►
From YouTube: IETF111-BESS-20210727-1900
Description
BESS meeting session at IETF111
2021/07/27 1900
https://datatracker.ietf.org/meeting/111/proceedings/
A
A
A
A
A
A
A
A
A
A
A
A
A
A
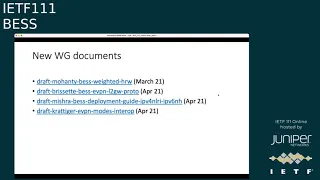
Hrw,
okay,
4d
working
group
documents-
oh
actually,
there's
a
mistake
in
them,
so
mahanti
best
weighted
hrw
was
adopted.
The
evpn
l2
gateway
protocol
was
adopted
on
in
april.
The
deployment
guide
for
ipv4
and
lri
toyota
v6
next
stops
on
in
april
and
evpn
modes.
Interoperability
was
adopted
in
april
as
well.
A
A
number
of
them
are
on
the
agenda:
the
redundant
multicast
source,
the
rfc
74,
32,
bis,
draft,
the
bgp
multicast
controller
draft
evpn,
sr
p2mp
and
evpn
fast
df
recovery
for
evpn
mhpa.
The
working
group
article
is
in
progress.
The
comments
need
to
be
addressed
for
that
the
evpn
geneve
draft,
so
this
is
using
geneve
as
a
data
plane
within
evpn.
A
Sam
has
updated.
The
draft
it
needs
to
have
another
round
of
working
group
last
call
to
cover
off
any
other
comments
from
the
working
group,
the
ipvpn
interworking
draft,
so
that
one,
I
think
that
the
audio
chairs
just
just
posted
a
review
to
the
list
and
there's
a
number
of
comments,
detailed
comments
in
that,
but
obviously
the
chairs
and
the
authors
of
this
draft
need
to
to
look
at.
Thank
you
very
much
to
the
rdr
chairs.
For
that.
A
The
evpn
per
multicast
flow
df
election
draft
as
a
bunch
of
comments
that
are
being
addressed
and
I
believe
the
the
intention
is
to
go
for
a
working
group.
Last
call
after
this
ietf,
the
mvpn
seamless
interoperability
draft
there's
a
new
version
which
will
be
updated
next
month,
evapn
bfd,
the
draft
is
being
updated.
New
version
is
planned
for
after
this
itf
bgp
sd1
usage
draft.
A
We
believe
there's
a
new
version.
That's
that's
ready.
The
pbb
vpn,
I
said
cmac
flush
draft.
We
understand
that.
There's
implementations
that
now
exist
to
that
and
that's
ready
to
progress
to
the
next
stage.
Likewise,
for
the
evpn
martial
split
horizon
draft,
that's
ready
to
progress,
we
believe
to
the
next
stage
the
extended
evpn
optimized
io
draft.
From
the
author's
side.
We
understand
it's
ready
to
move
forward,
but
martin's
waiting
for
the
one
procedures
draft
to
move
ahead.
B
C
Yeah,
thank
you
francisco,
hey,
I
think
proad
would
be
a
work
with
glasgow
because
see
we've
been
updating
it.
Based
on
the
latest
comment,
there
was
something
around
the
how
we
mapped
the
vid
single
tag
and
double
tag.
This
has
been
addressed
with
the
latest
update,
so
I
think
that
the
next
step
will
be
asking
for
work
with
glasgow.
A
D
The
bgp
yang
model's
been
getting
some
targeted
focus
by
the
authors
of
that
draft,
and
it's
not
done
but
is
making
substantial
progress
and
a
core
portion
of
the
work
that
we've
been
doing
is
making
sure
that
module
interwork
can
happen.
So
we've
been
looking
at
modules
such
as
the
l4v
vpn
model,
to
make
sure
that
we
can
actually
apply
the
extensions
in
the
pgpa
model
to
the
various
best
models
and.
A
A
A
F
Two
two
beginning
or
initial
slides,
covering
just
very
quickly
port
active
draft
and
the
ves
drive,
so
I
won't
be
too
long
on
those.
So
the
port
active
draft
is
a
mature
draft
and
we
have
updated
it
based
on.
You
know,
clarifying
comments
received,
so
in
our
view,
this
draft
is
essentially
now
ready
for
open
group.
Last
call.
G
G
E
A
E
F
Okay,
go
ahead,
okay,
so
for
virtual
ethernet
segment,
it's
really
just
more
of
a
shepard
update
as
it
went
forward.
I
think
I
made
some
comments
basically
on
just
the
the
legibility
of
that
draft,
and
so
the
version
7
essentially
you
know,
incorporate
some
clarifying
changes
and
a
new
section,
introducing
basically
the
concept
or
the
terminology
of
grouping
which
was
essentially
prevalent
in
the
document,
but
never
really
given
a
name.
F
F
In
the
spring,
this
last
spring
2021,
I
think
it
was
right.
After
itf-110,
I
emailed
the
working
group
basically
asking
feedback
on
that
initial
zero
zero
version,
which,
thanks
to
feedback
from
sasha,
patrice
jorge
john
michael,
a
zero
one
version
has
been
posted
and
that's
what
I'm
going
to
be
presenting
today.
F
F
So
the
next
important
update
in
red
on
this
slide
was
to
add
a
section
describing
a
new
bdf
designated
forwarder
elected
state.
So
a
backup
df,
whereby
the
7432
previously
df
election
algorithms,
effectively
defined
a
single
df
versus
multiple
non-dfs
through
implementation
and
the
years
basically
found
out
that
there
is
one
particular
non-df.
That's
a
little
bit
more
important
than
the
others
in
the
sense
that,
based
on
the
df
election
algorithm
he's
basically
the
next
one
at
bat
for
df.
F
F
So
it
is
a
completely
new
section
and
section
19
also.
The
second
bullet
that
has
read
specifies
the
use
of
domain
wired
control.
Sorry,
the
main
wide
common
block
and
defines
the
use
cases
for
that
other
than
that.
So
in
the
one
minute
I
have
left,
there's
updates
to
the
flow
lab
flow
label,
usage,
inclusion
of
p2mp,
lsps
and
so
on.
So
a
significant
update
to
the
document
in
terms
of
restructuring
renaming
cross-references,
editorial
changes.
F
F
A
H
Okay,
hello,
everyone.
My
name
is-
and
I'm
here
to
give
you
an
update
on
this
document
that
describes
procedures
for
delivering
mvpn
and
evpn
services
over
an
sr
network.
Next
slide,
please
so
a
quick
history.
The
document
was
originally
published
in
2019,
which
included
only
procedures
for
mvp
and
services.
H
So
the
earlier
versions
of
the
document
covered
procedures
for
binding
mvpn
evpn
services
to
an
srp
to
mpp
tunnel.
The
significant
update,
that's
coming
in
as
part
of
this
version
is
procedures
for
binding
these
services
to
an
ingress
replication
feature
in
lsi
network
we've
added
sections
to
cover
both
srm
pls
and
srv6
for
srm
pls.
We
there's
really
no
new
additional
procedures
required.
Besides,
what's
already
defined
in
rfc
7988
for
srv6
we've
defined
procedures
to
attach
an
srv6
multicast
service
set
to
the
bgp,
mvp
and
auto
discovery
routes.
H
H
So
while
we
are
the
co-authors,
we
are
adding
on
looking
to
add
more
content
to
this
document.
We
appreciate
feedback
from
the
working
group
and
you're
seeking
comments
at
this
point
to
help
improve
the
document.
So
we
welcome
that
and
with
that
I
conclude
my
presentation.
If
there's
any
questions
I'll
be
happy
to
answer.
A
J
J
All
right
so
just
to
continue
for
the
mvpn
evpn
is
our
point
to
multipoint
we're
taking
it
a
step
further
with
the
sr
point
to
multi-point
policy.
Originally,
we
had
this
in
the
idr
working
group.
That's
where
the
draft
is,
but
we
thought
we
should
present
it
in
best
as
well,
because
there
is
a
another
presentation
and
another
work
that
is
trying
to
address
the
same
type
of
transport
downloading
via
bgp.
J
So
we
wanted
everybody
to
be
in
sync
and
understand
the
both
methods
next
slide.
Please,
or
do
I
have
control
of
it
myself?
No,
it's
I've
done
it
perfect.
So
here
are
the
drafts
that
we
are
working
when
it
comes
to
the
point
to
multi-point
sr
point
of
multiplane
or
what
we
call
the
tweetsie.
There
is
a
replication
segment
that
is
already
adopted
in
the
spring.
There
is
a
point
to
multiplying
policy
itself
as
well.
J
I
will
go
through
it,
which
is
within,
pin
again
there's
a
yang
in
a
spring,
the
mvpn
evpn
it's
adopted
within
this
working
group,
and
there
is
a
bunch
of
other
ones.
There
is
one
in
the
pce
how
the
controller
downloads
the
point
multipoint
three
into
the
pcc.
If
you
will
and
then
there
is
this
pgp
sr
point
multipoint
policy
which
again,
as
I
mentioned
it's
in
the
idr,
but
we
need
to
find
the
home
for
it,
whether
it's
best
or
idr.
J
J
So,
to
give
you
a
little
bit
of
background,
what
is
this
sr
point
to
multiplying
policy?
Is
you
folks
already
know
it
based
on
the
evpn
and
mvpndra
adopted
here?
But
basically,
all
it
is
is
a
point
to
multiplying
policy
that
identifies
the
root
and
a
set
of
leaves,
and
it
contains
a
bunch
of
replication
segments.
J
If
you
want
to
think
about
the
replication
segment,
they
are
like
forwarding
instructions
where
they
provide
the
outgoing
interface
based
on
an
incoming
seat
based
on
an
incoming
label
and
there's
going
to
be
a
set
of
outgoing
interfaces
that
you
can
forward
your
traffic
on.
That's
what
the
replication
segment
is
and
I'll
talk
about
that
a
little
bit
later
on.
J
It
is
identified
by
a
root
and
tree
id,
which
is
very
common
when
it
comes
to
the
point
of
multipoint
trees
and
there's
two
way
to
initiate
these
three.
So
when
I
say
a
tree,
obviously
I
mean
it
is
a
transport
mpls
path
end
to
end
mpls
transport.
This
is
nothing
to
do
with
the
service
itself.
The
service
rights
over
this.
This
is
the
underlay
transport
point
to
multi-point
lsp.
J
If
you
will
so,
there's
pcc
initiated
in
the
pcc,
initiated
the
evpn
or
mvpn
procedures
will
identify
the
leafs
throughout
the
network,
we'll
communicate
that
via
bgp
to
the
root
and
the
root
will
use
some
mechanism,
whether
it's
pce
or
whether
there
is
a
hook
from
the
pce
into
the
bgp
session.
To
read
all
that
information,
the
the
controller
will
actually
figure
out
where
the
roots
are
where
the
leaves
are
based
on
that
mpvgp
session.
J
That
is
ongoing
between
the
root
and
the
leaves
and
when
it
figures
out
the
leaf
and
the
root,
it
calculates
the
tree
and
it
downloads
it
down
to
the
pccs.
There
is
another
way
of
doing
it,
which
is
pce
initiated
in
the
case
of
pc.
Initiate
you
go
on
to
the
controller
itself,
and
you
say
here's
my
route
here
are
my
leaves
and
based
on
that
the
tree
is
calculated
via
whatever
algorithm
spf,
whatever
the
algorithm
is,
and
it
gets
downloaded
to
the
pccs.
The
other
replication
segments
nexus
like.
J
J
It
the
the
reason
that
we
have
multiple
path
instances
under
a
candidate
pad
is
because,
if
you
want
to
do
global
optimization,
we
create
a
second
tree
based
on
the
optimized
path
and
we
switch
from
one
pad
instance
to
the
second
pattern.
Sense.
Now,
in
the
point
of
multiplying
policy,
the
canada
paths
are
really
used
for
redundancy.
J
So
what
that
means
is
that
there
is
a
primary
and
then
there's
a
bunch
of
backups,
the
one
with
the
highest
performance,
the
canada
pad
with
the
highest
preference,
is
the
primary
one
in
this
draft,
as
you
will
see
later
on,
we
actually
propose
ecmp2,
based
on
the
same
tlvs
that
we
are
using
in
the
unicast
sr
policy.
So
there
is
a
weight
and
you
will
see
that
we
can
use
that
for
ecmp
purposes.
J
So
two
candidate
pad
can
have
the
same
weight
and
they
can
be
used
in
an
ecmp
pair
if
you
wish
next
slide
please
so
I
already
talked
about
this.
I'm
gonna
go
quickly.
It
comes
when
it
comes
to
the
replication
segment
itself.
What
it
is
is
the
incoming
label
and
set
of
instructions
for
outgoing
oifs
outgoing
interfaces,
and
it's
really
what
the
instructions
that
are
residing
on
the
data
path
is
so
it
contains
the
fast
rewrite
information
as
well.
J
If
you
want
to
protect
one
of
your
oifs,
you
can
create
a
protection
next
hub
to
protect
that
outgoing
interface
and
it's
really
the
data
path
instructions
to
forward
the
packet
for
an
incoming
level
to
outgoing
for
incoming
seed.
I
should
say,
because
srv6
is
actually
used
here
too,
to
have
a
set
of
outgoing
interfaces.
J
J
They
can
be
connected
via
a
unicast
sr
segment,
a
segment
list
if
you
will
and
that's
the
power
of
this
replication
segment,
so
you
could
create
a
replication
segment
on
the
route
if
you
will
and
then
have
unicast
segment
routing
take
that
packet
all
the
way
to
the
leaf
for
ingress
replication
or
connect
two
replication
throughout
the
network
via
a
unica
segment
routing.
So
if
some
part
of
the
network
doesn't
support
multicast
or
replication
segment,
you
can
use
unicast
segment
routing
to
connect
these
two
replication
segments
together.
Next
slide,
please.
J
So
this
is
what
I
already
talked
about
again
quickly.
The
root
has
the
point
to
multi-point
policy.
The
point
multi-point
policy
resides
only
on
the
root.
It
is
identified
by
the
root,
node
leaf
note
and
the
tree
id
by
the
root
id
and
the
tree
id,
and
then
the
replication
segments
are
downloaded
via
the
controller,
whether
it's
pce
or
whether
this
is
point
to
multiple
policy
that
you're
talking
about
after
calculation
of
the
tree.
The
replication
segments
are
downloaded
on
every
single
node.
J
J
So
when
it
comes
to
the
point
of
multiplying
policy
and
bgp,
we
tried
to
get
keep
the
idea
very
much
in
line
with
the
unicast
as
our
as
our
policy.
So
we
created
the
new
nlri,
which
is
the
point
to
multiplying
policy,
a
new
safi
for
that
and
we
created
two
rod
types.
These
two
rough
types
one
is
used
for
point
to
multiplying
policy
and
the
other
one
is
actually
used
for
replication
segment
again.
J
J
I'm
not
going
to
go
too
much
into
detail
here.
You
can
read
the
draft,
but
the
main
idea
here
for
us
was
to
keep
the
point-to-point
multi
policy
in
line
with
the
unicast
draft,
and
the
reason
is
very
simple:
if
there's
already
a
code
that
we
are
using
for
the
unicast
sr
policy,
we
just
want
to
extend
that
code
and
to
that
procedures
to
the
point
to
multiplying
policy.
So
again,
we
download
the
policies
via
the
candidate
paths
and
the
path
instances
are.
J
As
I
mentioned,
there
are
two
different
path:
instances
for
each
candidate
active
and
a
standby.
Sorry,
there
are
two
path:
instances
under
each
candidate
path
for
global
optimization.
So
this
what
you're
looking
at
is
really
the
route
type
for
the
point,
multiplying
policy
and
next
slide,
and
this
one
is
the
route
type
for
the
replication
segment.
J
J
If
you
can
see
there
is
the
protection
and
the
reason
that
we
added
that
is
most
of
the
time
we
can
use
segment,
routing,
unicast
segment,
routing
for
protection
using
lfa
ti,
lfa,
remote
lfa,
whatever
is
available
on
the
unicast
domain,
but
there
could
be
some
cases
that
there
are
no
unicast
segment
routing
and
you
might
want
to
protect
one
of
your
outgoing
interfaces
via
a
replication
segment
itself.
So
you
could
create.
J
A
G
B
G
A
B
B
B
B
B
B
B
It
also
supports
np
to
np
and
supports
sr
srp2p,
even
though,
however,
the
entire
approach
itself
is
not
sr
specific,
except
when
it
comes
to
srp
compute.
Of
course,
it
also
supports
both
overlay
and
underlay
signaling
by
overlay.
Here
I
mean
that
it
can
be
used
to
to
signal
bgp
and
vpn
states
onto
the
keys
in
the
vrfs
and
it
all
it
uses
t
e
a
to
encode
foreign
information
next
slide.
Please.
B
B
B
B
The
major
difference
is
in
the
panel
encapsulation
attributes.
As
a
woman,
I
mentioned
that
when
it
comes
to
srt
p20p,
it's
similar
to
the
p2p
case
policy
information
is
encoded
in
the
in
a
tunnel.
Encapsulation
attributes
attached
to
the
route
and
all
the
replication
branches
are
encoded
in
a
single
panel
in
the
tunnel.
Encapsulation
attribute
for
bgpm
cast
is,
in
my
view,
is
more
aligned
with
the
traditional
tunnel
encapsulation
attributes
it
does
not
carry
carry
policy
information
in
the
gea
and
all
those
branches.
Each
branch,
replication
branch
is
actually
a
ta
tunnel.
B
B
B
So,
but
those
segments
are
encoded
as
sub-trees
of
a
single
p2p
policy
tunnel
instead
of
treating
them
as
different
tunnels
in
the
ta.
My
understanding
is
that
this
is
down
because
the
policy
information
it
has
to
because
the
tas
each
tlb
and
ta
is
a
tunnel.
So
the
policy
information
cannot
be
encoded
as
a
tunnel
and
so
to
to
to
do
that.
B
B
B
I
have
this
example
on
the
right
side,
for
example,
in
this
tea,
where
I
have
four
tunnels:
one
of
the
tunnels-
I
I
should
say
quote-unquote
tunnel,
one
of
the
tunnels
is
actually
used
to
replic,
represent
the
upstream
information
where
the
traffic
should
should
come
from
what
the
incoming
label
is.
Things
like
that
and
other
tunnels
are
outgoing
replication
branches
when
we
encode
this
way
to
me,
it
is
more
aligned
with
the
initial
paa
structure
and,
more
importantly,
this
will
simplify
mp2
mpl.
B
B
For
example,
we
may
be
able
to
use
a
single
sapphire
for
both
bgpm
class
and
srt
p2p
policy
approach,
and
when
it
comes
to
srp10p,
we
can
even
for
pgpm
cars,
even
though
today
we
don't
use
a
separate
route
for
policy
information,
and
we
can
also
do
go
that
way.
Use
a
separate
route
to
include
the
policy
information
instead
of
using
using
attributes
and,
more
importantly,
when
it
comes
to
encoding
the
4d
information
for
for
tree
nodes,
we
can
probably
use
either
style
of
the
gea.
B
For
for
a
between
the
bgpm
pathway.
Is
that
we
use
panels
of
basically
top-level
glvs
in
the
tea
as
replication
branches
and
and
or
you
can
do
it.
The
srt
p
compua,
where
we
only
the
ta
only
has
a
single
tunnel
and
that
single
tunnel
will
encode
multiple
downstream
nodes
and
for
each
downstream
nodes.
You
can
have
different
segments
to
reach
that
downstream
nodes.
That
is
similar
to
p2p
policy
next
side.
Please.
B
B
B
As
long
as
we
need
to
support
the
controller
signal,
ip
multicast
or
controller
signals
mltp
tunnel.
So
from
that
point
of
view,
I
my
I
would
prefer
to
have
a
single
cell,
but
I'm
fine
with
supporting
both
styles
and
so
now.
The
next
question
is:
do
we
want
to
have
a
single
document
to
cover
both
or
just
keep
them
separate?
B
B
Yes,
so
we
don't
have
any
conclusions
yet
we
want
to
see
comments
and
I
don't
want
to
point
out
that
the
bgb
bgb
and
m
respect
king
and
it
should
proceed
on
its
own
it.
It
is
self
sufficient
and
cover
all
the
scenarios,
but
we,
while
it's
perceived
on
its
own,
we
we
will
have
the
considerations
for
sharing
sapphire
and
raw
types
with
the
srg
p2md
and
with
consideration
for
potential
merge
from
that
another
approach.
K
K
J
B
B
K
For
the
chair's
comment,
my
comment
about
error
handling
was
independent
of
underlay
overlay.
It's
about
getting
the
right
error
handling
to
work
for
the
bgp
protocol,
so
I'm
I'm
not
I'm
not!
I'm
not
suggesting
one
is
better
than
the
other,
or
this
doesn't
apply
to
both.
It
does
apply
to
both
that
we
want
to
get
the
error
handling
when
it
passes
through
bgp
right.
L
L
B
L
B
M
M
So
from
the
feedback
from
the
adoption
call.
One
of
the
main
key
points
I
think
was
clarifying.
I
think
the
goals
of
the
draft
which
which
were
updated
as
well
as
ipv6,
only
the
p
ipv6,
only
pc,
peering
architecture
and
design
framework,
where
we
have
ipv4
and
ipv640,
which
occurs
as
it
did
before,
with
the
dual
with
just
with
the
traditional
dual
stack
period,
but
now
without
an
ipv4
address
defined
on
the
pc
attachment
circuit.
M
So
in
june,
after
the
adoption
call,
we,
we
had
a
meeting
with
all
the
co-authors
from
each
of
the
vendors,
so
cisco,
juniper,
arista,
nokia
and
huawei,
and
we
did
a
deep
dive
into
the
architecture
and
the
ipv4
v6
only
peering
design
and
came
up
with
four
test
cases.
Then
we'll
go
over
that
in
the
draft.
In
the
in
the
presentation.
M
So
we
so
I
took
the
lead
on
that
through
our
verizon
engagement
with
the
entec,
and
we
also,
I
guess
another
big
update
in
the
draft
is
we
got
all
the
we
nailed
down
the
vendor
platform,
so
we'll
go
through
that
in
the
code
revisions
for
the
testing
as
far
as
the
ipv6,
only
pc,
peering
interoperability
testing
status.
So
when
we
we
we
investigated
that
in
june,
when
we
met
with
all
the
co-authors,
we
discussed
the
feasibility
and
practicality
of
interoperability
testing.
M
I
think
that
really
the
biggest
thing
was
logistics,
shipping
hardware
to
a
central
location,
and
that's
where
the
idea
of
using
a
third
party
like
ian
tech
to
test
so
so
we
so
first
we
looked
at
so
we
did
actually
also
talk
about
use,
possibly
doing
virtual,
but
due
to
caveats
and
issues
related
to
not
having
physical
hardware,
the
the
results
of
the
test
would
not
be
as
accurate.
So
we
we
scrapped
that
idea
and
this
we
all
came
to
a
consensus
that
we
definitely
need
physical
hardware.
M
So
from
from
looking
through
looking
at
the
antec
option
since
the
test,
the
test
was
in
july
and
we
really
had
such
a
short
time
frame,
we
hadn't
done
the
the
prerequisite
testing
you
know
at
that
point.
It
just
wasn't
useful
because
the
time
frame
wasn't
possible.
So
we
we
decided
that
we
can
accomplish
basically
the
same
goals
that
we
plan
to
do
with
the
iqv6.
Only
appearing
the
architecture,
testing,
the
end-to-end
testing,
with
the
four
use
cases
that
we
put
together,
that
we
can
do
that
per
vendor.
M
So
it
would
be
vendor
pacific
testing,
so
we
would
be
able
to
accomplish
all
the
same
goals
and
really
the
goal
is
that
after
this
draft
you
know
we
testing
is
completed.
We
you
know-
and
this
draft
gets
published,
that
other
vendors.
You
know
that
that
are
not
part
of
this
test,
that
they'll
they'll
be
able
to
look
at
the
draft
and
be
able
to
implement
this.
M
The
solution,
as
well
as
well
as
operators
around
the
world
can
can
take
advantage
of
this,
and
we
I
do
plan
to
take
this
up
and
grow
as
well
as
the
routing
working
group
and
probably
submit
a
draft
to
talk
about
ipv6
only
period
as
well
as
take
this
up
with
the
operator
working
groups
and
whatnot,
as
well
as
other
other
working
groups,
to
actually
help
with
the
proliferation
of
ipvs
and
so
on.
Here
next
slide.
N
A
M
So,
basically,
the
four
test
cases
we
have
so
it's
the
first
test
cases
end-to-end
ipv6,
only
peering,
pc,
so
global,
tabling
over
v4
core,
then
vpn
over
v4,
core
p,
so
v6
only
pure
and
vpn,
over
v4
core
then
test
three
case.
Three
is
ipv6,
only
pc
and
then
global
over
a
v6
core
and
then
the
same
vpn
or
vpn
over
v6
core.
M
How
would
it
originate
that
not
having
a
v4
address?
So
we
came
to.
We
came
up
with
an
idea
that
we
would
possibly
plan
is
what
we'll
test
is.
We
would
put
a
loopback
a
b4
loopback
on
the
pe,
so
he
can
originate
that
that
icmp
response
back
towards
a
ce
with
that
with
that
loop,
so
below
are
the
platform.
So
we
we
nailed
down
all
the
platforms
for
cisco,
juniper
nokia
huawei.
M
The
risk
is
the
only
one
that
we
we're
still
waiting
on
feedback
on,
and
then
we
did
some
preliminary
testing
with
jennifer
and
and
that
that
went
well
looks
like
there
were
some
code
issues
on
on
on
20.
You
know
20.4
r2,
but
when
they
tried
21.4
everything
works
so
so
far,
so
good
with
the
testing
and
we'll
keep
keep
the
the
draft
up.
You
know
updated
with
you
know,
ongoing
testing
that
happens
next
slide.
G
M
A
A
I
I
I
The
draft
was
already
uploaded
adopted,
we
already
discussed
it
a
number
of
times.
We
incorporated
feedback
from
the
working
group,
so
this
revision,
what
it's
doing
is
fixing
a
few
typos
and
minor
things
add
in
a
new
section
factor,
one
that
is
talking
about
the
the
advertisement
of
the
dcb
labels,
the
dcb
labels
or
domain
wide
common
block.
I
So
in
this
section,
basically,
we
extend
the
use
of
the
dcb
labels
so
that
they
are
completely
independent
of
the
pmsi
label
that
you
advertise
in
the
imac
or
spmc
route.
So
now
we
can
use
it
along
with
ingress
application,
pmc
trees
and
they
can
be
used
even
if
they,
you
know
the
pta
attribute.
Does
not
use
a
tcp
label
next
slide.
Please.
I
So
we're
still
seeking
for
more
working
group
feedback
and
then
we
realized
we
need
to
add
some
more
clarifications
about
the
the
use
of
context
labels
based
idx
in
the
communities
along
with
this
draft,
because
there
were
some
things
that
were
not
100
clear.
So
we
would
do
that
and
after
that
the
document
would
be
close
to
be
done
and
that's
it.
A
I
So
we'll
talk
about
three
things:
a
short
introduction,
the
use
case
that
we
are
covering
in
revision,
two
of
the
draft
and
the
conclusions
and
next
steps
next
slide.
Please
so
the
draft
version
0
was
presented
by
ali
in
ietf
99,
and
it
was
at
the
time
an
extension
of
the
evpn
alias
impressive
procedures.
But
in
this
case
for
the
evpn
symmetric
irb
model
with
the
evp
and
mac
ip
routes,
then
we
added
in
version
one.
We
added
support
for
evpn
prefixed
routes
and.
J
I
I
I
Basically
the
procedures
are,
is
pretty
similar
to
the
layer.
Two
case,
the
in
this
case
you
have
the
three
leaves
they
are
attached
to
the
same
tenon,
so
they
have
an
ipv
verse,
configured
and
leaf
one
and
leaf
two
are
attached
to
the
same
broadcaster
main
where
the
ethernet
segment
is
hosted,
and
the
difference
here
is
that
the
v5
on
the
ipvertf
has
an
irb
sub
interface,
which
is
attached
to
a
different
broadcast
domain
right,
but
we
are
able
to
using
the
mac
ip
routes
with
the
internet
segment.
I
I
So
in
order
to
do
that,
we
attach
also
the
ipf
route
target
and
then,
with
that
information,
v5
is
able
to
install
the
the
host
route
associated
to
an
ethernet
segment.
Identi
identifier
that
is
resolved
to
the
two
leaves
with
one
leaf
two
and
similarly
leaf.
Two
can
also
synchronize
the
hose
rod
next
slide.
Please.
I
So
now,
when
you,
you
learn
the
the
mac
idp
of
the
host
behind
ce1,
you
populate
a
host
route
in
leave,
one
you
can
advertise.
You
know
ip
prefix
route,
also
a
tag
with
the
ethernet
segment,
identifier
right
and
we
do
the
same
thing
with
the
ip
ad
variation
and
for
epa
routes.
So
we
add
the
ipv
veriflow
target
so
that
the
the
routes
can
be
imported
by
lv5.
I
So
in
the
same
way
we
can
actually
in
the
ipv5
we
can
install
the
the
prefix
associated
to
the
ethernet
segment
that
is
resolved
to
the
two
leaves,
and
similarly
we
can
do
the
synchronization
in
leaf
two
next
slide.
Please
and
finally,
the
other.
The
other
use
case
we
wanted
to
address
with
this
draft
is
when
you
have
the
ethernet
segment,
purely
as
a
layer
3
construct.
C
Patrice,
hey
hi,
but
he's
from
cisco
hey.
How
are
you
quick
question
about
six
or
seven?
I
think
it's
pretty
much
the
same
diagram.
If
you
can
go
there,
might
you
yeah,
I
can
see.
I
can
see
this
as
a
as
a
natural
evolution
of
what
you've
been
doing
right
for
a
while,
the
and
thanks
for
that
tori.
One
of
the
questions
I
have
for
you
is
on
the
leave
side
of
the
slides.
Why
do
you
need
a
bridge
domain
there?
I
C
N
C
I
I
C
I
I
C
A
C
This
first
one
which
is
evpn,
is
aware,
bundling
it's.
We
put
an
updated
version
recently
on
behalf
of
these
authors,
cisco
and
nokia
juniper,
and
it's
been
reviewed
also
by
everyone
on
the
parties.
I
guess,
if
we
go
to
the
next
slide,
I
think
just
a
quick
refresh
about
what
we
are
trying
to
achieve
here,
all
right.
C
D3
and-
and
what
is
happening
here,
is
that
we're
going
to
be
learning
the
mac
right
and
inside
the
b1
and
we're
going
to
say,
oh,
that,
like
is
associated
with
b1.1
and
and
usually
speaking
with
whenever
you
have
an
esi
you're,
going
to
start
doing,
synchronization
of
data
like
your
arp
and
stuff
like
that
across
the
viewing
pe.
So
therefore,
here
what
you're
going
to
be
seeing
is
that
visually
speaking,
the
mag
that
you're
going
to
be
synchronizing
will
not
have
the
vid.
What
I
put
here
in
yellow
is
usually
not
there.
C
So,
therefore,
when
the
mac
is
getting
on
the
other
side,
you
have
no
clue
to
which
bridge
part.
It
belongs
to.
The
only
thing
that
you
will
know
is
dsi
and
then
and
then,
and
whenever
you're
updating
your
mac
forwarding
table,
you
won't
know,
should
I
point
to
I've
been
in
10,
20
or
30,
because
all
the
traffic
coming
from
your
rb
is
untagged.
C
C
C
H
O
This
is
not
errata,
because
this
is
a
basically
a
new
service
interface
type.
Instead
of
before
we
had
a
vlan
and
their
bundle
service
that
per
vlan.
When
you
advertise
the
route
it
puts
that
into
the
different
broadcast
domain,
so
vlan
in
patrick's
example,
vlan,
10
2030
each
would
go
into
the
different
broadcast
domain.
O
What
we
want
to
do
in
here,
we
want
to
treat
the
vlan
not
as
a
broadcast
domain,
but
as
a
sub
interface
and
be
able
to
pack
identify
the
packet
which
sub-interface
it
is
coming
from
and
put
it
into
the
same
broadcast
to
make
so
vlan
10
2030
in
patrice
example.
They
all
associated
with
the
same
broadcast
domain.
H
But
isn't
that
one
of
those
services
defined
in
the
base
draft?
Also
there
were
three
services:
one
was
the
vlan
specific.
As
you
mentioned,
vlan
identifies
the
broadcast
domain,
but
another
service
was
that
you
can
have
multiple
vlans
in
the
broadcast
domain
as
well.
Just
a
curiosity,
I'm
not
sure.
If
that's
the
case,
then
I'm
fine,
you
know,
but.
O
In
that
one,
the
vlan
is
basically
the
vlan
would
be
opaque,
so
you're
right
I
mean
there
is
another
one
that
we
put
all
and
it's
called
vlan
bundle
service.
So
there
are
three
services:
vlan
based
vlan
bundle,
service
and
vlan
available
service
with
the
vlan
bundle.
You
put
all
the
vlans
into
the
same
broadcast
domain,
but
the
villain
is
opaque.
You
don't
care
about
the
vlan,
you
don't
look
at
the
villa
in
here.
We
want
to
look
at
the
vlan
and
say
this
vlan
means
this
sub
interface.
O
P
O
This
is
about
vlan.
This
is
about
having
basically
optimizing.
The
number
of
the
mac
addresses
that
you
want
to
keep
in
this
in
the
in
your
bridge
table.
Instead
of
creating
three
different
bridge
tables,
you
can
have
one
bridge
table
one
broadcast
domain
for
one
bridge
table
and
have
use
each
of
these
vlan
as
a
sub
interfaces.
P
C
All
right,
so
the
second
one
here
is
the
evpn
vpws,
seamless,
migration,
so
okay.
So
this
is
a
very
interesting
one
and
you
can
see
there's
a
lot
of
people
who
help
and
contribute
to
that
draft.
So,
thanks
to
everyone,
it's
many
people
from
cisco,
jennifer
and
nokia,
and
then
many
vendors
also
who
sponsor
who
sponsor
us.
So
we
can
tbl
linkedin,
verizon,
wireless
and
comcast.
So
next
slide,
please
so,
okay,
so
just
to
tell
you
what
what
happens
right
so
about
well.
It's
a
year
ago,
pretty
much
right.
C
So
the
the
consensus
was
to
merge
these
two
draft
into
a
single
one,
because
there
were
a
lot
of
similarities,
a
lot
of
commonalities
as
well,
and
the
merging
happens
over
well
since
the
last
idea
physically.
So
I
took
the
lead
on
that
and
and
and
with
the
help
of
of
other
parties.
I
think
we
got
something
pretty
good
for
now.
To
be
honest,
it's
I
think
it's
a
very
good
draft,
so
I
will
as
a
next
step.
C
I
will
ask
everyone
to
to
go
over
it
and
you
and
read
it.
I
think
it's
it's
worth
it.
One
thing
that
you
will
not
see
is
all
the
vpls
side,
because
there's
already
an
rfc
and
yet
another
giraffe
about
it
and
in
my
mind
I
really
want
to
keep
the
two
very
separate,
like
we've
done
for
our
system,
m432
and
the
and
the
rc8214.
C
A
C
C
Perfect
so
the
initial
proposal,
there
was
two
approach
being
discussed
there
or
being
explained
and
approached
one
which
is
which
was
a
df
election
handshaking.
So
there
was
an
fsm
being
used
to
speed
up
the
recovery
after
failure
with
an
ethernet
segment,
and
the
second
approach
was
more
like
simpler,
which
is
the
ntp
based
synchronization
solution.
C
C
So
what
we
decided
is
I
asked
you
see,
you
saw
it
on
the
alias
and
also
I
asked
your
vendor
if
we
can
just
take
out
the
approach
number
one
and
move
ahead
with
the
ntp
base
station,
which
is
very
simple
to
be
honest
and
people
accepted.
So
there
was
no
objection
on
the
alias,
and
so
therefore
I
just
updated
the
draft.
Take
it
out
the
approach
number
one
and
explain
it
and
just
move
forward
with
number
two.
So
that's
what
this
is
next
slide,
please
so
again,
shipping
solution
for
us.
N
G
Q
Q
This
will
be
transparent
to
see
devices
and
it's
going
to
leverage
the
bgp
control
plane
that
already
exists
for
the
l3
service
advertisements,
we'll
use
a
combination
of
the
es
import
route
target
and
the
evi
road
target
extended
communities
to
make
sure
that
beachbe
will
only
import
these
layer.
Three
sync
routes
on
the
pe's,
the
service
keys
that
are
attached
to
the
same
esi
and
have
the
same
evi.
Q
Q
Q
Q
Q
Q
Q
Q
This
gives
load
balancing
through
bhp
multi-pass
support,
but
it
means
that
hp
now
needs
to
have
the
adjacency
information
in
order
to
forward
the
packets
and
with
the
hashing
rules
of
the
ce
it
could
be
that
only
one
service
pe
will
hear
the
arp
and
responses
so
we'll
use
a
route
type
2
ipmaq
to
synchronize
these
arp
entries
or
nd
entries
between
the
two
service.
Pes,
because
this
is
a
route
sync
only
evi,
really
mac
only
route
type
sync
is
not
needed
similar
for
multicast
services.
Q
Q
It
also
improves
in
case
of
failover.
We
have
these
pre-populated
on
the
other
pe,
and
the
final
case
is
if
there's
an
igp
between
the
customer
ce
and
the
certain
single
service
pe
there
could
be
a
benefit
if
we
have
the
customer
learned
routes
to
be
synced
to
the
other
pe
that
allows
the
second
p
to
advertise
this
to
remote
peers
and
provide
load
balancing,
as
well
as
faster
conversions.
Q
Q
So
we're
requesting
the
group
to
provide
some
feedback,
we're
interested
in
many
ideas
and
questions.
We
can.
We
can
answer
those
as
well
and
we
also
want
to
do
some
further
study
into
instead
of
just
an
igp.
If
we
have
bgp
running
between
the
p's
and
c's
how
to
support
that,
and
then
I
open
it
up
to
questions.
A
L
L
So,
just
like
I
explained
just
now,
there
are
two
problems
scaling
and
the
convergence
in
large
mpls
lesson
plus
networks,
and
the
solution
is
based
on
a
new
address
family
in
pcp
called
empty,
this
name
spaces,
and
today
we
have
like
three
options
for
doing
option
interface
options.
So
option
abc.
So
this
is,
you
can
consider
it
as
a
combination
of
option
b
and
option
c,
so
we'll
discuss
how
it
works
and
the
advantages.
L
So
the
goal
is
so
basically
in
any
seamless
mpls
network,
the
lo
zero
or
the
loopback
of
every
pe
is
actually
reachable
on
every
border
node
that
does
next
top
set
and
we
have
mpls
route
and
desktop
scale
on
all
the
border
nodes
and
its
ingress
service
nodes
proportional
to
the
number
of
nodes
in
the
network
and
also
ecmp
across
them.
So
the
goal
is
to
reduce
the
number
of
protocol.
Next
off.
L
There
are
visible
to
be
a
function
of
the
number
of
regions
instead
of
the
number
of
routers
itself,
and
this
will
improve
the
scaling
properties
of
the
border
nodes
and
serving
the
service
nodes
as
a
whole,
and
it
also
includes
the
convergence
properties
of
the
network
by
detecting
and
repairing
traffic.
Much
closer
to
the
failure
so
freely
does
not
propagate
into
it.
So,
following
two
slides,
I
just
have
an
example
of
the
topology
that
we're
going
to
follow
next.
L
So
here
we
just
explained
what
is
the
scale
problem.
So
basically,
we
show
here
an
example
of
reason,
one
and
a
report
region,
two
and
region.
One
has
like
hundred
pes,
which
may
have
some
service
deployed
on
them,
and
it
is
advertising
the
label
vl5,
for
example,
with
the
loopback
of
pe
one
and
the
label
to
reach
the
pe.
L
One
is
the
lte1,
and
this
goes
up
to
pe2
and
p2
sends
information
the
packet,
so
the
packet
is
shown
at
the
bottom
and
we
do
next
top
cells
at
the
bottom
nodes,
vn4
vn2.
So
here
we
see
that
pe
2
will
have
to
have
the
forwarding
state
of
all
the
100
pes
and
as
well
as
the
vms.
So
this
is
the
explosion
of
scale
scaling
problem
exactly.
L
So
here
it
just
explains
what
the
conversion
form
when
pe
one
goes
down.
The
withdrawal
that
p1
has
gone
down
has
to
propagate
until
p2,
after
which
p2
can
do
a
pick
repair
to
choose
the
pe
pl.
Sorry
pe
2
prime
we'll
choose
p2.
So
how
do
we
shorten
this
convergence
time
so
that
repair
happens
at
b
and
one
itself
exactly.
L
L
Interest
of
the
network,
including
the
ps
and
other
other
remote
piece
and
what
it
does
is
a
region,
is
extracted
out
by
a
one
context:
protocol
next
up
instead
of
n
protocol
npe
lo
zeros,
and
when
we
are
doing
the
advertisement,
the
rr
does:
label
change
to
a
private
label
context
and
changes
the
next
after
the
context
protocol
next
top.
Let's
go
to
the
next
slide
and
explain
with
the
topology.
L
So
here
we
see
that
pes
p1
to
p100.
They
have
advertised
the
real,
whatever
labels
that
we
have,
that
they
advertise
today
and
rr
is
actually
changing
the
next
half,
it's
rewriting
it
to
cp
and
h1,
so
cpn
h1
is
the
context
protocol.
Next
up
that
identifies
this
specific
region
and
bn1
bn2.
They
advertise
the
context
label
of
2
cp
nh1
in
some
transport
family
like
lu,
and
what
that
label
does.
Is
that
label
when
it
reaches
bn
1bn2?
It
does
a
lookup
in
the
context,
protocol
context
table
cpnh1,
dot
mpls.
L
So
now
any
traffic
that
p2
prime
is
sending
towards
the
cp
and
h1
will
hit
these
context
tables
and
the
rr
it
actually
installs
predictable
routes.
For
example,
it
can
infer
that
c1
is
connected
to
vp1
p2.
When
it
receives
these
routes
from
cpu
and
p2,
it
can
advertise
the
same
label
towards
cpnh1
mpls
table
in
vl1
pn2.
So
in
a
way
we
have
done
what
we
would
do
with
option
b,
where
we
are
doing
next
top
cells
at
the
bottom
nodes.
G
L
L
So
this
shows
how
the
failure
is
absorbed
so
basically
at
bn1.
If
you
see
the
pl
ce1,
that
is
the
mpls
route
labeled
route
in
cpns1.npls.
That
is
a
private
label
that
is
allocated
by
the
rr
and
upside
allocated
installed
in
the
bm1
and
vm2.
So
the
same
plc
e1.
It
is
having
a
primary
next
stop
towards
p1
and
backup
to
our
next
stop
towards
pe
2..
So
next
slide
please!
L
L
So
if
bn1
goes
down,
then
also
the
traffic
that
is
coming
will
go
to
bn2
and
it
will
hit
the
same
label
plc
e1
so
because
of
which
the
traffic
repair
will
happen
with.
So
there
is
no
convergence
event
that
needs
end-to-end
propagation.
That
is
the
whole
advantage
of
this,
and
we
see
that
the
software
changes
required
are
only
on
the
rr
and
the
border.
Node
and
the
whole
network
gets
the
benefit
exactly.
L
Yeah,
so
these
are
the
advantages
we
get
the
scaling
and
we
get
the
topology,
basically
convergence
advantages,
and
it
is
actually
service
from
the
agnostic
so
that
services
that
are
deployed
on
the
ps
they
can
be
lgbt
and
or
anything
that
binds
services
to
labels
and
protocol
next
stops,
and
so
it
will
work
with
legacy.
Pes
also,
and
it
will
work
with
any
transport
family
that
can
advertise
this
context
label.
So
it
looks
like
there
is
a
lot
of
advantages
to
this
mechanism.