►
From YouTube: IETF108-NMRG-20200729-1100
Description
NMRG meeting session at IETF108
2020/07/29 1100
https://datatracker.ietf.org/meeting/108/proceedings/
A
A
A
A
A
So,
as
you
know,
so
this
is
a
online
meeting.
As
already
said,
the
session
has
been
recorded.
There
is
no
blue
sheet,
as
it
will
be
automatically
automatically
recorded
based
on
the
and
the
login
in
the
amitako
note
that
you
have
to
enter
the
queue
before
saying
before
speaking.
So,
please
use
the
button
in
the
mythical
to
enter
the
queue
otherwise
be.
A
Please
keep
your
module,
muted
and
video
half,
although,
as
as
an
in-person
meeting,
it's
important
that
you
state
your
name
and
if
you
want
any
affiliation
when
you
start
speaking
just
for
the
just
for
the
at
least
for
the
audio
stream,
but
also
to
be
aware
who
is
thinking.
These
are
multiple
people
speaking
here.
We
just
a
reminder
with
the
different
links
that
we
use.
A
So
but
of
course
everybody
can
also
take
take
note
in
the
in
the
collaborative
tool,
so
the
agenda
of
today
is
a
quite
dense.
We
give
the
priority
today
to
new
topic,
a
recent
topic,
a
new
contribution
I
would
say
so.
We
have
after
this
introduction.
We
have
the
introduction
of
the
concepts
of
digital
twin
network.
I
will
do
then
a
quick
summary
of
the
status
of
the
read
search
challenge
in
artificial
intelligence
for
network
management
document.
A
B
B
B
B
B
B
Quality
companies
are
nc,
products
creates
digital
training
between
physical
network
and
the
business
intent
based
on
ai
big
data
and
the
cloud
to
achieve
a
full
lifecycle,
operation
and
maintenance
area
networks.
Product
step
t
builds
digital
team
entity
based
on
teleco
tele
operators,
backbone
network
and
to
achieve
routing,
optim,
optimization
and
network
failure
simulation
next
slide.
Please.
B
According
to
the
definition,
there
are
four
key
characteristics
of
dtm:
they
are
data
model,
mapping
and
interface
data
as
a
cornerstone
for
constructing
dtn
system,
and
the
model
is
a
ability
source
of
digital
twin
network.
Our
where's,
the
data
model
builds
built
in
our
virtual
training
network
can
be
designed
and
flexibly
flexibly
combined
to
serve
network
applications
and
the
real-time
inter
interactive
mapping
between
a
physical
network
and
the
virtual
network
is
the
most
typical
feature
that
dtn
is
different
from
network
simulation
system
or
platforms.
B
B
B
This
dtm
system
network
network
automation
can
be
can
be
run
on
effectively
on
a
interactive
platform
for
simulation,
and
it
will
be
with
lower
time
cost
and
lower
opex,
as
well
as
lower
source
impact
on
real
network.
The
second
benefit
type
is
more
intelligence
for
network
decision
making
without
detailed.
B
Currently,
there's
higher
trial
risk
due
to
a
lack
of
real
network
for
natural
innovation,
and
the
speed
is
slow
on
deploying
new
innovation,
for
example,
ibm
system
network,
ai
application,
etc
for
risk
adverse
network
operators
with
dtm
system
with
dtn
system.
It
will
be
effective,
there
will
be
effective
worship,
training
network
and
it
will
be
more
easier
to
access
for
researchers
than
to
speed
up
network
innovation
from
prototype
to
deployment
next
slide.
Please.
B
Here's
a
simple
case
study
that
dtm
can
as
an
enabler
for
ibm
system.
We
know
ibm
is
being
discussed
in
many
sdos,
like
here
in
itf
and
in
itu,
etsi,
etc.
Ibm
system
requires
that
that
user's
intent
can
be
assured
automatically,
while
continuously
adjusting
the
policies
and
validating
the
real
time
simulation.
B
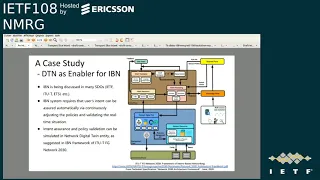
The
the
the
the
figure
shows
here
is
a
ibm
frameworker
stressed
by
ito.
Itot-Fg
network
2030's
architectural
document.
In
this
framework,
natural
digital
training
is
a
key
enabler
in
measurement
to
play.
A
intent
assurance
and
the
policy
validation
can
be
simulated
in
network
digital
training
before
control
changes
are
pushed
to
real
neural
network
deployment
deployment.
B
B
B
B
A
C
Thanks
so
thanks
for
your
presentation,
I
found
it
super
interesting,
very
ambitious
and
quite
clear.
Honestly,
I
have
two
questions.
Do
you
are
you
considering
this
digital
twin
technology,
for
wired
networks
or
also
for
other
kind
of
scenarios?
That's
the
first
question
and
the
second
one
is
how
I
understand
that
this
is
the
next
step.
But
how
do
you?
How
do
you
see
which
kind
of
technologies
do
you
think
that
they
will
be
needed
to
to
build
this
kind
of
system.
B
B
C
B
B
B
A
A
So
next
presentation
is
about
their
research
challenge
in
artificial
intelligence
for
network
management
documents.
So
again,
jerome
france
was
speaking
with
the
head
of
contributor
of
this
document
this
time,
not
as
a
chair,
so
here
we
just
give
an
update
of
the
status
of
this
document.
So
for
for
a
few
of
them,
you
are
no
bit
more
aware
of
where
there
is
in
the
document.
So
let
me,
let
me
remind
a
bit.
The
goal
of
the
document
is
to
to
look
at.
A
Basically,
what
are
the
specificities
of
the
use
of
artificial
intelligence
for
network
management,
so
I
will
not
go
into
the
detail
of
each
section
that
we
are
now
looking
at,
but
basically
we
wanted
first
to
a
bit
find
the
the
scope
of
what
is
difficult.
For
me,
network
mentioned
where
basically
hey.
I
can
help
and
then
basically
try
to
see.
Oh,
what
will
be
the
goal
of
ai
to
help
in
this
problem.
That
would
be
the
second,
let's
say,
part
introduction,
part
of
the
document.
A
A
A
And
yeah,
of
course,
we
one,
let's
say
one
side
or
one
direction
of
the-
that
we
identifying
the
different
challenges
is
that
for
network
management,
not
only
for
network
management,
but
in
our
case
it's
it's
also
the
case
that
wind
does
not
need
only
let's
say,
artificial
intelligence
with
the
for
extracting
knowledge,
but
we
really
need
to
have
some
operational
actions
after
that.
So,
basically
are
what
we
call
ai
for
actions.
A
So
here
just
again
like
we,
I
don't
have
time
to
go
deep
into
the
detail
of
if
each
of
them
for
people
attending
regularly
and
imagining
some
of
them
have
been
presented.
There
are
few
new
ones
that
are
the
I
think
the
last
three
ones.
So
one
is
about
integrating
external
events,
so
meaning
that
when
you
want
to
take
a
good
decision,
you
cannot
only
count,
maybe
on
the
data
that
you
can
take
from
your
network,
but
you
also
need
to
exploit
some
external
data.
A
One
also
is
a
problem
of
commercialization
of
a
based
product
that,
of
course,
you
can
do
nice
products,
a
nice
evaluation
in
a
lab
environment
of
simulated
environment,
and
then
the
idea
is
also.
Can
you
easily
transfer
this
knowledge
or
generalize
this
knowledge
to
be
applicable
to
another
environment
in
production
and
also
a
more
focused
topic
on
the
explainability
of
the
artificial
intelligence
projects
that
is
not
only
specific
to
network
management,
but
very
important
also
for
us.
A
So
next
steps,
let's
say,
are
the
following,
so
the
idea
was
to
create
a
draft
from
this.
Currently,
it's
a
google
document
that
was
easy
to
for
everybody
almost
to
contribute,
and
then
we
will
create
some
draft
with
all
the
contributors
in
order
to
have
some
visibility
to
this
document,
a
bit
more
and
also
some
dedicating
meetings
that
we
still
have
to
organize
and
to
to
work
specifically
on
the
content
of
the
document.
A
A
A
A
B
B
Hello,
chair,
yeah,
here's
the
question,
and
this
is
chancho,
and
my
question
is
that
I
I
I
reviewed
the
the
google
doc
and
in
section
three
it
is
about
the
the
use
cases
right
and
in
your
in
your
current
plan.
It
shows
that
use
cases
it's
not
in
our
short-term
plan.
Is
that
correct?
We
we
need
now
just
focus
on
the
ai
challenges.
Is
that
right.
A
Yes,
it's
it's
correct,
because
we
we
also
tried
before
to
to
collect
some
use
case
in
in
different,
let's
say
activities
or
and
unfortunately
it
it
does
not
work
so
well.
So
because
then
we
just
have
a
collection
of
use
case
which
are
very
specific
so
in
this
process.
So
we
want
you
to
try
something
else
more
looking
at
to
the
challenge
more
in
a
generic
fashion.
I
know
it's,
it's
sometimes
a
bit
odd,
but
previous
try
does
not
work
when
we
focus
on
your
skates.
Unfortunately,.
A
D
D
Thank
you
so
as
a
summary
of
the
draft,
so
the
target
the
objective
would
be
basically
to
leverage
on
the
internet
based
networking
technologies
for
requesting
transporters
license
so
basically
to
generate
a
slices
at
transport
level.
The
use
case
that
we
do
for
c
is
basically
the
fact
that
there
will
be
upper
systems
processing,
end-to-end
network
slices.
That
would
require
some
of
connectivity
so
basically
to
to
create
the
slices
also
at
the
transport
level
and.
D
D
Of
internet
based
an
example
of
this
could
be
the
3gpp
management
system
that
basically
could
request
some
connectivity
between
parts
of
network
slices,
extending
from
the
run
from
the
radioaccess
network
to
the
mobile
packet
core.
So
having
a
need
in
the
middle
of
all
these
slice
parts
to
connect
them
and
to
ensure
a
certain
performance,
service,
level
objectives,
and
so
on
so
far,
so
the
the
transporter
slices
are
foreseen
to
be
requested
to
a
transporter
slice
controller.
D
So
the
the
intent
based
solution
will
lie
on
top
of
this
transfer
slice
controller,
so,
basically
feeding
the
normal
interface
of
these
transfer
slice
controllers.
The
benefits
that
we
do
for
by
using
these
mechanisms
would
be
the
portability
of
the
solution
across
implementation.
So
if
we
move
into
the
internet
based
space,
we
basically
simplify
the
the
way
of
requesting
slices
independently
of
the
implementations
that
we
could
have
underlined,
also
to
have
a
simple
way
of
expressing
transporters
like
needs,
and-
and
this
could
be
interesting
in
for
the
cases
of
vertical.
D
D
So
the
original
or
the
primary
version,
the
0
version,
was
presented
in
singapore.
So
from
that
point
till
now,
basically,
what
we
have
done
is
to
to
clean
up
the
text
also
to
improve
the
section
on
translation
approaches.
We
have
updated
also
the
intent
definition
in
line
with
the
adopted
draft
in
the
nmrg.
D
So
basically
we
we
have
synced
up
with
with
that,
and
also
we
have
the
jeff
tansura
as
co-author,
so
is
now
on
board
and
helping
us
to
move
this.
This
effort
forward
next
slide,
please
yeah.
Here.
I
would
like
to
to
highlight
the
point
that
in
in
the
this
working
group,
there
is
a
an
ongoing
activity
on
transport
license,
so
this
working
group
charter
and
specifically
a
design
team
to
work
on
that,
and
there
are
several
documents,
been
been
in
progress.
D
Basically,
so
definition
of
framework
drops
are
basically
essentially
discussed
in
in
this
working
group,
so
are
close
to
be
ready
for
adoption.
Let's
see
what
happens
in
during
this
itf
meeting.
There
is
also
some
other
initial
work
on
on
transport
slicing
young
models,
and
there
are
some
alternative
models
that
we
need
to
work
more
on
them
to
see.
Finally,
what
could
we
finally
define
in
this
respect-
and
there
is
also
some
additional
work
on
translation
of
parameters
for
the
northbound
interface
of
this
transporter's
list-
controller
artifact.
D
So,
basically,
what
we
understand
is
the
this
working
in
transpose
lies.
Intense,
put
complement
the
the
working
keys
by
offering
this
intent
based
approach.
That
would
be
basically
simplifying
the
way
of
requesting
these
slices
for
external
customers.
That
could
not
be
so
much
aware
of
the
technology
behind.
So
basically,
we
do
foresee
that
this
intent
base
could
assist
on
these
customers
to
request
the
slices
and
feed
somehow
the
normal
interface
of
the
transporter
slice.
Controller
next
slide,
please!
D
So
as
next
steps,
we,
basically
our
ideas
to
keep
developing
interface
capabilities
for
transported,
license
so
enter
into
the
details
about
the
how
we
could
do
what
would
be,
let's
say,
the
mechanisms
for
translating
this
intent
based
to
that
input.
That
would
be
required
in
the
nobel
interface,
I'm
probably
focusing
not
only
on
service
on.
D
Conditions
in
the
network
are
revolving
and
so
keep
analyzing
the
attributes
in
the
generic
slice
template
that
has
been
defined
in
both
the
sma.
Well,
it's
been
defined,
in
fact,
in
dsma,
and
three
epp
is
adopting
this
as
a
generic
slice,
template
and
particularizing
for
different
specific
use
cases
in
what
is
called
negative
templates
so,
basically
working
about
this
idea
of
the
place
to
understand
what
would
be
the
kind
of
parameters
that
could
be
part
of
the
intent.
D
A
F
G
Yep,
okay
yeah,
so
so
I
I
guess
the
yeah.
So
that's
interesting!
I
guess,
of
course
the
question
is
where
you
see
the
relationship
with
the
nice
controller
and
given
the
fact
that
there
is
going
to
be
northbound
interface
there.
Basically,
the
question
where
that
north
pole
interface
ends
and
what
the
intent
basically
provides
on
top
or
really
what
the
delta
is.
I
think
that's
going
to
be
one
of
the
key
questions,
and
I
think
this
is
this
may
be
useful
actually
to
to
to
to
flash
it
out.
G
Basically
how
how
large
that
that
delta
is.
This
is
not
entirely
clear
to
me
actually
how
the
two
would,
how
the
two
would
relate
or
if
you
would
basically
make
the
transfer
slice
controller
the
basically,
if
that
would
be
itself
an
intent-based
system
or
if
you
view
the
intent-based
system
as
something
northbound,
basically
and
and
it
talks
to
the
northbound
and
it
talks
to
the
to
the
controller
system
and
do
you
have
any
do
you
have
a
view
on
that.
D
What
I
have
in
mind
is
that
this
intent
based
approach
would
basically
translate
the
the
request
being
expressed
in
the
form
of
this
slide
templates
to
basically
to
put
these
to
the
format
expected
in
the
northbound
interface
to
basically
doing
the
translation
from
one
template
to
the
northbound
interface.
So
this
is
one
reason
what
I
could
have
in
mind
right
now,
but.
D
D
The
usage
of
intents
for
for
interconnection-
let
me
also
here
highlight
the
that
this
work
has
been
partially
funded
by
phi
group
project.
So
if
we
can
move
to
the
next
slide,
please
so
here
the
idea
would
be
to
somehow
to
reconsider
how
the
interconnection
could
evolve
in
in
the
next
future.
So
today
the
in
the
present
moment
of
operation.
Basically,
the
interconnection
is
considered
only
as
a
pure
interchange
of
ip
traffic,
so
basically
the
establishment
of
the
setting
up
of
these
vp
sessions
for
transiting
and
feeding
traffic
from
one
provider
to
another.
D
So
the
current
model,
so
looking
just
simply
to
an
interface
of
traffic,
basically
limit
the
capability
of
interchanging.
These,
these
other
capabilities
that
we
could
have
in
the
future
that
are
basically
enabled
by
these
network
virtualization
and
programmability
paradigms
that
are
entering
nowadays
in
the
operational
networks.
So
the
point
is
how
to
realize
composite
service
that
could
combine
compute
and
network
capabilities
traffic
in
into
from
the
different
operators.
D
So
can
we
move
to
the
next
slide
please?
So
the
the
target
of
the
summary
of
the
draft
would
be
basically
to
leverage
on
this
intern
based
networking
technologies
for
handling
and
reaching
the
connection
request.
So
not
only
traffic
but
something
else.
The
scenarios
of
applicability
would
be,
for
instance,
interconnection
of
non-public
to
public
networks
in
5g.
So
again
in
these
new
services
that
are
for
common
for
political
customers,
that
we
will
have
some
network
capabilities
in
their
own
premises.
D
So
how
to
request
interconnection
to
public
operators
and
how
to
express
the
needs
in
terms
again
of
functions
or
cloud
capabilities
in
this
public
networks,
and
so
on
so
far.
Also,
second,
scenario
of
applicability
would
be
a
multi-domain
network
and
service
request,
and
here
we
maybe
we
can.
We
could
point
out
to
section
4.4
in
rfc,
8568
and
finally
multi-domain
network
virtualization,
as
is
stated
in
draft
bernardo's
energy
multi-domain,
zero
one.
There
will
be
for
sure
other
examples.
D
This
is
what
was
just
some
of
them
for
for
highlighting
the
relevance
of
the
case.
So
the
benefits
that
we
could
expect
is
to
establish
a
common
and
normalized
method
among
service
provider.
For
automated
interconnection
and
again
not
only
said
enough
of
interchange
of
traffic,
but
also
connecting
to
computing
capabilities
that
are
in
the
footprint
of
the
of
other
providers
or
functions.
Not
only
computer
capabilities
also
could
be
service
functions
that
could
be.
D
Of
other
operators
and
find
a
way
also
a
simple
way
of
expressing
a
rich
interconnection
further
than
pure
ibm
traffic
interchange.
So
next
slide,
please
so
as
next
steps.
After
this
initial
version,
the
idea
would
be
to
keep
developing
this
interface
capabilities
for
interconnection
aspects
so
and
trying
to
figure
out
what
could
be
the
kind
of
information
that
could
be
part
of
vba's
interconnection.
D
Intent,
request
comments
to
nmrg
a
group
to
an
energy
community
and
inputs
for
feeding
new
versions
to
see
if
it
is,
there
is
interest
in
the
group
for
for
this
and,
if
so,
to
position
the
this
draft,
also
as
a
one
potential
energy
in
ten
use
case
also
related
to
work
item
five
in
the
work
plan
of
the
enemy
and
enemy
group.
So
that's
all
from
my
side
general.
Thank
you.
A
A
A
A
I
Very
good,
so,
thanks
for
having
me
today,
I
want
to
present
an
mrg
those
two
drafts
that
I've
been
presenting
in
the
past
on
behalf
of
many
people
from
different
horizons,
and
you
could
see
the
different
names
and
companies
over
there.
The
first
draft
is
about
an
architecture
service
assurance
for
intent,
based
networking
and
the
second
one.
This
is
about
the
yang
modules
for
service
assurance,
so
those
two
drafts
were
updated
on
monday
because
we
spent
some
time
in
the
hackathon
last
week
and
want
to
benefit
from
the
the
feedback
over
there.
I
I
I
Since
we
infer
that
health
score,
it's
a
complementary
solution
to
the
end-to-end
probing
with
o1
or
t1,
or
similar
ipsla
protocols,
where,
from
there
being
threshold
based
on
the
one-way
delay
or
packet
loss
or
jitter,
we
could
directly
see
the
real-time
experience
of
the
user.
So
next
slide,
please,
actually
you
could
go
to
slide
f5
directly.
I
So
in
there,
in
terms
of
components
for
architecture,
we've
got
at
the
top
and
orchestrator
which
is
going
to
configure
the
services,
and
we
extract
those
service
instances
in
orchestrators
in
orchestrator
and
we're
going
to
to
deduce
the
graph
and
we're
going
to
have
a
lot
of
metrics
that
needs
to
be
monitored.
In
order
to
understand
the
assurance
of
some
some
components
and
those
metrics
will
be,
you
know
retrieve
from
router
switches,
virtual
whatever
you
name
it.
I
This
architecture
is
open,
it's
flexible,
it
applies
to
multiple
environments
and
then
we're
going
to
stream
via
telemetry
the
health
score
and
all
the
symptoms.
Okay,
and
what
we
want
to
do
is
standardize
the
apis.
What
is
in
yang
in
there
to
be
able
to
extend
this
graph,
which,
in
the
end
will
be
distributed
on
the
next
slide?
I
I
Now
I
want
to
spend
more
time
on
the
next
slide,
because
there's
what
I
mentioned,
that
there
was
like
a
research
aspect
to
it.
So
if
you
go
on
slide,
seven,
please
and
with
the
poc
and
by
the
way
the
display
quality
is
not
great,
but
you
could
see
the
top
of
the
slide.
There
are
two
two
crossed
arrows
and
if
you
click
on
that
it
will
be,
you
will
have
a
bigger
definition.
I
I
It's
a
tunnel
and
the
service
has
a
tunnel
will
depend
a
couple
of
things
on
the
left-hand
side,
the
turtle
interface,
which
in
turn
will
depend
on
the
health
of
the
physical
interface
that
depends
on
the
health
of
the
device
that
depends
on
the
health
of
the
data
plane
and
same
thing
for
estimation,
but
also
the
health
of
the
service
will
depends
on
the
health
of
the
connectivity
ipv4
connectivity.
In
this
case
that
will
depends
on
the
igp.
I
So
you
see
also
that
there
are
some
dotted
lines
and
some
full
lines.
This
is
a
distinction
between
informational
dependencies
and
impacting
dependencies
at
the
very
bottom.
You
see
the
telemetry
health
if
the
telemetry
is
kind
of
broken
it
impact
my
tunnel.
Maybe
not.
However,
it's
important
you
to
know
it
same
thing
for
ecmp.
I
I
What
has
been
what's
changed
is
that
I
stressed
in
the
in
in
the
document
that
this
architecture,
which
is
open
and
flexible,
so
it's
applicable
to
a
typical
networking
service,
but
also
to
wireless
to
5g
and
to
vim
a
virtual
infrastructure
manager.
As
long
as
you
can
extract
somehow
the
service
or
the
intent
from
the
orchestrator,
then
you
could
have
this
graph
and
the
next
step
is
to
be
able
to
group
those
graphs
together.
I
We
also
stress
that
ntp
is
required
over
the
place,
it's
kind
of
obvious
if
you
default
management
and
we
introduced
the
notion
of
symptoms.
History
start
because
if
you
start
collecting
all
these
symptoms,
maybe
because
you
want
to
inject
that
into
your
big
data
lake
along
with
machine
learning
and
see
what
you
could
get.
I
What
we
learn-
and
maybe
it's
in
too
much
the
details,
but
what
we
learned
from
the
hackathon
is
that
we've
got
the
nation's
graph
version
and
the
last
change,
and
we
keep
that
basically
for
postmortem
right.
If
you
had
an
issue
yesterday,
you
want
to
troubleshoot,
you
could
give
a
history
of
this
assurance
graph
along
with
all
the
symptoms,
and
the
specifications
were
not
that
clear,
because
you
have
two
mechanisms
to
do
so
and
we
make
those
serious
compulsory.
I
We
also
explain
what
a
change
means,
because
just
saying
I've
got
a
new
version
of
the
graph
right,
but
what
is
a
change?
It's
a
dependency,
it's
a
status
etc,
and
we
rename
also
label
to
description,
because
when
reading
the
the
the
yang
model
realized,
there
were
like
two
different
concepts
called
labels
all
right.
I
The
next
and
last
slide
I
want
to
be
respectful
of
the
time
is
that
feedback
is
very
interesting
to
us-
maybe
more
feedback
to
not
only
to
this
the
two
draft,
but
also
to
the
open
source
code
that
corian
will
be
sharing
later
in
this
session
and
for
information.
As
I
mentioned
the
beginning,
we
are
considering
work
abruption
in
ops
lwg,
so
with
this,
I'm
not
sure
if
there
is
time,
but
I
will
any
any
questions
or
comments.
G
G
The
question
is
how
much
it
can
substitute
actually
monitoring
this
higher
level
concept
itself.
So
now,
when
you
say
I
use
this
to
infer
how
healthy
this
is-
and
I
don't
do
this
by
observing
the
entity
just
by-
but
I
do
it
just
by
observing
what
my
model
thinks
that
how
the
components
go
into
this
are
doing
that
basically
risks
risks
that
you
don't
have
an
accurate
picture
right
I
mean,
unless
you
are
very
certain
that
you
have
captured
everything
in
the
model
that
could
possibly
impact
this
higher
level
concept.
I
I
Good
question
alex
thanks,
so
first
of
all,
we
could.
What
is
the
typical
way
to
to
do
monitoring
these
days
is
that
we
just
look
at
synthetic
traffic,
probing
end-to-end
and
we
just
say:
okay,
there
is
something
wrong,
but
you
consider
network
as
a
black
box,
and
you
know
a
tracer
will
not
help
you
to
see
there's
an
issue
with
ecmp
or
with
the
key
os
whatever
so
now.
What
we're
offering
here
is
the
reverse
direction
we
go.
We
try
to
assure
components
by
components
right
so,
at
least
in
the
slide.
Seven.
I
Something
which
is
important
is
that,
if
you
go
back
to
slide,
seven
is
that
we
are
able
to
tell
where
the
problem
is
not
so
if
we
say
we
monitor
the
interfaces
and
they're
part
of
the
service
and
this
there
they
have
no
problem.
So
this
is
a
good
thing
already
now
to
come
back
to
your
point
that
we
need
to
complete
the
complete
graph,
the
more
complete
it
is,
the
better
obviously
based
on
my
previous
point,
that
any
of
the
components
that
you
could
exclude
from
troubleshooting
is
a
step
in
the
right
direction.
G
J
I
And
one
last
thing
I
want
to
say
is
that
if
we
conclude
that
there
is
an
issue
with
you
know
an
orange
tunnel
interface
there
and
I
didn't
cut
and
paste
the
symptoms
there.
But
basically
this
is
something
like
there
is
no
traffic
and
their
interface
right
and
again.
This
is
like
a
symptom
which
is
related
to
that
component,
and
now
we
could
do
closed
clip
automation
to
say
I
have
to
correct
that
specific
interface
component,
wherever
it
is.
G
B
I
I
I
I
think
that
in
the
end,
whatever
it
will
be
into
operational
network,
the
only
metric
that
counts
to
me
is
if
we're
going
to
help
the
support
team,
the
operational
team
and
somehow,
based
on
the
feedback
you've
seen
like
multiple
operators
being
involved
there
based
on
the
first
feedback.
This
is
helping
a
lot,
as
I
stressed
before,
because
we're
able
to
to
say
what
is
not
according
to
our
needs
and
if
I
take,
for
example,
a
device
there
right
and
a
device
is
red.
Okay,
sure
there
is
a
vendor
specific
aspect
to
it.
I
So
I
work
for
cisco
and
you
know
I
should
be
able
to
tell
if
my
cisco
router
behaves
correctly
and
not
asking
every
single
of
my
customers
to
pull
or
stream
the
cpu,
the
memory,
the
saf
entries
and
all
this.
So
somehow
my
customers
should
be
able
to
rely
on
on
me
to
to
discover
what's
wrong.
And
if
I
combine
this
with
my
support
teams
through
which
I'm
receiving
all
different
calls,
then
I
could
guarantee
that
I've
got
some
results.
So
the
number
of
calls
receiving
cisco
is
also
like
a
good
metric.
A
Okay,
thank
you
benoit.
I
know
that
holga
has
also
a
question,
but
I
recommend
there
maybe
to
to
send
you
an
email,
because
we
have
to
to
move
on
to
the
next
presentation
and
thank
you
very
much
and
yeah.
Okay,
good.
We
have
somebody
to
do
to
be
javascript
because
we
we
lose,
we
lost
our
javascript.
Thank
you
very
much.
So
next
presentation
is
is
a
continuation
because
it
would
be
the
I
can't
report
from
korean.
J
J
J
We
wanted
to
leverage
the
same
architecture
and
yarn
modules
to
do
so
as
collector.
We
envisioned
pmsct
and
our
telegraph
and
as
additional
component
to
the
same
architecture.
We
envisioned
influx
db,
graffana
and
or
chronograph
a
slide.
Please
and
the
core
component
of
the
same
architecture
that
we
use
for
the
hackathon.
Is
this
open
source
scene
engine
that
I've
been
developing
for
a
few
months
and
which
comes
with
two
visualization
tool
tools?
So
the
adjunct
can
be
described
in
three
steps:
inputs,
metrics
and
rules.
J
J
J
You
are
able
to
access
this
data
via
shared
memory
by
using
a
basic
and
curses
console
app
and
also
by
exporting
data
using
the
ietf
service
assurance
young
model
through
gnmi
in
a
javascript
based
web
app
slide.
Please-
and
this
is
what
it
looks
like
it's
pretty
small,
but
on
your
left,
you
can
see
the
so
the
console
app.
So
this
is
the
screen
of
the
matrix.
So
the
vendor
dependent
value
at
the
top.
J
You
see
the
red
lines
which
are
the
positive
symptoms,
and
you
can
see
as
argument
the
full
denomination
of
the
node
that
triggered
the
symptom,
which
would
be
the
service
and
your
on
the
other
side.
You
can
see
the
graph
dependency,
the
service
graph
and
the
dependency,
so
nodes
are
services
and
edges
are
dependency,
so
you
can
see
how
the
else
malicious
propagates
along
edges.
You
can
play
with
it
because
it's
in
javascript
and
you
can
use
it
to
dig
for
root,
causes
slide.
Please.
J
So
the
critical
part
of
this
tool
is
the
rule
engine,
because
this
is
what
it
used
to
highlight
symptoms
and
to
derive
health
scores.
The
isd.
The
idea
is
to
leverage
service
expertise
to
highlight
anomalies
or
health
problems
via
rules
you
can
define
rules
based
on
variables
which
are
given
or
independent
metrics.
J
You
also
have
basic
operators
at
your
disposal
alongside
more
complex
operators
which
analyze
temporal
aspects
which
allows
to
select
or
to
to
extract
how
a
variable
has
evolved
over
time.
So
at
the
bottom
you
can
see
examples
of
rules,
so
we
have
a
string
that
describes
it,
a
node
to
which
it
should
be
plugged
and
checked
a
severity
and
then
the
actual
condition.
So,
for
instance,
the
first.
J
J
J
So
I
believe
this
is
a
very
promising
approach,
which
has
a
lot
of
use
cases
and
a
few
that
benoit
have
described
so,
for
instance,
if
you
have
this
networking
company
that
has
a
lot
of
network
devices
on
which
you
install
a
sane
agent,
then
you
have
it.
Then
this
company
is
providing
service
for
a
client
that
requires
a
subset
of
those
network
devices.
You
can
simply
collect
the
aseron's
graph
from
those
devices
concatenate
them
to
build
your
client
service
assurance
graph
and
by
monitoring
the
top
root
node
health
score.
J
J
J
We
also
did
more
work
on
interoperability
by
with
the
alexa
leonardi,
adding
the
excision
support
for
the
excellent
exporting
to
the
cisco
same
collector,
which
is
based
on
pay
on
a
pipeline
slide.
Please
and
finally,
the
next
steps
for
me
are
to
work
on
a
more
complete
rule
engine
to
increase
the
versatility
of
the
rule,
expressions
because
it's
very
important,
then
I'm
going
to
consider
the
addition
of
end-to-end
probing
tools
as
input
sources
to
have
some
kind
of
empirical
view
of
what
is
going
on
in
the
network.
J
Then
the
next
big
step
is
this
multi-node
asurance
graph,
concatenation
architecture,
which
is
probably
going
to
be
interesting.
There
is
also
parallel
work
by
canon
to
add
gnmi
support
to
pmsct,
which
would
make
the
excision
interoperable
with
pmcct
at
one
point
in
the
next
month,
I'm
going
to
work
on
a
paper
on
a
specific
use
case
of
the
same
agent
and
finally,
I
believe
the
value
of
this
tool
relies
on
the
amount
of
input
and
on
the
amount
and
the
quality
of
rules.
A
A
Okay,
may
I
ask
you
a
question
because
it's
it's
actually
to
both
you
and
benoit,
because
I
remember
that
benoit
said
that
hi
katan
was
also
helpful
to
to
revise
the
document.
I
was
wondering
about
perspective,
or
captain
can
help
the
development
of
draft.
So
can
you
is?
Are
you
or
benoit
say
what
was
helpful
for
the
document
after
the
academy.
A
I
Okay,
so
the
best
thing
to
do
is
to
take
the
two
draft
I
mentioned
before
and
look
at
the
diff.
So,
for
example,
we
explain
what
the
change
is
whenever
we
do
like
a
new
version,
a
plus
one
in
the
assurance
graph
version,
explain
what
a
change
is.
We
explain
how
to
process
this
from
the
agent
from
the
collector.
I
I
Okay,
these
are
unlearned
and
and
also
a
couple
of
things
that
are
more
implementation,
specific
because,
as
corian
mentioned,
he
was
able
to
send
his
dx
agent
to
what
we
developed
internally
in
the
poc.
I've
been
sharing
and
we're
about
to
see
the
information,
so
it
was
exchange
of
information,
both
direction.
I
K
J
E
Yeah,
it's
just
something:
it's
just
something
that
needs
to
be
thought
about,
because
it
seems
to
me
as
though
that
this
is
going
to
cover
a
broad
range
of
problems.
So
we
want
to
make
sure
that
the
time
scale
is
commensurate
and
also
that
the
overhead
of
doing
this
doesn't
itself
drag
the
system
down.
A
I
E
I
This
one,
yes
you've
got
a
large
scaling
issue
and
square
issue
and
specifically
whenever
we
want
to
monitor
like
the
the
last
packet
loss
now,
what
we,
what
we
do
here
is
streaming
information,
regular
basis
from
typically
routers
or
virtual
machine
etc,
and
it's
going
to
depend
on
which
use
case
we
try
to
do
so.
If
I
take
two
key
os
well
sure
you
want
to
knit
earlier,
if
we
take
like
the
stability
of
routes
in
an
igp.
I
I
Subservice
type,
and
if
done
right-
and
this
is
why
we
need
a
graph-
is
that
every
single
component
is
monitored
a
single
time,
which
is
by
the
way
which
we
are
trying
to
avoid
that
in
the
in
the
past,
every
single
nms
would
pull
the
interface
counters.
Just
because
it's
the
right
thing
to
do.
People
believe,
but
in
this
case
the
monitor
would
be
self-monitoring
itself.
E
I
I'm
going
to
rely
on
model
driven
telemetry,
because
the
traps
which
is
based
on
snmp
and
maps
doesn't
provide
the
right
data
model
that
I
need.
We
have
to
make
sure
that
the
model
that
we
need
is
the
same.
One
is
used
for
configuration
and
since
yang
is
used
for
configuration,
we
must
be
using
the
same
yank
for
streaming
telemetry,
so
model
driven
telemetry
right.
F
In
data
aggregation
and
data
composition,
so
you
could
have
some
kind
of
I
don't
know
how
to
collect,
buffering
or
data
back
playing,
so
that
would
alleviate
as
well
overloads
and
like
not
that
you
have
to
go
down
to
every
every
single
component.
In
many
cases,
what
this
could
become
more
important
is
in
in
these
models.
E
F
I
You're
free
right,
there
is
detectoration.
If
I
take
back
the
example
of
the
number
of
routes
right,
as
I
mentioned
in
that
case,
you
want
a
delta
of
number
of
routes
for
igp
to
pretend
it's
stable
or
not,
and
this
is
where
is
why
we
sometimes
need
things
such
as
a
baselining
right,
which
is
somehow
a
different
view
of
your
data
aggregation,
and
if
there
is
a
delta
compared
to
the
baseline
of
number
of
routes,
then
we
report
a
symptom,
so
fully
agree
with
you.
Diego
data
aggregation
is
key.
A
A
K
Thanks
jerome
and
thank
you-
everybody,
I'm
walter
cerrone
from
university
of
bologna
and
I'm
presenting
the
short
report
on
what
we've
been
doing
on
on
the
hackathon
about
multi-level
approach
to
ibm.
This
actually
was
actually
the
first
time
ever.
I
think
that
nmrg
was
proposing
a
project
to
the
ietf
hackathon,
and
it
was
also
my
my
very
first
time
for
this
kind
of
this
kind
of
event.
K
K
K
This
demonstration,
one
is
was,
is
the
one
related
to
the
concept
and
definition
which
that
actually
definition
of
it
then
refers
to,
and
the
other
was
about
the
intent
classification,
because
we
are
dealing
with
different
level
of
intent.
So
this
is
actually
a
very
a
very
important
way
to
to
see
if
the
classification
is
actually
fit
to
the
to
the
ideas
that
we
have
next
slide.
Please.
K
So
the
specific
problem
that
we
wanted
to
solve
was
to
apply
the
intent
concept,
different
levels
that
actually
may
correspond
to
different
stakeholders.
So
we
came
up
with
this
idea,
together
with
the
other
people
that
have
been
working
with
me
to
have
an
infrastructure
provider
that
basically
provides
some
sort
of
slice,
intent,
interface,
a
service
provider
that
actually
consumes
that's
less
intent
and,
on
its
own,
provides
a
service
intent
to
customers
and
then
customer
or
vertical
vertical
services
that
actually
consume
those
service
intent
interfaces.
K
I
think
this
is
this
perfectly
fit
with
the
the
presentation
that
luis
gave
earlier
about
the
the
slice,
intent
and
interconnection
intent
that
I
mean
we've
been
working
on
this
before
we
were
aware
of
the
the
work
by
by
we
saw.
I
see
definitely
some
important
connecting
point
here
that
we
are
going
to
definitely
look
into
in
the
future.
K
K
We've
been
working
on
this
concept
for
a
while.
We
is
also
consequence
of
the
the
demonstration
that
we
have
in
an
emergency
meeting
in
october
last
october
in
rome,
where
we
tried
to
put
together
our
ideas
having
this
kind
of
intent
interfaces
that
operating
at
different
levels.
So
we
were
able
to
make
this
before
concept.
We
were
able
to
to
demonstrate
actually
how
we
were
we,
we
could
set
up
first,
our
size,
intent
and
then
some
service
intent.
K
K
K
K
K
We
actually
didn't
have
the
chance
to
to
do
any
hands-on,
collaborating
work.
Probably
we
that
the
project
is
still
not
mature
for
that,
and
maybe
we
will
be
able
to
do
that
in
future
events,
future
racket
and
events
like
this,
but
we
we
had
a
really
fruitful
discussion
on
on
the
system
itself
and
on
the
idea
and
on
the
next
steps
there
were
some
people
involved
that
I
would
like
to
thank
because
they
they
offer
very
good
suggestions.
K
One
a
few
comments
came
from
ferrat
and
navid
about
their
approach:
how
to
integrate?
Actually,
our
idea
with
their
approach
to
express
high
level
intents
that
need
to
be
translated
in
something
that
can
be
mapped
in
our
solution,
for
instance,
because
we
basically
make
a
sort
of
mapping
between
a
high
level
intent
expressing
json
format
to
network
function
and
network
service
descriptions
descriptors
in
the
nfv
environment.
K
So
next
step
should
be
actually
how
we
can
actually
express
the
intent
in
something
different
in
a
different
language
that
can
also
be
translated
into
what
we
are
doing
in
there
in
the
lower
layer.
Let's
say,
and
also
we
had
also
a
good
discussion
with
olga
how
we
can
actually
classify
the
approach
that
we
have.
According
to
the
internet
classification
work
that
they
they've
been
doing
in
the
draft.
K
There
is
a
link
to
the
video
session
to
the
video
recording
of
the
session.
We
recorded
all
the
all
the
sessions,
so
both
the
presentation,
the
the
demonstration
and
the
discussion
afterwards.
So,
if
you're
interested
you
can
follow
that
link
and
then
you
have
access
to
the
video
next
slide.
Please
talking
about
intent,
classification,
we
act
after
after
the
as
an
outcome
of
the
of
the
academic
session.
We
tried
the
first
attempt
to
follow
the
methodology
in
the
draft
about
classification.
K
So,
basically,
based
on
that
I'm
going
through
this
quickly,
then
we
can
have
a
discussion
offline.
If
anyone
is
interested,
we
consider
this
approach
that
could
be
both
a
carrier
and
a
data
scientist
solution,
because
we
are
actually
focusing
on
nfv
approach,
an
sfv
scenario
and
then
the
intent
is
type.
K
K
I
think
we
we
we
consider
two
different
selection,
two
different
types
for
slicing
tank
and
intent
and
service
chaining
time
again.
This
is
just
the
first
attempt.
So
maybe
it
needs
more
discussion
for
the
discussion,
but
I
think
we
could
better
discuss
this
with
other
people
and
then
came
up
with
a
full
classification
of
our
intent.
I
also
we
we
we
found
some
correspondence,
some
some
good
fitting,
with
also
the
intense
scope,
metroscope,
abstractions
and
and
so
on
next
slide.
Please.
K
This
was
it
was
what
I
was
talking
about
before
the
validation,
monitoring
observation,
interaction
with
transport
networks,
and
I
see
that
several
presentations
before
this
one,
we're
actually
touching
those
points,
so
we
will
definitely
need
to
to
get
in
touch
and
to
look
into
the
draft
being
been
developed
in
this
on
these
topics,
because
they
will.
This
will
really
help
to
to
build
a
complete,
iabn
and,
of
course,
extend
implementation.
Our
use
case
to
a
more
complex
scenario,
including
multiple
things
and
multiple
point
of
press
next
slide.
Please.
L
Yes
hi,
I
just
want
to
say
thanks
to
vote
for
adding
kind
of
the
the
taxonomy
and
and-
and
it
is
good
to
know
that
we
don't
need
any
additional
categories.
So
we
will
follow
up
after
this
meeting
to
see
from
their
experience.
What's
the
best
way
to
kind
of
present
that
kind
of
information
for
parks
going
forward
thanks
walter.
K
Yes
thanks,
sir,
actually
I
I,
as
the
first
obtained,
we
basically
were
able
to
to
to
select
all
the
options
that
are
already
there
in
the
draft
and
we
didn't
think
about
any
missing.
At
least
this
is
not
what
we
we
had
in
mind,
so
there
is
there's
not
seem
to
be
anything
missing
now,
but
maybe
we
need
to
think
about
more
about
that
so,
but
we
can
definitely
follow
up
on
that.
K
K
Okay,
I
think
there
is
a
question
on
the
on
the
chat.
It
says.
Consider
approach,
allow
multiple
levels
of
intent,
levels
of
intent
beyond
the
two
levels.
Well,
this
is
a
good
question.
It
could
I
mean
we
were
thinking
about
the
use
case
of
you
know
a
physical
infrastructure
provider,
a
virtual
service
provider
or
a
virtual
operator,
let's
say,
and
then
a
service.
K
Service
customer,
let's
say
so,
that's
why
we
focus
on
two
levels.
I
think
it
depends
on
the
level
of
obstruction.
So
maybe
this
can
be
extended
to
multiple
levels,
especially
if
maybe
infrastructure
is
made
different,
I
would
say
sub
infrastructure
or
different
segment.
Maybe
you
can
have
multiple
levels
also
at
that
layer,
because
you
may
want
to
express
something
that
encompasses
the
whole
infrastructure
and
then
maybe
you
need
to
map
that
or
decompose
that
into
intense
that
relates
to
different
segments.
So
this
is
a
possibility.
A
M
M
M
M
Secondly,
consumer
phase
interface
is
used
to
deliver
high-level
fallacy
from
itunes
of
the
user
i2
and
the
user
is
that
the
security
of
the
meterator
desi
volt
and
lastly,
another
facing
interface
is
used
to
deliver
specific
global
security
of
fallacy
from
security
control
to
the
twelve
security
functions
next
slide.
Please.
M
M
This
figure
shows
basically
the
button
the
administrator
deliver.
High-Level
policy
such
as
sns
some
policy,
such
as
the
company
employee,
cannot
access
as
a
website
such
as
instagram
youtube
during
a
work
time
after
that,
after
work
time,
they
can
access.
So
we
implemented
our
itunes
f
system
on
top
of
nfpe
architectural
framework.
So
please
refer
to
on
this.
Our
latest
magazine
paper
for
detailed
information
next
slide,
freeze.
M
Now
this
figure
is
very
important,
so
I
think
this
is
most
relevant
to
nmrg,
so,
basically,
itunes,
user,
deliver
high-level
policy
such
as
employee
cannot
access
during
work
time,
so
secure
controller.
Has
the
security
policy
translator
consists
of
three
modules:
data,
extractor
data,
converter
policy
generator,
so
data
converter,
extract,
high-level
policy
into
high
level
data
and
the
data
converter,
converts
high
level
data
into
low
level
data
and
the
finally
policy
generator
construct
xml
file
that
is
loadable,
descriptive
policy
next
slide.
Freeze.
M
M
What
we
got
done
so
we
restored
itunes
that
framework
on
top
of
openstack
web-based
itunes,
user,
console-based
security
control
and
developer
management
system.
That
is
a
dms
and
also
scripted
fallacy
translator
was
used
so
also,
we
reflected
the
latest
revision
of
data
young
models
next
slide,
freeze.
M
So
what
we
learn,
we
recognized
the
importance
of
a
security
policy
translator
to
support
ibm
based
security
services.
So
currently,
are
we
developing
automatic
mapping
between
level
young
attribute
and
the
low
level
young
attribute.
Secondly,
we
are
planning
to
develop
the
installation
of
loadable
young
production
rules
to
generate
xml
file
for
low-level
security
fallacy.
So
next
steps
we
implemented
two
things
this
coming
november,
exam
project.
We
implement
two
things
next
slide,
please
so
this
shows
our
open
source
project.
You
can
get
the
open
source.
Also,
we
put
a
demo
video
clip
into
youtube.
A
H
Oh,
can
you
hear
me
now
yeah,
okay,
sorry
about
that?
Hey,
a
great
work
with
this
hackathon
project
and
thanks
for
sharing
it
here,
one
question
that
came
to
mind.
Looking
to
your
presentation,
I've
seen
that
this
group
has
done
quite
a
lot
of
work
with
the
i2ns
framework
on
top
of
openstack,
or
is
there
any
thought
to
make
a
contribution
to
the
openstack
project
to
actually
get
this
incorporated?
H
M
Okay,
charles
yeah,
there
is
a
good
suggestion,
so
yeah
I
will
seriously
consider
to
okay
contribute
to
openstack,
so
my
colleague,
you
can
see
social
university.
Professor
young
kim
his
team
is
mainly
working
for
openstack,
so
I
will
discuss
with
him
how
to
contribute
to
openstack
for
our
italian
staff.
Also,
maybe
you
can
give
me
some
guidance
to
contribute
to
openstack
society.