►
From YouTube: IETF113-PEARG-20220321-1200
Description
PEARG meeting session at IETF113
2022/03/21 1200
https://datatracker.ietf.org/meeting/113/proceedings/
A
A
B
B
B
C
C
C
Moving
on
to
the
agenda,
the
blue
sheets
are
generated
automatically
by
your
attendance
in
meet
echo.
These
days,
shivan
will
be
acting
as
javascribe,
we'll
be
monitoring
the
chat.
So
if
there's
anything
to
put
in
there,
you
would
like
asked
at
the
mic.
Please
prepend
it
with
mike
and
he'll
bring
that
to
you.
C
C
Before
we
get
going,
I
will
just
quickly
ask
that
or
remind
people
that
participants
in
the
room
will
need
to
join
queue
via
meet
echo,
and
then
they
can
go
up
to
mike
to
ask
the
questions,
but
when
they
do,
please
do
state
your
name
clearly
as
with
masks.
It
makes
it
particularly
hard
to
see
who
is
speaking.
C
And
the
full
participants
can
keep
their
audio
and
video
muted
when
they're,
not
speaking
that
will
be
much
appreciating.
I
see
that
there
is
an
echo,
I
hope.
That's
not
me.
I
will
switch
to
a
headset
okay,
some
folks
are
hearing
it
and
some
aren't
so
I
don't
know
if
it's
okay,
maybe
the
in-room
like
yeah,
maybe
mike,
is
picking
something
up.
Hopefully
that
will
get
sorted
out.
C
D
D
D
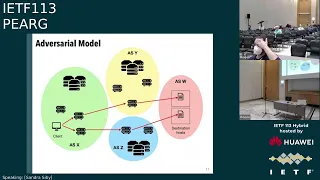
Now,
since
the
channel
is
encrypted
the
client
sorry,
the
adversary
does
not
know
which
web
page
is
being
visited
by
the
client.
All
the
adversary
can
see
is
some
metadata
of
the
traffic,
and
in
this
scenario
the
ip
addresses
we
assume
that
there
are
measures
such
as
ech
or
encrypted
dns,
so
that
the
adversary
does
not
see
the
domain
that
the
client
is
visiting.
D
D
D
So,
in
our
scenario,
we
are
interested
in
seeing
how
website
fingerprinting
works
over
a
quick
connection
between
the
client
and
the
destination
now
website.
Fingerprinting
on
quick
traffic
is
not
new,
it's
actually
already
been
done,
and
this
work
was
actually
presented
at
the
ietf
last
year
and
they
concluded
that
it
is
no
harder
to
fingerprint
quick
traffic
as
compared
to
tcp
and
the
adversary
can
identify
pages
over
a
quick
connection
with
high
accuracy.
D
So
if
you
look
at
the
quick
rfc
there
is
this
option
for
a
quick
padding
frame
that
allows
you
to
increase
the
size
of
quick
packets
and
the
rc
specifies
that
this
padding
could
potentially
be
used
to
provide
protection
against
traffic
analysis.
And
this
is
what
we
are
interested
in.
Exploring
further.
D
D
So
what
we
want
to
do
now
is
the
goal
of
the
adversary.
Here
is
to
identify
the
correct
web
pages
web
page
among
all
the
web
pages
that
are
hosted
on
a
single
ip.
So
since
the
ips
are
seen
by
the
adversary,
they
can
already
filter
traffic
based
on
ip
address,
so
they
just
need
to
identify
which
web
page
is
being
visited
among
all
the
web
pages
that
are
posted
on
one
ip
address.
In
our
scenario,.
D
So
we
do
our
experiments
with
a
quick,
dominant
data
set
of
150
pages
here.
So
we
did
this
by
crawling
the
web
pages
in
popular
lists
such
as
the
alexa
one
million.
This
is
similar
to
prior
work.
That's
been
done
on
free
traffic
and
we
looked
at
which
web
pages
have
a
high
proportion
of
quick
traffic
since
quick
is
still
being
adopted.
A
lot
of
web
pages
are
still
transmitting
their
resources
over
non-quick
connections.
D
But
since
we
are
analyzing
quick,
we
wanted
to
build
something
which
has
primarily
quick
traffic,
and
we
found
that
for
our
data
set,
we
had
approximately
70
percent
quick
traffic
on
average.
Just
want
to
note
that
previously
we
tried
to
be
more
realistic
and
we
partnered
with
cloudflare
to
look
at
domains
that
are
hosted
on
a
single
ip
and
get
the
traffic
traffic
for
those,
but
those
had
only
about
four
percent
peak
on
average.
So
we
went
with
this
method
to
build
our
data
set.
D
As
I
mentioned,
this
is
the
process
that
we
have
for
the
for
the
website.
Fingerprinting.
But
now
we
see
here
in
the
second
step,
we
apply
a
defense
to
the
traffic
sample
which
I'll
come
to
in
the
upcoming
slides,
and
then
we
pass
this
defended
sample
into
the
classifier
and
we
see
how
well
the
classifier
performs
against
these
defended
traces
I'll
be
using
a
couple
of
well-known
classifiers
from
the
literature
which
is
there
in
the
yellow
box
below.
If
you
have
any
questions,
you
can
ask
me
about
that
later.
D
D
So
in
order
to
hide
the
directionality-based
features,
we
now
perform
this
defense,
where
we
inject
dummies
randomly
into
the
trace,
and
what
we
actually
see
is
that
injecting
dummies
does
decrease
the
performance
of
the
classifier,
but
it
also
comes
with
a
high
cost.
So
we
see
that
it
goes
down
to
about
six.
It
goes
down
by
about
16
percent
in
the
worst
case,
but
with
a
hundred
percent
overhead.
When
you
add
these
dummies-
and
this
is
not
including
the
additional
traffic
just
is
injected
in
order
to
hide
the
packet
based
features.
D
D
Now
so
far,
I've
talked
about
an
unconstrained
adversary
and
this
adversary
observes
all
the
traffic
and
also
performs
this
classification
with
all
the
traffic
that
it
sees.
But
in
reality
it
is
possible
that
you
don't
have
a
perfect
adversary
and
adversaries
can
be
constrained
not
just
in
the
amount
of
traffic
they
see,
but
also
in
what
they
do
with
this
traffic.
D
D
So
in
order
to
see
what
this
is
actually
observed,
how
much
of
the
traffic
we
generated
trace
curves
from
the
client
for
all
the
pages
in
our
data
set
and
observed
how
the
stray
shots
pain.
So
this
is
the
result
from
one
of
the
vantage
points
that
we
conducted
the
experiment
from
we
did
this
on
multiple
vantage
points
and
we
observed
similar
trends,
and
what
we
see
is
that
there
are
only
a
few
large
asls
that
can
observe
a
large
proportion
of
the
traffic
in
the
first
place.
D
D
Another
interesting
thing
that
we
saw
was
that
google
actually
has
a
large
relevance
on
the
pages,
so
more
than
80
of
the
pages
on
our
data
set
contain
at
least
one
resource
that
is
hosted
by
google
and
found
that
actually,
these
resources
could
be
ordered
differently
and
different
web
pages,
which
means
that
timing
to
google
resources
is
a
low
cost
fingerprint
and
can
have
up
to
77.9
percent
f
score.
This
means
an
adversary,
for
example
like
an
isp.
D
D
So
in
order
to
simulate
this,
we
use
something
called
sampled
net
flow.
So
what
happens
here
is
that
the
packet
races
are
sampled
and
then
flow
submarines
are
created
and
these
are
sent
to
the
centralized
location
and
we
perform
the
attacks
this
with
the
submarines,
instead
of
the
packet
traces
and
we
experimented
with
various
sampling
rates,
what
happens
to
the
adversary's
performance?
D
D
D
So
what
we
actually
find
is
that
is
that
the
network
layer
defenses
in
the
case
of
both
unconstrained
and
constrained
adversaries,
do
not
efficiently
hide
a
lot
of
the
global
features
and
the
main
reason
for
this
is
that
they
do
not
know
the
sizes
of
traces
in
advance
to
efficiently
design
padding
strategy.
So
there
is
no
application
layer,
information
that
is
given
here,
and
so
you
need
to
randomly
inject
dummies
or
add
size
based
feed
size
based
defenses,
and
this
could
increase
the
overhead
of
these
network
layer
defenses.
D
So
in
order
to
do
this,
we
started
analyzing
the
structure
of
the
pages,
so
here's
a
quick
refresher
on
terminology
that
I'm
going
to
use.
So
let's
say
that
we
are
visiting
example.com,
you
might
have
resources
from
exam
from
the
same
domain
example.com,
and
these
are
called
first
party
resources
or
you
might
have
resources
from
other
domains.
D
So
here
you
have
tracker.com,
and
these
are
called
third-party
resources
and
when
we
look
at
the
web
page
structure,
what
we
see
is
that,
in
our
data
set,
18
of
the
web
pages
actually
have
a
very
small
number
of
first
party
resources.
So
you
actually
have
a
large
prevalence
of
third
parties
and
there
is
in
a
large
prevalence
of
google
resources
in
our
data
sets.
So
24
of
the
pages
actually
even
have
more
than
50
percent
of
google
resources.
D
So
what
does
that
mean
when
it
comes
to
applying
a
defense?
It
means
that
third
parties
are
contributing
a
large
proportion
of
resources
to
the
webpage
and
in
order
to
apply
a
defense,
we
actually
would
need
cooperation
from
all
the
parties
that
are
supplying
some
resource
to
the
web
page.
And
we
actually
did
do
experiments
on
this.
Where
we
hid
the
resources
from
third
parties
or
from
first
parties
to
simulate
the
scenario
of
only
one
of
these
parties
participating
in
the
resources.
D
And
then
we
went
for
the
application
defenses,
so
we
applied
the
same
packet
and
space
padding
to,
but
at
the
application
layer.
So
we
are
protecting
the
actual
resources
here
and
we
still
see
that
the
packing
is
ineffective
here
once
again
because
of
the
because
the
adversary
just
uses
the
ordering
based
resources.
D
D
At
the
same
time,
if
we
decide
to
implement
things
on
the
application
layer,
they
come
with
a
whole
set
of
other
complexities,
so
they
would
require
some
sort
of
coordination
between
parties
or
we
would
have
to
talk
to
developers
on
how
to
how
to
write
code
so
that
resources
are
always
fetched
in
some
sort
of
a
standardized
manner.
And,
finally,
all
of
these
changes
in
the
application
layer
could
potentially
have
a
large
impact
on
client
experience.
D
E
Yes,
I,
how
are
you
sandra?
Thank
you.
I
have
a.
I
have
a
question
for
you
if
you
think
of
the
definitions
slightly
different,
where
the
adversary
is
actually
the
client
sending
traffic,
because
his
malware
and
he's
doing
some
data
leak
or
lateral
movement
and
the
one
sampling
is
the
protection
software.
E
E
C
F
E
D
Yeah,
so
so
in
this
scenario,
what
you're
saying
is
that
actually
analyzing
the
network
traffic
would
be
a
good
thing
because
you
want
to
detect
the
malware.
Yes,
yes,
I
mean
what
I'm
saying
right
now.
Is
that
generally
most
of
the
defenses
that
we
have,
or
rather
in
this
scenario
anything
to
prevent
this
detection
are
not
going
to
help
much.
D
D
B
F
F
The
paper,
but
my
understanding
is
that
you
removed
all
caches
and
just
made
a
single
web
page
load
to
the
index
page
of
each
popular
domain
name
and
the
goal
was
just.
Can
you
distinguish
loading
the
index
page
with
no
caching
of
one
domain
versus
another
in
cases
where,
for
example,
they're
hosted
by
the
same
cdn
or
something
like
that.
E
F
Various
other
situations
like
that,
because
it
seems
like
many
of
the
times
that
we're
worried
about
the
network
adversary,
we're
worried
about
them,
learning
what
I'm
reading
or
or
the
contents
of
my
messages
or
lots
of
different
threats
and
that's
not
to
downplay
the
threat
of
them,
knowing
that
I'm
even
going
to
a
particular
domain
name.
But
does
this
threat
also
apply
to
learning
what
pages
I'm
visiting
or
or
cases
where
the
network
traffic
is
going
to
be
mixed
or
resources
will
be
cached,
et
cetera,.
D
Yeah,
that's
a
good
question
and
this
is
also
a
field
of
research
in
this
area.
So,
like
you
said,
we
are
working
with
relatively
clean
traces
here,
where
we
are
assuming
no
caching
and
like
no
background
traffic
and
it's
just
the
home
pages,
but
we
are
planning
now,
for
example,
to
do
some
experiments
where
we
are
also
visiting
subpages
of
different
websites
to
see
how
well
this
attack
is
going
to
work,
and
there
is
also,
I
think,
work
done
by
others.
D
Now
there
are
some
papers
coming
up
where
they're
looking
at
fingerprinting
in
the
presence
of
all
these
factors
that
add
some
noise
but
yeah.
I
I
would
say
that
this
is
kind
of
the
worst
case
for
the
worst
case.
I
mean
the
best
case
for
the
adversary
and
all
of
these
factors
would
possibly
lead
to
a
reduction
in
the
f
score.
C
C
G
A
H
C
H
H
Okay,
just
to
hit
the
mic
with
the
mask:
okay,
I'm
going
to
talk
a
little
bit
about
gdpr
and
relation
with
the
ip
addresses
in
general,
a
little
bit
as
the
title
say
that
how
layer
eight
meets
layer?
Three:
okay,
knowing
I'm
not
a
lawyer,
just
to
be
clear.
So
this
is
my
interpretation.
I
spent
some
time
reading
and
so
I'll
give
you
some
some
some
interesting
point
that
we
may
discuss
later
on.
So
I'll,
really
one
slide
history,
some
terminology,
and
then
we
dig
a
little
bit
in
gdpr
and
ip
addresses.
H
There
is
a
a
few
slides
that
make
a
clear
link
between
existing
rfcs
and
gdpr.
If
time,
we
will
go
over
that
as
well.
Okay,
so
gdpr
came
into
effect
in
2018.
So
it's
not
that
long
ago
replaced
a
very
old
data
protection
act
in
europe.
It
is
a
regulation
which
means
it
is
slightly
more
complex
than
a
simple
law,
because
there
are
articles
which
are
the
law
itself,
but
there
are
also
recitals
which
are
notes
that
explain
actually
how
to
apply
the
laws.
Okay,
which
is
the
body
of
gdpr.
B
B
H
As
I
can
okay,
thank
you.
The
key
point
is
personal
data.
Okay,
what
is
personal
data
is
anything
that
can
identify
a
natural
person.
Not
a
legal
person
like
a
company
is
different,
a
natural
person
like
me
all
of
you
in
the
room
and
connected
elsewhere,
name
personal,
addresses
anything
that
can
can
identify
ourselves
information
concerning
our
employment,
financial
information.
You
have
the
details
in
this
slide,
which
is
pretty
worthy.
There
are
also
sensitive
information,
which
is
like
ethnic
origins
or
really
religious
belief
or
anything.
H
It's
real
personal
choices
in
a
certain
way
and
any
other
information
that
actually
you
you
are
willing
to
disclose
by
yourself,
for
example,
to
your
employer.
Okay,
in
this
last
bullet,
I
put
my
employer,
but
it's
just
any
employer
can
or
any
entity
can
ask
you
for
some
information
that
you
may
wish
to
discuss,
but
is
really
personal.
H
H
Okay,
because
if
you
give
the
data
to
someone
that
someone
is
controlling
your
personal
data,
okay
and
he
may
wish
to
do
some
processing-
which
is
the
action
of
taking
your
data
and
making
something
to
get
some
stats,
for
example
right
this
is
the
processing
and
the
the
the
entity
that
does
the
processing
is
the
processors,
okay,
which
is
actually
doing
the
processing.
Now
it's
kind
of
a
headache,
but
these
three
things
are
correlated
and
do
overlap.
H
Okay,
it's
like
I
connected
to
my
isp.
I
sign
a
contract.
I
give
some
personal
information.
The
isp
controls
my
personal
data
that
I
gave
to
him.
Okay,
and
he
may
decide
to
do
some
stats,
okay
and
he
decides
how
to
process
the
data,
but
not
necessarily
does
it
itself.
He
can
ask
somebody
else,
a
third
party
to
do
it,
which
will
be
the
processor
okay.
H
H
Is
clearly
stated
that
any
online
identifier
is
personal
data?
Okay,
especially
this
applies
to
ip
addresses,
and
the
european
court
of
justice
ruled
that
it
is
personal
identification
data
because
you
can
associate
and
retrieve
a
lot
of
other
information,
even
if
you
use
temporary
addresses
okay.
So
as
such,
it
falls
specifically
under
gdpr
and
privacy
protection.
H
The
first
very
simple
principle
is
lawfulness
fairness
and
transparency,
which
basically
says
that
if
I
give
my
personal
data
to
my
isp,
I
expect
that
it
does
use
my
personal
data
according
to
the
law.
Gdpr
is
part
of
it.
Okay,
you
know
in
an
undiscriminated
discriminatory
manner,
okay
and
in
a
transparent
manner,
which
includes
my
explicit
consent.
I
will
come
back
to
this
a
little
bit
later.
H
Second
principle
is
purpose
limitation
is
the
fact
that
my
isp
is
not
allowed
to
use
my
personal
data
for
whatever
he
wants.
Okay,
he
is
able
to
to
use
my
ip
address
in
order
to
count
my
packets
for
billing
purposes
is
not
allowed
to
look
what
is
in
my
packets
in
order
to
measure
how
much
shopping
I
do
online,
because
this
is
not
related
to
the
service
that
it
proposes.
The
isp
is
proposing
internet
connectivity.
H
Okay,
third
principle
data
is
minimization
is
the
fact
that
mysp
is
allowed
to
collect
as
much
data
that
is
needed
to
offer
the
service,
but
not
more
for
of
that.
Okay,
so
he
can
certainly
again
access
to
the
ip
header,
the
transport
header,
to
provide
the
service,
but
not
access
the
content
of
my
packet
in
order
to
look
at
what
I
actually
do
exactly,
even
if
it
isn't
clear,
okay
accuracy
for
the
principle
is
the
fact
that
anything,
the
isp
gathers
of
me
must
be
accurate.
H
Okay,
that
or
error
free,
if
you
wish,
okay,
storage
limitation
is
the
fact
that
my
my
data
cannot
be
archived
forever.
Okay,
there
is
typically
a
limited
amount
of
time
that
my
data
can
be
collected.
Then
it
should
be
deleted
if
I
do
not
ask
actually
to
do
it
beforehand,
because
there
is
this.
Also,
this
aspect
that
actually
I
I
have
the
right
to
be
forgotten,
so
that
I
can
ask
to
delete
all
my
data.
Okay.
H
This
is
interesting,
is
kind
of
tussling
somehow,
because
on
the
on
the
one
side,
we
have
gdpr
that
asks
storage
limitation
on
the
other
side,
load
enforcement
and
for
some
minimal
time
to
to
keep
some
logs
for
accountability
and
traceability
of
some
stuff.
So
there
is
a
balance
to
strike
there
at
some
point.
Okay,
security,
integrity
and
confidentiality
is
just
that.
H
If
I
give
my
personal
data
to
the
isp,
I
assume
that
isp
is
doing
his
best
to
protect
my
personal
data
and
they
gonna
not
do
not
go
out
in
the
wild
okay,
which
brings
to
the
fact
that
is.
He
is
actually
accountable
for
my
personal
data
and
even
in
the
case,
as
I
explained
before,
that
my
isp
is
the
console
of
my
data,
and
it
gives
my
data
to
someone
else
in
order
to
process
them,
okay,
to
perform
a
processing
and
in
something
goes
wrong
and
the
processor
actually
leaks.
H
So
this
is
really
high
level
what
happens
in
gdpr
and
how
we
can
relate
with
with
the
ip
protocol
stack.
So
you
know
that
gdpr
is
peculiar,
for
the
european
union
is
not
the
only
example.
Okay
in
this
table,
there
is
a
summary
of
other
laws
regulation
you
can
find
all
over
the
world.
Okay,
there
are,
there
are
more
or
less
or
similar
and
they
all
more
or
less
consider
ip
addresses.
H
H
Another
interesting
peculiarity
is
the
fact
that
in
japan,
even
anonymized
data
covered
by
the
appi,
which
is
the
the
japanese
equivalent
of
gdpr,
which
is
not
the
case
in
here
for
gdpr
in
europe
once
you
anonymize
the
data,
and
you
are
sure
that
there
is
no
way
to
go
back
and
find
the
the
the
original
information
gdpr
is
out
of
the
scope.
Okay
and
all
of
the
laws
are
based
on
on
consent.
H
Usually
explicit
consent,
which
means
that
you
have
to
take
an
expletive,
explicit
action
to
give
your
concept,
which
means
when
you
are
in
europe,
you
have
this
pop-up
window.
That
say
you
accept
the
cookies
and
you
have
to
to
to
click
yes
or
no,
and
today
we
have
also
different
settings.
This
is
a
explicit
action.
Okay,
you
cannot
just
put
some
place
in
the
webpage.
Oh
by
the
way
we
are
collecting
cookies.
H
H
H
C
I
To
what
extent
do
you
think
that
new
protocols,
such
as
mask
over
quick
and
oblivious
technology,
to
some
extent
render
this
conversation
about
the
privacy
of
ip
addresses,
or
indeed
you
know
the
actors
that
you've
mentioned
in
your
presentation
kind
of
obsolete?
Really?
Do
you
think
that's
a
fair
comment?
You
know
that
if
the
evolution
of
mask
proxies
and
oblivious
kind
of
make,
this
idea
a
bit
exponential
and
a
challenge.
H
H
C
H
A
A
C
G
Yeah
all
right,
thanks
and
thanks
for
time
on
the
agenda.
This
is
a
research
group
document.
If
people
recall
I'm
presenting
it
only
because
the
other
authors
who've
worked
on
this
draft
for
a
very
long
time,
no
longer
have
the
capacity
to
continue
working
on
it.
So
a
lot
of
the
content
in
the
slides
and
the
draft
itself
is
not
written
by
me,
but
I
am
it's
steward
at
the
moment.
Happily
so
yeah
joe
hall,
he
was
originally
in
my
position
at
cdc
when
he
started
writing
this
in
november
2014..
G
So
that's
quite
some
time.
I
think
one
of
the
challenges
of
this
draft
is
that,
of
course,
it's
a
you
know.
Contentious
topic
uses
the
word
censorship
throughout
it's
not
something
that
atf
is
used
to
talking
about,
but
also
that
the
more
time
that
passes
the
more
sort
of
techniques
can
be
added
refined.
You
know
so
at
some
point
I
think,
there's
a
recognition.
G
This
has
been
made
this.
This
has
been
recognized
multiple
times
in
perigee
that
it
just
has
to
sort
of
be
published,
so
we're
working
towards
a
document
that
is
good
enough
to
be
published,
but
also,
you
know,
has
sort
of
a
time
stamp
on
it
when
it
does
get
published
and
everything
that
sort
of
evolves
after
that
can
be
captured
in
a
different
way.
G
So
yeah
there's
it's
gone
through.
One
research
group
last
call
we'd
like
to
by
the
end
of
this
presentation
and
then
on
the
list
very
soon
move
to
another.
Last
call:
that's
my
goal
here,
we're
now
on
the
fifth
version,
since
the
research
group
adopted
it
and
the
changes
that
we've
made
most
recently
have
been
to
scale
back
the
section
on
self-censorship
to
the
bare
minimum.
G
So
the
contents,
the
summary
of
the
draft,
it's
in
essentially
four
parts,
there's
a
section
that
sort
of
helps
to
define
what
to
block.
Then
that's
followed
by
a
section
on
how
to
detect
what
to
block
after
you've
defined
it,
and
then
the
last
part
is
really
about
the
actions
that
you
can
take
to
block
it
and
then
there's
some
discussion
of
how
the
network
is
layered
and
and
how
that
actually
matches
yeah.
I
just
saw
a
list
of
point
in
the
chat,
which
is
absolutely
right.
G
We've
talked
a
lot
about
how
this
could
be
a
living
document,
but
also
how
it
might
be
useful
to
to
actually
get
it
published
once
and
then
think
about
how
to
keep
it
up
to
date.
So
we
are
tracking
this
in
github.
You
can
see
the
open
issues
these.
This
is
a
just
sort
of
list
of
what's
open
and,
in
my
analysis
of
the
way
to
move
forward.
G
G
One
is
to
introduce
this
concept
of
sensor
maturity
because
again,
I
think
this
is
something
that
maybe
changes
over
time.
I'm
not
sure
it
adds
a
great
deal,
and
I
also
I'm
just
not
very
sure
or
clear
what
the
text
on
sensor
maturity
should
be
since
there's
not
been
a
suggestion
and
then
the
other
one
I
suggest
dropping
is
changing.
G
So,
throughout
the
document
we
have
a
sort
of
trade-offs,
caveat
under
most
subsections,
meaning
that
you
know
there's
a
cost
to
the
censorship
of
some
degree
and
there's
just
been
a
suggestion
that
we
changed
that
terminology
from
trade-off
to
cost
to
implement,
but
I'm
actually
looking
at
the
text.
I
don't
think
that
the
terminology
change
is
really
warranted
and
also
it
would
require
us
to
do
more
word
smithing,
because
then
we
tend
to
say
trade-off
colon
the
cost
to
implement
this.
You
know
so
it
would
be
really
redundant
and
kind
of
yeah.
G
G
We
know
that
we
need
to
incorporate
81,
55
and
64
into
the
next
version
and
then
we'll
go
to
the
list
right
after
that's
done
and
hopefully
ask
the
chairs
for
another
last
call
but
wanted
to
stop
there.
I
think
to
ask
if
there
were
any
questions
or
comments
thanks
again
for
the
time
we
have
like
three
minutes
left.
I
think
thanks
mallory.
Are
there
any
questions
from
the
meeting
today.
C
Otherwise,
I
think
I
can
to
say,
from
the
chair
point
of
view,
we're
very
keen
to
see
this
version
move
forward.
Now
that
there's
been
some
action
on
it
again,
so
we
would
be
very
keen
to
have
a
discussion
about
setting
a
provisional
date
for
getting
to
the
next
research
group
last
call
so
that
we
have
some
time-based
targets
to
move
this
forward
because,
as
you
say,
it
really
needs
to
be
published
at
this
point
in
time.
So
perhaps
we
can.
We
can
chat
about
offline.
G
C
G
Reasonable,
I
think
it
should
be
fairly
imminent.
Really
it's
just.
I
feel
really
confident
that
the
changes
I
need
to
make
I
can
make
it's
just.
I
need
the
reviewers
who
originally
raised
them
to
just
give
me
their
stamp
of
approval,
because
I
want
to
get
it
right
and
I
would
just
also
say
I
forgot
to
sort
of
say
this
in
the
presentation-
and
maybe
it's
only
tangentially
relevant,
but
there's
also
a
new
brand
new
zero
zero
draft.
That's
going
to
be
presented,
I
think
three
times
at
ietf
113
on
ip
blocking.
G
This
is,
I
think,
you
know,
reading
between
the
lines
in
response
to
some
of
the
requests
that
have
been
made
of
various
infrastruct
internet
infrastructure
to
action,
russia's
behavior
during
its
war
on
ukraine,
and
that's
a
good
draft.
If
folks
want
to
read
it,
I
think
there's
some
overlap
here,
there's
definitely
some
stuff
in
the
ip
blocking
space
that
isn't
in
this
draft.
So
I
don't
want
to
open
that
whole
can
of
worms.