►
From YouTube: IETF114-MAPRG-20220729-1630
Description
MAPRG meeting session at IETF114
2022/07/29 1630
https://datatracker.ietf.org/meeting/114/proceedings/
A
A
A
So
this
is
an
irtf
group,
but
this
still
falls
under
under
most
of
the
node
well
points.
One
point
is
intellectual
property
everything
you
contribute
here.
It's
also
converted
into
the
itf
and
you
have
to
declare
intellectual
property.
You
might
know
this
already
by
now.
Hopefully
otherwise,
please
read
it
up,
then,
as
you
can
see,
or
is
it
hard
not
hard
to
miss?
This
meeting
is
recorded
and
will
be
published
on
youtube
at
some
point
so
which
is
also
good.
A
A
A
And
then
this
one,
you
should
also
kind
of
know
by
now,
but
many
were
telling
you
if
you
want
to
say
something
at
the
cube.
Please
join
the
queue
and
meet
echo.
Please
also,
if
you
don't
want
to
contribute.
Please
join
me
echo
because
that
will
also
generate
our
blue
sheets
and
the
blue
sheets
will
tell
us
like
how
big
our
room
is
next
time
and
these
kind
of
things
that's
really
important
to
sign
up
when
you're
in
the
room.
You
don't
need
to
put
on
your
video
and
audio.
A
A
The
first
talk
is:
is
a
heads-up
talk,
because
it's
a
little
bit
kind
of
out
of
the
focus
of
this
group.
What
this
group
is
usually
doing.
Our
focus
is
on
measurements
of
protocols,
but
we
thought
it
might
anyway
be
interested,
so
we
invited
tal
to
give
a
short,
10-minute
heads-up
of
his
work
and
I
think
he's
remote
yeah
hi.
C
C
B
I'm
miriam
just
since
we
didn't
go
through
the
whole
agenda
of
the
presentations
today.
I
think
we
have
seven,
including
this
intro
and
so
people
will
have
the
10
or
15
minutes,
and
then
we
have
a
few
minutes
in
between,
but
I
want
to
apologize
in
advance
if
we
have
to
cut
you
off,
but
we're
just
going
to
try
to
keep
to
that.
So
everyone
has
their
allotted
time.
C
C
C
We
see
the
download
and
upload
speeds
as
a
function
of
time,
and
we
see
that
starting
from
the
beginning
of
the
conflict,
the
performance,
degraded
and
that's
not
very
surprising,
but
on
the
right
side
we
see
russia
so
starting
from
the
beginning
of
the
conflict,
the
performance
actually
improved
and
it
improved
more
significantly
than
in
previous
months.
So
that
was
kind
of
surprising.
C
D
C
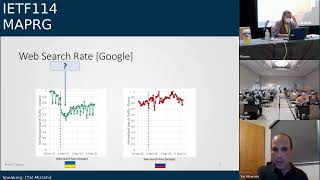
Millions
of
people
crossed
the
border
to
the
countries
around
ukraine
and
millions
of
other
people
had
to
be
displaced
inside
ukraine,
and
there
are
statistics
statistics
that
are
published
by
the
un.
We
can
see
here
a
graph
showing
the
number
of
refugees
as
a
function
of
time.
So
if
we
take
this
graph
and
we
take
its
first
derivative,
we
see
the
rate
of
refugees
as
a
function
of
time.
So
we
take
that
graph
of
the
rate
of
refugees.
C
We
see
it
on
the
left
here
and
we
compare
it
to
the
rate
of
google
maps
traffic.
Okay.
This
is
what
we
see
in
the
middle,
the
google
maps
traffic
rate,
and
we
see
that
there
is
a
very
clear
correlation
between
these
two
graphs
and
obviously
people
had
to
move
around
people
had
to
travel
to
the
border.
C
So
they
had
to
use
google
maps.
That's
not
surprising
what
we
see
on
the
right
side.
The
rightmost
graph
is
the
mobile
to
desktop
ratio.
So
again
people
had
to
travel.
People
had
to
use
their
mobile
phones,
so
we
see
a
significant
difference
here
in
how
the
basically
the
usage
profile
changed
over
this
period
of
time.
C
One
one
of
the
important
things
to
point
out
is
that,
in
order
to
help
the
refugees,
what
the
u.n
is
trying
to
do
is
to
try
to
map
where
refugees
are
staying.
So
the
u.n
is
kind
of
trying
to
keep
track
of
how
many
refugees
are
staying
in
each
country
and
that's
obviously,
that's
very
important
in
order
to
help
them
and
in
order
to
do
that,
what
the
un
does
is
it
collects
data
from
humanitarian
organizations
from
governments
and
the
data
from
governments
is
based
mainly
on
border
crossing,
but
the.
E
C
With
that
is
that
when
people
travel
inside
the
eu,
basically
that's
not
monitored
in
any
way.
So
if
people
cross
the
border,
there's
no
way
for
the
governments
to
know
that,
so
the
information
published
by
the
un
is
not
necessarily
accurate
regarding
the
eu
countries.
So
what
we're
suggesting
here
and
that's
what
we
see
on
the
right
side
in
pink-
is
to
use
publicly
available
available
measurements
from
the
internet
in
order
to
try
to
estimate
how
many
refugees
are
staying
in
each
country.
C
F
C
C
So
more
generally
speaking,
we
took
data
on
the
top
15
ukrainian
sites,
the
most
popular
ukraine
ukrainian
sites,
and
we
use
data
about
the
visit
rate
from
each
country
and
we
computed
a
maximum
likelihood
estimation
of
how
many
ukrainian
people
are
staying
in
each
country
and
that's
basically,
what
we
see
in
the
graph
here
at
the
bottom
kind
of
a
histogram
showing
how
many
people
in
each
country
and
what's
it.
Basically,
we
believe
that
this
methodology
can
be
used
in
order
to
complement
some
of
the
data
that
is
already
published
by
the
un.
C
C
D
C
D
G
Hello,
ian
williams,
with
amazon,
I
just
had
a
question.
One
of
your
slides
had
some
points
regarding
the
redirects
from
or
like
visitors
from
certain
countries
on
like
say,
google,
google,
ukraine
was.
You
know
how
many
visitors
from
from
from
germany.
I
know
google
has
like
a
no
country
redirect
option.
If
you
were
in
google's
shoes.
Would
you
have
recommended
say
enabling
that
for
this
crisis,
to
prevent
this
kind
of
disclosure,
or
do
you
think
it
would
wouldn't
have
been
useful.
C
C
G
E
Kenji
china
mobile,
I
remember
during
the
the
war
and
after
a
couple
of
weeks,
the
starling
has
installed
is
like
a
second
pass.
So
have
you
ever
mentioned
anything
for
it
like
a
backup,
that's
going
to
know
the
damage
but
they're
going
to
at
least
relieve
some
burden
from
from
the
damage
the
infrastructure
through
the
starting?
Thank
you.
C
E
E
No,
no,
the
things
like
I
remember.
After
a
couple
weeks,
the
starlink
has
been
in
store
over
the
sky
on
ukraine,
and
then
that
is
like
a
backup
pass.
So
have
you
ever
measured
anything
it's
like
a
backup.
Does
that,
like
a
relief,
some
burden
from
the
management
that
you
have
done
for
those
damaging
infrastructure?
Thank
you
on
correct
on
terrestrial
network.
Thank
you.
H
A
A
I
You
know
all
this,
don't
you
next
slide.
You
know
all
that.
Don't
you
next
slide
standard
intro,
don't
eat
it.
The
way
we
do.
This
is
trying
to
actually
do
extremely
large
scale
measurements,
equipping
the
server
and
using
an
online
ad
campaign
to
enroll
almost
unwitting
clients.
It's
an
ad.
It's
a
really
simple
ad.
If
you
click
on
it,
I
pay
more.
So
if
you
see
an
ad
from
ap
nick
just
leave
it
alone.
Okay,
don't
touch
it!
I
pay
more.
I
If
you
click
the
ad
system
that
we've
configured
does
around
20
million
eyeball
based
networks,
eyeball-based
users
per
day,
and
one
of
the
interesting
things
about
ads
is
that
the
ad
network
tries
extremely
hard
to
enroll.
A
different
set
of
people
every
sort
of
period,
so
we
don't
go
and
inflict
the
same
ad
on
the
same
set
of
users
and
it
actually
gets
around
some
forms
of
measurement
bias,
because
if
you
keep
on
touching
the
same
endpoint,
you
just
see
that
end
point.
You
don't
see
a
generic
collection.
I
I
I
Additionally
in
the
content
header
of
this
delivered
one
by
one
pixel,
we
put
the
alt
service
directive,
which
of
course,
if
you're
following
what
I
just
said,
doesn't
work
because
you
get
an
ad
it
fetches,
a
bunch
of
urls.
The
ad
stops
it's
a
unique
name.
No
one
should
ever
ask
for
that.
Name
again.
So
when
I
put
in
a
content
directive
saying
if
you
ever
come
and
visit
this
property
again,
you
will
use
quick.
I
Won't
you
you're
never
going
to
come,
so
we
had
to
actually
alter
the
ad
and
in
this
particular
case,
the
ad
scripts
go
fetch.
This
url
start
a
two
second
timer
and
then
schedule
the
same
fetch
again
so
tell
the
browser
to
go
refetch
to
see
how
much
we
could
tickle
by
just
basically
doing
that
refresh
for
refetch.
I
I
I
just
said
that
next
slide,
so
there's
a
difference
in
quick,
whether
the
browser
or
whatever
the
user
agent
is,
is
triggering
by
the
dns,
which
will
happen
on
the
first
time
you
fetch,
or
if
it's
using
the
content
directive,
which
will
only
happen
on
the
second
time,
because
the
first
is
yeah,
it's
just
tcp
tls,
it's
http,
2
or
whatever.
The
second
fetch
makes
a
difference.
So
here
are
two
lines
for
june
and
july.
The
red
line
is
actually
the
second
fetch
and
what
we're
seeing
is
around
3.5
percent
of
users
actually
use
quick.
I
The
second
time
around
the
lower
down
one
is
the
blue
line.
That's
around
one
percent
of
users
use
http
3
on
the
first
query.
Next
line
next
slide
now
you
kind
of
think,
particularly
if
you
believe
apple
you're,
all
running
the
current
version
of
ios
and
even
if
you're
you're,
running
chrome,
the
nag
ware
is
good
enough.
Now
you're
all
running
chrome.
What
is
it
100,
whatever
it
is,
and
it's
actually
quite
difficult
to
go?
No,
I
don't
want
to
upgrade
no,
no,
no!
No,
no,
and
you
find
yourself
typing,
no
all
the
time.
I
So
in
theory,
these
vendors
are
doing
a
pretty
good
job
of
getting
us
all
up
to
the
same
release
levels
because
the
stuff
that's
out
of
date.
You
shouldn't
be
running
anyway.
So
when
we
look
at
this
by
country,
population
of
quick
use
next
slide
what
you
actually
find
on.
The
second
fetch
is
a
pronounced
sort
of
bias
and
the
country
at
26
or
something
yeah
28
is
malta,
and
even
the
central
african
republic
in
africa
yay
a
massive
use
of
quick
on
the
second
fetch.
I
I
have
no
idea
why,
and
I
have
no
idea
why
those
national
variations-
I
just
don't
know-
I
don't
think
it's
a
measurement
bias.
It's
the
same
measurement
all
the
way
around,
but
the
relative
level
per
country
does
vary
a
lot,
which
is
odd
next
slide,
and
now
we
look
at
the
first
fetch
now,
don't
forget,
there's
really
only
one
browser
that
does
this
and
one
platform.
I
Actually
I
don't
know
if
it's
a
platform,
it's
certainly
safari,
not
even
sure
you
can
get
safari
on
linux,
but
if
you
could
maybe
it'll
do
the
same
thing.
Who
knows,
but
it's
safari
on
ios
safari
on
macos
and
oddly
enough,
maybe
denmark
is
just
in
love
with
apple
product,
but
certainly
it
has
the
highest
rate
of
first
fetch,
and
this
is
largely
european,
largely
northern
european
as
having
the
highest
rates
africa
much
much
much
much
much
lower.
So
again,
huge
amounts
of
national
variation
next
slide.
I
So
I
actually
had
four
questions
when
I
looked
at
this
and
I've
sort
of
given
you
some
hints
already
who's
doing
quick
and
why?
What
are
the
mss
values?
You
know?
What's
the
connection
failure
rate
like
because
putting
all
of
our
traffic
over
udp
port
443
is
not
something
we
used
to
do
10
years
ago
and
if
you're,
using
cpus
or
firewalls
it's
kind
of
this
is
crap
traffic,
I'm
going
to
drop
it,
so
you
know
how
much
is
being
dropped
and,
last
but
not
least,
the
whole
rationale
or
not
the
entire
rationale.
I
I
The
android
platform
is
seen
in
about
84
percent
of
ads
ads,
see
android.
Most
of
the
time
ads,
see
mac
os
about
one
percent
ads,
see
ios
iphones
about
five
percent.
It's
the
market
share
of
eyeballs,
as
seen
by
google's
ad
system
fair
enough.
As
far
as
I
can
see,
with
other
stats,
not
too
far
off
some
kind
of
truth.
I
I
The
first
fetchers
are
still
doing
it.
The
second
time
the
dns
is
working,
it's
sticky,
but
now
android
the
second
time
around
goes
yep
gonna,
do
it
as
well.
So
that's
why
the
android
number
rises
on
the
second
pitch
next
slide,
so
which
user
agent.
Now
this
is
what
the
browser
claims
it's
running.
You
know
there
are
lies,
there
are
more
lies
and
there's
the
browser
string
lies
which
are
the
best
lies
of
all.
So
you
know
with
a
strong
grain
of
salt
about
who's
reporting.
I
What
you
know,
what
you
actually
find
again
is
safari
is
first
fit
first
fetch
and
no
others,
so
the
4.1
percent
of
chrome,
probably
lying,
who
knows
in
the
second
fetch
what
you
find
is
the
chrome
numbers
come
in
81
on
chrome,
16,
on
safari
firefox,
which
was
only
ever
0.8
of
eyeballs,
which
is
pretty
low
market
share,
and
it's
declining
very
very
quickly.
First
fetch.
I
I
don't
think
it's
doing
anything
if
it
is
doing
dns.
It's
not
clear
from
this
and
on
the
second
fetch
again
point
eight
percent
to
one
percent
of
share,
not
clear.
What's
going
on
next
slide
so
who
does
it
safari?
Does
it
with
the
dns
https
query
they
may
or
may
not
also
be
sensitive
to
the
content
directive,
but
if
they're
doing
the
dns
query,
that's
the
sticky
bit.
That's
the
bit
that
triggers
it.
I
You
know
it's
kind
of
if
you're
going
to
ask.
Why
not
follow
up
the
hint
we'll
go
into
that?
It's
an
interesting
point.
Secondly,
the
alt
service:
this
is
a
low
number
there's
a
lot
of
chrome
and,
if
all
of
chrome
says
alt
service,
I'm
going
to
do
it
we're
seeing
a
remarkably
small
capture
rate.
It
is
tiny,
there's
something
going
on
there.
So
that's
the
first
question
on
to
the
next
time
is
moving
next
slide.
I
You're
right,
the
next
question
was
packet
size
in
quick,
you
must
must
must
must
never
fragment.
So
what's
the
distribution
of
packet
sizes,
the
standard
says
in
the
first
packet
pad
to
1200
and
around
45
percent
of
1200,
the
maximum
packet
size
I
ever
saw
was
a
tiny
percentage
doing
a
little
bit
over
1350.
I
So
most
of
quick
sits
in
that
magic
thing,
which
is
somewhere
between
1200
the
minimum
according
to
quick
and
a
realistic
maximum
of
1400,
no
one's,
doing
path,
mtu
and
extending
beyond
that.
Next
slide.
Next
question:
what's
the
connection
loss,
this
amazes
me
that
I'm
only
seeing
half
most
of
the
problems
we
have
with
b6
and
it's
a
much
worse
connection,
failure
rate
in
v6
around
two
and
a
half
percent.
Is
the
packet
being
sent
back?
I
You
give
me
a
sin.
I
give
you
a
synack
the
filters
and
firewalls
at
the
front
of
you
go.
V6
is
evil
drop
the
packet,
and
so
you
actually
see
quite
a
visible
drop
rate
and
you
would
have
thought-
or
I
would
have.
These
cpes
sometimes
were
built
in
the
paleolithic
era
before
dinosaurs
and
you
go
udp
443
wow.
That's
evil
but,
interestingly,
if
I
take
one
day
and
look
at
some
20
million
sessions,
there's
the
exact
numbers
there.
I
The
second
packet
comes
through
in
all,
but
46
000
attempts,
which
is
a
phenomenally
low
failure
rate
of
0.24,
so
whatever's,
going
on
whatever
reason
the
first
packet
hits
me
and
I've
no
idea
if
the
first
packet
never
got
to
me
because
that's
a
problem
on
the
other
sort
of
direction
in.
I
can't
tell
if
I
didn't
get
a
packet,
but
when
I
got
one
almost
always
the
responder
gets
my
packet
and
I
get
the
next
quick
packet
coming
in,
so
that
handshake
rate
is
better
than
v6.
It
is
amazingly
good
next
slide.
I
I
I
am
moving
so
quickly
yeah,
I
know
time
is
tight.
I
use
the
browser.
Timer
browsers,
not
only
lie
in
the
browser
string,
browsers
line
and
elapsed
time
so
taking
the
browser
timer.
I
get
this
pattern
next
slide,
there's
a
definite
bias
in
the
in
the
measurements
to
say
the
timed
amount
to
fetch
a
quick
versus
fetching
over
any
other
protocol.
It's
faster
a
lot,
no,
but
then
again
there's
a
huge
variation
in
rtts,
but
on
the
whole,
it's
faster
four.
I
I
I
If
you've
ever
tried
to
do
this
manually
on
a
chrome
browser,
you
actually
have
to
hit
the
sentinel
again
and
again
and
again
to
actually
make
it
flick
too
quick.
So
it's
not
deterministic
and
it
takes
time
so
that
two
second
fetch
seems
to
be
too
fast.
I
have
to
wait
longer
for
that
directive
to
get
sort
of
sticky
inside
chrome
for
the
next
fetch
to
trigger.
So
I
think
I
was
jumping
the
gun,
so
that's
bad
and
that's
why
the
numbers
are
low.
Next
slide
right.
I
I
I'm
only
telling
you
use
http
3.,
I'm
not
saying
here's
the
v4
address
and
here's
the
v6
address
in
the
https
record,
so
safari
has
to
separately,
go
and
fetch
that
and
there's
an
internal
race
condition,
because
if
it
gets
an
answer
for
the
address
records
and
doesn't
get
an
answer
for
the
https
guess,
what
it's
going
to
do.
Speed
is
more
important
at
that
particular
point.
I
So
we're
now
altering
this
measurement
to
actually
put
the
hints
into
https
to
see
if
that
will
tickle
the
rest
of
the
apple
side,
to
actually
go
down
the
quick
path
from
the
start.
I've
been
talking
to
apple
as
well.
At
this
point,
it
also
seems
that
not
every
https
answer
converts
to
quick
anyway,
there's
a
certain
amount
of
seeing
how
well
it
goes,
and
I
think
that
reaping
rate
of
query
to
fetch
is
actually
being
throttled
somewhat
by
apple
itself.
I
Secondly,
why
all
the
countries
different?
I
have
no
idea.
Are
there
regional
defaults,
other
various
pieces
of
browser
software
variant
region
by
region?
That's
a
browser
question.
It's
not
a
jeff
question
next
slide
wow.
That
was
it
I
think,
I'm
in
under
the
minutes
there
dave
there
is
a
url
down
at
the
bottom.
I
didn't
do
the
qr
code.
This
stuff
is
being
run
every
single
day
with
about
20
million
users
every
single
day
being
enrolled.
As
the
picture
changes,
the
picture
on
that
web
page
will
necessarily
change
to
reflect
current
reality,
and
I'm
done.
F
I
I
Oddly
enough
since
march,
as
you
saw
from
the
previous
talk,
getting
ads
into
certain
parts
of
the
world
is
now
extremely
difficult,
and
I
see
very
few
ads
in
those
countries.
Yes,
but
of
the
bits
you
see,
it's
all
the
same
equipment,
it's
all
the
same
view
and
does
ad
blocking
buy
us
these
numbers.
I
don't
think
it
biases
them
per
se.
E
H
I
The
two
second
delay
happens
at
the
instruct
the
browser
not
two
seconds
between
subsequent
fetches,
because
browsers
have
more
complexity
than
any
operating
system
that
ever
got
built,
and
so
the
variance
between
in
time
between
those
two
features
seems
to
be
an
extraordinary
amount
of
variance
ben,
and
it
actually
is
a
separate
piece
of
work
to
understand
what
the
true
variance
is,
just
as
a
quick
out
on
the
way
we're
going
to
change
this.
Is
that
we're
going
to
change
the
ad
to
fetch?
The
second
time.
I
H
To
give
you
okay,
so
so
my
feedback
would
be
try
something
like
http
connection,
close
the
connection,
close
header
or
otherwise,
like
from
the
server
side,
close
that
http
2
connection
as
soon
as
you've
sent
the
response,
because
what
you
want
is
for
the
client
to
be
initiating
a
new
socket
to
see.
Should
I
use
http
3.
if
the
client
already
has
an
open,
http
2
socket
to
the
server
it
might
just
reuse
it,
instead
of
going
through
the
delay
and
and
complexity
of
opening
up
a
new
http
3
session.
H
The
other
thing
I
would
say
is
for
for
the
https
ip
hints
in
general,
ip
hints
are
only
necessary
if
your
target
name
is
not
dot.
So
we
can
talk
about
that
in
more
detail,
but
I
would
I
would
encourage
you
to
set
your
target
name
in
the
https
record
to
dot
the
magic
default
value,
which
means
I'm
not
doing
anything
interesting
in
terms
of
redirection
here.
That
makes
the
iphone
relevant.
J
Is
it
better
all
right
so
yeah,
everyone
in
the
room
knows
that
web
performance
is
important
and
better
performance
leads
to
better
revenue
and
better
use
engagement.
In
order
to
do
that,
websites
typically
use
cdns,
which
have
servers
spread
across
the
globe,
typically
called
cdn
edge
at
the
cdn
edge.
We
have
protocols
like
http
and
tcp
that
controls
the
rules
for
request
and
response
and
rules
for
data
transmission.
J
J
J
Okay,
is
this
one-size-fits-all
approach
really
optimal,
so
in
practice,
users
are
not
really
homogeneous
because
they
come
from
different
regions.
They
have
different
last-minute
connections
like
2g,
3g
4g,
and
they
have
different
devices
and
the
reason
this
makes
it
a
challenge
to
select
right
configuration
is
that
protocol
performance
is
sensitive
to
all
these
features.
J
So,
assuming
that
we
have
different
network
paths
with
different
delay,
different
loss
and
different
bandwidth
properties,
the
choice
of
optimal
congestion
control
might
be
different.
So
a
consequence
of
this
observation
is
that
the
one-size-fits-all
approach
might
not
be
optimal
when
we're
talking
about
heterogeneous
connections.
J
J
J
The
second
is
hand-picked
where
operators
run
out
multiple
measurements
from
in
different
regions
and
based
on
that,
they
see
that
okay,
these
configurations
are
working
better.
So
we
we're
going
to
select
those
and
the
third
one.
We
see
some
evidence
in
literature
that
people
are
building
dynamic
systems
where
they
use
algorithms
like
business,
optimization
or
reinforcement
learning
to
tune
their
configuration,
but
they
are
mostly
limited
to
either
a
single
configuration
like
initialization
window
or
a
single
layer
like
tcp.
J
So
in
order
to
test
that
we
leveraged
some
public
packet
traces
and
we
got
a,
we
got
a
network
trace
from
a
production
cdn
with
billions
of
users
across
the
world,
and
we
used
that
traces
to
simulate
a
representative
network
condition
in
a
local
testbed.
So
what
we
did
was
for
each
of
the
network.
We
sweep
the
entire
configuration
space.
So
basically,
from
the
server
side,
we
set
every
possible
configuration
for
tcp
and
http
configurations
and
we
measured
page
load
time
for
alexa
top
on
it
website.
J
In
the
third
case,
the
green
line
we
use
bayesian
optimization,
which
is
a
algorithm
for
auto
tuning
systems
and,
interestingly,
the
improvement
results,
are
not
that
good,
because
we
noticed
that
this
algorithm
is
not
really
a
good
fit
for
network
internet
measurement
case
where
we
have
lots
of
dynamicity.
We
have
lots
of
noises
and
it
sort
of
derails
the
optimization
process,
and
finally,
we
see
the
results
for
the
oracle
which
tunes
across
the
different
layers,
and
we
see
we
make
team
observation
here.
J
Second,
the
gap
between
the
orange
and
the
red
line
basically
motivates
that
we
we
should
use
crosslayer
tuning
instead
of
tuning,
just
a
single
configuration
like
congestion
control
and
finally,
the
the
gap
between
the
red
and
the
our
green
line
shows
us
that
the
existing
algorithm
for
autotuning
are
not
that
a
good
fit
for
this
case.
So
we
need.
We
need
a
better
algorithm.
J
So
we
faced
a
number
of
challenges
in
the
design
of
confignator,
since
we
are
talking
about
internet
into
environments
and
cdn
scale.
There's
a
cure
associated
here.
If
it's
just
a
bad
configuration,
then
it's
going
to
hurt
performance
and
possibly
revenue
and
further
there's
high
dimensionality
of
devices
and
last
mile
connection,
there's
network
dynamics,
because
network
changes
over
time
and
there's
noise.
J
So
these
sort
of
properties
makes
it
hard
to
create
a
performance
model
that
can
accurately
represent
the
performance
of
the
configuration
so
that
we
can
select
the
right
one.
And
finally,
we
have
some
system
limitations
that
we
don't
have
the
networking
stacks
available
right
now
that
can
tune
the
configurations
in
a
low
overhead
manner.
So
we
can
use
things
like
set
socket
rpt,
but
it
means
that
we
are
going.
We
need
will
need
to
change
application
code
itself
and
we
want
it
to
be
non-invasive.
J
J
So
for
tuning
the
configurations,
we
wrote
a
kernel
module
and
several
callbacks
through
which
we
can
tune
tcp
and
http
configurations,
and
since
this
config
agent
is
on
the
fast
path
it
it
caches,
configuration
mappings
that
the
control
pin
generates
and
it
use
that
for
real-time
configuration
decisions
at
the
control
point
side,
it's
it.
It's.
The
workflow
looks
something
like
this.
So
config
agent
with
that
runs
on
servers,
sends
data
about
a
connection
feature
such
as
network
and
performance
metrics,
like
page
load,
and
these
disinformation.
E
J
But
the
property
of
the
algorithm
that
we
developed
was
that
that
should
be
minimum,
so
the
search
should
be
directed.
So
that's
why
there
is
a
negative
impact
here,
but
we,
the
algorithm,
tries
to
keep
it
to
a
minimum.
So
in
the
paper
we
have
experiments
where
we
sort
of
try
out
different
versions
of
of
the
algorithm
and
show
that
this
is
sort
of
the
minimum
that
we
can
get
right
now.
H
J
If
everyone
is
sort
of
running
these
sort
of
systems,
then
they're
kind
of
competing
against
each
other.
Because
if
the
choice
of
my
competition
changes,
then
my
choice
is
also
bound
to
change
so
yeah.
We
don't
really
address
the
game.
Theory
aspect
in
this
paper
yet,
but
we
are
currently
looking
into
it
more
in
the
future.
Work.
K
K
So
this
means
it
has
been
grown
to
a
very
complex
ecosystem,
which
means
now
that
in
the
initial
handshake
the
clients
and
servers,
they
need
to
exchange
a
lot
about
a
lot
of
information
about
their
own
capabilities,
such
that
you
can
find
a
mutual
encryption
base
and
the
idea
of
this
work
was
now
we
can
collect
this
metadata
and
we
can
use
it
to
fingerprint
a
tls
stack
on
the
server
like
tls
stack
as
a
combination
between
config
implementation
hardware.
So
next
slide,
please
all
right.
So
if
I'm
talking
about
fingerprinting,
what
does
it
mean?
K
It's
basically
just
collecting
characteristics
about
tls
that
you
summary
represent
as
a
fingerprint
and
then
you
build
a
database
that
maps
these
fingerprints
to
something
that
is
just
not
directly
related
but
somehow
useful
and,
for
example,
you
could
have
see
these
three
fingerprints
here.
Maybe
one
in
indicates
an
idf
web
server.
Another
fingerprint
might
indicate
an
nginx
docker
image
or
even
a
malicious
commanding
control
server.
K
Of
course,
these
are
all
just
indicators,
but
they
work
so
next
slide.
Please
all
right!
So
let's
have
a
short
look
at
the
tls
1.3
handshake,
and
what
information
is
there
that
we
can
use
for
fingerprinting
so,
as
you
can
see
like
the
tls
works
by
for
that,
a
client
sends
a
server
hello
to
a
server
that
initiates
the
handshake.
K
It
contains
the
version
session,
specific
information,
cypher
suits
and
a
whole
bunch
of
tls
extensions.
Now
the
server
looks
at
it
and
responds
with
a
server
hello
that
again
contains
a
version,
a
cypher
suit
and
tls
extensions
that
are
usually
a
response
to
the
versions
from
the
client
and
then
now
tls
1.3
specific
the
handshake
gets
encrypted.
You
get
these
encrypted
extensions
certificate,
extensions
and
so
on,
and
now
all
this
information
that
is
written
in
bold
somehow
depends
on
the
tls
stack,
that
is
on
the
server.
K
So
if
we
collect
this
information,
we
can
use
it
to
fingerprint
the
server
right
continue.
Please
all
right!
Why
should
you
need
such
a
thing?
So
there
were
three
applications
we
thought
about
how
this
could
be
used.
First
of
all,
an
intrusion
detection
system
could
use
such
a
fingerprinting
mechanism
to
just
gain
an
additional
source
of
information.
K
For
example,
you
could
fingerprint
all
the
servers
in
network
flows
and
then
just
look
up
the
fingerprints
in
a
database
of
known,
malicious
fingerprints
or
you
could
use
it
in
intel
white
measurements
where
you
really
use
these
fingerprinting
fingerprints
to
actively
hunt
for
new
threats
or
you
could
use
it
to
monitor
your
own
servers
right
now.
Basically,
if
the
fingerprints
change
from
your
own
server,
something
happened,
this
might
be
intended
or
unintended.
K
You
might
intend
to
change
your
software
or
there
has
even
been
a
melbourne
infection
happening
and
somehow
changing
the
dtls
deck
right
next
slide.
Please
all
right!
So
before
I
get
into
some
results,
let
me
share
a
small
problem
we
had
in
the
beginning.
It
was
that
we
did
this
fingerprinting
with
some
default
client
hellos
from
the
library
it
just
didn't
work,
so
it
was
actually
because
we
didn't
collect
enough
information
from
the
server.
Due
to
this
question,
answer
design
of
tls.
K
That
is
intended
to
hide
information,
but,
as
you
can
see,
this
is
an
example.
So,
in
the
client,
hello,
just
looking
at
the
cypher
suits
in
a
client
hello,
this
line
sends
a
whole
bunch
of
cypher
suits.
It
could
be
hundreds
of
cypher
suits
to
the
server.
The
server
looks
at
this
list
and
selects
a
single
cypher
suit,
and
from
this
example,
you
can
see
why
tls
fingerprinting
is
already
quite
common
for
clients,
because
the
client
reviews
a
lot
of
information
about
it.
So
the
server
does
not.
K
So
that's
not
a
lot
of
information,
and
this
led
us
came
to
the
conclusion
that
well,
we
should
not
use
default
client
hellos.
We
need
some,
how
unusual
client
hellos
that
really
trigger
new
behaviors
from
the
server,
and
we
need
to
send
multiple
client
hellos
to
the
server
that
somehow
complement
each
other.
So
we
learn
even
more
and
like
a
third
point
was
like.
K
If
you
take
too
many
requests
all
right,
this
led
us
to
these
three
research
questions.
So,
first
of
all,
how
can
we
relate
now
similar
deployments?
How
can
we
improve
the
effectiveness
effectiveness
of
our
client
hellos
and
what's
not
the
informants
of
use
cases?
So,
let's
have
a
look
at
the
first
research
question
basically
relate
these
servers
by
well
fingerprinting,
but
in
a
way
that
we
extract
all
these
handshake
features
from
the
tls
handshake
in
a
way
that
similar
deployments
have
the
same
fingerprint
and
base
code.
K
We
did
we
just
extracted
all
this
information,
put
it
together
in
one
big
string.
So
this
you
can
see
this
is
our
format,
but
it's
of
course
kind
of
arbitrary.
You
can
see
it
contains
the
version,
cipher
extensions
and
also
the
tls
alerts,
which
are
error.
Codes
in
from
the
tls
protocol,
because
error
handling
is,
of
course,
also
implementation
specific
and,
as
we
send
multiple
requests
to
server.
Well,
we
just
combined
all
these
representations
in
one
big
fingerprint
all
right,
then,
let's
have
a
look
at
the
second
research
question.
K
How
can
we
prove
now
the
effectiveness?
Well,
we
did
this
basically
had
this
challenge
that
we
do
not
know
every
implementation.
So
how
should
we
know?
What's
the
ideal
combination
of
client
hellos,
we
should
send,
but
what
we
can
definitely
do.
We
can
somehow
optimize
the
effectiveness
of
our
client
hellos,
and
we
did
this
by
doing
this
empirically
by
basically
just
first
of
all
measuring
effectiveness,
which
is
the
metric.
We
use
the
distinct
number
of
fingerprints.
K
We
were
able
to
collect
from
the
servers
as
a
metric
then
perform
the
measurement
with
a
whole
bunch
of
randomly
generated,
client
hellos,
and
then
we
just
pick
the
combination
of
client
hellos
that
maximize
this
metric,
and
this
way
we
generated
10
like
scanning
client
hellos.
We
used
in
the
following
analysis,
all
right.
So,
let's
have
a
look
at
the
the
last
point.
Does
this
work
now?
Therefore,
we've
designed
a
smooth
study
that
with
weekly
measurements,
where
we
scan
these
two
top
lists
and
two
block
lists.
K
F
K
But
their
service
could
also
be
verified
through
other
means
as
well.
So
we
can
generate
a
ground
truth
through,
for
example,
the
a
s
or
certificates.
They
return
and
that's
what
we
did.
We
evaluated
this
cdn
detection
with
this
ground
rule
and,
if
you're
not
so
familiar
with
classification
metrics,
so
we
used
precision
and
recall
so
precision
is
basically
the
number
of
correct
classifications.
We
did
and
recall
how
many
of
these
ct
answers
from
the
ground
truth.
We
are
now
able
to
detect.
So
let's
have
a
look
at
the
results.
K
You
can
see
that
the
like
the
metrics
are
quite
high
for
all
of
them,
so
this
detection
works
interesting,
at
least
for
us
was
for
cloudflare
and
fastly.
It
was
astonishingly
high.
So
the
precision
was
above
99,
which
means
their
gls
configurations
are
very
unique
among
in
the
internet
and
they're
quite
easy
to
to.
We
were
able
to
detect
them
quite
easily
and
what's
also
interesting,
for
us
at
least
was
that
with
this
method,
we
were
able
to
detect
also
quite
a
lot
of
often
at
cdn
servers,
sometimes
in
even
unexpected
places.
K
So,
for
example,
for
cloudflare,
we
saw
some
servers,
but
there
were
actually
reverse
proxies.
A
third
party
has
set
up
that
somehow
proxied
all
the
traffic
we
sent
to
cloudflare.
You
know
why
they
did
this,
but
yeah.
We
saw
this
all
right
so
and
second
use
case.
We
had
a
look
at
the
command
control
servers
so
where
we
now
really
are
able
to
fingerprint
or
detect
even
potentially
malicious
servers.
K
To
make
this
more
realistic,
we
just
had
a
look
at
new
additions
to
the
tool
list
and
because
this
classification
wasn't
that
obvious
anymore,
we
now
considered
like
how
often
we
saw
a
fingerprint
from
top
list
versus
from
block
list
to
kind
of
generate
a
score.
How
certain
we
are.
We
now
found
a
commander
control
server
and
if
this
score
was
above
a
certain
threshold,
we
just
classified
it
as
a
cnc
server
all
right.
So
let's
have
a
look
at
the
results.
K
Just
on
the
x-axis
is
now
the
threshold
above
which
we
classified
this
see
the
server
as
cnc
server,
and
you
can
see
three
different
sources
of
input
data
we
used
so
on
the
left.
You
see
just
the
t,
dls
fingerprints,
we've
designed
and
which
actually
works
quite
fine
already,
so
the
precision
is
okay.
Let's
say
the
recall:
isn't
that
high,
especially
for
the
higher
thresholds,
we
had
a
look
at
how
to
improve
this,
and
we
noticed
some
like
noticed
some
strange
hdb
server
headers,
but
they
weren't
really
good
enough
to
detect
these
servers.
K
K
This
is
quite
good
and
that's
also
how
we
expect
people
will
use
such
a
fingerprinting
mechanism,
just
as
in
conjunction
with
additional
indicators.
All
right.
Let's,
let
me
conclude
our
work.
So
in
this
paper
we
proposed
a
selection
of
handshake
features
and
the
encoding
as
fingerprints
as
a
mechanism
to
relate
tls
servers.
We
also
provide
a
metal
methodology
to
find
new
client
hellos
for
scanning
or
just
provide
always
some
10
general
purpose.
Clienteles.
K
K
A
B
Marcus,
that's
really
interesting.
I
wanted
to
ask
you
for
a
comment
on
you
had
a
slide
up
where
you
showed
four
cdn's
and
the
varying
precision
and
recall
on
them.
I
maybe
I
missed
it,
but
how
were
you
determining
the
ground
truth
about
which
cdn
they
were
on
and
the
reason
I'm
asking
is:
what
did
you
do
with
content
that
was
multi-cdn
like
did
that
come
up?
Did
you
did
you
see
content
that
you
wanted
to
validate,
but
the
that
content
providers
using
multiple
cdns.
K
A
L
E
M
Okay,
so
thank
you
for
all
inviting
me
I'm
constantine,
I'm
a
phd
student
at
rwh
university
in
germany
and
I'm
going
to
present
you
the
results
of
our
paper,
in
which
you
took
a
look
at
the
influence
of
resource
prioritization
on
actual
hedge
of
line
blocking
and
the
performance
when
using
this
with
hp3,
and
this
is
joint
work
with
ike
and
klaus,
but
before
getting
actually
into
the
results.
Let
me
give
you
a
short
introduction.
M
I
guess
most
of
you
already
know
that,
but
just
let
me
quickly
repeat
this,
so
we
want
to
load
a
website
and
for
maximum
performance.
You
would
like
to
load,
of
course,
all
of
the
resources
in
parallel,
so
you
would
like
to
load
the
html,
but
you
would
also
like
to
load
already
the
resources
that
you
discovered
so,
for
example,
the
two
images,
the
red
and
the
blue
one
and
with
hdb1.
M
You
then,
just
open
multiple
tcp
connections
to
load
these
resources
in
parallel,
however,
this
of
course
came
with
the
the
overheads
of
opening
multiple
tcp
connections
and
because
of
that
with
http
2,
it
was
introduced
to
use
just
a
single
tcp
connection
where
you
then
multiplex
the
different
resources
in
in
streams
and
stream
frames
over
this
one
tcp
connection.
However,
the
issue
is
that
tcp
is
completely
unaware
of
the
streams,
so
it
just
sees
a
opaque
byte
stream,
and
this
can
lead
to
transparent
head
of
line
blocking.
M
We
saw
this
information
and
basically
we
could
use
the
other
information
for
the
red
and
the
green
resources,
but
tcp
doesn't
know
this
and
just
now
waits
for
the
re-transmission
of
its
last
segment.
So
we
have
to
wait
for
run
round
trip
time
and
the
browser
does
not
get
further
information
in
that
time
with
hbe3.
Instead,
quick
is
used
and
quick
has
multiple
streams
implemented
on
the
transport
layer.
These
streams
are
now
independent,
so
we
don't
have
any
interest
stream
head
of
line
blocking
anymore.
M
So,
for
example,
we
now
have
again
the
case
where
the
blue
resource
information
is
lost
during
the
transmission.
However,
quick
knows
that
this
is
only
in
influencing
the
blue
resource
stream
here
and
the
red
and
the
the
green
information
can
still
be
forwarded
to
the
browser.
However,
for
this
to
work,
of
course,
multiple
streams
have
to
be
active
and
we
can
also
get
to
the
case
where
only
one
of
the
streams
is
active,
and
in
this
case
we
get
the
same.
M
The
same
case
that
again
now
this
this
one
stream
is
waiting
for
the
retransmission
and
because
basically
only
this
one
stream
is
active.
The
whole
connection
is
waiting
for
the
retransmission
and
how
this
data
is
now
scheduled
with
quick
so
which
stream
is
actually
sent
in
which
stream
frames
is
actually
sent
on.
The
wire
basically
depends
on
the
server,
so
how
the
server
depends
decides
how
to
send
it
and
how
the
quick
stack
then
decides.
M
Then
there's
an
approach
by
chrome,
which
uses
a
sequential
scheduling,
but
they
reorder
that
important
resources
are
sent
earlier
than
unimportant
resources
and
there's
firefox,
which
used
with
hb2
a
mixture
of
rated
round
robin
and
sequential
scheduling,
and
because
this
deal
depends
on
because
this
influences
how
data
is
sent.
This,
of
course,
also
influences
the
performance.
M
There
has
been
some
related
work
on
that,
and
basically,
this
regulated
work
found
out
that
for
hp2
and
also
for
hdb3,
the
round-robin
and
great
round-dropping
approaches
are
actually
worst
while
the
chrome
and
the
firefox
approach
is
actually
the
best
or
the
better
one.
Why
better?
Because,
in
that
specific
work
also
website,
specific
prioritization
strategies
have
been
discussed
and
they
found
that
if
you
have
website
specific
knowledge,
for
example,
one
image
is
very
important.
M
You
get
even
better
resource
prioritization
results
in
that
regard,
however,
what
we
can
also
see
here
is
that
this
sequential
scheduling
from
chrome
showed
best
results
here,
although
it
would
be
worse
for
head
of
blind
blocking,
because
we
would
then
monopolize
this
connection
as
we've
seen
in
the
example
before
so.
Basically,
we
would
say:
okay,
this
problem
is
now
solved.
We
just
know
there
is
no
no
influence.
M
So
loss
hasn't
really
been
looked
at
in
the
related
work
in
this
regard,
and
our
idea
was
then
to
look
at
the
the
impact
of
prioritization
on
the
actual
head
of
hdb3
performance
under
loss,
and
for
this
we
then
use
different
scenarios
where
we
change
the
laws.
The
last
person,
the
rtt
and
the
bandwidth
and
then
also
tested
different
prioritization
strategies,
and
we
did
this
to
identify
the
head
of
line
blocking
and
the
performance,
and
for
this
we
downloaded
35
websites.
M
We
replayed
those
websites
in
a
test
bed
and
then
measured
the
speed
index
and
the
head
of
line
blocking
so
how
many
bytes
were
actually
blocked
during
re-transmission
and
then
tried
this
and
then
measured,
basically
the
speed
index.
Let
me
just
skip
the
the
testbed
implementation
in
the
interest
of
time
and
let's
get
directly
to
the
results
and
for
the
results.
M
What
we
will
see
is
always
the
relative
median
difference
to
chrome
and
we
use
chrome
as
our
sequential
baseline
and
what
we
can
see
for
the
head
of
line
blocking
is
that
for
very
low
that
for
very
low
bandwidth.
We
see
an
improvement
in
head
of
line
blocking
so
basically
the
head
of
line
blocking
is
reduced,
but
we're
using
a
parallel
strategy
in
comparison
to
chrome,
sequential
scheduling,
but
we
can
see
that
the
differences
are
vanishing
when
we're
using
higher
bandwidths.
M
M
That's
actually
points
where
the
whole
website
fitted
into
slow
start,
because
the
website
was
very
small
and
basically
we
could
transmit
everything
of
that
without
having
any
loss.
So
that's
also
one
point
that
we
have
to
look
at
and
for
the
speed
index
we
can
see
in
a
comparable
results
where
we
see
that
for
lower
bandwidths.
We
can
see
even
some
improvements
in
speed
index
when
using
parallelism
on
the
median
case,
so
the
curve
is
slightly
moved
to
the
left.
However,
these
benefits
are
also
vanishing
with
higher
bandwidths.
M
This
is
actually
due
to
the
same
case.
On
the
one
hand,
we
have
fewer
laws,
but
on
the
other
hand,
we
have
a
higher
bandwidth,
so
more
of
our
resources
can
be
transmitted
in
that
time
and
we
also
have
a
higher
congestion
window
with
higher
bandwidths,
and
that
leads
to
the
fact
that
sometimes
the
resources
are
just
smaller
than
our
congestion
window.
So,
even
when
we're
using
sequential
scheduling,
still,
multiple
streams
have
been
active
because
just
the
resources
ended
and
the
next
stream
could
start.
M
M
However,
this
benefit
is,
is
really
subtle,
so
we
can
see
that
on
the
left
side,
a
lot
of
the
the
data
points
in
the
red
circle
are
below
our
s
curve
and
on
the
right
side,
we
can
see
that
a
lot
of
the
data
points
are
above
this.
So
it's
not
as
strongly
as
for
the
head
of
line
blocking,
and
we
were
wondering
why
this
is
actually
the
case.
M
So
we
then
looked
into
the
data
a
little
closer
and
we
found
that
different
websites
behave
differently
when
using
this,
and
because
of
this,
we
then
looked
into
the
correlation
between
loss
and
the
speed
index,
and
here
we
can
see
the
correlation
for
the
speed
index
and
head
of
line
blocking
and
basically
a
red
means
that
there
has
been
a
correlation
which
was
negative.
So
we
could
see
that
the
head
of
line
blocking
has
been
reduced,
but
the
speed
index
got
worse,
while
blue
means
that
we
had
a
positive
correlation.
M
So
the
speed
index
was
also
improving
when
the
head
of
line
blocking
was
improving,
and
here
we
can
see,
for
example,
for
wikipedia.org
that
we
can
see
only
not
very
strong
positive
correlations
or
even
red
patches,
so
negative
correlations.
While
for
newyorktimes.com
we
see
very
strong
positive
correlations
and
the
interesting
difference
between
wikipedia.org
and
newyorktimes.com
in
our
data
set
is
basically
that
these
are
two
different
extrema
for
the
website
size.
So
wikipedia.org
is
our
smallest
website
and
newyorktimes.com
is
our
biggest
website.
M
I
would
also
like
to
go
into
the
details
for
other
loss
patterns
and
also
what
the
impact
of
the
round
trip
time
is.
However,
I
cannot
go
into
detail
here,
but
I
can
just
tell
you
that
the
loss
pattern
is
very
important
because,
when
you
have
bursts
around
robin
is
again
really
well
bad,
because
you
are
then
affecting
a
lot
of
the
streams
and
for
the
round-trip
time
you
can
tell
you
that
higher
rtts
increase
the
round
trip
time
or
the
retransmission
penalty,
and
so
in
smaller
rtt
cases.
M
M
However,
mainly
in
cases
for
large
websites,
smaller
bandwidths,
higher
rtt
scenarios
or
where
rendering
loss
was
was
seen,
and
we
could
also
see
that
the
new
extensive
prioritization
scheme
that
has
been,
I
think
it
has
been
a
draft,
I'm
not
sure
if
it's
standardized
now
for
http
3.
It's
this
new
scheme,
we
haven't
seen
a
big
difference
between
using
the
old
scheme
or
this
scheme
here.
So
all
in
all,
we
can
say:
http
3
prioritization
is
still
website
dependent
which
related
workforce,
but
it's
now
also
network
dependent.
A
F
L
A
B
A
L
A
A
L
N
Everyone,
my
name
is
bong
and
I'm
a
boston
researcher
at
the
university
of
chicago
and
today
we'll
be
presenting
our
work
on
measuring
the
accessibility
of
domain
name
encryptions
and
its
impact
on
internet
censorship,
and
so,
regardless
of
the
expansions
of
https
traffic
plaintext
domain
names,
are
the
last
piece
of
unencrypted
information
that
is
still
lightly
visible
onto
the
internet.
So
where
is
domain
name?
Information
exposed
and
the
slide
here
shows
you
the
common
places
where
domain
name
information
can
be
monitored
by
any
network
level.
N
So
this
other
network
packet
that
I
capture
when
visiting
istanbul.com
and
the
first
place
that
you
see
here,
is
through
the
next
query
and
respond
and
after
getting
packed
back
the
ip
address
of
example.com,
the
client
initiated
the
2s
handshake
to
port
443,
and
the
second
place
here
you
can
see
is
in
the
server
name
indications
where
you
can
see.
Sample.Com
domain
name
and
the
exposures
of
the
domain
name.
N
And
so
you
know
this
is
clear
that
domain
name
encryption
can
help
improving
the
security
and
privacy
for
internet
users.
But
it's
also
take
away
the
visibility
into
plaintext
domain
name
from
the
network
traffic,
and
so
that
has
motivated
us
to
investigate
how
domain
encryptions
impact
internet
censorship.
N
More
specifically,
we
want
to
know
whether
any
sensor
out
there
are
taking
a
a
step
ahead
to
plot
domain
name
encryption
technologies,
and
if
domain
encryption
is
not
blocked,
which
means
it's
accessible,
then
can
it
help
to
circumvent
traditional
internet
censorship.
Technology,
like
dns,
poisoning.
N
N
So
here
is
what
we
found
from
the
measurement
conducted
by
this
system.
We
could
conclude
that
censorship
based
on
plaintext
domain
names
is
still
widespread
and,
as
dns
tampering
has
been,
you
know
detected
in
many
countries,
so
here
the
top
five
countries-
china,
russia,
iran,
indonesia
and
india,
but
we
didn't
observe
any
dns
based
locking
of
the
domain
name
of
major
dlt
lds
resolver
like
we
have
dns.google
or
we
have
dns
last
cloudflare.com.
Those
are
popular
dlt
us
resolver,
but
we
didn't
see
any
tambourines
dns
tampering
when
resolving
those.
N
N
N
I
I
try
to
use
the
service
of
google
resolver
and
what
what
have
finished
here
is
that
I
could
finish
the
the
the
dns
lookup
for
the
ip
address
of
dns.google.com
right.
But
then,
as
soon
as
I
I
start
the
tcp
stream
to
do
the
dns
over
to
s
over
https,
then
it's
blocked.
So
the
thing
is
the
ip
address
of
popular
the
us.
Resolver
are
widely
known
and
therefore
dropping
traffic
based
on
just
the
resolver
ip
and
port
443
pairs
is
enough
to
block
penis
over
https
too.
N
Although
you
know
among
our
community,
we
say
if
we
do
dns
over
https,
because
it's
run
on
port
403,
then
it's
just
a
more
collateral
damage,
but
just
think
of
like
what
else
like
what
other
service
that
may
run
on
8.8.8.8
right.
So
it's
just
obvious
and
so
another
blocking
that
we
observed
what's
in
saudi
arabia,
which
is
against
cloudflare
resolver,
and
we
observe
this
to
be
a
centralized
effort,
because
we
we
observe
the
same
blocking
signatures
in
multiple
asses
in
this
country,
so
whatever
the
domain
name
and
with
cloudflare.dns.com.
N
As
soon
as
we
start
the
ts
handset
we
complete
it,
we
send
a
client
hello,
they
detect
it
in
the
client,
hello,
then
there's
they
inject
the
reset
packet
to
another
connection,
and
so
for
the
case
of
russia.
We
see
a
decentralized
blocking
efforts
against
encrypted
sni,
which
means
that
we,
we
don't
see
it
everywhere
in
russia
there
and
here
in
the
countries
that
we
see
some
efforts
of
blocking
this
protocol
based
on
the
two
biosignatures
of
encrypted
sni.
Basically,
this
blocking
mechanism
is
similar
with
the
way
great
firework.
N
And
so
with
that,
we
we
move
on
to
to
answer
the
final
questions
that
we
ask
is
like.
If
all
of
these
technologies
is
accessible,
it's
not
blocked
or
somehow
we
get
it
to
work,
then
can
it
help
to
circumvent
traditional
censorship
mechanisms,
and
so
we
use
encrypted
dns
when
crawling
sensor
website,
and
so
this
encrypted
dns
in
some
country
I
say:
oh
china
block
it.
Russia,
I
block
it
iran's
locker.
N
N
So
the
takeaway
here
is
that
if
we
run
out
of
dns
over
https
server,
we
don't
get
blocked
and
we
use
that
to
visit
the
website
that
were
found
censored
earlier
and
so
the
finding
is
that
a
lot
of
them
in
country
like
russia,
indonesia
and
india.
You
can
actually
defeat
censorship
just
by
using
this
technology,
but
then
in
china
and
iran
we
couldn't
to
set.
N
We
couldn't
do
it
successfully
because
a
lot
of
this
website
they
don't
support
encrypted
sni,
and
so
you
could
bypass
dns
censorship,
but
then
at
the
ts
handshake
you
still
expose
the
domain
name,
information
and
because
china
and
brand
they
also
have
filtering
at
that
layer.
So
we
couldn't
bypass
it,
and
so
the
key
men
take
away
from
from
this
30
is
that
domain
encryptions
can
help
to
partially
circumvent
internet
censorship
based
on
plaintext
domain
name
based
on
plaintext
dns
resolutions.
N
A
A
B
Yeah
thanks
vong.
This
is
interesting.
Just
following
on
to
some
comments
in
the
in
thread
was,
I
think,
a
reasonable
follow-up
question
would
be.
Do
you
know
of
any
work
that
tries
to
classify
the
types
of
censorship,
for
instance,
so
that
you
would
know
if
the
if
the
censorship
was
trying
to
block
malware
or
sexually
explicit
content,
as
opposed
to
say
a
political
motivation.
N
So
I
so
in
in
the
case
that
we
found
here
is
like
most
of
the
domain
that
we
found
to
be
blocked.
Actually,
a
lot
of
them
are
political
motivated
blocking
rather
than
malware,
because
this
30
is
based
on
the
block
list
that
used
by
the
citizen
lab,
which
is
a
mostly
politically
motivated,
blocked
website.
N
P
P
One
sort
of
nuance
I
want
to
point
out
is
that
you're
focused
mostly
on
the
censorship
case,
and
even
in
these
cases
where
there's
blocking
and
censorship
is
indeed
applied,
you
still
preserve
the
property
of
confidentiality
of
what
people
are
looking
up,
rather
than
having
to
say
what
your
destination
was
going
to
be
with
an
encrypted
dns.
You
just
can't
ask
that
question
right.
P
What's
being
blocked,
is
your
connection
to
a
well-known
resolver,
and
that
is
a
strictly
better
situation
than
you
were
in
before
of
someone
looking
at
the
plain
text
and
throwing
that
away.
So
even
in
these
situations
we
have
like
ratcheted
the
problem
forward,
at
least
from
confidentiality
point
of
view.
P
I
guess
my
second
note
is:
you
are
making
sort
of
a
call
here
to
back
encrypted
client
hello,
and
I
just
want
to
say
I'm
actually
bullish
on
that.
I
think
that's
going
to
work
out
the
distinction
you
draw
here
of
the
old
esn
I
and
the
migration
to
group
decline.
Hello,
I
think
all
you're,
seeing
there
are
those
gears
turning
a
little
slowly,
but
I
don't
think
it's
really
ever
exception
in
the
marketplace,
so
cool.
Thank
you
for
this.
P
N
O
A
O
O
O
L
A
O
O
Hey
look
at
that
amazing,
okay,
hi
everyone,
great
I'm,
going
to
talk
a
little
bit
and
thanks
to
miria
and
dave
for
the
invite
to
the
group,
it's
great
to
see
a
lot
of
familiar
and
friendly
faces.
I'm
going
to
talk
about
some
work,
we've
been
doing
to
measure
the
availability
and
response
times
of
some
of
the
public
encrypted
dns
resolvers.
O
I
think,
as
this
group
probably
knows
very
well-
I'm
not
going
to
spend
any
time
on
the
background
of
encrypted
dns
or
dns
over
https,
as
this
group
probably
also
knows
pretty
well,
there
are
some
so-called
mainstream
resolvers
I'll
define
what
I
mean
by
that
in
just
a
minute.
But
what
we
were
interested
in
in
sort
of
looking
at
in
this
work
is,
if
you
go
to
like
dns
qrik
proxy
there's
a
whole
bunch
of
other
dns,
do
dot,
resolvers,
etc.
That
are
listed
on
that
page.
O
O
You
can
see
the
full
list.
I've
I'll
put
some
examples
up
in
just
a
minute,
but
the
the
the
gist
of
this
work
is
to
try
to
really
figure
out
how
many
public
encrypted
dns
resolvers
are
out
there
that
you
can.
You
can
actually
use
that
aren't
some
of
the
some
of
the
usual
suspects
and
credit
to
rania
sharma.
O
L
O
Part
of
this
you
can,
you
can
see,
I
think,
from
from
the
page
as
there's
a
is
an
open
source
tool
for
measuring
encrypted
dns
performance
that
we
used
to
perform
these
measurements.
You
can
you
can
find
it
from
that
page.
I
linked
that's
an
ongoing
and
active
development.
Actually,
as
we
consider
as
we
continue
work
in
this
space.
O
And
then
we
study
how
the
performance
of
these
resolvers
differ.
Based
on
vantage
point,
because
you
can
imagine
some
of
the
some
of
the
usual
suspects
they're
highly
replicated,
but
some
of
the
others
that
are
further
down
on
the
list.
You
know
they
may
be
deployed
in
a
particular
country
or
continent,
and
so,
if
you're
going
to
measure
that
performance,
you
probably
want
to
measure
it
from
you
know
from
the
nearby
as
well
as
not
nearby.
So
we
did.
O
We
continue
to
expand
on
this
work,
I'll
talk
about
that
in
the
in
the
conclusion,
because
we
only
did
it
from
these
three
vantage
points
and
it
was
a
one-time
shot,
but
we're
extending
that
first,
let
me
sort
of
talk
about
the
context.
So
modern
browsers
provide
a
few
choices
for
encrypted
dns
resolvers.
We
define
those
as
mainstream,
so
you
can
see
the
choices
here
this
by
the
way
is
as
of
a
couple
months
ago,
it's
constantly
changing.
So
if
you
see
a
mistake,
please
let
me
know
so.
O
The
performance
of
these
is
is,
of
course,
of
interest
in
the
the
draft
paper
that
I
linked
does
you
know,
provide
measurements
on
all
those
and
we
do
comparisons
against
those.
We
were
also
interested
in,
like
all
these
other
doe
resolvers
that
are
supposedly
running.
Are
they
actually
running
and
can
you
use
them
and
so
forth,
so
so
yeah?
So
we
measured
a
bunch
of
different
things.
One
was
availability
which
doe
resolvers
are
active
and
responding
to
queries.
O
O
I
guess
in
the
context
of
what
that
round
trip
latency
is
and
then
finally,
of
course,
what's
the
query
response
time,
the
experiment
setup,
we
had
three
global
vantage
points,
as
I
mentioned
here.
They
are
this
particular
study.
We
did
queries
to
google
and
netflix,
and
this
is
not
a
full
list
of
the
resolvers
that
we
queried
for
that.
I
couldn't
fit
them
all
on
the
slide.
O
O
O
O
So
you
can
see
basically
about
a
you
know:
78
success
rate,
which
is
well.
Let's
leave
it
at
that
good,
okay.
So
here
here
what
we
do-
and
I
hope
this
is-
this-
is
large
enough
for
you
to
see.
But
here
what
we
do
is
we
look
at
how
the
mainstream
resolvers
perform
and
I'm
going
to
walk
through
this
kind
of
one
one
box
plot
by
one
box
plot.
O
L
O
For
each
resolver
you
can
see
the
red
in
the
red
or
the
top
of
the
group.
It's
it's
a
grouped
box
and
whisker.
You
can
see
the
ping
time.
So
that's
just
like
icmp
ping
and
again
that's
that's
a
distribution,
so
you
can
see
a
green
line
for
each
of
those
that
shows
like,
what's
the
the
median
ping
time
and
you
can
see,
some
of
these
are
pretty
close
right.
If
you're
in
north.
L
O
O
O
You
know
offered
in
as
options
in
your
browser,
and
so
things
to
pay
attention
to
here.
Are
you
know
the
molded
ones,
and
then
we've
basically
got
three
of
these
one
per
vantage
point.
So
if
you
want
to
just
kind
of
focus
on
the
main
takeaways,
you
could
sort
of
start
by
looking
at
north
america.
This
is
by
the
way
this
is
from
I'm
showing
one
of
these.
The
paper
has.
Has
it
does
this
three
different
times?
O
So
you
see
north
america,
local,
we're
measuring
north
of
this
group
here,
our
north
american
doe
resolvers,
as
measured
from
north
america,
and
we
put
the
mainstream
dough
resolvers
on
all
three,
because
we
assume
they're
replicated
in
all
three
places
but
like
dracoplan9ns2.com,
that's
sitting
somewhere
in
north
america,
whereas
public
dns
iij.jp,
that's
in
japan.
So
that's
why
you
see
that
on
the
asia
plot.
So
a
is
north
america
to
north
america.
Local
b
is
north
america
to
asia.
O
So
that's
why
you
see
higher
higher
ping
response
times
here
you
can
see
these
are
clearly
geo-replicated
and
then
here
we've
got
north
america
to
europe.
Okay,
so
a
bunch
of
things
you
can
take
away
here
certain
and
then,
as
I
mentioned
just
to
repeat,
these
are
sorted
by
median
dns
encrypted
dns
response
time,
so
the
better
performing
ones
according
to
that
median
are
or
towards
the
top.
So,
as
expected,
you
would
see
those
mainstream
resolvers
sort
of
closer
to
the
top.
O
One
of
the
things
that
we
didn't
do
in
this
study.
I
noticed
I'm
coming
up
on
time
that
we
are
in
the
process
of
doing
is
also
doing
page
load
times.
This
is
just
this
is
just
doe
response
time
if
you
presumably
also
care
about
web
page
loads,
but
I
I
think
you
know
this
is
pretty
interesting
for
a
number
of
reasons.
I
think
we
expect
the
the
the
mainstream
resolvers
to
perform
pretty
well,
but
another
thing
that
I
think
the
ietf
is
considering.
O
A
lot
is
consolidation
right
and
for
the
healthy
you
know
for
a
healthy
dough
ecosystem.
It
is
good
to
have
many
organizations
that
operate
dough,
resolvers
that
we
can
use
that
perform
well,
and
I
think
there's
there's
good
news
and
there's
news
here.
I
don't
know
if
you
know
I
don't
know
if
there's
bad
news,
but
there's
certainly
information
here
about
other
resolvers
that
that
others
can
use
in
other
places
to
to
invest.
O
This
is,
I
think,
my
final
plot
and
then
I'll
kind
of
come
to
conclusions,
but
that
was
a
little
trick.
You
know
that
was
a
little
bit
of
an
eye
chart,
and
so
one
of
the
things
that
we've
also
been
sort
of
looking
at
is
you
know
how
do
these
resolvers
perform
with
respect
to
to
network
round
trip
time
right,
because
that's
that's
the
fair
comparison
in
in
some
sense
from
like
wherever
we
happen
to
be
sitting.
Where
is
that
resolver
right
and
then
you
would
expect
it
like?
O
O
If
you
look
at
sort
of
how's
it
going
in
north
america,
asia
and
europe-
and
you
can
in
each
point
here,
each
blue
point
is
a
doe
resolver,
and
so
so
I
don't
know
what's
good
things
should
not
be
probably
below
the
line
so,
but
but
you
can
see
here
that
you
know
how
we're
doing
as
far
as
you
know,
the
existence
of
of
performant,
though
resolvers
around
the
world.
So
this.
O
O
Also
that
actually
seems
to
perform
pretty
well,
even
though
it
wasn't
globally
replicated.
So
I
think
this
presents
some
some
interesting
early
findings.
Some
opportunities,
as
I
mentioned,
there's
a
bunch
of
ways
that
they're
following
up
on
these
measurements,
and
I
look
forward
to
the
feedback
of
the
map
rg
and
again.
Thank
you
so
much
to
dave.
L
A
A
Okay,
that
means
we're
at
the
end
of
the
session,
we're
at
the
end
of
the
ietf
meeting.
I
just
want
to
say
one
more
thing.
This
time
we
only
got
a
very
few
contributions
and
we
were
very
lucky
that
we
reached
out
to
some
people
and
they
said,
but
then
it's
less
yes
to
present
here,
and
so
we
had
a
nice
program
but
we're
depending
on
contributions.
So,
like
let
people
know
about
this
group
if
anybody's
doing
measurements,
please
come
to
us
and
tell
us
about
it.
That's
very
helpful.