►
From YouTube: IETF112-ICCRG-20211108-1600
Description
ICCRG meeting session at IETF112
2021/11/08 1600
https://datatracker.ietf.org/meeting/112/proceedings/
A
B
B
So
I'll
start
off
by
with
the
with
the
irdf
note
well,
which
is
pretty
similar
to
the
ietf
model.
If
you're
not
familiar
with
it,
you
should
you
should
read
this
carefully
at
a
high
level.
I
will
simply
point
out
that
you
are
simply
following
these
idf
processes
and
policies
by
participating
in
terms
of
your
the
intellectual
property
of
anything
that
you
share.
You
are
expected
to
file
ipr
disclosures
on
anything
that
you
file
that
might
have
ipr
that
you're
aware
of
otherwise
read
the
note
for
more
details.
B
Generally,
I
will
just
point
out
one
thing
on
the
code
of
conduct:
please
work
respectfully.
This
is
a
group
of
people
from
many
different
backgrounds
and
many
different
with
many
different
views
be
respectful
and
have
respectful
discussions
and,
finally,
the
goals
of
the
irdf,
specifically
pointing
out
that
the
irtf
conducts
research
and
it
is
not
a
standards
organization.
B
So
as
you
as
you
engage
as
you
participate
and
as
you
discuss
items
bear
in
mind
that
we
are
not
trying
to
standardize
anything
here
and
with
that,
let's
get
to
the
agenda.
So
basically
we
have.
We
have
a
number
of
things
today,
we're
going
to
start
with
a
a
a
different
item
than
usual,
which
is
source
priority
flow
control
and
data
centers
from
jk
lee
who's
at
intel,
and
I
will
let
him
talk
about
this.
B
B
After
that,
it's
going
to
be
more
things
that
you
are
used
to
we're
going
to
start
off
with
we're
going
to
go
on
to
a
ccid
for
bvr,
for
dccp,
followed
by
a
presentation
from
ayosh
mishra
on
the
game.
Theory
behind
running
cubic
and
dvr
you've
seen
ayush
in
the
past
at
iccrg,
and
I'm
looking
forward
to
this
presentation,
and
then
we
have
updates
on
bbr
v2
from
ravine
and
neil
and
ian
and
praveen
is
also
going
to
give
us
an
update
on
our
like
that.
B
Yes,
hi?
Oh
there
you
go
wonderful,
so
you
can
for
for
all
the
speakers
you
can.
You
can
present
your
own
slides.
You
just
have
to
go
to
the
little
start,
slides
share
button,
which
is
right
next
to
the
hand
the
raised
hand
thing
on
the
left.
There
we
go
and
I
will
allow
you
to
do
that,
which
you
should
now
be
able
to.
C
C
Yeah
I'm
going
to
talk
a
little
bit
about
source
flow
control
or
a
little
bit
more
degenerative
form
which
is
source
priority
flow
control,
source
pfc,
and
this
has
been
a
collaboration
mostly
between,
inter
and
recently,
we
started
to
talk
about.
You
said
i3,
a
report
condo
and
then
lilly,
probably.
C
Oh
sorry,
I
need
to
click
here
good,
so
I
don't
think
I
need
to
go
through
what
kind
of
conditions
are
there
in
data
center?
There
are
multiple
different
types,
but
one
type
we
are
looking
at
right
now
is
incase
condition,
which
is
mostly
caused
by
the
money
to
one
traffic
pattern,
and
it
mostly
happens
that
the
last
of
switch
is
the
last,
of
course,
for
our
second
half
switches
and
it
drastically.
C
So
yeah,
obviously
for
congestion.
We,
the
community,
has
been
working
on
entering
condition,
control
for
many
many
decades
and
at
hell
level
yeah.
It's
end-to-end
signaling
from
four
direction:
data
packets
and
echoed
by
the
receiver,
so
that
the
sender
can
adjust
its
transmission
rates
and
condition
window.
C
It
takes
multiple
rtts
to
actually
flatten
the
curve
like
if,
if
the
rate
adjustment
mechanism
is
a
cut
rate
by
half
open
the
reaction
architecture
of
congestion,
that
means
that
16
to
one
in
case
will
take
another
rtt
for
eight
to
one
four
to
one
down
to
one
to
one
and
eventually
we
want
to
really
cut
the
rate
down
to
zero
if
there
is
a
having
cast
so
that
we
really
flatten
the
curve.
That
means
that
many
rtt
times
will
be
required.
C
At
the
same
time,
there
are
a
number
of
flow
control
mechanisms,
mostly
layer,
two
and
well
known
for
i3
pfc,
and
they
are
really
mean
to
prevent
congestion
practicus
from
the
beginning,
by
ex
employing
something
like
exonyx
of
low
latency
reaction
mechanism
that
is
guaranteed
to
be
happening
within
one
microsecond.
Detection
and
reaction
can
should
happen
within
one
microsecond,
as
required
by
the
standard,
and
but
it's
a
hopper
hub
flow
control.
C
C
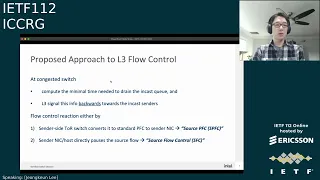
So
this
is
the
one
slide
summary
of
the
our
proposer,
so
the
key
idea
is
very
simple:
at
the
congested
switch
which
we
just
first
compute,
the
minimum
time
required
to
drain
that
target
in
case
q,
where
you
can
expect,
is
something
like
a
expected
surgeon
time
of
the
queue
and
the
signal
is
signal.
Packet
is
generated
and
carrying
the
information
backwards
for
the
incas
senders,
and
there
are
two
different
ways
for
us
to
consume
this
information.
The
first
one
is
the
sender
side.
C
Top
of
rec
switch
can
convert
this
layer,
three
signaling
packet
back
to
standard
pfc
to
directly
pause
the
sender,
nic
cues,
so
we
call
it
source
pfc
or
the
signal
information
can
be
forwarded
back
to
senders
and
then
sender,
link,
hardware
or
host.
Networking
stack
can
directly
consume
that
information
and
pause
the
search
flow
and
we
call
it
source
flow
control
or
sfc.
C
So
what
you're
talking
about
here
is
that
simple
cartoon
data
center
with
two
senders
and
one
receiver
there's
an
interest
happening
so
typically,
when
we
enable
pfc
and
2n.
That
means
that
the
the
destination
top
of
rec
switch
will
create
pf's
priority
flow
control,
and
this
will
pause
the
upstream
aggregation
core
switch
links
instead
of
that.
What
we
do
here
is
that
we
assume
some
simple
mechanism
at
the
switch
ingress
which
can
learn
about
the
ongoing
congestion
at
the
switch
egress.
C
So
even
before,
when
we
fold
the
package
from
ingress
to
egress,
the
ingress
pipeline
has
some
capability
to
generate
a
signaling
packing
back
to
the
senders
and
here
for
source
pfc.
We
are
assuming
that
I
actually
implemented
that
the
source
side,
topper
work
switch,
can
simply
convert
this
layer,
three
similar
packet
to
pfc
frames,
so
that
it
can
immediately
pause
the
in
case
senders.
C
So
the
entire
detection
and
reaction
can
happen
within
sub-rtt
time,
where
the
rtt
is
congestion-free
based
rtt,
and
here
we
are
not
really
aiming
to
replace
entering
condition
control.
This
is
more
about
kind
of
emergency
brake
or
reaction
to
having
cast,
because
we
are
not
really
pausing
any
of
the
inter-switch
links.
There
is
no
head
of
line
blocking
happening
between
the
inter-switch
links
and
no
phd
side
effects
are
expected.
C
Of
course,
we
can
deploy
this
mechanism
every
switch
in
the
data
center,
but
from
our
simulations
and
test
beds,
top
of
rack
switch.
Only
upgrades
can
actually
give
us
mostly
bang
for
the
buck,
because,
I
think
mostly
happens
at
the
last
stop
switch
and
the
signal
link
between
this.
These
couple
rack
switches
can
still
give
us
pretty
good
reaction
to
most
of
the
heavy
intestine.
C
Meanwhile,
when
the
heavy
congested
queue
is
being
drained,
but
finally,
the
entry
and
condition
signal
will
be
received
by
the
receiver
and
then
echoed
by
the
receiver
back
to
sender.
So
here
the
point
here
is
that
the
this
source,
pfc
reaction,
can
be
much
faster
than
the
heavy
condition.
Control
reaction
to
the
heavy
incase,
when
the
especially
qdap
is
pretty
large.
C
C
There
are
two
in-case
flows
happening
at
the
same
time.
Here
the
the
experiment
is
designed
in
a
way
such
that
the
the
link
between
top
of
rack
switch
1
and
to
r2
will
be
a
head
of
line,
blocked
mostly
by
the
in
case
happening
at
the
receiver.
2
will
pfc
pause,
the
omnics
port
and
which
will,
in
effect,
create
head
of
line
blocking
also
for
the
flows
of
sender,
one
to
receiver.
One.
C
C
We
have
a
case
with
the
remote
pfc
or
source
pfc
enabled,
and
you
can
see
that
the
q
that's
at
the
order.
Three
congested
links
are
pushed
down
to
drastically,
with
more
than
sometimes
tens
of
order
of
magnitude.
Difference
with
that,
you
may
wonder
what
would
be
the
throughput
performance
so
with
so.
This
is
the
measurement
of
the
flow
completion.
Time
of
this
more
than
the
thousands
of
flows
or
rdma
write,
request
and
yeah.
C
So
you
may
wonder
what
information
we
need
to
carry
for
this
layer,
3
signaling
packet,
so
key
id
is
very
simple,
so
we
have
some
more
detailed
backup
slide
at
the
back
down
the
road.
How
we
can
convey
these
signaling
informations
in
the
i3
802.12
cz,
which
is
the
draft
cim
here,
means
that
conditional
isolation,
messaging.
C
So
when
we
generate
a
signal
in
packet,
we
can
just
swap
the
source
ip
from
the
data
packet
and
then
use
them
as
the
user's
destination
ip
of
the
signaling
packet.
With
that
the
packet
will
be
forwarded,
signal
packet
will
put
it
back
to
the
sender
and
we
can
still
carry
the
original
destination
ipod,
the
incas
traffic.
C
It
can
be
optionally
used
to
cache
some
of
the
post
time
at
the
sender
side
top
product
switch.
I
can
talk
about
that
more
later
and
we
can
also.
We
should
also
carry
something
like
a
dhcp
or
vlan
pcp,
whatever
qs
priority
information
that
is
needed
to
identify
the
actual
pfc
priority
queue
to
pause
at
the
center
nick
and,
most
importantly,
we
we
carry
the
pulse
time,
duration
or
expected
surgeon
time.
C
It
should
be
the
smaller
or
the
equal
than
minimum
drain
time
to
reach
the
target
shoot
ups.
So
here
the
target
q
depths
could
be
something
like
an
ecm
thresher
or
slightly
over
lower
than
that.
When
we
tried
to
try
with
different
values,
they
didn't
really
make
big
difference,
because
our
reaction
was
the
spx
reaction
is
really
fast
and
optionally.
We
can
carry
some
additional
condition:
locator
information
like
a
switch
for
qids,
but
that's
really
optional.
Even
without
the
information,
the
entire
protocol
behavior
should
be
the
same.
C
C
So
just
as
a
data
point,
there
is
actually
recent
paper
nsdi
this
year,
something
called
onramp
which
also
implements
such
a
similar
flow
level.
Connection
level
flow
control
mechanism
implemented
at
the
linux
q,
disk,
so
yeah.
In
order
to
make
a
reaction
and
consumption
of
this
information,
we
need
some
changes
on
the
software
stagware.
C
We
need
to
modify
the
rdm
hardware
stack
and
there's
one
example
in
the
nsd
paper
back
to
this
question:
how
does
it
differ
from
source
crunch,
which
is
actually
duplicated
rfc,
I
think
more
than
10
years
ago,
as
I
understand,
there
are
multiple
reasons
why
source
quench
has
been
deprecated
first,
it
didn't
really
specify
which
information
to
carry
or
how
to
consume
and
react
to
that
information
at
the
sender
side,
and
so
we
in
sfc
or
as
tfc.
We
clearly
specified
that
we
just
carry
the
pulse
time.
C
Duration
for
the
drain
time,
duration
and
we
promote
that
the
immediate
flow
control
so
that
incas
senders
can
really
stop
sending
immediately,
rather
than
aim.
This
style
of
transition
control,
especially
for
data
center
and
yeah
source
quench,
was
really
designed
for
or
promoted
for
when
internet
transition
handling.
But
we
are
promoting
this
sfc
for
data
center,
with
single
administrative
domain
and
in
case
of
layer,
two
data
center
there.
What
has
been
something
called
i3
qcn,
it's
actually
quite
similar.
C
C
Answer
is
one
of
the
questions
and
some
additional
questions
are
shared
by
the
itp
community
by
separate
emails.
So
at
high
level,
how
do
we
secure
the
protocol?
We
assume
this
will
be
for
single
domain
data
center
with
trusted
switching
devices,
and
I
can
make
some
argument
that
the
signaling
between
switches
for
source
pfc
it
could
be
similar
to
error,
dp
and
bgp,
and
then
I
understand
that
there
is
a
bgp
encryption
mechanism,
but
in
reality
it
hasn't
been
really
used
for
many
regions.
C
It
cannot
really
serve
the
problem
of
malicious
or
poorly
implemented
router
and
it
can
actually
cause
additional
headaches.
So,
as
I
understand
no
one
not
really
heavily
turned
on
the
bgp
encryption
mechanisms
and
for
the
signaling
for
sfc
source
flow
control.
For
the
sender
transport
to
react,
we
can
see
that
this
is
quite
similar
to
ecm
marking,
where
the
data
center
switches
for
intermediate
switches
and
routers
are
provide
some
information
in
the
actual
data
packet
and
consumed
by
the
sender
side
transport.
C
Here
we
are
generating
the
new
new
signaling
packet
instead
of
modifying
or
marking
on
the
inband
data
packets.
But
you
know
such
that.
The
information
is
provided
by
the
switches
and
then
directly
concerned
by
the
end
host
is
pretty
similar
in
my
opinion,
and
then
ecn
is,
has
been
heavily
used
in
data
centers
these
days,
something
like
a
dc-tcp.
C
C
And
another
question
was
yeah:
is
it
only
for
rocky?
Yes,
rdma
is
a
primary
use
case
and
then
rocky
b2
is
the
most
popular
transfer
of
today.
But
we
see
more
new
type
of
transport
for
rdma
or
rma
mechanisms
are
rising,
and
so
we
believe
we
can
have
many
different
rdma
transports
in
a
similar
way
to
scale
on
standard
ethernet
fabric,
and
we
have
some
some
argument
how
this
can
be
a
good
fit
for
the
machine
learning
training
in
the
backup
slide.
C
So
if
you
want,
you
can
take
a
look
and
sfc
can
also
be
applied
to
non-rdm
use
cases
as
similar
to
on-ramp
paper
from
nsdi,
and
we
are
currently
performing
some
evaluations
with
the
tcp
traffic
and
you
may
wonder
that
the
ig-28
signal
link
is
still
sub-rtt,
but
it
can
be
still
proportional
to
the
network
rtt.
If
the
network
size
is
growth,
so
then
isn't
it
too
slow.
C
So
we
have
a
simple
mechanism
that
we
can
catch
the
pause
time
per
destination,
ip
at
the
sender,
site,
top
project
switch,
and
this
information
can
be
used
to
instantly
pause,
another
sender's
coming
from
the
same
connected
same
switches
and
then
handy
gearing
for
the
same
destination.
Ip
can
be
immediately
paused
without
waiting
for
them
to
be
trend,
reach
out
to
the
sender,
side,
receiver,
side,
tour
and
their
account
back.
C
C
Thanks
for
the
opportunity
and
the
planet,
the
i3
is
simply
extending
the
existing
in
80
2.1
qcd
conditional
isolation
mechanism.
It
already
has
a
layer,
3
mechanism,
so
we
can
simply
extend
it
to
enable
something
like
a
source
pfc,
but
I
can
easily
imagine
that
if
you
really
want
to
do
source
flow
control
for
the
transport
to
make
use
of
this
information,
then
ietf
can
be
a
better
forum
to
discuss.
C
D
C
C
Yes,
hbcc,
I'm
also
part
of
the
effort.
It's
still
four
direction,
signaling
so
hpcc.
You
can
imagine
this
as
a
really
multi-bit
ecn.
So,
instead
of
just
one
bdcn,
it
carries
the
multiple
information
about
the
condition
like
qdaps
and
then
link
utilization,
but
still
in
the
four
direction,
data
packet
and
echoed
back
by
the
receiver
back
to
sender.
So
it
still
kind
of
suffer
from.
C
C
F
Yeah,
okay:
here
we
just
want
to
double
check
hello,
hello,
yes,
okay,
hey
john,
I
have
a
particular
question
regarding
your
slide.
6
the
example
in
the
normally
in
data
center
of
the
tor
switch
or
for
the
other
aggregation
switch
from
the
downlink
to
uplink
you're,
going
to
have
some
ratio
not
just
like
the
one
you're
showing
in
the
slide,
six
like
the
downlink
100
gig,
and
the
update
also
100
gig,
normally
just
like
a
photo
one
ratio.
F
C
Yeah,
that's
a
fair
question.
Thanks
yeah
this,
this
has
been
intentionally
designed.
The
topology
has
been
intentionally
designed
to
just
nail
down
on
the
head
of
line
blocking
issue
and
when
we
simulated
the
larger
scale
simulation
for
320
servers
yeah,
we
definitely
created
a
full
bisection
than
this
topology.
Without
any
oversubscription,
and
here
there
we
could
still
see
that
pretty
good
flow
completion.
Time
improvement,
even
for
the
dc
qc,
which
is
the
actually
improve
the
cqc
and
also
hpcc,
and
there
was
another
presentation
from
at
i3.
C
So
if
you
sorry
yeah,
this
particular
highlighted
link.
If
you
can
click
on
this
one.
This
was
the
measurement
study
done
by
huawei
a
month
after
our
initial
presentation
in
i23,
and
then
they
actually
quickly
the
prototype
and
then
demonstrated
when
their
rdma
traffic
is
mixed
with
tcp
with,
I
think,
normal
of
a
subscription
or
maybe
small
over
subscription.
C
B
C
But
I
think
the
fundamental
difference
is
that
incas
can
still
happen,
because
you
cannot
really
perfectly
synchronize
all
the
senders,
especially
with
rdma
each
centers
blasting
at
line
rate.
If
somehow
they
happen
to
collapse
in
the
within
one
or
two
rtt
time,
maybe
more
than
just
three
or
four
senders.
They
can
easily
just
fill
up
the
queue
very
quickly
right
and
the
entry
condition.
Controller
still
has
to
kind
of
have
the
signal
passing
through
the
congested
queue
and
reaching
the
receiver
and
echoed
back
so.
B
B
That's
going
to
the
ieee
and
if
there's
any
feedback
that
you'd
like
to
pass
along,
I
think
it
will
be
welcome
either
on
the
on
the
research
group
mailing
list
or
directly
to
jk,
and
with
that
I
am
going
to
move
to
the
next
presentation
natalie.
I
hope
you
say
I'm
saying
your
name
right,
I'm
not
sure!
Yes,
I'm
here!
G
So,
first
of
all,
the
motivation
to
bring
bvr
to
the
tccp
protocol
relies
on
the
fact
that,
right
now
for
dccp,
there
are
only
three
congestion
control,
algorithms,
standardize
it
and
all
of
them
are
lost
bases.
So
we
thought
about
bringing
vbr
precisely
because
it
is
a
non-loss-based
acc
algorithm.
G
G
G
So
once
we
finish
our
first
implementation
of
bbr
for
dccp,
we
started
some
evaluation
in
a
controlled
environment
using
a
single
path
and
a
multiple
scenario.
In
this
evaluation,
we
compared
the
performance
of
our
implementation
of
bvr,
which
is
cc85
with
the
performance
of
cci2,
which
is
the
default
congestion
control
for
the
ccp.
G
G
G
So
we
started
an
analysis
of
this
problem
and
we
figured
out
that
what
was
the
cause.
The
point
is:
a
bbr
requires
the
restoration
of
the
congestion
window
when
it
leaves
the
property
phase,
so
it
restores
the
congestion
window
from
a
quite
low
value
to
the
value
it
had
previous
entering
this
phase.
G
G
G
So
to
solve
this
problem,
we
apply
the
temporary
solution,
which
is
that
we
trigger
this
synchronization,
but
we
don't
wait
for
the
confirmation
to
update
the
local
values.
That
means,
as
soon
as
we
trigger
the
synchronization,
we
can
update
the
local
value
and
proceed
to
restore
the
congestion
wind.
G
Now.
The
question
is
that,
as
I
said,
this
is
a
temporary
solution
and
we
would
like
to
start
a
discussion
to
know
what
is
the
best
approach
to
solve
this
problem.
So
maybe
a
new
or
an
enhancing
feature
for
the
sequence
with
the
negotiation
is
necessary,
or
maybe
there
can
be
a
different
approach
that
help
us
to
solve
this
problem.
G
G
The
second
question
comes
about
this
sequence:
window
negotiation.
So
we
have
described
the
problem
and
we
would
like
to
receive
some
feedback
about
it
and
to
start
as
well
a
discussion
there,
but
if
we
are
not
sure
what
should
be
the
right
place
to
start
the
discussion
either
here
in
ccr
in
iccrg
or
in
tsbwg.
B
H
That
we'd
be
able
to
discuss
this
on
the
mailing
list
and
make
some
progress
with
the
algorithm
and
the
proposal,
I'm
not
sure
where
the
home
would
be,
but
it
lies
between
these
two
groups
and
whatever
the
home,
you
shouldn't
be
discouraged.
Please
please
discuss
how
to
fix
it
and
please
discuss
the
issues.
H
E
E
B
I
Not
the
id
for
this
but
yeah,
I
like
I,
I
I
support
this
work
as
well,
but
I
am
a
little
concerned
that
this
is
racing
a
little
bit
ahead
of
the
actual
tcp
bbr
work,
which
I
I
think
probably
has
a
little
more
data
to
support
it.
So
I
mean
it
seems
like
most
bbr
discussion
at
this
point
is
happening
in
iccrg
and
you
could
certainly
do
a
drafting
iccrg.
I
B
J
Among
chairs
is
fine,
I
think
icc,
as,
as
I
think,
iccrg
is
the
right
place
to
discuss
the
technology,
and
it's
also
the
right
place
to
figure
out
appropriate
timing
when
the
timing
is
appropriate.
Tsvwg
is
almost
certainly
the
the
venue
to
work
on
the
directness
here
and
standardization,
but
need
to
get
the
timing
right
and
make
sure
that
it's
it's
it's
well
coordinated
with
bbr
as
a
whole.
K
B
L
L
Okay,
so,
since
pbr
was
introduced
in
2016,
a
lot
of
websites
have
made
the
performance
driven
decision
to
actually
adopt
it
and
use
it
to
send
data
for
their
websites,
and
companies
like
google
and
spotify
and
dropbox
have
reported,
seeing
lower
delays
and
better
throughput,
especially
in
lossy
networks,
where
act,
locked,
loss-based,
algorithms,
like
cubic,
are
known
to
suffer
and
clearly
this
trend
has
got
on.
Since
we
did
a
measurement
study
in
late
2019.
L
So
the
question
we
want
to
ask
is:
where
is
this
transition
really
heading?
So
this
transition
in
the
internet's
congestion
control
landscape
is
definitely
not
a
new
thing.
We've
seen
in
the
past
that
renault
dominated
internet
in
the
early
2000s,
slowly
transitioned
into
an
internet
that
was
mainly
cubic,
dominant
and
much
like
gbr
does
today.
Even
back
then
cubic
basically
gave
you
better
throughput
and
better
utilization
guarantees
on
the
internet,
which
is
why
people
moved
on
to
it.
L
But
there
is
one
key
aspect
in
terms
of
which
this
transition
from
cubic
to
bbr
is
very
different
from
the
transition
that
we've
already
seen,
which
was
between
renault
to
cubic.
So
the
transition
between
render
to
cubic
was
essentially
between
two
window-based
loss-based
algorithms.
So
they
were,
they
both
had
the
same
congestion,
control
philosophy.
L
They
both
reacted
to
the
same
congestion
signal,
and
that's
why
you
know
we
didn't
really
face
a
lot
of
problems,
but
right
now,
as
you
have
more
and
more
websites
replacing
using
bbr
to
replace
the
existing
loss-based
algorithms.
What's
that
actually
doing,
is
it's
creating
a
paradigm
shift
in
how
congestion
control
is
done
on
the
internet?
L
So
the
question
we
want
to
ask
is
given
this
performance
improvement
that
bbr
has
given
us
so
far.
Where
do
we
actually
expect
this
transition
to
move,
or
in
other
words,
if
you're,
seeing
such
good
performance
benefits?
Is
it
reasonable
to
expect
everyone
to
switch
from
cubic
to
bbi
at
some
point
in
the
future?
L
L
So,
let's
look
at
the
example
on
the
slide
here.
Let's
say
we
have
a
network
with
seven
senders
and
of
the
seven
centers.
Four
of
them
are
running
bbr
and
three
of
them
are
running
cubic,
and
given
this
network
configuration
and
congestion
control,
algorithm
distribution,
each
of
the
flows
are
getting
some
share
of
the
bottleneck
bandwidth.
L
That
essentially
means
that
this
conjunction
control,
algorithm
distribution,
is
the
nash
equilibria
for
that
network,
or
basically,
this
is
the
fixed
share
of
cubic
and
bbr
flows.
We
have,
in
the
network,
there's
really
no
incentive
for
the
number
of
bbr
flows
to
increase
or
for
the
number
of
cubic
floors
to
increase.
L
Now
a
conjecture
in
the
paper
is
that
we
think
this
nash,
equilibrium
equilibria,
will
exist
in
all
kinds
of
networks
where
you
have
senders
and
senders
running
cubic
and
vbr
flows,
and
this
is
actually
quite
a
big
claim
to
make,
which
is
why
we
still
say
that
it's
a
conjecture,
but
we
have
good
reason
for
making
this
conjecture.
So
in
the
paper
we
go
over
the
exact
observations
that
we
made
based
on
how
cubic
and
bbr
interact
and
how
these
observations
actually
guide
us
towards
making
this
conjecture.
L
But
in
the
interest
of
time
I'm
only
going
to
discuss
the
key
observation
over
here,
which
will
hopefully
convince
you
guys
that
yeah
there
might
indeed
be
a
nash
equilibria.
When
you
know,
n
number
of
flows
compete
at
a
common
bottleneck,
so
over
here
I'm
going
to
plot
a
graph
for
a
system
where,
let's
say
we
have
symmetric
senders.
So
all
my
senders
have
the
same
rtt
and
they
only
differ
in
the
sense
of
which
congestion
control
algorithm
they
choose
to
run
now.
L
We
know
from
other
measurement
studies
that
when
you
have
a
very
small
number
of
bbr
flows
in
the
network,
they
can
get
a
disproportionately
high
share
of
the
bottleneck
bandwidth.
So
I'm
going
to
plot
this
as
point
a
in
the
graph
on
the
slide.
So
on
this
graph,
basically,
on
the
y-axis,
I
have
the
combined
throughput
of
all
the
bbr
flows
and
on
the
x-axis
I
have
the
percentage
of
bbi
flows
in
each
congestion
control,
algorithm
distribution.
L
L
L
So
the
interesting
thing
about
this
graph
is
that
when
you
actually
plot
out
these
values,
every
point
at
which
your
gray
line
intersects
the
fair
share
line
that
essentially
signifies
the
nash
equilibrium
point
in
the
network,
so
the
fair
share
line-
I'm
sorry,
I
didn't
go
over
it
earlier,
but
the
fair
share
line
is
basically
the
line
at
which
all
your
flows
get
the
fair
share.
So
if
bpr
was
getting
the
fair
share
in
this
network,
the
the
data
points
would
follow
the
fair
share
line.
L
So
let
me
actually
go
over
why
we
actually
claim
that
this
intersection
point
in
this
graph
is
going
to
be
the
nash
equilibrium.
So
to
do
so,
let's
zoom
into
one
of
these
intersection
points.
So
at
this
intersection
point
basically
what's
happening-
is
that
the
average
bandwidth
of
all
the
cubic
flows
equals
to
the
average
bandwidth
of
all
the
bbr
flows,
which
is
why
neither
of
them
wants
to
switch
to
the
other
kind.
L
But
why
do
we
say
that
this
is
actually
the
nash
equilibrium?
Well,
we
say
this
intersection
point
is
the
nash
equilibrium,
because,
let's
say
we
move
to
the
right
of
this
point,
which
would
signify
that
a
cubic
flow
in
my
current
configuration
wants
to
switch
to
running
dbr.
So
when
we
do
this,
we
will
actually
be
transforming
the
entire
system
into
a
regime
where
bbr
flows
perform
worse.
L
So,
in
both
cases
the
cubic
floor
does
not
switch
to
bbr,
because
that
would
mean
meaning
to
moving
to
a
region
where
bbi
performs
worse
and
similarly,
the
bbr
flow
does
not
want
to
switch
to
cubic,
because
that
would
mean
moving
to
a
regime
where
cubic
floors
perform
worse
and
because
there
is
no
incentive
for
any
floor
to
switch
to
the
other
strategy.
At
this
intersection
point.
This
by
definition,
becomes
our
nash
equilibrium
point
now.
L
L
But
beyond
the
exhaustive
proof,
we
also
wanted
to
empirically
validate
some
of
the
claims
of
our
conjecture,
which
is
saying
that
the
nash
equilibrium
will
always
exist.
So
what
we
did
was
we
set
up
networks
with
six
nine
and
12
floors
where
all
these
flows
shared
a
common
bottleneck,
bandwidth
and
in
each
experiment.
Exactly
one
third
of
these
flows
had
2050
and
etms
rtts,
and
this
was
basically
to
simulate
flows
of
different
rtts
competing
with
each
other,
and
then
we
wanted
to
see
how
this
actually
impacts
the
existence
of
the
nash
equilibrium.
L
So,
just
to
recap,
if
we
have
a
three-floor
system-
and
we
say
that
cbc
or
the
first
floor,
running
cubic
the
second
floor,
running
bbr
and
the
third
floor
running
cubic
again
is
the
nash
equilibrium
that
basically
means
that
when
your
distribution
is
bbc,
the
first
flow
gets
worse
throughput.
When
your
distribution
is
ccc.
The
second
flow
gets
worse
through
part
and
when
your
distribution
is
cbb,
the
third
flow
will
get
worse.
Throughput.
L
L
So,
while
actually
calculating
the
nash
equilibria,
we
experimented
with
different
link,
speeds
and
different
buffer
sizes,
and
the
entire
point
of
this
was
to
see
how
the
link
speed
and
the
buffer
sizes
impacted,
where
the
nash
equilibria
lied.
Predictably,
buffer
size
had
the
biggest
impact
on
the
on
the
distribution
at
the
nash
equilibria.
L
L
So,
to
summarize,
the
findings
of
our
short
paper
is
that,
despite
bbi's
current
throughput
benefits,
we
think
it's
unlikely.
That
cubic
is
going
to
disappear
soon,
and
this
is
because
we
think
that
dbr's
performance
benefits
that
we
see
on
the
internet
today
are
going
to
wane
as
more
and
more
people
on
the
internet
start
running
bpr.
L
Now,
obviously,
there's
a
lot
of
future
work
to
be
done
in
this
paper.
We
want
to
come
up
with
a
formal
proof
for
general
inflow
game.
We
also
want
to
look
at
the
effect
of
more
complex
network
utilities.
So
in
our
paper
we
assumed
a
very
simple
utility
function
where
every
flow
wanted
to
maximize
its
throughput.
But
obviously
that's
not
true
on
a
real
network
flows
are
likely
to
care
about
both
throughput
and
delay,
and
the
utility
function
is
likely
to
be
a
combination
of
these
metrics.
L
B
Thank
you
so
much
for
your
time.
Irish.
This
is
a
very,
very
interesting
piece
of
a
number
of
people
in
the
queue
already,
but
I'm
going
to
ask
a
question
before
I
get
in
there.
I
actually
took
two
quick
questions.
One
of
them
is
that
you
seem
to
suggest
cbb
and
bbc
as
two
different
experiments,
and
I
want
yes
that
seems
to
me.
I
said
the
order
in
which
flows
entering
choose
makes
a
difference.
B
L
B
B
B
K
Hi
thanks
this
is
this
is
quite
interesting.
I
I
do
have
some
kind
of
extra
complexity
to
add
on
to
this
whole
thing,
which
kind
of
at
least
my
thoughts
on
how
this
replicates
or
does
not
replicate
the
real
world.
So
it's
it's
worth
it
noting
that
the
most
valuable
flows
are
commonly
the
short
ones
that
are
very
accurate.
K
The
conical
example
is
things
like
search
and
ads,
and
in
the
case
of
my
employer,
you
generate
a
lot
more
value.
You
certainly
want
more
value,
provide
something
like
youtube,
video
and
given
the
amount
of
value,
it's
actually
kind
of
incentive
compatible
to
make
sure
your
your
long-term
flows
are
not
too
aggressive
and
that
they
move
out
of
the
way
quickly
when
something
that's
high
value.
K
Like
start,
your
ads
comes
up,
and
the
the
other
thing
to
note
is
it's
not
uncommon
to
have
between
10
and
20
connections
for
a
single
page
load
on
the
internet
and
when
you're
dealing
with
that
kind
of
chaotic
environment
where
nothing
really
gets
out
of
startup
or
very
rarely
it's
it's
very
difficult
to
reason
about
the
congestion
control
performance.
Right
like
like
the
congestion
avoidance
phase,
is
basically
like
irrelevant.
K
You
can
largely
like
remove
it
from
the
congestion
controller
and
it
would
like
largely
work
the
same
for
search
and
a
number
of
other
major
websites.
It
obviously
matters
intensely
for
youtube
that
matters
intensely,
for
you
know
a
large
flow
like
an
uploader
or
download,
but
but
I
guess
even
for
a
given
provider,
it
might
actually
be
instead
of
a
compatibility
like
make
your
congestion
avoidance
scheme,
not
too
aggressive,
to
make
sure
that,
like
smaller
flows,
which
are
higher
value
like
our
favorite,
and
so
I
think
I
think
it's
complicated.
L
L
So
yeah,
all
those
things
definitely
complicate
things
a
lot,
but
currently
from
what
we
are
working
on
is
the
assumption
that
all
your
flows,
that
all
the
flows
that
you
care
about
are
substantially
long
such
that
they
enter
congestion,
avoidance
mode,
and
then
we
want
to
see.
You
know
how
how
performance
is
going
to
change
for
these
considerably
longer
flows.
I
I
The
other
the
other
one
is
that
as
more
and
more
people
adopt
cubic
towards
the
nash
equilibrium
that
that
buffers
that
buffer
occupancy
drops
and
therefore
that
the
the
benefit
of
adopting
bbr
instead
of
cubic
lessons,
and
so
the
the
nth
person
to
adopt
cubic,
has
no
incentive,
because
the
other
bbr
people
have
already,
you
know,
reduced
the
buffer
occupancy.
So
I
don't
know
if
you
can
speak
to
either
of
those
intuitions
if
they're,
if
both
or
neither
or
one
of
them,
is
correct.
In
your
view,.
L
So
there
you
have
one
box
that
belongs
to
bbr
and
one
box
that
belongs
to
cubic
and,
as
you
put
more
and
more
flows
into
the
cubic
foot
box
or
more
and
more
flows
in
the
bbr
box,
the
boxes
don't
increase
in
size
linearly
compared
to
the
number
of
flows
you're
putting
into
them,
which
is
why
we're
getting
diminishing
returns
and
which
is
why
you
know
the
the
rate
of
acceleration
when
you
reach
the
nash.
Equilibrium
point
keeps
on
reducing
in
terms
of
the
the
performance
benefits
that
you
get.
M
M
Because,
obviously,
it's
going
to
be
very
sensitive
to
how
far
apart
those
lost
points
are.
So
I
think
you
might
get
very
different
answers
to
in
the
question
of
what
cc
is
incentivized
if
there's
sort
of
a
mix
of
dynamically
entering
short
flows.
So
I'd
love
to
see
that,
in
a
future
version
of
this.
L
Yeah
yeah,
so
we're
definitely
considering
different
kind
of
workloads.
I
think
it's
a
great
suggestion
that
we
should
look
at
a
mix
of
short
flows
and
long
flows
and
see
how
things
are
changing.
In
fact,
another
thing
that
we
are
exploring
currently
is:
if
you
remove
right
now,
we
were
just
experimenting
with
long
flows,
but
we
also
want
to
experiment
with
what
happens
when
you
have
video
workloads
and
when
you're
dealing
with
video
workloads.
L
Ideally,
the
utility
function
that
we'll
be
looking
at
would
not
be
the
throughput,
but
actually
the
qoe
that
your
client
is
calculating
so
yeah.
Thank
you
for
your
suggestion.
I
mean
all
these
all
these
different
aspects
of
the
problem
I
mean
we
have
been
also
trying
to
reason
about
it.
A
lot
and,
in
fact
the
biggest
problem
we're
facing
right
now
is
really
you
know
to
come
up
with
a
nice
systematic
way
to
explore
all
the
different
things
that
can
happen
in
this
space.
K
E
E
So
I
think
certainly
reducing
latency
is
one
of
the
goals
on
the
internet
right,
so
for
all
the
players
here,
the
utility
function
might
not
be
just
maximizing
throughput,
so
that
should
be
taken
into
account,
and
the
other
thing
here
is
that
there's
certainly
a
benefit
to
standardizing
on
one
algorithm
in
the
long
term.
So
when
you
look
at
it
from
purely
you
know,
engineering
efficiency
point
of
view,
there's
one
algorithm
that
can
give
you
better
throughput
and
lower
latency.
That's
what
everyone.
L
E
L
L
You
know,
switch
to
that
oracle
algorithm
just
based
on
performance,
because
that
would
mean
that
okay
in
this
graph,
we
basically
want
our
designed
algorithm
to
always
exist
north
of
the
fair
share
line,
and
I
mean
that
you
can
obviously
design
based
on
whatever
utility
function
is
you
can
design?
You
know
a
utility-based
algorithm
that
only
maximizes
that
utility
but
yeah?
B
B
The
last
thing
that
you
just
said,
which
is
to
I'd,
be
very
curious
to
see
how
you
can,
if
you
can
extend
this
to
the
zoo
of
algorithms
that
you
found
either
on
the
internet
and
with
that
I'm
going
to
move
on
to
the
next
presentation
thanks
again
ayush
and
please
I
wish
it
was
on
the
iccrg
mailing
list.
So
if
you
want
to
have
any
discussion
on
this,
please
take
it
there.
B
E
E
E
E
C
E
Now,
why
is
this
important?
So
one
of
the
reasons
why
just
a
center
side,
conjunction
controller,
is
not
good
enough
in
practice
is
because
a
lot
of
a
lot
of
software
uses
cdns
a
lot
of
cdns
currently
don't
have,
for
example,
that
bet
plus
support
it's
harder
to
update
all
cdns
to
have
the
right
congestion.
Controller
proxies
can
prevent
effective
use
of
led
bat
on
the
end
to
end
path.
E
Also,
if
you
have
proxies
on
the
path
then
effectively
from
the
server
side,
you're
not
actually
measuring
the
right
bottleneck
and
are
able
to
basically
throttle
your
sanding
rate,
and
the
receiver
has
a
very
clear
information
about
which
download
it
things
are
background
downloads
compared
to
foreground
download.
So
there's
advantages
logistically
in
doing
it
on
the
receiver
side,
and
this
work
is
based
on
this
draft,
which
is
currently
active
in
iccrg.
E
E
Algorithm,
so
all
right,
let
met
plus
plus
an
outlet
bat.
Our
implementation
on
of
our
led
by
is
based
on
lightbed
plus
plus.
So
it
includes
all
the
additional
mechanisms
that
were
introduced
in
ledbet
plus
plus,
like
using
rtt
measurements
instead
of
one-way
delay,
slower
than
reno
condition.
Window
increase
with
the
adaptive
factor,
as
well
as
the
multiplicative
condition
window
decrease
with
the
adaptive
reduction
factor.
E
So
we
did
simplify
this
compared
to
ledbet,
plus
plus,
so
we
currently
are
doing
one
slowdown
period
per
basically
a
measurement
interval.
So
this
was
deliberately
done
to
simplify
the
code.
We
haven't
compared
one
approach
to
the
other,
but
this
just
a
simpler
implementation
and
we
also
simplify
the
base
delay
implementation
based
on
the
outlet
by
draft.
E
So
we
do
require
negotiation
of
time
stamps.
So
what
this
means
is
that
if
the
application
did
request
or
let
bat
and
the
timestamp
negotiation
may
fail
with
the
server
in
that
case,
we
need
to
reflect
that
up
to
the
application,
so
it
can
implement
its
own
fallback
logic
to
throttle,
for
example,
using
a
fixed
rate.
E
Currently
we
don't
take
an
action
if
a
data
packet
is
received
without
timestamps
after
establishment,
so,
for
example,
a
middle
box
is
stripping
timestamp
options.
We
are
currently
not
reacting
to
that.
That's
actually
a
the
standard
says.
You
know
the
receiver
should
drop
those
packets,
but
we
currently
don't.
This
is
an
area
where
we
would
like
to
continue
some
investigations
to
see
what
the
draft
should
recommend,
but
we
are
collecting
data
on
this
to
see
how
prevalent
this
is
in
the
wild.
E
E
I'm
I'm
leaving
your
question
open
here,
I'm
a
co-author
on
the
outlet
red
draft.
This
work
is
this
presentation
was
about
the
implementation,
but
now
that
we
have
an
implementation
based
on
the
draft,
I
wanted
to
ask
janna
and
and
the
group
whether
you
know
we
should
consider
publishing
drafts
as
an
experiment.
E
E
So
the
way
the
algorithm
works
is
continuously
measure,
bandwidth
round
trip,
time,
packet
loss
and
then
ecn
markings
from
the
network
and
basically
figure
out
a
rate
that
the
sender
should
be
sending
packets
at.
There
are
some
notable
additions
in
v2
compared
to
v1,
so
the
bandwidth
probing
time
scale
is
adaptive.
Loss
and
ecn
have
been
incorporated
into
the
network
model
and
then
even
when,
even
when
we
are
application
limited,
we
want
to
basically
adapt
to
loss
and
ecn
information.
E
E
E
Tcp
stack
it's
currently
available
as
an
experimental
knob
in
windows,
11
insider
builds,
the
raid
based
pacer
was
built
into
tcp,
so
we're
not
using
a
pacer,
that's
outside
the
tcp
module
and
the
way
this
works
is
that
basically
on
each
send
we're
computing
an
allowance
based
on
the
time
since
the
last
send
and
effectively.
If
the
allowance
does
not
allow
us
to
send
us
the
send
the
package
at
that
time,
we
schedule
the
pacing
timer
to
send
the
remaining
data.
E
So
one
of
the
challenges
for
us
was
because
this
code
is
also
integrated
into
the
linux
kernel.
One
of
the
challenges
was
that
and
because
the
code
is
not
final,
it's
still
evolving.
We
wanted
to
integrate
this,
but
still
leave
most
of
the
code
intact,
so
that
we
can
enable
direct
comparisons
between
you
know,
future
versions
and
be
able
to
you
know,
pull
in
those
changes
easily.
E
One
of
the
simplifications
we
did
was
we
currently
don't
do
any
ecn
handling,
so
we
currently
assume
there's
no
ecm
marking
happening
on
the
network.
So
that's
just
a
simplification,
but
eventually
we'd
like
to
add
that
in
I
would
like
to
say
that
this
sort
of
we
called
it
a
reverse
engineering
approach.
Basically
just
looking
at
code
and
trying
to
implement
a
conjunction
control
algorithm
is
something
we've
done
for
the
first
time
and
it
was
very,
very
hard.
E
So
one
of
the
interesting
things
was
hey.
You
know
this,
this
is
primarily
aimed
to.
You
know,
reduce
latency.
Let's
run
it
at
you
know:
ultra
low
latency
test
cases
where
you
have
like
back
to
back
systems
in
the
same
rack
and
loopback
test
cases,
and
we
see
that
there's
actually
a
cpu
usage
bottleneck,
so
the
algorithm
is
executing
more
cycles
compared
to
cubic.
E
We
also
did
an
inter
region
test
in
the
in
the
azure
cloud
and
we
see
about
20
throughput
improvement
and
not
much
difference
in
latency,
and
this
is
a
low
loss
sort
of
not
you
know,
over
saturated
network.
Basically,
so
there's
ample
headroom
and
we
see
basically
throughput
improvements,
but
not
much
difference
in
latency
in
this
particular
test
case.
E
Significant
fairness
issues
still
so
in
all
our
lab
tests,
we
see
that
cubic,
dominates,
bb
or
v2
across
a
range
of
test
cases,
so
I
think
in
bbr
v1
we
sort
of
had
an
opposite
problem
with
some
of
the
shell
buffer
cases,
but
in
this
case
we
find
that
I
think
maybe
we
have
over
compensated.
A
little
bit
and
cubic
is
dominating
bbr
v2
and
currently
it
doesn't
seem
incrementally
deployable.
E
Of
course,
if
you
have,
if
you
have
a
network
in
workload
where
you
can
guarantee
that
it's
only
going
to
be
bbr
v2,
then
it's
certainly
deployable,
but
otherwise
for
any
sort
of
incremental
deployment.
Currently
we
have
significant
finance
issues
so
next
steps
here,
so
neil
did
promise
he'll
bring
a
draft.
I
think
his
talk
is
next.
C
E
Looking
forward
to
that,
but
basically
we
would
like
to
help
review
that
draft
and
adopt
it
and
take
it
forward
and
change
our
implementation.
According
to
the
community
feedback,
we'd
like
to
resolve
the
fairness
issues
when
cubic
shares,
the
bottleneck,
link
and,
of
course,
the
cpu
usage
optimizations
that
need
to
be
looked
at
and
finally,
deployment
production,
a
big
shout
out,
and
thanks
to
neil
and
newton
for
all
their
help
on
this
work.
B
Thanks
so
much
praveen,
I
I
want
to
say
I
don't
we
don't
have
time
for
questions.
There
are
negative
time
for
questions,
but
if
you
have
a
really
quick
question
asked
here
or
I
would
recommend
that
you
take
it
to
the
chat,
if
you
can,
because
we're
already
behind
way
behind
on
time,
do
you
have
a
burning
learning
question
that
you
want
to
ask
in
person.
N
Not
really
just
very
quick
comment
so
about
our
light
pattern
like
that
possible,
it's
the
gain
factor
and
the
the
target.
These
are
the
two
things
I
I
just
wanted
to
say
that
we
shipped
these
two
last
year
in
our
tcp
implementation
and
the
gain
factor
that
we
are
using
and
the
target
we
probably
played
with
it
a
little
bit
because
it
wasn't
working.
The
additive
increase
wasn't
going
as
fast
as
I
was
expecting
and
the
throughput
was
really
suffering.
B
It's
available
for
others
to
see
later
when
they're
doing
the
implementation
work,
so
not
just
for
this,
but
for
praveen
and
neil
when
you're
having
your
conversations,
if
you're
able
to
have
it
on
the
channel
they'll
be
very,
very
welcome
as
well.
Thanks
for
your
presentation,
praveen.
That
was
very
it's
exciting
to
see
this
work
move
forward,
and
I
want
to
now
hand
it
over
to
neil
neil.
I
know
that
we
are
behind,
so
the
rest
of
the
time
is
yours.
M
Can
you
guys
hear
my
audio
yep,
visible,
okay,
great
so
yeah?
So
I
wanted
to
give
a
quick
update
about
bbr
work
going
on
inside.
Our
team
and
ian
will
also
be
presenting
some
updates
on
the
quick
side
as
well
and
I'll
make
this
super
quick.
So
I
just
wanted
to
talk
a
little
bit
about
the
deployment
status
code
status
and
then
give
a
super
high
level
overview
of
the
internet
drafts
that
I
updated
the
site
last
night.
M
Obviously,
that
would
be
useful
to
have
a
draft
documenting
the
algorithm,
and
you
know
this
is
always
part
of
the
plan
and
we
apologize
for
this
not
happening
sooner,
and
we
also,
of
course,
want
to
invite
the
community
to
read
the
drafts
and
offer
any
kind
of
feedback
both
low-level
editorial
feedback,
algorithm
ideas
or
bug
fixes
test
results.
Anything
is
useful
and
welcome
so
in
terms
of
deployment
status
of
vbr
at
google
right
now.
M
I
also
wanted
to
mention.
We
have
praveen
mentioned
cpu
usage
and
we
do
have
a
apache
set.
That
introduces
a
fast
path
for
ppr
processing
that
we
did
find
was
useful
in
bringing
the
cpu
usage
between
to
parity
with
cubic
for
our,
at
least
for
our
production
workloads,
which
we
will
be
sharing
when
we
get
time,
let's
see
the
status
of
the
code,
this
is
just
a
sort
of
repeat:
we
have
open
source
versions.
M
You
can
find
the
links
in
the
slides,
so
the
bbr
functionality
is
sort
of
split
between
two
different
drafts,
as
it
was
in
the
original
release
for
pbrv1.
So
the
first
draft
is
a
delivery
rate
estimation
algorithm
and
that
covers
a
bandwidth
sampling
mechanism.
That's
used
by
both
pvr
version,
one
and
version
two,
and
it's
also
just
generically
available
in
linux.
Tcp.
You
can
use
those
bandwidth
samples,
no
matter
what
congestion
control
is
in
place
and
being
used.
M
So
the
other
piece
of
this
puzzle
is
the
bbr
congestion
control
draft
itself.
That's
also
been
updated
to
cover
the
current
pbr
version,
2
algorithm
right
now.
It
just
includes
the
aspects
relevant
to
the
current
public
internet,
so
the
core
model
and
the
loss
response
and
the
strategy
for
coexistence
with
cubic
and
reno.
The
ecm
part,
is
only
missing
due
to
time
limitations.
That's
still
used
at
our
site
and
still
part
of
the
long-term
roadmap.
We
just
haven't
had
time
to
put
that
in
the
draft.
So
I'll
do
that.
M
And
then
then
I
posted
a
couple
pictures
that
I
think
you
know
as
pictures
by
themselves.
They
won't
have
enough
context,
but
I
am
hoping
they'll
be
useful
to
folks
who
are
making
their
way
through
the
draft
reading
the
content
and
they
could,
you
know,
use
a
little
picture
to
help
put
everything
in
context
and
make
it
a
little
more
clear.
So
this
is
a
sort
of
high
level
block.
E
M
And
then
the
next
picture
that
I
think
might
be
useful
to
people
is
just
a
picture
of
the
parameters
in
the
model
and
how
they
fit
together.
And
we
don't
have
time
to
go
into
detail.
But
all
of
these
are
defined
in
the
draft
and
at
a
high
level,
you
can
say:
there's
basically
a
set
of
parameters
about
the
data
rate
that
the
algorithm
thinks
is
appropriate
and
then
some
parameters
about
the
data
volume
or
you
know,
amount
of
in-flight
data
and
a
key
part
of
that,
of
course,
is
the
bdp
estimate.
M
That
sort
of
starts
up,
and
this
shows
its
evolution
through
the
state
machine
with
the
level
of
in-flight
data
superimposed
on
top,
so
you
can
sort
of
get
a
sense
of
how
these
things
interact
and
again
we
don't
have
time
to
go
into
it,
but
this
might
help
visualize.
What's
going
on
in
the
text
of
the
draft
so
yeah.
In
conclusion,
we've
updated
the
drafts
to
cover
pbr
version
two
and
we
look
forward
to
feedback
if
people
have
time
to
read
and
high
level
feedback,
low
level
feedback.
M
K
So
I'm
going
to
walk
through
three
today
there
are
a
number
of
others
that
I
had
time
to
outline
and
also
a
number
of
others
that
I
do
not
yet
have
a
good
qe
experience
for
so
yeah.
Let
me
go
for
it,
so
the
the
tljr
is
basically
that
bbrv2
is
very,
very
close
to
achieving
the
same
youtube,
video
qe
as
well
as
search
latency
as
bbr
b1,
with
these
tweaks
and
a
few
others,
but
these
are
kind
of
the
most
substantive
ones.
K
K
Just
you
know,
because
that's
kind
of
the
intent-
and
I
think
that's
deemed
hopefully
acceptable,
but
that
the
key
issue
is
that
rebuff
rate
and
those
other
metrics
are
not
seriously
harmed
as
as
a
result,
consumer
related
research
search
actually
has
been
a
little
bit
easier
really
so
far,
it
looks
like,
and
possibly
due
to
the
fact
that
bbr2
is
a
little
bit
less
aggressive
search.
Latency
seems
to
be
pretty
robustly
pretty
close
to
neutral.
K
So
one
challenge
is
today:
when
you
start
up
due
to
loss,
you
set
imply
high
to
bdp
that
that
means
that,
unless
you
are
extremely
nicely
out
clocked
in
an
extremely
smooth
manner,
you
are
going
to
be
sewing
limited
before
you
ever
achieve
the
max
bandwidth.
That
kind
of
has
resulted
in
bdp
and
similarly,
once
inflate
high
is
low,
it
can
be
very
difficult
or
even
impossible
to
grow
it
substantially.
K
So
my
my
proposed
fix
is
relatively
simple,
which
is
you
track
the
maximum
bytes
delivered
in
a
round,
not
the
maximum
fight
to
be
clear.
The
max
bytes
actually
delivered,
so
that
should
indicate
that
the
pipe
is
at
least
that
large,
because
actually
to
look,
though,
when
you
put
that
many
guys
in
lounge
around
and
as
a
result,
you
have
a
lot
less
of
a
bandwidth
crash
when
aggregation
is
present
and
as
well
as
like
when
you
have
excessive
loss.
K
K
So
the
next
one,
that's
an
issue
that
neil's
talked
about
a
few
times
is
early
provo
exit
and
similarly
like
the
lack
of
inflight
high
growth
during
promo,
which
is
kind
of
related,
so
probate
up
connects
it
early
due
to
queueing
the
queueing
criteria.
Is
you
exit
probe
up
if
it's
been
at
least
minority
in
probe
up
and
to
be
clear
probe
up
in
these
slides
means,
probe
bw
colon
going
up
from
needle
slots,
and
the
bytes
in
flight
are
greater
than
1.25
times,
bdb,
plus
2
mss.
K
K
So
the
the
simple
solution
that
we
currently
have
in
our
code
default
enabled
is
you
wait
at
least
one
round
instead
of
min
rtt
in
cases
when
there's
a
lot
of
aggregation,
the
min
rtt
can
be
an
order
of
magnitude
smaller
than
the
smooth
rtds,
that
kind
of
ends
up
being
necessary,
and
then
you
put
on
the
extra
act
and
the
for
the
in-flight
check.
This
isn't
perfect.
K
This
does
increase
pre-transit
rates
somewhat
measurably,
it's
still
massively
less
than
dvr1,
but
this
extra
criteria
is,
in
some
cases
a
little
bit
aggressive,
but
it
it
at
least
is
proof
that
there
are
solutions
out
there.
That
kind
of
like
avoid
this
early
exit
and
don't
cause,
like
you
know,
a
huge
amount
of
collateral
damage.
K
K
K
There
are
some
spots
in
startup
is
otherwise
that
we
do
have
limited
checks
if
you
were
app
limited
and
you
still
couldn't
get
your
queue
under
the
target,
probably
something's
not
going
great
and
so
making
code
a
little
less
sensitive
to
checks.
It's
kind
of
a
potentially
side
benefit
of
this
and
yeah
the
last
one
was
excessive
time
and
probe
rt
this
one's
pretty
simple.
K
Basically,
when
you're
coming
out
of
quiescence
and
you're
in
pro
rtt,
you
don't
leave
until
like
a
full
round
has
passed,
because
you
need
an
ack
to
kick
yourself
out
of
probe
rtt,
and
so
that
means
you
know
you're
sending
it
like.
Well
less
than
half
the
bandwidth
for
a
full
round.
We
independently
discovered
this
apparently
anticipated
quick.
So
apparently
it
was
a
good
idea
and
yeah
tcp
already
has
this.
This
fix
in
as
well,
but
it's
kind
of
worth
noting
just
because
it's
it
does.
K
It
can
increase
the
amount
of
time
and
probe
rgt
when
you're
doing
app
limited
traffic
and
we
noticed
there's
a
number
of
youtube
flows
where
you'd
get
a
chunk
and
then
stop
for
a
while
and
get
a
chunk
and
so
on
and
so
forth.
And
when
you
finish,
the
last
chunk
you'd
still
be
in
pro
partsd
cool.
So
that's
it.
M
M
Did
you
what
well,
I
don't
know
if
we
have
time
to
go
on
the
specifics,
but
the
the
the
reaction
to
the
econ
is
very
similar
to
dc
tcp.
So
there's
a
every
round
trip
where
there's
a
where
there's
ecn,
marking,
there's
sort
of
a
multiplicative
decrease
thoughts
proportional
to
the
exponentially
weighted
moving
average
of
recent
ecn
marks
so
yeah.
So
hopefully
that's
a
quick
summary.
There
are
also
details
about
it.
N
M
N
Okay,
the
second
question
I
had
was
regarding
the
the
points
that
ian
noted
about
in
flight
high.
So
it's
not
is,
is
the
in
flight
high
not
set
again
after
the
loss
like
I
was
assuming
it
would
be
said
again.
You
know
once
you
have
a
last
year,
you
set
it
to
bdp,
but
then
you
have
probably
another
stage
where
you
would
increase
the
in-flight
high,
or
am
I
understanding
it.
M
C
M
That
you're
willing
to
put
in
the
network
and
then
your
bandwidth
estimate,
which
is
the
rate,
the
delivery
rate
that
you
can
achieve
and
once
you've
decided,
you
can
only
fit
a
certain
amount
of
data
inside
the
network.
Then
that
implicitly
bounds
the
rate
that
you're
able
to
achieve
and
then
because
it's
bounding,
the
rate
you're
able
to
achieve
that
bounds.
M
Sometimes,
if
there's
a
packet
loss
early
on
that,
can
limit
your
sense
of
the
safe
volume
of
data
which
limits
your
bandwidth
estimate
limits,
your
probing
and
you
can
kind
of
get
stuck
in
these
cases,
and
you
know
there
are
a
couple
of
different
ways.
You
can
fix
that,
and
you
know
ian
and
I
are
both
continuing
to
experiment
with
that.
M
It
gets
a
little
tricky,
though,
because
then,
once
you
fix
that
which
I
think
is
is
fairly
straightforward
to
do,
then
it
impacts
your
coexistence
behavior
with
cubic
and
reno,
because
then
you
end
up
causing
packet
loss
more
often,
and
so
I
think
the
algorithm
might
need
to
be
a
little
more
shrewd
about
how
it
schedules.
It's
been
with
probing
once
it's
more
robust
about
pushing
up
to
encounter
loss
in
these
cases.
B
E
Yeah,
hey
thanks.
Neil
really
appreciate
the
new
drafts.
I
will
certainly
go
over
them,
provide
my
feedback,
one
quick
question
on
the
logistics.
So
do
these
drafts
reflect
the
code,
that's
in
the
sort
of
out
of
kernel
repo
that
we
are
using
as
the
basis
or
is
this
a
reflecting
work?
There
is
not
part
of
that
code,
so
that
was
one
question
and-
and
I
also
had
a
suggestion
for
ian-
is
to
like
you
know,
whatever
enhancements
you've
made,
you
know,
bring
them
twice
as
dirty
to
the
draft.
K
Neil
has
a
variety
of
simulations
and
test
scenarios
that
I
don't
easily
have
available
to
me
and
and
kind
of
vice
versa
to
some
extent,
and
so
we
kind
of
need
to
make
sure
that
something
I
changed
that,
like
works,
great
for
youtube,
doesn't
like
destroy
like
data
center
applications.
So
we
do
need
to
kind
of
go
back
and
forth
and
I
think
that'll
take
some
time.
M
Is
a
question
about
which
version
yeah?
This
should
correspond
very
closely
to
the
code.
That's
currently
on
github,
there
may
be
one
or
two
small
differences
where
there
are
two
different
behaviors
available
in
the
github
code
and
the
draft
documents,
the
one
that
we
currently
recommend,
but
otherwise
it
should
be
very
similar.
M
I
I'll
short,
my
question
so
you're
implying
that
the
quick
and
tcp
inflation
is
diverging
a
little
bit
and
obviously
there's
a
practical
issue
there,
but
is
is
the
different?
Are
the
differences
solely
related
to
the
applications
involved,
or
are
you
seeing
like
protocol
specifics
that
are
driving
these
divergences?
I
M
D
K
K
Frequent
similar
approaches
are
fairly,
it's
read
for
tcp,
but
they
kind
of
the
the
way
they
manifest
themselves
are
a
little
bit
different
and
that,
along
with,
like
some
of
the
scheduling
being
user
space
means
that
I
think
the
traces
and
the
ack
lines
tend
to
look
a
little
bit
different
and
I
think
kwik
suffers
a
little
more
from
the
aggregation
effects
on
the
public
internet
due
to
a
variety
of
these
factors.
So
my
experience
with
pbrv
one
is
quick
was
impacted
more
by
aggregation
yeah.
That's
that's.
Definitely
all
different.
M
Yeah,
although
it's
interesting
because
inside
in
the
data
center
case,
tcp
also
does
see
massive
degrees
of
aggregation,
because
when
your
rgts
are
super
small
in
the
data
center,
then
the
aggregation
that
the
the
nics
are
doing
or
your
software
is
doing
then
becomes
massive
in
the
in
the
traces
again
at
these
very
tiny
rtt's.
So
so
yeah.
So
I
think
there's
plenty
of
aggregation
on
both
sides
and-
and
I
think
yeah,
I'm
sure,
we'll
be
able
to
coalesce
on
a
single
final
algorithm.
B
B
But
thank
you
for
for
for
all
the
presentations
and
thanks
neil
ian
and
praveen
for
shortening
your
discussions
and
allowing
the
the
the
first
timers
to
take
some
more
time
to
present
their
stuff.
But
I
want
to
thank
everybody
for
being
here.
This
is
a
fantastic
session
and
I
look
forward
to
more
discussions.
I've
just
created
a
slack
channel
so
use
that
as
well
and
we'll
see
you
next
time.