►
From YouTube: IETF110-QUIC-20210310-1200
Description
QUIC meeting session at IETF110
2021/03/10 1200
https://datatracker.ietf.org/meeting/110/proceedings/
B
C
B
A
Should
we
should
we
get
started,
then?
Okay,
hello,
all
welcome
to
the
quick
working
group
meeting
session
for
itf
110.
If
you're
not
meant
to
be
in
this
session,
please
leave
the
room
now,
while
you
have
the
opportunity,
this
is
a
virtual
session.
We
have
today
three
chairs
just
to
help
lift
the
load.
So
matt
is
our
new
chair
to
come
on
board
and
help
take
over
from
lars
as
he
transitions
away
I'll.
Let
lars
maybe
speak
to
some
of
that
in
a
bit
more,
but
yeah.
A
We've
got
a
quite
busy
agenda
today:
lots
of
presentations
of
adopted
items
with
a
few.
You
know
as
time
permits
stuff,
which
we
can
come
on
to
in
the
agenda
bashing
in
a
moment.
But
yes,
the!
Where
are
we
the?
This
is
what
we're
looking
like
for
now.
We
did
have
some
hackathon
activity
during
the
last
week
and
lars
is
going
to
give
an
update
of
that.
A
A
We
should
bring
up
the
note
well
just
in
case
you're
not
familiar
with
it.
We
are
part
way
through
the
week
now,
so
you
should
be
probably
familiar
with
this,
but
this
details
was
a
good
entry
point
into
detailing
how
you
contribute
to
the
itf,
including
you
know,
lots
of
stuff
around
pattern,
policies
or
importantly,
our
code
of
conduct
and
how
you
interact
with
the
group
and
participate.
So
if
you're
not
familiar,
please
go
away
and
look
at
the
note.
A
A
A
Agenda,
I
guess
oh,
that's
a
good
point.
So
let
me
let
me
scroll
down
a
bit
just
to
to
give
the
full
view
of
the
agenda
so
to
go
through
them
in
just
a
little
bit
more
detail
for
people
we'll
we've
got
equal
balance
of
time
for
presentations
from
the
different
adopted
items,
so
the
ops
drafts
manageability
and
applicability
slides.
Then
we
have
tommy
talking
about
the
datagram,
slides,
sorry,
the
data
grammar
extension,
then
david
talking
about
vision,
negotiation
and
finally,
martin
with
the
quick
lb
stuff.
A
We
we
think
the
quick
lb
might
be
a
little
heavier
than
the
others,
which
is
why
we
put
it
at
the
end,
but
yeah
we'll
we'll
try
and
get
through
those
things.
And
then
we've
got
possible
presentations
from
martin
or
jonah
about
their
possible
things
we
might
want
to
adopt
before
moving
on
to
some
planning
and
wrap
up.
So
the
question
is
to
people:
does
anyone
want
to
bash
that
agenda.
B
No,
we
don't
because
there's
nothing
really
to
to
do
for
us
at
the
mall,
but
we
have
a.
We
have
a
charter
proposal
out.
I've
seen
one
suggestion
so
far
come
in.
That
was
like
an
editorial
change
that
is
easy
to
make
and
I
guess
the
call
for
feedback
from
the
communities
you
know
better
than
I
might
was
another
couple
days.
F
B
Yeah-
and
maybe
it's
sort
of
in
just
the
summary-
is
that
the
quick
working
group
changes
it's
its
format
a
little
bit.
It's
sort
of
now
that
we've
we've
finished
version,
one
of
the
documents
or
the
base
drafts
we
sort
of
changing
changing
gear
and
the
hdp
part
qpeg
and
http
we're
handing
over
to
the
hdbis
working
group
for
maintenance.
B
We
are
continuing
to
maintain
the
other
documents
that
we
have,
or
we
will
soon
publish
we're,
also
going
to
maintain
operability
and
manageability
documents
and
related
ones.
We
are
going
to
maintain
the
extensions
that
we're
gonna.
We
have
worked
on
already
we're
gonna,
do
new
extensions.
Those
may
or
may
not
be
in
support
of
higher
layer
protocol
bindings
too
quick.
B
I
guess
the
sort
of
the
thinking
is
that
if
you
want
to
layer
a
protocol
on
top
of
quick-
and
you
require
a
complicated
extension
to
do
that-
that
extension,
we
probably
would
want
to
do
inside
the
quick
working
group.
If
you
need
something
very
straightforward,
you
know
you
can
do
that
elsewhere
in
the
itf,
together
with
your
binding
or
even
outside
the
itf.
B
B
A
So,
if
anyone's
looking
at
this
agenda
and
wondering
why
we're
not
talking
about
any
issues
on
those
documents,
it's
because
effectively
they're
they're
done,
there's
still
some
work
to
do
in
terms
of
all
48,
etc
kind
of
changes,
but
yeah
we've
updated
some
of
the
guidance
on
the
base,
dress,
repo,
just
to
say,
like
we're,
not
we're
not
accepting
anything.
Now
we're
done
here
we're
ready
to
ship.
We
need
to
go
through
the
process,
but
please
don't
come
along
and
open
issues
about.
A
It
would
be
nice
to
have
this
or
that
if
there's
there's
fundamental
problems
with
the
protocol,
security
issues
or
major
editorials,
we
need
to
involve
the
whole
community
in
the
itf,
not
just
this
working
group
and
together
with
our
responsible
ad,
we'll
be
able
to
do
that.
But
yeah.
Please
please
take
this
seriously
because
the
ship
is
is
going
it's
it's
almost
over
the
horizon,
so
we
can
be
very
grateful
but
I'll
I'll
be
quiet
for.
B
Now
yeah
one
quick
addition.
I
talked
to
the
rfc
editor
the
other
day
and
the
expectation
is
that
we
will
see
the
first
batch
of
these
documents
pop
out
into
auth
48
in
in
a
time
that
sort
of
measured
in
weeks
and
not
months.
So
it's
it's
going
to
be
reasonable
soon,
since
the
queue
over
there
is
pretty
short,
as
you
guys
probably
know,
the
http
related
documents,
http
and
qpac
are
waiting
for
some
work
in
the
http.
B
B
Part
of
that
is
because
we
are
sort
of
just
switched
over
to
using
version
one,
and
not
all
stacks
have
sort
of
made
that
change
yet,
and
also
a
lot
of
the
interrupt
testing
is
now
actually
happen
in
an
automated
fashion.
All
the
time
thanks
to
martin
seaman
and
this
interrupt
runner,
and
so
there
you
have
a
bit
more
green,
which
means
implementations
that
already
support
zero
x1
as
a
version,
wherever
you
see
only
red.
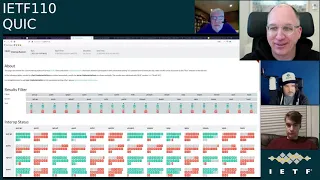
B
C
But
that's
quite
interesting.
It
shows
two
things.
As
you
said,
I
mean
the
academy
is
moving
from
basic
stuff,
like
a
very
thing
that
everybody
can
do:
zero
rtt
to
performance
like
verifying
that
everybody
can
hit
several
gigabits
of
performance.
That's
one
part,
so
it's
maturity,
and
the
other
thing
which
is
interesting
is
that
this
shows
that
the
work
done
by
the
various
operating
systems
to
make
udp
work
better
is
starting
to
pay
off.
I
mean
a
year
ago.
C
Those
performance
would
have
been
about
500
to
600
megabits,
instead
of
one
to
five
gigabits,
and
so
the
difference
is
because
I
mean
they've
been
worked
on
in
linux
and
in
windows
to
make
a
udp
faster
with
things
like
udp
gso
and
that
that
is
paying
off.
That
means
that
the
the
operating
systems
are,
in
fact
adapting
too
quick,
and
that's
good
news
for
the
working
group.
D
So
I
guess
I
can
go
ahead
and
I
don't
really
actually
need
to
be
in
the
queue
I
can
just
go
ahead
and
start
sending
apparently
hi.
I
am
not
iriegnt
and
I
will
be
talking
about
the
operations
drafts
applicability,
manageability
next
slide.
This
tl,
dr,
is
mainly
for
people
who
are
not
here
today,
so
they
can
tell
whether
they
need
to
look
at
the
slide
deck
or
not.
Mainly.
Thank
you
all
very
much
for
participating
in
the
working
group.
Last
call.
D
D
D
So
we're
going
to
talk
about
you
know
a
couple
of
open
issues
with
input.
A
couple
of
things
might
need
text
we're
going
to
talk
about
those
right
now
so
next
slide.
A
recap
updates,
in
version
revision,
10
a
bunch
of
editorial
changes
in
both
documents.
Thank
you,
everybody
for
all
the
reviews,
a
few
content
changes
that
are
primarily
editorial
or
slightly
more
than
editorial.
D
The
the
big
one
here,
I
think,
is
a
new
section
on
icmp
handling.
So
if
you
have
not
it's,
this
is
number
249
in
the
manageability
draft.
So
if
you
have
not
had
a
look
at
revision
10,
these
were
mainly
editorial,
mainly
sort
of
like
small
fixes.
Before
this
meeting,
however,
there
is
some.
There
are
some
changes
to
the
to
the
the
content.
So
please
do
go.
D
D
The
main
reason
we
want
to
bring
this
to
people's
attention
is
that
it
changes
the
reference
structure
of
this
document
right
like
so.
It's
a
pr
discussion.
Extension.
It's
the
first
time.
We
would
discuss
an
extension
in
these
operations
drafts.
However,
since
this
is
now
a
milestone
of
the
working
group,
it
seems
like
it's
it's
a
reasonable
thing
to
point
to.
There
is
a
recommendation
on
acting
and
reducing
the
act
rate
on
constrained
links,
which
we
believe
is
ready
to
merge.
Please
do
go,
have
a
look
at
number
233.
D
If
you
have
opinions
on
accra
constraint,
we'd
like
a
couple
more
eyeballs
on
this,
we
will
be
intend
to
merge
that
one
relatively
soon
so
speak
now,
there's
an
open
issue,
so
we've
basically
talked
about.
There's
been
some
text
going
back
and
forth
on
the
use
of
probing
packets
in
order
to
actually
start
getting
information
into
a
congestion
controller
about
the
capacity
of
a
link.
This
is
I,
I
think
we
we
had
a
different
term
for
this.
D
At
one
point,
it's
currently
being
called
in
this
pr
priming
the
cc
there
are
questions
as
to
what
what
is
priming
the
cc.
I
think
we
call
that
preheating
at
one
point
there
seems
to
be
some
going
back
and
forth
in
the
terminology
here
we'd
like
some
input
here
on
whether
we
should
change
the
wording
or
whether
it's
even
important
to
say
this.
H
Give
the
audio
works,
but
maybe
it
does
cool
and
I'm
not
sure
we
need
this
text,
which
is
my
main
comment
on
that
issue
with
the
primer
cc,
and
if
we
don't
say
it,
we
can
still
do
it
and
in
future
we
can
specify
it.
If
we
say
here,
I
think
we
really
need
to
be
careful.
We
explain
what
prime
means
that
somebody
has
looked
at
the
cc
implications
of
doing
this
badly
and
that
we
give
appropriate
advice
and
I'm
not
sure
we're
in
the
position
to
those
last.
H
G
Let
me
yeah,
let
me
reply
to
that,
so
the
intention
here
really
was
just
like
to
mention
what
pro
packets
can
be
used
for.
This
is
a
kind
of
a
list
of
things,
and
this
is
like
one
potential
use
of
pro
pack.
It's,
I
don't
think
we're
at
the
position
where
you
want
to
like
recommend
a
specific
algorithm
or
whatever,
because
we
don't
have
one,
but
I
think
it's
still
a
good
use.
It's
still
something
that
can
be
very
valuable
in
future,
and
I
would
like
to
have
it
in
here.
G
C
I
F
G
D
G
Yeah-
and
there
was
a
comment
in
the
chat
saying
this-
this
is
kind
of
internal
and
not
really
something
that
the
application
can
impact.
But
I
think
the
reason
why
we
mentioned
it
here
because
is
because
some
of
the
applications
might
want
to
actually
impact
that.
So
you
might
want
to
consider
if
you
can
provide
any
kind
of
interface
for
it,
because
it
might
be
more
important
for
for
some
applications
than
others.
D
That
was
what
I
was
going
to
say
so
now,
I'm
moving
on
to
manageability,
so
we've
got.
We've
had
some
discussion
on
the
text
on
udp
timeouts.
Previously
the
document
was
citing,
I
think,
some
work
that
lars
did
about
15
years
ago
on
the
distribution
of
udp
timeouts
in
the
in
the
internet,
saying
we
want
to
be
longer
than
that
30
seconds,
which
is
everywhere
now
we
have
we're
pointing
to
recommendations
in
rfc
4787.
D
That
says,
you
know
not
less
than
two
minutes
for
most
udp
traffic
and
please
go
above
that.
We
believe
that
this
is
the
right
most
recent
advice
that
we
want
to
give
you
know.
We
also
understand
that,
like
there's,
you
know,
two
minutes
is
what
we're
saying
in
terms
of
of
of
timeouts
on
the
endpoints
there's
30
seconds
in
the
network,
so
there's
a
little
bit
of
of
a
difference
between
the
advice
and
what's
widely
deployed
right
now,
but
we
do
think
that
4787
is
the
right
recommendation.
D
So
if
people
have
other
input
on
that,
please
jump
on
to
pr222
before
we
merge
it.
We've
also
added
the
proposed
section
on
so
guidance
for
path
mtu.
So
this
is
guidance
that
essentially
says
you
know.
Please
drop
a
large
quick
packet
rather
than
fragmenting
it,
so
that
quick
gets
the
feedback
that
it
needs
to
adjust
its
mtu.
D
D
The
nat
section
has
been
rewritten
to
minimize
text.
There
was
some.
There
was
some
redundancy
in
there.
It
hadn't
actually
been
had
a
very
fine
editorial
comb
on
it.
Now
it
has,
it
is
an
editorial,
or
at
least
the
intention
is
that
it's
editorial,
but
it's
huge
so
more
eyeballs
on
that
one
before
we
merge
it
would
be,
would
be
good
so
on
to
the
next
slide.
D
In
section
nine
talks
about
the
algorithm
and
then
there's
like
you
know,
pseudocode
in
the
appendix
that
goes
into
more
detail.
There's
a
request
in
this
issue
to
remove
the
the
text
in
the
appendix.
However,
it
might
be
helpful
for
the
community,
so
we'd
like
more
input
on
that
as
well.
Again,
please
in
the
in
the
bug.
That's
number
244,
just
like
what.
D
D
G
I
J
So
getting
all
the
versions
we
know
about
into
the
registry
should
be
relatively
straightforward.
We
can
just
do
a
quick
poll,
we
can
scrub
the
the
wiki
that
we
have
and
I
think
we're
in
the
process
of
appointing
experts
for
those
re
for
those
registries
now.
So
we're
not
quite
at
the
point
where
we
can,
where
we
can
take
those
things,
but
we
should
be
able
to
have
that
in
time
for
this
document
to
be
published.
D
That
sounds
like
that
sounds
like
it
sounds
like
that
one's
resolved
yay.
Thank
you
magnus
for
stopping
me
through
my
race
through
this
document
and
then
a
a
third
a
bit
on
connection
id
requirements.
I
believe
that
this
was
originally
before
these
were
tightened
up.
This
is
older
text.
I
believe,
before
these
were
tightened
up
in
the
transport
document.
We
wanted
to
have
some
text
here
and
now
it
essentially
just
repeats.
D
D
D
So
basically,
you
know
how
like
talking
about
how
a
a
like
dos
classification
could
be
done
with
knowledge
that
comes
from
the
server
on
your
endpoint
about
at
least
connection
id
links,
if
not
connection
id
data,
so
that
would
need.
We
would
need
text
on
that.
If
there
are
authors
who
would
like
to
help
us,
please
jump
into
240
or
just
assign
it
to
yourself
same
with
respect
to
our
recommendation
to
tell
metal
boxes
to
ignore
the
version.
D
G
Yeah,
I
think,
on
on
178.
It's
really
also
about
what's
the
recommendation
we
actually
want
to
give
here,
like
the
current
recommendation
is
stated
here,
but
the
the
issue
was
also
about.
Is
that
the
right
recommendation
do
we
need
to
change
this
and
then
like
what
would
be
the
new
recommendation?
So
this
would
be
helpful
if
more
people
could
look
at
this
and
comment
on
this.
H
Yeah,
I
may
have
been
a
part
in
both
of
these
perhaps,
and
I'm
still
interested
in
finding
the
right
answers
here,
because
these
are,
these
are
actually
two
tricky
ones
from
where
I
was
the
last
one
might
be
more
to
do
with
the
whether
it's
a
constrained
environment
or
an
enterprise
or
a
different
deployment
context
to
which
many
people
are
thinking
about
quick,
so
that,
if
we
think
about
them
in
that
context,
maybe
we
get
a
bit
more
view.
If
anyone
is
willing
to
try
and
provide
text,
I
was
certainly
willing
to
help
contribute.
H
D
H
H
D
To
to
get
us
started
on
that
excellent
thanks
so
much
so
that
brings
us
to
the
end.
You
can
go
and
look
at
the
last
slide,
but
it's
basically
you
know
step
one
merge
pr
step.
Two
question
mark
step,
three
publish
so
again.
I
think
I
haven't
heard
anything
here
that
changes
our
estimation
that
we
are
definitely
ready
sort
of
after
we
we
close
the
last
issues
on
applicability,
but
well
ready,
like
post
wglc,
we're
ready
to
send
it
up.
D
D
A
There's
something
really
important
you
might
have
like
a
minute,
but
beyond
that
I
think
I
think
this
gives
a
good
picture
of
where
we're
at
and
we've
got
some
people
signed
up
to
help
guys
keep
cranking
that
handle
so
there's
other
editorial
issues
on
that,
because
so,
if
people
feel
inspired,
please
check
it
out
and
get
involved.
I
would
say
all.
K
K
Please
all
right,
so
the
status
here
is,
I
think,
we're
in
pretty
good
shape.
We
have
looking
through
the
issues
list.
I
would
say
four
substantive,
open
issues,
that's
the
ones
that
we
want
to
discuss
today.
There
are
a
couple
other
editorial
issues
that
you
can
go
and
look
at
on
the
github,
and
I
want
to
highlight
that
this
work
is
actively
the
basis
for
what's
going
on
in
the
mask
and
web
transport
working
groups.
K
So
please
you
know
if
you're
really
interested
in
this
stuff.
If
you
go
there,
you'll
have
all
the
time
you
want
to
argue
about
the
details
of
how
you
use
datagrams
and
those
are
very
active,
and
I
want
to
highlight
also
that
mask
has
been
doing
interop
testing.
It
did
that
last
week
during
hackathon,
so
we
have,
you
know
four
or
five
plus
different
implementations,
doing
interop
with
datagrams
and
application
work
on
top
of
datagrams.
K
So
I
think
we
now
have
a
pretty
good
experience
using
this
and
we're
in
a
place
where
we
can
hopefully
close
out
the
issues
and
make
good
decisions
about
them,
and
our
milestone
currently
is
to
have
this
shipped
off
to
the
isg
by
july.
So
I
think
we
can
do
it.
Let's
just
try
to
converge
on
these
issues
and
get
it
shipped.
D
I
K
One
of
our
open
issues
is
a
eternal
topic
that
keeps
coming
back,
and
this
is
the
current
iteration
of
it
issue.
Six
talking
about.
You
know
why
don't
we
have
any
flow
ids
at
the
quick
transport
layer,
and
this
has
been
something
that's
been
discussed
since
you
know
before
this
was
adopted
since
the
very
earliest
discussions
we've
had
versions
with
the
fluidity
versions
without
we
currently
do
not,
I
think,
every
time
we
come
back
to
this.
K
Eventually
we
get
to
the
point
where
we
say
that
you
know
that
there
is
no
transport
level
function
of
a
flow
identifier
of
a
datagram
if
it
does
not
influence
any
flow
control.
Any
behavior
like
that
at
the
transport
layer
itself.
Currently,
the
text
in
section
5
does
explain
that
applications
can
define
their
own
demuxing.
K
It
kind
of
gives
the
example
of
how
http
3
is
doing
that
with
a
flow
identifier.
Currently,
the
question
keeps
coming
up.
I
do
believe
that,
overall,
the
discussion
has
consensus,
that
we
are
doing
the
right
thing,
but
it
seems
to
me
from
the
issue
that
what
we
want
to
do
is
kind
of
end
up
with
an
editorial
change,
to
just
really
highlight
and
make
clear
what
you
should
do
if
you
need
to
do
demoxing.
K
One
of
the
suggestions
was
essentially
just
to
pull
the
current
text
in
section
5
into
its
own
subheading,
so
it
shows
up
in
the
table
of
contents,
it's
its
own
section,
5.1.
That
explains
that
you
know.
If
you
need
identifiers,
you
can
define
them
in
this
way
and
it's
purely
application
semantics
at
that
point.
L
So
I
mean
I
just
want
to
like
I'm
not
advocating
for
one
thing
in
particular,
but
I
think
it'd
be
supposed
to
lay
out
what
the
cost
of
this
position
are
and
the
benefits
the
benefits
position
is
not
to
carry
any
machinery
in
in
this
draft
or
in
your
datagram
quotation.
If
you
don't
need
full
ids,
the
cost
of
this
position
are
one
sort
of
document
mechanics
which
is,
if
you
want
full
ids.
L
You
have
like
you
know
if,
like
just
like,
have
a
document
which
largely
probably
means
h3,
you
know
it's
380
gram,
so
you
have
like
an
extra
like
little
little
document,
shim
in
between,
like
in
between
between
your
document
datagram,
which
is
not
a
big
deal
if
you're
using
h3
and
then,
if
you're,
not
using
h3,
then
you
have
to
like
make
a
new
make
a
new
thing,
almost
like
a
three
datagram,
like
maybe
a
copy
http
when
crossing
out
h3
everywhere
right
and
those
are
the
cost
and
benefits
these
two
positions.
Correct.
K
Yeah-
and
you
know
just
to
highlight
some
of
the
conversations
we're
having
in
mask
where
we're
working
on
h3's
use
of
datagram
we're
still
trying
to
converge
there
about
you
know
what
does
this
identifier
mean,
and
I
think
you
know
we're
even
calling
into
question.
Is
it
really
a
flow
identifier?
Is
it
more
of
just
like
an
application
label
on
a
set
of
messages?
So
I
I
think
yes,
there
is.
K
It
puts
a
bit
of
burden
on
the
application,
but
it
also
gives
the
application
a
lot
of
freedom
to
define
what
it
wants
to
put
is
this
identifier,
and
it
may
even
be
that
http
3
won't
strictly
use
it
as
a
flow
identifier
that
it
may
be
thought
of
something
more
broad
than
that.
I
think
that's
one
of
the
reasons
really
not
to
put
it
here.
L
Sure
yeah,
I
I'm
not
objecting
that.
I
think
I
mean
the
perhaps
one
way
to
resolve
this
issue
would
be
as
well
as
making
the
sort
of
changes
you
make
to
make
a
what
let's
say
I
put
this
to
like
have
like
a
section
that
explains
this
a
little
I
mean
I
guess
you
already
have
one
but
so
point
to
age,
three
and
basically
say
if
you
know
if
in
future,
to
determine
that
like
essentially
like
a
zillion
use
of
datagram,
something
from
my
perspective.
L
If
everyone
uses
these
three,
this
will
like
a
total
non
problem
right
and
everyone
uses
h3.
They
usually
they
can
just
point
to
hpd
hd
datagram,
and
that
has
a
flow
id
and
some
machine
accomplished,
and
I
like
to
do
is
like
have
two
more
two
slices
out
of
one
and
if
they're
turned
out
to
have
a
lot
of
applications,
you
want
to
datagram
and
want
flow
ids
and
don't
do
h3.
Then
all
we
need
to
do
is
like
clone
a
tree.
L
K
L
M
Yes,
no,
I
just
wanted
to
say
that
most
of
the
arguments
we've
heard
from
folks
about
wanting
flow
ids
sounded
like
they
wanted
to
multiplex
multiple
applications
over
quick,
and
that
was
intentional.
Well,
that
was
discussed
in
this
working
group
and
intentionally
rolled
out
of
scope
for
quickv1
and
so
like
right.
Now
you
only
have
one
application
and
it's
identified
by
your
alpn
and
so
like
once.
M
I
think
folks
realize
that
they
like
wanting
this
at
the
up
at
the
transport
layer,
became
less
useful
whereas
having
it
at
your
application,
makes
total
sense
on
the
topic
of
folks
who
wanting
to
use
this.
The
h3
datagram
document
has
about
like
one
paragraph,
which
is
hey.
The
datagram
starts
with
a
flow
id
and
then
the
entire
rest
of
the
document
is
about
how
you
integrate
this
with
http
3..
M
It's
about
the
setting.
It's
about
how
you
negotiate
it
in
a
very
http
specific
manner.
Right
now,
for
example,
it
uses
an
http
header.
If
another
application
wants
to
use
this,
we
don't
need
to
like
clone
or
split
off
a
document.
They
can
just
write.
A
sentence
like
us,
which
is
the
datagram,
starts
with
a
flow
id
and
here's
what
a
floyd
means
in
our
application
and
here's
how
we
negotiate
it.
So,
like
the
like,
I
don't
really
see
the
value
in
centralizing
this.
M
N
K
K
K
Technically,
you
know
that
that
is
something
that
is
just.
There
is
already
a
default
behavior,
but
we
would
do
well
to
specifically
say
that,
and
so
the
consensus
on
the
issue
seems
to
be
like.
Everyone
agrees
that
a
packet
with
only
datagram
frames
should
be
treated
like
any
other
packet,
and
so
if
a
implementation
detects
loss
or
has
the
pto,
then
it
should
send
a
ping
frame
in
order
to
kind
of
kick
things
off
again.
K
J
K
J
P
P
So
the
point
here
is
that
you
know
datagram
packet
is
lost.
No
acts
are
received,
you're
not
going
to
retransmit.
Anything.
We've
seen
this
problem
before
in
transport
and
that's
kind
of
the
point
is
that
you
know
just
deal
with
the
same
way.
We
do
it
for
packets
that
we
typically
quick.
Do
not
retransmit.
That's
really
the
point
here
and
if
you
don't
have
anything
enqueued.
If
you
want
to
evoke
an
act
from
the
other
side,
then
you
send
a
pink.
J
Right
so
this
is
this
is
what
the
recovery
draft
specifies,
but
what
benefit
does
that
provide
so
say,
you've
only
ever
been
sending
datagrams
that
you
don't
care.
What
possible
value
is
there
to
that?
Is
it
it's
probably
related
to
the
bytes
in
flight
and
all
of
the
other
loss
recovery
machinery
right.
P
It's
it's
a
cleanup
stuff.
I
mean
we've
gone
back
and
forth
on
this
and
honestly,
I'm
trying
to
page
in
some
of
this,
because
the
discussion
happened
here
almost
a
year
ago
on
this
particular
issue.
But
I
think
that
the
the
two,
the
two
positions
you
can
you
can
take.
We
won't
do
anything
if
there's
nothing
to
send.
Basically
what
what
happens
is
if
I
don't
have
an
ack,
but
I
have
nothing
to
send,
then
I
can't
receive
an
act
back
from
the
peer.
Q
P
It's
me
deco.
Can
you
hear
me
now?
Yes,
thankfully
informed
me
that
my
audio
was
disconnected
for
some
people,
but
they
reconnected
again,
so
I'm
grateful
so
yeah.
I
mean
that
those
are
the
two
options
as
we
as
they've,
been
in
transport.
We've
taken
the
general
stance
of
saying:
please
send
a
ping
so
that
you
can
do
your
math
correctly
unless
there's
a
reason
to
do
it
differently.
Here
I
would
just
stick
with
the
same
that
sort
of
okay.
J
M
E
R
O
A
K
All
right,
so
next
one
is
a
bit
more
fun.
The
issue
around
you
know
how
do
we
actually
negotiate
the
support
for
the
datagram
frame?
Currently
there
is
a
transport
parameter
and
it
is
a
max
datagram
frame
size,
and
so
this
is
specifically
the
size
of
the
entire
frame
here.
There's
a
proposal
and
a
pr
to
switch
this
from
a
max
datagram
frame
size
to
a
max
datagram
payload
size
such
that
you're.
K
K
Currently,
if
you
have
a
zero
set
in
your
max
datagram
frame
size,
that
means
that
you
do
not
support
the
datagram
frames
at
all.
We
do,
I
think,
want
to
be
able
to
support
sending
zero
length
datagram
frames.
So
if
we
switch
to
datagram
payload
size,
then
zero
would
presumably
still
be
a
valid
datagram
support
and
you
would
only
be
able
to
send
empty
datagrams,
which
is
a
bit
weird
but
sure
on
the
issue.
There's
also
discussion
of.
Do
we
actually
need
any
limit?
Can
we
just
say
I
support
datagrams?
K
L
K
L
Right
right
right,
like
I
guess
what
I'm
saying
is
like
that
we're
I
mean
so
so
right
so
you
can
say
I
don't
support
datagrams
by
not
saying
this
at
all
right
and
exactly
and
so,
and
there's
no
and
and
the
way
you
say
like.
I
don't
care
about
size,
as
I
assume
to
offer
like
ffff
or
something
right,
yeah.
It's
like
do
not
normally
large
number
right,
and
so
I
mean
I
guess
the
question
is:
is
it?
Is
there
a
reasonable?
L
K
M
Just
to
explain
the
reason
that
right
now,
zero
means
not
allowed
it's
to
make
implementations
easier
and,
in
general,
all
of
the
other.
Well,
all
of
the
core.
Spec
var
and
transport
parameters
in
quick
have
a
default
value
and
so
making
a
default
value
of
zero.
Here
it
makes
it
easier
to
implement
that
way.
You
say,
oh,
if
I
don't
receive
it,
I
set
it
to
zero
and
or
if
I
receive
it
with
zero.
It
means
the
same
thing
and
that's
why
they're
like
this
in
the
spec.
M
L
Of
go
ahead,
derek,
but
now
I'm
confused,
because
it
seems
to
me
that
now
zero
and
not
present
have
different
semantics,
because
zero
means
I
always
support
empty,
datagrams
and
and
and
not
present
and
and
they're
not
present
as
crazy
semantics,
because,
like
I'm,
I
mean
like,
if
you
don't
send
this
again,
we
all
agree.
If
you
don't
send
the
extension,
you
can't
send
datagrams
right.
I
mean
like
that's
like
that
has
to
be
the
case
right.
Yes,
well,
yes,
and.
M
L
M
L
Well,
I'm
excited,
I
guess
I.
I
certainly
don't
think
that
like
like
I
I
mean
I
just
ignore
it
and
it
seems
like
there
are
two
kind
of
like
annoying
issues
here
right.
One
is
like
it's
annoying
to
have
to
like
take
into
account
the
different
size
when
you
figure
out
what
you're
allowed
to
send
and
so
like
that
seems
like
motivation,
that's
tommy
says
that's
motivation
for
making
this
change,
and
then
that
just
comes
with
this
annoying
implementation
issue
that
you
indicated,
which
is
now
like
it's
anointed
with
the
extension
right.
L
Not
I
mean
I
guess
I
I'm
le.
I
think
I'm
a
little
less
persuaded
by
the
like,
but
by
like
the
default
like
default
versus
default
value
argument
than
others
maybe,
but
so
I
guess
you
know
if
I,
if
I,
if
I
have
to
pick,
I
guess
I
would
say,
like
you
know,
fine,
like
you
know,
zero
zero
means
the
the
stupid
thing,
which
is,
you
can
only
send
zero
length
datagrams
and
I
think
we
could
also
require
we
could
also
forbid.
L
L
M
K
M
One
yeah
and
the
last
10
second
thing
I'll
say,
is
because
this
is
kind
of
deployed
in
running
code.
In
a
bunch
of
places,
I
would
be
inclined
to
keep
it,
as
is
because,
if
we
change
it,
we'd
have
to
renumber
the
transport
parameter
and
we
have
already
have
a
nice
one,
byte
value.
That
would
be
nice
to
keep
yeah,
and
it's
also.
O
E
Word
yeah.
I
just
wanted
to
go
back
to
what
you
were
saying
about.
Do
we
really
have
a
reason
to
limit
the
size
beyond
the
packet
size
already
I
there
was
some
discussion
on
the
issue
and
I
never
saw
a
good
reason
to
actually
have
the
limit
at
all
all
right,
so
I
my
personal
preference,
would
just
be
to
have
a
enable
disable
the
feature
transport
parameter
and
leave
it
at
that.
C
K
Good
to
know,
I
think,
then
I
would
kind
of
lean
towards
saying
we
either
leave
it,
as
is
essentially
as
an
escape
hatch
for
future
applications
to
limit
the
size
if
they
want
to
or
we
switch
it
to
a
boolean.
Essentially
so
we'll
continue
that
on
the
issue,
but
this
has
been
very
useful.
Thank
you.
Next
slide
very
quickly.
K
K
The
issue
is
opened
about
asking
what
happens
if
the
receiver
drops
act
frames
before
actually
delivering
them,
and
this
essentially
raised
the
conversation
around
who
effectively
owns
the
buffer
of
incoming
datagrams,
quicker
the
application
and
the
suggestion
in
the
issue,
and
I
think
my
preference
would
be
to
say
that
you
know
conceptually
once
you
have
received
a
datagram
you've
enacted
it.
It
is
kind
of
between
that
quick
implementation
and
the
application
to
ensure
that
the
application
doesn't
unknowingly
drop
it.
K
So
either
you
immediately
deliver
it
up
to
the
application
and
the
application
owns
the
queue
of
datagrams,
and
if
it
runs
out
of
space,
it
can
drop
them
or
if
quick
is
doing
that
for
you,
it
has
to
let
the
application
know
that
it
ended
up
dropping
some
packets
because
they
ran
out
of
room.
So
there's
no
case
in
which
you
silently
are
losing
datagrams,
but
telling
the
other
side
that
you
have
processed
them
david.
M
I
just
added
some
just
wanted
to
add
some
implementation
experience
here.
So
in
web
transport
we
use
datagrams
and
in
particular
in
the
implementation,
the
quick
stack
and
the
javascript
that
consumes
the
web
transport
datagrams
are
not
in
the
same
process
in
chrome,
and
so
the
application
and
the
transport
here
are
running
in
separate
processes,
and
there
is
no
synchronous
interface
between
them.
Everything
is
asynchronous,
and
so
the
there
is
no
possibility
of
like
the
the
quick
stack
is
not
going
to
wait
for
an
asynchronous
quality
application
in
back
before
it
can
act.
M
M
K
Useful
right,
I
think
if
the
conversation
in
the
issue
was
saying
that
if
you
have
at
least
at
least
a
way
to
query
like
did
you
drop
any
packets
for
me
like
just
as
metadata
here.
That
would
allow
the
application
level
if
it
needs
to
do
any
application
level
signaling.
Depending
on
what
you
know.
Let's
say
it's
doing,
video
frames
or
something
and
it
wants
to
do
a
reset
because
it
realized
it
had
a
big
loss
event
and
lost
a
ton
of
frames
or
it
is
missing
something
that
it
can
do.
K
E
E
It
makes
sense
that
for
implementations
that
do
cue,
that's
practically
going
to
be
required,
but
that's
also
an
assumption
like,
for
instance,
ms
quick
does
not
cue.
It's
an
inline
indication.
So
hey
it
for
us.
It
was
easy
to
support
this,
but
I
was
sad
to
hear
that
other
implement
implementations.
It
was
not.
K
M
M
M
So,
just
a
very
brief
trip
down
memory
lane
here
to
explain
how
we
got
here
so
google,
quick
added
versioning
pretty
early
on
in
its
history
and
a
little
bit
later,
because
to
avoid
to
avoid
downgrade
attacks.
Well,
sorry,
because
they
had
multiple
versions,
then
it
needed
version
negotiation
and
then
to
avoid
downgraded
attacks.
It
eventually
added
downgrade
protection.
M
M
He
identified
that
if
you
have
a
server
deployment
where
you
have
different
versions
rolling
out
at
different
times
or
like
a
multi-cdn
scenario
where
you
could
have
some
of
your
fleet
support
some
versions
and
the
other
ones
support
other
versions,
because
they're,
like
maintained
by
another
vendor
this
downgrade
protection
feature,
could
actually
fail.
Connections
that
should
have
been
valid
if
you
end
up
like
hitting
one
side,
getting
a
version,
negotiation
hitting
the
other
and
then
getting
confused,
because
the
other
doesn't
support
the
same
ones
as
the
first
one.
M
So
at
the
time,
because
we
really
wanted
to
make
progress
on
the
quick
core
documents
and
not
get
blocked
by
these
design
issues.
The
decision
of
the
working
group
was
to
remove
version
negotiation
from
the
core
documents
and
say
that
this
would
be
handled
by
an
extension
and
so
ecker,
and
I
in
early
2019
then
published
this
as
an
individual
draft,
which
then
early
2020
was
adopted,
and
here
we
are
so
next
slide.
Please.
M
All
right,
so
the
as
we
were
saying,
the
core
documents
are
out
the
door
almost.
What
do
we
have
right
now
in
the
spec,
so
in
quick
v1
and
in
the
environs
we
define
the
format
of
a
vm
packet,
which
is
a
server
to
client
packet,
saying,
hero
versions,
I
support
and
in
the
core
spec.
It
says.
If
you
receive
this
during
the
handshake,
you
abort
your
connection,
because
it
means
that
the
server
doesn't
support
your
version,
but
you
don't
retry
with
another
version
because
there's
no
downgrade
prevention
system.
M
If
your
implementation
only
supports
quickview
one,
that's
fine,
because
if
the
server
you're
talking
to
doesn't
or
the
you
know,
the
peer
you're
talking
to
doesn't
support
v1
while
you're
done,
but
as
we're
moving
forward
like
people
are
going
to
want
to
work
on
different
versions
of
quick.
So
we
might
need
something
in
particular.
One
of
the
reasons
this
isn't
too
bad
is
that
for
http
3.
M
But
you
know
quick
is
a
general
purpose
transfer
protocol
and
not
every
application
is
http
3.
So
we
do
need
a
robust
for
a
negotiation
mechanism
going
forward
and
another
requirement
that
got
tacked
onto
this
draft
is
the
idea
that
spending
an
entire
round
trip
to
negotiate.
The
version
is
a
lot
of
wasted
time
and
it
would
be
nice
if
we
didn't
have
to
do
that
in
most
cases.
So
this
is
what
this
draft
does
next
slide.
Please.
M
So
the
draft
introduces
two
types
of
version:
negotiation
incompatible
and
compatible.
So
the
incompatible
one
is
the
simplest.
The
client
sends
its
first
flight.
The
server
doesn't
support
it,
it
can't
parse
it.
It
just
sends
a
version.
Negotiation
packet
and
the
client
restarts
with
a
new
version.
M
More
people
support
quick,
voicemail,
quickv2,
it'll
start
with
quickv1,
and
then
the
server
based
on
the
initial
can
say.
Oh
actually,
quickv2
is
better.
Let
me
seamlessly
reply
with
quickv2,
because
I
still
understand
quick
view
one
and
can
transfer
that
to
quick
v2
and
in
particular
one
of
the
neat
things
is.
If
we
look
way
way
down
the
road,
you
can
reach
a
point
where
the
server
doesn't
necessarily
need
to
fully
implement
quick.
If
you
want
anymore,
this
still
works.
M
M
I'm
going
to
parse
this
as
a
quick,
v2
first
flight
and
just
respond
as
if
I
had
received
that
so
the
the
conceptual
thing
is,
you
apply
a
transformation
from
one
first
flight
to
another
in
practice
that
transformation
might
be
as
trivial
as
simply
saying.
Oh
well,
imagine
that
the
version
long
header
was
the
other
version,
because
the
first
flight
format
is
the
same,
but
we
kind
of
left
that
open-ended
because
it'll
it
allows.
M
M
You
could
say
well,
if,
if
you
send
a
first
flight
without
that
frame,
then
it's
compatible.
You
can
switch
it,
but
if
it
has
it,
then
it
it's
not,
and
so
then
you
can
on
the
client
say:
oh
well,
I'm
hoping
for
compatibility
from
the
server
I'm
not
going
to
use
this
new
frame
and
therefore,
because
I
didn't
use
this
new
frame,
I'm
gonna
be
able
to
to
ask
for
compatibility
from
the
server
and
now,
how
do
you
ask
for
this?
What
does
that
mean
next
slide?
M
M
M
The
reason
for
that
is
is
that
is
our
best
extension
point
for
the
handshake
in
quick
and,
additionally,
it
is
authenticated
because
it
ends
up
in
the
tls
transcript,
and
so
that
is
one
key
required
property
for
downgrade
attacks.
Is
that
the
for
future
versions?
They
need
to
make
sure
that
the
handshake
version
information
is
authenticated,
and
so
how
does
it
work?
What
does
the
client
send
so
it
sends
the
so
the
currently
attempted
version.
M
It
is
just
a
mirror
of
what's
on
the
log
header,
so
that
doesn't
provide
any
useful
information,
but
what
it
does
is
it
forces
the
value
in
the
long
header
to
show
up
in
the
tls
transcript
to
prevent
an
attacker
from
messing
with
it.
Then
the
previous,
previously
attempted
version
is
in
the
case
of
an
incompatible
version
negotiation,
so
you're
sending
a
first
flight
after
you've
received
over
a
negotiation
packet.
You
say,
oh
by
the
way,
I
initially
tried
that
version,
and
you
told
me
it
didn't
work
again.
M
This
is
to
prevent
downgrade
attacks
and
then
it
it
also
has
the
it
copies.
The
contents
of
the
version
negotiation
packet
it
receives,
which
is
like
the
received
negotiation
version
and
the
idea
there
is
again
to
put
that
entire
payload
of
the
vm
packet
into
the
tls
transcript
in
order
to
make
sure
it
is
authenticated.
So
an
attacker
cannot
mess
with
a
single
bit
of
it.
M
Some
folks
have
said
on
issues
that
it's
kind
of
overkill,
and
it
is,
I
think
we
could
probably
get
the
security
properties
with
a
little
less
information.
But
in
my
personal
opinion,
is
getting
these
things
right
is
always
tricky
so
going
with
the
let's
just
authenticate.
Everything
makes
it
safer
because
it
means
we
it's
harder
for
us
to
get
it
wrong.
Like
they're,
we
can't
have
confusion
attack
because
there
is
something
we
forgot
to
authenticate
and
then
finally,
the
last
thing
the
client
sends
is
the
list
of
compatible
versions.
M
M
The
server
will,
so
the
negotiated
version
is
again
echoing
the
what
it's
sending
on
the
long
header,
similarly
to
make
sure
it
lands
in
the
in
the
transcript,
and
then
it
also
says,
and
by
the
way
here
are
all
the
versions.
I
support
so
the
idea
there
is
if
there
are
versions
that
are
not
compatible.
So
let's
say
the
server
also
supports
quick
version
42
and
that
is
so
different
from
quickview,
one
that
it's
not
compatible,
that
it
can
tell
the
client
and
the
client
can
save
in
a
cache
somewhere.
M
Oh
this
server
speaks
quickv42
next
time.
I
connect
I'm
maybe
going
to
try
that
so
like
if
your
client
already
has
an
all
service
cache,
for
example,
that's
you
know
kind
of
the
same
conceptual
thing
where
I
would
put
this
so
the
next
time
you
want
to
talk
to
the
server
instead
of
saying.
Oh,
let's
just
use
quickv1,
because
I
know
most
people
support
this.
M
It's
like
we
can
use
quickv42,
which
is
amazing
and
the
way
downgrade
prevention
works
is
by
is
on
the
server,
and
that
was
this
is
a
different
from
a
difference
from
what
google
quick
did
and
what
the
original
igf
specification
did.
But
it
allows
for
multi-cdn
or
gradual
deployment
in
servers
where,
let's
say
you
have
a
server
fleet
where
you
support
a
set
of
versions
and
you're,
going
to
change
that
to
a
new
one.
M
M
Okay,
all
my
servers
are
supposed
to
support
this,
and
if
something
doesn't
match
that,
then
I
declare
the
downgrade
attack
or
similarly,
if
you
have
multi-cdn,
you
can
say
I
support
this,
and
the
rest
of
the
fleet
can
also
support
that.
So
you
can
put
that
in
your
in
the
state,
so
that
puts
that
responsibility
on
the
server,
because
it's
the
server's
job
to
know
what
its
fleet
situation
is.
M
M
If
we're
going
to
change
that
design
decision,
we
need
to
revisit
some
design
choices.
So
the
question
is:
where
can
compatibility
be
defined
so
right
now?
One
of
the
features
of
the
current
draft
is
that
compatibility
can
be
defined
anywhere.
So,
let's
say
quick
version.
Foo
and
quick
version
bar
are
defined
by
two
independent
groups
of
people
at
the
same
time,
and
they
don't
know
about
each
other
and
those
versions
come
into
existence.
M
For
example,
probably
as
part
of
that
work,
we'll
say,
one
and
quick
v2
is
compatible
with
quickview
or
quickv1
is
compatible
with
quickv2,
and
vice
versa,
and
here's
how
you
do
the
transformation
in
both
directions,
but
that
might
not
always
be
the
case.
But
what
does
that
mean
in
terms
of
like
the
impact
on
the
draft
after
the
assigned
decision?
It
means
that
the
client
and
the
server
can
disagree
on
whether
two
versions
are
compatible,
because
if
the
document
got
written
later,
it's
possible
that
the
client
knows
about
it
and
implemented
it.
M
But
the
server
doesn't
so
it's
possible
for
the
client
to
say:
hey,
here's,
an
initial
version
foo
and
also
I'm
compatible
with
version
bar
and
for
the
server
to
say:
oh
no,
no,
I'm
not
compatible.
I
don't
think
foo
is
compatible
with
bar.
So
what
happens
if
they
disagree,
if
the,
if
the
client
doesn't
think
it's
compatible
and
the
server
thinks
it's
compatible,
that's
the
trivial
case,
because
the
client
just
doesn't
add
that
to
the
compatible
versions
and
the
server
will
just
treat
it
normally
of
okay.
M
M
M
M
All
right
and
that's
kind
of
it
we
think
the
yes
ecker-
or
I
guess
just
before
we
we
think
the
document
is
getting
to
be
in
good
shape,
but
we
wanna
hear
feedback
from
folks
and
also
we're
gonna
need
more
implementation.
Deployment
experience
we
haven't
implemented
this
in
google
stack
yet
and
that's
my
fault,
so
we're
gonna
try
to
get
to
that
pretty
soon.
We
don't
want
to
ship
this
without
implementing
it
first,
but
I
would
love
to
open
the
floor
to
anyone.
Please
send
you
know,
questions
comments.
A
J
Get
in
chat-
and
you
know
this-
I
think
this
is
the
wrong
design.
So
I
don't
think
this
is
already.
I
I
think
we
need
a
a
much
simpler
design
than
what
he
presented
here.
I
realized
this
is
the
maximal
design
and
you
expressed
your
willingness
to
look
for
something
that's
a
little
more
more
manageable.
I
think
there
is
a
more
manageable
thing
here
that
doesn't
require
probably
about
half
of
the
fields
that
you
have
here
and
I
I'd
like
to
to
explore
whether,
but
whether
that's
possible
here.
J
M
Thanks
empty
before
you
go
when
you
say
you,
you
want
a
simpler
design.
Do
you
have
something
in
mind
like
because
I
I'm
totally
game
for
simplifying
things,
but
I
would
love
to
see
a
proposal
like.
Are
there
specific
simplifications
that
you
can
think
of
without
any
without
losing
features,
so
those
we
would
definitely
get
or
do
you
have
features
that
you
want
to
drop
that
might
allow
us
to
simplify
the
design,
in
which
case
which
features
are
those.
J
So,
just
just
very
briefly,
when
it
comes
to
version
upgrade,
the
principle
that
we've
always
applied
is
that
the
client
offers
a
list
and
the
server
chooses
and
that
that
can
work
here
and
when
it
comes
to
incompatible
version.
Upgrade
you
just
invert
that
which
is
that
the
server
offers
a
list
and
the
client
chooses,
and
I
think
that
gets
us
90
of
the
way
to
having
a
functional
and
secure
upgrade
system
and
you've
got
a
bunch
of
stuff.
In
here.
S
Yeah
you
mentioned
a
couple
times
that
this
is
perhaps
somewhat
complicated
and
I
was
wondering
I'm
not
going
to
weigh
in
on
the
complexity
point
right
now,
but
I
was
wondering
to
what
extent
this
has
been
analyzed.
I
was
sort
of
triggered
with
my
ech
hat
on
in
terms
when
you
mentioned
things
like
downgrade
attacks
and
and
whatnot,
and
can
you
speak
to
that.
M
Oh
absolutely,
there
has
been
exactly
zero
analysis
of
this
apart
from
me,
looking
at
it
and
being
like
this
seems
fine,
and
so
therefore
it
must
totally
be
fine
right,
disclaimer,
I'm
not
a
security
expert.
So,
yes,
we
would
before
shipping
definitely
want
to
have
folks
look
at
this,
and,
in
particular,
one
of
the
reasons
for
adding
the
like
version
from
the
long
header
in
here
did
come
out
of
security.
Research.
M
M
S
M
L
Sorry,
I'm
an
author
of
this
draft,
so
that
was
not
intended
to
knock
on
david
yeah.
I
mean,
I
think
you
know
dave,
and
I
talked
a
bit
about
this
separately.
I
think
you
know
there
may
be
three
issues
here.
One
issue
is:
do
we
actually
need
all
the
functionality
that
this
draft
provides
and
we
do
we
need
both
compatible
and
compatible?
L
So
as
a
concrete
example,
you
know
in
tls
and
tls,
you
know
the
tls
1.3
client,
hello
is
a
valid
tls.
One
client
hello,
you
know,
assuming
of
course
you
offer
tls1
as
a
version
and
so
that's
a
simpler
kind
of
concept.
I
think
we
should
quite
get
away
with,
but
we
could
discuss-
and
the
third
question
I
think,
is
given
all
these
given
these
sort
of
functional
constraints
that
this
draft
adopts.
L
Is
this
the
simplest
design
that
provides
the
security
value
that
you'd
like
to
have
or
and
and
the
functionalization
as
well?
And
so-
and
I
think
that's
the
part,
but
I
think
I
I
guess
I'm
a
little
unclear
when
martin's
challenging
just
this
last
point.
Are
they
challenging
a
number
of
other
points?
So
I'd
probably
helpful
to
draw
that
on
later,
but
I
agree,
this
is
like
extremely
complicated
design,
and
so
both
it's
worth
asking
is
the
right
functional
requirements
and
b's.
M
T
T
The
the
trouble
here
is-
we've
defined
the
invariance
to
say
once
you
get
to
the
version
field
that
defines
everything
else
that
is
in
the
packet
it
might
or
might
not
use
tls
you
might
or
might
not
have
heard
of
it.
You
can
send
a
greased
version
with
completely
incomprehensible
payload,
and
all
of
that
is
legal
per
the
invariants
and
stuff
we've
already
said.
T
I
don't
think
we
have
the
choice
to
go
back
on
that
now
and
to
me
that
that
means
we
can't
really
toss
incompatible
version
negotiation
out,
and
I
think
that
probably
is
the
was
the
right
design
now.
Does
that
make
this
complicated?
Yes,
are
there
things
we
can
simplify
about
this?
I'm
not
sure
it'd
be
nice,
but
I
don't
think
the
path
to
simplification
is
retroactively.
Changing
the
invariance
to
you
always
have
to
know
about
all
previous
versions.
Versions.
Are
linear
versions,
use
tls.
M
Thanks,
no,
I
totally
agree
with
you
and
you
know,
even
just
saying
all
versions
use
tls
is
like
a
non-starter.
We
still
have
google
quick
with
quick
crypto
in
in
production,
and
that
is
a
real
version
and
we
do
have
a
mechanic
like
we
will
at
some
point.
You
know
deprecate
and
remove
this
version
from
google
servers
and
we
need
a
way
to
like
send
a
version,
negotiation
packet
to
the
client
and
for
half
that
to
fall
back
gracefully
without
a
downgrade
being
possible.
So
totally
agree
with
you.
M
There
is
absolutely
a
need
for
incompatible.
One
thought
that
comes
to
mind
is
we
could
end
up
splitting
this
into
two
drafts,
one
being.
How
do
you
secure
incompatible
version
negotiation
and
one
is
how
do
you
do
compatible,
which
is
trickier
and
more
complex?
That
might
be
a
way
to
simplify
this.
This
corpus
of
work,
dkg.
C
C
So,
in
my
mind,
version
lego
shipment
first.
This
is
a
security
feature
and
there
is
no
such
thing
as
very
complicated
security
features
and-
and
the
other
thing
is
I
mean
it
was
to
be
simple.
I
mean
the
client
is
going
to
say
hey.
I
propose
this.
I
would
also
accept
that
that
and
that
and
the
cell
might
just
pick
one
and
if
it
is
more
complicated
than
that,
then
we
have
lost,
and
I
understand
the
fact
that
the
sermon
I
want
to
say.
C
I
M
Yes
and
then
I
really
want
to
insist
on
that.
I
like
failed
to
come
up
with
something
like
much
simpler
and
without
dropping
features,
and
I
totally
understand
but
like
pl,
please
come
and
let's
have
the
discussion
on
the
list
or
on
the
issues
about
which
features
you
think
aren't
useful
and
we
can,
you
know,
remove
to
simplify
the
design
and
which
design
proposals
you
have
that
also
make
things
simpler.
Would
love
more
participation,
all
right
thanks
everyone
for
your.
U
U
So
you
know,
obviously
quick
is
very
opaque
to
middle
boxes,
including
middle
boxes,
that
you
want
to
have
help
you
like
load,
balancers
and
so
there's
there's
a
few
there's.
Basically,
two
main
things
here:
one
is
how
to
encode
stuff
in
cids
for
the
use
of
those
of
those
friendly
middle
boxes,
and
the
other
thing
is
how
to
encode
stuff
and
retry
tokens.
U
U
Okay,
so
let
me
start
with
retry
services.
This
is
a
little
more
straightforward,
so
they're,
basically
two
modes
here.
One
is
that
one
is
a
non-shared
state
one
which
is
what
it
implies,
that
other
than
the
fact
that
the
retry
service
exists.
The
server
doesn't
need
to
know
anything
about
how
what's
happening
there,
and
the
idea
here
is
that
servers
will
not
generate
retried
packets
under
any
circumstances
and
and
the
service
is
fully
responsible
for
generating
those
those
packets
and
also
authenticating
them
on
on
the
on
the
ingress.
U
The
shared
state
is
a
has
more
flexibility
in
its
in
its
use
model,
where,
in
theory,
retry
packs
will
be
generated
by
either
the
server
or
the
retry
service
and
there's
some
more
shared
state
there.
We
have
this,
you
know,
distribute
keys
and
so
on.
Since
the
last
since
ietf
109,
this
has
been
pretty
substantially
revised
thanks
to
christian,
to
improve
the
security
properties.
Of
that
token,
the
other
the
stuff
in
green
there
is
relatively
newish.
U
The
other
thing
is,
we
clarified
a
little
bit
the
handling
of
unsupported
versions,
the
retry
service
decks
used
to
say
that
recharge
services
must
admit
all
unknown
versions,
which
obviously
is
good
from
extensibility
perspective.
Not
necessarily
something
would
really
happen
in
the
real
world.
So
in
an
effort
to
be
a
little
more
realistic,
we've
we've
suggested
that
servers
should
be
able
to
control
the
allow
or
deny
list
of
versions.
U
U
Okay,
cid
encoding,
so
this
is
kind
of
the
heart
of
the
document.
There
are
a
bunch
of
different
things
here.
One
is
link
software
coding,
which
is
mainly
meant
to
to
assist
hardware
offload
of
crypto,
because
cid
look
up
without
knowing
the
cid
link
is
is
kind
of
hard.
According
to
the
hardware
people
I
talked
to.
U
Excuse
me:
there's
some
management
of
key
rotation
and
config
changes
and
there's
a
fairly
stable
design
for
that
where
the
first
two
bits
of
the
cid
indicate
the
corresponding
configuration,
and
so
you
know
when
you're,
when
you're
rolling,
when
you're
rolling
out
a
new
config,
the
load
balancer
is
for
a
while
speaking
two
configs
and
then
obviously
the
servers
will
be
speaking
one
one
one
of
those
two
and
the
the
load
balancer
is
able
to
decode
both
of
them.
So
there's
kind
of
six
possibilities.
U
Certainly
in
the
past,
we've
had
a
lot
of
discussions
of
these
three
algorithms
and
I
think,
there's
been
general
agreement
that
those
are
correct.
What's
new
is,
is
the
server
id
allocation
mechanism
so
up
to
now
up
to
ietf
109,
you
would
manually
configure
a
mapping
of
server
id
to
server
and
obviously
all
the
servers
would
have
to
be
issued.
U
So
the
idea
is
that
you
do
not
configure
server
ids
a
priori.
You
just
kind
of
learn
them
over
the
course
of
operation,
and
that
has
some
drawbacks
and
some
some
advantages
to
it
next
slide,
and
so
that
mechanism
could
be
used
with
either
with
any
of
the
algorithms
give
you
kind
of
six
permutations
of
cid
encoding.
U
Okay,
so
this
is
the
this
is
maybe
talking
to
the
server
id
case
more.
So
we
have
a
situation
here
where
the
load
balancer
starts
with,
knowing
that
there
are
two
servers
out
there,
but
has
no
server
ids
in
its
table.
Similarly,
the
the
servers
have
no
server
ids
in
their
list
of
of
authorized
server,
ids
next
slide.
U
So
the
reason
not
to
do
this,
of
course,
is
that
static
config
is.
The
reason
to
do
this
is
that
static
config
of
individual
server
is,
can
be
sort
of
a
pain,
but
this
does
create
a
little
more
state
as
you'll
see,
and
it
has
an
unfortunate
corner
case,
which
is
not
catastrophic,
but
I'll
I'll
show
it
here
in
a
minute.
U
So
let's
say
that
we
have
a
a
packet
that
comes
in
and
again
so
everyone's
on
config
zero
of
you
know
of
since
they're,
a
bunch
of
code
they're,
two
bits
to
configure
these.
These
configuration
code
points,
so
a
packet
comes
in
with
config
zero
and
it's
and
it
like,
if
you
decode
it,
it
comes
out
with
the
server
id
and
so
the
next
slide,
and
so
the
load
balancer
will
just
sort
of
make
an
arbitrary
routing
decision
with
this
one
and
send
it
to
abcd.
U
So
then,
some
other
time
another
another
initial
packet
comes
in
and
has
it
in
has
a
and
when
you
need
to
code
it
the
server
id
conduct
to
be
2b0
and
again,
there's
an
arbitrary
choice
and
it
goes
to
abcd.
So
now
there
are
now
two
entries
in
the
table
and
abcd.
You
can
use
either
server
id
to
generate
its
own
connection.
Ids
next
slide.
U
Okay,
so
one
problem
we
run
into
is:
if
it
is,
if
we
get
since
the
the
client
connection,
ids
the
client
generated
destination
connection,
ids
are
essentially
random.
It
could
correspond
to
config
code
point
that
that
is
that
doesn't
exist
in
the
actual
infrastructure,
and
I
thought
a
lot
about
cute
ways
to
do
this
and-
and
I
don't
think,
there's
a
way
to
resolve
the
ambiguities
here
next
slide.
U
So
what's
going
to
happen,
is
this
going?
If
this
is
going
to
be
rounded
say
this
will
be
routed
to
efgh
and
there's
no
way
to
extract
a
server
id
for
this
one?
So
really
all
one
of
those
four
config
rotation
code
points
is
is
is
reserved
for
for
temple
routing,
just
in
case
everything
sort
of
falls
apart,
there's
just
something
you
can
do
there
so
really
in
this
case
efgh,
because
we
just
started
up.
We
have
no
allocated
server.
U
Ids,
there's
really
no
way
to
proceed,
except
to
use
the
configure
id
config,
the
connection
id
that
tells
the
load
balancer
to
just
to
use
to
use
for
couple
routing
for
that
one.
So
this
is
a
fairly
transient
state.
Once
something
comes
in
next
slide
when
something
comes
in
with
config
0
that
happens
to
get
routed
efgh
next
slide,
then
then
there
will
be
something
in
the
table
and
then
the
circle
will
be
able
to
replace
all
its
cids.
U
So
given
like
a
decent
amount
of
volume,
once
you
have,
you
know
on
the
order
of
four
initial
packets
come
in
after
you
know,
restart
or
whatever
a
server
should
have
a
server
id
allocation
it
can
use.
So
this
is
probably
not
a
real
practical
issue,
but
there
is
a
weird
corner
case
here.
So
you'll
note
the
the
state
issue
that
instead
of
having
approximately
order
of
the
number
of
servers
entries
in
the
server
id
mapping,
the
load
balancer
has
over
time.
U
Essentially
you
know
two
to
the
number
of
bits
in
the
server
id.
That's
storing
in
a
table
now
ian
says
that
google
does
something
like
this
in
their
current
deployment
and
that
the
state
there
is
manageable,
so
there's
some
implementation
experience
that
indicates
that
this
is.
This
is
a
manageable
load.
Next
slide.
U
So
that
has
so
the
the
dynamic
the
dynamic
allocation
method
is
currently
in
the
editor's
draft,
which
I
thought
was
easier
to
talk
about
that
way.
But
you
know,
I
think,
that's
something
we
should
still
open
for
discussion.
We
can
talk
about
if
that's
something
we're
supporting.
If
we
want
to
support
both
methods,
we
want
to
just
go
to
dynamics.
Nobody
likes
static,
something
to
discuss
the
other
open
issue
that
needed.
Some
discussion
was
another
one
of
ian's
suggestions
and
today,
server
id
length
is.
U
This
is
arguably
a
bike
shed,
but
server
id
links
are
currently
expressed
in
octets.
We
could
express
it
number
of
bits
which
would
allow
you
know
bytes
to
be
some
bytes
to
be
dedicated
to
server
id,
and
so
not.
There
are
certainly
cases
where
you
only
need
a
certain
amount
of
entropy
and
server
id
and
you
might
kind
of
bite
off
the
cid
length
which
is
kind
of
nice,
but
it's
yet
more
complexity.
You
know
big
boundaries
versus
by
boundaries.
U
All
right,
so
I
would
like
to
stop
here
and
and
just
take
some
discussion
on
these
points.
The
other
thing
I'll
add
is
a
I've
actually
attempted
to
implement
both
static
and
dynamic
and
well
static's
been
around
for
a
while.
I
know
how
to
do
that.
The
dynamic
one
does
add
some
complexity
because
to
preserve
the
ability
of
new
servers
to
get
server
ids.
U
What
what
I've
added
to
the
design
from
what
ian
initially
submitted
was
some
sort
of
timeout,
where,
eventually,
if
the
server
has
a
server
id
has
not
been
used
for
a
while
kind
of
goes
back
into
the
pool
for
reallocation,
and
that
raises
some
complexity.
Where,
like
you,
really
have
to
look
at
packets
and
once
you've
already
sort
of
made
a
load
balancing
decision,
you
have
to
look
at
packets
and
see
if,
like
the
survivor's,
been
used.
Q
So
I
I
I
worry
that
there
are
too
many
options
here.
I
wonder
if
it
would
be
wiser
to
pick
one
that
we
really
think
is
the
the
safest
option
and
in
each
of
our
different
categories
here
and
and
recommend
those
get
some
implementation
experience
and
see
if
the
other
ones
are
really
needed
or
see.
If
the
problems
that
arise
are
the
ones
that
we
expect,
maybe
maybe
there'll
be
unexpected
problems
in
steps.
U
Yeah
lucas,
can
you
go
to
the
next
slide,
you're
kind
of
just
leaning
right
into
the
next
thing
I
wanted
to
discuss.
So
this
is
so.
As
I
said,
these
drafts
have
really
gotten
to
the
point
where
we've
reached
the
limits
of
just
sort
of
brainstorming,
about
use
cases
and
different
requirements
and
really
to
me
the
real
obstacle
now
is
implementation,
and-
and
I
would
hope
that
that
would
provide
some
insight
into
what
ben
is
saying.
Is
that
like?
What
do
we
really
need
here?
So
these
are
the
known
implementations.
U
Two
of
them
are
mine.
One
is
just
a
library
to
allow
you
to
like
encode
and
decode
server
ids,
and
I
just
lost
the
slides
another
one
is
again
an
nginx
based
implementation
of
the
load,
balancer
slash
retry
server
side
of
this,
and
I
did
a
bunch
of
work
on
this
last
week,
so
the
slide
is
a
little
outdated.
The
only
thing
that
is
missing
that
is
that
is
currently
in
the
draft,
is
the
shared
state
retry
service,
which
I
was
going
to
try
to
tackle
after
110..
Also.
G
U
U
Q
Q
I
think
that
we
should
be
very
cautious
about
making
recommendations
in
standards
track
documents
that
violate
the
security
and
privacy
properties
that
we've
promised
in
other
standards
track
documents,
especially
because
the
load,
balancer
and
server
are
usually
relatively
closely
coordinating
entities,
and
so
they
require
less
standards
guidance
if
they
really
want
to
go
off
and
do
something
on
their
own.
I
think
that
in
general
we
should
try
to
stick
to
the
safest
options,
and
if
people
want
to
do
something
unsafe,
they
can
probably
manage
it
on
their
own.
Q
U
U
Speaking
about
the
plain
text
thing
I
mean,
I
think,
that's
a
reasonable
concern.
That's
been
kind
of
floating
around
from
the
beginning,
because
this
design
has
existed
for
the
beginning.
I
think
there's
been
a
lot
of
interest
in
supporting
it
from
you
know
the
quick
community,
which
is
generally
very
sensitive
to
these
privacy
issues
and
one
of
the
things
one.
U
That
the
server
mapping
does
not
become
evident,
and
so
people
have
tended
to
view
this
as
a
more
of
a
continuum
of
privacy
rather
than
a
a
like
private,
not
private.
You
know
duality
so
nevertheless,
that's
a
good
comment
and
I
think
it's
absolutely
worth
discussing
if
we
still
have
consensus
that
the
plaintext
cid
algorithm
should
be
in
there.
U
Okay,
so
I
I
I
just
again
I'd
like
to
sort
of
say
that
I
think
this
document
is
stuck
until
until
we
get
some,
maybe
some
more
reviews
and
and
particularly
some
more
implementations
to
go
forward.
I
I
don't
feel
really
comfortable
going
to
the
last
call
and
then
with
the
current
implementation
state
of
this
document.
So
thanks.
A
I
B
So
given,
given
that
we,
we
can't
actually
formally
adopt
anything
at
the
moment
anyway,
because
we
are
not
recharged
yet.
I
think
I
think,
wasting
time
on
running
the
polls
doesn't
make
sense.
I
think
we
should
just
tell
people
that
you
know
these
documents
to
many
that
have
expressed
an
opinion
in
the
past
seem
like
no-brainers
for
adoption
they're,
both
sort
of
reasonably
widely
implemented
already,
and
they
have
seen
quite
a
bit
of
discussion.
So
we
we
plan
to
hold
it
up.
B
B
C
Yeah,
it's
it's
less
implemented.
There
are
fewer
implementations
than
for
the
other.
Two,
that's
clear.
On
the
other
hand,
I
mean
it's,
it's
quite
useful
and
it's
very
simple.
I
know
of
at
least
two
implementations,
so
it'd
be
nice
that
we
had
some
visibility
of
that
some
higher
visibility
of
that
in
the
working
group.
B
So
I
don't
see
anybody
coming
up
to
the
queue
to
to
disagree,
that
we
should
run
an
adoption
call
for
those
when
we're
recharged.
So
I
guess
the
plan
is
to
do
that.
The
other
thing
we
sort
of
discussed
in
the
back
channel
here
between
the
chairs
is
that
version
negotiation
seems
like
it
might
need
more
face
time,
and
so
one
one
way
forward
would
be
to
see
if
we
can
do
an
interim
on
version
negotiation
between
now
and
11,
in
order
to
give
people
some
some
more
time
to
discuss
this.
I
B
B
B
Mata
lucas
is
there
anything
else
that
you
guys
want
to
discuss
as
part
of
the
wrapper
future
meetings.
I
guess
we
will
continue
to
read
at
itfs
and
we'll
continue
to
do
interims
when
we
need
them
implementation
drafts.
We
are
on
the
final
one,
hopefully
for
a
while,
which
is
the
one
on
version
one
and
that's
the
etc.
A
In
this
in
this
session,
so
this
is
a
draft
that
we
are
considering
adoption
of
based
on
the
rechartering
activity.
So
it's
it's
there,
it's
in
holding
effectively
until
rechartering
completes,
but
in
case
you
haven't
yet
seen
any
of
the
presentations
robin's
done
throughout
the
various
other
sessions
at
the
itf.
A
He
he's
given
some
overviews
to
other
groups
that
might
be
interested
and-
and
you
might
remember,
that,
there's
the
concept
of
a
main
schema
and
then
a
quick
and
h3
profile
over
over
that,
but
in
the
first
instance,
we'd
probably
be
looking
at
doing
q
log
in
this
group
and
I'm
working
with
some
others
to
understand
their
needs
that
that
then
the
whole
thing
could
be
kind
of
generalized
and
worked
on
elsewhere.
If
people
would
be
interested
in
the
far
future.
B
Yeah,
it's
surprising
that
this
is
the
one
session
where
robin
didn't
present.
But
if
you
look
at
the
charter
proposal
text
right
sort
of
it
talks
about
a
logging
format
which
we
lumped
in
with
the
operation,
operability
and
manageability
topics,
because
it
sort
of
belongs
there
and
and
that
text
is
there,
because
we
all
we,
as
luca
said,
we
assume
we're
gonna,
adopt
part
of
the
q
log
work
here,
specifically
the
one
that's
related
to
quick.