►
From YouTube: Technical Oversight Committee 2020/10/23
Description
Istio's Technical Oversight Committee for October 23rd, 2020.
Topics:
- Update on TOC structure and vacancies
- The current pain of Istio upgrades and how to make it better
A
You
know
we
we've
had
some
pretty
the
trc's
goal
has
been
to
make
help,
make
technical
decisions
and
operate
by
consensus
right
and
to
help
drive
the
project
forward
and
we've
been
pretty
consistent
about
making
sure
that
you
know
anyone
gonna
come
into.
The
two
c
has
a
long
track
record
in
the
project,
including
being
a
working
group
lead,
and
I
think
you
would
expect
to
see
those
kinds
of
things
carry
forward,
but
we're
going
to
work
on
a
charter
and
try
and
make
that
a
little
bit
more
formal.
A
A
An
effective
way
of
helping
a
committee
operate
by
consensus,
but
we'll
try
and
get
this
done
as
quickly
as
possible
and
all
feedback
will
be
welcomed.
The
process
will
be
done
like
the
steering
one.
There
will
be
a
github
pr.
People
will
be
asked
to
provide
feedback
et
cetera,
et
cetera.
I
don't
have
a
fixed
timeline
for
getting
this
done,
but
as
soon
as
possible.
B
A
B
B
So
the
problem
that
we
have
been
observing
in
the
community
is
even
though
we
have
gone
from
1
0,
with
our
first
production
greatest
year
to
nine,
which
will
be
the
next
one.
After
one,
eight
upgrades
are
pretty
surprising
right.
There
are
hidden
failures.
Yeah
we
have
been.
We
have
been
changing
the
way.
C
B
B
D
All
right
cool,
so
yeah,
the
you
may
recall
that
we
had
a
survey
that
we
covered
about
a
month
ago
in
the
toc
with
regard
to
upgrade
practices
that
showed
that
there's
a
lot
of
users
running
old
versions
of
istio,
and
so
the
ux
working
group
was
asked
to
circle
back
with
a
few
users
and
get
kind
of
qualitative
feedback
of.
Why?
Because
the
survey
really
couldn't
answer
that
for
us.
So
next
slide,
we
were
able
to
interview.
E
D
So
we
presented
the
three
or
we
we
didn't
present
two.
We
interviewed
three
users,
mindbody
akamai
and
autotrader.
They
were
very
helpful
in
sharing
their
experiences
with
the
ux
working
group.
All
of
the
videos
are,
I
believe,
available
now
on
the
ux
working
group
channel
and
their
notes
are
available
in
the
drive
doc,
but
this
presentation
is
going
to
try
to
synthesize
some.
D
Some
conclusions
from
these
interviews
also
keep
in
mind
that
these
users
are
all
large-scale
users
of
istio,
long-time
users
of
hpo
mindbody
being
the
most
recent
istio
adopter
at
1.2,
the
others
started
sometime
before
1.0
and
the
particular
users
we
interviewed
are
platform
owners,
so
they're,
not
authoring
applications
or
even
paying
much
attention
to
individual
application.
Configuration
on
istio
they're
responsible
for
their
entire
platform.
Kubernetes
operations,
istio
control,
plane
upgrades
the
ci
cd
pipeline.
All
of
that
is
their
responsibility.
D
So
let's
start
looking
go
ahead
and
look
at
the
next
slide,
so
I
had
hoped
that
I
could
bring
out
a
particular
common
theme
from
each
of
these
interviews
of
here's
the
technical
problems
that
we're
running
into.
But
the
truth
is
it's
just
a
thousand
small
problems
when
you
upgrade
istio,
there
are
a
lot
of
tiny
things
that
tend
to
go
wrong
and
for
upgrades
I'm
talking
particularly
about
minor
version
upgrades
patches.
D
The
feedback
is
that
those
are
relatively
stable,
and
so
we,
I
don't
think
that
I
can
synthesize
any
one
common
thing
we
could
do
technologically.
That
would
solve
all
of
these
issues.
As
a
matter
of
fact,
carl
pointed
out
in
his
interview
that
I'm
interviewing
some
of
the
most
complex
users
of
istio,
who
have
you
know
hundreds
to
thousands
of
services
running
with
all
kinds
of
different
configurations
and
constraints,
and
the
truth
is
that
istio
is
not
going
to
be
able
to
test
for
all
of
those
scenarios
as
a
project.
D
E
Mitch
one
one
question
I
have
is
so:
okay,
so
for
for
patch
releases
we're
not
seeing
a
big
problem.
That's
good!
I'm
wondering
if
these
changes
are
intentional.
You
know
people
are
taking
the
opportunity
to
break
things
when
they
can
and
and
so
maybe
what
we
really
need
to
do
is
say.
Even
these
sort
of
things
should
not
be
done
when
at
all
possible.
D
Yeah,
that's
I.
I
think
that
would
cover
some
of
these.
Some
of
these
also
are
istio
being
used
in
ways
that
we
did
not
anticipate.
We've
heard,
I
can't
recall,
which
working
group
covered
this
recently
in
the
last
two
weeks.
There
was
a
feature
change
that
involved.
Some
undocumented
features
of
I
think
envoy
filters
and
that
caused
outed
or
caused
problems
for
some
users
on
upgrade,
but
we
had
never
documented
those
features.
We
never
expected
users
to
to
leverage
filters
in
that
way.
Yeah.
E
E
C
B
B
B
A
Well,
I
think
mitch.
One
thing
I
would
note
is
that
a
lot
of
the
ones
there
are
because
of
infrastructural
changes
right
in
a
base
layer
right,
there's
a
kind
of
fundamental
layer
of
istio,
that's
changing
between
releases
and
until
that
layer
stops
changing
right
or
we
get
way
better
at
testing
we're
going
to
continue
to
have
the
same.
E
Problem,
I
I
think
louis
that
I
I
have
seen
some
cases
where
the
change
wasn't
necessary,
but
but
but
the
person
I
talked
to
felt
that
it
was
the
right
time
to
make
that
sort
of
change
so,
for
instance,
making
our
port
numbering
more
consistent,
where
we
really
didn't
have
to
do
that,
but
that
was
considered.
You
know
it.
A
cleanup
and-
and
you
know,
between
minor
releases
is
when
you
can
make
breaking
changes.
I
think
we
could
push
back
against
more
yeah.
D
The
next
three
slides
really
deal
with
kind
of
telling
the
story
of
what
these
users
are
doing.
In
each
case,
the
users
use
a
pipeline
for
deploying
changes
to
their
service
mesh
and
that's
changes
both
in
terms
of
upgrading
the
istio
control
plane
itself,
as
well
as
just
tweaking
a
virtual
service.
Those
changes
go
through
then
they
called
them
various
things,
but
basically
a
development
staging
and
production
pipeline
where
they're
trying
to
identify
issues
as
early
as
possible.
This
is
very
much
like
software
development
life
cycle.
D
D
These
are
not
things
that
they've
that
have
gone
wrong
before
in
previous
versions,
and
so
they'll
write
a
test
for
development
to
catch
them
the
next
time
those
never
trigger
again.
The
good
news
is
we're
not
breaking
the
same
thing:
twice:
we're
finding
new
and
interesting
ways
to
break
istio,
so
that
does
make
development
of
minimal
value.
It
means
that
they,
they
don't
spend
too
much
time
in
their
development
environments.
D
Testing
is
steel,
staging
attempts
to
be
a
complete
reproduction
of
production,
and
they
do
identify
a
lot
of
issues
here,
but
then,
if
they're
going
to
need
to
change
istio
as
a
result,
now
they've
got
to
go
back
through
the
development
process
again
and
then.
Likewise,
there
are
a
good
number
of
issues
that
will
make
their
way
into
production,
because
there
is
no
environment
like
production,
no
matter
how
hard
we
try
and
again
when
we
identify
an
issue
in
production,
we
start
this
pipeline.
Over
again,
we
make
a
change.
D
That
means
that
eight
months
out
of
the
year,
our
users
are
upgrading
istio,
and
this
is
just
in
order
to
be
able
to
stay
on
a
supported
version,
because
we
don't
support,
upgrades
and
I've
used
the
one
one
through
one,
four
time
frame,
because
it
makes
it
easy
to
see
on
this
calendar
because
we
don't
support,
say
one
one.
Two
one
three
there's
no
way
to
take
a
break
from
upgrades.
D
D
All
right
and
we
can
go
to
the
next
slide,
the
other
half
that
we're
hearing
from-
and
this
almost
sounds
like
contradictory
advice.
We've
got
these
quarterly
releases
and
people
are
constantly
having
to
evaluate
upgrades
at
the
same
time.
Releasing
quarterly
is
actually
a
huge
release.
We're
calling
these
minor
updates,
but
the
perception
from
our
user
is
that
some
of
them
could
have
been
a
major
version.
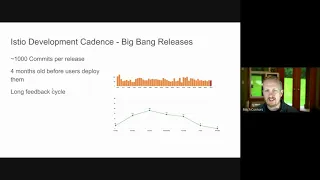
Increment
there
are
about
a
thousand
commits
per
average
in
a
quarterly
release
of
istio
by
the
time
a
user
gets
to
deploying
them.
D
Some
of
those
commits
are
four
months
old.
So
if
there's
a
bug
found
in
them,
there's
a
huge
context
switch
for
the
developer,
who
needs
to
go
back
and
figure
out
what
the
problem
was.
I
think
there's
also
a
little
bit
of
a
lack
of
an
intrinsic
benefit
or
motivation
for
developers
to
go
to
their
code,
that
is,
for
they
were
working
on
four
months
ago
and
patch
particular
issues.
D
B
G
H
H
D
So
and
actually
the
patch
releases
bring
up
a
good
point
regarding
that
calendar,
if
you're
in
the
validation
process
say
you're
in
staging,
getting
ready
to
move
to
production
and
a
cve
is
announced
and
a
new
patch
release
of
that
version,
you
start
over.
That's
not
necessarily
a
bug
in
istio,
but
it
impacts
the
the
workflows
of
our
users
and
the
quality
of
life
of
the
platform
owners
at
these
companies,
and
that
is
a
common
scenario.
A
D
They
do
their
experience
with
patch
releases
is
that
there
are
far
fewer
issues,
issues
identified,
but
often
they're
taking
a
patch
and
a
minor,
so
they'll
be
running
one
five
in
prod
they're
evaluating-
I
I
don't
know
what's
in
it,
but
1,
6,
12
and
then
let's
say
1
6
13
is
a
security
release.
Now
they've
got
to
start
their
process
over
to
evaluate
the
1
5
to
1
6,
13
migration.
So.
E
One
thing
I'd
like
to
add
there
there's
an
interesting
side
chat
going
on
in
this
about
some
changes
that
we
made
as
part
of
our
postmortem
process
for
security
releases,
changing
how
we
we
create
these
flush
releases,
where
we're
trying
to
do
a
mix
of
of
give
users
the
ability
to
take
minimal
patch
releases
while
reducing
our
own
workload.
I
suspect
that
that
has
actually
increased
the
frequency
of
the
releases
for
the
1
6
branch,
and
it's
not
just
like.
B
Yeah,
I
mean
that's
a
fair
point,
josh
and
also
that
the
fact
that
we
are
no
longer
breaking
users
when
they
use
patch
upgrades.
That's
a
big
thing
previously.
That
was
not
happening,
so
we
should
recognize
that,
even
though
we
have
12
patch
releases,
it's
actually
stable.
So
that's
a
good
thing.
We
just
need
to
fix
the
other
pieces.
B
D
I
So
one
other
one
other
thing
I
think
we
need
to
be
explicit
about
is
is
the
use
of
blue-green
deployments
right
it.
It
is
supported,
some
customers
do
use
it,
but
we
don't
provide
any
explicit
guidance
on
it
and-
and
in
fact
that
is
exactly
the
reason-
the
the
reason
they
use
it
is
to
skip
multiple
versions.
D
We
got
two
different
voices.
There.
Two
of
our
users
said
that
when
a
cve
is
announced,
they
will
evaluate
whether
it
impacts
their
particular
utilization
of
istio
and
then
decide
other
the
the
one
other
user
said
that
every
cve
they
immediately
immediately.
If
they're
evaluating
one
six
and
a
one
six
cve
is
announced,
they
will
go
to
the
latest
patch
right
away,
but.
J
Okay,
I
have
a
quick
follow-up
and
that's
a
question
generally
for
the
toc.
Should
we
consider
extending
the
early
disclosure
mailing
list
to
very
large
users
of
this
too,
because
of
that
which
means
we
will
provide
to
these
large
users,
something
that
they
can
evaluate,
possibly
an
early
patch.
They
can
build,
or
something
like
that-
is
this
something
that
makes
sense.
B
D
Well
and
francois,
the
the
talk
that
we
had
a
month
ago
actually
had
some
conclusions
regarding
security
releases,
and
that
was
that
visibility
is
too
low
on
cves
and
patch
releases.
We
had
a
good
number
of
users
and
I
don't
remember
off
the
top
of
my
head,
the
number,
but
you
can
look
back
to
the
slide
deck
on.
D
D
Are
we
ready
to
move
on
to
to
recommendations?
Yeah,
that's
good,
so
these
are
kind
of
my
summary
recommendations
that
I
take
from
this
data
and
I've
divided
them
between
strategic
and
tactical,
because
there
are
changes
that
we
can
make
immediately
and
there
are
changes
that
are
going
to
take
longer
to
roll
out
strategically.
D
D
D
Combining
these
two
together,
I
think,
would
look
something
like
a
long-term
stability
and
edge
release
channel,
although
there
are
a
number
of
different
ways
to
do
this.
We
talked
about
this
recently
in
the
test
and
release
working
group.
There
are
a
dozen
strategies
we
could
adopt
along
those
lines
and
lots
of
terminology
in
that
area.
I
don't
want
to
get
into
the
details
there,
but
I
think
that
there
are
a
good
number
of
users
who
would
like
to
see
these
two
sort
of
levers
change
across
the
project.
D
D
We're
here,
we're
not
hearing
from
users
that
they
have.
These
features
that
they
absolutely
must
see
from
istio
or
they
will
leave.
What
we
are
hearing
from
users
is
that
we
are
breaking
them
on
upgrade
very
frequently,
and
that
is
motivating
them
to
very
seriously.
Consider
other
service
mesh
offerings.
B
B
How
often
do
we
keep
up
with
the
community
versus
how
much
stability
we
provide
to
our
existing
customers?
Everything
is
in
a
bind
right
at
some
point
in
our
release
cycle.
We
have
to
move
over
to
the
new
stuff
and
then
we
break
our
customers,
or
we
say
no.
We
are
going
to
support
them.
Support
one
for
for
five
years.
E
D
That
has
value,
and
I
don't
want
to
detract
from
it-
I'm
a
huge
fan
of
the
canary
upgrade
process.
I
think
it's
coming
to
ingress
gateways,
hopefully
in
one
eight,
as
I
recall,
which
I
I
think
is
just
a
great
development.
However,
for
these
larger
users,
they
are
already
pursuing
their
upgrades
in
a
very
safe
way.
D
The
upgrade
is
breaking
production
or
that
they're
seeing
production
traffic,
outages
they're
already
have
so
many
safeties
and
pipeline
checks
involved
in
deploying
istio
that
that's
not
happening.
The
problem
is,
they
know,
they've
got
to
upgrade
production
within
three
months
and
ironing
out
all
of
the
kinks
through
their
pipeline
within
that
three-month
time
frame
is
very
painful
yeah.
So.
B
At
acosta
and
hang
on
a
minute,
so
we
have
been
the
underlying
themes
here
that
we
are
seeing,
I
think
louis
alluded
to
initially,
which
was
we
changed,
the
underlying
infrastructure
too
often,
whether
it's
the
fundamental
charts
organization,
the
install
mechanism
or
how
you
get
telemetry
overall.
So
we
need
to
stabilize
that
core.
B
B
C
Yeah,
I
just
just
wanted
to
say
that
maybe
we
should
not
even
have
a
1.9,
but
we
should
start.
You
know
adopting
this
recommendation
of
having
a
one-year
support
and
ship
small
ship
smaller
releases
and
take
1.8
and
treat
it
as
a
lts
that
will
support
for
one
year
and
keep
doing
small
incremental
patches
that
we
can
guarantee
and
we
can
test
that
don't
break
releases.
I
mean
kind
of
freeze
features
and
have
a
different
branch
where
we
can
do
any
breaking
changes
for
next
year.
C
B
D
E
So
go
ahead,
please
amanda,
I'm!
So
sorry,
I'm
speaking
over
your
hand.
I
just
want
to
set
this
up
so
that
we
can
have
the
discussion
after
this
meeting.
It
sounds
like
we
should
have
more
people
talking
about
this
concretely.
What
are
the
next
steps,
and
it
can't
just
be
the
test
and
release
working
group.
It
needs
to
be
more
of
the
people
that
also
make
the
changes
that
may
not
attend
that
group.
D
Yeah
the
test
and
release
working
group
as
far
as
prioritizing
stabilization,
their
role
is
to
provide
a
framework
it's
not
to
actually
implement
tests
or
ensure
a
high
degree
of
coverage.
That's
that's
on
the
various
working
groups
that
are
contributing
those
features.
There
is
a
bit
of
a
question
mirage
that
you
raised
about
who
decides
how
long
our
support
policy
is.
Sorry.
E
E
I
missed
your
question.
Josh.
Are
you
saying
I
I
I
want
to
have
since
we're
not
going
to
be
able
to
come
up
with
a
concrete
list
of
everything
we
have
to
do
to
solve
this
problem?
In
this
meeting,
I
want
to
be
able
to
set
up.
You
know
some
some
discussion
that
lasts
after
this
meeting,
where
we
can
come
to
some
sort
of
recommendation.
K
B
A
A
B
A
Or
more
directly
like,
could
there
be
a
distinct?
Could
we
very
explicitly
make
this
responsibility
of
a
working
group
and
I'm
not
saying
which
one
right
where
there
are
people
who
work
on
this
on
a
daily
basis
and
view
it
as
their
primary
function
to
solve
this
problem
right?
Toc's
job
is
generally
to
help
set
agendas
and
we're
not
execution
body
right
here.
We
we're
not
the
ones
on
a
day-to-day
basis,
writing
code
or
any
one
of
these
things
or
writing
tests
right.
That's
what
we.
D
D
B
L
E
A
A
Right,
okay,
so
like
where
the
other
part
goes
like,
we
can
decide
right,
but
it
you
could
view
it
as
taking
environments
and
splitting
it
into
or
creating
another
working
group
or
something
of
that
nature.
But
we
very
explicitly
have
an
install
and
upgrade
working
group
and
then
we
figure
out
everything
else
around
it.
D
E
I
A
A
A
M
Yeah,
I
think
that
the
big
common
factor
with
most
of
the
bugs
was
people
doing
the
easter
d
and
related
changes
with
bespoke
setups,
and
so
we
obviously
tested
some
of
these
cases.
But
then,
when
carl
comes
and
has
these
obscure
setups
which
we
haven't
tested,
then
they
run
into
edge
cases,
and
so
now
that
we're
not
doing
these
architectural
changes
like
the
changes
that
we're
doing
in
networks
are
fairly
stable.
The
one
concern
of
a
similar
path
is
the
bts
stuff
right.
That
is.
M
C
B
C
Do
it
I
know
no?
No,
but
but
the
expectations
that
every
three
months
we
can
break
stuff.
So
if
we
move
to
an
expectation
that
you
you
move
everything
off
by
default,
like
we
already
already
said,
you
know
it's
off
by
default,
it's
it's
guarded.
It
goes
over
six
months,
it's
a
process,
you
get
feedback,
you
get
that
and-
and
you
don't
turn
it
on
by
default
ever.
A
A
I
B
B
E
E
N
D
O
D
A
N
B
Yeah,
I
was
just
going
to
say,
I
mean
we
hear
a
lot
from
carl,
which
is
great.
He
has
been
a
vocal
supporter
and
also
when
things
break
surface
the
problems,
and
even
though
we
look
at
his
use
cases,
some
of
the
simpler
use
cases
are
currently
very
broken,
just
install
an
upgrade,
and
I
deal
with
them
on
a
daily
basis
with
our
customers
who
come
from
upstream
mysterio.
So
I
don't
think
we
can
just
say
this
is
a
problem
of
bespoke
configuration.
L
And
I
I
agree
with
that.
I
think
back
to
what
savannah
was
asking.
I
think
we
should
think
about
what
can
we
do
for
one
eight
right,
one
eight
hasn't
gone
out
of
the
door
yet
so
for
me,
if
I'm
a
user
right
now,
you
know
it's
so
hard
for
me
to
figure
out
what
might
be
changed
between
one
seven
to
one
eight.
Unless
I
do
a
diff
on
our
installation
api,
I
mean
that's
the
biggest
thing
you
know.
L
Is
there
anything
we
could
improve
our
user,
because
I
I
think
I
was
in
one
of
the
car
when
mitch
asked
the
one
of
the
user
present
and
the
user
said.
Interestingly,
I
love
helm
because
values.yaml,
I
know
where
to
find
out
the
configuration
knobs,
but
with
operator
I
don't
know
where
to
find
my
configuration
knobs
and
I
remember
when
we
used
to
have
helm
as
our
installer.
We
actually
have
a
single
page
where
we
publish
to
user
like
between
one
two,
two
one
three,
these
are
the
changes,
that's
been
deprecated.
These
are
added.
L
These
are
the
default
changes,
so
we
have
all
that
info
for
the
helm
user
back
when
we
were
doing
that
properly.
Now
that
data
is
just
not
visible.
Unless
you
go
to
source
code
to
compile
and
oftentimes,
there
wasn't
enough
tooling
to
help
people
to
detect,
and
you
guys
don't
know.
We.
We
sometimes
forgot
to
put
things
in
the
release.
Notes
especially
upgrade
notice
too,
and
we've
been
kind
of
filling
in
upgrade
notice,
as
release
went
out
when
the
user
reporting
problems.
L
C
I
I
think
the
consensus
environment
is
that
values.yamlglobal.cml
and
and
all
the
other
stuff
is
deprecated
and
mesh.
Config
is
the
only
thing
that
we
we
support
for
upgrade
and
document,
because
we
are
going
to
operate
histo
and
some
people
operate
here
without
using
helm
or
operator
and
centralistiond
may
use
whatever
it's
using.
So
we
cannot
support
as
a
user
as
a
stable
api
values
or
camera.
E
So
but
yeah,
but
so
cost-
and
I
mean
part
of
this-
is
we
need
to
make
sure
that
it's
not
just
in
the
heads
of
the
developers
who
wrote
the
code.
We
need
to
make
sure
that
for
a
final
solution
for
an
end-to-end
solution,
it's
actually
polishing
in
front
of
the
user
and
somebody
on
the
outside
can
consume
it.
C
D
C
B
A
C
B
C
C
D
C
A
E
O
L
E
C
I
say
I
agree,
you
know
documentation
and
expectations,
setting
expectations
that
you
know
mesh,
config
and
values.
Are
you
know,
and
that
will
also
allow
us
to
keep
one
rotate
alive
and
upgrade
it
for
longer,
because
again
we
and
since
centralized
ud
is
launching
one
eighth,
that's
probably
the
right
moment
to
do
it.
M
M
C
C
C
A
L
C
B
M
One
thing
I
want
to
comment
on
this
is
going
way
back,
but
we
say
some
idea
of
support
releases
for
one
year
or
something
along
those
lines.
We
have
very
different
interpretations
of
support
than
our
users
in
some
cases.
So,
for
example,
today
we
say
we
support
1.6
and
at
this
point
in
time,
when
it's
end
of
life
in
what
two
or
three
weeks,
there
is
a
very
small
chance
that
we
will
be
backboarding
bug
fixes
right.
M
If
the
security
really
came
out,
we
would
certainly
support
it,
but
we
have
users
specifically
here
carl,
who
has
issues
that
have
been
fixed
on
master.
We
have
tons
of
bugs
that
we
say
this
is
fixed
on
master,
please
upgrade
or
this
6117
please
upgrade
and
we
don't
backboard
the
fix.
And
so,
if
we
claim
like
there's
basically
two
levels
of
support,
it's
like
the
minimum
yeah
we
can
claim
we
support,
because
we
do
the
security
fixes
and
then
what
we
actually
support
like.
M
Sometimes
it's
not
even
1.7
at
this
point
like
we
fix
plenty
of
bugs
on
master
and
we
don't
backboard
them
right.
We
don't
backford
everything,
and
so
we
we
should
take
that
into
account.
If
we
consider
something
like
one
year,
because
that's
just
gonna
get
worse
and
worse,
I
can't
imagine
most
bug
fixes
being
backboarded
a
year
back
unless
there's
like
extreme
complaints
by
users
and
yeah
developers,
it's
just
going
to
be
pushed
to
master
and
someone
will
pick
it
up
eventually,.
E
What
I'd
add
is
in
the
context
of
security
releases,
where
we
do
go,
you
know
all
the
way
back
the
people
who
are
responsible
for
the
back
port.
You
know,
especially
for
you
know
things
like
backboarding
to
onboard
releases
that
are
a
year
old.
They
complain
a
lot.
It
is
very
hard
for
them,
because
the
code
has
changed
so
much
over
the
span
of
a
year.
So
we
have
to
really
think
through
this
decision.
Before
we
make
it,
it
can
be
very
high
cost
to
go
that
far
back
in
time.
M
B
A
We
allow
you
to
inject
right
and
then
there's
a
question
right
where
customers
have
used
those
things,
and
then
we
now
where
we
never
made
a
statement
of
support
before,
but
now
we're
going
to
have
to
maybe
provide
tooling
to
help
them
assess
that
they're
using
an
unsupported
thing,
because
the
number
of
touch
points
with
the
system
that
people
can
customize
right
now
is
so
high
right.
What
are
all
of
the
apis
today.
K
B
C
That's
well
as
a
workaround.
It
is
reasonable
to
recommend
it.
I
mean
I'm
saying
not
as
an
api.
It's
in
this
release.
If
something
is
broke,
you
can
use
this
environment
to
turn
it
off
or
to
alter
the
behavior.
Just
like
you
would
use
an
avoid
filter.
I
mean
it's
specific
to
a
revision,
it's
specific
to
a
specific
thing
that
you
you
are
doing,
but
it's
not
an
api
that
you
can
rely
cross
versions
that
that
will
work.
C
C
C
B
C
To
clarify
a
bit
I
mean
in
google
when,
when
a
new
feature
is
developed,
it
is
starts
as
an
experiment,
that
is,
you
know,
role
to
few
users,
to
dog
footers,
to
internal
users
and
so
forth.
And
after
you
know
long
process,
it
goes
into
the
production
and
the
apis,
but
it
always
starts
as
an
experiment.
That
is,
you
know,
restricted
to
to
the
most.
You
know:
internal
user
doctors
and
kind
of
risk,
aware
people.
A
C
A
B
A
A
You
know,
I
think
it
would
be
so
if
we
could
codify
the
way
that
we
enable
experiments,
that
we
want
users
right
and
be
very
strict
about
how
it's
codified
and
make
any
tooling
aware
of
it.
That
might
help
remediate
the
situation
right,
but
then
that
requires
that
that
codification
to
exist
as
part
of
a
supported,
schema
right.
It
is
an
api.
It's
an
api
to
use
right
things
that
are
not
supported,
and
you
know
we
can.
We
can
make
that
api
simple
right
now
right,
but
it
has
to
exist
in
a
place.