►
From YouTube: IETF110-6MAN-20210309-1200
Description
6MAN meeting session at IETF110
2021/03/09 1200
https://datatracker.ietf.org/meeting/110/proceedings/
A
A
A
A
The
goal
is
to
give
time
to
the
speakers
to
basically
make
the
case
for
what
they
are
proposing
and
see
if
the
working
group
is
interested
the
second
session
on
thursday
morning
or
at
least
thursday
morning,
my
time
will
include
the
usual
introduction
and
document
status,
we're
getting
a
report
from
the
spring
compression
design
team
and
then
working
group
and
act.
Active
working
group
drafts
next
slide,
and
so
this
is
today's
agenda.
C
Great,
that's
great
okay,
so
so
this
is
about
ipv6
ipv6
solution
for
the
5g
edge
computing,
sticky
service.
We
presented
this
at
ietf109
and
we
got
quite
a
few
comments.
So
we
address
those
comments
and
come
back
with
the
update.
Next
slide,
please,
okay!
So
this
is
just
a
brief
update
background
of
the
5th
computing
project.
So
this
is
the
3gpp
tr23
for
748.
C
C
One
of
the
requirement
there
is
those
edge
computing
services
are
controlled
by
their
application
function,
controller
and
they
are
using
any
cash
addresses,
and
you
can
see
here
that
from
battery
core
user
traffic
is
anchored
to
pack
a
psa
pdu
pdu
session
anchor,
which
is
part
of
the
function
of
the
user
plan
function
and
there's
always
router
to
ingress
router
to
the
ldn
local
data
network
and
those
services
edge
computing
services.
Any
kind
servers
are
located
in
the
mini
data
center
in
very
close
proximity
to
the
upf
function.
C
There
are
many
of
them
to
achieve
the
mission
critical
services,
so
the
assumption
is
that
those
servers
are
not
directly
attached
and
not
very
far,
and
there
are
many
of
them
there
and
any
cache
is
used
to
address
multiple
servers
actually
server
to
up
to
the
network
perspective.
Actually,
maybe
the
application
layer
load
balancers.
They
may
have
multiple
load
balancers
with
multiple
servers
behind
them,
but
from
the
network
perspective,
it's
the
only
the
the
load
balancer
be
visible
next
slide.
Please.
C
The
differences
to
different
egress
routers
are
not
very
large.
The
benefit
is
any
of
them
can
serve
the
service
and
but
but
you
need
to
stick
to
specific
ones
if
you
move
and
they
could
have
unbalanced
distribution
like
because
the
ue
move
frequently
so
that,
even
though
you
plan
ahead,
you
put
three
load
balancing
attached
to
three
routers,
because
ue
movement
all
anchored
towards
like
particular
site
and
so
causing
one
site
to
be
over
utilized,
others
being
less.
C
C
So
the
sticky
service
is
really
about
the
assumption
that
not
all
services
need
sticky
service,
only
the
ones
which
need
the
network
to
optimize.
They
register
with
the
3gpp
and
then
switch
pp,
recognize
those
services,
and
then
the
network
provide
additional
optimization
to
distribute
among
different
equest
routers.
C
C
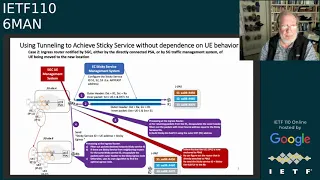
So
using
the
tunneling
to
achieve
sticky
service,
what
it
is
is
one
the
router
ingress,
router
ra,
based
on
the
running
status,
that
is
distributed
from
the
e-waste
router
and
create
a
tunnel
and
to
the
specific,
the
the
egress
router
like
r1,
be
selected,
and
when
the
ue
moved
to
another
location,
the
router
itself
will
be
able
to
distribute
the
sticky
service
id
and
flow
id
and
sticky
egress
address
to
the
neighboring
ingress
router.
Those
are
statically
configured.
C
Each
router
is
configured
with
a
set
of
the
routers
which
are
close
by
that
the
service
when
they
move
to
anchor
to
their
corresponding
psa
their
the
user
traffic
should
stay
together
with
to
the
sticky
egress.
Bear
in
mind
that
many
of
those
applications
are
capable
of
handling
different
locations
it
just
at
application
layer,
they
can
actually
coordinate,
and
you
move
the
session
id
at
the
application
layer,
but
it
just
takes
time
and
for
some
mission
critical
services.
They
would
like
network
to
help
them
to
achieve
better
to
stick
to
the
original
one.
C
So
internal
service
that
the
5g
core
could
coordinate
with
the
ingress
router
so
that
so
that
that
the
because
the
session
movement,
the
session
control
in
the
5gc
5g
core,
can
know
that
when
you
e
move
from
side
a
to
side
b,
there's
a
session
control
that
keep
that
grease
period
transition.
It
knows
where
the
next
upf
is
going
to
a
correspondingly.
C
C
So
here
it
is
like
we
can
either
use
the
destination
extension
header
or
the
hubba
hub
extension
header
in
the
tunnel,
so
that
the
traffic,
when
coming
back
and
in
the
in
the
middle
of
the
network,
they
know
where
to
send
it
to
in
a
tunnel
and
keeping
track
of
the
information
so
that
all
the
intermediate
nodes
is
aware
of
this
particular
service
has
to
be
sent
to
the
ingress
r1
next
page.
Please.
C
And
in
the
document
we
propose
this
sub
tlv,
which
we
call
sticky
distance,
sub
tlv.
So,
with
sticky
service
we
have
sticky
type
like
and
the
sticky
type
showing
that
how
much
this
particular
service
needs
to
stick
to
the
original
egress.
Some
can
be
strongly
need
to
be
stick
to
some
can
be
loosely
sticked
to
and
then
there's
most
important
information
is
the
destination
destination.
Basically,
egress
addresses
egress
address
for
the
sticky
for
the
service
to
be
sticked
to
next
page.
Please.
C
C
B
C
C
So
those
information
need
to
be
propagated
to
the
ingress
router,
so
that
the
past
computation
can
include
not
only
the
round
trip
delay,
because,
typically,
today,
networking
when
we
have
multiple
paths
to
a
destination,
we
always
use
our
network
parameter
like
distance
routing
distance
to
determine
which
one
is
the
optimal
one.
So,
with
those
additional
information,
the
ingress
router
will
be
able
to
combine
the
routing
distance.
D
B
B
A
A
A
My
thinking
is
that
it
would
be
more
appropriate
to
ask
six
men
to
adopt
this
once
it's
actually
a
real
work
item
somewhere
else
and
then
then
it
would
be
reasonable
for
us
to
evaluate
you
know
the
the
ipv6
extension
headers
you're
proposing,
but
I
think
until
that
happens,
I
think
it
might
be.
I
think
it's
a
little
early.
B
B
E
E
F
E
Slide
please
the
contents
of
the
presentation.
I
will
mention
only
two
points
that
are
described
in
this
draft
in
the
introduction,
a
little
bit
of
the
problem
statement
for
vislak
and
the
one
slide
on
the
implementation
of
v-slot,
but
in
the
draft
there
are
more
topics
that
have
been
given
equal
importance.
E
E
Then
what
are
the
reasons
for
longer
than
64-bit
prefix
length
and
then
using
greater
than
64
prefixes
by
isp
is
normally
strictly
prohibited,
so
we
don't
have
a
race
to
the
bottom
problem,
a
brief
comparison
between
static,
slack,
dhcp,
v6
and
v-stack,
and
then
again
some
variable
strike
use
cases,
and
then
I
will
go
now
to
describe
some
points
of
the
problem
statement
next
slide.
Please.
E
Well,
there
are
very
many
aspects
of
this
problem.
We
selected
only
a
few
of
them
that
I
try
to
illustrate
with
a
figure
in
the
center
of
the
slide
and
the
bullets
bullet
points
in
the
right
part
of
the
slide
in
the
center
of
the
slide
in
the
upper
part,
you've
seen
the
figure,
the
internet
and
a
ggsn
which
is
part
of
the
3gpp
network
and
that
advertises
a
64
prefix
to
the
ue,
which
is
the
user
equipment.
E
E
E
It
is
also
impossible
in
implementation
to
use
slack
with
a
prefix
of
length
65
in
the
router
advertisement,
for
example,
in
linux.
This
is,
is
not
working
simply.
This
makes
that
the
problem
is
that
it
is
impossible
to
extend
the
network
to
multiple
subnets
beyond
the
user
equipment
for
further
description
of
the
problem.
We
refer
to
this
draft
mishra
v6
variable
slack
problem
statement
that
is
pasted
at
the
bottom
of
the
slide.
E
E
E
The
default
value
of
this
parameter
is
zero,
which
means
that
the
slack
behaves
acts
as
before
uses
64-bit,
ids
and
prefix
themes.
But
if
an
operator
sets
this
value
to
1,
it
makes
that
prefixes
of
length
other
than
64
are
accepted
for
slack.
For
example,
a
host
that
receives
a
63
in
an
array
will
form
an
ia
in
interface,
id
of
length,
65
and
subsequently
an
address
of
length
128
bit.
F
E
And
we
have
also
submitted
for
consideration
to
linux
maintainers,
but
we
have
some
feedback
from
them
asking
the
status
of
of
this
proposal
that
we
have
here
at
idea
in
open
bsd,
we
have
learned
that
there
is
an
implementation
of
rfc
7217
that
works.
Okay
with
variable
length,
freelance
in
slack
and
in
this
is
not
work.
The
variable
slack
is
not
working.
Only
64-bit
ids
are
implemented,
respecting
the
samples
and.
F
E
So
that
is
the
implementation
that
I
was
trying
to
present
and
at
this
point
I
might
wonder
if
there
are
any
comments.
Otherwise,
I
have
an
additional
slide
on
the
on
what
we
discussed
not
publicly
but
privately,
with
a
few
people
about
the
potential
next
steps.
But
if
there
are
any
comments
here,
I'm
I'm
interesting
to
we
are
interesting.
We
authors
are
interesting
to
hear
these
comments.
G
I'm
sort
of
like
a
deja
vu
right.
I
think
we've
been
in
the
discussion
a
couple
of
times,
but
I
have
like
two
questions.
First
of
all,
why
are
you
calling
the
easy
behavior
above
my
understanding
is?
We
are
all
here
to
discuss
how
operating
systems
should
behave
and
after
we
agree
on
something
that
should
be
implemented.
G
If
operating
system
started
to
do
something
which
is
currently
prohibited
by
rfcs,
I
would
not
call
it
a
bug
right
if
they
start
doing
this
like
we
all
can
go
home
and
just
forget
about
making
any
standards,
because
operating
system
would
do
whatever
they
want,
and
I'm
also
a
bit
confused
about
the
draft.
I
read
it
and
in
the
beginning
of
it
the
draft
it
said
we
want
to
do
prefixes,
which
are
shorter
than
plus
64,
and
we
go
and
explain
why
and
yes,
we're
also
allowing
longer
prefixes.
G
But
operators
should
not
do
this
no
and
then
the
earliest
cases.
I
found
in
the
document
talking
about
longer
prefixes
and
I
could
not
find
any
compelling
use
case
for
shorter
one.
So
I'm
not
sure
why
we
need
this,
especially
providing
that
I'm
quite
sure
that
operators
would
not
listen
right,
they're
only
doing
360
for
now,
because
they
could
not
do
longer
as
long
as
you
allow
them
to
do
longer,
it
would
be
the
race
for
the
bottom
and
our
way
you
should
not
do
this
would
not
work.
E
On
the
calling
it
a
bug
report,
I
think
it
is
because
the
tool
of
submitting
proposals
of
improvements
is
called
a
bug.
Reporting
too
like,
if
I
remember
correctly,
but
okay,
probably
buggies-
should
not
be
used,
but
we,
we
could
also
see
it
as
a
suggestion
for
a
new
functionality
that
that
could
also
be
a
experimental
functionality
if
you
wish,
into
which
some
things
are
tried,
but
by
default
they
should
be
off
of.
E
With
respect
to
the
question
of
these
shorter
and
longer
prefixes,
okay,
now,
basically
I
agree
with
you
that
if
this
luck
allows
for
longer
prefixes,
then
operators
might
be
tempted
to
allocate
longer
prefixes
to
the
end
users,
and
that
could
create
the
raise
to
the
bottom
problem,
and
that
is
not
good
and
should
be
avoided.
There
should
be
something
some
tool
some
may
can.
I
don't
know
that
should
not
allow
for
this
to
happen.
I
don't
know
what,
but
now
for
shorter
than
64
shorter
than
64
prefixes,
then
that
is.
E
E
Maybe
we
could
clarify
it
and,
and
then
the
third
point
that
to
answer
this
is
that
if
the,
if
this
document
does
not
progress
or
is
outright
rejected,
not
even
as
experimental
accepted
or
if,
if
this
is
completely
stopped,
then
in
the
implementation,
I
must
say
that
I
will
be
again
tempted
to
use
this
66
prefixes
inside
the
extended
network,
because
the
operators
will
always
allocate
a
64
and
then
the
only
thing
one
could
be
tempted
to
do
is
to
create
66
out
of
this.
So
that
is
a
conditional.
E
E
And
I
I
a
few
suggestions
were
made,
but
it's
nothing
private
about
this,
but
I
really
try
to
push
this
forward,
but
I
I'm
not
try
I'm
not
clear
how
to
proceed
and
how
to
so
one.
One
of
the
point
that
was
listed
is
to
to
make
a
liaison
between
ietf
and
3gpp
and
maybe
make
the
most
of
this
work
at
3gpp
such
that
make
a
requirement
at
3gpp
to
to
advertise
shorter
than
64
prefixes
to
the
user
equipment.
That's
a
possibility.
E
Generic
tunnel
encapsulation
protocol-
I
think
that
is
a
3gpp
protocol,
so
these
two
concepts
could
work
together.
A
third
bullet
suggests
that
maybe
we
could
ask
ayana
for
a
sub-range
of
this
one
ffe
slash
three
space.
All
these
addresses
that
start
with
zero,
zero,
zero
binary,
which
is
not
subject
to
the
64-bit
bin
boundary,
and
this
this
could
be
performed
on
a
experimental
kind
of
activity
into
which
not
only
v-slug
would
could
be
used,
but
maybe
other
drafts,
and
maybe
a
little
bit
of
small,
longer
prefixes,
but
smaller
space
in
this
that
could
be
allocated.
E
E
Next
bullet
is
to
use
a
method
like
in
draft
naveen
into
which
a
host
puts
a
specific
request
in
rs
return,
solicitation
to
request
multiple
64
prefixes
or
a
non
64
prefix.
Maybe
that's
another
protocol
proposal,
and
then
I
know
that
pascal
to
bear
as
a
activity
proposal
for
ipo
over
wireless
and
since
this
happens
on
a
wireless
link,
maybe
bring
this
like
there
and
also
eduard
proposes
an
activity
or
a
sort
of
concept
on
next
generation
slack,
and
maybe
visla
could
be
part
of
that
next
generation.
E
Slack,
that's
a
another
potential
and
then
again,
somebody
also
proposes
not
is
is
always.
Is
there
another
way
possible
for
this
to
to
proceed?
Is
there
another,
because
the
problem
is
still
there?
All
mobile
operators
allocate
a
64
to
a
user
equipment
and
many
user
equipments
need
to
extend
beyond
so
that's
the
that
is.
That
is
my
last
slide
yeah.
I.
B
Hope
I
managed
to
well
I'm
all
years
now
I
listen.
You
seem
to
be
missing
at
least
in
homeland.
This
was
also
discussed.
You
know
many
years
ago
in
the
solution
they
at
least
implemented
was
just
to
use
the
atp,
which
supports
other
prefix
lengths
just
fine
at
least
there.
You
have
a
solution
that
is
widely
implemented
and
supported
in
all
equipment.
B
E
B
H
Ahead
yeah,
so
I
actually
had
a
question
about
the
the
modems,
the
modem
vendors
blocking
dhp
pd.
I
mean,
I
think
that
seems
like
you
know,
do
you
have
data
on
why
they
do
this,
because
I
mean
it's:
it's
not
so
written
in
any
standard
that
they
should
do
this
and,
in
fact
the
3gpp
release.
10
standards
do
support,
release,
10
and
above
and
now
we're
on
release,
15
or
16.
They
do
support
dhb,
so
hppd,
it's
a
supported
part
of
3gpp.
H
So
the
other
thing
is,
you
know,
given
that.
I'm
not
sure
that
you
know
there's
actually
a
problem
solved
here
if
your
primary
use
case
is
to
be
able
to
assign
a
larger
than
a
shorter
than
64
prefix
to
a
mobile
node,
that's
already
supported
by
this
gpp
standard.
This
is
a
deployment
problem
and
writing.
A
new
draft
is
unlikely
to
affect
the
the
reasons
why
it
is
or
is
not
deployed.
E
Yes,
so
with
respect
to
why
some
or
most
mobile
model
manufacturers
block
dhcp
v6,
because
that
is
what
they
block,
they
don't
block,
in
particular
the
pd
part
of
the,
but
the
http
v6
blocking
the
http
v6
means
blocking
the
port
numbers
of
the
http
v6
and
or
blocking
the
multicast
part
of
the
http
v6.
These
are
the
two
things
that
are
blocked
by
various
ones.
Now
why
they
do
that,
we
have
a
list
of
reasons
why
they
do
I
mean
we
speculate.
Why
they
do
we
don't
know
exactly
why,
and
even
some
people
are.
E
E
E
H
E
Yeah
yeah
yeah-
it
is
true.
It
is
also
suggested
to
do
to
make
this
more
of
a
3gpp
document
or
a
requirement
at
3gbp,
and
my
reply
to
that
is
that
sometimes
3gpp
does
refer
to
internet
drafts
when
writing
their
own
requirements,
and
so
that
is
a
probably
a
possibility.
I
mean
yeah
we
could.
We
could
try
to
to
do
that,
rather
than
then
pushing
this
forever
at
itf
and
yeah.
It's
a
good
suggestion
that
we
take
into
account
we.
We
will
also
look
into
that
3gpp.
E
B
I
Okay,
good
because
it
shows
there
is
some
error
there.
Okay,
thank
you
chair
and-
and
this
is
a
a
very
new
draft-
it's
zero
zero
version
draft
and
in
this
draft
we
introduce
and
also
an
associated
channel
over
ipv6
and
this.
For
short,
we
named
this
associated
channel
as
ach,
and
the
current
scope
is
ipv6
networks.
I
I
And
if
you
see,
if
you
look
at
the
the
right
bottom
graph
there
and
it
shows
where
the
sh
in
the
in
one
network
node
and
the
control
and
management
planes
can
control
element,
planes
generate
the
control
and
management
messages
and
carried
it
in
the
associated
in
associated
channel
and
transmitted
in
the
data
plane
in
next
page.
Please.
I
The
associated
channel
id
is
identified
there.
It
is
defined
there
and
the
control
and
management
messages
can
be
carried
in
the
in
the
fixed
messages
in
the
in
the
value
field,
and
this
ach
flat.
This
is,
it
is
a
htrv,
so
this
drv
can
be
flexible,
encapsulated
in
the
ipv6
extension
headers,
including
the
doh
hubbar
hub
or
srh.
I
I
I
We
list
three
particles
that
used
for
the
oem
functions,
and
we
also
identifies
these
several
problems
that
these
protocols
with
this
protocols,
for
example,
these
protocols
are
designed
for
to
perform
different
functions,
different
oem
functions,
but
they
also
have
overlapped
functions
and
they
use
different
session
identifiers
and
also
deep,
dating
capitals
lead
in
the
ipip
packet
and
if,
if
there's
and
and
because
they
are
defined
for
this
defined
as
an
end-to-end
session.
So
the
intermediate
node
is
not
aware
by
the
end
and
end-to-end
session.
I
So
we
try
to
come
up
with
a
simple
solution
to
carry
these
oem
messages
in
the
ach,
because
the
ach
is
a
tlb
encapsulated
in
ip
layer.
So
this
so
this
info
this
all
these
oem
messages
are
encapsulated
in
in
pure
a
epilator
and
it
to
reduce
the
the
number
of
particles
sessions
and
also
unified
the
session
identifiers
yeah.
The
figure
below
it
shows
that
there,
the
example
is
that
if
we
encapsulated
delay
management
measurement,
the
ach
tlv
inside
the
ipv6.
I
Actually
I
actually
used
a
doh
header,
and
this
and
this
ach
this
d,
s
h,
t
always
is
encapsulated
in
the
ip
layer
and
transmitted
from
r1
to
r4
when
r4
receive
it
and
it
will
process
the
htrv
as
it.
Since
it
is
the
last
it
is
the
destination
of
the
ap
pass
and
we
will
need
to
receive
the
htrv
it
processed,
the
the
the
tre
and
measure
the
delay
next
page.
Please.
I
I
Another
protection
switch
request
to
r1
to
ask
ask
around
to
switch
the
the
forwarding
pass,
but
this
message
is
is
using
another.
This
message
is
using
another
associate
channel
and
this
in
on
this
associate
channel.
It
is
end
to
end
the
the
t.
The
s
hdrv
is
encapsulated
in
the
doh
header,
because
it
is
a
message
sent
from
end
to
end
to
tell
r1.
I
And-
and
we
yes
actually
so
far,
we
have
already
received
a
lot
of
comments
and
suggestions
to
about
this
draft.
So
we
would
like
to
have
more
discussion
on
this
topic
and
to
refine
this
sh,
how
it's
used
in
ipv6
network
and
expect.
Maybe
since
ip
since
segment
routing
srv6
is
a
specific
type
of
ipv6.
I
We
may
also
want
to
specify,
may
maybe
specify
the
ac
how
ach
used
in
on
how
a
sh
used
over
srv6,
maybe
in
another
draft-
and
we
also
see
there-
are
different,
depending
on
the
applications
that
the
the
ach
can
be
used
in
different
ways.
So
we
better
would
better
to
to
separate
the
draft
to
specify
the
application
used
in
ach
yeah,
and
I-
and
I
also
want
to
say
that
actually
sh
is
not.
Maybe
I
have
two
examples
here,
but
ash
is
not
designed
for
only
for
oam.
I
A
J
K
I
I
I
I
I
I
A
A
I
Yeah
yeah,
actually,
this
word-
this
topic
includes
two
drafts.
One
is
the
the
draft
named
second
segment
routing
for
redundancy
protection
in
spring
working
group,
and
the
second
is
the
this
one
is
the
srh
extension
for
this
redundancy
protect
protection
and
yeah.
I
will
give
this
this
the
introduction
for
both
of
them
yeah.
I
I
I
Yeah
to
support
the
the
relentless
protection-
actually,
we
defined
four
information
and
the
first
first
is
the
redundant
segment
redundancy
segment
it
is.
It
performs
the
packet
replication
function
on
the
redemptive
node,
and
it's
associated
with
a
redundancy
policy
actually
is
a
variant
of
the
sr
policy
and
in
in
and
in
case
of
the
srv6
that
we
define
a
new
behavior
and
are
and
the
the
second
piece
of
information.
The
second
information
is
the
merging
segment
and
is
the
similar
to
the
redundancy
segment.
It
performs.
I
The
map
package
of
amni
alignment,
elimination
on
the
merging
node
and
new
behavior
and
m
is
defined
and
to
identify
the
unique
flow
and
and
identify
the
packet
sequence
with
within
one
flow
that
we
define
the
flow
identification.
The
sub
and
sequence
number
there,
and
in
this
drafted
we
extend
the
srh
option,
optional,
tre
to
encapsulate
encapsulate
them,
and
the
last
information
is
that
we
define
this
redundancy
policy.
Actually,
it's
a
variant
of
sr
policy.
I
I
Yeah
we
here
we
take
a
service
success
example
to
show
the
redundancy
protection
process.
Actually
here
we
have.
We
have
two
different
two
choices
to
deploy
this
this
process
and
the
difference
is
depending
on.
Where
do
you
want
to
assign
the
flow
id
and
generate
the
sequence
number
and
the
first
choice
is
to
use
it?
I
Of
course,
in
the
past,
all
over
the
the
the
srv6
pass
forwarding
pass,
and
the
second
choice
is
that
you
have
this
two
information
only
between
the
redundancy
node
and
the
merging
node
I
want
to.
I
want
to
explain
the
all
these
headers,
but
let's
just
focus
on
the
trv,
the
in
the
orange
in
the
orange
color
in
orange-
and
this
is
this-
will
identify
the
the
flow
identification.
I
I
That
is
the
behavior
definition
that
defined
in
the
merging
node
in
the
merging
segment
so
yeah.
I
think
that
that
that
is
what
I
want
to
explain
here,
that
there
are
two
different
choices,
but
no
matter
which
different,
which
choice.
This
information
will
be
encapsulated
in
the
in
the
fpv6
header,
where
the
merging
node
proceed
process,
the
the
the
merging
segment,
so
it
always
in
they
are
always
encapsulated
together
in
one
ipv6
header
yeah.
I
I
If
we
want
to
use
it
only
between
the
redundancy,
node
and
merging
node,
I
think
that's
that
it's
it's
okay
to
use
it
as
the
ipv5
v6
flow
label,
but
if
you
want
to
use
it,
if
you
want
to
have
the
have
the
flow
identification
from
the
ingress
of
the
app
of
the
srv6
domain,
that
means
that
you
will
have
yeah
this.
This
flow
label
will
be
used
for
ecmp
and
also
used
for
the
for
this
redundancy
protection,
so
that
would
be
some
conflict
there.
I
think
yeah.
Next,
please.
I
I
Yeah,
if,
if
I
have
a
preference,
I
think
I
prefer
to
use
it
here
in
the
srh
optional
trv,
because
I
see
if
you
use
it,
I
have
already
mentioned
if
you
use
it
in
in
the
ipv6
header
that
will,
and
this
information
is
encapsulated
at
the
ingress
node.
That
will
that
I
mean
the
ipv6
flow
label
can
only
be
used
for
this
function,
but
not
for
the
ecmp,
like
ecmp
in
other
parts
of
the
the
forwarding
pass.
K
I
K
And
the
iona
registry,
for
that
looks
like
it's
ietf
review,
which
means
you
know
it
doesn't,
which
means
this
doesn't
have
to
be
done
in
six
man,
so
this
could
be
done
by
spring
or
could
be
to
somewhere
else
I'll.
I
you
know,
I
don't
know
I'll
leave
it
to
you
and
the
chairs
in
the
group
to
decide
if
it
belongs
in
six
man,
but
I'll
just
observe
that
I
I
think
it
doesn't
have
to
be
done
here
in
order
to
get
your
allocation
so.
I
E
L
Make
the
same
comment
as
as
eric
on
where
this
could
live
but
but
since
that's
already
made,
I
just
want
to
make
a
comment
on
the
on
the
flow
label.
If
you
do
want
to
move
this
flow
id
into
the
flow
label,
load,
balancing
nodes
are
supposed
to
take
into
account
more
than
just
the
flow
label
when
they,
when
they
determine
how
they're
going
to
be
performing
ecmp
or
ucmp
load
balancing.
I
A
F
I
Yeah,
actually,
we
have
this
history
that
we
first
proposed
this
in
that
that
and
after
a
few
meetings
that
they
they
propose
that
we
should,
because
this
this
thing,
the
implementation.
Now
the
the
it
includes
the
the
segment
definition
and
also
this
how
to
encapsulate
this
metadata
and
also
include
the
the
the
yeah,
the
the
the
the
srv,
the
sr
policy
definition.
I
So
they
they
they
shift.
This
worked
from
that
net
to
spring
and
if,
if
the
chairs
agree
that
we
can,
we
can
have
this
I
and
allocation
in
spring
working
group.
I
think
we
can
just
focus
on
the
screen
working
group
and
then,
after
the
after,
it's
all
done,
and
we
come
back
to
then
that
if,
if
it's
necessary
yeah,
actually
this
works
proposed
like
two
years
ago
to
then
that
first.
I
A
B
B
M
M
What
it
is
is
an
overlay
interface
configured
over
multiple
underlying
interfaces
and
if
you
look
at
the
diagram
on
the
left,
that's
from
rfc
5558
from
back
in
2010,
you
can
see
that
thing
called
the
vet
interface.
Is
that
side?
Looking
thing
that
is,
got
some
substance
over
underlying
interfaces
and
then
later
in
2016
in
rse
7847,
a
better
diagram
was
drawn
and
you
can
see
the
omni
interface.
There
is
at
a
layer
below
ip,
but
above
the
underlying
data
link
interfaces.
M
So
what
about
the
omni
interface
characteristics?
It's
an
ordinary
ip
interface
with
a
9180
mtu,
and
what
that
means
is
that
the
ip
layer
expects
the
interface
to
deliver
packets
or
fragments
up
to
9180
bytes
internally.
The
interface
performs
ip
encapsulation
to
convey
original
ip
packets
up
to
9180
bytes
over
the
diverse
underlying
interfaces.
M
M
Please
so
what
the
ola
ol
is
is
an
omni
interface
sub
layer
below
the
ip
layer,
but
above
the
underlying
interfaces,
and
it's
based
on
rsc
2473
encapsulation,
ipv6
encapsulation.
In
other
words,
when
the
ip
layer
delivers
a
packet
to
the
omni
interface,
remember,
it
can
be
up
to
9180
bytes,
the
ol
inserts,
an
rc
2473
encapsulation
header
and
appends
a
two
by
trailing
fletcher
checksum
to
the
form
the
oal
packet.
M
We
count
the
trailer
as
part
of
the
payload
at
this
point,
where
we
put
the
the
payload
length
in
the
oel
header.
The
oel
next
then
uses
ipv6
fragmentation
to
break
the
oal
packet
into
fragments
containing
no
more
than
the
maximum
payload
size.
So
there
you
see
the
fragments
and
each
one
of
them
has
a
payload
in
blue.
That
is
a
portion
of
the
original
ip
packet
that
is
no
larger
than
the
mps,
and
the
final
fragment
has
that
little
trailing
check
sum
attached
to
it
next
chart.
Please.
M
So
how
do
we
find
out
this
maximum
payload
size?
So
some
hops
in
ipv6
oil
destination
paths,
could
be
over
tunnels
over
ipv4
through
ipv6,
over
ipv4
translators,
etc,
and
the
packets
could
also
be
asked
to
traverse
multiple
concatenated
inner
networks
with
diverse
ip
protocol
versions.
I'll
talk
more
about
that
later,
the
ipv4
minimum
path,
mtu
of
576
is
therefore
assumed,
unless
there
is
better
knowledge.
M
M
M
So
for
an
example,
if
we
had
a
1500
byte
original
ip
packet,
that
would
take
up
four
aol
fragments
three
fragments
with
400
by
payloads
and
the
final
fragment,
with
302
by
payload,
which
includes
the
two
octet
trailer,
but
fortunately
larger
per
path.
Maximum
payload
size
values
can
often
be
determined
so
that
we
don't
have
to
have
all
of
this
overhead
and
all
these
fragments
that's
chart.
Please.
M
M
M
M
The
only
oil
extension
headers
that
can
be
included
are
one
fragment
header
and
one
orh,
but
no
other
ipv6
extension
headers
and
that
allows
oil
destinations
to
drop
any
non-final
fragments
less
than
minimum
mass
impaired
size
of
payload,
which
defeats
the
tiny
fragment
attacks
and
oil
destinations
drop.
Oil,
fret,
packets
and
fragments
with
oil
extension
headers
other
than
a
single
fragment
header
and
a
single
omni
routing
header
nice
chart.
M
So
here's
what
it
looks
like
in
a
single
network
traversal,
we
have
an
original
source
that
sends
an
original
ip
packet
that
traverses
some
edge
network
until
it
gets
to
a
node
that
has
one
of
these
omni
interfaces.
You
can
see
the
diagram
on
the
left
there
with
the
omni
interface
and
that
omni
interface
then
performs
oil
packetization
and
then
breaks
the
oil
packet
into
encapsulated,
fragments
that
you
see
down
by
the
blue
cloud
there.
M
M
M
Okay,
okay,
so
then
the
second
intermediate
node
concatenates,
the
red
and
the
yellow
networks
together
at
a
layer
below
ip
and
then
the
packet.
Finally,
pops
out
to
the
final
destination,
where
the
omni
interface
nearest,
the
final
destination,
removes
the
encapsulations
and
forwards
the
original
ip
packet
to
the
final
destination
next
chart.
Please.
M
M
M
It's
a
new
capability
for
hosts
to
dynamically
tune
packet
sizes
for
optimal
performance
without
loss.
Next
chart,
o
ol
is
a
new
ins
sub
layer,
so
it
has
to
include
its
own
integrity
check.
It
uses
fletcher
because
it's
dissimilar
from
the
underlying
inner
interface
crc32
and
the
upper
layer.
Internet
checksum
underlying
networks
can
disable
udp
checksums,
if,
if
possible,
because
we've
got
the
oil
checksum
and
the
some
underlying
network
cops
might
not
include
integrity
checks
at
all.
M
M
So
bridging
of
multiple
network
segments,
the
omni
link,
consists
of
segments
joined
by
oil
and
intermediate
nodes,
acting
as
bridges
as
I
showed
in
that
earlier
diagram.
Some
examples
of
what
these
blue,
red
and
yellow
networks
would
be
in
civil
aviation.
We
have
these
multiple
providers,
including
aaron,
ceda,
inmarsat
and
others.
M
Another
example
might
be
bridging
network
segments
within
an
enterprise
network.
Another
example
might
be
bridging
multiple
enterprise
networks
like
boeing,
airbus
lockheed
just
to
name
a
few
names
there,
but
an
even
more
relevant
example
to
this
group
is
that
this
can
be
used
to
bridge
the
ipv4
and
ipv6
internets.
M
B
M
M
M
M
Please
so
the
omni
option
is
an
ipv6
neighbor
discovery
option
with
one
or
more
sub
options.
So
you
see
the
omni
option
there
on
the
left.
It
has
essentially
a
blank
slate
that
you
write,
sub
options
into
and
then
the
sub
option
format
is
on
the
right
there,
where
you
have
this
5-bit
subtype,
11-bit
sub-length,
and
then
the
sub-option
data
sub-option
types
include
pad
1
pad
in
and
several
others
they're
in
the
document.
M
Large
object,
fragmentation
across
multiple
omni
options
is
not
currently
supported.
It
be
specified
in
the
future
if
necessary,
but
at
this
point
it
doesn't
look
like
it's
needed,
but
ipv6
neighbor
discovery
message
is
as
large
as
the
omni
interface.
Mtu
are
permitted.
9180
bytes
for
an
ip6
neighbor
discovery
message
with
no
ipv6
fragmentation
per
rsc
for
6980.
M
M
This
allows
us
to
test
the
one-way
path
from
the
oil
source
to
the
oil
destination
across
any
concatenated
and
underlying
networks
in
the
path
individual
probes
are
expendable.
They
don't
interfere
with
data
traffic
and
single
probe.
Success
may
indicate
the
opportunity
to
increase
the
path
maximum
payload
size,
but
we
still
need
continuous
probing
to
detect
path.
Nps
changes
in
case
there's
a
change
in
the
path
next
chart,
and
this
is
what
it
looks
like.
M
So
the
ol
source
sends
a
large
ns
message
on
the
left
hand
side
it
may
or
may
not
make
it
to
the
final
destination
if
it
makes
it.
The
final
destination
sends
a
small
neighbor
advertising
message
in
the
reverse
direction
and
that's
going
to
be
assured
to
traverse
all
paths
back
to
the
original
source.
So
that's
how
we
do
the
one-way
probing
to
get
our
maximum
payload
size
larger
for
for
the
oil
fragmentation
next
chart.
A
B
So
it's
going
to
be
1600
to
1800
utc
that's
morning,
west
coast,
us
and,
in
the
meantime,
follow
up
on
a
mailing
list
with
you
know,
if
there's
any
interest
in
in
these
drafts
that
you
know
have
a
chance
of
you
know
either
finding
other
working
groups
to
continue
their
work
or
or
be
adopted
here.
But
we
need
to
see
some
active
interest
in
the
working
group
to
pick
any
of
them
up
alexandra.
Do
you
want
to
say
something.
E
B
Yeah
I
didn't
yeah,
I
forgot
to
put
a
draft
in
the
in
the
poll.
The
first
poll
was
just
a
test
and
the
second
one
was
for
the
first
draft
we
had
today.
I
didn't
run
the
polls
for
the
for
the
other
drafts,
so
we'll
have
to
take
that
to
the
mailing
list.
If
there
is
interest
to
to
continue
work
or
in
this
working
group
or
in
other
places,.