►
From YouTube: IETF104-PEARG-20190325-0900
Description
PEARG meeting session at IETF104
2019/03/25 0900
https://datatracker.ietf.org/meeting/104/proceedings/
A
A
A
B
B
Dear
okay,
the
the
slides
are
not
quite
scrolling
properly,
but
okay,
so
I've
been
looking
at
internet
measurement.
Since
2013
I
worked
on
the
past
wider
tool
for
internet
transparency,
measurement
I've
been
contributing
to
tor
projects,
since
2015
I
want
to
just
set
the
the
scope
of
this
early
on
this
isn't
about
the
ethics
of
internet
measurement.
That's
a
very,
very
wide,
broad
topic.
This
is
specifically
about
safety,
making
sure
that
other
users
of
networks
that
you're
measuring
don't
come
to
harm.
B
B
There's
a
lot
of
related
work
in
this
area.
Some
people
have
already
pointed
out
other
related
work,
I
didn't
know
about
on
the
PRG
mailing
list.
If
you
know
of
other
related
work
that
I
haven't
heard
of,
please
do,
let
me
know.
There's
lots
of
people
in
different
communities
have
come
up
with
their
own
assessments
of
safety
and
ethics
in
their
measurements,
but
there
hasn't
been
much
inter-community
discussion
on
this.
B
So
I'm
going
to
give
a
little
bit
of
the
background
where
I'm
coming
from
this
isn't
gonna
be
a
talk
about
how
tor
works,
but
hopefully
I'll
give
you
enough
that
you
can
understand.
What's
going
on,
talk
primarily
is
producing
open-source
code
and
then
there's
a
volunteer
run
Network,
and
this
network
provides
security,
privacy,
anonymity,
it's
robust,
is
authenticated.
It
provides
integrity
depending
on
how
you
use
it.
It
gives
you
these
properties
and
we
need
to
monitor
this
network
and
make
sure
that
it's
working
scaling.
B
Okay,
that
is
healthy
and
one
of
the
things
that
we
measure
from
this
network
is
the
number
of
directly
connecting
users.
At
the
moment
we
have
somewhere
between
2
million
and
8
million.
According
to
a
recent
paper
and
daily
users
of
Tor,
we
can
use
this
data
to
detect
censorship
events.
If
the
censorship
in
the
country,
then
maybe
the
number
of
users
of
Tor
goes
up.
If
there's
attacks
against
the
network,
maybe
Tory's
blocked
in
a
country,
the
number
of
users
goes
down,
we
can
evaluate
when
we
make
changes
to
the
software.
B
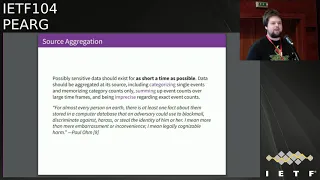
The
philosophy
that
we've
tried
to
follow
is
that
we
only
handle
public
non
sensitive
data
and
each
analysis
goes
through
a
rigorous
review,
often
by
academics,
before
publication
of
data
or
analysis
and
we're
guided
by
the
Tor
research
safety
board,
which
is
a
group
of
academics
and
tor
researchers
and
tor
developers,
and
they
basically
a
service
for
members
of
the
Tor
wider
community
to
assess
whether
or
not
research
that
people
want
to
do
on.
Tour
is
safe.
B
The
three
principles
that
we
try
and
follow
a
data
minimization
source
aggregation
and
transparency,
so
data
mineralization
is
where
we
try
and
capture
only
the
the
least
amount
of
data
possible
to
answer
the
questions
that
we
have
and
the
level
of
that
detail
should
also
be
as
small
as
possible.
So
it's
not
just
about
limiting
the
the
properties
that
were
captured,
but
also
the
resolution
of
them.
B
The
in
in
the
tor
network.
We
capture
at
relays
and
the
relays
are
operated
by
volunteers.
We
have
distributed
trust
against
across
those
relay
operators
and
they
are
doing
the
aggregations
before
submitting
any
statistics,
so
also
we
make
sure
that
the
the
raw
numbers
are
existing
for
as
little
time
as
possible
and
then
we
throw
them
away
as
soon
as
we
have
our
aggregate
and
everything
is
open-source.
B
We
publish
design
documents,
technical
reports
on
how
we
are
doing
things,
and
hopefully
people
are
looking
at
these
and
if
they
spot
any
problems,
then
we're
very
happy
to
fix
them.
So,
going
back
to
the
general
case,
the
shortcut
to
making
sure
that
your
honor,
your
honor
network
and
you're
performing
safe
measurement,
is
to
have
no
one
else
on
that
network.
B
So
one
one
case
study
comes
in
unique
users
of
Tor
the
easy
way
the
the
web
analytics
approach
is
you're
tracking.
All
the
IP
addresses
you've
seen
and
then
you're
working
out.
How
many
unique
IP
addresses
you
saw
over
a
day
in
2010,
we
came
up
with
a
method
of
measuring
the
number
of
users
in
tor.
We
didn't
want
to
count
all
of
their
IP
addresses
and
we
saw
there's
a
little
bit
on
how
it
all
works.
B
The
first
step
of
a
talk
line
connecting
to
the
networks
it
needs
to
have
a
view
of
the
network,
so
it
reaches
out
to
a
directory
server
to
get
a
list
of
all
the
currently
running
tor
relays,
and
we
can
count
this
list
of
sorry
count.
The
number
of
directory
requests
that
are
made
and
from
that
infer
the
number
of
tor
users.
So
we
don't
handle
IP
addresses
at
all
this.
B
B
So
that's
how
we
get
this
graph,
and
this
this
is
in
an
area
of
problems
known
as
the
count,
distinct
problem.
Where
you
have
a
number
of
things,
you
want
to
know
how
many
unique
things
there
are
across
this
data
set
and
a
few
methods
have
been
developed,
'iv
of
doing
this
in
a
privacy-preserving
way,
one
of
which
is
hyper
log
log
from
google.
B
This
was
originally
designed
where
you
have
really
large
data
sets,
and
you
want
to
count
the
number
of
unique
items
in
it
in
a
probabilistic
way
or
fad,
or
a
really
large
data
set
is
one
IP
address.
We
don't
even
want
to
have
that,
so
this
can
be
adapted
for
that
use
case.
To
keep
track
of
the
number
of
IP
addresses.
B
We've
seen
proof
count
is
another
system
with
distributed
machines
with
counters,
and
they
use
secret
sharing
to
submit
their
results
to
a
what
we're
calling
a
tally
reporter
and
then
the
aggregate
from
the
network
can
come
out,
but
the
individual
accounts
can't
be
disclosed
and
another
another
system
is
private,
set.
Union
cardinality
and
I'm
told
that
currently
this
is
computationally
infeasible,
but
I
hope
that
in
the
future
this
this
might
also
be
an
alternative
and
there
are
a
whole
bunch
of
others
as
well
report
and
proclo
from
Google
and
prio
from
Mozilla.
B
B
This
may
or
may
not
be
something
that
could
be
considered
safer.
I'm
gonna
have
discussion
on
it
nonetheless,
and
I
want
to
ensure
that
all
types
of
possible
harm
are
covered.
So
in
some
cases,
thinking
back
to
a
study
that
I
did
with
EC
n
transparency
through
the
internet
we
found
there
were
some
Reuters
that
you
send
an
e
CN
packet
through
in
their
crash.
They
refuse
to
root
future
packets.
Now,
thankfully,
those
riches
are
gone,
but
that
has
the
possibility
of
crashing
someone's
home
router,
which
is
not
something
you
want
to
do
at
scale.
B
D
B
So
going
back
to
the
the
two
million
number,
there
was
a
test
done
with
the
new
proof,
count
strategy
and
they've
discovered
eight
million
unique
IP
addresses
per
day,
and
when
we
revisited
what
we
were
really
counting
in
that
graph
we
found
we
were
actually
counting
the
number
of
concurrent
users.
So
while
we
had
thought
that
that
was
the
average
session
length
it
turns
out,
we
were
wrong.
There
are
in
fact
eight
million
ish
daily
users
by
unique
IP
address,
but
then
that
also
doesn't
consider
not
and
a
whole
lot
of
other
issues.
E
Still
felt
it
so
I
had
a
quick,
redo
draft
and
I
think
it's
the
thing
and
I
hope
it
finds
a
home
somewhere,
whether
it's
in
purity
or
something
I,
think
it's
a
good
piece
of
work
to
continue
and
I
guess
so
does
just
positive
feedback.
Basically,
okay,
thank
you.
I
guess,
I
have
a
question
too
I
mean
had
to
what
extent
are
you
trying
to
reach
out
and
get
input
from
other
people
doing
kind
of
large-scale
surveys
on
the
Internet.
B
Definitely
all
feedback
is
good
feedback,
the
large
scale,
measurements,
small
scale,
measurements,
there's,
obviously
different
classes
of
measurements.
So
you've
got
your
active
measurement
where
you're
sending
probes
out
into
the
internet
and
maybe
talking
to
other
people's
servers,
in
which
case
you
might
incur
the
bandwidth
costs
or
whatever,
and
then
you've
got
the
passive
measurements,
which
is
large,
large
scale.
But.
E
B
A
C
Yeah,
sorry
so
I
have
another
question
you
were
mentioning
the
or,
if
account
is
primarily
the
system
that
you
currently
use
in
this
or
project
to
do
all
this
measurement
and
I
think
there
were
discussions
in
the
past
about
potentially
using
prio.
Have
there
actually
been
at
the
experiments
done
using
prio
for
a
tour,
and
can
you
comment
on
potentially
the
differences
between
prio
improve
con
okay,
so
I.
B
Can't
comment
on
what
the
differences
are:
I
don't
know
the
system
pre
or
that
well,
but
what
I
do
think
prio
is
in
the
browser.
Yes
right,
so
we
currently
don't
have
any
client
assistant
metrics
at
all.
Tor
browser
does
not
have
any
telemetry.
All
of
our
telemetry
is
in
the
release.
So
if
prio
is
more
suitable
for
climate
system,
attrex
I'm
not
sure
it's
it's
possible
that
we
might
do
that
at
some
point
in
the
future,
but
it's
also
possible
that
the
community
might
not
want
that
at
all.
Ever
so
yeah
sure.
F
C
G
H
Yes,
I'm
here,
I
can
hear
me.
Yes,
awesome
things.
So,
thanks
for
the
opportunity,
my
name's
Ryan
guest
I'm,
a
Software
Architect
at
Salesforce
I
work
on
our
security
and
data
privacy
terms.
My
email
is
up
here.
Do
you
want
to
reach
me
after
or
I'm
also
available
on
Twitter
siobhan
Quinto
next
slide?
Okay,.
H
Looks
like
there's
a
little
lag
on
the
presentation
reckon
see
in
there
remote
video,
where
you're
at
so
one
of
the
things
we'll
talk
about
is,
is
posted
aces
really
two
things.
One.
Some
of
the
techniques
is
for
identifying
personal
data
and
application
logs
where
a
SAS
provides.
We
have
lots
of
the
enterprises
using
our
system
when
I
strike
a
balance
between
providing
log
analytics
tools
to
developers
analytics
folks
as
well
as
our
customers,
so
we
actually
send
our
logs
to
customers
of
our
system,
so
they
can
get
an
idea
what's
happening
in
their
organization.
H
So
the
non-identifying
personal
data-
we
have
really
two
techniques,
one
is
store
a
dictionary
base
and
this
is
a
general-purpose
technique
that
can
be
used
across
many
domains.
We
use
across
acquisitions
as
well
so
with
a
new
company
joins,
are
merges
with
us.
We
have
a
torch,
our
general
purpose
tool.
We
can
run
against
their
log
data
or
each
type
of
data
store.
H
The
main
thing
here
is:
we
use
common
names.
We've
started
with
the
top
Leonard
census
names
over
a
certain
amount
of
time.
We
also
look
at
different
location.
Identifiers.
Us
states
is
a
popular
one
and
that
can
give
us
insights
on
to
where
potential
customer
data
may
be
leaking
into
blogs.
Next
slide.
H
We
also
have
a
couple
formats
unique
to
our
domain,
so
we
have
user
IDs.
We
always
know
start
with
zero,
zero,
five,
all
by
15
other
alphanumeric
characters
and
then
various
different
types
of
custom
identifiers
is,
you
can
think
of
such
as
a
DES
SDK,
a
piece
or
I'll
follow
a
certain
format,
and
so
things
unique
to
our
domain.
H
H
So
then,
from
there
we
go
and
look
at
you
know
after
we
found
data
or
potential
place
or
data
maybe
enter
your
logs.
How
do
we
go
and
we
anonymize
that
or
then
we
have
I've
put
together
a
collection
of
eight
of
the
most
popular
techniques
we
use.
We
use
a
little
more
than
this,
but
really
what
we
try
to
do
is
develop
a
tool
set
that
we
share
with
developers.
H
So
they
can,
they
can
have
these
and
they
can
know
so.
Windy
is
one
on
one
to
use.
Another
so
may
seem
self-evident,
but
data
deletion
is,
is
the
first
one.
We
start
so
there's
certain
class
of
data
that
we
don't
want
to
see
at
all.
So
things
like
Social,
Security
numbers
credit
card
numbers.
We
don't
want
any
of
our
downstream
systems
to
have
to
deal
with
these,
so
just
drop
it
like
a
star
next
slide.
F
H
Is
really
popular
when
we
talk
about
things
like
error
messages
in
our
system,
so
a
lot
of
times
we
don't
care
what
you
generate
an
error
message,
but
more
how
many
times
it
happened.
So
we'll
minimize
everything
we
can
from
the
air
and
just
bucket
by
it.
That
gives
us
insight
into
how
things
are
doing
without
much
easier
generate.
The
error
will
cause
the
exception.
Next
slide.
H
Next,
somewhere,
that
is
called
generalization
so,
where
I
live,
the
ISPs
are
chronologically
numbered
every
residents.
So
give
me
an
ISP
give
me
an
IP
address.
You
can
drill
down
the
exact
location
that
someone
is
one
of
the
requests
our
marketing
team
was
they
only
track
ip's,
but
really
they
were
using
it
to
figure
out
sort
of
what
the
top
countries
using
their
system
work,
so
we'd
only
sort
of
reduce
the
granularity
and
just
leave
the
Geo
IP
location
service
and
just
bubble
up
in
the
logs
or
analytics.
H
A
similar
thing
to
IP
address
that
we've
done
is
ok
way
to
use
category,
so
this
use
case
is
popular
with
our
performance
team.
Would
it
look
a
response
time?
Our
service
is
from
different
places
around
the
world.
Really
what
they
want
to
do
is
know
how
far
away
the
client
is
from
our
originated
data
center
and
track
performance
there.
H
H
Tokenization
is
also
something
that
we
use.
We
keep
a
key
value
store
of
that
set
of
tokens
over
a
vein
that
we
define
an
everywhere
downstream.
We
replaced
the
token
we
replace
the
value
with
the
token
that
gives
us
the
advantage
of
serving
things
like
right
to
be
forgotten,
requests
or
get
her
attention
requests
where,
after
certain
amount,
I
want
to
forget
everything
we
know
about
the
user,
just
delete
that
token
without
having
to
worry
about
changing
it
in
a
bunch
of
immutable
data
stores.
H
H
Believe,
there's
a
talk
later
about
differential
privacy,
so
I
won't
go
into
much
detail,
but
essentially
that's
important
to
us
is
for
certain
categories
of
numerical
values.
What
we
do
is,
we
add,
a
amount
of
noise
along
a
fixed
distribution
and
we
use
that
to
having
some
privacy,
and
so
when
we
have
large
amount
in
doing
more
complex
machine
learning
models.
H
The
noise
really
cancels
out
and
you
can
hide
it
of
a
set
of
data
without
having
your
exact
details,
exposed
next
slide
and
the
last
technique
I'm
going
to
talk
about.
It
is
encryption
with
a
set
of
access
controls.
So
ten
trustus
is
AEST
to
sit
for
encrypting
data,
but
really
brings
the
access.
Controls
and
key
management
provide
some
unique
opportunity
to
do
some
cool
things.
H
So
you
can
have
any
keys
for
a
customer
for
a
specific
tenant
in
our
system
also
for
a
service,
and
you
can
then
decide
how
often
you
want
to
rotate
those
things.
And
how
long
do
you
serve?
Retain
older
legacy
keys
after
location,
so
you
can
do
things
like
if
you
wanted
to
do
sort
of
wide
access
took
over
the
whole
service.
You
can
just
delete
the
key.
G
H
Then
the
downstream
systems
would
be
unable
to
decrypt
the
data.
So
has
some
really
interesting
properties,
or
you
know,
for
forcing
data
privacy,
especially
over
a
certain
time,
is
most
useful
to
us.
So
next
slide
and
thank
you
for
letting
me
present
some
of
the
work
we're
doing.
We
think
it's
some
pretty
interesting
stuff
I
have
my
contact
informations
on
the
first
side,
if
you're
doing
similar
things,
I
have
feedback,
we'd
love
to
hear
from
you
and
I'll
be
available
to
take
some
questions.
H
I
Benkei
duck
and
don't
wanna
get
too
far
in
the
weeds,
but
you
mentioned
some
bits
about
data.
Encryption
and
sort
of
the
key
management
for
that
and
I
was
wondering
if
there
was
anything
interesting
to
say
about
you
know
having
the
keys
available
for
different
services.
Or
you
know,
different
levels
of
the
service
are
different
levels
of
access
to
different
services,
since
presumably
the
data
is
only
going
to
be
encrypted
with
one
key
at
a
given
time,
but
maybe
I'm
wrong
about
that.
H
Yes,
so
one
key,
but
with
the
idea
that
scope
towards
the
application
logging
use
case
in
the
same
log
line,
there
may
be
different
he's
encrypting
the
data,
so
a
log
may
have
sort
of
a
service
specific
encrypted
value
and
then
ciphertext
that's
interpreted,
may
be
a
user
specific
value
and
then
yeah
access
controls
around
those.
We
use
a
a
variety
of
things,
but
most
important
for
that
is.
H
J
Hi
Ryan:
this
is
Pallavi
I'm
from
Salesforce
too
so
I
had
a
question
not
about
the
hire
like
you
know,
encryption
of
the
data
but
of
identifying
customer
data
because
I
think
to
identify
the
data
you
must
be
following
certain
regex
or
some
known
type
of
searches.
So
I
think
that
would
also
be
of
interest
because
those
need
to
be
tweaked
on
a
regular
basis
just
so
that
something
doesn't
slip
through
the
cracks
and
because
if,
if
the
identification
doesn't
happen,
then
all
of
these
things
like
something
might
slip
through
the
cracks.
H
We
haven't
standardized
per
se
and
I
mentioned
kind
of
alluded
to
this.
It's
a
combination
of
sort
of
general
things
that
you
would
work
against
any
data
set,
but
also
things
that
are
very
specific
to
our
organization.
Some
strong
assumptions
we
make
about
how
the
data
is
formatted
and
we
use
a
combination
of
those
were
our
teams
right
now
are
figuring
out
the
right
balance
between
how
restricting
me
things
or
how
are
loosed
investigating
some
ml
techniques.
H
We
have
problems
with
false
positives.
Just
to
give
an
example,
the
food
web
browsers
user
agents
look
like
IP
addresses.
The
version
numbers
also
hit
some
interesting
info
in
positives
there,
but
it's
really,
like
you,
said
some
constantly
refining
trying
to
get
that
around,
and
you
know
you
know:
Salesforce
were
very
metrics
driven
I'm
trying
to
report.
You
know
how
well
we're
doing
and
tracked
that
so
like
he
said
and
make
sure
we're
continuously
laundering
this.
It's
not
just
a
point
in
time,
but
constantly
going
forward.
How
do
we
improve
this?
H
J
C
Ryan
I've
one
follow-up
question
with
respect
to
kind
of
showing
or
asserting
how
effective
the
analyzation
techniques
you're
using
are
you
had
mentioned
a
fuse
of
different
or
privacy
is
one
of
the
techniques
I'm
wondering
if
you
can
comment
further
on
how
you
choose
things
such
as
the
amount
of
randomness
budget
that
each
client
has
or
like
each
node
has
or
whatever
you
want
to
use
whatever
the
right
terminology
is
and
how
you
choose.
For
example,
epsilon
to
you
know,
maximize
the
utility
versus
privacy
trade-off
for
that
particular
mechanism.
Yeah.
H
And
this
is
something
we're
still
very
early
in
essentially
what
we
try
and
do
is,
you
know,
sort
of
parameterize
this
and
then
each
specific
use
case
can
provide
inputs
on
how
you
know
like
what
their
kml
movie
is
and
how
you
know
how
private
they
want
things
or
how
a
less
private
they
want
things.
So
it's
very
much
right
now
on
a
smooth
use,
a
case-by-case
basis,
I
could
get
somewhere.
We
published
some
more.
You
know
general
principles,
but
right
now
I'd
say
usually
a
cross-functional
group.
H
C
H
Yeah
absolutely
I
need
you
dig
into
that,
but
yeah
you're
right,
there's
a
lot
of
overlap
and
a
lot
of
different
groups
are
doing
very
similar
things.
So
I
appreciate
the
opportunity
to
share
here
and
sort
of
give.
You
know
our
perspective.
What
we
have
found
works
for
us
and
yeah.
Exactly
feedback
like
that
is
generally
appreciated.
Yeah.
K
All
right
thanks,
everyone
I'm
going
to
talk
about
a
project
called
privacy
pass,
which
is
interesting
technology
in
the
privacy
world,
so
as
a
high-level
overview,
its
privacy
pass,
is
a
lightweight
zero
knowledge
protocol
and
before
getting
into
the
details
of
what
it
is
and
and
how
we
can
use
it,
I'm
going
to
give
a
little
bit
of
context
as
to
how
this
came
from
and
in
relation
to
CloudFlare,
the
company
I
work
for
and
how?
What
with
what
problem,
sort
of
inspired
the
solution.
So
CloudFlare
has
a
service,
that's
reverse
proxy!
K
So
if
you
have
a
website
or
web
service
and
you're
using
CloudFlare
requests
go
through
CloudFlare
and
then
they
come
back
that
there's
a
TLS
connection
between
the
client
and
and
CloudFlare.
And
if
something
is
not
cached,
then
the
request
goes
all
the
way
back
to
the
origin
and
there's
another
little
tiny
red
blob
there,
which
is
for
bad
requests
or
requests
that
are
malicious
in
one
way
or
another.
And
this
is
where
the
problem
space
occurs.
K
So,
in
order
to
reduce
malicious
activity
and
malicious
activity,
is
spam
or
comet
spam
or
requests
that
have
have
malicious
payloads,
there's
several
different
techniques
that
are
used
online
to
help
protect
sites
against
these
sort
of
things
and
reduce
the
load
on
on
websites,
one
of
which
is
a
user
challenge.
This
can
be
in
as
a
sort
of
demonstrate
here
as
a
CAPTCHA.
K
You
might
have
seen
this,
and
so
what
happens
is
the
browser
is
presented
with
some
sort
of
challenge
to
prove
that
it's
it's
human
and
once
that
challenge
has
been
passed,
then
a
cookie
is
issued
that
allows
clearance
bypass
for
this.
So
one
of
the
issues
here
is
that
the
default
security
levels
are
such
that
for
requests
coming
from
clients,
for
which
the
the
the
site
has
no
previous
information.
K
K
So
we
want
to
kind
of
reduce
that
problem
and
one
of
the
ways
that
you
could
think
of
doing
it
is
figuring
out
how
to
potentially
solve
a
challenge
and
get
some
back
some
sort
of
currency
or
some
sort
of
proof
or
token,
or
something
like
this
that
that
you
did
solve
this
this
and
something
that's
anonymous.
So
it
wouldn't
it
be
nice
to
have
some
sort
of
online
equivalent
to
cash
so
that
you
can
do.
K
Withdrawals,
encourage
and
then
make
a
transaction,
and
have
these
two
things
be
on
linkable,
so
withdrawing
cash
in
and
and
paying
for
it
would
be,
would
be
on
linkable
so
and
in
the
analysis,
is
actually
not
that
great
right.
So,
if
you
think
of
cash
in
a
world
where
cameras
are
ubiquitous,
then
you
have
serial
numbers
on
every
piece
of
every
bill,
and
so
actually
it
is
trackable
from
withdrawing
from
a
bank
account
to
paying
somewhere
else
as
long
as
there's
cameras
everywhere.
So
what
what's?
K
What's
sort
of
a
better
analogy
here
and
I
would
propose
that
that
a
better
analogy
would
be
a
self
printing
money
that
gets
the
shirt
I'll
describe
how
this
works,
so
you
would
get
a
bill
put
in
an
envelope,
put
a
serial
number
on
it
and
then
take
a
piece
of
carbon
paper.
This
is
a
very
rough
physical
metaphor
here,
but
it's
a
piece
of
carbon
paper
in
it
seal
the
envelope,
send
it
to
an
official
authority
who
then
signed
the
outside
and
say
yeah.
K
This
is
an
official
bill
and
then,
when
you'd
open
it
up,
you
would
have
the
official
bill
and
the
authority
that
has
signed
it
would
have
no
knowledge
of
the
serial
number,
and
so
this
would
be
a
this
would
be
an
untrackable
cash
bill
if
you
will-
and
so
this
is
the
metaphor,
that
kind
of
was
Medivh
ad
Chomp
back
in
the
80s
when
he
invented
the
idea
of
ecash
and
from
a
high
level
it.
This
is.
This
is
based
on
a
cryptographic,
property
called
blind
signatures
or
blind
blind
signing.
So
there's
two
flows
here.
K
G
K
Then
return
goods,
so
I
may
go
into
a
little
bit
too
much
math
in
this,
but
I'll
try
to
try
to
make
it
easily
easy,
but
in
terms
of
RSA
there's
kind
of
two
values
you
have
an
e
and
which
is
a
public
key
and
a
DS.
It
is
a
private
key,
and
this
is
how
a
Tommy
and
ecash
works.
Is
you
take
your
token
k
and
you
multiply
it
by
a
random
number
exponentiated
by
the
public
key,
send
it
to
the
server
the
server
exponentially.
K
It's
by
its
secret
key
sends
it
back,
and
you
can
just
divide
out
this
random
number
and
you'll
get
a
pair,
K
and
K
to
the
D,
which
is
essentially
a
token
and
a
soakin
token
exponentiated
by
the
server's
private
key.
And
if
you
want
to
redeem
that
you
send
it
to
any
third
party,
they
exponentiate
by
the
public
key
check
to
see
if
it
matches
and
if
it
does
then
great.
This
is
something
that
was
definitely
signed
by
a
third
party.
K
The
server
gives
you
a
blind
signature
and
then
later,
if
you
see
another
CAPTCHA,
you
can
take
the
token
in
the
signature,
send
it
to
the
server
and
get
a
bypass
from
that
bypass
that
couch
without
solving
it.
Essentially,
so
is
this
it.
This
is
privacy
class.
Well,
not
exactly.
This
is
this
was
our
original
paper
that
we
submitted
to
pets
and
and
were
and
got
rejected,
because
you
know
it
wasn't
that
satisfying
to
use
this
slow,
1980s,
cryptography
and
there's
been
recent
advancements
in
this
field
that
are
similar
to
eat.
K
Things
like
ecash
that
we
could
have
used
and
we
decided
eventually
to
look
into
and
to
use,
and
the
two
fundamental
ideas
here
are
that
of
an
OPR
F,
which
is
an
oblivious
pseudo-random
function.
This
is
very
analogous
to
blinding
it's
it's
a
client
and
the
server
compute
a
value
such
that
the
server
doesn't
know
if
the
result
is,
but
the
service
required
to
be
a
part
of
it
and
then
another
concept
called
vrf,
which
is
a
random
function.
K
That
is
computed
using
a
private
key,
and
you
can
prove
that
the
private
key
was
used
to
compute
it,
and
so
taking
these
two
concepts,
we
came
up
with
something
called
we're.
Calling
a
vo
PRF,
which
is
a
verifiable
opr
affix
takes
concepts
from
both
and
I'll
kind
of
walk
through
what
that
is,
as
in
terms
of
inspirations
and
work.
There's
a
lot
of
previous
work
on
here.
Friedman.
K
First
came
up
with
a
no
PRF
Yaqui
and
all
came
up
had
used
this
to
do
something
called
a
do
set
intersection
and
in
2014
the
idea
the
real
idea
of
a
vo
PRF
came
about.
It
didn't
have
all
the
features
that
our
final
privacy
pass
did,
but
it
was
used
for
privacy
password,
protected
secret
sharing
and
a
type
of
fake
algorithm.
K
We
came
up
with
prime
seabass,
so
what's
my
time
like
so
I've
got
quite
a
few
things,
we're
good,
ok,
great!
So
hopefully
this
is
this.
This
will
be
clear,
but
I'll
walk
you
through
exactly
what
how
privacy
pass
works.
There's
a
few
fundamental
things
to
keep
in
mind:
one
is
the
setting
in
which
we're
doing
the
computation
and
the
setting
is
a
prime
order
group.
K
You
can
imagine
this
as
the
group
of
points
on
an
elliptic
curve
for
say
elliptic
curve,
Elmen,
and
it
has
to
be
a
prime
order
group,
which
is
just
a
small
wrinkle,
but
in
any
case
group
elements,
I'll
denote
them
with
capital,
letters
such
as
P
or
Q,
and
then
the
fundamental
operation
you're
doing
on
these
is
scalar
multiplication.
So
if
you
are
taking
a
point,
P
and
multiplying
it
by
itself,
n
times
or
I,
get
no
adding
its
itself
9
n
times
that
CL
in
multiplication,
oh
I
heard
something.
K
The
last
two
pieces
are
hash
to
group
element.
This
is
a
function
that
takes
a
scalar,
a
token
and
outputs.
A
group
element
that
is
random
in
in
a
in
a
statistically
average
sort
of
random
way,
uniformly
average
random
and
then
the
last
piece.
This
is
the
this
is
the
only
kind
of
tricky
concept,
which
is
that
of
a
discrete
log
equivalence
proof.
K
This
is
the
only
place
in
which
zero
knowledge
comes
into
play
here,
but
the
idea
is
that
two
points,
two
pairs
of
points
can
be
analogously
related
to
each
other,
so
PNR
can
be
related
to
each
other
like
Q
and
s
using
the
same
multiplier.
So
if
you
have
P
and
s
times,
P
and
Q
and
s
times
Q,
you
can
prove
that
this
s
there
is
an
S
such
that
you
know,
P
is
e
times.
K
S
is,
is
s
times,
P
and
Q
times
s
is
s
times
Q,
and
you
can
do
so
without
revealing
what
s
is
so
this
is.
This
is
really
used
for
in
envy
ahrefs
and
it's
used
in
other
places
for
proving
that
a
specific
private
key
was
used
and
these
scalars
are
usually
private
keys.
So
this
is
going
to
be
denoted.
Dl
a
Q
P
to
R
is
the
same
as
cute-ass
all
right.
K
So,
with
these
fundamental
pieces,
I'll
walk
you
through
a
naive
construction
of
how
this
would
work
and
iterate
through
until
we've
kind
of
ironed
out
all
the
problems.
Okay,
so
scenario,
one
client
takes
a
point
on
elliptic
curve
T
and
sends
it
to
the
server
and
the
server
has
a
private
key
secret
number
s
and
multiplies
T
by
s
and
sends
it
back
and
then
later
the
client
will
take
this
T
and
this
s
of
T
send
it
to
the
server.
K
Then
the
server
can
check
to
see
that
had
previously
been
issued
by
taking
the
T
multiplying
by
s
and
see
if
it
equals
to
the
second
point,
and
so
this
this
this
step
is
called
a
routine,
and
this
is.
This
is
a
very
naive
scenario
that
everything
is
everything
here
is
built
on,
is
multiplying
by
a
secret
value
on
the
server
side.
Since
the
server
knows
s,
you
can
you
can
compute
s
of
T.
So
the
problem
here
in
this
situation
is
that
during
the
issuance
and
the
Redemption,
the
same
s
of
T
is
sent.
K
K
So
the
problem
here
is
this
is
great,
but
this
is
slightly
malleable
if
you
have
T
and
s
of
T,
if
you
multiply
them
both
by
any
scalar,
say
two
or
three
or
four
or
five,
then
you're
going
to
get
an
infinite
number
of
valid
pairs
that
you
can
redeem.
So
one
issuance
gives
you
an
infinite
amount
of
options.
So
that's
bad
all
right.
So
how
is
this
salt
well
I,
remembered
I
mentioned
hash
to
group
element
this.
If
you
think
of
cryptographic
hash,
it's
one
way,
you
can
traverse
it.
K
That's
a
multiple
of
the
other
T,
because
this
is
a
one-way
function.
You
really
can't
get
another
pair
you're
guaranteed
to
have
a
unique
pair
and
there's
a
slight
problem
with
this
situation.
It's
it's!
It's
really
not
not
that
big
of
a
problem
but
but
essentially,
if
you're
sending
this
token,
it's
not
actually
bound
to
any
specific
message.
So
if
you
happen
to
be
sending
it
over
an
insecure
channel,
then
someone
could
take
this
and
you
know
associate
it
with
a
different
message.
K
So
there's
a
trick
you
can
do
here
and
which
is
rather
than
sending
s
times
T,
rather
than
sending
sort
of
the
sign
point
where
you
can
do
is
sign
a
message
and
an
H
Mac
of
that
message
with
s
of
T,
and
so
how
does
the
server
compute
this?
Well,
the
server
takes
T
hashes
it
to
the
point.
Capital
T
multiplies
by
s,
and
then
it
has
the
key
for
the
H
back
so,
rather
than
explicitly
checking
that
the
s
T
that
was
sent
is
actually
the
same
as
s
TS
are
computed.
K
You
just
check
that
the
H
Mac
is
computed
correctly,
which
is
which
is
great,
and
so
this
this
goes.
This
goes
through
pretty
nicely,
but
this
this
is
really
as
far
as
you
can
get
with
just
a
no
PRF
itself.
This
is
this
is
essentially
a
no
PRF
construction.
The
problem
here
with
is
is
tagging.
Is
the
idea
that
this
s
could
be
chosen
uniquely
for
each
individual
and
or
if
there's
you
know
a
nest,
that's
chosen
for
everybody
and
then
an
S
that's
chosen
for
the
one
target.
K
When
you
send
in
your
redemption,
then
they
can
track
you
essentially,
and
so
what
is
the
proof?
What
is
the
way
to
fix
this,
and
this
is
where
the
DL
EQ
proof
comes
into
play.
Essentially,
at
this
point,
the
server
publishes
a
generator
point
and
generate
your
point,
multiplied
by
its
secret
key,
which
is
essentially
like
a
diffie-hellman
public
key
and
it
publishes
it
somewhere,
Universal
somewhere,
like
the
tour
consensus
or
somewhere
like
a
certificate,
transparency,
log
or
somewhere,
where
every
client
knows
that
this
is
going
to
be.
K
The
unique
value
could
be
embedded
into
the
software
which
is
sort
of
what
we
did,
and
so
the
idea
is
here
when
you
send
back
the
server's
SBT.
You
also
proved
that
SBT
relative
to
the
blinded
token
is
this
is
analogous
to
G
to
s
to
the
G,
so
that
the
it
was
the
same
scalar
that
was
used
to
multiply
this
is
this
is
how
VRS
work,
they'd,
say:
okay,
this
is
a
proof
that
we're
using
this
the
exact
same
s
for
you,
that
is
in
the
public
domain,
and
this
is
great.
So
this
is.
K
This
is
mostly
the
end
of
how
privacy
pass
works,
except
that
there's.
This
only
gives
you
one
Redemption
per
issuance.
So
there's
this
is.
The
text
is
a
little
small
here,
but
essentially
we're
doing
this.
We
can
do
it.
Multiple
time
say
three
times
you
can
get
solve,
one
CAPTCHA
send
in
three
different
tokens.
The
problem
in
this
case
is
that
these
D
leq
proofs
are
a
little
bit
big
a
little
bit
expensive.
K
So
we
came
up
with
a
small
optimization
that
you
can
actually
compress
these
three
do
aq
proofs
into
one,
and
so
you
can
issue.
You
know
three
tokens
and
give
one
deal
EQ
proof
for
all
of
them
simultaneously,
and
this
is
it
this
is.
This
is
essentially
how
privacy
pass
works
is
when
you
solve
a
CAPTCHA.
You
come
up
with
three
unique
values
T
or
in
this
case
it
could
be
up
to
30,
depending
on
on
how
your
can,
how
your
configure
so,
let's
say,
30
you
hash
them
all
two
points
on
the
curve.
K
You
blind
them
all
send
them
to
the
server
the
server
multiplies
them
all
by
its
secret
key
gives
a
deal
EQ
proof
that
the
same
secret
key
was
used
for
all
of
them
sends
it
back,
and
then
you
can
individually
redeem
them
each
with
this
H
max
system.
Ok,
so
this
is
it
for
the
protocol
and
also
I
guess
a
year
and
half
ago
we
release
privacy
pass
as
a
Firefox
and
Chrome
extension.
K
K
There's
a
slight
issue
here:
relative
to
chummy
and
ecash,
where
anyone
could
validate
these
these
tokens.
So
vo
PRS
are
not
publicly
verifiable.
You
have
to
actually
have
the
private
key
to
check
that
the
token
is
correct,
so
it's
more
like
a
voucher
than
cash,
but
the
it's
one
small
downside
relative
to
to
the
RSA
version,
but
the
speedups
you
get
by
using
elliptic
curves
and
by
having
all
the
space
savings
is
really
except
for
it.
K
There's
a
no
PRF
submission
to
see
FRG,
that's
currently
on
revision3
and
we're
also
looking
into
different
applications
of
the
idea.
For
example,
there's
a
draft
submission
for
TLS
to
use
these
tokens
to
do
anonymous
resumption.
There
was
a
recent
paper
about
how
TLS
session
resumption
is
a
tracking
vector.
This
is
meant
and
to
solve
that,
you
can
think
of
this.
You
can
do
use
this
to
do
anonymous
referral
codes.
That's
an
another
interesting
idea,
we're
exploring
and
anything.
That's
really
a
single
bit
of
zero
knowledge.
K
Proof
can
be
used
for
this,
so
if
you
wanted
to
have
a
privacy
pass
token
that
validates
that
is
run
by
say,
a
government
and-
and
that
proves
that
you're
over
18
or
at
work
X
Y,
Z,
EU
citizen-
you
can
use
this.
It's
very
lightweight,
there's
no
advanced
math
for
that,
and
so
with
that,
I
will
open
it
up
to
questions
and.
L
Wes
heard
of
Chris
I,
fascinating
work,
I
I,
really
like
the
intent
behind
it
and
the
desire
to
I
guess
the
goals
behind
it
as
well,
as
is
the
way
to
say
it,
a
couple
of
quick
questions
so
one
you
said
that
there
is,
of
course,
some
sort
of
expense
you
know
related
to
it.
Do
you
have
any
percentage?
You
know
CPU
increased
to
actually
do
the
level
of
math
associated
with
it.
Yeah.
K
So,
in
order
to
do
to
do
this
from
the
client
side
and
from
the
server
side,
it's
it's
really
one
elliptic
curve
scalar
multiplication,
so
it's
cheaper
than
TLS
handshake.
So
this
was
this
was
one
of
the
goals
with
RSA.
It
was
slightly
more
expensive
and
this
it's
yeah
I,
guess
one
elliptic
curve
operation
per
token.
Okay,.
L
That's
not
that
bad
yeah,
so
the
next
question
and
there'll
be
a
follow-on
is
from
what
it
sounds
like
there's,
a
limited
number
of
tokens
that
you
hand
a
client,
so
maybe
you
hand
back
30
or
something
like
that
and
after
30
they
come
back
and
they
have
to
solve
a
CAPTCHA
kin.
Is
that
correct?
That's.
K
Right,
yeah,
there's
not
an
infinite
number
of
I've
tokens,
so
it's
deciding
on
the
parameters
is
use
case
dependent
and
we
found
that
30
or
so
was
enough
that
it
reduced
the
it
reduced
the
friction
for
users.
Quite
a
lot,
and
you
know
you
can
you
can
you
can
you
can
technically
modify
the
code
to
do
up
to
a
hundred
on
the
server
side
but
yeah?
It
really
depends
on
use
case
and.
L
K
In
fact,
on
the
client
side,
once
you've
unblinded
your
token,
then
you
don't
have
any
secret
state
at
all.
You
can
just
you
can
share
your
actually,
even
with
the
blinded
token
you
can.
You
can
share
with
anybody.
So
one
thing
to
keep
in
mind
that
I
didn't
mention
on
the
server
side
is
that
there
does
have
to
be
some
level
of
double
spend
protection,
because
the
these
could
be
potentially
computed
multiple
times
but
yeah.
K
If,
if
all
in
all,
there
are
some
other
larger
ecosystem,
things
that
are
brought
up
by
by
issues
like
this,
such
as
farming,
you
could
imagine
someone
could
do
a
lot
of
farming
and
solve
a
lot
of
CAPTCHAs
and
then
kind
of
use
it
to
bypass
things
on
a
wider
scale,
but
but
generally
yeah.
We
think
that
having
key
rotation
is
a
way
to
to
help
reduce
that
and
metrics
show
that
it
hasn't
been
abused.
L
K
That's
right,
and
so
it
would
be
one
you're,
essentially
multiplying
we're
reducing
the
cost
but
you're
not
eliminating
it.
So
in
order
to
get
30
tokens,
you
still
have
to
solve
one
CAPTCHA,
so
you're
you're,
multiplying
the
value
of
solving
one
CAPTCHA
by
a
factor
of
X
Rex's
number
of
tokens.
There.
L
Still
nobody
behind
me,
so
you
talked
about
double
spending
on
the
server
side,
so
you
actually
have
implemented
something
on
that
you
it's
not
in
your
slides
from
I
saw.
So
you
have
something
that
simple,
that's
checking
double
spending
and
is
that
double
spending
checking
infinite
in
lifetime
or
yeah.
K
So
it's
we
are,
our
implementation
of
double
spending
is,
is
changing,
we're
we're
rewriting
this
to
you
leverage
a
new
platform.
That's
a
JavaScript
based
platform
called
workers
that
has
more
robust
double
spend
protection,
but
essentially
you
have
to
you
have
to
keep
the
double
spend
strike
register
as
long
as
the
lifetime
of
the
server's,
private,
key
and
so
key
rotation
is
the
way
to
actually
reduce
that
and-
and
so
you
do
get
in
into
a
little
bit
of
a
little
bit
of
a
chicken
and
the
egg
problem.
K
If
right
now
in
the
very
first
version
of
privacy
pass,
we
hard-code
the
server's
keys,
so
we
haven't
been
able
to
rotate
and
so
we're
coming
out
with
the
new
version
in
the
next
few
months
or
so
that
allows
that
to
be
updated
on
a
dynamic
basis.
Well,
anyway,
very
cool,
good
work,
ok,
keep
going
well!
Thank
you.
C
Yeah
Nick
I
have
a
quick
question,
so
the
DL,
a
key
proof,
is
a
very
elegant
way
to
solve
the
key
tagging
problem.
Were
there
any
other
earlier
designs
that
you
considered
in
order
to
address
that,
like
you,
can
imagine,
for
example,
the
server
signing?
What
is
the
blinded
token,
providing
the
public
key
back-end
and
clients
like
gossiping
it
to
see
that
they're
both
having
the
same
view
of
the
key
yeah.
K
The
it
all
boils
down
to
the
same
problem,
which
is
key
key
rotation
and
key
distribution
and
Trust
of
key
rotation.
So
we
did
consider
publishing
that
in
in
places
that
the
client
can
be
assured
of
a
shared
global
view.
So
something
like
the
certificate
transparency
log
is
is
one
way
to
do
it
and
distributing
it
from
a
central
source
that
is
signed
by
a
long
term.
Key
is,
is
sort
of
the
design.
That's
that
we're
considering
for
the
the
rotation
going
forward.
C
K
Yes,
potentially
I
think
that,
in
terms
of
HTTP
and
using
this
as
an
HTTP
mechanism,
there's
nothing
that
would
prevent
this
from
being
standardized
we're
first
exploring
Federation
with
respect
to.
We
have
our
own
capture
provider,
but
we're
now
currently
experimenting
with
a
company
that
has
called
H
CAPTCHA
that
does
their
own
CAPTCHA
as
well
as
a
company
called
arc
rose
labs
who
has
something
called
fun,
CAPTCHA
and
and
as
I
mentioned
at
the
end,
this
is
potentially
generalizable
to
a
lot
of
things.
So
yeah.
K
M
N
So
first
we
want
to
thank
everyone
for
letting
us
have
this
presentation
today.
This
is
going
to
be
a
very
high
level
view
of
differential
privacy.
Some
of
the
slides
will
contain
mathematical.
Notation
do
not
be
alarmed.
It
looks
like
there's
a
lot
of
it,
but
it's
for
completion.
It's
in
case.
You
forgot
something
about
Exponential's
or
mean
values,
it's
all
in
there
and
it's
so
you
can
go
back
and
review
the
slides
without
feeling
that
you're
completely
lost.
N
N
O
N
O
So
what
we
have
here
is
we
have
D
and
we
have
our
D
Prime
in
the
notation.
So
this
represents
two
data
sets
that
differ
on
just
a
single
element,
so
they
are
the
same
up
to
one
row
and
then
we
have
M
here,
which
is
a
mechanism
which
we
apply
to
our
data
set.
This
will
be
something
like
a
query
life.
It
could
be
a
statistic:
computing
the
mean
value
or
the
variation
of
something
and
going
forward.
O
O
So
we
have
our
P
of
M
here,
which
is
then
our
probability
distribution
of
our
mechanism
M.
So
this
is
the
range
of
all
possible
values
that
our
mechanism
can
take
and
then,
of
course,
these
sort
of
the
probability
that
it
will
assume
each
and
one
of
those
values
we
have
here,
which
is
our
standard
exponential,
which
we
have
taken
to
the
power
of
epsilon.
And
then
we
have
this
additive
Delta
here.
O
So
what
we're
trying
to
achieve
here
is
to
make
it
so
that
the
distributions
of
our
of
our
mechanisms
are
sufficiently
similar,
make
it
so
that
it's
equal
roughly
equally
likely
to
assume
any
value,
no
matter
if
a
certain
person
is
included
in
the
data
set
or
not
so,
and
we're
using
our
epsilon
and
Delta's
to
sort
of
achieve
this
next
slide,
please
so
epsilon
and
Delta
here
become
our
privacy
parameters.
These
are
parameters
that
we
can
choose
ourselves
to
enforce
a
given
a
given
level
of
privacy.
O
O
What
if
we
choose,
epsilon
and
Delta,
for
instance,
to
be
very
small?
What
this
inequality
here
will
tell
us
is
that
the
probability
distributions
of
our
queries
on
our
data
sets
that
differ
by
only
an
element
are
not
going
to
be
very
different.
They're
going
to
be
quite
similar,
or
at
least
is
going
to
put
a
bound
on
how
similar
or
dissimilar
they
can
be,
and
if
epsilon
and
Delta
are
very
large.
Well,
then
they
can
differ
by
quite
bitte.
O
O
Right,
yes,
so
now
we're
talking
a
bit
about
some
methods
on
how
to
apply
this
and
we're
going
to
start
off
with
the
the
method
as
it
was
originally
proposed
in
the
original
paper,
and
that
is
to
perturb
the
answer
to
a
query.
So
we
have
a
data
set
and
someone
queries
us.
They
ask
something
about
our
data
set.
O
So
what
we
do
is
that
we
compute
the
true
answer
so
to
speak,
and
then
we
add
a
bit
of
noise
to
this,
and
then
we
give
back
the
noisy
answer,
so
the
person
receiving
the
answer
knows
that
ok,
this
is
roughly
correct,
but
it's
not.
It
doesn't
know
if
it's
higher
or
lower
than
the
actual
answer
next
slide.
Please.
O
So
the
most
common
way
of
doing
this
is
to
add
some
sort
of
noise
that
is
either
Gaussian
or
laplacian.
But
basically
what
this
means
is
that
we
add
noise
from
a
symmetric
distribution
right.
So
it's
equally
likely
to
take
away
as
it
is
to
add
to
our
data,
and
this
noise
is
added
in
such
a
way
that
it's
dependent
on
epsilon
and
Delta,
meaning
that
we're,
if
we
have
very
small,
epsilon
and
Delta,
so
we
want
to
add
a
lot
of
privacy.
O
O
N
So,
there's
a
second
method
that
you
can
also
use
for
differential
privacy,
which
is
to
perturb
the
measurement
so
rather
than
perturb
being
an
answer
to
a
query
to
a
database.
You
make
sure
that
whatever
goes
into
the
database
is
already
perturbed
when
it
gets
there.
There
are
some
different
ways
of
doing
this.
One
of
them
is
commonly
applied
at
the
IETF
you
remove
or
encrypt
identifiers,
so
that
they're
garbled
when
they
reach
the
database.
You
can
also
imagine
perhaps
swapping
data
between
different
identifiable
flows.
N
N
You
can
also
randomize
responses,
which
means
that,
with
some
probability,
you
allow
anyone
that
inputs
data
into
your
database
to
just
provide
a
false
answer
to
your
database.
Now
these
methods
also
have
drawbacks,
the
obvious
one
being
that
if
the
data
in
your
database
is
not
true
or
if
it's
swapped,
you
will
also
worsen
estimated
quality.
N
So,
for
instance,
you
need
to
trust
the
randomization
mechanism
used
or
the
swapping
mechanism
used
for
your
paths.
You
need
to
trust
that
they
haven't
secrety
and
secretly
introduced
some
other
identifier.
That
was
not
the
one
that
was
removed
and
so
yeah.
It
has
some
of
these
drawbacks
that
are
really
very
difficult
to
work
around
with
differential
privacy.
N
Therefore,
at
the
Delta
differential
privacy
is
not
the
only
privacy
needed.
It
only
deals
with
a
very
specific
case
of
a
very
specific
case
when
we
are
trying
to
protect
the
identity
of
an
originating
individual
for
some
piece
of
data
when
you're
making
a
query
to
a
specific
database,
so
Donna
sanitization
and
security
are
still
going
to
remain
very
important.
N
Data
minimization
is
still
going
to
be
probably
the
primary
method
that
we
can
use
to
effectively
protect
privacy
at
the
Delta
differential
privacy
is,
furthermore,
not
the
only
way
that
we
can
quantify
how
much
privacy
we
are
protecting.
So
there's
a
very
good
study
from
2015
made
by
Isabel
Wagner
and
Dave
akov,
where
they
found
hundreds
of
privacy
metrics
that
are
all
usable
to
assign
a
quantification
of
how
much
privacy
is
preserved
in
a
given
setting.
We
can
recommend
highly
going
through
that
survey
and
looking
at
the
various
ways
in
which
privacy
can
be
quantified.
N
So
if
you're
comfortable
with
statistics,
I
can
highly
recommend
it
to,
but
just
be
warned
that
it
invokes
the
central
limit,
theorem
and
other
methods
from
statistics
that
you
might
have
to
have
prior
familiarity
with
to
to
enjoy
for
the
ietf
community.
I
think
one
challenge
for
differential
privacy
is
that
it
mostly
applies
to
api's,
because
this
is
either
about
how
you
put
data
into
a
database
or
how
you
respond
to
the
query
to
a
database.
N
Also,
we've
been
reflecting
on
whether
explicit
congestion
notification
could
be
an
application
of
this
randomized
response
mechanism,
because
you're
really
interested
in
aggregate
data,
not
in
this
specific
data
of
each
entity.
That
provides
the
response,
but
we're
very
open
to
ideas
on
other
potential
use
cases
that
people
are
familiar
with
from
their
own
work
at
the
internet,
Engineering
Task
Force.
I
Benkei
duck
so
with
this
bit
on
the
last
slide
about
potentially
introducing
random
or
false
data
into
your
actual
protocol
streams.
It
sort
of
seems
like
the
key
insight
you'll
need
to
do,
that
is
to
figure
out
what
random
distribution
to
use,
because
you
know
futures
try
to
use
a
uniform
random
distribution
for
like
the
bit
values.
That's
going
to
be
most
likely,
not
representative,
of
what
the
normal
flow
is,
and
so
it
seems
like
this
is
inherently
going
to
be
a
case-by-case
sort
of
analysis
to
figure
out.
I
N
So
in
randomize
responses,
the
typical
thing
that
you
would
do
is
is
some
discrete
distribution,
so
you're
not
in
the
Gaussian
or
laplacian
space,
but
in,
for
instance,
the
quick
spin
bit
case.
Either
you
spin
the
bit
or
you
don't
so.
The
natural
distribution
to
choose
is
Bernoulli
distribution
or
binary
to
point
distribution.
N
And
then
you
say
with
some
probability:
P
you
give
the
correct
transition
and
bid
and
if
it's
not
P
like
yeah,
so
the
way
that
I
imagined
this
would
actually
be
implemented
in
a
computer
is
that
you
generate
the
random
number
between
0
and
1.
And
then
you
choose
some
cutoff
point
and
if
the
random
number
you
generate
the
post
below
the
cutoff
point,
you
spin
and
if
it
was
above
it
you
don't.
And
maybe
you
know
this
is
the
very
simplest
case.
It's
one
of
the
simplest
distributions
out
there.
It's.
O
P
P
They
have
a
chapter
on
differential
privacy
where
they
claim
that
anonymization
can
can
be
easily
undone
with
large
enough
data
sets
and
the
differential
privacy
in
and
of
itself
protects
the
individual
data
set,
but
can
be
attacked
by
using
secondary
outside
data
sets
that
are
large
enough,
so
in
in
in
our
world
today,
right
provide
differential
privacy
on
my
data
set.
I
may
be
providing
information
that
someone
else
will
incorporate
with
their
own
large
data
set
and
be
able
to
diya
naanum
eyes
that
information.
N
The
observation
is
entirely
correct.
Differential
privacy
is
a
statistical
method.
So
what
you're
talking
about
this
sort
of
similar
to
this
repeated
query
privacy
budget
thing
that
Christopher
mentioned
that
you're,
creating
statistical
uncertainty
around
one
additional
individual
in
the
data
set
and
differential
privacy
does
only
exactly
that.
This
is
what
it
can.
It
can
provide,
repudiate
repudiated
properties
for
a
single
individual
that
is
additional
to
a
data
set
with
respect
to
another
query
to
that
data
set
worth
individual,
not
there,
but
it's
not
a
catch-all
for
all
privacy
problems.
N
P
L
How
do
you
ensure
that
there's
a
potential
error
between
the
noise
itself
causes
a
issue
with
the
there's
multiple
aggregation
functions
that
could
end
up
sorry,
I'm,
jet-lagged,
multiple
aggregation
functions,
where
some
may
be
able
to
help
distinguish
the
noise
between
the
rest
of
the
material.
So
if
you
were
able
to
run
four
or
five
or
six
different
aggregation
functions
that
the
difference
that
noise
would
affect
them
each
differently
and
therefore
you're
actually
getting
slightly
less
privacy.
Because
of
that
does
that
make
any
sense
that.
L
N
N
Well,
I
mean
it's
there
I.
It
looks
like
again
a
version
of
the
privacy
budget
problem
that
if
you
make
repeated
queries
to
the
database,
then
you
can
compensate
for
the
noise.
That's
added
the
typical
way
of
doing
differential
privacy's
is
adding
noise,
but
many
of
you
have
would
have
studied
engineering
you're
familiar
with
stuff
like
the
Kalman
filter.
There's
many
different
filtering
technologies
that
or
filtering
algorithms
that
we
already
use
on
a
day-to-day
basis
exactly
to
get
rid
of
noise
from
measurements.
N
So
now,
if
differential
privacy
adds
noise
and
reasonably
yes,
we
can
remove
the
noise
by
performing
the
same
types
of
filtering
mechanisms
that
we've
been
doing
to
faulty
measurements
already
for
what
60
70
years
and
it's
important
to
recognize
that
asian
and
differential
privacy
when
you're
thinking
about
applying
it
to
a
project
that
it
does
do
exactly
what
it
says
on
the
box,
and
that
can
be
very
useful.
But
it
has
these
limitations,
including
the
ones
that
you
brought.
Okay,.
L
Thank
you
yes,
I
mean
there's
the.
If,
if
I
had
to
aggregation
functions,
aggregation
function,
one
and
aggregation
function,
two
I
could
run
an
aggregation
function
twice
and
it
would
give
I
think
the
perfect
mathematical
level
of
knowledge
of
how
much
I'm
protecting,
but
if
I
run
aggregation
one
and
then
aggregation
to
the
cost.
To
me
in
terms
of
a
budget
would
be
the
same,
but
I
may
be
able
to
use
the
difference
between
those
aggregation
functions
to
get
a
slightly
less
privacy
reduction,
for
example.
A
Mean
it's
a
concern
so
with
respect
to
this
spin
I
think
you
know
they,
like
you
said.
The
whole
thing
is
about
the
privacy
budget.
With
enough
queries,
you
can,
you
know,
figure
out
exactly
what
you
want
to
figure
out.
It
might
be
kind
of
complicated
right
to
ask
an
on
path
observer
to
only
take
five
measurements,
so.
N
N
Q
Just
wanted
to
remark
back
on
your
point
about
api's
I.
Think
we've
been
a
little
bit
narrow
in
this
community
about
what
is
an
API,
because
it's
a
human
being
interacting
with
the
system,
but
there's
no
really
good
reason
why
an
API
can't
be
thought
that
something
like
a
one
end
of
a
protocol
connecting
with
another
can't
be
thought
of
as
exactly
that.
Database
interaction
as
well
and
similarly
a
measurement
a
measurement
agent
receiving
data
is
you
could
define
it
as
an
API
to
so
I.
R
N
An
explicit
congestion
notification
somebody
suggested
to
me
could
be
an
interesting
application,
so
if
you
have
any
ecn
folks
in
the
room,
you
are
very
welcome
also
to
talk
to
me
and
anybody
in
the
room
who
thinks
this
might
be
suitable
for
them.
That
hasn't
been
mentioned.
Please
please
do
approach
remaining
so
I
think
the
easiest
cases
to
look
at
at
least
for
now
is
places
where
you
have
on/off
answers.
So
basically
you
can
use
a
binary
distribution
to
say
rather
than
giving
a
true
or
false
answer.
N
You
give
a
true
or
false
answer
with
some
probability
and
all
the
other
things
that
are
more
complicated
like
if
you
can
choose
between
five
different
options
to
communicate
in
your
in
a
header
packet
header,
for
instance,
then
you
would
need
to
have
a
more
complicated
distribution
than
binary
distribution.
So
we
could
certainly
think
about
that
tomb
for
randomized
responses,
but
we
would
have
to
do
a
bit
more
mathematical
work
to
make
it
still
useful
for
aggregate
measurements.
S
When
we
started
looking
into
this
topic,
we
first
took
a
look
at
the
consumer
identity
provider
market
which
looks
roughly
like
this
with
offerings
from
Google
and
Facebook,
claiming
around
90%
of
the
consumer
identities
now
per
se.
This
is
obviously
this
might
not
be
a
problem,
but
if
we
look
into
the
recent
past,
some
issues
arise
from
this
fact.
S
The
first
one
are
privacy
concerns.
So
obviously
those
companies
want
to
make
money
and
they
offer
the
services
for
free
and
in
turn,
they
monetize
this
mountain
of
data.
They
are
sitting
on
also
this
data
can
be
used
for
opinion
shaping
and
mass
surveillance
data
collection,
which
is
an
infringement
on
the
users
privacy.
S
It
is
actually
lower
than
the
risk
actually
face,
and
obviously
the
last
one
is
simply
the
fact
that
this
seems
like
an
market
oligopoly
where
there
can
only
be
one
or
two
or
a
handful
of
so
provide
us.
That
is
used,
as
maybe
the
reasons
of
liability
risks,
but
might
also
just
be
because
they
offer
so
so
good
services
in
the
area
of
social
media
that
they
simply
have
this
amount
of
users,
but
identity
Federation
has
been
around
for
decades
and
it
does
not
seem
to
take
off
in
any
way.
S
So
our
approach
to
this
problem
to
those
issues
was
that,
maybe
maybe
we
need
to
approach
this
differently.
Our
primary
objective
was
that
we
must
enable
users
to
exercise
the
right
to
digital
self-determination,
and
in
order
to
do
that,
we
must
avoid
third-party
services
that
basically
allow
users
to
match
the
identities
and
share
the
data,
and
this
should
be
done
using
an
open
and
free
service
which
is
not
under
the
control
of
a
single
organization
and/or
our
business.
S
In
summary,
we
were
to
empower
users
to
reclaim
the
control
of
their
digital
identities.
This
is
also
whether
the
name
for
for
the
idea
comes
from,
so
let
me
explain
what
reclaim
actually
does
and
how
it
works
in
order
to
explain
what
reclaim
does.
Let's
look
at
what
or
some
of
the
tasks
that
those
identity
provider
services
actually
provide
to
users
and
to
websites
and
services
that
use
them?
S
The
first
thing
they
offer
is:
they
allow
identity,
provisioning
and
access
control,
so
the
user
is
able
to
create
an
account
and
basically
create
an
identity
management,
personal
data
and
share
this
data
with
third
parties.
The
service
itself,
then,
enforces
the
access,
control
and
authorization
decisions
of
the
user.
S
S
Italy
noted
that
the
second
thing
can
be
addressed
or
is
addressed
recently
using
privacy
credentials
based
on,
for
example,
non-interactive
see
large
proofs,
which
we
have
seen
in
the
in
the
previous
talk
in
privacy
pass
as
well,
and
reclaim
actually
focuses
on
the
first
issue.
So
the
reclaim
ID
focuses
on
the
idea.
How
can
we
actually
allow
the
user
to
provision
identities
to
to
manage
identities
and
share
this
identity
data,
whether
it
is
third
party
asserted
or
not
using
a
decentralized
system?
S
In
a
nutshell,
reclaim
ID
combines
a
decentralized
directory
service,
so
a
service
that
is
used
to
basically
hold
and
provision
identity
data
with
a
cryptographic,
access
control
layer.
Now?
What
does
this
mean?
A
directory
service?
We
maybe
know
active
directory
and
but
name
systems,
I
actually
also
decentralized
directory
services.
S
Now
our
implementation
of
this
idea
does
not
use
the
name
coin
blockchain
and
instead
uses
with
new
name
system
and,
if
you're
interested
in
the
security
properties
of
the
human
name
system.
There's
actually
talk
in
this
week,
I
think
on
Thursday,
but
I,
don't
remember
by
Christian
who
will
talk
on
it.
Another
research
group.
S
However,
the
problem
with
name
ID
specifically,
but
in
general,
when
using
such
a
decentralized
directory
service,
is
that
this
data
is
more
or
less
public.
So
anybody
who
has
a
specific
resolver
is
able
to
retrieve
the
identity
data
and
read
it.
So
we
added
a
cryptographic,
access
control
layer.
Basically,
you
can
always
add
a
cryptographic,
access,
control,
layer
using
symmetric,
cryptography
and
a
very
complex
key
management,
and
but
in
order
to
reduce
the
complexity
of
the
key
management,
we're
using
attribute
based
encryption.
S
A
true
based
encryption
allows
us
to
define
access
policies
on
the
ciphertext
which
simply
reduces
the
amount
of
keys
we
need.
So,
let's
look
at
an
example
how
it
works.
The
user
would
basically
register
a
namespace
in
in
the
name
system
in
the
directory
service
and
populated
with
resource
records,
and
those
resource
records
basically
hold
the
users
information,
such
as
an
email
address.
S
Now
this
email
address
is
encrypted
using
a
true
based
encryption,
which
means
the
user
has
a
private
key
and
a
policy,
and
this
policy
says,
for
example,
my
email
address
can
only
be
decrypted
using
a
key
that
contains
the
attributes,
email
and
the
user.
Does
this
with
every
attribute,
so
in
the
end,
the
namespace
is
populated
with
a
number
of
cipher
texts
which
represent
the
users
identity
attributes.
S
If
the
user
now
wants
to
authorize
a
third
party
to
access
a
set
of
attributes
in
his
identity,
namespace,
what
it
does
is,
it
creates
a
single
new
key,
which
is
an
a
B
user
key
and
the
user
attaches.
The
set
of
attributes
wants
to
share
to
that
key.
So,
instead
of
having
to
create
or
share
n
keys
in
order
to
share
and
attributes,
the
use
only
means
a
single
key.
S
S
Attributes
which
are
not
attached
to
the
key
cannot
be
decrypted
by
the
requesting
party.
Now,
obviously,
if
you
wanted
to
use
such
a
system,
we
do
not
want
to
burden
the
user
other
third
party
for
that
matter,
with
any
kind
of
key
management
and
and
name
system
specifics.
So
what
we
did
in
our
implementation
and
then
our
design
was
that
we
built
an
up
MediConnect
layer
on
top
of
this
idea.
S
So
under
the
hood,
it
basically
works,
like
I
just
explained
in
this
example,
but
from
the
point
of
view
of
the
user
and
the
integrating
website.
For
example,
it
works
just
like
any
generic
Open
ID
Connect
provider,
so
it
basically
all
searches
to
do
or
protocol,
although
I
should
say
that
the
Open
ID
Connect
protocol
and
the
earth
protocol
are
not
specific
enough
to
actually
address.
S
For
example,
if
the
requesting
party
or
the
website
wants
to
have
a
specific
credential
asserted
by
a
special
identity
provider,
this
is
currently
not
possible
due
to
the
protocol
being
still
very
simplistic,
but
in
general
this
works
and
here's
the
standard.
So,
in
summary,
we
have
implemented
this
idea
as
part
of
lunette,
which
is
a
peer-to-peer
system.
S
There's
a
functional,
proof-of-concept
demo
else
on
git
lab,
which
you
can
find
under
the
the
link
here,
although
it
does
not
really
finished,
it's
a
very
rough
around
the
edges
and
we
want
to
make
it
a
bit
more
user
accessible
because
yeah,
it's
still
coming
directly
out
of
research
and
we're
still
working
on
making
it
practical
usable
yeah.
Thank
you.
Any
questions.
T
U
You
Alex
mayor
over
from
Nick
Toth
80
I
was
wondering
at
the
moment
that
you
associate
the
public
key
of
the
attribute
based
encryption
with,
with
a
name
on
the
new
name
service.
Your
name
system.
Aren't
you
like
reducing
privacy
significantly,
because
then
it
allows
somebody
else
to
like
collate
various
a
BES
via
the
same
name.
So
if
I
put
like
different
proofs
or
no,
my
no
idea
how
you
call
them
under
a
single
name
and
it's
very
easy
for
somebody
else
to
like
discover
that
this
was
produced
by
the
same
identity
yeah.
So.
S
Basically,
it
doesn't
distinguish
it,
so
you
always
know
which
identity
it
is
because
you're
looking
up
a
specific
identity.
Namespace
are
you
talking
about
if
you're,
if
you're,
using
this
the
same
attribute
in
different
identity
for
different
identities,
because
okay?
Well,
if
you're
using
different
identities,
then
you're,
probably
using
different,
a
be
private
keys
internally,
which
which
makes
it
indistinguishable
from
each
other.
However,
you
could
argue
that
using,
for
example,
privacy,
preserving
credentials,
so
their
knowledge
groups
as
attributes
does
not
make
that
much
sense,
because
you're
always
identifiable
as
the
single
identity,
so
yeah
well.
U
I'm
trying
to
compare
it
with
other
self
sovereign
identity
systems
like
sovereign
or
you,
port,
where
you
have
a
pair
Y,
is
relation
and
you
essentially
cannot
discover
a
real
identity
and
unless
that
person
was
revealed
so,
but
but
by
putting
it
behind
a
single
name,
that's
often
criticism
with
the
DNS
like,
oh
you
put
it
in
the
DNS,
so
everything
is
like
it
I'm
not
the
same
name,
so
you
know
exactly
who
it
is.
But
what
so.
S
S
Problem,
if
you
have
used
gns
yes,
but
in
DNS,
are
also
named
coming
for
that
matter.
You
can
just
create
new
problems
whenever
you
want,
so
obviously,
if
you
use
the
same
saloon,
you
are
trackable,
but
you
can
just
create
new
ones
that
will
because
they're
effectively
just
public
private
keepers.
Okay,
thank
you.
G
Telephone
exchange
I
have
a
question
which
is
also
actually
I'd,
say
a
comment
for
everyone:
who's
interested
in
these
kind
of
things.
Having
worked
for
some
years
now
on
a
project
which
is
very
similar,
except
that
we
use
the
DNS,
because
we
don't
have
a
problem
with
the
delay,
so
I
mean
the
the
problem.
Now
is
that
there
are
like
a
hundred
different
projects
that
are
trying
to
do.
G
These
kind
of
things
well
in
the
real
world
are
only
basically
two
and
say
single
sign-on
identity
systems
that
are
in
white
use,
googles
and
Facebooks,
and
maybe
in
your
who,
we
have
dei,
does
public
identity
system
for
taxes
and
this
kind
of
stuff.
So
I
guess
that
the
problem
that
we
have
is
they
I
think
we
have
also
people
agree
that
we
need
something
like
these,
which
can
put
a
user
back
in
charge.
G
But
how
can
we
get
that
option
and
the
real
problem
is
actually
that
we
are
dividing
in
like
up
like
I'd,
say
50
different
projects
with
slightly
different
ways
of
doing
the
same
things,
and
some
people
use
the
block
to
some
others.
But
in
the
end
with
the
same
objective,
but
please
we
also
divided.
We
don't
get
anywhere
so
I,
don't
know
if
you
have
any
reflection
of
these
or
strategy
for
an
option.
Yeah
I
agree.
S
Wholeheartedly
so
yes,
but
I,
think
if
all
of
those
projects
actually,
for
example,
use
the
standard
of
maybe
connect,
for
example,
to
use
them.
Then,
if
the
users
become,
if,
if
you
offer
the
software
to
users
and
show
the
benefits
in
terms
of
privacy,
for
example,
they
might
just
start
using
them.
So
there's
no
reason
why
you
cannot
put
a
generic
openly
connect
discovery
button
on
a
website,
so.
V
V
S
V
Say
other
questions
about?
How
does
how
do
you
so
one
the
reasons
that
I,
for
instance,
use
Google
single
sign-on
is
for
digitalocean,
for
instance,
it
is
the
most
secure
way
to
log
on
the
digital
ocean.
Is
you
can
use
aq
factor,
authentication
device?
They
don't
have
one
any
other
way.
How
do
you
address
that
level?
The
authorization
issues
okay.
S
So
the
well,
the
the
digital
ocean,
for
example.
Probably
so
you
want
to
login
using
two-factor
authentication,
but
I'm
assuming
digital
ocean
doesn't
really
care
how
you
login,
basically
that's
something
that
Google
just
does
for
you,
so
that
that
then
depends
on
the
actual
complete
implementation,
because,
ultimately,
connect
doesn't
really
do
authentication,
so
some
an
authentication
scheme.
Obviously
you
could
extend
it,
but
that's
not
really
in
scope
of
the
system.
Well,.
V
W
A
nation
was
on
I
think
the
whole
notion
of
sort
of
pinning
this
on
the
back
OSS.
Always
probably
a
mistake
like
progress
in
the
web
of
space
is
probably
gonna
make
SSO
as
a
value
proposition
like
pretty
useless
anyway.
I,
don't
think
I,
don't
know
what
that
means
for
Google
and
Facebook
Simon's,
probably
nothing,
but
in
the
cases
where
Federation
actually
works-
and
there
are
a
number
of
cases
where
it
does,
work
is
because
relying
parties
actually
want
and
get
information
about.
W
Add
your
own,
for
instance,
where
you're
basically
sharing
an
affiliation
right,
I'm
part
of
the
club,
and
that
gets
me
access
to
the
network
and
in
those
situations
it
has
nothing
to
do
with
SSO,
and
it
has
nothing
to
do
with
at
least
not
perceive
user
privacy
like,
but
it
has
everything
to
do
with
UX,
so
I
think.
If
to
make
progress
in
this
space,
you
actually
have
to
focus
on
UX,
not
technology,
because
that's
where
the
really
hard
problems
are
yeah.
S
I
think
I'm,
maybe
to
just
comment
on
that.
Briefly,
the
what
it
does
is.
Actually
it's
just
a
service
any
of
MediConnect
provider
just
allows
it
just
provides
a
service
that
allows
the
relying
party
or
the
the
website
to
retrieve
this
identity
data
when
the
users
offline
as
well.
So
it's
not
just
a
direct
interaction
and
a
single
sign-on
issue.
It's
also
a
service
that
provides
this
identity
data
as
a
service
right.
W
M
M
S
S
X
Hi
I'm
Brooks
coffered
I
work
for
giant.
This
is
my
first
IAT
fi
RTF
sort
of
a
meeting
so
anyway
I'm
here
to
talk
about
the
next
generation
of
the
Internet.
So
if
you
have
been
to
a
welcome
and
presumably
the
first
time,
you
turn
up
OIT
if
it
was
a
welcome,
you
would
have
at
some
point
come
across
the
mission
of
the
ITF,
and
this
is
to
make
the
internet
work
better.
X
Now,
in
our
net
foundation,
have
a
goal
of
to
create
correct
the
Internet
of
tomorrow
and
as
such,
they
got
approached
by
the
European
Commission
to
work
on
a
series
of
documents
because
well
they
they
discovered
this
to
be
a
problem.
This
is
from
a
presentation
by
I'm,
not
here
at
the
moment
that
actually
the
Internet
is
not
necessarily
serving
what
we
hoped
it
would
serve,
and
so,
in
a
short
space
of
time,
it's
well
as
you
can
see
from
the
presentations
day
and
the
problems
you're
trying
to
solve
by
being
in
this
room.
X
How
are
we
going
to
rebuild
a
currently
working
system
working
to
some
definition
of
working
because
there's
a
lot
of
moving
parts
and
you
know
trying
to
build
something
new
or
improve
the
user
privacy
on
top
of
that
working
infrastructure
is,
is
going
to
be
a
challenge,
so
I
know
net
foundation.
I
did
it
be
analysis,
some
some
consultations
produced
some
paperwork
and
in
a
vision,
and
that
has
resulted
in
European
Commission
funding
stream
to
be
able
to
explore
this
area.
X
In
fact,
it
was
a
very
big
sort
of
architectural
document
of
all
of
the
things
you
could
possibly
look
at
and
then
they
decided
that
trying
to
work
on
all
of
those
things
individually
isn't
going
to
work.
The
the
heap
would
crumble.
So
we
have
this
next-generation
internet
open
call
process
where
a
few
of
these
open
chords
are
kicking
off
right.
X
Now,
it's
being
built
with
a
larger
ecosystem,
so
in
our
net
foundation,
happens
to
talk
to
giant
the
organization,
I
work
for
where
the
association
of
research
networks
in
Europe
the
ripe,
NCC
lots
of
ISP
groups
in
order
to
get
their
feedback
on
what
should
what
work?
We
need
to
undertake
in
order
to
improve,
improve
the
situation,
and
so
there'll
be
a
lot
of
funding
programs
coming
on
stream
in
the
coming
years,
and
at
the
moment
there
are,
there
are
four
actually
it'll
be
an
elated
slide.
X
So
this
is
ngi
vision
document
you
can
go
to
ng,
itu
/
vision,
and
I
get
a
copy
of
this
report
that
Annette
Foundation
developed,
and
this
shows
the
the
current
funding
stream-
that's
coming
on
board.
So
this
is
a
pitch
for
you
to
come
with
your
ideas
to
these
open
core
processors
and
and
seek
funding
to
complete
this
work.
X
So
at
the
moment
there
are
four
fact
of
open
calls
in
green
run
by
mo
net
foundation,
distributed
data
distributed
ledger
group
in
in
orange,
and
this
privacy
and
Trust
enhancing
technologies,
which
is
the
the
project
that
I'm
involved
in
a
consortium.
There's
also
three
I
think
the
deadline
for
these.
These
are
the
proposals
for
people
to
run
these
open
core
systems.
So
there's
three
projects
that
are
currently
the
deadline
is
real
soon
now
it
may
be
at
the
end
of
this
month.
X
So
a
no
net
foundation
are
looking
after
our
search
and
discovery
and
privacy
enhancing
technology.
These
are
open
calls
that
have
a
very
low
barrier
to
entry,
not
everyone's,
always
successful,
and
but
they
offer
money
in
the
range
of
five
thousand
euros
to
50
thousand
euros.
They
have
a
and
they
and
they
run.
These
calls
regularly
every
two
months.
These
calls
pop
up
throughout
the
the
cycle
of
this
project.
X
A
neonate
foundation
also
offer
and
other
funding
opportunities
so
check
their
website
for
more
giant
is
part
of
a
consortium,
privacy
enhancing
technologies,
and
we
have
money
up
to
a
hundred
thousand
euros
for.
Unfortunately,
a
slightly
weightier
application
process
and
the
ledger
project
offers
up
to
two
hundred
thousand
euros
on
distributed
data,
distributed,
ledger
technology
and
blockchain
projects,
and
you
can
find
this
information
on
the
ng
ITU
website
so
yeah.
These
are
the
these
are
the
currently
open
open
calls.
X
The
deadlines
are
ever
so
slightly
different,
so
any
o-net
foundations
run
every
two
months.
Their
deadline
is
the
1st
of
April,
but
also
on
the
1st
of
April.
A
new
call
will
open
for
them
and
run
for
a
period
of
two
months.
Enjoy
trust
and
ledger
have
open
calls
that
end
on
the
30th
of
April
and
will
be
running
additional
calls
later
in
the
year,
so
we're
not
as
agile
as
Internet
Foundation
to
have
this
very
rapid
process
that
we
hope
these.
X
These
proposals
will
be
slightly
longer
more
involved
and
we
provide
some
other
support
infrastructure
in
getting
your
applications
across
the
line.
You
can
also
contact
us
and
we
can
give
you
advice
and
guidance
in
the
lead-up
to
submitting
a
call,
but
once
you
submit
something
we
we
can't
talk
to
you
until
the
assessments
out
so
feel
free
to
talk
to
us
leading
up
to
that,
and
this
is
how
you
can
directly
contact
me
or
visit
the
NGO
our
website
and
look
at
open
courts.
R
R
X
Can
yeah
you
can
still
apply
it,
it
has
to
be
for
the
benefit
of
Europe,
so
it's
not
exclusively
for
projects
or
people
resident
in
the
European
Union.
It
does
make
it
easier
and
once
the
individual
open
call
projects
have
done
their
assessment,
there's
actually
a
final
group
within
the
European
Commission
that
decides
whether
it
passes
this
bar
of
being
beneficial
for
Europe
or
operating
within
Europe.