►
From YouTube: 🖧 IPLD weekly Sync 🙌🏽 2020-11-23
Description
A weekly meeting to sync up on all IPLD (https://ipld.io) related topics. It's open for everyone and recorded. https://github.com/ipld/team-mgmt
Tags:
A
A
I
actually
can't
recall
what
I've
worked
on
last
week.
It
must
have
been
more,
but
I
can't
can
only
recall
that
my
biggest
successes
are
that.
Finally,
the
prs
emerged
so
lib
p2p
is
now
using
the
lightest,
rust,
multi-hash
and
forest.
The
rust
fico
implementation
is
using
the
latest
rust,
martial
and
rust
cid,
and
so
the
good
news
is
the
so
there
isn't.
So
if
I
talk
to
the
people
from
forest
that
the
performance
like
they
couldn't
really
measure
a
difference,
but
they
could
at
least
measure
that
is
so.
A
The
quote
is
strictly
better
performance,
so
it's
certainly
not
worse.
It's
definitely
better,
but
it's
probably
not
measurable,
but
still
there.
No
regression
there.
So
that's
great
good
to
know,
and
probably
also
like
the
only
p2p
folks
would
have
said
something
if
there
would
be
a
regression.
So
it's
good
yeah,
that's
pretty
much
it
next.
On
my
list
is
danielle
cool.
B
So
last
week
I
basically
finished
the
multi-codec
library
the
week
before,
but
this
is
just
an
fyi
that
I
plan
on
tagging.
The
first
post
rewrite
release
tomorrow.
So
if
anybody
has
any
last
feedback,
please
speak
now,
and
I
did
polish
up
the
names
a
little
bit
last
monday.
So
now
the
names
are
a
little
bit
more
idiomatic
go
and
the
code
generator
is
also
smaller,
which
isn't
nice.
B
B
So
I
spoke
to
rod
about
like
exactly
what
are
the
differences
between
the
two
schemas
and
how
important
it
is
to
support
the
old
one
versus
the
new
one,
because
supporting
the
old
one
is
useful
today,
because
we've
got
a
lot
of
data
in
that,
so
the
actual
difference
is
only
in
the
element
type,
because
the
new
one
is
kind
and
the
old
one
is
keyed.
I
think
I
got
that
right.
So
michael
actually
came
up
with
an
idea
to
just
make
like
a
double
union.
He
called
it.
B
So
there's
an
agenda
item
about
this
later,
so
we
can
take
a
look
at
that
and
I
also
spoke
to
will
about
potentially
using
this
instead
of
the
file
coin
hand
idl
in
his
stuff,
because
right
now
I
believe
he
uses
that
with
an
ipld
prime
node
wrapper,
which
is
like
read-only
for
doing
things
like
selectors
and
stuff.
So
I
think
I'm
pretty
close,
because
I've
got
most
of
the
stuff.
B
I
need
to
read
existing
notes,
I'm
just
missing,
because
the
prototype
is
there
and
a
bunch
of
stuff
is
there
I
think
I'm
just
missing
refi
and
maybe
some
other
bits
like
caching,
of
link
loading,
but
most
things
should
be
there.
I
think
I
also
gave
a
talk
about
ghost,
build
cache
which
went
pretty
well,
there's
a
video
up.
B
If
anybody
wants
to
watch
that
and
I'm
giving
a
talk
tomorrow
about
init
time
in
a
time
tracing
in
go
116,
which
is
pretty
niche,
but
if
anybody
has
super
large
go
binaries
that
take
a
long
time
to
start.
Those
are
all
the
unit
functions,
doing
work
and
with
116
you
can
actually
measure
how
long
they
take
per
package,
which
is
really
nice
and
the
last
thing
it's
something
that's
been
going
on
for
a
bunch
of
months.
B
I've
brought
it
up,
I
think
once
or
twice
before,
but
we're
kind
of
redesigning
the
encoding
json
package
into
like
a
version
two.
But
it's
not
public
yet
because
we
don't
know
if
it's
gonna
be
a
version
two,
maybe
the
experiment
is
gonna
fail
horribly,
it
probably
will.
But
I
can
share
some
details
later
if
anybody's
interested
and
that's
it
for
me.
A
Thanks-
and
this
actually
reminded
me
what
I
did
last
week-
I
was
speaking
at
a
virtual
meetup
and
I
prepared
almost
all
week
the
talk
that
was
it
and
there
will
be
a
recording,
so
there's
no
recording
now,
but
there
will
be
recording,
published
sometime
yeah
so
and
next
on
my
list
is
the
rod
a
similar
week.
Vodka,
it's
been.
C
A
lot
of
the
week
actually
on
slides
for
michael's
chunking
tree
presentation,
which
I
don't
think,
and
I
think
most
of
you
probably
haven't
seen,
but
I
think,
because
I've
spent
some
time
trying
to
understand
the
algorithm
and
then
figuring
out
how
to
explain
it
in
a
way
that
would
help
me
if
I
was
just
looking
at
slides
to
understand
it.
So
I
think
that
slides
are
pretty
good
at
getting
to
the
core
of
the
algorithm
and
and
so
they
they're
probably
worth
sharing
at
some
point.
C
So
I
think
there's
there's
just
there's
still
just
a
little
bit
of
a
little
bit
of
the
the
security
case
like
the
collision
case.
That
needs
to
be
sorted
out.
That's
that's
really
a
fundamental
problem
that
needs
to
be
needs
to
have
a
solid
solution
before
we
can
trumpet
this
thing
loud
and
wide,
and
that
continues
to
bother
me-
and
I
know
michael
thinks-
he's-
got
solutions
for
that.
C
C
But
I
think
I've
got
a
final
form
in
a
pr
that
I'll
merge
today
in
the
specs
repo.
Just
because
there's
there's
a
genesis
and
then
there's
a
genesis
in
falcoin
and
and
these
two
things
need
to
be
described
in
our
docs,
because
one's
different
to
the
other
and
so
trying
to
extrapolate
from
lotus
code.
C
How
people
think
and
talk
about
this
thing
didn't
go
as
well
as
I
hoped,
and
it
required
some
intervention
from
various
people
to
clarify
the
issues
around
it
anyway.
I
I
think
the
the
pr
is
good
enough
as
it
is
to
clarify
that
language
and
the
situation.
So
that's
all
I'll
say
about
that.
That's
really
all
the
notable
things
for
me
this
last
week.
D
One
of
the
interesting
ones
is
the
natural
like
base
type
that
graphql
exposes
as
a
scalar
is
called
id
and
it
is
very
natural
for
us
to
say
our
cids
are
that
id
type,
but
since
that
is
a
built-in
graphql
type.
That
means
you
do
not
get
to
easily
override
anything
about
that
type,
because
it's
built
into
the
graphql
library
and
for
instance,
that
means
you
can't
then
define
how
to
pretty
print
cids
in
their
stream
form,
while
holding
them
in
their
byte
form
right.
D
D
There's
a
couple
pr's
in
go
ipld,
prime
one
that
was
minor,
that's
merged,
another
one.
That's
has
the
code
generation
look
at
the
destination
package
that
it
is
generating
code
into
and
skipping
a
generation
of
types
if
they're
already
defined
in
that
destination
package
somewhere,
not
in
auto
generated
code
as
a
way
to
just
let
you
take
a
type
and
define
it
with
some
weird
custom
things
and
not
have,
and
then
also
coach
and
the
other
things
that
aren't
there.
D
D
Interesting
thing
of
note
to
this
group-
maybe
is
I
added
another
cache
that
seems
to
be
pretty
effective
at
the
speed,
and
that
is
a
realized
object
cache.
So
this
graphql
server
keeps
a
in
memory
thing
of
cid
to
ipld.node
of
the
parsed
things.
So,
rather
than
going
back
to
the
data
store,
it
reuses
those
nodes
that
it
has
parsed
and
realized,
and
that
seems
quite
useful
and
a
layer
that
we
should
have
a
cache,
for
that
is
quite
simple
right,
like
that's
just
you,
you
do
an
lru.
D
Or
do
you
make
some
cash
when
you
do
it
the
only
place
where
it
was
annoying
because
of
my
other
hacks
that
I've
been
doing
because
lotus
on
its
state
routes,
sometimes
until
the
upgrade
of
v2
actors?
It
didn't
have
a
layer
of
indirection
at
stake
roots,
so
it
just
directly.
The
state
group
pointed
to
the
hampt
of
actors.
Instead
of
this
now
defined
state
route,
object,
which
is
a
sid
of
the
hampton
factors
and
a
version
id
and
the
way
that
I
unified.
D
But
now
that
means
there's
two
ipld
nodes
with
the
same
cid
in
that
case,
so
I
am
keying
on
both
the
cid
and
the
type
of
the
ipld
node,
because
I
do
know
what
that
type
is
going
to
be,
so
my
keys
are
uglier
than
they
need
to
be,
ideally
and
that's
sort
of
my
fault
and
my
misuse
of
cds.
In
some
sense-
and
I'm
sure
people
will
feel
strongly
and
happy
at
me
for
that
choice.
But
that's
where
we
are.
F
A
A
E
So
that
yeah
sorry,
I'm
still
trying
to
not
laugh
at
the
pronunciation
of
them,
so
there
is
a
recording
from
last
week.
I
was
also
in
the
ranks
of
people
giving
talks
and
so
there's
a
what's
new
and
ipld
talk
that
was
recorded
as
part
of
the
ipfs
meetup
last
week,
and
there
is
a
link
to
where
that
exists
on
youtube.
E
My
section
is
like
only
10
minutes
of
that,
so
if
you
want
a
really
brief
overview
of
what's
up
and
what's
new,
it's
about
as
brief
as
it
gets,
there's
a
lot
of
other
stuff
in
that
video,
but
I
made
a
link
there
with
the
time
offset
too
in
go.
I
feel
the
prime
code.
There
are
a
couple
of
small
things
merged,
for
example
the
cogen
output
rearrangement.
So
finally,
cogen
will
output
a
finite
number
of
files
instead
of
a
file
for
every
type
which
was
operationally
annoying
so
fixed.
E
I
was
doing
some
discussions
with
will,
as
he
already
mentioned,
about
how
we
might
integrate
adl
stuff
in
practice,
and
I
think
it
seems
like
we're
probably
going
to
do
some
present
tense
shortcuts,
which
are
aimed
towards
letting
people
do
arbitrary,
weird
stuff
and
then
that'll.
Let
will
do
what
he
wants
and
then
there'll
be
a
rather
distinct
roadmap
for
like
how
we
want
to
integrate
adls
well
in
the
long
term,
and
that's
going
to
be
a
little
we're
going
to
take
that
one
slower.
E
The
present
tense
shortcut
is
probably
going
to
be
something
that's
unique
to
cogen
and
just
like
really,
let's.
It
will
assume
that
a
human
is
very
much
in
the
loop.
So
it's
going
to
be
it'll,
be
safety's
off
sort
of
scenario
and
we'll
see
how
that
goes
and
other
than
that.
A
lot
of
this
week
seemed
to
disappear.
For
me,
too,
working
on
a
lot
of
planning
and
scoping
docs
and
just
plain
thoughts
for
the
future.
So
more
docs
about
that
will
probably
come
out
later
and
that's
about
it.
This
week.
G
Yes,
so
a
lot
of
glue
work
again
this
week,
stuff
that
is
interesting
for
ipld
aside,
for
you
know,
falcon
plus
dumbo
drop
space
series.
2
started
something
interesting.
We
hooked
up
will's
front
ends
to
not
yet
complete
and
somewhat
unstable
version
of
an
sql-based
data
store
that
has
like
everything
in
it,
including
state
and
clinic
receipts.
G
Well,
supposedly
everything-
and
it
is
currently
served
a
lot
of
people
already
using
it,
and
speaking
of
naming,
I
like
to
call
this
graphil
ql,
because
it
rolls
over
the
tank
very
nicely
and
yeah
that
that
that
was
interesting
to
get
to
get
running
on
a
very
short
notice,
because
the
team
really
needed
that
another
thing
that
was
done.
A
lot
was
moving
around
various
versions
of
the
data
store
for,
for
various
purposes,
solidifying
a
little
bit
more.
G
What
actually
needs
to
happen
for
this
to
be,
you
know
available,
at
least
for
our
ipld
needs
going
forward,
and
I
hope
by
next
week
I'll
be
able
to
talk
about
this
more
more
in
detail.
But
for
now
everything
is
still
very
much
in
the
air
and
it's
just
it's
just
really
really
difficult
to
navigate
through
all
of
this.
When
everything
you
try
takes
like
an
hour
and
a
half
so
yeah,
but
welcome
to
big
chain
and
yeah.
F
Hey
yo
so
yeah
I
had
some
more
calibration
stuff
last
week
and
then
more
doing
2021
planning
still
got
to
get
that
ready
this
week
and
then
yeah.
I
did
a
bunch
more
work
on
cadb
got
it
working
and
benchmarking.
It
looks
great.
It's
really
fast
code's
a
mess,
though
I
just
like
hadn't,
really
implemented
these
trees.
Much
and
then
yeah.
F
Just
things
got
like
wildly
out
of
hand,
and
so
it's
working
really
well,
but
there
are
some
bugs
and
hunting
them
down
has
just
been
so
painful
with
the
way
that
it's
written,
so
I'm
looking
at
as
I
was
looking
at
kind
of
like
breaking
it
apart
and
putting
some
better
kind
of
abstract
layers
in
there.
I
realized
that
there's
just
a
much
more
abstract
version
of
these
trees
that
I
could
implement
and
then
use
that
implementation
of
those
trees
to
do
this
database
or
any
other
data
structures.
F
So
I
started
poking
at
that
a
little
bit
seeing
what
that's
like
the
caching
layer
we're
talking
about
was
funny.
I
have
one
of
these
catching
layers
already
in
cadb
and
then
now
I'm
porting
it
over
to
this
other
one
and
the
funny
thing
about
it
is
like
I'm
actually
making
the
addresses
of
the
nodes
sort
of
abstract,
because
in
cadb
those
those
are
just
integers
for
the
file
offset
and
and
then
like
in
the
other
merkle
structures
like
they're,
obviously
going
to
be
cids.
F
H
A
F
F
F
F
G
E
B
Intentional
well,
the
implementation
wouldn't
really
allow
mixing
them.
It's
just
that.
Well,
at
least
from
my
use
case,
there
would
be
an
api
entry
point
that
says:
use
the
old
stuff,
another
one
that
says
use
new
stuff
and
then,
depending
on
that,
I
follow
one
path
or
the
other.
Does
that
make
sense.
C
E
C
I
I
so
here's
the
thing
I
this
is
fine,
except
it'd,
be
nice
not
to
do
that
in
the
formal
spec
like.
Maybe
this
could
be
something
that
could
be
here's
how
you
can
combine
both
of
them.
You
know
why
not
both
thing,
because
that
you
know
the
the
key
union
is
so
horrible
like.
I
don't
really
want
to
bake
the
key
union
into.
E
F
E
F
C
C
F
Yeah,
I
mean
that's,
not
the
that's,
not
the
most
annoying
tiniest
lock
that
you
I
create
like,
but
I
don't
know
what
was
it
gonna
say:
oh
yeah
so
maybe
like
this
could
move
down
to
the
bottom
and
we
could
basically
have
a
schema
for
the
unified
thing
at
the
bottom,
instead
of
just
like
the
one
off
for
file
coin.
If
we're
going
to
use
this
to.
F
C
I
know
this
question
of
of
linking
to
the
root
node
and
keeping
your
configuration
out
into
the
an
external
thing.
I'm
not
totally
sold
on
that,
except
in
the
case
where
the
root
node
is
interchangeable.
With
other
nodes
of
the
graph
like
in
the
in
the
vector
spec
you
can,
you
can
pull
out
other
any
any
arbitrary
node
and
make
it
the
root
node,
and
that's
a
nice
pattern
where
you
could.
If
you
had
your
configuration,
that
was
a
bit
more
advanced,
you
could
have
that
separate.
E
F
F
F
You
could
just
take
this
schema
and
and
use
the
the
value
data
in
line
and
there
you
actually
may
want
to
say
like.
Oh,
no.
I
actually
want
to
be
linking
out
here
because
yeah
and
because
it's
not
a
big
deal,
you're,
not
creating
tiny.
You
know
there
are
tiny
blocks
at
that
point.
To
do
the
every
on
every
mutation
you
were
already
going
to
have
to
re-link
it.
C
There's
so
many
variables
submit
to
it's
very
difficult
to
say.
One
thing
is
objectively
worse
than
another,
but
I
think
we
know
that
the
size
of
cids
is
really
costing
far
coin,
because
they're
explicitly
storing
everything.
And
so
once
you
push
towards
smaller
blocks,
then
the
size
of
cids
becomes
a
real.
C
C
G
Yes,
but
also
falcon
is
one
of
the
very
few
chains.
Pretty
much
zone
chain
can
think
of
where
you
can
literally
start
from
a
state
route
and
get
everything
else
from
somewhere
else
and
be
assured
that
the
entire
thing
is
correct.
You
basically
don't
have
any
of
this
stuff
that
you
are
fighting
in
bitcoin,
that
you
know
you
have
pieces
of
the
chain
which
are
not
actually
encoded
into
any
of
the
hashes
anywhere
they're.
Just
you
know,
nonsense
and
stuff,
like
that,
we
don't
have
any
of
that.
G
C
Yeah
that
that's
that's
the
pro
of
ipld,
but
there's
no
reason
you
can't
combine
the
two
worlds,
because
the
problem
with
bitcoin
is
that
they
they've
approached
it
without
this
lens
of
every
block.
Every
addressable
block
is
a
thing
they're
devoid
of
that
lens.
They
just
they
just
have
this
sense
of.
C
So
there
should
be.
There
should
be
a
synthesis
of
both
worlds
possible.
Where
you
can
say
these
parts
are
so
trivial
that
they
don't
need
to
exist
on
disk.
I
don't
know
what
they
are.
I
mean
I
can't
point
to
any
examples
on
the
far
coin
chains.
Just
and
maybe
that's
maybe
that
comes
from
not
acknowledging
this
and
then
just
saying.
Well,
everything
has
to
exist.
So
therefore,
we're
just
going
to
lay
it
all
out
like
this,
but
if
you
said
well,
not
everything
has
to
exist.
There
is
these
implicit
pieces
that
will
exist.
G
Yeah,
I
I
believe
when
we
spent
a
little
bit
more
time
actually
analyzing
the
chain,
and
you
know
internalizing
the
structures
from
you
know
from
a
general
perspective
and
what
we're
doing
we
will
end
up
in
a
situation
where
it
will
be
like.
Oh,
they
actually
need
all
of
that,
because
if
you
think
about
it,
what
the
chain
actually
does
is
kind
of
unprecedented,
where
every
single
thing
ever
existing
needs
to
ping
you
every
24
hours
like
that's,
not
something
the
chains
normally
do
so
yeah.
G
Like
like,
like
take
the
take
the
entire
system
of
vector
ids,
it's
literally
how
to
increment
primary
key.
You
know
an
integer
which,
when
you
have
a
chain,
reorg
is
rewritten
so
like
that
the
type
chain
internally
points
to
things
by
a
simple
integer,
and
when
you
have
a
reorg,
you
need
to
go
back,
match
every
single
integer
from
the
previous
state
to
a
stable
address
and
rewrite
them
to
the
new
integers
that
are
now
in
in
in
chain,
because
the
state
is
different
and
you
go
forward
with
that.
G
So
even
this
kind
of
stuff
they
already
like
shaved
as
much
as
they
can
by
basically
not
using
the
no
cryptographic
stable,
addresses
and
they're
like
all
these
really
encodings.
For
for
for
all
for
all
the
you
know,
partition
populations
and
stuff
like
that,
so
yeah
I
I'm
actually
not
sure
there
is
much
to
shave
without
yeah.
I
don't
know
we'll
actually
will
know
more
at
this
at
this
stage.
He's
done
who
most
closely
like
had
a
like
birthday
view
of
the
entire
thing.
I
guess.
D
Yeah,
I
mean,
I
think
we
need
to
look
at
delta's.
My
suspicion
is
that
there
are
sub
trees,
that
always
change
together,
where
being
able
to
collapse.
Links
would
be
beneficial
to
us
because
they're
not
referenced
other
places,
but
I
don't
have.
I
I
think
we
need
tooling
to
identify
what
those
places
are,
so
that
we
can
be
better
informed
about
how
to
structure
things.
I
don't
think
we
just
know
that
offhand.
C
A
C
So
this
back
of
the
hampton
question:
okay,
so
linking
from
the
root
to
the
root,
the
config
to
the
root.
Let's
call
it
it's
not
I'm
not
a
huge
fan
of
it,
but
it
does.
It
does
help
us
to
support
far
coin.
You
know
with
that
additional
schema
change
and
it
does
also
just
open
the
door
to
for
use
cases
where
people
will
show
up
and
say
I
don't
want
to
store
the
configuration
with
the
data.
C
F
F
A
C
F
C
E
The
idea
that
was
touched
upon
earlier
of
we
should
write
something
in
the
spec,
that's
terse
and
clean
and
is
what
we
want
and
then
shove
in
a
couple
of
alternative
schemes
as
appendices
which
can
be
any
of
these
implementation
choices
or
even
several
of
them
and
just
highlight
them,
for
contrast
is
like
as
an
implementer.
You
might
want
to
do
this.
That
does
this
funny
union
here,
because
it's
really
useful
in
practice.
For
this
compatibility
reason,
I
think,
having
several
of
those
documents
show
up
is
actually
super
reasonable.
A
F
F
C
Yeah,
so
what
I
would
do
in
javascript
is
I'd,
have
the
front
end
algorithmic
piece
and
then
the
back
end
layout
piece,
but
where
we're
at
with
like
ipld
prime
is
that
becomes
really
tricky,
because
the
the
layout
piece
is
so
intertwined
with
the
algorithmic
piece,
and
I
think
I
think
daniel
you
said
you
could
see
a
path
to
doing
that.
But
you
would
end
up
having
to
like
sub
packages
and
it
would
just
get
messy
and
awkward.
B
E
And
as
long
as
we're
conscious
of
that,
that's
a
totally
fine
trade-off
to
make.
But
we
probably
do
want
to
be
really
conscious
of
a
document,
because
if
there
was
some
totally
other
implementation
of
schema
logic
that
had
different
costs
than
this,
we
might
not
be
feeling
the
desire
to
make
these
choices
at
all.
F
F
A
A
A
If
you
have
those
characters
in
and
you
have
a
filename
with
those
characters,
what
can
happen
on
the
output
like
if
you
print
it
somewhere
on
the
terminal
or
something
you
get,
the
control
characters
get
could
get
in
your
way
of
everything,
and
then
I
briefly
discussed
this
with
with
with
alex
whether
this
should
be
on
the
deck
protocol,
buffers
layer
or
if
it
should
be,
as
it
is
about
printing
things
out
on
the
printing
out
layer.
Basically,.
G
Ls
does
the
right
thing:
tartar,
the
writing
and
so
on
and
so
forth,
and
our
answer
is
what
we're
just
going
to
drop
them.
I
mean
like
we
need
to
like
either
escape
the
morning
code
them
or
you
know
or
indicate
somehow
that
there
was
some
more
stuff
they
are
just
dropping.
Then
it's
like
silly.
I
don't
know.
A
Okay,
so
I'm
I'm,
we
could
also
like
totally
escape
them
like
so
and
so,
or
also
it's
important.
So
it's
really
so
it's
only
so
in
in
this
pr.
On
the
javascript
side,
it's
really
about
like
if
you
get
it
returned
as
a
javascript
object.
So
of
course
like
for
for
creating
the
hash
and
so
on.
Of
course
you
keep
the
original
data
around
because
well
you
don't
want
to
have
it
has
changed,
but
it's
just
for
if
you
get
back
a
javascript
object.
I
D
A
You
so
if
you,
if
you,
if
you
deserialize
the
so
you
have
the
serialized
the
protocol
buffers
and
you
deserialize
it
into
javascript,
then
what
you
see
in
javascript
and
we
say
dot
name
to
get
the
name
of
the
link.
It
will
have
those
characters
stripped
off
like
just
remove
that's
what
the
current
pr
is
doing.
G
C
A
A
G
C
G
D
A
C
C
A
A
Yeah,
so
it's
so
it!
So
it's
even
about
like
like
strings
as
like,
like
valid
duty
of
eight
strings,
so
we're
not
talking
so
just
as
a
context.
We're
not
talking
about
arbitrary
bytes,
we're
talking
about
like
it's
the
value
of
a
strings,
because
it's
the
first
characters
of
s
key
so
just
as
yeah
for
next
okay.
So,
okay.
C
Well,
here's
here's
one
reason
I
mean
you're
gonna
have
to
craft
a
response
to
this,
but
one
reason
is
if
they
want
the
my
growth
path,
migrate
path
to
the
next
generation
of
of
the
stack.
This
is
just
not
going
to
work.
It's
not
going
to
fly
there
at
all,
because
we're
very
strict
about
data
model
forms
as
object,
shapes
being
able
to
round
trip
and
not
having
any
of
these
special
properties.
There's
no
special
properties,
no
hidden
properties,
no
rewriting!
Nothing
of
that.
C
It's
just
what
you
get
is:
what's
there,
so
you've
got
to
deal
with
all
that
junk
up
up
the
stack.
If
it's
a
problem
to
you,
we're
not
going
to
be
patching,
these
minor
things
all
the
way
down,
yeah,
because
if
you
were
to,
if
you're
here's
another
argument,
if
you're
a
round
trip
to
this
dag
pb
data
into
daxybore,
for
some
reason,
which
you
can
do,
you
have
the
same
problem.
But
now
it's
in
daxybor,
where
you
don't
have
these
defined
properties
in
javascript.
They
are
just
properties
that
come
out
of
the
data.
C
F
B
C
C
There's
just
like
this
one
key
piece.
I
think
that
if
you
get
that,
then
you
can
see
what's
going
on
so
here's
the
problem
right,
we're
trying
to
what
we
really
want
is
a
a
way
to
store
a
sorted
list
of
entries.
That's
that's
like
the
holy
grail
for
our
data
structures.
Once
we
have
that
we've
got,
we
can
do
so
much
with
that
and
maybe
there's
different
variations
of
what
we
want
out
of
that.
C
So
maybe
there's
different
data
structures
that
will
do
this
for
us,
because
we
we
have
different
utility
for
them,
but
but
really
once
we
have
something
that
we
can
store
sorted
and
we
can
query
in
assorted
ways
to
do
range
queries
on.
Then
we
can
leverage
that
up
to
produce
all
sorts
of
really
interesting
tooling.
C
On
top
of
this,
so
right
now
we
have
a
hamptons,
our
really
our
general
purpose,
data
structure
that
serves
so
many
purposes,
but
and
it's
it's
got
so
many
really
nice
properties,
but
it's
the
lack
of
sorting
means
that
it
stops
short
of
being
a
general-purpose
data
structure.
So
let's
say,
we've
got
a
list
of
things
here
we
want
to
sort.
This
is
this:
is
the
generic
problem
space
there?
C
Node
to
point
two
that
works
except
mutations,
become
a
problem,
because
if
you
want
to
do
inserts,
then
you
have
this
shuffling
problem.
So
an
insert
will
cr
will
make
an
overflow
that
then
impacts
it
can
impact
the
whole
tree
if
you
do
it
in
the
right
place,
and
so
you
have
to
rewrite
every
node
if
you
insert
something
at
the
beginning
of
it.
So
it's
it's
a
it's
a
yucky
solution
for
what
we.
C
What
we
care
about
and
the
same
thing
with
deletes,
make
spaces,
and
you
have
to
shuffle
everything
back
up
again,
just
to
get
the
canonical
form
with
the
maximum
branching
factor,
so
really
not
a
pleasant
solution.
So
the
the
idea
that
michael
and
nicola
have
been
working
on
is
to
treat
these
entries
as
if
they
were
something
that
you
were
putting
through
a
chunking
algorithm
and
so,
which
that
was
the
piece
for
me
of
just
viewing
these
things
differently.
C
Viewing
them,
essentially
as
a
string
of
of
like
a
string
of
bytes
that
you
were.
You
were
scanning
through
and
finding
some
way
to
slice
them
up
in
in
a
predictable
manner.
So
if
you,
if
you
scan
through
this
list,
where
do
you
find
predictable
break
points
that
you
can
always
break
and
turn
them
into
nodes?
C
And
you
can
do
that
with
chunking
and
chunking
algorithms
and
you
can
actually
do
really
simple
chunking
algorithms,
so
in
in
this,
in
the
form
that
might
so,
mccollum
had
was
actually
using
a
proper
chunking
function.
So
but
michael
just
decided.
Well,
we
just
we
have
randomness
here
in
the
form,
predictable
randomness
in
the
form
of
cid.
C
So
if
you
have
a
well
actually
the
cid
in
this
instance,
you
have
but
you,
but
if
you
just
have
a
hash
function
for
the
the
entry.
So
if
it
was
just
a
string
and
you
hash
the
string,
then
you
could
just
get
an
identity
from
that
hash
function
in
some
way.
So
just
turn
that
predictably
or
as
stably
into
a
a
number
within
a
certain
range,
and
so
in
michael's,
current
iteration
just
take
the
last
four
bytes
you
get
a
32-bit
integer.
C
Your
range
is
zero
to
max
that
you
win
32..
You
can
then
choose
a
branching
factor
that
will
give
you
a
way
of
slicing
these
things.
So
if
you,
if
you
divide
your
index
space
up
into
your
branching
factor,
so
let's
say
your
branching
factor
is
four:
you
divide
max.
U
and
32
by
four
and
then
you've
got
your
four
slots.
C
C
Is
this
lower
quarter
of
the
address
space
of
the
identity
space
and
at
that
lower
quarter
whenever
whenever
one
hits
that,
then
we
should
break
there,
and
so
that
gives
us
a
probability
of
one
in
four
of
hitting
a
break,
which
then
gives
us
that
branching
factor
of
of
roughly
four
of
approximately
four
so
in
here
we've
got
two
two
of
these
entries
have
hit
the
the
threshold,
and
so
we
just
we
chunk.
So
we
say:
okay,
we
we.
C
When
we
read
along
long
and
long,
we
found
one
that
met
so
we're
going
to
say
this:
is
our
branch
so
treat
these
as
a
close
operation
for
our
our
node?
And
then
you
end
up
slicing
your
set
into
a
set
of
nodes
based
on
this
close
operation.
So
we've
got
one
close
here
and
one
close
here.
That's
given
us
three
nodes
and
it
seems
a
bit
sloppy
like
these
things
are
not
exactly
the
right
size
and
that's
true.
C
C
So
you
you
you
hash
and
index
these
the
the
entries
in
your
next
layer
as
well
in
the
next
layer
they
just
they're
links
to
the
base
layer
where
they
a
starting
index,
so
that
you
can
traverse
it
later
on.
But
you
can
run
the
same
hash
over
that
and
do
the
same
thing,
and
so
you
might
end
up
also
splitting
at
the
at
the
next
layer
as
well.
C
So
if
you,
you
know,
get
this
this
threshold
below
the
threshold,
then
you
branch
again,
and
so
you
end
up
with
multiple
layers
and
you
just
keep
on
running
the
algorithm
until
you
get
a
single
root
and
then
inserts
mean
you
just
run
the
algorithm
again
over
the
set
and
they
all
because
this
they're
stable,
they
all
produce
the
same
index,
the
same
identity
and
you
still
have
the
same
breaks
so
new
and
then
new
elements
will
either
fit
in
the
set
or
introduce
new
breaks.
So
here
we've
got
one
in
the
top
there.
C
C
And
then
the
same
thing
for
removal-
and
you
can
either
remove
elements
like
this
one
here
that
is
just
in
the
middle
of
a
node
or
you
could
remove
a
split,
in
which
case
you
would
be
joining
nodes.
So
so
these
mutations-
don't
always
just
they
don't
always
just
affect
one
node
and
a
path
up
the
tree.
They
can
also
affect
a
neighbor
and
and
as
you
think,
about
the
way
that
the
tree
works
you
can.
C
This
effect
does
compound,
as
you
go
up
the
tree
because
you're
generating
new
data
here,
because
the
cids
change,
so
these
things
may
shuffle
a
bit
but
you're,
never
in
a
situation
where
this
is
likely
to
propagate
across
the
whole
tree
like
it's,
certainly
not
at
the
base
layer,
but
there
will
be
more
mutation,
cost
within
the
middle
of
the
tree
than
with
a
hamped
or
other
data
structure,
but
it's
it's
relatively
minimal
and
also
within
the
probability
of
the
branching
factor
you
define
so
this.
This
is
the.
C
What
was
this
one
illustrating?
This
is
insertions
that
may
cost
you
this
is.
This
is
a
perverse
case,
so
it's
not
it's
it's.
You
could
push
this
one
to
the
extreme
so
where
we
insert
we
go
from
from
here,
do
we
do
it
we
insert
b
and
then
we
we
end
up
creating
a
new
sc
id
here
which
has
a
break
and
then
the
next
one
has
a
new
cid,
because
you've
split
it.
Does
that.
H
C
Oh
you've
inserted
a
thing
here
and
then
you've
created
a
new
city
which
is
in
the
within
the
threshold.
So
in
the
second
level
we've
got
these
these
three
nodes
and
then
you
do
the
same
thing
here
and
then
you've
got
a
break,
and
so
you
you
end
up
creating
more
levels
here,
but
these
over
time
within
probabilities.
Again
they
sort
of
bounce
back
to
the
right
shape.
C
F
C
E
C
Will
you
know
within
that
sort
of
flex
and
the
randomness
just
discourages
thin
trees?
So
the
problem
we
have
with
the
amt
is,
you
can
have
these
really
thin
trees
because
there's
no
way
of
of
biasing
it
towards
thickness,
because
you
are
brute
force
just
using
your
indexes
to
to
define
the
shape
of
the
tree,
which
is
pretty
gross.
C
So
so
it
has.
Has
this
thickness
property,
that's
similar
to
a
hampt
and
the
the
big
deal
about
this?
Is
it's
canonical
for
any
given
data
set?
So
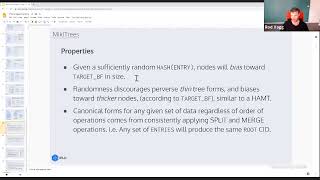
even
though
it
looks
like
they've
got
this,
this
random
craziness,
going
on
any
given
data
set
regardless
of
intermediate
removes
or
inserts,
will
form
a
canonical
form
with
a
a
canonical
root
cid,
which
is
what
we
want.
C
So
that's
that,
but
there
is
this
one
problem
which
is
that
it's
cheap
to
create
collisions,
because
because
the
branching
factor
is
just
dividing
the
address
space
into
you
know
into
that
that
segment,
it's
it,
it
doesn't
cost
you
much
to
to
craft
entries
that
will
be
below
the
threshold
to
create
a
break
or
to
not
create
a
break.
So
in
this
instance
we've
you
know,
somebody
could
create
a
bunch
of
entries
that
don't
break,
and
so
you
end
up
getting
these
really
big
nodes
which
can
break
some
systems.
C
We
do
have
limits
on
node
size
on
that
that
we
can
store
in
our
storage
systems
or
trend
or
transport
across
transport
layers.
So
we
really
do
need
to
protect
against
this.
So
that's
the
really
outstanding
one
there's
been
a
couple
of
solutions
proposed
so
far
for
that-
and
I
think
michael
and
michael
are
discussing
through.
F
Yeah,
there's
there's
a
bunch
of
ways
to
solve
this.
Actually,
it's
just
that
these
solutions
are
increasingly
kind
of
complex
the
less
you
control
the
access
patterns
so
like,
if
you,
if
you
have
like,
if
you
just
own
the
data
structure,
you
can
just
insert
tombstones
into
the
structure
whenever
you
see
an
overflow
and
then
it's
becoming
part
of
the
canonical
list,
and
so
it's
it's
not
actually
out
of
hash
or
anything
right.
F
If
everybody's
applying
the
changes
kind
of
in
a
different
order,
and
then
they
need
to
come
up
with
it
with
a
particular
structure
that
becomes
a
little
bit
more
difficult
because
you
could
end
up
with
just
the
tombstones
in
different
places,
depending
on
when
you
pulled
it
or
a
case
that
I
have
in
dagdb
is
like
the
it's
an
index,
so
the
canonical
form
is
not
actually
the
data
structure.
It's
it's
a
view
of
a
different
data
structure,
and
so
you
can't
be
inserting
these
tombstones
really
it.