►
From YouTube: Policies and Telemetry WG Meeting - 2019-01-16
Description
Agenda:
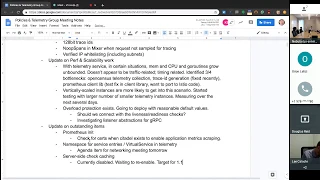
Recent changes in 1.1
- 128bit trace ids
- NoopSpans in Mixer when request not sampled for tracing
- Verified IP whitelisting (including subnets)
Update on Perf & Scalability work
Update on outstanding items
- Prometheus init
- Namespace for service entries / VirtualService in telemetry
- Server-side check caching
Pending changes
- Pod annotations for policy enforcement
- Better close handling in adapters
- OOP Adapter Auth (is target still 1.1?)
Beyond 1.1
- Istio Multicluster
A
A
A
So
I
just
created
this
short
little
agenda
a
minute
ago,
things
that
are
top
of
my
mind
and
maybe
people
can
add
to
it.
I
just
want
to
go
over
some
of
the
recent
changes
that
affect
policy.
In
telemetry
we
switch
to
using
128
bits
for
trace
IDs.
This
was
a
request,
so
that
was
pretty
easy.
In
mixer
we
were
having
issues
around
random
number
generation
for
tray
suspense,
and
so
we've
opted
to
use
no
ops
bans
when
the
requests
came
through
was
not
selected
for
sampling
and
the
tracing
that
should
dramatically
improve
contention.
A
There
I
verified
the
work
that
been
done
for
ID
whitelisting,
including
using
subnets,
and
the
way
this
and
there's
some
discussion
on
this
feel
or
discuss
that
is
theö
about
that
as
well.
Some
of
the
stuff
that
I've
noticed
in
the
last
week,
it's
kind
of
an
addition
to
improve
Indian
test
stability.
So
I
don't
know
if
there's
other
things
that
people
want
to
discuss,
changes
dimension.
C
Of
the
reference
scalability
work
yeah,
so
so
I
think
some
of
it.
It
may
be
repetition.
But
we've
had
this
issue
with
telemetry,
specifically
that
under
circumstances
with
telemetry
memory
and
CPU
and
guru,
teens
gonna
grow
unbounded
and
until
basically
consumes
everything
there
isn't
and
then,
if
then,
it's
killed.
C
It's
not
just
traffic
related
because
normally
under
the
same
amount
of
traffic,
everything
works
fine.
So
it
is.
It
is
definitely
a
timing
of
type
issue
which
causes
is
to
telemetry
to
get
into
that
sort
of
spot
under
the
same
amount
of
load.
What
we
have
found
in
debugging,
that
is,
there
are
three
or
four
bottlenecks
that
that
those
requests
can
hit
because
of
contention
right
because
there
are
these
shared
resources.
C
One
of
the
first
ones
that
we
hit
was
the
open,
sensors
internal
telemetry
collection.
Then
there
was
the
face
ID
right
and
face
ID
involved,
creating
random
number,
which
had
another
shared
resource
which
had
lots
of
contention
and
then
ultimately,
the
Prometheus
adapter
itself,
which
has
internal
cues,
and
that
was
the
final
potential.
C
C
But
one
of
the
things
that
came
out
of
all
this
is
that
large
is
to
telemetry
instances
right
which,
which
are
vertically
scaled
by
using
like
2030
CPUs
and
using
lots
of
memory,
it's
more
likely
that
they
get
into
this
sort
of
scenario.
So,
in
addition
to
kind
of
solving
this
and
getting
to
the
root
and
fixing
all
these
things,
we
have
just
started
testing
with
a
much
with
a
larger
number
of
smaller,
easier
telemetry
instances.
C
And
the
expectation
is
that
when
you
have
smaller
telemetry
instances,
they're
less
likely
to
have
this
sort
of
like
huge
contention
of
thousands
of
connections
being
concentrated
in
one
and
then
causing
downstream
effects.
So
we
are
they're,
actually
testing
and
measuring
that
right
now,
and
that
could
be
done
in
next
several
days
and
in
addition
to
that,
we
have
already
added
overload
protection
right,
which
was
added
just
a
few
few
months
ago.
C
We
want
to
have
we
want
to
deploy
these
with
a
reasonable
overload
protection
as
a
default,
which
means
that,
even
if
it
does
get
into
that
sort
of
situation,
it
won't
kind
of
continue
throwing
unbounded
just
use
of
everything.
All
load
protection
will
kick
in
and
kick
out
some
of
the
traffic.
So
let
me
how
that
works
is.
C
F
D
D
D
From
the
GC
team
on
on
the
applying
back
pressure
and
there's
Network
less
don't
pick
up
the
requests.
If
you
can't
deal
with
it,
yeah
that
just
have
a
disability,
that's
really
what
you
want
right.
So
they
just
need
a
little
callback,
some
somewhere
that
calls
back
in
to
us
and
then
we
can
tell
them
stop
right,
sit
there
for
a
while
and
then
then
you'll
get
the
request.
Oh
you.
C
Know
what
I
think
so
your
PC
server
takes
Avery,
similar
abstraction
as
the
thing
that
it
uses
right.
Normally,
we
just
pass
in
the
regular
listener
attraction
which
is
nectar
listener,
so
we
could
actually
introduce
something
there
that
says:
I'm
just
not
going
to
read
from
the
socket
now
until
there
is.
There
is
something
more
I'm
doing
something
similar
for
for
pilot,
also
by
cooking
in
two
there
and
setting
in
an
abstraction,
but
I
think
that
that
should
be
something
because
actually
it
could
be
generic,
oh
yeah.
We
could
try
that.
B
C
C
C
H
I
A
G
C
C
A
G
D
B
C
E
D
F
D
G
C
G
D
I
D
D
C
D
A
A
A
H
C
D
D
A
J
I
G
A
C
B
C
D
D
I
think
the
key
difference
is
who's
responsible
for
managing
the
cohesiveness
of
the
these
annotations.
If
it's
on
the
pod,
it's
up
to
the
user
to
make
sure
that
all
the
positive
their
workloads
have
that
annotation.
If
we
do
it
in
a
CD
that
just
says
this
workload
has
this
feature
and
we
take
over
that
responsibility.
C
J
J
D
Think
maybe
this
the
annotation
approach
is
the
the
terminal
case.
The
thing
can
be
global.
You
can
have
it
next
at
the
main
space
level,
and
then
you
can
target
an
individual
pod
farm
say
you
behaved
this
way,
so
I
think
what
really
matters
here
is
cohesiveness
with
the
rest
of
the
platform,
and
so
there
there's
Suzanne
has
a
half
more
than
half
of
it.
D
D
Needs
to
go
so
that's
saying:
look
we're
gonna
converge.
Everything
else.
Meanwhile,
we're
going
to
go
over
here,
we'll
do
something
totally.
So
if
it's,
if
the
annotations
seem
like
a
reasonable
thing,
but
it
needs
to
be
done
in
the
context
of
history
or
the
whole
if
it
makes
sense
for
mixer
things,
and
it
probably
makes
sense
for
other
things
as
well.
Oh,
we
have
done
some
elevations
already
yeah,
so
yeah,
but
we're
not
tracking
them
they're,
not
systematically
documented
the
responsible.
D
C
C
A
C
G
C
I
think
I
think
that
it
would
be
on
a
case-by-case
basis.
It's
like,
whatever
description
you
have
put
the
metadata
there
and
it's
stupid
inside,
like
whatever
the
vehicle.
Is
you
so
in
theory?
It
it's
not
incompatible
right,
it's
just
a
map
and
you
stick
it
somewhere,
yeah
and
as
long
as
you
make
it
available
to
the
injector
and
then
eventually
to
pilot.
G
K
C
D
G
D
C
D
D
A
I
say
beyond
one
one:
there
in
some
people
raising
questions
about
multi,
cluster,
telemetry
and
policy
and
having
issues
and
I
don't
know
that
we've
spent
much
time
at
all.
Looking
at
that,
so
I
was
going
to
start
looking
at
that
over
the
next
couple
days
to
see
what
happens,
I
think
the
people
who
added
the
original
code
me
no
longer
you're
participating
the
project
so
anyways,
which
is
something
else
to
be
aware
of
their
might.