►
From YouTube: IPLD weekly sync (Textile Threads deep-dive)
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
C
B
I'm
going
to
be
recording
as
well,
just
because
I
don't
trust
the
the
live
thing
anyway,
thanks
everyone
for
joining
us.
If
you're
watching
on
this,
this
is
ipld.
We
weekly
think,
although
we're
a
little
bit,
we
weren't
supposed
to
have
one
this
week.
Apparently,
we've
switched
to
every
second
week,
but
we
we're
joined
by
the
good
folks
at
textile
who
and
we're
going
to
focus
today
on
threads
and
possibly
a
little
bit
of
buckets.
B
So
the
textile
data
structure
and
a
protocol
for
collections
of
data
and
links
of
things.
So
we
have
there's
a
bunch
of
people
with
interest
with
technical
questions
about
threads
and
we'd
love
to
get
these
guys,
giving
us
a
some
technical
background
that
is
deeper
than
what's
easily
accessible
through
the
documentation,
so
I'll
hand
it
over
to
carson
or
sander.
And
let
you
guide
us
through
and
we'll
pepper,
with
peppy,
with
questions
as
they
come
up.
A
D
A
And
then
the
thread
as
a
collection
is
basically
a
collection
of
all
these
logs
and
addresses
associated
with
the
peers
involved
in
that
log
and
various
other
metadata,
including
some
keys,
which
I'll
talk
about
in
a
second
and
then
in
practical
use.
You
know
if
you
have
multiple
peers
that
are
interacting
on
a
given
data
set.
A
One
of
the
most
useful
ones
is
that
you
can
essentially
defer
materializing
that
view
until
the
time
that
it's
needed,
because
you
know
that
there
cannot
be
any
conflicts,
because
only
one
peer
is
responsible
for
their
given
log.
You
can
deal
with
so
there's
never
going
to
be
conflicts
on
sort
of
the
right
side,
but
there
could
be
conflicts
on
the
read
side
when
you
actually
try
to
materialize
that
view,
and
so
it's
up
to
the
peer,
that's
materializing
the
view
to
deal
with
those
conflicts
when
they
arrive.
A
So
this
is
really
nice
for
distributed
systems,
because
you
can
basically
not
worry
about
like
you,
can
exchange
data
and
then
deal
with
like
problems
later,
and
this
turns
to
be
really
useful
property
from
where
we
came
from,
which
is
like
in
the
mobile
world
and
like
collaborating
peers
and
things
like
that,
where
you
don't
want
to
waste
time
or
effort
trying
to
deal
with
conflicts
ahead
of
time.
You
end
up
with
these
crazy
branching
structures.
A
Okay.
So
a
log
is
keyed
by
the
peer
id
and
standard
feel
free
to
jump
in.
If
I
like,
miss
or
go
over
and
brush
over
something,
really
simple
or
sorry
really
important,
but
anyway,
we've
got
our
logs
each
peers
responsible
for
writing
to
them
and
a
log
is
essentially
a
hash
link.
Hash
linked,
append
only
log
of
like
ivory
blocks.
A
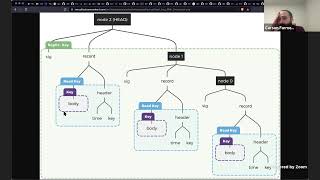
In
fact,
it's
a
hashtag
rec
log
of
records.
We
call
we
call
those
sort
of
higher
level
thing
records
and
the
records
each
one
contains
what
you
can
kind
of
see
here
in
this
figure,
which
is
it's
got
like
some
header
information,
including
the
the
key
or
sorry
the
time,
and
we
use
the
term
time
loosely.
That's
generally,
some
sort
of,
like
you
know,
logical
clock
or
something
like
that.
A
To
represent
time,
it
need
not
be
wall,
clock
time
and
then
the
key
that
is
used
to
encrypt
the
body
of
that
record.
So
you
actually
stick
the
key.
It's
a
randomly
generated
key
each
time
that
gets
stuck
in
the
header
and
then
that
all
gets
wrapped
by
an
additional
key
called
the
read
key,
which
you
can
see
here
and
the
read
key
is
used
to
encrypt
the
body
stuck
in
the
header
or
sorry.
The
key
is
used
to
decrypt
the
body.
That's
stuck
in
the
header.
A
The
reason
for
this
multi-layered
sort
of
way
of
doing
things
is
that
that
allows
a
peer
to
pass
or
a
group
of
peers
to
pass
off
a
replica.
Sorry,
it
used
to
be
called
a
replicator
key.
Now
it's
called
the
service
key,
but
anyway
you
can
pass
off
that
key
to
a
service
provider
that
surface
provider
can
track
log
updates
over
time
without
being
able
to
access
the
contents
of
those
log
records.
A
So
they
only
need
to
get
sort
of
like
one
layer
deep.
So
they
can.
They
can
follow
the
hash,
the
hash
links,
but
they
can't
go
any
deeper
than
the
read
if
they're
not
given
the
read
key,
and
that
gives
some
useful
properties,
because
now
we
can
have
like
trustless
service
providers
on
the
network
that
do
nothing
more
than
just
replicate
the
thread
content,
but
don't
actually
contribute
directly
to
like
the
update
or
like
editing
of
any
actual
thread,
content
and
yeah.
A
Then
that's
where
the
hash
linking
piece
comes
in
the
bodies
themselves
can
be
pretty
much
any
or
any
arbitrary
data.
In
practice
these
are
ipld
blocks,
and
so
in
theory
you
could
have.
You
could
have
kind
of
blocks
all
the
way
down
and
you
could
have
peers
that
are
exchanging
like
actual
ipld
blocks
in
the
body.
A
A
But
in
practice
we
also
find
that
you
know
people
also
want
multi-tenant
systems
where
you
basically
have
like
one
thread
peer,
that's
actually
responsible
for
other
peers
threads,
and
so
that
presents
like
sort
of
new
design
design
decisions
that
you
have
to
end
up.
Making
kind
of
on
top
of
this-
and
we
could
talk
about
that
as
well,
because,
that's
probably
in
practice
the
bigger
challenge
than
like
coming
up
with
a
peer-to-peer
protocol,
it's
one!
It's
like
a
multi-tenant
use
of
that
peer-to-peer
protocol.
That
makes
things
a
bit
more
tricky
anyway.
A
E
You
said
it
has
something
to
do
with
making
sure
that
someone
can
replicate
the
structures
without
needing
to
see
into
the
other
encrypted
bodies.
I
got
that
part
okay,
so
this
has
a
lot
to
do
with
where
data
storage
block
boundaries
are.
I
guess,
because
you're
worried
about
replicating
with
with
some
model
of
blocks
in
mind
right,
that's
yeah!
I
think
I'm
following
you.
A
Yeah,
it
sounds
like
those
confirmations
are
all
yes,
that's
right,
I
mean
so
the
key
like
there's
a
there's,
different
layers
that
you
can
have
with
the
with
the
body
in
particular.
Right.
So,
in
fact,
buckets
is
an
example
which
we
can
talk
about
later.
That's
like
a
practical
use
of
of
what
goes
into
the
body,
but
in
some
cases
the
body
will
be
just
a
reference
to
like
something
stored
on
ipfs
and
so
really
the
thread.
E
A
So
if
it's,
if
it
so
we
we'd
have,
we
have
users
doing
kind
of
both
things.
If
it's
big,
then
generally
you
just
store
like
the
cid
reference
to
the
big
thing,
and
then
you
store
the
big
thing
in
ipfs
and
then
it
doesn't
really
matter
just
like
any
sort
of
blockchain
thing
that
you
stick
the
cid
there,
you
store
the
other
thing
somewhere
else
and
that's
what
buckets
wraps
that
process
up.
Basically,
unless
then.
F
Yeah
sorry
carson
to
interrupt,
I
was
gonna
say.
Maybe
a
clear
distinction
is
like
blob
data
versus
ipld
data
because
yeah
with
buckets,
there's
no
point
in
storing
like
file
like
data,
because
you
wouldn't
or
at
least
for
buckets,
there's
no
merging
of
there's
no
resolution
of
blob
like
data
at
this
layer.
But
you
could
imagine
some
application
having
like
a
megabyte
of
application
data
that
it
does
make
sense
to
do
like
resolution
on
or
to
actually
track
that
state
through
time
but
like
for
buckets
it's
just
files.
E
Split
and
how
it's
persistent,
so
I
guess
the
clarification
I'm
looking
for
is
if,
if
you
have
the
the
replication
key
aka
the
service
key
you're,
giving
that
to
somebody,
because
you
want
them
to
be
able
to
confidently
replicate
the
thread
and
all
of
its
component
blocks
of
data
and
then,
if
there's
any
complex,
large
or
multi-block
structure.
That's
inside
of
that
body
region,
then
that
is
a
separate
responsibility
to
figure
out
how
that's
persistent.
F
F
Yeah,
so
right
now
back
when
we
did
this
originally
we
didn't
have
there
wasn't
that
around?
So
it's
done
in
kind
of
a
kind
of
a
crude
way.
We
basically
just
symmetrically
encrypt
each
so
each
like
the
the
body
gets
encrypted
symmetrically,
so
that
key
there
is
just
a
basic
symmetric
encryption
key
and
the
same
with
the
the
read
key
and
the
rep.
F
But
that's
something
we'd
love
to
improve
on
is
figuring
out
the
right
way,
and
maybe
that's
something
that
we
can
use
like
ipld,
prime
codecs,
for
because
it's
really
cumbersome
to
traverse
a
log
like
you
need.
You
need
to
have
the
the
right
algorithm.
You
know
you
need
to
know
how
to
do
it
basically
and
it's
not
self-describing
in
any
in
any
useful
way.
F
F
F
Something,
like
is
people
love,
so
we
were
trying
to
kind
of
emulate
that
and
that's
where
we
landed
on
this
log-based
sort
of
event,
sourcing
architecture,
where
a
thread
is
basically
yeah.
It's
a
collection
of
these
logs
that
represent,
if
you
combine
the
tips
of
all
those
they
represent,
some
state
that
can
be
resolved
into
a
document
in
a
collection.
F
So
it
could
be
like
you
know,
you
can
imagine
a
to-do
app
or
something
where
one
to
do
is
a
is
a
document
from
one
log
or
maybe
collaborated
on
the
multiple
logs,
so
that
the
way
that
those
logs
are
resolved
into
some
state
is
left
at
a
higher
layer
which
carson
mentioned
earlier
and
in
our
threaddb
setup.
We
call
that
the
the
collection
or
a
collection
instance,
and
that's
where
the
kind
of
parallels
to
manga
db
start
so
that's
sort
of
like
a.
If
that
helps
with
some
context
and
motivation
around
this.
G
Dean
did
you
have
a
question
yeah?
Oh
that's
something
like
you
know
just
like
trying
to
formulate
it
a
little
better
thinking
off
of
what
what
eric
mentioned,
which
is,
does
it
do
users
tend
to
run
into
users,
tend
to
stick
with
small
amounts
of
data
in
the
body
or
like
because
it
because
I
assume
it
just
becomes
like
much
more
complicated
when
you
can't
just
send
the
replicator
key
and
the
thread
id
and
say.
F
F
G
F
They
see,
they
see
the
replicator
key
and
the
read
key,
because
they
have
to
be
able
to
actually
track
the
state,
but
we
don't
really
have
that
concept
of
like
replicate
a
bucket.
In
that
sense,
it's
buckets
are
more
more
like
you
can
add
a
pinning
service
to
a
bucket
or
you
and
I
could
share
a
bucket,
but
we
haven't
sort
of
extracted
that
the
replicator
functionality
into
the
bucket
world,
because
yeah
you
do
need
to
see
the
the
read
key
to
properly
pin
the
bucket.
B
So
there's
no
it's!
These
are
not
thought
of
as
like
complete
gags
like
they.
They
have
leaves
that
may
be
unresolvable,
whether
that's
in
a
bucket
or
something
else,
that's
within
that
body.
So
we,
I
guess
we
ought
not
to
try
and
think
too
much
about
these
things
as
complete
sets
from
a
route
all
the
way
down
to
the
leaves.
There's
a
there's,
a
boundary
like
a
discrete
boundary
where
you
hop
out
of
this
and
the
resolution
is
your
responsibility
at
the
api
layer
or
something
like
that.
F
Yeah,
if
it
was
some
codec
based
thing,
other
peers
could
could
understand
they
could
traverse.
They
don't
have
to
be
like
a
specific
thread
pier.
That
would
be
amazing.
We
even
chatted
a
lot
about
making
buckets
less
of
a
like
a
file
based
api
and
making
it
understand
just
generic
ipld
nodes
right
now.
It's
based
on
the
unix
fs
api,
so
a
bucket
yeah.
F
You
know
if
you're,
manipulating
the
dag,
that's
describing
a
unifi,
unix
fs
structure
or
some
other
file
structure.
Whatever
you
want
it
to
be,
it
would
be
really
nice
if
that
was
like
more
part
of
the
the
body,
and
then
you
could
be
more
specific
about
what
you
wanted,
the
your
replicator
to
replicate,
so
it
would
handle
like
the
whole
pinning
if
you
wanted
to,
as
well
as
the
replication
of
the
the
thread
so
be
kind
of
more
of
a
native
thing.
Instead
of
these
two
different
responsibilities,.
B
Yeah
the
graph,
the
complete
graph
thing
and
encryption
that
scene,
that
seems
to
be
the
bit
where,
whenever
we
try
to
come
up
to
encryption,
that's
the
bit
that
just
makes
it
so
complicated
that
it's
hard
to
get
over
that
line.
How
do
you
do
that?
Well?
Where
do
you
wrap
them?
Where
do
you
expose
them?
How
do
you
permission
them
all
that
sort
of
stuff
does
seem
to
be
one
of
the
harder
problems
here.
E
So
I
might
be
interested
in
hearing
some
more
about.
You
said
that
you
are
you're
letting
folks
and
you're,
seeing
folks
actually
do
the
construction
of
their
own
conflict
resolution
algorithms.
On
top
of
this
thread
structure,
I
would
love
to
hear
just
any
lessons
learned.
You
have
it
all
from
just
like
how.
How
is
that
going?
That
seems
like
a
wild
place
to
be
letting
code
breed
yeah.
A
A
We
also
have
the
concept
of
a
codec,
a
plugable
codec
that
you
can
use,
and
there
are
a
few
teams
that
have
done
that
and
then
I
believe
fleek
has
actually
done
some
like
document
crdt
implementation
on
on
top,
but
that's
a
little
bit
different
because
that's
more
like
that's
like
even
a
layer
removed,
they
just
sort
of
like
ship
data
around
and
then
all
the
crdt
stuff
happens
like
in
the
browsers
kind
of
separately,
because
there's
already
pre-baked
libraries
for
doing
that
stuff.
So
it's
really.
A
They
just
use
threads
as
like
the
distribution
mechanism.
If
you
know
I'm
probably
botching
exactly
what
it
is
that
they're
doing,
but
it's
sort
of
a
layer
removed,
but
any
type
is
the
one
that's
doing
the
sort
of
like
closest
to
the
metal
crdt
stuff
that
we
know
of,
and
then
our
crdt
is
like
a
ot
kind
of
inspired
crdt
for
the
the
db
api,
and
you
know
every
sprint.
A
We
like
put
off
develop
more
awesome,
crdt
implementation,
which
is
you
know
the
nature
of
the
thing,
but
we've
done
some.
We've
done
some
preliminary
research
to
do
like
sort
of
opaque
crdt
operations,
which
has
been
pretty
promising,
but
just
never
gotten
around
to
putting
it
into
production,
and
that
would
that's
like
fully
ipld
based
crdt
takes
advantage
of
the
hash
structure,
kind
of
stuff.
F
Yeah
any
type
is
a
special
case
because
they
have
at
this
point,
contributed
like
as
much
as
we
have
been
in
the
past
six
months
to
threads
to
all
layers
of
it
like
the
orchestration
between
peers
and
performance
enhancements,
and
so
it's
they're
like
essentially
on
our
team.
You
know,
but
I
think
probably
for
folks
to
really
dive
in
and
yeah
develop
their
own
conflict
resolution
mechanisms,
that's
kind
of
the
avenue
you'd
have
to
take,
because
we
don't
really
publish
publicize
or
have
any
documentation.
A
G
I
think
it
also
helps
that,
like
when
you,
when
you
build
the
thing
on
top
of
the
first
thing,
you
also
know
more
about
how
the
first
thing
works
than
when
you
wrote
it,
which
means
like
yeah,
some
of
it's
better.
Some
of
it
is
nicer
and
easier
to
work
with,
because
it's
the
abstraction
layer
and
some
of
it's
just
because
you
understand
the
bottom
layer
more
than
you
did
last
time.
A
D
A
Sorry
yeah
they
did
some
interesting
stuff
around,
like
tracking
thread
heads,
that's
sort
of
like
hash
based,
so
you
could
see
right
away
if
you're
in
sync
with
other
peers
in
a
given
thread
or
not
and
decide
very
quickly.
If
you
need
to
request
an
update
from
another
peer
and
that
sort
of
thing
that's
been
pretty
exciting.
B
Yeah,
no,
I
mean
sorry,
sorry,
go
ahead
ron.
I
was
just
wondering
if
we,
if
we
could
talk,
we
didn't
have
to
do
it
now,
but
I
just
want
it
was
interested
to
shift
to
the
the
view
materialization
side
and
the
practicalities
and
performance
and
whether
you
do
caching
all
that
sort
of
stuff.
Where
does
that
sit?
How
does
it
work?
That
seems
like
an
interesting
part
of
this
because
it
does
seem
like
you
know,
over
time,
these
things
are
going
to
get
big
and
messy.
A
D
A
G
G
No,
it's
totally
doable,
though
right
and
threads.
You
know
if
you
have
like
an
acl
of
all
the
peers
and
over
some
period
of
time,
some
fraction
of
the
peers
sign
off
on
the
update,
and
you
can
tell
that
because
they
have
all
the
hashes
that
point
in
the
right
places
right
like
it's
very
doable
it
just
it
just
takes
time
to
do
these
things.
F
F
G
F
F
So
there's
kind
of
this,
like
bi-directional
bridge
between
the
the
app
layer
and
the
networking
layer
and
the
when
that
player
decides.
Okay,
this
is
the
new
state.
It's
just
we're
just
dumping
that
json
it's
currently,
it's
all
json
at
the
app
layer
and
we're
just
dumping
that
into
a
go
data
store
and
then
it
can
be
read
just
from
like
a
feeling
api.
B
A
Yeah
actually,
so
that's
another
reason
why
a
lot
of
folks
use
like
the
hub
or
some
other
like
running
peer
is
that
they
could
they
can
have
sort
of
like
semi-participating
peers.
So
you
have
a
web
app
that
queries
the
hub
for
like
the
current
state,
but
then
adds
like
pushes
updates
to
that
state.
That's
to
avoid
that
exactly.
B
Right,
which
is
yeah
you
I
mean
again,
there's
the
blockchain
one
you've
got
the
light
nodes
and
the
full
nodes,
100
yeah,
yeah.
Okay,
that's
fair
enough!
That's
it
does
sound
like
a
hard
problem
to
to
solve,
but
it's
only
not
unsolvable
right
and
how
big,
how
big
practically
do
these?
The
the
are
these
getting
like?
Are
people
building
really
massive
data
sets
on
this.
F
Yeah
so
well
again,
fleek
and
any
type
are
our
biggest
users,
so
the
way
that
any
type
model
they
have
any
type
of,
if
not
familiar,
is
like
a
notion
based
app
or
notion
style,
app.
So
the
way
they've
modeled
it
is
that
each
database
in
notion
speak
or
each
each
page
has
its
own
thread.
So
any
updates
that
happen
there
go
into
that
thread.
F
So
you
can
imagine
you
know
thousands
of
edits
easily
happening
and
people
can
have
hundreds,
and
I
think
they
even
said
some
folks
have
like
thousands
of
threads.
So
these
things
become
it
becomes.
The
challenge
quickly
becomes
pushing
updates
to
peers,
and
that
becomes
like
a
very
intensive
heavy
lifting
thing
to
do.
F
B
F
B
Update
everything
in
the
in
these
massive
documents,
but
but
then
they
have
to
have
you
know
thousands
of
threads
going?
Is
there?
Is
there
any
sense
in
nesting
threads
do
p?
Do
they?
Can
you
track
threads
within
threads
or
is
there
do
you
have
a
better
mechanism
for
tracking
the
number
of
threads
that
like,
or
does
that
just
become
an
application
concern
where
it
depends
on
how
flexible
you
want
to
be.
F
I
think
it
always
comes
down
to
the
fact
that
there's
no
like
privacy,
so
a
thread
is
if
you
have
the
keys
for
a
thread,
then
you
have
the
keys
for
a
thread.
So
usually
the
application
decision
is
around
like
what
things
do
I
want
to
be
able
to
share
and
what
things
I
want
to
keep
private.
So
if
you
just
had
one
thread
for
every
user
and
they're
putting
all
their
stuff
in
there,
then
either
it's
public
or
it's
private.
You
know
so
it
becomes
like.
F
How
do
you
build
something
where
you
can
on
notion
create
a
little
page
and
share?
Just
you
know
a
section
of
that
page
or
you
know,
and
folks
always
want
like.
Oh
they
want
to
do
the
the
google
docs
style
like
share
with
specific
people
or
share
a
link,
only
people
with
access
to
the
link
and
that
kind
of
thing
so
yeah.
F
D
A
Because,
realistically,
a
thread
is
a
set
of
keys
right,
like
there's
not
much
more
to
track
than
that,
instead
of
keys
and
some
like
tracking
around
like
well
pure
ad
addresses
and
stuff.
But
it's
like
to
to
have
another
thread.
That's
like
that's
referencing.
A
lot
of
the
same
data
is
like
basically
the
cost
of
creating
a
couple
random
keys.
A
B
These
these
sort
of
architectural
choices
about
where
you
divide
things,
how
you
structure
things,
does
that
end
up
being
a
problem
for
users?
Do
you
end
up
having
to
deal
with
a
lot
of
those
sort
of
architectural
questions
about
how
they
structure
their
use
of
these
things?
Or
did
you
find
it's
obvious
for
a
lot
of
use
cases.
A
I
think
that
is
a
very
good
question.
I
think
you
know
most
of
our
users
interact
with
threads
via
the
database
api
and
then
their
questions
are
like.
How
do
I
structure
my
data
like
they'll,
be
the
same
questions?
Would
ask
of
a
mongodb
like
how
many
collections
should
I
have?
What
should
those
collections
look
like?
Should
I
can
I
reference
one
collection
type
in
another
collection
type
like
those
types
of
architectural
questions
we
don't
get
the
like.
A
It
would
be
swell
if
it
was
even
easier
for
us
to
use
threads
like
this,
and
we
looked
at
that
and
said
yeah.
That's
a
good
idea.
We
should
try
to
do
that.
So
you
know
it's
like
a
difference
of
where
people
are
coming
in,
but
for
the
most
part
with
like
our
javascript
sdks
and
the
questions
I
feel
the
most.
It's
like
someone
who
works
for
mongodb
would
answer
the
same.
A
Sets
of
questions
maybe
a
little
bit
differently
because
we're
talking
about
a
distributed
system,
but
then
you
know
I
try
to
say
we
try
to
do
things
like
okay.
Well,
you
know
right
now.
A
thread
is
like
not
that
cheap,
so
you
might
want
to
put
like
more
collections
into
your
thread
or
you
might
want
to
like.
Have
one
user
be
responsible
for
these
collections
and
one
user
b
you
know
do
some
of
that,
but
at
the
end
of
the
day,
it's
more
about
how
do
I
structure
my
database
for
my
application?
Then?
F
F
But
currently
it's
still
kind
of
bound
to
like
a
thread.
So
that's
where
some
of
the
expensiveness
of
having
multiple
threads
comes
from,
because
it
just
each
thread
adds
some
multiple
multiplier
to
like
how
chattery
your
note
is,
regardless
of
in
some
ways
how
many
peers
are
in
those
threads,
so
yeah
it
should
it.
It
should
be
that
it's
just
more
expensive
to
communicate
with
more
peers
versus
like
how
many
threads
do
you
have.
You
know
kind
of
obvious
in
hindsight,
but
that
was
our
our
initial
implementation.
A
B
Right,
I
I
have
a,
I
have
a
couple
more
things.
I
know
we're
running
up
we're
running
up
against
time.
Here,
there's
a
couple
more
things
I
want
I
wanted
to
cover,
and
I
want
to
make
sure
that
others,
including
michael
now,
have
their
chance
as
well.
One
is,
we
haven't,
really
touched
on
buckets
very
much,
and
I
I
just
don't
have
any.
B
I
don't
have
much
of
a
mental
mapping
of
buckets
at
all
other
than
this
is
a
unix
fs
representation
like
this
is.
This
is
a
unix
of
s,
materialization,
of
a
large
collection.
What
is
their
relationship
to
threads?
Are
you
doing
like?
Are
you
storing
like
take
pb
in
these
things,
or
are
you
doing
something
else
where
you
can
materialize
a
unix
fs
out
of
the
thread
model
or
what
is
the
relationship?
What
what
exactly
are
buckets
and
how?
What
is
their
relationship
to
threads.
F
Yeah,
so
a
bucket
is
built
on
threads
in
that
the
root
of
its
unix
fs,
dag
is
tracked
in
a
thread
and
that's
really
where
it
ends,
except
where
you
get
the
replication
piece.
You
know
minus
the
pinning
of
that
thread.
The
history
of
the
changes
in
the
bucket
can
be
replicated
using
the
thread
structure,
but
other
than
that
you
can
imagine
building
buckets
without
the
threat.
F
It's
full
node
encryption,
so
we're
encrypting
every
node
in
that
dag
unix
fps
tag
it's
multi-key
so
like
I
could
share
with
you
one
file
in
a
unix
fs
tag
and
you'd
be
able
to
encrypt
down
through
that
structure
and
encrypt
the
file.
The
leaf
that
I'm
trying
to
share
with
you
there's
an
acl
built
into
it.
It's
also
part
of
its
thread
schema.
F
So
it's
just
kind
of
like
sugar
on
top
of
unix
fs
is
basically
what
a
bucket
is
and
then
just
to
recap,
like
its
relationship
to
a
thread,
is
the
schema
is
tracked
in
the
in
the
thread
which
enables
like
the
sinking
of
a
bucket.
Basically,
so
if
carson
and
I
were
sharing
a
bucket
peer-to-peer,
then
I
would
receive
updates,
via
via
threads
of
changes
that
he
made
in
that
bucket
via
this,
the
hash
changing
or
the
metadata
about
paths
changing.
F
F
We
have
a
a
we
built,
a
pinning
api
that
lets.
You
interact
with
the
bucket
over
the
the
standard,
pinning
spec
so
yeah
again,
it's
just
like
sugar
on
top
unix
fs.
Basically,
people
who
are
familiar
with
s3
or
other
like
object,
storage,
just
things
that
they
want
like
immediately
when
they
start
using
unix
fs.
B
B
F
One
thing
we've
talked
about
is
just
severing
off
the
database
layer
and
focusing
more
on
the
network
layer,
because
what
we
always
run
into
are
people
asking
for
kind
of
like
complex
database
things
like
hey.
How
can
I
do
custom
indexing
like
we
provide
a
very
basic
indexing
mechanism,
but
if
people
want
to
do
custom
or
compound
indexes
or
like
aggregators
or
any
kind
of
like
complex
database
thing
that
are
baked
into
something
like
postgres,
that's
had
decades
of
development
like
we
just
never
we're
never
going
to
to
do
that.
F
Practically
speaking,
so
we
think
there's
a
way
to
back
into
that
and
maybe
create
connectors
for
more
advanced
databases
by
focusing
at
the
networking
layer
more
closely.
So
just
this
thread
structure,
that's
one
piece.
Another
piece
is
something
we've
touched
on,
which
is
like:
how
do
you
make
having
a
thread
inexpensive
so
that
people
don't
have
to
worry
about
when
they're
designing
their
applications?
They
don't
have
to
think
like
okay,
I
only
want
to
have
10
threads
total
per
user
and
stuff
like
that.
F
Just
getting
rid
of
that
restriction,
that's
something
we
need
for
like
for
any
type
and
some
of
the
other
heavy
users
and
then
the
last
kind
of
main
priority.
Well,
I
won't
say
the
last
one
of
the
other
priorities.
Is
this
multi-tenant
setup
so
that
people
can
use
the
replication
piece
of
the
thread
more
efficiently
and
that's
just
sort
of
like
basic
breaking
up
of
a
thread
node
into
multiple
responsibilities
and
then
basically
making
the
orchestration
mechanism
scale
at
a
multi-tenant
layer?
F
F
F
A
Yeah,
I
mean
I'm
definitely
interested
in
you
leveraging
some
of
the
aes
codex
stuff
that
michael
did
recently
and
like
taking
advantage
just
like
kind
of
standardizing.
That
whole
thing
a
little
bit
more
and
even
though,
like
single
writer
like
hash
link
logs,
are
sort
of
like
obvious
having
a
library
which
is
like
new
log.
Insert
record.
Is
pretty
nice
like
to
have,
and
it
would
make
you
know,
would
make
building
threads
really
easy,
but
would
make
other
people
who
want
to
build
similar
things
and
there's.
F
There's
things
that
would
be
cool
to
standardize
like
how
many
you
know.
Do
you
backlink
at
a
certain
interval
to
allow
for
parallel,
traversal
and
intelligent
ways,
other
ways
to
make
verification
of
the
log
faster?
You
know
things
like
that
that
would
be
cool
just
to
have
it
be
like
a
a
standard
sort
of
thing.
F
B
Time
so,
in
terms
of
of
where
we're
heading
in
our
interest
here,
is
that
we're
looking
at
this,
this
general
problem
of
collections
yeah
and
wanting
to
standardize
something
for
the
ecosystem.
So
how
do
we
instantiate
something?
That
is
a
reasonable
standard
that
serves
a
basic
set
of
use
cases
and
you
guys
have
done
the
most
work
in
the
ecosystem
in
creating
something
practical
and
what
we're
trying
to
figure
out
is
what
are
the?
B
H
H
H
A
fair
amount
of
things
that
people
seem
to
think
are
insured
by
the
protocol.
Aren't
like
one
big
one
is
that
you
know
like
there
is
no
guaranteed
uniqueness
anywhere,
like
the
the
uniqueness
is
of
like
a
chain
transaction
that
you
can't
actually
predict.
So,
if
you're
looking
at
an
nft
or
looking
at
nft
kind
of
like
metadata
or
any
of
the
assets,
you
can't
go
from
that
to
an
authenticatable
structure
like
that's
kind
of
one
problem.
H
There
there's
a
like
the
only
thing
that
really
like
tells
you
about
an
nft.
Is
this
token
uri,
which
we
have
like
now
sort
of
pushed
people
to
standardize
on
using
ipfs
urls
people
were
already
doing
this
right
like,
but
but
now
it's
like
really
clear,
like
you
need
to
do
that
and
the
spec
mentions,
like.
Maybe
you
want
to
point
this
at
a
metadata.json
file
that
conforms
to
this
particular
schema,
but
there's
a
lot
of
people
that
don't
do
that
and
then
a
few
people
that
just
break
the
entire
spec,
which
is
really
annoying.
H
H
You
don't
want
to
like
tool
that
outside
of
it
and
you're,
also
like
not
relying
on
any
outside
tooling,
like
any
offchain
tooling,
for
that
either,
which
is
kind
of
cool,
but
that
that
changes
like
some
of
the
ways
that
I
think
you
might
use
threats.
I
don't
know,
have
you
guys
thought
at
all
about
like
this.
A
Spec
works,
so
you
actually
mutate
did
a
decentralized
ident
identifier
document
for
a
given,
like
ethereum
address
by
posting,
to
the
address
your
different
like
updates,
and
then
the
events
on
that
smart
contract
can
then
be
queried
and
resolved
to
resolve
the
actual
document
so
effectively.
You
have
a
mutable
document
that
you
can
change
over
time
and
you
could
effectively
make
those
updates,
like
thread
record
updates.
Basically
but
they're.
A
You
know
they're
native
ethereum
events,
so
you
can
query
for
that
and
it's
pretty
cool
because
it
costs
money
to
it,
costs
a
lot
right
now
to
mutate
that
nft
or
that
did
document,
but
it's
cheap
to
query
it,
and
so
it's
great
for
dids,
because
you,
like
you
resolve
way
more
frequently
than
you
update,
yeah
yeah,
it's
the
same
same
setup.
I
think.
H
I
think
this
becomes
really
interesting
in
like
the
context
of
of
nfts
right,
because
if
you
look
at
kind
of
what
artists
and
different
people
are
doing
with
them,
they're
like
creating
kind
of
these
one-time
assets
and
then
there's
like
the
secondary
market
for
selling
them.
But
if
you
have
one,
that's
mutable
and
only
the
owner
can
mutate
it.
H
You
can
start
to
create
like
artistic
works
that
go
viral
and
selling
them
as
part
of
the
virality
and
moving
them
around
as
part
of
the
virality,
and
then
because
you
have
that
contract
for
a
percentage
of
every
sale.
That
actually
makes
that
much
more
profitable
than
like
these
big
ticket
sales
right
like
if.
H
That
really
goes
viral.
You
actually
capture
like
a
huge
amount
of
value
from
that
kind
of
like
a
yeah
yeah.
Like
a
friend
of
mine,
I
worked
on
the
worked
on
the
grimes
nft
and
we've
been
talking
about
like
a
mixtape
where,
like
when
you
own
it,
you
get
to
add
your
track
to
it,
and
people
sort
of
follow
these
mixtapes
when
they
get
popular,
greater
greater
resale
value.
Yeah.
F
H
It's
in
the
it's
in
the
contract.
You
write
it
in
the
contract,
so
you
have
to
define
it
right
and
there's
like
there's
a
de
facto
standard
right
now
that,
like
I'm
just
taking,
I
think
ten
percent,
I
mean
that's
it,
but
you
see
other
people
that
are
like
minting
them
like
putting
themselves
in
these
contracts.
H
Of
course,
you
see
like
you
see,
like
sometimes
artists,
don't
have
that
in
there,
but
I
think
that
you
yeah
there's
a
lot
of
like
cool
stuff
that
you
can
do
with
that
you
you
can
I
mean
you
can
spread
out
different
payments
of
different
percentages
to
different
wallets
and
stuff.
It
costs
more
money
to
create
it
because
there's
more
data
going
in.
But
you
know,
if
you
want
to
get
fancy
with
it,
you
can.
H
Yeah,
I
think
one
one
problem
I've
been
tackling
is
like
you
have
on
chain
and
off
chain
data
right
and
all
of
like
you
know,
if
you,
if
you
parse
the
chain,
you
can
take
some
of
the
chain
state
into
the
into
the
offline
or
into
the
off
state
right.
But
when
all
you're
passing
around
is
the
off
chain
data
references,
you
don't
necessarily
have
a
way
to
to
call
that
back
and
like
authenticate
it
right,
and
this
like
becomes
a
problem
when
you're
building
some
of
the
more
advanced
workflows
so
like
one.
H
A
H
F
Uri
yeah
super
cool.
I
think
one
thing
that
we've
been
missing
from
threads,
just
like
clear
use
cases.
You
know
that
we
can
really
rally,
because
you
can
imagine
doing
things
differently
like
if
or
like,
or
were
to
design
this
for,
iot
or
something
or
or
design
it
for
nft
tracking
or
so
there's
been
a
like
slight
paralysis
around
some
decisions,
just
like
without
super
clear
use
cases
you
know
and
right
now
we're
just
mostly
driven
by
our
heavy
users
but
yeah
yeah.
That
would
be,
I
mean
yeah
it'd,
be
great.
F
B
And
but
we're
working
on
the
you
know
the
basics
of
what
it
is,
what
it
is
we're
even
talking
about
right
now,
so
so
I
think,
maybe
maybe
in
the
next
conversation
with
you
would
be
simply
about
the
use
cases
that
we
are
seeing.
We
are
thinking
as
important
and
then
looking
at
the
intersection
of
those
with
what
you
have
and
then
like
that,
because
that,
and
then
that
should
make
things
obvious
for
all
of
us.
Really,
that's
that's
that's!
The
next
step
for
us
is.
A
B
Yeah
the
way
it
was
put
recently
was
that
this,
the
notion
of
collections
of
data,
particularly
you
know,
ipld
collections
of
things-
was
something
that
was
punted
early
on
in
the
ipfs
design
process
and
never
really
got
back
to,
and
it's
taken
it's
it's
taken.
People
like
you
to
come
up
with
ways
of
solving
that
and
it
really
would
be
good
to
have
something
that
was
advertised
as
a
standard.
B
A
I
mean
it's
the
same
thing
as
we
were
talking
about
with
dids
right.
It's
like
you
know.
If
you've
got
some
sort
of
definition
of
what
a
collection
is,
then
you
can
implement
that
on
ethereum
and
you
can
implement
it
in
just
hash
links,
ipfsc
ids
and
you
can
do
it
on
popcorn.
You
can
do
it
everywhere
and
that's
pretty
exciting.
H
What
like
what
is
like
a
good
multi-block
data
structure
for
storing
a
large
collection
of
cids,
because,
like
the
mutation
rate's,
just
horrendous
right
like
like
yeah
and
and
I
don't
think
that
we've
gotten
very
far
like
other
than
in
that
in
that
zag
spec,
that
I
wrote
there
is
a
compression
algorithm
for
cids
that
just
leverages
ordering
in
order
to
get
rid
of
the
prefixes
and
some
other
stuff.
So,
like
you
can
shave
like
15
off
of
the
size
of
just
like
a
bunch
of
cds,
but
other
than
that.
G
I
guess
just
briefly
on
the
networking
side
of
things
yeah.
If
you
need
stuff,
you
want
to
talk
through
things
I'm
available.
I
have
not
forgotten
our
conversation
about
trying
to
publish
many
many
ips
records
with
buckets.
I
I
should
have
some
nice
surprises
for
you
soon
and
yeah.
I
I
too
feel
the
pins
of.
I
would
love
to
work
on
the
cool
mutability
thing,
but
they're
all
these
immutable
things
that
need
to
get
taken
care
of
first.
F
Yeah
we've
started
to
do
a
little
test
ground
work
with
any
type,
just
to
basically
test
little
improvements
that
they've
been
making
and
we'd
love
to
just
like
throw
you
know,
gossip
pub
in
there
and
be
able
to.
Ideally,
we
could
like
play
with
little
variations
on
gossip
pub
here
and
there
and
just
like
see
these
things
run
at
scale.
G
In
test
run
because
I
know
like
we,
there
was,
there
was
a
group
of
folks
who
were
doing
a
bunch
of
testing
test
ground
with
a
lot
of,
especially
in
the
months
leading
up
to
file
coin
launch
to
be
like.
If
we
hammer
this
and
we
try
and
be
really
mean
about
this.
Well,
the
network
still
holds
up
okay
and,
and
they
did
fine,
so
so
you
should
be
able
to
test
those
things
larger.
G
One
thing
that
is
sort
of
interesting
is
that,
as
it
stands
right
now,
gossip
sub
has
a
maximum
number
of
topics
that
a
node
is
able
to
tell
you
that
it
is.
It
cares
about
so,
if
you're
running
a
single
node,
that's
trying
to
listen
on
a
million
topics
and
the
maximum
message
size
is
like
a
few
megs
you're
gonna
start
getting
real
sad
right
right.
F
G
Right
right,
especially
because
you
don't
really
need
the
100
gig
memory
boxes
are
square
and
what
you
really
need
is
a
whole
lot
of
cpu
right
here
yeah.
So
we
can
talk
about
ways
to
do
some
like
horizontal
scaling
here,
and
also
I
mean
if
we
really
wanted
to,
we
could
find
ways
to
expand
the
number
of
like
modified
gossip
sub
to
be
able
to
handle.
You
know
more
topics
more
subscriptions,
but
it
feels
like
there's,
probably
some
good
ways
to
do.
G
E
B
A
B
Answering
no
it's
good.
I
I've
appreciated
the
free
form
format
here,
because,
like
looking
at
documentation,
is
one
thing
because
it's
often
user
focused
and
then
the
white
paper
is
it's
got
this
academic
thing
about
it.
That
leaves
me
wanting
just
very
specific
details,
so
I
think
freeform
is
really
helpful.
Yeah
cool,
great
okay,
all
right
thanks.