►
From YouTube: IETF109-COINRG-20201119-0500
Description
COINRG meeting session at IETF109
2020/11/19 0500
https://datatracker.ietf.org/meeting/109/proceedings/
A
Okay,
well,
it
is
midnight
eastern
time
my
carriage
is
being
transformed
in
a
pumpkin
and
I
hope
I'm
not
losing
any
shoes,
but
I
guess
in
the
meantime
we
can
do
computing
in
the
network
and
so
good
morning
to
people
or
good
night
to
others.
This
is
again
computing
in
the
network.
The
three
chairs
are
here
jeffrey
here
from
the
wonderful
university
city
university
in
hong
kong,
eve
from
intel,
and
we
currently
in
montreal
concordia
university
next
slide.
A
So
you
can
connect
to
us
in
many
wonderful
ways.
Obviously
we
have
all
the
meeting
material
and
the
data
tracker
and
you
can
get
it
from
there
there's
another
pad.
There's
the
jabber.
We
still
don't
have
anybody
to
take
notes,
but
unless
we
have
that
in
the
next
few
seconds
in
any
way,
we
can
take
notes
from
the
recording
because
all
sessions
are
being
recorded.
A
A
So
this
is
the
usual
intellectual
property.
If
anybody
who
is
presenting
something
today,
especially
people
from
industry,
please
make
sure
that
you
are
very
much
aware
that
you
might
must
disclose
your
ipr,
and
I
think
the
big
thing
here
is
a
timely
manner,
because
in
other
research
groups
we
had
problems
with
the
timing.
A
A
We
have
to
remind
a
lot
of
people
also
that
this
is
the
irtf.
This
is
not
a
standards
development
organization,
we
have
a
mandate
of
conducting
research
of
fostering
research,
and
I
think,
as
the
chair
also
of
another
research
group-
and
this
one,
we
have
to
remember,
remind
I
think,
especially
draft
writers
that
when
they
write
a
draft,
it
is
not
about
something
that
will
become
a
standard,
but
something
that
should
highlight
what
is
the
related
research
and
why
the
research
community
should
be
aware
of
this
work.
Next
slide.
A
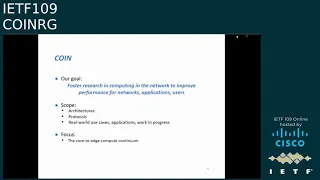
So
coin,
who
are
we?
I,
I
think
I
will
take
just
a
few
more
seconds
than
I
usually
take
on
on
this
slide
because
of
a
previous
meeting
that
happened
yesterday
for
some
of
you-
and
I
think
it's
yesterday
now
for
me
and
probably
earlier
today,
for
others,
our
goal
is
to
foster
research
in
computing
in
the
network,
and
what
does
it
mean?
A
That's
what
I
think
is
is
getting
to
be
interesting.
Our
scope
is
pretty
wide
and
we
put
architectures
and
protocols
and
obviously
real-world
use
cases,
application
and
work
in
progress
and
again
this
is
research
and
architecture,
research
and
protocol
and
research
and
use
cases
for
those
of
you
who
did
not
have
a
20-hour
day
or
had
time
to
sleep
in
the
middle.
There
was
this
morning
a
well.
A
I
guess
it
was
yesterday
by
now
a
meeting,
a
side
meeting
on
something
that
was
called
fight,
which
is
future
internet
protocol
evolution,
and
it
made
me
understand,
because
we
were
a
little
bit
we're
recited
in
that
meeting.
It
made
me
understand
that
a
lot
of
people
did
not
really
understand
what
what
we
were
about.
So
let
me
take
just
a
few
seconds
for
that.
We
are
about
adding
computation
in
network
nodes,
we're
not
doing
p4.
A
We
had
hackathons
on
p4,
because
p4
is
one
way
to
put
computation
in
some
network
nodes,
but
p4
is
not
everything,
we're
not
about
switches
somebody
this
morning
and
in
the
chat,
but
well.
These
people
are
looking
at
programmable
switches,
yes,
and
no
we're
about
research
at
in
the
network,
which
is
a
distributed
computer
board,
and
this
computer
distribu
computer
board
has
computing
units
and
storage
units,
and
these
units
are
connected
by
communication
means.
A
This
also
gives
us
an
incredible
amount
of
potential
uses
and
that's
where
the
research
becomes
so
interesting.
Those
of
you
who
were
at
at
sitcom
and
those
of
you
who
were
at
icn
could
the
conferences
this
year
could
see
that
there
was
an
awful
lot
of
research
on
this
potential
use
of
this
distributed.
Computer
board
and
routing
which
will
be
presented.
Sharon
is
on.
Now
is
one
of
these
applications.
A
This
is
the
in
the
network
of
the
computing
and
the
network,
but
there
is
also-
I
don't
know
if
I
don't
know
if
lars
on,
but
lars
and
davoran
have
raised
the
issue
that
we
could
also
be
doing
computing
on
the
network.
So
once
we're
done
filtering
packets
and
routing
them,
we
may
be
wanting
to
do
more
with
them
or
to
process
them
further
for
applications
in
iot
and
ar
vr,
so
we're
computing
in
the
network
layer
and
on
the
network
layer,
because
we
do
that.
A
A
So
I
think,
because
of
josiah
said
that,
because
of
what
I
just
said,
I
will
probably
take
on
to
me
to
update
the
the
description
of
the
working
group
on
the
data
tracker
to
make
sure
that
you
know
there's
no
assumptions
about
what
we
do.
That
is
something
that
we're
not
doing
so.
This
said
this
was
my.
This
was
my
spiel
and
I
will
let
it
to
jeffrey
to
introduce
the
agenda
and
our
growing
number
of
drafts.
B
Okay,
so
we
will
take
a
quick
look
at
the
current
current
drafts
and
the
milestones
before
the
presentation.
Then
the
presentation
will
start
from
an
use
case
ai
at
the
edge.
Then
there
could
introduce
their
direction
draft,
which
is
has
been
accepted
as
our
working
research
group
document
after
a
pre
last
meeting,
then,
if
we
introduce
the
data,
discovery
and
discussion,
this
is
the
following:
the
discussion
in
the
last
meeting
as
well
also
in
the
mailing
list.
B
Then
after
that
so
ike
or
dirk
the
question
will
introdu
will
induce
the
another
research
group
document
the
use
case
they
have
evolved
from
industrial
use
case
to
a
more
general.
Then
there's
some
updates
for
the
no.
So
the
there's
another
presentation,
so
that's
from
a
draft
initially
proposed
to
tsg
working
group,
but
they
are
just
one
use
cases
so
explicitly
mentioned
in
that
draft
that
is
related
to
coins
use
cases.
B
So
we
so
they
will
introduce
their
this
draft
briefly.
So
in
the
past
related
to
us.
So
then
there
will
be
some
updates
for
the
transport
document
and
the
application,
centric
microservice
and
the
security
and
then
finally
sophia
will
introduce
their
new
european
project
which
is
related
to
us
as
well.
B
So
after
that
hope,
we
can
have
some
time
to
discuss
the
future
plans
next,
please,
if
yes,
so
this
is
a
current
draft.
So
we
have
two
candidates,
research
group
documents,
the
the
use
case
is
not
not
specific
to
indulge
or
not
more
general,
and
then
the
second
is
the
culture,
the
conscious
direction.
So
we
hope
these
two
research
group
documents
can
contain
the
insights
or
discussions
in
you
know
in
this
group.
Then
there
are,
several
jobs
will
be
present
here
today
and
next
time
before.
A
B
B
Okay
next,
so
this
is
milestones
so
for
the
state
of
art
and
the
challenges.
Maybe
we
we
have.
We
have
at
least
partially
adjust
in
the
direction
and
direction
document,
and
but
we
need
more
contribution
about
the
requirement
and
the
implication
for
the
network
elements
and
for
the
use
cases.
We
now
have
the
use
case,
research
group
document,
and
we
can
discuss
further
on
that
and
okay.
So
as
for
the
scope,
as
we
just
say,
and
as
we
have,
we
have
discussed
this
a
little
bit
right.
B
C
B
E
C
D
All
right,
meanwhile,
I'll
just
start
talking,
I
guess
I'm
going
to
present
the
use
of
virtual
routing
to
help
call
me
use
cases
specifically
aji,
so
this
is
mostly
informational
because
it
shows
how
to
use
existing
hard
standards
implemented
already
in
software
and
hardware,
in
a
certain
way
to
help
aji
use
cases.
I
think
it's
been
a
very
edgy
itf
all
around.
So
there's
a
lot
of
interest.
D
D
Today,
mostly,
we
do
that
in
the
data
center,
using
leveraging
significantly
the
spine
leaf
architecture
to
scatter,
gather
workloads
and
maximize
concurrency
this
way,
and
that
is
fine
using
emr
data
break
spark
and
we
should
concentrate
when
we
can,
but
then
we
have
to
distribute
when
we
have
to
and
that's
when
we
want
to
push
edge
to
the
these
edge
mostly
have
to
do
with
situations
where
the
sla
is
a
sub.
Second.
So,
if
you
think
of
the
data
center
as
the
brain,
you
can
think
about
things.
D
The
load
is
of
the
raw
data
is
too
heavy
for
me
to
bring
in
a
timely
matter
to
the
data
center.
That's
another
situation
where
I
have
to
push
ai
to
the
edge
or
when
there's
a
commercial
or
regulatory
situation,
where
I
have
to
run
in
a
carrier
in
edge
premise
or
in
a
car,
oem
premise
or
in
a
municipal
premise
or
because.
G
D
Okay,
so
I'm
gonna
use
two
two
production
networks
that
hit
all
of
these
checkpoints
volume
of
raw
data
response
time,
the
cost
of
compute
and
constraints
that
they
must
be
pushed
to
the
edge.
So
one
of
them
is
mobility,
networks
and
car,
auto
big
data
information
gathered
by
cars
as
they
drive
by
vision
and
sensory
and
next
slide.
Please,
and
the
other
example,
is
cyber
where
switches
terabit
switches
are
sampled
at
gigabit
rates
and
and
generate
alerts
and
visibility
for
attacks
using
ai
all
right.
So
next
slide.
D
Please,
I'm
gonna
have
three
slides
on
virtual
routing,
there's
not
enough
time
to
deep
dive
into
it.
So
if
any
double
clicking,
it
can
be
done
in
the
offline
or
in
the
working
group
which
are
relevant
so
just
virtual
routing,
101.
Everybody
knows
sd1
vxlan
the
ability
to
run
a
logical
address
space
on
top
of
the
topological
address.
D
So
the
basic
virtual
routing
standards
tell
us
how
to
encapsulate
there's
a
few
ways,
but
they
don't
tell
us.
How
does
the
router
1.2
know
that
vbb
is
behind
1.3?
The
reason
they
don't
is.
You
could
claim
that
an
overlay
network
is
just
another
network
and
you
could
use
any
routing
protocol
of
your
choice
if
you
like
vector
path
or
link
state
or
whatever
next
slide.
D
Please
so
lisp
takes
an
extra
step
beyond
this
basics.
The
claim
here
is
that,
if
I'm
going
to
apply
logical
routing
in
the
logical
network,
then
I'm
going
to
have
topological
constraints
on
my
logical
addresses,
I'm
going
to
have
to
have
route
peering,
which
is
a
constraint
I'm
going
to
have
to
have
subnetting,
which
is
a
topological
constraint
and
lisp
notion
here,
is
that
I
can
use
an
overlay
routing
for
the
overlay
and
underlay
routing
for
the
underlay
and
overlay.
Routing
idea
is
quite
simple.
D
D
So
a
few
list
concepts
here
like
really
quick
eid
is
the
logical
address.
Our
lock
is
the
topological
address.
Xtr
is
an
ingress
aggress
tunnel,
router
and
rtr
is
what
we
use
here,
which
is
a
retaining
router,
which
is
if
aaa
is
on
verizon
and
bbb
is
on
a
tnt.
This
will
still
work.
Okay
next
slide.
Please-
and
this
is
the
last
slide
on
virtual
routing
and
then
jump
to
examples.
D
If
I
have
a
mapping
system,
then
I
can
define
a
multicast
scheme
which
is
different
than
what
we
know
from
pim
and
mbone,
which
is
more
like
tv
kind
of
multicast,
where
we
have
thousands
of
channels
to
millions
of
people.
If
I
use
a
mapping
system,
then
mlds
from
aaa
subscribing
to
s
comma
g
source,
bbb
theme
xyz,
the
mld
will
stop
at
the
the
tunnel
router
and
he
will
register
himself
as
subscribed
to
these
feeds.
D
So
when
bbb
will
send
a
packet
to
rtr
1.3,
it
will
look
up.
Okay,
which
rtrs
are
subscribed
on
behalf
of
the
peers
behind
them
will
replicate
to
them,
and
these
rtrs
in
turn
will
replicate
to
those
clients.
So
this
is
very
useful
for
what
we're
going
to
do
with
the
edge
reduction,
because
this
allows
us
to
have
millions
of
channels
for
thousands
of
endpoints,
and
this
will
be
a
very
effective
public
subscribe
for
reductions
all
right.
So
let's
take
a
look
at
how
this
works
next
slide.
D
So
if
every
in
every
sampling
cycles
and
every
switch
I'll
pick
up
some
tuples,
then
I
will
still
steer
them
to
one
location
which
keeps
tracks
of
this
five
tuple
a
mask
or
these
a
bunch
of
flows
or
one
flow.
Depending
on
how
I
divide
this
thing.
So
that
means
I
can
calculate
the
distribution,
the
bayesian
distribution
of
the
flow,
and
I
can
predict
what
it's
going
to
be.
D
I
can
create
visibility
to
the
entire
traffic,
even
though
I'm
just
sampling
a
fraction
of
the
traffic
and
I'm
tangent
to
the
network
and
without
any
inline
components.
And
when
the
flow
surprises
me,
then
I
can
raise
the
alerts.
So
this
has
been
very
effective
to
put
on
top
of
existing
situation
or
existing
protections.
And
this
mechanism,
which
is,
as
I
said,
tangent,
was
able
to
detect
ddos
like
a
minute
before
firewall.
D
D
Yeah,
it's
okay,
and
this
is
the
last
slide.
No,
no,
no
one
more,
no
back
back
one,
yes,
okay.
The
second
production
example
is
when
cars
drive
around,
they
steer
images
to
a
tiles
of
the
earth
which
have
an
ip
address,
an
eid
and
that
eid
is
calculating
the
state.
It's
calculating
changes
in
it
aggregates
detections,
and
it
creates
a
feed
over
for
other
cars
of
what's
going
on
in
this
exactly
location.
So
the
rest
is,
I
think,
self-explanatory
of
what
kind
of
ai
is
done.
How
does
it
reduce
the
data?
D
What
is
the
data
reduction?
You
can
take
a
look
at
it
yourself
and
if
there's
any
questions,
they'll
be
happy
to
go
offline,
homography
db,
scan
simplex
same.
I
think
the
important
point
here
is
that
this
method
of
achieving
concurrency
at
the
edge
is
based
on
existing
standard,
existing
hardware
that
performs
the
load
balancing
the
security
at
wire
speed
and
it's
very
practical
to
leverage
going
forward
in
this
direction.
A
A
I
A
J
A
D
Okay,
that's
a
great
question,
so
the
the
throughout
this
when
I
first
developed
it
for
for
mobility,
the
the
my
goal
was
to
invent
as
little
as
possible.
So
that's
why
I
took
the
lifting
overlay
standards
and
specifically
the
existing
lisps
as
standard.
So
now
a
what
from
what
we
observe
after
multiple
production
networks
and
use
cases,
is
that
what
changes
between
use
cases
is
a
what
is
the
addressable
space,
meaning
giving
a
problem?
D
How
do
you
divide
it
naturally,
so
that
it's
algorithmically
can
be
source
routed
to
achieve
distribution
and
power
processing
and
then
a
a?
What
else.
Changes,
of
course,
is
the
reduction
functions
which
are
domain
specific,
and
what
else
can
we
support?
So
the
next
step
will
be
to
to
generalize
but
keep
it
informational,
and
so
would
allow
you
to
to
take
a
a
family
of
problems
that
can
be
naturally
pre-partitioned
to
an
addressable
space
and
that
space
after
reduction
can
be
subscribed
in
scale
by
applications,
databases,
the
next
step
of
processing.
A
I
K
C
C
K
K
K
The
intention
of
this
draft
was
to
describe
for
for
the
group
essentially
or
summarize,
basically,
our
intentions.
So
what
why
are
we
doing
this?
What
do
we
mean
by
in
or
as
marijuana
say
earlier?
I
mentioned
on
network
computing,
so
kind
of
trying
to
characterize
the
say,
most
significant
ways
of
conceiving
this
so
presenting
some
some
thoughts,
so
so
at
what
say,
layers
or
say,
also
levels
of
complexity.
Can
you
think
about
computing
in
that
context,
and
also
trying
to
lay
out
the
research
landscape?
K
So
what
are
actually
interesting
questions
that
we
could
look
into
in
in
coin?
And
so
the
draft
so
far
is
say,
roughly
structured
like
this,
so
we
are
introducing
different
types
of
network
computing
systems.
We
kind
of
collected
some
useful
terms
trying
to
differentiate
ourselves
and
so
characterize
computing.
A
network
versus
packet
processing
network
computing.
So
talk
about
a
few
examples
from
maybe
different
points
in
in
this
overall
landscapes,
and
then
we
have
a
list.
K
K
K
It
was
an
interesting
point
raised
so
yeah
to
what
extent
yeah
should
we
consider
you
know
packet
processing
as
really
a
computing
in
the
network
thing
I
mean
we
have
some
work
like
we
also
talked
about
earlier
on
the
topic
so
yeah
we
are
could
be.
I
mean
interesting
to
discuss
so
how
much
we
want
to
do
on
that
in
the
future.
K
I'm
not
excluding
it,
but
so
in
general,
I
mean
the
idea
of
adopting
a
a
draft
is,
of
course,
also
that
the
group
takes
over
the
change
control
of
the
draft.
So
it's
also
now
up
to
you
to
really
check
it
more
carefully
and
tell
us
what
needs
to
be
added.
So
then
there
are
questions
of
discovery
in
the
research
challenges
so
whether
that
that
should
be
like
a
prominent
topic
there.
K
K
Maybe
you
know,
human
mobile
user
or
something
or
is
there
also
some
so
a
different
notion,
so
who
is
in
that
sense
invoking
a
distributed
computing,
for
example,
so
that
could
be
that
they
yeah
they
did
like
user
initiated
foreground
things.
We
would
also
have
some
so
kind
of
background
processing
or
something
so
we
actually
yeah.
K
We
are
currently
discussing
with
like
taco
operators,
for
example,
whether
there
is
a
point
in
using
like
a
coin
approach
to
network
management,
for
example,
and
that
could
maybe
a
bit
going
into
this
selection
also
related
the
lifetime
of
and
life
cycle
of,
in-network
compute
functions.
So
is
that
something
like
more
like
a
service
or
something
like
a
one-shot
status
invocation?
Of
course
there
is
probably
both,
but
so
maybe
better
describe
these
different
types
of
computing,
perhaps
other
things
that
we
came
up
with
result
provenance.
K
So
there
are
these
use
cases
where
you
know
computing
is
about
data
processing,
and
so
that's
interesting,
yeah
important
question.
So
how
can
you
trust
the
data
and
how
can
you
trust
the
computation
steps
on
the
data,
or
can
you
say
anything
about
that
bit
related
perhaps
to
the
previous
presentation
impact
of
mobility?
So
sometimes
you
want
to
you
know,
maintain
a
set
of
distributed
computing
nodes,
for
example.
How
is
that
possible,
or
what
are
the
challenges
when
things
are
more
dynamic.
K
K
K
Probably
one
end
of
the
spectrum
and
yeah,
we
have
seen
that
there
are
many
domain
specific
solutions,
industrial
iot
use
cases
and
so
on
on
the
one
side
would
be
good
if
they
are
not
only
you
know,
you
know,
point
solutions.
On
the
other
hand,
of
course,
there
is
also
good
reason
to
you
know,
have
maybe
kind
of
specialized.
K
You
know,
services
on
vms
or
represented
as
processes
this,
because
this
can
be
done
already
with
various
tools,
so
I
think,
there's
potential
to
go
a
bit
beyond
that
and
so
yeah
we
embrace
the
idea
of
supporting
disability
computing
better
as
we
as
we
discussed
before,
so
not
just
building
pipes
between
processes
and
yeah.
I
think
we
mentioned
that
last
time.
K
So
if
I
think,
if
we
run
into
this
problem,
we
probably
should
rethink
our
requirements
fundamentally,
and
so
I
think
it's
really
important
also
to
keep
the
security
model
in
mind.
So,
of
course
we
can,
you
know,
manage
to
steer
packets
to
any
point
in
the
network
where
some
compute
happens,
but
we
don't
think
that's
necessarily
helping
so
much.
So
it's
also
really
important
to
have
a
good
security
story.
So,
as
we
mentioned
before,
can
you
trust
the
nodes?
Can
you
trust
the
computation,
the
results
and
so
on?
K
So
that's
a
bit.
I
mean
it's
not
only
like
to
be
just
picked.
This
tcp
example
is
say
one
way
to
to
illustrate-
what's
probably
not
so
not
so
interesting
to
us
at
least
our
view.
So
far,
okay,
so
here's
the
plan,
so
we
will
resubmit
the
draft
now
with
the
new
name
currently
trying
to
think
about,
say,
yeah,
more
representative
use
cases.
So
I
mean
we
don't
want
to.
K
K
C
Okay
question
was
your
reference
to
the
use
cases
draft,
I
kind
of
like
the
idea
actually
of
using
that
as
a
holding
place
for
use
cases
that
are
interesting,
because
then
every
draft
every
other
draft
doesn't
have
to
re-enumerate
all
the
use
cases
was
that
what
you
were
saying,
sir,
or,
were
you
saying
you
were
on
the
line
with
it?
You
clarified.
K
Yeah,
I
mean
use
cases
in
terms
of
you
know:
yeah
classes
of
use
cases
so
representative
use
cases
that
yeah
reflect
some
different
categories
of
coin
concepts
or
realizing
coin
concepts.
Of
course,
I
don't
think
we
should.
You
know
we
should
use
an
internet
draft
to
collect
all
kinds
of
possible
use
cases.
I
mean
that
could
also
be
done
on
a
wiki
page
or
something
but
yeah.
Some
some
some
level
of
extraction
would
be
good.
I
think.
M
M
We
then
want
to
yeah
create
also
some
form
of
taxonomy
out
of
that,
so
that
we
just
don't
only
have
that
collection
of
use
cases,
but
also
some
yeah
for
the
good
coming
from
the
draft
yeah,
because,
just
as
dirk
said,
we
could
also
collect
use
cases
somewhere
else,
but
we
also
want
to
provide
them
some
form
of
taxonomy
from
that.
But
I
will
talk
about
that
later
as
well.
H
K
K
A
C
C
C
We
started
out
life
as
having
a
draft
that
was
specifically
around
data
discovery
for
edge
based
on
some
use
cases
that
in
fact,
we
presented
pretty
early
on
in
the
beginning
of
the
coin
endeavor
and
at
the
bath,
and
it
ended
up
that
we
there
were
quite
a
few
other
discovery
drafts
that
it
generated
kind
of
an
overarching
discovery,
problem
statement
and
also
then
a
mobility
discovery.
If
we
don't
see
your
your
screen
at
all,
oh.
A
E
C
Okay,
and
so
the
point
was
that
we
kind
of
expanded
into
three
drafts
around
discovery,
and
now
we
are
beginning
to
kind
of
re-coalesce
and
in
this
latest
iteration
xavier's
draft
on
mobility.
The
language
was
included.
Some
of
the
language
was
included
in
the
edge
data
discovery
draft
and
it
is
our
intention
to
revisit
whether
we
need
you
know
multiple
drafts
on
discovery
or
just
one.
But
I
wanted
those
of
you
who
hadn't
been
following
to
understand.
At
least
the
lineage.
C
Are
you
seeing
anything?
I'm
not,
it
seems
like
my
computer,
doesn't
move
it's
not
moving?
Okay,
let's
just
do
it
this
way,
then,
okay.
So
what
is
the
problem
here?
The
problem,
as
alluded
to
by
all
of
the
talks
today,
is
that
increasingly,
the
compute
capabilities
are
really
scattered
around
the
network
everywhere,
and
that
really
has
blurred
the
line
between
what's
the
network
and
what's
compute
and
what's
storage
and
just
as
the
compute
is
getting
scattered
increasingly,
a
consequence
of
that
is
that
the
data
is
getting
created
everywhere.
C
It's
getting
cached
and
copied
everywhere
and
each
time
it's
computed
across.
It's
transformed
and
becomes
yet
new
data,
so
data
begets
new
data,
and
so
we
have
this
problem.
That
data
is
scattered,
and
especially,
you
know
again
this
the
problem
sort
of
originated
with
with
these
sort
of
edge
use
cases
that
we
were
examining,
but
what
it
leaves
us
with
the
predicament
is
that
we
really
would
like
to
understand.
Then
how
do
we
find
this
data
or
pockets
of
data
data,
lakes
or
databases
and
within
those
pockets
of
data?
Specific
data
objects?
C
Really
the
network
is
agnostic
and
protocols
would
be
agnostic
to
what
it
is
they're
sending
it's
really
just
a
bag
of
bits
and
in
fact,
sometimes
we're
sending
around
the
compute
itself,
programs
and
services
that
are
the
executables
or
functions
or
algorithms,
because
we
need
to
move
them
around
because
in
fact,
the
data
measurements
they're
so
enormous.
If
it's
video
or
something
else,
sometimes
we
can't
move
the
measurement
data
or
the
monitoring
data.
We
have
to
move
the
compute
to
it.
A
C
That,
yes,
it's
better
okay,
and
so
last
time
there
was
quite
a
bit
of
discussion
about.
We
were
kind
of
on
the
brink
of
asking
the
the
group
whether
or
not
the
edge
data
discovery
draft
was
ready
to
be
adopted
as
a
draft
to
and
in
fact
drill
down
as
dirk
alluded
to
this
issue
about
discovery.
To
what
extent
is
that
an
attendant
problem
around
coin?
C
But
we
were
really
challenged
in
the
debate
and
question
and
answer
at
the
last
ietf,
and
so
we
thought
we'd
take
a
moment
to
say
you
know
why
do
we
think
that
discovery,
particularly
around
data,
is
fundamental
to
coin?
And
it's
because
at
least
my
mental
model
of
what
coin
is
or
what
computation
is.
Is
that
it's
a
function?
It
gets
performed
on
data
and
it
typically
generates
data,
and
so
all
three
of
those
aspects,
each
like
the
input
data
we
need
to
marshal
it
from
somewhere.
C
We
may
not
be
you
know,
things
are
not
always
tidy
containerized
workloads.
We
may
need
to
marshal
the
data
from
somewhere
on
the
fly,
particularly
in
autonomous
kinds
of
situations.
Furthermore,
it's
not
just
the
data,
we
may
be
marshaling,
but
we
may
be
needing
to
marshal
the
function
itself,
the
compute,
the
algorithm
and
so
forth,
because
again,
sometimes
it's
contextual.
C
What
it
is
that
we
want
the
function
to
be
and
then
sort
of
in
this
last
stage.
Of
course,
there's
output
from
the
computation
and
we
need
enough
context
and
metadata
about
our
place
in
the
universe,
whether
we're
mobile
or
you
know,
changing
dynamic
network
situations
to
understand.
Where
do
we
place
that
data
for
potential
reuse,
whether
it's
cached
or
replicated
or
archived
for
that
matter?
And
so
that's
really.
You
know
the
crux
for
why
we
we
think
data
discover
is
fundamental,
so
we
we
outlined.
C
Well,
research
groups
are
good
staging
grounds,
for
it
says
mature
ideas,
but
it
says
I
wanted
to
say
mature
ideas
that
are
not
mature
and
and
so
in
fact,
data
discovery
is
an
early
stage
idea
and
as
such,
it
has
no
specific
protocols
or
architectures
that
we're
recommending
at
this
point,
but
as
I
stated,
data
discovery
is
motivated
by
compute,
but
it's
also
motivated
by
mobility
and
network
dynamics
linking
back
to
the
previous
talks,
and
then
you
know
why?
Wouldn't
we
put
it
in
coin?
C
C
A
Okay,
so
the
first
one
and
for
for
the
sake
of
time
I
I
think
we
could
put
that
question
to
the
group.
I
think
you
were
right
in
saying
yet
people
were
thinking.
It
was
a
bit
off
topic.
But
again
when
I
started
listening
to
like
I
said
other
meetings
and
when
I
started
thinking
about
it
and
I
did
meet
with
seve
here
in
montreal,
I
think
we
had
a
good
discussion
about
what
it
could
mean.
A
C
Well,
I
don't
know
I
mean
like
I
could
bounce
this
question
back
to
dirk
I
mean
it
was
on
his
list
and
we
did
not
coordinate.
You
know
I.
I
didn't
prime
him
to
say
that
he
thinks
that
you
know
discovery
is
a
is
a
research
topic
or
a
research
direction
for
coins.
So
perhaps
you
know,
hearing
from
people
from
these
other
quarters
would
be
a
helpful
different
perspective.
I
mean
my
my
position
is
like
you
can't
do
compute
without
data
and
well.
J
C
N
Hey
guys
yeah,
so
this
is
actually
a
more
general
point,
not
so
much
related
to
this
particular
document.
Although
we
can
have
a
discussion
here
too,
so
I
want
to
say
that
I'm,
I
think,
actually
we're
wasting
a
lot
of
time
discussing
whether
something
should
be
adopted
by
a
working
group
and
it's
actually
not
a
working
group.
It's
a
research
group
right
or
not.
I
think
that
is.
That
is
just
a
waste
of
time
right.
I
don't
really
care
whether
something
is
a
research
group
document
or
not.
N
J
J
N
J
N
A
A
A
N
Yeah,
and
also,
I
think
you
want
to
have
much
more
q,
a
than
than
you're
having,
which
is
not
a
whole
lot
and
mike
it's
not
harmful
to
ask
for
research
group
adoption,
but
I
think
it
just
wastes
time
and
it
doesn't
matter.
What's
the,
why
does
it
matter
whether
this
is
a
research
group
document
or
not
it?
You
know
I
really
at
this
point.
At
least
I
don't.
O
Good
morning
I
mean
I
haven't
had
an
awful
lot
of
time
to
look
at
the
trout
yet,
but
I
do
think
the
topic
is
extremely
important,
but
I
wonder
in
terms
of
rg
relevance:
it's
not
about
rg
adoption,
it's
about
rg
relevance,
to
try
to
ask
the
questions
on
data
discovery.
More
I
mean.
Coin
has
two
aspects
in
the
title:
one
is
computation
and
data
is
probably
different.
I
truly
agree,
but
I
think
what
would
be
interesting
to
ask
questions
as,
to
what
extent
is
an
in-networking
question
or
relevance?
O
What
is
it?
Network
really
can
do
to
aid
the
problem.
The
problem
of
distributed
data
is
a
huge
problem
and
it's
it's
it's
extremely
relevant
in
some
of
those
questions
I
had
recently,
for
instance,
with
you,
know:
transportation,
automotive,
where
the
trend
stays
at
data
centralization
and
compute
centralization,
purely
because
you
know
oems
and
car
manufacturers
are
very
concerned
about
data
floating
about
and
not
being
under
their
control.
So
it's
a
huge
problem,
it's
very
relevant,
but
I
think
the
question
for
coin
would
be
to
not
forget
the
networking
part.
O
How
is
it
that
in-network
capability
can
aid
the
problem
and
not
discuss
problems
about
data
discovery
in
general,
because
you
know
that's
a
computational
issue
which
mutually
interesting,
but
I'm
not
entirely
sure
how
much
coin
can
shed
light
on
because
there's
a
huge
community
out
there.
So
it
would
be
good
to
hone
into
the
the
the
in
the
networking
part
quite
a
bit.
O
A
M
See
right
so
now
that
we've
had
a
discussion
already
on
the
use
cases
like
before
here.
Let's
get
it
going
again
so,
as
jeffrey
has
already
said
in
the
beginning,
we're
now
moving
away
from
the
only
sole
focus
on
industry,
but
we
know
all
the
other
use
cases
and
yeah
in
this
quick
presentation.
I
wanted
to
yeah.
J
M
M
M
M
We
then
want
to
have
a
similar
structure
for
all
of
those
use
cases,
so,
as
you
can
see
up
there
in
3.21
and
3.22,
for
example,
there's
also
some
part
of
that
in
what
phil
suggested
a
couple
of
minutes
ago
and
then
finally,
we
want
to
work
on
those
findings
that
we
have
there
and
then
create
some
kind
of
taxonomy
find
common
building
blocks
and
so
on
and
yeah
and
the
following.
I
want
to
go
a
little
bit
into
more
detail
on
the
different
aspects
that
I've
shown
here
on
the
slide.
M
M
But
then,
as
you
can
see
here,
the
in
the
5.2
are
also
thinking
about
some
form
of
h,
a
r
and
v
r.
So
the
dirk
has
a
use
case
or
or
some
ideas
on
that.
We
also
thought
that
it
might
be
a
good
idea
to
potentially
move
some
of
the
content
of
the
now
expired
draft
of
marijuana
over
to
this
draft
here,
and
there
are
also
a
couple
of
other
sources
that
we
could
think
of
at
this
point.
M
So
to
fill
this
initial
set
of
new
use
cases,
but
in
general
we
also
open
for
for
other
use
cases
and
what
we
are
generally
intend
to
have
as
a
structure
here
is
like
some
form
of
three-fold
approach.
We
first
want
to
have
a
short
motivation
that
generally
describes
the
setting
that
we
that
we're
looking
at
so
using
the
example
here
of
this
network
control.
M
We
just
described
here
that
cyber
physical
systems
are
increasingly
complex
and
that
local
control
in
that
scenario
is
not
often
are
often
not
really
sufficient
anymore
and
that
the
central
control
might
help
in
that
in
those
cases.
So
just
setting
the
the
major
the
general
stage
for
for
the
for
the
use
case,
then,
after
that,
we
then
plan
on
having
characterization
and
requirements.
M
Maybe-
and
one
of
the
biggest
questions
here
or
all
the
research
questions
mainly
revolve
around
the
question.
How
the
different
approximations
that
we
might
use
here
can
actually
be
derived
yeah.
Then
our
main
goal,
as
I
said,
is
not
only
to
collect
the
different
use
cases,
but
then
also
make
something
out
of
them.
And
here
I
already
said
that
we
want
to
create
some
form
of
taxonomy
and
for
that
we
want
to
then
actually
use
these
the
structure
that
we
have
for
the
different
use
cases.
M
So
the
common
setting
with
the
requirements,
perhaps
also
analyze,
algorithmic
properties,
of
solutions
that
could
be
applied
there
and
then
try
to
find
common
requirements,
common
combinations
of
requirements,
common
building
blocks
and
then
really
try
to
define
different
classes
of
use
case
that
we
have.
So.
I
think
the
kucha
also
said
something
similar
to
that
in
this
presentation.
M
So
this
is
really
what
we
intend
this
draft
to
be
so
a
collection
of
classes
of
use
cases
with
certain
requirements,
a
list
of
requirements,
maybe
so
that,
then
your
work
can
really
be
derived
from
those
use
cases,
and
then
yeah
really
focus
on
certain
aspects
of
the
use
guests
or
solve
problems
in
them.
And
the
big
thing
at
this
point
here
is
that
we
need
more
use
cases
for
that.
So
currently,
as
I
said,
we
only
really
have
the
industrial
use
cases
in
there.
M
The
other
use
cases
from
from
the
app
center's
draft
will
move
over
eventually,
but
even
then
we
only
would
have
like
three
large
groups
of
use
cases,
and
so
it
would
be
really
great
if
other
people
here
would
also
have
the
interest
of
contributing
use
cases.
So
the
in
the
first
presentation
we
had
like
this-
a
at
itu
ai
to
the
edge
use
cases
with
the
auto
and
the
cyber
cases,
so
that
sounded
really
interesting
and
yeah.
M
Thus
we
really
open
and
looking
for
collaborators
at
this
point
so
that
we
can
then
increase
the
diversity
of
the
use
cases
and
then
really
find
interesting
requirements
and
then
yeah,
hopefully
get
a
good
basis
for
a
future
work
at
this
point
yeah.
So
this
is
then
now
the
last
slide
yeah.
We
were
not
really
sure
about
our
status
as
a
research
group
draft,
but
in
the
beginning
we
solved
that
so,
let's
skip
over
it,
so
that
last
is
happy,
also
yeah.
What
do
we
need
for
our
draft
now?
M
We
really
need
input
on
our
approach
on
how
we
want
to
describe
and
include
use
cases.
So
if
this
separation
and
characterization
and
requirements
and
approaches
make
sense,
if
you
guys
have
better
ideas
for
that,
please
tell
them
so
that
we
can
then
really
improve
the
approach
here
and
perhaps
maybe
make
it
more
easy
for
other
people
to
contribute
as
well
yeah.
We
also
need
new
contributors
with
new
new
use
cases.
So
we'll
add
the
the
draft
sources
to
the
research
group
github
soon.
M
So
then
yeah
text
contributions
should
be
really
easy
and
yeah.
The
plans
for
the
immediate
future
are
that
we
will
first
move
the
use
cases
over
from
the
app
centers
draft
and
then
yeah
and
follow
our
own
guidelines
regarding
the
descriptions
of
the
use
cases
there
and
then,
as
soon
as
we
have
enough
use
cases
to
to.
We
also
want
to
start
with
a
rough
analysis
of
of
the
use
cases
so
that
we
can
then
yeah
start
in
the
right
in
the
direction
of
the
economy
and
yeah.
M
O
Dirk
trust
thanks
thanks
just
to
continue
on
on
on
what
like,
as
presented,
but
also
connecting
to
you
what
dirk
had
said
before
the
taxonomy
part
is
going
to
be
a
really
important
one.
I
would
really
like
to
invite
also
contributors
specifically
to
that
as
well.
It's
not
only
just
a
new
use
case,
but
also
taxonomy,
because
I
think
one
of
the
critical
pieces
in
the
use
cases.
First,
we
get
a
place
where
they
are
where
they
are
are
gathered.
O
That
was
the
first
idea
of
merging
things,
and
I
will
say
that
later
in
our
own
draft,
but
we're
going
to
to
do
that
so
just
to
move
them
out
of
individual
drafts.
That's
a
good
thing,
but
it
also
allows
us
to
essentially
look
at
the
use
case
and
make
sense
out
of
them.
I
think
doug's
common
about
there's
a
lot
of
edge
and
cloud
here
is
a
very
important
one.
O
I
mean
there's
nothing
wrong
with
the
use
cases,
but
the
ones
that
are
more
relevant
to
the
networking
part
and
and
are
not
just
in
the
expo.
It's
just
edge
cases
or
cloud
cases
which
which
might
have
an
interest
of
their
own,
but
maybe
doesn't
add
much
to
the
networking
part
sets
the
taxonomy
a
bit.
That's,
I
think,
really
really
important
and
and
I'd
really
like
to
see
anybody's
good
ideas
to
that
as
well.
O
Another
thing
I
just
looked
for
the
participant
list,
because
I
wasn't
entirely
sure
if
he
would
join
given
the
early
time,
but
I
will
connect
that
to
ike
directly.
I
had
spoken
to
a
potential
contributor
from
ucl
on
use
cases.
So
probably,
given
that
I
can't
seem
at
the
moment
in
the
participant
list,
I
probably
will
just
make
the
connection,
so
we
may
have
already
a
contributor
there
just
wanted
to
make
people
aware
of
that.
O
L
O
From
ucl
we've
been
talking
to
them
about
use
cases
related
to
arts
and
theater
and
how
some
of
them
being
extremely
demanding
on
the
network
and
how
the
network
might
help.
But
again
the
question
there
would
be.
How
can
in
networking
functionality
really
help,
or
is
it
all
down
to
intelligent,
maybe
edge
software,
which
is
still
an
interesting
use
case,
but
maybe
not
that
relevant.
For
this
group.
A
A
G
G
Yes,
yeah.
Thank
you,
hello,
everybody,
I'm
rich
kasai,
I'm
from
preferred
networks
and
white
project.
I'm
talk,
I'm
going
to
talk
about
separation
of
database
and
data
from
subreddits
in
the
trust
trailer.
This
draft
is
proposed
for
transport
layer
and
a
tsp
working
group,
but
some
of
the
topics
are
related
to
the
intellectual
computing
and
clinicality.
So
I
want
to
talk
about
that
here.
G
So
thank
you
for
taking
your
time
and
yeah,
we
started
thinking
about
the
layering
architecture
for
the
new
distributed
computing
paradigms,
including
the
mobile
or
multi-access
edge
computing
and
integer
computing.
I
personally
think
the
requirement
for
the
transportation
protocol
is
different
by
computation
models
such
as
the
data
center
networking
or
geographically
distributed
environment.
So
I'd
like
to
begin
with
more
general
learning
architecture,
rather
than
specific
protocols
to
extract
the
common
functionality
for
the
future
protocol
development
and
yeah.
G
G
But
recently
the
network
becomes
more
smarter,
so
qos
is
introduced,
middle
boxes
are
everywhere
and
recently
new
distributed
computing
products
such
as
the
edge
computing
in
data
computing,
are
introduced,
so
non-trans,
so
middle
boxes
introduce
a
non-transparent
functionality
that
may
be
added
by
that.
That
requires
to
load
package
to
middle
boxes.
G
Our
patent-based,
pcbs,
routing
or
software
defined
networking
technologies
distributed
computing
paradigms
are
required
to
make
the
network
smart,
and
these
often
use
overall
networks
to
allow
the
parties
to
the
target
computing
resources.
Next,
please
yeah,
thank
you.
So
I
started
thinking
about
the
transported
layer
functionality
to
separate
the
functionality
into
the
multiple
layer
for
the
future
protocol
development.
So,
in
this
draft
I
separate
I
divide
the
transport
layer
into
two
sub
layers.
G
For
example,
the
trajectory
or
waypoint
handling
to
us
a
designated
waypoint
for
the
some
kind
of
flows
and
the
bi-directional
connection
and
resource
management
for
the
networking,
such
as
condition,
control
and
the
data
flow.
Much
stretching
over
the
one
path
and
padded
duplication
may
be
implemented
for
particles,
recovery
for
roshi
network
or
links
like
fake
and
over
the
data
path.
Data
flow
layer
add
some
functionality
about
the
transmission
flow
control,
low
prioritization
engine
security
or
multi-pass
protocol
functionality.
G
G
So
in
network
computing,
I
don't.
I
think
I
don't
need
to
say
something
about
that,
because
everywhere
are
specialists,
but
the
electoral
computing
has
been
researched,
maybe
more
than
30
years,
and
the
active
network
is
one
of
the
the
beginning,
research
early
research
of
the
internet
of
computing,
and
then
the
recent
read
is
the
substructure:
training
has
been
discussed
in
the
iedf
and
in
the
data
center
networking
data
aggregation
distributions
used
for
is
used
for
all
reduced
procedure
for
the
distributed
development,
so
electro
computing
has
been
forecast
recently
again.
G
So
this
is
the
simplest
initial
computing
model,
so
nothing
in
no
intermediate
levels
stores
any
state
of
the
computation
and
database
information,
so
programs
are
installed
deployed
in
some
in-network
computing
components
or
in
network
computing.
Routers
like
this,
and
the
packet
going
through
the
louder
is
processed
according
to
the
program,
but
these
routers
don't
store
any
state
of
the
package
or
database.
So
in
that,
in
such
case
we
can
leverage
ecmp
global
customer
pass
because
the
the
data
path
is
not
is
not
required
to
be
cared
for.
The
united
computing.
G
G
G
G
So
this
is
the
the
the
bureau
failure
bureau
is
the
the
example
of
the
layering
for
this
computation
model,
so
the
data
path
needs
to
be
aware
in
this
computation
model,
but
the
data
flow.
I
mean
that
the
emitter
computing
routers
do
not
store
any
state
so
that
they
don't
require
any
flow
control
or
the
transmission
between
the
routers
at
the
end
and
host.
G
G
So
in
this
model,
the
initial
computing
routers
need
to
terminate
the
data
flow,
so
they
introduce
the
data
flow
rate.
They
need
to
implement
a
data
flow
layer
protocol
at
the
network-
computing
node
next,
please
so
I
will
have
one
minute
so
so
this
is
the
summary.
So
I
propose
a
separation
of
data
and
data
flow
layers,
so
that
path
is
to
be
aware
of
network
resources
and
trajectory
or
waypoints.
The
data
flow
layer
is
to
be
aware
of
computing
resources
and
flow
level
integrity.
G
A
K
Okay,
thanks
yeah
things
are
interesting,
so
I
mean
most
often
compute
functions.
You
know
want
to
do
something
on
the
payload
so
with
the
application
data.
So
what
security
model
should
we
apply?
For
you
know
your
data
flow
layers,
I
mean,
would
you
terminate
a
security
context
in
the
network
or
how
would
that
look
like.
G
C
C
M
L
Just
like
yes,
this
one!
So
if
you
look
at
the
data
flow
layer
where
you
got
the
data
flow
connecting
to
another
data
flow
layer
connecting
to
the
end
data
flow
layer,
the
application
layer
is
expecting
something,
and
typically
they
just
expect
that
the
packets
go
from
here
to
here
and
then
they'll
deal
with
it.
If
the
data
flow
layer
in
introduces
some
compute.
L
What's
the
end-to-end
expectation
anymore,
that
you
know
the
application
sends
something
from
from
the
left
and
the
right
wants
to
take
it
and
do
some
compute
on
it,
but
in
the
middle
somebody's
already
done
some
other
computer
on
it
and
it's
not
only
security.
But
what
is
the
end-to-end
correctness
of
what
is
going
on.
G
Yeah
good
point
yeah.
I
think
we
need
to
all
think
about
that
point
in
more
detail
in
future,
but
I
think
the
application
layer
needs
to
take
care
the
service
level
functionality
of
substance,
something
I
mean
the
the
usually
the
application
specified
the
service
identifier
instead
of
the
this
kind
of
the
middle
boxes
or
the
waypoints
of
the
computing
computation,
so
application
layer
should
handle
the
such
kind
of
the
service
level,
integrity
or
serviceable
functionality.
L
G
Oh
yeah
right.
I
think
this
draft
focuses
on
the
data
playing
function,
so
I
think
control
plane
requires
to
manage
the
how
to
load
or
where
should
be
the
waypoint
for
this
functionality
or
for
this
service.
So
the
application
layer
should
control
certain
things
and
the
data
translator
in
the
data
flow
layer
is
used
for
the
date
plane
protocol.
I
think,
in
my
opinion,.
A
P
Yeah,
so
it's
a
quick
question.
I
think
thanks
for
the
good
presentation,
so
I
have
my
question:
is
you
pointed
the
active
networks
in
the
beginning
of
the
presentation
and
the
first
question
recalls
asked:
it's
mostly
massaging
the
payload
right
with
the
data
flow
layer
with
the
small
program
there.
So
is
that
the
use
case
you
have
in
mind
or
so
are
you
doing
anything
which
is
not
to
not
to
do
with
the
payload
right,
but
still
applying
some
service?
The
compute
service
on
the
packet
here.
G
G
P
A
A
A
O
O
O
Good,
so
I
only
copied
the
abstract
here,
but
the
important
sentence,
the
very
last
one,
so
the
various
questions
that
at
the
moment
are
being
asked
about
transport
protocols
in
connection
with
coin
and
again,
the
the
last
subset
is
very
important
to
the
point
I
also
made
before
we
outline
a
number
of
research
challenges
and
use
cases
for
that
in
the
draft
and
from
the
structure.
These
are
the
main
updates.
O
So
again,
this
is
only
an
update
on
an
ongoing
draft
and
focusing
on
the
updates
discuss
later
a
couple
of
the
updates
we
made
in
addressing
and
flow
granularity.
We
added
a
new
section,
five
on
collective
communication
and
multi
for
multi-party
communication
and
the
challenges
that
transport
has
in
that
area,
and
we
also
renamed
section
8,
which
was
the
previous,
obviously
different,
numbering
before
into
transport
features
where
we
discussed
reliability
and
flow
and
updated
the
subsections.
O
O
O
We
also
amended
the
research
questions
by
various
aspects
on
node
selection,
constraint,
based
decision
of
that
selection
and
also
representing
the
treatment
by
coin
nodes.
There
are
several
research
questions
if
you
recall
the
structure
of
the
traffic,
you
always
ask
a
number
of
research
questions
in
each
of
these
subsections,
so
we
amended
these
aspects.
O
That's
the
reason
why
we've
done
that
in
the
draft
this
actually
is
new
mentioned
before
and
has
been
done
with
a
linkage
again
to
the
app
center
draft
which
comes
next
and
it
talks
about
possibly
ephemeral
and
short-lived
multi-point
communication
that
is
being
done
there.
There
are,
I
think,
at
least
two
use
cases
in
the
absence
of
draft
that
talk
about
this.
O
It's
a
multiple
communication
that
may
occur
even
at
the
request
level
only
and
that
questions
the
viability
of
current
transport
solutions
which
we
discuss
in
this
new
section
and
the
possibility
for
coin
nodes
to
support
aspects
that
you
would
need
to
do
from
a
transfer
perspective.
For
instance,
group
division
into
subgroups
is
one
of
the
aspects
we
identify
that
coin
nodes
could
be
helped
with
updates
on
section
8
again
different
numbering
before
we
renamed
this
section
to
transport
features
and
they
cover
reliability
and
congestion
control
subsections.
O
We
have
several
amendments
in
the
in
the
two
subsection
reliability.
We
mentioned,
for
instance,
the
the
possible
opportunity
to
use
coin
nodes
in
relation
to
network
coding
for
reliability.
That's
one
aspect:
there
we
also
added
again
a
question
on
the
what's
the
unit
of
reliability,
so
we
link
this
to
the
previous
discussion
in
the
flow
granularity
section
as
to
what's
the
unit
of
reliability
that
one
should
look
at.
O
How
do
you
separate,
or
how
do
you
join
the
flow
controls
into
potential
ephemeral,
resource
management
regime
that
you
can
use
for
the
multicast
response?
There
are
some
texts
and
there
as
well
and
again
always
trying
to
link
this
somehow
to
how
coin
can
help,
in
particular
the
in-networking
part.
So
I
know
I
keep
repeating
that,
but
it's
important.
O
What
are
the
future
plans
again?
Some
of
this
work
has
happened
fairly.
Recent
to
the
itf,
so
so
we're
intending
to
operate
update
this.
You
know
quite
quickly.
It's
a
clearer
linkage
to
the
various
use
cases
in
the
revised
use
case
draft.
That's
again,
where
also,
let's
say:
draft
wise
and
linkage-wise
things
become
a
bit
easier
because
you
can
just
link
to
a
single
draft
increasingly,
hopefully,
and
also
hopefully
rely
to
an
emerging
taxonomy
that
we
can
link
to
from
the
transport
craft.
O
O
I
think
similar
applies
here
for
the
transport
to
turn
the
research
questions
into
something
like
a
requirements,
language,
so
that
we
can
shake
that
out
and
maybe
at
some
point,
even
discuss
where
to
collect
all
those
requirements.
That's
a
little
bit
further
down
more
for
the
research
group
overall.
O
Obviously,
we
would
like
to
have
more
input
and
I
think
yeah-
that's
that's
more
important
and
mostly
important
to
get
more
people
involved
in
the
discussion
and
hence
the
call
for
more
contributors,
and
we
also
asked
the
question
here,
but
we
maybe
we
can
skip
that.
Given
the
discussion,
we
had
to
adopt
that
as
a
research
draft
that
at
this
stage
we
want
to
have
more
contributors
to
start
with.
J
O
Oh
okay,
good,
my
my
english
language
skills,
same
structure.
Here
you
can
read
it
later
general
structure.
We
still
include
the
use
cases,
but
they
will
be
moved
off.
We
have
a
very,
very
fine
small
refinements
in
there
for
the
update
and
that
will
all
be
carried
over
the
use
case
graph.
That's
an
easy
one.
We
do
have
requirements
again.
O
We
leave
them
here,
they're
derived
from
the
use
case
and
then
we'll
see
where
that
makes
sense
in
any
of
the
other
crafts
either
we
carry
them
over
in
the
use
case
draft
or
if
any
requirements
traffic
merges.
I
think
we
can
take
them.
They
are
quite
a
few,
which
is
good.
What
we
do
for
now
is.
We
will
update
them
in
the
next
revision,
with
a
clear
linkage
to
our
own
section
five.
O
But
then,
when
the
requirements
move
elsewhere,
we
have
to
restore
those
linkages,
so
the
main
focus
has
actually
been
on
number
five
on
the
enabling
technologies
and
we
added
more
tags
in
a
number
of
subsections.
We
added
new
text
in
in
section
five,
one
in
the
ones
that
are
shown
red,
either
new
text
or
edit
text.
O
There
so
on
the
compute
interconnection
layer,
two,
we
we
there
added
references
to
use,
l2,
switching
for
interconnecting,
distributed,
complete
resources
and
linked
to
efforts
that
are
going
on
at
the
moment
in
3dpp
and
generally
in
the
area
of
edge
computing
in
5g.
There's
some
references
added
and
some
text,
but
discuss
those
and
and
and
also
to
point
to
the
service
routing
in
distributed
l2
environments
as
a
similar
problem
to
input
data
center
server
scheduling.
Even
though
here
you
have
a
distributed
layer,
2
environment.
So
there's
some
text
to
that
regard.
O
O
I
sorry
extended
the
text
in
an
action
text
and
it
extends
the
discussion
in
the
subsection
before
section
5.4
and
service
routing
by
to
include
constraints
into
the
forwarding
decision
and
the
constraints
between
one
or
more
two
to
have
the
following
decision
with
one
one
or
more
services
and
candidates
there.
A
point
is
particularly
that
loaded
latency
may
not
be
the
only
constraints.
There
are
a
few
of
them
discussed
and
again.
O
The
relation
to
the
networking
part
is
in
the
support
of
the
network
in
the
matching
operations,
because
they
may
need
to
be
coordinated
across
several
routers
to
achieve
the
equivalent
to
a
service
scheduling
capability
that
you
know
from
intradata
center
scheduling
of
service
requests
in
a
distributed
setting.
So
there's
some
discussion
around
there.
That's
where
again
coin
specific
comes
more
in
also
reference
to
ongoing
work,
c
event,
dyncast
and
the
itf
ic
and
rg
work
et
cetera,
et
cetera.
So
and
that's
not
is
only
a
start
of
it.
O
There
will
be
more
references
if
possible.
As
I
said,
collector
communication
is
new
as
a
pattern
that
exhibited
in
a
number
of
microservice
scenarios,
as
we
have
in
the
use
cases
to
go
from
not
just
one
to
one
but
two
multi-point
use
cases.
We
also
observed
that
the
patterns
may
be
short-lived
in
other
use
cases.
O
If
there's
requirements
work
emerging
in
the
group,
we
are
quite
willing
to
and
happy
to
do
that
there
are
some
other
bits
and
pieces
missing
in
section
five,
so
section
five
is
the
core
section
for
the
future
plans
to
elaborate
on
to
make
clearer
linkages
to
other
crafts,
to
references
so
there's
that
goes
more
into
reality.
Overview
work
and
trying
to
tie
in
what's
been
done
elsewhere.
Ask
the
same
question
here,
but
that's
not
that
relevant
on
the
rg
draft
good,
I
shift
hopefully
again
something
else.
A
B
E
E
Q
However,
here
we
have
a
problem
with
current
networking.
Hardware
is
missing,
actual
cryptochips,
so
right
at
this
moment,
our
possibilities
are
a
bit
limited
here,
but
we
think
there
is
still
room
for
a
lot
of
interesting
research
and
we
also
hope
that
yeah
edict
will
be
available
in
the
future
yeah.
The
next-
and
this
is
one
subject
we
are
already
actively
working
on-
is
the
efficient
enforcement
of
network
policies.
Q
So
that's
what
was
already
part
of
the
first
draft
version
and
in
the
updated
draft
we
now
added
another
idea,
which
I
want
to
present
a
bit
more
detailed.
So
next
slide,
please
yeah.
So
we
call
this
in-network
vulnerability
patches,
and
this
works
a
bit
similar
to
anomaly
detection
and
policy
enforcement,
but
is
more
specific
and
yeah.
A
common
problem
of
legacy
and
resource
constrained
devices
is
that
they
are
often
hard
or
even
impossible
to
update
and
therefore,
later,
emerging
vulnerabilities
cannot
be
fixed
on
the
devices
themselves
and,
furthermore,
even
if
updates
are
possible.
Q
Q
A
A
I
would
suggest
that
you
continue
discussing
this
on
the
list,
which
I
think
is
the
right
place,
and
I
actually
put
it
down
the
notes,
but
thank
you
very
much
for
highlighting
the
research
projects
or
the
research
ideas
related
to
this.
I
think
every
presentation
should
have
this.
So
thank
you
very
much
so
phillip
you,
you
can
take.
Maybe
five
six
minutes
work
we're
going
to
be
a
few
minutes
overboard,
but
I
think
it's
fine.
J
E
J
It's
great
okay,
they're
coming
through
so
I'll
stop,
so
I'm
philip
earley
and
thank
you
very
much.
I'm
just
gonna
tell
you
very
briefly
about
a
collaborative
project
called
piccolo
that
we
just
started
about
in
network
compute.
5G
services.
Next
slide
would
be
nice,
so
we've
only
been
going
a
month.
So
these
are
just
some
first
initial
ideas
about
what
we're
going
to
do
and
about
the
use
cases
that
we're
looking
at
we've
got
listed.
J
Some
of
the
people
involved
there,
so
some
of
them
are
well
known
to
this
group.
So
I
think
we're
very
you
know,
I'm
very
pleased
with
the
with
the
set
of
partners
and
the
people.
We've
got
involved
and
we've
got
some
nice
use
cases
coming
and
we're
certainly
intending
to
to
contribute
in
coin
and
we're
keen
to
you
know
to
collaborate
through
forest
such
as
such
as
coin.
J
J
I've
got
a
slide
on
coming
up
on
the
vision,
processing
and
on
the
automotive
side.
We've
also
got
partners
interested
in
the
smart
street
lights
as
a
scenario,
and
we
meaning
they're
bt,
who
I
work
for
we're
interested
in
in
this.
Not
only
is
a
platform
you
know
this
kind
of
in
network
compute,
but
also
using
the
technology
to
do
autonomic
and
scalable
network
management.
J
Anyway,
I've
got
so
if
we
go
on
the
next
slide,
which
is
about
the
vision,
processing
use
case,
we're
looking
at
so
we've
got
a
uk
sme
called
sensing
feelings,
so
they
have
a
product
at
the
moment,
which
is
a
camera
which
has
in
the
camera
or
next
to
the
camera
chip
that
does
visual
processing,
so
they
have,
they
have
their
customers
or
what
they
do
is
provide
to
their
customers,
insight
into
people
in
real
world
spaces.
So
that
would
be
things
like
in
a
train
station.
J
J
So
what
we're
looking
at
in
terms
of
piccolo
is
in
in
the
camera
having
just
a
simple
image
conveyor
and
doing
the
visual
processing
in
the
operator
fog
in
the
edge
that
enabling
them
to
get
into
you
know
kind
of
long-tailed,
because
the
the
sensor
would
be
much
cheaper
device
or
maybe
to
you
know
if
you've
got
lots
of
cameras
in
the
train
station.
One
human
trying
to
look
at
100
cameras
instead
doing
automatic,
automated
attention
focusing
you
know,
which
picture
has
the
most
interesting
thing
happening.
J
So
that's
that's
a
vision,
processing
use
case
and
the
first
kind
of
example
we're
looking
at.
We
go
on
the
next
side,
so
we've
got
bosch
in
particular,
who
have
interested
in
the
automotive
use
cases
60
of
their
revenue
comes
from
from
automotive
stuff,
so
first
use
case.
We're
particularly
interested
in
there
is
infrastructure
assisted
driving.
So
this
is
electronic
horizon
all
kind
of
seeing
around
the
corners.
J
So
at
the
moment
there's
a
the
product
is
is
used
for
driver
assistance.
So
this
would
be
things
like
suggesting
you
slow
down
a
bit
and
hit
the
green
lights,
and
at
the
moment
the
approach
is
you've
got
these
roadside
sensors
that
send
their
information
to
a
central
cloud
and
that
then
pushes
the
information
to
the
cars.
A
We're
going
to
be
very
interesting
to
see,
I
think
the
whole
group.
What
do
I
say
I
say
we
are
going.
I
I
sound
so
regal.
Suddenly,
maybe
it's
the
british
thing
you
know
it's.
The
the
queen
here
is
very
popular.
The
not
the
queen
of
england,
the
queen
at
the
queen,
the
show
actually
the
queen
of
england,
is
not
popular
here,
but.
A
Only
people
who
understand
us
live
and
live
in
scotland
and
the,
but
yes
we're
going
to
be
very
interested
in
seeing
which
this
comes
through,
especially
it
is
research,
and
a
lot
of
the
contributors
of
this
group
are
contributors
to
your
project.
So
it's
going
to
be
really
cool,
we're
six
minutes
over
time.
A
So
yes,
we're
going
to
push
our
discussion
of
other
work
or
future
work
of
future
collaborations
to
a
february
interim
that
we're
going
to
organize
and
essentially
tell
everybody
about
very
soon.
I
would
encourage
people
to
use
the
list
better.
We've
had,
but
I
know
right
now
what
was
happening
everywhere,
it's
so
so
weird.
Nobody
has
time
to
do
anything
frankly,
and
so
our
schedules
are
kind
of
weird
and
but
anyway,
thank
you
to
the
top
of
88
people
who
joined
at
one
point.
A
Thank
you
very
much
to
the
other
three
montrealers
who
were
on
the
call
and
who,
like
me,
have
I
have
days
to
start
in
six
hours
and
maybe
less
actually,
if
we
consider
that
we
have
to
wake
up
around
seven,
for
those
of
you
in
europe
have
a
good
day.
For
those
of
you
in
your
in
in
asia
have
a
good
afternoon
and
for
people
in
california.
Well,
it's
still
long.