►
From YouTube: IETF99-DIME-20170717-1740
Description
DIME meeting session at IETF99
2017/07/17 1740
https://datatracker.ietf.org/meeting/99/proceedings/
B
C
C
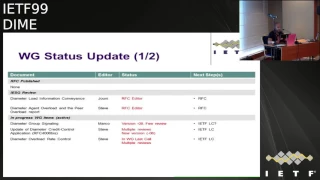
The
status
was
the
working
group
documents
or
non-market
good
documents,
so
basically
we
have
to
document
our
that
our
block
in
the
editor
queue
mainly
due
to
the
shepherd.
The
laziness
myself
so
I
need
to
review
one
of
them,
and
this
one
is
so
both
of
document
are
linked
to
the
third
one,
and
this
one
needs
a
review
and
to
go
through
the
AG,
and
so
there
is
no
issue
with
this
one
it
just
because
one
document
is
missing.
C
D
C
C
Okay,
the
first
one
would
be
the
diameter
group
singing
that
teasing
the
working
group
for
wine.
Now
we
have
received
a
new
version
of
the
document
and,
from
the
author's
point
of
view,
it's
quite
Tibble,
but
only
from
the
author's
point
of
view
within
more
review.
We
were
expecting
additional
reviews,
but
it
was
not
the
case,
so
the
next
step
normally
should
be
working
with
high
school
and
in
high
school,
but
maybe
Marco.
You
would
like
to
say
something
on
that.
E
Not
much
to
say,
as
I
said
before
last
ITF,
we
published
two
new
updates
on
covering
all
the
comments
that
have
been
made
before
it,
so
some
of
them
have
been
checked
on
peer-to-peer
phases,
some
in
discuss
and
confirmed
on
Manliness,
so
I
think
doc,
administrated
for
detail,
expert
review
and
we're
fine
and
happy
with
updating
again,
but
we
need
comments
to
progress
on
them.
I.
C
C
C
Yes,
just
to
be
able
to
send
it
to
the
for
a
HD
review,
so
my
test,
so
the
last
one
is
the
four
six
that
was
in
the
working
group
last
call
and
I.
Yes,
it's
where
it's
so
it
this
one
was.
We
had
one
working
group
last
call:
we
had
some
comments
but
fairly,
so
it
was
only
about
some
references
and
so
on,
but
not
a
deep
review
of
all
the
technical
content
and
so
on.
C
It
was
not
really
pointed
out
by
someone
else,
but
I
think
that
for
this
one
we
will
need
further
review.
It
could
be
through
I
think
that
the
working
group,
logical
process
anyhow
for
time
is
not
so
relevant,
but
we
can
initiate
a
second
one
based
on
the
new
version
on
the
version.
3,
publish
and
capturing
the
government
receive
so
far
for
the
first
working
group
last
fall,
but
we
will
need
anyhow
additional
review
because
an
especially
from
SF
5
guys
so
from
the
3gpp,
because
there
are
the
main
users
of
this
of
this
one.
C
After
that,
we
have,
the
diameter
will
be
P
level
security,
so
the
end-to-end,
the
security
for
the
emitter.
So
for
the
time
being,
we
have
no
draft
anymore,
because
the
the
last
one
expired
uni
will
not
have
so
much
time
to
work
on
so
I
think
he
I
will
not
speak
for
him
but
sir.
It
would
be
a
bit
too
to
contribute
on
this
one,
but
he
is
not
able
to
support
the
workload
alone.
What
we
on
Thursday
I
will
go
to
the
SAG
meeting.
C
The
security
meeting
and
I
would
ask
for
support
from
the
security
experts,
so
the
idea
will
be
to
to
to
motivate
people
to
work
on
this
on
these
documents.
The
solution
itself
doesn't
have
to
be
a
diameter
specific.
We
can
discuss
with
them
if
they
have.
If
there
is
something
easy
to
do
in
this
area,
for
the
emitters
that
could
be
applicable
to
diameter
and
based
on
the
output,
we
will
see
what
to
do,
and
also
after
the
discussion
on
the
working
with
Ben,
please
Ben.
A
So
what
I
plan
on
doing
siii
is
coming
up
in
three
weeks
and
I'm,
bringing
in
a
discussion
paper
basically
telling
them
of
the
status
of
this
work
here
and
where
you
know
it
gets
friendly.
Talk
at
that
meeting
you
know
and
ashley
has
been
brought
up
in
the
conversation
of
you
know,
5g
or
overall
securing
the
system
I'm
gonna.
Let
people
to
know
it's
it's
now
or
never,
forever
hold
your
peace
time
so.
A
C
A
comment
will
be
from
the
GSMA
point
of
view.
We
have
received
an
LS,
so
this
one
had
been
sent
to
3gpp
and
diameter
just
to
be
able
to
work
on
this
solution,
because
JC
may,
at
least
from
recoverin
point
of
view,
would
like
to
have
a
solution
to
recommend
in
their
specification.
So
at
least
from
from
start
point
of
views
are
expecting
a
solution.
After
that
I
think
it
will
depend
on
the
type
of
solution
that
would
be
a
dot
if
it
is
something
that
it
is
easy
to
implement.
F
C
F
For
mission-critical
deployments,
there's
a
two
security
domains,
one
of
them
being
the
operator
domain
and
one
being
the
mission
critical
operator
domain
and
we've
looked
at.
Securing
the
I
had
a
message
or
even
a
I
would
say
component
to
a
sip
message
level
securing
these
where
the
message
is
has
to
be
end-to-end,
secure
between
the
client
and
the
of
said,
the
host
and
the
mission-critical
service
provider.
I
wonder
if
there
are
Triple
A
requirements
where
you
you
can't
expose
certain
a
VPS
to
the
operator.
C
The
requirement
point
of
view
both
should
be
should
be
available
with
this
solution.
After
that,
it
will
depend
on
the
type
of
solution
that
we
will
adopt,
at
least
as
a
first
as
a
first
step,
but
normally
you
should
be
able
to
secure
the
signaling
on
only
between
gateways,
for
instance,
and
you
you
can
assume
that
your
your
the
different
system
are
secure
enough
to
get
rid
of
any
security
that
you
may
have
also
a
real
end-to-end
secret,
end-to-end
security
exchange
between
any
diameter
clients
and
any
diameter
server
mutton.
This
okay.
A
C
C
A
C
On
this,
I
can
I
can
come
at
this
point.
He
is
a
key
issue.
It
was
the
same
for
unis
that
it's
more
security
discussion
than
a
diameter
stuff
from
personally
I
could
help
on
the
diameter
aspects
and
and
how
to
convey
the
information
you're,
defining
the
ADP
and
even
figure
out
how
to
behave.
But
on
the
security
aspect
itself,
we
we.
We
need
some
some
expertise
coming
from
the
security
area.
Yes,.
C
G
G
You
we're
just
gonna
run
through
kind
of
the
updates
for
these
two.
So
next
slide,
please
so
predicted
units.
If
you
recall,
our
motivation
was
the
fact
that
we're
using
nfe
virtual
functions
basically
and
typically
right.
We
have
authorization
endpoints
as
a
part
of
this
inside
our
virtual
network
functions.
What
we're
kind
of
starting
to
do
is
divorce
the
CPU
that
computes
the
memory,
that
is,
the
I/o
resources
as
we
virtual
eyes
away
from
the
authorization.
So
we
see
a
much
bigger
distance
it
used
to
be.
We
had
fairly
predictable,
Hardware
and
sizes.
G
Now
our
thing
kind
of
fairness,
and
so
what
we're
trying
to
do
is
basically
sin.
Anytime,
an
authorization
occurs.
Basically,
a
successful
CCA
OCC
are
we're
trying
to
add
some
extra
information
in
this
case
time
add
a
match
to
the
amount
of
resources
that
may
be
utilized
following
the
tradition
of
used
service
units
and
granted
service
units.
We
just
call
it
predicted
service
units
with
the
full
understanding
that
the
units
that
we
actually
may
send
back
may
not
relate
to
the
actual
grants
credits,
maybe,
for
example,
in
terms
of
bytes
or
time.
G
However,
predicted
may
actually
be
more
granular
based
upon
the
system,
something
that's
meaningful
to
the
employee,
so,
for
instance,
disk
usage,
Network
IO
some
other
metric,
but
we
wanted
to
basically
inform
these
virtual
functions
a
little
bit
more
about
the
usage
that
they
can
expect.
This
is
especially
important
during
peak
times
for
the
VNS,
so
this
then
allows
us
to
basically
have
the
service
if
you
will
select
if
it
needs
a
new
scaling
event.
G
Other
things
you
know,
if
you
can
think
about
nfe
in
the
bigger
picture,
they
can
ask
for
scaling
events
or
they
can
just
stop.
Actually,
you
know
accessing
or
granting
requests
into
the
system.
So
this
allows
us
to
avoid
the
situation
that
we're
currently
in
today,
which
is
I,
have
to
overload
a
virtual
network
function
in
order
to
realize
I'm
in
trouble,
or
at
least
hit
a
threshold
toward
an
overload
before
I
realize
I'm
in
trouble
so
and
just
for
reference.
It's
still
about
three
to
four
minutes
to
spin
up
a
vnf
virtual
machine.
G
So
this
sort
of
information
is
important
to
us
anyway.
So
that's
the
the
base
motivation
with
this
and
it's
essentially
a
VP's
that
are
carried
along
during
an
authorization
next
line,
so
in
version
two
all
of
our
updates
were
editorial.
We
were
asked
in
the
last
meeting
to
really
put
that
information
in
the
introduction,
and
so
we've
rewritten
that
introduction
we're
a
bit
more
dictatorial
about
this
and
then
just
as
a
refresher
right.
This
is
essentially
the
the
same
old
same
old
in
terms
of
units.
G
The
only
difference
is
we
have
the
time
of
day
in
there
as
far
as
an
EVP,
to
give
you
the
idea
of
conditions,
and
then
our
assumption
with
the
series
is
that
there's
non-overlapping
times
with
respect
to
any
particular
unit,
it's
all
in
the
spec
pretty
straightforward.
At
this
point,
we've
had
a
couple
of
updates
before
the
last
meeting
we
had
updates
during
the
meeting.
G
I
have
not
received
any
new
updates,
so
what
I'd
like
to
do
is
push
for
this
being
adopted
either
out
on
the
mailing
list,
because
I
we've
had
quorum
issues
in
the
past,
but
push
for
this
to
be
adopted
as
a
worker
item
on
the
mailing
list.
After
this
meeting,
if
there's
no
other
material
updates
here.
C
G
C
G
What
we're
doing
here
is
two
things
so
in
the
user
plain
we're,
essentially
adding
metadata
as
another
filter
through
the
policy
group
matching
mechanisms
and
then
what
we're
doing
you
know
at
the
higher
level
if
it's
actually
implemented
before
the
user
claimed
we're
essentially
using
this
as
a
pre-screening
mechanism
to
figure
out
what
filter
IDs
apply.
The
good
news
is
it's
very
consistent
in
terms
of
the
back
office,
where
you
know,
if
you
think
of
old
service
order,
codes
or
bit
sets
or
really
just
flagging,
rules
to
policies
and
then
using
masking
to
figure
out.
G
You
know
when
a
particular
product,
X
or
Y,
implement
several
rules
rather
than
mapping
that
as
individual
IDs
for
just
one
of
these
as
mask
operations.
This
is
as
we
did,
our
work
and
everything.
What
we
found
out
was
happening
in
our
policy
decision
points
anyway,
and
we
also
notice.
We
have
some
other
updates
I'll
talk
about
here,
a
second
terms
of
examples
of
where
we
found
this
actually
being
applied,
particularly
in
open
flow
switches
in
the
metadata
fields.
G
So
we
also
wanted
to
pick
up
some
of
the
common
naming
that
we
kind
of
enjoy
over
in
3gpp
as
well
for
grouping.
So
this
is
all
about
efficiency
for
those
who
are
familiar,
3gpp
charging
characteristics.
It's
there,
it's
just
a
little
bit
more
generalized
next
slide.
So
this
is
once
again
an
editorial
update.
We
didn't
change
anything
structurally.
What
we
did
was
we
reworked
the
examples
based
upon
the
feedback
once
again
from
the
last
meeting.
So
next
slide.
G
So
as
a
reminder,
this
is
the
relationship
model,
and
here
we
talk
about
policy
entities
being
kind
of
your
rules
and
having
this
bitmask
assignment,
and
then
the
the
group
mapping
type
users
have
memberships
to
multiple
rules,
either
through
the
domain,
which
is
very
similar
to
a
base
name
as
well
as
the
the
bitmask
value.
So
this
is
your
base
relationship
model,
and
that
was
added
prior
to
the
last
meeting
so
before
that
ins,
alt
text
and
definitely
not
a
flood
inspect
to
read
so
next
slide.
G
So
we
have
a
couple
of
examples
that
we've
added,
but
this
is
more
of
the
visual.
So
one
of
the
issues
we
encountered
was
over
on
the
left
side,
so
in
Sdn
switches,
we're
typically
limited
in
terms
of
the
number
of
tables,
so
we
talked
about
Sdn
switches
serving
a
large
number
of
customers.
One
of
the
typically
issues
we
run
into
is
the
default
rule,
so
the
match
for
any
any
traffic
and
then
applying
different
treatments
in
the
typical
world.
G
If
we
just
stick
to
the
traffic
headers
themselves,
these
rules
overlap
and
we
need
multiple
tables.
What
we
did
by
adding,
essentially
the
metadata
information,
basically
the
match
type
and
the
membership
values
in
here
is
we've
added
them
in
this
example
to
table
0
on
the
rights,
and
so
what
you
see
is
essentially
and
we're
just
dividing
this
up
by
subnets.
But
what
we're
essentially
doing
is
we're
table.
G
1
would
actually
figure
out
what
subnet
you
belong
to
then
apply
your
subnet
specific
policy,
we're
able
to
with
this
metadata
value,
essentially
to
concatenate
that
into
a
single
table.
So
you
see,
if
we're
in
subnet
1,
we
set
the
membership
values
initially,
so
we're
just
setting
up,
basically
the
bit
mask
involved
and
in
the
next
table.
We're
actually
concatenated
so
you'll
notice
that
these
rules
no
longer
overlap
in
table
1
on
the
writes.
G
We
do
have
essentially
the
any-any
traffic
descriptors
in
on
table
one
on
the
right
and
we're
actually
now
relying
on
the
match,
type
and
membership
value
to
really
drive,
essentially
the
base.
So
in
table
0
you
set
that
membership
value
of
the
user.
Here
you
then
match
against
it
in
table
1
over
here.
This
allows
us
to
go
to
a
two
table
solution
and,
like
I
said
effectively
or
justic
the
filter
and
really
what
it
boils
down
to
is
especially
nasty,
end
switches.
G
G
This
is
a
much
simpler
example.
If
you're
not
doing
this
in
the
decision
point,
you
can
actually
apply
this
type
of
logic.
Upfront
or
excuse
me
in
the
enforcement
point.
You
can
apply
this
decision
up
front
at
the
decision.
Points
determine
that
at
runtime
also
cross-reference
it
with
your
time
of
day,
if
your
your
enforcement
point
doesn't
actually
enforce
time
of
day
and
then
send
down
the
active
rules
for
the
enforcement
point.
So
this
is
a
very
simple
example,
but
what's
important
about
this?
Is
it's
using
the
exact
same
fields?
It's
just
basically
pre
executing.
G
If
you
will
that
metadata
match-
and
this
really
just
boils
down
to
the
fact
that
we
do
not
change
a
user's
relationship
with
their
products
or
services.
Typically
during
the
session,
when
we
do
that,
we
typically
do
a
reauthorization
as
an
operator.
So
this
allows
us
in
certain
decision
points
to
execute
here.
So
we've
got
one
example
where
we
show
it
basically
expanding
the
filters
in
the
enforcement
point.
We've
got
the
second
example
where
we're
socially,
you
know
what
I'll
call
a
much
simpler
enforcement
point
enforcing
it
at
the
decision.
Point
then
sending
it
down.
G
So
those
are
your
two
easy
applications
and
you
can
imagine
combinations
thereof
and
all
sorts
of
optimizations
taking
place
if
there's
multiple
levels
of
hierarchy,
but
we
just
wanted
to
keep
it
to
a
couple
of
examples
here,
rather
than
spending
a
long
time,
writing
a
dissertation
and
an
RFC
next
slide.
So
we've
talked
a
little
bit
about
applications
today
we
actually
do
use
this.
So
as
an
operator,
you
know
when
and
I'll
give
one
real-world
example,
I'm
quite
sure
you
can
guess
which
operator
it
is
both
about
60
million
devices.
G
Upon
further
analysis,
you
know,
1200
rules
in
open
flow
across
sixty
million
devices
is
a
little
bit
daunting
and
just
not
going
to
work
at
the
end
of
the
day.
It
just
isn't
happening,
so
we
ended
up
using
the
metadata
as
we
described
along
with
the
binary
masking.
So
we
have
in
we're
a
mobility
side
in
this
implementation.
Three
table
downlink
design
once
again,
where
we
match
the
destination
IP
set
the
metadata
in
the
open
flow.
G
If
you're
familiar
with
that
and
then
carried
that
over
had
the
original
role
plus
the
extra
metadata
to
do
the
deduplication
and
in
executed,
we've
done
the
similar
design
in
the
uplink.
This
just
kind
of
gives
you
the
idea
values
in
terms
of
how
we
approached
it,
and
you
can
talk
to
me
later
offline.
If
you
have
more
questions
about
it,
a
similar
design
of
the
uplink,
basically,
the
1200
rules,
once
we
were
deduplicated
became
about
200,
and
then
we
found
some
other
optimizations
as
well
and
I
hate
to
say
it.
G
But
really
we
like
to
think
we
do
lots
of
things.
Arguably,
we
really
only
have
12
actions,
so
there's
only
12
to
16
rules
that
really
make
up
that
particular
what
we
thought
was
3040
distinct
products.
So
this
is
where
you
know
as
marketing.
You
think
you're
this
big
as
Network
designers.
You
think
you're
this
big
as
engineers,
you
think
you're
this
big
and
then
upon
further
review,
you're
doing,
like
maybe
twelve
or
sixteen
distinct
activities.
G
So
we've
been
able
to
use
this
technique
and
apply
it
in
our
systems
today
on
Sdn
switches
and
reap
the
benefits.
So
it
kind
of
gives
you
an
idea
of
where
this
is
I.
Think
next
slide.
So
next
steps.
This
is
not
a
fun
document.
It's
not
an
easy
one.
So
I'd
appreciate
more
reviews.
I
know
we
had
some
good
feedback
in
the
last
meeting
before
we
actually
even
bother
with
any
sort
of
last
call
I'd
like
to
hear
more
from
the
group.
C
H
I
C
G
So
we
pick
membership
domain,
okay,
not
to
confuse
right
so
base
name
right
is
more
of
an
organizational
concept
of
rooms
and
here
we're
trying
to
pull
that
up
in
sort
of
the
metadata
extraction,
because
we
did
not
want
to
confuse
people
who
were
already
actively
using
basically
as
a
convenience
mechanism,
but
we
wanted
a
simpler,
a
similar
aggregation
concept
and
still
maintain
backwards
compatibility.
So
we
don't
want
to
decoy
and
say
it's
something
completely
different.
G
We
want
to
keep
it
separate
enough
so
that,
because
we
do
use
base
them
as
an
operator,
so
we
wanted
to
basically
point
out
its
it's
similar
and
for
backwards
compatibility
purposes.
It
would
be
a
separate
AVP,
so
we
also
gave
it
a
different
name
since
we're
talking
about
sets
and
membership.
We
just
refer
to
it
as
a
membership
domain.
C
So
what
about
so
I
think
that,
as
you
said,
I've
read
the
document,
but
I
think
we
need.
I
would
need
also
another
review
to
be
able
to
understand,
because
actually
I
understood
the
exactly
the
mechanism
arriving
at
the
end
of
the
document,
especially
when
the
ADP
defined
I
think
it
would
be
useful
to
have
more
review
and
we
see
what
to
do
with
this
one
again.
Yeah.
G
C
G
G
And
yeah
and
I
think
quite
simply,
and
we
distinctly
say
it
in
just
a
few
sentences.
But
but
basically
all
of
our
filters
today
are
based
on
time
and
what's
in
the
packets
and
unfortunately,
when
the
times
the
same
and
the
rule
is
particularly
like
a
default
rule.
Unfortunately,
that
commonly
that's
the
most
common
overlap.
We
have
in
the
system,
and
so
and
so
that's
just
one
example,
but
that's
usually
where
we
run
into
but.
G
I
can
ignore
most
of
the
errors.
Then
this
will
be
made.
Thank
you
so
next
one.
So
you
know
as
I
apologize
but
I
wanted
to
be
a
little
bit
operator
specific.
So
we're
doing
a
few
projects
here
and
actually
I'd
said
you
there's
an
update
but
we're
doing
a
few
projects
here
in
implementation
and
open
source,
and
we
just
basically
notice
that
over
the
wire
everything
was
great
but
getting
to
consistency.
G
So
this
is
more
about
people
being
very
nervous
and
trying
to
get
code
done.
Then
it
is
about
aspect
being
right
or
wrong.
So
that
started
a
campaign.
We
essentially
thought
we,
you
know
as
a
litmus
test
to
prove
the
developers
wrong.
You
should
be
able
to
go
from
spec
to
code
very
quickly
and
do
most
of
it
not
to
automate
the
developers
but
to
really
validate
that
specs
can
be
a
validated
and
B.
Our
lettuce
tests
would
be
automatic
code
generation.
G
So
next
line
we
were
terribly
wrong
and
our
hypothesis
that
we
could
do
this
consistently
quickly
and
efficiently
or
in
some
cases
at
all,
we
ran
into
over
nine
hundred
and
seventy
different
errors.
Looking
at
thirty
different
specifications,
we
categorized
them
in
large.
Swaths,
hey
excuse
me-
and
this
is
just
the
highlight,
so
even
in
the
document.
Just
so
you
know,
I,
don't
list
all
973
errors
I
only
for
your
pleasure
only
go
through
broad
swaths
of
categories.
G
So
please
keep
in
mind
it's
not
an
exhaustive
list
in
the
document,
but
we
wanted
to
get
this
out
to
the
group
so
in
this
task
of
going
from
spec
to
code.
The
first
thing
we
found
was
too
many
table
formats.
We
couldn't
argue
that
it
was
a
change
over
time
because
some
of
the
specs
that
we
looked
at
started
and
ended
at
the
same
time.
So
it
was
just
inconsistent
table
formats
for
things
like
defined
in
imported
a
VPS.
The
imported,
a
VPS
were
actually
very
tough.
G
There
were
some
outright
errors,
particularly
in
3gpp
and
billing,
in
release
14.
A
good
example
is
a
lot
of
the
a
VP's
driven
by
extra
services
for
release,
12
or
at
least
13
are
mentioned
in
32
99
and
even
in
298
right
in
terms
of
the
over
wire
format,
but
they
do
not
appear
anywhere
in
any
other
document,
they're
around
typically
machine
type.
G
Communication
prosy
has
a
lot
of
a
VPS
defined,
in
fact,
there's
an
entire
swath
of
a
VPS
where
we
found
that
there
was
an
attempt
to
add
to
the
3gpp
registry,
and
then
it
looked
like
the
CR
never
made
it
through,
and
so,
when
you
actually
go
look
in
for
the
AVP
codes
than
missing
almost
64
ATP's.
So
there's
errors
and
we've
gone
back
and
looked
through
the
documents
as
a
group.
So
it's
a
bit
challenging
to
get
implementations
and
we've
documented
as
much
of
that
as
we
can.
G
But
these
are
all
typically,
we
found
actually
just
machine
errors
right
so
exactly
tried
to
do
something
or
there's
a
lot
of
document
references
and
we
chase
documents,
but
this
is
pretty
pretty
typical
across
the
spec,
so
keep
in
mind
we're
looking
at
a
lot
of
specs
as
well
so
didn't
know.
I
can
pause
any
time
for
questions
itself.
It.
G
G
So
you
start
tying
all
this
data
together
in
the
name
of
this
right,
textually
as
a
human,
you
can
read
it,
but
what
you
sit
down
and
say
how
would
I
write
code
to
actually
parse
a
document
validate
it
like
we
do
with
knits
and
verify
that
it's
good
things
start.
You
know
we
things
start
missing
in
the
documents,
the
next
one,
so
our
methodology,
basically
we
create
a
we
split.
You
know
not
because
we
need
to,
but
because
we're
experimenting
here
we
pull
out
the
AVP
defined
tables.
G
The
imports
tables
we
pull
out
metadata
based
upon
the
the
app
IDs,
and
then
we
convert
the
document
to
text.
We
actually
have
some
Python
that
converts
it
into
the
die,
a
fuzzy
format
that
automatically
generates
it
and
then
just
as
a
secondary
validation.
We
have
exporters
that
export
that
to
free
diameter
library
code
to
verify
that
we
actually
can
compile
something
and
we
might
have
an
idea
of
what
we
know.
G
What
we're
doing,
and
this
forced
us
into
individually
tackling
the
problems
a
lot,
and
it
also
forced
us
to
really
do
things
that
we
wouldn't
know
as
a
human
we
don't
care
about.
But
when
we
start
running
a
compiler,
we
totally
do
so.
This
really
forces
items
we
did
in
several
cases
have
to
add
items
as
a
appended
file
and
I
won't
even
begin
to
discuss
you've.
Seen
in
the
document,
we
recommend
not
using
emotes.
That's
how
bad
it
got
for
us
and
there's
lots
of
inconsistency
there.
G
So
this
is
kind
of
the
base
design
for
that
next
slide.
So
we
did
have
some
unexpected
use
cases
in
terms
of
a
VPS
that
refined
further
refined
an
existing,
grouped
or
command
so
because
we
didn't
have
the
linkage
back
to
the
original
a
VPS.
This
is
actually
really
hard
in
terms
of
setting
up
the
library
in
the
code
and
populating
libraries
at
the
code
level,
and
so
without
that
information,
what
we
found
was
we
generated
some
really
nice
code.
G
That
was
completely
useless,
because
what
would
happen
is
it
would
redefine
the
AVP
in
the
library
and
basically,
rather
than
saying,
I
extend
the
AVP,
which
many
libraries
support.
It
would
actually
attempt
to
re,
define
the
AVP
in
the
code
and
get
a
conflict
so,
for
you
know
the
API
soft,
where
that
was
incredibly
important,
although
it's
easy
to
detect,
because
if
we
look
at
the
a
VPS
that
are
imported,
we
can
realize
it's
defined
and
imported.
It's
a
very
simple
situation.
G
We
got
a
lot
of
inconsistencies,
we're
in
this
situation,
because
it's
defined
in
imported.
Sometimes
it
showed
up
as
an
import.
Sometimes
it
showed
up
as
a
defined,
and
sometimes
there
was
no
mention
of
anything
which
then
you
know
left
us
in
the
software
with
some
things
to
deal
with
and
there's
no
concept
right
of
imported
commands.
So
even
don't
even
forget
about
and
just
forget
about
it.
So
next
slide,
so
you
know
I
hate
to
say
it
I'm,
an
editor
of
four
thousand
six.
So
I
was
not
immune
to
this.
G
I
thought
I
had
a
good
spec
I'm,
just
I'm,
just
happy
I
found
like
only
two
out
of
the
whole
thing
so
and
will
will
correct
those
by
the
way,
with
the
cumulative
update.
Our
plan
is
to
correct
those
two
items
because
they
are
editorial,
as
well
as
the
the
update
on
the
reference
in
four
thousand
six
and
in
the
next
revision.
Excellent.
G
You
know
the
first
line
just
says
it
all
over
the
wire
diameters
fine,
trying
to
programmatically
pull
out
in
numeration
z--.
If
you
want
a
root
canal,
every
time
you
do
it
out
of
this
back,
you
go
for
it.
Part
of
it
boils
down
to
your
right.
We
don't
specify
the
label
formats,
we
don't
specify
the
orders
and
it
shows
even
in
some
documents
we
would
have
and
it
it
showed
the
age
the
longer
the
document,
the
more
revisions.
G
So
so,
typically
we
this
doesn't
happen
in
RFC's,
because
right
we're
kind
of
a
one-shot
and
multi
revision
documents.
We
would
see
three
or
four
different
formats
for
enumerations
in
the
same
document.
So
the
longer
lived,
your
application,
the
higher
probability
you
got
wild
inconsistencies
with
enumerations.
We
also
see
characters
that
are
invalid
in
any
language.
There
are
some
labels
that
have
slashes
in
them,
but
one
so
there's
there's
no
hope
of
generating
any
code,
let
alone
parsing.
So
we
did
see
some
crazy
things.
Just
plain
old
references.
G
We
did
see
reference
to
registries
which
we
would
expect
now
they
weren't
actually
enum
registries.
They
were
you
know
different
protocol
registries
and
other
items
so
and
we
didn't
see
reuse
of
enums,
which
was
interesting
where
they
would
either
extend
or
say
we
were
use
this
enum,
but
not
that
one
value
which
I'm
not
even
sure
how
we
would
go
about
enforcing
that
in
the
library.
So,
just
generally,
what
I've
got
my
group
doing
is
trying
to
avoid
enums
at
all
cost
at
this
point.
So
next
slide
recommendations.
G
G
We
need
to
decide
whether
or
not
we're
Kate
we're
truly
because
the
thing
is
diameter
over
the
wires
fine,
but
we
need
to
probably
decide.
Are
we
really
case
sensitive
when
it
comes
to
these
IDs
for
the
names
or
my
favorite
one
is:
could
we
please
get
consistent
naming
on
the
command
ylabel
versus
the
command
acronym
versus
the
actual
command
definition?
I
would
urge
you
to
look
at
re
authorization
request
and
the
number
of
ways
it's
actually
specified.
There's
a
running
bet
on
my
team
as
to
the
number
of
new
ways.
G
Every
time
we
learned
in
aspect
that
really
extended
one
more
time
by
the
way.
So
far,
the
answer
is
15
different
ways
to
specify
reauthorization
requests
in
text
so
far
so
good
anyway.
There's
a
lot
of
things
that
we
do,
this
don't
try
to
use
underscores
unless
it's
part
of
labels,
ready
I,
won't
go
into
the
details,
but
it
makes
life
interesting
for
software
in
general
and
n
constants.
But
it's
kind
of
this
next
slide.
G
G
Ok,
thank
you.
So
this
kind
of
shows
you
some
things
that
work
out
pretty
well
in
terms
of
formats
that
are
easy
to
parse.
If
you're
wondering
there
are
over
19
known,
regular
expressions
in
our
software,
it's
actually
just
do
tables
for
defined
tables.
We
reduce
that
from
28,
so
we
actually
cheat
and
reformat
we
drop
columns.
We
think
we
can
reduce
that
to
12
we'd
like
to
actually
just
reduce
it
to
2
going
forward,
so
we
understand
backwards
compatibility,
but
this
is
a
lot
of
work.
G
If
we
talk
about
programmatic
verification
next,
one
important
a
VP's,
if
you
import
them,
please
notate
just
please
do
it.
I
won't
go
into
a
long
diatribe,
but
it's
really
inconsistent
with
the
full
understanding
when
you're
refining
it
it's
a
little
murky
right.
That's
an
open
question!
What
you
should
do
when
you're
actually
running
this
right,
probably
adding
whether
or
not
you're
changing
the
N
bit
semantics,
which,
by
the
way
per
that
the
guideline
definitions
has
other
rules
that
kick
in,
but
at
least
noting
that
there
and
the
table.
G
So
we
understand
that
we
should
be
doing
some
compliance
checks,
which
has
also
caused
us.
Some
errors
will
help
us
out
next
level
group
a
VP's
and
really
commands
the
refinement.
We've
talked
a
little
bit
about
that.
A
couple
things
we
want
to
note,
so
we
do
assume
a
precondition
of
star
of
actually
inclusion
by
the
way.
There's
a
couple
violations
of
that
where
there
is
a
refinement
and
that
and
I
will
fully
admit,
we
accidentally
attempted
to
do
that
in
four
thousand
six
and
said
what
was
noted.
So
it
does
happen.
G
G
We
did
add
a
new
item
to
our
metadata
into
the
header
format
we
added
refines
and
then
the
the
app
idea,
refining
into
the
CCF
in
our
intermediate
format,
and
that
by
the
way,
took
care
of
this
issue
for
99%
of
our
actually
all
of
our
use
cases.
So
this
just
lets
us
know
it's
a
refinement
which
then
allows
us
then
to
properly
generate
code.
So
once
again
it
doesn't
hurt
diameter
over
the
wire,
but
it
does
help
in
code
generation,
as
well
as
the
engineer,
understanding
that
it
appears
in
this
map.
G
It
will
also
appear
in
a
different
app
ID,
that's
okay.
That
was
intentional.
Furthermore,
it
was
changed
in
the
new
app
now.
Arguably,
we
thought
at
one
point
that
we
only
refined
the
original
app
ID.
We
were
completely
proven
wrong
with
TS
2906.
One
I
would
urge
you
if
you
want
to
look
at
an
extreme
example
of
refinement,
use
cases
and
and
some
very
interesting
ATP's.
That's
probably
the
one
that
took
us
the
longest
over
a
couple
days
of
just
trying
to
figure
out
what
was
going
on
there
and
bringing.
C
G
In
but
it's
definitely
I
would
call
it
the
extreme
example
of
what
you
can
do
with
diameter,
also
to
me
at
least
academically
the
most
interesting,
but
by
adding
this
we
were
actually
in
pretty
good
shape.
Now,
one
of
the
more
open
questions
is,
if
you
could
do
something
like
limit
the
range
and
say
there's
only
five
ATP's
at
it
versus
the
starter.
That's
an
interesting
question
from
a
you
know,
a
programmatic
point
of
view,
computer
science,
point
of
view,
I,
don't
know
from
a
practical
point
of
view.
G
C
G
Possible
but
I
would
be
afraid
that
would
be
a
lot
of
semantics
checking
so
next
slide.
So
this
is
an
example
of
how
we're
applying
refines.
So
what
we
do
not
supply
the
appid.
We
look
for
the
original
definition
where
no
refined
statement
exists.
That
requires
a
search.
We
could
actually
probably
be
more
specific
and
add.
Another
keyword
called
defining
or
defines
which
actually
just
says.
This
is
the
definitive
route
for
this
code,
but
that
once
again
helps
out
with
this.
G
G
Yeah
yeah
yeah,
absolutely
so
I
think
we
get
yeah.
We've
got,
there's
there's
a
lot
of
little
stuff
in
here.
There's
some
some
great
open
questions
like
this.
Do
we
go
back
and
fix
the
things
we've
identified?
That's
a
that's
a
more
working
on
in
question
and
more
about
the
future
of
the
workgroup
I.
Also
don't
want
to
go
back
and
fix
things
that
we're
really
not
carrying
forward.
So
I
would
argue
it's
at
the
very
least.
G
We
have
a
class
of
unit,
thirty
twos
that
we've
seen
called
pseudo
enumerations,
where,
wherever
it
looks
like
in
the
spec
they're
trying
to
avoid
enums
altogether
and
do
we
want
to
support
that
as
a
use
case?
That
seems
to
be
kind
of
the
current
trend
and
some
of
the
later
specs
that
are
fairly
useful
and
then
what
do
we
want
to
do
undefined,
and
so
those
are
kind
of
the
open
questions
so
next
slide.
So
summary
here
is:
is
diameter
with
a
wires
fine.
G
This
is
evidenced
by
the
fact
that
we
all
interoperate
together
but
going
from
spec
to
validation,
respect
to
code,
that's
an
entirely
different
story,
and
so
there's
an
opportunity
for
for
doing
better.
We
can
add
a
few
things
into
the
form.
Oh
it's
entirely
optional
and
we
can
even
implement
some
of
the
other
formats.
These
are
all
minor
items.
They
don't
affect
anything
over
the,
but
if
we
decide
to
maybe
do
this
as
like
a
style
convention
as
opposed
to
something
that's
that's
normative.
G
We
can
talk
about
the
tool,
whether
it's
at
3gpp
or
whether
it's
part
of
the
I
wouldn't
make
it
a
part
of
the
nits
process
right
where
you
kind
of
get
rejected,
but
maybe
a
validation
tool.
I
know
Ben
was
in
the
back,
has
a
lot
of
yang
validation
and
stuff.
That
also
does
this.
So
we
know
it
can
be
done.
We
know
it
can
work
through
a
process,
but
it
would
be
nice.
You
know
I
think
as
an
author,
regardless
of
where
I'm
working
to
be
able
to
validate.
G
So
as
far
as
the
document
like
I
said,
we
wanted
to
get
this
out.
What
we
do
with
it
is
there
and
I
think
the
other
recommendation
is
enums.
Genomes
are
a
pain
in
the
rear
and
I
would
argue.
I
know,
Yanni
talked
about
it.
The
last
meeting,
but
enums
are
much
worse
than
I
anticipated,
I
I
know
he
knew
this
I.
You
know
I'm
feeling
the
pain
now
as
a
managing
a
team
of
ten
people.
Doing
developments
related
to
diameter
and
I
would
urge,
regardless
of
where
it's
done.
G
C
C
I
G
C
So
I
think
that
at
least
so
so
for
this
one
I
think
it
should
be
taking
to
account
when,
when
actually
drafting
a
new,
a
new
specification
and
so
on
for
the
existing
one,
I
think
it
would
be
actually
difficult
because
it's
just
a
documentation
issue.
But
whereas
there
is
something
to
clarify
I
think
that
it
can
be
done
either
by
an
errata
within
a
chair,
because
when
you
said
it
will
not
fix
normally
people
using
the
Arabs
documents
need
to
go
through
the
errata.
G
C
I
think
that
this
kind
of
document
could
be
so
from
my
point
of
view,
if
in
depending
on
what
we
would
do
after
that.
But
it
could
be
just
for
information
because
it
should
only
work.
It
could
be
at
least
useful
information
for
the
community,
and
it
could
be
also
even
referenced
by
other
things
that
there
is
no
guideline
here
just
to
highlight
what
could
be
wrong
or
what
could
could
cause
some
issues
if
you
are
not
taking
care
of
this
type
of
stuff,
for
instance,
and
then.
G
G
H
C
That
way
at
this
time,
but
the
comment:
ok
chief,
it
could
be
some.
We
have
some
document
just
explaining
all
the
issues
that
we
had
for
implementing
such
protocol
without
any
rationale
and
so
on.
Just
to
expand.
We're
ok
had
some
issues
and
that's
you
you
will,
you
would
know
you
would
decide
yeah,
okay,
I
will
I
will
not
propose
to
to
to
jam
to
so.
Thank
you,
lying
I
will
skip
the
milestone
just
to
highlight
the
fact
that
there
is
nothing
new
on
this.
C
C
Sorry,
yes,
so
we
have
few
people
in
the
room,
not
so
much
activity
on
the
on
the
mailing
list
and
we
have
an
additional
issues
that
I
will
not
be
able
to
to
go
on
my
March
chairmanship
and
I'm
working.
There
is
to
me
too
much
work
with
those
guys
in
3gpp.
No,
but
honestly
with
the
5g
stuff.
We
have
a
lot
of
coordination
internally
and
across
the
companies
and
also
we
need
to
set
up
columns
one.
C
So
at
least
I
will
not
be
available
as
I
was
in
the
past,
and
and
we
have
the
same
issue
with
the
Uni,
so
I
moved
from
a
company
to
another
company,
so
it
will
not
be
able
to
go
on
too
much
on
this
one.
So
we
have
a
clear
issue
here
about
about
the
future
of
the
working
group.
So
what
should
be
the
next
step,
except
closing
the
group
and
what?
If
it
is
a
case,
what
to
do
with
the
existing?
C
A
C
A
C
That
my
personally,
my
main
concern
would
be
to
know
exactly
when
to
stop
adopting
new
working
new
documents.
Just
one
shoe
that's
if
we
have
a
time
flying
or
at
least
a
work
plan
to
say
we
need
to
conclude
all
this
work
and
after
that,
it's
done
I
think
even
four
unit
will
be
achievable
because
we
aren't
the
same
in
the
same
situation.
So.
H
A
Group
winners
came
out
on
the
border
from
my
perspective,
because
that
kind
of
hits
a
little
deeper
into
the
where
you
use
the
protocol,
but
that's
not
out
of
the
question
right
that
we
could.
We
could
consider
that
as
well.
I
think
I
would
need
to
look
more
closely.
Think
more
closely
about
that.
For
me
to
do
it.
I
also
don't
have
to
be
the
eighties
sponsor
right,
but
assuming
it's
me
I
would
look
a
little
more
closely
at.
C
A
I
would
our
yeah
for
that
I
would
say:
let's
see
what
happened
to
SOG.
If
we
actually
see
some
realistic
interest
it
you
know,
maybe
that's
something
we
spent
up
a
little
mini
workgroup
for
maybe
that's
I,
don't
know
how
to
somebody
we,
lady,
sponsor
or
not
I
want
to
talk
to
the
security,
80s
and
I.
Think
Ben
was
maybe
Sadie.
A
C
Think
that,
if
it
is
only
I
would
say
only,
it
would
be
at
least
something
that
we
will
need
to
do
anyhow,
but
if
it
is
only
to
go
on
with
the
existing
one,
even
with
the
new
adopted
at
least
one
or
two
I
think
it
is
achievable
in
in
a
short
timeframe.
I
I
would
need
to
confirm
with
uni,
but
at
least
for
my,
we
will
need
to
share
the
work
and
we
will
need
all
volunteers,
because
it's
it's
not
only
about
the
chairs.
It's
also
about
people
reviewing
that
right.
A
C
I
will
talk,
I
will
ever
talk
also
with
a
cat
in
before
before
the
zagnut
II.
So
can
I
summarize
that
at
least
at
this
day,
so
and
obviously,
if
there
is
something
to
do-
and
there
is
interest
and
so
on-
it
would
not
preclude
to
reopen
a
new
group
based
on
this
one
or
in
a
new
in
a
new
in
the
new
context,
but.
C
So
the
existing
document,
the
existing
working
group
document-
will
be
pushed
forward,
at
least
for
the
predicta
clinics
we
can.
We
can
we
can.
It
will
be
confirm
on
the
manganese,
but
we
can.
We
can
assume
that
this
one
would
become
a
working
group
humans
and
for
the
group,
one
we
will
check
and
after
those
documents
we
will
close
the
working
group.
C
A
So
what
is
it
been
again?
My
point
was
that
if
those
two
drafts
predictive,
definitely
and
I-
and
maybe
group-
could
be
candidates
for
just
80
sponsorship-
hello,
it's
fine!
If
we
want
to
go
ahead
and
check
on
group
interest
and
adopt
them,
they
can
still
change
ad
sponsorship.
If
we
decide
to
shut
the
group
valve
okay,.