►
From YouTube: IETF 108: Technology Deep Dive on DNS
Description
This session was held at 1800 UTC on 23 July 2020. Everyone understands how the Domain Name System (DNS) works, but everyone is wrong!
Join João Damas, Wes Hardaker, Geoff Huston, and Warren Kumari as they cover the lesser understood aspects of DNS, and where the sharp edges are. This session will be especially valuable for those who think that they understand how the DNS works, as well as those who want to build something on top of the DNS.
A
A
A
A
A
The
session
is
only
90
minutes,
and
so
it's
mainly
going
to
have
some
introductory
stuff
and
some
deep
dive,
but
we're
likely
to
have
at
least
one
more
session
on
the
internet,
including
things
like
myths
and
misconceptions
that
will
likely
happen
at
ietf,
109
or
ietf110,
and
with
that
out
of
the
way,
and
because
we
have
more
content
that
we
have
time.
For
I'm
gonna
hand
it
over
to
wes.
Take
it
away.
B
All
right
thanks
warren-
hopefully
everybody
can
see
my
slides.
I
think
barry
indicated
that
he
could
so
the
three
of
us
are
going
to
go
over
stuff,
we'll
we'll
start
sort
of
high
level,
but
we'll
dive
pretty
deep
into
various
parts.
We
will
do
in
the
future
security
related
stuff.
This
is
a
ietf,
a
ietf
event,
part
of
ietf
108.,
welcome
everybody
to
ietf108.
This
is
besides
the
hackathon.
This
is
one
of
the
earlier
things
that
are
happening.
I
hope
you
have
a
great
week
next
week.
B
Please
do
note
that
the
notewell
for
the
idtf
does
cover
this
event
as
well.
I'm
not
a
lawyer,
so
I
won't
attempt
to
summarize
it
for
you,
but
you
had
to
go.
Read
it
on
the
ietf
website.
If
you
have
not
done
that
before
today,
we're
going
to
be
going
over
sort
of
three
major
topics:
I'm
going
to
talk
about
dns,
basics
and
beyond
the
basics.
B
B
So
this
is
how
the
internet
user
average
internet
user
sees
it.
We've
at
the
ihf
we've
designed
things
well
enough
that
you
know
we
hide
a
lot
of
the
complexity
in
many
protocols
that
dns
included.
They
want
to
go
to
a
website,
they
type
a
website
in
and
they
think
they
get
everything
back
from.
You
know
some
machine.
B
They
don't
understand
quite
how
it
works,
and
you
know
the
technical
person
typically
knows
a
little
bit
more
right.
They
know
that
they
have
to
look
up.
You
know
an
address
in
the
dns
first,
translating
the
name
into
an
ip
address
and
that's
done
by
dns,
and
then
they
do
http
or
https
to
you
know
a
server
to
actually
get
the
answer.
B
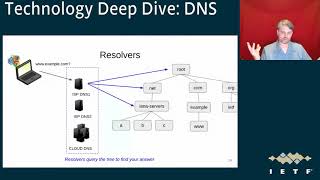
The
dns
is
a
lot
more
complex
than
that
and
we're
going
to
go
over
bits
and
pieces
of
this
whole
diagram,
but
there's
there's
lots
of
devices
and
boxes
involved
and
lots
of
servers
involved
just
to
even
complete
one
web
page
and
and
actually,
as
an
example
of
that
example.com.
As
many
people
know
as
a
as
a
domain
or
owned
specifically
to
deal
with
documentation
and
things
like
that,
it's
one
of
the
things
we
put
into
ietf
documentation-
and
this
is
what
a
web
page
generates.
B
B
The
dns
is
a
very
distributed
protocol
and
it
was
really
created
as
a
replacement
for
just
static
hosts
files
way
back
in
the
beginning
of
the
internet.
It
was
you
know
it
was.
People
were
shipping
around
these
static
host
files
of
addresses
and
names
associated
with
them,
and
then
they'd
have
to
update
them
on
a
regular
basis
and
that
got
unwieldy
and
clearly
doesn't
scale
to
the
millions
of
names.
B
That
we
have
out
in
the
world
today
so
the
the
envision
was
we
created.
This
tree
of
information
tree
is
sort
of
a
misnomer
because
it
really
looks
more
like
a
root
structure
than
a
tree,
but
it's
still
called
the
dns
tree
with
the
root
at
the
top.
A
lot
of
people
don't
even
know
that
the
root
exists.
B
They
think
that
net
com,
org
and
all
the
top
level
domains
are
really
the
top,
but
there
actually
is
a
system
above
that
which
we'll
talk
a
little
bit
more
about
and
then
there's
second
level
domains.
Things
like
example.com
is
one
at
ietf.org
and
icann.org.
As
some
other
examples.
This
diagram
is
going
to
repeat
a
lot.
I
am
not
showing
all
of
the
other
components
of
the
netcom
org
and
root
zones,
because
the
dot
net
zone,
for
example,
has
13
name
servers
associated
with
it
would
be
other
bubbles
around
and
so
does.
B
B
B
It
opens
a
a
request
to
your
isp,
typically
your
dns
resolver
and
the
isp,
and
though
the
job
of
those
boxes,
including
the
cloud-based
ones
that
are
talked
about
a
lot
in
the
ietf
lately
and
in
other
places,
the
job
of
them
is
to
go
actually
traverse
this
tree
to
find
the
answer
that
that
you
need
and
then
return
it
back
to
you,
there's
a
good
number
of
types
of
resolvers
and
there's
a
good
number
of
boxes
that
also
may
exist.
Your
wireless
box
often
acts
as
a
resolver,
the
hotel,
paywall
type.
B
You
know
thing
where
you
have
to
prove
that
you're
in
the
room
or
a
coffee
shop,
or
something
like
that
acts
as
a
resolver
as
well
and
treats
them
differently.
Joao
is
going
to
talk
a
lot
more
about
them
later,
but
there's
stub,
recursive,
forwarder
and
validating
he'll
talk
more
about
what
each
of
those
are
the
near.
The
end
of
the
talk,
priming
queries,
bootstrap
resolvers,.
B
When
you're,
when
a
resolver
starts
up,
it
really
doesn't
have
any
clue
about.
You
know
what
the
world
looks
like,
so
it
the
only
thing
it
has
is
a
hard-coded
list
of
addresses
of.
Where
do
I
get
started
and
it
the
first
thing
it
does?
Is
it
starts
up
and
asks
the
root?
Hey,
you
know
is
my
list
up
to
date.
Where
do
I
get
started?
Where
are
the
the
13
points
on
the
or
six
really
20?
Excuse
me,
26,
4
13
for
ipv4
and
13
for
ipv6.
B
Where
do
those
exist
in
the
world?
How
can
I
contact
them?
So
I
can
find
the
rest
of
the
tree,
so
this
is
called
a
priming
query.
You'll
see
that
in
a
lot
of
documentation
and
in
a
lot
of
discussion,
the
dns
is
a
distributed
protocol
and
it
does
that
by
delegations,
and
so
each
zone
is
allowed
to
delegate
any
sub
portion
of
its
name
structure
within
it
to
a
different
zone
where
a
zone
is
sort
of
a
collection
of
names
and
information
associated
with
one
particular
point
in
the
tree
and
delegations
occur
lower.
B
Looking
at
the
same
sort
of
diagram,
the
apex
of
a
zone
is
another
commonly
mis
heard
and
misunderstood
name.
It
is
the
top
level
name
associated
as
sort
of
the
entry
point
into
a
particular
zone.
It's
the
the
name
of
which
a
delegation
actually
arrives
at
oops
wrong.
Key
other
nodes,
of
course,
can
exist.
The
leaves
if
it's
the
end
of
a
if
it's
the
end
of
a
tree
right
is
the
the
bottom
node
in
a
tree.
B
You'll
find
that
it
is
called
a
terminal,
node
or
a
leaf,
sometimes
but
they're
terminal
nodes,
meaning
they're.
They
terminate
the
tree,
whereas
you
can
actually
have
nodes
in
the
middle.
You
don't
have
to
have
each
name
be
subdelegated
and
so
empty
nom
terminals
are
things
like
the
a
in
b.a.example.com,
where
there's
actually
no
data
there,
but
there
is
stuff
underneath
it
and
it's
actually
within
the
same
zone.
So
when
you
read
the
documentation,
you'll
see
things
like
terminal
and
empty
non-terminal.
B
You
can
come
back
to
this
slide.
If
you
ever
get
stuck
a
couple
of
important
things.
Duplicate
records
are
needed
in
both
the
parent
and
the
child
zones,
so
for
net
to
be
able
to
tell
clients
that
come
to
it,
hey.
Where
is
ianaservers.net,
it
has
to
have
a
list
of
where
to
send
people.
So
there
are
three
name
servers
for
ianaservers.net,
there's
a
b
and
c
dot
nanoservers.net
and
those
get
those
are
need
to
be
in
the
dotnet
zone.
B
So
what
happens
if
they're,
not
in
sync,
what
happens
if
dotnet
actually
has
a
and
b
and
the
ios
server
zone
has
b
and
c,
and
you
can
see
that
these
particular
zone
records
actually
don't
match.
Does
this
actually
work?
Well,
yes,
but
it
definitely
has
problems
and
causes
timeouts
as
a
resolver
might
go
to
a
a
and
you
know
a
will
either
answer
or
it
won't,
but
it's
still
the
wrong
place.
B
If
a
won't
answer,
if
a
will
not
answer-
and
it
doesn't
actually
have
the
information
for
the
client
they,
this
is
called
a
lame
delegation.
Another
term
that
confuses
people,
because
it's
sort
of
obtuse
in
terms
of
what
it
actually
means,
but
but
essentially
a
lame
delegation
means
that
the
there's
a
disconnect
between
the
parent
and
the
child
and
the
parents
still
holding
on
to
a
name
server
record
that
the
child
no
longer
uses.
B
B
So
let's
talk
a
little
bit
about
how
this
actually
happens,
how
the
parent
actually
refers
stuff.
So
let's
query.com
servers
about
example.com,
and
so
this
dig
is
a
popular
tool
that
comes
with
iscs
bind
there's
a
number
of
others
that
are
similar,
including
k-dig,
for
not,
for
example,
they
operate
in
a
similar
way
where
you
can
direct
a
request
at
a
particular
server
like
I
am
doing
here
with
a
dot
gt.
Dlcs
dl
gtldservers.net
is
a
server
for
dot
com.
B
So
if
we
send
that
server
a
request
for
www.inkexample.com-
and
we
ask
it
for
an
a
record
which
is
an
ipv4
address,
we'll
get
into
that
later-
it
will
give
back
an
authority
section
full
of
information.
So
it's
going
to
give
back
two
answers.
It's
going
to
say:
hey,
you
need
to
go
talk
to
a.I.a,
servers.net
and
b.I.n.servers.net
for
to
get
to
example.com,
so
only
those
servers
know
where
www.example.com.com,
of
course
doesn't
actually
know
the
depth
of
the
tree.
It
only
knows
where
example
is,
but
it
does
know
where
to
send
you.
B
B
B
If
you
want
to
get
to
example.com,
so
you
you
actually
redirect
you
to
a
completely
different
part
of
the
tree.
This
happens
all
the
time.
So
there's
another
interesting
one.
If
we
ask.net
server
for
where
is
ianaservers.net
and
we
say
where's
the
name
servers
for
for
inservice.net,
it
is
going
to
answer
well,
there
are
four
a
c
and
b
and
n
s
that
icann.org
so
completely
different
part
of
the
tree
again.
B
So
how
do
I
talk
to
my
to
a
ianoservers.net
if
it's
inside
ionservers.net
itself,
you're
actually
telling
me
to
go,
find
something
inside
the
zone
that
I'm
trying
to
get
to?
How
do
I
do
that?
So
it
gives
back
an
additional
section
that
contains
glue
records.
So
you
can
see
that,
in
addition
to
giving
you
just
the
names
of
the
name,
server
is
actually
going
to
hand
you
addresses
as
well.
These
addresses
need
to
be
in
sync
with
the
parent
and
the
child
as
well.
B
If
you
change
addresses
of
your
name
servers
you'd,
better,
tell
your
your
parent.
If
they're
within
the
zone
in
question,
these
are
called
glue
records,
another
name
that
you
will
see
frequently
in
the
dns
literature,
so
the
glue
records
are
required
when
you
have
delegations
to
when
you
have
name
servers
within
the
zone
that
you're
actually
delegating
to
the
parent
has
to
have
the
the
list
of
addresses
as
well,
and,
of
course,
they
should
match
so
pictorially
about
glue
nets.
Name
servers,
as
I
said,
know
where
the
authoritative
source
for
anna
servers.net
is.
B
B
In
other
words,
it's
handled
by
a
completely
different
part
of
the
tree,
so
that's
sort
of
the
overview
of
how
tree
navigation
works
at
a
very
high
level
in
how
resolvers
actually
have
to
you
know,
find
different
parts
of
the
tree,
we're
going
to
dive
into
the
dns
packet
and
how
it
sort
of
evolved.
The
stuff
on
the
left
is
actually
the
total
packet
count
or
the
total
packet.
B
B
It
ships
around
these
things
called
resource
records,
which
was
the
diagram
on
the
right,
and
a
resource
record
is
composed
of
a
triplet.
It's
composed
of
a
query
name,
which
is
the
actual
name
that
most
people
think
of
as
a
query.
Type.
For
example,
a
quad,
a
record
or
four
a's
is
a
ipv46
address,
and
it's
composed
of
a
query
class,
which
is
I
n
for
internet,
and
that
makes
up
the
99
of
what
exists
on
the
internet.
B
The
rest
of
the
classes
aren't
really
used
with
the
exception
of
a
ks
class,
which
is
a
special
case,
and
we
won't
go
into
that
today.
Resource
record
sets
all
they
all
match.
Each
of
those
three
as
a
is
a
triple
match,
an
atomic
unit
of
data.
You
can't
ask
for
just
a
sub-comportion
of
it.
If
you
want,
you
know
a
a
name
for
www.example.com
and
you
want
the
ipv6
address
for
it
in
the
internet.
You
you
get
back
all
the
answers.
B
You
can't
ask
for
just
one
or
just
a
couple
or
even
hand
back
just
parts
of
them.
Their
atomic
units
are
considered
complete.
This
becomes
important
for
security
later,
and
it
becomes
important
for
caching
as
well
note
that
they
are
not
ordered
the
answers
that
you
get
back
may
be
completely
different
than
when
you
ask
from
one
time
to
when
you
ask
for
the
next.
Some
people
think
that
they
are
ordered.
They
are
not
and
clients,
don't
necessarily
have
to
keep
them
ordered.
B
B
The
dns
packet
components
consist
of
sort
of
two
main
sections:
there's
a
header
with
a
transaction
id
which
is
unique
per
transaction
or
it
should
be.
There
are
flags,
we'll
talk
about
a
couple
of
them,
but
not
all
of
them,
and
then
there's
the
number
of
resources
records
in
each
section,
and
then
there
are
four
sections
following
that,
so
there
should
be,
of
course,
a
number
indicating
how
many
how
many
pairs
are
in
each
of
the
following
sections.
B
Like
the
question
answer,
authoritative
and
additional
we'll
come
back
to
that
one
real
quick
point:
you
note
that
the
number
of
resources
in
each
section
includes
the
question,
so
you
so
the
number
of
questions
in
the
original
request
has
to
be
there.
Well,
there
can
really
be
only
one,
except
that
that's
not
actually
true,
it
turns
out.
B
If
you
look
at
the
original
rfc,
it
actually
says
that
you
can
have
a
qd
count
or
a
question
count
of
greater
than
one,
but
that
is
not
used
today,
though,
the
packet
form
actually
format
actually
allows
for
it.
It's
not
actually
usable
and
really
there's
a
number
of
problems
that
people
realized
early
on,
like
you
know
how
what
happens
if
you're
querying
for
multiple
things?
Well,
do
you
wait
for
all
the
answers
to
come
back
before
you
return
to
the
client?
B
What
happens
if
you
know
one
has
an
answer,
and
one
has
an
error.
What
happens
if
there
are
two
different
errors
and
they're,
not
even
the
same
error
code,
and
they
realize
the
complexity
of
that
it
would
be
better
to
fire
two
questions
off
in
different
packets
and
different
requests
than
to
try
and
bundle
them
into
a
single
one.
A
quick
point
note
there's
probably
a
few
people
that
get
both
of
these
references
on
the
right,
if
you're,
if
you're
over,
if
you
don't
understand
the
bottom,
one
go
out
somebody
over
40.
B
If
you
don't
understand
the
top
one
go
out,
somebody
under
20.
anyway,
dns
packet
sections.
So
the
question
where
the
single
question
goes:
that's
that's
where
the
question
goes
in
in
the
packet
and
it's
repeated
in
the
response,
so
the
client
that
gets
the
response
back
should
have
the
question
that
can
look
up
and
say:
oh
yeah,
that's
what
I
asked
the
answer
to
the
question,
of
course,
would
go
into
the
answer
section.
There
can
be
multiple
answers,
of
course,
there's
the
authoritative
section.
B
This
is
a
really
critical
section
that
says
what
is
the
owner?
Where
are
the
name
servers
that
own
this
portion
of
the
tree?
Who
should
I
go
talk
to
to
make
sure
that
this
is?
This?
Is
the
authoritative
source-
or
you
know,
maybe
the
authoritative
source
is
who
you're
talking
to,
but
it's
it
references
who
actually
owns
that
portion
of
the
tree
and
then
there's
an
additional
section.
There's
lots
of
helpful
stuff
that
goes
into
the
additional
section.
B
We'll
talk
about
some
of
them
today
and
as
anything
else
you
want,
you
should
want
to
know,
but
you
really
can't
trust
so
if,
for
example,
glue
needs
to
go
in
there,
but
you
should
really
go.
Ask
the
authoritative
source
for
what
they
believe
their
answers
are.
If
you
remember
the
whole
notion
of
cache
poisoning,
it
used
to
be
that
servers
would
trust
anything
you
put
in
there.
So
you
could
completely
overwrite
somebody
else's
addresses
on
the
internet
if
they
asked.
B
B
So
what
happens
in
the
dns
when
things
actually
go
wrong?
So
what?
How
do
we
handle
the
errors
in
the
dns?
What
happens
when
you
know
a
resolver
can't
do
something
or
an
authoritative
server
can't
do
something
well.
The
good
news
is
that
there
is
a
response
code
in
the
field
and
one
of
the
mis
understandings
about
the
response
code
is
what
we're
going
to
go
into
next
and
how
it
is
actually
handled,
and
it
gets
a
little
bit
complex
because
we've
really
kind
of
tinkered
with
it
over
the
years.
B
You'll
notice
that
the
r
code
on
the
right
hand
side
is
the
last
four
bits
of
that
packet
header
for
dns
right
there.
The
problem
is,
is
there's
only
four
bits,
so
we
have
come
up
with
a
lot
more
reasons
for
having
errors
than
I
think
was
originally
envisioned,
and
there
are
certainly
way
more
than
16
problems
and
way
more.
You
know
response
codes
that
could
indicate
something
so
people
got
creative
about
the
whole
r
code
problem
and
about
other
problems.
B
How
do
we
extend
the
dns
in
general
when
we're
there's
no
more
packet
space?
This
is
true
for
a
lot
of
protocols,
there's
not
a
lot
of
extension
room.
Well.
What
if
now
hear
me
out
what?
If
what?
If
we
stuck
those
extra
bits
somewhere
else
and
then
we
smashed
them
all
together
later
right,
we
just
extended
the
packet,
and
so
thus
a
very
creative
hack
called
the
opt
resource
record
was
created
and
it
was
put
in
a
specification
called
eating
s0,
which
is
rfc
2671.
B
It
is
an
extended
pseudo
resource
record
that
adds
an
additional
that
adds
data
to
the
additional
section.
Clients
have
to
say
that
they
support
it.
They
have
to
send
one
first
before
servers
will
send
one
back
and
it's
required
by
some
protocol.
Modifications
like
dns
sec
dnsx
simply
won't
work
without
eating
serial
support.
Most
software.
These
days
does
support
it
and
it
reuses
the
resource
record,
byte
format.
B
So,
for
example,
the
features
of
it
in
two
include
a
much
larger
error
code
that
comes
out
to
12
bits.
Now
it
supports
additional
protocol
flags
that
are
needed
for
things
like
dnsec
and
it
adds
a
sort
of
an
mtu
path
like
discovery
for
for
max
message,
sizes
that
software
can
actually
handle
based
on
what
it
thinks
that
you
can
get
through
its
local
network,
for
example,
at
the
application
level,
not
at
the
ip
level.
B
It
adds
support
for
additional
dns
extensions
and
there's
a
few
of
those
that
exist
today.
I
did
not
enumerate
the
whole
list,
but
client
subnet
is
a
common
one
that
a
lot
of
people
know
about
which
is
used
by
cdns,
as
well
as
extended
errors
which
we're
going
to
talk
about
very
shortly,
so
the
opt
resource
record
field
reusage,
as
I
said
they
they
take
the
the
resource
record
field,
and
then
they
just
reuse
various
components
of
it,
because
so
it
can
still
be
parsed
easily,
there's
a
name,
but
it
must
be
empty.
B
So
the
name
is
actually
blank.
It's
a
null
name.
Basically,
the
type
value
is
41,
that
is,
the
opt
type
code
assigned
by
an
ayanna
there's
a
class.
So
instead
of
putting
in
class,
which
I
said,
was
internet
before
for
most
resource
records,
it
actually
transform
it
into
the
udp
payload
size
instead,
so
you
get
16
bits
to
say
this
is
the
maximum
payload
size
that
I
can
accept.
Please
don't
send
me
anything
bigger
than
that.
B
B
So
what
happens?
One
of
the
bits
in
the
original
thing
is
is
the
response?
Is
I'm
sorry,
one
of
the
the
original
bits
in
the
original
header
is
called
the
truncation
bit
and
it
basically
says
you
tried.
I
I
can't
send
you
as
much
information,
as
you
asked
for
you're
gonna
have
to
you
know,
come
back
with
a
different
question,
a
smaller
question,
or
a
comeback
over
tcp,
so
with
a
bigger
payload
size.
B
So
this
happens,
for
example,
when
the
opt
resource
records
max
message,
size
was
going
to
be
overflowed,
so
the
first
thing
that
happens
is
the
truncation
bit
is
set
and
then
different
implementations
do
different
things.
Some
try
and
remove
the
unimportant
items
and
shift
the
rest
of
the
information
back.
So
hopefully
you
get
at
least
something
some
servers
actually
drop.
Everything
and
just
tell
you
to
come
back
over
tcp
and
note
that
response
rate
limiting
is
a
ddos
defense
that
is
commonly
deployed
these
days
that
triggers
the
tc
bit.
B
If
you
start
asking
sort
of
the
same
question
over
and
over
and
over
from
a
single
address,
because
that
used
to
be
used
heavily
over
udp
to
do
packet,
reflection
and
that's
actually
stopped
a
lot
of
the
packet
reflection
attacks
anyway,
clients
have
to
come
back
over
tcp
to
get
the
full
answers.
It
turns
out
that
jeff
has
measured
that
some
of
them,
don't
they.
They
got
enough
information
that
they
saw
in
the
answer
and
they
didn't
need
to
come
back
to
get
the
rest
all
right.
So
what
happens?
B
If
you
get
more,
if
you
need
more
errors,
the
just
the
response
codes
themselves
aren't
necessarily
always
enough.
What
happens
if
you
have?
You
know
like
multiple
errors
or
two
exist,
or
you
want
to
augment
some
debugging
text.
Well,
what?
If
we
actually
kind
of
stuck
that
data
somewhere
else
too
so
coming
up
soon
as
an
extended
error.
B
So
there's
another
opt
resource
record
that
goes
inside
the
opt
research
record,
which
means
that
we
have
the
header
with
the
first
four
bits:
the
x,
the
opt
record
with
four
bit
with
an
additional
eight
bits
and
now
we're
putting
other
errors
inside
of
that.
So
it's
really
errors
all
the
way
down
you
sandwich
stuff
into
protocols
where
you
can,
when
you
need
to
extend
them.
B
So,
let's
dive
into
some
of
the
other
resource
record
types.
The
opt
was
a
special
case,
but
let's
look
at
the
more
normal
ones
for
a
bit
so
resource
record
types,
the
obvious
ones
most
people
know
most
of
these.
There
is
a
a
record
which
is
an
ipv4
address.
There's
a
quad,
a
record
which
is
an
ipv6
address.
B
There
is
a
soa
which
gives
sort
of
some
zone
information
and
it's
at
the
tip
of
the
apex,
and
it
talks
about
negative
caching
and
a
bunch
of
other
stuff
in
the
serial
number
of
the
current
zone,
and
things
like
that.
I
won't
dive
into
the
details.
There's
a
text
record
which
is
really
just
a
free-form
text.
Blog
we'll
talk
a
lot
more
about
that
one.
In
a
second,
but
first,
let's
talk
about
happy
eyeballs,
which
is
8305.
B
so
happy
eyeballs.
You
know
people
realize
as
we're
trying
to
deploy
ipv4
and
ipv6.
How
do
we
decide
which
you
know
address
family
to
use?
How
do
we,
you
know
deal
with
the
fact
that
users
really
don't
want
to
wait
a
long
time?
So
you
can't
you
know,
query
for
v4
and
then
wait
and
that
didn't
work
so
then
go
to
v6
or
vice
versa.
So
the
solution
is
we're
going
to
follow
this
step.
B
We're
going
to
go,
send
a
quad,
a
query
out
to
say:
hey:
where
is
www.example.com
and
the
resolver
will
start
chugging
away
at
that.
At
the
same
time,
the
client
is
going
to
send
another
request
immediately.
Thereafter,
it's
going
to
start
with
v6
and
then
it's
going
to
send
another
one
saying
oh
and
I
want
the.
I
want
the
a
record
too.
B
If
the
response
that
came
back
was
a
ipv6
record
and
quad
a
record,
you
get
to
open
the
connection,
yay
we're
done.
If
the
response
is
a
is
an
ipv4
record,
an
a
record
then
you're
supposed
to
wait
a
bit
like
50
milliseconds
is
what
the
document
recommends
for
a
quad
a
record,
and
if
you
don't
give
one
get
one,
then
you
just
you
know,
give
up
and
continue
with
ipv4.
B
B
The
other
common
thing
that
is
frequently
misunderstood
is
how
to
properly
use
c
names
and
d
names.
So
c
names
are
really
aliases
for
other
portions
of
the
tree.
They
can
be
in
the
same
zone
or
they
can
be
in
a
different
zone
and
d
names
are
aliases
for
the
zones
themselves,
sort
of
their
the
entire
zone.
B
So
here's
an
example
of
a
cname
record
in
red.
The
top
line,
which
is
js.example.org
with
a
ttl
of
3600
seconds,
is
a
cname
to
javas.example.com.
So
it's
pointing
from
one
zone
into
a
completely
different
zone,
saying
if
you
want
to
get
to
js.example.org,
you
should
really
use
this
other
name.
A
lot
of
resolvers
will
also
return
the
address
for
the
other
one
too.
B
B
Me
should
go
over
there
important
rules.
C
names
must
exist
at
a
alone
at
a
name.
It
shouldn't
have
other
information,
and
you
know
associated
at
the
same
name
except
for
dns
sec
records,
which
sort
of
change
that
a
little
bit
and
then
c
names
point
to
all
other
types.
You
can't
just
have
a
c
name
for
just
an
a
or
a
quad,
a
record.
If
you
have
a
c
name,
it
points
everything
to
the
other
name.
That
includes
name
servers.
Mx
records
serve
records.
You
know
anything
else
that
might
exist.
B
Text
records,
mx
records
are
mail
exchange
records
and
they
really
kind
of
answer.
The
question:
where
should
email
for
a
domain
name
be
sent?
It's
a
prioritized
contact
list
of
where
mail
should
be
sent,
and
so
they
can
exist
at
you
know,
leaf
nodes.
So,
for
example,
www.example.org
has
this
long
ipv6
address
it
all?
B
Where
does
that
mail
go?
And
you
know
the
mail
server
doesn't
exist,
typically
at
the
top
level,
the
apex
of
the
zone.
Now
it
is
handled
by
something
else,
but
more
importantly,
it
can
be
handled
by
a
completely
different
zone.
It's
very
common.
This
is
how
outsourcing
of
mail
happens
when
organizations
outsource
their
mail
to
some
mail
provider,
of
which
there
are.
You
know
many
and
in
fact,
that's
much
more
common
than
hosting
your
own
mail
server
these
days,
and
this
is
done
with
mx
records
wild
cards.
Nobody
seems
to
understand
and
get
right.
B
I'll
be
honest.
I
don't
use
them
much
myself
because
they
can
be
kind
of
complex,
but
if
you
go
read
rfc
4592
you'll
find
it's
actually
very
clean
and
very
well
written
much
better
than
the
original
text,
but
it
generates
responses
for
missing
data.
The
leftmost
label
must
be
an
asterisk
and
only
an
asterisk.
You
can't
have
fu
star
or
star
foo.
It
has
to
be
star
dot
period,
end
of
end
of
sentence.
B
It
matches
any
label
that
doesn't
exist
underneath
it,
including
sub-labels,
underneath
it
it
causes
a
name
server
to
synthesize.
An
answer
should
be
an
answer
not
and
answer
it
synthesizes
an
answer
on
the
fly
and
it'll
answer
for
anything.
The
client
asks
for
there's
really
good
examples
in
4592,
I've
included
some
down
below
that
are
sort
of
the
minimal
ones,
but
4592
has
much
much
better
ones,
including
what
happens
when
you
have
a
label
against
an
empty
num
terminal
using
a
term
from
before.
B
So
in
these
two
examples
are
star.example.com,
which
says
for
an
mx
record,
for
if
anybody
asks
for
an
mx
record
in
star.example.com,
I
want
you
to
return
mail.example.com.
Unless
that
record
already
had
an
mx
record
associated
with
it,
it
doesn't
wild
cards,
don't
overwrite
existing
things.
So
there's
some
example
responses
down
below
where
the
mx
records
match
for
either
one,
because
neither
one
of
those
hosts
had
an
mx
record
by
default,
but
asking
for
an
a
record,
never
matches
under
underbar
labels
are
another.
Was
there
a
question?
B
Nope
underwear
labels
are
another
thing
that
has
been
really
popping
up
a
lot
lately.
In
fact,
if
you
look
at
the
rfc
numbers,
it's
85
5
2
and
5.3
they're
much
more
recent
rfcs
a
long
time.
So
the
right
thing
to
do
is
when
you're,
adding
new
information
to
the
dns.
A
new
type
of
information
is
really
to
create
a
new
r
type.
You
can
ask
guyana
for
one.
You
need
a
specification.
B
I
think
it
has
to
go
through
expert
review.
It
doesn't
have
to
be
an
rfc
if
I
recall,
and
but
they're
slower,
to
deploy
it's
slower
for
resolvers
actually
understand
them
immediately,
because
it's
just
a
number.
It's
actually
not
necessarily
a
name,
and
almost
everything
can
understand
them
immediately,
but
it's
harder
to
put
into
his
own
file
because
there's
not
a
when
you're
writing
dns
records,
there's
not
a
name.
You
can
associate
with
it.
B
So
you
have
to
put
in
something
strange,
like
type
one,
two,
three
six
or
something
like
that,
but
so
people
started
putting
in
text
records
instead
and
and
it
became
a
little
overwhelming
because
they
were
putting
text
records
in
at
the
apex
of
zones.
We
had
some
for
spf
and
originally
dkim
and
domain
key
and
dns
ownership,
verification
which
is
used
by
google
and
facebook
and
docusign
and
a
bunch
of
things.
B
Well,
these
all
end
up
a
text
record
at
the
top
of
the
zone,
the
apex
of
its
own-
and
you
can
imagine
when,
when
things
go
off
in
query
for
these,
that
packet's
getting
bigger
and
bigger
and
bigger
the
more
you
know,
people
try
and
stuff
in
there.
So
the
right
solution.
We
decided
was
to
use
a
new
was
to
use
a
to
reserve
under
bar
as
a
prefix
to
special
case
names,
so
that,
instead
of
using
spf
at
the
apex
of
his
own,
it
should
be
underbarspf.example.com.
B
B
In
summary,
dns
is
a
globally
distributed
identifier
database.
The
important
takeaways
here
note
that
it
is
distributed
it
it.
You
know
it
is
owned
by
the
entire
world
and
there's
this
big
network
of
who
owns
different
sections
of
the
tree
and
delegation
happens.
The
amazing
thing
to
me
is
that
how,
in
the
world
did
this
scale
so
well
that
we
are
handling
this
much
infrastructure
all
over
the
world
and
it
works?
You
know
almost
continuously,
yes,
there's
been
some
outages,
but
it's
amazingly
resilient.
I
don't.
B
D
D
D
So
this
morning
I'm
going
to
talk
a
little
bit
about
how
the
dns
has
actually
managed
to
scale
and
what's
going
on
behind
the
scenes,
how
do
we
engineer
resilience
into
the
dns
and,
as
usual,
I
make
the
tools
that
we
have
to
actually
engineer.
Resilience
is
actually
really
simple:
it's
just
replication!
If
a
doesn't
work
choose
b
now
some
ways
you
can
go.
D
Well,
let's
ask
a
and
b,
both
together,
it's
just
a
race
who
cares
the
first
one
wins
b's
hanging
around
in
case
a
doesn't
answer
and
the
other
way
is
a
little
bit
slower,
but
certainly
tames.
The
system
down
in
terms
of
noise.
Ask
a
wait
if
you
get
no
answer
after
a
while
ask
b
in
the
one
case,
the
first
ask
everyone,
it's
really
snappy
and
fast,
but
it
overloads
the
system.
In
the
second
case,
you
actually
put
the
the
onus
on
the
end
user,
the
one
who's
serializing,
the
requests.
D
The
system
is
under
less
strain.
You
end
up
using
all
of
these
resources
if
you
have
to
as
backups
for
the
originals,
but
the
order
in
which
you
do
it
and
the
amount
of
strain
and
stress
you
put
on
the
system
and
the
time
you
need
to
actually
execute
that
differ
according
to
each
of
these
approaches.
D
So
of
course,
if
you're
considering
this,
you
really
have
to
think
about
what
does
a
unitary
dns
look
like
with
absolutely
no
replication
at
all
and
you
get
back
to
to
wes's
slide
that
here's
this
end
result
this
stub
resolver
at
the
end,
it's
configured
with
one
recursive
resolver
out
there
somewhere
that
does
all
the
heavy
lifting
and
that
recursive
resolver
at
least
at
the
start,
doesn't
know
anything
other
than
a
root
zone.
Priming
query,
so
it
asks
authoritative
servers.
Where
should
I
ask
to
find
the
answer?
D
D
The
problem
with
the
unitary
dns,
where
every
stub
resolver
has
only
one
each
stub
resolver
uses
only
one
recursive.
Each
domain
is
only
served
by
one
authoritative
server
with
one
address,
ipv6
or
ipv4
pick
one,
and
each
recursive
resolver
only
sends
a
single
query.
The
problem
with
that,
of
course,
is
you
can
touch
any
part
of
that
and
it
all
falls
over.
So
you
have
these
massive
numbers
of
multiple
single
points
of
failure.
D
If
your
recursive
resolver
stops
answering
it's
too
busy,
it's
decided
that
it's
a
sunday,
whatever
the
reason,
your
toast,
equally,
that
one
authoritative
server.
If
it
fails
everything
fails
in
terms
of
all
the
zones
that
it
serves
and
even
down
in
transport,
because
it's
udp
and
every
datagram
is
indeed
an
adventure.
D
Then
if
you
don't
get
the
answer,
what
do
you
do?
And
so
each
of
these
single
points
of
failure
make
the
dns
incredibly
vulnerable
to
not
even
hostile
attack.
It's
almost
casual
vandalism
would
take
out
huge
amounts
of
the
infrastructure,
so
this
kind
of
model
doesn't
work.
I
mean
it.
Just
simply
cannot
work
in
any
real
sense,
and
so
so
the
answer
is
just
simply
pump
up
the
number,
and
so
your
stub
resolver
there's
only
one.
U
might
be
configured
with
a
number
of
recursive
resolvers.
D
You
can
add
more,
but
not
necessarily
a
good
idea.
Now
in
a
dual
stack
world,
if
you
actually
use
the
name
of
those
recursive
resolvers,
they
actually
have
ipv4
and
ipv6
addresses,
and
the
libraries
will
discover
that
now.
Resolve.Conf
actually
claims
that
those
queries
in
the
in
using
those
protocols
are
made
in
parallel.
Well,
I'm
not
exactly
sure,
that's
the
case.
D
Often
they're
just
simply
made
in
order,
but
if
they
have
v4
and
v6
you'll
send
out
both
queries
at
the
same
time,
well
paste
by
10
milliseconds
at
once,
which
I
don't
think
happens.
The
order
in
resolve
dot
conf
is
usually
important,
and
so,
if
you
have
resolver
a
resolver
b,
resolver
c,
normally
you
will
find
resolver.
A
is
is
hammered.
Resolver
b
is
only
used.
If
you
don't
get.
An
answer
from
a
resolver
c
is
only
used
if
the
other
two
are
dead,
on
dead,
on
arrival
or
whatever.
D
So
that's
usually
the
case
that
order
is
important,
although
I
have
noticed
some
pieces
of
application.
Software,
including
the
chrome
browser
at
some
points
in
time,
started
doing
round-robining,
there's
nothing
wrong
with
round
robining.
It's
just.
What
do
people
assume
when
they
put
stuff
in
resolve.conf
is:
are
the
others
backups
for
the
first
or
is
everything
important
and
the
other
thing
is:
when
do
you
use
those
next
ones?
It's
either
a
udp
timeout,
which
is
most
typical,
you're
asking
a
question.
D
D
D
What
about
authoritative
servers?
It's
certainly
fashionable
to
use
more
than
one
authoritative
server
and
the
root
zone
is
a
typical
example.
It
had
13
for
the
anachronistic
reason
these
days,
that
you
could
stuff
13
names
and
13
ipv4
addresses
and
fit
the
entire
priming
query
answer
of
these
13
names
and
13
before
addresses
into
one
packet,
no
larger
than
512
octets,
but
that
was
a
different
age
in
a
different
world
as
soon
as
we
added
v6
to
the
root
zone
that
doesn't
work
anymore.
D
So
13
is
a
very,
very
big
number,
these
days,
most
folk
use
between
two
and
four.
If
you
actually
look
and
sort
of
comb,
the
world's
authoritative
servers
one
way
or
another,
it's
rare
to
find
four
or
five
hundred,
authoritative
servers,
and
indeed
insane,
because
you
can't
put
them
and
list
them
in
a
response
packet
and
equally
it's
kind
of
brave
or
or
should
I
say,
foolhardy,
to
simply
have
only
one
most
of
the
time,
except
for
any
cast
and
we'll
get
to
that
later.
D
So
the
rule
of
thumb,
which
in
this
case
is
not
a
bad
rule
of
thumb,
five
is
probably
you
know
too
many
and
larger
than
five
is
probably
you
know
way
too
many,
and
one
is
certainly
too
few
now,
when
you
have
all
these
authoritative
servers,
do
you
always
hammer
the
first
or
do
you
round
robin?
Well,
it's
up
to
the
recursive
resolver,
it's
up
to
the
the
query
out,
not
the
server
and
it
may
round
robin
it
may
not.
D
It
depends
on
who
what's
going
on
here,
the
list
itself
that
the
authoritative
server
gives
back
when
you
ask
for
an
ns
record
and
it
sends
back
a
list,
you
might
get
the
same
list
all
the
time.
The
server
itself
might
rotate
that
list
of
servers
because
it
wants
to
display
the
load
across
all
of
them.
D
D
What
about
resilience
in
transport
itself?
Well,
we
use
udp
for
the
dns
and
resilience
and
udp
are
not
things.
You
often
say
in
the
same
sentence.
In
fact,
you
never
do
because
it
isn't
all
bets
are
off
now.
The
issue
is,
of
course,
that
when
udp
dies
it
dies
silent.
Oh
I'm
dead.
No,
you
don't
you
just
nothing
happens,
crickets,
and
so
what
the
udp
sender
actually
uses
is
a
timeout
and,
depending
on
what
it
thinks
it
should
have
got
an
answer
back
in
that
time
period.
D
A
lot
of
these
timers
in
a
lot
of
this
code
is
actually
based
around
the
behavior
of
dial-up
modems
and
10
kilobit
lines,
9.6
kilobit
lines,
and,
to
be
perfectly
frank,
we
never
changed
anything,
and
so
what
you
find
timers
that
these
days
seem
like
eons,
paleolithic
periods,
where
entire
continents
will
move.
So
your
stub
resolvers
use
timeout
values
between
one
and
five
seconds.
D
Oh
my
god,
recursive
resolvers
are
more
with
it
and
they
typically
seem
to
use
timeout
values
between
300
milliseconds
and
up
to
one
second
happy
eyeballs,
for
example,
uses
a
biasing
of
only
50
milliseconds.
So
you
can
see
that
these
normal
timeout
periods
for
udp
are
generous,
perhaps
to
a
fault
but
they're,
certainly
very
generous.
D
Should
you
ask
the
same
server
again,
didn't
ask
the
first
time,
but
maybe
the
second
time,
because
optimism
is
effective
or
maybe
I
should
just
change
the
address
or
the
protocol.
If
I
ask
in
v4,
maybe
try
on
v6
or
if
I've
got
multiple
addresses
for
that
named
name
server.
I
should
flip
to
a
different
address
for
the
same
server
or
maybe
the
timeout
says
something
else,
and
I
should
ask
a
different
server
up
to
you.
D
There
are
no
rules
and
of
course,
when
do
you
give
up
well,
the
number
of
timeouts
is
typically
limited
and
normally
in
resolve.com,
it
says
to,
but
you
can
configure
it
up
to
five.
It
says
the
man
page:
when
does
people
normally
give
up
somewhere
between
two
and
four
is
typical,
so
it
depends
on
the
the
actual
library
that
you're
using
and
the
way
you've
configured
it,
but
it
will
try
a
few
times,
but
not
forever.
D
D
D
D
That's
a
different
question
because
sometimes
what
you
get
is
different
recursives
hiding
behind
the
same
name
or
even
the
same.
You
know,
protocol
address
and
the
same
protocol,
and
that
happens
a
lot
these
days
with
compound
resolver
farms,
and
so,
oddly
enough
you
can
actually
set
up
a
second
tcp
session
and
you
may
or
may
not
see
the
same
server
and
you
may
or
may
not
get
the
same
answer.
D
What
should
a
poor
stub
resolver?
Do?
I
don't
know
typically,
though,
if
you
get
back
an
answer
like
serve,
fail
or
maybe
refused,
you
might
try
again
even
with
tcp.
You
might
like
to
try
again
with
a
different,
authoritative
name,
but
you
might
try
again.
On
the
other
hand,
you
really
are
thrashing
at
this
point,
and
maybe
the
optimism
is
unwarranted.
Bad
is
bad
move
on
with
your
life.
There
are
other
things
to
do.
D
D
D
All
of
you
went
to
ietf.com
to
find
an
answer,
but
not
all
of
you
hammered
that
server,
because
often
the
recursive
resolve
that
you
used
simply
cashed
the
answer.
Here's
the
answer
I
received.
If
that
matches
your
question,
I'm
just
going
to
serve
it
here
locally
and
without
that
kind
of
cashing
the
dns,
as
we
know
it
wouldn't
now
cashing,
is
always
a
bit
of
a
balance
between
well
I'd
like
to
serve
you.
D
The
answer
that's
current
and
if
I
cash
it
for
all
five
years,
it
might
be
the
wrong
answer,
because
five
years
is
indeed
an
eternity.
On
the
other
hand,
if
I
do
case
it
for
five
years,
the
case
becomes
very
effective.
I'm
like
I
just
don't
ask
the
authoritative
anymore,
so
the
resolution
infrastructure
prefers
to
cache.
It
prefers
to
keep
it
for
longer,
because
it
can
instantly
give
you
the
answer.
That's
faster
and
the
cache
becomes
more
effective.
I
take
the
pressure
off
the
dns
servers
name.
D
Publishers,
however,
want
to
give
you
the
answer
and
if
they
want
to
change
that
answer,
they
want
that
answer
be
picked
up
by
the
system,
so
the
publisher
prefers
short,
even
if
the
dns
doesn't
like
it,
the
dns
itself
prefers
long
because
that's
what
makes
it
work
so
that
tension
actually
sits
inside
caches
and
ttls,
but
before
I
move
to
ttls,
let's
just
understand
who
caches
everyone:
stub
resolvers,
recursive,
resolvers,
forwarding
resolvers.
Even
your
browser
will
cache
because
caching
is
faster,
but
it's
not
mandatory,
so
who
doesn't
folk
who
don't
cage
it's
entirely
optional.
D
So
what
is
cached?
It
doesn't
actually
catch
the
entire
response.
It
cases
the
resource
record
itself
and
its
associated
time
to
live
value.
What
should
not
be
cashed?
Well,
as
we've
learned
to
our
to
bitter
experience,
additional
sections
are
generally
not
trustable.
You
should
not
tr,
you
should
not
cash,
those,
so
that's
a
sort
of
a
bigger
should
not,
but
there
are
a
number
of
other
corner
cases
where
caching
is
kind
of
interesting.
D
With
that
opt
section
commonly
referred
to
as
edna
zero.
There
is
an
option
for
the
client
to
place
their
subnet
or
if
the
client
is
deranged,
their
entire
protocol
address
into
the
query
and
that
query
is
passed
all
the
way
through
the
dns
infrastructure
right
up
to
the
authoritative
server,
and
so,
if
you're,
using
client
subnet,
which
you
shouldn't
the
answers,
cache
the
client
subnet
value
and
the
cache
can
only
be
used
if
the
subnet
value
and
the
query
name
both
match.
D
D
D
Well,
typically,
you
do,
but
you
only
serve
them
if
the
client
says
don't
check,
set
the
checking
disabled
bit
in
the
query.
Give
me
any
garbage
you'll
send
back
the
garbage
in
your
case,
what,
if
the
query,
has
no
edns
extensions
and
the
local
recursive
resolver
knows
that
it's
invalid
yeah
dns
insect
records
can
be
cached,
they're
different
records
to
many
others,
because
they
span
a
range
rather
than
an
individual
name.
D
So,
oddly
enough,
the
names
that
don't
exist
is
much
much
larger
than
the
set
of
names
that
are,
if
you
actually
case
those
gaps,
the
cache
becomes
incredibly
effective
because
it
starts
to
cache
the
entire
zone,
not
only
what's
in
there,
but
what's
not
in
there
now.
That
range
is
based
on
the
alphabetically
sorted
list
of
names,
so
that
you
know
that
all
the
names
between
a
and
d
don't
exist,
so
b.example.com
and
so
on.
D
The
insect
record
will
tell
you
no,
if
you're,
using
insect,
3
bad
idea,
you
actually
sort
the
hashes
of
the
names
and
perform
entirely
exactly
the
same
function
so
insect
and
then
sec
3
both
work
in
this
set.
How
long
do
you
keep
them?
The
cache
time
to
live?
The
ttl,
which
is
actually
given
by
the
zone
publisher,
says
to
the
rest
of
the
infrastructure.
D
D
D
You
can't
use
negative
numbers,
of
course,
but
you
can
use
zero
and
if
you
set
a
ttl
of
zero,
it
says
this
is
a
one-off
answer.
Enjoy
it
but
don't
reuse,
it
keep
on
asking
me
and
of
course,
every
single
cache
is
not
infinitely
sized.
So
in
some
ways,
if
the
cache
fills
older
answers
may
get
thrown
out
so
cash,
my
lifetime
might
be
a
lot
lower
than
the
ttl
even
under
high
load.
D
Replication
is
course
replication
simply
says.
If
you
don't
like
the
answer,
a
gave
you
try
b,
but
in
some
ways
we
can
do
better
and
use
the
routing
system,
and
while
this
was
incredibly
contentious
at
the
time
back,
then
don't
remember
when
anycast
is
now
part
and
parcel
of
why
and
how
the
dns
operates.
D
D
You
can
bring
new
instances
up
on
the
same
address
or
you
can
take
them
down
as
long
as
you
inform
the
routing
system,
what
you're
doing
but
the
clients
don't
need
to
know
so
new
instances
can
come
up,
instances
can
be
removed
effectively
seamlessly
and
the
client
simply
goes
to
the
closest
active
element.
That's
currently
serving
it,
and
so,
from
the
client's
point
of
view,
serial
enumeration
try
a
try,
b,
try
c
god.
This
is
boring.
Try
d,
try
e!
Are
we
dead
yet
try
f,
try
g
doesn't
work,
I'm
like
with
any
cast.
D
The
other
way
where
we
have
parallelism
is
in
a
slightly
different
sense
where
these
days,
the
amount
of
dns
and
the
density
of
query
often
receive
exceeds
the
capacity
of
single
engines,
no
matter
how
big
the
silicon
and
so
a
bit
like
the
web
server
systems
that
we
use
these
days,
we've
done
the
same
in
the
dns
and
a
massive
amount.
Almost
75
of
the
visible
recursive
resolvers
sit
inside
a
subnet
with
other
recursive
resolvers
that
the
authoritative
server
sees
so
what's
going
on.
D
Is
that
a
huge
amount
of
resolution
machinery
is
actually
sitting
inside
farms
where
you
have
a
common
front
end
that
takes
the
queries
the
service
address
and
these
workers
out
the
back
where
you
distribute
the
queries
that
you
get
to
one
of
these
workers,
but
then
goes
off
and
actually
does
the
query
sends
the
answer
back
from
or
through
the
source
address
of
the
front
end?
I
don't
even
need
to
go
through
the
front
end.
D
D
D
You
can
simply
take
the
source
address
and
nothing
else
if
you're
really
willing
to
unpack
the
packet
and
look
deeply
inside
the
packet
and
pull
apart
the
query
name.
You
can
hash
on
that
too,
or
indeed
you
can
do
adaptive
hashing,
where
you
load
up
engine
one
as
hot
as
it
will
take,
and
once
that's
loaded
up
additional
names
or
additional
queries.
D
You
then
load
up
on
the
next
and
the
next,
so
you
constantly
try
and
make
the
engines
run
hot,
not
balanced,
because
often,
as
we've
been
told,
hot
caching
is
more
effective
than
balanced,
low
valve
low
level.
Caching,
so
that
resolver
query,
farm
distribution
is
actually
an
interesting
question,
because
if
they're
all
they've
got
independent
caches,
then
q
name
hashing
is
really
effective
because
all
the
queries
for
the
same
name
go
to
the
same
engine.
D
D
D
Actually
using
every
single
engine
is
actually
running
in
the
long
run,
the
same
case
replicated,
which
is
less
efficient,
but
that
might
be
what
you
want,
and
there
are
certainly
mechanisms
that
share
the
case
across
all
these
resolver
farm
entities,
using
some
kind
of
multiple
of
broadcast
or
multicast
technology
to
maintain
all
of
them
with
the
same
cache.
But,
of
course,
that's
challenging
to
implement
reliably.
D
B
C
C
I'll
get
the
hang
of
these
one
days.
Okay,
so,
hopefully
you'll
be
seeing
this.
I
cannot
see
the
comments
because
I
just
went
full
screen
my
my
last.
My
section
will
be
shorter.
It's
just
an
overview
of
if
you
wanted
to
play
with
this
whole
thing
that
was
being
talked
about
up
to
now.
Where
do
you
get
go?
C
C
Initially,
they
came
into
existence
as
just
another
part
of
the
bsd
unix
api
and
the
calls
that
were
used,
and
that
is
still
in
use
were
ghost
get
hosts
by
address
by
name
that
was
10
set
hotel
functions.
They
appeared
in
1983
in
4.2
bsd,
which,
incidentally,
implemented
the
dns.
That
was
specified
in
rc882
and
aa3,
which
is
not
the
current
version
of
dns,
so
they
actually,
this
api
calls
predate
modern
day
dns,
which
came
into
existence
two
years
later.
C
C
C
It
has
also
a
stub
implementation
that
goes
with
it
called
stubby
and
provides
a
lot
of
language
binding,
so
you
can
use
it
from
different
programming
languages.
It
includes,
for
instance,
things
like
local
dns,
dns
validation,
which
is
useful
to
bring
that
functionality
closer
to
the
application
not
having
to
rely
on
on
other
pieces
of
software
to
do
it.
As
someone
already
mentioned
the
in
this
in
in
the
chat
linux
introduced
recently,
the
systemd
resolved
service
people
have
been
beaten.
It's
still
early
days
for
these.
C
C
Interesting
these
days
with
the
expansion
of
how
dns
is
being
transported
and
handled,
there
might
be
room
for
the
appearance
of
more
modern
apis
or
different.
Looking
apis
and
one
of
these,
which
is
kind
of
only
considered
right
now,
as
a
transport,
which
is
like,
though,
of
dns
over
cdb
actually
for
web
people,
will
look
a
lot
like
a
web
rest
api
with
some
opaque
blog
of
data.
But
well,
you
know,
there's
a
potential
to
develop
a
completely
new
api
or
that
or
even
a
new
dnx
moving
on
forwarders.
C
Forwarders
falling
between
stab
resolvers
and
recursive
resolvers,
both
in
where
they
sit
in
the
network
and
what
functionality
they
provide
to
the
network.
They
have
some
features
that
usually
are
typical
of
recursive
results
such
as
a
big
local
cache,
but
they
don't
usually
perform
the
recursive
lookups
themselves.
Rather,
they
receive
them
from
the
nodes
behind
them
that
send
them
queries
and
they
forward
them
to
a
full
service
recommended
resolver.
So
that's
basically
why
they
are
called
forwarders.
C
Typical
implementations
of
these,
the
most
famous
the
most
used
worldwide
is
dns
mask
a
piece
of
software,
that's
produced
by
simon
kelly
in
the
uk
and
it's
this
software
is
very,
very
popular
because
it
got
picked
up
early
on
by
route
manufacturers,
rather
home
hardware,
home
router
manufacturers,
and
it
got
dropped
in
and
most
a
lot
of
people
actually
use
it
without
even
knowing
right.
It
has
an
advantage
for
that
that
kind
of
embedded
device
that
has
limited
resources,
because
it
also
includes
a
dhcp
server
and
those
two
functions.
C
The
hpp
and
dns
are
something
that
every
home
network
needs,
but
it
has
been
evolving
and,
for
instance,
it's
been
supporting
the
asset
validation
locally
since
2014,
so
you
might
actually
have
that
supported
in
your
home
router.
By
now,
other
implementations
include
things
like
buying
bind
you'll
see
repeated
everywhere,
because
this
was
the
first
kind
of
reference
implementation
out
there
and
perform
all
the
functions.
So
it
comes
up
a
lot.
C
A
common
setup
that
you
see
that
you
didn't
use
to
see
earlier
on
at
isps
is
the
use
of
forwarders,
so
people
other
sps
need
to
provide
dns
services
for
their
customers.
It's
typically
been
one
of
the
services
that
isps
provide,
but
they
don't
want
to
have
the
hassle
and
of
having
to
cope
with
the
load
that
comes
with
the
recursive
resolver
with
a
lot
of
clients,
so
they
configure,
for
instance,
things
like
bind
as
pure
forwarders
and
let
other
open,
dns
resolvers
take
care
of
the
work
for
them.
Typically,
these
are
the
open.
C
The
software
used
in
these,
in
these
deployments
is,
is
a
mix
usually
of
open
source
and
proprietary
software,
sometimes
open
source
hiding
behind
a
front
end.
That's
for
friday.
That's
not
not
unusual,
and
and
since
google
started
doing
their
quad
thing
years
ago,
there
are
more
and
more
of
these
coming
up
and
there
are
also
commercial
services
like
opendns.
That
will
provide
not
only
dns
resolution
for
you,
but
also
sort
of
filter,
dns
resolution.
C
C
Some
of
these
seeds
that
we
are
used
to
control
are
proprietary
most
of
them.
At
least
there
is
one
that's
being
defined
on
the
idf
at
the
idf,
so
that's
at
least
you
can
get
a
picture
of
how
they
are
used.
Implementations
themselves,
open
source,
the
typical
ones
are
the
ones
listed
there
by
far
the
most
commonly
used
in
pro
in
closed
source
versions.
Some
of
those,
for
instance,
cq64
infoblox,
are
front-ends
for
open
source
implementations.
C
Others
are
fully
developed
in-house
by
the
companies
that
are
named
there
and
the
last
piece.
The
last
missing
piece
is
the
the
origin
of
all
the
dns
data.
The
authority
servers
the
publishers,
as
we
were,
referring
to
them
earlier
in
principle.
Their
function
is
pretty
straightforward.
You
load,
what's
used
to
be
a
zone
file
can
be
any
sort
of
database
and
then
surf
based
on
the
data.
That's
in
there
don't
do
anything.
There
else,
don't
be
more
creative.
C
Just
read,
write
read
from
the
disk
right
to
the
network,
but
of
course,
people
have
been
using
dns
for
35
years
and
the
scenarios
where
people
use
the
dns
go
way
beyond
a
simple
scheme
of
arrows
like
the
one
we
are
presenting
here.
So
enterprises
have
their
own
roots,
they
have
their
own
dna
view
of
dns
to
the
inside
and
the
outside,
which
is
different.
So
the
authority
dns
servers
have
grown
in
what
they
do
in
terms
of
functionality.
C
They
do
split
horizon,
basically
showing
different
view
of
dns
inside
your
network
and
outside
they
control
who
sees
what
and
when
they
will.
These
days,
give
you
often
give
you
different
answers,
based
on
which
isp
you
are
coming
from,
where
you
are
coming
from
in
the
world
trying
to
most
normally
trying
to
direct
you
to
the
content.
Delivery
address
that's
closer
to
your
service,
sometimes
not
quite
getting
it
right,
but
trying
at
least-
and
it's
a
place
where
there
has
been
a
explosion
of
features
both
at
the
protocol
and
the
application
level.
C
C
Some
of
them.
You
see
open
internet,
the
microsoft
version
of
the
dns
server
authority
server,
you
see
normally
inside
enterprises
that
use
active
directory.
Active
directory
is
based
off
an
idf
rfc
and
uses
the
dss
dc
mechanism,
but
microsoft
managed
to
really
hug
it
closely
and
then
extend
it
and
it's
slightly
incompatible
with
active
directory,
even
though,
for
things
like
buying
have
a
gss
txc
implementation.
C
C
There
is
one
that
I,
like
all
your
attention,
for,
which
is
the
nsds
produced
by
the
powerdns
guys.
I
think
this
is
the
best
example
of
software
for
the
dns
by
the
dns
people,
people
who
understand
the
dns
intimately
and
produced
a
load
balancer
that
takes
full
advantage
of
how
the
dns
works,
and
this
is
one
of
the
cases
where
they
want,
for
they
actually
analyze.
For
instance,
what
makes
a
cache
good
and
implemented
for
an
algorithm
that
makes
use
of
them
and
some
of
them
just
use
routing
techniques.
C
You
can
do
that
with
your
routers
with
which
is
outside
of
the
dns,
but
for
the
ns
benefit
in
the
not
so
good
part.
There
are
dns
interceptors
people
do
things
with
the
dns,
because
it's
a
control
point,
as
you
said
before,
and
this
can
range
from
simple
things
like
captive
portals
in
hotel
networks,
that
when
you
try
to
access
the
network,
will
intercept
your
dns
query
and
send
you
off
to
the
registration
login
page
to
censorship,
to
other
things.
C
We
wanted
to
have
a
section
on
myths
and
misconceptions,
but
we
couldn't
fit
it
in
these
90
minute
sessions.
So
hopefully,
if
there
is
a
part,
2
we'll
go
into
that
part
and
do
both
as
an
implementer
as
our
protocol
developer
elsewhere
in
the
itf
things
that
people
get
wrong
things
that
people
think
are
one
way
but
turn
out
be
sometimes
simpler,
sometimes
harder,
and
that
will
be
left
for
part
two.
C
D
A
D
Jeff,
I
said
eating
s0,
client
subnet,
and
if
you
actually
read
the
rfc
about
this,
you
actually
find
a
preamble
from
which
I
think
was
suggested
by
the
the
iesg.
That
says
this
is
a
really
bad
idea,
but
we
don't
actually
understand
how
to
unpublish
it.
Why
is
this
a
bad
idea?
Part
of
the
issue
is
that
if
I
saw
your
dns
queries
no
one
else's,
if
I
saw
your
dns
queries,
there's
nothing
about
your
life.
D
I
couldn't
know
because
the
dns
is
everything
and
and
the
way
the
dns
hides
this
astonishing
privacy
leak.
Is
that
each
query
as
it
moves
from
stub
to
recursive
to
authoritative
loses
the
identity
of
the
end
party
that
started
this
in
the
first
place,
all
the
authoritative
sees
is
google's.
Asking
me
questions
cloudflare
is
asking
me
questions.
Comcast
isp
is
asking
me.
D
Resolvers
are
asking
me
questions,
but
they
don't
know
who
now,
if
I
include
the
identity
of
the
end
user,
there's
no
secrets
anymore,
that's
really
bad
and
everyone
can
start
assembling
profiles,
that's
incredibly
bad,
so
why
these
folk
doing
it?
Why
are
they
butchering
your
privacy?
Well,
the
answer
was
actually
in
response
to
these
anycast
clouded
servers,
open,
dns,
resolvers
that
if
you've
made
the
cardinal
sim
to
use
the
dns
as
a
geolocation
steering
mechanism,
which
was
the
silliest
idea
known
to
the
dns
part
of
mankind.
D
C
A
D
C
A
D
D
Because
the
question
is
speaking
of
privacy,
what
are
your
views
on
q
name,
minimization
and
certainly
the
case
that
the
dns
is
incredibly
chatty,
because
when
it
asks
and
does
the
discovery
of
who
are
the
right
name
servers
for
this
zone?
Like
you
know,
www.example.com,
it
actually
sends
the
full
query,
name,
all
the
way
down
from
the
root
service
and
part
of
the
issue
about
root
servers
and
the
amount
of
information
they
see.
What
they
see
is
actually
full
query
names
now
in
terms
of
a
privacy
leak.
D
D
So
you
actually
asked
everyone
the
full
question,
because
if
a
zone
actually
had
a.b.c.d.example.com,
if
you
sent
the
full
query
name
to
the
example.com
server,
it
would
just
give
you
back
the
answer,
but
the
cost
of
that
implicit
efficiency
was
a
huge
leak
in
terms
of
privacy
and
be
perfectly
frank.
It
was
a
step
too
far
in
retrospect.
A
B
But
that's
because
they
refuse
to
use
one,
that's
a
completely
different
problem,
one.
Let
me
back
up
one
sec,
which
is
that
to
to
be
double
clear,
that
people
got
jeff's
point
he's
talking
about
ecs,
edness,
zero,
slash
the
opt
record.
I
posted
a
link
to
ayanna
in
the
in
the
meet
echo
chat.
There
is
a
lot
of
extensions
that
make
use
of
it,
and
so
he
jeff
is
not
saying.
Edf
zero
is
bad.
He
is
saying
that
that
ecs
he
has
issues
with
so
dude.
B
D
D
A
D
We
did
do
q
a
minimization
as
an
experiment
late
last
year
and
started
to
measure
how
much
of
it
was
around,
and
it
was
actually
quite
disappointing
in
some
respects
that
we
thought
it
would
be.
You
know
70
80
percent,
and
it
was
a
lot
less
than
that.
Do
you
remember
the
answer
joao,
or
do
I
quickly
need
to
go
and
find
it?
I.
C
A
B
Label
in
the
of
the
zone,
with
no
data
added,
because
I
that's
one
of
the
common
misconceptions
I
think
of
dns-
is
that
you
can't
have
that
every
every
dot
has
to
be
a
new
label.
You
know
when
you're
at
or
a
new
sub
zone
when
you're,
adding
stuff,
and
so
I
I
did
have
a
diagram
that
pointed
to
a
label
in
a
zone
that
had
nothing
else
but
sub
stuff
underneath
it
and
that
is
in
a
genome
terminal.
You
know
tina.
B
I
actually
started
measuring
key
name
minimization
at
usa,
isis
root
server,
and
I
need
to
go
back
and
finish
it
because
I
did
see
a
the
beginning
of
a
ramp
and
then
I
haven't
measured
it
since,
and
that
was
like
a
year
ago.
So
I
suspect
that
it's
actually
done
a
lot
better
lately
taking
a
while
to
get
deployed.
C
Yeah
there's
a
question
on
synthesizing
records
of
the
apex.
Unfortunately,
we
push
that
one
to
the
part
two
thing.
Hopefully
that
hope
that
happens
because
there's
always
questions
of
is
that
legal
is,
it
is,
does
it
work,
even
if
it's
not
legal
and
there
are
combinations
of
those
things?
Hopefully
we
get
to
do
that
on
part
two.
D
It
seems
that
the
larger
resolvers
are
way
way
more
conservative
about
innovation
and
putting
new
features
in
their
software,
and
what
we
are
finding
is
that
resolvers
that
live
way
out
on
the
edges,
where
they're
a
much
smaller
client
client
being
served
actually
do
more
of
the
leading
edge
or
bleeding
edge
of
software
than
everyone
else.
So
q
name
minimization,
three
percent
g.
Now,
of
course,
this
was
a
year
ago
august,
2019
and.
C
At
the
time
for
everyone
who
thinks
that
it
would
have
been
better
than
meeting
madrid,
I
am
actually
in
madrid-
it's
37
degrees,
77
degrees
centigrade
outside
bound
to
go
to
39
over
saturday
and
sunday
when
the
idea
would
begin.
So
perhaps
it's
not
an
entirely
bad
thing
that
this
got
moved
to
november
next
year.