►
From YouTube: IETF113-PRIVACYPASS-20220324-1200
Description
PRIVACYPASS meeting session at IETF113
2022/03/24 1200
https://datatracker.ietf.org/meeting/113/proceedings/
A
A
A
A
A
We
are
that
we
may
adopt
so
we'll
have
a
presentation
on
that
and
then,
if
we
have
time,
I
I
don't
know
if
mark
is
here
but
there's
some
updates
to
the
centralization
problem.
We
weren't
sure
if
we
were
going
to
have
time
for
that
presentation.
So
I
don't
know
if
if
mark
is
going
to
attend
or
not,
but
if
he
is,
we
can
get
get
him
to
give
us
an
update.
Are
there
any
other
additions
or
modifications
to
the
agenda
or
ben?
Did
I
leave
anything
off.
C
So
for
the
architecture,
the
the
biggest
change
that
went
into
the
last
revision
was
sort
of
an
exploration
of
deployment
considerations
for
ways
in
which
you
would
use
privacy,
perhaps
in
practice,
and
what
the
implications
are
on
sort
of
the
privacy
posture
of
the
protocol
with
respect
to
clients,
we'll
kind
of
go
through
the
main
highlights
of
those
deployment
considerations
here
and
talk
about
next
steps
for
the
draft.
After
that.
C
Later
on
in
the
architecture
document,
describes
what
the
role
of
the
tester
is
and
the
azure
is
in
the
issuance
protocol,
as
well
as
what
the
role
of
the
origin
is
in
the
challenge
and
redemption
protocol
tried
to
orchestrate
things.
Such
that
the
redemption
protocol
is
really
simple
and
lightweight
and
doesn't
really
put
a
lot
of
burden
on
the
origin.
C
Conversely,
the
issuance
protocol,
of
course,
sort
of
encapsulates
all
the
complexity
of
new
token
types
and
the
I
guess
relevant
privacy
properties
of
those
different
issuance
protocols
and
and
yeah.
That's
pretty
much
sums
it
up.
I
guess
the
the
overall
flow
of
the
the
the
protocol
sort
of
looks
like
this.
If
you
recall
so,
the
the
origin
of
the
server
on
the
right-hand
side
generally
would
ask
the
client
you
know
it
when
it
wants
to.
C
That
is
attesting
to
particular
properties
on
behalf
of
the
client
and
in
the
latest
version
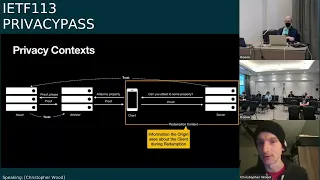
architecture.
Document
we've
introduced
this
this
notion
of
context,
so,
for
example,
during
the
redemption
protocol,
there's
a
redemption
context
and
the
redemption
context
sort
of
encapsulates
all
the
things
that
the
origin
of
the
server
would
see
about
the
client
during
its
interaction
with
the
client
for
the
purposes
of
redeeming
a
token.
C
So
that
might
be
the
origin
name
itself,
because
the
origin,
as
information
about
that
particular
redemption
context,
might
be
the
time
stamp
of
the
redemption
event
might
be
the
client
ip
address.
You
know,
whatever
information
there
is
about
a
particular
client
interaction
when
redeeming
a
token
with
a
particular
server.
C
C
If
you
take
a
step
back
and
ask
yourself,
you
know
what
is
at
least
in
a
deployment
of
privacy
pass.
What
is
meaningful
privacy
because
you
know
for
most
uses
of
privacy
pass
we're
trying
to
use
it
for
purposes
of
improving
client
privacy,
mind
you.
There
are
applications
of
privacy
password,
you
may
not
care
about
privacy,
but
for
this
particular
you
know
scenario
we
are
so
in
the
the
meaningful
privacy
we
claim
in
this
particular
setup.
C
C
C
C
C
B
Hey
you
said
time
or
space
here.
I
guess
I
would
have
expected
time
and
space,
because
whether
I
see
a
consistent
ip
address
over
a
long
period
of
time-
or
I
don't
know
your
ip
address,
but
I
but
you're
the
only
client
who's
who's
requesting
and
using
tokens
in
some
short
period
of
time.
It
seems
like
either
one
of
those
is.
C
C
Sure
and
that's
why,
in
this
particular
model,
non-interactive
tokens
sort
of
like
are
the
most
sensible
variant
in
particular,
because
spending
a
token
or
redeeming
a
token
does
not
mean
that
you
like
went
off
and
fetched
in
real
time.
It
just
means
that
at
some
point
in
the
past,
you
have
fetched
a
token.
So
there's
like
a
sort
of
a
natural
separation
between
the
two
over
over
time.
B
C
So
recall
the
the
the
meaningful
privacy
here
is
that
you're
not
being
you're
not
able
to
link
per
client
per
server
information.
So,
although
you're
able
to
like
link
these
two
events
together,
presumably
by
the
time
stamp,
you're,
not
linking
you're,
not
sort
of
revealing
any
per
client
information
by
virtue
of
using
a
sort
of
a
proxy
and
interacting
with
the
cert
for
the
tester
server.
In
that
particular
case,.
C
C
Okay,
moving
on
there's
also
there's
another
another
other
deployments
in
the
in
the
draft
as
well
deployment
models
in
the
draft
as
well.
Another
one
we
talked
about
is
this
split
deployment
model,
and
this
is
this
is
useful
for
different
attestation
mechanisms
that
are
less
privacy
friendly.
Like
say,
for
example,
the
client
is
demonstrating
that
has
you
know,
ownership
over
some
specific
type
of
application
account,
and
it's
like
specifically
logging
in
with
that
account
in
this
particular
model.
C
C
C
C
In
particular,
the
insurance
protocol
should
not
reveal
any
things
that
are,
you
know,
particular
to
the
to
the
origin
during
issuance,
but
thankfully
all
the
issuance
protocols,
like
the
the
blind
signatures
and
the
oprs
and
whatnot
naturally
sort
of
hide
this
information
by
virtue
of
being
blind
signatures
or
oblivious
suit.
Around
functions.
C
C
Which
means
that,
like
say,
for
example,
you
have
two
origins
that
both
accept
cross-origin
tokens:
they
both
have
to
sort
of
share
double
spend
prevention
state.
Otherwise
a
client
could
spend
a
token
at
either
one
of
these
particular
servers,
and
I
don't
think
we
explicitly
sort
of
make
that
obvious
in
the
draft
right
now.
So
there's
just
an
issue
to
sort
of
call
that
out.
C
There
is
also
some
existing
sort
of
privacy
parameterization
in
the
draft
which
sort
of
describes.
You
know
if
this
is
the
sort
of
like
size
of
the
anonymity
set
that
you
want
for
particular
clients.
Here's
how
you
should
arrange
your
issuers
and
arrange
your
testers
and
whatnot,
but
it's
still
sort
of
kind
of
highly
dependent
on
the
previous
incarnation
of
the
architecture
draft.
C
E
I
can
just
say
next
slide:
it's
it's
fine!
If
you
don't
mind,
yep,
that's
fine!
Okay,
all
right
next
slide
great!
So
I'm
going
to
talk
about
the
authentication
scheme.
This
is
the
document
that
we
discussed
at
the
interim
meeting.
It
is
newly
adopted
and
we
did
actually
publish
a
zero
one
version
just
this
week
with
a
couple
of
the
changes
that
I
will
talk
about
today.
E
E
E
This
is
because
this
field
was
not
necessarily
a
nonce.
It's
really
just
some
servers
chosen
context
that
they
want
a
token
bound
to,
and
I
want
to
point
out
that
the
fact
that
you
have
this
redemption
context
in
a
challenge
doesn't
actually
make
the
token
issuance
interactive
as
in
saying
that
the
client
needs
to
fetch
a
token
immediately.
E
It's
just
saying
that
this
token
is
bound
to
something
that
the
server
knows
for
purposes
of
double
spend
prevention
and
it's
something
that
isn't
exposed
to
the
issuance
protocol.
So
it's
really
just
between
the
client
and
the
origin.
That's
doing
the
redeeming
to
make
sure
that
you're
not
spending
a
token
that
someone
else
got
and
then
one
other
minor
rename
is
that
there
was
another
confusing
context,
name
in
the
actual
token
struct.
E
E
All
right,
then,
the
other
thing
we
want
to
do
is
talk
about
stabilizing
the
format
of
this
challenge
and
response.
We
have
several
implementations
that
have
been
testing
with
interop
and
to
encourage
the
deployment
of
these
experimentation
between
these.
The
authors
would
like
to
essentially
hear
any
issues
with
that
format
now,
so
that
we
don't
have
to
worry
about
changing
it
too
much
later
next
slide,
so
just
to
review
what
the
current
status
is
of
these
structures
in
the
challenge.
E
It
has
the
issuer
name,
which
tells
you
who,
who
is
allowed
to
actually
get
give
you
the
tokens.
On
the
other
side,
it
has
the
newly
renamed
redemption
context,
which
is
optional
and
is
essentially
just
some
random
server
chosen
context
that
they
want
to
bind
this
token
to
and
then
also
an
origin
name
to
scope.
This
token,
to
a
particular
origin
upon
redemption.
E
E
E
F
Ted
hardy
speaking,
if
you
wouldn't
mind
going
back
a
sled,
I
was,
I
was
typing
slowly,
so
it's
actually
about
this
for
the
opaque
origin
name,
which
is
optional.
If
you
wanted
to
have
something
that
covered
both
youtube-
and
you
know,
google
search
at
the
moment,
you
could
leave
this
out
and
the
redemption
context
would
handle
it.
F
You
could
present
it
and
neither
one
could
could
do
it,
but
I
was
wondering
whether
it
be
another
option
to
consider-
and
maybe
it's
not
needed-
is
to
allow
opaque
origin
name
to
to
have
more
than
one
appearance
in
the
struct,
so
that
you
could
specify
a
a
list
of
origin
names
that
are
covered
for
when
you
have
cases
like
that,
where
the
redemption
mechanics
in
the
back
end
are
likely
to
be
the
same,
but
the
origin
names
are
not.
So
I'm
not
sure
this
is
worth
doing.
E
Got
it
yeah?
That's
a
great
point
of
an
interesting
feature
that
this
could
have.
As
you
point
out,
it
could,
of
course,
just
use
cross
origin
tokens,
but
then,
depending
on
what
your
issuer
is
this,
that
could
be
a
much
broader
pool
of
origins
that
it
would
be
shared
with
and
not
just
google
and
youtube.
F
So
I
think
I
I
think
you're
probably
right
there,
that
the
there
could
be
something
else
it
uses
to
know
whether
it's
safe
to
do
the
cross-origin,
but
the
the
mechanics
of
this
in
the
back
ends
of
some
of
these
are
going
to
be
a
little
bit
wonky,
because
in
some
of
these
cases
the
same
redemption
mechanics
are
going
to
be
used
for
something
like
gcp.
So
you
could
have
instances.
F
So
if,
if
you,
if
we're
not
going
to
use
multiple
origin
names,
then
I
think
one
of
two
things
will
happen:
either
cross-origin
is
going
to
be
very,
very
common
to
to
major
services,
because
they
many
of
them
have
more
than
one
name
from
the
point
of
view
of
http
origin
or
you're,
going
to
have
to
have
some
other
system
to
kind
of
figure
out.
Oh
okay,
what
I'm
going
to
actually
use
to
figure
out
whether
it's
cross,
urgent
safe,
is
my
last
contact
for
them.
F
What
all
of
the
subject
names
were
in
the
certificate
or
something
like
that,
so
it
there's
some
trade-offs
here
and
a
simpler
trade-off
might
actually
just
be
to
say:
opaque
origin
name
can
and
can
occur
multiple
times,
because
then,
if
somebody
wants
to
to
scope
it
to
a
specific
set,
they
don't
have
to
rely
on
either
previous
contact
by
the
the
client
or
maybe
a
try
and
fail
with
cross
origin.
That
was
to
the
same
set
of
servers
but
to
different
actual
redemption
context.
So
just
just
a
thought.
G
E
E
If
you
want
to
challenge,
it
should
be
very,
very
simple:
you
essentially
just
need
to
choose
who
your
issuer
is
one
or
more
of
them
and
what
token
type
you
want
to
use.
So
what
issuance
protocol
you
can
choose
to
be
per
origin
or
cross-origin
and
to
the
discussion
we
were
just
having?
Maybe
you
know
there
is
a
in
between
you.
Essentially,
you
need
to
choose
what
is
that
value
of
kind
of
what
you
are
binding,
your
challenge
to,
and
then
you
can
choose
the
optional
context
that
you
want
to
have
so
for
this.
E
So,
of
course
you
can
have
an
empty
context,
but
you
could
have
some
very
simple
mechanics
like
doing
a
hash
of
the
client
ip
address
or
the
client
ip
address
subnet,
so
that
you
can
just
compare
these
tokens
to
other
clients
that
fall
within
that
subnet
or
you
could
have
something
associated
with
your
state
with
the
client.
So
if
the
client
has
a
long-lived
connection
with
you,
that's
doing
http,
2
or
http
3.
E
When
you
don't
have
a
context,
then
it's
very
easy
to
cash
it.
If
they
are
context-based,
then
you
have
generally
shorter
caching
lifetimes,
and
we
had
a
recent
issue
from
something
like
chris
pointed
out
that
you
want
to
probably
clear
any
cached
tokens
whenever
you
clear
your
cookie
state
or
something
else
that
would
otherwise
be
changing
the
client
state.
E
And
then
the
other
thing
that
you
want
to
do
on
the
client
side
is
to
verify
that
origin
name
information
to
make
sure
that
it
matches,
and
this
again
to
the
point
that
ted
brought
up
is
where,
if
this
is
expanded
to
include
multiple
things,
it's
some
verification
that
what
the
challenge
was
bound
to
actually
represents
what
you,
the
this,
the
state.
You
think
you
have
with
the
server
to
make
sure
that
you're
not
going
to
give
a
token
to
the
wrong
server.
E
All
right
so,
based
on
this
discussion,
it
sounds
like
we
have.
You
know
one
issue
where
we
want
to
kind
of
dive
in
a
bit
more
to
this
origin
name,
if
other
people
see
other
changes
that
to
the
formats.
That
would
be
useful.
That
would
be
great
to
hear
now
and
other
than
that
we
plan
to
continue
polishing
the
document
and
doing
interrupt
testing
if
people
are
interested
in
testing
with
this,
let
us
know
any
other
questions.
E
Yeah
we'll
go
back
and
forth
all
right,
so
next
we'll
talk
about
a
secondary
issuance
protocol,
so
the
main
core
issuance
document
talks
about
blind,
rsa,
blind
signatures
and
oprf,
and
these
are
just
very,
very
basic
usages
of
those
protocols,
but
we
have
another
issuance
protocol
that
has
been
defined
specifically
to
allow
per
origin
rate
limiting
next
slide.
Please.
E
So
rate
limiting
is
a
very,
very
common
part
of
fraud,
prevention
and
anonymous
access
across
web
and
in
apps
and
often
it's
something
that
does
rely
on
tracking
cookies
or
client
ip
address,
and
so
it's
not
a
great
thing
for
user
privacy
and
just
first
to
give
some
background
on
how
this
is
commonly
done
with
something
called
token
buckets.
Chris
is
going
to
walk
through
some
examples.
D
C
If
it's
empty,
you
can
add
the
tokens,
and
then
you
have
another
process
that
removes
tokens
from
this
bucket
and
this.
This
process,
that
is
removing
tokens,
is
typically
representative
of
something
that
wants
to
like
access
a
resource,
send
a
pack
out
on
the
network
or
send
an
api
call
or
do
whatever
basically
and
the
the
the
token
bucket.
Just
the
internal
check
is
basically,
you
know:
are
there
tokens
available
to
service
this
particular
request?
C
If
the
answer
is
yes,
as
in
that,
the
number
of
tokens
in
the
bucket
is
not
empty,
the
the
request
is
serviced.
If
it's
not,
it's
dropped
on
the
floor.
Leaky
buckets
are
sort
of
the
mirror
image
of
this
and
also
commonly
used
to
implement
rate
limiting.
But,
as
I
said,
this
is,
I
think,
a
simpler
mental
model
internally,
if
you're
to
sort
of
open
this
up,
take
a
look
at
the
sort
of
token
replenishing
process.
First,.
C
When
a
token
bucket
is
replenished,
the
very
first
obvious
thing
is
that
the
the
bucket
that
is
being
replenished
has
to
be
identified.
So
in
this
particular
case
you
can
think
of
it.
Like
you
know,
there's
a
hash
table
inside
and
the
hash
table
has
a
particular
index,
and
the
value
associated
with
that
particular
index
maintains
the
count.
D
C
Sorry,
the
resource
request
side.
Similarly,
the
bucket
has
to
be
identified,
and
so
that
involves
going
into
the
hash
table
and
then,
depending
on
how
many
tokens
your
particular
request,
corresponds
to.
Maybe
it's
like
you
know.
If
it's
a
packet,
size
and
bytes,
there
needs
to
be
n
tokens
or
whatever
here
we're
just
saying
that
each
request
counts.
As
one
token,
the
the
the
algorithm
identifies.
C
Decrements
the
the
count
by
one
and
if
it's
greater
than
zero
surfaces,
if
it's
not
it
just
and
drops
it
on
the
floor,
and
that's
basically
it
the
it's
pretty
straightforward,
the
the
you
know
you
have
to
identify
bucket
and
either
you
increment
increment
tokens
or
decrement
tokens
and
act
accordingly
or
service
requests.
Accordingly,
back
to
you,
tommy.
E
This
is
because
of
tor
or
proxies
or
vpns
or
just
being
on
a
shared
ip
on
a
public
network
and
a
basic
privacy
pass
token
is
useful
for
the
cases
where
I'm
just
going
to
get
really
gratuitous
captchas,
but
it's
not
always
enough,
both
for
some
functional
use.
Cases
like
the
metered
paywall,
but
even
for
some
of
the
just
the
captcha
prevention
cases.
E
E
So
I
could
have
a
bunch
of
legitimate
devices
that
are
being
used
as
a
click,
farm
or
captcha
farm,
or
I'm
just
trying
to
get
around
something
like
a
metered
paywall.
And
so
we
have
a
concern
that
in
many
of
these
cases,
we're
still
going
to
degenerate
to
people
being
blocked,
even
if
they're
using
basic
privacy
pass
next
slide.
E
And
then
the
rate
limited
token
variant
does
that.
But
it
also
is
attesting
that
your
access
rate
for
this
origin
was
below
a
certain
threshold
and
this
adds
mitigations
doesn't
completely
solve.
But
it
adds
a
lot
of
mitigations
against
devices
being
used
as
a
click
farmer,
captcha
farm,
and
it
also
allows
you
to
work
with
things
like
metered
paywalls,
even
without
giving
away
user
privacy
next
slide.
E
E
By
the
way
for
this,
for
the
thing
that
this
client
is
accessing,
they
should
only
be
allowed
to
access
it
either.
You
know,
let's
say
three
times
per
hour
or
five
times
per
month.
You
know
it
could
be
a
fairly
wide
range
of
rate
limits
and
the
tester
is
the
one
responsible
for
failing
the
request.
If
that
rate
limit
is
exceeded,
next
slide.
C
A
tester
has
access
to
neither
and
therefore
can't
compute
the
mapping,
and
this
mapping
is
basically,
you
can
use
it
as
an
index
into
whatever
other
data
structure,
you'd
like
to
use
for
enforcing
rate
limits.
So
if
you
think
back
on
the
the
token
bucket
example,
you
would
use
it
as
the,
for
example,
the
hash
table
index
that
would
use
to
store
and
associate
your
accounts
or
your
token
accounts
for
that
particular
or
client
per
origin
bucket,
and
so
the
flow
would
be
the
tester
computes,
the
secret
arc.
C
And
if
you
were
to
map
this
to
sort
of
the
flow,
the
issuance
flow
between
the
client
and
tester
and
the
issuer
sort
of
hand
waving
massively
over
sort
of
the
underlying
details
in
terms
of
how
this
stable
mapping
is
computed
reserve
those
details
to
the
document,
basically,
the
the
the
tester's
job
is
to
in
in
interacting
in
completing
this
protocol
between
the
client
and
the
issuer
is
to
compute
the
stable
mapping.
Decrement
account,
or
rather
that
should
say
increment
count.
C
You'll
find
that
the
the
slide
is
hilariously
wrong
in
terms
of
like
the
the
algorithm
but
like.
Hopefully,
the
idea
is
clear.
Basically
compute
the
mapping
apply
the
the
the
algorithm
and
either
eject,
accept
the
request
and
and
forward
the
token
response
back
down
to
the
client
or
drop
down
the
floor,
sending
the
client
down
an
appropriate
error
code,
and
this
you
know
the
the
close
reader
will
understand
why
this
is
wrong
in
terms
of
like
what
the
what
the
check
is
actually
doing.
C
C
C
As
tommy
said,
it
does
require
a
split
deployment
for
meaningful
privacy
in
particular,
because
the
issuer
does
need
to
learn
the
origin
name
in
order
to
associate
and
use
sort
of
the
right
origin
secret
for
computing,
the
stable
mapping
and,
as
a
result,
the
attester
who
cannot
learn
sort
of
per
origin
information.
Thinking
back
on
what
we
think
of
as
meaningful
privacy
needs
to
be
a
separate
entity.
C
There
are
today
a
couple
different,
operable
implementations
of
this
particular
variant
using
the
the
signature
scheme
with
ecdsa
previous
incarnations
of
this
draft
used
eddsa
for
the
crypto,
but
we've
since
changed
that
we
could
bring
it
back.
I
guess
we're
not
particular
in
the
type
of
crypto
here,
and
there
is
a
security
analysis
underway
for
sort
of
the
both
the
new
underlying
cryptographic
scheme,
as
well
as
sort
of
how
it
plugs
into
the
the
larger
rate
limited
issuance
protocol
and
what
the
resulting
privacy
properties
are.
B
B
If
I'm
a
magazine,
I
could
act
as
both
issuer
and
and
and
validator
and
users
could
make
an
account
with
my
with
my
origin,
and
then
I
would
say
you
know
you
have
a
free
account.
So
I'm
going
to
issue
you
three
tokens
a
month
and
then
I'm
going
to
execute
a
redemption
on
you
know
to
to
do
a
token
spend
event.
Every
time
you
attempt
to
view
an
article
and
so
you'll
run
out
of
tokens.
B
E
I
think
the
more
interesting
case
here
is
talking
about
the
cases
where
you're
trying
to
rate
limit
for
the
fraud
prevention
case.
Let's
say
the
actual
account
creation
time
right.
So
if
what
I'm
trying
to
do
is
prevent
you
know,
device
farms
from
creating
a
bunch
of
abusive
accounts,
that's
a
case
where
you
know
today
they
may
use
captcha
plus
rate,
limiting
on
ip
addresses,
etc
and
the
basic
token
issuance
there
isn't
always
going
to
be
enough,
because
they
that
will
still
not
give
you
confidence
that
these
aren't
abusive
devices.
E
E
E
Like
unless
you're
setting
up
a
new
one
of
those
accounts
for
every
service,
so
like
do
you
think
I
have
like
a
new
one-to-one
mapping
of,
like
some
other
rate,
limiting
service
right,
but
I
I
think
the
issue
then
is
at
that
point
it.
It
sounds
like
it
would
be
fairly
easy
to
know
when
I
signed
up
for
that
service
like
oh.
This
is
the
service
to
give
me
tokens
for
the
new
york
times,
and
so
that
thing
does
know
when
I
am
getting
those.
B
B
C
Yes,
I
assume
you're
done.
Thank
you.
The
the
key
challenge
here
was
in
that
in
trying
to
build
in
a
mechanism
for
sort
of
keeping
the
state,
we
did
not
want
the
the
thing,
maintaining
the
state
to
be
able
to
effectively
reconstruct
any
any
like
browsing
information
or
any
sort
of
pre-origin
information
about
the
the
the
thing
that
it's
enforcing
rate
limits
for
indeed
like
earlier
designs,
were
a
lot
simpler
and
but
they
enabled
the
attester.
C
I
don't
know
if
it
was
called
the
adjuster
at
that
particular
point,
but
they
enabled
the
attester
to
learn
that
information
and
in
in
trying
to
address
that
this
was
the.
This
was
not
the
first
solution
that
we
came
up
with,
but
is
it?
I
think
it
is
the
one
that
has
the
desired
functional
properties
as
well
as
the
desired
privacy
properties
and
and
just
to
heavily
plus
one
to
what
jonah
said.