►
From YouTube: IETF106-BESS-20191120-1520
Description
BESS meeting session at IETF106
2019/11/20 1520
https://datatracker.ietf.org/meeting/106/proceedings/
B
A
B
B
A
F
E
A
A
G
G
We
have
the
time
period
for
the
PDP
signaling,
so
p1
will
send
us
a
PDP
packet
to
all
the
other
piece
and
people
then
started
the
PDF
PDF
the
DFO
election
function.
So
it
takes
time.
So
in
order
to
improve
the
pump
akator
lost,
we
would
like
to
use
the
mechanism
dividing
up,
see
5
8,
8
4,
and
we
also
use
the
subcommittee
finding
the
exist.
Heater
working
group
structure,
Yoona
PLC
peeping,
to
appeal
the
decision
between
PDF
and
the
DF.
G
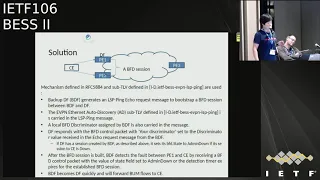
So
the
follow
is
a
procedure
that
can
be
used
to
build
this
PFD
station
between
p2
and
p1.
In
this
figure
it
means
the
B
D,
F
and
DF.
So
people
will
stand
as
a
request.
We
have
this
request:
P
D,
F
and
P
1
will
acknowledge
H
and
the
build
of
the
session
between
two
peas,
so
P
2
will
monitor
the
link
between
P,
1
and
C.
Then
D
F
in
this
figure
is
p1
will
send
a
periodical.
G
We
have
the
packet
to
p2
to
indicate
that
the
link
between
p1
and
C
is
works
normal,
but
in
fact
the
link
between
p1
and
SAE
failed
p1
will
send
the
PFD
packet
away.
State
said
set
it
to
an
amine
down
to
p2.
So
p2
will
know
that
as
the
link
between
p1
and
say
he
has
failed,
so
p2
will
elect
it
itself
to
be
DF
o
quickly
and
send
is
a
BAM
package
and
also,
if
there's
something
wrong
with
the
p1
and
p1
cannot
stand
as
a
periodical.
We
have
the
packet
to
p2.
G
P2
can
also
know
the
the
situation
from
the
PFD
piratical
detection
time,
the
PFD
detection
time.
So
people
will
also
notice
that
there
are
something
wrong
with
p1
and
the
p2
can
also
elected
itself
to
be
EF
and
the
forward
of
the
bomb
package,
and
so
this
job
has
been
presented
in
progress
meeting
and
that
we
receive
some
comes
from
Ali.
So
it's
very
useful
for
us.
So
we
add
more
detail
about
this
solution
to
hint
to
make
it
more
clear.
So
we
know
that
the
TF
will
send
a
periodical.
G
We
have
the
packet
to
the
PDF,
so
in
the
default
in
default,
the
PFD
multiplayer.
It
means
that
a
bill
has
relationship
with
the
detection
time,
so
the
default
value
is
3,
but
if
because
this
this
value
can
be
configured.
So
if
this
value
has
said
has
been
said
too
small,
for
example,
you
say
data
to
one,
so
one
PFD
pact
lost
may
lead
to
the
PFD
switch
over.
So
in
in
a
previous
slides.
Only
one
we
have
the
packet
lost.
G
Her
will
lead
to
the
P,
true
elected
itself,
to
PDF,
so
the
in
this
situation
may
be
P.
1
is
workers
normal.
Now
then,
two
PS
will
off
elected
itself
SDF
and
forwarding
a
duplicate
flows.
So
this
must
be
our
attention
be
paid
more
attention
to
not
to
configure
this,
where
you
choose
more
and
in
terms
of
the
behavior
changes
situation,
because
some
may
be
will
add
some
other
router
which
can
be
come.
The
new
PDF
joins
the
network,
the
older
PDF.
In
this
figure
we
serve
results
its
p2p
to
shoot.
G
A
people
is
no
longer
the
PDF
anymore,
so
people
should
must
send
us
a
PFD
packet
which
is
which
says
data.
Instead,
it
said
to
admin
down
to
p1,
to
remove,
make
p1
to
remove
the
PFD
station,
so
the
previous
P
of
the
station
has
no
longer
any
more
so
and
one
the
new
BDF
for
Senator
PFD
requests
the
two
DF,
a
new
bf
decision
will
be
built
for
it.
So
that's
all
the
solution,
any
comments.
H
H
G
The
worst
Q's
uses
for
it,
so
you
must
pay
attention
to
the
value.
You
must
sit
through
the
detection
time
to
our
reasonable
value
MP,
because
we
know
that
PFT
session
will
be
broken
down
due
to
some
reasons,
but
the
first
one
is
why
you'll
see
was
a
PFD
packet
which
data
is
sitting
down
and
the
second
is,
you
have
not
received
receive
the
PFD
packet
of
ours
for
a
period
of
time.
So
as
the
period
of
time,
it
means
detection
time.
If
you
set,
is
the
detection
ham
too
small.
H
J
Greg
Merson
City.
Well,
first,
you
don't
have
to
have
Monty
Hall
DF
D.
You
can
use
MPLS,
OSP
and
then
we'll
be
over
tunnel
so
and
you
can
construct
your
LSP
over
more
secure
domain
of
your
network
so
meaning
to
minimize
yes
again,
you're
right.
There
is
no
way
to
differentiate
where
the
path
fails
or
the
node
fails.
That's
challenge,
but
the
the
challenge
with
there
any
OEM
default
failure
management
so
because
we
don't
differentiate
between
death,
knell
failure
and
notable.
J
G
K
L
L
E
L
G
M
I
Himanshu
from
Siena,
so
yeah
I
think
that
the
problem
scope
is
it
does
exist
because
if
you
are
relying
on
the
withdrawal
after
yes
route
type
4,
it
will
take
some
time
for
the
bill
to
kick
on
the
DF
election
and
all
that.
So,
if
you
have
a
BFD
on
what
I
have
are
pbft,
it
can
expedite
that
election
with
respect
to
x
BFD.
You
always
have
to
keep
a
little
bit
longer
time
because
you
need
to
have
the
IGP
he'll
like
he
was
saying.
I
If
you
have
an
intermediate
nodes
that
fail
your
multi-hop
IPP
every
would
fail
as
well,
but
that's
always
the
hierarchical
fault,
timers
that
you
have
to
keep
you
how
to
let
the
IP,
FRR
and
other
stuff
to
to
take
care
of
that
I
think.
The
second
point
I
have
is,
instead
of
doing
this,
LSP
ping
to
bootstrap
the
BFD,
maybe
yes,
route
type
4
is
a
way
to
pass
the
discriminator
between
this
multi,
her
peers,
so
that
you
can
then
the
B
do
the
BFD
session,
or
maybe
even
seamless,
BFT.
I
G
Feu
seamless
be
a
fatigue
p2r
in
this
figure.
The
PDF
must
ascend
the
pure
raadhika
single
SPF
de
package
to
detect.
If
the
link
between
p1
and
the
see
he
has
Knox
normal.
So
it
depends
on
the
PE
to
send
the
periodical
right,
the
periodically
from
the
p2.
So
if
p2
is
configured
as
artists
and
as
a
tech
eater,
for
example,
we
send
the
packet
or
every
60
seconds
as
takes
a
long
time
right.
So
we
use
the
normal
PFD
station
to
detect
the
fader.
It's
looks
more
fast
right,
yeah.
I
From
Cisco,
so
I
had
the
same
thought
like
hooray.
He
just
said
conceivably.
If
we
have
a
PFD
session
between
p1
and
p3
yin,
would
that
help
like
it's?
The
PFD
like
you
see
to
p1
link
goes
down,
then
you
can
convey
fact
that
it
went
down
faster
through
BFD
through
to
p3
and
thereby
you
would
get
some
speed
up
as
compared
to
the
mass
Phaedra,
so
that
they're
outside
p3
will
be
switched
to
p2
faster.
Would
that
work
yeah.
G
I
G
And
the
patio
discriminator
may
be
different
because
we
know
that
we
know
the
subtly
defining
European
are
speaking
to
starter.
The
PFD
station
under
the
discriminator
will
be
different
from
the
other
PFD
station
between
p1
and
p2,
so
it
means
different
things
yeah,
so
you
will
not
confuse
with
it.
Yeah.
N
G
J
Marissa
T
there
is
a
problem
with
the
seamless
BFD,
because
seamless
BFD,
you
don't
have
expectation
of
the
guaranteed
failure
time
you
are
dependent
on
the
round-trip
time
and
because,
if
round-trip
time
will
be
changing,
that
might
affect
your
basically,
you
will
get
false
negative
okay.
So
the
positive
about
methods
that
asynchronously
independent
set
theoretic
messages
you
can
have
a
guarantee
of
when
you
do
failure,
detection.
G
And
so
the
second
foreign
fishing
is
for
as
a
v6
inter-domain
solution,
Philippian
service,
we
have
closer
sofa
under
Greg.
So
let
me
see
this
figure,
it's
our
normal
situation
in
the
future
Network
because
we
have
not
used
as
a
v6
in
our
network
now,
but
it
may
be
not
a
longer,
hang
and
made
him
more
time
for
it.
So
if
we
deploy
different
as
functions
in
different
areas,
it's
a
normal
situation.
King
should
work
because
such
as
in
the
s1
which
deploy
is
our
v6
on
me
and
we
deploy
some
pureeing
as
true.
G
Only
and,
for
example,
miss
suppose
that
the
SPR
one
can
support
Assad
mini
six
and
as
I
am
curious,
but
as
we
are
true,
only
support
SMP
RS
and
how
to's
teaching
the
true
Network
at
us
to
work
together.
So
we
find
that
if
we
hence,
we
can
sir
salute
give
the
solution
for
it
from
the
signaling
controlling
and
we
can
get
as
a
result
from
the
day
happening.
So,
let's
see
the
second
learning
controlling,
so
we
support
such
it
would
be
like
to
the
word
highs
root
from
c1
to
c2.
G
So
when
the
root
received
by
SPR,
one
is
a
BR
one,
shooter
assigned
and
special
MPR's
label
for
the
prefix
received
from
P.
We
know
that's
the
other
word
highest
function
for
procedure,
for
it
right
so,
and
the
one
SPR
to
received
the
the
special
label
and
it
well
may
treaty-
is
the
normal
and
advertising
the
English
to
network
and
so
as
well
and
the
say
to
will
receive
the
packet
disable
the
route
so
and
for
the
for
the
other
direction.
We
know
that
F
we'd
like
to
stand
as
a
route
from
c2
to
c1.
G
Sp
are
to
be
assigned
as
a
normal
able,
but
SP
are
one
will
Edward?
Has
this
prefix
to
be
one
and
associated
with
the
special
asabi
success
ID?
So
once
the
contra
playing
finishes
advertisement
that
cesar
data
bring.
So
if
I
pick
it
data
flow
packet
received
from
SP
are
one
from
p1
the
direction
from
p1
direction.
So
SPI
one
will
recognize
special
si
T
so
and
Maori
colonized.
G
It
should
be
replaced
with
the
book
with
an
level
label
stack
and
forward
it
to
SBR,
to
and
in
the
reverse
direction
the
one
s
PR
one
received
the
Emperor's
packet.
We
know
that
it
means
the
packet
is
encapsulated
with
some
top
level,
which
is
assigned
by
SP
or
one
spra
will
recognize
the
special
table
and
then
replace
me
know,
or
we
should
call
it.
We
remove
the
label
and
encapsulator
the
packet
irwins
ipv6,
and
maybe
they
are
something
s
are
etching
it
so,
and
then
s
BR
one
still
is
a
packet
to
s1.
G
So
then,
in
the
true
direction
the
flow
will
be
only
be
treated
SP
r1
and
the
no
hanging
or
the
errors,
such
as
p1
s,
PR
one
should
know
this
function,
because
this
function
has
local
significance
and
butter.
The
flow
will
be
forwarded
and
normal
and
received
as
a
destination.
So
it
will.
It
can
reserve
the
the
highbreed
networking
interconnection
issue.
So
so
that's
all
the
how
I
wanted
to
say
today
and
any
comments.
L
E
O
G
G
P
L
Good
afternoon
my
name
is
Jorge
Robin
nokia.
This
draft
talks
about
some
very
small
extensions
for
split
horizon,
filtering
and
multihoming.
If
you
can
multihoming
the.
What
do
we
mean
by
a
spree
horizon
filtering
well
in
evpn,
multihoming
split
horizon
is
basically
the
mechanism
that
is
avoiding
loops
when
you
have
all
active
multihoming.
L
For
instance,
if
you
look
at
the
left
hand
side
of
this
slide
and
you
have
an
all
active
Ethernet
segment
connected
to
c2
when
you
send
BOM
traffic
from
C
to
a,
for
instance,
to
p1
and
p1
floods
that
the
traffic
goes
back
to
p2
to
if
p2
is
the
DF,
you
know
we
want
to
really
avoid
the
traffic
coming
back
to
the
C.
So
the
mechanisms
to
avoid
that
coming
back
to
the
sea
and
to
avoid
the
loop
is
what
we
know
as
the
split
horizon
mechanism.
There
are
two
ways
of
doing
it.
L
The
first
one
is
the
ESI
label-based
split
horizon
type
and
the
second
one
is
what
we
know
as
local
bias
split
horizon
type,
so
the
first
one
relies
on
an
ESI
label,
in
other
words
1
c2
again,
since
traffic
BOM
traffic
to
p1
p1
needs
to
insert
and
an
ESI
label
at
the
bottom
of
the
stack
that
is
identifying
the
source
ESI.
So
when
that
gets
to
p2,
based
on
that
ESI
level,
p2
can
filter
and
avoid
sending
the
traffic
back
to
c2.
L
Now,
when
you
deal
with
IP
tunnels,
where
there
are
no
labels
like,
for
instance,
we
expand
or
MD
GRE,
there
is
no
labels
that
you
can
insert
in
the
data
path.
So
in
that
case
we
use
this
local,
biased.
Local
bias
basically
refers
to
the
fact
that
we,
in
the
same
situation
when
c2,
sends
bound
traffic
to
p1
p1,
will
forward
locally
to
all
the
local
Ethernet
segments
and
when
p1
sends
the
bump
travel
to
p2
p2
will
actually
filter
traffic
to
all
the
local
segments
that
are
shared
with
p1.
That
is
local
bias.
L
Now,
in
the
traffic
we
have
a
table
with
all
the
different
encapsulation,
supported
by
a
VPN,
the
default
split
horizon
type
and
whether
they
support
you
know
either
type,
and
in
some
cases
there
is,
there
is
no
choice.
There
is
only
one
one
way
of
doing
it,
but
in
some
encapsulations
you
actually
have
the
choice,
because
you
can
support
both
types.
So
the
idea
with
this
draft
is
to
add
some
very,
very
small
extension,
and
in
this
way,
basically,
we
signal
the
split
horizon
type
that
we
want
to
use
and
give
an
Ethernet
segment.
L
L
So
if
you
look
at
the
SR
basic
services
draft,
the
speak
horizon
filtering
is
based
based
on
something
equivalent
to
the
si
label
that
goes
into
the
argument
of
the
CID.
The
idea
is
that,
obviously
it's
an
IP
encapsulation,
so
you
have
the
choice
of
using
local
wires
and
in
some
cases
you
may
want
to
do
that
because
you
want
to
save
some.
You
know
extra
look-up
on
the
argument
of
the
set.
So
that's
why
we
added
this.
L
L
K
So
a
second
item
of
background,
there
is
another
draft:
it's
an
ID
addressing
essentially
the
EVP
integration
with
VPLS
in
all
active
mode.
So
this
is
so
that
draft
was
written
specifically
to
address
the
gap.
The
all
active
gap
that
I
listed
in
the
second
bullet
of
85/60
and
saw
the
remains,
essentially
they
still
the
the
first
bullet,
the
gap
for
VP
WS,
and
the
goal
of
this
draft
is
to
address
sorry
that
EVP
and
VB
WS
interrupt
for
both
LD
P
and
B
to
be
ad.
K
K
As
part
of
this
solution,
essentially
the
hybrid
P,
so
this
is
the
EBP
incapable
p
advertises
in
in
a
discovery,
phase
advertises
both
all
EVP
and
routes,
and
l,
DP
and
bgp
ad
and
point
information
that
it
knows
of
locally
and
then
obviously,
this
hybrid
PE
is
going
to
be
capable
to
receive
and
process
the
remote
information
discovered
from
all
of
the
remote
legacy.
Bees,
obviously
also
the
evpn
bees.
K
So
the
idea
behind
this
this
draft
is
that
all
of
the
logic
for
seamless
integration,
Reds
that
resides
on
the
hybrid
bees.
So
the
underlying
principle
is
that
the
legacy
P
so
basically
in
in
blue
here,
requires
essentially
as
close
to
zero
touch
as
possible,
and
we
define
in
this
draft
then
basically
very
similar
285
285
60,
a
preference
of
VP
WS
over
the
legacy
servers
via
del
DP
or
BGP
ad
for
bringing
up
sessions
and
as
part
of
that
then
the
legacy
pseudo
are
that
matches
this
new
EVP
in
vpw.
K
Essentially
it's
it's
it's
as
straightforward,
as
you
would
expect
from
a
starting
point
of
two
legacy
or
two
PS
that
support
only
legacy
pseudo
R's
LDPR
bgp
ad.
We
then
go
to
a
to
a
p1
that
now
is
a
hybrid
P
supports
DB,
pn,
DVP
anafi
and
as
such,
when
you
configure
a
VPN
on
this
legacy.
I'm
sorry
on
this
hybrid
be
the
in
addition
to
the
LDP
or
BGP
ad
routes.
K
The
the
p2
then
enables
the
DVP
anafi
and
since
evpn
is
preferred
in
this
case,
the
legacy
pseudo
are
in
blue
is,
is
brought
and
min
down,
which
will
result
in
either
label
withdraws
or
sudo.
I
status
down
or
status
TLV
I
think
in
bgp,
ID
and
essentially
now
the
the
unconfigured
the
legacy
pseudo
are
as
possible.
K
K
The
only
interesting
use
case
that
I'm
going
to
present
today
is
all
active,
because
single,
active
and
port
active
are
actually
quite
straightforward,
so
for
port
offer
for
all
active
sorry
for
a
p3
running
sudo,
a
redundancy
so
represented
here
when,
in
the
the
solid
blue
line
and
the
dotted
blue
line,
pe2
can
actually
leverage
the
existence
of
this
blue
dotted
line
to
forward
traffic
in
this
in
the
left
to
right
direction.
So
from
from
the
sea
into
the
core.
K
K
There
one
small
caveat
or
one
small
gotcha
to
the
scheme-
the
scheme
I
I
described
before
so.
If
you
look
back
essentially
on
the
right
side
at
p3,
there's
a
red
flow.
That's
arriving
on
the
back
up
pseudo
are
at
the
e3
if
p3
doesn't
actually
support
this
position
on
that
back
up
sewer,
and
we
have
seen
inflamation
implementations
that
do
not.
K
This
draft
then
presents
essentially
a
scheme
to
to
to
mimic
that
asymmetric
forwarding
from
the
previous
slide
by
essentially
having
PE
one
whose
EVP
unaware
and
has
an
active
pseudo,
are
in
an
active
session.
2
PE
3
have
PE
1
share
what
we
called
essentially
an
alias
to
our
label
over
to
PE
2,
to
share
the
session
between
p1
and
p3,
with
be
doing
this
in
in
in
such
a
way
that
p2
can
then
use
the
p3
next
stop
and
the
p3
label
for
sending
the
the
left
or
right
c2
core
traffic.
L
Corcoran
nokia
yeah,
so
it
would
be
good
to
have
some
feedback
on
the
mailing
list
about
these
two
solutions.
For,
for
me,
I
also
know
at
least
two
implementations
of
different
vendors
that
support
you
know
receiving
traffic
on
the
on
the
back
absolute
wire
label.
So
you
know.
Obviously,
if
there
are
some
implementations
and-
and
you
know
there
are
some
standard
documents
that
say
that
you
shouldn't
do
that
for
some
reason.
L
Obviously
we
need
to
look
at
the
other
solution,
but
if
this
is
a
perfectly
good
solution
and
as
you
know,
widely
supported
actually
solves
they,
they
they
issue
in
a
very
elegant
way
and
and
and
also
avoid
some
of
the
issues
of
the
other
solution.
In
the
other
solution,
you
actually
get
traffic
from
two
different
nodes
with
the
same
label
and
that
can
actually
bring
up
a
lot
of
potential
issues.
L
Q
This
is
from
juniper
I.
Have
the
same
comments
regarding
support:
ps3
active
backup,
like
I,
using
a
racing
label
for
point-to-point
pseudo
I
I.
Do
not
think
it's
protocol
limitation
to
have
a
two
different
pseudo
wire
from
PS
Reis
perspective
to
using
post,
p1
and
p2.
If
you
want
to
do
the
active
stem
by
IP
one
and
a
p2,
so
I
feel
like
we
probably
shouldn't
burden
with
just
any
the
protocol
to
add
aliasing
label
for
point-to-point
a
pseudo
I
so
similar.
Q
M
Q
My
name
is
when
I'm
from
a
juniper
today,
I'm
gonna
talk
about
evpn
and
BGP
based
layer,
2
VPNs,
seamless
integration.
They
have
on
a
casa
on
the
list
here
so
agenda
for
this
presentation
is
the
first
week
gonna
cover
in
seamless
integration
for
point-to-point,
repeatable,
Yasuda
y
PT,
EVP,
MVP
WS,
and
a
BGP
based
pseudo
wire
and
I'm
gonna
cover
how
to
support
single
home,
the
seamless
integration
port,
active
single,
active
and
all
active,
and
the
second
agenda
is
talk
about
extension.
Today's
existing
EVP
NV
PWS
multi-point
to
multi-point
seamless
integration
is
extension.
Q
Current
ifc
does
not
cover
the
hybrid
or
the
composite
PE,
see
him
doing
active
active
multi-homing.
So
this
is
just
extension
to
the
existing
ifc
for
active,
active
support
so
base
the
layer.
2
VPN
support,
different
type
of
payroll.
For
when
we
talk
about
seamless,
a
integration
it
is
for
the
payroll
is
Ethernet
frame,
so
just
want
to
make
it
this
career,
it's
just
for
Ethernet
pay,
Road
and
so
I'm.
E
Q
Layer,
2
VPN
and
as
the
blue
and
I
called
a
composite
PE.
Basically,
they
support
both
the
control
and
signaling
for
bgp
based
layer,
2
VPN
and
also
a
VPN
vp
that
race
layer,
2
VPN,
so
the
key
to
do
the
seamless
integration
is
three
things.
If,
if
we
have
legacy,
repeatable
is
running
doing
the
seamless
integration.
There's
no
update
of
after
can
definitely
cannot
update,
lacks
a
piece
running
in
the
system
and
but
a
foot
a
composite
PE.
Q
They
were
run
both
control,
pram
signaling
process,
whether
it
is
a
support
pack
or
compatibility,
they
run
BGP
based
the
layer,
2
VPN
control
branch,
ignoring
and
also
at
the
same
time,
running
EVP
MVP
W
based
Signori,
no
change
to
the
control
pram
for
the
core
on
both
sides.
A
hybrid
P
need
to
do
the
posts,
and
so
it's
always
backward
compatibility.
If
there
is
that
legacy
PE,
we
were
established
pseudo
wire
with
traditional
repeatable
s,
control
and
data
prem
procedures.
Q
If
the
other
side
and
running
evpn
so
evpn
only
take
a
high
preference,
the
pseudo
YB
p
WS
will
be
established
with
IEP
MVP,
the
Ria's.
So
basically,
it
just
three
point:
never
upgrade
no
appropriate
for
relax
a
PE
and
composite
our
hybrid
P,
whatever
always
do
both
control
and
signaling
and
if
both
support
its
a
VPN
take
preference.
So
that's
and.
Q
So
this
is
a
explain
like
in
the
situation
in
the
what
is
done
in
the
control
pram.
What
is
done
in
the
forwarding
plan
forwarding
plan?
It's
always
the
same,
but
control
plan.
We
need
to
run
those
protocol
in
the
composite
P
so
for
support
stimulus,
a
integration
under
composite
piece.
We
do
support
active
standby,
all
port
active,
basically,
what's
the
difference
between
active
stem
bar
and
a
port
active
is,
is
how
C
is
connected
to
the
motor
home.
The
P
input
active.
They
are
using
the
log
interface.
Q
So
this
is
a
help
customer
the
service
provider
if
they
are
doing
the
migration
one
natural
Ethernet
at
a
time,
so
they
migrate
one
region
at
a
time.
But
after
they,
you
know
cross
one
side
when
it
has
not
upgraded,
they
are
doing
the
tradition
of
the
PWS,
but
when
the
first
side
is
my
gray,
they
can
just
upgrade
a
Cee
to
do
the
luck.
They
do
not
have
to
do
a
second
migration
to
upgrade
to
see
from
a
separate
physical
interface
to
a
log
interface.
So
this
is
a
shortened
a
migration
cycle
right.
Q
So
this
helps-
and
it
can
also
go
directly
to
the
active
active,
but
in
the
active
active
case
since
the
Lex
API
layer
to
be
PNP,
they
do
not
know
how
to
do
active
active.
They
only
support
active
stem
by
so
traffic
from
Malak,
say
PE
to
the
composite
PE
is
only
it
will
only
choose
the
daf-2
for
the
traffic,
my
sister
composite
PE,
they
do
active
active,
so
we
can
have
a
symmetric
forwarding
going
on
here,
so
it's
showing
here,
but
it's
possible.
It's
just
also
saved
one
face
of
migration.
Q
So
as
a
topic
and
a
covering
this
talk
is
active,
active
support
for
point,
multi,
point
pseudo,
Y,
and
so
the
challenge
for
that,
as
traditionally
is
V.
Pos
only
can
support
active
standby
there's
a
couple
challenge
for
their
V
POS
does
not
not
like
the
evpn.
They
have
a
label
indicators
to
the
bomb
traffic.
They
do
not
support
spree
horizon
right.
So
that's
trouble
for
from
point
of
thumb
traffic
perspective,
but
with
seamless
integration
we
do
have
advantage
because
the
composite
PE
they
are
running
a
VPN
okay.
Q
They
understand
a
VPN,
they
do
EVP
em
procedures,
so
this
helped
us
overcome
the
limitation
in
the
VPLS.
Cannot
do
bomb
traffic
like
a
support
bomb
like
how
to
avoid
a
looping
or
duplicate
traffic,
so
the
composite
PE
they
can
using
the
e
BPM
process
sings
in
the
in
a
hybrid
or
compose
a
PE.
They
share
the
same
Mack
forwarding
table
so
they
can
use
in
the
evpn
procedure
the
ESI
label.
Everything
like
it,
just
no
change.
No
change
is
the
existing
evpn
process
to
overcome
the
VPS
limitation.
Q
One
is
a
layer
2
looping
for
BOM
traffic.
The
second
is
duplicate
a
bum
bum
traffic.
So
so
this
problem
is
solvable
Bom.
So
what
else
is
the
challenge
you
to
learn
active
active
while
the
other
side
is
the
VP
OS?
Is
that
Mac
flip-flopping,
because
C
is
connected
a
composite
PE
using
the
lag
interface
so
depending
on
a
hash
algorithm?
The
same
math
can
be
show,
learn
it
up
and
learn
on
ap1
and
ap2,
so
because
PE
can
learn
the
same
Mac
on
both
pseudo
I.
Q
So
this
is
a
another
challenge
to
support
a
VPS
active-active,
but
there
is
a
one.
Very
common
procedure
is
called
a
pseudo
eye,
Mac
painting
with
that
we
can
ping
this
Mac,
even
though,
in
the
course
data
plan
and
learning
for
VP
OS,
we
can
paint
a
Mac
to
one
particular
PE,
whichever
it
comes
first
and
at
that
particular
Mac
will
be
ours,
ping
er
to
to
one
of
the
P.
Q
Let's
say
its
first
is
coming
from
p2,
so
VPS
were
sink
c1
smack
is
always
accessed
by
the
p
p2,
even
though
later
he'll
under
Mac
from
PU,
and
it
will
do
to
the
Mac
pinning
on
the
pseudo
while
feature
they
will
never
have
a
flip-flop
or
Mac
painting
going
back
and
of
course,
of
course,
it
will
in
order
to
do
this.
Let's
say
p2
is
an
and
EF
R
I
supposed
today,
so
how
we
can
make
sure
we
can
afford
a
try
to
the
PT.
So
this
is
a
also
existing
control.
Q
Plane
protocol
help
us
solve
the
problem
because
we
can
advertise
vit
P
was
the
to
this
to
PE,
even
though
they
might
have
home
to
see
one.
They
can't
advertise
to
different
VI
D
for
the
instance
VAD.
So
this
way
both
p1
and
ap2
can
extract.
The
unica
has
no
unique
as
traffic
so
depending
on
what
you
have
a
P
V
PSP
is
how
they
learned
a
Mac.
So
the
traffic
for
both
no
unicast
and
a
bomb
traffic
are
symmetric
in
this
and
advantage
for
that.
It
does
not
need
any
folding
plan
change.
Q
Basically,
we
pretty
much.
You
can
use
existing
feature
for
VPS
and
the
seamless
EVP
MVPs
integration.
So
as
a
last
one
is
what
happen.
If
that
node
failure,
access,
link
FIRREA,
we
we
need
to
flush
the
VPS
PE
to
have
it
real
and
the
same
see
when
smack.
So
this
is
a
trigger
against
through
Mac
flush
mechanism
like
for
VPS.
We
have
this
forwarding
bit
when
it
changed
from
1
to
0
signal
to
the
VPS
PE.
They
were
automatically
refresh
the
Mac,
so
they
can
relearn
the
Mac
say
before
I
learn
from
p2.
Q
If
c1
Peters
link
fail,
they
can
relearned
Mac
from
PE
1.
So
this
overcome
it's
a
it's
just
used
a
control,
pram
process
to
its
advantage
for
VPS
P
and
a
support
active
active
for
VPS
P.
So
that's
all
so,
like
I
think
the
VP
WS
point
a
point
as
I
mentioned
in
the
beginning.
It's
the
three
things
for
Bako
compability.
We
can
now
upgrade
lakh
CPE.
We
need
to
do
tobacco
comparability
and
EVP.
Mvp
WS
always
take
precedence,
so
this
three
principle
can
be
applied
to
most
of
the
tree.
A
K
K
So
when
this
draft
it
addresses
basically
only
BGP
ad,
not
LD,
P
so
and
I-
think
we've
spoken
out
about
this
before
I
think
it's
you've
mentioned
it's.
It's
specifically
meant
to
be
BGP
BGP,
basically,
but
didn't
be
like
the
approach
of
ignoring
LDP
I
think
makes
it
a
little
bit
incomplete
in
terms
of
interrupts.
K
So
you
don't
haven't
really
spoken
to
it
here,
but
in
the
draft
itself
you
mentioned,
and
we've
discussed
about
this
one
I'm
not
too
worried
in
order
to
find
a
match
for
interrupt.
You
discuss
how
the
DVD
and
a
CID
on
the
Evi
route
on
e
VI,
a
deer
out
and
the
BGP
adv
Eid
need
to
match
in
order
to
set
up
that
that
interrupts.
That's.
Q
Not
true
because,
as
I
said,
mica
for
combos
appear,
they
are
just
execute
BGP
based
control,
branch,
signaling
and
also
EVP
MVP
tabrets
as
controller
and
Signori.
They
are
totally
independent.
This
is
as
I
as
I
show
up
in
this
diagram
here
at
the
little
circle
here.
This
is
the
control
plan,
they're
just
totally
independent.
They
just
advertise
their
own
control,
friend,
signaling
and
how
its
it
is,
configure
whether
they
use
the
same
VI,
ID
or
BPW
instanceid.
It's
really
the
provisioning.
It's
how
you
provision
this.
Q
It's
the
implementation
dependent
whether
you
want
to
do,
but
they
are
two
separate
control
plan
entities
before
the
hybrid
composite
PE.
Only
in
the
14th
there
is
only
one
they
have
to
either
go
with
the
traditional
way
to
establish
the
pseudo
ID.
Basically,
in
really
what's
matter
is
the
label
right.
Q
Yes,
if
it's
I
can
edit
the
text,
if,
if
it
is
a
confusing
I,
did
not
make
clear
in
the
text,
but
the
intention
is
it's
very
implementation
dependent
and
for
the
provisioning
model
you
use.
Yeah
I,
don't
know
in
emphasis
on
one
day
as
a
regarding
the
VP
WS
yeah
I
agree.
There
is
a
different
way
to
do
it.
There
is
a
forwarding
way.
There
is
a
control.
Pram
way,
as
we
presented
here
is
I.
Think
it's
a
lightweight
it.
It's
another
way
to
achieve.
Q
M
M
Q
M
Q
M
Q
If
automatical
for
the
service
provider
is
to
provide
active,
active
service
right,
so
they
can
save
one
migration
phase,
because
otherwise
they
have
to
wait
until
all
the
piece
in
a
network
to
be
upgrade
to
the
hybrid
or
composite
P.
Then
they
can
support
active
active
here
when
you
are
upgrade
p1
and
p2,
they
can
just
go
right
to
the
active
active,
see
Lac
interface
and
p1
active
active
when
they
upgrade
the
VP
SP,
which
may
be
another
natural
area.
Q
A
L
I'm
very
short,
I
just
wanted
to
highlight
that,
with
this
Mac
pinning
solution,
you
also
get
a
load
balancing
on
their
right
to
left
direction
right
because
some,
if
you
have
multiple
max
behind
a
c1,
some
max
will
be
pinned
to
one
to
the
wire
and
other
max
to
the
other
to
the
wire.
So
it's
actually
a
very
simple
and
efficient
solution.
Yes,.
A
P
L
A
L
P
Q
So
for
point
a
point:
unlike
a
point-to-multipoint,
they
do
not
have
a
concern
complicity
for
dealing
with
the
palm
traffic
looping
or
duplicate
a
palm
traffic
for
point-to-point
service.
No
matter
what
type
of
lacks
a
point-to-point
service,
it
is
it's
pretty
much
the
same.
You
have
to
support
backward
compatibility
and
evpn
always
take
proceedings
if
both
types
first
types
of
signaling
is
there.
So
it's
always
much.
We.
Q
All
right
so
yeah
so
here
is
a
just
quick,
quick
update
for
the
extending
optimized
ingress
replication
for
a
VPN
we
presented,
like
maybe
two
ITF
back
okay.
So
what
has
changed?
There
is
no
change
on
the
draft
front
and
juniper
has
implemented
this
feature
and
has
shipped
in
early
part
of
this
year
and
just
a
quick
summarize
for
this
feature.
This
feature
is
based
upon
the
optimized
ingress
replication,
so
it
inherent
order
good
benefit
for
optimized.
The
ingress
report
occasion
use
a
diagram
leaf
spine
topology,
for
example.
Q
I
only
draw
one
spine
here
you
could
have
a
many
more
spine
and
you
can
do
load
balancing,
but
just
for
simplicity
illustrate
the
benefit
it
has
is
say
on
a
leaf.
One
have
a
receiver,
for
example,
receive
a
mattock
Hasbro
I
need
to
send
two
odd
leaf,
just
presumably
behind
oddly,
if
there's
an
interesting
listener,
so
without
optimized,
ingress,
replication
for
EVP
and
leaf,
one
would
send
six
copy
of
the
same
logic
has
flowed
to
the
spine
was
optimized
ingress
replication.
Q
They
only
need
to
send
a
1-1
car
page
and
then
the
replicator,
which
is
a
spine.
They
replicate
the
traffic
to
the
rest
of
a
ollie
if
a
system
replication,
Leafs,
okay,
so
and
and
also
so
a
pen
was
saving
uplink,
then
we're
saving
and
also
alleviate
burden
of
a
I
leave
to
replicate
our
traffic.
Imagine
you
have,
and
the
leaf
is
over
two
hundred
three
hundred.
You
have
two
replicas,
so
many
copies
right
so
so
this
is
a
definite
benefit
for
optimized
ingress
replication.
Q
But
in
order
to
on
top
of
that,
in
order
to
support
modern
homing,
which
is
a
very
common
case
in
the
leaf,
because
the
doing
the
assistant
replication
replicator
has
to
decapitate
packets
and
then
encapsulate
the
packets
again.
So
in
order
to
support
motor
homing,
you
have
to
whether
it's
a
be
excellent
or
EBP.
An
MPI
is
in
case
we
want
to
do
ESI
in
case.
For
some
reason,
people
still
want
to
using
ESI
labels,
pre
horizon
label
for
for
multi-homing
support.
Q
So
it's
this
require
assistant
replicator
to
retain
the
relief
once
IP
edges
or
the
horizon
label.
So
this
is
a
very
much
complicated.
Ar
replicated
function
implementation,
even
if
it's
doable
some
commercial
chipset
is
not
even
achievable.
So
this
the
solution
is
to
address
the
mother
home
scenario,
so
extended
relief
is
doing
the
using
the
regular
normal
standard
procedure
to
replicate
a
traffic
to
the
to
its
peer
when
I
compete.
The
rescue
during
the
goes
to
the
leaf
spine
to
do
the
replication.
Q
A
C
R
What
we're
looking
at
here
is
an
idea
for
defining
something.
We
call
a
BGP
LS
filter
to
offer
a
way
of
building
a
control
plane
for
enhanced
VPNs
and
network
slicing.
So
what
is
what
is
this
stuff
we're
talking
about?
Well,
there's
a
working
group
draft
in
T's
describing
enhanced
VPNs,
and
essentially
they
are
VPNs
with
a
little
bit
more
required
by
the
user.
R
Sorry,
I'm
just
fight
this,
so
I
can
stand
up.
Yes,
the
user
requires
a
little
bit
more
from
the
VPN
in
terms
of
latency
delay,
jitter
resiliency
requirements,
so
it
looks
otherwise
like
a
VPN
and
so
it's
natural
to
build
on
the
VPN
technologies
and
what
we're
trying
to
do
is
manage
the
underlay
to
provide
those
VPN
services.
R
R
R
R
R
R
R
R
R
R
R
R
A
R
Slide,
thank
you.
We're
going
to
check
back
with
the
with
the
framework
to
make
sure
we're
actually
addressing
the
right
theme.
There
are
a
number
of
data
plane
and
control
plane
drafts
out
there
for
enhanced
VPN
we've
been
meeting
with
those
authors
already
this
week
and
we
think
we're
aligned,
but
we
need
some
to
do
some
iteration
on
the
draft.
So.
C
This
may
be
our
thuggin
all
to
you,
but
just
curiosity,
you've
talked
a
lot
about
filters
and
you've
talked
a
lot
about
the
attribute.
Could
you
first
provide
me
a
very
specific
description
of
what
you
mean
by
attribute?
There
are
a
lot
of
bgp
attributes.
I
assumed
you
meant
of
each
pls
attribute
within
all
the
components.
Attributes
am
I,
correct.
R
C
O
O
Would
suggest
if
we
could
consider
having
a
separate
officially,
we
could
still
use
a
lot
of
the
TLV
score
points
and
everything
defined
for
BG
pls.
We
have
another
officially
defined
for
using
the
same
in
in
LS,
V
R,
so
I
would
recommend
if
it's
possible
to
not
mix
it
up
with
BG
pls
and
have
a
separate
I
mean
something
like
s.
Our
policy
is
a
fee,
for
example,
yeah.
A
R
A
E
R
A
Okay
and
my
les
comment,
an
area
I
think
I
already
did
this
comment
by
email
to
you:
I'm
really
worried
about
visa
version
number
which
is
tied
to
the
full
topology.
So
each
time
you
have
a
topology
event,
you
have
to
push
back
everything
so
you're
slowing
down
the
conversion
time
compared
to
having
a
sequence
number
on
piece
of
the
pierogi.
R
S
Mandrax
nokia,
so
the
goal
here
is
to
distribute
let's
say
that
let's
say
separate
topologies
in
the
dedicated
VPNs
in
a
distributed
manner
in
order
to
do
distributed
te
kind
of
use
case
right
yeah,
so
the
question
I
have
is
given
that
you
get
from
a
controller.
You
push
it
back
down.
How
are
you
going
to
do
bandwidth
based
use
cases,
let
like
with
using
segment
routing,
so
the
what's
pushing
down
is
your
by.
S
S
R
This
exclusion
so
cut
that
that
if
the
controller
has
looked
at
the
link
and
said
the
link
has
dropped
this
much
bandwidth,
I
partition
that
bandwidth
and
I
give
that
link
with
only
a
smidgen
of
bandwidth
to
you
and
I,
give
the
same
link
with
a
different
piece
of
piece
of
the
total
bandwidth
to
somebody
else
and
they
are
operating.
They
believe
that
they
own
that
link
with
that
little
bit
of
bandwidth
and
all.
S
How
are
you
going
to
in
a
distributed
way,
figure
out
that
that
link,
which
is
used
by
multiple
pease?
How
are
they
going
to
relate
the
bandwidth
for
all
these
V
at
the
same
VPN,
going
to
the
same
link
which
is
shared
for
that
topology?
How
are
you
going
to
do
that
in
a
distributed
manner
with
Simon
routing?
Well,
certainly
so
you
have
to
lead.
You
need
to.
R
R
S
A
R
What
an
operator
can
sell
with
if
they
have
this
service,
is
a
vacant,
send
a
VPN
to
an
enterprise
where
that
VPN
has
brought
additional
service
level.
Commitments
like
latency,
like
resiliency
or
the
operator,
can
sell
a
service
to
another
division
of
the
operator,
for
example,
a
wireless
division
as
a
slice.
U
Defect
comments:
one
I
would
question
DCP
forwarding
at
all.
Using
color
gives
you
association
between
next
hop
caller
and
then
the
first,
if
lookup,
which
makes
it
straightforward
and
easy
lack
of
feedback
in
BGP.
It's
a
problem
in
general.
I
would
like
to
see
how
you
would
address
it
because
you
create
an
intended
State.
But
then
you
don't
know
what
the
resources
actually
have
been
allocated
and
operational
state.
So
you're
stuck
with
BGP
can
only
withdraw
right.
There's
nothing
between
so.
A
I
I
So
this
yeah,
so
this
is
some
related
evpn
multicast
work,
I
just
put
them,
which
I
thought
was
important
for
this.
So
the
first
one
is
the
IGMP
MLD
proxy
I.
Believe
it's
going
for
working
group
last
call
so,
and
the
second
one
is
the
per
multicast
flow
DF
election.
These
two
drafts
together
probably
account
for
85
to
90
percent
of
the
multicast
cases
for
the
EVP
on
the
last
two
one
is
the
optimized
ingress
replication
in
nvo
networks
and
the
other
one
is
the
boom
procedure
of
dead
drafts.
I
I
So
the
main
idea
is
you
don't
need
to
send
multicast
traffic
to
people
who
do
not
need
it
right.
So
in
this
case,
as
I've
shown
here,
this
P
2
and
P
4,
they
are
the
designated
forwarder
and
non-designated
forwarder
and
the
others
P
1
and
P
3,
assuming
the
conditions
that
I
showed
in
the
previous
slide.
They
exist
or
the
whole.
Then
we
don't
need
to
keep
them
the
multicast
traffic.
I
So
that's
what
I've
shown
and
last
time
when
we
presented
the
use
case,
was
from
a
DCI
perspective,
but
the
draft
mentioned
about
Pease
and
C,
so
to
clarify
that
I
have
put
two
slides.
So,
as
you
can
see,
the
solution
is
is
very
general.
It's
like
it
can
either
qualify
for
peas
or
DC
I.
It
doesn't
really
matter
okay,
so
this
I
already
said
that
DCI
2
and
DC
I,
for
they
only
need
to
send
their
inclusive
multicast
routes.
So
one
thing
here
is:
this
is
from
the
framework
RFC.
I
So
what
it
says
is
if
we
have
a
set
of
series
that
are
multi-home
to
the
same
set
of
peas,
then
to
get
good
entropy,
we
need
for
load
balancing
purposes
right.
What
we
do
is
we
take
the
es
into
consideration
inside
that
HRW
hash
function
so
as
to
get
a
good
spread,
and
some
of
this
the
English
is
written.
E
I
John
so,
but
for
this
one
for
this
particular
case,
we
do
not
really
want
the
es
to
creep
into
the
equation.
Why?
Because
we
want
for
both
this
s1
and
s2,
the
DF
should
be
unequivocally
the
same
same
DF
say
same
same
DCI,
which
means
that
we
can
set
the
es
to
0
and
then,
irrespective
of
the
es,
they
will
all
map
to
the
same
DCI
or
the
P.