►
From YouTube: 2020 07 08 GSoC Git Plugin Performance Project
Description
Jenkins Google Summer of Code project to improve the performance of the git plugin
B
A
So
yes,
so
so
what
I
did
was
I
created
a
Python
script
which
what
it
does
is
it
for
a
particular
organization.
It
fetches
all
the
repository
URLs
and
then
I
wrote
a
simple
Java
code,
which
would
which
would
apply,
gate
LS
remote
and
give
me
all
the
reference
map
and
I
took
it
sighs
and
then
I
mapped
it
to
the
size
of
the
repository.
How
did
I
get
the
size
of
the
repository?
A
I
used
the
github
API
available
for
it,
so
that
is
how
I
map
both
of
those
things
and
the
easiest
way,
because
the
Jenkins
repository
it
has.
It
has
more
than
a
thousand
depositories
the
organization.
So
it
was
so
when
I
started.
Looking
at
it
visually
I
thought
that
would
be
more
beneficial.
It
would
be
to
use
some
kind
of
a
matrix
to
metric
to
actually
find
out
if
there
is
a
genuine
relation
between
the
things
we
are
looking
at.
The
two
things
is
the
the
first
parameter
is
variable.
A
Is
the
number
of
references
for
off
a
particular
repository
and
the
second
parameter
is
the
size
of
the
repository,
so
the
experiment?
It
aims
to
find
a
positive
correlation
between
them.
If
there
is
one
or
not
so
there's
this
metric
metric
called
Pearson
correlation
coefficient.
It
basically
gives
us
a
value
between
0
to
1.
If
it's
of
what
I've
read
if
it's
greater
than
0.5
or
point
yeah
point
5,
the
relation
between
them
can
actually
be
said.
A
It
means
something
significant
and
so
so
what
we
got
with
the
Jenkins
report
with
the
Jenkins
organization,
I
got
it
point
two
and
then
I
tried
it
with
Netflix
repositories.
I
tried
just
randomly
different,
so
with
Netflix
I
thought
they
would
have
huge
repositories.
Just
a
guy
I
thought
that
since
it's
a
it's,
also
very
wily,
he
or
just
like
Jenkins
or
let's
just
not
go
there.
The
I
just
thought
that
the
repositories
would
be
big
and
the
references
would
be
in
interesting
way
same
with
Facebook.
A
They
also
have
some
great
open
source
products,
so
I
did
that
and
with
all
of
them
the
the
place
in
the
correlation
is
coming
very
low,
so
I
actually
also
looked
at
I,
have
posted
the
link
of
the
data
as
well.
If
you
want
to
see
that
all
raw
data,
what
what
I
could
see
was
that
for
a
500
size,
repository
I
saw
a
thousand
references
for
a
1
or
2
MB
repository
I
saw
a
thousand
references
so
that
basically
says
that
we
cannot
possibly
use
it
as
a
heuristic.
A
Then
that
would
get
into
totally
inconsistent
results.
So
you
can
you
can
look
at
the
raw
data
if
you
want
to
and
I
also
so
make
it
relate
to
make
it
a
little
easy
I
actually
plotted
the
number
of
references
and
the
size
on
a
graph,
and
this
is
for
the
Jenkins
repository
all
the
points.
So
this
was
on
a
log
scale
to
make
it
a
little
more
clear,
not
in
the
linear
one.
A
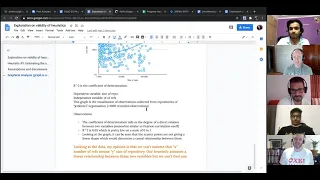
So
what
we
can
see
is
if,
if
there
was
a
correlation
between
so
this
is
a
scatter
plot,
so
there
if
there
was
a
if
there
was
a
significant
correlation
between
them.
So
here
in
this
graph,
you
can
see
two
things
which
which,
which
would
tell
you
that
the
correlation
is
not
significant
enough.
The
first
is
the
shape
of
the
scatter
plot
if
it
was
linear.
In
any
sense,
it
would
the
plot
would
the
line
you
seen
here,
the
linear
line
it
would.
A
It
would
be
around
that
it
would
work
in
actually
a
Motability
kind
of
word
for
it.
It
would
populate
that
the
point
should
populate
around
the
line
would
give
us
a
shape
where
we
could
say.
Okay,
there
is
a
linear
relationship
between
these
two
variables.
The
second
thing
is:
something
which
is
automatically
calculated.
A
R
square
is
the
coefficient
of
determination.
It's
kind
of
this,
it's
kind
of
similar
to
the
Pearson
coefficient
of
correlation
and
what
it
basically
means
is
if
R
square
is
greater
than
it's
also
it
also
it's
mark
its
measured
from
zero
to
one
and
for
our
case
the
value
was
0.05,
which
seems
not
less
than
what
we
would
want.
So
so,
from
the
observations
from
all
of
these
observations,
I
could
I
could
say
that
we
should
not
use
it.
A
C
We
I
guess
one
of
the
questions
I
had
was
like.
Were
we
actually
measuring
whether
number
of
refs
influenced
the
speed
of
the
fetching
and
stuff
like
that
too,
because
I
think
here,
you're
trying
to
say,
like
Oh,
a
number
of
refs
would
give
us
some
kind
of
deterministic
measure
of
how
big
the
repo
is.
But
did
we
actually
see
if,
if
number
of
refs
impacted
performance
in
a
similar
manner,.
A
Suggested
searching,
and
so
what
you're
saying
is
what
comes
under
the
benchmarking
experiments?
We
do.
Actually
he
analyzed
if
the
performance
is
affected
by
the
structure
of
the
repository,
the
parameters
we
have
for
the
repositories
like
the
number
of
reps
or
or
the
size
the
size
of
the
object.
This
this
experiment
was
solely.
It
was
constructed
just
to
find
out
if
the
heuristics
we
want
to
use
to
find
a
way
to
actually
estimate
the
size
is,
is
our
heuristic?
Something
is?
Is
it
actually?
Is
it
going
to
approximate
the
size?
A
So
we
were
not
actually
sure
because
previous
experiments
with
the
bench
ones
I
also
saw
that
the
number
of
reference
is
not
positively
correlating
with
the
size.
I
could
not
find
that,
but
I
did
that
with
just
for
repository,
so
I
was
not
sure
personally,
so
I
thought,
let's
take
a
large
number
say,
a
thousand
repositories
and
then
maybe
100
200,
and
let's
see
what
what
the
data
shows
us.
So
they
this
experiment
seems
to
do
that.
A
What
you
saying
comes
under
the
benchmarking
and
I
plan
to
do
that
home
car
has
actually
initiated
a
great
step
towards
it.
We
discussed
that
in
the
gate
on
the
Gator
channel.
We
pursued
that
to
find
out
if
the
number
of
reps,
actually
they
have
some
significant
effect
on
the
performance
of
ca'tridge.
My.
C
D
That
that
graph,
that
you
just
presented,
is
brilliant.
That's
showing
the
the
question
I
had
hey
could
I
see
the
raw
data.
You
just
showed
the
raw
data
with
that
graph.
It's
to
me
it
looks
very
clear.
No
way
should
we
trust,
then
the
output
of
LS
remote
as
any
kind
of
an
approximation
of
the
actual
size
that
our
repository
there's
just
not
enough
relationship
between
the
two
to
trust
that
data,
so
so
better
to
say
no
heuristic
using
LS
remote
than
to
use
use
it
and
have
it
be
wrong.
A
You
so
after
that,
so
the
question
I
had
after
finding
this
I
I
found
this
on
Sunday,
I,
think
and
then
I
had
the
question
that
so
what
should
be
each
other,
the
estimator
we
have
now.
It
has
only
two
as
possible
heuristics
right
now
we
have,
and
the
first
one
is
that
we
look
for
cache
local
depository
gate
directory.
A
If
we
had
have
that,
then
it's
the
best
thing
we
can
have,
then
the
second
we
were
thinking
was
to
to
expose
an
extension
for
the
plugins
which
provide
gate
services,
SCM
services,
so
so
with
with
those
two
URIs
takes.
My
concern
is
that
both
of
them
from
both
of
them,
we
it's
like
a
conditional
thing.
A
It's
it's
not
necessary
that
we
will
be
able
to
tell
the
size
of
the
repository,
because
if
some,
if
get,
if
the,
if
the
github
in
plug-in,
which
is
depending
on
the
gate,
plug-in,
has
not
implemented
our
extension,
we
will
not
be
able
to
use
that
the
github
api
is
to
determine
the
size.
It's
a
short
way
to
know
the
size
that
we
know
if
we're
exposing
it
as
I-I-I
assume
that
if
we
expose
it,
it
has
an
extension.
It
depends
on
the
plugins
which
are
implementing
that
extension.
Only
then
we
can
use
that
heuristic.
A
So
that
makes
us
prone
to
this
to
the
fact
that
whatever
heuristics
we
have,
they
they're
conditional
in
the
sense
that
they
might
work
or
we
we
might
tell
the
size.
We
will
be
accurate
about
it,
but
there
is
an
equal
of
probability
that
we
will
not
be
able
to
use
the
estimated
API
altogether.
So
that
is
something
I'm
a
little
as
a
little
actually
upset
that
we
should
give.
Why
does
get
not
provide
anything
which
which
would
not
depend
on
any
service
provider
or
the
local
cache?
A
So
I
actually
started
to
look
into
the
gate.
Internals,
that
is
the
plumbing
commands.
Gate
provides
and
it
was
actually
a
very
confusing
and
long
row.
It
seems
like
a
long
road
now
I
started
to
look
into
it.
I
was
looking
into
how
gate
fetch
is
implemented
and
then
I.
So
then,
I
had
this
idea
that
I
should
look
into
the
J
gates
source
code,
because
they've
all
they've
implemented
it
in
Java
and
I
know
a
little
bit
of
Java.
So
that's
the
best
way
to
actually
look
into
it.
A
So
so
so
I
thought
that
we
could
have
a
heuristic
which
would
estimate
the
size
which
will
actually
estimate
the
size
of
the
PAC
object,
the
compressed
object,
and
if
we
know
that
we
have
a
lower
boundary
on
the
size
of
the
repository,
which
is,
is
something
if
you
don't
have
any
kind
of
size.
But
so
the
PAC
config
is
basically
a
configuration
which,
when
Jake
it
is
trying
to
pack
the
object.
So
what
I'm
not
able
to
figure
out
is
so
what
I
saw
actually
to
my
own
this
to
my
own
self?
A
A
So
so
that
kind
of
disappointed
me
and
I
and
I
leading
to
I
think
an
observation
that
it
might
not
be
possible
for
us
to
look
at
a
remote,
git
server
and
then
just
look
at
the
packed
object
and
get
its
size
as
far
as
I
can
understand
how
git
is
written,
it's
it's
meant
for
us
to
download
the
pack
object
first
and
then
do
anything
we
want
to
with
it.
It's
not
possible
for
us
to
look
at
it
and
then
decide
if
we
want
to
download
it
or
not.
A
Look
at
this
size,
I
I
was
thinking
that
maybe
I
was
also
looking
at
the
transfer
protocols
get
revised,
but
I
was
not
able
to
figure
out
any
way.
I
looked
at
Stack
Overflow
I
looked
at
a
lot
of
Internet
resources,
but
people
have
not
found
and
it
consolidated
way
to
do
this
so
I'm
actually
confused
as
is.
Is
it
even
possible?
It
heuristic
in
itself
sounds
interesting,
but
I'm
not
sure
if
it's
possible
I.
B
Think
what
I
think
is
like
like
trying
to
get
the
details
of
the
dot
pack
object.
It's
somewhat
similar
to
the
square.
One
approach
that
we
were
trying
to
get
the
count
object,
get
count,
object
come
on.
It
is
somewhat
similar
like,
if
that's
possible,
to
get
get
the
remote
details
with
that
command.
Then
it
will
be
possible.
This
check
check
the
similarity
between
that
I
think
there
would
be
some
similarity
get.
B
A
B
A
For
home
car,
my
question
is
that,
even
if
we
look
at
how
good
count
objectives
working
gate
count,
objects
object
as
used
that
we
have
the
local.
We
have
the
repository
in
our
local
solution,
but
what
we
want
is
we
don't
want
to
clone.
The
repository
want
to
look
at
the
remote
server
and
get
the
size
so
I'm,
not
sure
if
this
would
give
us
the
answer.
This.
B
D
B
D
I
was
I
was
taking
home
cars
comments
to
mean
that
gate
count.
Objects
is
another
evidence
that
what
were
to
what
we
were
thinking
we
could
do
is
probably
not
feasible
right.
There
isn't
a
way
to
ask
the
remote
repository.
Give
me
your
size,
except
through
an
API
called
like
github,
so
so
get
git
itself
had
no
interest
and
I
could
understand,
Linus
doesn't
doesn't.
Actually
he
didn't
want
to
create
a
source
control
center.
He
didn't
want
to
create
a
competitor
to
source
control
management
systems.
C
Wonder
if
that
would
maybe
a
reasoning,
Explorer,
maybe
look
the
first
time
that
we
pull
a
git
repo.
Is
you
know,
gonna
be
whatever
it
is,
but
then,
after
that
we
would
have
a
determination
of
the
size
of
that
repo
and
we
would
potentially
be
able
to
track
that
over
time
if
it's
grown
or
or
decreased.
C
A
So
what
I
was
assuming
with
this
thing
was
that
the
cash
would
be
a
place
where,
if,
if
we
have
cloned
at
A+
for
the
first
time,
I
I
haven't
looked
in
the
code,
that
was
the
time
100%
sure,
but
I
assume
that
the
cash
would
have
the
repository
there.
The
local
repository
would
be
cashed,
so
then
I
would
have
a
place
where
I
can
know
that.
Okay,
this
is
the
size
of
the
repository
and
for
the
subsequent
days
or,
if
you
using
the
plug-in
for
anything
after
that,
we
could
then
optimize.
C
I'm,
just
saying
like
you
would
use
so
if
I'm
a
as
a
user
I
clone
a
repository
and
that
a
lot
of
times
I
believe
most
of
that
work
happens
on
the
agent.
If
you
have
more
than
just
the
master
domain
yeah,
and
so
you
would
be
able
to
just
use
whichever
whatever
disc
is.
Has
your
git
repository?
You
would
use
that
after
you've
done
your
clone,
potentially
the
idea
if
the
cache
isn't
like.
If
that
cache
is
reliable,
then
maybe
that's
the
right
way
to
go.
C
D
That
the
that
that
cache
on
the
master
is
is
used
by
multi
branch
and
so
users
that
use
multi
branch
will
tend
to
have
those
caches,
already
populated
and
and
so
I
think
I.
Think
it's
a
good
excuse
to
encourage
people
hey
if
you're.
If
you're
doing
this
work,
we
think
multi
branch
is
the
way
to
go
anyway.
Use
multi
branch
and
you'll
get
the
benefit
of
this
heuristic
already.
D
So
the
my
hunch
is
that,
most
of
the
time
the
heuristic
will
be
satisfied
because
the
cache
is
found
some
some
users
might
come
to
us
and
say:
oh
no
I'm
only
using
freestyle
project.
Sorry,
you
won't
get
the
benefit
until
you've,
cloned
it,
at
least
once
then,
and
for
me
the
fallback
is
still
the
fall
back
issues
command
line
get
and
commend
like
it
is
the
best
performing
in
large
repositories
anyway
right
there
for
the
places
where
we
could
gain
benefit
by
switching
to
Jake.
D
A
D
The
one
okay
yeah
I
I'm,
not
even
sure
you
need
to
acquire
a
lock
because
I
think
all
you
want
to
do
is
read
directory
contents.
And
if
it's
inconsistent
or
imperfect
you
just
don't
care
you're,
just
trying
to
get
a
quick
approximation.
So
I,
don't
even
think
you
need
to
acquire
the
lock.
You
just
get
the
look.
Get
do
the
get
cache
entry,
that's
a
directory!
And
now
you
can.
You
can
go
out
and
do
file
system
level,
access
to
that
directory
and
and
count
up
its
its
contents
and
the
size
of
its
contents.
A
So
the
last
I
I
already
discussed
it
before
the
meeting
started
actually
officially.
So
this
was
just.
This
is
just
how
I'm
I'm
actually
creating
or
designing
the
new
not
designing,
creating
the
other
cloning.
The
gate
SEM
telescope
for
our
needs,
the
size
estimated.
Thus
so
I
was
so
before.
Creating
the
class
I
started
to
look
at
the
SEM
API
and
we're
at
what
level
I
am
going
to
use
the
API
we
are
creating
and
how
am
I
going
to
what
all
should
I
provide
with
the
API?
A
Is
it
just
a
boolean
where
I
say
a
boolean
or
something
like
a
decision
that
we
use
Jake
a
dog
gate,
or
is
it
something
more
than
that?
I
was
I
was
looking
and
those
things
and
it's
mostly
exploration
right
now,
I
haven't
created
a
throated
I
was
even
but
I.
I
was
thinking
that
first
understand
the
level
above
the
gate
I
see,
and
that
is
where
the
builders
work
to
understand.
A
D
A
D
Know
yeah,
that's
true.
If
the
heuristic
it's
disastrous,
if
the
aristocratic
tells
us
that
the
two
gigabyte
Linux
kernels
should
be
downloaded
by
Jake
it
that's
a
disaster
right,
that's
an
unlikely
unlikely
outcome.
Given
the
given
the
correlation,
the
negative
correlation
or
the
non
correlation
you
found
between
our
estimators
and
and
repository
size.
Yes,.
D
Had
a
minor
business
item
I'm
going
to
be
out
next
week,
my
son
in
his
mid-20s
is
getting
married
and
so
I
really
I
will
be
unavailable
a
week
from
Friday
because
we'll
be
in
the
middle
of
all
sorts
of
things
in
a
neighboring
state
and
I
probably
will
be
on
a
bit
unavailable
a
week
from
today.
So
I'm
I'm,
not
I.
We
may
need
to
have
someone
else
host
the
zoom
session
rishabh.