►
From YouTube: IETF103-SIDROPS-20181106-1350
Description
SIDROPS meeting session at IETF103
2018/11/06 1350
https://datatracker.ietf.org/meeting/103/proceedings/
A
B
Afternoon
it's
Thursday
at
IAT,
f103
Thursday
said
my
mail.
It's
Thursday,
I'm
Chris.
This
is
care.
This
is
IETF
103,
if
you're
not
for
the
IETF
103
meeting,
you're,
probably
in
the
wrong
place.
It's
the
side.
Rob's
me
again,
I
at
HF
103.
If
United
right
for
cider
ops,
then
we
could
say
it'll
be
fun
or
you
could
go
on
to
where
you're
supposed
to
be
for
those
presenting
there's
a
little
X
down
here
on
the
floor.
Please
stand
on.
It
speak
into
the
mic.
B
B
Yes,
thank
you.
Tim
are
you
presenting
to
okay
I'll
type,
while
you
present
how
about
okay
paper?
Oh
my
god,
this
is
cider
ops.
This
is
cider
ops,
not
cider,
boom.
Okay,
back
to
serious
things,
there's
a
note!
Oh!
This
is
all
of
our
oh.
This
is
the
note.
Well
I!
Think
maybe
yes,
this
is
the
note.
Well,
let's
just
say
it
is
we
have
an
agenda,
here's
the
slides,
we're
almost
in
two
or
five
minutes.
We
have
two
hours.
B
B
B
E
Okay,
so
last
year
we
did
some
work
on
testing
route,
origin
validation,
there's
different
implementations,
and
we
made
some
observations.
What
I
thought
might
be
interesting
for
everybody
of
you
and,
if
not,
then
just
doesn't
do
at
all.
So
the
first
thing
what
we
were
looking
and
we
want
to
see
what
is
the
impact
on
convergence
time
we
also
very
interested
in
if
a
router
is
connected
to
one
or
more
caches.
E
What
happens
if
the
connections
break
down,
if
we
have
changes
within
the
connections
etc,
and
how
does
this
whole
thing
work?
We
tested
a
little
bit
the
implementation
of
Route
Orange,
motivations
and
routers,
and
if
they
implement
the
RFC
1897,
which
is
on
ibgp,
the
transmission
of
the
validation
state
and
also
what
kind
of
impact
this
has
on
my
BGP,
so
the
first
and
convergence,
and
so
what
we
did.
We
did
not
use
any
excess
of
policy.
Actually,
we
didn't
use
any
policies
at
all.
We
just
sent
around
700,000
routes
into
the
router.
E
We
measure
it.
How
long
does
it
take?
We
made
it
this
one
peer
these
two
peers,
and
then
we
did
the
same.
There's
a
hundred
percent
who
are
coverage.
What
this
means
is,
we
had
for
every
prefix
origin
full
match
prefix,
and
we
got
around
an
average
increase
of
between
two
to
seven
percent.
I.
Think
the
loss
even
was
one
point
eight,
so
we
rounded
to
South,
but
this
is
all
relative,
because
now,
if
you
put
policy
processing
on
top
of
it,
the
the
time
stays
the
same,
our
percentage
goes
down
so
I.
E
Think
rendi
at
one
point
made
some
statement
that
it's
neglect
to
Bill
and
I
think
we
can
pretty
much
confirm
that.
Then
we
looked
into
the
validation
caches,
which
is
kind
of
interesting.
So
we
we
used
a
combination
between
the
ripe
ncc
in
our
own
cache
test
harness.
There
was
a
little
bit
easier
to
fill
in
later
and
we
made
these
tests
like
where
the
routers
connected
to
a
cache
and
all
of
a
sudden.
The
connection
goes
down.
For
example,
we
just
put
the
cable
waited
a
little
bit.
E
We
notice
that
not
every
router
implemented
it
100%
the
way
as
the
RFC
specifies
it.
We
talked
to
the
vendors
we
got
fixes
for
that.
So
maybe
just
you
look
into
your
own
gear.
What
you
have
and
check
and
talk
to
the
vendors
there
are
fixes
out
there.
If
you
see
something
some
implementations
label
internal
routes
as
well,
it
some
allowed
to
have
the
validation
state
configured
some
take
the
validation
state
of
it
is
signaled.
We
are
CRC
1897.
E
Then
we
looked
into
the
a
s
set.
The
a
s.
Ed
is
an
interesting
thing,
so
some
routers
had
issues
with
the
ASM.
Actually
so
when
we
receive
your
ebgp
in
a
sh,
if
the
prefix,
we
cannot
determine
an
origin,
but
if
the
prefix
is
not
covered
and
it's
not
found
from
the
algorithm,
if
the
prefix
is
covered,
then
it
should
be
invalid.
Interestingly,
we
found
an
awful
lot
of
not
founds
which
didn't
switch
to
invalid.
E
We
receive
one
fix
from
one
router
vendor
so,
but
it
doesn't
necessarily
need
to
be
a
bug,
because
if
the
vendor
decided
I
don't
perform
origin
validation
on
routers
a
asset,
then
the
RFC
says:
if
you
choose
to
not
validate
it
set
label,
it
is
not
found
so
I,
don't
know
if
the
internals
of
the
routers,
if
they
just
chose
to
not
validate
it,
then
it's
fine.
If
they
chose
to
them,
they
have
a
back.
Maybe
you
should
look
at
your
gear?
E
How
this
one
reacts
to
that
right
now,
so
then
we
yeah
I,
think
I
talked
about
this
already
so
I
immediately
we
have
some
routers.
Basically,
as
I
said,
label
labor
the
updates
as
well
it
if
they
don't
see
anything
else
here,
the
ibgp
we
as
a
community
string,
another
router
labeled
these
as
unverified
what
I
actually
liked
and
they
didn't
do
anything
and
there's
also
kind
of
way
how
you
can
configure
it.
E
E
Thing
what
we
noticed
there?
Actually
we
didn't
only
notice
it.
We
we
actually
made
use
of
that
for
some
of
the
measurements
and
later
on,
we
thought
wait
a
month.
It's
actually
kind
of
an
interesting
behavior
number
one
is
the
prefix
packing.
So
if
I
receive
here
ebgp
and
update
this,
let's
say
three
prefixes
and
the
validation
says
two
of
them
are
valid
and
one
of
them
is
not
found.
E
Then
out
of
one
update
becomes
two
so
later
on.
We
notice
this
because
we
were
thinking
we
were
counting
the
updates
that
go
in
and
come
out
and
something
was
off.
We
were
wondering
why,
and
then
we
figure
here
actually
that
it
doesn't
need
to
be
something
bad.
It's
just
something
what
you
should
consider
if
you
turn
on
this
attribute,
but
becomes
more
interesting
down
here.
I
have
only
one
prefix
and
now
my
connection
to
the
validation
cache
starts
flickering,
it's
up.
It's
down
it's
up
its
down.
E
E
Always
hated
this
work,
conflicting
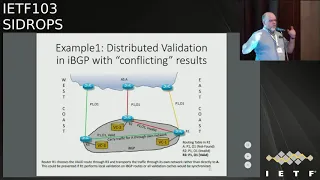
validation
results,
but
I
had
to
actually
educate
myself
a
little
bit
because
we
can
actually
have
conflicting
validation
results.
You
can
have
the
same
prefix
origin
in
the
router.
That
has
all
three
validation
states.
How
can
that
happen?
I
have
an
S
that
has
that
has
three
routers.
Every
router
has
their
own
validation
cache.
They
are
not
synchronized,
they
pull
at
different
times
and
one
router
might
say:
that's
this
prefix
origin
is
not
found.
This
one
says
it's
invalid.
E
This
one
says
it's
valid
and
then,
if
they
add
this
one
is
extended
community
string,
then
router
one
will
have
known
it's
table.
Prefix
one
origin,
one
three
times
with
three
different,
conflicting
validation
results.
Just
something
to
think
about
it.
This
may
be
local
processing
might
make
more
sense,
even
on
the
ibgp
side,
or
if
every
of
these
router
maybe
connects
to
a
centralized
validation,
cache
that
might
fix
some
of
the
things
so
that
at
least
see
validation
results
might
all
be
the
same.
E
Because
what
can
happen
now
is
if
our
one
receives
traffic
for
prefix,
1,
origin,
1
and
a
is
a
basically,
it
might
be
a
origin
1
actually
or
it
might
just
provide
through
the
router
it.
If
the
traffic
comes
in
here,
I
would
prefer
that
it
goes
out
right
away
to
a
say,
but
if
I
now
prefer
well
it
this
link
here
is
not
found.
This
one
is
invalid
and
this
one
is
valid.
E
So
now
our
one
carries
the
traffic
through
its
own
network
to
the
west
coast
and
then
sends
it
out
to
a
say
just
something
to
think
about
same
some
router
limitation
of
our
three
doesn't
do
any
art
from
router,
invalidation
and
router.
One
then,
by
default
declares
this
one
is
valid.
Just
if
you
deploy
this
just
think
about
how
you
have
to
create
your
policies,
to
maybe
avoid
certain
things
or
think
about
that.
These
things
can
happen.
E
E
Maybe
they
are
I,
just
didn't
find
them,
but
if
someone
starts
really
fresh
with
that,
they're
really
on
lost
lost
grounds,
because
we
even
saw
that
in
some
router
implementations
we
saw
some
labeling
that
would
imply
certain
settings
and
I
didn't
find
any
setting
that
could
activate
something
like
I
saw.
Some
using
this
primary
and
secondary
cache.
I
did
not
figure
out
how
how
can
I
say.
I
wanna
have
primary
secondary
cache.
I
figured
out
that
the
implementation
all
made
a
union.
E
E
E
So
the
question
here
is:
is
there
an
interesting
to
create
a
document
where
you
start
documenting
these
kind
of
experience,
things
for
people
who
come
fresh
and
I?
Think
yesterday
in
the
Grove
working
group,
they
were
talking
about
like
a
living
document.
What
can
be
always
updated?
Maybe
something
like
this
could
be
an
interesting
thing
in
this
regards,
because
things
that
might
be
an
issue
now
might
not
be
an
issue
in
six
months.
E
Maybe
things
that
we
don't
know
yet
are
an
issue
might
be
an
issue
in
six
months
and
something
that
has
value
for
especially
newcomers
I
mean
we
are
still
in
the
deployment
stage.
Many
people
come
in.
They
hear
this
the
first
time,
or
they
may
be
heard
at
ten
years
ago,
and
still
aren't
so
mighty
at
set
of
ten
years
ago,
but
they
don't
know
what
it
is
and
maybe
just
can
update
things.
E
So
for
someone
who
gives
a
quick,
quick
start
something
for
the
community
there,
you
can
exchange
a
little
bit
and
have
some
value,
not
something.
What
is
two
hundred
pages
long
was
something
that
is
maybe
I
always
hope
for
one,
but
maybe
a
handful
of
pages.
Maybe
some
it's
ideas
on
how
you
can
configure,
not
that
you
have
to
do
it
like
that,
but
just
what
you
have
to
consider
something
like
this.
So
that
is
one
thing,
and
we
also
think
that
we
will
we
plan
on
doing
some
more
tests.
E
If
there
is
something
that
some
of
you
really
would
like
to
see
drop
me
an
e-mail
or
Shriram
or
doc,
montgomery,
whoever
and
then
we
can
see
if
we
can
put
this
into
this
test,
what
we
want
to
do-
or
maybe
that
is
something
where
we
say-
hey,
that's
really
cool.
We
want
to
do
that.
I
mean
we
don't
have
limitless
resources,
but
if
there's
some
interest
in
testing
certain
things,
what
you
think
is
valuable
also
for
the
community.
Let
us
know
questions
I,.
G
G
E
E
G
E
G
G
F
E
G
H
Hello,
cute
ellipse,
so
my
thank
you
for
the
report.
My
question
is
it
made
me
anxious
that
if
we
are
losing
connection
with
the
cache,
the
state
of
perceived
roots,
maybe
change
from
valid
to
unknown
and
with
this
wonderful
extended
community,
these
roots
will
be
renounced.
All
routes
will
be
renounced
inside.
E
H
H
E
H
H
E
H
E
I,
don't
know
I
mean
the
thing.
The
thing
is
is
too
in
our
day
and
age.
So
if
you
take
I,
don't
wanna
endorse
any
product,
but
if
you
take,
for
example,
the
ripe
NCC
Valley
data
and
you
just
power
up
three
virtual
machines
and
different
physical
machines
and
you
connect
to
all
of
them,
you
have
it
anyway,.
E
Validation
is
not
expensive.
So
if
I
also,
if
the
problem
is
this,
if
I
have
a
system
there,
I
have
distributed
caches.
This
alone
gives
me
already
an
interesting
thing
that
I
can
have
different
validation
states.
How
do
I
deal
with
that?
What
do
I
want
to
do
about
that?
So,
if
I
say
I
validate
within
my
router,
every
particular
update
I.
E
H
E
E
The
thing
is
the
only
thing
what
we
want
to
do
is
here
think
about
it.
Think
about
the
implication.
Think
what
is
the
best
for
your
organization?
You
always
can
have
policies
of
what
you
want
to
send
out
what
you
don't
want
to
send
out.
I.
Think
the
more
important
thing
is
that
everybody
is
aware
that
there
are
some
things
that
can
happen.
You
might
be
able
to
see
something
in
your
outing
and
I
just
want
to
bring
you
a
pointer
to
say
hey.
Maybe
it
might
be
that
it
might
be
even
something
completely
different.
E
So
more
of
you
look
into
more,
we
test
the
more
interesting
things
we
see
the
more
questions
come
up.
Sometimes
you
do
something
wrong.
Sometimes
you
say:
hey
wait
a
moment
that
is
a
that
is
just
an
attribute
of
rpki
and
it's
fine
as
long
as
they
know
about
it
as
long
as
they
can
do
something
I
could
think
about.
E
If,
if
it
flickers
too
much
that
I
just
turn
off
my
validation
care
or
I
turn
off
the
r
Cena
1897,
so
I
only
sent
you
if
I
make
a
change
in
my
in
my
selection
process
until
I
have
a
stable
connection
so
and
there's
so
many
different
ways
and
I
don't
want
to
tell
you
what
you
have
to
do
and
I
don't
think
we
would
shouldn't
stand
here
and
say
what
you
have
to
do.
The
important
thing
is
that
you
know
there
is
something
and
you
have
to
make
your
own
decision.
I
Okay,
so
the
AF
set
as
far
as
I
remember,
was
considered
when
we
D
actually
designed
the
whole
thing
as
something
that
should
go
away
and
I'm,
not
completely
sure
whoever
we
were
completely
wrong
about
it,
and
it's
not
that
design
decision
is
now
biting
us.
On
the
other
hand,
one
if
one
really
wants
to
look
into
it,
one
should
recognize
a
assets'
essentially
happen,
because
some
AAS
is
creating
an
aggregate
root
and
that
essentially
means
that.
I
E
This
box,
that
is
actually
something
but
I,
always
like
to
open,
because
all
the
identification
identifies
to
identify
an
AI
said.
They're,
all
optional
I
can
make
a
cure,
got
a
guess,
pass
aggregation.
If
we
don't
put
my
asset
in
my
path.
If
we
don't
set
the
aggregator,
you
don't
know
it's
aggregated
and
all
of
a
sudden,
my
AS
IS,
the
auger,
is
the
originator.
So
why
is
it
not
the
originator
if
I
put
C?
E
I
I
think
we
really
ought
to
identify
some
repository
where
we
just
dump
the
stuff
that
we
find
then
what
we
get
along
and
that
may
be
later
on
be
refined
into
a
document
that
actually
has
consensus
and
while
okay
high
quality
and
whatever,
as
far
as
I,
can
tell
so
far,
we
really
have
not
yet
installed
or
recognized
such
a
repository
that
we
agree
to
actually
use
I
may
be
wrong.
I
may
have
forgotten
about
it.
F
E
But
I
mean
that's
a
good
idea
as
well.
I
mean
the
question
is
just
is
there?
Is
there
interest?
You
know
if
it
is
a
document?
If
it
is
a
github
thing,
if
it
is
I,
don't
know
what
what
other
people
will
come
fresh
into
the
whole
field
can
read
and
educate
and
get
some
ideas,
if
not
hey,
be
my
guest
I'm
fine
with
that
as
well.
It
is
just
an
idea:
I
throw
in
the
room
yeah.
F
Snider's
entity
too
short
remarks
in
terms
of
SS.
The
implementation
on
an
open,
Beach
PD
is
that
we
ignore
the
asset
when
doing
the
original
edition
procedure.
So
we
just
look
at
the
last
sequence
of
the
s
path.
The
implementations
I've
done
internet
exchanges
for
route
surfers
using
birth.
Birth
has
an
option
to
look
at
the
last,
not
aggregated
ASM
in
the
SPF.
So
we
could
just
shortcut
this
discussion.
Asl
does
not
exist.
I.
E
E
There
are
some
implementations
that
actually
allow
you
to
configure
the
heck
out
of
your
router,
and
you
can
do
whatever
you
want
with
that
you
can
even
roll
the
dice
so
I
think
if
the
vendor
provides
enough
document
enough
configuration
so
that
you,
as
user,
can
decide
what
you
want
to
do.
That's
fine
I
mean
it's
a
little
bit
of
problem.
If
other
everybody
uses
its
differently,
it
is
just
something
that
I
say.
Maybe
you
should
look
into
what
does
your
out
or
do
with
that
and
just
know
about
how
it
works
and
final.
F
Comments
when
speaking
to
operators
about
deploying
origin
validation,
a
question
that
often
arises
is
what
will
be
the
performance
impacts
and
then
I
sketch
out.
Well,
it's
patricia
cheese.
We
do
the
lookup
in
this
table.
The
table
only
has
this
specific
types
of
tuples,
so
we
can
do
it
in
microseconds
having
a
document
where
the
title
is
performance,
impacts
of
origin,
fala,
Dacian
or
something
more.
That
just
focuses
on
that
one
question:
what
is
the
impact
and
that
we
can
prove
that
there's
virtually
no
impact
would
be
very
helpful
in
promoting
original
validation.
G
E
So
there
are
situations
where,
for
example,
if
I
go
and
be
to
be
sick
for
a
second,
if
I
receive
routes,
I
might
want
to
do
lazy
evaluation,
so
I
just
want
to
take
them
in
I
want
to
do
my
route,
selection
or
whatever,
and
then
maybe
I
want
to
do
the
validation
later
on.
It
would
be
interesting
to
see
there
if
this
route
was
validated
or
not
not
just
to
sign.
E
Some
label
in
the
same
I
think
is
also
true,
with
Origin
validation,
the
algorithms
in
RFC,
68,
11
and
8205
specify
values
that
are
the
result
of
a
very
defined
algorithm,
not
validating
something.
If
I
just
assign
blindly
the
validation
state
I
watered
on
them
all
as
programmer.
For
me
personally,
if
I've
write,
something
and
I
have
pointers,
I
initialize
them
I,
either
set
them
to
nada
or
I,
have
them
to
some
objects.
E
The
for
me,
basically
an
unverified
and
and
a
verified
route
are
not
the
same
and
unverified,
and
what
sound
is
not
the
same.
If
this
is
the
same,
then
what
can
I
say
if
I
see
a
valid
route?
My
router
was
it
validated.
Was
it
not
validated?
There
are
some
routers,
as
I
said
before,
that
on
ibgp
label,
everything
is
valid
so
normally.
Well.
It
tells
me
that
this
raw
that
gave
me
the
result
that
this
route
is
valid
now
I,
just
labeled
it
it.
E
We
found
two
word
usages
and
I
learned
the
meantime.
There
also
a
couple
of
more
but
one,
for
example,
juniper
has
the
unverified
and
I.
Don't
I
don't
want
as
I'm
not
saying
that
I
want
to
prefer
this
vendor
to
any
other
I.
Just
say
they,
for
example,
have
that
I
liked
it
very
much
our
implementation
isn't
undefined
what
was
a
little
bit
more
semantics,
but
I'm
very
fine
with
unverified
as
well
going
to
RC
68:11.
E
So
we
we
wanted
to
have
unverified,
specifies
the
state
of
a
route
prefix
which
one
which
no,
which
no
evolution
has
been
performed
and
to
update
this
statement.
A
validation
is
not
the
fountain
or
au.
Its
implementation
should
initially,
they
initialize
the
validation
state
of
such
route,
to
not
found
to
the
sentence.
If
no
evaluation
over
out
prefix
is
performed
in
any
form,
the
implementation
must
initialize
the
validation
state
of
such
route
to
unverified.
E
If
I
would
have
that,
then
I
could
figure
out
if,
for
example,
the
routers
that
returned
on
the
a
s
set
they're
not
found
in
they
chose
to
not
validated
or
if
they
have
a
bug,
because
if
they
chose
to
not
validated,
they
should
be
unverified.
If
they
validated
I
know.
You
know
invalid.
If
I
have
a
covering
raw
to
this
also
RFC
1897
should
should
have
the
unverified
look
up
in
there
as
well.
I.
E
E
E
It
didn't
pass
validation,
so
if
I
did
not
validate
it,
if
it
didn't
even
attempt
it
to
evaluate
it,
then
I
should
say
it's
unverified
so
and
then
we
would
just
say
BGP
routes
feature
music
routes
must
be
initialized
using
the
BGP,
SEC
validation
state,
unverified
until
proper
evaluation
of
the
BGP
SEC
route
has
been
performed.
How
you
evaluate
is
different.
This
is
completely
up
to
you,
but
if
you
don't
do
anything
to
the
route,
it
should
be
unverified.
Why
should
I
set
it
to
not
valid?
Why
should
I
said
it?
Well,
it.
J
K
Both
the
origin,
validation
and
BGP
second
round
and
round
and
round
on
how
many
output
states
are
the
from
the
validation,
okay,
an
origin
validation
as
the
three
states,
because
they're
very
simple,
but
good
and
I
can
prove
it.
It's
bad
and
I
can
prove
it
and
everything
else.
What
the
flavor
of
everything
else
is
outside
the
scope
of
the
validation,
I
I
can
understand
an
operational
reason
why
you
might
care
what
flavor
of
on
of
not
able
to
prove
anything.
It
is,
but
that's
what
you're
talking.
E
Is
this
you
made,
you
made
something
very
important,
you
said
the
outcome
of
the
validation
algorithm.
If
I
don't
even
start
the
validation
algorithm,
then
I
need
to
initialize
it,
because
otherwise,
I
only
have
three
States
I
can
attach
to
this
particular
prefix.
Rc
6811
says:
if
you
choose
to
not
validate
something,
you
should
have
a
case
should
set
it
to
not
for.
K
Sure,
but
look
at
all
the
weight
look
at
all
the
different
reasons
why
you
could
have
failed
to
run
the
validation
out
for
them.
You
didn't
want
to
you
weren't
able
to
connect
to
something
you're
having
a
bad
day
and
you're
running
really
slowly.
There
are
a
whole
bunch
of
different
states
there.
The
point
was
just
to
skip
over
all
of
that
in
terms
of
the
specification,
as
I
said
in
your
implementation.
E
E
K
I
I
In
BGP,
SEC
kind
of
yeah
well,
actually,
actually
no
I
disagree
with
my
with
the
first
statement.
No,
actually
actually
marking
that
you
have
analyzed
analyzed
the
analyzed
the
state
of
stuff
or
you
have
not
really
really
is
significant.
Information
were
not
found,
as
it
is
labeled
in
original
validation.
I
I
Having
having
not
done
and
started,
the
test
really
is
really
is
a
different
thing,
and
it
makes
a
lot
of
sense
to
have
different
policy
decisions
based
on
that
and
with
the
BGP
SEC,
yes,
kind
of
the
Fate
we
have
done
for
checks,
and
we
found
it
is
invalid
kind
of
is
a
different
thing
than
in
origin.
Validation
were
the
unknown?
I
E
E
You
can
treat
them
the
same
you,
but
they
also
could
say
you
know
what
I
want
to
hold
back
on
them.
Maybe
I'll
oppress
them
or
I,
don't
know
whatever
you
like
reading
I
said
it
is,
it
might
be
of
interest
and
I
think
it
is
of
interest
to
determine
if
a
route
was
validated
or
not
and
just
assigning
they're
not
found
I.
I
And
not
distinguishing
they're
quite
certainly
creates
the.
What
was
your
turn
in
the
previous
talk
in
our
conflicting,
conflicting
state?
If
you
have
announcements
coming
in
from
a
Rooter
that
has,
for
whatever
reason
lost
the
capability
of
classifying
and
another
one,
that
actually
does
the
classification,
you
are
getting
a
conflict
knowing
knowing
that
the
one
has
lost
its
mind
and
cannot
really
tell
allows
you
to
say
well,
okay,
if
I
have
a
better
classification,
I
can
use
that.
B
I
suppose
are
you
proposing
to
write
a
document?
It's
discusses
this
problem,
no
I
mean
you're
you're,
proposing
to
either
write
to
biz
documents
or
write,
something
we
can
chat
about
in
on
list
at
the
next
meeting
or
whatever
about.
Should
the
states
should
there
be
another
state
or
you
just
bringing
up
a
problem
saying
this
is
interesting
and
we
should
fix
this,
but.
E
K
B
B
L
L
We
currently
have
no
proper
way
of
rolling
route
keys
in
the
RPI,
so
goals
of
this
whole
exercise
are
that.
Well,
we
want
to
be
able
to
do
it
in
a
reliable
way.
You
want
to
learn
from
the
in
a
sec
what
can
be
learned
there,
but
we
also
want
to
look
at
what
we
have
in
the
RTI
and
make
sure
that
this
has
a
soft
landing
into
the
existing
standards
that
we
may
be
able
to
leverage
things
that
we
have
here.
A.
L
L
L
You
don't
really
know
if
you're
going
to
need
an
unplanned
roll.
So
there
is
at
the
moment,
no
indication
of
when
you
plan
to
do
a
roll,
because
that
might
be
misleading.
You
might
say
I'm
going
to
roll
to
this
next
key
and
then
it
turns
out.
You
lost
some
X
key,
so
we
can
discuss
whether
that's
actually
useful
to
include,
because
you
know
this
should
not
happen
all
the
time.
L
But
for
the
moment
it's
not
in
there,
then
the
next
steps-
well,
okay,
don't
take
it
literally,
but
I
would
say
we're
going
forward
with
this.
What
we
want
to
do,
we
want
to
actually
make
some
running
code
and
anybody
interested
in
that
I
would
say:
let's
talk
and
work
together.
Somehow
an
option
might
be
to
do
that
at
an
ITF
hackathon
or
get
to
get
our,
but
you
know
there's
other
ways
as
well.
L
So
if
you're
interested
in
doing
work
in
in
this
space,
please
let
me
know
this
was
actually
the
executive
summary,
let's
say
so
reminders
all
what
we
do
is,
for
you
know
a
cast,
but
if
this
time
I
do
have
more
slides
on
how
the
process
actually
works,
so
is
it
time
to
go
through
that
then
I
might
do
that.
So,
okay,
now
the
current
situation,
we
have
trust
anchor
locators
that
are
either
shipped
with
a
relying
party
software
or
configured.
L
The
software
will
then
fetch
a
certificate,
verify
it
and
then
that
certificate
has
a
publication
point.
We
manifest
serial
and
other
stuff
like
a
certificate
or
a
child,
then
that
has
its
own
repository
and
so
on.
So
that's
where
we
are
today
and
if
you
want
to
reconfigure
the
chancre,
you
have
to
put
a
new
towel
into
your
relying
party.
So
far
so.
L
Instead
of
tell
to
avoid
that
confusion,
but
I
still
have
to
get
used
to
that
name
myself
so
I
might
say
sign
tell
why
excellent
have
you
known
them
so,
but
in
any
case,
what
you
can
do
just
using
one
key
like
today,
one
root
key
you
can
opt
into
to
having
this.
You
can
create
a
an
object,
a
tal
tag,
object
that
basically
refers
back
to
your
one
and
only
current
key
associate.
This
is
a
current
key,
so
invalidation
software
will
be
configured
with
the
trust
anchor.
L
It
will
find
the
tag
file
there
and
discover
okay,
that
the
crossing
car
used
is
still
current,
so
I'm
good
to
go
and
there's
nothing
else
to
look
at
importantly,
but
of
course
just
doing
this
won't
get
you
very
far
or
give
you
many.
You
know
benefits,
so
if
you
have
two
keys
well,
what
you
can
do
is
lots
of
drawings
here
in
this
state.
Both
keys
are
current.
L
Both
are
fine
if
you
configured
with
its
anchor
for
the
first
key.
What
you
do
is
you
find
a
the
blue
tea,
a
tag
object,
you
validate
it
and
it
refers
to
two
crossed
anchor
certificates.
There
are
curls,
so
you
will
then
need
to
look
at
both
well
one
you
already
looked
at,
but
you
don't
need
to
look
at
the
green
on
you'll
discover
there
are
a
new
tack
file
that
also
lists
these
two
keys.
That's
good!
So
you
don't
there's
nothing
else
to
look
at
as
documented
now.
L
L
Right
this
one
to
continue
here
right
and
I
left
that
in
manifest
in
crl
here
or
because
it
would
get
very
close
as
well.
So
another
approach
might
be
that
you,
you
would
say
you
have
to
take
the
union
of
everything,
that's
good
and
undo.
Something
like
that,
but
I
figured
that
you
know
this
is
the
easiest
seems
the
easiest
to
me
now
to
continue.
If
you
roll
to
a
new
key-
and
this
is
a
plan
roll,
what
you
can
do
is
you
can
well?
First
of
all,
you
introduce
a
new
key
three.
L
It
has
the
same
content
as
s2,
but
for
number
one
you
actually
stop
publishing
shell
certificates
on
all
that.
You
only
population
manifest
in
this
URL
and
a
new
long,
lift
attack
file
that
says
I
am
actually
revoked,
and
these
are
currently
the
new
keys,
yeah
I
guess
in
theory.
That
could
also
be
a
pointer
to
ta
three
there
at
this
point
to
here,
but
yeah.
It's
not
strictly
necessary.
Actually
the
this
file.
This
one
still
refers
back.
L
This
one
needs
to
be
revoked
letter
out
here,
because
essentially,
the
relying
party
only
discovers
this
when
you
already
learned
that
this
is
going
to
be
revoked,
and
if
you
would
keep
the
list
of
all
the
old
keys
around
all
the
time,
then
this
list
grows
in
road,
so
I
don't
think
it's
necessary
and
that's
it
really
on
plants,
though
I
didn't
make
a
slide
of
that,
but
I'm
plan.
That,
essentially,
is
you
have
no
ability
to
update
this,
so
it
will
stay
like
this
right.
L
So
the
viewpoint
from
ta1
will
will
be
ok,
1
&
2
are
current,
but
then
2
will
say
one
has
actually
revoked,
so
you
still
learn
about
it,
and
this
is
also
what
I
meant
with
there's
no
timing
indication
in
there.
You
could
include
it
and
if
you
know,
if
you
do
a
planned
role,
that
might
be
useful,
but
in
theory
there's
no
way
to
be
sure
that
you
don't,
you
may
have
to
do
it
on
that
role.
L
J
J
I
need
to
actually
publish
at
some
point
that,
after
looking
at
all
of
not
just
you
in
a
sec
but
looking
at
x.509
and
peak
Hicks
and
the
web
and
that
kind
of
stuff
there's
a
lot
of
takeaways
that
that
I've,
you
know
gotten
out
of
it
that
I
can
transcribe
into
a
couple
of
bullets
of
wisdom.
One
you
need
to
plan
on
doing
longer,
key
roles
lifetimes
and
you
were
probably
originally
thinking.
J
You'd
come
back
to
that
in
a
second
and
two,
you
really
ought
to
be
prepared
with
you
know,
multiple
keys
in
the
future
and
part
of
it
becomes
from
that
that
need
for
a
long
hero
and,
and
the
reality
is
that
in
all
of
these
systems
there
are
really
three
places:
three
ways
that
Keys
get
distributed
toward.
You
know
running
systems.
J
First
off
you
have
software
updates,
where
keys
or
basically
you
know,
encoded
weather,
whether
it's
a
you
know
a
flash
rom
in
an
in
a
router
or
whether
it's
actually
you
know
bird
being
installed
somewhere.
They
often
come
with
pre
distributed
keys
and
that
update
process,
especially
in
critical
infrastructure,
takes
a
very
long
time.
So
the
other
option
is
doing
something
like
fifty
eleven
and
DNS
SEC.
Where
you
know
there's
this
automated
update
mechanism,
not
everybody
turns
that
kind
of
thing
on.
J
So
you
can't
assume
that
the
that
is
always
going
to
be
the
case
and,
as
you
know,
warren
found
things
running,
docker,
don't
really
sort
of
have
that
longevity
of
measurement,
and
then
three
is
the
manual
configuration
where
you
know:
users
wait
until
the
very
last
second
before
they
finally
update
their
config.
You
can't
really,
you
know
worry
about
them
too
much,
but
but
my
takeaway
from
all
of
this
is
that
it
has.
J
It
takes
a
lot
longer
to
do
those
those
key
roles
and
and
therefore,
especially,
if
you're
planning
on
accommodating
the
software
pushes
the
the
you
know,
the
the
pre
packaged
software
pushes
that's
on
the
order
of
two
or
three
years,
so
it
might
actually
be
a
beneficial
to
have.
You
know
two
to
three
key
staging
in
advance,
not
just
one
or
two
and
being
prepared
for
that,
and
so
the
good
news
is
yeah.
You've
your.
L
But
the
document
also
says
something
about
that.
You,
you
may
actually
wish
start
shipping
this,
and
if
this
is
your
intended
new
key,
what
you
might
want
to
do
is
update
all
the
nine
party
software.
Then
there's
out
there
to
get
them
to
include
a
new
one
instead,
but
it
yeah.
You
probably
shouldn't
do
this.
You
know
every
week
and
and.
J
The
fact
that
you're
you're,
considering
using
double
signatures,
which
we
can't
we
couldn't
do
Indiana
Secretary,
Pat,
concise
constraints
and
things
like
that,
which
you
don't
really
suffer
from.
So
that's
the
positive
side.
But
at
some
point
you
still
have
to
turn
off
the
old
key
and
you're
still
going
to
break
every
that
failed
to
irrigate.
F
I
In
our
PK
in
rpki,
we
actually,
we
actually
need
to
expect
that
relying
party
implementation
has
some
heuristics
that
raise
alarms
if
things
start
to
fail
in
big
ways
or
while
okay
in
suspicious
ways
I'm
not
sure
that
all
of
the
existing
relying
party
implementations
do
this.
But
one
cannot
repeat
that
often
enough
until
it
is
this
way
and
of
course,
they
also
need
some
heuristics
how
to
deal
with
it
and
that
needs
that
needs
to
be
documented
in
some
ways.
I
So
now
for
DNS
SEC,
one
would
expect
that
yes,
operators
of
resolvers
get
some
feedback,
but
kind
of
the
expectation
in
rpki
deployment.
I
think
is
that
relying
parties
really
need
to
need
to
have
those
expose,
alarms
and
the
workarounds.
And,
yes,
that's
not
really
helping
helping
with
this
design.
L
M
L
J
You
know
an
absolutely
horrible
heartburn
up
until
you
know
a
month
ago,
where
they
finally
just
had
to
go.
We're
gonna.
Do
it
anyway,
without
knowing,
if
things
were
gonna
break,
and
you
guys
might
have
the
opportunity
to
kind
of
fix
that,
but
knowing
how
files
and
think
are
synced
I'd
have
to
go
it's
I'm,
two
years
out
of
having
real
associations
so
they're,
not
in
my
mind
at
the
moment.
So.
L
You
need
to
do
revalidation
top-down
all
the
time
anyway,
so
I
see
Russ
is
in
Lima.
You
suggest
that
a
document
to
me
where,
basically
inside
a
certificate
you
can
signal
this
is
going
to
be
the
next
key
I
looked
at
that,
but
I
figured
that
we
actually
have
a
way
here
to
to
do
this
as
well
within
the
up
yeah.
Because
of
how
its
published
you
need
to
Bro
validate
this
whole
repository
anyway,
so
you
can
have
an
object
there.
L
A
signed
object
that
these
things
that
we
want
to
communicate
and
that's
essentially
why
I
went
for
that,
but
I
think
in
in
terms
of
semantics.
It's
not
that
difference,
but
so
to
take
away.
It's
essentially
saying
these
keys,
our
next
public
key
fingerprint,
essentially
panel
location,
where
you
might
find
them
and
it's
communicated
within,
let's
say
in
banner
of
the
RPI
repository,
so
you
can
find
these
things
so.
J
You're
missing
my
point,
which
is
that
maybe
maybe
that
I'm
actually
talking
about
the
relying
party
signaling
to
to
the
people
that
it's
pulling
data
from
looking
at
the
routing
objects
saying
these
are
the
keys,
I
trust,
so
that
so
that
the
the
publisher
of
the
objects
can
say.
Oh,
it's
now
safe
to
switch
to
using
a
new
or
revoking
an
old
key,
because
all
of
the
relying
parties
have
now.
You
know
gotten
to
like
99%
of
accepting
the
new
key
and
without
that
signaling
measurement.
You
just
burn
heartburn,
interred
right.
L
L
N
You
know
you're
right,
that's
incomplete,
so
this
is
Russ
I.
Think,
there's
a
big
difference
between
what
Wes
was
just
talking
about
in
this,
because
our
certificates
have
an
expiration
date.
If
we
get
to
that
point,
it
doesn't
matter
that
is
not
the
case
in
the
environment.
Wes
is
just
talking
about.
The
other
thing
is
I.
Do
think.
M
D
So
Warren
Kumari,
the
other
other
thing
we
learnt
from
the
DNS
SEC
key
role.
Is
that
yeah
or
something
or
maybe
the
only
thing
we
learn
is
that
emergency
key
rules
are
really
really
really
different
to
regular
key
roles
and
actually
the
process
that
we
have
for
normal
key
roles
in
the
DNS
SEC.
Don't
work
at
all
for
KS
I
mean
for
emergency
roles
and
I.
Think
that
there's
some
correlation
here,
where
you
know
I
just
my
key,
is
no
longer
trust
able
needs
a
better
signaling
mechanism.
Maybe
okay.
L
Yeah
just
coming
back
actually
currently
the
document
says
these
keys
are
equivalent
and
we
have
no
way
of
telling
you
which
is
going
to
do
the
next
role.
So
you
can't
really
monitor
what
people
do
right.
Maybe
it's
better
to
change
it.
To
really
say
this
is
the
Intendant
X
key,
regardless
of
that?
Maybe
you
do
need
to
do
an
on
plan
thing,
because
then
you
can
monitor
whether
people
have
moved
over.
H
Good
afternoon
my
name
is
Alexander
Smurf
from
Goethe
lips
and
today,
I'm
going
to
provide
a
short
overview
of
about
all
works
that
are
related
to
rotis.
So
as
far
as
I
know,
there
are
three
active
drafts
in
different
working
groups.
First,
one
is
BGP
open
policy
and
it
is
related
to
preventing
networks
from
leaking
the
sector.
One
is
the
oldest
one,
and
now
it's
about
detection
of
flicked
prefixes
using
communities
and
the
last
one
is
using
your
application
object
here
and
is
capable
to
detect
both
mistake
and
malicious
activity.
H
So,
looking
at
this
comparison,
one
might
ask:
why
do
we
need
this
thing
with
communities,
because
we
already
have
something
more
powerful,
more
advanced
that
is
capable
also
to
detect
both
malicious
and
mistakes,
and
the
problem
is
time
and
time
does
matter,
taking
a
look
at
the
raw
deployment
process.
It
will
take
years
before
we'll
get
a
stay,
a
verification
in
the
world,
and
that's
why
we
decided
to
use
communities
to
detect
root
leaks.
H
H
H
You
know
there
was
a
update
of
a
spade
raft
and
authors.
Work
worked
really
hard.
As
a
result,
we
have
a
new
abstract
and
some
small
restructure
of
the
document,
but
there
was
an
important
clarification
in
the
version.
Zero
one
ace
be
is
not
trying
to
provide
a
full
ice
bath
check
instead
of
its
predecessors.
H
It's
just
provides
a
tool
to
detect
real
operational
problems,
hijacks
and
root
leaks.
That's
all
it's
not
a
general
solution
for
the
ice
bath.
It
just
a
solution
for
real
problems.
So
this
is
how
I
see
it
in
a
near
future.
I
hope
you
will
be
able
to
see
this
progress
in
half
in
half
year,
so
be
open
policy
seems
to
be
ready
nearly
ready
to
up
to
the
last
call.
We
already
have
two
implementations,
and
so
after
a
clean
up,
I
sure,
I
hope
there
will
be
a
logical
and
it
will
be
successful.
H
Second
root
leak.
Detection
is
also
near
a
radio.
So
after
it's
the
growth
session,
it
seems
that
we
finally
decided
to
go
on
with
large
communities
and
specified
format
for
these
large
communities.
There
should
be
no
location
anymore
and
ASP
is
be
a
verification.
It
seems
to
that.
We
are
ready
for
adoption
code,
so
I
requested
option
call
now.
I
I
O
H
H
M
C
O
Thank
you.
So
we
discussed
this
in
back
in
London
and
desert
policy,
and
here
the
idea
is
to
drop
invalids
if
it
is
covered.
If
there
is
another
prefix
route
in
in
the
router,
that
is,
for
the
less
specific
that
is
either
valid
or
not
found.
In
that
case,
the
most
specific
invalid
can
be
dropped.
So
this
is
a
joint
work
between
NIST,
folks
and
job.
O
So
just
to
recapitulate,
what
desert
policy
is?
Basically,
it
desert
stands
for
drop
invalid
if
still
routable.
So
the
idea,
as
I
said,
is
drop
invalid
if
a
valid
or
not
found
less
specific
route
exists,
and
why
why
do
you?
Why
do
we
want
to
do
this
or
policy?
So
if
a
rover
for
a
subsuming
less
specific
prefix
exists,
but
there
is
no
Rover
for
the
prefix
that
you
want,
you
want
you
announce,
then
the
desert
policy
working
elsewhere
in
other
a
SS.
It
ensures
that
the
traffic
for
the
more
specific
still
reaches
you.
O
You
are
the
legitimate
destination
for
it,
and
but
it
reaches
you
possibly
in
a
suboptimal
or
non
traffic
engineered
path.
Invalid
announcement
of
your
proof,
of
your
more
specific
by
you
or
others,
are
rejected.
So
that's
the
basic
idea
of
the
desert
policy.
We
updated
the
draft
to.
We
got
pretty
good
feedback
and
discussion
when
we
presented
it
in
London,
including
comments
on
the
list.
So
there
are
two
or
three
main
discussion
points,
questions
that
came
up
that
that
we
have
addressed
and
updated
that
the
draft
in
the
o2
version
these
are
included.
O
So
the
s0
question
s,
0
Toa
question
came
from
Tim
and
the
wording
in
the
draft
which
did
not
exist
before
it
says.
The
existence
of
an
S
0
Rover
for
a
prefix
means
that
the
prefix
or
any
more
specific
prefix
subsumed
in
it,
are
forbidden
from
routing,
except
when
there
exists
a
different
Rover
with
a
normal
ASN
for
the
prefix
or
the
more
specific.
So,
given
that
understanding
of
a
s0
rower,
the
desert
policy
must
apply
the
following
exception.
If
a
route
is
invalid,
due
to
na
s,
0
Rover
then
always
drop
that
out.
O
O
If
you
know,
ok,
let's
a
couple
of
more
minutes-
and
we
can
finish
through
this
and
go
to
the
questions
and
kay
you
raised
this
other
question
about
default
routes,
0.0,
v4
or
v6
in
the
routing
table,
so
those
must
be
excluded
from
consideration
in
the
desert
policy.
This.
What
I
think
I
would
wanted
to
see
so
that
that
wording
is
also
in
the
new
version
of
the
draft
John
Scudder
pointed
something
about
multihoming,
so
jeff
has
has
had
some
multihoming
question,
so
John
took
a
cue
from
that
and
he
posed
this
other
question.
O
So
in
this
scenario
there
are
2/20
force
at
the
bottom.
Those
are
aggregated
by
as2
into
a
slash,
23,
the
and
that
slash
23
gets
to
a
s4
and
why
another
path
through
a
s3,
the
slash
24
on
the
right,
also
goes
to
a
s4,
and
there
may
be
also
a
hijack,
also
happening
from
a
s5.
So
John's
point
was
that
the
in
the
case
of
multihoming
the
slash
24
on
the
right,
it
is
really
multi-home
so
that
it
can,
it
can
have
reach
ability
in
the
event
of
a
limit
link
failure.
O
So
in
this
example,
the
link
between
the
stash
24
on
the
right
and
the
s2
fails,
and
now
the
question
is
for
some
reason:
John
third
thought
that
a
s2
might
still
be
aggregating
and
forwarding
a
slash
23
to
AS.
Four
and
John's
concern
was
that
a
s4.
Now
he
drops
all
the
invalids
and
routes,
the
traffic
for
the
slash
24
on
the
right
to
a
s2
and
s2
has
no
way
to
deliver
it.
So
that
was
is
concerned,
then
he's
saying
that
sort
of
the
purpose
of
multihoming
is
lost.
O
But
the
point
is
this
is
happening
when
you
have
a
combination
of
things.
There
is
multihoming
Noro
as
are
being
created
by
this
slash
24,
and
there
is
also
a
link
failure.
So,
apart
from
the
from
the
combination
of
all
those
things
having
to
happen,
if
you
look
at
a
s2,
one
might
ask
if
the
link
is
down-
and
it
is
no
longer
has
announcement
for
the
slash
24
on
the
right.
Why
is
it
still
aggregating?
It
should
just
D
a
grenade
and
send
only
1/24
up,
so
that
itself
probably
answers
the
John's
question
in.
O
In
addition,
of
course,
any
multi-home
customer
in
in
any
scenario
should
be
all
should
be
always
crew
fool
about
rpki
if
they
don't
create
ro.
As
for
any
of
the
multiple
announcements
they
make
to
their
upstreams,
that
and
not
have
I
mean
not
having
rowers,
not
a
good
thing,
so
in
terms
of
conceptually
implementation
Jeff
had
this
was
not
in
the
original
draft
Jeff
before
the
London
meeting
I
spoke
with
Jeff
Haas
and
he
offered
some
interesting
insights
into
what
is
feasible
in
implementation.
O
So
so
that
aspect
is
now
captured
in
the
updated
draft.
So
the
next
two
slides,
which
talk
about
conceptual
implementation-
they
are
now
included
in
the
in
the
draft
yeah
yeah.
They
are
fully
described,
I
mean
they
are
described
at
the
level
of
conceptual,
implement
a
implementation.
So
Jeff's
idea
was
that
you
don't
do
the
desire
policy
as
part
of
the
path
selection
decision
process.
You
do
the
path,
selection
decision
process,
including
origin
validation,
and
then
you
put
your
valid
invalid,
not
found
routes
in
the
local
drip,
and
after
that
you
do.
O
That
is
their
policy
and
before
you
you'd,
send
the
routes
into
the
PHA,
but
the
ad
ribbons
from
the
local
rib.
That
is
where
they
in
between
those
two
is
where
you
do,
that
is
their
policy,
and
that
we
seem
seem
to
make
perfect
sense
for
many
people
that
that
looked
at
this
in
London
when
we
presented
it.
O
So
this
included
in
the
new
draft-
and
another
point,
is
that
you
can
have
these
three
situations
that
arise
a
valid
or
not
found
route
that
was
used
to
route
to
drop
invalids,
that
when
a
new
one
can
be
can
be
added
or
an
order
existing
valid,
not
invalid
route.
May
be
withdrawn,
or
you
may
have
a
PKI
state
changes
and
they're
out.
There
is
informed
about
it
in
all
of
these
three
situations
we
need
to.
We
need
to
do
something
that
is,
a
policy
needs
to
deep
refresh
and
those
are
described
as
well.
F
Job
Snyder's
entity
this
may
come
as
a
bit
of
a
weird
statement,
given
that
my
name
is
on
this
draft,
but
I
I
am
not
so
sure
at
this
point.
Whether
pursuing
this
draft
is
worthwhile
because
I
feel
we've
been
somewhat
overtaken
by
events.
If
I
look
at
origin,
validation
deployments
and
I've
had
some
handsome
experience
by
now.
The
mode
of
operation
simply
is
reject
invalid
and
deal
with
the
fallout.
The
DSD
is
our
mechanism.
We
came
up
with
that
as
a
sort
of
dampening
mechanism
to
ease
into
original
validation.
F
Give
him
that
there's
between
five
and
six
thousand
envelop
HP
announcements
in
the
default
free
zone
but
I
think
attacking
the
five
six
thousand
invalid
announcements
should
perhaps
not
be
done
through
a
router
change
where
we,
you
know,
upgrade
codes,
look
at
the
deployment
timeline
of
three
to
four
years
and
then
have
a
degree
of
tolerance
for
miss
configurations.
I
think
it
will
be
easier
for
everybody
if
we
just
reach
out
to
the
people
that
have
misconfigured
their
robust
and
asked
them
to
fix
it
or
delete
it.
F
New
Sanu
has
shared
some
research
on
the
right
routing
working
group.
Mailing
list
and
on
the
nanak
mailing
list
about
who
the
entities
are,
that
have
done
miss
configurations,
and
it
seems
that
the
majority
of
miss
configurations
comes
from
only
a
handful
of
companies.
So
I
think
this
is
a
I've
come
to
realize
that
this
may
be
a
disproportionately
big
hammer
for
a
problem
that
can
be
attacked
through
different
means
and
conceptually
I
like
this.
F
G
O
O
F
Apt
I
did
mention
that
I've
space
should
drop
envelops
right
now,
but
in
the
Dutch
networker
community.
We
are
deploying
original
edition
in
is
piece
where
we
do
the
same
philosophy
and
drop
in
fella
announcements
and
there's
a
significant
number
of
commercial
internet
providers
that
are
dropping
in
ballots
and
they
report
that
it's
not
harming
their
business
and
that
it's
a
viable
model.
So
you
are
able.
F
G
D
D
I
Who
do
folk,
I?
Guess?
The
timing
argument
is
fairly
important,
but
first
thing
is
I
hate
it
when
someone
explains
that
a
zero
rowers
are
anything
special.
The
only
special
in
the
a
s0
roars
is
that
we
know
that
routes
with
origin-
a
s0-
cannot
occur.
Hopefully
the
route
of
vendors
actually
enforce
that
or
VI
ISPs
in
their
routing
policy.
I
Yes,
well,
okay,
kind
of
kind
of
creating
special
semantics,
for
it
are
something
that
I
would
question
very
seriously,
but
K
you're.
Actually,
if
you
found
that
also
one
has
to
protect
against
using
the
default
routes.
Of
course,
that
is
something
where
you
figure
out
one:
okay,
you
do
not!
You
do
not
only
want
to
protect
against
zero
colon
colon
slash
zero.
You
also
want
to
protect
against
zero
colon
colon
slash
one
and
where
does
that
end?.
L
I
I
just
wanted
to
comment
quick,
Tim
evangels
quickly
on
the
ASE
or
thing
so
personally,
I'm,
not
a
fan
of
a
s.
0
robust,
but
I
brought
it
up
because
people
to
see
these
things
as
meaning
block
this,
and
if
that
is
intended,
then
you
would
need
to
do
something
extra
for
that
to
work
that
that's
what
my
point
is
not
that
I
actually
like
them
or
want
them
or
anything
I
think
that's
a
completely
separate
discussion.
P
So
hopefully,
this
is
a
shorter
version
of
what
we've
all
seen
once
before.
So
the
problem
statement
is
reasonably
straightforward.
We
have
to
have
a
coordinated
state
between
three
slightly
different
communities
of
actors.
We
need
code
to
both
sign
and
validate,
and
we
need
an
agreement
to
move
to
using
that
code
by
both
relying
parties
and
signers
and
we
have
to
decide
how
we're
going
to
move.
This,
of
course,
is
predicated
on
the
assumption.
P
We
want
to
move
in
any
class
of
technology
in
this
space
which
is
materially
going
to
alter
the
behavior
of
validation
or
demands
change
in
the
existing
software
suite
to
take
respect
to
something
like
an
OID
change
or
a
structural
change
in
the
certificate.
So
these
conditions
are
in
some
senses.
A
general
statement
would
apply
when
we
make
non-compatible
changes
to
the
system,
but
they
are
specifically
focused
in
this
conversation
on
validation,
reconsidered.
P
P
P
But
we
think
that
we
need
to
define
a
future
date
to
have
a
flag
day
and
give
somewhere
around
a
year
of
notice,
the
complete
migration
to
a
new
OID
and
a
new
model
of
validation,
and
our
intent
is
to
actually
go
into
the
nog
community
and
talk
with
operators
to
get
some
sense
of
convergence
and
consensus
from
that
community
of
what
they
want
to
do.
But
when
I
presented
this
idea
last
time,
I
got
very
strong
pushback
on
an
expectation
that
a
draft
should
exist.
That
is
a
formalism
that
can
be
talked
to.
P
P
We
can't
move
without
code.
We
can't
move
without
consent
and
agreement
by
relying
parties
and
Cas
to
adopt
this
new
technology.
We
can't
deploy
towels
specifically
in
our
rir
role.
Without
a
sense,
the
community
is
ready
for
them,
because
deployment
of
something
with
a
radical
new
OID
instantly
breaks
the
validation
model
for
everybody.
I
still
believe
that
we
are
in
that
golden
moment.
My
sense
of
the
number
of
active
party
who
are
engaged
in
this
is
that
it
is
less
than
500.
Now
we
can
quibble
about
what
the
exact
numbers
are.
P
I
am
involved
in
a
body
of
work,
with
a
collection
of
people
to
try
and
explore
the
space
and
understand
how
big
is
the
field
of
people
who
are
using
this
system.
So
we
already
have
a
problem.
It's
a
distributed
problem,
but
it's
not
internet
scale
in
the
sense
of
tens
or
hundreds
or
millions
of
people.
It's
500
engaged
entities,
and
it
feels
to
me
like
a
Flag.
Day
is
logistically
simple
and
actually
can
be
done.
P
We
can
do
this
so
I'm
seeking
working
group
adoption
for
a
zero
state
craft
that
has
been
authored
by
myself
and
Tim
Tim
was
in
the
RIR
system
and
wrote
the
initial
state
of
this
draft
in
his
previous
state,
but
he
has
since
moved
to
a
different
role.
He
now
works
in
NL
net
labs,
developing
rpki
software
router
Nader.
G
P
G
P
Sounds
like
something
that
should
be
on
sale
on
a
TV
shopping,
channel
yeah,
it's
brilliant
I,
mean
I,
think
I.
Think
it's
brilliant
yeah!
These
apps
perhaps
later
did
this
for
me.
So
he's
moved
role
and
will
probably
consider
an
author
shift,
because
it's
not
fair,
he
should
have
to
take
the
eggs
and
tomatoes
because
he's
not
actually
in
the
RIR
space,
but
nonetheless
he
remains
on
this
ground
state
craft
and
will
discuss
what
to
do
next.
But
this
is
assuming
we
get
adoption
and
clearly
there
are
many
things
in
the
conversation.
P
One
of
them
is
that
we
probably
have
some
flaws
in
the
model.
We
might
have
put
forward
timing,
constraints
or
behavior
constraints
that
are
wrong,
so
there
are
conversations
of
merit
around.
How
does
it
work,
but
there
is
also
the
more
important
conversation
for
me,
which
is
what
would
be
a
to
be
defined
date
if
we
were
going
to
do
this,
what
are
we
prepared
to
put
in
the
ground
as
a
stake
and
say
we're
aiming
to
move
in
2019
in
2020,
because
to
me,
that's
the
more
important
quality.
I
P
That's
that's
probably
a
fair
point.
If
we
were
going
to
actually
do
this
and
make
an
assessment
of
dependency
and
interdependence,
then
having
an
understanding
of
which
platforms
do
implement
support
for
this
would
or
could
implement
support
have
some
interrupts.
That's
reasonable,
I
believe
the
right
validator
has
code
for
this
model.
P
I'm,
not
convinced
that
it's
live,
but
I
believe
it
was
at
one
point
implemented
in
their
codebase,
but
there's
a
reluctance
to
undertake
a
body
of
work
that
doesn't
have
broad
consensus,
we're
left
with
a
problem
and
we
are
very
aware
of
our
exposure
of
risk
in
this
problem,
and
this
is
a
path
out
for
our
problem.
But
we
have
the
other
side
of
the
balance
book.
We
have
budgets
in
time
and
in
labor.
P
So
if
there's
no
community
intend
to
move,
then
asking
people
as
validation,
software
developers
or
see
a
signing
party
to
implement
is
a
burden
they
don't
need.
We
need
the
signal,
but
no
it's
a
fair
point.
We
would
need
a
matrix.
We
would
have
to
understand
interoperability.
I
can
stand
here
for
another
15
minutes.
If
you
really
want
20
minutes
of
me,
but
I,
don't
think
you
want.
B
P
Although
otherwise
we
put
2019
in
the
original
dog
but
X
hey,
it
feels
a
little
unrealistic
I,
don't
know
Jeff
Jeff
Houston,
really
his
points
really
quite
valid.
If
there's
no
code
I
like
setting
a
dates
yeah,
you
know,
don't
know
it's
fair
right.
You
need
code,
you
need
to
actually
have
version
and
write
your
code
before
you
can
figure
out
when
a
dates
valid.
That's
all
I'm
saying
so
we
probably
fantasy.
P
K
Rob
last
night,
so
it
should
not
be
news
that
my
gut
reaction
is
two
days
after
hell
freezes
over.
However,
I
completely
agree
with
verdigris
comment.
If
he
wanted
to
consider
this
seriously,
I
would
be
more
comfortable
with
deciding
whether
or
not
to
do
it
after.
We
know
whether
or
not
it
works
so
write
the
code
first
test.
If
you
can
prove
that
it's
harmless,
we
can
have
the
conversation
about
whether
it's
a
good
idea.
Okay,.
P
This
is
actually
very
good
input
because
we
have
a
coordination
meeting
this
week
and
we
can
actually
discuss
investing
the
time
to
do
the
code
base
to
provide
a
basis
to
make
the
move.
But
Rob.
You
are
an
author
of
validation
code
and
you
have
a
time
budget
for
work
in
this
space
and
it's
pretty
small.