stuff,
but
I'm
really
happy
that
it's
all
in
shape
already,
and
it's
looking
really
good.
I
A
A
A
Besides
submitting
yourself
is
to
encourage
your
researching
friends
to
to
bring
up
papers,
I
mean
if
everybody
in
this
room
submits
something
and
gets
a
friend
to
submit
what
other
amazing
choice,
but
I
have
had
in
mind
that
perhaps
the
committee
should
should
expand
with
respect
to
the
kind
of
continuing
versus
one-off
once-a-year
thing,
we're
thinking
slowly
about
the
idea
of
a
of
a
about
a
bunch
of
those
types
of
ideas
and
I'd
like
I'll.
Get
you
involved
in
that
conversation,
but
also
people
in
this
room.
A
We're
looking
to
try
to
increase
the
amount
of
applied
network
research
that
there
is
I
mean,
like
you've,
heard,
to
beautiful,
applied
network
research
topics
today
and
and
also
rods
topic,
but
many
times,
there's
a
very
big
gap
between
academic
research
and
what
we
could
then
do
something
and
build
in
in
the
real
world
internet
and
see
deployed.
So
we're
looking
to
just
enhance
those
relationships
in
every
way
we
can
okay.
I
And
that
you
actually
hit
on
exactly
the
last
thing,
I
wanted
to
say,
was
to
remind
people
to
solicit
for
it.
One
carrot
you
can
use
for
people.
One
thing
that's
nicer
about
in
our
W
that
say
IMC
is
the
talks,
are
recorded
and
we're
having
building
this
huge
library
of
awesome
presentations
by
those
people.
So
some
of
the
students
that
I've
solicited
to
come
to
IETF
format,
Margie
or
something
to
say
they
end.
I
M
A
I
Then
oh,
the
last
thing
is
the
program
committee
I.
It
looks
really
good.
It's
like
a
there's,
a
third
women
on
it.
Maybe
there's
looks
like
a
lot
of
third
of
the
people
are
ITF
participating
academics
already,
so
it's
looks
like
somebody
did
a
really
good
job,
but
we
should
tell
people
how
we're
doing
it.
Okay,.
A
Sounds
good,
okay,
anything
else
anyone
wants
to
bring
up
before
we
send
you
off
to
lunch.
Okay,
all
right!
Well,
thank
you
for
coming
see.
You
see
you
on
our
mailing
list,
see
you
tonight
I'm
going
to
give
another
little
bit
of
an
overview
tonight,
hopefully
more
successfully
in
the
analog
Department!
Oh,
and
there
should
be
another
blue
sheet.
If
someone
can
provide
the
other
blue
sheet,
that
would
be
helpful.