►
From YouTube: IETF108-MOPS-20200728-1300
Description
MOPS meeting session at IETF108
2020/07/28 1300
https://datatracker.ietf.org/meeting/108/proceedings/
C
D
C
A
A
I
think
we've
got
a
lot
of
interesting
stuff
on
the
agenda
and
we'll
just
have
to
keep.
If,
if
we
keep
pressing
forward,
it's
we're
not
trying
to
be
rude,
we're
just
trying
to
make
sure
that
we
get
through
a
lot
of
material
that
we
have
all
right
next
slide,
please!
Yes,
as
I
said,
we
have
a
fairly
healthy
agenda
right
here.
A
My
suspicion
is
that
by
the
end
of
the
session,
we
may
be
identifying
material
for
an
interim
before
the
ietf
109
meeting,
and
I'm
going
to
say
again
thank
you
to
glen
dean
for
being
our
note
taker,
but
please
anybody
else
who
wants
to
keep
an
eye
on
the
kodi
md
window
and
participate
in
helping
edit.
The
notes
would
also
be
appreciated
and
thank
you
to
magnus
westerlund
for
being
our
jabra
scribe
today.
A
A
E
Okay,
I'm
jake
holland,
I'm
giving
an
update
on
our
streaming
operation.
Operational
considerations,
draft
spencer,
dawkins
and
ali
have
joined
next
slide.
Please,
so
I
think
we
discussed
it
at
the
interim.
There
is
now
a
a
session
about
a
section
about
kobit
that
spencer
put
in.
We
changed
up
the
the
notes
for
contributors
section
and
put
it
near
the
front
where
it's
easier
to
find
and
read.
We
added
the
template
we
discussed
for
how
to
submit
the
issues.
E
E
E
I
think
some
of
the
authors
have
been
a
little
busy
and
the
the
new
issues
in
the
blue
at
the
bottom
here
are
just
the
new
references,
some
updates
to
the
references
for
the
new
coded.
It's
actually
named
extremely
unpredictable
traffic
patterns
to
go
with
the
unpredictable
traffic
patterns
and
the
issue
about
the
broken
gh
pages,
where
the
github
website
for
this
is
is
hosted
next
slide.
E
E
E
E
I
don't
know
taking
it
home
on
that.
I
think
that
ollie
had
a
some
notes
that
there
might
be
something
useful
to
say
about
it
without
stepping
really
out
of
out
of
bounds
on
you
know,
providing
guidance
on
use
of
rtp
or
anything.
So
I
don't
know
what
that
would
look
like,
but
I
think
that
I
would
suggest
that
we
go
ahead
and
move
things
forward
and
then
take
a
look
at
it
and
and
review
whether
it
looks
properly
in
scope.
E
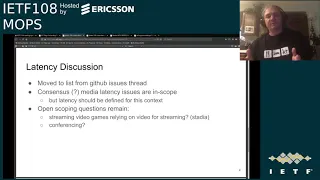
There
were
a
few,
but
the
main
point
of
the
of
the
open
scoping
questions
is
whether
we
should
say
anything
at
all
about
things
like
stadia.
Where
there's
you
know
streaming
of
video
games
that
relies
on
the
video
stream
and
has
tight
latency
constraints
and
whether
conferencing
with
the
sort
of
real-time
back
and
forth,
should
be
brought
up
or
mentioned
as
a
as
a
point
of.
E
F
C
E
Okay,
so
outside
of
the
latency
discussion,
I
just
wanted
to
remind
everyone
that
we
would
love
to
get
a
sort
of
list
of
issues
that
have
been
encountered
as
part
of
video
streaming
from
people
who
who
have
encountered
them
tell
us
about
them.
This
is
the
template
that
we
have.
There
was
one
minor
update
to
it.
I
think
the
the
trade-offs
mentioned,
because
often
it's
it's
trade-offs,
but
it's
roughly
what
it
looked
like
last
time,
but
I
don't
think
we've
gotten
anything
in
this
template
form.
E
A
A
What
I
think
I
would
like
to
do
is
say:
let's
frame
up
the
discussion
as
an
agenda
item,
either
on
an
interim
or
or
on
the
next
regular
meeting,
and
I
think
that
your
notion
of
trying
to
start
writing
some
stuff
up
so
that
we
actually
have
material
to
consider
and
aren't
just
some
wrestling
over
our
experiences
with
particular
technologies
is,
is
probably
the
best
plan.
Does
that
make
sense
to
you,
kyle.
C
Yeah,
I
I
think
definitely
having
something
teed
up
for
a
discussion
at
the
at
the
next
interim
would
be
a
good
idea.
I
think
we
should
probably
not
wait
four
months
to
the
next
meeting,
so
if,
if
jake,
if
you
can
throw
something
together,
you
know
we'll
figure
out
some
time
to
hold
an
interim
well
before
ietf
109.
A
E
C
E
E
E
C
C
C
G
C
H
Okay,
perfect,
so,
okay,
so
I'll
start,
okay,
so
hi
everyone.
My
name
is
chris
kobaccus.
It
is
my
pleasure
and
honor
to
be
here
and
present
at
the
ietf108,
and
thank
you
very
much
for
having
me
here
today.
I
will
provide
a
quick
status
update
and
an
overview
of
the
best
practices
for
end-to-end
workflow
monitoring
project.
This
project
is
being
worked
on
by
the
streaming
video
alliance
as
part
of
the
measurement
quality
of
experience
work
group.
Just
a
little
bit
of
background
about
myself.
H
So
quick
glance
at
the
agenda,
I
would
like
to
take
the
next
15
minutes
to
just
go
through
the
contributors
to
the
project.
The
industry,
motivation
for
the
project
goals
of
the
project,
the
qe
definition
adopted
by
the
project
project
scope,
a
quick
overview
of
the
proposed
framework,
followed
by
an
example,
application
of
the
framework
and
finishing
with
an
outage
detection
example
using
the
framework
approach
and
then
finishing
off
with
a
five-minute
q.
A.
H
So
the
project
was
born
out
of
the
industry's
need
for
systematic
and
comprehensive
approach
for
real-time
video
streaming
monitoring
as
such,
this
project's
contributing
companies,
along
with
the
rest
of
the
sva
membership
comprising
representative
mix
of
video
workflow
stakeholders,
including
content
owners,
for
example,
disney
service
operators,
for
example,
sky
and
now
disney,
as
well,
with
disney
plus,
for
instance,
and
vendors
specializing
in
quality
measurement
for
video
streaming,
including
data
zoom,
opticom,
simulator
and
thomas
edwards,
is
the
measurement
here
we
work.
Group
chair
and
myself,
along
with
brenton
of
touch
streams,
are
the
two
project
co-leads.
H
So
what
we're
seeing
is
that
the
industry
continues
to
have
a
need
for
a
comprehensive
end-to-end,
video
monitoring
framework
for
media
operations
and
knock
teams.
This
is
especially
important
as
they
need
to
be
able
to
proactively
detect
failures
and
degradations
and
efficiently
carry
out
customer
impact
assessment,
workflow,
fault,
isolation
and
root
cause
analysis
in
order
to
reduce
mean
time
to
detection.
I
mean
time
to
resolution.
H
However,
to
this
day,
these
diagnostic
and
measurement
activities
can
be
extremely
challenging
for
the
media
operations
teams
to
illustrate
here
we're
showing
a
prototypical
end-to-end
video
streaming
workflow
view.
We
use
this
view
in
the
best
practices
dock.
It
is
a
very
high
level
view.
It
emits
a
lot
of
complexity.
However,
it
does
focus
on
the
key
video
workflow
functions
and
video
transformations
from
left
to
right.
We
have
source
production
which
feeds
into
encoding.
H
So,
for
instance,
when
when
a
customer
is
experiencing
an
issue
such
as
a
frozen
screen,
teams
need
to
quickly
qualify
primarily
where
in
the
workflow
has
the
failure
occurred.
For
example,
is
it
the
customer
environment,
the
delivery,
the
content,
processing
or
even
the
source?
And
secondly,
what
is
this
scope
of
impact
on
the
customer
population?
Is
it
a
single
device,
a
single
household
single
region,
multiple
regions
or
even
an
entire
subscriber
base.
H
And
in
general
it
is
not
straightforward
to
establish
the
scope,
nature
and
the
root
cause
of
video
service
impacts
in
many
outage
or
degradation
scenarios.
It's
not
sufficient,
for
example,
to
only
instrument
the
player
or
the
cpe,
or
to
only
rely
on
cdn,
probes
or
cdn
logs
for
video
quality
information
in
the
following
example.
H
Suppose
we
want
to
know
the
quality
that
each
of
our
subscribers
is
receiving,
so
we've
instrumented
the
players
so
we're
getting
metrics
such
as
video
startup
time,
rebuffering
ratio,
average
media
bit
rate,
video,
start
failure
and
they're
all
showing
okay
they're,
all
showing
green
and
we've
also
instrumented
the
cdn
and
the
origin,
and
we're
getting
metrics
such
as
availability
response
time
bitrate
for
both
manifests
and
chunks
and
again
they're
all
green
they're,
all
showing
okay.
Everything
seems
fine
and
metric
wise
from
these
three
monitoring
points.
H
However,
then
viewer
is
getting
a
frozen
screen,
so
one
potential
scenario
that
makes
this
possible
is
as
follows:
the
source
can
fail,
the
encoder
loses
input.
However,
the
encoder
does
continue
to
generate
a
well-formed
video
stream
output
with
non-changing
pixels
and
the
rest
of
the
chain
doesn't
know
any
better
and
is
happy
to
deliver
the
content
along
and
play
it
out
for
the
viewer
and
resulting
in
a
frozen
screen
to
the
customer.
H
H
Instead,
it
can
occur
on
the
content
layer
itself
so
similar
to
the
previous
example.
We're
monitoring
our
players
in
our
delivery
at
cdn
and
origin.
These
metrics
show
healthy
delivery
and
play
out
metric
measurements
are
within
okay
ranges
in
green,
however,
then
viewer
again
is
receiving
poor
perceptual
video
quality.
For
example.
It's
not
not
a
sharp
it's
fuzzy
blocky
so
in
this
example
we're
receiving
a
pristine
source.
However,
the
encoder
is
too
aggressive
it
over
compresses
the
video,
but
still
produces
a
well-formed
video
stream.
H
H
The
previous
example
showed
that
network
layer
monitoring
is
not
sufficient
either.
In
other
words,
we
also
need
content
level
monitoring.
This
third
example
shows
another
interesting
property
of
video
workflows.
Video
workflows
can
regenerate
transport
layer
packets.
This
is
another
reason
why
video
workflow
issues
are
difficult
to
diagnose.
In
this
example,
again,
player
and
delivery
metrics
show
a
healthy
video
stream.
However,
the
video
quality
that
the
viewer
is
receiving
is
unwatchable
such
as
pixelating,
video
and
choppy
audio,
so
in
this
example,
we're
receiving
a
pristine
source
and
the
encoder
actually
does
a
great
job
with
compression.
H
H
H
In
general,
many
underlying
factors
can
contribute
to
to
contribute
to
poor
customer
viewing
experience,
not
just
the
examples
mentioned
above
different
root
causes
at
different
parts
in
a
workflow
can
introduce
different
impacts,
different
source
issues
such
as
poor
source
quality,
different
content,
processing
issues
affecting
encoding
transcoding
packaging,
such
as
for
ankle
quality
packet
losses
or
jitter
for
transport
quality.
Evp
idr
are
not
aligning
properly
drm
issues,
etc.
H
H
Another
complication
is
that
the
resulting
end,
your
quality
of
experience
in
general,
is
a
confluence
for
a
mix
of
multiple
unrelated
issues,
as
these
impacts
occur
along
the
workflow
they
propagate
downstream
and
they
mix
together,
making
it
difficult
for
media
operations
teams
to
isolate
the
different
issues,
delineate
workflow
areas
at
fault
and
identify
what
causes.
Moreover,
the
impact
is
not
necessarily
the
same
for
every
viewer
different
viewers
may
be
experiencing
different
quality
impacts,
depending
on
where
they
are
geographically,
what
device
they
are
using
and
what
assets
they
are
watching.
H
In
this
illustrative
example,
the
resulting
consumer
impact
is
due
to
several
root
causes.
Each
root
cause
contributing
its
own
quality
impact
picture
macro
blocking
is
introduced
at
source
due
to
packet
loss
pictures
losing
sharpness
of
the
encoder
due
to
over
compression
ringing,
noise
is
being
introduced
into
the
picture
and
content
level
at
the
transcode.
H
Top
profile
went
into
outage
of
the
packager
and
just
latency.
Spikes
at
the
origin
are
causing
jitter
and
distribution,
cd
and
edge.
Cache
failure
is
causing
unavailability
in
a
specific
region,
and
a
bug
and
latest
firmware
of
the
player
is
causing
intermittent
playback
issues.
For
a
particular
type
of.
H
Device
so
based
on
this
motivation,
the
project
goals
are
to
create
best
practices
on
implementing
a
system
to
capture
qoe
and
other
measurement
data
at
each
monitoring
point
across
the
workflow
identify
streaming.
Video
metrics
together
at
each
monitoring,
point
establish
guidelines
on
how
to
calculate
or
leverage
existing
metrics
at
each
monitoring
point
and
investigate
potential
for
an
end-to-end,
metric
or
metrics
across
all
monitoring
points.
H
So
the
project
adopts
the
itu-t
definition
of
qoe,
essentially,
as
we
saw
in
the
motivation
section,
any
issue
impacting
the
workflow
at
any
point
in
that
workflow
has
the
potential
to
impact
the
degree
of
the
light
or
annoyance
of
the
user
of
an
application
or
a
service
in
the
best
practices
document.
We're
not
attempting
to
define
a
single
qoe
metric.
H
So
the
scope
of
the
project
is
iptv.
Ott
systems
focuses
on
live
workflows,
the
scope
is
end-to-end
from
source
suggestion
to
device
output
and
play
out.
The
framework
can
be
applied
to
both
cloud-based
and
on-premise
based
workflows,
including
hybrid
workflows,
and
the
monitoring
is
geared
towards
operational
use
cases,
for
example,
detection
delineation
of
issues.
The
monitoring
instrumentation
is
also
focused
on
probes,
logs
and
player
apis,
so,
for
example,
application
performance.
Monitoring
solutions
are
not
considered
in
this
framework,
for
example,
node,
cpu
load
or
memory
utilization
or
temperature,
etc.
H
Secondly,
decompose
the
end-to-end
monitoring
scope
into
modern
points:
for
example,
sources,
input,
encoder
output,
transcoder
output,
package
output,
origin
output,
cd
and
output
player
output,
device
output,
then
decompose
each
modern
point
into
measurement
layers
content,
for
example,
the
video
encode
quality
itself.
The
envelope,
for
example,
the
network
and
transport
performance
and
availability,
metrics
auxiliary,
for
example,
any
other
relevant
modeling
information
such
as
drm
subsystem,
encryption
key
exchange
status,
authentication,
subsystem,
health
and
statistics
and
status
of
logins
of
subscribers
and
player
out
error
and
error
messages,
for
instance.
H
Fourth,
for
each
monitor
point
and
for
each
measurement
layer
describe
where
is
the
monitoring
taking
place,
for
example?
Is
it
at
the
source
on
premises?
Is
it
pulse
transcode
in
the
cloud?
What
is
being
monitored?
Exactly,
for
example,
is
the?
Is
it
the
video
content
itself,
or
is
it
the
impact
to
transport
stream
packet
headers,
or
is
it
the
ip
packet
headers?
For
example?
H
So
the
following
is
an
example
of
a
framework
application
for
an
ott
service
operator.
In
this
case,
the
operator
receives
high
bitrate
compressed
mezzanine
source
from
a
third-party
content
owner
the
operator
transcodes
and
packages
the
content
and
then
sends
the
packaged
content
downstream
to
a
third-party
cdn
provider.
H
So,
with
respect
to
monitoring,
since
the
framework
is
modular
in
nature,
we
can
choose
which
monitoring
points
to
deploy,
given
the
monitoring
needs
and
constraints
in
this
example,
since
the
operator
does
not
own
the
option.
Encoder,
therefore
encoder
output,
aka
transcoder
input,
is
monitoring
0.1
here
using
igmp
join
to
the
output
of
the
encoder.
H
The
operator
uses
a
probe
for
both
the
video
content
and
the
network
and
transport
layers.
Ipdp
and
p2ts,
for
example,
are
being
monitored
since
the
operator
owns
the
transcoder.
Hence
the
transcoder
output
is
monitoring,
point
2
and
similar
to
model
0.1,
also,
measures,
content
and
network
delivery
quality
using
probes.
This
is
done
for
all
multi-bitrate
profiles,
since
the
operator
owns
the
packager.
Hence,
package
output
is
monitoring
0.3.
H
H
H
H
So,
in
summary,
the
best
practices
document
presents
various
options
as
to
how
one
can
define
a
high-level
end-to-end
monitoring
approach.
The
different
monitoring
points,
different
monitoring
layers
and
the
different
monitoring
options,
including
purpose
advantages,
disadvantages
methods
and
metrics.
H
This
is
the
case
where
the
source
was
coming
in
clean
and
the
macro
blocking
was
introduced,
post
encoder
due
to
packet
loss,
hence
monitoring
wise.
Since
the
source
is
coming
in
fine,
our
content
and
network
level
metrics
show
a
healthy
source.
However,
at
encore
output
we
do
detect
impact
on
both
content
and
network
layers.
For
example,
our
video
qoe
algorithms
show
dipping
scores
and,
for
example,
our
network
metrics
indicate
packet
loss
or
signal
loss
working
downstream
content-wise.
H
H
Nonetheless,
even
though
the
content
is
encrypted,
we
can
still
modern
network
delivery.
In
this
example,
transcoder
output
does
not
show
any
network
level
issues
as
the
transcoder
regenerates,
the
ipudp
mp2ts
stack.
Similarly,
the
packager
and
the
abr
content
delivery,
for
example,
iptcp
http
hls
stack
metrics,
do
not
show
any
issues.
H
Yeah,
thank
you.
So
the
downstream
player
is
also
happy
to
play
the
content
out
with
good
startup
time
no
rebuffering
and
the
highest
quality
profile
being
played
out
all
player
event.
Metrics,
look
good!
No
errors
are
coming
in
from
players
as
well,
however,
pulse
device.
Once
again,
we
do
detect
perceptual
picture
breakup
with
qoe
algorithm
on
content
level.
H
C
C
A
A
C
D
Oh,
you
know:
one
of
these
crystals
strikes
me
and
this
sort
of
a
broad
question
is
that
you
know
this
presentation
did
do
a
great
view
of
for
application
and
encoding
delivery,
all
those
pieces
that
come
together
and
then
to
make
it
work.
You
know
one
of
the
things
that
that
you
guys
didn't
think
that
I
think
may
be
of
interest
to
the
future
here
at
the
ipf.
D
Is
the
larry
just
below
that
stuff,
which
is
never
clear
because
a
lot
of
these
pieces,
I
know
you
know
some
of
them-
go
over
well
managed
network.
That
means,
like
you,
know,
the
the
video
production
team
might
be
able
to
manage
their
network,
but
a
whole
bunch
of
other
pieces
of
this
go
over
unmanaged
networks,
the
open
internet-
and-
that's
always,
you
know
difficult
to
understand
from
an
algorithmic
perspective
in
the
player,
I'm
wondering
if
there's
potentially
future
work,
where
we
look
at.
D
How
do
you
connect
that
higher
level
and
give
it
awareness
of
what
it
is
behaving
on
the
open,
internet
and
other
networks?
Of
course,
where
I
can
better,
you
know,
inform
people
try
to
fix
the
problem,
but
also
maybe
algorithmically
be
able
to
respond
to
it
more
dynamically
and
I'm
not
sure
I'm
going
to
question
my
own
question
in
the
notes
holding
my
back.
H
So,
and
in
this
case
this
could
be
an
ott
streaming
service
operator,
and
you
know,
the
third-party
sources,
for
example,
could
be
coming
in
to
the
operators
transcoders
over
the
open
internet
and
also,
similarly
downstream.
The
service
operator
could
be
providing
the
packaged
hls
content
to
the
third
party
cdn
provider,
again
over
the
internet
to
the
cloud.
So
you
know
these
types
of
deployment
patterns
here
and
you
know,
could
speak
to
also
unmanaged.
You
know:
end-to-end
unmanaged,
video
service,
video
services,
including
you
know,
hybrid,
hybrid,
video
services.
H
You
know
partly
on
premises
partly
on
cloud
as
well.
As
you
know,
composed
of
multiple
stakeholders.
You
know
third
parties
providing
different
components
and
and
content
etc.
So
there
are
definitely
you
know
also.
You
know
the
internet
could
be
interspersed
anywhere
here
along
these
workflow
stages
and-
and
yes
absolutely,
you
know
in
terms
of
the
monitoring
work,
that's
that
that
we're
we're
working
on.
It
also
speaks
to
the
to
the
network
and
transport
layers,
not
not
just
the
application
layer,
not
just
the
content
layer.
H
C
I
C
H
G
C
G
Not
right
I
mean
so,
I
wrote
those
slides
to
be
a
basis
for
discussion,
so
it's
it's
a
good
material
for
reading
and
discussing
later
on
the
mailing
list
a
little
bit
less
to
present.
So
I
can
maybe
make
it
a
little
bit
faster
when
I
present
first
is
a
disclaimer.
I
didn't
spend
a
lot
of
time
on
it,
not
enough
to
to
make
it
a
real
conclusion
or
anything.
G
There
are
a
few
questions
when
it
comes
to
be
able
to
be
fair
and
to
be
informative
right,
we
need
to
be
able
to
have
a
good
basis
for
comparison
and
reproducible
tests.
So
people
do
not
trust
me
and
do
not
trust
anyone,
and
and
do
the
thing
by
themselves
again
and
are
able
to
reproduce
the
results.
We're
gonna
we're
gonna
reach
and
sometimes
fairness
is.
Is
it
doesn't
matter?
G
G
G
I
don't
think
that's
the
case,
but
they
don't
exactly
do
the
same
thing.
So
is
srt
a
transport
or
a
media
transport
and
the
example
I'm
giving
here.
The
definition
is
a
transport
is
something
that
is
not
specific
to
media.
It
can
transport
media,
but
it
can
also
transport
other
stuff
and
it
doesn't
have
anything
that
is
media
specific.
G
Just
like
you
can
put
media
in
https,
but
you're,
not
reaching
hls
right
hls
will
have
all
these
information
about
the
the
number
of
tracks.
The
type
of
the
tracks
which
codec
was
used
is
their
subtitle
and
so
on
and
so
forth.
That
comes
on
top
of
https
and
so
comparing
them
directly
like
this
is
difficult.
So
we
see
a
lot
of
non-media
transport
being
used
nowadays
to
transport
media.
I
could
cite
web
socket,
for
example,
and
so
the
question
is:
is
it?
Is
it
a
fair
comparison?
Number
one
and
number
two?
G
Is
it
a
comparison?
We
want
to
do
anyway
right
because
people
use
it
that
way,
so
people
are
interested
in
knowing
what
is
the
most
appropriate
when
it
comes
to
to
to
transporting
media
and
what
are
the
the
trade-off
in
between
those
different
protocols,
whether
they
are
a
dedicated
media
protocol
like
rtp
or
are
not
really
like
quick
by
default
right?
Is
it
still
interesting
to
use
quick
directly?
G
So
there
is
a
lot
of
different
angle
to
that
question
that
I
bet
I
read
and
discussed
on
the
mailing
list
after
there's,
actually
three
slides
of
them
to
try
to
be
as
thorough
as
possible.
Then
the
question
is:
which
features
do
we
want
to
test?
I
think
I
saw
a
lot
of
documents
that
were
describing
srt
advantage
over
rtmp
on
a
different
feature,
so
I
think
those
should
be
included
if
only
to
show
the
contrast
between
srt
and
rtmp
reliability.
G
F
G
To
network
condition
the
security,
however
hard
it
is
to
test
and
firewall.
Not
troublesome,
are
four
points
that
I
think
should
be
tested
to
a
certain
extent.
I
might
be
missing
other
points
that
are
important,
and
here
I'm
welcoming
feedback
from
the
group
to
tell
me
what
they
think
would
be
of
interest.
G
Finally,
I
think
there's
something
we
don't
speak
about
too
much,
but
that's
the
global
use
case.
I
think
the
previous
presentation
did
a
very
good
job
to
show
that
the
the
delivery
of
the
media
in
streaming
from
the
source
to
the
viewer
as
a
lot
of
steps-
and
I
don't
think
there
is
a
single
protocol
that
is
used
for
every
single
one
of
them
right.
So
my
understanding
from
outside
is
that
srt
or
tmp
today,
and
sometimes
with
rtc,
are
used
on
the
first
mile
from
the
capture
to
the
ingest
node.
G
Then
there
is
a
platform
that
does
the
chunking
and
the
encoding,
the
re-encoding,
the
transcoding,
the
abr,
all
that
things
into
hls
and
at
which
point
hls
is
used
for
the
final
for
the
delivery
side
of
thing
right.
If
that's
the
case,
it
would
be
very
interesting
to
narrow
the
scope
down
to
that
first
mile,
because
we're
not
in
the
p2p
mode
anymore,
but
we're
on
a
client
to
server
use
case
and
that's
a
difference
that
is
being
increasingly
made
in
the
past
two
years.
G
G
So
my
gut
feeling
it
looks
like
srt
will
not
be
a
full
media
transport
to
be
discussed.
Given
that
the
definition
I
gave,
even
though
it
can
transport
media,
it
has
some
advantage
over
rtmp,
but
those
advantage
might
overlap
with
existing
functionality
in
rtp
or
quick
for
that
matter.
I
think
that
was
the
the
result.
G
A
Has
not
been
made
and
we're
at
time
for
this
agenda
item
the
agenda
item
that
that
I
thought
we
were
going
to
have
was
a
discussion
of
we
were
going
to
following
on
discussion
a
month
or
so
ago
on
the
mailing
list
about
comparing
different
transport
protocols
and
how
crappy
the
comparisons
are
that
we
were
actually
going
to
do
our
own
effort
where
different
people
could
participate
instead
of
just
building
instead
of
having
arguments
over
personal
perspectives
and
or
gut
feelings
about
things.
So
I
think
that
we
need
to.
A
You
can
send
the
slides
to
the
list.
We
will
post
them
to
the
meeting
materials.
The
discussion
ongoing
is
still.
What
are
we
going
to
do
in
a
hackathon
in
order
to
actually
do
some
of
this
work,
because
I
think
I
do
think
it
is
actually
worth
doing
the
work
of
figuring
out
how
to
talk
about
different
different
protocols
for
transport
of
video
and
media
pursuant
to
the
agenda
item
we
just
had
a
moment
ago.
A
G
I
I
agree
it
makes
sense,
but
before
we
start
testing
I
mean
we
need
to
define
the
scope
and
what
we're
trying
to
achieve.
So
all
those
slides
were
about.
Can
we
narrow
the
scope
to
a
few
protocols
that
are
really
comparable
and
for
use
case
we
actually
interested
in,
and
I
left
everything
open
there,
because
I,
I
really
don't
have
the
answer,
but
what
you
want.
A
B
C
A
A
C
A
Yeah,
I
will
say
thank
you
to
all
of
our
presenters
who
put
time
and
effort
into
bringing
their
topics
to
us
today
and
thank
you
to
everyone
for
showing
up
and
for
our
next
challenge.
I
hope
we
can
get
to
a
point
where
we
can
have
a
discussion,
because
this
seemed
very,
very
quiet
all
right
thanks.
Everybody.