►
From YouTube: Config Working Group 3.29.18
Description
Meeting Notes https://docs.google.com/document/d/1P3p7zOpX66hPoZBi_CiC36JW7JmoaLWqE2sgHvdq5tY/#heading=h.j0vo8a9wjj6l
B
A
A
C
B
D
B
D
A
It's
according
minor,
I,
welcome
and
today
and
my
turn
will
continue
he's
on
presentation,
I'm,
the
config
architecture.
Are
you
guys
kidding
me
well,
okay,
so
so
before
we
start
and
again
please
put
in
your
names
and
the
attendance
and
the
meeting
notes
that
helps
us
to
see
who
has
been
meeting
and.
B
D
Okay,
so
I
guess,
let's
get
started
so
this
breaking
news
here,
just
I
wanted
to
touch
on
the
topic
we
discussed
last
week
on
concerning
service
config.
So
after
after
the
review
meeting
last
week,
spike
joy,
Oz
and
I
met
to
get
some
clarity,
Thank
You
spike
for
staying
thing
with
us
and
think
this
through.
So
fundamentally,
we
have
a
and
there's
been
I've
started
some
various
threads
on
the
the
news
groups
on
this
stuff.
D
D
So
it
boils
down
to
the
fact
that
we
really
need
to
treat
outgoing
traffic
differently
than
incoming
traffic
for
service,
and
we
can
separate
this.
So
what
I'm
proposing
here
is
the
the
introduction
of
what's
what
I'm
calling
consumer
config,
it's
a
chunk
of
configuration
state,
that's
associated
with
a
service
account
and
any
part
that
operates
using
that
service.
Account
is
subject
to
this.
This
config
state.
So
you
declare
and
then
the
attachment
model
is.
Is
this
similar
to
how
we
do
for
services?
G
D
We
can
have
permission
to
mess
with
the
service.
You
also
have
permission
to
mess
with
the
service
config.
Similarly,
we
put
the
service
account
in
the
same
namespace
as
the
consumer
config.
So
if
you
have
a
right
to
mess
with
one,
you
have
the
right
to
mess
with
the
other,
and
it
ends
up
being
a
fairly
a
reasonably
simple
policy.
If
you
apply
it
at
runtime
right,
so
we
can
easily
program
the
proxies
accordingly.
D
D
E
D
F
D
So
I
haven't
updated
the
architecture,
doc
I
haven't
updated
the
slide
deck,
but
largely
from
an
end
standpoint.
It's
it's
a
fairly
modest
change
to
what
we've
been
thinking
about,
but
any
place
any
diagram
that
shows
service
config
going
somewhere.
Well,
there's
also
consumer
configs,
going
to
the
same
place
effectively
all
right.
So
that's
the
breaking
news
back
to
a
regular
program,
all
right.
D
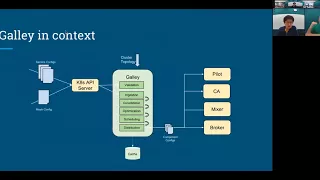
So
last
time
we
we
went
through
kind
of
the
overall
architecture,
the
role
of
galley
as
a
transformation
engine
that
takes
as
input
a
service
config
in
a
consumer
configs
and
then
the
rise
from
that
a
bunch
of
component
configs
that
are
delivered
through
components
in
the
mesh.
So
Galle
is
responsible
for
take
taking
a
series
of
service,
configs
and
kind
of
slicing
at
them,
combining
them
optimizing
them,
deduping
them
and
scheduling,
scheduling,
to
roll
out
to
the
the
components
alright.
D
D
We
can
catch
the
vast
majority
of
bad
configs
up
front,
but
there's
always
some
bad
configs
that
are
going
to
slip
through
and
hit
the
runtime
system,
so
just
manage
roll
out
staged
rollout
is
about
kind
of
minimizing
the
blast
radius
of
a
bad
config.
You
roll
it
out
the
small
number
of
customers
and
you
can
roll
back
if
there's
a
problem
so
in
the
typical
way
of
doing
this
kind
of
stuff
in
kubernetes
is
a
pod.
By
pod
you
can
say
that
phase
out
an
old
version
and
bring
up
a
new
version.
D
This
has
a
minimum
granularity
of
a
pod
effectively,
so
for
very
small
deployments,
it's
actually
kind
of
chunky
for
you.
You
could
potentially
bring
down
50%
of
your
service
if
you
have
a
a
pod
pod
service,
for
example.
So
we
want
to
do
some
finer
grain
finer
grain
splitting
more
than
smaller
grained
in
a
pod
okay.
So
what
we
want
to
do
is
provide
the
core
mechanisms
and
the
operator
is
the
one
that
actually
drive
is
the
intent
process.
D
So
the
operator
is
going
to
tell
us:
hey
I
want
to
go
from
version
a
of
config
to
version
G
of
config
they're
gonna
control,
the
the
loop
that
that
increments
us
from
0%
to
a
hundred
percent
of
the
new
config
and
they're
responsible
for
detecting
problems.
If
they
make
the
assessment,
is
the
config
rollout
proceeding
properly
or
not,
and
they
get
to
decide
whether
to
do
a
rollback.
D
It
seems
reasonable
to
think
that
once
we
get
the
core
infrastructure
working,
we'll
probably
provide
some
optional
opinionated
form
that
takes
care
of
this
stuff
on
behalf
of
the
operators,
so
something
that
automatically
telling
how
many
days
or
how
many
hours
you
want
for
your
rollout
to
last
and
it
will
check
particular
metrics
to
determine
whether
it's
successful
or
not.
But
for
now
we
just
provide
the
mechanisms
and
the
operator
is
driving
and
driving
things
all
right.
So
the
general
idea
of
what
we
want
to
do
is:
let's
see
how
the
dates
raise
this
okay.
D
So
when
an
operator
is
pushing
a
new
config
into
the
system,
they
can
specify,
along
with
that
config
some
rollout
parameters
that
specify
that
that
indicates
kind
of
how
we
want
to
select
between
this
config
and
the
one
that's
currently
in
the
system.
So
you
can
and
then,
as
the
operator
wants
to
move
to
the
new
and
newer
and
newer
versions
or
to
as
the
operator
wants,
to
move
from
0%
to
a
hundred
cent
of
traffic
on
the
new
config.
The
operator
just
pushes,
and
you
can
think
that
changes
those
those
selection,
selection
parameters.
D
D
But
what
that
means
is,
for
example,
when
delivering
the
config
to
mixer
mixer
would
receive
a
bundle,
a
component
config,
that's
divided
into
two
parts
and
the
old
stuff.
The
new
stuff
and
it'll
use
the
existing
mixer
selection
models.
Xing
miss
mixer,
a
pattern
matching
approach
say:
if
version
one
use
the
this
configuration
if
version
to
use
this
other
configuration
II
so
from
an
implementation
standpoint
to
support
this
model,
mixer
doesn't
doesn't
need
to
change
at
all.
D
Pilot,
however,
it's
a
more
challenging
challenging
work
to
support
this
kind
of
blended
architecture.
It
I
talked
to
Zach
about
this
before
we
thought
this
was
in
the
realm
of
possibilities.
If
it's
not,
then
the
the
fallback
plan
here
is
to
do
the
staged
rollout
to
the
to
the
sidecars
we'd
have
to
actually
you
to
be
at
the
pod
granularity
for
those
yeah.
E
I
mean
work
time,
given
that
we
already
have
requirements
about
basically
selecting
you
know
your
workloads
or
pieces
of
a
workload
into
not
just
you
know,
configure
alerts,
but
also
because
we
have
the
runtime
upgrade
process
right,
where
we
also
have
to
go
to
select
them
into
a
you
know,
is
to
v1
or
is
TOB
1.1.
It
seems
pragmatic,
at
least
to
probably
just
rely
on
that
mechanism
to
begin
with,
because
it's
kind
of
like
it's
it's
a
deployment,
oriented
canary
mechanism
for
config.
D
Well,
so
what
I'm
hoping
is
to
introduce
very
minimal
changes
in
the
proxy
to
support
this,
which
is
add
aid?
So
just
like
we
do
the
matching
rule
right
now,
you
could
match
on
versions
so
I'll
just
add
an
extra
match
clause
for
that
and
then
early
on
in
the
mixer
pipe
in
the
pipe
envoy
pipeline.
We
make
a
selection
to
decide.
Is
it
V,
1,
V,
2
and
communicate
that
down
the
line.
E
D
E
And
yeah,
obviously,
that
can
be
parameterization
to
pilot
to
control
its
selection,
including
the
selection
of
which
pilot
to
talk
to
right,
because
there's
also
so
yeah
as
long
as
we
can
find
a
way
to
line
those
two
up
with
a
a
sensible
config
model
right.
It's
my
indicate
that
we
need
something
that
controls
the
node
agent
a
little
bit
more
dynamically
than
we
do
today.
Yeah.
E
D
E
The
way
I
did
talk
to
a
bunch
of
potential
and
user
is
yesterday
and
they
mostly
seem
fine
with
the
idea
of
scoping
to
work
load
control,
Canarian
of
config.
If
ready,
you
know
it
wasn't
clear
whether
anything
were
fine-grained
added.
A
lot
of
odd
you
for
them,
yeah
other
than
percentage
of
traffic.
That's
animating
already.
G
Config
changes
that
that
were
trying
to
roll
out
like
I
think
we
we
discussed
this
and
I
want
to
make
sure
that
we're
still
on
this
page.
That,
like
the
service,
is
the
is
the
natural
grouping
of
how
we're
gonna
sort
of
say
that
you're
moving
from
config
a
to
config
B.
So
you
can't
you
can't
sort
of,
say:
I'm
gonna,
make
changes
to
two
different
services
and
and
sort
of
atomically
smoothly
roll
out
both
of
those
things
correctly.
D
D
Of
the
end
architecture
here
is
that
I
want
to
prevent
emergent
outages
as
a
result
of
config
push.
So
if
the
operator
has
a
valid
config
a
and
a
valid
consider,
the
fact
that
the
operator
is
is
moving.
The
system
from
A
to
B
should
not
trigger
any
emergent
failures
that
that,
because
of
us
right,
so
we
should
be
able
to
orchestrate
the
rollout
in
such
a
way
that
everything
keeps
running
at
all
time.
So
that's
the
objective,
I,
don't
know
if
we
can
get
to
100%
of
that,
but
that's
kind
of
the
North
Star.
D
So
as
far
as
config
distribution
is
concerned,
that's
why
we
have
notice
there's
a
split
model
here.
First,
we
generate
the
blender
config
and
distribute
it
throughout
the
mesh,
so
everybody's
got
the
new,
the
new
config
state,
but
the
selector,
the
selection
logic,
that's
driving,
whether
we
use
config,
a
or
conceive
B
defaults
to
continuing
using
the
old
version
continues
to
use
version.
A
so
distributing.
The
blended
config
has
no
visible,
hopefully
no
visible
effects
of
components
running
in
the
mesh.
D
D
With
the
eventual
consistency
from
that
standpoint
and
so
gradually,
then
traffic
can
move
from
A
to
B.
Once
everything
is
on
B,
then
we
do
another.
We
do
another
distribution
pass
through
all
the
components
that
so
they're
config
only
now
contains
the
state
for
B
and
rinse
and
repeat
over
time
all
right,
so
so
the
selection
process,
no
I,
don't
have
a
picture,
ok,
so
the
selection
process.
The
idea
is
when
the
a
request
begins
begins
life.
D
We
will
there's
different
paths
where
this
can
happen,
but
typically
say
on
the
request
incoming
to
your
service
early
on
in
this
processing
pipeline,
the
proxy
will
decide
based
on
some
heuristic.
Perhaps
they
just
a
random
number
generator
or
a
user
identity
or
that
kind
of
stuff.
It
will
decide
whether
this
requested
new
process,
as
version
a
or
version
B,
and
will
send
that
data
through
to
mixer
so
mixer.
If
the
proxy
was
on
version,
a
the
mixer
is
also
going
to
be
on
version
a
to
process
that
request
and
similarly
adapters
automatically.
D
In
a
request,
within
the
context
of
a
service,
so
this
is
not
trained.
Transitive
across
service
calls.
So
it's
it's
up
to
the
operator
to
coordinate
if
there's
dependencies
from
service
to
service
that
that's
an
the
operators
problem
all
right.
So
that's
that's!
Basically
all
I've
got
on
the
stage
roll
out
front
and
of
course
it's
people
are
always
worried
about
this.
D
D
D
So
what
this
means
is,
if
you're
running
in
a
single
cluster
environment,
the
user
is
going
to
do
Q,
cuddle
or
sto
cuddle,
whatever
to
push
config
state
and
galley
picks
it
up
from
there.
If
you're
on
a
multi
cluster
scenario
from
the
config
standpoint,
we
expect
that
there's
some
outside
agent
that's
going
to
distribute
the
configuration
across
the
clusters
so
that
galley
can
pick
it
up.
D
There
so
it's
very
loosely
coupled
across
clutter.
It's
it's
not
even
couple.
There
are
independent
instances
of
galleys
that
don't
know
about
one
another
and
and
it's
up
to
the
user
to
ensure
that
the
rest
of
the
system
is
consistent
around
it.
That's
our
first
first
stab
this
over
time.
Perhaps
we'll
find
we
need
some
port
nation,
but
so
this
means
in
particular,
as
we're
doing
staged
rollout
across
across
clusters
for
a
single
service
and
they're
going
to
be
in
potentially
different
different
states
of
their
their
their
rollout
for
a
single
service.
D
E
Mart
I'm
one
one
obvious
case
right
where
we
have
service
specifications
that
span
clusters,
but
service
implementations
that
do
not
write.
We
will
have
a
situation
where
a
consumer
in
one
cluster
is
operating
in
the
context
of
config
a
and
the
service
provider
in
the
context
of
another
cluster
is
operating
in
the
context
of
configured,
be
correct.
D
D
E
Right,
so
it's
going
to
be
interesting
right
if,
if
people
tend
to
use
lots
of
clusters
like
say,
I
put
a
bunch
of
clusters
in
a
single
availability
zone,
because
I
want,
like
the
administrative
properties
of
that
they're,
effectively
uncoordinated
because
we've
driven
and
we
drew
the
boundary
at
the
cluster
level
for
coordination
and
we're
just
gonna-
have
to
tell
operators
that's
the
way
things
are.
You
know
they
might
decide
to
use
one
control
plane
with
us
within
a
single
availability
zone
right.
E
D
D
That's
the
right,
the
reasonable
path,
alright,
so
in
terms
of
the
kind
of
musty
multi
cluster,
the
practical
considerations
in
the
short
term,
there's
basically,
three
three
major
major
patterns
that
kind
of
emerge
here:
one
is
the
manual
packaging,
a
distribution,
so
the
operators
got
the
intent
level
or
we
call
it
composable
configs.
They
run
a
packaging
tool
that
produces
a
service
config
file,
and
then
they
manually
push
it
into
each
cluster
and
so
they're
doing
it
by
hand
or
using
some
batch
script
and
that's
all
there
is
so
that's
probably
reasonable.
D
For
bootstrapping
and
small
news
cases
as
more
complicated
situations,
you
want
to
start
using
some
form
of
automation.
So
this
just
is
it's
very
simple,
so
you're
running
a
tool,
it's
responsible
for
delivering
the
config
to
all
the
services.
It's
effectively
you're,
replacing
the
to
all
the
clusters,
rather
so
you're,
replacing
a
Bosch
grip
with
something
a
little
more
a
little
more
robust.
The
next
step
is
where
the
packaging
step
is
actually
combined
with
the
distribution
step,
so
that
would
be
where
the
composable
config
is
is
directly.
There
is
the
direct
input
to
the
tool.
D
That'll.
Do
the
composition
and
the
distribution
all
in
one
step,
so
I
think
that's
the
kind
of
a
sweet
spot
for
a
larger,
larger
deployments.
It
avoids
an
extra
step
and
it
can
provide
some
decent,
decent
experience.
So
for
the
for
starters,
this
is
this
is
what
we're
going
to
build
the
the
manual
stuff
so
we'll
have
a
a
manual
config
packager
that
understands
how
to
do
the
transformation,
and
we
expect
that
somebody
else
is
in
the
business
of
distributing
this
stuff.
D
Okay,
all
right
covers
most
of
the
architectural
details
that
we've
got
figured
out
so
far
and-
and
this
is
kind
of
the
initial
set
of
implementation
tasks
that
we
think
we
can
deliver
we're
still
tweaking
those
so
we'll
see
how
how
it
ends
up.
Okay,
so
first
step
is
to
actually
get
Galli
into
pipeline,
and
this
is
work
that
that
has
been
doing
at
the
moment.
E
I
I
J
I
The
idea
is
to
actually
make
them
internal
API
is
as
opposed
to
public
API
X
from
there
on.
We
can
actually
say:
okay,
you
know
these
public
API,
our
internal
API
and
we
can
implement
in
them
in
the
most
efficient
way
possible.
Well,
let
me
think
right,
so
that
is
probably
gonna
be
like
this
is
kind
of
a
stepping
stone,
but
I
think
you
know
once
we
land
there,
you
can't
go
to
the
next
step
and
say:
okay,
you
know,
okay,
what's
the
best
right
thing
to
do
here,
yeah,
so
at
this
point
it
means.
D
E
D
So
let
me
get
there
in
a
couple:
slides,
okay,
all
right
so
service
config
will
be
the
next
step
here.
So
we
start
with
a
config
model
that
exposed
that's
exposed
to
the
user.
That
looks
a
lot
like
what
we
have
today,
but
we've
now
hidden
the
implementation.
That's
the
stuff!
That's
delivered
to
the
components.
The
next
step
is
to
start
introducing
service
configures
a
first
class
thing,
so
the
user
can
now,
instead
of
offering
using
the
existing
config
model,
can
oust
offering
using
service
configs
and
consumer
config
and
the
disability
support
both.
D
So
so
there
it's
it
completely
compact
or
compatible
kind
of
thing,
and
we
generate
the
same.
The
same
resources
on
the
back
end
that
that
the
components
consume.
Of
course,
this
is
and
I'm
sure
a
lot
of
this
work
can
be
done
in
parallel,
but
that's
kind
of
the
conceptual
stepping
that
process
right.
E
E
D
K
One
comment
that
I
had
was
I
mean:
probably
you
addressed
it
early
or
not.
I
joined
a
little
later,
and
this
is
JJ.
So
there
are
at
least
three
parts,
parts
to
that
I
see
in
terms
of
generalizing
country,
config
definition
and
second
is
distribution,
and
then
third
one
was
the
runtime
application.
Is
there
a
reason
to
combine
all
three
into
like
humongous
thing,
or
is
it
like
definition
and
runtime?
I
mean
I,
think
definition
and
runtime
would
be
more
much
more
useful
than
even
distribution
mechanism.
D
D
So
what
we've
tried
to
do
is
kind
of
understand
the
end
end
pipeline
and
figure
out.
How
is
the
best
way
for
us
to
get
there
from
an
implementation
standpoint
and,
as
I
said
before,
as
I'm
presenting
these
click
stops.
These
are
kind
of
high
level
high
level
places
where
we
can
be,
but
I'm
able
Eve
that
we'll
be
doing
work
in
parallel,
so
that
as
we're
implementing
Galli
we're
starting
to
work
on
the
service
config
format.
So
by
the
time,
but
the
time
we're
ready
to
use
a
service.
Config
we'll,
hopefully
have
a
definition.
E
D
What
this
is
trying
to
do
here?
Ok,
in
this
mode,
we
produce
the
existing
CR
DS
deliver
them.
They
exist
very
similar
to
the
existing
CR.
These
we
deliver
them
in
the
same
way
to
the
components
in
theory,
pilot
and
mixer.
Don't
need
to
change
relative
to
this
phase
now,
maybe
somebody's
working
on
this
at
the
same
time
like
Jason
over
there
and
he's
making
some
changes
there.
But
it's
it's
a
it's
a
freebie,
ok,.
E
D
E
E
I
So
I
think
lending
me
the
click
step
zero
in
that
sense
helps
in
the
sense
that
Kelly
is
in
there
and
then
we
can
now
start
doing
incremental
changes
into
the
system
right.
That
was
the
main
line
of
thinking.
Mid
click
stops
here.
Let's
separate
the
problems
from
each
other
right
now.
There
are
independent
problems
and
we
can
make
forward
progress
on
either
one
of
them.
So
we
can
say:
ok,
service
coffee
is
experimental.
We
can
have
an
experimental
implementation
of
service
coffee
in
galley.
D
F
D
Okay,
so
whoops,
so
here
we're
introducing
service
config
as
an
optional
input.
The
next
step
here
says:
okay,
now
the
output
side,
let's
start
actually
producing
component
configs.
So
that's
when
the
semantics
of
staged
rollout
are
effectively
encoded.
We
can
probably
do
start
doing
staged
rollout
at
this
point
in
the
scheme
of
things.
So
the.
E
I
But
also
implies
that
you
yeah
you're
right
from
the
get-go.
That's
the
other
thing
right,
so
I
think
it's
it's
a
yes.
We
can
do
this,
but
it's
probably
maybe
a
major
surgery,
and
it
was
a
new
component
right
which
I'm
generally
in
favor
of
but
this
the
clicks
top
Syria
is
a
bit
the
more
conservative
approach,
yeah.
E
D
Yeah
so
I
think
at
this
stage,
when
we
define
the
component
config,
that's
when
we
introduce
an
API,
that's
the
directly.
You
can
directly
program
and
Jason
and
I
discussed
yesterday
you
can,
you
can
have
this
API
and
have
it
consume
CDs
as
well.
If
that's
a
desirable
outcome
for
the
user,
all
right
so
that,
as
we
discussed
last
week,
if
I
think
we
discussed
this
exposing
see,
are
these
at
this
level
makes
the
the
configuration
model
more
visible
to
the
customer,
so
they
can
potentially
drink
debugging
athlete
or
visualization?
D
D
Basically,
at
this
point,
I
think
it
it
addresses
all
the
needs.
The
only
downside
is
extra
work.
We
need
to
do
it.
Yeah
I
mean
it's
okay,
all
right
so
now,
okay,
so
so
so
far,
we've
been
focused
on
the
kind
of
how
to
get
a
service
config
file
through
the
system
and
get
that
pipeline
working
the
next
step
after
that,
which
again
can
be
done
in
parallel.
If
maybe
we
have
more
resources,
is
the
composition
model
to
the
left
side
of
the
graph?
Can.
D
My
Rhys
most
recent
thinking
in
this
is
that
gali
gali
is
always
in
so
both
gallon
pallet
will
ingest
the
topology
in
some
form.
It's
conceivable
gali
would
call
Pilate
to
get
the
topology
information
or
something
but
I'd
like
gali
to
be
responsible
for
doing
at
least
high-level
charting.
So
it
needs
to
understand
kind
of
what's
available
out
there
in
order
to
do
the
charting
properly
I.
Think
Pilate
also
needs
the
the
topology
information,
but.
E
E
E
J
Proper
is
just
the
API
for
the
model
and
to
degeneration
plus
the
service
type
injuries,
though
that
could
be
in
sitting
alongside
pilot
as
I
collect,
config
sidecar
in
some
sense,
and
maybe
get
your
incremental
step.
So
it's
still
apparently
facing
your
victim
pilot
is
consuming
these.
That
pilot
proper.
Has
this
yeah.
E
It
gives
us
some
flexibility
in
the
long
run,
with
an
alternative
configuration
sources
and
right.
You
know
specifically
like
the
Cloud
Foundry,
guys
I
think
would
really
appreciate
if
we
gave
them
a
contract
that
they
could
use
with
Pilate,
where
they
could
push
config
to
it,
where
they
didn't
have
to
depend
on
our
configuration
pipeline.
E
G
J
Might
decide
to
keep
that
in
some
form
so
that
you
still
like
the
arguments
forefront
for
using
charities
and
having
visibility
into
the
config
state
without
having
to
do
a
GRCC
request.
Make
me
be
attractive.
I
think
you
keep
that
east.
You
can
move
it
into
Galilee
property
duplicating
all
these
config
sidecars.
There's
no
other
place
based
deeper
mental
approach
towards
down
we
directly
talking
about
what.
D
E
D
D
Okay,
all
right,
so
where
was
I
on
the
so
the
left
side
of
the
diagram,
so
the
idea
is
consuming
at
that.
With
this
approach,
the
user
is
not
able
to
edit
using
a
composable
config.
So
instead
of
having
these
big
monolithic
service
configs,
the
user
has
little
itty-bitty
pieces
that
get
composed
together
to
produce
the
service
and
things
the
user
can
continue.
Authoring.
D
Service
config,
that's
fine
too,
so
if
they
want
their
own
composition
model
their
own
tooling,
that
that
works
great
and
you
can
still
the
system
still
in
this
mode,
they're
still
ingesting
the
the
legacy
legacy
formats
and
the
final
final
step
here
is
just
remove
support
for
the
external
CR
DS.
So
now
the
user
is
either
required
to
use
service
saying
or
the
composable
config,
and
I
think
we're
done
yes,
so
that,
if
we're
lucky,
we
get
to
this
point
by
the
end
of
the
year,
while
the
Syrian
we
need
to
get
note.
D
C
E
E
E
D
E
Already
have
some
of
that
obviously,
traffic
splitting
the
network
level
gives
us
a
fair
amount
of
that
and
if
we
have
a
similar
feature
in
mixer
plus
the
ability
to
do
contextualization
to
workload
just
within
the
API
itself,
without
the
coupling
right,
so
operators
are
still
required
to
make
sure
that
their
semantic
consistency,
if
they
say
I,
won't
workload.
A
prime
using
config
X,
even
though
the
mixer
is
gonna,
be
on
config,
why
it
should
probably
still
mostly
work
yeah.
E
Those
are
relative
ease,
constrained
problems
to
solve
and
we
will
get
a
lot
of
really
useful
feedback
around
that
stuff
over
the
next
six
months,
because
you
see
robots
continue
to
occur
and
you
know
Indian
a
a
general
sense.
We
should
probably
you
know,
obviously
keep
improving
the
distribution
pipeline
for
efficiency
for
reasonability
etc,
but
give
customers
a
little
bit
of
time
to
kind
of
get
their
toes
wet
and
then
look
at
how
we
might
you
want
something:
solid
user
feedback
to
push
I
think
either
the
better
config
moment.
E
We're
gonna
want
good
user
feedback
from
that
post
one
hour
and
also
what
controls
they
wander
around
distribution
I.
Think
we're
gonna
want
some
good
feedback
on
that
for
one
I,
don't
want
to
kind
of
create
that
with
development
ever
too
much,
while
still
laying
the
groundwork
for
it
like.
We
know,
there's
stuff
that
has
to
happen,
and
you
should
put
some
of
that
stuff
in
place.
E
G
G
E
Thanks
yeah,
we
should.
We
should
obviously
talk
about.
You
know
six
top
one
versus
click,
stop
three
I
think
there's
some
nitty-gritty
stuff
in
there.
We
should
get
into
the
weeds
on
about
what
would
make
sense
in
terms
of
short
term
execution.
You
know
that
we
have
somewhat,
like
other
short
term
goals
around
reuse,
like
just
to
facilitate
I,
think
that
way
influence
that
prioritization
yeah.
D
E
A
A
D
A
On
this
affront
to
regarding
the
short
term
goes,
and
actually
we
just
started
a
wish
list
and
I
can
just
click
presenting
here
and
the
doc
also
exists
in
the
drive
so
we're
putting
together
something
that's
not
directly
dependent
I'm
sorting
out
the
service
comfort
format.
But
there
is
improvement
that
we
want
to
have.
I
would
invite
everybody
if
you
have
other
ideas
to
put
it
in
and
that's
the
things
like
we
have
been
thinking
about
and
I
haven't
putting
much
about
the
distribution
part
of
the
work
that
we
have
talked
about.
E
You
don't
think
that
part
is
well
captured
in
the
ongoing
architecture.
It's
been
a
pretty
reasonable
discussion
in
the
context
of
pilot,
so
I
think
we
should
capture
it
here
and
write
that
live
the
goal
there.
You
know
what
I
was
thinking
about
asking
you
know
Costin
or
SRAM,
or
someone
like
that
to
do
is
to
boom
timer
when
they
have
been
with
take
a
stab
at
defining
what
they
would
like
the
downstream
API
to
look
like
I
think
that
will
be
very
valuable.