►
From YouTube: IETF113-PIM-20220324-1330
Description
PIM meeting session at IETF113
2022/03/24 1330
https://datatracker.ietf.org/meeting/113/proceedings/
B
A
All
right
yeah
shall
I
start
here
then
I
guess
I
usually
do
this.
Please
yeah,
please
all
right!
Welcome
everyone
to
to
pym
here
in
vienna,
except
most
of
us
are
not
in
vienna
yeah.
We
got
the
full
agenda.
Let's
see
got
the
note.
Well
hope
everyone
has
seen
that
it's
the
same
as
it's
been
a
long
time.
A
Yeah
the
point
to
point
policy
ping,
which
is
the
working
group
draft.
We
got
the
pim
light
which
has
been
presented
before
now.
There
are
several
pretty
new
things:
let's
see
the
snipping
yang,
that's
some
something
that
was
taken
out
of
the
sleeping
yen
previously
to
to
be
able
to
publish
without
waiting
for
references,
but
now
we
might
want
to
move
forward
with
this
and
then
there's
several
other
new
proposals
proposals
as
well.
A
A
Yeah
I'll
send
an
email
to
that
working
to
the
working
group.
Later,
I
guess
about
what
changes
wherever
yeah
we're
going
to
make?
No
nothing
too
dramatic,
then
they
got
yeah.
The
dr
drafts
that
are
presented
this
meeting
a
gmp
mld
proxy
yang.
We
probably
requested
publication
of
that
since
more
drafts.
Here,
like
the
the
packing
drafts,
we
also
requested
publication.
A
A
A
A
D
So
good
morning,
good
afternoon
guys,
so
the
first
first
thing
is
to
talk
about
the
problem
statement.
So
this,
basically
our
current
pim
rfc.
It
talks
about
how
to
elect
a
pimdia
in
the
land,
and
in
this
case
we
are
showing
that
r1
is
the
dr
and
it
could
be
based
on
ip
address
or
based
on
its
prior
configured
priority.
D
D
D
Now,
coming
coming
to
the
backup,
dr
election,
how
how
exactly
we
should
be
doing
backup,
dr
election,
so
what
this
draft
talks
about
that
to
have
a
very
simple
mechanism,
so
I'm
I
have
just
pasted
from
7761
that
today
our
dr
election
mechanism
is
based
on
our
priority
and
our
ip
address,
so
so
everyone,
whether
it
is
r1
r2
and
r3.
There
are
exact
same
algorithm
to
identify
whether
I
am
eligible
to
be
dr
or
not
so
what
I
am
saying
instead
of
doing
some
extra
signaling
between
these
routers,
why
not
to
run
same
algorithm?
D
And
now
you
find
if
you
are
the
second
best.
So
in
this
case,
when
r1
runs,
the
algorithm
r1
knows
that
r1,
r2
and
r3.
All
three
are
in
the
lan,
and
priorities
are
190
and
80.,
so
r1
picks
itself
as
a
dr
now,
when
r2
is
doing
running
the
same
algorithm,
it
knows
that
it
is
the
second
best
router.
So
in
case
you
are
second
best
router.
You
definitely
can
qualify
for
backup,
drlx
backup.
D
Dr
now,
the
role
of
backup,
dr,
is
to
build
the
tree,
all
all
the
way
to
source,
and
you
may
backup
dr
will
be
getting
the
traffic
as
well,
but
backup,
dr,
is
not
going
to
forward
it
to
the
access
and
backup
dr
is
going
to
forward
it
to
access
only
when
r1
fails.
It
is.
It
is
kind
of
when
you
change
your
rule
from
bdr
to
dr.
That
is
when
you
start
forwarding
the
traffic.
The
benefit
of
this
mechanism
is
now
all
the
states
are
already
ready.
D
D
So
again,
there
are
deployments
where
they
don't
want
to
have
dr
election
happening
in
case
of
any
new
order
comes
into
the
network,
it
could
be
accidental
conflict
or
it
could
be.
Maybe
customer
is
really
trying
to
bring
up
a
router
which
was
earlier,
which
was
up
and
running
which
went
down,
and
now
it's
coming
up
back
in
in
this
these
cases.
D
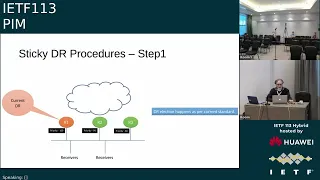
So
the
one
of
the
step
which
looks
pretty
straightforward
and
easy
to
do
is
so
first
first
step
is:
let's
have
dr
election
as
it
was
happening
today,
so
in
this
case
r1,
r2
and
r3,
they
have
three
priorities
configured
so
priority.
100
is
the
one
who
is
going
to
take
over
as
a
dr.
So
there
is
no
change
in
dr
election
procedure
next
step.
D
And
now
this
is
this
is
where
something
new
we
are
trying
to
define
that
once
you
have
taken
over
as
dr,
we
are
looking
at.
R1
now
announces
its
priority
as
mdr
max
when
I
say
pdr
max.
So
basically,
we
can
have
a
reserved
number.
Our
reserve
priority,
which
is
really
the
max
value,
which
should
not
be
user
configurable
value
and
it
is
kind
of
a
r1-
is
getting
a
sigma
4
that
now
r1
gets
that
max
value.
R1
starts
announcing
its
own
priority
as
this
highest
priority.
D
Now
what
benefit
we
are
going
to
get
out
of
it
when
r1
starts
sending
this
mdr
max
priority,
no
matter
who
is
coming
or
who
is
going
in
the
network,
it
is
never
going
to
change
the
dr
behavior.
It
is
not
going
to
cause
a
dr
reelection,
but
to
remember
that,
even
though
r1
has
been
configured
with
priority
100
now,
it
is
announcing
a
special
dr
priority.
D
D
Now,
when
sticky
dr
fails
or
the
router,
which
was
dr
earlier
fails,
so
what
is
going
to
happen?
So
in
this
case,
when
r2
r3
detect
that
there
is
a
failure,
they
are
going
to
rerun
dr
election,
and
if
there
was
a
vdr
vdr,
will
automatically
take
over
and
now
r2
is
the
one
who
is
going
to
start
sending
this
new
dr
priority
at
this
point
of
time.
What
is
going
to
happen?
Even
if
r1
comes
back
so
r1
priority
is
configured.
D
D
D
And
with
respect
to
ayana
consideration,
I
was
thinking,
and
maybe
we
can
definitely
discuss
whether
this
should
be
just
a
user
driven
approach
or
we
can
reserve
some
range
of
values
from
the
india.
So
mdr
is,
if
I
remember
correctly,
it's
32
bit
value.
So
there
was
a
thought
that
we
can
reserve
some
towards
end
some
values
which
you
should
not
be
allowed
to
configure,
and
we
will
use
one
of
the
number
as
a
max
dr
value
and
the
second
second
thing
which
needs
to
be
discussed.
D
E
D
So
I
have,
I
don't
think
there
is
a
really
need
for
a
sticky
bdr
as
well,
but
if
there
is
a
if
there
is
a
real
need,
I
I
don't
see
same
same
algorithm,
working
for
sticky
bdr
as
well,
but
in
that
case
bdr
has
to.
As
I
said,
if
we
are
reserving
the
range
of
max
value,
then
bdr
has
to
be
less
than
the
dr.
That's
all.
B
F
F
F
F
So,
according
to
the
problem
statement,
we
know
that
it
makes
the
network
more
stable
if
we
can
keep
their
unchanging
and
we
may
also
call
it
a
sticky
solution
and
a
new
bdr
rule
is
needed.
The
new
bdr
can
be
in
standby
mode
and
it
takes
over
the
dr's
responsibility
in
case
of
drca
note
forward
flow.
Next,
please.
F
And
so
the
solution
defined
in
this
draft
introduces
two
new
options
in
pim
hollow
message:
that's
the
difference
between
this
structure
and
the
mechanics
draft.
They
are
the
two
new
options.
Are
they
are
option
and
the
pdr
option,
and
this
solution
will
change
the
priority
carrying
function
defined
in
fc
7761.
F
Whenever
a
router
which
supports
supports
this
solution,
starts
to
work
in
a
lan,
it
should
send
the
pin
parallel
message
with
the
two
options
set
to
zero.
When
hello
hold
the
timer
expires.
The
router
receives
hello
message
from
other
router.
If
there
any
monitor
checks
the
hello
message
from
weldon
neighbors,
if
it
finds
that
there
is
their
option
set
to
non-zero
value,
it
won't
elect
itself
sdr,
even
if
it
has
a
higher
priority,
but
it
still
can
be
the
video
if
it
has
the
highest
priority
among
the
routers
except
there.
F
If
there
is
no
existed
deer
in
the
land,
then
router
has
the
highest
priority
will
be
the
fear
in
case
there
is
a
router
since
the
hollow
based
message.
Without
a
dr
or
dr
option,
then
all
the
routers
in
the
land
must
use
the
function
defined
in
fc761
to
elect
the
deer.
The
vr
will
be
instead
by
mode
the
button
not
forwarding
through
until
it
finds
at
the
dear
count
forward
flow.
Next,
please.
F
And
so,
let's
see
what
happened
when
all
the
router
starts
working
that
all
the
routers
send
the
team
hollow
with
the
drpr
option
set
of
zero
and
they
also
send
their
their
priority
when
the
hollow
hold
timer
experts,
the
router
with
the
highest
priority,
will
be
elected
and
the
bdr
will
be
elected.
Also,
all
the
daughters,
the
hello
message
with
dr
bdr
option
set
and
let's
see
the
second
situation.
There
is
a
working
dr
in
the
land
already
and
rotor,
with
a
high
priority
connects
in
the
net.
F
The
new
router
sends
the
team
hollow
message
with
drbdr
options
set
to
zero,
and
it
also
sends
the
their
priority
when
the
hello
held
timer
expires.
The
new
router
receives
the
hello
message
with
dr
option
set
to
the
working
dr's
at
best.
It
only
replaces
the
working
deer,
but
it
will
be
the
bdr
if
it
has
highest
priority
among
all
the
other
routers
except
working
there.
Finally,
all
the
routers
in
the
name
will
send
the
hollow
message
with
the
same
value
of
dr
on
the
bdr
option
set
next,
please.
F
F
F
And
so
this
is
a
summary
of
this
solution.
It
has
a
bdr
role
to
reduce
the
time
of
multicast
tree
rebuild
the
sticky,
dr
and
the
fastest.
Switching
of
video
can
minimize
the
packet
loss.
The
convergence
time
of
dr
election
will
be
one
hollow
hold
time,
and
the
solution
has
explicit
signaling,
because
the
two
dr
bdr
options
are
defined
in
hollow
message,
and
the
election
result
is
certain
because
either
the
router,
which
has
the
highest
priority,
is
elected.
F
E
B
So
we
have
these
two
drafts
that
we've
adopted
as
a
working
group.
The
idea
is
valid.
We
think
it's
a
worthwhile
effort
to
be
working
on
and
we
understood
the
different
solutions,
which
is
great,
so
we
either
continue
to
progress
these
drafts
on
their
own
and
update
them.
Like
mankamana
said
he's
gonna
update
his
draft.
I
guess
the
problem
is
that
it
seems
like
there's
continuing
creeping
overlap
between
the
giraffes,
so
we
need
to
try
to
avoid
that
do
the
would
the
authors
of
the
different
giraffes
prefer
to
keep
them
separate
is.
E
F
F
A
A
So,
ideally,
I
would
like
to
have
a
technical
discussion
like
yeah,
like
the
email
you
sent,
sadly
to
the
mailing
list
to
to
find
out
which,
which
method
actually
is
best.
You
know
what
what
are
the
pros
and
cons
with
each
other?
The
methods
is
there,
a
need
for
both
for
them
or
is,
is
one
better
than
the
other
in
some
way.
A
But
if
we
pick
a
solution,
then
yeah,
the
question
is:
do
we
want
to
have
a
yeah?
I
guess
we
want
to
have
a
draft
with
just
one
sticky
draft
from
sticky
dr
solution
right
that
the
working
group
picks
or
if
you
want
two
solutions.
Of
course
it
could
be
two
different
drafts,
I
know,
but
we
need
to
have
a
technical
discussion.
I
think,
probably
on
the
mailing
lists.
A
But
yeah
with
all
these,
with
all
of
your
offers
working
on
this,
I
am
also
wondering,
though,
if
it,
if
it
makes
sense
to
have
possibly
a,
I
don't
know,
merge
the
documents
or
have
a
new
draft,
whatever,
with
all
the
offers
together
or
that's
that's
a
different
matter.
I
want
to
focus
on
the
technical
discussion,
perhaps
on
the
mailing
list.
F
B
H
When
it
comes
to
the
replication
segment
and
the
point
to
multi-point
policy
itself,
we
are
almost
done
with
the
with
that
work.
There
are
a
little
bit
churn
on
those
drafts
so
talking
to
the
co-authors.
Maybe
we
start
doing
last
call
on
those
two
on
the
yang
side.
We
haven't
done
any
work
on
it,
so
you
know
I
would
appreciate
if
the
working
group
has
started
looking
at
the
yang,
if
they
have
any
comments,
please
bring
it
forward.
H
So
we
can
start
updating
those
I'll
try
to
revive
that
draft
in
the
spring
again,
but
yeah
any
comments
over
there.
You
know
I
would
greatly
appreciate
it,
so
we
can
have
a
you
know:
good
yank,
on
the
mvpn
side.
Again
we
are
working
on
it.
I
think
that's
best.
We
are
working
on
it.
We
are
trying
to
make
the
draft
complete.
H
I
think
the
next
one
I'm
guessing.
That's
the
pce,
so
yeah
that's
zero,
zero.
The
pce
has
been
adopted
right
now.
There
are
a
couple
of
vendors
that
are
working
on
the
pce
messaging
and
that's
why
it's
just
stuck
on
zero
zero,
probably
in
the
next
itf
or
the
one
after
we
do
have
some
implementation,
so
there's
gonna
be
more
churn
into
that
draft.
So
you
know
some
of
those
changes
will
come
forward
on
the
pce
side.
H
The
the
next
one
is
the
idr,
which
is
the
sr
point
to
multipoint
policy.
We
just
asked
for
adoption
call,
and
there
was
some
good
support,
so
it
should
be
okay.
The
last
day
is
actually
today
the
24th,
so
we'll
see
what
happens
there
and
the
last
but
not
least,
is
the
pink
which
is
the
this
draft
which
we
are
working
on
in
this
working
group.
So
that's
a
little
update
of
what's
going
on
with
this
point
to
multiplying
solution
from
all
draft
points.
A
H
Okay,
so
what
we
are
trying
to
achieve
here,
as
everybody
knows
when
it
comes
to
point
to
multi-point
policy
and
the
replication
segments,
it's
a
pce
solution.
So
there
is
no
signaling
on
the
network
itself
on
the
line
on
the
fibers
itself.
So
it
is
crucial
for
us
to
understand
what
the
failure
is
within
the
tree
going
from
the
root
all
the
way
to
the
to
the
leaves
of
these
of
this
puppy.
H
So,
basically,
the
point
of
this
draft
is
to
come
up
with
the
oem
mechanism
that
is
capable
of
testing
the
tree
for
each
candidate
path.
Again,
a
little
bit
of
reminder
on
the
route
you
can
have
multiple
canada
paths
that
they
are
redundant
and
the
active
candidate
pad
is
the
one
that
has
the
highest
precedence.
H
Any
other
candidate
pad
is
staying
there
as
inactive
and
based
on
the
failure
when
the
pce
or
the
controller.
For
that
matter,
realizes
that
there
is
a
failure
on
the
active
candidate
path,
it
will
switch
to
the
backup,
canada
paths,
if
you
will
so
each
one
of
these
candidate
paths
have
a
trio
for
its
own
through
the
network
they
can
be
set
up
accordingly,
through
the
network,
they
can
be
srlg,
meaning
that
they
can
be
completely
separate
from
each
other.
H
It
all
comes
down
to
the
controller,
how
they
want
to
set
up
these
canada
paths
through
the
network
from
the
root
all
the
way
to
the
host,
sorry
to
the
leaves.
So
that
said,
we
need
to
be
able
to
test
every
one
of
these
candidate
paths.
Now,
there's
a
second
concept
under
the
candidate
path,
and
that
concept
is
what
we
call
the
path
instance.
H
So,
basically,
if
a
candidate
pad
needs
to
be
optimized,
then
we
can
have
two
path:
instances
under
the
candidate
path,
that
the
second
path
instance
will
be
signal
through
the
network
through
an
optimized
path,
and
it
can
do
a
make
before
break
procedure
on
the
route
to
switch
from
one
path.
Instance,
through
the
second
pattern
sense,
so
you
keep
that
candidate
pat
up
and
running,
which
is
your
primary
cannon
pack.
So
this
draft
will
introduce
a
mechanism
to
test
every
single
one
of
these
canada
paths
and
every
single
one
of
these
path.
A
A
H
H
We
are
basically
reusing
those
rfcs,
and
I
guess
one
point
that
I'm
trying
to
make
here
is
that
this
draft
is
only
for
the
mpls
end
cap.
When
it
goes
to
the
srv6
oem
stuff,
then
there
is
a
draft
in
the
six
man
which
is
the
oem
for
srv6,
and
we
need
to
come
up
with
a
new
draft
that
reuses
the
srv6oem
packet
format
to
to
introduce
oem
functionality
for
point
to
multipoint
three
in
the
srv6
domain.
H
I
guess
one
thing
that
we
did
identify
into
this
draft
is
the
target
fake,
so
we
did
identify
the
point-to-multi-point
policy
target
fake
that
identifies
this
packet
to
the
oem
layer,
saying
that
this
is
really
for
point
to
multi-point
policy
and
the
tlv
to
identify
this
oem
packet.
If
you
could
go
to
the
next
slide,
please
and
I
realized
the
slide.
Numbers
are
wrong,
but
my
apologies
so
yeah.
So
this
is
the
the
tlv
that
actually
identifies
the
packet.
H
So
one
question
is:
does
it
make
sense
to
come
up
with
two
different
tlvs
one
for
ipv4
and
one
for
ipv6
and
drop
the
address
family
or
you
know,
one
tlv
is
sufficient
enough
and
you
know
keep
the
address
family,
but
the
length
becomes
variable
in
this
case.
So
that's
one
thing
that
you
know
if
you
have
opinions
on.
I
would
greatly
appreciate
if
you
can
feedback
me
or
to
the
to
the
authors.
H
A
H
H
So
maybe
that's
I
did
something
wrong,
okay,
so
the
next
one
is
pim
light.
Basically,
what
I'm
trying
to
achieve
here
is
to
have
the
working
group
to
come
up
with
a
baseline
for
this
draft
there.
There
was
a
lot
of
conversation,
emails
back
and
forth
on
the
on
the
working
group,
email
list,
which
is
great,
but
I
think
we
need
to
agree
on
the
baseline
and
what
do
we
want
to
do
here
and
based
on
that
agreement?
Take
it
forward
and
see
what
we
come
up
with
so
next
slide.
Please.
H
H
All
right
so
a
little
bit
of
history,
this
draft
well,
this
idea
came
alive
when
we
were
doing
the
last
car
for
beer
pim
signaling.
Basically,
in
that
draft,
what
we
wanted
to
do
was
to
send
the
the
multicast
estate
join
and
prunes
from
one
beer
edge
router
to
the
next
beer
edge
router
and
in
the
draft
field,
explained
that
we
are
only
sending
joins
and
prune
messages
as
a
signaling
from
1b
router
to
the
next
one.
H
Maybe
we
need
to
identify
a
brand
new
pim
interface
that
could
carry
only
the
pim
joints
and
prunes
without
actually
trying
to
bring
up
a
pim
adjacency
between
the
the
routers
or
two
peers
for
that
matter,
and
that's
where
the
idea
was
born.
So
basically,
we
are
not
trying
to
complicate
the
story
here.
All
we
are
trying
to
do
is
and
multicast
states
or
remove
the
multicasted
states
between
two
pim
routers
that
are
attached
either
directly
or
via
some
medium,
and
that
medium
can
be
anything
it
could
be
beer.
H
It
could
be
any
other
medium
and
then
the
next
question
is
if
there
is
no
hellos,
because
we
are
not
bringing
up
the
we
are
not
sending
pim
hellos,
it's
just
the
estates,
then
some
of
these
messages,
like
asserts
or
some
of
these
other
messages
that
are
really
relying
on
the
hellos,
might
not
get
accepted
or
processed
by
the
pim
routers
accordingly,
as
well.
So
next
slide,
please.
H
So
there
were
a
couple
of
well
not
couple
there.
There
were
a
lot
of
discussions
in
the
working
group
which
I'm
bringing
up
in
this
slide,
so
just
to
refresh
everybody's
memory.
One
thing
was
the
name:
some
people
didn't
like
light.
You
know
some
people
were
saying
it's
light,
transit,
etc.
So
we
need
to
come
up
with
a
name,
and
the
next
thing
is
there
are
conversations
again
if
we
can
use
hellos
from
other
type
of
protocols
like
igp,
to
revive
that
hello
messaging
between
the
between
the
two
router.
H
So,
even
though
we
don't
want
to
send
the
pim
hellos
on
this
specific
implementation,
can
we
kind
of
piggyback
on
some
other
type
of
protocol,
to
make
sure
that
the
two
pim
light
routers
are
still
up
and
running
and
communicating
with
each
other,
and
there
is
some
kind
of
heartbeat
between
them?
I
guess
the
next
question
was
as
of
now
in
the
draft.
H
We
you
know
if
it's
pim
light
interface,
do
we
need
to
explicitly
configure
this
interface
because
of
security
point
of
view
and
do
we
need
to
only
accept
the
joins
and
the
prunes
on
a
medium
that
has
this
interface
connected
to
it
and
if
so,
in
some
of
these
mediums
like
beer,
you
cannot
really
create
an
interface.
So
what
do
we
want
to
do
there
yeah?
C
Yeah,
so
my
recurring
wish
that
I
don't
get
for
30
years
now,
so
if
we
have
an
upstream
interface
with
a
multiple
possible
senders
of
traffic
and
when
we're
doing
a
cert
right
now,
we've
we've
termed
a
strong
rpf
to
be
able
to
filter
out
the
packets
based
on
who
sent
them.
We
never
did
this
because
that's
layer,
2
filtering
right,
you
would
need
to
know
which
of
the
upstream
pim
routers
would
send
something,
but,
for
example,
in
beer.
We
also
have
that
right.
C
We
have
the
brbfrid
in
the
header,
so
even
on
a
beer
site,
we
know
who
sent
it
whether
you
call
that
strong
rpf
or
you
have
a
virtual
interface
on
a
per
upstream
bfr
id
and
you're
effectively.
You
know
changing
your
rpf
interface
so
that
you
at
the
pim
level
representing
not
a
lan,
but
you
know
for
every
upstream
bfir
a
separate
point-to-point
interface.
I
mean
that's,
that's
that's
a
modeling
question,
but
in
the
forwarding
plane
you
obviously
want
to
receive
a
packet
and
filter
it
based
on
the
bfr
id
in
the
packet.
C
A
A
A
F
H
You
know
if
everybody
can
ponder
about
this
slide,
specifically
and
and
based
on
the
emails
that
we
receive,
we'll
update
the
draft,
and
you
know
in
the
next
ietf
we
can
do
another
presentation
and
you
know
see
whether
we
can
adopt
a
draft
or
you
know
how
to
move
it
kind
of
forward
kind
of
thing.
That's
that's
where
I
am
right
now.
I
I
think
you
know
I
in
the
next
sorry.
Can
I
go
to
the
next
slide.
My
apologies.
H
Yeah,
so
I
I
think
from
what
I'm
hearing
there
is
somewhat
of
an
agreement.
We
need
to
put
a
little
bit
more
meat
into
the
draft,
which
is
fine,
I'll
work
on
it.
You
know,
send
your
comments
into
the
what
what
we
just
discussed
so
I'm
getting
old.
You
know
I
might
forget
some
of
these
stuff,
so
please
send
it
into
the
email
working
group,
email,
I'll
I'll,
put
them
into
the
draft,
and
the
next
itf
will
take
it.
B
I
Hello,
hello,
everyone,
I'm
hunty
from
ireland.
Now
let
me
introduce
a
new
individual
draft
about
hmd's
moving
young
model
standard
for
l2
vpn
next
week,
and
this
is
the
first
version
for
the
presentation
and
the
effort
is
from
the
mankasi
on
design
team.
The
all
servers
and
also
that
from
everson
ibm
dream
pro
and
china
mobile
netflix.
I
I
I
And
now,
in
order
to
use
the
snooping
instances
in
the
alteration-
the
l2p,
the
htmp
smoothing
instance-
and
I
mailed
these
two.
So
in
order
to
use
the
snooki
says
in
albuvier,
we
argument
the
level
instance
of
cyborgs
as
african
and
the
instances
could
be
referenced
that
could
be
referenced
in
the
algorithm
service
like
below.
I
I
A
A
B
B
J
J
Firstly,
I
will
give
the
brief
introduction
of
this
draft
and,
as
we
know,
and
the
pmfr,
it's
a
very
important
protection
mechanism
for
the
multicast
deploys.
It
can
minimize
the
packet
loss
when
the
failure
happens
to
the
multicast
parts,
but
in
the
rfc
7431
it
can
only
use
the
rfa,
but
rfa
can
only
cover
part
of
the
network,
develop
topologies.
J
J
We
provide
a
new
mechanism
by
using
the
tfa
for
the
pmfr
and
it's
no
need
for
the
additional
extension
of
the
pin
protocol
just
to
use
the
existing
pin
features,
and
this
time
we
we
update
the
jobs
as
a
informational
drive,
and
that
is
a
recommending
recommendation
for
the
multicast
protection
deployment
in
the
sr
networks
next
step.
Please.
J
J
E
J
J
J
J
For
the
r4
in
the
vector,
we
use
the
tab
0
of
the
joint
attribute
and
it
will
look
up
the
unicast
routing
to
the
r4
and
hope
I
hope
to
send
the
pim
joint
from
the
r6
to
r4
and
the
the
second.
The
second
vector
is
that
the
exclusive
rpf
vector
attribute
that
the
tab
four
of
the
draw
attribute
it
will.
It
will
not
look
up
the
unicast
routing
table
and
just
specify
the
p
upstream
neighbor.
E
J
H
A
J
H
B
G
J
A
Yeah,
so
the
draft
looks
interesting
to
me
as
well.
I
wonder
I
guess
we
can
do.
We
can
do
a
call.
I
wonder
whether
we
you
know
whether
people
understand
really
enough.
What's
it
what's
in
the
document
or
or
not,
but
maybe
maybe
most
people
have
read
it
and
get
it.
Let's
we
can.
We
can
try
a
poll
and
see.
A
J
A
A
B
B
Great
thanks
now
we
now
now
we
have
a
few
drafts
and
it
looks
like
we've
got
a
decent
amount
of
time
here
that
all
have
some
something
to
do
with
point
to
multipoint,
srv6
and
related
ideas,
and
so
waymo
is
going
to
be
the
first
one
he's
just
getting
back
from
presenting
in
another
working
group.
So
he's
a
hero
for
getting
here
quickly.
K
The
existing
solution
based
on
sr
include
srp
2mp
policy
and
our
previous
draft
there's
a
v6
ptop
pass,
which
we
have
received
lots
of
comments
from
the
working
group.
So
these
existing
solutions
have
some
weakness
and
the
multicast
using
multicast
routing
overhead
is
a
good
alternative
which
takes
these
comments
into
account
and
also
is
more
scalable.
Next
page.
K
K
The
increase
of
the
tree
in
caps,
the
mycast
package
into
a
multicast
routing
header,
for
each
subtree
from
the
desktop
of
the
ingress
and
then
send
the
package
to
the
next
hop
and
then
finally,
the
package
will
reach
to
each
of
the
eagles
node
and
at
the
transient
node
after
transient
nodes
receive
the
package
transient.
Node
just
gets
each
of
the
linked
numbers
from
the
matrix
routing
header
and
then
find
the
next
hardware
address
from
the
link
number
from
the
label
table
and
then
send
the
package
to
the
next
home
at
the
equation.
K
C
K
A
K
K
K
K
So
for
the
which
is
for
the
equals
node
for
the
link
to
the
user
node,
those
are
number
of
branches
and
the
point
are
all
zeros.
And
then
we
can
introduce
a
flag
l
to
indicate
this
linkage
to
eagle
zone,
and
then
we
can
remove
those
two
fields,
lincoln
number
of
links
and
the
pointer
to
the
sub
tree.
So
in
this
way
we
can
reduce
the
overhead,
for
example
after
receiving
the
those
two
fields
for
the
link
to
the
equals
note.
K
K
So,
in
addition
to
that
improvement,
we
can
also
remove
the
link
example
field.
Using
a
bit
bit
set
one
indicate
that
the
beast
number
will
be
used
to
encode
the
encoded
link
numbers
from
a
node
b.
So,
for
example,
we
have
subtree
here
from
p3
to
p4
to
pe4
to
p
mark
p7,
so
in
this,
so
those
links
from
e4
can
be
encoded
by
bit
strings
and
also
we
have
a
p
flag
indicate
that
those
nodes,
in
addition
to
represented
by
the
beast
number,
and
also
indicate
that
the
light
swap,
is
a
leaf
nose.
K
K
K
K
K
The
mic.
Rolling
header
will
include
subtree
from
next
hop
and
then
the
english
node,
which
just
set
the
fuse,
such
as
sl
mb
and
the
b
in
the
multicast
rolling
header
to
the
corresponding
value
to
for
the
link
from
english
node
to
the
next
hop.
For
example,
here
mb
will
get
the
value
from
this
cycled
one,
which
is
a
value
corresponding
to
the
link
from
english
node
to
e1
next
hop
and
then
just
set
send
this
package
to
the
microsoft,
which
is
p1
next
page.
K
So
after
p1
as
transcendent,
receive
the
package,
so
it
will
send
a
copy
to
each
of
its
last
hop,
for
example,
for
electro
g2.
V1
just
sets
the
fuse
bmb
and
sl
in
the
header
to
the
corresponding
value
for
the
link
to
the
next
hop
and
then
deliver
to
the
to
the
next
hop.
That's
very
simple.
Without
any
modification
inside
of
the
tree
included
in
the
in
the
header
for
egress
node,
for
example,
for
from
from
p1
to
p8,
which
is
the
eagles
node.
K
B
As
a
individual
contributor
to
this
draft,
it
would
also
be
helpful
if
this
would
probably
be
something
that
we
need
to
discuss
of
course
further
on
the
list.
But
bob
hinden
did
mention
to
us
that
the
so
waymo
presented
this
in
six
men
as
well
this
week
and
bob
mentioned
to
us
that
the
header
format
and
processing
would
be
okay
for
six
man
to
discuss
but
a
whole.
B
B
It
probably
would
be
kind
of
similar
to
what
newman
did
very
successfully
with
point
to
multi-point
draft
and
having
a
replication
segment
defined
in
spring
and
then
the
stitching
of
all
those
segments
and
a
policy
done
here.
So
it's
kind
of
a
rough
equivalent
to
that.
So
just
wanted
to
throw
that
in
there.
I
A
A
L
A
A
C
C
Okay,
so
what
what
we
want
to
have
is
a
native
ipv6
srv6
solution
for
point
to
multipoint,
that
is,
stateless
homan
already
done
all
the
work
for
the
state,
full
ones
with
the
replication
segments.
So
this
is
intended
to
be
part
of
the
srv6
architecture
for
networks
with
only
ipv6
and
srv6,
so
where
the
operators
do
not
want
additional
layer,
3
forwarding
planes
for
multicast
that
are
not
ipv6,
and
we
want
this
as
much
as
possible
to
be
well
as
little
changes
over.
C
You
know
what
we're
doing-
let's
say
with
the
sra
chatter,
for
for
path,
but
just
the
same
thing
for
multicast
replication,
and
there
is
no
such
solution.
The
ietf
today,
that's
unicast,
only
srh,
but
we
already
saw
one
other
proposal
to
do
this
so
and
in
this
proposal
the
core
property
is
really
of
the
encoding
of
the
compressed
tree,
which
we
call
recursive
bit
string
structure
next
slide.
C
So
the
recursive
bit
string
structure
is
shown
on
the
right
hand,
side
that
is
in
the
blue
box.
The
whole
address
structure,
as
it
is
seen
for
on
the
first
router
a
and
that
router
a
simply
needs
to
examine
a
single
bit
string.
That
is
indicating
the
adjacencies
on
that
router,
a
to
which
it
should
send
packets.
So
in
this
example,
here
it
has
four
possible
adjacencies.
C
Two
of
them
have
set
bits,
so
that
is
an
adjacency
to
b
and
adjacency
to
c,
and
so
what
router
a
needs
to
do
is
simply
do
a
lookup
of
these
bits
in
the
bit
string
and
then
for
each
of
the
copies.
The
new
work
is
that
it
needs
to
rewrite
that
compressed
address
so
that
only
the
subtree,
for
that
particular
neighbor
is
the
active
address
for
that
copy
being
sent
and
active
means
it
could
be
rewritten
so
that
everything
is
thrown
away,
except
for
that
subtree
or
it
could
be
pointers.
C
That
basically
say
here.
The
active
part
of
the
address
is
just
that
subtree,
and
that
is,
I
think,
a
little
bit
also.
The
question
with
six
men,
because
shortening
an
address
is
something
that
is
not
officially
endorsed
by
rfc
8200,
but
it's
also
not
prohibited
so
we're
fairly.
You
know
not
not
opinionated
on
that,
but
let
the
iatf
decide
what
would
be
best
next
okay.
So
why
do
we
want
this?
So
all
these
wonderful
traffic
steering
things
we
can
get
out
of
that
right.
C
There
are
no
micro
loops
that
we're
getting
with
the
hop
by
hop
reconvergence
through
the
igp
when
we're
not
doing
source
routing.
So
now
that's
all
traffic
engineering
that
we
get
through
the
traffic
steering
of
indicating
the
tree,
but
even
if
we
compare
it
to
just
flat
bit
strings
that
are
not
encoding
the
whole
tree,
we
do
think
we
get
scalability
benefits
and
those
come
simply
from
the
consideration
that
this
working
group
and
the
original
protocols
we
did
right.
Pim,
sparse
mode
kind
of
our
biggest
success
is
based
on
the
predicate.
C
We've
got
a
large
network
and
the
multicast
delivery
is
a
tree
is
small,
so
we're
only
sending
to
a
relatively
small
number
of
receivers
in
a
large
network,
and
so
there
is
the
simple
thought.
Example:
without
a
good
picture,
consider
you
have
a
network
with
the
2
560
destinations,
egress
pe's
and
the
service
providers.
You
have
flat
bit
strings
of
256
bits
which
is
kind
of
some
existing
technology,
and
you
want
to
send
to
10
destinations.
C
Well,
if
you
have
flat
bit
strings,
you
might
be
unlucky
and
you
send
10
packets,
because
all
these
10
bits
that
you
send
to
are
in
10
different
bit
strings.
So
your
replication
efficiency
is
sent
to
10
destination
if
you're
lucky
it's
one
packet.
If
you're
unlucky,
it's
10
packets
with
flat
bit
strings,
and
if
you
use
this
rbs
scheme
in
the
validation
topologies
that
we
used,
you
can
get
always
away
with
a
single
packet,
because
you
can
always
encode
for
any
combination
of
10
receivers.
C
Any
tree
within
just
you
know
less
than
256
bit
of
rbs3,
so
that
so
even
rbs
does
encode
the
whole
tree.
It
is,
in
our
opinion,
even
more
efficient
in
many
cases
than
any
flat
bit
string
option
and,
of
course,
that
example
did
not
even
include
the
overhead
of
encoding
the
tree
and
flat
bit
strings.
So
so
we
think
that
this
recursive
bit
string
structure
is
of
all
the
proposals,
the
best
compressed
version
that
gives
the
best
replication
efficiency
next
slide.
C
So
here
again
in
a
little
bit
more
detail.
Hopefully
that
can
be
read
it's
a
little
bit
too
small.
For
me,
I
guess
here,
hopefully
it's
better
on
the
large
screen.
How
do
we
encode
and
process
so
all
the
length
fields
that
we're
using
are
in
bits
so
that
we're
efficient
if
a
router
has
n
neighbors,
then
the
bit
string
to
be
examined
on
that
router
has
n
bits.
C
So
in
our
example,
we
had
four
routers,
so
we
have
a
fib
with
for
rbs,
which
we
see
on
the
right
hand,
side
which
has
four
bit
entries,
and
each
entry
has
the
address
of
the
next
hop,
which
is
what
you
know
in
the
usual
segment.
Routing
fashion
would
be
the
destination
ipv6
address
in
the
outer
header
being
replaced,
and
then
we
have
another
column
that
says
whether
that
particular
neighbor
is
a
leaf
or
it's
an
intermediate
hop.
C
If
it's
an
intermediate
hop,
then
it
means
there
is
a
recursion
field
which-
and
that's
shown
here
in
the
middle-
in
the
address,
there
is
a
subtree
for
that
particular
neighbor,
and
that
is
then
what's
going
to
be
extracted
as
the
address
to
the
neighbor.
If
a
neighbor
is
a
leaf,
then
of
course
that
neighbor
doesn't
need
to
get
any
further
address,
but
the
packet
can
just
be
sent
to
the
neighbor
without
any
further
rbs
address.
C
So
as
far
as
processing
a
concerned
single
flat
bit
string
lookup
on
every
node
and
then
an
address
rewrite,
which
is
adjustment
of
pointer
or
extraction
of
a
part
of
the
address
and
making
that
the
address.
So
we
also
think
this
is
the
least
amount
of
complex
processing
in
the
forwarding
plane
of
any
of
the
compressed
options
that
we
have
seen
next
slide.
C
C
The
forwarding
is
the
same
right
segment
by
segment
forwarding
by
swapping
the
ipv6
destination,
address
from
the
forwarding
information
that
I
showed
that's
from
the
fib
so
that
we
have
compression
in
the
packet
just
bits
for
the
neighbors
and
then
in
the
fibs.
The
next
top
ipv6
addresses
and,
of
course,
yeah
we're
replicating
more
than
once.
That's
the
whole
point
of
the
multicast.
C
There
are
tlvs
in
the
srh
headers
optionally,
for
egress
node
functionalities.
We
would
think
that
we
start
saying
we
have
the
same
set
of
tlvs
but
we'll
have
to
work
through
which
of
these
are
applicable
for
multicast
packets.
Equally,
so
that's
some
tpd
work.
Srh
also
has
the
programmability
in
the
uncompressed
version.
C
When
you
have
long
addresses,
we
haven't
seen
use
cases
for
these
transit
top
programmability
functions,
so
we
haven't
considered
that
yet,
but
if
that
is
desirable
to
have,
then
we
can
look
into
this,
but
right
now
it's
maximum
compressed,
so
no
programmability
on
the
intermediate
hops
next
slide
right.
So
then,
the
next
steps-
and
mike
was
already
alluding
to
this.
C
As
an
extension
to
the
srv6
architecture
and
then
the
extension
header,
maybe
as
a
six-man
document,
I
think
as
soon
as
we
see
a
sufficient
support
for
the
technology,
I
guess
across
the
working
groups
we're
going
to
figure
that
out
and
then,
of
course
the
question
is:
do
we
want
extensibility
of
the
compression
mechanisms
in
terms
of
not
you
know,
fixating
only
on
one
of
course,
as
you
know
here
me
representing
rbs,
I
think
that's,
that's
great.
Is
it
sufficient?
C
C
L
C
Right
so
so
the
answer
is
that
it
can
definitely
work
incrementally
you
only
need
to
support
rbs
on
the
nodes
where
you
want
replication
to
happen,
but
at
that
point
in
time
what
you
need
to
do
is
to
define
the
fib
with
the
adjacencies
of
not
directly
connected
next
hops,
which
is
exactly
what
you
would
be
doing
with
the
loose
source
routing
in
the
unicast
case
as
well,
and
that
will
work
perfectly
fine.
But
of
course
you
may
have
more
adjacency
bits.
C
Then,
because
you
may
you,
may
you
have
just
let's
say
for
physical
links,
so
that's
just
four
bits
in
a
fully
upgraded
network.
But
if
you
go
to
three
or
four
hops,
you
may
need
to
have
more
bits
there.
So
the
performance
as
far
as
how
well
is
it
compressed
for
the
incremental
update
case
is
is
another
good.
You
know
performance
evaluation
that
would
need
to
be
done.
L
L
I
think
this
is
the
good
practice
of
srv6
is
to
provide
some
of
these
the
euler
solution
for
the
srv6,
so
I
think,
maybe
in
the
drought,
maybe
more
euro
situation
can
be
provided
or
maybe
there's
a
additional.
This
additional
euler
situation
draft
accompany
this
drought
for
better
understanding
about
this
solution.
C
Yeah,
so
I
think
right
now,
what
were,
I
think
also.
All
the
other
drafts
have
only
started
to
think
about
is
the
basic
forwarding,
plane
mechanisms
and,
as
I
said,
we
may
even
need
to
split
up
that
type
of
work
between
something
to
go
to
six
men
on
the
encoding
side
and
the
architecture
in
a
similar
way
that
we
had
it
in
spring
and
in
six
men
and
yeah.
None
of
none
of
this
covers
the
control
plane,
parts
of
it,
for
example.
A
B
Yes,
I
think
you
have
the
right
strategy
right
here
on
this
slide.
Tour
list
is
to
take
this
discussion
to
pim.
I
think
it's
the
right
place,
since
you
are
defining
a
new
type
of
segment
right.
That
part
would
likely
need
to
be
discussed
in
spring
kind
of
like
the
replication
segment
is
something
that's
done
in
spring,
but
we
can
stig-
and
I
can
help
figure
that
out,
if
there's
as
we
progress
does
that
make
sense,
okay,
and
we
need
to
move
on
to
the
last
presentation
we're
right
on
time.
Thank
you.
M
M
Basically,
srv6
has
already
provided
a
solution
for
unicast
service
to
indicate
it
p2p
passed
through
segment
least
in
srh
for
te
scenario,
and
there
is
no
flow
status
is
requested
to
maintain
in
the
intermediate
nodes,
which
is
very
beneficial
for
deployment,
and
also
there
are
several
srp2mp
solutions
under
discussion
for
multicast
te
besides
the
previous
two
to
presentations.
One
of
them
is
what
has
already
been
discussed
in
pim4.
M
P2Mp
pass
assignment
list
for
p2mp
pass
is
provided
to
the
ingress
node
and
there
are
two
arguments
for
each
seed
which
is
and
branches
and
ncs
to
indicate
the
next
level
of
subtree
after
replication,
and
for
this
document
we
will
provide
a
optional
solution
of
multicast
p2mp
pass
indication
for
multicast
te
on
next
slide.
Please.
M
M
A
second
list
will
indicate
the
p2p
path
and
in
the
end
point
it
will
update
the
segment
left
by
segment
left,
minus
one
and
the
destination
address
is
replicated
replaced
by
the
next
active
seed,
pointed
by
the
same
left,
which
steers
the
packet
to
the
next
indicating
node
or
adjacency
in
the
t
pass.
This
is
based
on
the
behavior
definition
for
the
function
of
and
or
and
dot
x,
in
rc8986
and
the
in
the
egress
node.
M
M
This
is
our
first
solution.
We
introduce
a
structural
segment
list
for
multicast
tree.
The
basic
idea
is
that
we
we
can
define
new
function
type,
which
is
called
antidote
replication
through
second
list,
for
specify
the
nodes
which
the
multicast
tree
passes
through
and
defines
two
parameters
in
each
seed,
which
is
called
the
replication
number
and
a
pointer
to
indicate
the
replication
forwarding
relationship
between
the
upstream
and
the
downstream
nodes.
M
So
what
is
solution?
Look
like
first,
there
will
be
a
second
list,
just
like
the
unicast
in
the
segment
list
will
contain
all
the
seeds
according
to
the
indicated
nodes
in
the
multicast
tree,
for
example,
in
the
picture
in
the
right
right
hand,
there
is
an
indicated
multicast
tree
and
for
each
node
there
will
be
a
seed
in
the
seminal
list
in
a
mod
custom,
routing
header
we
call
it
mrh
and
in
each
seed
there
will
be
three
parts
as
the
segment
format.
Just
like
the
the
unicast
sr6
seed.
M
There
is
a
locator
there's
a
function
and
also
two
arguments.
One
is
replication
number
which
could
indicate
how
many
packets
to
replicate
in
this
node
and
another
is
a
pointer
to
indicate
the
second
left
value
of
the
first
child
node.
The
basic
idea
here
is
that
if
it
is
a
p2
p
pass,
the
the
problem
is
very
simple:
we
just
we
just
set
the
segment
left
by
segment
left
minus
one,
but
if
it
comes
to
multicast
the
next
hub
downstream
node
will
be
a
group,
and
we
cannot
find
the
next
seed
only
by
minus
one.
M
So
we
have
to
indicate
how
many
packets
will
be
replicated
and
where
to
find
the
corresponding
seed.
So
we
have
we,
we
define
these
two
arguments,
and
so
correspondingly
the
the
behavior
is
then
the
packet
will
be
replicated
based
on
the
replication
number
and
updates
the
same
on
the
left
and
the
ipv6
destination
address,
based
on
the
pointer
and
forwarding
the
replicated
packets
to
the
downstream
nodes.
Next
slide.
Please.
M
Here
is
a
simple
example
and-
and
I
think
I
won't
go
to
detail-
maybe
if
you
are
interested,
you
can
see
the
whole
pro
progress
here
in
different
notes.
Next
slide,
please,
and
we
can
see
in
the
previous
solution.
The
the
drawback
is
also
very
obvious,
because
we
have
to
allocate
a
seed
for
each
node
in
the
multicast
tree.
The
the
header
expense
may
be
unacceptable
when
the
tree
is
large,
so
we
we
introduce
some
compression
method
to
with
local
b
stream.
M
M
Here
are
some
additional
thoughts.
Actually,
a
new
type
of
ipv6,
routine
header
for
multicast,
which
is
called
mrh,
is
mentioned
before
is
proposed,
and
we
think
this
mrh
is
requested
for
different
types
of
encoding,
p2mp
paths,
maybe
including
the
previous
presentations
and
other
possible
options,
and
so
maybe
we
think
more
contributions
are
needed
to
make
this
header
reasonable
enough
and
be
able
to
compatible
with
various
encoding
forms.
M
So,
and
also
maybe,
corporations
with
six
months
will
very
helpful,
and
here
is
a
very
simple
comparison
between
two
existing
documents,
which
are
very
similar.
One
is
recursive
subtree
and
for
the
the
former,
the
and
another
one
is
the
layered
replication
behavior
and
the
first
one
will
pop
the
irrelevant
segments
after
replication,
and
the
latter
keeps
all
the
segment
just
as
srv6
does
for
unicast
and
same
on.
The
left
is
used
to
locate
the
active
seed
and
for
the
local
b
stream
method.
M
M
So
the
we
hope
more
people
will
be
interested
in
this
work,
because
p2mp
passing
coding
can
be
complex
but
interesting
and
with
a
lot
of
possible
solutions.
So
we
think
more
more
work
can
be
done
here
and
for
our
document
comments,
our
feed
and
feedback
will
be
very
welcome
and
for
the
concept
of
of
mr6
and
based
on
ipv6
network,
we
will
we
have
already
proposed
above
and
if
people
are
interested
in
this
topic,
maybe
not
only
in
pim
and
relative
working
google,
we
can
also
discuss
in
above.