►
From YouTube: IETF110-SFRAME-20210309-1430
Description
SFRAME meeting session at IETF110
2021/03/09 1430
https://datatracker.ietf.org/meeting/110/proceedings/
A
A
A
A
So
I
don't
have
a
hugely
long
session
this
evening
or
this
morning
or
this
afternoon,
so
we
have
some
a
few
short
presentations
after
some
discussion
on
the
list
about
the
big
picture
stuff,
I
thought
it
might
help
to
get
someone
to
do
a
bit
of
an
overview
of
the
the
use
cases
in
the
skype.
So
we
actually
have
two
presentations
on
that.
I
think
tim's
going
to
be
talking
about
the
the
the
meta-level
questions
and
dr
alex
has
presentations
on
how
every
how
the
technical
pieces
all
fit
together.
A
A
A
B
B
B
I
mean
the
like
really
high
level
view
is
that
we're
protecting
your
data
from
your
service
provider,
so
that
you
know
alice
and
bob
can
have
a
a
private
conversation
without
their
mutual
service
provider
having
to
be
in
the
in
the
media
stream
in
terms
of
being
able
to
comprehend
it.
The
flip
side
is
also
true
you're.
Protecting
the
service
provider
from
your
data,
so
the
service
provider
is,
is,
is
given,
let's
say,
plausible
deniability
about
whether
they
were
exposed
to
your
share
dealing
plans
or
whether.
C
B
B
And
so
I
that
brings
us
to
the
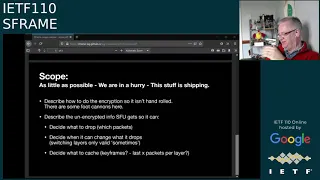
scope
and
what
and
to
my
view
again,
I
think,
like
what
we
should
be
doing
here
is
as
little
as
possible
like
we're
in
a
hurry.
This
stuff
is
shipping,
gypsy
have
already
got
people
doing
this,
and
the
risk
is
that
people
are
going
to
hand
roll
the
encryption
for
this.
For
this
use
case,
and
there
are
some
tremendous
foot
cannons
here
that
like
as
true
with
a
lot
of
encryption
this,
but
but
in
this
case
there
are
some
really
wonderful
ones.
B
I'm
can't
actually
think
of
anything
else
that
should
be
in
scope,
and
I
guess
so.
The
purpose
of
this
presentation
is
to
put
those
two
questions
out
there
like
is
there
more
to
the
scope
than
this?
Is
there
more
to
the
more
use
cases
than
this?
And
if
so,
what
are
they
and
do
they
fit
within
the
charter
and
that's
kind
of
pretty
much
all
I
wanted
to
say.
I
think.
A
B
D
D
So
there's
going
to
be
a
lot
of
this,
is
you
know,
going
to
be
a
fairly
hard
problem,
at
least
to
do
in
you
know,
in
generality
and
interoperabil,
with
good
interoperability,
as
opposed
to
I
know
what
I'm
you
know,
I'm
only
doing
this
codec.
I
know
that
means
I
send
bites
one
through
six,
not
safe.
You
know
with
my
encoder
implementation
and
done.
B
D
Are
generally
less
accurate,
that's
true,
but
that
does
imply
things
on
right
right
now.
I
think
there
are
certain
assumptions
that
the
ultimate
decoders
make
about
their
media,
that
you
know
you
know
that
there
is
a
certain
precision
in
it
that
you
know
that
they're
they're
it's
going
to
be
reasonably
self-consistent
about
you
know.
What's
in
it
and
you
know,
gaps
are
you
know,
semantically,
you
know
is
missing,
and
so
I
think
that,
but
that's.
D
D
Yeah,
and
though
so
I
mean
it's
there's
you
know
if
if
the
receiver
thinks
you
know,
a
gap
means
something
goes
needed,
and
the
sender
thinks
oh
gaap
is
just
because
I
chose
not
to
send
that
to
you
and
they
disagree.
They
said
the
receiver
doesn't
move
forward.
Then
you
have
a
problem
so
that
there's
you
know.
I
think
this
imposes
more
requirements
on
understanding,
potentially
messy
streams
on
the
ultimate
decoders
than
we
currently
have
right.
D
No,
it
doesn't
just
it's
something:
we're
going
to
need
to
look
at
and
decide
and
I
think
that's
something
we're
going
to
need
to
actually
just
decide
and
make
explicit
that
you
know
if
you
have
a
existing
implementation
that
assumes
a
reasonably
clean
stream.
Well,
if
you're
dealing,
if
you're
doing
s
frame,
sorry,
you
don't
get
that
you're
going
to
have
to
you
know
deal
with
mess.
F
To
underline
jonathan's
point
one
thing
that
I
don't
think
it's
been
written
down,
but
their
decoders
can
be
very
finicky.
An
example
is
vp8,
where
the
picture
id
not
only
has
to
be
monotonically
increasing,
it
has
to
be
sequential
and
what
that
means
is,
if
you
drop
a
frame,
even
if
it's
not
even
if
it's
discardable
it'll
cause
the
decoder
to
find
the
stream
undecodable,
and
what
that
means
in
practice
is
that
the
picture
id
has
to
be
rewritten
by
the
sfu.
F
F
And
there's
been
at
least
three
attempts
to
to
achieve
that.
The
other
thing
is
about
the
use
case
itself,
which
seems
to
assume
that
the
service
provider
is
separate
from
the
from
the
application
provider
and
the
the
problem
is
that
that's
a
business
model
which
doesn't
really
exist
to
any
significant
extent.
B
Of
that,
that's
not
really
true,
I
I
mean
totally
and
hence
the
to
the
second
point
totally
and
hence
the
the
the
wording
about
kind
of
plausible
deniability.
It's
not
an
absolute
it's
it's
a
it's
merely
moving
the
needle,
but
it
seems
to
be
a
moving
and
moving
of
the
needle
that
people
want
now
whether
they're
right
to
want
it
or
not,
is
kind
of
almost
not.
F
B
And
I
think
just
just
to
cover
the
first
point,
I
think
there's
an
assumption
there
that
that
rewriting
has
to
be
done
in
the
sfu,
which
is
kind
of
there's.
This
tacit
assumption
that
the
sfu
will
do
everything
it
has
to
do
so
that
the
the
decoder
at
the
far
end
doesn't
know
that
s
frame
is
involved,
and
I
think
what
we're
starting
to
hear
is
that
may
not
be
possible.
A
B
G
Okay,
great
so
I
I
thought
the
same
horn
here
that
that
bernard
and
jonathan
had
I
would
suggest
that
it
is.
It
is
a
it's
basically
impossible
to
do
this
in
a
generic
way.
I
would
suggest
to
add
to
the
requirements
that
there
should
be
codec
specific
restrictions
on
the
codec
bitstream
complexity,
things
like
okay,
if
you're
using
hvc
you
should
you
shall
not
use
gradual
decoder
refresh
you
want
to
have
a
keyframe.
G
H
Yes,
so
I
I
I
I
want
to
turn,
I
think
the
question
around
is
it:
is
it
really
decide
what
to
drop?
Is
it
they
decide
what
to
forward
and
and
and
for
because,
from
my
perspective,
we
are
talking
about
media
streams
here
and
that's
maybe
the
high
level
assumption
at
least
is
that
there
are
several
media
streams.
It's
not
just
one
set
of
packets
that
you
have
to
select
some
random
set,
but
it's
it's.
We
actually
have
some
underlying
structure
and
that
still
comes
through
here.
B
H
But
so
I
on
that
I
mean
that's
the
other
aspect.
I
didn't
bring
it,
but
so,
unless
you
have
congestion
or
saying
your
resource
shortage
in
the
bandwidth,
okay,
fine,
you
can
send
everything.
But
the
moment
you
have
constrained
the
amount
of
resources
and
you
need
to
confirm
to
that.
Then
you
need
to
select
the
set
which
works
and
if
you're
gonna
drop
random
things,
you're
gonna
get
to
something
that
doesn't
work
because
you
are
not
going
to
be
able
to
if
you're
completely
random
drop.
B
H
Yes,
but
be
able
to
repair,
it
means
that
you
actually
need
to
understand
if
something
that
was
lost
is
something
that's
useful
for
you,
which
means
that
you
have
to
have
structures
that
tells
you
that
the
things
that
didn't
derive
was
something
that
you
needed,
and
that
is
a
thicker
part
of
the
problem
here,
because
if
you
don't
have
know
that
this
is
an
rtp
stream
at
certain
layer
and
that
you
lost
something,
you
either
need
to
make
it
shift.
And
do
I
need
this
layer?
H
H
Yes,
and
you
have
to
have
that
structure
showing
up,
I
mean
that's
what
rtp
does
to
you
if
you
use
it
correctly
today
and
that
needs
to
be
preserved
when
you
put
s
frames
in
rtp
payloads,
so
you
can
understand
which
things
you
did
care
about
or
not,
and
if
the
relay
was
related
to
not
to
something
you
cared
about,
even
if
it's
only
the
receiver
or
the
sender.
That
knows,
if
it's
useful,
in
which
contexts.
I
I
That
is
saying
which
of
these,
what
the
streams
are
in
the
way
in
such
a
way
that
the
consumers
of
those
streams
can
make
a
choice.
I
think
that
is
sufficient
to
be
able
to
solve
this
problem.
So
say,
I've
got
a
phone,
that's
on
a
a
weak
link
that
can
make
the
choice
of
which
streams
it
is
going
to
consume,
and
it's
only
that
end
device
that
can
make
decisions
like.
J
Yeah,
so
a
higher
level
question
about
this
slide
the
scope.
Looking
ahead
at
the
other
presentations,
I
I
see
since
a
little
mismatch.
I
like
to
make
sure
that
the
group
understands
which
way
we're
going.
You
know
clearly
this
all
started
from
being
able
to
just
support
and
end
encryption,
but
I
think
a
lot
of
the
mechanisms
that
are
being
proposed
are
really
about
insertable
streams
in
general
transforms
on
the
media
in
general
packetization
formats
for
rtp
in
general.
J
So
I
wonder
whether
or
not
the
group
is
is
going
to
favor
general
solutions
or
maybe
even
prohibit
a
general
solution.
Are
you
really
only
focused
on
providing
the
end-to-end?
You
know
secure
media
solution,
and
is
it
a
goal
or
a
non-goal
or
explicitly
don't
want
to
support
things
that
are
more
generic
than.
J
B
But
but
my
my
opinion
is
we're
in
a
hurry
and
we
should
limit
this
as
as
far
as
possible
if
it
happens
that
an
easy
solution,
that's
generic,
drops
out,
then
that's
great,
but
I
think
the
idea
that
we
should
track
track
insertable
screen
streams
and
make
them
a
dependency
on.
This
would
be
a
mistake.
A
I
I
think,
I'm
thinking
we
might
have
to
take
this
to
the
to
the
mailing
list,
and
hopefully
dr
alex
can
get
himself
in
queue
and
we
can
have
a
discussion
about
the
next
thing,
but
unfortunate
because
that
was
going
well
thanks,
tim
got
got
things
rolling.
I
I
would
encourage
people
to
write
down
their
their
thoughts
and
put
them
into
an
email
that
we
can
talk
about,
because
no
emails
is
much
harder
to
work
with
than
emails.
A
A
K
Right
so
as
one
of
the
author
of
the
original
document
and
all
the
subsequent
document
scenes
and
of
the
charter
we've
been
requested
during
the
charter,
part
of
sram,
to
give
a
big
picture
document
and
to
show
which
part
belong
to
which
group,
as
in
the
past
20
minutes,
many
people
pointed
to
there
are
parts
that
are
media
encryption
in
a
part,
rtt
packetization,
payload
question
and
so
on
and
so
forth.
So
I'm
sorry,
I
couldn't
come
up
with
an
informal
draft
yet,
but
it's
going
to
come
here
next
and
that's
why.
K
The
first
slide
is
about
evt
core,
as
friend
and
in
part
whip,
where
we're
going
to
put
all
the
excellent
question
and
problem
we
have
within
their
respective
working
group
within
a
global
picture
and
hopefully
within
draft.
So
some
of
the
draft
didn't
exist
last
time
and
are
going
to
be
cited
and
going
to
speak
about
in
this
session
letter
about
sergio
and
by
richard
on
specific
point.
But
the
big
picture
I
think,
is
needed
to
avoid
the
20
minute.
We
just
passed
next
slide.
K
So,
just
looking
at
the
original
webrtc
one
which
was
supposed
to
be
p2p,
we
had
something
like
this,
which
is
very
simplify
a
source,
an
encoder,
an
rtp
packetizer,
the
srtp
part
with
the
the
key
creation
and
the
key
exchange,
and
then
a
transport.
So
it's
simplified
it's
a
little
bit
more
complicated
and
that
I
put
some
of
the
rfc,
obviously
not
all
of
them,
and
this
is
what
the
rtp
redundancy
and
condition
control
can
look
like
with
the
pli
sli
and
everything
that
fits
into
the
profile
for
simplification.
K
K
So,
very
quickly,
we
had
to
hide
the
media
server,
so
it's
a
truncated
way
of
the
media
path
where
we
don't
put
the
receiver.
We
just
put
a
sender,
a
media
server
and
a
receiver,
and
each
of
sender,
media
server
and
receiver
act
like
a
webrtc
peer
and
so
now
what
what
was
an
end-to-end
encryption
in
p2p
become
a
hub
by
hope,
and
we
can
see
exactly
the
same
thing
for
illustration
purpose.
K
K
First,
you
need
to
add
an
additional
filter
between
the
codec
and
the
rtp
payload,
and
that's
what
the
the
draft
and
vt
core
about
kodak
agnostic
is
made
and
there
will
be
a
full
presentation
by
sergio
and
uen
on
on
the
topic
here.
This
is
the
ietf
point
of
view.
There
is
nothing
about
the
web
and
this
is
what's
going
to
be
presented
at
nft
core
next
slide.
K
Now,
if
you
look
now,
if
you
assume
now
that
the
media
is
encrypted,
the
media
server
might
not
be
the
existing
media.
Server
might
not
be
able
to
do
the
job
they're
doing
today,
because
they
depend
on
access
on
the
rtp,
payload
header,
and
so
you
need
to
decide
which
information
the
sfu
needs
and
where,
to
put
it
so
so
far,
the
idea
was
to
take
the
information
needed
in
a
structured
way
and
to
put
it
in
a
rtp
header
extension
one
or
two
years
ago,
at
adt
core.
K
K
So
now
you
have
two
antagonist
thing,
which
is:
I
want
encryption
as
much
as
possible,
but
I
still
want
an
sfu
if
I
don't
have
an
sfu
in
the
loop,
I'm
still
p2p
and
an
end
to
an
encrypted,
and
then
I'm
done
right.
So
one
of
the
first
questions
still
unsolved.
That
will
require
discussion
at
ivt.
Core
is
what
do
we
do
in
that
rtp
heater
extension
next
slide.
K
The
second
question
is
now:
I
need
to
exchange
a
key
end
to
end,
as
opposed
to
exchange
a
key
hub
by
hope.
How
do
I
do
that?
So
here?
The
exchange
of
the
key-
you
know
you
rotate,
the
key
and
so
on
is
is
orthogonal
to
really
the
media
encryption,
so
the
s
frame
group
was
charted
to
define
a
media
encryption
independently
of
the
use
case
and
independently
of
of
the
key
exchange
a
little
bit
like
in
a
perk
group.
K
K
K
There
is
corresponding
implementation
in
safari
with
extra
additional
security
things
because
of
the
web
modes,
earth
threat
model,
and
there
is
another
implementation
using
olm
by
gt.
I
think
saul
is
in
the
call
today.
Maybe
he
will
tell
us
a
little
bit
about
that
and
I'm
pretty
sure
that
webex
is
doing
things
pretty
differently,
but
they
all
fit
that
diagram,
where
you
need
to
have
a
secure
way
to
exchange
the
key
and
the
key
management
need
to
be
external
next
slide.
K
Now,
if
we
go
specifically
into
insertable
stream
and
by
the
way
the
name
has
just
changed
so
can
tell
us
what
the
new
name
is,
I'm
not
sure
what
it
is
anymore,
but
the
idea
is
now
in
in
in
a
web
application
in
a
native
application.
You
control
everything,
but
in
a
web
application
the
trust
model
is
different.
You
do
not
trust
the
javascript
with
the
traditional
webrtc
implementation
yeah
with
the
traditional
webrtc
implementation.
The
key
is
generated
by
the
user
agent.
K
It's
never
it's
never
passed
on
by
the
javascript
and
so
we're
good.
Now
we
need
to
find
a
way
to
apply
that
as
frame
transform
and
to
get
the
key
directly
in
a
user
agent
right.
So
here
you
we're
gonna,
create
a
an
api
called
insertable
stream
api
until
this
week.
That
will
allow
us
to
inject
encrypted
content
to
the
rtp,
but
we
haven't
solved
the
problem
of
the
the
encryption
and
and
the
exchange
of
the
key
outside
of
the
javascript.
K
K
This
is
what
you
get.
So
the
little
difference
is
the
dotted
white
block.
Is
the
insertable
stream
api,
where
you're
gonna
plug
in
the
sram
transform,
which
is
protected
in
the
c
plus
plus
part
of
the
of
the
browser
in
the
user
agent
and
then
the
external.
So
now
I'm
going
to
let
sergio
and
uen
explain
a
little
bit
more
on
the
rtp
packetizer
problem
and
I'm
going
to
let
richard
speak
about
the
mls
4
key
exchange.
K
A
L
A
L
So
the
first
is
is
like
the
continuation
of
the
presentation
that
alice
has
done.
Is
that
really
with
the
with
s-frame?
What
we
are
doing
is
inserting
a
new
element
in
the
rtp
and
in
the
media.
Changes
define
it
in
the
rtc7656,
the
the
rtp,
how
it
was
called
the
taxonomy
rtp.
So
what
it
introduces
is
a
new
is
a
new
element
that
does
the
transformation
that
transforms
then
the
encoder
stream
that
comes
from
the
front
encoder
before
it
gets
to
the
packetizer.
B
L
F
L
It's
it's
really
is
both
I
mean
is,
for
example,
you
cannot.
I
mean
to
make
it
work.
Bp8
and
vp9
are
were
cases
because
there
is
not
much
mangling
of
bytes
when
you
do
the
bucketizing,
but,
for
example,
is
four
and
you
cannot
apply
directly
to
the
to
the
end
to
the
to
the
frame,
because
you
have
to
pass
the
the
the
null
unit.
So
you
have
to
do
a
lot
of
specific
things
in
the
in
the
media
frame
in
order
to
to
create
the
packet.
So
it
is
a
bit
of
both.
I.
E
F
Yeah
also,
you
know,
I
think
it's
a
it's
assumed
here,
that
the
transformer
doesn't
really
communicate
with
the
packetizer
in
any
formal
way.
I'm
just
questioning
whether
that's
a
hard
requirement.
I
mean
that's
how
insertable
streams
works,
but
it
also
creates
a
number
of
problems
in
that.
If
you
increase
the
data
size
for
some
reason
now,
the
packetizer
doesn't
know
what's
going
on
so
anyway.
I
I
would
just
question
whether
I
think
this
is
a
slide
about
the
actual
architecture
that
shipping,
rather
than
the
architecture,
necessarily
that
we
need.
H
And
then
you
have
a
second
packetizer
afterwards,
because
you
need
to
say
the
media.
Encoding
is
outputting
some
data,
but
in
reality,
if
you're
talking
about
scalable
code,
video
codes,
for
example,
you're
not
putting
out
one
encoder
stream,
you're
outputting
multiple
encoded
streams,
and
you
need
to
packetize
those
individually
and
with
the
right
amount
of
metadata,
even
internally,
to
be
able
to
figure
out
where
it
belongs
to
and
and
and
then
you
transform
it
into
decrypt
protected
form,
and
then
you
packetize
it
again
for
the
transport,
yes
to
fit
r2p
in
that
sense.
H
So
I
think
we
have
to
be
very
aware
that
we're
actually
having
several
steps
here
and
and
what
you
packetize
before
you
encode
is
is-
is
an
important
question.
But,
okay
in
this
case,
it
often
happens
and
it
ends
up
in
the
especially
in
webrtc.
It's
gonna
end
up
in
the
in
the
implementation
in
maybe
in
javascript
domain,
but
but
it's
highly
relevant
so.
L
A
L
M
That's
robust
and
I'm
wondering
if
there
are
are
ways
which
would
fit
the
rtp
model
better,
which
did
this
in
a
way
which
you
know
did
the
encryption
of
the
contents
in
a
way
which
reflected
knowledge
of
the
particular
payload
formats,
and
that
would
then
simplify
the
rest
of
the
design,
but
by
encrypting
in
a
payload
in
a
codec
aware
way.
Rather
than
trying
to
do
this
in
a
codecognostic.
L
L
L
The
the
the
only
thing
about
the
robustness
is
that,
at
least
in
webrtc
implementation,
we
are
not
using
that.
So
much
so
I
mean
while
well
rtp,
is,
is
implemented
or
has
defined
it
in
into
a
very
in
details,
for
example,
let's
use
for
slices-
and
I
have
not
seen
any
implementation-
that
it
is
really
using
it
a
part
of
in
a
very
codec
a
specific
way.
Yes
without
rtp
knacks,
fake
and
things
like
that,
but
I
don't
have
not
seen
much
traction
of
a
percodec.
M
L
I
would
love
to
hear
more
about
how
that
it
is
say,
use
and
how
how
it
is
done
or
where
it
is
done,
because
I,
at
least
in
the
series
that
I
know
it
is
not
also
done
so
if
magnus
can
provide
more
details
about
how
this
game
codec
specific
robustness
is
using
cnsp
use
and
something
like
that.
I
would
really
like
to
see
it.
H
I
didn't
really
understand
because
when
I'm
talking
about
detecting
losses,
I've
talked
about
that
on
on
in
classic
rtp,
which
is
on
ssrc
level,
you
can
see
a
gap
for
a
particular
ssrc
in
the
sequence
number
space,
and
then
you
know
that
you're
missing
something
and
if
you
mapped
one
ssrc
to
one
stream
or
layer
in
certain
case
you
would
know
that.
Oh
I'm
missing
this.
I
know
that
people
have
many
cases
implemented
with
scalable
codecs.
H
They
do
maintain
part
of
the
structure
saying
okay,
at
least
in
the
higher
levels,
and
in
some
cases
you
smashed
everything
together
and
say:
okay,
I'm
going
to
repair
and
it's
select
and
assume
that
the
sfu
done
the
right
thing,
but
with
s
frames
you're
not
having
that
insight
into
this
as
easily,
you
probably
want
to
have
more
ssrcs,
so
you
can
see
that
you
lose
a
particular
layer
that
you're
forwarding.
So
you
can
try
to
decide
if
you're
going
to
repair
this
and
know
that
this
is
a
particular
layer
for
a
particular
source.
N
Let's
just
try
to
reiterate
the
point
here
of
of
that.
I
I
think
what
I
heard
from
and
magnus
is-
and
I
I
totally
agree
with.
I
think
we
just
need
to
think
about
this
way
of
that
in
your
picture
like
if
you
zoom
in
on
all
of
that,
where
the
encoded
stream
goes
into
the
media
transformer,
it's
not
really
a
stream.
N
It's
already
been
basically
packetized
at
that
point
and
there's
that
encoded
stream
actually
is
packetized
in
some
form
before
it
even
comes
in
and
that
packetization
is
inevitably
codec
specific
at
some
level
I
mean
you
know
you
have
to
implement
different
code
for
for
different
things.
There
I
mean
I
get
audio
separate,
I'm
talking
about
scalable
video
type
things,
so
I
think,
if
we
just
sort
of
reflect
on
that's
already
sort
of
happening,
it
sort
of
maybe
re-changes
how
you
frame
and
think
about
this
conversation.
L
L
I
need
to
know
them.
I
need
to
know
some
metadata,
but
I
don't
need
to
know
the
actual
format.
So,
yes,
I
need
to
know
some
this
metadata,
so
if
it
is
an
iframe
if
it
is
in
some
other
stuff
that
is
later
on
in
the
presentation
and
but
I
don't
need
to
know
the
actual
format
or
the
syntax
or
the
bytes,
but
I
need
I
for
sure
need
to.
L
N
So
I
think,
really
focusing
on
what
the
gap
between
those
what
the
sfu
needs
to
do,
a
good
implementation.
What
the
other
things
need
to
do.
It
is
the
right
thing
to
do,
and
I
I
don't
think
that
the
arguing
this
is
how
we
already
implement.
It
is
really
compelling
for
people
here,
like
I
think,
like
really
trying
to
get.
E
N
Right
design
for
s
frame
is
what
we're
trying
to
do
here,
so
I
I
mean,
pull
apart
those
of
what
you
know
like
the
the
like
the
form
of
argument
of
the
sfus
that
are
already
implemented.
Do
it
this
way,
therefore,
we
have
to
implement
the
clients
like
this,
like
that's,
not
very
compelling.
Both
the
sfus
and
the
clients
need
to
change
to
implement
s
frame,
we're
defining
what
both
of
them
do
here.
So,
let's,
let's.
A
A
C
Yep
all
right
yeah,
I
have
audio
but
no
videos,
sorry
so
yeah.
This
is
about
that's
tremendous
and
thanks
alex
for
the
queue
up
here
next
slide.
Please
I'm
going
to
breeze
through
this
pretty
quickly.
This
should
be
pretty
straightforward
and
non-controversial
so,
like
alex
said
s
frame
needs
a
way
to
get
keys.
Mls
is
a
way
to
provide
keys
in
srtp.
We
needed
a
way
to
get
keys.
C
E
C
C
C
So
you
kind
of
need
to
map
the
sequence
of
group
keys
into
the
key
id
space,
and
you
also
need
to
make
them
per
sender,
keys
and
signal
which
sender
you're
using
so
what
the
draft
defines
is
like
how
you
derive
these
person,
your
keys
and
how
you
signal
them
using
the
key
id
field.
Next
slide,
please
to
do
this.
We
just
do
kind
of
the
obvious
thing
for
deriving
for
sender
keys.
We
first
export
a
key
from
the
mls
context,
exactly
the
same
as
dtls's
rtp
does
with
tls.
C
They
use
an
exporter
to
get
a
key
and
then
the
first
sender
keys
are
just
derived
by
hkdfing
things
off
of
the
that
master
seeker
that
epoch
secret
the
index.
That's
input
here
is
something
we
assume
is
configured
mls.
One
of
the
things
it
also
provides
is
an
index
each.
Each
participant
in
the
group
knows
what
has
a
unique
index
of
that
that
participant's
location
in
the
group.
C
So
we
can
reuse
that
index
here,
and
so
we
just
encode
that
index
and
use
it
as
a
as
an
infinite
hkdf,
so
that
we
get
unique
keys
per
sender,
then
to
signal
the
stuff
in
key
ids.
We
just
take
the
two
integers.
We
truncate
the
epoch
to
a
certain
number
of
bits,
and
we
shift
over
the
cinder
index
on
by
that
number
of
bits
and
put
that
on
the
left-hand
side,
so
we're
here
we're
using
the
the
extensible
nature
of
the
key
id
field.
C
That
say
a
variable
length
integer
up
to,
I
think
64
bits
and
taking
advantage
of
that
to
to
you,
know,
put
these
numbers
two
numbers
in
there.
Instead
of
just
you
know,
one
opaque
number
now.
The
idea
of
this,
this
e
is
capital
e
number
here
is
that
we
we're
only
going
to
carry
a
certain
number
of
bits
of
epoch.
C
C
Please,
the
only
other
technical
content
here
is
negotiation
of
the
the
aforementioned
things.
So,
obviously,
if
you're
going
to
do
s
frame
encryption,
you
need
a
cipher
suite
you're
going
to
encrypt
with
the
s
frame.
Spec
defines
a
collection
of
cipher
suites
that
we
just
referenced
here.
They
have
ids
and
we
it's
a
typical
kind
of
offer.
Selection
paradigm
is
in
tls.
C
The
difference
is
that
in
mls,
the
participants
put
this
offer
in
a
key
package
that
describes
their
capabilities
and
then,
when
they
are
welcomed
into
a
group,
they
find
out
what
the
group
is
using
for,
for
you
know
the
specific
choices
for
these
parameters,
the
only
other
parameter
besides
the
cipher
suite
is
the
number
of
epoch
bits,
so
the
the
epoch
underscore
bits
field.
Here
is
the
same
as
the
e
field.
C
C
Yeah,
so
we
have
implemented
this
key
management
part
in
the
s
frame
repo
there.
You
know
this
is
the
scheme
that
we're
you
know
working
on
putting
into
into
web
access
we're
doing
the
the
stream
implementation
there
document-wise.
I
think
it's
pretty
okay,
it's
it's
obviously
functional
at
least
to
a
basic
level.
I
think
raphael
was.
I
don't
know
if
he's
on
the
call.
This
morning
he
was
thinking
about
adding
some
recommendations
about
how
you
manage
the
mls
groups
that
you
use
for
s-frame.
C
But
I
think
mostly,
like
I
said
at
this
point:
it's
pretty
functional
and
mostly
just
it's
going
to
stay
abreast
of
s
frame
as
this
frame
evolves
towards
standardization
and
that's
all
I
have
so
yeah.
I
think
this
is
in
pretty
good
shape.
Then
I
I
would
like
to
propose
the
working
group
take
it
on
for
that
deliverable
I
mentioned
at
the
top.
A
Thanks
richard
well
in
the
last
minute,
we're
not
going
to
be
having
a
lot
of
opportunity
to
discuss
this,
but
what
I
think
we
might
do
with
this
one
is
take
that
list
and
we
can
have
a
discussion
about
that.
It's
unfortunate
that
the
other
work
that
we
have
sort
of
doesn't
really
exist,
and
so
in
terms
of
it's
not
formally
adopted.
So
it's
almost
like
putting
the
cart
before
the
horse
in
a
way,
but
we
can.
A
We
can
probably
have
that
discussion
on
the
list
because
looks
good,
and
with
that
I
think
we
are
all
done.
I
noticed
my
co-chair
has
arrived
welcome
thanks
to
our
minute
taker
watson,
who
has
produced
some
excellent
notes
here
and
thanks
to
everyone
for
coming
and
having
such
a
a
good
discussion.
Maybe
next
time
we'll
have
more
time
to
discuss.
E
Bye
yeah.
Thank
you.
Martin
thanks
also
watson
for
note
taking
my
sincerest
apologies.
I
saw
the
utc
plus
one
time
zone
and
misinterpreted
it
as
utc.
So
here
I
am
three
minutes
early
for
a
meeting.
That's
actually
an
hour
late.
I'm
so
sorry
about
that.
Thank
you.
Everyone
and
I
look
forward
to
catching
up
with
the.