►
From YouTube: IETF108-PRIVACYPASS-20200731-1410
Description
PRIVACYPASS meeting session at IETF108
2020/07/31 1410
https://datatracker.ietf.org/meeting/108/proceedings/
B
B
D
Okay,
I
think
we
can
get
started
now,
so
this
is
privacy
pass
working
group,
our
first
meeting
as
a
working
group,
which
is
pretty
exciting.
So
here's
some
information
which
you
probably
already
figured
out
if
you're
here,
the
one
thing
we
do
want
to
go
through
is
the
note.
Well
so
we'll
leave
this
up
here.
It's
the
thing.
You've
probably
seen
all
week
if
you've
been
at
a
couple,
other
meetings
leave
it
up
here
for
another
couple
seconds
and
then
I'll
give
it
over
to
to
ben.
A
B
B
So
in
this
slide
we
can
see
the
relations
between
the
proposed
documents
and,
as
you
can
see,
I
gonna
display
the
privacy
pass
protocol,
which
is
related
to
the
architecture
and
also
to
the
http
api.
So
I
hope
this
slide
explains
a
little
bit
why
we
started
with
the
with
the
protocol
first.
So
next
slide.
Please.
B
So
the
content
of
the
document
describes
basically
what
what
is
the
the
the
meaning
of
the
privacy
pass
protocol
together
with
the
security
properties
that
are
attached
and
that
are
required
for
this
to
work,
also
describe
the
faces
of
the
protocol
and
describe
the
api
that
we
expected
to
be
used
by
the
by
any
implementation
of
this
protocol,
so
also
in
section
seven.
It
gives
a
specific
instantiation
of
the
privacy
pass
protocol
using
vo
prefs
and
using
bio
prs.
B
B
So,
first
of
all,
some
definitions,
so
it's
important
to
note
the
difference
between
these
two
concepts,
so
authorization
means
like
granting
to
privilege
to
users.
Meanwhile,
authentication
is
something
that
people
just
confuse,
but
authentication
means
like
the
process
to
that
is
used
to
identify
a
user,
so
privacy
pass
protocol
is
about
authorization,
so
in
that
sense
next
slide.
Please.
B
B
It
must
be
hard
for
the
issuer
to
link
a
redeem
token
with
other
tokens
that
were
previously
issued,
so
this
varies
from
a
property
for
giving
the
privacy
of
of
the
redemption.
The
second
one
is
unforgivability.
Of
course
we
don't
want
that
tokens
which
are
generated
off
the
air,
so
clients
cannot
bring
in
more
tokens
than
those
that
were
initially
granted.
B
B
So.
Basically,
the
protocol
is
composed
by
three
phases.
The
setup
phase,
which
is
an
offline
phase,
which
is
very
simple,
is
just
the
server
generates
a
pair
of
keys
and
made
a
the
public
key
available
in
to
the
client,
so
the
clients
can
fetch
the
server
key
before
the
start
before
starting
the
protocol.
B
B
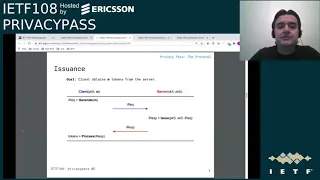
So
the
instrument
is
a
one
round
trip
protocol
in
this
case.
The
goal
of
this
is
we
want
that
a
client
can
request
a
certain
amount
of
tokens.
In
this
case,
the
client
starts
the
protocol
by
generating
an
issue
request
for
the
number
of
tokens
that
the
client
wants
to
to
obtain
from
the
server.
He
sends
the
request
to
the
server
and
then
the
server
using
the
secret
key.
B
It
prepares
a
response
with
tokens
that
are
sent
back
to
the
clients,
so
the
client
can
process
this
issue
request
first
for
extracting
the
tokens,
but
also
there's
an
important
step
here
that
he's
able
to
verify
whether
the
tokens
were
processed
with
the
with
the
server
secret
keys.
That's
why
he
uses
the
public
key
of
the
server
to
have
a
guarantee
that
the
tokens
were
honestly
created
in
the
next
one,
so
yeah
in
redemption
in
redemption.
B
So
now
the
client
has
in
his
position
a
certain
amount
of
tokens,
so
he
take
one
of
those
and
he
want
to
spend
this
talking
with
the
server.
So,
in
order
to
do
that,
he
started
by
constructing
a
redemption
request
with
the
token
which,
basically,
it
packs
the
token
and
sends
to
the
server
the
server.
B
So
so,
in
this
case,
one
of
instantiation
of
the
protocol
is
using
vo
prfs,
so
an
opr
ref
is
actually
a
protocol
that
can
be
used
for
collaboratively
computing,
so
the
random
function.
So
this
and
the
random
function
text
takes
us
an
input,
the
server
key
secret
key
and
some
client
input
x
and
the
output
that
is
equal
to
y,
which,
which
has
this
property
that
happens
to
be
oblivious.
B
That
means
that
the
client
only
can
learn
the
output
of
the
function,
but
there's
no
way
that
the
client
learns
something
about
the
secret
key
of
the
server
and
at
the
same
time,
this
server.
It
cannot
it's
it's
difficult
for
the
client
for
the
server
to
learn.
What
is
what
was
the
client
input
that
he
uses
to
to
compute
the
function?
B
So
so
the
with
this
property
is
an
opr
ref
and
in
order
to
get
from
an
opr
rf
to
a
b
or
prf,
the
vn
stands
for
verifiable,
which
means
that
the
server
has
a
way
to
prove
to
the
client
that
the
the
output
of
this
protocol
was
actually
computed
with
the
secret
key
that
he
that
the
server
usually
commits
to
to
this
key.
So
this
allows
to
to
the
client
to
to
to
be
able
to
verify
that
the
output
was
corrected
using
that
secret
key.
B
So
in
relation
with
this
theoretical
construction
with
the
privacy
pass
protocol,
so
you
might
notice
that
the
pair
x
y
of
input
correspond
to
a
resumption
token.
So
what
happens
during
redemption
is
that
the
server
actually
receives
this
token
and
internally
checks,
whether
this
equation
holds
or
not.
So
if,
if,
if
it
is
also
that
say
that
the
data
cannon
is
valid
well
next,
one
please.
B
Yeah,
so
so
the
description
of
the
of
the
vo
pref
is
is
in
the
draft.
It
currently
provides
some
constructions
which
are
based
on
on
prime
order
groups
and
also
the
api
of
the
bo
prf
draft.
Actually
maps
web
121
to
the
privacy
pass
api.
So,
as
you
can
see
like,
the
five
functions
that
are
used
for
privacy
pass
are,
are
mapped
one
to
one
to
the
vo
prf,
so
the
sec
in
regarding
the
security
analysis
of
this.
B
B
Yeah
finally,
regarding
the
extension
policy,
so,
as
I
mentioned
before,
the
br,
we
want
that
the
privacy
protocol
can
be
extended
either
by
different
implementations
or
different
extensions
of
the
protocol.
So
and
any
new
extension
should
add
a
new
cipher
to
it
to
the
list
and
also
must
instantiate
the
api
that
we
are
describing.
B
B
So
there
are
some
examples
of
what
are
some
potential
extensions
to
the
to
the
privacy
pass
protocol.
The
first
one
is
a
pmb
protocol
or
pmb
tokens.
Currently,
the
vo
prf
doesn't
allow
to
to
include
certain
metadata
on
the
redemption
tokens,
but
this
extension,
the
pmb.
It
allows
to
include
certain
metadata
metadata
bits
on
it.
So
the
description
of
the
protocol
is
on
the
on
this
apron
paper.
B
B
B
D
A
How
about
now
yep
that's
good
okay,
so
it
says
please
join
the
queue.
If
you
have
comments
ben
schwartz,
chair
hat
off,
I
think
that
it
would
be
helpful
to
avoid
describing
this
as
extensible
and
instead
just
present
it
with
the
understanding
that
change
control,
if
adopted,
would
pass
to
the
working
group,
and
so
the
protocol
might
be
altered.
E
E
Hi
this
is
alex,
so
I
think
on
the
on
the
extensions
from
what
we're
imagining
is
like
the
core
protocol
will
have
like
a
set
of
side,
suites
and
any
extension
would
just
like
append
extra
cipher
suites
to
that.
So
it
wouldn't
like
the
extensions,
wouldn't
interfere
like
with
the
actual
like
api
or
the
message
flow.
It
would
just
be
about
specifying,
like
a
new
site,
suite
identifier.
F
F
I
guess
one
question
this
might
be
more
towards.
The
chair
is
like
this
accessibility
question
like
there's
how
the
working
group
extends
this
protocol
or
changes
the
underlying
protocol
and
like
what
the
like
final
work,
product
of
the
working
group
is
going
to
look
like
and
if
it
has
extensibility
after,
like
we've,
as
the
working
group
have
made
all
the
decisions-
and
I
guess
I
assume
this
extensibility
more
refers
to
the
former,
which
is
like
part
of
the
like
passing
over
change
control.
A
Yeah,
so
maybe
we
can
draw
a
distinction
between
this
slide
that
says
and
previous
slides,
that
listed
potential
extensions.
I
think
it's
it's
fine
to
talk
about
the
protocol
as
designed
to
be
extensible.
I
just
don't
think
that
we
should
necessarily
speculate
too
much
right
now
about
what's
going
to
be
in
the
core
protocol
and
what
would
what
would
be
an
extension?
That's
tbd.
E
E
So,
relating
to
the
previous
diagram
that
armando
showed,
the
architecture
document
focuses
on
how
we
integrate
the
privacy
plus
protocol
into
an
ecosystem
where
there
are
multiple
servers
on
clients
and
then
stephen
is
going
to
relate
like
the
http
api
that
we
sort
of
talk
about
in
this
in
the
in
the
existing
documents
that
we
have
after
that.
So
next
slide.
Please.
E
So
the
one
of
the
the
core
principles
of
the
architecture
document
is
to
analyze
the
relationships
between
the
clients
and
the
service,
so
the
ecosystem
of
the
like
a
private
plus
ecosystem,
contains
like
multiple
clients
and
multiple
servers
and
the
client
engages
in
private
class
interactions
with
those
servers
with
multiple
servers.
So
it's
issue
tokens
by
service
and
it
redeems
tokens
and
the
reason
that
we
talk
about
the
ecosystem
in
these
terms
is
because
actually,
the
privacy
requirements
of
the
protocol
are
only
like
in
only
like
their
fruit.
E
In
this
context.
So
if
we
think
that's
the
unlinkability
requirement
that
our
monday
presented,
the
unlinkability
requirement
is
only
only
has
utility
in
relation
to
the
the
end
tokens
that
are
issued
under
the
given
key.
So
a
client
anonymity
is
only
within
the
set
of
all
clients
that
are
issue
tokens,
and
so,
if,
if
that
number
of
tokens
is
small,
that
number
of
clients
is
small
or
there's
a
significant
number
of
keys.
E
E
So
the
organization
of
this
document
first
takes
into
account
the
overview,
the
ecosystem
and
the
different
participants.
So
one
of
the
things
I
didn't
mention
on
the
previous
slide
is
the
the
key
management
story,
and
that
comes
next.
So
actually
in
for
this
key
committing
property,
we
need
clients
to
be
able
to
retrieve
the
server's
public
key
in
order
to
check
that
issuance
data
was
committed
to
properly,
and
so
we
have
to
factor
into
this
ecosystem.
E
So
that's
something
that
we
highlight,
although
it's
more
of
a
policy
question,
and
that
we
don't,
we
don't
really
get
into
a
specific
topic.
I
will
talk
about
that
later
as
well,
and
then
the
key,
the
core
sort
of
body
of
the
document
is
the
privacy
and
security
considerations
of
the
protocol,
because
the
protocol
only
has
utility
when
we
can
ensure
the
privacy
of
the
clients,
and
then
there
are
also
security
considerations
associated
with
how
the
server
runs
and
related
to
those
privacy
considerations.
E
We
then
give
like
concrete
parameterizations
of
the
the
anonymity
sets
that
we
could
expect
to
construct,
given
different
settings
and
different
like
variables
in
the
ecosystem
and
then
finally,
we
talk
about
how
the
extension
policy
that
we
mentioned
in
the
protocol
document
like
sort
of
also
impacts
the
architecture
so
next
slide.
Please.
E
So
in
this
talk,
I'm
going
to
synthesis
I've
synthesized,
like
those
sections
into
five
key
questions,
I'm
going
to
cover,
and
each
of
these
questions
relates
to
a
different
facet
of
the
document,
but
there
are
also
open
questions
that
are
yet
to
be
solved
associated
with
each
of
these
questions
so
and
yeah.
In
this
talk,
I'm
going
to
structure
it
around
these
five
questions.
E
So
an
early
open
question
that
we
have
around
like
how
we
embed
these
servers
into
the
ecosystem
is
actually
around
like
how
we
mitigate
server
centralization.
So
this
is
something
that's
come
up
in
the
previous
ihf
meeting
and
also
on
the
mailing
list,
and
it's
like
how
we
mitigate
against,
like
consolidation,
around
a
small
number
of
servers
that
are
admitted
access
based
on
some
like
policy,
which
is
like
restricting
the
number
of
servers.
E
E
E
We
give
these
recommendations
around
how
a
key
registry
should
be
built
because
it
I'm
going
to
talk
about
in
the
privacy
analysis
but
like
there
were,
there
were
concerns
about
how
keys
are
updated
and
things
like
that
which
affect
the
privacy
of
clients,
but
is?
Would
it
be
interesting
for
the
working
group
to
specify
such
a
registry
concretely,
and
if
we
were
to
do
that?
Would
that
exist
here
in
the
architecture
document?
E
Would
it
exist
in
like
application
specific
documents
like
the
http
api
or
its
own
separate
document,
or
would
we
like
take
existing
technology
from
elsewhere
and
like
build
out
that
key
management
story
from
using
that
instead?
So
next
slide?
Please
so
in
terms
of
what
these
key
registries
actually
look
like
they
contain.
Essentially,
the
data
that's
contained
in
in
any
given
configuration
update
is
like
the
server
identifier,
which
is
like
the
fully
qualified
domain
name
of
the
server
the
cypher
suite.
E
E
And
likewise,
if
the
server
wants
to
rotate
its
cypher
suite,
then
it
must
do
so
in
a
key
update,
because
there's
only
one
valid
key
at
any
given
time.
So
next
slide,
please
so
on.
The
third
question
relates
to
like
client
server
trust,
and
so
it's
like
how
do
clients
actually
choose
which
service
to
trust
and
again
so
I
mentioned
before
that.
E
We
we
think
this
is
more
of
a
policy
question,
but
essentially
that
it's
important
that
clients
only
store
and
redeem
tokens
with
servers
that
they
trust,
because
when
we
redeem
a
token,
they
reveal
that
they
have
interacted
with
that
server
in
the
past.
But
the
important
factors
that
we
bring
up
in
the
document
for
ascertaining
this
trust
essentially
come
down
to
whether
the
client
trusts
the
key
registry.
E
That's
holding
the
server
key
data
and
whether
the
like
ephemeral
reason
for
initiating
this
issuance
redemption
flow
is
something
that
the
client
trusts
as
well.
So
what
we're
imagining
here
is
like
maybe
there's
some
lists
of
key
registries,
that
the
client
trusts,
and
maybe
it
can
edit
that
and
then
the
reasons
for
initiating
the
issuance
and
redemption
are
like,
like
controlling
the
client
implementation
and
issuance,
and
redemption
mecha,
like
interactions,
are
only
allowed
in
very
like
structured
situations.
E
If,
like
a
server,
is
identified
to
be
trusted
like
our
not
just
our
ban,
then
we
could
add,
then
we
could
remove
it
from
an
alarm,
let's
say
or
and
likewise
I
we
could
also
have
block
lists
rather
than
allow
this.
But
this
is
this.
These
are
kind
of
like
open
questions
that
we'd
like
to
sort
of
get
more
opinion,
opinions
on
as
well
and
a
key
open
question
that
we
have
around.
This
is
actually
like.
E
How
do
we
assess
whether
the
service
is
acting
maliciously
in
order
to
like
ban
it
from
the
ecosystem
or
to
like
sanction
it?
So
obviously,
like
there
are
mechanisms
for
checking
whether
the
service
acting
maliciously,
if
they're
posting
strange
key
updates
it
like,
for
example,
if
they
rotate
in
a
key
really
often,
then
that
will
reduce
the
size
of
the
anonymity
set
for
any
client
that
gets
tokens
from
a
particular
epoch,
but
actually
how
we
assess
whether
that
is
happening,
and
then
how
do
we
react
to
it?
E
So
if
it's
client
administered
auditing
do
clients,
then
gossip
with
each
other
to
to
propagate
whether
they
think
a
server
is
malicious
or
not,
or
do
we
have
like
regular
external
audits
that
are
checking
the
key
registries
so
yeah?
This
is
another
open
question.
So
next
slide
please
so
then.
The
fourth
question
relates
to
like
the
server
running
mode,
so
these
are
actually
like
from
a
functionality
perspective.
What
we
recommend
the
interactions
for
client
servers
to
look
like
so
the
client
api.
E
What
the
two
key
principles
that
we
want
to
try
and
enforce
with
these
running
modes
is
that
the
client
api
is
equivalent
in
in
most
of
them
in
the
sense
that
the
client
doesn't
actually
have
to
change
how
it
interacts.
It's
merely
the
entity
on
the
other
end,
that's
kind
of
changing,
and
then
the
tokens
that
are
being
that
are
issued
to
a
client
are
completely
independent
of
the
mode.
E
So
when
we
talk
about
these
running
modes,
we're
talking
about
like
the
redemption
side
of
the
protocol,
and
so
if,
if
an
issuing
server
is,
is
exercising
different
running
modes
in
different
places,
then
the
tokens
themselves
will
be
valid
for
any
of
those
running
modes.
So
if
we
go
to
the
next
slide,
firstly,
on
the
issuance
side,
actually
the
the
flow
of
the
protocol
is
like
is
pretty
much
a
server
authenticated
operation.
E
So
I
mean
the
server
could
do
something
clever
by
like
allowing
trusted
entities
to
issue
tokens
on
its
behalf,
but
essentially
the
client
is
performing
some
operations
with
server
trusts
and
the
server
issues
taken,
but
totally
back
to
the
client.
So
this
is
relatively
simple
and
the
next
slide
is
and
then
the
redemption
side.
We
have
four
different
running
modes.
E
So
essentially
the
first
is
single
verifier,
and
this
is
the
essentially
the
the
simplest
running
mode
in
the
sense
that
it
maps
almost
identically
to
what
we
present
in
the
price
protocol
document,
so
clients,
essentially
just
redeem
tokens
directly
with
the
issuing
server
like
the
same
fully
qualified
domain
name
and
the
server
just
returns
the
response
or
perform
some
other
action
based
on
whether
the
redemption
is
successful
or
not.
Next
slide,
please
so
the
second
mode
is
delegated
verifier.
E
So
in
this
scenario,
there's
obviously
the
concern
that
the
the
intermediate
verify
could
just
steal
the
client's
tokens,
because
the
the
tokens
are
they're
client,
essentially
just
stealing
tokens,
and
so
I
think
here
there
are
some
extra
mitigations
that
we
should
probably
put
in
place
on
this
initial
redemption
between
the
client
and
the
intermediate
verifier,
and
I
think
I
think
in
the
http
presentation
after
this
one,
there
are
options
for
doing
that.
So
next
slide.
E
Some
valid
redemption
in
the
past,
and
the
client
can
then
use
that
signed
redemption
record
with
the
with
the
verifier
to
prove
that
it
has
a
valid
redemption
and
there's
some
caching
things
that
we
can
do
here
and
again.
This
is
a
running
mode.
That's
used
in
the
http
api
documents.
I
think
steven
will
be
talking
about
that
in
more
detail.
E
Next
slide,
please,
and
so
the
final
mode
relates
to
public
verifiability.
So
in
the
previous
three
running
modes,
we
assume
essentially
a
symmetric
exchange
whereby
the
the
issuing
server
is
essentially
terminating
all
redemptions
in
the
in
the
end
and
in
the
public
in
the
public
verifier
mode.
We
assume
a
different
property
on
redemption
tokens
in
that
they
are
publicly
verifiable
using
the
service
public
key
associated
with
the
protocol.
E
Preserving
technology
is
that
the
number,
the
total
number
of
clients
in
the
system
obviously
gives
an
upper
bound
on
the
on
the
anonymity
set
size
of
all
of
all
the
clients,
because
you
just
belong
to
all
the
clients
in
the
ecosystem,
but
likewise
for
the
number
of
clients
accepting
tokens
for
from
a
server
you
you,
you
bind
yourself
to
that
unlimited
set.
So
if,
if
you're
part
of
only
a
small
group
of
clients
that
accept
tokens
for
one
particular
server,
then
then
anyone
triggering
redemptions
that
you
reveal
for
that
server.
E
You
you
bind
yourself
to
that
small
group,
so
so
this
is
obviously
an
important
factor
and
then,
at
a
more
granular
level.
Some
of
the
extensions
we've
been
talking
about
may
add,
like
small
number
of
metadata
bits
and
certain
tokens,
and
essentially
what
these,
what
these
extensions
do
is
use
more
keys
on
the
server
side
for
issuing
tokens,
while
still
maintaining
the
like
privacy
pass
api.
E
If,
if
servers
are
performing
lots
of
key
rotations,
then
you
you'll
you'll,
you
will,
you
will
have
tokens
in
smaller,
epochs
and
so
you'll
be
part
of
a
small
anonymity
set
and
likewise
assume,
like
the
reason
we
assume
independence
of
key
registries
is
because,
like
potential
collusions
between
servers
and
key
registries
could
lead
to
servers,
posting
different
keys
in
different
places,
which
would
then
potentially
like
tag
clients
into
again
smaller
segmented
client
basis.
So
next
slide,
please.
E
So
one
of
the
things
we
do
in
the
document
is
try
and
concretely
parameterize
what
we
want
the
ecosystem
to
look
like,
and
so
this
table
is
taken
from
the
document,
one.
That
a
few
of
the
things
I
wanted
to
highlight
currently
is
that
we
have
some
firstly,
as
we
have
these
fixed
values
and
it'd
be
good
to
get
more
opinions
on
like
what
is
actually
like.
The
same
value
for
like
a
minimum
anonymity
set
size
like
what
recommended
key
lifetimes
of
applications.
E
Do
they
need
like
should
like?
Can
we
can
we
afford
to
have
smaller
key
windows?
I
guess
this
is
all
so
this
is
these.
Things
are
all
related
into
like
this
final
equation,
which
is
in
the
third
like
sort
of
box
here,
and
that's
one
of
the
biggest
restrictions
that
we
currently
have
in
the
document
is
that
the
maximum
allowed
services
is
logarithmically
like
related
to
the
like
total
user
base.
E
This
means
is
that,
like
if
a
client
supports,
if
a
client
holds
like
tokens
for
four
issues
at
a
given
time,
then
if
a
client
was
to
try
and
retrieve
trying
to
issue
tokens
from
a
new
server,
it
would
have
to
delete
tokens
from
one
of
the
existing
servers
they
hold.
And
so
what
we're
trying
to
do
here
is
like
simulate
an
ecosystem
where
the
client
can
only
hold
tokens
for
a
small
number
of
issuers.
E
And
if
we
can
do
this
effectively,
then
we
can
remove
the
restriction
on
the
number
of
issuers,
because
we
could
have
a
large
number
of
issuers
but
clients
only
supporting
at
any
given
time
a
small
number
of
them,
and
so
this
limits
the
sort
of
possibilities
for
segmenting
the
client
user
base.
Although
I
shouldn't
know
that
this,
like
this
logarithmic
equation,
we
have
on
the
right,
doesn't
necessarily
directly
translate
to
this.
Setting,
because
a
client
can
hold
tokens
for
four
issues
can
hold
tokens
for
four
completely
different
issues.
E
So
there
is
some
privacy
disparity
in
these
two
different
things,
but
I
think
going
down
this
sort
of
angle
might
be
like
might
give
us
some
alleviation
on
this
restriction.
It
would
also
be
good
to
hear
more
opinions
on
whether
there
were
different
mechanisms
for
like
avoiding
this,
like
total
bound
on
the
number
of
issues.
E
Finally,
the
extension
policy
and
so
armando
laid
out
what
we
currently
have
the
extension
party.
I
know
there's
been
some
discussion
on
this,
but
essentially
what
we
currently
have
in
mind
is
like
any
extension
to
the
protocol
is
essentially
just
going
to
introduce
new
cyber
suite
identifiers
and
those
cycle.
E
E
Just
to
like
raise
the
open
questions
that
I
I
brought
up
throughout
this
presentation.
So
we
have
three
core
open
questions,
but
there's
a
lot
of
room
for
discussion
on
a
lot
of
different
topics.
So
the
three
core
ones
that
I
at
least
picked
out
were
getting
suggestions
from
mitigating
against
server
centralization
and
whether
we
do
that
in
this
document
or
whether
it
lives
in
a
more
like
specific
document
related
to
well
within
the
working
group.
E
A
E
Yeah
so
servers
and
issuers
are
kind
of
like
I'm
thinking
of
them
identical,
but
essentially
I
wanted
to
like
differentiate
between
like
these
intermediate
verifiers
that
can
that
can
like
like
ask
for
client
redemptions,
but
it's
ain't
like,
but
but
by
server.
We're
talking
about
like
an
issuing
entity
that
issues
the.
E
G
Let's
see,
how
do
I
do
this?
Let's
see
here,
we
hear
you
now,
okay,
great
thanks,
so
a
point
on
this
first
bullet.
This
is
in
the
charter
addressing
this
issue
this
centralization
issue.
My
I
have
two
sort
of
responses
here.
I
my
feeling
here
is
that
this
would
be
a
separate
document.
It's
not
really
an
architectural.
G
G
Let
me
see
if
I
can
make
sense
of
that
that,
as
the
architecture
and
protocol
documents
go
forward,
I'd
like
to
see
this
centralization
document
also
move
forward
so
that
they
are
sort
of
tied
together
as
it
were,
and
for
the
chairs
information.
This
is
something
I'd
be
about
willing
to
volunteer
to
work
on,
but
I
I
just
don't
see
this
issue
as
being
something
that
you
would
address
in
a
traditional
architecture
document
I
could
be.
G
I
could
be
convinced
otherwise,
and
your
slide
number
seven
sort
of
gets
that
sort
of
hits
at
the
issue.
You
don't
have
to
go
back
to
the
slide,
but
it
was
in
your
presentation
and
so
in
reacting
to
this
first
bullet
here.
I
guess
my
two
points
are
that
I
really
do
see
this
as
a
separate,
a
separate
document,
but
I'd
like
to
see
them
tied
together,
so
that
the
architecture
and
the
centralization
paper
or
the
centralization
draft
move
together
through
the
approval
process.
G
F
I
guess
one
question
is
like
a
lot
of
these
like
how
we
deal
with
server
centralization.
How
we
do
key
registries
is
going
to
be
somewhat
use
case
dependent,
and
I
guess
like
how
much
we
want
privacy
pass
like
the
architecture,
centralization
doc
or
whatever,
to
like
limit
what
the
use
cases
will
do
versus
like
providing
a
like
guideline
for
like
what
things
should
be
taken
into
account
here.
I
think,
given
that,
like
yeah,
I
think
maybe
making
this
separate
from
the
core
architecture.
F
Dock
makes
sense,
but
I
guess
there's
also
going
to
be
cases
where,
like
a
key
registry,
just
is
like
a
lot
of
overhead
when
you're
like
use
case,
doesn't
really
need
that,
and
I
guess
seeing
like
to
what
extent
the
privacy
pass
working
group
documents
want
to
support
different
use.
Cases
built
on
top
of
privacy
passes.
Another
question.
E
Yeah,
I
think
that's
something
that
we're
currently
aiming
for
with
the
architecture
is
kind
of
like
giving
these
like
more
like
high
level
guidelines
on
what
things
should
look
like
and
then,
hopefully,
like
the
use
cases,
will
kind
of
like
take
on
those
guidelines
and
give
like
more
concrete
constructions
of
the,
like
particular
different.
Like
thing
entities
that
are
involved.
A
C
E
Yeah,
I
think
I
think
you're
right.
I
think,
there's
we're
not
quite
clear
on
exactly
what
like
an
attribute,
corresponds
to
in
the
ecosystem
right
now,
but
the
way
we're
thinking
about
it
is
like
a
a
given
server
that
issues
tokens
is
issuing
for
like
one
attribute
and
that's
what
the
like
bit
that
you
get
in.
Your
token
is
like
corresponding
to
so.
In
your
example
like
a
driver's
license,
there
would
be
like
an
issuing
entity
in
the
ecosystem
that
issued
tokens
for
that
thing,
and
there
was
a
key.
E
H
Hear
audible
now
I'll
I'll
go
audio
only
because
who
knows
about
getting
video
working,
so
I
I'm
relaying
a
point
guy.
I
got
out
of
band
from
chelsea
kanwa
of
waterloo
university
she's
on
the
mp3
stream,
not
on
tech
chat.
She
points
out
that
in
the
case
of
tor,
if
you
have
an
anonymity
network
like
tour,
then
you
can
detect
malicious
key
registries
by
doing
something
as
simple
as
building
multiple
circuits
to
a
key
registry
and
doing
the
key
ratios
parallel
key
registries
and
comparing
the
results.
H
So
there
may
be
some
mitigations
available
with
that.
If
you
assume
some
extra
technologies,
she
also
observes
that
in
a
if
you
don't
have
an
anonymity
network
like
tor,
then
you
have
identifiers
like
ip
addresses
that
can
be
used
to
do
external
correlations.
There's
a
limit
on
how
much
you
can
get
from
these
these
sorts
of
things
anyway.
H
So
there's
a
couple
points
from
chelsea.
I
would
add,
on
top
of
that
as
well,
that
it
would
be
interesting
to
if
we
could
see
if
there's
maybe
a
couple
of
additional
assumptions,
one
could
make
that
might
you
might
get
from
the
environment
anyway?
Kind
of
like
the
the
the
ip
address
tracking
stuff
anyways
that
could
perhaps
simplify
the
the
number
of
mechanisms
we
have
to
employ
here,
because
this
is
this
is
looking
kind
of
on
on
the
edge
of
you
know.
The
ietf
is
not
all
that
good
at
doing
hard
things.
E
Yeah,
I
think,
they're
a
good
point.
I
think
the
point
about
like
it's
important
to
emphasize,
that
the
price
pass
basically
only
provides
anonymity
to
the
extent
in
which
it
is
then
used
in
like
a
broader
framework.
So
yeah,
that's
it's
true
that
if,
if
you
have
other
identity
and
identifying
features,
then
they
will
reveal
who
you
are,
and
I
think
on
the
tour
thing
it.
H
E
E
F
The
reason
to
put
it
in
a
header
instead
of
throughout
the
body
is
that
there's
a
possible
idea
of
like
moving
this
off
of
just
being
well
known,
endpoints
and
like
letting
an
issuer
do
privacy
past
issuance
introduction
at
any
end
point,
for
example,
for
a
capture
server.
You
might
want
to
have
the
endpoint
that
receives
a
capture.
Result
be
the
one
that's
also
giving
you
back,
your
privacy
pass
tokens
redemption.
You
may
also
want
to
also
return
other
information
other
than
just
the
like.
F
In
this
header,
we
were
looking
at
using
the
structured
header,
which
is
a
http
draft,
currently
in
that
working
group
to
encode
the
type
of
message
that
is
being
sent,
whether
it's
an
issuance
or
a
redemption
request
and
the
actual
protocol
data
inside
of
it
next
slide
so
for
issuance
the
privacy
pass
header
for
the
most
part,
contains
all
the
blinded
or
all
the
blinded
nonsense
that
the
client
of
the
issuance
would
want
to
send
probably
stacked
up
and
batched
together.
Since
you
don't
want
to
do
one
http
request.
F
F
The
response
would
then
contain
the
signed
blinded
tokens
in
the
same
header
with
a
separate
message
tag
and
the
server
would
be
for
sure,
if
would
be
responsible
for
using
the
other
data
inside
that
request,
to
determine
whether
to
send
a
token
back
either
if
it's
a
captcha
challenge
or
finding
that
challenge.
If
you
have
some
sort
of
authentication
or
login
information
using
that
to
look
up
your
is
human
attribute
or
whatever
other
policy
the
server
might
use
to
determine
when
to
issue
tokens.
F
F
F
F
The
server
does
the
whole
verification
step
and
then
return
for
now,
a
signature
that
says
yes,
this
token
is
valid.
The
signature
is
not
too
required
when
you're
doing
when
the
client,
which
is
redeeming
the
token,
is
immediately
consuming
the
results,
since
this
redemption
was
hopefully
done
over
some
secure
channel
https,
but
is
more
useful
for
the
other
forms
of
redemption
next
slide.
F
F
This
is
mostly
only
useful
if,
like
you're,
worried
about
a
malicious
issuer
or
verifier.
That
is
trying
to
do
something
funny,
but
this
is
more
useful
in
the
delegated
case.
Next
slide
this
case,
the
person
asking
for
a
verification
or
token
isn't
actually
the
person
who's
going
to
be
consuming
this
in
the
end.
F
It's
also
useful
if,
in
the
web
case,
where
you
have
a
lot
of
parties,
you
want
to
pass
on
this
proof
to,
but
you
don't
want
to
be
using
one
token
for
every
party,
though
that's
more
limited,
based
on
the
use
case
that
you're
using
this
api
in
possibly
like
in
the
web
http
use
case.
This
would
be
useful
for
a
lot
of
third-party
content
embedded
on
a
top-level
site
and
each
third-party
content
doesn't
care
about
getting
like
a
unique
token.
F
F
Next
slide
so
for
key
management
in
this
api,
it's
very
similar
to
the
descriptions
in
the
architecture
dock.
We
need
to
worry
about
any
sets
based
on
the
keys
used,
notably,
we
are
also
worried
about
like
if
the
keys
change
over
time
we
don't
want
to
like
have
some
clients
under
old
keys
and
some
clients
under
new
keys.
So
we
need
both
like
thumb
and
force.
Standard
rotation
limits,
otherwise,
like
an
issuer,
can
just
change
their
keys
every
five
seconds
and
have
a
bunch
of
keys
in
play.
F
So
we
need
this
sort
of
consistent
keys
across
the
ecosystem,
but
we
also
want
some
form
of
audibility,
so
we
can
detect
when
an
issuer
is
acting
badly
and
changing
their
cues
very
frequently,
there's
a
number
of
ways.
You
can
then
optimize
on
top
of
this.
Assuming
you
have
this
append
only
consistent
log,
which
it's
a
question
whether
the
working
group
should
be
defining
it,
this
sort
of
log
or
leaving
it
to
the
use
cases
or
something
else.
F
One
optimization,
assuming
you
have
this
magical
log
is
if
the
client
doesn't
want
to
be
talking
to
the
log
for
every
issuer,
it
could
just
talk
directly
to
the
issuer
itself.
That
would
need
to
do
this
in
a
anonymous
way
that
doesn't
have
any
information
that
the
issuer
could
use
to
figure
out.
What
user
you
are.
F
F
So
yeah,
some
of
the
open
questions
left
from
the
current
draft
of
the
hp
api
is
whether
we
keep
this
concept
of
protocol
endpoints
using
dot
well
knowns.
Currently
we
have
a
well
known
for
issuance
redemption
and
the
actually
getting
key
commitments
or
whether
we
generalize
this
so
that
the
issuer
can
use
any
endpoint
to
do
issuance
and
redemption.
F
There's.
Also,
a
question
of
this
is
mostly
a
low-level
http
api
for
how
to
interact
with
privacy
pass
as
a
core,
but
we'll
also
need
some
sort
of
higher
level
apis,
probably
in
other
standards
groups
like
the
w3c
for
actually
having
like
browsers,
communicate
with
issuers
and
to
what
extent
we
want
to
maintain
consistency
with
those
or
just
leave
that
up
for
other
groups
to
have
to
be
consistent
with
what
privacy
pass
puts
out.
A
A
A
E
Hi
yeah,
alex
speaking
so
I
guess
from
like
our
perspective,
like
what
like
some
other
thing
like
one
of
the
things
that
we
like
to
like
raise
is
the
is
like
the
key
management
story,
and
I
think,
because
we
have
a
good
idea
of
like
what
we
need
from
these
things,
and
we
like
talk
about
it
in
different
documents.
But
it
would
be
good
to
get
like
more
opinions
on
what
would
be
like
a
satisfiable
solution
to
the
problem
like
from
like
an
auditing
perspective
and
also
from
like
a
functional
perspective.
E
I
I
F
I
guess
from
the
buff
we
actually
wanted
to
like
generalize
some
of
the
use
cases,
but
some
of
the
like
base
use
cases
we've
been
considering
is
things
like?
If
is
a
human
bit,
for
example,
capture
results?
If
a
website
has
a
particular
a
strong
reason
to
believe
that
a
user
is
actually
real
and
being
able
to
pass
it
on
to
other
websites
that
may
not
actually
have
the
capability
of
gaining
that
information.
F
So
if
you
complete
a
capture,
we
imagine
that
the
issue
would
then
return
some
number
of
tokens
and
then
eventually
like
that,
those
tokens
would
be
used
up,
so
the
user
would
have
to
come
back
and
do
another
proof
of
work
to
get
more
tokens.
It
would
be
up
to
issuer
policy
to
see
like
how
many
tokens
they
would
give
out
for,
like
certain
amount
of
proof
of
work.
I
F
Then
we
have
similar
issues
in
the
current
world
where,
if,
like
you,
have
a
bot
farm
in
one
place,
that
is
just
a
lot
of
people
clicking
through
captures
and
getting
lots
of
tokens.
I
guess
effectively
really
it's.
I
guess
in
third
party
state
at
the
moment
they
could
do
actions
like
that
yeah.
I
guess
there
is
the
disadvantage
of
like
since
tokens
can't
be
tracked
back
to
where
they
were
issued.
F
Yeah
yeah,
I
think
it
would
require
a
decent
amount
of
infrastructure
to
avoid,
like
you're,
captured,
just
turning
it
into
using
privacy
pass
and
not
becoming
a
huge
threat
vector,
but
I
think
there
are
some
rate
limits
that
will
help
with
that.
I
guess
alternative
things
are,
if
you
have
more
of
like
a
user
identity
and
like
that,
user's
use
of
your
website
has
made
it
so
you
believe,
they're
human,
then
you
can
associate
how
much
trust
you've,
given
them,
how
many
tokens
you've
issued
to
whatever
identity
you
have
in
that
case.
I
Yes
did
not
detect
is
what
I'm
wondering
about
here,
because
the
whole
way
that
an
abused
loop
works
is
that
if,
if
you
say
this
user
is
valid
and
they
behave
badly,
then
the
to
close
that
loop
back,
you
get
a
report
that
that
particular
user
behave
badly,
and
you
can
then
associate
that
back
to
who
you've
been
handing
these
tokens
out
to.
So,
if
you
have
a
badly
behaving
user
that
you're
giving
tokens
to
and
they
then
go
go
out
and
use
that
that
decreases,
the
trustworthiness
of
usa,
token
issuer
and
you
don't.
C
F
F
I
I
I
E
I
E
Sure
that
I
mean
yes,
but
I
guess
you
don't
have
to
accept
the
tokens
we're
not
like,
and
I
think
this
comes
into
like
the
centralization
of
questions
as
well.
I
I
think
these
are.
These
are
all
good
points,
because
if,
if
you
centralize
things
and
say
like
there's
like,
for
example
like
if
you
control
different
websites-
and
you
you
accept
token
on
people's
behalf-
then
yeah-
you
have
a
you-
have
a
good
point.
E
I
I
C
I
mean
so
I
I
have
a
kind
of
unrelated
question
to
manage
to
do
the
key
management
or
key
registry,
or
whatever.
Does
that
mean
there's
going
to
need
to
be
a
secondary
organization
similar
to
the
cab
forum,
which
has
yeah
and
baseline
requirements
for
issuers
is,
do
we
need
to
will
there
need
to
be
this
whole
other
ecosystem
of
infrastructure.
F
F
A
A
A
A
A
K
E
Yeah,
I
yeah
you
made
a
good
point
and
I
think
the
the
the
situation
we're
assuming
at
least
in
the
architecture
and
http
api,
is
that
you
have
this,
that
each
verifier
has
its
own,
eventually
consistent,
double
stem
protection
and
when
when
and
that
double
spent
section
only
corresponds
to
that
verifier.
So,
there's
no
like
global
double,
spend
check
for
the
all
the
verifiers
in
the
ecosystem.
It's
it's
more!
It's
it's
concentrated
to
a
single
verifier.
E
E
Yeah
exactly
one
of
the
reasons
why
we
don't
we
don't
enforce
the
we're
spending
we
kind
of
give
like
recommendations
is
because
I
mean
firstly,
there
are
some
situations
where
people
have
brought
up
in
the
past.
There
might
be
applications
where
double
spending
might
be.
Okay,
though,
you
do
lose
like
the
linkability
property,
when
you
do
that,
and
secondly,
because
with
with
the
restriction
in
mind
on
the
on
verifies
acting
independently,
that
there's
not
really
a
good
way
of
doing
global
double
speculation.
E
K
E
Yeah,
so
tokens
are
only
valid
for
the
key
pair
that
they're
issued
by
so
when
a
server
is
like
rotates
its
key.
It
should
also
clear
out
its
entire
storage,
so
so
one
of
the
trade-offs
with
like
the
key,
the
key
cycles
is
we
don't
want
them
to
be
too
small,
but
we
also
don't
want
them
to
be
too
long
for
the
reason
you
bring
up
in
the
clients
could
just
like
fill
like
a
server's
like
like
token
storage
system
for
checking
double
spends.
E
And
also
like
with
these,
with
these
token
storage
systems,
like
you,
can
use
like
efficient
data
storage
mechanisms
as
well
like
bloom
filters
and
things
to
mitigate
against
like
the
size
of
that
storage
increasing.
So
you
only
really
need
to
check
that
things
are
contained
that
you've
seen
things
in
the
past.
You
don't
you
don't
need
to
keep
like
the
entire
list
of
tokens.
D
Okay,
well,
I
think
we're
probably
reached
the
end
of
the
conversation
for
today.
I
think
next
steps
are
to
you
know,
hopefully
have
more
folks
read
through
the
documents,
so
we
can
continue
discussion
on
the
list
and
you
know
in
a
short
period
of
time,
we'd
like
to
as
ben
mentioned,
call
for
adoption
of
these
documents
and
see
how
the
group's
feeling
is
towards
that.