►
From YouTube: IETF106-PEARG-20191118-1330
Description
PEARG meeting session at IETF106
2019/11/18 1330
https://datatracker.ietf.org/meeting/106/proceedings/
A
B
B
B
E
So
this
is
a
draft.
That's
been
alive
for
a
very
long
time.
I've
made
absolutely
no
progress
since
the
last
IETF,
because
I
changed
jobs
and
my
job
now
is
been
difficult.
So
to
speak,
but
anyway,
I
have
a
list
of
issues.
I
think
I
just
threw
in
the
chat.
I
may
not
have
hit
return
Christian.
If
you
want
to
hit
return
on
my
computer
they'll
post
but
I'm
hoping
to
get
through
those
in
December
and
that's
I,
guess
the
update
thanks.
B
F
And
from
scripts-
and
you
thank
you
for
imitation
and
today,
I
will
share
our
research
on
privacy,
preserving
my
home,
oh
home,
amorphic
encryption
and
my
talk
was
divided
into
two
paths.
First,
ever
introduced
some
Merrick
back
ones
of
homo
encryption
and
then
I
reintroduce
the
main
applications
of
homework
encryption
and
now,
let's
begin
with
the
first
part.
F
Okay,
that's
simple
definition:
what
is
homophily
encryption
and
both
of
these
tours
are
variations.
For
example,
encryption
is
the
process
of
encoding
of
a
message
and
a
meaningful
message
into
randomness.
Like
message,
for
example,
we
can
use
the
side
Caesar
cipher
I
used,
which
was
invented
about
2,000
years
ago,
and
in
this
encoding
the
message
welcome
to
NTU
can
be
transformed
to
a
meaningless
message.
F
The
key
is
dusta
to
shift
every
character,
three
positions
and
what
is
homomorphism
home
of
ism
is
a
structure
preserving
map
and
that's
it
will
preserve
the
Arabic
breaker
structures
and
combined
it
together,
we'll
get
the
whole
mafia
encryption.
So
that's
the
definition
of
homogeneous,
and
if
we
can
preserve
the
arabika
structure,
then
we
get
the
home
of
encryption.
F
It's
only
support
single
operations
such
as
addition
or
multiplication,
and
it
was
used,
the
in
data
aggregation
or
some
construction
of
MPC
protocols,
and
it
is
very
easy
to
design
such
a
kind
of
algorithm
and
but
for
the
second
type
of
form
of
encryption.
The
follicle
mark
encryption.
We
required
to
support
unlimited
numbers
of
operations
and
it
can
both
supports
a
multiplication
and
addition
and
a
little
surprise.
It
is
very
difficult
to
design
such
kinds
of
encryption
algorithms.
F
It
was
named
at
the
holy
grail
of
the
cryptography
area
and
remains
at
the
open
problem
of
about
30
years,
and
it
does
result
of
our
entry
in
2009
and
between
these
two
types
of
form
of
encryption.
There
are
many
method,
helps
of
algorithms,
for
example,
the
humorous
some
words
home
of
encryption.
It's
a
keen
supporter
limited
the
numbers
of
operations
and
it
is
also
widely
used
in
the
area
of
privacy.
Protecting
okay
said
this
is
a
brief
history
of
home
of
encryption,
I
taste
nearly
as
old
as
the
public
encryption
itself.
F
It
was
first
proposed
in
1978
and
after
30
years
development,
the
First
Folio
movie
encryption
occurred,
and
after
that's
about
ten
years,
we
have
the
folio
moving
here.
They
were
developed
a
very
quick
light
and
then
now
we
have
many
public
implementations
which
we
can
get
from
the
github,
oh
and
and
elsewhere,
and
the
standardization
process
is
already
underway
and
for
the
standardization
for
the
partial
home
of
encryption,
we
already
have
a
standard
that
was
published
by
ISO
this
year.
F
This
is
a
list
of
the
mainly
current
open
source
libraries
for
home,
of
encryption
and
and
for
integer
or
finished
field
operations.
We
have
Cu
an
HD
lab
and
on
the
hand
rhythm
and
for
the
bullying
gates
operation.
We
have
tfhe
in
the
effort
aw
and
this
our
alpha
baker
in
the
internet.
We
can
get
so
freely.
F
F
Bootstrapping
is
seems
very
fast.
For
example,
we
need
13
milliseconds
for
one
operation
of
the
n
kind
of
gates,
but
since
any
real
application,
if
we
constructed
by
using
the
boolean
gate
gates-
and
it
may
take
many
gaze
operations,
so
the
real
applications
may
be
less
efficient.
Now,
let's
see
some
tests
the
results
of
the
different
kinds
of
libraries.
If
we
want
to
do
the
integer
addition
or
multiplication,
for
example,
we
want
to
do
the
integer
addition.
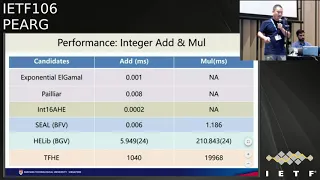
F
Then
we
can
use
the
exponential
argument
or
pallium
or
just
simple
lettuce
based
encryption
and
the
performance
is
very
good
of
example.
We
only
need
to
one
microsecond
for
the
exponential
argument
and
the
women
need
eight
microseconds
for
the
Palio
and
less
than
one
microseconds
for
the
lettuce
based
encryption.
F
For
example,
the
seal
library
King
completes
the
interior
edition
in
six
micro
second,
and
also
for
one
millisecond
for
the
operation
of
multiplication,
and
if
we
want
to
do
unlimited
operations
of
addition
and
multiplication,
then
we
can
use
the
AG
lab.
It
may
takes
five
milliseconds
for
the
addition
and
about
200
milliseconds
for
multiplication.
It
is
much
slower
and
if
we
want
to
do
the
interior
addition
by
using
the
basic
boolean
gates,
then
it
takes
about
one
second
to
complete
the
addition
operation
and
about
20
seconds
for
multiplication.
So
it's
much
slower
with
the
bullen's.
F
Also
the
boolean
circuit
is
Matsuura,
but
we
can
construct
any
kinds
of
operation
by
using
the
blowing
gates.
For
example,
we
can
design
the
the
circular
for
integer
addition
and
the
flows,
number
addition
and
subtraction
and
a
multiplication,
or
even
the
square
root
operation
or
the
sine
function
or
the
exponential
function
that
we
can
construct.
Any
kinds
of
functions
by
using
the
bull
engage,
and
it
is
much
slower,
for
example,
the
exponential
function
may
takes
about
100
and
some
save
for
our
seconds.
F
So
it
is
very
simple,
but
this
kind
of
realization
it's
always
not
very
efficient,
of
our
real
applications,
and
so
we
need
to
design
different
kinds
of
protocols
are
specific
protocols
for
different
kinds
of
applications,
for
example,
in
the
data
collection
data,
retrieval
is
a
sharing
and
a
determining.
We
may
need
to
design
the
protocol
of
data
aggregation,
private
information,
retrieval
and
private
set
intersection
and
the
privacy
preserving
computation
protocols
to
design
these
kinds
of
protocols.
We
may
use
many
kinds
of
or
primitives
and,
for
example,
the
differential
privacy
technique.
F
F
Now,
let's
begin
with
the
very
simple
application:
that's
in
occurs
in
the
data
collection
and
the
left,
a
the
famous
feature
published
the
banister.
It
shows
that
the
power
usage
gets
from
the
smart
meters
may
leak
the
information
of
the
users,
what
you
are
doing,
your
home,
for
example,
from
this
video
when
we
get
the
information
that
the
user
may
be
get
up
in
the
morning
before
AIDS
and
prepare
his
breakfast
and
then
washing
and
then
about
went
to
eat
his
lunch
and
went
to
get
to
sleep.
F
So
in
this
scenario,
we
need
to
aggregate
the
data,
the
power
usage
of
each
hot
work,
each
user
and
get
a
summarizations
and
send
this
summarization
to
the
control
center,
and
this
is
mainly
the
most
simple
and
the
most
mature
application
of
home
encryption.
In
this
case,
the
online
needs
additive
homem
of
encryption,
for
example.
F
We
can
just
add
the
usage
of
each
harm
together
and,
according
to
the
tables
previous,
we
can
see
that
addition
is
very
efficient
and
in
case
of
data
retrieval,
for
example,
the
user
want
to
get
some
public
database
access
some
public
database.
Although
the
data
itself
is
public,
but
the
access
pattern
will
leak
the
privacy
of
the
users,
for
example.
F
Previously
we
can
solve
this
problem
by
using
multi
servers
and
we
need
to
assume
that
these
servers
I
will
not
concluded
together
to
recover
the
privacy
of
the
users.
But
this
kind
of
assumption
is
not
reasonable
for
most
of
the
real
applications.
So,
let's
see
how
to
protect
the
privacy
by
using
homomorphic
encryption,
that
the
user
only
need
to
encrypt
every
index
by
a
separate
text
and
for
the
item
he
want
to
get.
F
He
does
the
encrypt
one,
for
example,
that
the
eyes
index
and
for
all
other
index
he
just
encrypt
0,
and
then
the
server
will
multiply
each
data
to
the
ciphertext,
and
we
know
that
for
for
the
index
I
the
X
I
will
be
encrypt.
This
position
will
get
in
quick
encrypt
of
XII,
for
our
other
positions
will
be
the
encrypt
of
Bureau.
Then
this
server
summarize
all
the
staff
tags
together
and
only
to
send
one
ciphertext
to
the
user,
and
then
the
user
can
be
grabbed
it
and
it
gets
what
he
wants.
F
F
For
example,
we
can
divide
the
potatoes
in
the
server
into
one
hundred
blocks
and
in
this
case
the
user
only
need
to
send
one
hundred
the
ciphertext
and
the
server
all
like
I
need
to
send
over
one
hundred
suffer
texts
the
back
so
instead
of
sending
about
to
us
to
a
ten
thousand
subtext.
In
this
case,
we
all
I
need
to
send
200.
A
server
text
is
a
balance
between
the
truth
passes
and
we
can
make.
If
we
use
the
most
of
the
more
powerful
form
of
encryption,
we
can
make
this
project
still
simpler.
F
In
this
case,
the
user
only
need
to
encrypted
enix
I
want
only
one
self
text
and
this
server
for
each
index.
He
doesn't
finish
the
compare
operation
and,
if
I
equal
to
j,
then
it
will
be
encrypt
of
one
and
for
all
other
positions.
It
will
be
in
subtext
of
zero
so
and
he
still
summarize
all
the
subtext,
the
NS
and
the
results
back.
So
in
this
protocol
we
only
need
two
to
ciphertext
and
communication.
Bandwidth
is
very
efficient,
but
we
have
already
seen
that
fall.
Aha
moment.
Inclusion
may
be
not
that
efficient.
F
So
we
can
improve
this
protocol
by
our
very
careful
design
of
macedon
coding
methods.
We
can
encode
the
message
instead
of
encrypted
the
message
directly.
We
just
encrypted
it
to
a
polynomial
for
time
limits.
I
will
not
have
enough
time
to
describe
the
technical
details,
so
I
would
like
at
this
equation,
and
in
this
case
we
only
need
the
additive
hormone
encryption
and
to
complete
the
Equality
test
and
achieve
the
bandwidth,
efficiency
and
the
computation
physician
together
this
a
more
complete
scenario.
Maybe
the
user
want
to
outsource
his
data
to
the
server.
F
In
this
case,
all
the
data's
X
is
also
the
encrypt
a
safer
text
and
in
the
last
scenario,
it
is
a
plain
text.
So
in
this
case
we
may
need
to
to
do
much
more
about
the
design
of
the
protocol
and
the
encoding
to
avoid
the
usage
of
multiplication
and
only
use
the
computation
for
additional
home
of
encryption
and
makes
the
protocol
and
more
efficient,
and
in
this
case,
besides
the
operation
of
a
read
operation,
the
user
may
be
want
to
update
his
data's
stored
on
the
server.
F
Then
the
writes
operation
may
also
leak
his
privacy
so
to
protect
this
kind
of
privacy.
We
mainly
the
more
complex,
oblivious,
Ram
techniques
and
I
will
not
describe
that
this
thing
here.
Ok,
that's
the
case
of
a
data,
retrieval
not
let's
say
that
they
are
the
case
of
for
data
sharing,
in
this
case,
Alice
and
Bob
both
have
to
parrots
at
it
assess
and
they
want
to
computer
the
intersection.
It
is
a
very
simple
as
Nauru.
F
Obviously
we
can
solve
this
problem
by
using
the
hash
function.
For
example,
Alice
just
said
that
each
of
his
value,
the
hash
value
of
each
of
his
data
to
Bob
and
Bob,
send
back
each
value
the
hash
value
to
Alice
and
then
each
of
them.
Every
of
them
can
just
compare
the
hash
values
and
to
find
out
their
intersects,
but
this
protocol
is
notice
cure
forgiven
boy.
F
If
the
the
space
of
Alice
and
Bob's
in
the
setter
is
not
big
enough,
then
we
can
search
all
the
possible
inputs
and
find
that
data's,
and
we
can
also
we
can
resolve
this
problem
by
using
a
very
different
exchange
like
protocol,
and
this
is
secure
but,
as
in
Bob
also
needed
to
many
to
do
many
kinds
of
module
exponential
computations,
which
is
very
time-consuming
and
with
himavan
homomorphic
encryption.
We
can
intend
only.
F
F
And
but
the
prediction
is
in
plain
text:
it's
efficient
now
and
the
the
first
step.
We
need
to
analyze
what
kinds
of
competitions
we'll
need
in
application
of
neural
networks,
for
example
the
commercial
convolution
there's
is
a
simply.
The
computation
of
matrix
multiply
a
vector
and
the
loot
layer.
Ok,
is
we
need
to
comparison
in
this
direction
and
in
the
for
connection
they
are.
F
We
also
need
computation
of
matrix
multiply
vector,
and
so
we
can
design
a
very
simple
protocol
to
complete
the
computations
based
on
the
bullying
bullying
gates,
although
we
can
see
that
it
is
very
inefficient
and
we
can
achieve
the
operation
of
the
linear
operation
by
using
additive
homo
be
inclusion,
but
in
this
case
we
cannot
compute
the
active
layer
or
the
signal
or
the
redo
function
by
using
the
additive
home
encryption.
This
is
what
we
are
still
research
now
and
ok
friendly.
It
were
concluding
with
komova
encryption.
F
Firstly,
we
can
achieve
the
bull
and
circular
gates
at
the
X
or
in
the
end
and
the
arithmetic
addition
and
multiplication,
and
with
these
rhythms
we
can
achieve
many
any
kinds
of
algorithm
or
bullying
circuit,
and
then
we
can
so
any
kind
of
generic
or
some
problem
with
a
generic
resolution,
and
we
also
can
design
as
basic
approach
calls
for
each
kinds
of
applications
and
we
can
get
efficient
solutions.
Okay,
thank
you.
B
D
G
How
does
this
ok,
perfect,
so
I
need
to
start
with
a
very
important
concept
of
inference
attacks.
If
you
have
some
data
about
individuals,
it's
possible
to
combine
it
with
some
other
information
and
use
advanced
statistical
methods
or
machine
learning,
algorithms
to
infer
further
information
about
those
individuals.
This
has
been
shown
many
times
in
the
research
community
and
on
different
types
of
Delta,
for
example,
on
Facebook
Likes,
you
can
infer
information
about
personal
data
and
also
it
could
help
to
identify
whose
data
is
in
the
data
set,
for
example,
for
location
data.
G
You
just
give
me
five
random
locations
from
their
trajectories.
You
are
almost
unique
in
the
world
alright,
so
this
is
a.
This
is
basically
the
main
risk
of
sharing
the
data
itself
either
it
can
infer
some
sensitive
information
further
than
what
is
already
in
the
data
or
identify
the
individuals
in
the
data
set.
So
there
has
been
a
lot
of
efforts
on
how
to
protect
data
privacy.
Data
sanitization
through
removing
sensitive
information
or
removing
identities,
has
been
one
idea,
but
and
there's
a
huge
business
on
this
by
anonymizing
data.
G
Basically,
what
happens
is
that
an
attacker
has
some
background
information
that
links
it
with
the
data
that
you
release
to
infer
information
about
the
data
which
is
not
in
the
release,
information
right
and
this
can
go
for
like
different
types
of
data,
and
recently
we
have
also
shown
that
machine
learning
algorithms
can
extract
patterns
from
the
data.
Even
it
has
been
obfuscated
a
lot.
So
if
you
see
this
kind
faces
in
the
that
are
used
for
anonymizing
data,
it's
not
anonymous
anymore,
so
machine
learning
models
can
can
reconstruct
the
identity
of
individuals.
G
So,
in
general,
this
is
what
I
call
inference
avalanche.
There
is
some
piece
of
information
that
is
released.
There
is
some
information
that
the
attacker
has
combined
together
can
lead
to
more
inference
about
the
individuals
whose
data
was
used
for
a
computation
and
doesn't
matter
what
type
of
computation
I'm
going
to
give
you
some
information
about
at
an
oil
statistics
and
machine
learning,
and,
for
example,
for
for
statistics,
you
have
some
data.
You
want
to
release
many
statistics
about
the
data
records
in
your
data
set.
G
The
attacker
can
run
an
inference
attacker
to
identify
which
data
sets
could
have
produced
these
statistics
and,
as
you
increase
the
number
of
statistics
that
you
about
your
data
set.
The
plausible
later
said
that
could
have
produced
these
data.
6
reduces
and
some
of
them
have
higher
probability
of
being
the
true
original
data
set,
and
it
has
been
shown
that
the
attacker
can
actually
reconstruct
the
via
the
full
data
set
with
negligible
error,
as
the
number
of
statistics
increases.
G
Even
if
the
statistics
are
noisy
a
little
bit
all
right
or
it
can
be
used
to
identify
whose
data
was
using.
The
in
the
data
set,
for
example,
NIH,
is
to
release
the
statistical
information
about
the
DNA
of
individuals
who
are
in
their
data
sets
so
the
allele
frequencies,
if
you're
familiar
with
the
DNA
data
and
from
that
researchers,
managed
to
find
out
whose
data
isn't
that
data
set.
That
resulted
in
this
summary
statistics
which
are
very
harmless
right,
so
just
I'm
just
releasing
the
average
value
of
each
attribute.
G
G
What
is
the
topic
of
this
talk
that
I
want
to
briefly
talk
about,
and
that
is
the
information
leakage
through
machine
learning
models
right,
so
you
would
say
well
if
I'm
anonymizing
data
yeah,
there
are
a
lot
of
attributes
which
are
in
the
data
set
I
understand
how
the
attacker
can
join
this
data
set
with
some
other.
It
is
to
reconstruct
the
identities.
If
you
really,
as
a
statistics,
maybe
I
can
tell
why
this
can
lead
to
the
inference
attacks,
but
machine
learning
models,
even
those
who
design
machine
learning
model.
G
Don't
know
why
the
machine
learning
models
work
right.
So
then,
how
can
an
attacker
exploit
the
information
which
is
embedded
in
a
machine
learning
model
to
infer
the
data
set
that
was
used
for
training
of
it,
so
in
a
setting
that
we
have
is
that
we
have
some
data
set
and
that
we
use
using
some
training
algorithms
to
construct
a
model
that
does,
for
example,
a
classification
for
us
at
the
time
of
inference
or
the
test.
G
What
you
do
is
that
you
send
some
data
points
and
the
model
tells
you:
what
is
the
probability
of
each
class
associated
to
the
data
that
you
have
shared
all
right,
very
simple,
very
useful.
There
are
a
lot
of
services
out
there,
machine
learning
as
services
provided
by
cloud
service
providers
today
that
you
don't
even
need
to
understand
how
machinery
works.
You
just
upload
your
data,
they
train
a
model
for
you,
and
then
you
have
this
very
simple
API
through
which
you
can
access
it.
G
All
right
and
also
you
know,
we
know
that
machine
learning
is
eating
the
world,
so
everyone
is
now
using
machine
learning
for
everything,
any
data
that
they
have.
So
it's
very
important
to
ask
whether
the
predictions
that
I
get
from
the
model
actually
leak
any
information
about
the
data
that
was
used
to
train
the
model,
but
note
that
at
the
time
that
you
get
the
predictions,
the
data
is
gone
right.
So
at
first
phase
one
we
train
the
model.
Now
in
Phase
two
we
just
interact
with
the
model.
G
You
send
the
query,
you
get
a
prediction
right.
So
how
can
this
leak
information
about
the
training
data
I
mean
before
that?
I
need
to
clarify
what
leakage
means,
because
when
you
interact
with
a
model
you
learn
information
from
the
model
right.
You
didn't
know
that
this
patient
is
susceptible
to
cancer.
Now
you
know
you
didn't
know
whether
you
need
to
invest
in
this
plan
or
invest
in
the
other
plan,
but
now
you
know
which
one
is
more
important
right.
You
didn't
know
these
things
before
interacting
with
the
model.
G
So
not
any
information
that
you
learn
from
the
model
is
privacy
violating.
So
what
is
leakage
here
if
I
can
learn
something
about
you
by
interacting
with
the
model
that
I
could
have
not
learned
if
you
were
not
in
the
data
set
means
that
the
model
is
leaking
information
about
you
right,
because
if
I
get
some
model
and
then
I
interact
with
the
model
and
I
learned
that
you
know
half
of
the
population
or
male
half
of
the
population
or
female,
it
doesn't
matter
if
your
data
was
there
or
not
right.
G
So
this
is
just
generic
patterns
about
the
data,
but
if
I
learned
that
the
chance
that
an
individual
particular
individual
has
cancer
but
I
couldn't
tell
that,
while
just
looking
at
the
general
patterns
of
the
population
means
that
the
model
is
leaking
information
about
that
individual
right.
So
this
is
what
we
call
leakage
and
one
more
particular
way
of
measuring
leakage
is
to
tell
whether,
by
interacting
with
the
model,
I
can
tell
whether
your
data
was
used
in
the
training
set
of
the
model
or
not.
Okay,
and
this
is
what
we
investigated.
G
G
Some
very
simple
statistics
that
I
want
to
show
to
you
is
that
basically,
the
models
are
more
confident
on
the
data
that
they
have
seen
compared
to
the
data
that
they
haven't
seen,
and
this
piece
of
information
could
be
exploited
by
the
attacker
right.
So
the
behavior
of
the
models
with
respect
to
the
data
that
they
have
seen
during
the
training
is
quite
different
from
the
behavior.
G
The
models
with
respect
to
the
data
that
they
see
for
the
first
time
right-
and
this
is
statistical-
difference-
could
be
exploited
by
the
attacker,
and
this
is
exactly
what
we
explored
if
the
model
is
released
for
various
reasons.
Now
you
hear
about
transparency
in
machine
learning,
so
the
yes,
okay,
on
what
model
do
you
use
for
certain
decision-making?
You
might
have
even
access
to
the
model
parameters.
This
is
what
we
call
the
white
box
access
in
the
model.
G
You
know
how
the
model
come
up
with
with
a
decision,
and
you
know
if
you
look
at
these
different
types
of
machine
learning
tasks,
they
extract
all
sorts
of
simple
to
very
complex
features
about
the
data
that
help.
You
then
later
on,
classify
the
data,
and
what
we
ask
is
whether
the
parameters
of
the
model,
each
information
for
those
of
you
who
want
be
interested
in
the
techniques.
G
The
best
machine
learning,
algorithms
that
are
out
there
for
some
benchmark
data
set,
and
what
shows
is
that
the
ones
that
are
even
the
best
in
terms
of
accuracy
that
generalize
the
best
leak
the
most
they
have
huge
capacity.
These
machine
learning
models
have
so
many
parameters
to
embed
the
function
that
they
want
to
learn
and
they
use
some
of
this
capacity
to
learn
the
task.
The
rest
is
used
to
memorize
information
and
that's
a
footprint
right,
so
we
went
through
all
these
different
values
of
parameters
by
looking
at
the
data
and
later
on.
G
So
today,
I'm
asking
this
question:
if
you
look
at
different
privacy
regulations,
it
says
that
the
personal
data,
or
any
information
which
are
directly
or
indirectly
related
to
an
identified
around
at
fybel
natural
person,
so
basically
the
information
that
can
help
you
to
single
out
an
individual
and
say
okay.
This
is
this.
This
information
is
related
to
this
particular
individual
and
now
I'm,
saying
okay,
that
the
models
enable
us
to
single
out
individuals
from
any
data
and
until
ok,
this
data
was
using
the
training
set.
G
G
Should
we
treat
models
similar
to
the
way
that
we
treat
raw
data,
because
what
the
attacks
show
is
that
you
can
infer
a
whole
lot
of
information
about
the
models
from
the
models
about
the
training
data
right.
So
it's
a
big
question
here,
so
I
want
to
just
say
a
few
words
about
what
to
do
right
so
as
privacy
experts.
The
first
thing
that
that
we
do
is
to
just
identify
why
you
need
to
use
the
data
in
what
process
and
what
is
your
trust
model?
G
Do
you
trust
the
machine
on
which
you
do
the
computation
to
trust
the
entity
that
is
going
to
see
the
the
end
result
of
the
computation?
What
is
a
trust
model
and
based
on
the
trans
model,
based
on?
Why
you
want
to
use
the
data
we
can
design
privacy-preserving
computations,
that
protect
against
these
kind
of
inference
attacks,
whether
you're
outsourcing
the
data,
whether
it's
a
collaborative
type
of
computation,
whether
you
want
to
do
data
analytics
or
you
want
to
enable
data
release
for
acceleration
and
visualization.
G
All
of
these
need
different
types
of
tailored
defense
mechanisms
so
for
privacy,
tourism
and
computation
in
order
to
protect
against
the
attacks
that
I
mentioned.
What
do
we
do?
Do
we
need
to
make
a
choice
and
one
choice
that
we
make
is
to
just
say
what
I
am
I'm
fine
if
general
patterns
about
the
data
set
are
shared,
but
I
want
to
protect
the
information
about
individuals
right,
we
need
to
allow
some
information
to
be
shared.
Otherwise
the
data
is
useless
right.
The
computation
is
useless.
So
what
computations?
G
What
kind
of
information
do
I
allow
to
to
be
to
be
communicated
the
general
patterns,
the
ones
that
are
not
dependent
on
individual
records
and,
at
the
same
time,
I
want
to
protect
information
leakage
about
individuals?
I,
don't
want
one
data
point
to
significantly
change
the
result
of
the
computation
so
that
the
attacker
can
exploit.
In
other
words,
if
you
want
to
go
and
collect
data
or
convince
the
customers
or
the
data
holders
to
provide
data
for
you
for
your
computation,
you
want
to
tell
them
that.
Well,
whether
you
participate
or
you
don't
participate
right.
G
G
Few
other
techniques
that
I
refer
to
them,
as
sharing
without
sharing
you
have
huge
data
set.
You
want
to
release
this
data
set
or
you
want
to
learn
something
from
the
data
set
instead
of
sharing
the
data,
why
not
constructing
another
data
set,
which
is
very
similar,
but
not
the
same
as
the
original
data?
G
H
If
anyone
has
attempted
to
categorize
different
machine
learning
models
as
models
that
you
could
remove
your
data
from
that
is
not
only
can
your
information
be
added
to
the
model
to
make
the
model
more
accurate,
but
that
at
some
later
date
you
could
take
an
existing
model
and
and
knowledge
about
a
person's
information
and
effectively
remove
them
from
the
data
set.
Is
there
any
attempt
to
break
that
kind
of?
Does
the
question
make
sense
yeah?
So,
basically,.
G
There
are
two
ways
to
look
at
this
problem
right.
One
is
by
construction
right
when,
when
I
include
your
data
in
the
training
set,
can
I
minimize
is
the
influence
of
your
data
to
the
model
so
that
somehow
approximately
everybody's
data
is
removed
already
right,
so
I
learned
the
general
patterns,
but
the
information
about
it
in
the
individual
or
the
influence
of
each
individual
on
the
model
is
bounded
right.
So
somehow
everybody's
data
is
remove,
except
that,
like
there
is
this
small
epsilon
information
about
each
individual
which
which
which
influences
the
model.
G
So
it
is
one
way
to
to
look
at
it,
and
the
second
way
is
well.
If
I
want
to
totally
remove
all
the
bits
of
information
that
you
contributed
to
the
model.
Can
we
provide
the
provable
guarantee
that
now
your
data
is
removed
for
certain
types
of
models
is
much
easier
for
complex
models.
I,
don't
know
such
as
deep
learning.
G
There
does
not
exist
a
provable
technique
yet,
but
but
people
are
working
on
it,
so
this
is
a
problem
that
that
researchers
are
working
on
it
on
how
to
I
shouldn't
prove
that
all
the
information
about
your
data
is
removed
from
the
model,
because
otherwise
you
can
just
now
retrain
the
whole
model,
but
you
don't
want
to
do
that
right.
So
how
can
I,
with
minimal
effort,
remove
all
the
information
and
prove
the
guarantee
proof
yeah?
You.
G
You
don't
want
to
retrain
right,
so
what
I'm
saying
is
that
overall,
you
want
to
have
minimal
effort,
but
provable
guarantee
that
the
data
is
completely
removed
if
you
train
it
with
differential
privacy,
as
this
is
what
we
are
we
are
doing
now,
then
the
the
influence
is
already
minimum.
Okay.
So
how
much
more
guarantee
can
you
provide?
Then
then,
that's
an
open
question
right
for
complex
models.
I
G
So
these
are
two
different
trust
models
right
so
who
the
adversary
is
right
is
the
adversary,
the
one
who
is
doing
the
computation
or
is
the
adversary,
the
one
who
is
observing
the
result
of
the
computation
right?
So
what
I
was
talking
about
mostly
is
about
the
adversary's
observe
the
result
of
the
conversation
all
right.
So,
let's
say,
for
example,
if
you
have
a
central
server
that
blindly
trains
the
model
for
you
later
on,
you
use
the
model
for
certain
applications.
Then
the
inference
attack
is
against
the
one
who
can
observe
the
mulcher
yeah.
No.
I
I
understand
but
I
guess
my
question
I'm
getting
at
is
that
many
situations
in
which
the
adversary
is
the
is
is,
is
the
people
doing
them
is
the
site
which
is
doing
the
training
itself
right,
which
is
the
machine
learning
site
and
that's
why
you
want
these
privacy-preserving
training
systems
and
so
I
guess
the
question
I'm
interested
in
is:
is
that
a
stronger
model
in
the
sense
that,
if
you
were
in
the
formal
sense
of
strong,
namely
that
if
you
were
protecting
as
that
model,
do
you
also
protect
against
this
kind
of
attack?
No.
G
No,
no,
no
okay.
So
these
are
two
different
types
of
attacks.
Basically,
one
one
is
the
attacker
who
observes
the
other.
One
is
the
one
that
infers
later
on
with
whatever
is
or
catch
you
later
yeah,
so
you
have
n
numbers.
You
want
to
compute
the
average
somebody
computes
the
average
for
you
without
seeing
the
numbers
right.
Somebody
observes
the
average
value
right.
J
Hello,
can
you
owe
me
hello
guys,
so
this
is
a
talk
about
how
we
can
improve
privacy
preservation
by
using
a
method
of
personal
tagging
it
at
the
source.
So
let
me
start
with
some
basics.
What
is
log
data
so
obviously,
so
we
all
understand
log
data
is
nothing
but
a
record
of
information
activity
of
a
user
system
or
an
application.
J
So
the
lot
of
devices
application
services
do
log
the
information
about
the
activity
of
the
user,
so
log
data
is
always
useful
to
many
actors
in
the
systems,
whether
it's
a
developer,
who
can
use
it
for
debugging
troubleshooting
purposes?
Also,
it
could
be
operationally
useful
to
monitor
system
performance
measurements,
Layton
sees
and
not-
and
of
course,
now
nowadays
for
marketing
to
do
analysis
on
the
systems
who
understand
what
is
the
user
behavior?
What
is
the
user
usage
of
a
system
of
a
service
resource
usage,
metrics
and
things
like
that
and
a
very
important?
J
Obviously,
the
use
of
log
is
security
monitoring,
so
we
all
already
have
a
lot
of
tools
which
can
consume
a
lot
of
blocks
and
be
able
to
determine
what
happened
to
an
event.
If
there's
a
security
breach,
if
there
is
a
anti
abuse
or
a
fraud,
so
logs
are
very
useful
source
of
information
to
go
back
track
and
figure
out
what
happened
to
the
system
and
what
went
wrong
in
the
system.
J
So
this
is
a
basic
life
cycle
of
a
log.
If
you
look
at
right
from
this
generation
of
the
log
to
its
preservation,
it
starts
right
from
the
source
where
a
user
activity
gets
triggered
and
it
could
be
any
intermediary
in
the
path
looking
at
the
user
flow
as
its
forwarding
it
or
processing
it.
So
every
system
in
the
path
does
contribute
some
information
about
what
is
happening
to
the
user
and
what
system
itself
is
doing
with
the
user
and
user
activity.
J
J
So
if
you
look
at
the
logs
logs
have
been
that
for
many
decades
right,
so
we
have
seen
right
from
the
Network
Devices
to
applications
generating
the
logs.
So
what
has
fundamentally
changed
from
the
log
semantics?
So
obviously
there
is
more
personalization
of
the
log
itself,
so
there
is
more
applications
that
are
trying
to
pin
the
user
information
into
a
log.
So
obviously-
and
another
trend
that
we
are
seeing
is
locks-
are
no
longer
just
owned
by
an
organization
or
owned
by
a
department
in
the
organization.
J
So
it's
more
shared
either
within
the
organization
or
across
boundaries,
or,
of
course
geographies
as
well,
so
largely
for
kind
of
purposes
that
we
already
saw
and
and
also
the
log
itself,
is
no
longer
analyzed
in
in
silos.
So
it's
basically
combined
with
other
events
of
the
user
or
the
system,
so
there's
tools
that
can
do
indexing
and
then
come
out
with
a
common
understanding
of
what
the
user
or
a
system
or
a
service
is
trying
to
do
so.
It's
no
longer
just
in
silos.
J
There
is
also
cases
where
the
log
itself
can
be
vulnerable,
especially
when,
when
you're
sharing
with
the
third
party
services,
the
log
data
can
be
vulnerable
which
can
result
in
sensitive
data
leakage.
So
obviously
also
app
also
has
a
lot
of
regulations
in
terms
of
how
you
handle
your
log
data
and
how
do
you
share
it
with
different
parties
so,
and
also
a
very
important
shift
in
terms
of
the
log
usage
is
the
monetization
of
the
log,
so
just
going
from
from
monitoring
and
management
ability
management
to
monetization.
J
So
what
about
privacy
and
log?
So
it's
there
are
already
organizations
that
define
log
data
as
part
of
their
privacy
policies.
They
basically
address
what
which
log
data
is
being
collected,
how
they're,
using
the
log
data
and
with
whom
they
are
sharing
a
lot
of
vendors,
do
provide
that
user
policy.
Log
usage
policy,
but
again
the
shift
is
now
towards
more
regulation
of
the
loss,
especially
from
a
privacy.
The
privacy
working
groups
are
more
focusing
and
regulating
the
log
itself,
the
log
data
itself.
J
So
how
so,
when
we
look
at
log,
so
we
see
a
lot
of
challenges
in
terms
of
how
do
you
identify
something
that
is
sensitive
in
a
log?
How
do
you
protect
the
log,
so
obviously
is
a
lot
of
ways
in
which
we
can
process
the
logs,
but
at
the
same
time
it's
very
subjective
in
terms
of
what
a
log,
what
is
sensitive
data
for
in
a
log?
So
it's
something
that
the
application
knows
very
well.
So
this
whether
additional
IP
addresses
is
something
sensitive
or
personal.
J
Again,
it
depends
on
how
the
log
is
used
and
how
it's
collaborated
with
other
events
in
the
system.
But
at
the
same
time,
we
are
seeing
a
lot
of
vendors,
providing
various
tools
like
machine
learning.
Data
set
dictionary
based
methods
to
actually
go
into
the
log,
read
the
log
and
find
out
what
is
very
critical
about
the
log
and
try
to
provide
a
way
to
mask
it
or
hide
it.
J
So
I
think
if
you
look
at
what
is
happening
in
terms
of
the
privacy
preservation
or
data
preservation
in
in
locks,
so
it
it
requires
some
kind
of
a
framework
that
we
see
here
like
right
from
this
generation
to
the
point
of
preservation
of
privacy
preservation.
So
it
starts
with
log
generation.
So
this
is
a
kind
of
a
framework
that
we
can
envision
in
terms
of
the
whole
privacy.
Even
you
apply
privacy
to
the
log.
J
It
starts
from
the
generation
where,
potentially
you
can
tag
the
log
with
some
kind
of
a
metadata,
so
some
kind
of
an
accession
token
or
whatever
right.
Then
there
are
various
ways
to
do
that.
So
imagine
if
we
can,
at
the
source
point
to
a
system
that
this
data
that
I'm
going
to
put
it
in
a
log
is
going
to
be
very
sensitive,
or
it's
has
some
degree
of
sensitivity
to
it
right
and
that
in
turn
can
go
into
a
detection
system
so
where
we
don't
have
to
do
any
specific,
hard
coding.
J
Of
course,
you
can
complement
this
with
other
existing
methods
and
then
be
able
to
detect
what
is
private
data
or
personal
data
in
the
system
and
the
log
and
then
be
able
to
additionally
define
what
you
want
to
do
with
the
data.
Whether
you
want
to
remove
the
field
from
the
log
or
you
just
want
to
anonymize
mask
it
or
do
anything
any
actions
specific
to
the
log.
So.
C
J
Also,
you
can
have
different
actions
defined
to
different
fields
in
the
logs
potentially,
so
that's
where
we
saw
it
could
be
differential
reduction
actions
that
you
can
enforce
in
the
law
so
based
on
that
idea.
So
the
proposal
here
is
to
look
at
a
way
in
which
the
source
can
define
some
kind
of
metadata,
so,
as
I
said
like
which
can
potentially
indicate
the
interesting
fields
or
sensitivity
fields
within
the
log
that
is
being
generated,
so
most
of
us
have
standard
long
formats
that
most
applications
use.
J
So
imagine
if
you
can
add
another
framework
or
another
data
to
it,
saying
that
while
you're
defining
this
log
also
look
at
what
is
going
to
be
sensitive
in
the
log.
So
if
you,
if
the
source
can
assert
that
within
the
at
the
time
of
generation,
so
it
could
be
more
useful
or
more
deterministic
in
the
way
the
data
could
be
preserved
or
policy
enforced.
J
So
this
is
a
an
approach
that
we
investigated,
where
you
can
add
something
like
a
PII
data
within
a
log,
so
it
could
be
at
the
field
level
saying
that
every
field
you
can
tag
it
with
a
private.
True
or
false
kind
of
indicator-
or
it
could
be
at
a
log
level
where
you
can
enumerate
all
the
variables
or
all
the
identifiers
in
the
log
saying
that
this
the
private
feeds.
J
So
this
is
not
something
new
that
is
happening
with
a
lot
of
precedence
in
terms
of
how
or
the
the
whole
method
of
identifying
data.
So
I
hear
some
vendors
that
are
already
doing
one
way
or
the
other,
so
the
so.
Each
one
has
of
course,
its
own
way
in
syntax
or
a
CLI
that
they
define
to
pretty
much
define
what
private
data
is
in
a
what
constitutes
a
private
data
and
in
a
log.
J
So
this
is,
of
course,
a
proposal
that
has
been
submitted
so
we'll
be
welcome
to
get
feedback
on
what
you
think
in
terms
of
this
problem
statement.
So
here
is
some
hackathon
results.
We
just
try
to
put
it
together
and
try
to
compare
it,
but
one
of
the
reg
X
based
approaches.
So
obviously
the
results
is
that
that
an
explicit
marking
you
have,
of
course,
has
more
deterministic
results
with
heuristics,
or
maybe
a
data
set
based
approach.
You
can
get
into
wrong
classifications
or
Miska
or
something
else
which
is
not
private,
better
getting
mangled.
J
H
Traditionally
the
IETF
has
not
bothered
too
much
with
what
happens
outside
of
the
network
protocol
and
the
this
is
now
is
starting
to
sort
of
starting
to
look
at
what
gets
into
what's
what's
stored.
As
a
result,
I
think
that's
useful,
but
I
can
imagine
there
might
be
some
people
who
are
scared
about
seeing.
H
Mission
creep
or
something
around
it,
but
I
do
think
that
we
that
we
should
be
addressing
it
I'm
wondering
whether
you've,
whether
you've
looked
also
at
systems
for
like
deterministic
or
format,
preserving
encryption
for
logs
yeah.
It
seems
like
it
sort
of
fits
into
this
general
framework.
I
know
that
there
was
some
discussion
with
Indy
Prive
about
IP
address
within
deep
breath.
The
I
don't
remember.
There
was
other
discussion
here,
the
IDF
about
about
that
kind
of
work,
and
it
might
be
worth
trying
to
fold
in
these
questions
about.
H
D
K
This
is
interesting.
We
have
actually
been
trying
to
address
this
at
the
basic
level,
because
it's
sexual,
a
problem
you
have,
whenever
you
have
an
application
that
generates
logs
today
in
Europe
at
least
you
have
to
defend
and
perfected
that
personal
information,
even
just
the
IP
addresses
that
are
in
the
logs,
so
we
have
been
experimenting
with,
for
example,
and
clipping
the
IP
addresses
in
place
and
in
a
way
that
they
can
be
light
of
the
cripton,
if
necessary,
but
with
proper
procedures
in
case
of
monitoring
law
enforcement
in
this
kind
of
stuff.
K
So
maybe
it
would
make
sense
to
have
some
kind
of
best
practices
across
the
industry
on
how
to
do
this
in
a
consistent
way,
even
if
each
application,
even
for
the
same
kind
of
service,
has
different
log
formats.
Maybe,
but
maybe
some
discussion
on
general
principles
could
be
useful
so
that
we
get
to
a
good
way
of
doing
this.
L
Like
your
approach,
a
lot
there's
only
one
question
that
I
had
with
it,
which
is
you
specifically
said,
no
hard-coded
rules
and
I,
don't
understand
the
motivation
for
that
of
why
you
wouldn't
do
both
hard-coded
rules
and
machine
learning,
because
her
rule,
hard-coded
rules
are
pretty
much
a
guaranteed
ground.
Truth
always
will
match
because
I'm
removing
you
know
a
user
name
field
that
I
know
about,
whereas
if
you
just
let
the
machine
learning
component
take
over
it,
just
make
it
a
80%
chance
of
removing
now
sometimes
can.
J
L
J
Yeah
that
that's
a
good
point,
so
obviously
it's
going
to
be
like
a
compliment
to
what
mesh
methods
are
already
there,
so
just
that
it
could
be
another
input
for
a
machine
learning
model
to
see.
Okay.
This
is
the
indication
from
the
source
that
the
degree
of
sensitivity
could
be
there.
So
that
way
it
could
be
used
well.
L
M
J
I
Schwartz,
if
you're
looking
for
a
place
at
the
IETF
to
do
this
kind
of
work,
I
would
suggest
narrowing
scope
here
or
narrowing
generality
and
trying
to
look
very
specifically
at
a
specific
existing
systems
that
generate
logs.
One
that
comes
to
mind
is
HTTP
request,
logging,
which
is,
of
course,
almost
universal.
I
That's
a
case
where
the
IETF
has
substantial
authority
and
if
we,
for
example,
identified
different
kinds
of
different
specific
header
fields
that
that
should
be
logged
differently
in
different
circumstances.
That's
something
that
we
could
reasonably
make
a
recommendation
about.
I
also
know
that
there
are.
There
are
people
out
there
who
believe
that
servers
will
log
their
HTTP
requests
in
different
ways
and
have
encoded
assumptions
about
that
into
how
their
clients
behave.
So,
for
example,
I've
seen
I've
seen
assumptions
in
systems
related
to
doe
that
requests
of
the
form
get
will
have
their
full
query
path.
I
J
I
think
that's
agreed
that
generalization.
Is
it
a
part,
part
yeah,
because
some
of
the
vendors
that
we
are
seeing
there
again
focused
on
a
very
specific
type
of
log
that
they
want
to
provide
the
redaction
so
the
very
specific.
For
instance,
they
only
look
at
HTTP
packet
or
they
only
look
at
maybe
SF
CFL
kind
of
a
formatted
log,
so
but
I
think
you're
pretty
right
in
terms
of
saying
that
we
have
to
narrow
the
scope.
J
D
N
Allison
Menken
Salesforce.
Thank
you
for
the
great
presentation.
I
support,
adopting
this
as
an
IEEE
RTF
document.
Just
to
back
to
something
that
Ben
just
said,
I
think
you
don't
really
have
the
option
of
being
very
prescriptive,
but
you
can
actually
provide
of
you
can,
but
it
will
won't
be
standard,
but
you
can
provide
questions
and
guidance
that
can
later
be
valid
valuable
into
the
standards
process.
N
A
thing
that
struck
me
about
that
was
I
mean
there's
a
there's,
a
saying
that
the
best
logs
for
privacy
are
the
ones
you
don't
retain,
and
you
you
gave
this
great
statement
that
you
know
people
have
more
and
more
reasons
why
they're
retaining
and
using
logs.
Perhaps
this
document
could
also
talk
about
kind
of
a
time
limit
like
at
a
certain
point.
N
J
So
I
think
it
also
depends
on
the
policy
privacy
policy
itself.
Right
I
think
there
are
a
lot
of
organizations,
the
regulations
that
define
what
is
the
timeline
I
think
it's
a
good
input,
but
we'll
have
to
look
at
it
from
the
privacy
policy
point
of
view
and
see
if
we
can
put
those
guidelines,
but
you
are
right
in
terms
of
identifying
a
specific
time
limit.
As
you
said
right,
it
should
be
useful
at
some
point
of
time.
It
may
be.
We
have
to
be
more
pragmatic
about
that
agree.
Thank
you.
M
B
Thank
you
all
right,
so
there
seems
to
be
some
interest
in
this
document
and
there's
some
overlap
with
work.
That's
going
on
in
the
IETF
can
I
get
a
quick
show
of
hands
from
people
in
the
room
who
have
read
this
so
a
couple
hands
go
up
how
about
a
show
of
hands
of
people
who
are
interested
in
this
particular
topic?
A
lot
more
hands
noted,
okay,
so
I
guess,
based
on
that
I
I'm
gonna
do
a
home
for
adoption
right
now.
B
So
the
question
is
pretty
simple:
if
you
support
adoption
of
this
particular
document
into
the
research
group,
please
home
now,
and
if
you
do
not
support
adoption,
please
home
now,
all
right.
So
there
seem
to
be
stronger
support
for
adoption.
Of
course,
we'll
confirm
on
the
list
and
go
from
there
and
if
you
have
any
comments
on
the
document
in
the
meantime,
please
you
know
reach
out
to
the
authors
or
something
on
the
list
as
well.
That'd
be
helpful.
J
B
Alright,
hello,
everyone
names,
Chris
Wood.
This
should
hopefully
be
very
quick
because
we
talked
about
this
last
meeting
in
Montreal,
or
there
was
a
talk
similar
today
in
our
W
paper
that
was
presented
and
we
presented
some
results
that
were
similar
to
it.
So
this
is
just
going
to
go
over
the
document
that
we
have
sort
of
describing
the
network
based
website
being
a
pending
problem
and
ask
you
some
questions
so
some
background
for
people
who
were
not
there
in
Montreal
and
don't
really
know
what
I'm
talking
about
website.
B
B
We
basically
went
and
looked
at
a
bunch
of
research
papers
that
were
published
on
this
topic
and
summarized
them
both
for
our
own
knowledge
and
hopefully
for
the
benefit
of
others,
who
potentially
read
this
here's
the
outline
of
the
document.
If
you
have
not
looked
at
it,
so
it
basically
it
goes
and
describes
the
general
problem
describes.
B
Maybe
it's
useful
to
the
IETF
or
I
or
TF,
who
knows,
and
if
it
is
useful,
should
this
happened
here
in
perigee
or
elsewhere?
Who
knows?
Does
the
scope
need
to
change
if
we
take
things
out,
remove
things
whatever
and
similar
to
Joe's
draft?
This
is
sort
of
problematic,
because
the
nature
of
this
document
is
whenever
new
paper
is
published,
I
go
in
and
summarize
it
and
put
it
in
and
that
sort
of
implies
that
you
know
publishing
it.
B
I
Lot
of
questions,
all
right,
I
mean
yeah,
go
I
mean
yes,
this
is
absolutely
useful.
You
know
we,
you
know,
there's
like
a
long
list
of
mechanisms
that
allow
you
know
that
allow
passive
or
active
observers
to
determine
what
your
you
know.
What
browsing
behavior
is-
and
you
know
once
we
finish
like
removing
all
the
ones
that,
like
just
like
steak
flat
out
what
pressing
behavior
is.
You
know
eventually,
this
will
come
like
the
easiest
way
to
do
it
and
so
getting
a
handle
on
how
to
fix
that.
It
seems
like
super
critical
I.
I
Think
PRG
seems
like
the
right
place
for
this.
It's
hard
to
see
where
else
it's
gonna
sit,
I,
don't
think
HTTP
really
is
gonna
like
know
what
to
do
with
this
I
think
you
know
that
the
output
of
this
work,
you
know
or
recommendations
for
a
shippi
should
do
to
like.
Actually
pretty
figure
pretty
harder
would
be
something
you
could
feed
into
HTTP
I
I
agree,
like
probably
having
an
RFC,
doesn't
seem
like
super
like
how
fol
cuz
it's
kind
of
static.
You
know,
I,
don't
know.
I
Maybe
the
IDF
application
process
is
lightweight
enough,
that
you
could
like
crank
out
new
RC
every
year
or
something,
but
the
existence
of
this
document
seems
like
super
helpful,
so
I
would
encourage
you
to
keep
at
it
and
I
guess:
I,
don't
know
the
RTI
process
well
enough,
but
you
know
a
dump
things
working
group
items
at
the
signal.
This
is
like
something
that
we
think
is
important,
sometimes
viable,
yeah.
B
I
E
C
E
Really
helpful
for
a
number
of
reasons
and
they've.
Never
you
know
touched
protocols,
I
think
the
scope
is
right.
I
do
wonder
if
there's
gonna
be
a
way
to
capture
things
that
maybe
don't
make
it
necessarily
into
the
academic
literature.
I
know,
that's
where
you
sort
of
started
from,
and
maybe
that's
something
to
think
about
like
what?
What
level
does
it
reach
to
make
it
in
there
and
I
guess
in
terms
of
being
living
I,
don't
know,
there's
nothing
wrong
with
having
an
ID
that
gets
updated,
occasionally
and
and
peeled
off.
E
B
H
B
I'm
a
bit
unhappy
with
the
term
website:
fingerprinting,
it's
just
what's
used
traditionally
in
the
literature
typically
because,
like
it
started
off
in
tour
in
that
particular
way
and
they've
just
carried
it
forward
so
yeah.
If
there's
a
better
term,
the
more
accurately
capture.
What
we're
trying
to
actually
do
today,
I
will
happily
use
it
not
sure
what
it
would
be
so.
H
So,
what's
interesting
is
that
it
used
to
be
that
you'd
say
website
fingerprinting,
because
you
were
distinguishing
between
that
and
other
forms
of
network
traffic
fingerprinting,
but
now
that
most
network
traffic
wants
to
be
HTTP
traffic
in
the
first
place,
all
of
a
sudden
we're
back
to
kind
of
network
traffic,
fingerprinting,
point
yeah,
so
so
I'm
not
sure
what
balances
as
far
as
the
live
document
or
whatever,
please
keep
working
on
it.
Let's
have
revisions
for
it.
H
If
it
turns
out
that
it's
useful
to
say
here's
what
we
think
network
traffic
fingerprinting
looks
like
in
2020.
That's
a
that's
a
perfectly
legitimate
document
to
produce.
As
long
as
we
continue
to
revise
that,
you
know
the
the
baseline
draft
that
produces
that,
so
that
maybe
we
want
another
one
at
four
twenty
twenty
five,
but
that
but
but
yeah
I
do
I
do
think.
H
O
Gotta
go
back
to
first
principles
here:
miss
Richard,
Barnes,
I'm,
just
gonna
+1.
All
the
comments
about
this
being
valuable
work
and
caging
mostly
cover
what
I
was
thinking
about.
You
know
extending
to
non
web
applications
because,
like
everybody,
uses
HTTP
now
and
concerns
for
fingerprinting
what
apps
are
on.
Your
phone
is
very
similar
to
consume
a
fingerprinting.
O
What
websites
you're
visiting
as
far
as
stability
like
I,
wouldn't
be,
it
doesn't
seem
like
we
would
fail
here
if
we
produced
a
snapshot
at
the
time
and
revisited
at
the
time
a
one
thing
that
could
be
done
to
give
this
a
bit
more.
Longevity
is
to
think
about
whether
there's
some
you
know
abstractions
one
could
make
over
the
techniques
in
the
literature
and
to
discuss
general
classes
of
attacks.
I
mean
kind
of
call
those
out
as
guidance
for
things
people
to
consider
in
in
designing
protocols.
O
We
did
this
there's
something
similar
a
few
years
ago.
A
few
IAB
folks
and
I
did
a
draft
about
censorship
techniques
on
ways
you
could
do
blocking
where
we
talked
about
generic
classes
of
approach
to
that
that
problem,
so
to
speak
and
in
ways
that,
in
the
you
know
the
advantages
that
the
the
ways
they
could
be
deployed
and
the
things
they
break
and
so
I
think
a
similar
approach
could
could
work
here.
I
haven't
I,
admit
dived
into
the
document
real
detail,
but
that
would
give
that
this
document
a
bit
more
longevity
yeah.
B
C
Hi
Colin
Perkins,
we'll
see
if
this
microphone
falls
down
before
I
finish
talking,
see
ya,
I
think
this
work
is
useful.
I
think
this
research
group
is
as
good
a
place
as
any
to
do
the
work
and
I.
Don't
have
any
objections
to
that
in
terms
of
the
the
living
document
type
thing
if
you've
only
ever
published
RFC's
via
the
IETF
side,
I
think
you'll
find
the
process
is
perhaps
lighter
weight
in
the
IRT
F.
C
Yeah
I
mean
XML
fee-free,
but
you
know
means
you
can
add.
Pretty
pictures
no,
but
I
mean
seriously
I,
think
you're
keeping
this
sort
of
finger
life
as
an
internet
draft
and
occasionally
pushing
out
snapshots
as
an
RFC
and
makes
a
lot
of
sense
you
that
this
is
the
state
of
the
world
as
of
2020
or
whatever.
It
is,
and
then
just
keep
keep
it
ticking
over
and
then,
in
a
couple
years
time.
Well,
we'll
publish
another
one:
okay,
yeah.
D
A
P
P
So
we
are
working
on
solutions
that
are
decentralized,
end-to-end
peer-to-peer
for
reasons
of
mitigating
the
adverse
effects
of
process
monitoring,
because
it's
an
attack
to
privacy
and
has
been
documented
in
RC
and
centralized
elements
are
usually
more
prone
to
attacks,
because
if
you
have
two
centralized
delavane,
you
have
everything
and
if
it's
centralized
the
effect
is
limited
usable.
Because
message,
encryption
has
law
for
most
Internet
users,
I
mean
who
of
you
has
already
tried
to
set
up
PGP.
P
Okay,
a
bit
less
anyway,
but
whoever
would
consider
that
people
who
are
not
attending
the
idea
throwing
something
completely
different,
are
able
to
set
out
the
PGP
kind.
Okay,
zero
and
that's
actually
where
it
comes
from.
We
need
folks
fixed,
is
usability
challenged
by
automation,
because
people
are
simply
not
able
to
do
it
on
their
own
if
they
are
not
getting
enough
help
and
that's
where
it's
coming
from
is
usable
and
privacy.
P
We
consider
privacy
is
a
human
right,
so
this
medical
tech,
TV
team,
show
I
can't
go
into
all
details,
but
basically
it's
about
enhancements
to
application
protocols
for
decentralized
usable
privacy.
It's
based
on
opportunistic
security
and
the
whole
thing
emerged
from
the
initiative
of
pepper,
pretty
easy
privacy.
P
It's
a
foundation
that
piece
doing
implementations
in
this
area,
but
it's
not
limited
to
that.
It's
also
like
other
people
working
in
the
field,
for
example,
autocorrect
are
invited
to
participate
directly,
actively,
contribute
to
meet
up,
and
the
goal
is
to
define
the
missing
pieces
like
key
management,
private
key
synchronizations
message,
formats,
trust,
well
change,
etc.
I
can't
go
into
details
of
this.
P
We
meet
in
so-called
non
working
group
sessions
during
IDF
meetings,
with
the
exception
of
this
one
you're
not
having
these
kind
of
sessions.
Otherwise
he
had
it
last
free
IDF
meetings.
I
think
we
have
a
mailing
list
set
up
made
up
at
ITF
talk
and
you
can
subscribe
there
if
you're
interested
in
the
field
and
at
some
point
in
time
we
are
aiming
for
both
to
be
an
ideal
working
group
and
work
on
this
a
bit
more
in
the
proto
sense.
P
Then
there
is
the
application
corner,
which
the
brown
corner,
for
example,
use
it
in
email,
but
also
instant
messaging,
and
we
are
even
using
it
for
banking
transaction,
for
example,
Swift
Network
is
using
the
same
technology.
Then
we
have
the
private
key
synchronization
area
like
that.
You
have
different
devices
and
generate
the
key
with
one
the
ability
to
encrypt
your
email
and
read
the
email
on
the
other
devices,
usually
don't
work
unless
we
share
the
keys
and
we
have
a
solution
for
that.
P
It's
already
implemented
and
the
green
area
is
like
the
core
area
with
requirements,
the
cost
of
end.
What
you
hear
as
next
is
basis
for
that
green
area.
It's
the
fret
analyzes
that
out
of
the
fret
analyzes
that
is
discussed
in
this
next
presentation,
requirements
are
coming
or
part
of
requirements
are
coming.
So
now
we
know
where
this
next
presentation
is
fit
to
and
I
would
end
or
to
in
raqqa
stem.
Q
Okay,
I
might
need
the
speaker,
maybe
not
like
that.
So
hello,
everyone,
thank
you
for
Pierre,
G
and
ITF
for
inviting
me
and
for
this
long-standing
contribution.
I
want
to
break
this
presentation.
Actually,
it's
a
call
for
stimulate
discussions
and
to
call
for
contributions
under
the
keywords,
a
break
down
the
title
of
this
presentation
on
this
four
points:
a
systematic
analysis
of
security
and
privacy,
threats
for
private
messaging
and
what
I'm
talking
about
private
messaging
I'm
talking
about
emailing
and
instant
messaging.
Q
What
is
usually
been
done
in
the
RFC
and
the
first
f70
P
821
back
in
1982,
we
build
it.
I
did
with
a
very
nice
system
SMTP,
but
initially
without
security
into
consideration.
So
we
found
out
a
bunch
of
threads,
for
instance,
two
least
one
monthly
middle
attacks.
Then
we
started
designing
systems
that
you
have
that
ahead,
like
client-server
decryption,
like
start
TLS,
and
you
had
all
these
nice
analytics
of
Gmail
showing
is
to
our
browser,
like
all
your
flight
is
at
that
time
you
should
consider
going
because
there
is
a
traffic
or
not
surprisingly.
Q
Q
So
we
shouldn't
consider
trusted
the
servers
of
email
servers
and
be
some
basic
servers
that
they
only
keep
the
information
only
to
ourselves.
So
we
start
building
end-to-end
encryption
as
mine.
We
thought
that
centralized
systems
they
might
even
not
be
that
robust
and
privacy
security
privacy,
preserving
because
they
might
send
different
public
keys.
We
have
open
PGP,
and
this
summer
we
had
this
proofing
of
certificate
poisoning
which
I'm
not
going
to
go
into
technical
details,
but
essentially
they
break
up
open
GP
because
they
made
it
very
buggy
and
large
start
shining
sorry
signing
certificates.
Q
Ok,
we
found
out
ways
to
have
internal
encryption
with
great
security
protocols,
but
then
now
what
there
is
a
harder
problem
with
metadata
and
this
great
person,
the
general
for
NSA
director,
said
that
well
by
the
way,
we
might
don't
know
to
what
you
are
saying,
but
we
kill
people
based
on
metadata
and
even
there
are
like
academic
work,
very
good
academic
work
or
like
projects
successful,
but
still
there
is
no
application.
So
where
are
we
now?
Q
There
is
a
lot
of
academic
work,
but
usually
the
approach
is
like.
We
think
that
these
threats
are
really
relevant,
but
what
we,
if
we
do
it
the
other
way
around,
we
start
mapping
the
list
of
threats
and
we
start
like
instead
of
running
after
the
attacks,
we
start
designing
systems
by
very
beginning,
so
EF
first
started
to
on
this
direction:
try
to
evaluate
and
try
to
make
a
list
of
design
security
features,
but
this
specific
is
a
website,
but
this
is
limited.
Categories
is
obsolete
right
now
and
it
evaluates
only
existing
apps.
Q
So
the
aim
of
this
internet
document
is
about
to
assess
to
have
a
security
and
privacy
threat.
Modeling
requirements
are
a
holistic,
systematic
approach
and
for
assessing
existing
systems
or
this
when
designing
a
new
system
systems.
You
can
use
it
for
as
a
guideline,
and
this
takes
into
consideration
technical
threats,
security
and
privacy,
but
also
the
user
threads.
There
is
keep
on
discussion
on
intelligent
service
about
backdoors,
and
this
is
not
a
technical
vulnerability.
This
is
an
issue
of
opening
a
backdoor
in
their
system,
and
this
is
a
user
threat.
Q
Q
So
as
we
will
we'll
show
you
a
little
bit
later
on,
we
have
a
system
model,
we
define
the
system
model,
meaning
what
exactly
the
entities
and
the
functionalities
which
are
the
adversaries,
what
the
adversaries
can
do,
the
class
of
threads,
the
class
of
requirements
and
later
on
in
a
later
phase
in
this
document,
or
in
a
later
on,
we
will
have
the
risk
approach,
because
now
we
consider
the
threads
uniformly.
But
maybe
you
want
to
evaluate
the
threads
and
then
which
are
the
crypto
protocols.
We
have
all
the
crypto
primitives,
for
instance,
OTR.
Q
Q
If
I
am
to
say
the
system
model
in
a
halt,
it
could
be
the
Italian
Bob
wants
to
communicates
and
want
to
exchange
messages
or
it
wants
to
exchange
emails
or
instant
messaging
using
instant
messaging
systems.
And
here
we
have
the
networking
nodes
and
we
have
splitted
the
trust
establishment,
which
is
essentially
to
have
identity,
key
and
contact
management
and
third
parties,
and
what
we
can
do
is
we
can
start
playing
with
the
threads
with
adversarial
models
and
when
we
say
adversary
model
we
are
talking
about.
Q
Whether
advisor
is
a
passive,
we
say
owners
but
curious.
It
tries
to
not
break
the
system,
but
it
tries
to
extract
as
much
information
as
possible.
It
can
be
active
adversary
and
can
be
internal
or
external,
and
here
is
the
list
that
we
start
have
started
compiling
and
this
first
list.
The
first
two
columns
is
about
security
threats
and
and
security
requirements,
and
this
is
extracting.
This
is
a
methodologies
being
used
by
Microsoft
with
a
straight
framework.
Q
So
essentially,
we
try
to
find
out
all
the
possible
threats
in
these
classes
of
attacks,
classes
of
threat
and
the
corresponding
requirements.
So
the
same,
seeing
as
a
methodology,
we
did
it
with
privacy,
but
I
ever
see
uses
we
used
an
academic
were
called
Linton,
which
we
adopted
it
for
our
needs,
and
I
want
to
highlight
three
specific
points
so
for
confidentiality,
information
disclosure
there
is.
This
is
a
threat
to
security
and
privacy.
Q
However,
for
non-repudiation
it
might
be
a
requirement
as
a
security,
but
an
issue
to
privacy
in
the
for
a
privacy
can
be
an
issue
and
it's
actually,
how
are
the
arts
been
built
that
has
plausible
deniability
so
having
a
map
of
threats
and
requirements?
We
can
very
beginning
at
the
very
early
States
point.
Q
What
we
need
to
do.
Another
thing
is
the
privacy
interdependence
think
about
the
case
where
you're
installing
an
what's
up
or
a
signal,
and
all
your
contacts
go
into
the
clouds,
and
that
is
a
matching
who
has
this
application?
So
essentially
what
you
do
you
send
your
whole
social
network
to
the
cloud
provider
of
what's
up
to
do
the
matching
and
notify
your
home
has
the
same
contact?
Who
has
the
same
person
stole
the
same
application
so
in
signal
there
was
a
lot
of
discussion.
Q
Q
Q
Bob
is
considered
as
adversary.
An
OTR
has
been
designed
considering
this
this
very
much
this
very
principles
of
confidentiality,
entity
and
data,
education
forward,
secrecy
and
deniability,
so
we
can
start
called
peeking
threats
that
we
need
to
design
a
system
for,
and
we
have
specific
countermeasures
and
having
the
whole
map
of
adversarial
models.
We
can
say
exactly
what
we
need
to
do,
instead
of
going
the
other
way
around
saying
I
believe
which
can
be
as
an
expert.
Q
Well,
there's
a
lot
of
work
that
needs
to
be
done
so
usability
issues
on
top
of
EDP
and
bgp
has
been
discussed
in
the
previously,
and
there
are
three
Kaka
demic
papers
from
99
16
and
0
6.
So
we
have
a
key
management
issues
and
still
the
problem
remains
about
how
we
can
use
it,
how
we
can
make
it
more
usable,
so
that
can
be
another
issue
and
the
requirement
that
we
need
to
design
our
system.
Q
Q
There
is
a
lot
of
discussion
about
post
quantum
crypto
and
there
is
a
call
by
professors
and
academics
and
experts
in
the
field
that
we
need
to
start
considering
moving
towards
that,
because
the
time
that
will
pass
so
companies
to
adapt
for
new
plot
to
design
new
protocols
it
takes
time.
Information
that
we
are
storing
in
our
system
needs
to
keep
it
for
10
to
50
years.
So
we
already
need
to
start
designing
new
systems
that
would
consider
post
quantum
security
instead
of
running
afterwards.
We
need
to
be
proactive,
so
that's
all
for
my
site.
I
Then
Schwartz,
thank
you
for
forgiving
the
deep
thought
to
the
important
topic.
I
I
definitely
support
this
work
in
this
area
and-
and
this
draft
seems
very
well
written
but
I
had
a
few
comments
about
this.
I
think
that
this
is
a
fairly
opinionated
draft.
It
doesn't
seem
like
a
neutral
summary
of
the
field.
It
seems
more
like
a
coherent
framework
that
you're
presenting
I
was
just
giving
it
a
name
essentially
presenting
it
as
a
new
named
framework.
I
I
would
also
suggest
thinking
about
it
as
a
framework,
instead
of
describing
it
as
an
analysis,
or
especially
using
the
word
requirements
which
occurs
a
few
times
in
the
draft.
Certainly
if
the
IETF
requirements
refers
pretty
specifically
to
setting
yourself
up
to
do
specific
protocol
based
work
at
it
doesn't
seem
like
that's.
The
real
purpose
here
I
would
clarify
the
scope.
I
Those
are
really
important
security
threats
and
it's
fine
to
say
to
make
them
out
of
scope,
but
we
should
clarify
scope
and
I
would
suggest
thinking
about
this
in
terms
of
communication,
not
just
messaging,
both
because
I
think
the
the
technology
itself
doesn't
matter
and
because
video,
because
that
what
we're
really
thinking
about
here
is
communication
between
people,
whatever
form
that
takes
in
particular
video
chat
and
related
stuff,
I
think
it
has
important
privacy
concerns
that
we
should
be
thinking
about.
Thank.
Q
K
Up
in
exchange,
I
just
want
to
be
sure
that
I
understand.
What's
the
objective
of
the
work
you're
opposing
because
I
mean,
are
you
trying
to
write
a
set
of
requirements
to
then
design
yet
another
instant
messaging
protocol
that
this
time
will
be
private
and
secure?
And
so
because
I
think
that
it
was
already
pointed
out.
First
of
all,
in
the
scenario
an
email
and
instant
messaging
is
pretty
different
because
an
instant
messaging
you
only
have
walled
gardens
and
when
you
have
walled
gardens,
there's
no
way
you
can
exclude
it.
K
Whoever
lost
the
server
of
the
service
you're
using
so
that's
already
I
mean
a
basic
problem
from
any
care
for
any
kind
of
privacy
security.
You
want
to
to
grant
with
email
it's
different,
because
you
could
choose
your
server,
but
still
you.
You
have
lot
lots
of
other
things
to
address,
but
also
I
mean,
having
spent
some
time
time
to
me
in
the
real
world,
convinced
some
big
email
operators
to
just
adopt
existing
technologies
like
Dane
and
DNS
SEC,
for
example,
to
make
it
efficient,
more
secure.
K
I
agree
that
that
the
problem
is
this
problem
is
not
very
high.
In
request
of
their
users
or
of
the
people
that
runs
the
service,
so
some,
if
you
really
want
to
advance
the
discussion,
maybe
there's
non-technical
things
that
we
should
discuss.
If
you
want
to
put
this
only
at
the
technical
level,
then
I
would
like
to
understand
what
the
objectives
are.
What
what
you
want
to
achieve
in
practice.
Q
So
the
objective
of
this
internet
document
is
to
do
it
in
a
way
of
mapping
the
threads
in
the
technical
aspect
from
a
very
beginning,
instead
of
pointing
later
on.
We
have
this
thread:
let's
try
to
patch
it,
let's
try
to
figure
figure,
how
we're
gonna
design
a
system.
So
this
is
like
for
evaluating
existing
systems
and
protocols,
and
all
you
want
to
design
a
new
and
I've.
Q
Q
One
thing
that
you
said
is
system
messaging
and
emailing
is
different.
Yes,
but
one
is
low
latency,
the
other
is
high
latency.
Well,
nowadays,
both
systems
and
in
the
in
the
messaging
aspect.
They
both
have
common
points
with
both
if
we
just
remove
the
XMPP,
if
we
just
remove
the
SMTP
like
the
transport,
how
we
transport
on
the
format,
if
we
see
it
like
us
what
we
need
to
safeguard,
so
we
send
text
who
set
attachments
and
we
have
our
archiving
or
searching.
We
have
I.
K
I
Paris
koala
I
mean
this
is
an
interesting
space.
I
guess
I'm
a
little
less
sanguine
about
this
document
particular
document
that
Ben
is
the
as
Victoria
was
saying
like
trying
to
like
span
email
and
instant
messaging
in
video
straight
me
just
really
difficult.
You
know,
like
the
MLS
work
here
house,
like
a
fairly
well-defined
threat
model
in
the
organizer
document
that
rise
like
map
output.
I
The
threat
model
is
but
a
lot
of
it's
actually
fairly
specific,
like
the
MLS
setting
and
so
and
and
the
if
we
try
to
like
expand
that
to
email,
I
think
it
wouldn't
work
very
well
and
I.
Think
actually
part
of
like,
like
as
an
example
of
that
on
the
slides
you
have
about
like
how
awful
PGP
is
interface
is
like
basically,
don't
apply
any
instant
messaging
systems.
It
actually
have
extremely
streamlined.
I
It
is
like
designing,
secured
your
first
measuring
right
now
to
like,
if
you
want
to
work
in
there's
a
meshing
problem
to
engage
there,
and
if
you
want
to
write
like
an
email
for
analysis
like
this
might
be
an
okay
place
for
this.
But
then
this
document
needs
some
provision
to
like
actually
be
that.
I
Q
Q
Q
Maybe
you
were
set
up
like
we
start
doing
as
a
systematic
way
of
threads
and
identify
the
whole
spectrum
by
bringing
the
expertise,
everyone
has
and
then
have
an
internet
document
that
will
help
and
guide
others
that
will
like
to
design
engineers
that
would
like
to
design
right
is
it
like
did
I
answer?
Why.
I
Again,
what's
the
question
I
guess
what
I'm
saying
is
that,
like
this
document
would
not
be
helpful
for
designing
MLS,
it
would
not
advance
the
state
of
the
art.
It
might
be
useful.
Some
other
versions
dog
in
the
beasts
for
analyzing
email.
But
if
you
want
to
contribute
to
the
design
of
the
protocols
we're
actually
doing
here,
then
I,
don't
think
a
document
census
tract
is
gonna,
be
very
helpful.
Very.
O
Quickly,
Richard
Richard
Barnes
yeah,
similar
page
to
echo
at
all
I
think
you
know.
I
I
agree
that
this
is
an
important
problem
with
the
state
of
messaging
security,
especially
for
email,
is
really
terrible,
but
I
don't
think
it's
because
we
don't
understand
the
problem
sufficiently.
In
contrast
to
dr.
Woods
document
about
a
fingerprinting
where
there
is
like
open
uncertainty,
you
know
active
research
about
what
the
threats
are.
O
I
think
we
actually
understand
the
problem
pretty
well
and
even
in
the
MLS
case,
we're
writing
a
document
to
document
the
threats
were
addressing
in
the
architecture
for
addressing
those
threats,
that's
more
about
kind
of
consolidating
on
a
view
and
making
sure
that
everyone's
in
the
same
page,
because
everyone
already
had
fairly
detailed
internal
models,
all
of
the
vendors
who
are
coming
to
the
table
for
MLS,
and
so
that
was
more
of
a
consolidation
effort
than
research
really
so
I
think
this
is
probably
not
appropriate.
Work
for
a
research
group
here.
H
This
is
dkg,
so
I
think
I
agree
with
Eckert
and
Richard
that
this
document
might
be
too
broad
to
be
particularly
useful.
In
contrast
to
what
Ben
was
saying,
Ben
I'm
suggesting
maybe
we
could
abstract
it
even
further
I
mean
the
way
you
had
split
up
your
architecture.
It
looks
a
lot
like
you
could
use
it
to
discuss
IPSec
in
that
you
have
trust,
you
know
Association
context,
and
then
you
have
the
actual
messaging
security
and
you
have
to
transport
all
of
these
things
right.
H
Given
the
evidence
for,
like
the
low-hanging
fruit
that
we
saw
from
a
fail,
there's
room
to
identify
more
problems
there
and
so
I.
Don't
I.
Don't
think
this
is
going
to
be
fallow
ground
for
for
research,
even
but
but
I
do
think
that
it
needs
to
be
more
scopes
to
be
useful
or
entitle
more
tightly
scopes
to.
R
R
Q
Threads,
it's
mainly
these
documents
about
technical
threats
which
threats
can
be
the
classes
of
threats,
and
what
actually
does
it
mean
and
private
communication
private
messaging
system
in
a
future
consideration?
We
need
to
think
about
just
we
with.
We
think
that
we
should
also
consider
other
user
threats
in
terms
of,
but
this
is
can
be.