►
From YouTube: IETF109-ICCRG-20201120-0500
Description
ICCRG meeting session at IETF109
2020/11/20 0500
https://datatracker.ietf.org/meeting/109/proceedings/
A
A
A
A
A
Well,
welcome
to
iccrg.
This
is
the
meeting
after
six
months
and
it's
been
a
while
so
we've
had,
I
had
a
large
number
of
people
having
things
that
we
unfortunately
could
not.
We
did
not
have
enough
time
to
present
here,
but
I
want
to
start
off
this
meeting
by
before
I
do
the
agenda
bash
just
very
quickly.
Note
a
couple
of
things.
First,
the
note
well,
as
you
all
know
applies.
A
I
am
probably
going
to
slowly
start
insisting
that
those
who
want
a
presentation
slot
actually
have
initiate
a
discussion
on
the
list
first,
so
that
it
doesn't
seem
like
a
one-shot
thing.
We
always
have
this
problem
with
iccrg.
I
think
where
people
come
to
a
presentation,
walk
away
and
it's
10
minutes
of
engagement
for
three
months,
which
is
not
particularly
exciting
or
interesting,
and
there's
no
continuity.
A
I
want
people
to
bring
topics
up
on
the
list
and
if,
if
the
topics
are
interesting,
I
would
like
to
give
that
time
on
the
agenda,
and
I
will
say
that
topics
that
are
getting
discussion
on
the
list
will
will
have
priority
when
it
comes
to
agenda
time
at
a
meeting.
So
keep
that
in
mind
and
I'll
move
along
one.
A
Oh,
I
don't
remember
the
name
of
the
talk,
but
it's
about
the
chain,
fairness
index
and
and
and
moving
past
the
chain,
fairness
index
to
measure
fairness
amongst
flows
and
it's
a
very
interesting
piece
of
work.
I
encourage
you
to
show
up
and
and
and
and
give
feedback.
I'm
sure
you
will
be
interested
in
this
talk
with
that.
Let's
get
started,
we
have
a
packed
agenda
today,
so
we're
going
to
try
and
keep
this
on
time.
A
So
it's
a
packed
agenda.
Let's
keep
this
to
the
speakers.
Let's
keep
this
within
time.
I'm
gonna
try
and
move
you
along.
If,
if
I
need
to-
and
I
would
like
to
get
started
so
I'm
gonna
take-
I
think,
charge
of
the
slides
here
and
I'll
run
them.
I
know
sylvester.
You
were
going
to
try
and
do
your
own
slides
and
that's
fine,
but
I
will
I'm
going
to
cue
praveen.
Now,
I'm
going
to
switch
this
to
my
to
to
your
slides,
praveen.
A
C
B
B
B
B
So
what
is
our
led
by
a
quick
recap?
So
what
we
want
to
do
is
we
want
to
bring
the
benefit
of
light
back
plus,
plus
to
the
receive
side
of
the
transport
connection.
For
those
who
don't
know
what
ledbet
plus
plus,
is
it's
an
improvement
over
the
original
lightbet
rfc
to
solve
a
bunch
of
shortcomings,
of
that
rfc,
so
network
plus
plus,
is
a
sender
side,
congestion,
control
algorithm.
What
we
want
to
do
is
bring
the
same
benefits
of
that
algorithm
to
the
received
side
of
the
transport
connection.
B
How
we
do
this,
we
use
the
flow
control
mechanism.
So,
as
you
know,
each
tcp
packet
contains
the
window
field
which
advertises
to
the
peer.
How
much
data
it
can
buffer-
and
that
is
typically
a
typical
tcp
implementation-
would
tune
that
buffer
over
time
to
make
the
performance
good.
So
we
would
increase
the
window
as
long
as
the
sender
is
able
to
keep
up
and
the
application
is
draining
data.
But
in
this
case
what
we
want
to
do
is
use
that
as
a
throttle
so
based
on
the
ledbet
algorithm.
B
B
B
B
End
to
end
the
the
network
on
the
client
side
might
be
overloaded,
and
just
doing
it
in
one
path
of
the
network
is
not
sufficient
and,
of
course,
there's
like
cases
where
the
receiver
application
has
more
information
about
exactly
which
connections
need
to
be
lower
priority
and
might
not
be
able
to
communicate
that
to
the
server
side
and
doing
this
just
using
the
client
side.
Application
has
a
lot
of
advantages,
including
having
enforcing
any
sort
of
preference
that
the
local
application
or
operating
system
that
wants
to
apply
a
less
than
best
effort.
B
B
So
the
update
I
have
is
that
we
have
an
implementation
now
in
the
windows.
Operating
system
is
based
on
the
draft
it's
implemented
for
tcp.
We
already
had
an
api
and
sort
of
configuration
in
the
os
to
turn
on
ledbet
plus
plus
the
same.
One
also
enables
our
led
bat.
So
when
you
enable
this,
you
get
less
than
best
effort
in
both
send
and
receive
directions.
B
It
includes
all
the
additional
mechanisms
of
led
by
plus
plus
the
r
led
by
draft
leaves
it
open
to
the
implementation.
At
least
the
current
version
of
the
draft
leaves
it
open
to
the
implementation
to
either
use
lead
battery
led
by
plus
plus,
we
have
chosen
to
implement
all
of
the
goodness
of
lightbulb
plus
plus,
which
includes
rtt
measurement
slower
than
reno
increase
for
the
window.
B
B
B
B
B
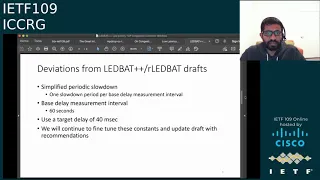
So,
instead
of
targeting
only
a
90
reduction,
we
are
basically
doing
one
slowdown
per
each
measurement
interval
and
that
measurement
interval
is
also
different
than
the
one
for
ledward
plus
plus,
which
was
30
seconds.
This
is
like
60
seconds
period
for
measuring
the
base
delay.
It
was
basically
a
periodic
slowdown.
B
The
target
delay
of
60
milliseconds
was
used
in
lightweight
plus,
but
we
found
that
on
the
receiver
side,
we
have
to
use
a
lower
value.
We
are
still
sort
of
experimenting
and
tuning
these
constants,
and
once
we
have
more
results
with
a
real
world
workload,
we
will
update
the
draft
with
the
correct
recommendations.
B
So
I
have
some
initial
lab
results.
I
don't
have
data
from
like
a
white
deployment
yet,
but
this
is
just
to
show
the
effectiveness
of
the
algorithm
as
implemented
on
the
receive
site.
So
this
is
just
a
cubic
short
flow
that
kicks
in
during
the
middle
of
a
are
light
but
connection.
As
you
can
see
the
connection
lamps
up
the
center
doing
slow
start,
then
we
basically
enter
the
slowdown
period.
That's
the
initial
slowdown
and
we
throttle
the
sender
completely.
B
This
is
what
would
have
happened
if
the
sender
was
using
ledbet,
plus
plus,
but
in
this
case
it's
the
receiver
throttle
in
the
center
and
then
we
exit
the
slowdown.
We
continue
our
growth,
but
then
the
cubic
flow
kicks
in
and
the
reaction
is
pretty
immediate.
We
can
sense
the
delay
build
up
in
the
bottleneck
and
we
back
off
to
the
minimum
rate,
which
is
the
two
packet
window
that
is
recommended.
D
D
B
B
Please
this
demonstrates
the
latecomer
this.
This
basically
shows
that
the
latecomer
advantage
problem
does
not
exist
with
our
leadback.
So
what
happens
here
is
that
when
the
late
camera
flow
starts,
the
slowdown,
the
periodic
slowdown,
basically
allows
the
flows
to
remeasure
the
base
delay
and
that
causes
the
both
the
flows
to
sort
of
fair
share,
and
we
don't
see
that
the
late
gamer
gets
undue
advantage
and
completely
throttles
the
first
floor.
B
This
sort
of
shows
the
interled
bat
fairness
for
outlet
blood
flows.
These
are
four
different
outlet.
Bright
flows,
staggered
started,
as
you
can
see,
there's
periodic
slowdowns
happening
for
all
of
these
flows.
As
a
result,
they
all
measure
the
base
delay
accurately
and
they're,
able
to
like
fair
share
the
link
amongst
themselves.
B
B
This
is
the
low
latency
competition
effectively.
This
is
the
problem
where
the
queue
is
small
enough.
Actually,
there's
a
mistake
on
the
slide.
The
the
queue
size
was
actually
250
packets,
so
this
is
actually
a
shallow
queue
and
because
we
can't
build
the
queue
we
can't
exceed
the
target
delay
so
that
bite
would
not
back
off.
B
We
had
the
same
experiment
with
ledbet
plus
plus
and
when
it
was
a
sender,
and
we
would
see
that
it
was
actually
taking
much
smaller
share
compared
to
cubic,
but
with
our
ledbit,
we
are
seeing
that
there
is
actually
a
little
bit
more
competition,
it's
almost
as
if
they're
fair
sharing,
but
this
is
a
problem
we
will
continue
to
investigate.
We
haven't
root
caused
this
yet,
but
this
this
is
something
that
needs
to
be
investigated,
so
certainly
different,
behavior
than
what
we
saw
with
the
library
plus
on
this
intersect
next
slide.
B
B
That's
sort
of
the
summary
of
where
we
are
at
the
next
step
for
us
is
to
take
this
implementation
out
for
a
spin
with
a
real-world
software
update
workload
and
measure
its
effectiveness
measuring
this
is
hard
less
than
best
effort
in
general.
Metrics,
for
this
are
really
really
really
really
hard
problem,
particularly
because
the
goal
is
to
actually
improve
other
traffic.
We've
had
cases
where
people
had
to
drop
off
the
call
and
go
tell
their
family
members
to
like
stop
doing
things
on
the
network.
So
you
know
it's
it's.
B
Basically,
a
user
experience
measurement.
We
have
ways
of
doing
this,
so
we're
still
working
on
creative
ways
to
measure
the
effectiveness
of
this
algorithm
in
the
real
world.
We
want
to
do
constant
tuning,
there's
a
bunch
of
magic
constraints.
I
think
this
applies
to
both.
Let
that
plus
plus
an
outlet
pat.
B
The
other
thing
we
want
to
explore
is
the
making
the
target
value
dynamic.
Currently,
it's
60
milliseconds
for
ledbet,
plus
plus
and
40
milliseconds,
for
our
left
back.
We
would
like
to
figure
out
a
way
to
tune
this
based
on
the
bottleneck
link.
One
of
the
challenges
here
is
that,
because
it's
a
less
than
best
effort
algorithm,
we
can't
really
send
at
a
very
high
rate,
to
to
figure
out
the
the
capacity
of
the
link.
So
this
is
a
challenging
problem,
we're
still
figuring
out
how
best
to
do
this.
B
B
B
On
the
our
ledbet
side,
we
may
want
to
think
about
just
referencing
light,
but
plus
plus
I
I
don't
really
see
the
point
of
going
back
to
lead
back
with
the
known
problems.
We
also
want
to
update
the
draft
based
on
the
data
and
the
tuning
on
the
ledward
plus
plus
side.
We
want
to
add
pseudocode.
That's
been
an
ask
from
a
lot
of
people
so
that
the
rfc
is
draft
is
easier
to
read
and
implement,
and
there
is.
B
There
has
been
a
suggestion
to
also
make
it
alone,
instead
of
having
to
refer
the
original,
ledbet,
rfc
and
sort
of
replace
the
original
one,
and
that
there's
a
third
point
I
miss
here,
which
is
to
also
make
it
agnostic
to
transport
right
now.
Both
of
these
drafts
are
very
much
specific
to
tcp,
whereas
they
could
also
be
applied
to
quick.
So
that's
the
third
sort
of
work
that
needs
to
happen
for
these
drafts.
With
that,
I
think
I'm
done
with
my
talk
and
I'll
be
happy
to
take
questions.
C
Thank
you.
Thank
you
for
this
certainly
an
interesting
idea.
I
have
to
ask
a
question,
though,
like
if
you
had
your
way,
would
you
prefer
a
server-side-only
approach,
because
assuming
all
servers
implemented,
something
that
was
of
the
shape
of
led
back
plus
plus
and
we
didn't
agree
on
the
hdb
priority,
strap
that,
like
the
like
lowest
priority,
actually
like
indicated
a
congestion
drill,
change,
and
maybe
we
can
get
like
similar
results,
just
an
idea,
it's
kind
of
cross
layer,
but
given
them
like
very
aware,
but
their
opposites
worth
thinking
about.
B
If
you,
if
you
look
at
the
original
problem
right
so
yeah,
you
could
do
this
on
the
server
side,
which
is
how
we
started
out
with
as
a
conversion
controller.
The
challenge
is
the
proxies
the
challenges
not
in
not
all
applications.
We
can
modify
to
inform
the
sender
about
which
connection
is
lower
priority,
so
there's
some
challenges
doing
just
just
on
the
server
side.
One
of
the
good
parts
of
our
ledbet
is
that
it
can
easily
coexist
with
the
ledbet
plus
plus
on
the
sender.
So
there's
no
like
interrupt
problem
here.
B
D
B
C
E
B
F
F
B
B
So
we
have
a
filter
that
we
window
filter
that
we
apply
to
all
these
rtt
samples,
which
allows
us
to
sort
of
weed
out
the
delay
tax
samples.
One
of
the
things
I
would
point
out
is
that
the
workloads
we
are
looking
at
are
mostly
continuously
transferring
data,
because
these
are
like
update
workloads
which
always
have
data
to
send,
even
if
it
is
in
chunks
so
applying
the
window
filter
for
the
most
recent
and
received
rtd.
Samples
is
really
important
that
will
allow
you
to
sort
of
overcome
the
delay,
rack,
inflating.
D
B
B
D
G
I
gathered
from
slide
eight
that
it
seems
like
you're,
assuming
some
kind
of
delay
bandwidth
product
queue
size
in
the
network.
It
doesn't
work
well
on
small
queues.
Let
me
ask
you
explicitly
what
assumptions
is
led
back
making
about
the
network
queue
sizes
and
in
relation
to
this
sort
of
recent
work
about
trying
to
reduce
the
amount
of
buffering
in
the
network?
B
B
That's
the
best
solution
we
could
come
up
with,
as
I
explained
earlier,
detecting
exactly
what
the
bottleneck
capacity
is
is
a
hard
problem
for
a
less
than
best
effort,
congestion
control.
So
all
of
these
are
good
areas
for
research.
I
also
think
that
the
as
I
mentioned,
the
target
value
that
we
have
is
fixed
right
now
and
making
it
dynamic
is
also
an
important
problem
that
should
be
solved.
H
H
Opening
back
up
and
I'd
be
curious
to
know
if,
if
either
you've
seen
anything
like
that,
and
is
that
one
of
those
cases
where
we
say
well,
it's
fine
because
you're
trying
to
be
background
flow
anyway,
and
so,
if
it's
going
to
take
you,
you
know
two
and
a
half
minutes
before
you
get
back
up
to
actually
transferring
real
data.
That's
fine!
Because
it's
in
the
background
or
is
there
is
that
going
to
be
a
problem
with
this
kind
of
a
strategy.
B
So
that's
an
interesting
problem,
so
we
haven't
done
at
scale
measurements.
So
I
can't
tell
you
if
you
have
seen
that
problem.
That's
a
short
of
work!
That's
upcoming,
I'm
very
happy
to
keep
an
eye
out
for
that.
So
thanks
for
the
heads
up,
if
the,
if
that
becomes
a
problem
yeah
I
mean
we
don't
want
to
go
artificially
slow
either
I
mean
yes,
we
are
trying
to
do
these
things
in
the
background,
but
if
there
is
enough
capacity,
we
want
to
be
able
to
saturate
it.
B
One
of
the
also
the
other
problems
with
going
slower
than
reno
has
been
that
you
know
if
you're,
really
on
a
big
van
link
and
you
artificially
slow
down,
it
takes
a
long
time
to
to
come
back
up.
So,
yes,
that
is
also
an
avenue
for
more
improvements,
possibly
but
I'll,
keep
an
eye
out
and
keep
you
posted.
Hopefully
another
update
in
one
of
the
other
upcoming
iccrgs.
So
thank
you.
A
I
want
to
take
a
quick
moment
to
thank
praveen
for
this
there's
clearly
a
lot
of
interest
in
this
work,
and
I
think
it's
the
results
are
super
interesting.
I
have
questions
about
them
as
well,
but
I'm
going
to
hold
them
off
for
the
list,
which
is
the
plug
I
want
to
make
here.
Please
take
these
questions
to
the
list.
I
think
that
we
want
to
see
continued
engagement
on
the
list.
Praveen's
already
said
that
he's
interested
in
they
are
interested
in
in
getting
feedback
on
how
to
make
things
better
here.
A
Please
please,
please
take
those
to
the
list.
Make
suggestions,
engage
in
conversation
there.
I'd
love
to
see
more
of
this
happen
on
the
list,
instead
of
just
during
the
q
a
session
here
at
the
iccrg
meeting.
I
I
wanna
yeah
I'll
say
that
just
one
comment
I
to
make,
which
is
that
people
are
talking
about
doing
this
per
stream
in
quick
or
in
http,
and
that
is
very
tricky.
A
A
I
I
I
So,
with
this
in
mind,
what
we
wanted
to
do
was
we
wanted
to
uncover
the
exact
extent
of
bpr's
deployment
on
the
internet
and
maybe
refresh
our
view
of
what
the
current
internet
congestion
control
landscape
looks
like.
So
to
do
this,
we
set
out
to
do
a
congestion,
control
census
of
sorts
to
measure
the
20
000
most
popular
websites
on
the
internet
and
figure
out
what
congestion
control
algorithm
theorem
next
slide.
Please.
I
Second,
we
would
also
want
to
extract
a
common
feature
from
variety
of
congestion
control.
Algorithms,
since
we
don't
know
up
front
what
the
remote
condition
control
algorithm
is,
and
finally,
we
will
need
to
identify
these
congestion
control,
algorithms
within
short,
http
page
downloads.
So
this
was
a
design
decision
that
we
took
very
early
into
this
measurement
study
and
the
reason
was
that
most
of
the
websites
that
we
were
aiming
to
measure
serve
http
pages,
so
it
would
be
the
best
candidate
for
conducting
such
measurements.
I
So
the
first
issue,
which
is
isolating
the
network's
dynamics,
is
start
by
gordon
by
localizing.
The
connection
bottleneck,
so
gordon
does
this
by
date
limiting
the
connection
right
before
the
client
and
the
reason
we
do.
This
is
because
this
provides
us
an
opportunity
to
directly
control
the
bandwidth
that
the
sender
sees
and
it
also
minimizes
the
risk
of
random
packet
losses
on
the
internet
that
can
potentially
be
hard
to
account
for
when
we
are
doing
our
measurement
next
slide.
I
I
The
second
issue,
which
was
selecting
a
common
feature
to
extract
from
all
our
congestion
control
algorithms.
We
dealt
dealt
with
this
by
actually
choosing
the
seventh
of
the
remote
congestion
controller
as
the
common
feature
in
our
measurement,
and
the
reason
we
did.
This
was
because,
since
whether
your
congestion
control
algorithm
is
window-based
or
raid-based,
it's
always
going
to
have
a
cap
on
how
many
packages
that
you
have
in
flight,
and
this
can
essentially
become
it's
essential.
I
I
So
in
this
case
all
the
packets
that
we
received
before
we
see
a
retransmit
is
going
to
be
the
value
of
the
first
congestion
window
or
c1.
Next,
we
start
a
new
connection
after
some
time
and
this
time
we
accept
c1
number
of
packets
before
we
start
dropping
packets.
Again
till
we
see
a
retransmit
and
in
this
case
the
new
number
of
packets
that
we've
dropped
will
become
c2
or
the
second
condition.
I
I
I
The
last
issue
that
we
had
to
deal
with
was
dealing
with
short,
http,
page
downloads,
so
how
we
can
deal
with
this
is
really
simple.
We
can
either
look
for
larger
pages,
which
is
exactly
what
we
did.
We
crawled
the
target
domains
for
the
largest
pages
we
could
find
and
since
our
measurements
are
made
on
a
packet
basis,
we
use
the
smallest
mtu
that
was
allowed
by
the
network
path
or
during
the
connection.
So
this
basically
allowed
us
to
extract
as
many
packets
as
we
could
from
a
given
excise.
I
So,
while
making
these
measurements
gordon,
actually
simulates
our
two
key
network
stimuli
in
a
way
to
l-set
characteristic
responses
from
a
remote
congestion
controller,
and
we
can
encompass
the
stimuli
in
something
what
we
call
a
network
profile
and
this
network
profile
will
be
applied
to
each
measurement
that
coordinates
so
in
this
network
profile.
What
garden
does
is
it
emulates?
I
A
packet
drop
the
first
time
this
event
exceeds
80
packets
and
it
immediately
gets
a
bandwidth
change
after
receiving
1500
packets,
and
it
does
these
changes
while
emulating
an
rtt
of
100,
ms,
the
exact
details
for
why
we
use
these
numbers
and
why
we
choose
these.
Two
network
stimuli
can
be
found
in
the
paper
next
slide.
Please.
I
I
I
And
what
we've
seen
is
that
our
shape-based
decision
tree
based
classifier
works
reasonably
well
to
identify
a
bulk
of
the
algorithms
and
any
misidentifications
that
we
see
are
basically
between
algorithms
that
have
a
very
similar
congestion
of
congestion
window
evolution
shapes,
which
is
something
that
we
expected.
But
even
given
that
we
can
see
that
for
most
of
our
identifications,
the
accuracy
is
more
than
90.
I
So
the
measurements
of
the
websites
themselves
were
made
from
servers
in
singapore,
mumbai,
paris,
sao
paulo
and
ohio
and
for
the
websites.
Given
our
network
profile,
we
found
that
16
of
the
pages
were
less
than
the
optimal
page
size
of
165
kb,
so,
basically
based
on
our
network
profile,
we
calculated
you
know
in
the
worst
case
scenario,
what
is
the
minimum
page
size
that
we
need
to
get
a
reasonably
long
event
graph
that
we
can
identify?
I
So
it
turned
out.
This
number
was
165
kb,
but
68
of
the
pages
we
measured
were
lower
than
this
number,
so
in
case
they
were
lower
than
this
number.
What
we
did
was
we
did
a
classification
and
our
best
effort
basis,
which
is
that
if
we
could
make
identification,
we
went
ahead
with
it,
but
if
you
couldn't,
then
it
was
just
classified
as
a
short
flow.
I
I
However,
it
looks
like
bbr
has
been
adopted
at
an
unprecedented
rate
since
its
introduction
in
2016,
and
it's
now,
accounting
for
almost
18
of
the
top
20
000
alexa
websites.
We
also
identified
a
slightly
modified
version
of
pvr
being
deployed
by
167
google
owned
domains,
and
you
will
be
referring
to
this
slightly
different
variant
as
pbr.
I
I
I
Another
thing
I
would
like
to
note:
circling
back
to
there
being
a
difference
between
the
video
congestion
control
algorithm
and
the
http
webpage
congestion
control,
algorithm
gordon
actually
identified
netflix.com
to
be
using
cubic
to
serve
its
web
pages,
but
when
we
actually
reached
out
to
netflix
it
turns
out,
they
actually
use
new
reno
to
deliver
video
next
slide.
Please.
I
So
in
the
measured
websites
about
14
of
them
were
either
short
flows
that
we
discussed
earlier
or
did
not
respond
to
our
measurement
methodology
but
of
the
remaining
websites
that
did
actually
respond
and
give
us
long
enough.
Even
graphs.
We
found
that
most
of
them
are
reactive
packet
losses,
but
a
significant
number
of
them
do
not
reactivate
losses.
I
I
I
I
I
Control
algorithms,
so,
for
example,
since
ppi
we
have
seen
we
have
seen
proposals
for
variants
like
copper
and
pcc,
we're
watching
which
are
also
rate-based,
and
ideally
we
would
like
to
identify
them
as
well.
So,
since
the
measurement
study
we
have
extended
gordon
to
measure
the
received
rate
along
with
the
sea
wind
and
turns
out
receive
rate
is
quite
handy
to
differentiate
between,
I
mean
not
just
differentiate
that
identify
copa
and
pcc
privacy
in
controlled
experiments.
I
Lastly,
we
would
also
want
god
to
emulate
a
larger
variety
of
networks
stimuli.
So,
for
example,
there
might
be
slightly
modified
versions
of
qubit
or
renault
that
don't
respond
to
one
packet
loss,
but
two
or
three
packet
losses
that
we
are
not
able
to
emulate
and
therefore
we're
not
able
to
identify
them,
and
we
would
also
want
gordon
to
identify
sub-rtt
behaviors
since
right
now,
we
are
constrained
to
measuring
just
a
per
rtt.
Seventh
next
slide.
I
I
I
I
So
we
have
done
a
lot
of
interesting
work
in
this
front
and
I
will
not
go
into
the
details
of
it
in
the
interest
of
time,
but
allow
me
to
illustrate
one
of
our
key
results
through
a
very
simple
experiment,
so
we
ran
multiple
instances
of
tent
flow
experiments
with
different
shares
of
them
running
dbr
and
cubic.
So
first,
we
had
only
one
bpr
and
nine
cubic
first
or
the
second
trial
we
introduced
bbr2,
and
we
kept
on
doing
this
till
all
our
flows
for
pbi
and
the
graph
on
the
right
plots.
I
I
Please
the
second
research
question
we're
trying
to
look
at
is
understanding
the
database,
congestion
control
mechanic,
so
bpr
and
other
new
internet
congestion
control.
Algorithms
that
have
been
proposed
since
have
been
predominantly
replaced.
Examples
of
this
would
be
coppa
and
pcc,
we're
watching,
and
it's
quite
common
for
these
algorithms
to
work
on
type,
send
rate
and
receive
rate
feedback
loops
to
basically
inform.
I
What's
going
on
at
the
bottleneck,
we
feel
that
this
is
a
new
congestion
control
mechanic,
that's
still
not
completely
understood,
and
what
we
essentially
need
to
do
is
we
need
to
be
answer.
Some
of
the
key
congestion
patrol
questions
like
on
convergence
and
fairness
will
be
in
the
rate-based
setting.
I
A
E
I
Yeah
so
yeah,
I
think
that's
a
really
interesting
point
and
I
think
that's
a
little
short-sighted
on
my
my
half
so
cuba.
I
agree
that
cubic
can
actually
be
both
mi
and
d
and
aimd,
but
as
far
as
actually
measuring
how
often
it
does
this
on
the
internet.
I
don't
think
it
would
be
possible
to
do
this
without
current
tool,
since
we
essentially
isolate
the
flow
we
are
measuring
in
the
localized
bottleneck.
So
it's
really
not
competing
with
other
flows.
I
I
Window
response
is
not
consistent,
so
given
pbr
and
dvr
v2,
we
can
distinguish
between
them,
but
given
ddr
v2
and
some
noisy
measurement
on
the
internet,
we
are
not
able
to
pick
whether
it's
dpip2
or
not.
So
we
need
to
do
a
significant
amount
amount
of
work
in
that
direction.
To
be
able
to
make
this.
I
That's
actually
an
interesting
idea,
but
we
have
not
done
this
so
far,
but
that's
definitely
a
direction
we
would
like
to
look
into
so
I
mean
not
only
just
excellent
but
possibly
later
on
being
able
to
classify
quick
connections
as
well.
So
those
are
the
two
key
directions
that
we
have
not
specifically
looked
into
so
far,
but
he
definitely
would
like
to
look
into
in
the
future.
A
Well,
thank
you,
everyone
for
your
questions
and
thank
you
ayush
again
for
presenting
this,
I'm
assuming
that
you're
going
to
be
subscribed
to
the
iccrg
mailing
list.
Yes,
yes,
okay,
excellent!
So
if
people,
if
you
have
questions,
take
it
to
the
list,
please
I
wish
we'll
be
there
on
the
list
and
you
can
also
give
him
more
suggestions
for
what
he
could
do
to
continue
this
work,
because
I
think
this
is
very
useful
work
and
its
use
is
also
in
being
able
to
find
out
how
the
internet
is
changing
as
time
goes.
A
K
K
As
we've
looked
at
our
experiences
with
bbr
and
prr,
and
the
question
of
how
scalable
are
these
various
styles
of
multiplicative
decrease
when
there
are
large
decreases
in
the
available
bandwidth
and
then
I'll?
Do
a
quick
summary
of
the
status
of
bbr
at
google
and
a
quick
wrap
up,
and
just
just
to
sort
of
set
the
context
here
about
what
we're
trying
to
aim
for.
K
For
this
talk,
we
we
mainly
wanted
to
share
our
experience
with
some
of
these
experiments
and
algorithms
were
trying
out,
and
we
wanted
wanted
to
invite
the
community
to
share
any
feedback.
You
have
and,
of
course,
always
encourage
you
to
share
any
test
results
or
issues
you
see
or
patches,
traces
or
ideas
generally
next
slide,
please.
K
K
K
And,
of
course,
you
know,
this
crowd
will
notice
right
away
that
this
use
of
network
rtt
means
that
there
are
particular
scopes
where
this
is
an
appropriate
and
feasible
algorithm,
and
in
particular
this
is
appropriate.
Where
you're
you
have
traffic,
that's
inside
a
network
with
a
unknown
topology
or
a
known
rtt
properties,
which
applies
to
a
lot
of
today's
data
centers,
which
have
very
regular
topologies,
where
the
operators
know
the
expected
rtts.
K
K
So
in
terms
of
where
swift
has
been
used
so
far,
it
has
been
used
in
production
inside
google
data
centers
by
a
a
user
space,
and
networking
stack
called
snap
in
the
sosp
publication
about
that
system
in
sosp
2019,
and
this
is
used
in
for
a
significant
amount
of
traffic
within
google
data
centers,
where
this
is
an
appropriate
environment.
Since
a
we,
we
know
the
target
network
rtt
we're
aiming
for
and
b.
K
So
how?
So?
Why
would
we
want
to
use
delay
as
a
congestion
signal?
There
are
a
couple
different
advantages,
so
the
first
sort
of
class
of
advantages
is
that
it
provides
a
richer
source
of
information
about
how
much
cueing
is
at
the
bottleneck,
and
this
is
quite
interesting
because
it
actually
allows
you
to
to
get
a
quantitative
notion
of
the
current
degree
or
magnitude
of
queuing,
which
is
something
that
you
can't
really
get
from
ecn
or
lost
signals.
K
And
this
is
useful,
because
this
allows
you
to
react
more
quickly
in
cases
where
there
is
a
long
queue
to
get
rid
of
that
cue
more
quickly
and
dissipate
that
congestion
more
quickly,
but
also
correspondingly.
It
allows
you
to
avoid
overreaction
and
potential
underutilization
if
the
queue
is
actually
short.
K
And
you
can
think
about
that
ambiguity.
If
you
consider,
for
example,
a
dc-tcp
style
shallow
threshold
ecn
signal
where
you
might
have
a
a
sustained
ecn
signal
that
lasts
for
quite
a
while
and
the
you
know
an
ewma
filter
of
that
might
turn
that
into
a
very
high
alpha,
for
example.
But
it's
still
quite
possible
that
that
q,
even
though
it
has
lasted
a
long
time,
is
quite
shallow,
and
so
it's
quite
easy
for
an
algorithm
to
sort
of
overreact
to
that.
Whereas
a
delay
signal
allows
you
to
avoid
that
issue.
K
It
makes
things
actually
quite
difficult
to
translate
into
application
performance.
So
if
you
tell
someone
to
expect
a
0.1
loss
rate,
what
are
applications
supposed
to
do
with
that?
They
don't
really
know
how
to
translate
that
into
into
latency
expectations.
And
it's
a
tricky
thing
to
do,
and
finally,
at
a
high
level,
a
key
piece
of
the
puzzle
here
is
that
to
make
this
work,
we
need
accurate
delay,
measurements
for
network
and
host
delays.
So
next
we'll
talk
about
that
next
slide.
Please.
K
You
can
sort
of
visualize
as
the
purple
path
of
the
packet
there
and
the
sort
of
vertical
distance
of
the
represents
the
the
network
rtt.
So
the
we
can
consider
a
specific
example
depicted
here.
If
we,
if
we
look
at
the
sender
here,
the
data
center
tcpa,
it
schedules
some
packets
or
schedules
a
packet
to
be
released
at
a
particular
time
from
the
pacing
layer
that
packet
travels
across
the
network
as
data
p1.
K
It's
received
at
the
receiver
here
at
the
receiving
nic,
but
then
there
are
all
sorts
of
interesting
delays
that
can
happen
on
the
receiver
side
for
various
reasons.
So
one
big
delay
source
that
we've
noticed
is
power,
saving
c
states.
So
often
servers
that
are
not
running
at
you
know:
100
cpu
utilization
on
all
the
cpus
will
take
the
opportunity
to
go
into
a
power
saving
state
and
if
the
packet
arrives
and
the
nic
that's
handling
the
receive
interrupt
is
actually
in
a
power
saving
state.
K
Other
delays
happen
because
the
tcp
stack
might
be
processing
a
whole
queue
of
packets,
not
just
one
packet
and
then,
of
course,
in
tcp
and
other
protocols.
There's
often
an
intentional
delayed
ack
mechanism
that
comes
into
play
as
the
receiver
is
trying
to
piggyback
that
ack
on,
hopefully,
some
outgoing
data
segment
later
on,
and
so,
if
you
think
about
all
of
these
delays,
you
could
have
various
combinations
and
in
this
protocol
what
happens?
Is
the
receiver
is
able
to
convey
that
receiver
actually
back
to
the
sender
and
to
do
that?
K
We
use
basically
a
new
timestamp
option
that
we've
described
earlier
in
the
week
in
the
linked
internet
draft
here
that
we
are
calling
extensible,
timestamps
or
ets.
So
you
can
check
out
the
tcpm,
slides
and
presentation
and
also
the
the
linked
internet
draft
that
describes
the
details,
but
basically
we'll
we'll
talk
about
some
of
it.
K
So
how
is
the
signal
used
in
the
algorithm?
So
in
bbr
swift?
This
is
an
extension
of
bbr
v2,
where
the
core
aspects
of
bbr
v2
are
unchanged
and
in
particular,
if
a
connection
does
not
have
the
delay
as
available
as
a
signal,
it
is
going
to
behave
exactly
as
the
algorithm
that
we've
documented
at
the
itf
and
open
source
with
respect
to
its
response
to
ecn,
loss,
bandwidth,
min
rdt
and
so
forth.
K
But
what
we
have
here
is
an
extension
to
br
v2.
That's
based
on
the
swift,
algorithm
and
key
piece
of
this
is
basically
that
a
new
configuration
parameter,
which
is
the
target
rtt
the
rtt
value,
that
the
algorithm
is
trying
to
seek
in
some
sense
and
trying
to
maintain
rtt
values
near
that
target
and
inside
of
a
data
center.
You
can
think
of
this
as
being
in
the
ballpark
of
or
in
the
order
of
a
100
microseconds.
K
Basically,
the
algorithm
at
its
core
says
that
if
the
network
rtt
that's
been
measured
is
greater
than
the
target,
then
we
do
a
multiplicative
decrease
where
the
multiplicative
decrease
factor
is
essentially
proportional
to
that
excess
delay.
And
here
the
excess
delay
is
quantified
as
network
rtt
minus
the
target
rtt
and
that's
turned
into
a
fraction
by
dividing
that
by
the
network
rtt.
So
you
can
think
of
this
intuitively
as
saying
what
is
the
fraction
of
the
delay
that
we're
seeing?
E
K
Great
yeah
I'll
just
thanks,
so
just
a
quick
sketch
of
the
kinds
of
results
we
see
with
this
this
class
of
algorithm.
So
here
we
have
a
sort
of
very
simple
or
basic
in-cast
scenario.
With
two
machines:
each
machine
is
sending
a
thousand
bulk
tcp
flows
so
with
2000
flows
in
total
and
we're
comparing
dc
tcp
bbr
v2
with
ecn
and
bbr
swift.
The
thing
to
notice
here
is
that,
because
of
the
large
number
of
flows
and
and
dc
tcp
is
sort
of
operating
sea,
wind
bound
and
act
clocked.
K
It
is
basically
trying
to
maintain
at
least
one
packet
in
flight
for
each
flow,
which
leads
to
a
very
large
standing
queue
of
all
of
those
excess
packets,
which
leads
to
a
large
loss
rate
that
you
can
see
here.
Six
percent
for
one
machine
66
for
the
other
machine,
and
it
also
has
some
some
sort
of
fairness
issues,
whereas
bbr
v2
with
ecn
does
a
little
better.
It's
a
little
bit
more
fair.
K
The
retransmit
rate
is
considerably
lower
around
1.6
1.7
percent
and
the
fairness
is
a
little
better
or
actually
comparable.
I
guess
to
dc
tcp
and
then,
if
we
look
at
bbr
swift,
the
you
can
see
that
the
the
algorithm,
because
it's
able
to
use
the
pacing
rate
to
match
its
sending
to
the
aggregate
delivery
rate,
it's
able
to
keep
that
queue.
Nice
and
small,
correspondingly
achieve
a
very
low
loss
rate
here.
K
The
loss
rate
is
is
about
.05
percent,
and
you
can
see
there
that
the
network
rtt
on
average,
is
around
93
microseconds,
corresponding
to
the
50
microsecond
target
that
was
used
in
this
particular
experiment,
and
you
can
see
the
jane's
fairness
index
is
is
fairly
good.
So
that's
just
a
quick
comparison
to
give
you
a
sense
of
the
properties
next
slide.
Please.
K
K
So
perhaps
the
slide
title
here
is
a
little
provocative,
but
I
thought
it
was
interesting
to
to
sort
of
raise
this
issue
that
we've
seen,
because
our
experience
is
showing
that
both
on
data
center
traffic
and
on
the
public
internet.
This
is
an
interesting
issue.
So,
as
this
audience
well
knows,
traditional
tcp
congestion
control
uses
a
multiplicative
decrease
upon
round
trips
that
have
packet
loss,
reno
will
cut
to
0.5
of
the
old
congestion
window
cubic
will
cut
to
0.7
per
round
trip.
K
So
in
theory,
what
happens
in
these
kind
of
scenarios?
Is
that
with
something
like
reno?
You
expect
a
number
of
round
trips
of
very
high
packet
loss
until
the
flow
reacts
fully
and
adapts
to
the
new
congestion
window
and
in
particular
you
expect
a
number
of
round
trips.
That
is
basically
the
old
bandwidth
divided
by
the
new
bandwidth,
and
then
you
take
the
log
base
two
of
that
ratio.
That
tells
you
how
long
you
expect
to
to
see
these
high
losses.
K
So
if
there's
a
thousand
x
cut
in
the
fair
share
bandwidth,
you
can
see
10
rounds
of
high
loss.
That's
the
theory!
In
reality,
it's
it's
actually
a
little
bit
different
with
traditional
tcp
loss
recovery
before
rack
it
actually
couldn't
handle
consecutive
rounds
of
loss.
What
tends
to
happen
instead?
Is
you
get
a
re-transmission
timeout?
You
cut
your
congestion
window
to
one
and
you
slow
start
back
up
with
tcp
rack,
but
but
no
proportional
rate
reduction.
K
You
actually
see
a
reality
that
matches
the
theory,
multiple
rounds
of
high
loss,
and
this
can
be
quite
painful
and
we've
definitely
seen
this
in
experiments
where
you
use
rack,
but
no
prr
in
the
public
internet.
When
you
run
into
a
policer
it
can
get
quite
ugly.
But
finally,
if
you're
using
rack
and
prr,
you
get
a
nice
kind
of
behavior,
where
the
sending
rate
is
bounded
to
be
quite
near
the
delivery
rate,
and
thus
this
keeps
the
loss
rate
at
sort
of
a
reasonable
level
while
still
robustly
probing
for
bandwidth
and
this.
K
K
D
K
K
And
just
a
quick
status
update
so
for
youtube
and
google.com
public
internet
traffic,
we've
deployed
bbr
v2
for
a
small
percentage
of
users
as
an
ongoing
experiment.
As
we
refine
the
algorithm
and
code,
we
see
reduced
queuing
delays
and
reduced
losses
versus
pvr
v1,
getting
closer
to
cubic
levels
for
google
internal
traffic,
we're
deploying
bbr
v2
as
the
default
and
we're
in
transition
there.
K
Currently,
it
is
used
as
a
congestion
control
for
most
of
the
internal
traffic
within
google.
This
is
using
the
algorithm,
as
previously
described
with
bandwidth,
then
rtt
ecn
and
loss
as
signals,
as
I
mentioned
before,
we're
still
in
the
process
of
rolling
out
the
code
for
this
network.
Rtt
signal
inspired
by
swift
next
slide.
K
And
in
conclusion,
we
are,
you
know,
actively
working
on
bbr
v2
and
this
variant
we're
calling
bbr
swift
continuing
to
iterate,
and
we
are,
you
know
open.
We
love
to
hear
feedback
on
these
approaches,
test,
results
and
so
forth,
and
we
definitely
appreciate
the
survey
results
from
the
previous
presentation,
for
example.
K
A
F
K
So,
in
the
wan
case,
we
are
not
using
the
the
network
rtt
signal
the
basic
practical
issue
there
is
that
usually
for
land
paths,
you
don't
know
the
target
round
trip
time
ahead
of
time
and
so
in
our
deployment.
So
far,
we
are
we're,
definitely
just
using
the
target
rtt
within
a
data
center
for
the
wan
flows,
they're
just
using
ecn
and
lost
signals.
K
You
know,
I
guess
I
briefly
alluded
to
that
in
terms
of
perhaps
using
ecn
signals
to
find
the
delay
the
target
delay
at
which
we'd
like
to
match,
based
on
the
transition
between
rtt's.
Above
that
point,
where
we
see
ecn
marks,
our
gt
is
below
that
point
where
we
see
no
ecm
marks,
use
that
as
a
sort
of
way
to
find
a
target
rt
dynamically
for
for
when
phase,
but
that's
a
future
work.
K
A
All
right
well,
thank
you
so
much
neil
and
thank
you
video
for
that
question.
Please
continue
this
conversation
on
the
mailing
list.
Again,
I'm
sure
a
lot
of
people
are
interested
in
the
relationship
between
dbr
swift
and
that
that
plus,
plus
and
and
questions
on
dbrv2.
Please
continue
that
on
the
mailing
list,
thanks
neil
silvester
you're
up
with
your
I'm
going
to
bring
your
presentation
up
and
there
we
are
take
it
away.
L
Can
you
see
it?
Can
you
hear
me
well,
can
you
hear
me
yes,
okay,
and
can
you
also
see
my
screen?
Yes,
okay,
thank
you!
So
hello,
everyone,
I'm
sylvester,
and
with
my
co-authors,
we
are
interested
in
internet
resource
sharing,
so
we
run
some
tests,
but
studies
on
fairness
and
we
chose
bbrv
to
condition
control
as
a
new
wave
of
congestion
control
to
control
compared
to
existing
ones,
because
it's
designed
to
be
friendly
to
cubic
flows
as
opposed
to
e1.
It
has
scalable
ecm
response
and
it
already
has
some
deployments.
L
So
we
use
three
machines
connected
and
train
chain
topology
in
our
test
bed:
traffic
generator
receiver
and
the
button
in
the
middle
and
on
the
sender
and
receiver.
We
installed
the
bbr
v2
alpha
kernel
and
we
used
default
linux
settings.
We
implemented
several
aqms
in
dpdk,
tail
drop,
pi
gsp
step,
pi
square,
dual
pi
square
and
and
virtual
drawer
queue
core
stateless
aqm.
L
L
So
this
is
an
example
measurement
results.
We
have
two
connection
classes
connection
classes
are
identified
by
congestion,
control
and
rtt,
so
this
was
cubic.
Ten
millisecond
and
bbr
10
millisecond
rtt
is
over
one
gear
per
second
button.
Like
we
change
the
number
of
connections,
half
is
from
one
connection
class.
The
other
half
is
from
the
other.
L
The
buffer
size
is
set
as
a
factor
of
the
rtt,
so
0.5
means
five
millisecond
in
this
case
buffer,
and
we
present
plot
the
relative
good.
Where
one
is
the
ideal
and
the
relative
good
put
of
a
connection
class
is
the
average
good
put
within
the
connection
clause
divided
by
the
ideal,
perfect
pair
connection,
fair
share,
and
we
also
studied
several
like
aqms.
L
L
So
what
happens
with
the
different
aqms
we
plotted?
The
tail
drop
results,
the
grey
shadow
for
reference,
so
with
pi.
The
the
fairness
is
very
similar
to
tail
drop,
while
with
gsp
we
have
seen
huge
degradation
compared
to
drop
for
a
smaller
number
of
users,
and
it
was
similar
to
teradrop
for
a
larger
number
of
users.
L
So
what
is
what
is
csaqm
mentioned
as
a
result,
so,
in
addition
to
existing
aqms,
we
also
have
it
of
course,
csaqm,
which
is
a
core
status
resource
sharing
framework.
It
can
apply
a
wide
variety
of
policies,
not
only
fair
sharing
and
it
can
enforce
these
policies
for
heterogeneous
traffic
mixes,
and
it
also
scales
well
with
a
very
large
number
of
flows,
because
the
algorithm
itself
is
stateless
and
it's
also
conduction
control
independent.
It
puts
no
assumption
on
how
the
condition
control
behaves.
L
It
relies
on
packet
marks
with
different
values.
Larger
values
mean
more
important.
Packets
in
conditional
situations,
packets
with
smaller
values,
can
be
dropped
or
marked
with
a
condition
experience.
Dcm,
flag
and
the
button
like
behavior
is
purely
based
on
the
packet
values.
So
we
don't
have
to
do
any
flow
identification.
We
don't
have
to
use
separate
queues
or
decode
the
policy
information
anyway.
Therefore,
the
implementation
can
be
very
simple
and
fast.
L
L
We
also
also
use
the
dc-tcp,
like
condition
controls,
so
we
we
compare
the
fairness
of
dc-tcp
and
vbrv2
in
scalable
mode
in
in
this
case,
instead
of
changing
buffer
size,
we
change
the
target
delay
as
a
factor
of
rtt
and
our
key
findings
here
is
that
why
the
step
aqm
prefers
dc
tcp,
pi
square
aqm
for
pi,
squared
the
bbrp
v2,
and
this
actually
hard
to
choose
which
one
is
better
and
for
pi
square.
The
fan
is
improving
as
the
number
of
flows
grows
by
by
which
step
it.
L
L
L
It
is
clear
that
step
and
pi
square
both
connection
classes
are
marked
the
same
and
because
the
two
condition
controls
use
the
ecn
feedback
differently.
This
results,
in
that
fairness,
as
shown
in
the
previous
figure
and
with
csaqm,
there
are
seemingly
no
connection
connection
with
the
marking
ratios
of
the
connection
classes.
So
there
is
no
clear
formula
how
to
mark
the
the
packets,
but
this
is
exactly
the
the
right
marking
ratio
to
to
achieve
good
fairness.
L
L
L
And
we
believe
that
this
is
because
vbrv2
applies,
the
model-based
condition
control.
But
what
happens
if
the
network
works
with
different
models?
So
this
this
kind
of
unfairness
can
happen
then,
and
comparing
that
to
to
do
our
cue
called
stateless
aqm
that
can
that
can
provide
a
pretty
good
fairness
by
not
applying
not
assuming
anything
about
the
condition
control
used.
L
L
Bbr
v2
vs
cubic
fairness
is
very
dependent
on
settings.
I
actually
shown
some
some
good
results.
Sometimes
it
can
become
quite
bad
and
dc-tcp
versus
bbr,
v2
scalable
mode
in
in
general,
provides
that
fairness
and
then
an
interesting
finding
we
have
we
have
seen
is
that
aqm
tunes
for
a
specific
congestion
control
have
actually
the
potential
to
hurt
the
resistance
even
more
and
and
they
very
rarely
have
it,
even
though
they
they
hop
in,
for
example,
multi-rtt
scenarios
when
the
specific
condition
control
is
used.
L
So
in
summary,
the
condition
control
evolution
has
accelerated.
It's
also
possible
to
use
a
space
congestion,
control
or
condition
controlling
in
bpf,
but
it's
very
hard
for
a
new
congestion
controller
to
be
both
innovative
and
to
be
fair
to
existing
condition
control.
So
we
don't
want
to
say
in
any
way
that
bbr
v2
is
a
bad
congestion
control.
L
L
So
what
can
be
done?
How
can
we
provide
fairness?
What
are
the
ways
forward
so
today,
fairness
is
dominated
by
end-to-end
condition,
control
and
and
over
provisioning,
and
we
question
whether
this
is
still
the
way
or
or
whether
actually
tcp,
friendliness
to
reno
and
or
data
center.
Tcp,
a
point
of
facification
and
the
similar
point
of
a
classification
is
aqm's
tuned
for
a
specific
condition.
Control
behavior.
L
L
So
we
believe
that
cooperative
approaches
like
csaqm
has
a
good
potential
for
controlling
resource
sharing
flow
identification
and
policy
decisions
are
done
at
that
point
endpoint
or
at
the
network
edge.
In
this
case,
the
implementation
in
the
routers
is
then
very
simple
and
invariant
to
the
number
of
flows
or
invariant
to
the
policies
used,
though
it
requires
a
header
field,
but
to
be
on
the
fair
side.
Headers
or
some
kind
of
solutions
are
needed
for
for
for
many
other
solutions
like
we
have
ecn,
we
have
an
l4
s
bit
or
we
are.
L
We
are
proposing
enough
for
usb,
and
also
there
is
the
scp,
but
this
this
one
requires
a
new
header
field
so
to
to
compare
these
solutions
created
a
table
with
the
free
methods
and
condition,
control
in
network
and
cooperative
sharing,
so
engine
condition,
control,
provides
fairness
by
congestion,
control
issue,
condition
control,
but
it
has
fairness
issues
and
there.
Ftt
unfairness
is
hard
to
solve
in
network
scheduling,
provides
very
good
fairness
and
actually
solves
rtt
and
fairness
by
cooperative
resource
sharing
provides
fairness
by
marking
packet
marking,
plus
aqm.
L
There
is
limited
control
of
anthrax
in
the
in-network
scheduling
scenarios
and
with
the
cooperative.
If
actually
the
marking
is
done
at
the
end
point
there
can
be
high
control
high
amount
of
control,
while
it
can
be
limited
if
there
is
edge
marking.
So
it's
if,
if
the
entrance
is
not
communicating
with
the
edge
and
congestion
control
evolution
is,
is
constrained
by
end-to-end
condition,
control
based
fairning
fairness,
because,
because
of
the
harm
to
existing
congestion
control-
and
it's
less
constrained
constrained
in
the
two
other
cases
and
the
bottleneck
complexities
is
low
for
end-to-end
condition
control.
L
This
is
basically
the
buttons
we
have
today.
We
don't
have
to
change
anything
for
the
in-network.
We
believe
that
in
most
cases,
some
kind
of
cpu-based
solution
is
needed,
especially
for
high
number
flows
or
especially,
if
you
want
to
control
higher
ories
of
resource
sharing.
While
it's
medium
for
cooperative,
we
were
able
to
successfully
implement
the
aqm
in
in
p4.
L
There
is
no
need
for
signaling
for
end-to-end
condition,
control.
There
is
a
high
need
of
signaling
for
every
potential
button,
like
in
the
in-network
case
and
depending
on
how
how
we
do
marking
some
kind
of
signaling
might
be
needed,
and
actually
the
packet
marking
is
a
kind
of
inbound
signaling.
Also
also
the
antenna
condition
country
is
a
cooldown
state
of
effort,
so
it
doesn't
require
standardization.
L
First
question
is
what
more
to
include
in
these
type
of
evaluation:
congestion
controls,
aqms
rtts
also,
what
is
what
are
the
typical
implementations
when
it
comes
to
operating
systems
and
meaningful
defaults
of
the
of
the
congestion
controls,
also
very
important
question
to
to
discuss
and
and
is
that?
What
are
the
typical
battery
lacks?
What
is
the
speed
of
them?
How
many
flows
do
we
have
over
them
and
how
many
button
actually
consider
in
the
path?
L
And
the
third
interesting
question
is:
is
the
effect
of
the
sub
millisecond
internet
on
fairness,
so
some
caches
are
very
close
to
the
edge
and
do
and
flow
still
have
a
chance
when,
when
sharing
a
button
like
form
with
these
submission
flows,
so
you
can
find
our
results
at
this
web
pages
and
I'm
looking
forward
to
your
questions
and
comments.
Thank
you.
M
Hi
here,
can
you
hear
me?
Yes?
Yes,
thank
you
for
this
work.
It's
very
interesting
and
I
think
it
opens
also
a
very
interesting
discussion,
because,
indeed,
from
from
alpharest
point
of
view,
the
strategy
here
is
to
try
to
line
up
long-term
congestion
controls
to
to
be
fair
so
that
the
aqm,
like
you
showed,
doesn't
need
to
make
differentiation
between
the
different
types
of
congestion
controls
well
for
alpharest,
we
did
a
big
up
between
the
classic
and
and
alpha
s
traffic.
M
Definitely
it's
also
a
good
discussion,
whether
we
we
should
do
this
differentiation
or
not
from
within
the
network,
and
whether
the
network
is
really
responsible
for
doing
this,
or
that
we
also
should
focus
also
on
the
cases
where
it's
not
possible,
to
do
something
in
the
network
to
also
make
sure
that
congestion
controls
really
have
a
common
protocol
and
a
common
behavior
related
to
ecn
marking
definitely
drops,
but
also,
I
think,
it's
more
important
to
to
have
this
behavior
on
the
longer
term.
So
yeah.
K
A
A
A
D
D
Yep
so,
as
I
mentioned
in
tsvwg,
if
you
were
there,
this
is
going
to
be
a
bit
of
an
invitation
to
collaborate,
because
when
we
first
started
on
l4s
back
five
years
ago,
I
think
dc
tcp
that
we
were
using
version.
319,
the
linux
linux
kernel
just
happened
to
work
really
well,
but
and
we
carried
on
using
it
for
maybe
three
years,
because
we
were
really
focusing
on
aqm
products.
We
were
mainly
network
companies.
D
We
were
dealing
with
the
some
safety
aspects,
but
we
were
largely
just
sticking
with
what
worked
and
when
we
tried
to
use
later
versions
of
the
kernel.
It
didn't
work
that
well,
but
we
were
mostly
just
sticking
with
what
we've
got
and
then
we
started
getting
criticisms
that
didn't
work
with
later
kernels
and
finally
started
looking
at
it
and
found
there
was
a
real
rat's
nest
of
tangled
bugs
and
they
seemed
to
have
come
into
the
linux
kernel
since
319
and
it's
taken
us.
D
It
took
us
months
to
work
it
all
out
anyway.
So
coon's
going
to
talk
a
bit
about
that.
In
the
middle
of
this
talk,
I
mean
we,
we
fixed
it
probably
about
a
year
ago
now,
but
we
haven't
really
talked
about
it
since
so
what?
What
we
really
think
is
that
it
got
a
bit
of
a
bad
reputation
for
not
being
it's
possible
to
reproduce
any
of
our
results,
because
no
one
could
use
it
on
the
latest
kernel,
and
so
we
we
want
to
do
a
bit
of
a
relaunch.
D
Now
that
the
code
base
is
usable
for
others,
you
know
it's
been
up
against
the
latest
version
of
the
kernel
now
for
a
good
year
or
so,
and
so
and
also
it
seems
likely
that
we're
going
to
start
seeing
deployments
in
the
network-
probably
not
like
in
the
next
few
months,
because
they're
going
to
depend
on
the
code
point
assignment,
but
once
that
does
come,
I
think
the
you'll
start
to
see
it
in
production
networks.
So
I'll
come
back
to
the
invitation
to
collaborate
at
the
end.
D
D
Whereas
once
you
move
to
the
end
system,
it
can
smooth
based
on
its
own
round
trip
time,
and
it
always
the
end.
Systems
that
are
using
a
particular
bottleneck
can
all
be
smoothing
on
their
own
round
trip
times
and
also,
very
importantly,
the
zero
there
that
they
actually
get
the
signal
with
no
smoothing
delay.
D
D
D
I
said
I'd
go
quick
and
I'm
not
am
I
through
this,
so
the
the
way
that
the
end
system
smooths
in
in
dc
tcp.
This
is
really
the
only
difference
from
reno
other
than
a
load
of
implementation.
Details
different,
but
it's
the
only
real
design
difference.
It
just
takes
a
fraction
of
the
marks
every
round
trip.
Time
doesn't
ewma
of
it
and
then
uses
that
ewma
to
scale
down
the
reductions,
which
is
why
it
does
a
reduction
by
extent.
Next.
D
D
D
And
you
know
you
can
have
a
look
at
this
slide
in
your
own
time,
because
the
point
of
it
is
merely
to
show
that
there's
more
stuff
added
on
the
bottom,
including
bug
fixes,
which
you
know
obviously,
performance
improvements.
And
when
I
say
bug
fixes
these
aren't
sort
of
code
bugs
they're
performance
bugs
where
the
effect
of
the
bug
is
to
reduce
the
performance
so
kuhn.
I
don't
know
whether
you
want
to
pick
up
on
this
side,
I'll
move
straight
to
the
next
one.
M
Yeah
next
slide,
I
guess
for
the
time
so
first
slide
I
want
to
show
is
the
the
the
improvements
we
did
in
in
prague.
We
had
to
do
in
prague
to
to
solve
the
the
quite
bad
degraded
behavior
of
data
centers
being
the
recent
kernels.
So
if
you,
if
you
look
the
queuing,
latency
spikes
are
very
high
and-
and
we
found
out
it's
mainly
due
to
less
responsiveness
on
on
one
hand
because
of
rounding
downs,
also
not
enough
number
of
bits
which
were
used
in
integers.
M
M
Let's
say
classic
congestion
control,
but
had
a
huge
impact
on
on
data
center
tcp
and
also
to
to
even
further
improve
smoothing.
We
also
found
that
the
there
was
a
need
for
partial
additive
increase
so
instead
of
when
there
is
a
slide
for
it
non-response
at
a
certain
time,
which
makes
it
also
vary
a
lot.
M
So
in
our
prague
version
we
fixed
all
those
and
it
was
really
difficult
because
we
had
to
remove
all
of
them
before
we
got
the
good
result
again.
So
we
spent
quite
some
time
a
few
years
or
a
year
ago
or
more
than
a
year
ago,
in
the
meantime,
so
to
get
back
our
initial
3.19
results.
So
I
think
that's
very
important
to
know
if
you
want
to
do
experiments.
Please
use
prague
instead
of
data
center
tcp
in
the
latest
kernel
next
slide.
M
If
you
are
aware,
if
data
center
tcp
is
driven
by
an
aqm
which
is
smoothing
like
in
a
coupling
or
or
in
in
pi
square
or
whatever
other
aqm
you
you
need,
you
expect
that
every
round
trip
time
there
are
marks,
but
classic
congestion
controls
and
also
data
center
tcp
took
it
over.
It
suppresses
the
additive
increase
in
the
round
trip
time
after
a
multiple
decrease,
so
when
it's
in
the
congestion
window
reduce
state.
M
So
it
goes
down
because
it
allows
it
to
increase
again
and
then
certainly
it's
the
probability
is
too
low.
So
so
all
of
these
interactions
were
creating
extra
periods
of
going
up
going
down,
which
are
not
good,
of
course,
and
then
also
for
round
trip
time
dependence,
if
you
have
a
very
big
round
trip
time.
Of
course,
if
you
compete
with
a
small
round
trip
time,
you
will
definitely
get
every
round
trip
time
marks.
So
that
means
that
a
bigger
round
trip
time
will
get
pushed
down
completely.
M
So
this
is
an
important
difference
between
prague
and
data
center,
tcp
that
we
have
in
in
prague
so
in
prague.
What
we
do
we
increase
on
every
ack,
except
on
the
ones
that
echo
an
ecn
mark.
So
it's
a
kind
of
proportional
additive
increase
as
well,
so
we
we
do
only
one,
a
half
a
packet
increase
if
50
of
the
the
packets
are
marked
in
that
case,
okay
next
slide.
M
So
so
to
to
compare
a
little
bit,
what
are
the
the
the
real
benefits
of
of
using
prague
or
alfres,
or
the
data
center
tcp
kind
of
flows?
Is
that
obviously
we
have
a
very
smooth
throughput
and
a
very
low
latency.
You
see
here
in
in
blue
at
the
right.
We
are
below
one
millisecond,
still
having
full
link
utilization
in
a
wide
range
of
cases.
M
M
It
was
a
little
bit
shifted
behind
because
of
all
the
the
safety
issues
and
and
the
the
discussions
on
the
mailing
list,
but
anyway
that
there
are
potentials
to
to
clearly
potentials
to
to
optimize
that
so
comparing
it
to
okay,
the
best
case
codal
five
milliseconds
on
on
a
bottleneck.
There
is
still
a
significant
improvement.
Let's
say
next
slide.
M
So
one
of
the
things
we
have
also
worked
on
is
a
better
round-trip
time
independence
and
we
can
play
with
it
and
and
do
whatever
we
want
with
it.
So
that's
that's
the
main
message,
the
the
the
discussion-
and
there
is
a
lot
of
discussion
on
the
mailing
list
about
what
it
should
do,
but
I
mean
tcp
practicing
itself
can
be
made
completely
round
with
time.
Independent
like
is
shown
at
the
right
side.
So
here
we
have
different
flows
from
half
a
millisecond
around
three
times.
M
We
enable
this
conversions
towards
fair
share,
so
you
see
after
a
while,
all
the
rates
go
and
share
the
link
evenly,
and
why
do
we
not
immediately
do
that,
because
we
think
it
would
be
a
good
strategy
to
start
from
a
dynamics,
point
of
view
to
still
get
the
benefits
of
your
lower
latency,
but
fairness
and
convergence
is
is
a
process
of
longer
time.
So
we
only
need
to
that's
over
longer
time,
so
we
don't
want
to
disadvantage
smaller
round
trip
times
when
it's
about
dynamics,
but
we
want.
M
We
don't
want
to
this
this
or
give
these
advantages
to
to
the
longer
round
trip
times
if
it's
a
matter
of
of
downloads
and
if
the
round
trip
time
is
very
long
well,
there
is
not
much
the
base
round.
Retime
is
already
very
long.
There
is
not
much
possibility
to
do
interactive
applications
and
the
the
shorter
term
interactive
mechanisms
will
will
not
make
a
big
difference.
M
So
that's
a
little
bit
the
strategy
that
we
that
we
follow,
but
that's
of
course,
also
for
discussion
or
it
can
be
adapted
based
on
applications
that
that
use
this
mechanism.
But
the
the
good
point
is
that,
and
I
think
it
can
be
done
in
every
congestion
control
that,
after
a
while,
if
you
have,
if
you
are
in
a
very
steady
state
that
you
can
all
convert
to
the
same
fair
throughput
for
the
rest,
it's
it's
still
a
matter
of
being
non-responsive
and
and
use
whatever.
M
D
Okay,
bob
yeah
yeah,
just
I
think,
look,
there's
just
one
more
two,
more
slides,
actually
and
I'll
go
very
quickly,
because
I've
said
a
lot
of
this
before
so
we
think
there's
a
lot
of
potential
in
exploiting
high
fidelity
ecn
markings,
particularly
as
there
are.
There
are
signs
that
there
are
going
to
be
operators
deploying
that
so
you
know
network
operators.
D
So
there's
a
list
here
of
possible
topics
to
work
on.
I
I
was
hoping
we
could
go
through
this,
but
I
guess
it's
a
bit
late.
Just
so
you'll
just
have
to
quickly
look
at
them,
but
they're.
You
know
if
there's
any
people
in
the
room
that
are
looking
for
a
research
project.
You
know
coming
to
the
end
of
a
masters
wanting
to
do
a
phd
or
whatever
or
phd
students.
Looking
a
bit
lost
or
anyone
who's.
D
D
A
E
D
M
J
M
J
M
I
think
it
even
doesn't
matter
it's
it's
just
in
the
long
term,
when
we
are
in
a
kind
of
steady
situation
where
we
want
fairness
in
download
situations
or
or
whatever.
If
you,
if
you
really
can
measure
what
is
the
the
share
of
each
flow
there,
we
want
to
converge
to
or
an
obeyance,
let's
say
to
a
kind
of
marking
probability
to
rate
equation,
and
that's
all
of
it.
It
doesn't
mean
that
you
have
to
be
a
imd.
M
M
It
is
important
to
converge
because
that's
where
it's
measured,
but
on
a
short
term,
you
can
do
whatever
you
want.
Well,
that's
maybe
another
point
of
discussion.
What
are
we
going
to
allow?
But
in
alpharest
you
still
need
to
keep
the
the
the
latency
low,
for
instance,
but
well
that's
the
main
difference.
D
D
A
All
right
with
that
yeah
I
will
call.
I
will
call
this.
This
is
thank
you
so
much
bob
and
cone
and
jonathan
for
asking
the
questions,
but
I'm
sorry
that
we
had
to
rush
a
little
bit
at
the
end,
but
thank
you
so
much
and
thank
you,
everybody
for
staying
eight
minutes.
Past
time
this
has
been
an
excellent
session.