►
From YouTube: IETF108-OPSAWG-20200728-1410
Description
OPSAWG meeting session at IETF108
2020/07/28 1410
https://datatracker.ietf.org/meeting/108/proceedings/
B
Yeah:
okay!
Okay,
that's
that's
that
hello.
Everyone
welcome
to
the
obviously
wg
and
the
office
area
meeting.
This
is
the
online
virtual
meeting
for
the
itl
108
absolute
show
exercise
as
usual.
We
start
from
the
note.
Well,
please
make
sure
you
understand
the
notes
well
and
those
important
legal
issues.
Basically,
all
your
contributions,
including
your
writer,
the
presentations
or
the
video
needs
for
the
itf
rules
and
next.
C
B
C
B
You
speak
over
time,
we
will
have
to
cut
the
line
or
stop
speaking
and
next
here
is
the
working
group
status.
Two
working
group
drafts
the
text
protocol
and
the
sbi
are
in
the
rfc
added
queue.
We
do
not
have
much
thing
to
do
and
two
working
group
drafts
the
tekkercian
model
and
the
model
automation
framework
finished
the
last
call
and
we
just
submitted
to
the
iesg
and
the
network.
Telemetry
framework
draft
is
getting
stable.
C
B
A
No
just
that
the
new
meat
echo
format
here,
if
you
want
on
the
on
the
minutes,
if
you
launch
the
code
emd
in
a
different
tab
that
way
you
can
have
both
up
at
the
same
time,
if
you
want
to
add
some
some
thoughts
and
we
have
a
five
minute
gap
at
the
end
or
and
then
meet
echo,
will
hard
cut
us
off,
I'm
told
so,
just
again,
as
general
said,
be
cognizant
of
your
time.
That's
that's
all.
I
have
to
add.
B
D
You
now,
can
you
hear
me
now?
Yes,
absolutely
perfect,
I
have
the
double
mute
okay,
so
this
is
the
most
common
problem
these
days.
Okay,
so
we'll
start
with
a
with
an
update
on
the
on
the
several
vpn
related
modules,
which
is
the
two
working
group
documents.
This
is
the
l2nm
and
the
3nm
and
the
new
individual
document
that
came
out
of
them.
Okay,
so
please
next
slide,
okay,
so
which
were
the
goals
of
preparing
the
next
version
of
the
otf3
name.
We
had
three
main
goals.
D
One
of
them
is
address
the
comments
that
we
received
in
the
mailing
list
from
the
people
that
were
implementing
the
the
draft
which
we
received
a
few
of
the
comments.
The
second
goal
is
to
address
the
junk
doorster
review,
which
also
was
sent
a
bunch
of
comments,
and
the
third
one
is
that,
as
you
know,
we
are
maintaining
in
github
a
list
of
issues
with
the
additions
to
the
draft
or
new
things
that
can
be
covered
bugs,
etc.
D
D
D
D
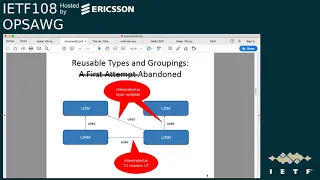
Okay,
so
the
first
attempt
that
we
did
in
the
first
version
of
the
draft
is
okay.
We
have
the
l3nm
which
uses
some
of
the
things
of
l3sm,
and
we
have
a
two
name:
that
okay
uses
some
er
of
the
groupings
and
some
of
the
definitions
that
we
did
in
earthquake
and
also
a
part
that
we
came
from
electrician
and
apart
from
send.
But
next
slide.
D
Please
and
this
or
this
line
of
work
was
a
little
bit
abandoned
because
we
received
a
feedback
from
people
implemented
that
they
interpreted
that,
for
example,
having
l2
and
m
using
a
component
from
l3
sm,
it
was
interpreted
as
okay.
The
l2
requires
the
r3,
so
people
say
no,
I
am
just
implementing
l2.
I
don't
want
to
implement
l3,
also
that
the
l2nm
uses
things
from
this
lr3
service
model.
D
So
this
is
why
we
decided
okay,
let's
have
a
vpn
common
module
in
which
the
two
common
models
that
we
are,
the
the
two
models
that
we
are
defining
now
the
l2
and
l3
name
uses
this
vpn
common
module.
So
next
slide,
please
and
potentially
the
idea
is
that,
as
per
suggestions
in
the
in
the
mailing
list
that
the
two
already
existing
service
module
could
use
in
a
future
if
they
have
a
base
version,
they
could
also
benefit
from
this
vpn
common
module.
Okay,
so
please
next
slide.
D
So
the
approach
is
to
extract
first,
that
the
nodes
that
are
common
for
both
the
3
and
m
under
3sm
and
then
we
filter
out
also
against
the
the
layer
2..
So
we
are
starting
just
with
everything
that
is
common
between
all
the
all
the
modules
and
we
did
a
check
that
all
these
common
groupings
are
are
available
and
are
referenced
in
the
r3
name.
So
we
think
that
from
the
design
perspective,
that
goal
is
made.
So
the
scope,
as
mentioned,
is
clear
to
everything
that
is
available
in
the
in
all
the
documents.
D
D
So
what
is
the
next
step
for
this
one?
So
as
what
we
have
been
doing
in
this
common
model
is
just
take
out
the
the
common
the
common
groupings,
from
the
main
from
the
main
modules,
the
main
modules
are,
let's
say,
not
not
change,
okay,
that's
what
the
content
is
is
from
from
there.
So
we
do
think
that
this
is
a
seems,
a
a
good
approach,
so
we
record
the
working
group
to
endorse
this
approach.
D
Okay,
so
we
want
to
ask
you
if
there
is
any
objection
here
and
our
question
is
okay,
if
you
are,
if
you
are
happy
with
this
way
of
working
of
this
vpn
common
module,
if
we
publish
this
as
a
standalone
document-
okay,
so
this
this
draft
that
we
have
published
as
individual
working
as
individual
document,
we
adopt
it
and
and
we
go
with
it
and
publish
it
as
a
standalone
document,
or
we
include
it
in
in
the
l3,
for
example,
in
the
earth,
rna.
Okay.
D
A
A
Okay,
not
seeing
anyone
get
into
the
the
line,
though
jeffrey
jeff
haas,
says
in
the
chat
refactoring.
The
common
stuff
at
this
point
is
reasonable,
since
the
model
has
reached
some
maturity
in
jeff's
ass
for
the
audio,
so
you
have
the
mic,
please
affiliation
name
and
go
for
it.
Jeff
has
with
juniper.
E
This
may
be
faster
than
typing.
The
refactoring
at
this
point
is
reasonable,
because
the
models
have
actually
gotten
enough
content
that
makes
sense
to
do
so.
The
main
thing
I
suggest
is
look
for
things
that
are
appropriate
for
iana
to
maintain
so
that
you
can
separate
those
into
a
separate
module
and
allow
those
to
be
extended,
without
necessarily
limiting
other
things
they
may
want
to
use
in
the
future.
A
Thank
you.
So
that
brings
us
to
a
a
hummable
question
here,
so
that
doesn't
sound
like
there's
any
other
objections.
In
fact,
one
support
with
reasoning,
so
the
question
you
raise
is:
should
this
effort
be
published
as
standalone
jeff
made
an
argument
to
kind
of
make
this
as
perhaps
agnostic
as
possible,
or
should
it
be
included
in
the
l,
three
and
m
draft?
A
So
if
everyone
could
go
over
to
the
kind
of
survey
looking
thing
next
to
the
chat
thing
on
the
left
of
the
right
or
left
part
of
the
pane,
we're
going
to
start
a
hum
hum,
if
you
feel
this
should
be
a
standalone
document,
this
vpn
common
module-
this
should
be
in
a
standalone
document
and
hum
is
now
active.
You
can
either
not
hum
hum
softly
or
hum
loudly.
A
Okay,
the
hum
is
closed.
Forte
is
the
perhaps
the
loudest
we
could
have
gotten
in
here.
Chairs
are
not
allowed
to
hum
as
participants,
and
I
think
some
of
the
meat
echo
people
in
here
can't
hum
nonetheless,
one
more
if
you
feel
that
this
should
be
so
hum
now,
if
you
feel
this
should
be
included,
this
common
module
should
be
included
as
part
of
the
l3
nm.
A
A
And
pianissimo
so
very
soft,
though
maybe
some,
but
it
sounds
like
from
a
consensus
point
of
view
on
this
call
oscar
the
the
thoughts
are
that
it
should
exist
and
be
a
there.
Wasn't
any
objection
and
should
exist
in
a
standalone
draft
will
of
course
ratify
or
get
final
list
consensus,
but
sounds
like
you
have
some
direction
there.
F
D
A
A
D
D
So
here
we
have
some
statistics
of
how
now
the
the
new
document
looks
like
so,
for
example,
the
groupings
were
from
35
groupings
that
we
have
in
the
in
the
first
version
of
r3nm
in
the
version
that
we
were
preparing
using
the
command
module
it.
It
has
just
two
groupings
specific
in
that
module,
so
in
and
in
the
common
one
we
are
having
like
eight,
so
you
see
that
we
reduced
significantly
the
number
of
of
them.
D
D
D
So
the
first
thing
is
the
the
issues
that
are
at
are
closed.
So
we
closed
since
the
last
itf
meeting
16
issues.
So
here
I'm
not
gonna
go
in
detail
of
them,
but
I
have
sent
a
full
report
to
the
main
list.
So
people
can
check
all
those
issues
that
were
closed,
so
if
anyone
finds
that
any
of
them
needs
to
be
revisited
reopened
please
and
go
and
uncheck
there,
okay.
So,
for
example,
just
just
to
to
highlight
one
of
them:
we
have
the
rtrd
auto
assignment
issue.
D
D
I
think
this
is
important,
a
new
kind
of
policy,
not
only
rooting
policies
but
also
incorporated
the
forwarding
policy,
so
that
is
the
behavior
on
the
packets
that
enter
the
brf
so
to
differentiate
those
so,
for
example,
the
forwarding
policy
you
can
do
it
within
with
an
acl-
and
we
just
here
add
a
name
to
the
policy.
Okay,
so
we
don't
enter
in
the
graph,
how
it
is
done
so
there's
there
are
that
works
in
the
idf
to
tackle
that
okay.
D
D
There
are
some
descriptions
and
some
references
to
to
add.
There
is
a
very
interesting
discussion
that
also
was
made
in
the
in
the
open
to
the
list
for
the
busy
sessions
parameter
support.
We
know
that
the
bdp
session
is
one
of
the
key
topics
in
the
cpe
communication,
so
people
wanted
to
expose
northbound
some
of
these
parameters,
so
the
discussion
is
on
how
much
we
open
from
from
bgp.
This
is
not
a
device
model,
but
we
are
leveraging
some
northbound.
D
So
here
there
are
already
nine
pull
requests
to
to
close
some
of
these
issues
they
are
pending
for
for
reviews
for
some
for
some
text.
Okay,
so
you
can
chime
in
and
and
please
you
can
review,
discuss,
okay,
so
next
slide,
please
so
just
just
to
highlight
what
is
one
of
the
issues
that
has
been
going
recurrently,
so
we
had
a
solution
that
did
not
fully
was
not
fully
adequate
for
all
the
implementers.
So
we,
after
the
the
feedback
received
and
several
combinations
and
several
conversations,
we
finally
decided
to
go
for
the
explicit
solution.
C
D
D
So
this
is
the
topic
that
was
write
more
more
discussions
also
in
the
intel.
So
it
was
to
highlight
it
here.
So
please
next
slide,
and
with
this
I
I
finish
so.
The
next
step
is
release
the
offer
version,
which
addresses
all
the
comments
from
the
implementers
and
the
young
doctor
review
and
includes
the
the
common,
the
com
module
and
then
we'll
work
in
resolving
all
the
remaining
issues
and
the
issue
a
note,
5
version
around.
D
A
G
I
think
it
was
answer
in
the
chat
yeah.
So
basically
I
was
thinking
for
the
rest
of
you.
I
was
thinking
that
maybe
the
the
young
doctors
review
could
be
revisited
because
we
wanted
to
have
something
in
common
with
your
third
draft
and
more
reply
that
actually,
even
that
one,
I
was
too
optimistic
to
believe
that
the
groupings
would
be
used
in
two
or
four
drafts.
So
I
think
this
this
was
answered
by
mo.
A
H
H
We
see
the
ample
s
top
labels,
transport
labels,
the
top
label,
iprs,
prefix,
number
and
so
on.
But
what
changes
from
impellers
to
ample
segment
routing
is
basically
the
label
protocol
the
protocol,
which
provided
the
label
from
the
control
plane
and
here
in
this
real-life
capture
we
see
ldp,
even
though
it's
no
more
ldp,
it's
now
secret
routing
and
the
reason
for
that,
if
you
go
to
the
next
slide,.
H
We
find
easily
at
ayana
at
the
ipfix
registry.
If
we
go
into
the
ipfix
amplis
label
type,
we
immediately
see
that
the
segment
routing
is
not
present
and
what's
missing
is
basically
the
code
points
for
isis,
ospf,
v2
and
v3
segment.
Routing
next
slide,
please
going
one
step.
Further
segment.
Routing
is
about
seed
types,
so
these
seed
types
have
actually
a
meaning.
It
can
be
an
instruction
it
can
be,
a
service
can
be
topologies.
H
H
So,
just
to
give
you
an
example
how
the
city
type
could
actually
help
to
give
us
visibility
in
how
segment
routing
is
actually
steering
forwarding
that
the
traffic
within
the
network
is
if
we
would
have
the
segment
routing
seat
type
dimension
available
in
case
of
ti
lfi
ti
lfa
one
of
the
applications
of
segment
routing.
Then
we
could
do
easily.
With
the
collected
metrics,
a
query
saying
show
me
all
the
impeller
segment
routing
control
traffic,
where
adjacency
seeds
are
used.
H
Group
them
by
label
stack
and
show
me
through
which
interfaces
and
nodes
this
has
been
forwarded.
So
that
allows
you
then
very
easily
to
see
when
basically
ti
lfa
jumped
into
action.
So
in
basically
what
it
means.
It
say
we
need
to
update
the
emperor's
top
label
type
registry
and
we
could
add,
introduce
an
tip
with
type
registry
at
the
ipfix
sienna.
H
I
already
have
collected
feedback
from
the
spring
and
ops
awg
working
group,
I'm
also
since
I
presented
yesterday
at
spring,
I
received
feedback.
I
should
also
collect
feedback
from
lsr
and
I'm
palace,
which
I
just
did
today,
and
I
submitted
a
request
to
ayanna
received
already
in
an
ipfix
entity,
doctor
review,
and
I
would
like
to
call
adoption
on
ops,
awg
working
group.
A
A
So
middle
of
the
road
piano
is
the
is
the
result
of
the
of
the
hum.
So
maybe
some
support
forte
was
the
the
last
strong
or
indication
of
strongest
support,
so
piano.
So
not
the
quietest
we'll
take
this
to
the
the
list
and
see
we'll
do
a
call
for
adoption
there
thomas
and
see
if,
as
a
as
a
participant,
it
seems
without
the
chair
hat,
it
seems
like
useful
work.
A
A
I
I
It's
a
software
bill
of
material
by
the
way
I'm
presenting
this
on
behalf
of
myself
and
scott
rose
from
nist,
and
this
is
a
a
software
bill
of
material-
is
essentially
a
software
inventory
or
a
software
manifest
of
the
device
or
a
package,
and
so
you
could
think
of
it
as
doing
like
apt
list
or
an
rpm-qa
to
find
out
what's
on
the
device,
and
there
are
a
couple
different
formats
for
how
a
software
bill
of
materials
could
be
generated.
Here
are
three
I'll.
I
I
I
So
what
can
s-bombs
be
used
for?
Why
doesn't
me
care
about
any
of
this
right?
The
first
is
that
if
you
have
a
pat,
if
you
have
a
bunch
of
packages
and
these
s-bombs
contain
relationships
between
packages,
then,
if
you're
a
supplier
of
if
you're
like
a
downstream
supplier
of
of
a
big
software
package,
you
can
look
upstream
and
determine
if
you
have
any
license
pollution,
that
is
to
say
suppose,
you're
using
gpl
when
you
shouldn't
be
using
gpl
as
an
example.
I
I
Are
you
vulnerable
for
any
particular
version,
and
do
you
even
have
that
version
on
your
network
and
there's
a
third
which
is
a
dependency
analysis
for
critical
systems?
That
is
to
say,
are
you
are
the
packages
that
you're
using
appropriate
for
critical
use,
and
if
you,
if
you
evaluate
them,
do
you
find
that
one
is
a
weak
link,
for
instance,
next
slide.
I
So
what
does
any
of
this
have
to
do
with
the
ietf?
We're
not
the
ones
driving
s-bombs
per
se,
the
they're
being
driven
elsewhere?
The
healthcare
industry
is
driving
these.
They
they
they're
looking
to
require
these
software
builds
and
materials.
We
saw
some
discussion
in
the
suit
working
group
where
the
gentleman
who
works
in
the
energy
sector
indicates
that
the
north
american
electrical
corporation
already
requires
a
certain
software
build
materials
for
their
devices.
So
we're
not
pushing
these
things.
I
They
all
they
did
was,
you
know,
send
it
around
using
email
and
then
the
next
round,
they
they
stuck
them
all
on
a
common
file
server
and
that's
fine
for
a
proof
of
concept,
but
in
real
life.
That's
not
the
way
things
are
gonna
work.
You
have
to
actually
know
how
to
find
these
things,
so
you
need
a
discovery
mechanism,
it
so
happens.
I
have
one
and
that's
a
pretty
good
opportunity
for
manufacturer
usage
descriptions
what's
interesting
about
using
manufacturing
usage
descriptions
for
this
one.
I
Is
that
we're
not
talking
about
access
control
or
anything
like
that,
we're
talking
about
nearly
an
attribute
of
the
device,
which
is
that
this
thing
has
a
software
bill
of
materials,
and
so
there
are
several
different
ways
in
which
you
might
locate
one
of
these
software
builds
and
materials.
One
of
them
is,
is
the
thing
on
the
device
itself,
the
the
other
is?
Is
it
somewhere
in
the
cloud,
the
reason
it
might
be
on
the
cloud
not
on
the
device
itself?
The
device
has
no
interface
to
retrieve
the
darn
thing.
I
The
third
is
that
you
might
actually
have
to
make
a
phone
call.
The
medical
people
are
particularly
careful
about
what
information
they
release.
I
just
got
off
the
phone
with
the
medical
device.
Manufacturers
say
we're
not
releasing
any
of
these
s-bombs
unless,
of
course,
we
have
the
appropriate
customer
relationship
and
there's
an
agreement
as
to
how
the
things
are
going
to
be
used,
and
what
format
are
these
things
in?
This
is
another
thing
that
needs
to
be
discovered.
I
Is
it?
Is
it
the
swift
or
cyclone
dx
or
spdx,
or
something
else
right?
So
these
are
the
two
sort
of
mechanisms
that
that
have
to
be
answered.
It
turns
out
that
you
know
mud
is,
is
a
perfectly
fine
way
to
answer
the
former
question
and
the
latter
question
is
conveniently
answered
by
something
else
next
slide,
please,
which
would
be
the
my
media
type
on
down
on
bullet
five.
I
I
It
allows
for
local
cloud
and
call
me
options
and
it
specifies
a
mechanism
for
local
access.
Like
are
you
if
you're
going
to
use
local
access?
Is
it
going
to
be
a
co-app
or
http
or
https,
and
if
it
is
local,
then
we
create
a
well-known
registry
to
go
retrieve
the
thing
and
when
we
do
that
right,
when
you
go
to
retrieve
it,
you
can
use
the
my
media
types
to
indicate
what
the
format
is
now.
I
The
our
assumption
in
this
is
that
the
tooling
the
receiving
end
of
this
of
this
s-bomb,
the
consumer,
is
going
to
have
to
be
able
to
handle
pretty
much
all
types
make
that
assumption,
because
the
chances
are
that
a
device
is
not
likely
to
to
choose
multiple
formats,
but
even
if
they
are
it
turns
out.
Http
is
pretty
good
about
that,
and
I
presume,
though
I
do
not
know
for
sure
that
co-op
would
have
a
way
to
allow
for
this.
I
We
might
have
to
be
a
little
stricter
about
co-op,
and
that
is
something
that
the
draft
needs
needs
review
on,
and
so
it's
it's.
It
relies
on
the
underlying
protocols
to
establish
whatever
security
is
needed,
so,
for
instance,
if
we
talk
about
http
or
https,
then
presumably
one
would
use
the
the
security
mechanisms
in
http
or
hdbs
in
order
to
manage
authentication
and
authorization
for
co-op.
You,
you
or
co-op
s.
The
same
would
be
true
next
slide.
Please.
I
So
the
drafts
out
there
in
fact
there's
a
poc
out
there.
I
can
talk
a
little
bit
about
that.
It
took
an
entire
30
lines
of
code
to
write
the
poc
30
lines
of
python
ain't
that
cool
so,
but
the
first
question
we
have
is:
are
there
more
than
one
of
these?
Software
builds
and
material
on
a
device?
And
if
so,
how
do
you
go
retrieve
them?
We
haven't
really
addressed
that
in
the
draft
yet,
and
we
haven't
really
addressed
that
in
the
draft.
I
I
I
Where
you
know,
maybe
you
see
the
name,
it
looks
familiar
and
you
know
that
there's
a
vulnerability,
for
instance
in
a
particular
version,
but
maybe
the
vendor
back
patched
it
back
ported
the
patch
into
one
version,
in
which
case
when
the
s
palms
released.
What
ends
up
happening
is
that
your
phone
rings
off
the
hook,
because
they
see
that
you've
got
open,
ssl,
101b
right
or
some
other
package
like
libxml
that
might
have
a
bug
or
whatever
it
is
right.
You
back
patched
it,
but
your
customers
don't
know
that
yet.
I
So
this
is
not
something
that
s
bombs
deal
with
directly.
We
know
we're
going
to
need
to
do
more
work
on
that
particular
question.
It
may
not
be
100
tightly
bound
to
this
particular
issue,
but
it's
something
that
we're
addressing.
We
know
we
need
to
address
and
then
I
think
that's
my.
I
think
I
have
one
more
slide
but
before
we
do
that,
let's
let's
go
for
questions.
C
Michael
richardson
settlement
software
works,
so
I
I
this
is
great
work.
Thank
you
elliot
and
I
hope
we
adopt
this
document.
I
I
thought
your
the
business
of
the
telephone
call
and
the
other
stuff
was
a
little
bit
interesting
and
I
guess
I'm
a
little
bit
confused
by
the
local,
the
bit
of
the
the
sbom
local
and
how
you've
enumerated
a
bunch
of
mechanisms,
but
then
said
the
url
is
well
known
and
I'm
wondering
why
you
just
merged
that
into
the
uri
in
the
first
place,.
I
Yeah
thanks
for
the
question,
michael,
so
what
let's,
let's
think
about
what
you've
got
you've
got
a
device.
That's
on
the
network,
it's
reporting
in
a
mud
file
that
it
uses
that
it
has
an
s
bomb
and
it's
accessible
by
https.
So
where
do
you
go?
Look
for
the
s-bomb
at
that
point?
Well,
it's
possible
that
you
could
just
say:
let's
go,
you
know
here
is
the
locale.
Only
in
the
mud
file,
you
might
have
many
devices
using
the
same
mud
file.
I
So
what
host
name
do
you
put
in
in
in
the
domain
part
for
the
for
the
s-bomb?
I
didn't
have
an
answer
for
that.
So
what
I
was
going
to
say
is:
let's
just
choose
the
mechanism
and
place
a
well
and
create
a
well-known
uri,
in
which
point
you
can
then
retrieve
and
you
can
fill
in
the
the
the
host
name
with
your
local
information
does.
Does
that
answer
your
question.
C
It
it
I
understood
that
part.
I
just
didn't
understand
why
I
seems
weird
to
enumerate
co-app
co-app
http
https
there,
rather
than
just
putting
some
special
token
into
the
uri
to
me
that
that's
maybe
a
detail
and-
and
I
I
also
find
that
I
guess
I
find
it
a
little
bit
weird-
that
the
device
is
capable
enough
to
provide
its
s-bomb.
I
A
E
E
He
gave
the
good
example
of
like
open,
ssl
being
able
to
have
some
way
the
enumerate
that
this
components
in
the
system-
and
you
know
if
you
happen
to
know
this-
is
vulnerable.
It's
a
thing
for
you
to
look
for.
So
that's
the
useful
thing
number
one
last
comment
is
that
you're,
giving
the
ability
to
retrieve
stuff
through
uri
and
one
of
the
things
I
think
you
probably
want
to
have
in
here-
is
the
document.
E
I
I
would
love
some
help
on
that,
and
so,
if,
if,
if
you're
interested,
please
feel
free
to
contribute
on
that
front,
one
of
the
things
we
have
to
just
make
sure
we're
managing
is
the
multiple
different
formats
and
what
should
be
internalized
and
what
is
externalized,
but
I
would
love
to
help.
I
mean
really
early
days
on
this
there's.
No,
I
don't
have
right
answers
there.
F
So
warren
kumari
record
apologies.
If
this
was
covered,
I
was
juggling
faiths
for
many
things:
I'm
okay
having
somebody
a
software
bill
of
materials.
If
it's
somebody
somebody,
I
already
have
a
relationship
with
right.
If
I
know
what
they're
going
to
do
with
the
nation,
etc,
if
I'm
just
selling
you
a
light
bulb,
I
might
not
be
quite
as
comfortable
sharing
the
fact
that
it's
using
the
following
17
libraries.
F
I
I
got
I
got
a
couple
answers
for
you
there,
oh
warren,
and
and
thank
you
for
your
question.
It's
a
good
one.
The
first
question
is
nobody's
forcing
anybody
to
produce
these
s-bombs.
At
least
I'm
not
well
I'll.
Take
it
back,
I'm
not
forcing
anybody
to
produce
these
things,
nor
will
the
ietf
it
might
be.
The
you
know.
The
north
north
american
grid
might
force
those
people
to
produce
something
or
the
fda
might
force
the
the
medical
manufacturers
to
produce
something.
I
I
The
cloud
might
then
say:
I
need
you
to
altitude,
you
have
a
log
in
in
order
to
get
credentials,
you
might
have
a
two
and
read
to
certain
terms,
or
you
might
just
say,
I'm
not
giving
them
out
or
call
me
if
you
really
need
it.
So
these
are
sort
of
the
options.
The
goal
here
warren
is
for
me
and
for
the
ietf
I
think,
to
not
impose
policy
in
this
regard,
but
to
allow
for
without
flexibility
for
those
sorts
of
policies.
Does
that
answer
your
question.
F
I
think
you
know
weren't
still
in
the
yes
kind
of,
although
if
you
create
a
standard,
you
know
they
will
come.
If
you
make
the
standard,
it's
very
easy
for
a
regulator
to
say
you
know
this
exists.
Therefore,
you
must
use
it
and
publish
it.
Michael
had
mentioned
that
you
know
it
is
specifically
the
light
bulbs
who
should
be
publishing
this
and
while
I
personally
agree
the
light
bulb
manufacturer
might
not
don't
get
me
wrong.
I
I
like
this
idea.
I
support
this
idea.
It's
just
there
is
some.
F
I
We
can't
stop
regulators
from
doing
stupid
things,
that's
for
sure
and
and
well
people
tend
to
get
it's
like
trying
to
stop
a
bus,
that's
out
of
control.
Sometimes
you
don't
want
to
stand
in
front
of
it,
but
at
the
same
time
right
what
we
can.
What
we
can
do
warren
is
perhaps
state
clearly
that
our
view
is
that
these
might
not
be.
We
don't
take
a
position
on
whether
these
are
useful
for
everybody
right
and
we
could
stay
safe
stuff
like
that.
I
I
don't
know
how
effective
that
would
be,
but
it
it
or
we
could
go
further
lauren
and
take
the
exact
opposite
approach
and
say:
actually
we
think
these
are
really
cool
and
you
should
do
them,
but
I
think
before
we
say
that
we
have
to
answer
the
other
question,
which
is
how
do
you
know
if
something
is
really
vulnerable?
Lest
all
of
our
phones
start
ringing
off
the
hook,
we
stopped
going
to
ietf.
So
we
start
working
for
customer
support.
A
There
there's
been
a
few
discussions
on
this
in
the
chat
doug
montgomery
started.
Maybe
the
s
bomb
should
always
just
point
to
a
manifest
that
we
define,
including
the
checksum
michael
said,
warren.
It's
precisely
that
the
light
that
the
people
like
bold
people
want
to
know
the
s
no
want
to
know
the
s
bomb.
Four
jeff
haas
said
agreed
doug.
A
What
I'm
mostly
arguing
is
the
manifest
needs,
a
bit
of
structure
for
audit
and
enumeration,
and
the
s-bomb
record
needs
the
ability
to
identify
a
specific
version
of
the
manifest
doug
agrees.
I
was
thinking
the
s-bomb
manifest
could
provide
a
level
of
indirection
for
all
the
possible
encoding
formats
and
warren
to
michael,
yes,
but
the
light
bulb
manufacturer
might
not
want
to
share
that.
If
the
standard
exists,
people
may
be
forced
to
publish
using
it.
I
personally
think
it
is
useful,
but
michael
yep.
A
Some
regulators
might
insist
that
it's
not
really
our
problem
and
doug
larger
user
communities
already
requiring
these.
I
don't
think
the
existence
of
an
interoperable
signaling
message
will
change
that
and
michael
to
doug
the
s-bomb
is
signed.
So
it
sounds
like
to
the
last
bullet
point.
There
is
some
interest
I'll
forego
the
the
hum
for
saving
us
35
seconds
and
we'll
take
this
to
the
list,
but
I
think
there's
both
interest
and
some
things
to
be
discussed
and
worked
out
to
push
this
work
forward.
Okay,
thank
you
very
much
for
the
time,
joe.
A
A
J
J
The
draft
in
ops
working
group
this
in
this
meeting
and
this
vpn
performance
monitoring
is
trying
to
fill
the
gap
for
the
vpn
service,
monitoring
for
the
layer,
3
vpn
and
also
we
are
also
taking
account
of
their
2
vpn.
Also
for
the
service
delivery,
automation,
delivery.
So
we
will
try
to
use
this
model
to
to
to
send
the
notification
to
the
up
to
client
layer
about
how
the
vpn
service
being
status
and
so
and
here's
the
the
assumption
of
this
draft.
J
J
These
figures
try
to
give
a
more
clear
view
about
why
this
like
which
place
this
modeling
is
fitting
to
like.
Currently,
there
are
three
in
them
and
also
their
three
and
them.
Work
has
been
working
on
in
the
progress
in
this
working
group
and
they
are
doing
for
the
configuration
the
service
configuration,
but
this
model
is
at
the
same
level
and
trying
to
collect
the
different
performance
monitoring
status
at
the
service
level.
J
And
this
is
the
example
that
we
are
trying
to
give
a
clear
view
of
what
this
model
can
can
be
work
for,
like
from
the
service
level.
There
are
two
sides
side,
a
and
side
b
and
the
network
level
and
service
level.
They
they
will
more,
have
more
interest
in
the
what's
going
on
between
c
one
two
c:
it
doesn't
care
too
much
about
the
underlay
performance.
J
There
are
two
vpn
one
is
hub
and
spoke,
the
other
is
a
point
to
point
and
they
will
have
some
relationship
to
the
underlay
topology
and
then
in
this
modeling
there
will
be
have
the
relationships
from
the
performance
monitoring
level
that
what's
the
relationship
with
the
only
topology
and
vpn
service
topology,
what
the
site
will
be
located
in
node,
one
node,
two
node
five
and
and
then
there
could
be
abstracted
link
between
those
nodes
and
what
that
will
be
the
performance
metric
will
be
next.
Please.
J
And
here's
the
the
approach
we
think
the
vpn
service
performing
can
can
augment
to
the
current
a
basic
network
topology
model
like
we,
we
just
augment
the
like
the
per
node.
They
will
see
what
work,
whether
this
node
is
for
this
specific
site
and
how
many
routes
for
this
person
for
this
network
like
if
this
net
network
is
implemented,
vpn
technology,
then
what's
this
network
will
support
how
many
routes
and
then
at
the
level
of
the
like
the
the
abstract
link?
J
J
A
A
I
may
have
missed
it
on
the
list
concerning
this,
so
I'm
I'm
curious
as
to
how
how
much
I
mean
we
we
can
do
a
hum,
but
how
much
support
how
much
iteration
has
gone
on
respective,
to
the
other,
at
least
the
adopted
work
in
the
l2
and
l3
nm
modules
trying
to
understand
clearly
there's
some
integration.
There
there's
some
there.
There
is
some
thought
of
interoperability,
but
I'm
just
curious
what
the
what
the
can?
What
the
thinking
of
of
that
group
has
been
on
this.
A
K
C
K
L
Apologies,
I
had
to
step
out
for
a
couple
of
minutes,
so
I
missed
the
very
er
end
of
that
presentation
and
any
questions
you
asked.
But
one
question
I
have
is,
I
think,
bo
you
mentioned
this
had
been
presented
in
best
before
I
was
just
wondering
how
much
discussion
had
happened
in
bess
or
how
like
how
much
maturity?
Is
this
draft
system
relatively
fresh
or
had
it
been
in
best
for
a
while.
K
Yeah
to
answer
the
rover,
it's
a
question.
Actually
this
job
has
been
around
in
best
for
for
a
while.
Actually
we
actually
present
this
job
actually
got
a
lot
of
interest
about
the
talk
with
the
best
share
offline.
They
think
it
seems
for
this
worker
not
not
in
the
scope
of
best,
so
they
actually
they
put
in
this
job
in
a
in
a
covered
operating
machine
q.
But
you
know
they
are
hesitated
to
to
adopt
this.
So
we
in
last
item
meeting
we,
we
lost
the
idf
internal
meeting.
K
We
also
present
this
working
best
and
best
chair
also
have
some
concerns.
So
we
risk
some
discussion
to
address
some
concern
from
the
chair
to
clarify,
for
example,
whether
to
define
some
new
message,
a
new
metric.
Actually,
we
actually
get
this
result
and
a
bit
with
this
new
version
of
data,
and
we
also
checked
routing
area
id
about
every
director
about
this,
whether
we
didn't
get
a
feedback,
and
so
we
think
actually
you
know,
based
on
you,
know,
indication
from
a
better
chair.
We
think
you
know
they
they
think.
L
K
L
K
A
K
C
K
Yeah,
yes,
this
job
that
focuses
on
you
know,
for
air2nm
and
elsewhere
I
mean
I'm
actually
focused
on
top
top
down
service
delivery.
For
this
performance
management
model.
Actually
you
know,
focus
on
you
know
is,
is
kind
of
top
down.
Is
it's
portal
up
performance
monitoring,
so
they
you
can
create
the
closed
loop,
build
for
the
automated
system.
Yeah!
It's
complimentary,
yeah.
L
N
N
A
A
A
A
A
N
N
N
If
there
are
some
access
networks
not
deploying
savvy,
then
there
may
still
be
sources
spoofing
in
their
core
networks
for
network
level
c,
it
can
be
divided
into
ingress,
acl
and
urpf
solutions.
The
problem
of
ingress
is
their
solution.
Is
that
it
requires
many
configuration
to
update
if
there
is
a
routing
change
or
prefix
change
and
for
urpf
it
includes
a
strict
erpf,
neuse,
erpf
feasible,
pass
erpf
or
fperpf,
and
a
recently
proposed
enhanced
fadeable
pass
erpf
or
efp
urpf.
N
First,
let's
look
at
the
strict
drpf
it
takes
the
source
address
as
a
destination
address,
to
look
up
the
flip
and
if
the
outscreen
interface
of
the
fifth
matches
the
income
interface
of
the
package,
then
pass
it.
Let's
use
this
figure
as
an
example:
lotter
1
advertises
its
prefix
p1
and
p2
to
the
outer
2
and
the
letter
2
further
advertised
to
router
3.
While
letter
1
only
advertises
its
prefix
p2
directly
to
router
3.
in
this
case,
if
zotero
1
since
of
a
sends
a
valid
flow
flow.
N
N
For
loose
erp,
it
also
takes
a
source
address
as
a
destination
address,
to
look
up
the
fee
and
if
the
address,
if
the
address
exists
in
the
field,
then
pass
it,
we
just
use
this
same
example.
If
letter
one
sends
a
flow
with
just
always
a
forge
the
source
address
which
is
source
address
p3
in
this
case,
if
it
is
sent
to
letter
two
and
letter
two
further
otherwise
has
the
further
sentence
to
letter.
N
N
N
N
Next
next
yeah
yeah,
okay,
actually
to
to
overcome
the
problem
of
fp
erpf
efp
rpf,
is
recently
proposed.
There
are
two
algorithms
in
fp
rpf
algorithm
a
and
algorithm
b.
Both
of
them
are
designed
for
interest
keys
in
algorithm
a
and
yes,
we
are
set
all
the
prefixes
received
for
for
another
s
on
each
customer
interface
that
received
an
update.
Let's
take
this
figure
as
an
example:
s1
advertises
its
prefix
p1
to
s2
advertise
its
prefix
p2
to
s3
and
advertise
its
prefix
p3
to.
B
N
So
in
this
example,
if
we
draw
algorithm
a
as
well,
we
are
just
combining
all
the
prefixes
in
the
neurons
for
s1,
that
is
p1,
p2
and
p3,
and
it
will
include
this
set
in
the
rpf
list
on
each
on
the
each
of
these
customer
interfaces
that
it
receives
an
update
that
is
interface,
1
and
interface
2
in
this
case.
So
when
s1
sends
the
flows
with
p1,
p2
and
p3
as
the
source
address,
these
flows
will
be
correctly
accepted
and
the
interface
1
of
s4
next.
N
However,
if
we
just
slightly
change
the
setting,
if
we
assume
that
s1
only
advertise
the
prefix,
p1
and
p2
to
s3
and
does
not
advertise
any
prefix
to
s2
in
this
case,
if
again,
s1
senses,
three
flows
with
p1,
p2
and
p3
as
a
source
address,
essentially
flows
to
s2
and
s2
further
forwards
to
s4.
In
this
case,
these
three
flows
will
be
incorrectly
delight
and
interface,
one
of
s4,
because
s4
does
not
receive
any
update
from
interface
one.
So
it
will
not
put
these
prefix
preferences
into
its
rtf
list.
Next.
N
N
In
this
case,
that
is
a
p1
and
a
p2
of
s1,
and
the
second
part
is
the
prefixes
learned
from
its
peer
or
provider
interfaces.
In
this
case
it
is
a
p3,
so
see.
Actually
it's
just
the
unit
of
these
two
parts
that
is
p1
p2,
p3
and
s4.
We
have
put
this
set
all
of
these
customer
interfaces,
no
matter
whether
it
receives
an
update
from
that
interface.
N
N
N
N
Now,
if
s3
sends
two
package,
one
valid
packet
with
p1
as
a
source
address
and
an
invalid
packet
with
p3
as
their
social
address,
so
the
strict
urpf,
new,
crpf
and
fprpf
will
have
some
problems
to
okay,
either
to
drop
the
legitimate
package
or
to
accept
the
forty
packet
for
efp
erpf.
If
we
run
algorithm
a
it
will
drop
the
next
mid
package,
and
if
we
draw
wrong
efp
algorithm
b,
it
will
accept
the
photo
package.
N
N
N
So
again,
if
81
sends
two
packets
that
is
with
a
valid
package
with
p1
as
a
social
address,
and
I
invalid
the
packet
with
p3
as
their
social
address.
If
we
run
strict,
erpf
or
loose
erpf
or
fprpf,
it
will
again
either
drops
the
electron
packet
or
accept
the
forty
package
and
the
efp
rpf
is
designed
for
intro
as
keys.
So
it
does
not
apply
in
this
scenario.
N
N
Okay,
that's
all
of
my
presentation,
so
a
big
we
we
find
that
the
existing
urpf
technologies
cannot
cover
all
the
network
scenarios,
so
a
more
advanced
technologies
are
required
to
just
to
to
get
a
more
accurate,
safe
in
network
level.
So
your
comments
are
appreciated.
Thank
you
comments
from
the
audience.
O
P
A
Thank
you
dan
with
that.
That
concludes
the
ops
awg
portion
and
it
looks
like
rob.
We
owe
you
a
thanks
for
stepping
in
and
taking
some
some
good
notes
there.
I've
seen
so
appreciate
that
and
I
will
hand
it
over.
Oh,
I
think
warren's
coming
in,
I
warned
I
was
going
to
hand
it
over
to
you
and
rob
for
the
ops
area
unless
there's
some
ops,
awg
comment
you'd
like
to
make.
F
F
Them
for
you
so
hi.
Everyone
welcome
to
the
ops
area,
part
of
the
combined
ops
area
and
ops
awg
meeting
the
chairs
have
kindly
agreed
to
carry
on
running
the
session
and
dealing
with
slides
and
things
like
that,
and
hopefully
they
will
be
willing
to
also
help
with
minutes
or
can
somebody
else
do
that
chairs?
Are
you
okay,.
F
Thank
you
very
much
and
as
just
a
very
quick
update,
we've
been
discussing
the
possibility
of
having
something
like
an
iot,
oh
yeah.
I
guess
I
should
turn
on
my
camera
as
well
will
probably
be
a
lighter
there.
We
go
hey
so
yeah,
it's
a
very
quick
update.
We've
been
discussing
the
idea
of
having
an
iot
operations
and
onboarding
working
group.
This
is
still
very
much
an
early
discussion
and
you
know
there
isn't
really
a
charter
yet
or
anything
like
that.
E
G
All
right,
so,
okay,
let
me
start
so
I'm
benoit
with
cisco,
and
I
want
to
present
those
two
drafts.
Those
drafts
have
been
updated
yesterday
because
you
received
some
feedback
from
the
hackathon
last
week
and
next
those
two
draft.
We
have
a
one
presentation
where
korean
will
be
presenting
the
results
of
the
hackathon
and
how
he
implemented
the
sane
architecture
in
open
source.
So
we
thought
it
was
interesting
to
you
to
create
as
well.
So
maybe
we
want
to
keep
all
the
questions
for
the
end
to
be
respectful
of
the
time.
G
G
G
G
G
G
So
we
have
at
the
top
an
orchestrator,
an
orchestrator
configure
services.
We
discussed
today
about
lgb
and
ultra
vpn,
and
what
we
do
out
of
that
is
that
we
extract
the
service
type
and
service
instances
into
what
we
call
a
syn
orchestrator
and
we
did
use
the
intent,
the
intent
being
basically
the
services.
G
G
There
is
plenty
of
code
which
is
basically
which
makes
it
impossible
to
solidize
and
we're
not
going
to
summarize
the
same
agent.
However
solidizing
the
apis
means
that
this
graph
would
become
distributed.
I'll,
come
back
to
that
point,
okay
and
slide
8.
Please,
because
I
made
a
mistake
in
the
order.
So
this
is
basically
a
proof
concept
that
we
created,
and
this
is
maybe
what
will
mean
what
we
will.
What
will
make
you
understand?
What
we're
doing?
G
We've
got
a
top
a
service-
it's
let's
say
a
tunnel
in
this
case,
a
tunnel
for
its
coca-cola
and
all
the
concepts
I
explained
in
the
draft
here
I'm
going
to
go
and
explain
them
here,
so
this
service
to
work.
It
depends
on
the
left-hand
side
on
the
health
of
the
tunnel
interface
and
then
that
interface
depends
on
the
hairs
of
the
loopback
interface.
That
depends
on
the
health
of
the
device
that
depends
on
the
health
of
the
data
plane
and
telemetry,
but
also
in
the
middle.
G
That
service
depends
on
the
health
of
the
connectivity
between
source
and
end
point.
So
this
is
what
we
mean
here.
So
what
we
do
here
is,
as
I
mentioned,
we
doing
the
assurance
of
every
single
blocks
in
there
and
we
infer.
This
is
important.
We
infer
the
health
score
of
the
top
service
here.
We've
got
a
couple
of
boxes
that
are
arranged,
so
we
see
at
the
right
hand
side
that
the
value
of
the
service
is
zero,
five.
G
So,
okay,
it's
not
one.
It's
zero!
Five.
We
believe
there
is
something
wrong.
The
value
here
is
that
we
show
our
problem
is
not,
but
also
where
it
could
be,
and
I,
for
example,
the
the
tunnel
on
the
left-hand
side
or
interface.
I've
not
displayed
the
the
same
template.
There
is
no
traffic.
Clearly,
there
is
something
wrong.
G
I
clicked
for
that,
one
on
the
ecmp
fair
load
and
we
see
a
symptoms
telling
okay,
it's
not
fairly
balanced,
which
means
that
we're
doing
baselining.
So
what
is
imply?
You
know
we're
not
trying
to
go
after
the
assurance
where
interface
is
down.
This
is
just
too
easy
as
an
example,
we
just
do
close
loop
automation.
We
enable
it.
Okay,
big
deal
we're
after
the
things
where
we're
about
to
tell
the
symptoms
on
specific
components,
and
you
see
also
dotted
lines
and
then
full
lines.
G
We've
got
the
notion
discriminate
draft,
which
is
about
informational
dependencies
and
impacting
dependencies
if
I've
got
a
dependency
on
ecmp.
Is
my
service
affected?
Well,
it
depends.
However,
it's
already
a
good
symptoms
to
have,
and
I
see
a
message
from
reshap
telling
that
it's
difficult
to
see
the
the
the
drawings
there
I
put
like
a
high
quality
in
there,
but
and
I'm
not
sure
what
happened.
G
I'm
not
sure
if
it's
clearer,
if
the
slide
turns,
I
haven't
done
anything
okay.
So
if
you
look
at
the
right
hand,
side.
Oh
thank
you.
That
is
way
clearer.
If
you
look
at
the
right
hand,
side
as
well,
if
you
click
on
the
fair
load,
you
see
the
list
of
impacted
services,
which
is
key.
Whenever
you
do
troubleshooting
the
network,
you
want,
you
have
to
understand.
Okay,
there
is
one
issue
with
that
component
and
I
know
it
impacts
many
services.
G
So
this
is
what
we've
been
doing
with
the
young
modules
with
the
poc
and
okay.
If
you
go
back
to
slide
seven
now,
please,
I
hope
I
explained
all
the
concepts
right
and
what
has
changed
is
last
time.
Well,
we
stress
that,
actually,
we
have
an
open
architecture,
a
flexible
architecture
that
allows
to
have
distributed
graphs.
G
Some
of
those
graphs
could
be
in
a
router.
Some
could
be.
You
know,
coming
from
an
orchestrator
with
a
tunnel
l2vpn
and
vpn,
but
also
for
wireless,
also
for
a
5g
or
a
vim,
and
this
is
one
of
the
difficulties
we
see
with
operators
is
that
we've
got
different
groups
in
charge
of
a
different
aspect
of
the
network,
because
you've
got
young
models
for
all
these.
For
this
graph
we
could
easily
add
dependencies.
G
Let's
assume
that
the
operator
has
got
an
issue
had
an
issue
yesterday
at
3
pm,
we
could
go
back
and
see
exactly
what
happened.
We
also
described
better
what
a
change
mean
and
we
clarify
a
couple
of
things
in
a
draft.
For
example,
we
get
two
notion
of
labels,
so,
okay,
maybe
it
was
quick,
but
first
of
all
I
presented
already
and
second
of
all,
I
want
to
make
sure
we've
got
time
for
korean
to
present.
I
believe
this
is
my
last
slide
and
we'll
have
a
q
a
in
the
end.
M
M
M
Please
so
I
am
writing
an
open
source
same
agent
alongside
two
visualization
tools,
so
the
agent
can
be
described
in
three
steps:
the
inputs,
the
metrics
and
the
rules.
So
first
the
inputs
works
by
discovering
data
sources
and
then
gathering
data.
So
what
I
mean
by
discovering
data
sources
is,
for
instance,
you
will
enumerate
all
the
api
for
all
hypervisors
and
find
out
which
one
is
running
on
the
node,
that
you
run
the
dx
agent
on
and
then
pull
data
from
the
virtual
machine.
M
C
M
M
Well,
you
want
to
discover
if
they
run
a
dns
subservice
if
they
run
a
dhcp
sub
service
or
if
they
are
running
any
ecmp
and
so
on
and
so
forth,
and
the
final
step
is
the
rule
step
which
aims
at
applying
rules
on
those
normalized
data
in
order
to
derive
symptoms
which
are
then
used
to
compute,
a
health
score
pursue
service.
And,
finally,
the
the
health
analysis
are
transmitted
alongside
the
service
dependencies.
M
M
This
screen
is
actually
the
matrix,
so
you
can
see
all
of
under
independent
value
at
the
top.
You
see
the
red
lines.
There
are
positive
symptoms
and,
just
after
you
can
see
the
full
identification
of
the
node
that
triggered
it
and
on
the
other
side
you
see
the
tree.
So
each
node
represents
a
subservice
and
each
edge
represents
a
dependency.
M
Next,
please
so
yeah
you
can
zoom
out
please.
So
the
critical
part
of
this
tool
is
the
rule
engine,
because
this
is
what
is
used
to
highlight
the
symptoms
which
are
later
used
to
derive
health
scores.
So
the
idea
is
to
leverage
the
service
expertise
to
highlight
anomalies
using
rules,
so
rules
are
basically
expression
based
on
variables,
which
are
the
metrics,
the
vendor
independent
data
which
are
at
your
disposal
alongside
basic
operators
and
a
little
bit
more
complex
operators.
M
So
at
the
bottom
you
see
examples
of
rules,
so
you
have
a
name
to
define
it,
a
node
to
which
it
should
be
attached
and
checked
a
severity
factor
and
on
the
right
side,
the
expression
of
the
rule
so,
for
instance,
the
first
one.
It
checks
if
the
interface
has
changed
state
up
to
down
down
to
up
six
or
more
time
on
the
last
minute
and
if
it
did,
the
symptom
is
triggered,
but
you
can
also
check
buffer
or
occupancy
ratios
check
for
any
increment
of
a
given
error.
M
M
So,
in
my
opinion,
this
is
a
very
promising
approach,
because
it
has
a
lot
of
use
cases
you
might
want.
For
instance,
let's
say
you
have
this
company,
which
owns
a
lot
of
devices
on
which
you
are
running
same
engines,
the
dx
agent,
for
instance,
and
you
have
the
company
as
a
client
that
uses
a
subset
of
those
devices.
M
For
instance,
you
can
find
the
consequences
of
a
component
failure
by
using
the
the
dependency,
so
you
can
find
what
are
going
to
be
the
consequence
of
this
and
what
are
going
to
be
the
impacted
clients,
for
instance,
and
of
course
you
can
still
use
it
to
monitor
multiple
unrelated
service
health
slide.
Please.
M
M
So
we
interface
it
with
dx
agent
and
then
collect
it
in
telegraph
pmcct
and
to
a
visualization
to
slide
these.
So
this
is
what
happens
when
the
health
is
at
100
percent
slide
please.
So
this
is
chronograph.
So
then
we
see
a
health
score
that
decreases
slightly
and
you
can
use
the
tools
to
dig
up
for
the
root
causes
so,
for
instance,
use
dx
web
with
your
node
gnmi
target.
M
As
argument,
and
here,
if
you
zoom
very
close,
you
can
see
that
the
red
path,
basically
at
the
bottom,
leads
you
to
dpdk
buffer
allocation
error
and
to
a
lack
of
huge
pages.
So
this
problem
can
be
fixed
straightforwardly
by
allocating
more
huge
pages,
or
you
could
also
use
the
dxtop
interface
slide.
Please.
M
We
did
also
more
interoperability
work
with
alexander
leonardi.
Adding
support
for
the
execution
export
to
the
cisco
sign.
Collector
slide,
please.
So.
Finally,
the
immediate
next
steps,
at
least
for
me,
are
working
on
a
more
complex
rule
engine
to
allow
for
more
versatility
in
the
rule,
expressions
possibly
to
investigate
the
addition
of
an
end-to-end
probing
tool
as
input
source
to
have
some
kind
of
empirical
view
of
what
is
going
on.
Then.
The
next
big
step
is
this
multi-node
graph,
concatenating
step,
which
I
believe
is
very
interesting.
M
C
F
G
So
we're
presenting
in
both
of
the
margin
up
to
blue
g,
since
we
plan
onto
advising
interfaces
with
yang
model
and
since
it's
a
new
architecture,
I
believe
it's
fits
observable.
Ug,
ops,
area
nmrg
is
more
research
aspect
and
by
the
way
we've
been
developing
this
project
for
two
years
now.
So
I
believe
we
did.
Our
research
part
already
hands
the
proof
of
concept
and
the
yang
module
api
and
the
hackathon
for
interrupt.
F
And
I
suspect
we
have
actually
run
out
of
time,
but
I
don't
think
we
might
manage
to
get
another
question
in.
So
thank
you
very
much
benoit
and
everybody
else
for
showing
up
for
the
session.
Let's
carry
on
the
discussion
on
the
mailing
list.
I
personally
think
that
it's
interesting
to
discuss
it
in
nmrg,
but
I
think
the
actual
work
part
of
it
is
likely
to
happen
somewhere
in
this.