►
Description
ACM, IRTF & Internet Society Applied Networking Research Workshop 2017 - Part 2
Prague, Czech Republic
Saturday, July 15, 2017
A
So
I'm
Spencer,
Dawkins
I
think
the
Argos
kind
of
nudged
me
to
starting
the
next
session,
which,
on
transport
just
to
say
this
out
loud
I'm,
one
of
the
eight
transport
area,
directors
of
the
IETF
and
I'm
thrilled
and
smart
people
show
up
to
solve
problems
that
I
have.
So.
Thank
you.
Thank
you
all
in
advance
for
the
work
that
you
have
done
and
continue
to
do
so.
A
First
presentation
we
have
up
is
one
set
on
a
paper
about
a
testing
mechanism
called
copycat
presenters
Korean
and
he
is
a
PhD
student
at
the
University
Research
Unit
in
networking
at
the
University
of
leash
working
on
middle
box
measurements,
middle
box
impact
on
transport
protocols,
he's
collaborating
on
the
EU
H,
2020
measurement
and
architecture
for
middle
box
to
Internet
mommy.
Prior
to
that
he
was
an
intern
at
Symantec
research,
labs,
working
on
malware
analysis.
So
to
nobody
thanks.
B
For
the
introduction,
so
I
will
present
you
this
tool
called
copycat,
that
is
at
testing
for
differential
treatment
of
neutrons
for
protocols
in
the
Y,
but
this
is
joint
work
between
University
of
liège
and
ETH
Zurich.
So
let's
say
you
want
to
deploy
and
test
a
new
transport
protocol
of
yours
or
a
new
extension
to
a
transport
protocol.
What
can
you
do?
What
choice
do
you
have?
You
can
either
implement
in?
We
did
within
a
network
simulator
and
and
then
run
it
whenever
you
want.
B
You
can
run
it
in
a
control
if
you
have
access
to
any,
and
you
can
also
run
it
in
the
wall
between
a
few
nodes
that
you
have
access
to
with
the
requirement
of
having
to
patch
them
so
that
they
speak
your
protocol.
What
this
tool
introduces
here
is
stateless
testing,
so,
basically,
without
having
to
implement
your
protocol
on
any
node,
you
are
able
to
observe
how
the
pass
react
to
the
wire
image
of
your
protocol
and
infer
any
differential
treatment
in
term
of
connectivity
or
quality
of
service.
B
So
the
idea
is
to
run
pairs
of
flows,
one
reference
flow
and
one
experimental
flow.
The
reference
flow
will
serve
as
the
ground
truth
for
the
comparison
and
is
a
vanilla,
TCP
flow
that
just
transmits
some
data.
Then
the
experimental
four
can
either
be
UDP
on
on
UDP
based
and
is
composed
of
two
pairs
of
headers
inner
headers
or
tunnel
headers
and
outer
headers.
So
the
inner
headers
are
analyticity
as
well
and
will
be
used
to
TCP
control
the
flows.
Then
the
outer
headers
can
either
be
so
in
the
case
of
UDP,
there's.
B
First,
a
UDP
header
by
the
dedicated
socket
and
then
there's
an
optional
extra
header
that
can
either
be
quick
or
plus.
Then,
in
the
case
of
the
non
UDP
experimental
flow,
you
are.
You
have
the
possibility
to
use
whatever
transport
header
that
you
want
by
defining
it
in
raw
bytes.
So,
for
example,
you
can
use
it
to
test
GCC,
PSC,
TP
or
anything.
B
Then
the
architecture
of
the
tool
is
very
basic,
client-server
or
receiver
sender
architecture.
So
first
we
created
two
new
virtual
network
interface,
which
is
simulation
of
network
layer
device
that
operates
at
layer
3.
Then,
if
we
create
two
TCP
sockets
binds
one
to
the
internet
facing
interface
and
want
to
join
interface,
socket
our
basic
data
writer
readers.
B
Then
it
will
create
a
new
DP
or
a
socket
depending
on
your
choice
of
experimental
flow,
bind
it
to
the
internet
facing
interface.
Then
it
will
simply
act
as
a
terminal
endpoint
by
the
capsule
ating
any
packet
received
from
those
sockets
and
writing
it
on
the
tune,
interface
and
reciprocally,
encapsulating
anything
read
from
the
chena
interface
and
forwarding
it
towards
the
Internet.
B
In
terms
of
comes
with
a
few
features,
you
can
set
up
the
flow
scheduling
to
be
so
that
the
two
flows
are
wrong:
parallely
or
sequentially.
You
can
choose
a
network
layer,
v4
v6
or
you
can
even
do
the
network
layer
butter.
So
in
this
case
it
will
run
two
pairs
of
clothes
instead
of
one
in
the
IDS
to
infer
differential
treatment
based
on
the
network
layer.
So
it
will
run
to
reference
flow,
one,
zero,
one
v6
and
then
two
experimental
flow,
one
v4
and
v6,
and
it
works
on
fuses.
B
So
we
tested
this
tool
for
the
UDP
encapsulation
for
transport
evolution
use
case
so
basically
just
run
the
experimental
flow
to
be
UDP
with
no
extra
header.
We
deployed
it
on
planet,
louse
and
digital
ocean,
which
is
cloud
hosting
solution.
We
roll,
we
run
it
on
a
few
ports.
We
run
flows
of
different
sizes
calibrated
from
the
TCP
initial
window,
so
that
for
the
smallest
flow
all
day,
the
packet
was
sent
out
once
at
once,
and
then
we
just
collected
the
flow
and
analyzed
them
to
infer
any
different
cell
treatment.
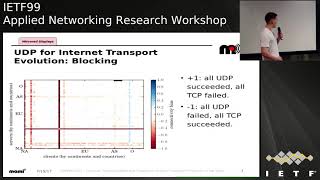
B
So,
first
in
terms
of
blocking
so
here
in
access,
you
have
the
clients
per
continent
per
country,
and
why
is
the
server's?
The
color
legend
is
the
more
read
the
more
you
GP
is
more
impaired
than
TCP,
the
more
blue,
the
more
the
opposite.
So
you
have
those
two
red
lines.
Other
brands,
which
are
in
the
case
of
one
node,
rocking
all
UDP
traffic
in
both
direction,
then
I,
don't
know
if
you
can
see
with
there
are
some
black
dots
here,
which
are
cases
of
TCP
blocking
as
well.
B
So
this
is
probably
an
overloaded
node
still
most
TCP
connectivity
is
good.
Then
there
are
so
lot
of
cases
with
no
connectivity
bias.
So
the
gray
squares-
and
the
third
case
are
the
transient
connectivity
problems,
so
the
light
shades
of
blue
and
red.
But
what
is
interesting
here
is
that
there
are
clearly
line
shed.
B
B
So
here
we
plotted
the
distribution
that
we
first
separated
between
low
throughput
high
throughput.
So
we
can
see
for
the
plain
lines
that
low
throughputs
I
have
Shooto
no
true
put
bias
and
when
they
have
it
is
balanced
between
better
UDP
and
better
TCP.
In
the
case
of
high
throughput
on
digital
ocean,
there
is
more
bias,
but
it
is
balanced
as
well
then,
in
the
case
of
planetlab,
there
is
some
sign
of
imbalance
month
on
the
tcp
is
better
side.
B
B
Once
again,
we
splitted
the
distribution
at
50
milliseconds,
so
we
can
see
that
for
low
latency
there
is
once
again
Shooto
no
biases
for
high
latency
on
digital
ocean
bias
are
balanced
and
for
planetlab
we
see
the
same
sign
of
imbalance.
Ball
on
the
tcp
is
better
side,
and
this
explained
is
partially
imbalance.
Man
in
throughput,
in
the
throughput
bias.
B
B
A
C
C
C
E
B
E
F
F
So
that's
a
small
enough
sample
size
that
you
can't
really
say
much
about
it.
There
was
a
ripe
Atlas
study
that
we
did,
which
was
actually
part
of
the
bigger
paper.
So
the
archive
paper
that
you
pointed
to
where
we
found
about
3.5%
and
I,
think
we've
presented
that
at
map
RG
a
couple
of
a
parties
ago
and
then
the
number
that's
been
floating
around.
F
So
that
includes
ripe,
Atlas
probes,
which
do
include
some
home
access
networks,
but
they
tend
to
be
biased
toward
people
who
know
people
who
know
people
who
are
network
geeks
right
so
actually
that'd
be
a
really
interesting
talk
to
do
at
a
future
map
or
to
your
mat
in
ripe,
is
sort
of
if
the
the
social
network
of
ripe,
Atlas
hosts
just
and
I'm,
actually
halfway
serious
about
that.
Just
to
have
it
just
to
be
able
to
answer
the
bias
question
that
always
comes
up
every
time
you
say
I'm
using
right.
That
was
for
this.
F
What
none
of
these
and
then
there
was
that
the
quick
numbers,
so
the
quick,
the
quick
blocking
numbers,
was
about
5%
right,
not
was.
That
was
not.
That
was
taking
the
thing
that
that
we're
measuring
here
and
conflating
it
also
with
with
the
blockage
right,
so
it
was
in
5%
of
cases.
Tcp
was
faster
right,
so
it's
places
where
you
have
not
just
deep
red
lines
here,
but
also
kind
of
reddish
lines
in
the
connectivity
bias
or
in
the
in
the
RTT
bias.
F
What
none
of
these
studies
look
at
her
enterprise
networks
right,
there's,
not
a
whole
lot
of
Chrome
to
YouTube
on
enterprise
networks,
I
mean
and
there's
I
haven't
really
seen
any
attempts
to
quantify
how
much
we're
missing
there.
The
Sam
knows
stuff
is
not
going
to
give
you
a
lot
of
enterprise
network
information.
F
I'm
guessing.
Are
there
any
people
who
operate
enterprise
networks
in
this
room?
Okay,
great
so
having?
It
would
be
really
interesting
to
find
a
way
to
have
visibility
into
those
networks
that
would
not
compromise
sort
of
their
business
requirements,
and
that's
a
but
I
think
is
a
really
hard
problem
for
this
community
to
well
solve,
but
I
mean
think
about
first.
So.
A
You
had
the
to
be
just
basically
Brian
has
the
opportunity
to
the
unique
opportunity
to
throw
a
problem
over
the
wall
and
then
run
around
on
the
IETF
side
and
catch
it
or
on
the
IAB
side
and
catch
it
good,
good
job,
guy
yeah.
It
didn't
work
but
I
speaking
for
Mike
Sweeney
as
a
transport
area,
director
I
think
that's
one
of
the
spookiest
things
to
me
about
all
of
this
and
I'm
really
interested,
not
necessarily
for
people
in
this
room,
but
I'm
really
interested
in
ideas
on
how
to
get
visibility.
In
that.
G
G
A
A
So
next
up
we're
talking
about
tracking
transport
evolution,
layer
evolution
with
path
spider
got
yet
is
a
born
in
Belgium,
worried
it
also
to
secondary
school
as
a
bachelor's
of
science
and
electrical
engineering
from
Delft
University
of
Technology.
Currently
in
the
final
semester
of
his
electrical
engineering
and
information
technology,
master's
at
ETH.
Sorry
outside
of
academia
also
involved
in
the
hacker
scene
by,
for
example,
by
organizing
Oh
Oh
to
that
less
than
13
and
shot
2017.
So.
H
Okay,
I'm
good
morning,
everyone,
together
with
some
people
from
it
and
University
of
Aberdeen,
we've
been
looking
into
a
tracking
transport
layer
revolution
with
pops
fighter,
and
when
you
see
this
title,
I
think
it
really
calls
for
two
main
questions.
The
first
one
is
why
we
do
you
want
to
track
transfer
to
a
revolution
and
the
second
one
is
what
the
hell
is
false
fighter.
H
So
the
answer
to
the
first
question
I
think
most
of
you
will
know-
and
that
is
that
these
days
the
Internet
is
full
and
full
and
full
of
middle
boxes
and
they
heavily
interfere
with
our
connections.
So
if
you
want
our
services
to
keep
working,
transport
protocols
have
to
react
on
these
interferences,
and
you
could
do
that
by
some
feeling
in
your
left
thumb
or
by
some
anecdotal
evidence.
But
if
you
want
to
do
it
properly,
then
you
really
have
to
do
that
driven
by
data.
H
So
we've
tried
to
collect
this
data
through
active
internet
measurements
and
for
that
we've
built
a
tool
chain
of
which
fought
spider
is
the
central
component,
and
this
tool
chain
can
be
used
to
run
a
control,
experiments
against
pretty
much
any
protocol.
You'd
want
to
measure
and
pretty
much
any
target
that
you
want
to
measure
and
then
and
the
output
of
our
measurements
are
what
we
call
conditions,
for
example,
at
the
condition
ec
and
connectivity
works
that
are
associated
with
pots.
H
So
in
this
talk
we'll
start
by
first
looking
at
the
basic
architecture
of
all
spider.
So
what
does
it
do
and
then
also?
How
have
we
incorporated
pot
spider
into
a
cloud
based
measurement
system,
a
system
that
allows
us
to
run
many
measurements
both
over
a
long
period
of
time,
to
really
track?
What
is
changing
and
also
many
measurements
together
over
a
short
period
of
time?
So
we
can
eliminate
trenchant
effects
and
then
we'll
actually
look
after
at
three
studies
that
we've
done
for
three
protocols
with
very
different
levels
of
deployments.
H
So
how
we
do
this
is
by
opening
two
TCP
connections.
First,
we
open
up
a
vanilla,
baseline,
TCP
connection
and
then
quasi
simultaneously
with
that
TCP
connection
with
the
protocol
under
test.
We
compare
the
results
of
these
two
connections
and
based
on
that,
we
try
to
deduce
whether
using
the
protocol
under
test
actually
impede
some
connection
or
not
so
part.
Spider
internally
looks
like
this:
you
have
a
bunch
of
worker
threads,
typically
about
50
or
200,
or
something
that
all
get
their
measurement
targets
from
a
large
queue.
H
They
then
synchronize
with
a
configurator
that
ensures
that
your
system
is
in
the
right
state
for
the
measurement
you
want
to
take.
For
example,
if
you
want
to
take
an
NEC
end
measurement
for
the
baseline
measurements,
the
kernels
should
have
easy
and
switched
off.
If
you
want
to
do
your
expand
experimental
measurement,
it
should
have
it
switched
on.
This
is
system-wide,
so
everything
needs
to
be
synced
up.
Then
they
generate
an
traffic
to
the
desk
targets
and
the
day
that
they
have
on
the
connection
they
sent
to
what
we
call
the
murder.
H
So
this
is
typically
things
like
the
five
tuple
and
whether
the
connection
failed
or
not.
Basically,
what
you
get
from
your
API
calls,
and
then
we
have
an
observer
thread
that
sniffs
on
all
the
test
test.
Traffic
that's
generated
also
generates
records,
for
example,
which
flags
were
set
in
the
TCP,
headers
and
so
forth.
Also
sends
this
to
the
merger
merger,
then
figures
out
which
which
records
belong
together,
merges
them
together
in
one
outputs
and
that's
the
file
that
you
actually
look
at.
H
So
this
allows
us
to
figure
out
whether
certain
protocols
and
peed
on
functionality,
yes
or
no,
but
only
from
one
location
and
but
in
the
internet.
You
typically
have
two
places
where
impairments
exist.
Well,
actually,
three,
you
have
your
access
network,
then
you
have
impairments
close
to
the
target
and
you
have
impairments
close
to
the
network,
but
we
measure
from
data
centers,
so
we
rule
out
the
access
network.
H
So
we're
not
very
interested
in
that
and
you
want
to
be
able
to
distinguish
between
the
two,
because
when
you
have
a
problem
in
the
Internet
core,
that's
obviously
way
more
troubling,
then
when
some
idiots
puts
up
a
broken
box
somewhere
at
his
house.
So
how
we
distinguish
between
these
is
by
running
multiple
measurements
simultaneously
from
different
vantage
points
around
the
globe
and
our
measurements
with
use
digitalocean
data
centers.
And
then
we
look
at
whether
a
connection
with
the
protocol
under
tests
always
fails.
H
So
from
all
vantage
points
in
which
we
say
okay,
clearly,
there
must
be
something
close
to
the
target.
That's
broke,
that's
broken
and
we
say
that
this
target
exhibits
side
dependency
or
whether
it's
only
sometimes
fails
and
sometimes
work
we're
clearly
depending
on
which
polity
tract
to
take
through
the
core.
H
You
get
impairment,
or
not
so
we
say,
there's
pot
dependency
and
then
to
make
sure
that
we're
not
just
measuring
transients.
We
run
every
measurement
also
multiple
times
very
close
together
in
time,
and
only
if
we're
really
sure
that
every
time
we're
seeing
the
same
kind
of
impairments,
we
say:
okay,
this
is
path
or
side
dependent.
H
Then
then,
we've
combined
this
into
a
cloud
based
measurement
system,
and
that
has
to
always
up
note.
It
has
an
Orchestrator
which
runs
saltstack,
which
is
an
open
source
and
pretty
awesome
cloud
provisioning
system
and
then
a
PTO
or
a
Patras
parentsí
observatory.
So
if
you'd
want
to
run
your
measurement,
what
you
do
is
you
SSH
into
the
orchestrator.
You
set
up
your
measurement
campaign
and
then
the
orchestrator
will
periodically
spawn
a
bunch
of
measurements.
H
Cloud
notes
render
measurements,
and
these
measurements
will
then
upload
the
raw
data
into
the
PTO,
and
then
you
also
connect
to
the
PTO,
and
you
set
up
what
we
call
analyzers,
which
define
how
data
should
be
processed
and
then,
whenever
new
data
is
received
at
the
PTO
will
automatically
process
it
and
will
populate
it
in
a
database.
For
you,
and
then
we
have
a
nice
front
and
that
you
can
use
our
web
front-end
that
you
can
use
to
query
for
your
results.
H
So
with
the
system,
as
I
said,
we
run
measurements
on
three
different
protocols.
The
first
one
that
we're
looking
at
today
is
DHCP
or
differentiated
services,
which
is
part
of
the
IP
header.
It
gives
you
I,
think
a
six
bit
field
that
you
can
use
to
tag
packets
into
different
service
flows
or
whatever
you
want,
and
this
is
quite
often
used
by
network
operators
internally
and
then,
when
the
network,
when
the
packets
leave
their
net
or
guilt
bleach.
The
fields,
however,
related
to
weapon
there's
a
web
RTC.
H
There
have
been
proposals
to
also
use
this
field
to
send
data
from
ant
hosts
to
servers
and
the
question
that
we're
looking
at
is
just
doing
this
impede
on
your
functionality,
yes
or
no,
and
then
another
question
that
we're
looking
at,
which
is
more
by
the
way
thing
is:
is
there
any
link
between
the
DHCP
code
points
you
get
back
from
a
server
and
the
ones
you
sent
and
ideally
there
should
be
none.
So
how
do
we
measure
this?
H
Well,
that's
why
the
first
will
open
up
a
regular
TCP
connection
where
you
set
to
the
DHCP
code
point
to
zero,
which
is
the
default
value,
and
then
we
open
up
a
second
connection
with
a
non-default
DHCP
code
point,
and
then
we
see
if
the
second
connection
fail.
We
assume
that
the
syn
packet
must
be
dropped,
so
something
is
impeding
on
our
function
or
on
our
connection,
so
results
again.
We've
measured
this
from
digitalocean.
This
is
true
for
all
the
measurements.
H
This
is
Los
MLS,
a
it
promise,
and
we
see
that
for
the
code
point
that
use
for
testing
that's
code,
point
46
or
expedited
forwarding.
We
see
absolutely
natural
blocking.
So
if
you
look
here
in
the
table,
see
that
of
all
the
successful
connection,
attempts
with
the
baseline
case,
only
half
a
percent
or
so
failed
when
using
a
non
standard,
DCP
code
points
and
of
this
half
a
percent
pretty
much
all
of
them
exhibited
some
sort
of
path
dependency.
So
there's
almost
no
blocking,
but
the
blocking
there
is
is
file
dependence.
H
Tcp
TFO
is
a
protocol
that
allows
you
to
when
you
connect
to
a
server
over
TCP
exchange
cookie
and
then,
if
you
connect
again
to
that
server,
you
can
send
it
to
cookie,
and
if
the
cookie
is
right,
you
can
actually
also
already
send
data
on
the
same
packets.
So
you
can
basically
cut
round-trip
delay
time
or
you
have
loading
delay
time.
So
I
wonder
around
trip
time
so
again
for
a
measurement.
H
First,
we
open
up
a
vanilla,
TCP
connection,
and
then
here
we
we
actually
deviate
a
bit
from
our
standard
procedure,
because
there
is
an
API
issue
or
was
an
API
a
show
issue
for
the
DFO
api.
We
saw
a
very,
very
long
time
outs
when
the
connection
failed.
So,
in
order
to
to
avoid
those,
we
only
open
up
a
TFO
connection
if
this
baseline
connection
actually
succeeded.
H
So
first
we
create
a
first
connection
and
we
do
a
cookie
exchange,
and
then
we
create
observations.
Whether
this
cookie
was
received
or
is
not
received.
Then
if
we
did
receive
a
cookie
and
we
closed
action,
we
open
up
a
new
connection.
We
send
the
cookie,
we
send
the
data
and
then
we
see
was
this
data
act.
Was
it
not
act
or
did
the
connection
fell?
All
together
results?
H
H
H
Then
the
third
protocol
that
we
looked
at
is
ECM
or
explicit
congestion
notification,
and
this
allows
routers
on
a
part
to
signal
congestion
to
end
house
without
dropping
packets.
So
again
we
do
our
usual
yadi
yadi.
We
open
up
a
baseline,
TCP
connection
and
quasi
simultaneously
we
open
a
TCP
connection
where
we
try
to
ego,
negotiate
ecn.
We
look
depending
on
which
one
of
these
connections
work.
H
We
say
that
ecn,
connectivity
is
working,
broken
transient
or
the
host
is
just
offline,
and
then,
if
is
in
connection,
if
the
ecn
connection
is
working,
we
will
load
the
TCP
connection
a
bit
more
and
we'll
see
every
receive
any
of
the
easy
encode
points.
So
we
see
whether
we're
actually
also
doing
easy
and
after
negotiating
it
so
results,
we
see
that
server-side
ecn
deployment
he
increasing,
which
is
nice.
H
It
also
keeps
increasing
on
v6,
where,
before
it
was
a
bit
flaky,
it's
now
actually
getting
quite
good,
and
we
also
see
that
the
impairments
that
or
after
you
negotiated
ecn,
there
are
still
some
impairments.
But
this
the
level
of
impairments
there
is
staying
quite
static
over
time
and
then
another
quite
interesting
thing
that
we
did
is
we
looked
at
hosts
that
showed
easy
and
pal
dependency
and
we
applied
geo
analysis
on
them
on
them
via
GRI
P,
and
then
what
we
saw
is
at
the
three
countries
that
show
it's
most
easy
and
PAH
dependency.
H
H
H
This
is
less
than
one
in
10,000
and
we
think
the
reason
that
this
happens
is
because
firewalls
like
the
Great
Firewall,
are
probably
very
heterogeneous
installations,
so,
depending
on
which
sensor
network
censor
ship
box,
you
hit
you
get
easy
N
or
you
don't
get
it,
and
you
can
also
see
here
and
the
light
purple
lines
show
how
stable
the
PAS
dependency
is
over
time,
and
you
see
that
it's
actually
not
stable
at
all.
So
it's
really
based
on
what
we
think
it's
really
based
on,
like
which
box
you
hit
and
yeah.
H
H
H
C
C
H
H
F
H
So
once
we
get
this
back
up
and
running,
the
idea
behind
this
setup
is
that
it
actually
just
keeps
running,
so
your
measurements
start
automatically
and
your
analysis
starts
automatically
and
we
have
a
web
front-end
that
will
be
public
or
is
public.
So
the
idea
is
that
this
is
a
continuous
thing,
so
you
can
really
see
how
this
evolves
over
time.
Yeah.
I
So
and
I
saw
some
indication
that,
between
your
the
first
runs
and
the
second
runs
in
your
experiments,
you
can
a
baseline
failure
rate
since
they're
going
up.
Have
you
any
understanding
of
what
that's,
depending
on,
even
for
without
do
you
remember,
on
which
light
or
which,
being
at
the
table
for
like
the
Sen,
for
example,
you,
let's.
H
I
F
F
You
should
pay
them
about
two
thousand
USD
per
run,
and
there
was
a
chunk
of
about
three
weeks
when
we
ran
this
test
between
not
having
an
Alexa
list
that
we
could
that
we
knew
that
we
could
legally
do
something
with
and
Cisco
opening
the
umbrella
top
million
domains
list,
which
has
kind
of
replaced
Alexa
for
for
these
sort
of
things,
so
that
January
2017
run
runs
a
list
that
we
cobbled
together
ourselves
from
other
public
sources.
That
was
meant
to
replace
the
Alexa
top
million
list.
F
So
there
is
in
a
couple
of
these
cases,
there
were
not
actually
comparing
apples
and
oranges,
we're
comparing
or
not
actually
premiering
apples
and
apples,
we're
comparing
apples
and
plums,
maybe
they're
related,
though
the
trees
look
about
the
same.
But
there
are
some
differences
there
that
that
can
can
change
the
coverage
a
little
bit.
Thank.
A
J
A
Yeah
I
want
it
I
just
wanted
to.
Thank
you
all
again
for
doing
for
doing
this
work
about
things
that
I
worry
about
we're
having
the
conversation
in
a
couple
of
ITF
working
groups,
which
will
be
hopefully
closing
on
this
week
about
opening
up
our
ability
to
do
more
experiments
with
ecn,
and
so
we're
gonna
be,
like
I,
said
we're
gonna.
This
is
interesting
to
us
now
and
I
think
it
will
be
more
interesting.
A
D
A
Next
talk
is
take
your
own
share
of
the
pie,
and
this
is
Sylvester
is
a
senior
researcher
at
Ericsson
research
Budapest.
He
received
an
MSC
and
electrical
engineering
from
Budapest
University
of
Technology
and
and
economics.
His
main
area
of
interest
is
traffic
management,
including
control
of
resource
sharing,
network
cooperation,
scheduling
and
dimensioning.
So,
thank
you.
So
mr.
M
So
joint
work
with
Laurent
University
of
Budapest
and
I
am
the
presenter
day
they
couldn't
make.
So
what
is
our
goal
with
pv
pi?
We
would
like
to
create
an
amalgam
which
is
simple
to
implement
only
drops
or
marks
upon
arrival
to
queues,
and
we
would
like
to
implement
simple
and
scalable
so
sharing
policies
building
on
their
per
packet
value
concept
we
be
published
before,
but
I
will
I
will
give
an
introduction
to
that,
and
we
would
also
like
to
keep
dog
at
queuing
delay
building
on
the
pike.
M
So
what
what
is
a
perfect
value
framework?
It's
a
resource
sharing
framework
which
allows
a
wide
variety
of
detailed
and
flexible
policies.
It
enforces.
These
policies
under
all
were
possible
for
traffic
combinations
and
scales
are
given
with
the
number
of
the
flows.
So
it's
it's
defines
resource
sharing
policies
for
all
situations
by
so
you
put
it
back.
It's
value
functions,
it's
it's
done,
for
example,
a
policy
node,
and
then
it
proposes
a
packet
marker
at
the
edge
of
the
network
which
masks
get
value
on
each
packet
based
on
these
throughput
value.
M
Functions
belonging
to
that
flow,
so
that's
that's
at
the
edge
and
within
the
network.
Resource
needs
only
need
to
maximize
the
total
transmitted
value.
They
don't
this.
This
results
in
implementing
the
policies
we
don't
need
for
any
flow
over,
and
so
you
don't
need
to
know
about
these
packets
which,
to
which
flow
they
belong
or
which
is
the
policy
of
that
packet.
M
So
it's
more
than
every
packet
expresses
the
gain
of
the
operator
and
the
packet
is
delivered
and
it's
relative
implement
in
importance
on
the
packet
in
value
per
bits
and
again
every
source
node
aims
to
maximize
the
transmitted
that
packet
value.
So
how
to
do
that
we'll
be
detailing
later,
and
then
there
is
a
congestion
threshold
value
in
this
value
space
below
that
value.
M
In
an
ideal
system
below
that
value,
all
packets
should
be
robbed
above
the
Tropic,
it
should
be
transmitted,
and
this
this
value
results
from
the
combination
of
available
capacity
amount
for
fir
traffic
and
the
packet
value
composition
of
that
of
the
traffic,
and
it's
actually
a
pretty
good
descriptor
of
what
happens
in
our
system,
and
this
complements
end-to-end
condition
control.
We
will
show
that
it
enforces
Furness
only
low,
controlled
loss
has
to
be
provided
by
the
intent
and
condition
control
and
and
only
to
avoid
that
packet
problem.
M
So
if
you
have
a
single
bottle
net
or
if
you
have
a
network
where
that
that
packet
program
cannot
happen,
you
can
even
live
without
condition,
control.
Of
course,
it's
it's
a
question.
What
happens
to
your
application
then?
And
with
this
even
incompatible
condition,
controls
can
coexist
in
a
network.
M
So
what
are
these?
You
put
packet
value
functions?
This
is
actually
derivative
of
the
utility
function
and
it
defines
the
desired
throughput
of
a
flow
of
a
clause
for
all
conditions,
rational
values.
So
what
what
is
an
example
for
that?
We
have
three
classes
here:
gold,
silver
and
background
so
and
the
horizontal
lines
are
conditioned
rational
values.
M
Silver
flow
should
get
one
megabit
per
second,
and
the
gold
should
get
the
rest
and
and
after
that,
after
Gold
gets
early
for
mag,
we
change
the
weights
between
backgrounds,
even
gold,
from
four
to
two
to
ten
to
four
and
again,
this
is
the
throughput
value
function.
This
is
only
known
at
the
packet
marker
and
from
down
was
a
packet
walk
marker?
These
policies
are
communicated
by
packet
marking
only
and
the
resource
not
don't
have
to
know
anything
about
these
policies
about
the
number
of
flows
only
have
to
read
these
packet
values.
M
So
how
does
a
packet
marker
look
like
requirement?
Is
that
if,
if
all
packets
below
a
condition
of
threshold
value
grow
up
in
the
throughput
of
the
remaining
package
shall
be
as
defined
by
the
tvf
at
this
threshold?
And
it's
very
simple
to
to
imagine
a
simple,
just
quantize
the
function
makes
token
buckets
with
the
packet
values
and
the
lengths
of
the
supid
region
and
choose
the
token
bucket
with
the
highest
PB,
where
there
are
enough
tokens
a
simple
example
for
pocket
marking.
M
Okay,
so,
as
I
said,
the
task
of
the
resource
nodes
within
the
network
is
to
maximize
the
total
transmitted
value
said,
the
simplest
of
whom
is
to
always
serve
the
packets
with
the
highest
packet
value
first,
which
is
not
practical,
because
you
want
to
keep
ordering
within
flows
at
least
so.
The
second
simplest
in
in
concept
organ
is
a
five-four
implementation
and
then,
when
the
queue
becomes
full
drop,
the
packet
with
the
smallest
packet
value
first,
but
still
meet
queue,
dropping
might
not
always
be
possible,
see
you
have
to
have
salt
free.
M
It's
it's
quite
well
published
in
the
literature.
There
are
improvements
to
it
as
well,
so
how
we
can
translate
party
to
the
per
packet
value
concept.
What
we
do
is
that
for
each
incoming
packet,
we
maintain
an
empirical
cumulative
distribution
function,
so
we
we
basically
make,
for
example,
histogram
out
of
the
incoming
packets.
We
run
the
PI
machinery,
we
calculate
the
dropping
probability,
basically
the
same
way
as
spiders,
but
instead
of
of
applying
it
directly
and
independently
of
the
packet
value.
We
take
that
value
in
the
e
CDF
and
update
the
condition
threshold
filter
accordingly.
M
M
It's
we
only
implemented
for
the
PI
controlling
to
avoid
32
milliseconds
in
our
simulations,
and
then
we
drop
it
and-
and
we
have
seen
some
kind
of
like
oscillations
in
this
CTV's,
so
I
will
I
will
show
that
and
we
actually
had
sometimes
has
to
have
have
had
to
increase
the
timing
window
for
collecting
this.
This
EC
DF,
because
there
weren't
enough
data.
So
this
is
this
part.
When
we
we
translate
the
probabilities
to
filter
values,
it's
definitely
a
point
to
improve
and
to
get
further
ideas
on.
M
M
Milliseconds
I
think
we
used
only
because
we
wanted
to
compare
to
to
the
PI
paper
which
we
used
as
a
reference,
and
we
had
a
propagation
delay
again:
40
100
millisecond
the
second
values
again
to
be
able
to
compare
to
the
PI
paper,
and
we
have
TCP
users.
They
generated
one
or
five
TCP
connections
per
flow,
so
flow
where
we
apply
sweepit
value
function,
so
the
flow
has
policies.
So
if
in
case
the
user
had
five
TCP
flows,
these
were
handled
together.
Even
the
packet
marker
didn't
differentiate
with
with
them.
M
We
used
five
cc's
TCP
flows,
because
sometimes
a
single
TCP
flow
wasn't
aggressive
enough
or
the
drop
of
a
single
packet
was
was
too
high
and
the
resource
sharing
wasn't
as
as
we
intended
and
UDP
traffic
is
completely
non
congestion,
control
and
high
speed.
Usually
it's
something
like
60%
of
the
bottleneck
capacity.
So
if
we
have,
for
example,
free
UDP
flavors
as
in
simulations
we
have,
they
could
already
completely
over
harm
the
TCP
flows.
If
we
wouldn't
have
any
kind
of
resource
sharing,
control
solution,.
M
So
this
is
the
simple
simulation
case.
We
have
only
gold
and
silver
TCP
sources,
five
TCP
connections
per
flow
and
we
changed
the
number
of
flows
from
one
one:
one:
gold,
one
silver,
2,
2
to
4,
4
and
8,
8
and
and
using
flow
calculus
and
knowing
the
truth
put
value
functions
is
possible
to
calculate
the
desired
resource
sharing.
So
what
what
is
what
we
defined?
M
So,
if
you
know
we
have
this
number
of
sources,
this
T
V,
Fe
DVF's
and
this
capacity,
then
it's
simple
math
to
calculate
these
desired
shares
and
once
you
can
see,
if
we
have
not
too
many
users,
there
are
some
deviations
from
the
from
desire
chairs.
But
as
the
number
of
sources
increases,
the
the
actual
share
got
by
the
users
is
very
close
to
be
to
be
desired,
and
this
is
mainly
because.
M
M
It
took
time
for
the
TCP
flows,
especially
the
gold
TCP
flows,
to
again
reach
its
desired
chair
and
and
and
during
that
time
we
didn't
have
any
any
chance
to
do
anything
and
as
the
number
of
flows
increases,
we
have
more
chances
to
to
drop
the
right
packet
there
by
TCP
adapted
to
the
dry
stupid.
So
again,
the
throughput
results.
So
this
this
was
the
region
when,
when
it
took
time
for
the
gold
TCP
flows,
they
actually
reach
again
the
desired
chair,
I.
M
Also
bought
to
the
queue
length
here
for
this
to
compare
to
the
pride
result.
So
this
was
the
desired
key
lengths
and
you
can
see
that
when
we
increased
the
number
of
sources
we
increased
at
30,
60
or
90
milliseconds.
There
was
a
spike
in
in
queuing
delay,
but
otherwise
it
it
was
like
around
the
queuing
delay
pretty
pretty
well
and
at
the
end,
I
will
compare
it
to
the
actual
PI
implementation.
It's
very
similar
to
PI.
Pi
also
has
this
overshot,
larger
or
smaller?
M
M
We
have
three
of
them
and
then
at
30
millisecond,
we
we
start
having
TCP
flows,
increase
them
from
1
1
to
2,
2,
&,
4,
4,
and,
and
what
you
can
see
is
that
again,
if
we
have
not
too
many
TCP
flows,
then
we
are
somewhat
away
from
the
desired
sure,
but
pretty
close
to
them
and
as
we
increase
the
number
of
flows,
the
flow
is
get
about.
The
desire
and
also
UDP,
gets
smaller.
M
So
you
just
expected
so
elaborating
on
this
I
mean
what
happens,
for
example,
if
we
use
PI
in
this
case,
if
we
use
Phi
in
this
case,
all
packets,
all
of
with
equal
probability.
So
what
will
likely
happen
is
that
if
you
have
like
10%
or
even
even
higher
probability
of
dropping
TCP
flows,
TCP
flows
get
basically
no
throughput
by
why
the
UDP
flows
get
get
all
of
the
capacity.
And
here
just
by
looking
at
the
packet
values
and
getting
the
statistics,
you
can
achieve
a
very,
very
similar
system.
M
M
One
more
simulation
results
with
dynamic
bottlenecks.
In
this
case
V
we
had
I,
think
yeah,
one
one
TCP
flows,
one
silver
and
one
gold,
and
we
changed
the
capacity
of
the
system.
We
changed
from
10
max
250
ml
to
100
Meg
back
250
back
to
10.
We
wanted
to
see
what's
the
transient
behavior
of
the
system
and
again
transients,
especially
ramping
up
transients
takes
some
time,
but
the
system
can
realize
the
desired
we
saw,
sharing,
pretty
and
and
in
the
final
results
I
am
presenting.
We
wanted
to
compare
it
to
the
actual
PI
resource
sharing.
M
So
this
scenario
is
as
close
to
to
the
scenario
in
the
PI
paper
as
s
as
possible,
so
we
have
a
10
megabit
per
second
bottleneck.
5
TCP
flows
to
UDP
flows
and
the
target
delay
under
on
tip
time
is
is
like
in
the
PI
paper,
and
we
actually
in
the
paper.
We
have
a.
We
have
another
situation
results
where
we
we
didn't
reach
the
desired
B
so
sharing
as
well
as
here.
So
what
we
did
there
is.
M
We
increase
the
ECD
of
window
again,
a
cdf
window
is
how
long
you
collect
statistics
about
your
packets
to
translate
your
dropping
probability
to
condition
threshold
value.
So
we
had
to
increase
that
to
actually
reach
this
nice
desired
resource
sharing
here,
and
we
also
have
to
increase
the
number
of
CCP
connections
per
flow.
But
if
you
take
there
at
the
values
in
the
PI
paper,
it
was
the
to
two
crosses
get
about
the
same
capacity.
Why?
M
We
suspect
there
weren't
throughput
values
in
the
PI
paper,
but
what
we
suspect,
because
of
the
equal
dropping
probability
TCP
flow,
is
there
ever
completely
overhand
and
it's
even
with
the
default.
It's
not
completely
over
hand
here,
and
if
you
choose
some
of
the
parameters,
you
can
again
approach
the
resource
sharing
quite
well.
M
So,
in
summary,
we
created
a
PvP
algorithm
which
can
govern
its
own
sharing
by
combining
the
pie
and
third
packet
value
concept.
Drop
ability
is
calculated
by
PI
and
is
translated
to
congestion,
threshold
value
filter
in
in
the
PPV
concept,
and
this
results
a
much
more
practical
resource,
not
implementation
of
in
this
concept,
because
the
previous
implementation
had
to
drop
mid
Q,
which
is
often
not
possible
and
using
a
necessary
simulations.
We
have
showed
that
it
can
realize
it
is
OD
so
sharing
and
keep
their
target
queuing
delay.
M
Of
course,
we
have
some
further
work
to
do.
We
need
further
simplification,
actually
keeping
the
the
EC
DF
can
be
a
still
quite
costly,
especially
for
high
speed
links.
Of
course,
there
are
the
options,
but
we
we
have
to
look
into
these
options
and
also
the
the
filter
crash
horse
has
to
be
stabilized
by
by
also
improving
transient
behavior.
It's
pretty
ok
right
now.
M
If
you
have
a
few
number
of
high
speed
flowers,
this
filter
can
can
be
switched
on
and
off
fairly
often
or
if
you
have
many
UDP
flows,
there
can
be
problems
with
it.
Of
course,
pie
itself
is
tuned
for
TCP
flows,
so
it's
not
surprised
that
it's
not
not
behaving
like
perfectly
for
UDP
flows.
On
the
other
hand,
it's
it's
actually
somewhat
surprising
that
it's
working
that
valve
it
with
the
UDP
non
congestion,
control,
flows.
N
Yeah
you
actually
mentioned
my
question
already
on
the
last
on
the
last
slide.
I
was
wondering
how
much
computational
complexity
and
state
you
actually
need
for
the
inverse
CDF
and
how
you
maintain
whatever
the
last
window
of
values
of
measurement
values,
you
have.
How
do
you
implement
this
in
practice
we
have
or
up
to
which
speeds?
Could
you
would
you
assume
that
you
can
maintain
this?
This
just
curious.
M
K
M
When
it
comes
to
practical
implementations,
we
are
thinking
about.
Actually
practical
implementations
are
can't
really
going
to
into
many
details.
Of
course
you
can.
You
can
always
maintain
a
histogram
and
erase
that
histogram
from
time
to
time
you
can
quantize
the
value
space
or
use
smaller,
very
specific.
We
use
the
single
byte
value
space
here
for
the
per
packet
value.
So
it's
not
like
amazing,
not
not
like
a
huge
value
space,
but
we
are
actually.
M
This
was
per
class.
No,
this
is
per
bottle.
Mac,
so
again,
I
mean
the
thing
with
the
concept.
Is
that
add
the
resource?
Node,
you
don't
know
about
classes,
you
don't
know
about
flows.
You
only
know
about
know
about
packet
values,
so
you
need
a
singly
CDF
per
resource
node.
So
it's
it's.
It's
probably
fine.
It's
I
mean
the
whole
thing
with
the
concept
is.
The
scale
was
with
the
number
of
flows,
because
you
don't
know
about
the
number
of
flows
at
over
at
the
bottom.
Like
all.
N
E
If,
let's
say
my
pockets
belong
to
the
economic
class
with
the
gold
one
right
and
then
most
preferred
to
be
dropped,
my
pockets
will
drop
from
the
flow.
Because
of
this
mechanism
it
does
set
the
spy
on
stickam
account
VH
the
flow,
for
example,
I
assume.
If
my
flow
packets
are
constantly
dropped,
their
value
will
start
increasing.
Sometimes
else
my
session
will
be
reached
or
will
be
impaired,
I
mean.
M
The
the
thing
is
in
the
pocket
marking,
so
if
you're,
if
you're,
if
your
throw
is
responsive
and
your
your
packets
are
completely
and
constantly
dropped,
then
your
flow
rate
will
be
likely
below
your
your
fair
share
rate
and
then
the
packet
marking
dogyum.
We
make
make
sure
that
your
all
your
packets
has
value
higher
than
the
condition
threshold
value,
which
means
that
none
of
your
packets
will
be
dropped
until
you
are
above
your
fair
share.
I.
E
M
It's
it's
compensated
based
by
packet
marking.
So
let's
say
your
fair
share
is
hundred
magnet.
The
second
condition
threshold
value
is
hundred
and
then
SS.
If
you
are
transmitting
with
99.9
again
I'm
talking
about
to
complete
the
ideal
system.
But
then
all
your
packets
will
have
value
higher
than
hundred.
A
Wanted
to
take
I
want
to,
like
you
know,
some
place.
We
have
this.
This
quote
that
you
know
to
every
to
every
problem.
There
is
a
solution
that
is
obvious,
simple
and
always
wrong,
and
when
I
was
when
I
was
looking
at
your
paper
where
it's
like
you
know.
Well,
we
have
this
tool.
We
have
this
other
tool.
We
should
put
them
together
and
I
was
really
worried
that
you
were
gonna
trip
over
the
you
know.
This
is
obviously
the
right
thing
to
do.
A
B
O
So,
first
of
all,
what's
the
NEET
library,
the
neat
libraries
use
a
library
for
network
communication,
which
means
you
have
a
non-blocking
and
call
that
based
concept
and
unified
API
for
all
network
protocols,
so
you
can
use
TCP,
UDP,
SCTP
setp
in
kernel
and
userland.
In
the
same
way,
no
different
new
difference
in
how
you
use
the
API
and
the
neat
library
runs
on
Linux,
FreeBSD,
NetBSD
and
Mac
OS,
and
it's
lip
UB
base
and
you
were
interested
in
the
project
visit
me
project
org.
There
are
some
more
information
about
the
library.
O
So
what's
the
demo
oops?
Oh
it's
this
slide.
The
Neve
Murray
is
between
the
application
and
the
the
network
protocols
like
UDP,
TCP,
SCTP
and
other
protocols
like
web
RTC.
We
just
added
web
RTC
support
and
we
have
Forks
now
working
on
web
RTC
in
the
athan.
So
we
will
present
tomorrow
demo
with
rod
with
web
RTC
data
channels
and
needless
between
the
application
and
the
protocols.
O
So
how
does
the
setup
look
like?
We
have
on
the
left
hand,
side.
We
have
the
client,
we
called
it
need
Forks,
because
it's
Firefox
of
a
need
and
the
client
is
connected
wire
to
10,
megabit,
Ethernet
connections
to
two
routers
and
we
called
the
routers
heavy
blue
box.
I
will
explain
why
we
call
them.
Have
people
works
later,
and
here
we
have
two
more
10
megabit
Ethernet
connections
which
are
connected
to
the
server.
The
server
runs,
tht
TBD
and
all
these
four
networks
have
11
different
subnets.
O
The
need
Forks
is
Firefox
using
need
and
we
only
support
HTTP
over
TCP
and
our
SCTP
SCTP
means
multihoming.
So
we
can
use
several
paths
which
are
available
and
firefox
over
need
runs
on
linux
and
freebsd,
and
it
is
possible
to
use
to
be
used
on
mac
OS.
But
it's
not
running
that
stable
and
now
a
demo.
We
are
using
FreeBSD
11
and,
as
I
explained
earlier,
to
network
interfaces.
O
The
non
need
components:
heavy
blue
box,
it's
a
router
between
a
server
and
the
client.
It
has
dummynet
running
with
the
custom-made
web
GUI
and
we
are
able
to
filter
TCP,
UDP
and
SCTP
on
both
paths
also
based
on
FreeBSD.
The
server
is
a
modified
version
of
THC
TBD,
supporting
TCP
and
SDP,
also
running
previously
11
stable,
also
to
network
interfaces.
O
The
set
up
is
located
here
and
we
will
show
file
download
them
over
HTTP.
We
are
HTTP
once
running
with
TCP
and
once
this
SCTP
and
the
need
library
will
check.
Ok,
which
network
protocols
are
available
on
the
path,
for
example,
testing,
TCP
and
SCDP,
and
will
try
to
use
SCTP
if
available,
because
SCTP
offers
multihoming
and
it
should
be
2
times
faster,
and
if
the
net
library
discovers
ok,
we
can't
get
up
connection
with
st-pierre.
There
will
be
an
automatic
fallback
to
TCP.
O
Set
up
again,
here's
the
client,
which
is
this
machine
where
the
presentation
is
running
on-
and
this
is
the
happy
blue
box
stack
and
on
the
bottom,
you
have
Cisco
switch
between
the
laptop
which
is
not
connected
today,
because
it's
not
usable
to
always
switch
the
project
of
intuitive
machines.
There's
the
happy
blue
box
router,
and
here
we
have
the
network
server,
which
is
this
little
box.
This
is
the
happy
blue
box
tag.
This
is
the
client
I.
O
O
Expected
1.1
megabyte
per
second,
which
is
roughly
10
megabits,
and
it
takes
some
time.
I
will
stop
it
here,
so
we
keep
the
browser
open.
So
nothing
will
change.
On
the
on
the
client
side,
we
go
over
to
the
heavy
blue
box
and
allow
TCP
SCTP
and
the
to
the
box
machine
again.
I've,
not
restart
the
browser,
just
rerun
the
connection
test
since
now
we're
using
a
CD
B
and
if
we
start
off,
I
download
same
file
again,
we
see
it's
using
two
paths
and
we're
reaching
roughly
the
double
amount
of
speed.
O
P
O
A
Q
O
R
Q
In
the
motivation
for
that
is
to
get
rid
of
the
middle
boxes,
I'm
trying
to
see
where
you're
coming
from
with
this
work,
because
to
get
the
you
know
to
do
more
tests
and
evolve
and
I
think
Paul
Hoffman
for
Nike
and
is
doing
some
studies
on
a
volitional
stack
on
the
network.
So
I'm
just
trying
to
understand
the
real
motivation
behind
it
because
behind
the
knee
project.
O
To
get
a
new
API
to
get
rid
of
the
socket
API
and
sort
of
a
unified
API
for
network
communication,
where
you
can
seamlessly
integrate
new
network
protocols
like
maybe
in
the
future,
quick
or
something
else,
and
you
don't
have
the
I,
don't
the
application
that
developers
don't
have
to
learn
a
new
way
to
to
communicate
with
the
network
depending
on
the
network
protocol.
This
was
the
main
motivation
and
need
offers.
O
Many
typical
Network
tasks
like
DNS
resolution
buffering
and
happy
eyeballing,
so
testing,
which
network
protocol
is
available
when
we
try
to
communicate,
need,
will
try
all
the
different
combinations
and
you
have
a
policy
system
where
you
simply
say:
okay,
I
want
a
secure
message.
Oriented
communication
need
do
your
best,
and
then
it
comes
up
with
a
we
have
established
connection
and
yeah
choose
the
best
protocol
for
you.
So.
A
If
I
was
to
either,
then
your
your
explanation
of
the
motivation
is,
of
course
correct
the
if
I
was
going
to
talk
about
the
meta
motivation,
how
you
you
know
how
you
end
up
in
a
place
like
this
in
the
fur
in
the
in
the
first
place.
So
we've
had
this
problem
with
coming
up
with
deployable
new
transport
protocols
for
a
while
and
I
I've
actually
got
a
picture
that
I'm
using
in
another
presentation
this
week
of
two
to
two
feet
with
sneakers
on
and
the
laces
are
tied
together.
A
But
you
know
this
is
the
oh.
We
couldn't
possibly
change
our
operating
system
kernel
because
the
the
fire
me
if
I
walls,
don't
understand
the
protocols,
so
we
couldn't
possibly
change
our
firewalls,
because
why
would
we
do
that
since
nobody's
implemented
the
new
transfer
protocols,
lather
rinse,
repeat
for
what
15
or
20
years,
so
we
toured
a
working
group
called
taps
to
try
to
you
know
and
so?
Well,
like
you
know,
we
were
to
start
chewing
on.
This
is
a
number
of
levels.
A
One
of
them
was
well,
you
know,
get
the
stuff
out
of
the
kernel
space.
So
you
know
now
you're
in
user
land,
so
so
that
was
there
was
one
thing
but
but
yeah
you
know,
the
other
thing
was
well
the
applications.
You
know
they
could
come
up
in
a
request,
sed
PE,
but
they
don't.
You
know
they
come
up
and
request
TCP
and
that's
what
they
request.
A
Turning
SCTP
on
and
having
that
be
preferred.
That
is
what
you
know:
the
transport
community
as
I
understand
it.
It's
been
hoping
for
it
for
like
25
years,
so
the
taps
working
group
that
we
chartered
Aaron
it's
around
here,
someplace
for
three
or
four
years
ago,
I'm
trying
to
remember,
but
that
working
group
in
the
IETF
was
chartered
to
come
up
with
kind
of
the
descriptions
of
ways
that
people
use
transport
and
how
that
maps
on
to
existing
transport
protocols.
A
You
know
you're
kind
of
working
back
from
that,
and
this
this
work
is
closely
tied
to
the
temps
working
group
in
the
IETF,
but
like
I
say
that
this
is
a.
This
is
a
I
think
this
is
thrilling
to
me
and
I'm,
not
the
most
thrilled
person
about
it.
So
really
really
they
say
a
really
pleased
to
see
where
this
is
going.
A
That
said,
I
got
a
couple
questions
for
you
guys
so
I
guess
you
know
the
the
biggest
the
biggest
one
for
me
was
when
I
was
looking
at
the
paper.
I
was
kind
of
assuming
that
the
policy
manager
was
going
to
be
the
most
interesting
and
novel
part
of
this,
and
the
paper
didn't
really
discuss
that.
The
policy
manager
much
that
I
saw
and
I
was
curious.
If
what
you
all
had
been
thinking
about
that
and
and
if
you
had
any
thoughts
that
you
were
able
to
share
about
that,
can.
A
Yeah,
so,
okay,
so
the
short
form
of
the
question
is
I,
come
up
and
I
say:
I
want
I
want
something
it
does
this
and
this,
and
this
and
I
have
let's
say
in
a
happy
world
six
transport
protocols
that
could
do
that.
How
do
you?
How
does
the
policy
manager
make
that
decision
about
like
one
of
the
tries
or
what
it
tries?
A
O
There
are
several
ways
to
specify
which
network
protocol
or
which
appliqu
which
traffic
you
prefer.
For
example,
you
can
be
very
precise,
saying:
okay,
I
only
want
to
allow
TCP
and
SCTP,
which
we
did
in
this
demo,
and
you
can
add
preference,
so
you
say:
ok,
I
prefer
a
CDP,
but
if
setp
is
not
available,
try
TCP
so,
and
this
is
very
specific
way
and
which,
otherwise,
you
can
say.
Ok
the
policy
manager
I
want
to
create
a
connection
to
Spencer
and
I
want
to
be
message
oriented.
R
O
We
we
have
who
can
make
a
clue
saying.
Ok,
last
time
or
last
ten
times
we
talk
to
Spencer,
we
use
TCP
and
SCDP
was
not
available
and
all,
for
example,
ipv6
was
not
available.
Only
TCP
/
IP
v4,
and
this
is
how
the
policy
manager
works,
need.
It
is
possible
to
run
it
without
the
policy
manager
also.
So,
if
you
don't
want
to
run
the
policy
manager,
just
leave
it
and
run
it
without,
it
is
possible,
but
the
policy
manager
gives
you
huge
benefit.
Yeah.
A
S
A
I
got,
you
know,
started
speaking
only
for
myself
for
whatever
that
me
whatever.
That
matter
means
right
now,
that's
speaking
only
for
myself,
you
know
it's
like
I
think
you
know
this
is
beautiful.
What
we're
looking
at
now
is
beautiful
and
oh,
let's
say:
multipath
is
beautiful,
and
so,
when
you
take
this
and
multipath
and
I'm
trying
to
like
I,
say
I'm
trying
to
understand
how
that
works.
A
When
you
start,
when
you
start
having
more
than
in
equals,
two
of
the
different
ways
to
that
you
could
get
someplace
that
might
work
and
might
have
different
characteristics
and
stuff
like
that.
You
know
if
n
was
six
at
each
one
of
these
levels
with
is
that
so?
Is
that
a
good
thing
or
a
bad
thing
so
but
think
yeah?
But
thank
you,
okay,.
N
Just
a
quick
follow-up
on
correspond,
so
this
is
a
kind
of
policy
spider
that
you're
then
taking
in
multiple
things
from
a
trapeze,
but
my
question
was
actually
so
this
with
the
memory
and
so
forth
is
all
good.
These
are
right
now
fixed
nodes
that
are
connected
by
Ethernet
to
some
networks.
Obviously,
whatever
you
are
doing
is
going
to
change
rapidly.
The
moment
you
have
mobile
nodes
that
are
seeing.
N
T
Maybe
you
can
bring
up
the
picture
of
the
architecture
to
say
a
bit
more
say
bit
more
about
how
the
policy
system
works,
so
you
have
the
the
policy
manager.
So
when
the
application
makes
its
request,
it
goes
into
the
policy
manager.
That
first
makes
a
translation
from
some
high-level.
If
I
ask
for
low
latency,
for
instance,
you
have
some,
you
have
a
policy
information
base
that
can
map
this
to
what
it
means
in
terms
of
protocols.
T
Then
there
is
a
characteristics
information
base,
and
this
is
the
port
that
has
the
dynamic
information
about
the
network.
So
this
is
what
mentioned.
Gori
also
mentioned
can
be
populated
by
different
sources.
So
in
pairs
example,
for
instance,
for
them
for
the
mobile
network,
it
will
have
information
gathered
from
the
modems
of
the
mobile
network
on
the
current
connection,
technology
and
measurements
that
you
have
so
this
you
can
feed
by
different
sources.
T
When
you
get
knowledge
about,
if
this
connection
worked
or
not
that
as
Felix
was
mentioning,
then
this
is
also
cached
back
into
one
component
of
the
characteristics
information
base.
So
the
happy
eyeballs
is
is
one
of
the
sources
for
the
zip,
but
other
sources
can
also
populate
that
with
the
dynamic
information,
so
I
think
we
will
also
talk
about
these
issues
in
the
tab
session
in
in
the
coming
excellent,
excellent
I.
You.
A
N
N
Think
we're
doing
so.
We
have
some
set
up
tables
behind
you
and
then
there
is
across
the
hallway
slightly
to
the
right,
a
room.
Where
is
there
where
there
will
be
waiting
a
hot
lunch,
buffet
I
hope
it
will
be
waiting
right
now
we
already
EE
for
one,
but
usually
people
are
setting
up
early,
so
you
can
stay
around
here.
You
don't
have
to
get
lost
in
the
hotel
maze
and
just
have
lunch
around
here,
we'll
reconvene
at
2
o'clock,
but
then
it's
for
the
third
session
enjoy.
Thank
you.