►
From YouTube: IETF110-BESS-20210310-1200
Description
BESS meeting session at IETF110
2021/03/10 1200
https://datatracker.ietf.org/meeting/110/proceedings/
A
B
C
Okay,
it's
now
1
pm
europe
time
so
it's
time
to
kick
off
this
best
meeting
session
again
a
new
online
session
that
we
have
to
to
do.
Unfortunately,
let's
start
our
review,
so
not
well!
So
if
you
are
not
aware
of
in
not
well,
please
have
a
look
and
ensure
that
you
are
complying
with
the
rules
that
are.
C
C
C
C
We
also
have
a
couple
of
discus
on
vr,
evpn
flags
and
proxy
app
nd,
mostly
because
of
the
nd
aspect
of
the
ipvc
aspects
of
the
proposal
so
jorge.
I
have
seen
that
you
have
restarted
the
discussion
with
with
iesg,
so
so
do
you
think
we
will
be
able
to
to
come
to
a
resolution
regarding
this.
These
two
drafts.
E
Hey,
can
you
hear
me
yes,
yeah,
so
the
n
a
flags
I
think
I
cleared
all
the
discus,
but
there
is
one
remaining
comment
that
I
I
well.
I
need
to
go
back
to
the
reviewer
and
see
what
else
we
need
to
do.
The
other
one
yeah,
I'm
not
actually
replying
to
all
the
emails
and
resolving
all
the
all
the
discuss.
E
C
C
C
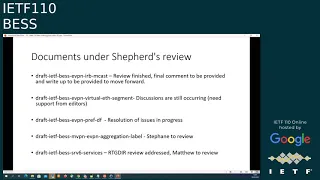
One
of
the
I
would
say
issue
which
is
happening
in
the
draft
is
now
the
shepherd
has
taken
over
the
edition,
the
document,
which
is
not
really
good.
The
shepherd
is
really
here
to
to
help
solving
the
issue
driving
the
document
forward,
but
it's
not
a
release
job
to
do
to
do
the
edition,
so
we
really
need
support
for
the
all
the
coders
of
the
document
to
to
to
make
via
the
appropriate
edition.
So
we
can,
we
can
move
forward
evpn
prefdf.
C
C
F
C
C
We
don't
have
any
document
yet,
which
is
ready
for
its
first
working
group
call.
However,
we
have
two
documents
where
we
need
a
new
working
group
last
call
because
there
was
some
substantial
comments
that
have
been
addressed
or
changed
introduced
in
the
draft.
So
we
need
a
new,
a
new
working
group
review
and
we
will
proceed
right
after
the
atf
with
this
newer,
short
working,
replace
call.
So
the
first
one
is
beyond
an
equal
cost
slot
balancing.
C
So
there
was
some
controversy,
a
couple
of
itf
backs
of
reusing
the
existing
link,
bandwidth
communities
and
so
on.
So
everything
has
been
sold.
All
the
references
have
been
cleaned,
so
we
need
a
review
again
of
the
working
group
to
ensure
that
we
can
move
forward
with
the
new
with
the
latest
version,
igmp
mld
proxy.
C
C
We
have
one
new
working
document
from
the
last
atf,
which
is
the
evpn
redundant
multicast
source
and
we
don't
have
yeah.
We
just
have
a
single
document
which
is
ready
for
working
group
adoption
in
our
queue.
So
if
you
think
that
your
individual
document
could
be
ready
for
working
or
production,
don't
hesitate
to
to
pull
us,
you
don't
have
to
wait
for
an
atf
to
to
do
that.
Just
send
us
an
email
and
we
will
assess
if
your
document
could
be
could
be
ready.
C
C
C
E
C
Yes,
exactly-
and
this
is
what
I
have
could
recommend
that
I'm
still
pending
some
replies
from
the
idr
share.
So
there
was,
if
I
remember
correctly,
two
points
to
address
and
discuss
which
were
the
rules
of
aggregation
and
also
the
how
we
are
managing
the
propagation
of
the
attributes,
especially
what
process
do
we
need
to
to
introduce
between
the
two
groups
to
ensure
that
every
new
attribute
is
getting
the
right
propagation
rules?
C
H
C
H
I
C
H
C
So
I'm
really
wondering
how
we
should
move
this
document
forward
and
if
one
of
the
solutions
to
move
the
document
forward
could
be
to
split
the
document
and
to
have
the
distribution
of
the
engine
completely
separated.
So
I
I
would
like
I
would
be
happy
to
hear
the
opinion
of
her
of
the
editors
of
the
drafter
regarding
the
receiver
of
the
progress.
C
And
the
other
one
is
evpn
geneva,
so
there
was
a
couple
of
comments
after
the
working
room
classical
and
the
draft
has
expired
and
nothing
has
been
replied
and
I
so
the
draft
was
edited
by
sami.
If
I'm
not
mistaken-
and
I
guess
sami-
has
moved
to
to
to
some
of
her
responsibilities,
so
I'm
even
not
sure
that
he
actually
wants
to
to
continue
the
worker
on
that
one.
So
I
will
try
to
pull
him
again
and
in
case
he
don't
want
to
to
continue.
C
B
B
B
B
It
covers
any
any
use
case
where
you
have
any
type
of
edge:
peering,
so
ebgp
edge,
peering,
pc,
peering,
either
core
or
data
center
enterprise
or
service
provider,
where
you
have
dual
stack
peering
so
now,
instead
of
having
dual
staff
hearing,
the
best
practice
would
be.
You
know,
once
the
interoperability
testing
is
completed
between
the
five
major
vendors
in
this
draft
is
published,
is
that
we
would
now
be
able
to
carry
that
v4
enter
an
lri
over
an
ipv6
next
top.
B
The
major
gain
is
that
we
would
eliminate
all
v6
peering
on
on
the
edge
period
and
it
does
allow
the
further
proliferation
proliferation
of
ipv6
and
elimination
of
edge,
so
object
savings.
So
no
more
vcd
for
addressing
on
that
edge
tiering,
as
well
as
opex
cost,
to
maintain
the
v4
edge
period
and,
of
course,
ipv4
address
depletion
the
five
major
vendors
that
we
have
on
board.
That's
that
confirmed
supporting
this
feature
we
have
from
cisco.
We
have
our
representative
from
juniper.
We
have
lily
wang
from
nokia.
B
We
have
adam
simpson
and
from
aristo
we
have
queen
yang
and
then
finally
from
huawei
we
have
sheng
long
chen.
So
those
five
vendors
are
the
folks
that
I've
mentioned
are
the
primary
point
of
context
for
the
interoperability,
testing,
legit
and
logistics
of
getting
the
interoperability
testing
completed
as
quickly
as
possible.
Our
goal
is
to
get
the
once
once
this
draft
is
adopted.
B
We
would
like
to
get
started
on
logistics
related
to
the
interoperability
testing
for
this
for
this
document,
as
as
the
support
is
there,
but
we
want
to
make
sure
that
any
operator
around
the
world
we
have
got
some
feedback,
verizon
included,
that
they
want
to
start
the
proliferation
proliferation
of
ipv4
ipv6
on
the
edge
and
elimination
of
e4
appearing.
So
this
this
is
a
it's
a
hot
draft
that
I
think
a
lot
of
them.
A
lot
of
operators
around
the
world
can
really
take
really
tremendous
advantage
of
this
trap.
B
B
Minutes
yeah,
you
can
just
go
to
the
last
slide.
It's
okay
is
that
okay,
so
we
have,
we
have
all
five
vendors
on
board
and
then,
if
you
can
go
to
the
one
slide
before
this-
and
this
is
work
group
adoption
we're
just
working
just
the
work
of
adoption.
Okay,
there
you
go
so
so
we
would
like
to
ask
any
feedback
from
the
work
group
related
to
this
draft
progressing.
B
As
a
best
practice.
We
have
had
a
lot
of
feedback
from
operators
at
verizon
included,
as
I
mentioned,
that
we
have
the
five
vendors
on
board
and
we
want
to
start
the
interoperability
state
testing
as
quickly
as
possible
as
as
this
is
a
hot
topic
and
as
there
is
tremendous
gain
to
to
eliminate
the
v4
period,
the
edge
hearing.
B
B
We
decided
that
for
this
interoperability
testing,
we
will
just
test
that
primary
use
case
and
then
really
the
goal
is
to
kind
of
to
get
this
get
the
interoperability
testing
done
as
quickly
as
possible.
So
we
can
progress
this
draft
and
get
it
published.
So
operators
around
the
world
can
start
the
elimination
of
v4
and
the
overall
ipv4
and
address
to
depletion
issues
on
on
major
appearing
points
that
folks
around
the
world
can
start
immediately.
B
C
B
Yes,
so
I
changed
it,
it
was
standards
track
and
I
changed
it
to
best
practice.
So
so
this
this
would
become
like
the
ubiquitous
best
practice
for
any
edge
peering
to
carry
ipv4
an
lri
over
an
ipv6
next
top.
Once
we
complete
the
interoperability
testing.
This
would
make
this
the
the
official
practice
for
any
any
operator
they
could.
They
can
look
to
this
document
as
a
as
that
primary
use
case
to
help
with
that
proliferation,
and
we
have
all
the
results
of
the
interoperability
testing.
B
C
J
J
Omr,
request
requirements.
Framework
sorry
is
not
in
the
enter
his
queue.
It's
waiting
right
up,
so
I
can
send
corrected
slides
if
you
like
next
slide.
This
shows
the
oam
framework
that
is
in
that
graft,
which
is
waiting
right
up
and
this
craft
I'm
talking
primarily
about
here.
It
concerns
the
network
oem
layer
there
between
the
pe's
and
well
in
yellow
next
slide.
J
So
what's
changed?
The
previous
draft
was
a
little
unclear.
It
tended
to
speak
about
oam
and
fault
management,
pretty
generally
at
least
in
the
sort
of
introductory
in
the
heart,
abstract
and
stuff,
like
that.
This
graph
is
clear
that
it's
just
focused
on
network
layer,
fault
management
it.
This
draft
includes
an
extension
to
the
bfd
discriminator
path
attribute
I'll
talk
a
little
bit
more
about
that
on
another
slide.
J
The
existing
attribute
only
covers
vfd
active
tails,
point
to
multi-point
use.
It
allocates
a
unicast
mac
address,
as
well
as
a
multicast
mac
address
for
use
as
an
inner
mac
address.
When
you
need
that
and
it
as
usual,
has
some
minor
tweaks
and
editorial
clarifications
from
the
o2
version
next
slide.
J
So
on
vfd
discriminator,
this
is
specified
in
the
best
mvpn
fast
failover,
which
really
is
in
the
rfc
editor
queue.
This
statement
is
correct
and
as
specified
in
that
draft,
there's
a
bfd
mode
field
that
gives
the
the
this
attribute.
Where
you
can
associate
the
vfd
discriminator
over
the
path,
has
the
vfd,
discriminator,
optional,
tlps
and
also
this
mode,
and
currently
only
one
mode
is
specified
which
is
specifically
for
point
to
multi-point
vfd
sessions.
J
So
this
draft
adds
a
mode
of
the
vfd
discriminator
path
attribute
for
point-to-point
vfd
sessions,
since
it
it
needs
that
the
tlv
is
there,
there's
the
one
tov
defined
it's
in
the
mvpn,
fast
failover
draft,
which
is
for
source
ip
address,
and
it's
required
to
provide
the
ip
address
of
the
multi-point
head
for
a
point
to
multi-point
vfd
session,
and
it's
used
that
way
in
this
draft,
as
well
as
in
the
mvpn
fast
failover.
Draft
next
slide.
J
So
comments
and
suggestions.
Welcome
the
plan
is,
what's
planned
by
the
authors,
is
to
add
pbbn
to
this
draft
coverage
and
then
to
request
working
group
last
call
which
we
believe
we
can
should
be
able
to
do
before
the
next
ietf
meeting.
So
I
wanted
to
present
at
this
meeting
just
to
update
people
on
the
status
of
the
draft.
E
Yeah,
I
just
wanted
to
say
that
so
last
time
I
I
made
a
few
comments
and-
and
I
I
didn't
see
any
updates
or
you
know
any
changes
addressing
those
comments
in
the
new
version,
so
I
I
sent
an
email
this
morning,
so
if
you
can,
you
can
look
at
it
and
and
address
my
comments.
That
would
be
great.
Certainly
thank
you
for
the
email.
C
K
So
this
is
a
draft
which
has
progressed
some
five
or
six
versions
with
the
working
group
feedback
before
adoption,
and
even
though
this
is
just
a
zero
one
version,
it
is
a
relatively
mature
working
group
draft,
with
multi-vendor
support
and
adoption
of
several
known
implementations
by
service
providers
and
in
our
views,
it's
since
it's
a
mature
draft
and
it's
the
board
active
is
beginning
to
be
referred
to
in
other
individual
drafts
and
discussions
as
a
third
baseline
gold
balancing
mode.
We
believe
it
is
ready
for
a
last
call.
K
K
There
have
been
incremental
updates
based
on
working
group
feedback
for
each
of
these
six
versions,
and
this
sixth
version
is
no
exception.
It
incorporates
somewhere
within
group
feedback.
Also,
it
is
still
an
individual
draft,
but
it
is
mature.
It
has
actually
implementations
and
deployments
it
is
deployed,
so
we
do
believe
the
draft
is
ready
for
an
option,
but
here
also
more
comments
are,
of
course,
always
welcome.
C
J
C
C
L
L
So
the
the
idea
behind
this
or
or
the
broader
spectrum
is
that
we
have
different
modes
in
various
evpn
drafts,
for
example,
in
service
interface.
We
have
a
section
6
in
rfc
7432,
which
defines
the
different
service
interface
modes.
We
have
irb
draft
which
defines
two
different
forwarding
modes
there
and
we
have
the
irb
core
connectivity
as
part
of
the
prefix
advertisement.
L
So
in
in
all
of
these
different
drafts
and
rfcs,
we
have
different
use
cases
defined
and
with
different
use
cases.
We
have
different
modes
of
operation
there,
which
are
generally
mutual
exclusive,
as
they
are
divine
defined
in
there,
but
as
as
we
saw
given
that
not
everything
is
really
a
must
for
implementation,
and
very
often
it
becomes
that
some
of
these
use
cases
are
adjacent
to
each
other.
There
there
is
the
critically
criticality
for
interoperability
between
them
next
slide.
Please.
L
So
the
key
focus
on
this
draft
is
in
the
area
of
service
interfaces
integrated
by
the
bridge
and
irb
core
connectivity
model.
So
we
we
aim
in
this
draft
to
achieve
interoperability
between
these
different
defined
modes,
and
we
don't
really
want
to
redefine
all
of
these
different
functions
which
are
present
in
the
various
drafts
and
rfcs.
But
we
want
to
make
sure
that
there
is
a
clear
mode
of
operation
documented
and
defined
in
how
these
different
modes
can
interoperate
to
each
other.
L
L
Look
at
the
interoperability
between
v,
vlan
of
air
bundle
and
vlan
based
the
service
interface
in
rfc
7432,
the
asymmetric
irb
and
the
symmetry
guy
rb,
the
slow,
2
irb
modes
which
we
have
in
the
inter
subnet
draft
and
then
the
irb
core
connectivity
model.
We
look
at
the
interface
less
at
the
interface
full,
unnumbered
mode.
Next
slide.
Please.
L
You
see
on
the
very
left
hand,
side,
you
see
a
vlan
of
air
bundle
service
pe
you
see,
on
the
right
hand,
side
a
vlan
based
service
interface,
pe
and
in
the
traditional
mode,
which
you
see
on
the
top
left
with
vd1
vd6
in
green
within
mac
vrf2
of
p1.
You
see
how
normally
you
would
advertise
these
bundled
pe
bundled
pd's
within
their
the
classic,
multiple
bds
per
evi,
the
eve
attack
information
there
and
the
common
route
target
for
the
whole
mcref.
L
When
it
comes
to
vlan
based,
we
have
different
attributes
which
are
required.
For
example,
we
don't
care
or
we
don't
want
the
ethernet
attack
to
be
present
there.
So,
in
order
to
interpret,
we
ask
in
this
specific
model
on
pe
one
to
go
into
a
single
dd
per
evi
mode,
with
a
clear
route
target
for
the
automatic
vrf
design
and
sending
with
an
if
attack
of
zero,
how
the
vln
based
mode
actually
would
also
define
it
there.
So
it's
kind
of
a
hybrid
for
the
v
for
the
service
interface
on
pe
one.
L
Section
4.2,
specifically
and
section
4
overall,
is
focusing
on
the
irb
interoperability.
We
look
there
at
the
asymmetric
irb
to
symmetric
irb.
We
defined
on
what
is
actually
required
from
the
asymmetric
irb
to
be
sent
that
symmetric,
irb
or
hybrid
irb
mode
here
in
p2
represented,
would
be
able
to
achieve
communication.
L
We
define
them
as
advertising
the
mac
ip
routes
from
the
asymmetric
irb
as
it's
traditionally
being
there,
but
then
the
install
of
the
specifics
on
the
symmetric
irb
we
would
put
in
by
basically
allowing
the
the
mpls
label
one
as
well
as
the
mac
ip
bindings
to
be
installed
over
the
l2
tunnel
on
the
pe
2.
We
also
anticipate
that
there
might
be
other
non
other
pes
which
are
non
interoperable
with
the
asymmetric
irbs.
So
we
would
allow
that
symmetric
irb
to
symmetric
irb
to
stay
existing.
L
The
last
section
or
the
last
area
of
interoperability
is
around
section
five,
which
is
the
irb
core
connectivity
modes.
You
see
here,
on
the
left
hand,
side
the
interface
less
model,
you
see
on
the
right
hand,
side
p2,
the
interface
full
unnumbered
model.
So
here
again
we
are
defining
on
what
is
being
needed
in
order
to
get
interoperability
between
these
different
connectivity
modes.
We
see
the
interface
full.
Unnumbered
irb
requires
an
additional
mac,
ip
routes
to
define
or
to
do
create
the
recursions
for
for
the
next
stop
there,
which
interface
less
doesn't
need.
L
So
status
of
the
draft
said
we
submitted
first
in
july
2019.
We
did
a
lot
of
field
work
prior
to
that
we're
currently
in
version
zero.
Three
there's
a
version
before
which
we
are
going
to
do
with
some
minor
updates,
and
hopefully,
with
a
lot
of
feedbacks
from
the
working
group
itself.
We
have
actually
implementation
at
various
stages.
At
various
vendors,
we
did
some
active
testing
with
juniper
nokia
and
cisco
juniper
nokia
as
part
of
the
multi-vendor
interoperability
showcase
at
entc.
L
L
So
with
this,
what
we
achieved,
for
example,
the
service
interface
interoperability,
we
did
vlan
based
on
a
cisco
pe
and
we
had
the
juniper
villain
of
air
bundle,
implementation
there
and
did
interoperability
there
thanks
a
lot
for
all
the
help
there
from
from
various
people
from
from
juniper.
During
this
entc
event,
we
actually
also
did
the
irb.
L
Interoperability
was
very
interesting
because
at
that
point
the
implementation
of
the
cisco
symmetric
irb
was
kind
of
seamless
or,
let's
call
it
hidden
to
everyone
else,
and
we
achieved
with
juniper
the
asymmetric
irb
implementation,
as
well
as
a
couple
of
other
vendors
irb
core
connectivity.
We
we
do
that
interoperability
testing
for
for
a
couple
of
years
now
to
get
with
nokia,
which
has
the
interface
full
on
numbered
implementation.
L
M
L
That
that
is
correct
when
we
would
do
layer,
2
forwarding
to
pe
one
post
routing
on
ingress
on
the
asymmetric
side,
that
is
in
one
direction
in
the
other
direction,
we
would
do
exactly
the
same
would
actually
behave
kind
of
an
asymmetric
irb
pe
on
the
symmetric,
irbp
side,
so
kind
of
a
hybrid.
At
that
point,.
M
M
Yeah
so
yeah
as
a
comment
is
about
vlan
aware
and
the
vdm
bundle
service
vm
based
on
the
video
aware,
bundle
service,
and
I
think
the
draft
said
the
video
and
our
bundle
service
must
have
one
billion
only
one
bridge
domain
for
video
where
bundle
service.
Usually
people
choose
this
service
interface
service
mode.
They
have
a
multiple
vlan
inside
mac
roof.
M
I
think
it
is
a
option
to
support
bd
aware
route
target,
because
the
route
target
is
the
key
for
the
interrupt
between
two
service
modes,
so
I
would
suggest
to
remove
the
keyboard.
You
must
also
maybe
consider
support
the
interrupt
with
vlan
aware
bundle
service
with
more
than
one
bridge
doorman
and
then
require
each
british
domain
to
have
eddie
specifically.
L
Sure,
absolutely
absolutely,
when
we
can,
we
can
discuss
that
online
offline
as
well.
One
one
comment
I
would
like
to
make
is
that
in
signaling
to
a
vlan
based
pe,
you
require
not
only
the
media
of
air
route
target.
At
that
point,
you
would
also
need
to
ensure
that
you're,
not
advertising
the
east
attack
identifier
to
be
different
than
zero.
L
Yes,
you
could
ignore
it
on
the
receive
side,
but
it
would
be
better
to
have
clear
signalization
that
this
is
a
single
bd
per
evi
mode.
At
that
point
and
the
clarity
on
the
route
target,
if,
if
the
sending
side,
meaning
the
the
vlan
of
erp,
would
send
it
in
the
in
the
proper
format
to
the
demand-based
one,
but
from
from
the
rest,
what
you
mentioned,
that
sounds
absolutely
fair
and
I'm
happy
to
discuss
that.
M
N
N
N
A
quick
reminder
here
in
the
ietf:
we
have
defined
a
solution
for
inter
domain
intent
or
sla
aware
path
computation
using
srte.
It
is
a
mature,
widely
deployed
and
supported
solution.
The
solution
documented
in
this
draft
defines
the
notion
of
color
to
represent
intent
in
the
network
control
plane
next
slide.
Please.
N
N
Now,
in
the
srt
solution,
the
ingress
p
even
may
request
an
sr
pce,
that's
in
the
domain
to
compute
the
inter
domain
path.
Since
the
srpc
will
be
aware
of
the
the
interdomain
topology,
the
srpc
will
return
a
label
or
a
set
stack
which
the
pe
will
install
and
use
in
the
data
plane.
The
rest
of
the
network
doesn't
have
any
state
for
this
path.
N
N
So
we
see
here
an
evolution
of
that
automated
steering
as
the
previous
case,
but
here
the
the
inter-domain
path
is
set
up
using
bgp,
hop
by
hop
route,
distribution
and
best
path
computation.
In
this
example,
a
route
to
e3
for
color
c1
is
originated
from
a
border.
Router
say
node,
32
origin
may
be
originated
from
an
igp
and
it
is
propagated,
hop
by
hop
across
the
domain
until
it
reaches
e1
at
each
hop.
A
best
path
is
computed
which
may
recurse
over.
You
know
intra
domain
color,
well,
paths.
N
N
So
when
we
look
at
the
problem
statement,
we
you
know
consider
some
of
the
basic
parameters
of
the
target
deployments,
the
the
reference.
Topologies
are,
you
know
the
well-known
ones,
but
we
observe
you
know
a
vast
increase
in
the
scale
of
the
network
in
in
some
cases
to
the
order
of
a
few
hundred
thousand.
You
know
nodes
in
the
network
and
then
we
also
see
you
know
a
number
of
intents.
That
needs
to
be.
You
know,
may
need
to
be
supported.
We
listed
some.
N
You
know
common
ones,
so
even
considering
just
these
examples
there's,
like
five
intents
with
around
300k
nodes,
we
end
up
with
up
to
a
1.5
million
routes
in
the
network,
and
that
has
some
significant
impact
on
you
know
on
the
protocol
and
that's
what
we
consider
in
the
draft
next
slide.
Please
here,
yeah
we'll
just
list
a
few
more
intent
use
cases
for
you
know
reference.
The
draft
goes
into
more
detail
with
the
you
know,
with
topology
and
illustrations
next
slide.
Please.
N
A
few
key
aspects
to
call
out
here
is,
of
course,
consistency
with
deployed
solutions.
That's
the
srpc
based
solution.
Here
we
again
call
out
you
know
the
use
of
color
to
drive
automated
steering.
We
also
realized
the
problem.
Scope
is
wider
than
just
the
transport
intent
aware.
Paths
may
need
to
be
supported
in
the
vpn
service
layer.
N
You
know,
based
on
the
feedback
we
you
know
received
both
you
know
between,
say,
ce
to
ce
across
the
provider,
in
a
core,
but
also
beyond
and
and
as
well,
because
a
provider
network
is
also
made
up
of
different
administrative
authority.
You
know
domains.
If
you
will,
there
isn't
there's
a
there's.
A
presence
of
various
interworking
options
like
interest
option
a
and
option
b,
and
this
intent
awareness
needs
to
be.
You
know,
propagated
across
them
too.
Similarly,
a
support
for
nfe
and
service
chain
integration
is
also
necessary.
N
N
Also,
you
know
going
back
to
my
example
about
the
scale
that
has
an
impact
on
all
the
nodes
in
the
network,
both
on
the
data
plane,
especially
when
you
know
mpls,
you
know,
is
you
know,
implemented
or
used,
as
well
as
on
the
control
plane
with
you
know,
bgp
and
again,
we
list
the
considerations
in
the
draft
next
slide.
Please
so
this
work
is,
you
know
the
result
of
a
collaboration
with
many
folks.
N
You
know
both
among
the
operators
and
vendors
and
we
thank
the
folks
for
their.
You
know
contributions.
We
also
recognize
that
there
has
been
work
in
this
area,
specifically
by
the
co-authors,
of
the
seamless
sr
draft
we
reached
out
to
them.
You
know
back
in
november
december
to
work
towards
a
joint
in
our
effort.
Jim
utaro
has
helped
facilitate
these
discussions.
N
N
C
N
N
So,
from
the
problem
statement
analysis,
it's
clear
to
us
that
we
need
a
new.
You
know
bgp
safy,
for
the
ability
to
signal
multiple
routes
to
the
same
endpoint
prefix.
You
know
one
per
color
with
that
the
solution
draft
describes
the
essential
elements
that
are
needed.
Focusing
on
the
aspects
listed
below
I
think
to
highlight
here
is
we
have
focused
on
because
it
is
a
new
safety.
We
have
focused
on
defining
extensions
that
provide
efficiency
and
extensibility
and
improve
upon
some
of
the
legacy
constraints
we
have.
N
So
yeah,
so
the
the
we
start
with
the
nlri
I
mean
this,
is
you
know
the
critical
element,
the
nlri
key?
We
propose
to
be
endpoint,
comma
color,
where
endpoint
is
the
you
know
the
ip
prefix
of
the
you
know
the
traffic
destination
in
the
in
the
in
the
transport.
That's
say
the
pe
address
and
then
color
is
the
same.
32-Bit
value.
That's
used,
you
know
by
sr
policy.
The
color
here
serves
two
purposes.
N
It
distinguishes
the
route
per
intent
and
it
also
indicates
the
intent
that
is
satisfied
by
the
route
right.
This
color
is
defined
by
the
user
and
it's
consistent
on
all
the
devices
within
you
know:
network
managed
by
an
administrative
authority,
a
so-called
color
domain.
If
you
will-
and
of
course
this
color
is,
as
mentioned
earlier-
the
same
as
the
bgp
color
external
community
next
slide,
please.
N
N
The
routing
semantics
that
follow
from
it
are
quite
simple
and
straightforward
and
they're
essentially
the
same
as
used
for
the
bgp
ip
safi
or
the
bgp.
You
know
labeled,
unicast,
safi.
The
simplicity
has
benefits
both
in
the
protocol
processing
as
well
as
in
operationally
for
folks
who
run
the
network
a
key
benefit.
N
It
inherently
provides
ecmp
aware-
and
you
know,
backup
paths
at
every
hop.
You
know,
for
example,
if
there
were
two
you
know,
route
to
ap
originated
from
two
abrs.
They
automatically
become
multiple
parts
of
the
e-commerce
c
prefix
at
an
ingress
node
in
that
domain.
This
leads
to
a
faster
localized
convergence
within
the
domain
driven
by
igp.
N
You
know,
detection
and
also
you
know,
prevents
this
failure
from
creating
churn.
You
know
beyond
the
domain
and
of
course
it's
also
the
most
efficient
from
a
subscription
or
a
you
know
filtering
point
of
view
as
needed
for
the
automated
steering
next
slide.
Please
the
other
aspect
we
consider
is
the
encapsulation.
N
We,
you
know
the
there
is
a
need
for
multiple
encapsulations,
even
within
a
domain
for
coexistence
and
migration,
from
one
technology
to
the
other,
and
we
want
to
allow
that
the
necessary
signaling
to
be
done
efficiently
and
operationally
simpler.
So
we
use
in
non-key
tlvs
to
signal
the
different
encapsulation.
You
know,
data
for
for
a
route
we
also
in
terms
of
encoding,
plays
the
you
know,
variable
part
in
the
nlri,
the
rest
in
the
attribute
the
goal
again
being
efficient
packing
of
the
bgp
updates.
N
N
We
also
define
an
extensible
nlri
in
a
model.
Here.
The
details
are
in
the
draft
of
course,
but
just
to
as
a
quick
intro,
we
encode
a
route
type.
You
know
to
account
for
newer
use
cases
that,
may
you
know,
come
in
future.
We
encode
a
key
length
to
allow
new
route
types
to
be
opaquely.
You
know
transited
through
transport
rrs
in
the
network,
and
we
already
you
know
test
upon
the
use
of
non-ktlvs
for
the
encapsulations
we
recognize
there.
N
N
N
Coming
to
the
bgp
car
route,
validation
and
resolution,
you
know
both
I
mean
at
every
hop
this.
This
is
you
know
the
the
essentially
the
processing
of
the
next
hob,
a
a
bgp
car.
Next
hop
will
resolve
by
default
over
another
color
aware
path,
that's
present
in
the
domain
that
could
be
an
igp
path,
or
it
could
be
also
another
bgp
path.
N
N
N
We
also
propose
to
use
the
the
encapsulation.
You
know
after
validating
its
presence
in
our
programming
in
the
data
plane,
and
this
validation
can
be
augmented
by
a
dynamic
performance
measurement.
You
know
system
where
you
know
needed
a
second
aspect
from
a
resolution
point
of
view
yeah.
As
I
said
earlier,
the
resolution
is
recursive,
so
it
can
happen
via
you
know,
any
available,
bgp
or
igp
mechanisms.
N
This
is,
you
know,
a
callback
to
the
service
route.
Automated
steering,
steering
that
we
noted
in
the
problem
statement
is
just
indicating
the
you
know
the
vpn
route
in
this
case
as
it
you
know,
when
it
resolves
over
a
bgp,
color
aware
route,
there
can
be
other
options.
You
know
it
could
be
a
combination.
You
have
multiple
options:
bgp
card
sr
policy,
igpfa
and
based
on
the
preference,
the
appropriate
path.
End-To-End
path
would
be.
N
N
So
here
we
come
to
the
case,
albeit
a
corner
case
where
the
transport
network
has
to
traverse
across.
You
know
different
color
domains
that
is
domains
where
the
color
to
intent,
mappings,
actually
change.
Now.
This
is
not
expected
to
be
the
common
case.
Usually
if
the
network
goes
across
such
different
administrative
authority
boundaries,
it
is
likely
that
there
is
a
vpn
layer.
N
You
know
interworking
that
is
used
like
in
race
option
a
or
b,
but
for
the
case
where
a
transport
may
extend,
we
define
a
you
know
a
solution
using
an
extended
community
to
carry
the
local
color
mapping
across
such
a
boundary
such
that
this
color
then
can
get
remapped
to
the
receiving
domains
in
a
local
color
and
used
within
the
domain.
A
key
thing
to
note
here
is
the
the
nlri
of
the
power
route
itself
is
not
rewritten.
It
is
preserved,
end
to
end.
N
N
So
it
can
be
noted,
you
know
from
the
draft
that
the
bgp
protocol
extensions
itself
themselves.
Are
you
know?
Quite
you
know
simple,
but
the
complexity
really
comes
from
the
the
scaling
you
know
requirement,
and
so
we
analyze
the
impact
of
scaling
on
both
the
data
plane
and
the
control
plane
on
the
data
plane
side.
We
note
the
use
of
you
know
a
few
different
designs
and
we
analyze
the
benefits
of
those
design.
N
You
know
on
taking
state
away
from
the
core
border
routers,
for
example,
but
with
the
resulting
you
know,
complexity
at
other
points
in
the
network,
such
as
the
ingress
pe
or
the
border
router,
and
the
same
thing
you
know
for
for
the
control
plane.
Next
next
slide,
please
okay,
yeah!
So
so
this
is,
you
know,
obviously
the
initial
version,
but
we
welcome
you
know
feedback
from
the
working
group.
E
Hey
dj,
thanks
for
the
presentation,
I
have
two
questions
about
it,
the
first
one
so
in
the
the
new
nlri
you
are
you're,
including
the
prototype
and
also
the
the
key
length,
and
you
mentioned
that
allows
raw
reflectors
to
basically
validate
the
key
length
and
protect
the
router.
Then,
if
the
the
road
type
is
unknown.
E
N
We
should
certainly
discuss
that.
I
think
the
the
the
the
behavior
you
note
for
the
exiting
safies
I
mean
that
is
something
that
has
driven
the
you
know
the
introduction
of
this.
You
know
this
key
length
because
you
know
based
on
experience
of
introducing
new
route
types,
for
example,
you
know
with
evpn.
N
E
E
C
O
Holy
holy,
you
are
well
aware
of
transposes
came
in
vpn,
so
it's
a
similar
concept
that
if
you
have
a
per
prefix,
you
can
carry
the
the
function
part
into
the
with
the
nlri
for
bgb,
packing
efficiency
and
the
locator
and
the
other
part
in
the
attribute.
So
it's
on
the
similar
lines,
you're
well
aware,
so
it's
exactly
the
same.
E
O
E
E
O
N
Very
quick-
I
just
want
to
follow
up
on
the
previous
comment
now
that
I
think
this
is
probably
a
comment
not
just
to
the
authors,
but
also
for
the
work
group
now
that
we
are
going
to
be
proposing
a
nlri
packing
where
you
know,
there's
a
extended
set
of
information
in
the
key.
So
somebody
needs
to
take
a
look
at
to
see
whether
this
is
the
right
direction
that
we
want
to
have
a
nlri
grow.
N
N
P
P
O
So
so,
as
you
are
aware,
that
sr
v6
is
composed
of
locator
and
the
function
in
the
arguments
and
we
can
carry
a
full
sr
succeed
or
as
an
encapsulation
information
or
we
can
carry
a
variable
part
like
a
function
which
will
change
with
each
transport.
So
that's
what
and
that's
what
we
want
to
carry
in
the
tlb.
C
Q
Think
I
think
it's
clear
to
use
the
enc
as
an
key
advertising
and
have
a
question
that
I
say
that
you
also
use
a
row
type
tool
in
the
ri.
So
I
don't
know
I
want
to
know
whether
we
may
we
may
define
more
root
types
for
the.
We
may
use
row
types
to
specify
which
type
of
the
encapsulator
we
may
use
or
not.
N
That's
a
good
question.
I
think
right
now,
the
approach
we
have
taken
is
to
use
you
know
one
route
type
and
actually
signal
multiple
encapsulations
on
it,
that
the
the
option
of
signaling
a
different
route
type
for
you
know
different
end
cap
is
was
considered,
but
then
that
still
results
in
the
advertisement
of
multiple
routes.
So
we
decided
not
to
do
it,
but
that's
something
again.
You
know
we
can
discuss.
C
P
P
P
P
So
seamless
sr
is,
is
a
distributed
solution.
It's
it.
You
know
it's.
The
requirement
is
to
be
able
to
come
up
with
a
distributed
solution
that
does
not
use.
You
know,
there's
no
single
device
that
that
would
have
the
complete
knowledge
of
the
entire
database
of
the
entire
network,
but
sort
of
the
independent
domains
will
advertise
their
reachability
and
then
stitch
them
together
at
the
border
to
build
an
end-to-end
path.
P
So
the
first
requirement
that
we
want
to
wanted
to
cover
as
part
of
this
is-
is
you
know,
as
an
igp
domain
and
how
these
different
domains
are
organized
in
the
in
the
network.
We
have
taken
some
common
deployment
cases,
it's
not
an
exhaustive
list,
so
the
first
one
is
multiple
as
connected
with
ebgp,
where
you
have
as1
as2
as3.
P
As
seen
on
the
right
side.
First
diagram
and
ebgp
is
used
to
connect
these
domains
and
and
whatever
solution
space
has
to
address.
You
know
this
kind
of
deployment.
The
second
one
is
a
single
as
with
multiple
igp
and
same
border
node.
So
you,
if
you
see
abr
one
abr
two,
these
are
on
border
nodes
and
you
they
have
on
the
left
side,
an
igp
and
on
the
right
side,
another
igp,
so
there's
a
common
border
node
and-
and
you
can
see
that
they're
they
are
connected
using
ibgp
sessions.
P
The
third
use
case
is
a
single
as
multiple
igp,
but
no
common
border.
So
you
can
see
that
the
abrs
are
separated.
There
is
no
common
bot.
They
are
all
same
as
like
as1
the
domain.
One
domain
two
and
domain.
Three
are
all
using
as1,
but
there
there
is
no
common
border
node
and
they
are
still
connected
using
ipgp
sessions
and-
and-
and
these
are
kind
of
you
know
as
an
igp
domain
requirements
that
that
have
been
covered
in
the
draft
next
slide.
Please.
P
So
the
so,
the
requirement
is
also
to
be
able
to
cover
heterogeneous
tunneling
technologies
in
each
of
the
domains.
For
example,
srm
pls
with
ipv4
and
ipv6
srm
pls
with
dual
stack,
srv6
tunneling
end
to
end
and
then
srte,
as
defined
by
the
segment
routing
te
policy
should
also
cover
flex
algo
for
srm
pls
and
srv6,
and
additional
requirement
is
also
to
be
able
to
cover
rsvp
and
ldp
based
tunnels,
as
well
as
pure
ip
fabric,
where
which
is
incapable
of
supporting
mpls
or
srvs
externally
mechanisms
next
slide.
P
P
So
the
other
type
of
requirements
that
that
the
document
talks
about
is
the
various
sla
requirements,
so
various
constraints
that
that
needs
to
be
satisfied.
When
you
build,
you
know
an
end-to-end
path,
so
latency
delay
variation
and
link
loss,
the
end-to-end
bandwidth
constraints,
link,
inclusion,
exclusion,
constraints,
link,
node
and
domain
inclusion,
exclusion
constraints.
P
P
P
So
we
also
want
to
focus
on
merger
and
migration
requirements,
so
the
the
networks
are
always
evolving
and
changing,
and
you
know
we
have
to
capture
the
requirements
are
arising
out
of
these
constant
change
in
the
network.
So
as
part
of
these
mergers
and
migration
requirements,
we
have
covered
these
aspects
where
you
know
a
solution.
P
Should
inter-operate
with
existing
seamless,
mpls
solution
which
is
based
on
bgplu?
So
if
certain
nodes
are
not
upgraded
to
the
new
solution,
you
should
still
be
able
to
create
an
end-to-end
path
and
and
and
this
new
solution
should
interoperate
with
pgplu
so
other
another
aspect
of
these
mergers
and
migration
is,
is
you
know,
use
cases
that
would
require
option
a
and
option
b
type
of
deployments?
And
these
you
know
intent
based
paths
end
to
end
should
cover
those
cases
as
well.
P
So
the
next
one
is
the
inter
domain
intent
translation
requirements.
This
is
this.
This
you
can
imagine,
arises
out
of
mergers
where
there
may
be
another
network
that
you
know
that
is
acquired
and
that
uses
a
different
intent
mapping
and,
and
so
the
solution
should
be
able
to
map
these
different
different
intents
represented
using
different
notations
in
the
two
domains.
P
So
it
should
also
have
native
support
for
best
effort
paths,
so
you
should
not
require
to
run
two
different
families,
for
you
know
be
able
to
one
for
best
effort
in
another
for
intent,
based
path.
So
this
this,
the
solution
should
be
able
to
natively
support,
best
effort
paths,
and
it
should
also
interoperate
with
other
tunneling
mechanisms
such
as
like
one
domain
having
srv6
in
another
having
mpls
and
so
on.
So
next
slide.
P
P
P
Sure
I'll
quickly
cover
yeah,
so
we
have
also
captured
other
requirements
like
availability
operations,
and
you
know,
traffic
steering
requirements
and
interaction
with
other
approaches
such
as
centralized
approaches
and
also
multicast
requirements
like
in
this.
If
you
are
building
a
network
for
this
kind
of
an
architecture,
what
are
the
multicast
requirements?
You
know
that's
covered
in
as
well
in
the
draft
next
slide,
please
so
we
are
requesting
review
and
comments,
and
the
bgp
car
problem
statement
also
talked
about
similar
requirements.
P
D
Hi
everyone.
Can
you
hear
me?
Yes,
absolutely
go
ahead.
Thank
you.
So
thank
you
for
the
opportunity
I'm
going
to
present
the
pgp
class
4
transport
planes
today
next
place
next,
at
least
so.
Thank
you
for
the
previous
two
speakers
who
have
explained
the
problem
statement
really
well
so
I'll
just
show
the
agenda
and
then
go
that
the
solution.
We
can
skip
the
problem
statement,
so
I'm
going
to
actually.
D
D
Slide
so
the
way
bgpct
solves.
The
problems
that
have
been
described
is
like
so
the
tunnels
of
the
similar
characteristics.
The
operators
can
classify
them
into
transport
classes
and
the
transport
class
is
a
construct
that
is
identified
by
a
32-bit
color,
and
this
supports
different
types
of
transport
tunnels.
D
Also
the
srt
flex
algo
hypnos
srv6.
It
can
be
anything
and
the
vgpct
is
a
new
vgp
transport
layer
address
family,
it's
like
lu
with
where
you
can
save
with
rdnrd,
which
follows
4364
procedures.
So
it's
happy
76.
and
you
can,
you
can
think
of
it
as
like.
Even
today,
we
carry
transport
layer
routes
in
l3bpn
in
some
scenarios
like
30s
career.
D
And
so
we
reuse
the
existing
mechanisms
of
the
route
distinguisher
to
distinguish
different
instances
of
a
tunnel
endpoint,
and
we
use
a
new
type
of
route
target
new
format
of
route
target
to
identify
the
transport
class
that
the
road
belongs
to
so
which
basically
extends
the
tunnel
across
inter-domain
boundaries
by
preserving
the
same
transport
class
end-to-end.
Basically,
it
preserves
it
by
resolving
the
vgp
next
hop
over
the
tunnels
belonging
to
the
same
transport
class,
without
allowing
any
fallback
at
the
transport
layer,
and
it
follows
the
4364
option.
D
C-Style
procedures
to
create
swap
routes
on
the
domain
boundaries
and
these
double
domain
boundaries
could
be
either
abrs
which
are
doing
bgp
next
top
itself
or
it
could
be
asbr
which
are
doing
with
vpn
stop
itself.
So,
whichever
node
is
doing
a
bgp.
Next,
stop
itself
for
the
bgpct
routes.
It
becomes
a
part
of
border
node
which
stitches
two
different
types
of
tunnels
and
that
stitching
element
or
emitting
forwarding
state
could
be
either
mpls
or
srv6.
D
So
in
this
draft
we
basically
can't
focus
on
mpls,
because
that
is
the
de
facto
deployed
technology
today,
and
there
are
other
traffic,
explain
other
technologies
and
it
works
in
conjunction
with
often
a
option
b
scenarios
as
well,
so
that
your
transport
class
can
be
preserved
across
the
boundaries
and
the
way
service
routes
they
resolve
over.
A
resolution
scheme
and
resolution
scheme
is
nothing
but
an
ordered
set
of
transport
classes,
which
is
like
one
color,
followed
by
another
color
or
default
transport
class,
the
default
tunnels.
D
So
they
resolve
over
a
resolution
scheme
by
virtue
of
carrying
a
mapping
community.
So
the
mapping
community
is
nothing
but
a
bjp
community
that
maps
to
a
resolution
scheme
and
for
service
routes.
They
use
the
color
extended
community
which,
by
default,
says
resolve
over
color
end
with
a
optional
fallback
to
best
of
all
tunnels
and
the
transport
target
that
we
have
defined
here.
That
is
on
the
bgpct
route
that
results
directly
on
the
color
and
tunnels,
and
that's
for
the
reason
of
preserving
the
transport
class
end-to-end
next
slide.
D
D
So
this
is
just
a
recap
to
show
what
does
a
format
look
like,
so
it
just
has
no
new
things.
It's
the
plain,
boring
rfc
4364.
well
proven
format
where
we
have
the
transporter
of
target
and
the
cd
traffic.
So
we
just
have
new
code
points
for
the
safy
and
the
target
so
that
there
is
no
collision
with
the
service
layer
next
slide.
D
D
So
this
just
shows
a
pictorial
representation
of
whatever
we
discussed
so
far.
So
in
this
case,
pe
one
one
is
the
egress
node
and
it
has
multiple
color
tunnels
and
we
see
two
domains:
as1
as2,
where
es2
has
two
domains
again
with
the
avr
in
the
middle.
So
there
are
like
three
transport
domains
and
they
are
different:
lsb
tunneling
protocols
in
each
domain
of
various
colors.
D
D
It
avoids
path,
hiding
when
the
transmitting
r
asbr
and
it
allows
unambiguously
identifying
the
originating
pe
for
debugging,
and
it
also
allows
any
cast
transport
endpoints,
which
can
participate
in
multiple
domains,
which
may
not
necessarily
agree
on
the
color,
and
it
also
allows
cross
selection
after
stripping
the
rd
when
necessary.
So
this
is
helpful
for
faster
convergence
and
also
to
keep
the
churn
local
to
the
domain,
where
the
churn
is
happening.
So,
basically,
rd
is
a
good
identifier
of
convenience.
D
And
the
route
targets
that's
even
more
helpful
to
propagate
the
transport
class.
It
allows
forming
venn
diagrams
of
color
domains
as
desired,
where,
for
example,
the
core
network
is
having
more
fine
grained
colors
and
access
networks
or
any
new
use
cases
that
can
come
in
future
and
yeah.
Creating
color
is
an
attribute
part
of
the
nlri.
It
just
helps
not
having
to
rewrite
the
lra
or
having
to
guess
where
the
color
is
coming
from.
D
It's
just
always
in
the
router
and
another
important
use
of
reusing
4364
is
able
to
use
the
target
constraint
procedures,
so
the
service
layer
routes
and
the
transport
layout
routes
now
can
have
a
clean
api
where
we
can
discover
the
transport
classes
that
the
npe
needs
and
it
can
request
in
the
bgpct
layer.
So
that
becomes
an
on
demand.
Next
top
it
will
only
require
the
transport
routes
that
it
needs.
D
E
D
D
C
D
Router
reflectors
doing
that
stops
off
so
there's
an
easy
way
to
avoid
it
using
ct
where
you
don't
provision
the
color
tunnels
between
the
abs
so
automatically
the
router
resolution
procedures
will
not
have
abr,
choose
other
apr
as
a
next
stop
and
only
will
choose
the
asbrs.
So
that
was
just
another
anecdotal
note
that
I
wanted
to
share.
D
O
D
Can
have
a
multitypical
rdt
for
our
target.
It
has
the
same
semantics,
so
a
route
can
at
a
box,
it
will
have.
It
will
map
to
one
transport
class
unambiguously,
but
the
route
can
carry
multiple
route
targets
so
that
different
nodes
in
the
network
can
import
it
into
different.
So
it
can
help
with
mergers
and
renumbering
kind
of
use.
Cases.
C
T
T
This
presentation
contains
three
parts.
First,
I
will
introduce
the
layer
three
accessible
interfaces
for
evpn
surveys
and
then
I
will
introduce
the
solution.
We
proposed
to
simplify
the
deployment
of
layer,
3,
accessible
evpn,
and
the
last
part
is
about
the
further
actions
of
this
draft
and
next
slide.
Please.
T
T
T
T
T
T
T
T
T
T
T
T
U
D
C
E
V
C
S
S
Next
slide,
so
evpn
has
been
widely
successful,
you
know
deployed
and
so
on
so
on
and
you
grow
a
lot
of
horns
bells
and
buttons,
and
it
is
not
an
easy
technology
to
deploy
and
configure.
So
you
really
have
two
choices.
These
days
you
either
have
a
magic
controller,
which
you
know
it's
a
fine
thing
and
probably
large
deployment
is
a
very
good
idea,
but
it
has
its
own
set
of
challenges.
S
S
But
of
course
you
know
we
will
not
support
all
possible
variations.
So
here
is
a
slide.
The
links
are
barely
legible.
So
of
course
we
talk
about
rift.
So
we
talk
about
id
fabrics
which
are
built.
You
know
in
very
predictable
way,
some
kind
of
claw
variation
and
we
figured
out
that
actually
with
drift,
we
have
enough
information
to
completely
evp
and
ztp
without
any
user
input
and
the
model
that
we
support,
but
the
draft
is
open.
S
Right
is
basically
ibgp
and
we
put
rod
reflector
on
the
top
of
the
fabric
and
we
run
integrating
routing
and
bridging
on
the
leaves
which
lots
of
people
are
moving
towards
that.
A
couple
of
things
we
found
which
are
non-obvious
is
that
if
you
want
to
stretch
vlans
well,
you
can't
derive
the
same
values.
You
know
on
all
the
fabrics,
so
we
we
allow
for
an
optional
fabric
id
and
that
will
allow
you
to
stretch
the
lens
and
we
can
ultimately
get
the
right
stretch
and
not
stretch
vlans
by
doing
that.
S
S
S
And
it
doesn't
have
some
first
details,
so
basically
the
draft
will
flash
out
how
you
derive
all
the
variables
that
are
necessary.
You
know
like
a
cluster
id,
whatever
the
loopbacks
and
router
ids
and
as
you're
on
and
so
on.
That
will
be
all
filled
in
because
the
draft
right
now
is
pretty
naked.
We
just
didn't
have
time,
you
know
to
put
all
the
details
and
next
slide.
S
People
want
to
know,
you
know
how
many
l2
type,
2
and
type
5
rods
will
happen
with
all
the
bgp
sessions
came
up
and
so
on
and
so
on,
and
we
can
basically
stick
it
into
the
key
value
store
of
rift
flood
it
up
and
then
the
top
of
the
fabric
just
like
today,
you
see
the
underlay.
You
can
also
look
whether
the
whole
authoring
vpn
came
up
and
is
saying
nothing
too
ambitious,
but
you
know
makes
this
stuff
as
simple
as
sticking
l2
switches
together
again
next
one.
Please.
S
Right
so
next
revision
will
have
the
algorithms,
and
we
also
do
the
type
5
irb
variables,
because
we
kind
of
commented
them
out
simply
no
time,
and
we
also
talked
about
how
we
put
the
stuff
into
the
key
value
store.
Co-Authorship
is
welcome.
There
is
an
open
source
python,
something
like
that
can
be
easily
hacked
in,
and
another
interesting
observation
is
that
if
you
participate
as
leaf
only
you
only
need
to
leave
implementation
for
rift,
which
is
far
far
simpler
than
the
whole
thing,
and
that's
the
end
of
my
stick.
Any
questions.
Observations.
C
S
Well,
they're
mostly
concerned
about
how
to
bring
obsession
I
mean
I'm
not
sure
which
draft
we're
talking
about.
I
mean
I'm,
I'm
aware
that
we're
talking
now
about
the
v6
of
the
v4
v6
draft
and,
of
course,
all
the
you
know
auto
session
for
bgp.
I'm
very
well
aware
of,
what's
going
on
there,
I'm
not
aware
of
the.
S
C
S
R
A
W
S
A
W
Yeah,
I
think
ac
lindem,
cisco,
I'm
on
the
design
team
with
the
two
jeffs
and
wim.
I
think
the
autocom-
it's
will
be
quite
a
stretch
to
take.
We
have
to
be.
We
have
the
bgp
role
to
just
have
a
role
of
router
plays
to
do
with
everything
for,
and
that's
really
supposed
to
be
plug
and
play
for
this
for
this
work,
but
also
it
generally
doesn't
go
more
than
one
hop
the
solutions
we're
looking
at
for
the
data
center.
So
that's
not
this
isn't
within
the
scope
right
now,.