►
From YouTube: IETF104-IPPM-20190325-0900
Description
IPPM meeting session at IETF104
2019/03/25 0900
https://datatracker.ietf.org/meeting/104/proceedings/
B
Good
morning,
everyone
there's
this
thing
on
yeah
it's
on
yeah,
it's
the
ITF.
We
gotta,
you
know
be
very,
be
very
serious
about
the
microphones
hi
I'm
Brian.
This
is
Tommy.
We
are
the
co-chairs
two
of
the
three
co-chairs
of
IPP
M.
This
is
IPP
em
I,
see
many
familiar
faces
here,
you're
all
in
the
right
place,
if
you're
not
here
for
AI
ppm,
then
you're
in
a
wrong
place.
B
B
We
know
so
we
have
a
exceptionally
full
schedule
today,
so
I
would
basically
go
ahead
and
jump
right
into
it.
This
well,
it's
been
a
while,
since
we
have
like
a
first
thing
Monday
morning
meeting,
so
we
should
actually
actually
show
the
note
well,
because
some
people,
this
might
be
the
first
time
you
see
it.
This
is
an
IETF
meeting.
Anything
you
say
in
this
meeting
is
an
IETF
contribution.
B
B
Like
I
said
full
schedule,
we're
actually
gonna
do
from
the
chair
here
on
some
discussion
about
the
status
of
things
that
are
currently
in
last
call
we
the
exception
of
the
metric
and
initial
registry,
so
we
can
have
a
little
longer
discussion
about
that.
To
make
sure
we
wrap
that
last
call
up.
The
other
last
calls
that
we're
in
I
think
are
pretty
straightforward.
B
We
have
essentially
three
suctions
of
working
group
work.
We
have
the
metric
registry
discussion
because
we'd
like
to
get
that
finished
and
ready
to
send
up
to
a
Shepherd
after
this
meeting.
The
next
one
is
the
IOM
discussion
we'd
like
to
basically
take
some
action
items
that
are
slipped
since
the
last
time.
This
is
on
our
our
side,
the
chair
side
that
we
need
to
to
go
through
and
we
need
to
figure
out.
You
know,
what's
the
right
home
for
these
things,
where
you
know
where
we're
gonna
move
this
work
forward
and
how
we
get.
B
You
know
some
some
real
progress
on
this
before
the
montreal
cycle,
and
then
we
have
in
20
minutes
at
the
at
the
end
of
that
section,
on
alternate
marking
and
related
work.
I
strongly
suspect
that
we
have
under
scheduled
time
for
these
discussions.
We
are
going
to
focus
on
the
metric
registry
IOM
and
alternate
marking.
We
will
make
sure
that
we
have
sufficient
time
for
all
three
of
those
topics
during
this
slot.
If
that
means
that
we
have
to
push
the
next
screen
off,
then
so
be
it.
B
B
So
we're
experimenting
a
little
bit
with
the
format
and
we'll
see
how
that
works
in
Montreal.
For
today,
hopefully
we
can
get
to
these
four.
There
were
like
four
or
five
other
presentations
that
came
in
too
late
to
even
get
on
this
list,
but
if
we
don't
get
to
these
I
apologize
to
the
people
here,
congratulations
84-68
has
been
published
since
the
last
time
I
think
it
was
in.
It
was
basically
in,
like
all
48
the
last
time,
yay
progress,
one
more
thing
off
our
list,
int
fi,
ppm,
Timur
yang,
is
still
in
miss
ref.
B
Right:
it's
just
the
registry:
okay,
cool,
good,
okay
check.
We
have
the
last
call
on
graphite,
EFI,
ppm,
initial
and
metric
registry,
which
was
extended
to
end
with
the
discussion
today
will
follow
up
anything
that
happens
there
on
the
list.
Obviously,
but
we're
going
to
finish
that
out.
Thank
you
to
everyone
who
commented
after
if
the
end
of
the
first
last
call.
C
D
B
E
E
E
So
this
is
just
a
reminder
where
we're
basically
measuring
and
defining
how
we
describe
Route
ensembles,
it's
a
whole
list
of
routes
here
and
you
can
see
how
that
would
be
matching
up
with
the
diagram
where
you've
got
one
one
place
of
divergence
there,
one
one
multipath,
three
one
and
three
next
slide.
So
the
most
important
part
about
this
list
of
things
is
the
hops
it's.
It
is
an
ordered
list.
E
We
sorted
that
some
terminology
out
and
there's
a
reminder
what
it
looks
like
and
there's
a
so
hij
was
a
host,
but
we
can
learn
much
more
about
that.
It
has
to
have
an
identity.
That's
always
been
a
part
of
this
either
an
IP
address
or
a
DNS
resolve
name,
but
we
can
also
add
things
like
the
arrival
interface
departure,
interface,
timestamps
and
round-trip
delay
measurements
associated
with
that
host
and
I've
got
some
green
stuff
there.
That's
what
we've
associated
with
on
resolving
some
comments.
E
We've
associated
those
two
interfaces
with
RFC
58-37,
so
we've
got
more
backup
now,
basically
for
the
kind
of
information
that
we're
putting
in
next
slide.
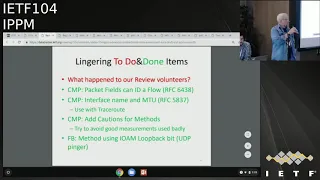
So
here's
the
lingering
to
do
and
done
we
had
a
whole
bunch
of
reviewers.
Where
are
you
where's
Aliyah?
Where
is
yari?
Who
was
volunteered?
Not?
Actually
a
volunteer
will
resolve
that
on
the
next
slide,
but
we
did
all
these
other
things.
E
We've
got
packet
fields
can
ID
a
flow,
that's
an
important
one
and
that's
a
now
reference
to
64
38
I
just
talked
about
the
interface
names,
so
we'll
use
that,
and
these
are
all
Carlos
Carlos
Pena
taro
co-author
comments
before
he
was
an
author
we've
added
some
cautions
for
the
methods
we
have
in
the
draft.
We
can
easily
do
that
for
some
others
and
Frank.
We
had
a
comment
from
you
about
the
IOM
loopback
bit
and
I
believe
that
we've
covered
that
now.
So
next
slide
the
next
steps.
E
It
doesn't
make
sense
to
ping
to
death
our
volunteer
reviewers,
so
we
need
some
more
volunteer.
Reviewers
and
I
know.
There's
people
interested
in
this
topic.
Everybody
measures
traceroute
everybody
measures
it
with
Parrish
traceroute.
Every
a
lot
of
people
use
the
MDA
algorithm
when
they
measure
traceroute,
so
where
we're
trying
to
go
a
few
steps
beyond
that
that
methodology,
but
that
was
kind
of
our
starting
place,
and
so
now
everybody
in
the
room
can
raise
their
hand
and
volunteers
or
reviewer
great.
What?
Oh
that's
a
foot
footer
right,
yes,
I
remembered
you
should.
E
Should
be
a
good
thing,
thank
you,
foot.
Anybody
else,
Frank
Frank!
Thank
you!
Frank
and
a
lot
of
people
are
hiding
behind
the
column.
Here,
that's
okay.
They
used
to
be
a
round
column.
So,
okay,
we
didn't
get
too
many
volunteers,
but
we've
got
got
a
few.
So
please
review
and
read
the
draft
and
in
particular
sections
five
and
six
round
trip,
delay
and
analysis.
That
would
be
good
if
we
got
some
more
delay
review
of
that.
But
everything
is
up
up
for
topics
please
Brian!
Oh
you'll!
Do
the
dodo?
Oh
yes,
so
take.
B
E
A
E
While
we're
switching
slide
decks
here,
I
wanted
to
make
mention
that
the
groupers
now
received
two
liaisons
on
the
top
of
capacity
measurement
and
there's
going
to
be
a
side
meeting
about
that
during
this
week.
Please
come
and
see
me
after
this
session.
If
you
would
like
to
join
that
few
people
have
already
said
so
by
email.
So
please
please
come
see
me
so
now
we're
talking.
E
Gonna
sort
it
out
and
we'll
put
it
on
the
list
got
it.
Thank
you,
okay,
it'll,
be
in
the
next
couple
of
days.
Let
me
say
that,
and-
and
you
know
out
of
the
way
of
most
sessions,
I
would
guess
so.
This
is
the
performance
metric
registry.
We
have
initial
contents,
that's
the
draft
you're
looking
at
there
and
then
next
slide
is
the
registry,
the
the
design
of
the
registry
itself
without
contents.
So
again,
I'm
Mel,
Morton,
we've
gone
through
18
versions
of
this.
E
E
So
we've
got,
you
know
basically
tons
of
information
in
a
series
of
columns
which
I'll
show
you
on
the
next
slide,
but
we
had
originally
talked
about
early
different
kinds
of
identifiers,
zwi
needed
and
that's
what
we're
gonna
concentrate
our
final
discussions
on
today
next
slide.
So
we
have
this
concept
up
at
the
top
of
categories
in
blue
and
then
the
off
to
the
off
to
the
right.
We
have
the
various
columns,
so
the
the
summary
column.
E
That's
it
that's,
what's
actually
going
to
appear
in
the
I
Anna
web
pages
version
of
the
registry,
so
just
the
ID,
the
name,
the
Uniform
Resource
identifier,
z'
description,
references
change,
control
and
version
number
of
the
registry
that
the
entry
conforms
to
and
that's
pretty
much
all
you're
gonna
see
on
the
web.
Unless
you
click
through
and
we'll
talk
through
we'll
talk
about
that
in
just
a
moment.
E
The
rest
of
the
categories
are
the
metric
definition
method
of
measurement,
the
output
formats,
additional
information
than
any
comments
that
come
in
as
we're
kind
of
revising
these
metric
things.
So
next
slide.
So,
as
I
said,
we
had
a
simpler
plan
for
delay
for
display
of
these
registry
entries.
So
I
just
a
reminder.
What
the
some
looks
like
this
is
what
you
know:
it's
a
little
bit
jammed
together,
but
this
is
what
the
webpage
and
I
Anna's
website
would
look
like.
E
You
can
see
descriptions
there
for
things
like
round-trip
delay,
which
is
an
active
metric
which
is
UDP,
which
is
95th
percentile
of
the
units
of
the
measurement
there
and
so
forth,
and
you
know
we
and
we've
got
a
lot
of
related
metrics.
They
basically
use
almost
all
the
same
references
and
so
we've
a
little
bit
consolidated
on
the
detailed
information
when
we
did
that.
E
So
each
major
section
in
the
initial
contents
draft
sometimes
specifies
as
many
as
four
metrics
like,
for
example,
if
there's,
if
there's
delay
and
lost
there,
those
are
very
closely
related
metrics
in
the
way
we've
defined
active
metrics
in
IP
PM
here,
so
we've
tried
to
save
some
space.
So
that's
the
simple
version:
a
little
with
a
little
more
information
off
to
the
right
there.
That's
what
you
would
see
and
you'll
be
able
to
click
through
to
an
HTML
eyes
text
file.
G
E
G
G
B
E
E
G
E
C
E
Yeah,
that's
right
and
in
fact,
I
mean
this
first
round
of
metrics
that
we're
looking
at
there
are
any
thanks.
Are
there
they're
all
going
to
be
defined
in
the
initial
contents?
Rfc,
so
they'll,
basically
all
have
the
same
number.
At
the
start,
there
might
be
new
numbers
and
new
metric
names
that
result
from
that
if
we
change
them.
So,
let's,
let's
work
that
let's
work
that
detail
out,
see
how
see
what
we
can
clarify
about
that
all
right.
E
So
so
this
results
in
a
you,
saw
those
names
and
they're
kind
of
a
complicated
format.
But
it's
a
good
format
in
that
it's
it's
fairly
exact.
What
we
decided
to
do
was
to
have
a
fairly
well
specified
set
of
sub
elements
for
the
names
that
you
can
use,
and
each
of
these
elements
is
defined
here,
for
example,
so
our
tea
delay
is
round-trip
delay.
That
seems
pretty
simple,
one-way
delay
same
thing,
so
there's
going
to
be
a
sub
registry
for
each
one
of
these
and
people
can
add
to
these
over
time.
E
This
is
exfoli
extensible.
But
the
main
point
is
that
we
don't
want
someone
saying
like
what
you
spelling
out
one
way,
delay
and
also
meaning
the
same
thing
as
Oh
W
delay.
That's
the
that's
the
main
point
here.
So
it's
a
it's
just
a
matter
of
nailing
down
specific
names
for
the
kinds
of
metrics
we've
used
quite
frequently,
next
slide.
Alright.
So
so
here's
the
content
updates.
So
we're
closing
the
working
group
last
call
opens.
E
We've
got
the
we
had
a
good
set
of
comments
from
height
Oregon's
Ellie
from
the
Nick
in
Brazil,
and
we
clarified
the
description
of
roles.
There.
We've
got
a
typically
in
measurement,
we've
got
an
active
measurement.
In
particular,
we've
got
a
source
of
the
active
stream
and
we've
got
a
destination
that
all
those
active
packets
have
been
sent
to
and
you
need
to
nail
down
which
role
you're
playing
when
you're
specifying
a
metric
for
measurement
and
your
measurement
device
is
going
to
conform
with
this.
E
So
we
we've
clarified
that,
and
we
also
made
some
references
to
the
L
map
framework
and
the
L
map
yang
model,
which
height
or
was
was
actually
using
down
in
Brazil,
so
that
helped
him
out
a
lot.
We
got
another
I
Anna
review
from
Michelle
cotton.
Michelle.
Are
you
here?
No,
no?
Okay!
How
about
Tom,
Pech
and
Dale
are
whirly.
E
Okay,
well,
we
got
a
good
review
from
Michelle.
We
resolved
all
those
comments.
I
believe
we've
resolved
every
comment
except
the
the
kind
of
combination,
Tom
and
Dale
won,
which
was
about
considerations
for
the
Uniform
Resource
name
that
we
thought
we
would
add
here.
So,
let's
see,
oh
yes,
and
one
of
the
other
comments
was
that
I
Anna
uses
a
group
name
now,
so
we've
adopted
that
concept
and
it's
actually
in
our
mock-up.
So
our
next
slide.
E
It's
the
performance,
metrics
group,
and
if
you
go
to
Ayana
registries,
this
is
the
kind
of
thing
you
see:
the
dates,
the
registration
procedures,
the
experts
and
and
and
so
forth,
who
are
involved
and
then,
as
you
as
you
scan
down
the
page,
you'll
see
a
click
click
through
to
the
performance,
metrics
registry
and
then
the
performance,
metric
name
elements
and
we've
both
we've
seen
both
of
those
in
the
in
the
previous
slides.
So
that's
how
this
thing
would
typically
be
constructed
now
next
slide.
E
So
here's
the
question
for
today
we've
got
these
three
things:
we've
got
names
of
the
metrics
that
we
worked
out
in
great
detail
with
the
Buenos
Aires
format.
We've
also
got
a
16-bit
integer,
which
is
the
identifier,
and
we've
got
this
thing
that
we
thought
we
were
going
to
define
called
the
art.
You
are
in
the
uniform
resource
name.
It
was
going
to
be
under
the
ITF
level.
It
was
going
to
define
a
new
level
of
metrics.
It
was
going
to
define
a
new
level
under
that
for
performance
and
we
would
simply
be
a
prepending.
E
This
you
are
in
to
the
name,
and
that
would
make
the
complete
name.
So
the
real
question
is:
do
we
need
that
now
and
all
the
also
the
URI
contains
a
URL
to
the
file,
which
is
the
HTML
HTML
eyes,
dredge
estreet
entry?
If
you
go
look
at
the
draft,
if
you
look
at
the
major
sections,
those
are
the
kinds
of
information.
Those
major
sections
are
what's
going
to
appear
when
you
click
on
this
URL,
it's
going
to
bring
up
all
the
detail.
Why
are
we
doing
that?
E
Because
it
would
make
the
registry
completely
unusable
if
every
column
was
way
off
to
the
right,
and
if
everybody
who
wanted
to
write
a
new
metric
had
to
start
from
some
some
some
big
column,
column
or
thing
on
the
IANA
page,
it's
a
lot
easier
for
people
to
just
grab
this
text.
File,
modify
it
to
their
heart's
content,
write
another
internet
draft
that
then
becomes
an
RFC
that
then
would
be
introduced
in
the
registry
or
or
an
internet
draft
that
could
go
under
expert
review.
E
That's
that's
the
way
that
that
metrics
from
other
standards
bodies
can
get
listed
here.
If
it
becomes
a
standard,
someplace
else
or
if
another
standards
body
wants
a
registered
metric,
then
the
group
of
registry
experts
would
review
that.
So
the
question
for
the
group
is:
do
we
need
all
three
of
these
things
and
and
I'm
happy
to
put
in
that
I
think
the
answer
is
no.
Once
we
came
around
with
the
with
a
very
well-defined
naming
format
and
obviously
we
have
the
the
integers
for
the
identifiers.
E
I
mean,
frankly,
if
I,
if
I'm
going
to
use
this
these,
these
two
information
pieces
of
information,
I
will
use
the
numeric
identifier
in
a
protocol
and
I'll
use
the
name
format
in
documentation
or
you
know
an
actual
report
of
measurements
using
the
registered
metrics
and
I.
Don't
need
the?
U
RN
so
comments
on
that
I.
B
E
B
B
H
E
I
B
E
J
J
E
E
B
E
B
B
H
B
C
L
L
L
L
You
one
minute
thing
ready
some
framing
things
so
so
Tony
asked
me
to
go
and
kind
of
host
this
particular
session.
We
try
to
go
and
pull
in
everybody
that
has
something
on
Io
em
so
that
at
least
we
get
the
whole
thing
discussed
later
on
categorized
grouped
and
then
have
a
conversation
on
how
we
want
to
go
and
take
the
individual
categories
forward
and
then
eventually
also
in
the
video
drafts,
even
more
so
there's
a
sweetie
sensitive
than
so
next
slide.
So
from
an
overall
agenda
perspective.
L
This
is
how
we're
thinking
of
spending
the
40
minutes.
We
have
one
working
group
draft
which
we
typically
refer
to
as
the
data
drafts
or
the
data
formats
and
there's
been
a
bunch
of
discussions
and
updates
on
that
particular
draft.
We've
got
to
go
and
go
through
these
individual
updates
and
then
we're
going
into
the
second
section
that
should
get
us
to
a
understanding
on
how
we
want
to
go
and
take
all
the
individual
drafts
that
we
have
on
I
related
topics
forward,
and
we
categorize
these
individual
drafts
in
well
for
five
main
categories.
L
The
biggest
category
a
category
is
carrying
the
data
fields
in
various
protocols,
which
is
what
we
call
encapsulations.
We're
gonna
go
through
this
entire
raft
and
then
see
and
decide
on
whether
we
agree
on
the
categories
and
what
to
do
with
these
individual
categories,
taking
them
forward
in
certain
cases.
It's
relatively
easy,
if
you
think
of
you,
need
a
yang
model
for
IOM.
L
Where
should
we
go
and
anchor
that
most
likely
here?
But
the
ancap
draft
thing
is
a
less
obvious
discussion.
So,
let's
have
that
after
we
understand
what
encap
drafts
exist
and
maybe
a
very,
very
quick
verification
round,
but
I
don't
think
that
we
have
time
for
individual
discussions,
which
is
why
next
slide,
we
showed
you
all
a
bunch
of
site
meetings
to
go
and
clean
up.
Individual
documents
have
site
discussions
on
all
these
various
documents.
L
The
first
one
is
happening
today.
The
second
one
is
happening
on
Wednesday,
where
we
still
have
to
go
and
figure
out
which
room
we're
gonna
go
use
because
well,
there
should
be
empty
rooms,
but
we
don't
know
which
one
to
use
yet
and
the
third
one
is
tomorrow
and
tomorrow.
We
don't
really
want
to
go
and
focus
on
editing,
but
we
want
to
go
and
focus
on
how
people
use
or
intend
to
use
individual
IOM
data
fields
and
come
up
with
additional
deployment
considerations.
L
We
started
having
some
of
these
discussions,
especially
around
v6,
but
we
want
to
go
and
have
these
discussions
in
a
broader
way,
given
that
we
have
a
large
set
of
encapsulation
drafts
for
now,
so
we
Neah
understand
or
better
understand
how
people
want
to
go
and
deploy
those
things
for
other
domains,
and
that
leads
me
a
thing
to
go
and
jump
in
into
the
data
fields,
updates
and
I.
Believe
Shweta
is
gonna,
go
and
take
us
through
the
first
set
of
updates.
L
If
you
click
on
the
next
slide,
I
think
the
main
clarifications
fall
into
three
main
groups.
One
is
a
load
of
editorial
cleanup
and
so
thanks
for
especially
special
thanks
to
the
the
people
at
the
hackathon
last
time,
because
they
kind
of
went
into
degree
things
and
figure
out
a
bunch
of
editorial
myths.
And
then
there
is
two
major
updates.
One
is
immediate
export
and
one
is
active
and
well
shred
that
give
us
an
update
on
I.
Think
two
of
these
two
birds.
A
M
Better
now
so,
okay,
so
the
there
are
corresponding
issues
to
all
the
github,
the
comments
that
were
received
on
mailers
from
a
bunch
of
people,
so
we
have
given
links
to
the
github
issues
and
comments
and
how
they
were
addressed
there,
Joseph
very
briefly
here
so
namespace
was
introduced
after
the
work
group
after
the
draft
was
that
up
adopted
in
the
work
group.
So
there
was
additional
clarification
required
on
what
feels
in
the
i1.
Data
really
makes
use
of
the
the
namespace
context.
M
Initially
we
referred
to
some
of
the
fields
which
would
be
interpreted
like
the
timestamp.
The
unit
for
the
timestamp
would
be
based
on
what
names
me
names
face.
The
the
timestamp
fields
have
been
added
in,
so
we
have
given
a
additional
idea.
Examples
there
in
0-5
version
of
the
draft.
The
next
clarification
was:
what
does
the
transit
node
update
other
than
its
own
node
data?
So
we
clarified
that
it
could
possibly
update
the
checksum
based
on
the
encapsulation
and
yeah.
It
definitely
updates
the
remaining
length
in
a
pre
allocated
trace
option.
M
The
next
set
of
changes
were
related
to
the
flags
field
in
the
ion
Trace
header.
So
we
introduced
two
new
flags
which
we
will
discuss
in
the
next
two
slides
the
loop
back
bit,
which
was
essentially
to
when
you
see
there
is
a
failure.
You
want
the
packet
to
go
back
in
the
reverse
direction,
to
see
till
where
the
packet
reach.
M
M
Then
there
was
the
comments
on
the
must
ensured,
so
we
those
are
updated
according
to
the
two
one
109,
then
a
bunch
of
changes
to
the
trace
type
bits
which
was
increased
to
24
bits
from
16
bits,
but
there
was
redundant
16
bit
in
examples
as
well
as
in
the
description,
so
those
were
updated.
The
next
next
part
is
how
the
the
no
data
is
stacked.
So
we
go.
The
no
data
is
populated
in
a
stack
manner
instead
of
Q,
so
that's
uniform
across
reallocated
and
incremental.
So
that's
again
a
text
clarification.
M
M
So
this
goes
back
to
the
point
1
in
the
edits,
so
we
had
a
reference
to
tube
for
referring
to
the
e2e,
how
it
applies
to
a
group
of
packets,
so
that
has
been
updated
to
the
packet
group
instead
of
tube
just
so
that
we
don't
have
to
refer
to
another
terminology
which
the
tube
was
undefined,
so
we
have
modified
it
to
packet.
So
that's
that's
the
bunch
of
editorial
changes
that
have
happened.
N
M
That
the
ion
header
for
each
of
these
options
is
also
part
of
the
data
fields
and
without
that,
it's
not
really
possible
to
have
a
uniform
representation
of
the
I
own
data
in
different
protocols.
While
this
doesn't
define
the
protocols,
the
the
header
for
the
trace
e
to
e,
by
by
the
nature
of
definition
of
the
options
itself,
that
that
is
integral
to
the
part
of
the
data
raft.
It's.
H
N
B
Not
my
fault
to
submit
a
standard
track
graph
on
India
and
IO
am
based
measurement
methodologies
to
the
iesg.
So
that's
what's
in
the
Charter
right,
so
I,
don't
necessarily
want
to
get
into
a
discussion
about
the
wording
of
the
milestone,
because
we
don't
have
that
much
time.
I
think
that
the
the
idea
is
is
that
the
this
document
was
brought
in
on
to
IP
p.m.
B
the
data
model.
That
is
here
is
sort
of
the
minimum
viable
non
encapsulated
thing
that
you
can
use
to
support
these
measurement
methodologies
and
I'm,
not
making
I'm
not
making
a
technical
decision
is
the
chair
here,
but
it
seems
to
me
that
what
I'm
hearing
from
the
editorial
team
is
that
you
can't
actually
just
pull
this
out
without
any.
B
K
N
M
K
M
M
N
So
we
had
a
discussion
mailing
list
and
these
particular
enhancements
that
being
added
again
outside
of
the
scope
of
the
document
and
I
believe
that
Frank
understood
and
said.
Yes,
that
probably
means
that
that
could
be
should
be
in
a
separate
document.
So,
but
you
put
it
in
this
document.
Nevertheless,
I.
L
Frank
poppers,
given
that
that
was
addressed
to
me
I
think.
That's
not
true.
What
I
said
is.
We
are
defining
flags
and
data
fields
in
this
document.
That's
what
we're
doing
we're
not
defining
the
behavior,
the
control
plane
and
whatever
happens
around
that
in
this
particular
document,
but
we
need
a
place,
we're
to
define
the
flag
and
that's
the
day
to
draft.
L
So
we
can-
and
that's
also
why
we
have
the
de
session
tomorrow,
how
people
want
to
go
and
deploy
the
thing
how
they're
using
it.
We
will
have
a
raft
of
probably
additional
documents
that
talk
about
how
you
use
certain
things,
but
we
need
an
anchor
point
where
we
define
the
flag
and
that's
also
what
I
said
on
the
email
on
the
mailing
list.
N
B
Said
I'm
Brian
trauma
as
an
individual,
so
I
I
do
want
to
raise
a
little
bit
of
a
flag
here
that
this
particular
so
I.
Don't
I,
don't
really
have
an
opinion
on
the
you
know
the
control
versus
data
thing
great,
like
you.
Obviously,
if
you're
doing
anything
in
band,
you
need
some
way
to
have
some
in
band
control
information
for
exactly
what
gets
done.
The
things
I
do
think
that
there
are.
B
There
are
probably
dragons
here
in
that
when
you
take
a
system,
that's
designed
such
that
you're,
never
touching
the
forwarding,
plane
and
you're
allowing
the
forwarding
plane
to
do
things
to
the
packets
like
so
the
one
of
the
points
the
octave
flag
is
to
say,
okay.
Well,
you
can
stick
in
a
different
cue
if
you
get
in
trouble.
B
For
example
right,
you
are
now
modifying
the
operation
of
the
system
that
you're
measuring,
which
means
that
you're
doing
an
entire
different
sort
of
you
know
theoretical
basis
for
how
you
how
you
manage
these
things,
I'm,
not
saying
don't.
Do
it
I'm,
just
saying
that
this
needs
to
be.
There
needs
to
be
like
a
little
sort
of
like
red
and
black.
You
know
button
thing
here,
it's
like
if
you
use
these
active.
B
If
you
use
this
encapsulation
for
active
measurement
that
you
are
mixing
with
passive
measurement,
you
need
to
be
very
careful
about
the
design
of
the
of
the
measurement
unless
it
is
a
reason
not
to
do
it.
It's
a
reason
to
put
a
big
flashing
light
on
it
and
say
be
careful
here,
because
I
think
this
starts
to
be
the
boundary
between
things
that
were
pretty
sure.
We
know
how
to
do
and
the
problem
is.
B
M
B
Turn
this
into
something
it
goes
into
a
separate
document:
I
really
don't
care
about
that
argument
like
as
yeah
I
guess
as
a
chair
I'm
supposed
to
but
like
his
individual.
You
know
if
the
stuff
is
there,
fine,
if
I
can
read
it
if
it's
usable,
that's
great,
but
this
is
I'd
like
to
call
this
out.
As
you
know,
we're
crossing
a
threshold
here
and
we
need
to
be.
We
need
to
be
mindful
that.
G
You
live
in
also
individual
comment.
I
can
just
very
much
agree
and
it
goes
even
one
step
further,
because
if
you're
going
into
active
measurements-
and
you
actually
dublicate
impecca's
integrating
data,
then
you
have
to
consider
congestion
and
all
you
can
all
these
kind
of
things.
So
it's
a
completely
different
part
of
considerations
and
I
would
really
recommend
you
to
rather
design
a
completely
different
protocol
for
it
and
not
try
to
squeeze
it
in
here.
I
would
be
very
careful
about
it.
L
So
I
think
we
are
over
exaggerating
what
this
is.
You
can
do
it
without
the
active
flag
at
the
expense
of
another
ICL
that
filters
out
that
other
traffic
right.
So
this
thing
was
introduced
to
help
the
implementation
and
make
it
simpler.
You
can
do
active,
you
can
do
anything
with
IOM,
because
all
we
carry
is
metadata
in
packets
and
whether
these
packets
are
active
measurements
or
a
customer
traffic.
Our
UN
doesn't
know.
This
is
a
help
to
an
implementer.
L
N
B
Maybe
at
this
point
this
to
the
site
me
because
we
were
talking
about
this
but
again
I'm
I'm
not
reacting
to
the
flag,
because
I
think
the
flag
is
a
problem
I'm
reacting
to
the
flag
because
it
it
it
brought
this
flexibility
to
my
attention
and
even
with
that
flexibility,
you
know
comes
responsibilities.
You
know
not
to
not
the
internet
so.
F
F
M
This
doesn't
really
mean
that
right,
even
within
the
domain,
if
you
don't
really
want
to
add
I,
want
to
all
the
data
packets,
but
you
want
to
do
some
troubleshooting
and
craft
packets
and
send
do
some
active,
OEM
and
you'd
want
to
come,
get
the
complete
trace
and
not
not
kind
of
active
measurements.
You
could
use
IOM
within
the
ICMP
being,
for
example,
right
and
get
the
entire
trace
and
half
delays
before.
F
B
B
G
So
I
do
understand
that
this
is
a
data
mode
and
you
can
do
whatever
you
want
with
it
right,
but
it's
it's
designed
with
a
certain
scope
in
mind
and
disco
with
the
I.
The
Instituto
is
kind
of
you
know
what
we
focus
on
and,
however,
I
think
what
you
actually
want
is
not
talking
about
active
measurements.
Yeah,
it's
talking
about
having
a
flag
that
tells
you
please
drop
this
packet,
so
it
maybe
that's
a
name.
G
You
should
give
the
flag
just
to
be
future
proof,
but
I'm
still
not
sure
if
it's
the
right
approach
and
on
the
point
of
easy
making
implementation
more
easy.
Just
because
it's
more
easy
to
implement
doesn't
mean
it's
the
right
design
choice
right,
sometimes
it's
it!
It
has
a
benefit
about
making
people
think
about
what
they
actually
do.
Then
trying
to
just
get
the
easiest
way
out.
No.
M
G
O
G
So
it
doesn't,
it
doesn't
advise
anybody
to
WK
pickets
or
whatever,
but
it
has
this
example
in
the
text
right
now
and
no
matter,
if
you
call
it
active
or
drop
or
whatever,
if
you
drop
a
packet,
there's
an
assumption
that
it's
not
needed
anymore
and
maybe
it's
created
somewhere
and
it's
if
you
create
your
own
packets,
you
have
to
put
a
big
warning
in
there.
This
is
a
this
has
implications
on
congestion
control
and
you
have
to
carefully
think
about
it.
Right,
that's
like
minimum.
You
have
to
do.
O
Sure
so
for
immediate
export
flag,
so
we
added
another
flag
so
currently
up
until
this
flag,
all
the
data
collection
used
to
be
embedded
in
the
packet
itself,
and
the
idea
here
is
to
enable
also
for
our
notes
to
export
the
data
immediately,
instead
of
embedding
it
into
the
packet.
The
motivations
are
related
to
security
concerns
that
raised
in
some
environments,
space
limitations
within
the
headers
implementation
simplicity.
So
it
helps
implementers
to
collect
data
from
data
plane
and
also
the
potential
loss
of
telemetry
data.
If
a
packet
that
someone.
H
O
P
So
you
mentioned
you
can
combine
this
visit
e
to
e
mode,
but
we
have
discussed
in
the
email
instance
that
that
just
makes
that
make
a
mess
about
the
semantics,
because
e
to
e
means
just
to
do
this,
but
from
suppose
ends
no
not
supposed
to
be
processed.
Art
earrings
are
on
the
unfolding
past.
So
the
better
way
to
do
that
is
actually
just
support,
another
mode
in
everywhere.
P
O
B
O
L
You
can
either
export
at
every
single
node
or
you
can
have
nodes
decide
on
whether
they
want
to
go
and
export
and
carry
on
and
I
think
you
had
a
preference
to
do
a
must
statement.
You
have
to
go
and
export
everything
as
opposed
to
a
node
decides
on
well
I
I
filled
up
to
a
certain
level,
so
I
had
say
room
for
six
Hobbes
and
from
now
onwards
I
don't
have
room
anymore,
so
I
can
go,
and
rather
than
do
nothing
I
can
go
an
export.
B
So
there
needs
to
be
a
really
big
anti
foot
gun
section
I
mean
I,
guess
you
can
call
security
considerations,
but
it's
really
about
how
to
ensure
that
there's
a
safety
envelope
for
misconfigurations,
because
it's
very
easy
just
to
blasts
you're,
you're,
monitoring,
collection
system
off
the
metal,
and
then
you
know,
there's
a
problem
right
because
I
went
down,
but
it's
hard
to
diagnose.
I
am
I'm,
not
sure
exactly
what
shape
that
safety
envelope
should
take.
It
might
require
additional
information
in
this
header,
just
just
as
input.
L
L
B
L
Questions
at
the
end,
please
yeah
so
I
think
this
11
minutes
so
first
on
is:
let's
go
do
that
this
is
not
even
an
individual
draft
just
for
reference
and
shì
encapsulation
is
adopted
by
SFC,
so
that's
progressing
there
for
people
who
kind
of
miss
it
here.
It's
their
next
one,
so
Brian
Weiss
has
been
shepherding
this
wick
for
a
while.
L
Don't
believe
that
he's
in
the
room
is
he
here
he's
not
so
he
came
up
with
a
encapsulation
that
works
for
protocols
that
use
either
type
as
next
header,
so
things
like
it
works
for
GRE.
It
works
for
genève
and
there's
been
a
discussion
and
I
believe
he's
updated.
The
draft
per
the
working
group
discussion
last
time
on
how
to
go
and
allocate
that
particular
Kok
point
next
IOM
over
v6
I
think
Shweta.
M
So
we
have
map,
although
I
am
options
that
are
defining
the
data
draft
Habba
hop
and
destination
options
in
v6
there
are
the
trace
options
and
proof
of
transit
that
needs
to
be
updated
by
multiple
nodes
in
the
hops.
Multiple
hops
are
mapped
to
haba
haba
options,
while
the
e
to
e,
which
is
a
ion
domain,
boundary
option,
is
mapped
to
a
destination
option.
L
M
So
we
have
a
draft
to
explain
what
how
it
should
not
break
8,200,
and
this
is
mostly
to
have
all
the
considerations
for
deploying
it
in
v6
and
how
the
options
should
not
break
any
of
the
v6
most
stuff,
like
inserting
data
in
flight,
which
is
not
allowed
by
8200.
How
we
can
get
around
that
and
the
solutions
possible
solutions
for
it
are
listed
in
this
draft.
L
O
V4
options
now,
yes,
so
we
suggest
the
new
draft
for
encapsulating
IOM
in
before
the
idea
is
not
new,
as
some
of
you
may
I'm
at
ease.
So
RFC
791
already
suggests
to
embed
some
television
data
into
the
ipv4
options,
so
we
simply
follow
this
idea
and
essentially
suggest
to
expand
the
ability
to
insert
more
types
of
Iowan
data
into
the
ipv4
options.
O
L
There
is
another
one
on
integrated
tactic:
optical
in
situ
OAM.
Do
we
have
anybody
here
that
would
represent
that
draft?
No
I
believe
it
is
about
using
I
at
the
optical
layer
and
I
believe
it's
even
informational.
So
anybody
wants
to
go
and
add
another
sentence:
nope
okay.
Next
one,
then
we
go
into
the
wild
wild
west
of
I
and
segment
routing.
So
there
is
one
draft-
and
we
have
another
similar
one
later
on-
that
talks
about
segment,
routing
and
MPLS.
D
L
L
D
P
Okay,
yeah,
okay,
so
in
addition
to
our
OEM
we
expect
there
will
be
some
other
in
natural
services
which
need
add
some
instruction
header
to
the
MPS
packet.
So
the
current
a
common
approach
is
use
some
indicator
in
the
label
stack.
Then
they
will
compete
as
the
location
between
the
label
stack
and
is
the
payload.
So
that's
not
scalable
solution.
So
here
we
actually
propose
you
to
add
the
extension
headers
to
allow
me
to
stack
or
the
service
header
or
instruction
header
together
just
after
the
normal
MPs
label
stack.
So
that's
a.
We
believe.
L
D
P
So,
basically
again,
the
current
approach
is
to
put
the
instruction
header
and
also
the
metadata
together
for
the
ipv6
or
SR
v6,
as
that
will
cause
some
performance
issues.
So
we
think
that
a
more
efficient
ways
actually
splits
our
instruction
header
and
is
a
metadata
part
into
the
different
service
header.
So
we
prefer
to
put
instruction
header
before
maybe
the
SRH,
if
it's
a
v6
case
or
the
routing
options,
and
then
then
puts
the
metadata
part
after
after
that.
That
will
be
a
more
efficient
solution
in
term
of
performance.
I
M
M
We
have
this
draft,
which
defines
how
the
raw
data
can
be
can
be
in
I
mean
encapsulated
in
the
IP
fixed
records
by
setting
by
defying
a
bunch
of
set
IDs,
and
it
also
defines
how
additional
contacts
like
a
bit
of
the
IP
header
or
any
of
the
preceding
headers
to
IOM
can
be
included
alongside
the
I
on
data
and
options
itself.
It
does
does
give
additional
context
on
why
this
data
was
exported,
whether
it
was
exported
because
the
packet
was
getting
dropped
out
due
to
conditional.
L
H
L
Think
that
draft
is
progressing
for
a
while.
It
tries
to
go
and
really
help
with
AI
OEM
configuration
of
individual
notes,
because
there
is
a
load
of
operational
things
that
need
to
happen
for
IOM
to
work
that
it's
not
really
covered
anywhere,
because
we
don't
transport
that
information
in
a
control
protocol
or
in
the
data
plane
itself
and
hence
there's
been
work,
done
to
go
and
drive
configuration
to
the
notes
and
that's
covered
in
this
particular
draft
and
progressing
for
a
while
next
IOM
profile.
How
Thomas.
R
Raha
wowie,
so
this
is
a
new
draft
and
the
idea
is
that
it
defines
profiles.
The
profile
is
a
use
case
or
set
of
use
cases
in
IO.
Am
it
typically
defines
a
set
of
rules
that
limit
limit
the
scope
and
functionality
to
a
specific
subset,
and
by
doing
that,
we
believe
it
simplifies
implementation,
interrupt
testing,
it's
important
to
emphasize
that
quite
a
bit
of
a
profile
can
be
defined
by
specific
assignment
of
the
rank
model,
the
IOM
Inc
model
and,
like
we
said,
there's
a
discussion
tomorrow,
a
side
meeting
at
6:30
p.m.
R
S
P
So
we
can
notify
the
note
on
the
past
who
generates
the
postcard
packet
to
the
some
connectors
so
in
this
draft,
basically,
we
covered
this
two
different
variations,
the
first
variation
with
the
instruction
header.
We
intend
to
make
it
another
option
for
the
IOM
solution,
but
Sasa
the
second
variation
with
the
marking
capability.
I
think
it
has
its
own
merit,
and
so
it's
supposed
to
be
a
independent
standalone
solution.
Do
you
want
to
work
here,
or
are
you
planning
to
do
it
somewhere
else,
III
like
to
lay
this
trout
to
be
adopted
here?
Definitely.
L
Think
that
brings
us
to
the
end
and
I
think
the
key
questions
if
you
want
to
go
and
once
might
more
further
I
think
it
makes
sense
to
have
a
discussion
on
what
we
want
to
go
and
get
it
opted
here
and
or
how
were
you
want
to
go
in
which
categories
we
want
to
go
progress
here
and
once
we
are
clear
on
the
categories
on
how
to
go
and
do
that.
I
have
a
view
on
on
how
we
might
go
and
skin
that
and
cap
cat.
B
I'm
not
gonna
open
to
my
coins,
yet
please
stay
in
queue.
If
you'd
like
yeah
yeah,
we
have
some
ideas,
so
Tony
Rony
sat
down
last
night
with
the
intention
to
look
at
these
and
actually
spent
a
bit
more
time
than
we
were
intending
to
it's
like
wow.
This
is
actually
I
mean
yeah
I
knew
there
were
bunch
of
slides,
but
this
is
a
long
list.
B
We
have
to
think
about
it
and
I
apologize
that
I
didn't
have
a
chance
to
get
an
email
to
the
list
before
last
night's,
stupid
late,
but
I
think
for
the
decision
here-
and
this
is
something
that
was
was
I,
think
discussed
in
Bangkok
and
we
just
didn't
follow
up
on
it
because
you
know
I
paid
zero
attention
to
anything
since,
since
Bangkok
for
paternity
leave
and
job
change
reasons
we
compute
le
blame
it
on
me.
Yeah
I
will
totally
take
the
blame
for
that
I
mean
Tommy,
helped
it
but
yeah.
B
So
the
the
question
is:
first:
is
there
another
home
for
this
right
and
we'll
look
at
the
six-man
situation
right
like
there's
a
working
group?
They
do
v6,
maintenance
and
they've
said
we
don't
actually
want
you
to
bring
options
to
us.
You
know,
have
people
who
understand
the
option.
Do
it
in
another
working
group,
so
I
think
the
four
six
men
that
you
hit
that
you
had
the
first
question:
is
there
another
working
group?
Yes,
do
they
want
it?
No,
let's
adopted
my
ppm
right,
I.
Think
that's
pretty
clear.
B
B
Sh,
this
is
an
SLC.
We
don't
worry
about
it.
Good
check
this
one
I
have
a
whole
bunch
of
questions
about
so
I'm
gonna
skip
it
I-I'm
over
ipv6
I
think
we
had
pretty
good
success
with
the
PDM
header,
how
we
collaborated
between
the
two
working
groups
or
we
do
the
work
here.
We
want
to
make
very
clear
to
the
ipv6
people
that
were
not
like
trying
to
sneak
something
in
underneath
them.
So
you
know,
work
here
happens
here,
copies
both
lists.
G
M
L
G
G
L
G
L
G
Mean
if
you
don't
see
the
discussion,
don't
conclude
and
I,
don't
know
how
that
will
happen.
I
don't
know
what
the
discussion
will
be
because
it
didn't
happen
yet,
but
if
you
don't
see
it
concluded,
why
not
go
through
the
end
of
the
process
there
will
be
like?
Is
she
considerations
of
birthdays
and
concerns
right?
You
have
to
get
in
touch
with
this
community
and
you
have
to
find
it.
L
B
Okay,
actually
now
we
got
to
go
back
up
to
the
ether
type
thing,
so
it
turns
out.
We
don't
have
an
8:02
dot.
Three
liaison
manager,
I
thought
we
didn't.
We
have
NATO
to
that
one
liaison
manager,
which
is
not
the
right
thing
to
do,
for
forgetting
an
ether
type.
Have
you
talked
to
Eric?
What
one's
not
either
nitrate?
Isn't
one
I
thought
one
was
like
other
in
caps
and
stuff.
B
He
talked
to
Eric
Nord
Marc
about
this.
We
should
probably
loop
him
in
on
making
sure
that
we
do
the
right
thing.
I
am
I
am
disinclined
to
adopt
a
document,
a
nine
ppm
that
assigns
an
ether
type
just
because
it
seems
kind
of
difficult
to
justify
under
the
Charter
and
I
am
not
sure
what
the
right
working
group
for
this
is
maybe
int
area
or
maybe
ad
sponsorship.
L
B
L
L
B
L
G
I
have
before
we
do
before
we
go
on
here.
I
have
a
more
high-level
question
like
because
I
think
you
said
this
at
some
point.
You
need
to
discuss,
use
cases
in
scenarios.
You
can
need
to
figure
out
what
you
actually
need.
I,
don't
think
just
like
spreading
20
grafts
over
the
whole
IETF
is
a
good
strategy
and
a
different
side.
It
could
be
like
to
concentrate
on
like
two
or
three
of
these
first
and
then
get
them
through
the
process
and
then
talk
about
the
other
ones
later
and.
B
N
N
B
D
Since
being
yet
okay,
it's
zero
zero
one.
I
just
wanted
to
point
out
that
the
extension
there
isn't
over
left
with
extensions
draft,
which
is
in
the
MPLS
working
group
yeah,
and
we
have
also
seen
transport
I
ppm
that
also
talks
about
some
part
of
this
as
well.
So
there
is
overlap
in
different
routes
for
this
world
is.
D
B
Groups
of
authors
should
sit
down
and
talk
to
each
other
and
income
to
the
working
group.
I
think
like
so
following
the
policy
that
we
came
up
with,
which
I
think
is
a
pretty
good
one.
If
you
can
get
these
in
spring,
that's
the
right
place
to
go
because
spring
doesn't
have
a
policy
like
six
men
that
says:
hey.
We
don't
care
about.
Your
extension.
Headers
just
make
sure
you're
not
trying
to
sneak
one
over
on
us
Greg.
You
have
a
point
here:
yeah
actually
I.
N
N
N
N
B
The
explained,
the
rationale
that
we
had
for
you
know
saying
do
it
here
is
that
that
was
the
process
that
we
had
with
PDM
and
it
worked
pretty
well
I
think
the
segment
routing
stuff
is,
it
is
much
larger
than
PBM
was
right
and
that's
why
it
doesn't
work
well
for
that.
The
IOM
encapsulation
kind
of
sits
between
those
two
right,
because
PDM
was
a
self
self-contained
thing.
B
N
B
D
G
Really,
in
the
charter
of
six
minutes
very
explicit,
they
have
the
authority
to
maintain
extensions
modifications,
but
the
working
group
may
review
document
from
another
working
group
and
in
consolidation
with
the
responsibility.
Both
working
groups
may
recommend
the
IH
deeds
that
the
six
men
working
group
has
gone
but
yeah
to
move
on,
and
but
the
the
consensus
from
the
sixteen
working
groups
needs
to
say
neither
first,
we
need
to
go
there
first,
like
if
they
say
they
want
to
do
it.
G
B
T
T
Name
is
Johanna
from
Huawei
I'm
a
new
nice
table
mated
to
draft
I.
Think
one
draft
is
it
related
to
LM
named
multi
multi
pencil
compared
to
my
moment.
This
is
for
the
MP
and
use
MP
scenario.
What
will
consider
for
this
Naru
I
think
on?
Please
pay
more
attention
to
my
draft.
I
have
no
chance
to
present
to
my
idea
so.
B
A
J
J
I'm
not
fully
convinced
personally
that
the
extension
had
a
thing
is
done
for
places
where
you
want
to
add
this
to
your
equipment.
So
in
a
constrained
environment
where
you've
got
an
operator
who
really
wants
to
do
this,
then
extension
headers
likely
work.
So
please
don't
just
throw
it
away
because
you
think
it
might
not
work
across
the
whole
inset
at
the
moment.
Wait.
B
Yeah,
so
one
of
the
one
of
the
little
notes
that
that
came
out
of
the
discussion
is
the
8200
is
designed
for
less
constrained
environments
and
yeah.
You
know
we
generally
say
hop-by-hop
headers,
they
kind
of
suck
in
the
internet.
But
if
you're
touching
the
equipment
to
the
point
that
it's
going
to
be
able
to
do,
IO
am
you
can
fix
the
hbh
at
the
same
time.
That's
a
good
point.
B
B
I
L
B
L
K
L
G
B
My
slightly
different
question
is
I'd
like
to
see
the
the
overall
technical
architecture
of
what
it
is
you'd
like
to
have
great
and
then
filter
that,
through
the
roadmaps
of
each
of
the
working
groups,
that
you
need
to
get
consensus
on
to
get
it
done
and
then
batting
I'm
not
following.
What
do
you
mean
with
architecture
yeah.
L
B
To
box,
and
so
there's
IOM
right,
there's
the
data
model
right.
There
are
a
set
of
processes
that
operate
on
the
data
model
and
then
there
are
set
of
encapsulations,
and
then
there
are
a
set
of
interactions
between
the
encapsulations
right
in
trying
to
figure
out
where
to
prioritize
how
to
find
a
plan
to
get
this
through
the
IETF.
It
would
be
very
nice
to
have.
M
B
Of
boxes
and
lines
that
we
can
kind
of
put
crosses
through
and
say
we're
gonna
triage
this
out
of
the
way
in
in
the
first
phase
right
like
so,
it
seems
to
me
like
if
you
want
to
go
fast,
just
looking
at.
What's
you
know
what
I
think
is
possible?
I
think
the
ether
type
thing
is
probably
possible,
but
I
need
to
talk
to
people
to
know
whether
that
is
or
we
need
to
talk
to.
People
know
whether
it
is
and
I
can
make
those
introductions
and
get
that
conversation
started.
B
I
think
the
six
main
thing
is
the
next,
the
next
highest
impact
thing
and
that's
a
little
hairy,
because
we're
doing
a
lot
of
other
stuff
ipv6
at
the
time
right,
it's
like
so
we're
you
know,
segment
routing
is
causing
a
bandwidth
problem
and
networking
right,
and
this
is
related
to
segment
routing
like
kind
of
deeply
right.
So
it's
it's
it's
getting
all
the
things
putting
them
on
order
is.
Is
yes,
it's
hard
beyond
that.
I'm
I'm,
not
sure
how
to
prioritize
the
other
in
calculations.
L
G
I
think
I'm
basically
saying
the
same
thing,
but
I
want
to
ask
question.
First.
You
said
people
are
putting
this
in
hardware.
What
are
people
putting
in
hardware
not
like
all
of
those
20
encapsulations
right,
which
one
are
people
putting
in
hard
way,
which
and
one
other
ones
people
actually
want
to
deploy.
B
G
L
G
C
U
O
Burak
also
from
Mellanox,
also
hardware
manufacturer.
The
intention
is
to
support
these
particles
right
when
is
provender,
but
the
intention
is
the
support
IOM
for
this
protocol.
So
I
don't
see
any
protocol.
That
is
maybe
again.
Unfortunately,
the
important
protocols
are
being
blocked
for
a
long
time
and
the
non
important
protocols
support
by
IDF
like
genera
fight.
We
would
like
to
have
solutions
for
what
people
are
running
actually
in
the
network,
not
something
that
is
not.
V
Sorry
so
as
a
6-man
member
and
I
responded,
a
couple
of
emails
and
I
would
say
this
when
this
work
is
brought
into
six-man
I'll
be
one
of
them
to
say.
Unless
this
draft
or
any
of
the
visits
related
drafts
are
changing
the
protocol
specification,
six
men
is
not
the
right
home.
Six
men
could
provide.
The
guidance
could
provide
the
feedback,
but
that's
not
the
place
for
the
working
group
for
this
draft
to
be
adopted
in
networking
room.
Let's
heads
up.
N
N
I
N
U
I
have
an
observation
about
the
encapsulation,
so
the
way
I
understand
the
layering.
There
is
a
protocol
header.
There
is
a
data
header
which
we
call
it
as
a
metadata
header,
and
then
there
is
a
data
itself
in
today's
presentation.
I
saw
a
lot
of
flags
which
are
squeezed
in
into
the
data
header,
which
effectively
impacts
the
forwarding
behavior
of
the
packet
in
this
case
ion
packet
I
think
that's
not
correct
the
right
place,
I
think
one
of
the
person
made
that
point
earlier
as
well.
The
right
place
is
in
the
protocol
header.
U
C
Cool,
thank
you
all
right,
I
think
we're
out
of
time
for
this
I
have
a
couple
comments
of
like
what
I'd
like
to
see
as
next
steps
and
directions.
To
summarize
so,
first,
it's
great
that
we're
having
some
side
discussions.
Please
have
those
please
send
out
summary
and
notes
of
that
to
the
whole
I
ppm
list,
so
we
can
follow
up
on
what
is
discussed
there.
As
far
as
the
related
drafts
and
encapsulations,
it
seems
like
we
have
a
next
step
to
do
on
the
ethernet
side
on
the
ethertype,
we
have
a
presentation
in
six-man.
C
N
C
L
C
C
You
can
leave
them
resolved
and
maybe
let's
write
up
these
other
behaviors
in
other
draft
that
maybe
we
fold
in,
but
let's
have
that
discussion
separately,
just
to
really
focus
and
clarify
what
we're
doing
and
then,
if
we
want
to
essentially
adopt
that
other
work
and
fold
it
back
into
the
document.
We
can
do
that,
but
we
can
do
that
as
a
working
group
and
we
can
be
really
confident
in
that.
So
I
think
that's
practical.
C
H
B
Point
is
is
that
we
basically
want
to
get
to
the
point
where
we
have
high
confidence
in
a
set
of
the
bits
in
the
header,
so
that
Hardware
work
can
continue
and
then
the
things
we
have
lower
confidence
on
like,
however,
we
punked
them
in
the
document,
we
need
to
say:
okay.
Well,
these
are
the
things
that
you
can.
These
are
the
things
that
you
can
do
now.
B
These
are
the
things
that
you
can
leave
to
later
and
development
cycle
and
whether
that's
a
separate
document
or
you
know,
I,
you
know
eventually
we
want
to
produce
a
set
of
readable
artifacts
so
that
others
can
implement
to
those
as
opposed
to
implement
interoperability
with
our
do
that's
out
there.
But
that's
really
kind
of
an
editorial
question
is
how
many
documents
there
are
when
we,
when
we
finally
do
the
thing,
but
it
needs
to
be
sort
of
like
clearly
marked
great
like
so
that
and.
L
B
Can
speak
to
the
IP
fix
thing
because
I'm
I've,
you
know
I'm
sorry
that,
like
there
isn't
working
group
for
that,
the
correct
place
to
take
that
would
be
ops,
AWG
I'm,
not
sure
that
they
care
you
can
maybe
send
a
heads
up
to
that
list.
Hey
we're
considering
some
data
export,
some
which
would
extend
IP
fix
the
primary
or
is
actually
gonna,
be
an
Ino
review,
because
that's
that's
where
the
the
informational
machines
come
out.
B
C
You
know
I
would
say
like
for
all
of
them.
Let's
choose
the
priorities
if
you
want
to,
let's
focus
on
like
if
you
want
to
choose
your
priorities
as
two
different
in
caps
types.
Let's
focus
on
those.
If
you
want
to
choose
your
priorities
as
not
an
in
caps
type,
but
one
of
these
other
drafts
choose
that
I.
B
C
U
W
I'm
al
raqqa,
syria,
from
telecom
italia.
This
is
the
draft
about
multi-point
alternate
marking
performer.
We
are
already
presenting
so
que.
We
can
go
home
very
quick,
so
we
have
a
much
time
for
the
next
draft.
Okay,
it
is
drafted,
define
a
way
to
monitor
moot
point
flow,
it's
possible
to
define
as
a
single.
W
Monitor
from
the
point
of
view
of
a
packet
loss
and
average
delay
next
slide,
define
is
to
locate
where
is
the
I
get
lost,
for
example,
or
a
big
delay
this
can
we
use
a
property
of
trust
of
a
graph
that
is
clustering?
Next
slide,
it's
possible
to
divide
the
graph
in
clusters.
The
cluster
is
the
smallest
sub
graph
that
have
the
property
of
a
packet
loss.
The
propolis
is
dead
old.
A
packet
that
come
inside
that
is
part
of
graph
is
equal
to
the
packet
that
go
out.
W
If
there
is
a
path
across
the
difference.
Is
the
packet
loss
so
it's
possible
to
locate?
Where
is
the
impairment?
Also,
if
you
monitor
all
the
traffic,
is
a
single
flow
next
one
for
a
delay,
we
use
a
method
that
is
named,
make
me
in
delay
that
is
already
defined
in
RFC
8321.
The
visit
summary
summarization
about
the
time
stamp
in
input
and
the
summarization
all
the
time
step
in
output
and
difference
between
the
two
is
the
min
delay.
So
this
min
delay
is
true.
W
W
The
air
FEC
5475
that
combined
with
our
FCAT
321
400,
making
came
monitory
single
packet,
identifying
the
single
packet
using
the
edge
of
the
packets,
so
it's
possible
to
filter
using
a
part
of
the
issue
to
capture
the
sell
catch,
the
same
packets
in
all
points
of
the
network,
where
the
suspect
pass
and
then
to
compare
using
the
remaining
part
of
the
hashing
to
identify
the
single
packets.
Okay,
there
is
a
case
study
that
is
drafted
of
Sam
bonnet
model
young
FSM.
They
define
a
CDN
fine,
using
this
methodology
next
slide.
W
Okay,
there
is
only
changes
from
the
last
version
is
the
introduction
for
any
cast
traffic.
So
it
is
a
kind
of
monitoring
framework
with
unicast
and
anycast
traffic,
because
the
interest
they
any
gas
traffic
is
one
too
many
flow.
That
is
a
case
that
is
already
foresee.
Okay,
so
when
we
want
to
study
the
path
to
became
an
FC,
and
so
we
ask
you,
if
all
is
ok,
there
is
some
comments
and
so
on.
W
W
Defined
by
Brian
tram
in
previous
I
ppm
draft
ppm
spinner,
this
methodology
is
a
form
of
art
and
marking
that
works
in
a
client-server
protocol,
and
the
main
ideas
of
this
methodology
is
that
the
measurement
is
explicit.
There
is
no
reason
to
send
packets
of
OM,
for
example,
to
share
the
data,
but
the
measurement
is
library,
seeing
the
length
the
time
of
the
square
wave
that
is
generated
using
this
pin
bit.
W
So
if
an
observer
was
during
the
path
only
measuring
the
length
of
the
square
wave,
it
can
measure
the
end-to-end
a
client/server
delay
after
t-spin
bit.
Other
two
bit
are
defined
in
this
draft
that
define
the
valid
age
counter
that
corrected
the
spin
bit
in
case
of
some
parents
out
of
sequence
in
particular,
so
the
the
measurement
of
discarded
to
avoid
errors,
losses
and
so
on.
We
can
go
okay.
I
already
said
that
some
limitation
in
the
spin
bit
that
back
is
the
improvement.
To
avoid
is
a
mutation.
W
The
packet
loss
tend
to
cause
wrong
estimates
because
the
edge
can
change
in
the
ordering
can
cause
false
periods,
shorter
periods,
that
is
only
a
reordering
of
the
edges.
In
other
problems,
they
all
in
the
traffic,
because
all
the
measurement
made
using
real
traffic
if
there
isn't
the
real
trophy
threesome
also
the
measurement
cannot
suffice.
Okay,
we
introduced
two
new
bits.
Instead,
the
two
bits
of
biology
counter
our
proposal,
the
first
one
is
the
delay
sample
the
day
sample
is
the
double
marking.
Let
me
say,
of
FEC
8321.
W
W
The
properties
of
a
spin
beat
of
a
end
of
the
dice
sample
is
possible
to
have
a
two-point
a
round-trip
delay
in
order
to
separate,
if
we
have
a
two
measurement
point
or
a
one
measurement
point
on
both
the
direction
to
separate
the
delay
between
the
delay
to
the
left
and
between
the
right
to
the
right,
we
can
skip
okay
using
a
simple
formula.
We
can
subtract
the
delay
from
the
different
measurement
point
to
have
the
measurement
of
the
delay
in
the
middle.
W
So
we
can
measure
part
of
the
network,
part
of
the
different
domain,
different
operator,
domains,
to
divide
the
delay
and
to
measure.
Where
is
the
delay?
Okay,
short
comparison
between
back
the
previous
proposal
and
delay
sample.
The
new
proposed
are,
the
main
difference
are
that
BEC
uses
to
beat
and
in
a
sample
only
one,
but
there
is
some
drawbacks
for
a
delay
sample,
because
using
a
one
bit
if
there
is
a
loss
of
the
delay
sample,
we
use
empty
period
without
delay,
sample
to
signal
to
the
server
if
there
is
a
loss.
W
So
this
measurement
is
discarded
because
we
have
only
one
bit.
We
can
use
a
code
as
back
do.
Another
problem
is
that
we
have
a
more
complicated
observer
implementation-
okay,
because
in
this
case
the
asada
implementation
was
made
using
a
waiting
period
in
order
to
skip
the
auto
sequence.
Strength
is
detours
also
of
out
of
sequence.
Instead,
the
back
here
discard
the
measurement.
Okay,
we
can
go
run
trip
packet
rows.
We
had
the
second
add
additional
bit
that
measure
round-trip
packet
loss.
W
The
client
marks
a
train
of
packets
that
this
packets
bounces
between
try
and
the
seller
to
complete
two
rounds
ever
server
accounts
the
market
packets
during
the
transit
company
numbers
to
find
losses.
The
problem
is
to
maintain
the
same
speed
on
market
packets
during
the
two
direction.
So
we
use
a
talking
system
in
order
to
maintain
the
speed
of
market
packets
with
packet
loss
in
the
two
direction.
In
order
to
have
the
same
properties
of
spin
beat,
we
can
go
to
the
last
last
words
about
before.
W
B
You
much
so
individual
thanks
lot
for
this
work.
This
is
pretty
cool,
I.
Think
there's!
You
know
when
we
took
the
spin
bit
too
quick.
There
is
a
very
clear
signal
that
you
know
one
bit
is
okay,
but
you
don't
get
enough
out
of
the
two
extra
bits
for
the
back
for
them
to
do
that
there.
That's
why
I
brought
as
an
individual
sort
of
that
the
general
sort
of
framework
for
giving
these
things
into
IP
PM,
because
I
think
they
can
be
applied
to
any
protocol.
B
B
We
should
probably
have
discussion
on
the
list
as
to
whether
we'd
like
to
adopt
generalized
measurement
methodologies
based
on
things
like
the
spin
bit
going
on
going
forward
in
the
working
group.
So
so
thanks
a
lot
for
that
I
think
we
should.
We
should
have
that
discussion
and
I'll
try
to
kick
it
off
without
my
shirt
on
Thanks.
W
Sequence
is
possible
in
this
case
with
the
double
marking.
Let
me
say
to
measure
also
particular
delay
that
occurred
in
case
of
auto
sequencing
in
stead
of
spin
beat
that,
for
this
case,
is
impossible
to
measure
so
for
maximum
average
delay
is
not
so
significant
for
a
for
me
when
maximum
the
device
sample
is
very
useful.
Okay,
the
loss
that
is
not
measured
in
now.
P
P
Unfortunately,
in
many
a
protocols,
14
transport
protocols,
it's
very
hard
to
find
them,
find
the
place
to
allocate
this
to
the
speeds.
So
also
you
know
with
just
a
single
PD.
We
can
only
do
one
thing
we
can
just
do
the
effect
account
in
order
to
the
environment,
so
that's
also
not
very
scalable.
If
we
don't
want
to
do
both
or
to
do
more
C's.
Obviously
it's
very
hard
to
extend
this
protocol,
so
so
the
basic
idea
is
that
we
actually
we
can
use
a
you
know
if
you
can
enhance
this
with
a
flow
ID.
P
Basically,
it
can
help
us
to
identify
out
which
flow
go
through
the
merriment.
Also,
we
can
reserve
some
more
data
to
do
more,
see
see
the
future,
so
so
here,
apparently
I'll
just
use
trying
to
use
the
existing
piece
from
the
packet
header
are.
Maybe
no
sufficient
to
support
that,
but
today
we
have
this
IOM
solutions
and
some
other
postcard
base.
Telemetry
many
other
invent
American
schemes
all
need
to
insert
some
actual
extra
instruction
header
to
the
packet.
P
So
so
that's
why
we
propose
actually,
in
those
instruction
headers
there
are
some
enough
unused
space
reserved
base
to
be
able
to
use
to
support
these
kind
of
features.
Therefore,
we
propose
to
just
reuse
to
power
some
piece
from
those
instruction
headers
to
supports
the
enhanced
alternate
margin,
so
the
first
solution
in
the
in
the
end-to-end
IOM
trees
mode,
no
a
mode
basically
right
now
there
are
16
reserved
piece,
so
we
can
allocate
two
piece
to
do.
P
One
for
the
loss
meant
another
for
the
delay,
merriment
and
also
we
enhance
this
header
with
a
flow
ID
to
check
out
the
flow
to
be
mirrored
next
and
for
the
for
the
post
card
based
telemetry.
Currently,
there
are
also
in
the
current
specification.
There
are
also
eight
reserved
piece
that
can
be
used
for
other
purpose.
Therefore,
we
borrow
to
base
offer
same
thing
to
do
the
lost
merriment
and
today
merriment.
P
R
H
R
So
this
draft
has
been
around
for
a
while
just
a
very
short
background.
What
we
want
to
do
is
to
measure
the
traffic
between
two
measurement
points:
MP,
1
and
MP
2.
Next,
please
FC
83
21,
which
was
mentioned
here.
A
couple
of
times
defines
alternate
marking.
The
idea
is
that
you
use
a
single
bit
in
the
header
to
mark
the
traffic,
the
color
changes
periodically,
and
that
allows
you
to
measure
the
traffic
next,
please,
the
same
RFC
also
defines
double
marking.
R
The
idea
is
that
you
have
two
separate
bits:
one
for
loss
measurement,
the
other
for
delay
measurement
next,
please.
So
what
do
I
do
in
the
current
draft?
We
do
two
things.
Actually
one
is
to
present
a
few
new
marking
methods
which
are
specifically
efficient.
They
use
either
a
single
bit
per
packet
or
zero
bits
per
packet
and
provide
the
same
functionality
that
we
saw
for
lost
measurement,
delay
measurement,
and
the
draft
also
summarizes
all
the
existing
alternate
marking
methods
out
there
and
summarises
kind
of
compares
between
them.
R
Next,
please
so
there's
a
bunch
of
related
drafts
which
make
use
of
alternate
marking
in
one
form
with
another
or
another,
and
some
of
them
are
pretty
new.
Some
of
them
have
been
around
for
a
while.
We
believe
that
all
these
drafts
can
make
use
of
our
draft,
and
we
believe
that
all
the
authors
of
these
drafts
should
certainly
be
familiar
with
this
draft
and
should
have
an
opinion
about
it.
So
we
want
to
encourage
people,
especially
the
authors
of
these
drafts.
R
Please
review
and
please
send
us
comments
next,
please
one
feedback
that
we
received
from
al
thanks
al
there
were
several
comments,
but
the
most
notable
one
is
that
we
may
want
to
split
the
draft
into
two
drafts
just
to
separate
between
defining
new
methods
and
summarizing
what
we
have
so
far,
so
we're
considering
to
do
that.
We're
looking
for
more
feedback.
So
please,
if
you
think
this
is
a
good
draft.
Let
us
know
if
you
think
it
is
a
bad
draft.
R
N
N
What
updated
we
identify
now
there
are
types,
so
their
idea
of
extensions
is
that
we
have
their
base
header,
which
is
backward
compatible
with
their
t1
test
packet
format
that
is
followed
by
TL.
Via
for
extensions.
In
these
types
we
identified
the
mandatory
range
and
optional
range,
and
so
to
use
extensions.
N
N
Testing
of
the
network
on
different
causes,
directing
not
not
only
generating
from
the
sender
on
the
different
cost
markings
but
instructing
the
reflector
to
use
a
specified
cost
value
on
reflected
packet
and
recording
their
information
than
being
received
next
slide.
Please
so
extra
padding
is
a
similar
to
packet,
beginning
that
is
defined
in
Oh,
womp
and
t1,
and
our
proposal
is
to
minimize
use
of
extra
padding
in
stamp
just
to
guarantee
that
that
gets
our
symmetrical
size
and
then
to
control
their
size
of
the
test
packet
using
the
extra
padding
TOB.
Next
like
this.
N
N
Yes,
if
you
look
back
in
all
womp
and
tea
womp,
we
believe
that
their
attempt
or
intention
of
error
estimate
could
have
been
what
we
are
trying
to
do
with
the
tee
times
to
MTO
V
in
the
timestamp
till
V.
It
characterizes
only
for
the
reflector,
not
for
the
sender,
because
again
sender
will
no
ingress
and
egress
of
the
test
packet,
how
the
time
stamps
being
received
and
how
their
clock
synchronization
on
a
sender.
N
So
we
obtaining
this
information
only
from
the
reflector
and
to
try
to
characterize
their
source
of
quark,
synchronization
and
method
of
getting
their
wall
clock
time
of
day
time.
Stamping,
because
these
affect
their
our
accuracy
of
the
measurement
next
so
of
course,
of
service
already
I
have
mentioned.
That
idea
is
to
verify
how
class
of
service
done
over
the
path
I
think,
because
often,
especially
in
multi
service
wireless
access,
where
they
provide
2g,
3G
and
4G
5g,
these
a
map
to
different
classes,
sometimes
remapping,
might
be
missed.
N
Configurate
and
operators
are
really
pulling
their
hair
trying
to
test
it,
because
why
this
class
of
traffic
gets
squeezed
where
it
should
not.
So
the
idea
is
to
give
it
operators
to
to
explicitly
specify
a
course
of
service
on
a
test
packet
and
then,
basically,
you
can
generate
the
sequence
of
test
packets
with
the
predetermined
cost
marking
and
then
receive
it
back
and
analyze
and
see
whether
relamping
happens
in
their
path
and
if
it's
as
designed
or
there
is
some
problem
and
then
do
investigation.