►
Description
A July 23, 2020 special edition of the Jenkins Platform Special Interest Group meeting to highlight platform related Google Summer of Code projects including:
* Git plugin performance improvement project - Rishabh Budhouliya
* Custom Jenkins build service project - Sladyn Nunes
* Windows services and YAML support - Buddhika Chathuranga
* External fingerprint storage - Sumit Sarin
* GitHub checks API - Kezhi Xiong
A
A
A
I
believe
the
google
calendar
has
been
updated,
but
I'll
check
that,
after
this
meeting
and
I'll
double
check
that
it's
in
the
platform
page
we're
now,
including
them
regularly
in
platform
pages,
I
still
have
the
action
to
open
a
jet
for
docker
operating
system
support
and
we've
still
got.
As
far
as
I
know,
the
docker
build
rework
pr
and
the
alpine
image
update
pr.
Now
on
that
one
I've
been
doing
interactive
testing
with
it,
and
it's
been
working
quite
well.
A
B
So
we
dropped
support
for
the
net
framework
2
from
the
recent
weekly
release
and
going
for
what
the
framework
4
is
the
minimum
requirement.
So
what
it
means
for
users
there
might
be
some
extra
upgrade
steps
if
they
want
to
keep
using.net
framework
to
do
xero.
I
have
just
submitted
a
blog
post
for
that.
It's
still
in
drafts,
but
if
somebody
is
interested,
you
can
take
a
look
and
it
also
unblocks
updates,
for
example,
we're
working
on
yaml
configuration
support
and
a
windows
service
wrapper.
B
B
B
B
It
happens
due
to
two
reasons,
so.
Firstly,
we
hit
the
issue
with
preliminary
password,
expiration
official
docker
agent
images.
It
was
a
critical
bug,
inputting
jenkins
users
as
well.
Now
it's
resolved
and
thanks
to
alexa
for
purchase
and
the
release,
you
won't
be
able
to
see
it
here.
It's
only
in
the
agent
changelog,
I
mean
the
docker
agent
part
right
and
yeah
still,
even
with
this
clutch,
we
are
not
able
to
release
msi
packages,
because
there
is
another
issue:
is
code,
signing
and
packaging
on
windows.
B
We
trace
them
back
to
breaking
changes
in
the
container
environment.
We
use
basically
it's
about
instantaneous
shift
for
windows,
and
we
cannot
do
much
about
that.
So,
if
you're
interested
you
can
go,
join
a
jenkins
set
to
this
rc
channel,
but
basically
it
looks
like
we
will
be
waiting
for
microsoft
during
this
new
version.
B
B
If
not,
you
may
have
to
ship
it
without
a
messiah
installer
as
well,
which
would
be
unfortunate
because
yeah,
the
new
msi
installer,
actually
includes
a
lot
of
patches
and
updates
by
alexa.
So
we
would
be
interested
to
ship
that
or
maybe
it
still
makes
sense
to
do
it
in
that
one
lcs.
So,
let's
see
so
the
work
around
this
trivial
you,
instead
of
using
msi
packaging,
you
just
download
war
file
and
replace
manually.
There
is
no
magic
day.
It
will.
A
B
Be
on
the
agenda
like
so
officially,
we
have
three
projects
which
are
part
of
bathroom
seek,
so
it's
get
a
plugin
performance
improvements,
then
a
custom
jenkins
distribution,
build
service
and
third
project
just
second,
oh
yeah,
windows,
services
and
yaml
support.
Sorry,
but
we
also
have
other
students
on
the
call.
So
we
have
smith
who
is
working
on
external
fingerprint
storage,
which
is
arguably
a
part
of
jenkins
platform
as
well,
and
you
have
casual
who
is
working
on
a
github
checks
api.
C
A
D
So
for
this
phase
for
the
phase
two
one
of
the
major
deliverable
we
had
for
gate,
performance,
gate,
plug
and
performance
improvement
was
to
implement
the
the
insights
we
gained
from
the
benchmarks.
We
did
the
throughout
the
phase
one.
So
now
what
we've
done
is
that
we
have
created
a
class
inside
the
git
plugin,
which
is
right
now
being
called
as
the
gets
repo
size,
estimator
class,
so
the
name
might
change,
but
so
this
is
the
architecture
and
I'm
going
to
explain
what
it
does.
D
So
this
class
will
enable
git
plugin
to
recommend
the
optimal
gate
tool
for
the
current
repository
size.
So
if
we
have
the
size
of
the
repository,
we
will
be
able
to
tell
which
implementation
we
should
use
and
the
rule
we
will
use
for
the
to
tell
that
was
derived
from
the
benchmarks
we
executed
during
the
phase
one.
So
so
the
so
from
the
starting.
The
the
class
takes
can
be
instantiated
using
two
things.
D
D
What,
then,
what
it
does
is,
first
it
can
it
checks
for
cash,
so
the
multibranch
project,
it
stores
cash,
the
the
dot
gate
repositories
are
stored
as
cash
for
the
multi-branch
project.
So
what
we
do
is
we
estimate
the
size
of
the
repository
using
that
cash,
and
then
we
apply
our
rule
to
recommend
the
tool.
The
git
tool
you,
the
plugin,
should
use-
and
one
thing
I
forgot
to
tell
is
that
we
will
not
check
out
any
repository.
D
The
aim
of
this
class
is
to
to
to
estimate
the
size
without
checking
out
the
repository,
because
if
we
check
out
the
repository
and
the
whole
purpose
of
improving
their
performance,
it
kind
of
doesn't
make
sense.
The
second
option
is
using
other
plugins
to
find
out
the
size.
Now,
how
are
we
doing
that?
D
D
D
D
Now
we
tried
doing
that
with
multiple
parameters
like
the
number
of
branches
for
the
repository
the
commit
history,
the
commit
size
and
the
number
of
tags,
and
while
we
were
doing
these
experiments,
we
made
sure
that
the
size
of
the
repository
is
not
changing,
because
if
that
changes
then
there's
no,
we
cannot
infer
anything
from
these
tests,
so
the
first
test
you
see
is
you
see
here
is
from
so
the.
What
we
do
here
is
that
we
are
varying
the
number
of
branches.
With
each
repository.
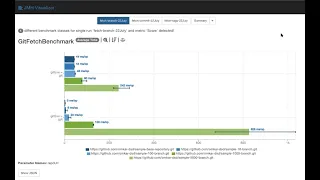
D
There's
one
sample
base
repository
with
just
one
branch,
then
it
increases
to
10
to
100,
2000
and
then
to
5000
and
what
you're,
seeing
here
the
graph.
The
most
obvious
thing
is
that
the
performance,
the
time
taken
by
gate
fetch,
is
increasing
as
the
number
of
branches
increase.
That's
the
obvious
fact
difference
in
implementations,
g,
git
and
j
gate.
If
you
can
see,
j
gate
is
performing
better
for
branches
less
than
100..
D
It
is
performing
better
than
git
in
those
cases,
and
I
think
that
is
the
only
valuable
insight
we
have
from
this
from
this
benchmark.
Also
yeah.
I
think
that's
that's
it.
For
this
benchmark,
the
next
one
is
here:
we
try
to
keep
the
size
constant
and
we
vary
the
number
of
commits
the
number
of
commits
they
start
from
one
ten
hundred
thousand
and
five
thousand
in
a
similar
fashion.
D
What
we
can
see
here,
two
noticeable,
I
would
say
points
the
first
is
that
there's
not
much
of
a
difference
in
the
performance
of
git
fetch,
with
varying
the
number
of
comments,
as
you
can
see,
with
git
it's
it's
almost
same,
there's
a
one
millisecond
or
a
difference
or
so
for
j
gate.
It's
also
the
same
thing,
but
the
second
point,
the
difference
between
git
and
jigget
is
is
again.
We
can
see
that
j
gate
is
performing
better
in
all
cases,
for
the
number
of
comments
if
for
for
that
parameter.
D
So
this
is
also
something
interesting
here.
The
last
test
is
tags,
so
here
also
we've
done
the
same
thing.
We've
tried
to
keep
the
size
constant
and
we've
increased
the
number
of
tags
in
this
test.
One
of
the
major
thing
I
could
find
out
was
that
the
of
the
effect
of
increasing
the
number
of
tags
is
affecting
the
performance
of
get
fetch
magnitude
wise
in
a
I
would
say
see.
D
D
That
is
the
amount
of
time
it
takes.
If
we
have
too
much
tags
so
and
again,
there's
a
difference
between
j
get
and
get
j.
Git
is
performing
better
in
all
cases.
So
from
these
tests,
what
we
can
infer
is
that
j
get
can
perform
better
than
get
so.
We've
we've
seen
conditions
where
jaged
is
performing
better
than
git
before
these
tests.
D
D
B
B
A
D
D
E
D
And
one
more
thing-
and
I'm
not
sure
if
it's
a
question,
but
one
thing
I'd
like
to
say,
is
that
to
make
that
class
useful
for
git
plugin,
I
need
to
go
to
the
to
plugins,
like
they
get
github
brand
source
or
git
lab
or
bitbucket,
and
either
encourage
the
developers
there
or
create
the
extension
extensions
myself
so
that
when
we're
using
multi-branch
project-
and
we
have
those
plugins,
my
class
is
able
to
derive
the
information.
We
need
to
recommend
the
best
implementation.
D
E
So
I
don't
have
a
slide
deck
ready.
I
hope
I
can
save
that
for
the
for
the
demos,
but
I
do
have
a
couple
of
updates
that
I
would
like
to
share
with
the
with
the
platform
say.
So,
as
we've
seen
in
the
last
demo,
we
had
the
packet,
the
custom
distribution
service
being
able
to
generate
at
least
your
packages
given
a
set
of
plugins.
So
if
you
could
you
know
you
could
provide
the
service
with
a
couple
of
plug-ins,
it
would
go
ahead
and
generate
the
the
package.
E
I'm
sorry
the
configuration
package
that
you
need
to
generate
the
wall
so
for
this
for
this
phase,
two
for
the
phase
two
milestones,
one
of
the
major
milestones
was
being
able
to
to
generate
the
var
file
and
being
able
to
share
community
configurations.
So
these
were
the
two
major
ones
and
additional
to
that
was
one
of
the
the
third
ones
was
being
able
to
make
pull
requests
using
a
bot.
So
I'll
just
talk
about
some
of
them
in
detail,
and
then
you
know
not
taking
up
too
much
time
here.
E
A
couple
of
them
would
be
I'll
start.
Just
give
me
a
second
yeah,
the
wire
download
feature,
so
one
of
the
major
things
that
we
added
this
time
was
the
wire
download.
So
you
can
now
hit
the
var
generation
and
it
will,
you
know,
just
just
download
the
wire
file
for
you,
given
a
particular
configuration,
so
you
can
generate
the
configuration
provided
to
the
service
and
then
the
service
will
generate
the
wi-fi
for
you.
E
It
will
obviously
download
it
as
well
what
we
there
are
a
couple
of
downfalls
to
this.
We
do
not
support
configuration
as
code.
So
if
you
provide
a
configuration
as
code
section
in
your
configuration
file,
it
will
likely
break
because
there
is
no.
We
do
not
have
support
for
that.
As
of
now,
maybe
that's
something
to
apply
to
the
readme
later
on
when
the
project
gets
self-hosted
but
yeah.
E
For
now,
we
do
not
have
configuration
as
code
support,
so
that
is
one
thing
in
the
var
download
feature
that
we've
added
the
next
feature
that
we
came
to
add
was
the
community
configuration
page.
So
now
we
do
have
a
community
configuration
page
where
users
would
be
able
to
share
all
of
the
configurations
that
they've
developed,
so
for
now
it
just
it
just
is
on
a
local
repository.
So
if
I
think
I
can,
I
can,
I
can
see
it.
It's
custom
distribution
service.
E
Just
give
me
a
second
I'll
find
that
repository
up
till
then
it
is,
it's
just
hosted
locally
on
my
account
and
I
hope
it
gets
hosted
later
on
to
the
jenkins
organization
so
that
everyone
can
find
all
of
the
community
shared
configurations.
They
have
its
own
release
cycles
and
so
on
and
so
forth.
Another
feature
that
this
that
this
update
supports
is
that
you
can
add
your
own
url.
E
E
You
know,
configure
a
repository
where
you
can
host
all
of
your
configuration
that
user
docs
have
not
yet
been
added,
but
they
will
be
added
soon,
so
that
the
users
can
see
what
kind
of
what
kind
of
steps
to
follow
to
be
able
to
customize
it,
but
for
now
yeah,
if
you
run
it
locally,
you
can
definitely.
You
can
definitely
store
your
configurations
on
that
community
config
repo.
E
That
was
the
second
update
and
the
third
one
which
was
major
but
wasn't
added
to
this
to
this
milestone,
was
being
able
to
create
pull
requests
automatically
using
a
checked
custom
distribution
service
bot.
So,
as
the
mentors
decided
that
this
we
do
not
quite
know
yet
whether
the
plugin
will
be
hosted
on
as
a
service
as
a
web
application
or
a
web
service.
E
So
this
this
pull
request
doesn't
quite
make
sense
as
of
now,
because
because
there's
no
there's
no
point
in
having
a
bot
if
the
if
the
service
is
not
hosted
so
so
these
this
was
another
update
that
we
tried
to
add
but
yeah,
but
as
a
mentor
decided,
we
would
maybe
put
it
for
history
if
the
service
is
hosted
on
on
on
on
a
service,
so
yeah
no
fun
not
ended
anyways.
That
was
the
two
updates.
The
third
update
was
just
some
minor
search
functionalities.
E
You
know
so
that
you
can
search
plugins,
you
can
search,
you
can
search
community
configurations
and
so
on
and
so
forth.
These
were
just
some
other
minor
updates,
not
major,
and
the
last
update
was
that
you
can
now
the
docker
compose
works.
There
are
still
changes
being
made
to
it,
but
you
can
definitely
and
quick
start
it
so
yeah
that
was
the
last
update
so
that
now
the
project
seems
to
be
in
a
condition
where
it
can
be
self-run
by
the
community.
E
There
are
some
changes,
as
you
can
see.
This
connect
backend
and
front-end,
using
the
new
docker
config
compose
we're
still
working
on
that,
but
yeah.
You
can
still
test
out
a
couple
of
the
features
as
of
now
so
yeah.
These
were
the
major
updates
and
we
have
achieved
almost
all
of
the
milestones
for
phase
two,
so
yeah
yeah
project
looks
in
a
good
condition.
B
D
B
C
C
Version
2,
master
and
ucla
is
almost
finished
and
there
are
some
discussions
about
that
and
will
be
merged
in
v3,
and
this
this
next
turn
is
doing
updates
into
version
three
assets.
So
I
think
I
I
I
might
not
be
able
to
merge
the
new
cli
with
shanthi
before
phase
two
finishing
I
I
don't
know,
however,
and
so
there
are
a
few
ongoing
sub
updates
at
the
moment.
So
those
are
there
are
extensions
in
windows
stopper,
like
shared
direct
mapping,.
C
C
Those
things
are
getting
in
a
more
structured
way
like
in
the
java
configuration
also
in
codebase
as
well
and
yeah,
and
how
I
have
published
a
yaml
all
option
sample
option
file
where
user
can
use
this
file
where
all
the
configurations
has
implemented
as
a
test
file.
So
user
can
use
this
as
a
to
create
the
configuration
file,
so
it
has
not
matched
it
and
there
is
a
another.
Full
request
has
been
created
for
new
updates
for
camera
computing
support.
C
So
if
you
talk
about
new
cli
and
redirect
command
has
been
removed
so
in
the
of
the
phase,
one
updates.
So
those
are
the
major
updates
that
I
have
to
tell
about
this
project.
So
there
are
two
open
pull
requests
at
the
moment
which
I
have
to
complete
one
for
new
cli.
So
it
is-
and
I
think
I
don't
I'm
not
sure
you
can
merge
it
in.
C
C
B
So
basically,
this
project
is
one
of
the
reasons
why
we
do
the
groundwork
for
dotnet
framework
support
in
the
junk
score,
because
yaml
configuration
support
is
quite
highly
demanded
by
configuration
management
tools
so
landing.
That
would
help
aging
administrators
a
lot,
especially
if
they
use
various
tools
to
deploy
a
windows,
service
and
yeah.
I'm
really
happy
to
see
that
we
are
getting
close
to
the
first
release
of
this
support.
So
hopefully,
next
week
by
the
democracy
will
be
out.
B
A
A
B
D
A
D
You
can
hear
me
right
awesome,
so
I
don't
have
exactly
a
presentation
set
up
so
rather
short
notice
for
today's
meeting,
but
I
I'll
just
talk
about
the
project
and
what
we
did
in
phase
two.
So
as
a
quick
recap
for
phase
one.
What
we're
basically
building
is
an
external
fingerprint
storage
engine
for
jenkins.
So
all
your
jenkins
fingerprints
can
be
stored
instead
of
on
the
physical
disk.
They
can
be
stored
inside
an
external
storage
and
as
a
reference
implementation.
D
We
built
the
we
built
the
refer
readers,
fingerprint
storage
plugin
around
it,
so
you
can
configure
redis
and
your
fingerprints
will
automatically
be
saved
inside
the
external
storage.
So
this
is
what
we
did
in
phase
one,
but
so
there
were
few
aspects
that
were
remaining
some
few
missing
features
that
we
went
that
we
targeted
in
this
phase.
So
one
was
that
earlier
we
had
to
so
if,
if
the
plug-in
was
configured
so
basically
at
installation,
the
the
plug-in
was
configured
directly.
D
So
now
we
refactored
it
to
user
descriptor
implementation
so
that
now
the
user
can
go
to
jenkins
configuration
page
and
can
choose
the
external
fingerprint
storage
engine
they
desire.
So
tomorrow
say
we
get
another
fingerprint
storage,
plugin,
say
postgres
or
say
mysql,
then
you
know
the
user
can
just
install
the
plugin
and
then
choose
which
program
they
want.
So
that
was
one
of
the
features
and
that
was
released
in
2.248
jenkins.
D
Also,
the
next
feature
we
targeted
was
the
fingerprint
cleanup
so
as
a
context
where
the
fingerprints
they
automatically
get
deleted
on
a
periodic
basis.
Whenever
there
the
builds
they
are
referred
to,
are
no
longer
present
on
the
system.
So
when
the
builds
they
are
referring
to,
they
are
no
longer
on
the
system.
The
fingerprint
is
supposed
to
be
deleted,
but
this
functionality
was
not
yet
present
for
external
storages.
So
we
designed
that
we
extended
the
fingerprint
storage
api
to
support
this.
D
These
were
untouched
earlier.
So
now
we
have
introduced
a
lazy
migration
system
where,
whenever
a
finger,
an
old
fingerprint
is
referenced,
it
is
automatically
transferred
to
the
external
fingerprint
storage
as
and
when
it
is
used.
So
that
is
all
fingerprint.
Migration
was
something
we
targeted
and
we
improved
the
testing
for
our
plugin
and
I
think
that's
about
it.
That's
what
we
targeted
and
we
might
be
looking
at
a
new
reference
implementation
in
the
coming
weeks.
A
A
D
D
B
B
So
this
all
this
api
is
still
in
better,
but
it
looks
pretty
solid.
So
hopefully,
in
one
of
the
next
lcs
releases,
we
will
be
able
to
say
that
this
api
is
in
je
and
yeah
one.
They
think
that
now
everybody
can
develop
their
own
implementation
of
storages.
So
again
in
this
project
submit
just
works
on
reference
implementations,
but
as
for
the
plugable
storage
stories,
we
actually
invite
users
and
jinx
adopters
to
implement
something
for
their
own
needs.
B
D
Yeah,
so
actually
that
is
something
I
want
to
discuss
in
today's.
We
have
a
sync
up
today,
so
yeah.
Basically
that
is
that
is
tracing
essentially,
but
we
were.
We
had
some
roadblocks
along
the
way
for
tracing,
because
you
know
it
also
needs
a
use
case
and
we
tried
starting
threads
on
the
developer
mailing
list.
But
we
didn't
get
so
yeah
it's
july
and
we
didn't
get
many
use
cases
so
yeah
so
we'll
see
what
happens.
A
B
B
A
reference
implementation
released
and
get
feedback
from
adopters
feedback
from
core
maintainers,
and
then,
if
everything
is
fine,
I'll
accept
that
jab
and
make
a
epa
public,
so
I
don't
expect
it
to
happen
for
the
september
release
so
most
likely
it
will
be
three
months
long
and
maybe
sometime
in
december
we
may
make
it
je,
but
yeah
by
december.
We
will
hopefully
have
enough
field
feedback
about
the
feature.
So
looking
forward
to
that,
thank
you.
Okay,
but
apis
are
quite
popular.
For
example,
artifact
manager
still
uses
beta
apis
from
the
jenkins
code.
A
A
F
Yeah
I
just
consumed
the
api,
the
general
api
implemented
before
no
one
is
plugging
and
the
code
coverage
plugin
and
there's
a
disappointing
disappointing
feature
is
that
we
can't
send
those
train.
The
features
train,
the
graphs
to
the
diagrams
from
the
jenkins
to
github,
because
there's
those
diagrams
in
the
jenkins
pages
using
his
views,
are
html
based.
But
what
github
needed
is
just
a
link
to
the
images,
so
we
didn't
implement
that
feature,
but
we
provided
some
markdown
based
trend
charts.
I
hope
that
works.
Fine
as
well.
B
Yeah,
it's
a
great
start
and
maybe
in
the
future
we
could
have
images
as
well,
because
there
are
other
use
cases
where
images
could
be
useful.
For
example,
the
previous
cloud
native
seek
meeting,
we
had
a
discussion
about
jenkinsfeld
runner
and
it's
a
pass
engine
which
executes
pipeline
and
then
stops
obviously
without
providing
you
web
ui
and,
for
example,
if
it
was
able
to
dump
reports
as
html
or
as
images
again,
it
would
be
really
helpful.
B
F
B
It's
technically
feasible
problem
that
it
might
be
producing
a
lot
of
traffic.
You
will
need
to
cache
these
images
some
way.
Maybe
you
may
need
to
put
these
images
to
cdn
again
somewhere
and,
for
example,
github
allows
to
actually
attach
image
to
issue
commands
to
pull
requests.
There
is
no
magic
there.
It
just
uploads
it
somewhere
using
kpi
and
then
uses
this
link.
So
maybe
we
could
use
a
github's
image
hosting
service
for
that,
if
not
yeah
rest
api
definitely
makes
sense.
B
A
B
B
A
B
Yeah
we're
doing
project
weekly
check-ins
these
mentors
well
this
year,
it's
a
bit
informal,
but
still
we
try
to
contact
everyone
every
week.
But
if
you
miss
something
it's
time
to,
let
us
know
because
next
week
is
evaluation
and
if
you
haven't
voted
yet
in
the
doodle
license
for
demo
times.
Please
do
because
we
need
to
schedule
the
meetings
this
phase
most
likely.
We
will
do
it
again
as
internal
event,
but
yeah
for
the
next
coding
phrase.