►
From YouTube: IETF-CORE-20211013-1400
Description
CORE meeting session at IETF
2021/10/13 1400
https://datatracker.ietf.org/meeting//proceedings/
A
B
A
A
Okay,
we
are
two
past
the
hours,
so
I
think
we
can
start
welcome
everybody
to
this
core
interim
meeting.
I
am
marco
tiloca.
My
co-chair
is
how
many
minutes-
and
this
is
an
official
itf
meeting,
so
the
knot
will
apply
as
usual.
We
are
recording
now
try
to
find
some
time
to
get
familiar
with
this.
It's
not
just
ipr.
A
Now
then,
we
can
start
with
a
main
document
update
and
before
going
into
sentimental
data
city,
we
got
a
few
days
ago
the
news
that
the
document
was
finally
approved
for
publication.
Eco
request
tag,
that's
a
great
news
per
se
and
also
for
other
documents
that
are
waiting
in
the
queue
in
cluster
280.
A
A
D
Okay,
so
we
now
have
confirmation
that
the
discusses
will
be
cleared
with
the
next
revision,
so
we
we
have
three
items
that
essentially
come
from
the
comments
that
we
still
need
to
resolve
and
then
I
think
we
should
be
done
well,
maybe
one
or
two
little
editorial
things.
So
this
is
really
the
last
round
and
if
you
want
to
follow
this
process,
of
course,
this
is
best
done
in
the
repository
where
you
find
the
merge,
pr's
and
and
occasional
editorial
fixes.
D
D
Well,
it
turns
out
it's
different
abnf
and
they
actually
have
changed
something
there
after
like
20
years-
and
this
is
the
the
parameters
part
for
the
media
type
definition
the
in
that
syntax.
The
word
media
type
actually
stands
for
a
content
time
and
not
a
media
type
name,
but
that
that's
a
long
story
anyway.
D
So
up
to
now,
it
was
like,
like
below
in
in
the
rfc
7231
definition
where
you
had
a
type,
a
slash,
a
subtype
and
then
zero
or
more
parameters,
each
of
which
is
led
in
by
a
semicolon,
and
the
new
syntax
actually
allows
you
to
leave
off
the
parameter.
So
you
can
have
lots
of
of
semicolons
like
in
in
the
example
here
below.
So
the
example
up,
there
is
how
it
should
look
like,
and
the
example
below
is
what
the
new
syntax
allows
now
this
is.
D
This
is,
of
course,
complete
garbage,
but
it's
what
lots
of
implementations
actually
do
and
accept
so
the
http
people
decided
they
want
to
have
that
in
their
media
type.
Syntax
and
the
question
really
is:
do
we
have
to
follow
this
change,
or
do
we
want
to
have
clean
media
type?
Definitions
like
they
have
been
in
rfc,
2616
and
1731
for
for
a
couple
decades
now
and
yeah?
D
A
E
I
agree
with
christian
here
I
mean
I
think
we
shouldn't
divert
from
http
without
a
good
reason,
but
I
think
this
is
a
good
reason.
That's
really
what
they
allow
and,
as
you
said
like,
we
don't
have
that
problem
and
and
when
we
need
to
go
between
hdb.
If
someone
does
that
on
hcp
side,
we
can
sanitize
before
we
go
to
the
nml
side,
but
we
don't
have
to
luckily
sanitize
the
other
direction
because
it
would
be
correct
anyway.
So
yeah,
I
would
go
with
the
original
one.
D
Okay,
so
let's
go
to
the
next
example
where
we
actually
have
been
deviating
from
http,
and
maybe
we
should
fix
that
so
http
has
a
construct
called
quoted
string
which
you
actually
can
find
in
the
parameter
where
your
parameter
value
is
either
a
token
or
a
quoted
string.
That's
why
we
have
to
to
look
at
the
the
structure
of
quoted
string.
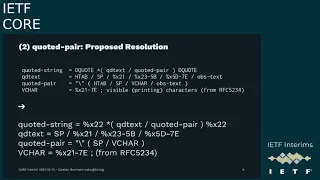
D
D
D
D
So
in
cinema
we
normally
make
sure
that
we
only
have
fields
that
essentially,
must
be
understood
when,
when
that's
needed,
so
we
have
this
underscore
concept,
and
here
with
the
media
type
information,
we
don't
know
whether
the
recipient
will
know
the
specific
media
type
used.
The
parameters
used,
any
content,
codings
used
and,
finally,
any
content
format
numbers
registered
for
the
first
three.
D
So
this
this,
the
cinema
creator,
just
assumes
that
the
implementation,
on
the
other
hand,
on
the
other
end,
knows
these
things
or
has
a
way
to
acquire
that
that
knowledge,
if,
if
needed-
and
I
don't
think
that
is
any
different
from
other
sentimental
features
and
to
me
the
important
thing
is
that
the
recipient
limitation
knows
that
it
needs
to
be
updated
to
understand
these
things.
So
we
are
never
sending
anything
where
the
recipient
trips
over
that
and
misunderstands
it.
D
D
A
F
D
No
again,
I
I
would
like
to
understand
what
mike
said
that
you
should
have
look
at
the
github
repo
that
there's
a
lot
of
brownian
motion
there
in
in
the
issues
and-
and
we
are
really
understanding
things
that
that
we
should
change
and
should
need
not
change.
And
a
lot
of
things
is
going
on
there.
But
it's
all
essentially
about
answering
the
the
discuss
and
comment
positions
from
from
the
the
isg.
A
A
G
Yeah,
let's
try
yeah.
I
think
this
looks
better
okay,
so
this
is
a
brief
status
update
on
what
we've
been
doing
in
the
in
the
design
team
meetings
for
coral
we've.
I've
shown
a
few
things
at
the
previous
interim.
Most
of
that
is
now
merged,
so
the
information
model
model
is
described
as
a
graph
with
that
structure.
G
On
top
that
that
can
be
used
to
guide
the
client
and
to
give
some
things
like
sequence
in
there,
even
though
they
are
not
statements
of
their
own,
but
they
can
help
the
client
process
things
the
right
way
and
forms
and
embedded
payloads
are
still
kind
of
out
of
scope
for
the
information.
Well,
they
are
built
on
top
of
that,
so
the
form
is
kind
of
a
step
of
interaction
that
might
later
be
optimized
in
the
serialization,
but
doesn't
make
the
information
model
any
more
complicated.
G
I
think
that
the
latter
is
just
easier
to
handle
and
it's
probably
also
easier
to
explain
and
to
to
handle
implementations,
because
you
don't
have
to
introduce
all
the
terminology
to
to
say
that
this
is
a
literal,
but
its
identity
is
kind
of
it's
an
entity
of
its
own.
It's
just
easier!
So
that's
what
I
suggest
that
the
document
be
be
moved
on
to.
G
G
G
Whereas
coral
should
convey
valid
information
to
a
device
that
will
later
act
on
it.
So
that
mean
thing
is
that
means
that
we
can't
just
define
a
conversion
from
link
format
to
coral
and
say
that
these
are
equivalent
because
they
might
not
be.
There
are
unregistered
attributes
in
link
format
and
all
kinds
of
things
that
that,
if
we
defined
an
equivalence
we
would
we
might
break
existing
applications.
G
I
don't
know
of
such
applications,
but
web
links
in
in
the
very
general
sense
like
in
as
they're
used
in
http
link,
headers,
etc,
are
used
in
ways
that
are
not
compatible
with
this,
which
is
why
there
is
a
sentence
at
the
start
of
this
conversion.
That
says,
if
you're
doing,
basically,
if
you're
doing
things
like
we
do
here,
then
this
works
for
you.
But
it's
up
in
per
application
and
if
you're
doing
things
differently,
then
you
might
need
to
extend
this
conversation.
G
G
So
the
sensors
thing
there's
a
link
from
from
the
root
with
the
implicit
host
relations
to
sensors
and
these
sensors
have
a
content
type
and
a
title,
and
here
come
in
all
the
parts
where
the
conversion
really
makes
it
takes
a
stance
on
properties
that
we
demand.
So
content
type
is
really
a
numeric
thing
and
can't
just
happen
to
be
a
string
also
because
the
syntax
isn't
nailing
it
down.
Interfaces
are
split
up
by
white
space,
as
6690
describes
it
into
semantic
relations
that
are
usable
all
on
their
own.
G
G
So
if
we
can
rule
this
out,
I
think
that
there's
some
simplification
to
be
gained
and
the
last
topic
is
on
the
on
the
question
of
whether
what
we're
describing
as
an
open
world
or
a
closed
world
model
that
is,
can
you
did
you
something
from
the
absence
of
statements
that
this
is
not
that?
That
statement
is
not
true,
because
it's
neither
stated
nor
implied
by
any
of
the
other
statements.
G
G
One
reason
this
went
out
is
not
so
much
the
readability
topic,
but
what
was
this,
but
also
the
topic
of
what
idea?
Does
this
give
the
user?
So
all
the
document,
all
the
the
examples
that
we
had
of
the
text
notation
introduced
these
basically
directives.
That
said,
we
have
this
prefix
now
on
this
prefix
now,
and
these
have
no
corresponding
element
in
in
the
tag
in
the
binary
notation.
G
So
it's
like
it's
like
if
you,
if
you
were
explaining
co-op
transfers
in
terms
of
http
transfers,
and
then
people
get
all
the
wrong
impressions
that
there
are
strings
transferred
where
they
are
actually
not.
So
this
is
one
reason
where
this
went
out
and
also
one
reason
why
this
looks
a
lot
different
here.
C
Yeah
selecting
the
correct
ones
there
you
go
yes,
perfect
right,
so
I
would
like
to
present
some
updates
that
have
happened
on
these
drafts
about
key
updates
for
all
score,
we're
now
moving
towards
version
zero.
Two
of
this
document,
which
we
will
submit
before
the
cut
update
for
the
next
meeting-
and
I
see
the
slides,
look
a
bit
blurry
by
the
way,
but
hope
it's
fine,
just
a
recap
first.
So
basically,
this
draft
covers
two.
C
And
the
key
point
here
is
that
if
you
don't
follow
these
limits,
it
may
be
possible
for
an
adversary
to
break
the
security
properties
of
the
aad
algorithm.
So
the
two
main
parts
of
this
document
are
first,
the
study
of
these
limits
and
their
impact
on
oscore,
which
means
defining
appropriate
limits
for
os
core
defining
counters.
C
That's
inspired
by
the
current
appendix
p2
of
oscore,
and
the
goal
is
that
you
want
to
generate
a
new
master
secret
and
you
must
result,
and
thus
you
will
get
new
sender
and
recipient
keys,
meaning
fresh
keys
to
use
and
in
the
context
of
the
limits,
if
you're
a
key,
you
can
reset
these
counters
back
to
back
to
zero
and
this
method.
We
propose
also
achieves
perfect
forward
secrecy
so
going
into
a
bit
into
the
key
limits.
Part
just
as
a
recap.
C
What
this
is
about
so
again,
it's
discussed
in
the
c4d
draft,
and
the
key
point
is
that
you
must
limit
the
amount
of
times
you
use
a
key
for
encryption
and
also
how
many
times
you
use
a
key
when
decryption
fails
and
basically
what
we
have
done
in
this
document
is.
We
have
selected
fixed
values
for
q,
v
and
l,
so
yeah
q
is
the
encryption
usage.
C
How
many
times
you've
used
the
key
for
encryption
v
is
sometimes
decryption
has
failed
and
l
is
the
message
size
in
cypher
blocks
and
from
these
fixed
values.
We
have
calculated
these,
I
a
and
c
a
probabilities
which
is
basically
the
probability
of
breaking
integrity,
properties
and
the
probability
of
breaking
confidentiality
properties
and,
depending
on
the
selected
q,
v
and
l.
You
of
course
achieve
different
values
for
ian
ca.
C
But
the
key
point
is
that
these
probabilities
must
be
acceptably
low,
so
you
have
to
choose
appropriate
input,
values
to
achieve
good
output
probabilities,
and
we
have
documented
this
in
the
graph
with
so
with
multiple
examples,
and
then
I
go
into
a
bit
of
updates.
What
has
changed
now
since
the
last?
Well,
what
we've
been
doing
in
terms
of
updates
with
the
document?
C
So
the
first
point
we
added
was
saying
that
you
have
to
explicitly
limit
the
size
of
protect
the
data
to
be
sent
in
an
us
core
message,
because
if
you,
depending
on
the
l
value
you
set,
the
probabilities
will
be
influenced.
So
that
means
that
whatever
l
you
have
selected,
the
implementation
should
not
exceed
the
l
value,
meaning
they
have
to
limit
how
big
messages
they
send.
C
So
your
constraint
is
l
times
the
block
size
for
the
algorithm,
and
you
don't
want
the
cause
of
plain
text,
authentication
tag
and
cipher
padding
to
exceed
this
size
because
then
you're,
essentially
not
following
that
l
value
you're
going
higher
than
you
should
and
of
course,
if
the
message
turns
out
to
be
too
big,
and
you
want
to
send
a
really
big
message.
Well,
you
can
split
it
with
block
wise
and
then
it's
multiple
small
messages.
C
G
C
I
see
yeah
the
right.
We
could
definitely
possibly
extend
the
tables
we
have
currently
with
that.
The
way
we
did
it
now
with
l
is
because
all
the
formulas
are
defined
in
terms
of
l
and
that's
the
yeah
symbol
that
you
will
see
in
the
forum
as
from
the
cfrd
document.
But
yes,
it
may
be
useful
for
for
for,
like
readability,
to
also
have
the
size
in
bytes.
C
Yeah
so
one
update
we
did
here
was
we
actually
increased
the
selected
l
value
we
had
for
all
algorithms
except
aes,
128
ccm8
from
2
to
power
8
to
2,
to
power
10,
because
we
realize
that
we
still
maintain
acceptable
ca
and
ia
probabilities,
even
increasing
the
l
value,
so
basically
increasing
the
l
value
means
that
you
get
higher
probabilities,
but
we
still
see
that
with
2
to
the
power
of
10.
These
are
acceptable.
C
And
basically
the
point
is
that
in
the
c4d
document
they
define
they
mentioned
that
you
may
want
to
aim
for
c
a
and
I
a
lower
than
2
to
the
power
of
minus
50..
So
that's
the
limit
they
set
there
and,
as
you
can
see
in
this
table
here,
even
with
with
increasing-
and
we
still
are
well
much
better
than
2
to
the
power
-50
in
terms
of
our
probabilities.
C
C
And
by
the
way
we
handle
as128
ccm8
as
a
different
case,
because
that's
the
most,
that's
the
one
that
that
you
may
end
up
with
probabilities
that
are
quite
high,
like
it's.
You
have
to
analyze
that
separately.
So
I
will
go
to
the
next
slide,
and
here
you
can
see
an
analysis
of
as128
ccm8
where
we
have
added
some
more
values.
In
the
current
table.
C
We
had
we
added
a
new
value
for
v,
while
still
so
you
can
see
we
added
v
to
the
power
of
14
here
on
the
left
side,
and
with
that
we
really
hit,
I
a
probability
2
to
power,
minus
50
and
the
ca
is
is
better
than
that.
So
that's
not
a
problem,
so
in
fact
we
could
here
increase.
We
could.
This
could
be
like
a
recommended
good
set
of
values
for
for
implementers
to
use,
while
still
hitting
this
2
to
the
power
minus
50
probabilities,
but
an.
C
C
C
A
recap,
by
the
way,
so
the
the
second
part
of
this
draft
is
we
defined
a
new
method
for
rekeying
our
score
and
again
based
on
loosely
based
on
the
appendix
b2
current
method.
That's
in
the
oscar
rfc
and
essentially
the
clients
and
server
exchange,
two
nonsense,
r1
and
r2,
and
we
have
this
update,
ctx
function.
That
takes
the
nonsense
as
input
and
from
that
derives
a
new
security
context
and
you
basically
go
from
your
current
security
context
to
an
intermediate
context,
and
then
you
end
up
with
your
new
context.
C
So
it's
robust
and
secure
against
rebooting
you
it's
only
one
round
trip.
After
that
you
can
use
the
new
context,
it's
compatible
with
establishment
of
a
context
with
adobe
protocol,
so
you
can
actually
use
that
of
exporter.
If
you,
if
your
original
context
was,
was
established
red
dog,
you
only
have
one
intermediate
security
context
derived
and
the
id
context
does
not
change
throughout
this
procedure
and
it
can
be
initiated
by
either
the
client
or
the
server.
C
Yeah-
and
one
update
we
have
done
now-
is
that
we
have
removed
the
r1
value
in
the
response
in
the
client
initiator
keying.
So
this
is
just
like
it's
in
appendix
p2
of
our
score.
Basically,
you
don't
need
r1
in
the
response
from
the
server,
because
you
can
already
correlate
the
response.
One
request,
one
through
the
core
token,
so
it's
really
kind
of
redundant
here
to
also
include
r1
in
the
response.
C
Further
updates,
so
we
added
recommendations
on
the
minimum
length
of
r1
and
r2
and
again
r1
and
r1
concatenated,
with
hardware
used
as
nonsense,
and
we
motivate
this
based
on
similar
considerations
as
in
appendix
p2,
and
currently
we
recommend
the
minimum
8
bytes
for
r1
and
r2
and
yeah.
A
question
here
is:
if
this
is
sufficient,
I
see
christians
raising
his
hand.
G
Yeah,
I'm
basically
asking
a
similar
question,
as
as
we've
had
in
in
request
tech
recommending
and
recommending
a
minimum
of
eight
bytes
is
might
be
good,
but
we
should
take
care
that
devices
that
can
work
on
an
incrementing
schedule
also
can
do
that
so
that
they
can
keep
it
short.
If
they
can
be
sure
that
it
will
not
be
reused.
D
C
That
may
be
a
good
point
that
we
shouldn't
lock
out
maybe
more
embedded
implementations
if
they
can
do
this
in
a
in
a
safe
way.
Yeah,
yes,
so
also,
yes,
for
the
text
needs
to
be
added
about
like
collisions
and
and
the
birthday
paradox
etc.
So
we
will
expand
the
current
text
a
bit
with
some
considerations.
C
So
that's
every
new
observation
will
have
a
request
have
a
partially
higher
than
partially
asterisk
and
by
the
so.
The
drawback
is
that
you
have
big
jumps
in
the
partial
iv,
which
means
faster
consumption
of
the
partial
of
ease
and
also
larger
communication
overhead,
because
you're
sending
more
data
as
they
are
bigger
in
the
messages
themselves.
C
C
C
I
go
to
the
next
step.
Yeah,
we
added
a
six
dish
as
a
use
case
for
this
procedure,
because
currently
60
is
used
as
appendix
p2
to
handle
failure,
events
and
basically
think
the
the
arc
can
use
appendix
b2
with
the
pledges
and
this
new
key
update
procedure
can
be
a
nice
replacement
for
appendix
b2,
especially
for
six
dish,
because
one
good
property
here
is
that
it
preserves
the
id
context
across
three
keying.
C
C
So
here
it's
one
advantage
of
appendix
v2,
basically
in
this
new
procedure-
and
we
also
say
now
that
this
this
draft
will
update
rfc,
8613,
also
deprecating
and
replacing
appendix
b2.
So
it
will
essentially
become
the
new
appendix
b
tool
and
so
two
questions
here.
Is
it
okay
to
supersede
those
core
appendix
b2
procedure
and
secondly,
is
the
wording
which
shows
okay,
which
is
deprecating
and
replacing.
C
C
We
also
did
some
editorial
improvements
harmonizing
the
terminology
and
we
also
use
the
terminology
for
iana
considerations
from
rfc
8126
and
one
open
question
here
is:
should
we
select
a
name
for
this
breaking
procedure
so
it
could
have
like
a
short
name.
That's
easy
to
refer
to
so
like,
for
instance,
now
the
you
know
a
score,
you,
you
can
call
it
appendix
b2
procedure,
but
it's
a
bit
for
this
new
one.
It
could
possibly
be
nice
to
have
a
an
easily
said
and
referrable
name.
C
And
then
a
couple
of
open
points
and
next
step,
so
one
thing
we
want
to
do,
of
course
is
address
open
points,
we're
actually
tracking
a
number
of
issues.
I
think
we
collected
all
the
issues
that
we
have
on
the
gitlab
repo
and
that's,
of
course,
open
for
anyone
to
to
visit
and
take
a
look
at,
and
we
also
want
to
further
refine
these
limits
and
update
the
tables,
possibly
to
change
the
selected
qv
and
l
values.
We
have
to
to
find
unit
to
become
to
come
closer
to
this
2
to
power.
C
G
G
So
if
there
is
in
a
bird
for
oscar,
so
if
there
is
inner
block
rising,
then
the
messages
are
limited
to
what
one
kilobyte
anyway,
and
if
there
is
outer
block
rising,
then
the
old
new
alternative
to
chunking
it
in
one
kilobyte
blocks
is
sending
the
whole
representation
which
might
easily
exceed
any
l
that
is
feasible.
So
that
takes
a
bit
of
pressure.
I
think
out
of
the
l
discussion,
unless
we
really
want
to
use
bird
for
oscar.
C
Right
right,
we
actually
have
an
open
issue.
I
think
tracking
this
point
about
wanting
really
large
l
values,
but
I
think
I
agree
with
you
that
since
saying
typically
in
blockwise,
I
mean,
I
think,
like
an
l
of
two
to
the
power
of
ten.
Yes,
yours,
as
you
said
you,
you
will
be
using
inner
blockwise
as
a
client
sending
sending
sending
requests.
C
So
I
think
we're
we
may
very
well
be
be
fine
in
terms
of
their
limit,
maybe
more
interesting
to
look
at
increasing.
Possibly
we
could
increase
q.
I
believe
because
we
have
a
good
margin
in
when
it
comes
to
the
ca
probability
and
q
and
v
affect
these
probabilities
in
different
ways
due
to
how
the
formulas
are
structured.
C
A
H
H
H
Okay,
now
I
only
need
to
yeah
okay,
great
good
thanks.
Okay,
I
have
to
seem
to
have
a
similar
problem
as
the
other
presenters
that
it's
somewhat
low
res,
but
I
guess
we
can
manage
with
that
so
yeah,
I'm
martin
landers
I'd
like
to
talk
about
our
draft
about
dns
queries
of
a
co-op
and
yeah.
If,
if
you
want
to
read
it,
I
provided
the
name
of
it,
of
course,
and
we
decided
to
do
the
discussion
for
now
on
github.
H
You
can
find
the
link
also
on
the
slides.
So
let's
first
talk
about
why
we
think
we
need
it,
as
you
probably
know,
dns
isn't
encrypted.
So
anyone
who
requests
a
name
from
an
iot
device
to
a
dns
server
has
runs
the
risk
that
they
will
be
eave
dropped,
and
so,
when
using
an
encrypted
transport
with
co-op,
we
can
encrypt
it
similar
as
we
as
it
is
done
with
dns
over
http
or
dns
over
tls.
H
But
this
these
two
protocols,
of
course
conflict
with
the
constraint
use
case
and
an
additional
advantage.
When
we,
for
example,
look
at
dns
over
dtls
is
that
we
can
share
the
same
system,
resources
that
we
use
for
co-op.
If
you
have
a
co-op
client
on
the
node
to
then
also
use
for
dns,
so
the
same
sockets,
the
same
buffer
can
be
used
and
we
can
also
reuse
the
co-operative
transmission
mechanism.
H
To
give
you
a
basic
overview
is
basically
that
we
encapsulate
the
dns
queries
in
a
co-op
request.
Those
then,
of
course,
can
buy
a
dns
over
co-op
server,
be
relegated
to
another
dns
server
and
then
get
our
dns
response
back
and
then
encapsulate
the
co-op
response
in
a
dns
response,
so
really
basic
at
the
moment
so,
and
the
message
format
as
basic,
as
is
basically
also
the
same
as
we
have
in
dns
over
http.
So
we
said
that
the
message
should
be
in
a
co-op,
confirmable
message.
H
H
The
first
one
is
that
we
have
in
the
cache,
timings
or
the
timings
and
information
is
valid,
have
relative
time
controls
and
so
in
the
stl
and
in
co-op
it's
a
max
age
option
and
that
leads
to
the
time
frames.
That
ttl
is
that
the
ttl
is
cached
for
in
the
cache,
basically
to
run
out
to
be
maybe
out
of
date.
H
What
is
http
is
doing,
and
the
other
issue
we'd
like
to
discuss
is
if
we
really
need
all
the
three
methods.
If
you
look
at
the
table
on
top
of
my
slides,
you
basically
see
that
both
get
imposed,
which
are
the
one,
the
methods
that
were
used
in
the
original
doh
both
have
disadvantages,
because
post
is
not
cacheable
and
with
get
because
it.
H
The
query
is
in
the
uri,
it
is
not
clockwise
transferable
and
also
we
need
the
special
yuri
template
to
have
some
to
define
where
the
query
actually
is
in
the
uri,
and
we
all
don't
have
all
these
disadvantages
with
fetch
so
yeah.
The
current
state
is
that
if
we
get
rid
of
is
especially
git,
we
don't
need
some
way
to
exchange
the
euro
template
which
is
done
with
like
the
way
it's
done
in
doh.
H
But
the
thing
is
maybe
this
isn't
that
much
of
a
problem,
because
we
actually
looked
at
the
implementations
of
fetch
in
all
in
15
active
force.
Implementations,
which
means
active,
is
that
it's
that
the
last
change
was
less
than
a
year
ago
and
there
most
of
them
already
support
fetch
and
then
again
also,
as
carson
pointed
out
on
the
mailing
list,
fetch
is
nearly
trivial
to
implement
if
you
want
to
have
a
full
overview
over
that
list.
There
is
also
this
gist
by
of
mine,
which
you
can
look
at
and
yeah.
H
So
I
basically
summarize
the
questions
we
have
for
the
core
group.
First
of
all,
if
this
topic
is
relevant
at
all
for
core
anu
in
any
way
or
and
yeah,
the
two
questions
I
went
into
detail
for
which
was
the
how
to
handle
the
relative
aging
and
caching
and
if
get
or
post
should
be
avended
completely
or
partly
or
only
mentions
in
the
appendix
or
yeah.
D
So
I
I
strongly
believe
that,
given
that
we
have
had
fetch
for
half
a
decade
now
we
might
want
to
use
it,
and
if
every
single
application
protocol
does
not
use
fetch,
because
there
is
that
single
legacy
implementation
that
still
doesn't
do
fetch,
then
of
course
nobody
will
do
that
fetch
because
you
don't
need
it.
So
we
should
simply
do
the
right
thing
to
do
here.
D
H
D
D
D
Maybe
well
a
lot
of
environments
have
the
ability
for
for
a
dns
client
to
actually
push
information
to
the
dns
server.
That's
called
dns
update,
okay,
and
that,
of
course
requires
some
form
of
authorization
and
therefore
authentication,
but
given
that
we
already
want
to
have
some
some
form
of
protection
for
privacy
here,
that's
maybe
not
such
a
big
cost
to
pay.
So
it
may
be
relatively
easy
to
to
add
a
dns
update
function
to
this
protocol.
H
D
Yeah
yeah,
I'm
not
a
dns
update
specialist,
so
maybe
we
should
find
some
with
somebody
from
the
dns
space
yeah.
Michael,
that's
a
good
comment.
This
should
happen
in
dns
up
with
review
from
car.
So
I
think
that
there
there
is
a
protocol
component
that
we
should
put
in
and
there
is
operational
considerations
component.
That
probably
should
be
done
in
dns
up.
H
D
H
D
So
this
this
is,
to
a
large
part,
also
a
simply
document
creation
kind
of
thing
I
mean
at
some
point
we
want
to
have
dns
update.
Is
that
something
we
want
to
put
right
into
the
first
bucket,
or
do
we
open
a
second
bucket
for
it?
That
has
a
lot
to
do
with
what
kinds
of
experts
do
we
have
available
at
a
particular
point
in
time?
So
that's
not
really
a
technical
decision.
It's
really
a
a
lot
of
decision
about
how
we
just
want
to
proceed
to
to
rest
this
efficiently.
H
H
F
H
F
D
D
H
H
Maybe
we
can,
if
we
decide
that
the
that
get
and
post
should
go
out.
Maybe
we
can
do
a
resubmission
for
that,
but
yeah.
I
guess
regarding
the
timeline
we
were
planning
to
have
this
topic
basically
done
as
soon
as
possible
possible,
so
yeah,
it's!
We
don't
want
to
spend
years
on
this.
We
maybe
only
in
the
timeframe
of
months
matias,
wants
to
say
something.
I
And
second
I
mean
what
is
what
would
be
the
expectation
of
a
updated
draft.
Would
it
be
that
we
clarify
why
dns
over
corp
is
needed
compared
to
dns
over
dtls,
for
example,
because
I
mean
dns
over
udp,
it's
martin
said
why
we
don't
want
to
use
it
because
it's
not
encrypted.
So
if
it
all,
it
would
be,
then,
as
it
were
detailed
as
so
is
the
expectation
that
an
updated
version
includes
this
type
of
discussion.
I
B
D
I
I
J
A
Okay,
if
there's
nothing
else
on
this,
thank
you
martinez
for
the
presentation
looking
forward
for
the
update
you're
welcome
one
comment
in
the
chat:
yes
welcome.
Thank
you.
Okay.
We
have
one
last
point
in
the
agenda
for
today.
That's
the
possibility
of
rechartering
building
on
some
text
proposed
a
few
weeks
ago,
and
we
actually
received
some
input
from
from
yoran
today
off
list
on
on
the
initiative
itself
and
on
possibly
better
text
you
can
see
there
is
a
starting
point.
J
Right
yeah
you're
on
here.
Can
you
hear
me?
Yes,
okay,
good,
so
I
I
actually
looked
at
the
charger.
I
read
it
and
I
it's
kind
of
long,
so
I
don't
want
to
take
a
stand.
I
think
this,
I
think
the
recharging
idea
is,
is
actually
a
good
one.
If
you
read
it,
you
realize
that
there
are
things
that
are
out
of
date
and
that
that's
something
that
might
come
come
back
to
us.
J
J
J
E
H
J
J
Transfer
this
time
yeah.
But
let
me
let
me
then
just
verbally
explain
what
I
tried
to
do
so
I
mean,
if
you
look
at
the
it's,
it's
like
a
three-page
charter,
and
what
you
can
do
is
that
the
first
third
of
the
charter
is
is
like
the
old
charter.
It's
it's
talking
about
constrained
devices
and
proxies,
and
and
caching
and
so
on,
and
that's
that
seems
very,
very
much
valid
and
not
not,
I
mean
up
to
date
and
then
there
are
two
pages
which
is
describing
more
detail.
J
What
what
the
work
is
going
on,
and
I
think
that
what
we
could
do
is
to
keep
the
first
third
and
I
have
a
concrete
proposal
for
that
and
then
to
basically
go
either
just
on
a
high
level,
what
other
topics
or
just
a
bullet
for
each
of
the
topics.
So
what
I
did
was
just
take
the
actual
text
and
remove
remove
parts
without
going
into
editing
the
actual
content
just
removing
stuff
and
that
still
left
something
like
two
and
a
half
pages.
But
the
second
and
third
pages
are
essentially
bullets.
J
A
Right
we
need
to
have
this
shared
somehow
also
for
other
people
to
see
and
contribute.
So
probably
the
easiest
way
is
using
the
same
hackmd
where
the
original
first
proposal
was
loaded
and
well.
You
hit
the
link
in
the
minutes,
but
I
can
put
it
in
the
chat
again,
so
you
can
just
draw
a
line
on
top
and
and
copy
paste
here.
Did
you.
D
A
J
A
J
D
K
J
Right
stop
and
then
we
have
something
here,
the
stop
yeah
exactly
so,
and
then
then
it
comes
basically
the
discussion
about
candidate
work
items
and
then
I
replaced
them
with
bullets,
and
that
I
mean
that's
it.
So
the
black
text
is
the
original
text,
which
is
current
in
the
in
in
the
charter,
and
the
red
text
is
what
I've
added.
So
most
most
things
are,
are
just
the
an
optimized
version
of
the
current
charter.
J
D
H
D
H
J
K
Yes,
you
believe
the
rechartering
is
a
good
effort
and
I
am
still
looking
for
the
working
group's
opinion
about
this
should
be
done,
or
this
should
not
be
that
and
karsten.
You
have
voiced
your
opinion
previously
that
we
need
to
be
careful
if
we
do
any
type
of
rechartering
and
I'm
still-
I
don't
know
if
you
your
view,
has
changed
about.
We
should
do
this
or
not.
I
guess
it
depends
on
what
the
possible
charter
or
work
charter
will
look
like
at
the
end
of
our
effort.
A
D
K
I
think
that
what
could
happen
is
that
the
isu
becomes
even
more
attentive
to
the
drafts
that
are
brought
to
them
and
you
know
they'll
be
like
okay.
This
is
not
in
scope
of
the
charter
and
it's
going
to
be
harder
to
motivate
it's.
You
know
at
the
limit
of
the
charter
and
like
at
that
point
we
will
have
we'll
we'll.
A
B
Yeah,
so
I
mean
it's
kind
of
a
strange
situation,
because
I
think
everybody
wants
to
achieve
the
same
goal,
which
is
to
facilitate
the
new
work,
but
I
think,
like
besides,
I
mean
it's
kind
of
like
besides
the
point,
because
what
we
really
need
is
group
participation
for
it
to
to
move
forward,
and-
and
I
think
that
that
should
be
the
the
main
focus
and
people
should
start
thinking
about
the
issue
and
comment
on
it.
So
that
anything
that
can
happen
actually
happens.