►
From YouTube: IETF-CBOR-20221019-1400
Description
CBOR meeting session at IETF
2022/10/19 1400
https://datatracker.ietf.org/meeting//proceedings/
B
Yeah
my
main
point,
bringing
this
on
the
agenda
again,
is
that
cd8
is
likely
to
issue
a
working
of
last
call
in
the
next
few
days,
and
we
said
we
wanted
to
synchronize
our
time.
Tech
document
with
that,
and
that
appears
to
be
in
a
relatively
stable
state,
with
a
possible
exception
of
one
pull
request
that
proposes
adding
ut1
to
the
time
scales
provided.
B
B
B
C
My
name
is
Martin
for
those
who
don't
know
me,
yeah
first
I
will
present
our
motivation
and
introductions
and
the
definition
of
it
and
then
give
some
examples
on
analysis
and
then
some
to
be
done.
So
this
is
the
motivation.
Is
that
in
core
and
DNS
up
and
deprive
we
currently
discuss
a
method
to
transport
DNS
over
Co-op.
C
The
problem
there
is
that
the
packet
size
exceeds
8215
for
pdu,
depending
on
query
names
very
quickly.
If,
as
you
can
see
in
the
graphic
below,
and
so
we
have
fragmentation-
which
we
of
course
want
to
avoid,
because
with
high
bracket
loss,
we
only
multiply
the
packet
loss,
and
so
we
need
a
compression
format
for
DNS
messages.
C
C
C
The
resource
record
is
also
a
sibo
array
that
which
at
minimum
contains
a
TTL
and
the
resource
data,
either
encoded
as
a
byte
string
or
if
it's
a
domain
name
also
as
a
text
string
and
it
optionally
can
contain
the
name
and
the
record
type
both
default
to
those
that
are
in
the
question
and
basically
a
response,
then,
is
an
array
of
arrays.
Each
array
in
that
array
corresponds
to
a
section
and
yeah,
and
basically
only
at
minimum.
The
answer
section
is
required.
C
But
we
can
also
amend
the
original
question
as
I
said,
optionally,
so
yeah
it's
a
simple
example.
I
can
give
you
here
a
query
for
an
IPv6
address
for
example.org,
and
this
results
in
a
sibo
object.
That
is
certain
bytes
large
compared
to
the
52
bytes.
A
normal
DNS
wire
format.
Has
this
allows
us
for
compression
of
400
percent
and
same
goes
for
the
corresponding
response,
where
we
have
a
compression
rate
of
283.3
percent.
C
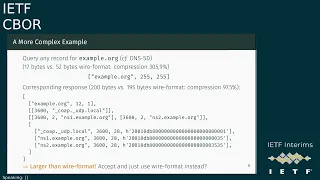
But
when
we
look
at
a
little
complex
example,
for
example,
if
we
want
to
query
any
record
from
example.org
as
we,
for
example,
do
with
the
service
Discovery.
Sometimes,
then,
of
course
the
query
is
still
quite
well
compressed
but,
for
example,
for
the
corresponding
response,
even
with
all
the
Illusions
I
we
provided,
we
only
have
a
compression
rate
of
97
97.5
percent,
so
yeah
we
have
it's
larger
than
the
format
and
the.
So
the
question
is:
do
we
just
accept
it
or
you
induce
a
wire
format?
Instead,
yes,
Carson.
B
Yeah
I
didn't
want
to
to
interrupt
your
presentation
of
this
slide,
so
I
think
what
what
we
are
seeing
here
is
that
for
more
complex
queries,
the
built-in
message
compression
and
in
section
4.4
of
RFC
1035-
actually
works.
It
doesn't
do
a
lot,
but
it
does
something.
So
in
this
example,
it
would
actually
compress
the
the
three
occurrences
of
example.org
by
using
the
the
built-in
suffix
compression
of
RFC
1035.
C
B
So
if
we
look
at
this
some
more
or
actually
it's
not
three
times
it's
five
times,
if
you
look
more
closely,
you
also
see
in
this
example,
I'm
not
sure
this
is
very
realistic
opportunity
for
prefix
compression
in
in
the
IP
addresses.
That
is
something
that
RFC
sorry
1035
cannot
use,
but
that
we
could
use
I.
Think
the
interesting
question
is:
can
we
Define
application
oriented
subset
of
the
sibo
package
specification
which
essentially.
A
B
B
C
B
Yes,
the
the
idea
behind
chicas,
it's
called
Static
context,
data
conversion,
the
ideas
to
actually
identify
something
that
is
specific
to
the
relationship
between
the
the
two
parties
that
communicate
using
shake.
So
you,
you
know
that
a
specific
form
of
UDP
packet
or
whatever
is
going
to
be
used
a
lot.
And
if,
if
you
do
that,
then
she
gives
you
a
very
good
compression.
B
C
If
we
look,
for
example,
just
in
in
how
it
devices
sometimes
as
well
most
of
the
time
communicate
just
an
example,
they
want
to
request
the
IP
address
of
the
Cloud
Server.
Then
the
Cloud
Server
has
some
domain
where
we
definitely
could
already
predict
that
it
might
be
rvs.com
or
something
like
that,
so
I
think
at
least
there
is
also
some
predictability
where
we
could
leverage
Shake,
but
yeah.
Maybe
maybe
check,
is
the
wrong
way
to
go
here.
I
didn't
think,
that's
that
hard
through.
Yet
to
be
honest,.
B
B
B
I,
don't
know
two
or
three
bytes
four
bytes,
so
that
already
would
be
more
than
the
the
five
bytes
that
we
are
seem
to
be
losing
here
by
not
using
30
10
35
compression,
and
we
would
maybe
be
able
to
make
use
of
the
fact
that
we
have
opportunity
for
prefix
compression
on
on
IP
addresses,
which
are
also
relatively
large,
particular
with
IPv6,
so
that
that
would
be
an
additional
Improvement.
So
I
think
that
might
be
worth
investigating.
C
B
B
Yeah,
my
recommendation
would
be
to
use
everything
you
you
need.
You
want
from
the
reference
mechanisms
in
sibo
packed,
but
not
necessarily
use
the
same
table
setup
mechanism,
because
the
DNS
specific
table
setup
mechanism
may
may
be
more
efficient
and
maybe
more
appropriate
for
the
restricted
profile
we
are
likely
to
find
for
sibo
packed.
So
a
generic
sibo
pack.
Implementation
might
still
work
with
this,
but
might
have
to
use
the
the
DNS
specific
table,
setup
mechanism
and
DNS
only
implementation.
A
C
B
B
Agree,
yeah
yeah
good,
so
the
the
other
question
was
edna0
and
I
must
admit.
I
may
have
known
what
edns
0
does
exactly
10
years
ago,
but
I'm
not
sure
I
still
fully
remember.
So.
This
is
your
typical
example
of
bringing
two
technologies
together
and
you
need
Experts
of
both
Technologies
and
and
in
the
Civil
working
group.
We
can
bring
the
Civil
expertise,
but
we
don't
necessarily
have
the
the
other
expertise.
I
see
that
there
is
a
DNS
directorate
review
of
this
document
already
being
scheduled.
Did
you
see
that
as
well.
C
C
B
Mean
this
is
this
document
is
a
very
early
stage,
so
getting
too
much
attention
for
this
is
probably
not
not
the
right
thing
to
do,
because
people
remember
it
in
in
the
early
stage
that
it
is
so
I
think
it
would
be
good
to
to
have
a
DNS
directorate
member
look
at
this,
but
not
necessarily
the
whole
DNS
Community,
okay
about
it.
At
this
point.
B
Yes,
I
I
didn't
prepare
slides
for
this,
because
most
of
what
what's
in
their
draft
already
is,
has
been
on
on
slides
in
in
previous
meetings.
The
main
contribution
of
of
this
version
of
this
new
draft
is
that
I
have
narrowed
this
a
little
bit
down
and
focused
on
what
we
actually
might
want
to
do
in
in
the
specific
CDL
2.0
project,
I
mean
we
can
always
do
a
CDA
3.0.
So
if,
if
somebody
who
has
a
better
computer
than
I
have
could
just
present
this
draft
from
the
link.
A
B
A
A
D
B
B
A
D
B
So
this,
as
you
can
see
from
the
table
of
contents
on
the
right,
this
has
essentially
three
main
items.
One
is
about
syntax
issues,
some
of
which
clarifications
and
I
don't
know
whether
we
want
to
do
this
in
the
same
document
and
some
are
extensions,
and
then
there
is
a
discussion
about
the
processing
model
and
discussion
about
the
module,
superstructure
and
I
want
to
quickly
comment
on
on
these.
B
So
on
the
syntax
deficits
item,
the
the
biggest
requirement
that
I'm
getting
again
and
again
is
how
do
I
write
CDL
that
deals
with
ranges
of
tag
numbers.
So
if
you
look
at
the
syntax,
the
abnif
for
the
syntax
that
we
have
in
in
at
the
top
of
the
screen,
this
only
allows
for
an
unsigned
integer
right
now
for
the
tag
number.
So
it
requires
you
to
commit
to
a
specific
number.
B
B
So
in
RFC
9277,
we
have
a
number
of
tags
allocated
for
Content
types
for
Content
formats.
Excuse
me,
so
it's
this
166h
something
to
a
16.
It's
something
else.
That's
the
range
and
by
putting
this
range
or
the
real
name
for
this
range
into
angle
brackets
and
into
the
position
where
normally
the
unsigned
integer
would
have
been.
We
have
a
convenience
Syntax
for
providing
ranges
for
tag
numbers.
So
this
is
something
that
that's
really
very,
very
small
increment,
but
it's
incompatible
with
the
CDJ
1.0
syntax.
B
B
The
the
problem
really
is.
This
is
again
only
providing
literals,
and
so
we
are
kind
of
committing
the
same
mistake
that
we,
we
are
repairing
for
something
else
in
2.1
where
we
actually
want
to
be
able
to
write
cddl
for
what
goes
there.
So
I
don't
have
a
particular
ly
bright
idea
how
to
do
this
at
this
point
in
time.
So,
for
instance,
maybe
one
wants
to
to
put
in
a
b
and
F
for
the
thing
that
is
in
the
single
quotes.
B
B
2.3
is
just
a
number
of
router
reports
that
that
have
to
be
done
again.
This
could
be
a
separate
document
because
we
want
to
fix
these
error
Raja
for
8610
as
well.
I,
don't
think
we
want
to
reissue
86
gen,
but
we
might
have
a
small
Corrections
and
clarifications
document
that
has
these
fixes
in
an
agreed
way.
I'm
not
going
to
go
through
the
details
here,
because
it's
very
tedious
but
I
think
it's
clear
that
we
want
to
address
all
the
errata
number.
B
Three
really
is
the
the
biggest
item
and
and
one
that
maybe
goes
a
little
bit
beyond
what
we
are
defining
in
the
language.
The
processing
model
people
are
going
to
write
programs
that
actually
make
use
of
CDL
in
an
unexpected
ways.
So
we
cannot
forecast
all
kinds
of
processing
that
people
will
do
with
acidity,
but
on
the
other
hand
we
probably
need
to
have
a
whoops.
B
B
B
The
the
feature
doesn't
work
very
well
at
the
moment,
so
that
that
would
have
to
be
improved
a
little
bit,
but
basically
that's
something
that
we
already
can
do
with
cdda
1.0.
What
we
might
want
to
add
with
2.0
is
ways
to
tell
the
annotator
what
information
is
useful
and
what
information
can
be
left
out,
because
if
the
tool
would
really
tell
everything
it
knows,
it
would
be
way
more
comments
than
actual
meat.
B
So
the
the
one
of
the
things
that
that
annotations
that
are
put
into
the
model
may
be
useful
for
is
adding
little
pieces
of
predicates
or
little
pieces
of
programs
that
operate
on
the
data
item
and
can
be
used
for
doing
things
like
co-occurrence
constraints.
Of
course,
at
some
point
we
run
into
this
evaluation
language
problem.
We
don't
have
a
common
view
of
what
an
evaluation
language
might
be,
and
it
probably
is
necessary
to
yeah
at
least
you.
B
And
finally,
the
the
one
thing
we
could
do
with
annotations
or
based
on
annotations
is
to
actually
do
transformation.
So
we
describe
how
validated
data
item
could
be
interpreted
in
a
different
way.
So
if
you
have
some
some
structure,
that
really
is
is
just
syntactic
stuff.
You
might
be
able
to
get
rid
of
of
the
noise
in
that
syntax,
using
a
transformation
step,
and
this
also
can
be
used
for
doing
things
like
adding
and
default
values,
or
doing
some
other
Transformations
that
that
convert
syntactic
sugar
into
a
canonical
form.
B
So
my
my
proposal
here
is
to
actually
continue
writing
these
implementations
and
and
do
interesting
things
with
the
implementations
and
maybe
do
an
initial
Syntax
for
putting
annotation
information
into
a
CDL
spec
that
these
implementations
can
actually
use,
and
maybe
that
simple
syntax
could
go
into
CDL
2.0,
but
the
the
actual,
a
specific
mechanisms
and
and
processes
might
be
separate
documents.
So
we
can
keep
the
language
simple,
but
can
build
complicated
things
on
top
of
that,
if
we
want
to.
B
Foreign,
so,
finally,
the
the
most
requested
major
feature
is
a
module
superstructure
and
we
have
looked
at
a
way
to
provide
this
in
such
a
way
that,
at
least
for
for
a
limited
amount
of
time,
2.0
based
specification
can
still
meaningfully
be
processed
by
a
CDA
1.0
implementation.
So
we
would
use
something
that
that
looks
a
little
bit
like
like
pragmas
or
preprocessor
statements,
or
something
in
in
other
languages
to
to
Define
these
modules.
B
Like
the
the
hash
include
mechanism,
the
C
language
uses
where
the
using
module
actually
points
to
the
used
module,
or
we
could
do
this
more
like
the
the
way
C
language
modules
are
linked
together,
where
you
essentially
provide
names
in
one
module
that
can
be
picked
up
in
the
other
module,
but
you
don't
really
tell
the
system
where
that
that
first
module
can
be
found,
so
both
has
advantages
and
disadvantages
directly
referencing.
Another
module
can
be
very
inflexible
if
you
want
to
start
using
a
new
version
of
that
module.
B
Somehow
using
external
information
can
be
difficult.
If
yeah,
you
essentially
want
to
to
throw
things
together,
and
you
now
need
to
add
all
this
external
information
that
that
says
how
things
are
working
together.
You
essentially
start
writing
Linker
scripts,
so
I
think
we
need
to
understand
what
we
want
to
do
here.
B
And
there
are
some
more
text
that
explains
how
how
this
is
it's
a
little
bit
difficult
but
but
can
be
done
yeah.
So
this
is
Ina
references
but
of
course,
the
more
likely
thing
we
want
to
use
as
references
into
other
cddl
modules
and
one
place
where
we
might
find
things
we
want
to
import
might
be
rfcs
and
the
very
simple
syntax,
like
RFC
1990.org,
to
reference
that
we
actually
mean
the
the
oid
rule
that
is
defined
in
RFC
1990
might
be
an
easy
way
to
get
cross-references
between
different
documents.
B
So
it
would
be
possible
for
an
RFC
to
provide
something
like
a
cddl
library
that
other
specifications
can
use
to
to
reference
this,
and
this
we
could
explicitly
support
this,
and
this
is
for
for
two
explicitly
interacting
with
namespaces,
by
providing
a
way
for
cd8
specification
to
say
this
document
actually
exports
three
names.
So
these
are
the
names
you
are
supposed
to
use
from
from
this
document
and
yeah,
then
of
course
Define
what
that
is,
I
I
didn't
copy
of
all
of
RFC
1990
here.
B
So
that's
why
this
is
the
looks
a
bit
trivial,
but
that
that's
essentially
the
idea
and
then
there
could
be
an
explicit
import
syntax
on
the
other
side
as
well.
So
you
don't
have
to
say
RFC
1990.0id.
Each
time
you
use
an
as1
object,
identifier,
so
I
think
I
presented
that
before
yeah
retroactive
exporting
is
something
we
could
do.
This
is
useful
for
CDL.
B
This
is
actually
even
way
more
useful
once
we
notice
that
cddl
and
ABN
F
actually
are
very
similar
in
this
respect,
so
retroactive
exporting
from
existing
rfcs
into
a
b
and
F
specifications
that
that
reference
that
existing
ABN
F,
that
might
be
very,
very
useful,
so
445
defines
a
basic
idea.
What
operations
could
be
provided
here?
B
B
D
I
heard
from
I
think
I'm
still
on
on
my
mic.
If
I
switch,
all
things
will
go
straight
on
your
training,
I
heard
from
Amanda
just
last
week
that
they're
doing
a
major
overall,
an
upgrade
to
the
storage
formats
and
mechanisms
in
the
Iona,
Registries
and
initially
prototyping,
it
I
think
was
service
names
and
Port,
but
into
other
regular
grades
and
I.
Don't
know
if
you're
already
up
to
date
on
that
I
figured.
You
probably
were
Karsten,
but
maybe
there's.
B
D
D
A
D
D
D
Not
that
I
want
to
see
you
do,
but
I
would
suggest
Carson
checking
in
with
honest
and
Brendan
in
particular
and
Dave
color,
because
one
of
the
three
of
them
may
very
well
have
in
the
rat's
teeth,
suit
and
other
things,
spectrum
and
idea
of
something
they
desperately
wish.
They
could
express
in
cddl
and
certainly
can't
in
cddl
1.0.
Without
you
know,
and
without
informal
annotation
or
whatever.
Without
you
know,
just
doing
it.
D
A
D
A
A
A
Please
reply
on
the
list.
If
there
are
things
you
would
like
to
see
on
the
agenda
at
the
115
session,
so
so
that
I
can
put
together
an
agenda
I,
don't
know
whether
this
gen
will
be
on
115
he's
still
on
family
leave,
so
I,
don't
know
if
he'll
be
participating
in
115
or
not.
I
will
check
in
with
him
on
that.